使用C++11让程序更简洁
类型推导
引入auto和decltype。
auto
1 | auto i = 10; // i是int |
初始化不能使编译器推导产生二义性,如把u写成u=6.0则不予通过。
使用auto声明的变量必须马上初始化,以让编译器推断出类型并在编译时将auto替换为真正的类型。
1 | int x = 0; // |
a和c的类型推导结果很明显,auto在编译时被替换为int,b的推导结果表明auto不声明为指针,也可以推导出指针类型;d的推导结果表明当表达式是一个引用类型时,auto会把引用类型抛弃,直接推导成原始类型int。f的推导结果表明表达式带有const时,auto会把const属性抛弃掉,推导成non-const的int。规则如下:
- 当不声明为指针或引用时,auto的推导结果和初始化表达式抛弃引用和cv限定符(const和volatile)后类型一致
- 当声明为指针或引用时,auto的推导结果将保留初始化表达式的cv属性。
- auto不能用为函数参数。
- auto无法定义数组!
auto的推导和函数模板参数的自动推导有相似之处。1
2
3
4
5
6
7
8template <typename T> void func(T x) {} // T -> auto
template <typename T> void func(T *x){} // T -> auto*
template <typename T> void func(T& x){} // T&-> auto&
template <typename T> void func(const T x) {} // const T -> const auto
template <typename T> void func(const T* x){} // const T*-> const auto *
template <typename T> void func(const T& x){} // const T&-> const auto &
注意:auto是不能用于函数参数的。
何时使用auto?看一个例子,在一个unordered_multimap中查找一个范围,代码如下1
2
3
4
5
6#include <map>
int main()
{
std::unordered_multimap<int, int> resultMap;
std::pair<std::unordered_multimap<int, int>::iterator, std::unordered_multimap<int, int>::iterator> range = resultMap.equal_range(key);
}
这个 equal_ange返回的类型声明显得烦琐而冗长,而且实际上并不关心这里的具体类型(大概知道是一个std::pair就够了)。这时,通过auto就能极大的简化书写,省去推导具体类型的过程1
2
3
4
5
6
7#include <map>
int main()
{
std::unordered_multimap<int, int> map;
auto range_map.equal_range(key);
return 0;
}
decltype
auto所修饰的变量必须被初始化,C++11新增了decltype关键字,用来在编译时推导出一个表达式的类型。decltype(exp),exp是一个表达式。1
2
3
4
5
6
7
8
9
10int x = 0;
decltype(x) y = 1; // y -> int
decltype(x + y) z = 0; // z -> int
const int& i = x;
decltype(i) j = y; // j -> const int &
const decltype(z) * p = &z; // *p -> const int, p -> const int *
decltype(z) * pi = &z; // * pi -> int, pi -> int*
decltype(pi) * pp = π // *pp -> int *, pp -> int **
y和z的结果表明,decltype可以根据表达式直接推导出它的类型本身。这个功能和上节的auto很像,但又有所不同。auto只能根据变量的初始化表达式推导出变量应该具有的类型。若想要通过某个表达式得到类型,但不希望新变量和这个表达式具有同样的值,此时auto就显得不适用了。
j的结果表明decltype通过表达式得到的类型,可以保留住表达式的引用及const限定符。实际上,对于一般的标记符表达式(id-expression),decltype将精确地推导出表达式定义本身的类型,不会像auto那样在某些情况下舍弃掉引用和cv限定符。p、pi的结果表明decltype可以像auto一样,加上引用和指针,以及cv限定符。
pp的推导则表明,当表达式是一个指针的时候,decltype仍然推导出表达式的实际类型(指针类型),之后结合pp定义时的指针标记,得到的pp是一个二维指针类型。这也是和auto推导不同的一点。
推导规则:
- exp是标识符、类访问表达式,decltype(type)和exp的类型一致;
- exp是函数调用,decltype(type)和函数返回值类型一致;
- 若exp是一个左值,则decltype(type)是exp类型的左值引用,否则和exp类型一致。
1 | struct Foo {int x;}; |
a的类型就是foo.x的类型,foo.x是一个左值,可知括号表达式也是一个左值,decltype的类型是一个左值引用。
在泛型编程中,可能需要通过参数运算获得返回值类型:1
2
3
4
5
6
7
8template <typename R, typename T, typename U>
R add(T t, U u) {
return t+u;
}
int a = 1;
float b = 2.0;
auto c = add<decltype(a+b)>(a, b);
改成:1
2
3
4template <typename T, typename U>
decltype(T()+U()) add(T t, U u) {
return t+u;
}
考虑到T、U可能是没有无参构造函数的类,可以如下:1
2
3
4template <typename T, typename U>
decltype((*(T*)0) + (*(U*)0)) add(T t, U u) {
return t+u;
}
返回类型后置语法通过auto和decltype结合使用,可以写成:1
2
3
4template <typename T, typename U>
auto add(T t, U u) -> decltype(t + u) {
return t+u;
}
返回类型后置语法解决了返回值类型依赖于参数而导致难以确定返回值类型的问题。1
2
3
4
5
6
7int& foo(int& i);
float foo(float& f);
template <typename T>
auto func(T& val) -> decltype(foo(val)) {
return foo(val);
}
模板的细节改进
模板的右尖括号
尽可能将多个右尖括号解析成模板参数结束符。
模板的别名
重定义一个模板1
2
3
4template <typename Val>
using str_map_t = std::map<std::string, Val>;
str_map_t<int> map1;
使用新的using别名语法定义了std::map的模板别名str_map_t。
实际上,using的别名语法覆盖了typedef的全部功能,两种使用方法等效。1
2
3
4
5typedef unsigned int uint_t;
using uint_t = unsigned int;
typedef std::map<std::string, int> map_int_t;
using map_int_t = std::map<std::string, int>;
using定义模板别名:1
2
3template <typename T>
using func_t = void(*)(T, T);
func_t<int> xx_2;
函数模板的默认模板参数
1 | template <typename T = int> |
当所有模板参数都有默认参数时,函数模板的调用如同一个普通参数,对于类模板而言,哪怕所有参数都有默认参数,在使用时也要在模板名后跟一个“<>”实例化。
1 | template <typename R = int, typename U> |
在调用函数模板时,若显式指定模板参数,由于参数填充顺序是从左往右的,因此,像下面这个调用,func<long>(123),func的返回值是long,而不是int。
列表初始化
在C++98/03中的对象初始化方法有多种。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int i_arr[3] = {1, 2, 3};
struct A {
int x;
struct B {
int i;
int j;
} b;
} a = { 1, {2, 3} };
int i = 0;
class Foo {
public:
Foo(int) {}
} foo = 123;
C++11中提出了列表初始化的概念。1
2
3
4
5Foo a3 = {123};
Foo a4 {123};
int a5 = {3};
int s6 {3};
a3虽然使用了等于号,但是仍然是列表初始化,因此,私有的拷贝构造不会影响到它。
a4和a6的写法是C++98/03不具备的,可以直接在变量名后跟上初始化列表,来进行对象的初始化。
new操作符等可以用圆括号初始化的地方可以使用初始化列表:1
2
3int* a = new int {123};
double b = double {123};
int* arr = new int[3] {1, 2, 3};
聚合类型:
- 类型是一个普通数组
- 类型是一个类,且
- 无用户定义的构造函数
- 无私有或保护的非静态数据成员
- 无基类
- 无虚函数
- 不能有{}和=直接初始化的非静态数据成员
对数组而言,只要该类型是一个普通数组,哪怕数组的元素并非聚合类型,这个数组本身也是一个聚合类型:1
2
3
4
5
6int x[] = {1, 3, 5};
float y[4][3] = {
{1, 3, 5},
{2, 4, 6},
{3, 5, 7}
}
当类型是一个类时,首先是存在用户自定义构造函数时,1
2
3
4
5
6
7struct Foo {
int x;
double y;
int z;
Foo(int, int) {}
};
Foo foo{1, 2.5, 1}; // ERROR!
这时无法将Foo看成一个聚合类型,必须以自定义构造函数构造对象。
如果受保护(protected)成员是一个static的,则可以不放在初始化列表里。
如果类定义里的成员变量已经有了赋值,则不可以使用初始化列表。
上述不可使用初始化列表的情况可以通过自定义构造函数实现使用初始化列表
初始化列表
任意长度初始化列表
C++11中的stl容器拥有和未显示指定长度的数组一样的初始化能力:1
2
3
4int arr[] = {1, 2, 3};
std::map<std::string, int> mm = { {"1", 1}, {"2", 2}, {"3", 3} };
std::set<int> ss = {1, 2, 3};
std::vector<int> arr = {1, 2, 3, 4, 5};
这里arr未显式指定长度,因此它的初始化列表可以是任意长度。
实际上stl中的容器是通过使用std::initializer_list这个类模板完成上述功能的,如果在类Foo中添加一个std::initializer_list构造函数,它也将拥有这种能力。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Foo {
std::vector<int> content;
public:
Foo(std::initializer_list<int> list) {
for(auto it = list.begin(); it != list.end(); it ++){
content.push_back(*it);
}
}
}
class Foo1 {
std::map<int, int> content;
using pair_t = std::map<int, int>::value_type;
public:
Foo1(std::initializer_list<int> list) {
for(auto it = list.begin(); it != list.end(); it ++){
content.insert(*it);
}
}
}
Foo foo = {1, 2, 3, 4, 5, 6};
Foo1 foo1 = { {1, 2}, {2, 3}, {3, 4} };
用来传递同类型的数据集合:1
2
3
4
5void func(std::initializer_list<int> list) {
for(auto it = list.begin(); it != list.end(); it ++){
std::cout << *it << std::endl;
}
}
std::initializer_list的一些特点:
- 轻量级容器类型,内部定义了iterator等;
- 对于
std::initializer_list<T>,可以接受任意长度的初始化列表,但要求必须时同种类型; - 有三个成员接口:
size()、begin()、end(); - 只能被整体初始化或赋值。
- 只能通过begin和end循环遍历,遍历时取得的迭代器是只读的,因此无法修改其中一个值。
- 实际上,
std::initializer_list非常高效,内部并不负责保存初始化列表中元素的拷贝,而是只储存列表中元素的引用而已。
防止类型收窄
类型收窄指导致数据内容发生变化或精度损失的隐式类型转换,包含以下几种:
- 从浮点数隐式转换为整型;
- 从高精度浮点数转换为低精度浮点数,如从long double转换为double或float;
- 从整型数隐式转换为浮点数,并超过了浮点数表示范围;
- 从整型数隐式转换为长度较短的整型数。
初始化列表不会允许类型收窄的转换发生。
基于范围的for循环
for循环的新用法
在<algorithm>中有for_each可以用于遍历:1
2
3
4
5
6
7
8
9
10
11
12#include <algorithm>
#include <iostream>
#include <vector>
void do_cout(int n) {
std::cout << n << std::endl;
}
int main() {
std::vector<int> arr;
std::for_each(arr.begin(), arr.end(), do_cout);
return 0;
}
可以改成:1
2
3
4
5
6
7
8
9
10#include <iostream>
#include <vector>
int main() {
std::vector<int> arr;
for(auto n : arr) {
std::cout << n << std::endl;
}
return 0;
}
n表示arr中的一个个元素,auto则是让编译器自动推导n的类型,在这里n的类型被自动推导为vector中的元素类型int。
基于范围的for循环对于冒号前边的局部变量声明只要求能支持容器类型的隐式转换。
如果需要在遍历时修改容器中的值,则需要使用引用:1
2
3for(auto& n : arr) {
std::cout << n++ << std::endl;
}
基于范围的for循环的细节
auto自动推导出的类型是容器中的value_type,而不是迭代器:1
2
3
4
5std::map<std::string, int> mm = { {"1", 1}, {"2", 2}, {"3", 3} };
for(auto ite = mm.begin(); ite != mm.end(); ite ++)
std::cout << ite->first << "->" << ite->second << std::endl;
for(auto& val : mm)
std::cout << ite.first << "->" << ite.second << std::endl;
从这里就可以看出,在基于范围的for循环中每次迭代时使用的类型和普通for循环有何不同。
对基于范围的for循环而言,冒号后边的表达式只会被执行一次
基于范围的for循环倾向于在循环开始之前确定好迭代的范围,而不是在每次迭代之前都调用一次arr.end()
让基于范围的for循环支持自定义类型
基于范围的for循环将以以下方式查找容器的begin和end:
- 若容器是一个普通的array对象,那么begin将为array的首地址;
- 若容器是一个类对象,那么range-based for将试图通过查找类的begin()和end()方法来定位begin和end迭代器;
- 否则range-based for将试图使用全局的begin和end函数定位begin和end;
对于自定义类型来说,实现begin和end方法即可,通过定义一个range对象看看具体的实现方法。
首先需要一个迭代器实现范围取值:1
2
3
4
5
6
7
8
9
10
11template <typename T>
class iterator {
public:
using value_type = T;
using size_type = size_t;
iterator(size_type cur_start, value_type begin_val, value_type step_val);
value_type operator*() const;
bool operator!=(const iterator& rhs);
iterator& operator++(void);
}
构造函数传递三个参数初始化,分别是开始的迭代次数,初始值和迭代步长。operator*用于取得迭代器中的值;operator!=用于和另一个迭代器比较;operator++用于对迭代器做正向迭代。
迭代器类的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23template <typename T>
class iterator {
private:
size_type cursor_;
const value_type step_;
value_type value_;
public:
using value_type = T;
using size_type = size_t;
iterator(size_type cur_start, value_type begin_val, value_type step_val):
cursor_(cur_start), step_(step_val), value_(begin_val) {
value_ += (step_ * cursor_);
}
value_type operator*() const { return value_; }
bool operator!=(const iterator& rhs) const { return (cursor_ != rhs.cursor_); }
iterator& operator++(void) {
value_ += step_;
++ cursor_;
return (*this);
}
}
std::function和bind绑定器
可调用对象
可调用对象有如下几种定义:
- 是一个函数指针
- 是一个具有operator()成员函数的类对象
- 是一个可被转换为函数指针的类对象
- 是一个类成员指针
应用如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37void func(void) { ... }
struct Foo {
void operator()(void) { ... }
};
struct Bar {
using fr_t = void(*)(void);
static void func(void) { ... }
operator fr_t(void) { return func; }
};
struct A {
int a_;
void mem_func(void) { ... }
};
int main(){
void(* func_ptr)(void) = &func; // 1.函数指针
func_ptr();
Foo foo;
foo(); // 2. 仿函数
Bar bar;
bar(); // 3. 可被转换为函数指针的类对象
void (A::*mem_func_ptr)(void) = &A::mem_func; // 4. 类成员函数指针
int A::*mem_obj_ptr = &A::a_; // 或是类成员指针
A aa;
(aa.*mem_func_ptr)();
aa.*mem_obj_ptr = 123;
return 0;
}
可调用对象包装器-std::function
std::function是可调用对象包装器。它是一个类模板,可以容纳除了类成员指针之外的所有可调用对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#include <iostream>
#include <functional>
void func(void) {
std::cout << __FUNCTION__ << std::endl;
}
class Foo {
public:
static int foo_func(int a) {
std::cout << __FUNCTION__ << "(" << a << ") ->: ";
return a;
}
};
class Bar {
public:
int operator()(int a) {
std::cout << __FUNCTION__ << "(" << a << ") ->: ";
return a;
}
};
int main(){
std::function<void(void)> fr1 = func;
fr1();
std::function<int(int)> fr2 = Foo::foo_func;
std::cout << fr2(123) << std::endl;
Bar bar;
fr2 = bar;
std::cout << fr2(123) << std::endl;
}
结果是:1
2
3func
foo_func(123) ->: 123
operator()(123) ->: 123
给std::function填入合适的函数名,它就变成一个可以容纳所有这一类调用方式的函数包装器。
std::function作为函数入参:void call(int x, std::function<void(int)>& f)
std::bind绑定器
std::bind绑定器用来将可调用对象与其参数一起进行绑定,绑定后的结果使用std::function保存,并延迟调用到任何我们需要的时候,用途为:
- 将可调用对象与其参数一起绑定成为一个仿函数;
- 将多元可调用对象转成一元或者(n-1)元可调用对象,即只绑定部分参数。
1 | int main() { |
在这里,我们使用了std::bind,在函数外部通过绑定不同的函数,控制了最后的执行结果。我们使用auto fr保存std::bind的返回结果,是因为我们并不关心std::bind真正的返回类型(实际上std::bind的返回类型是一个stl内部定义的仿函数类型),只需要知道它是一个仿函数,可以直接赋值给一个std::function。当然,这里直接使用std::function类型来保存std::bind的返回值也是可以的。
std::placeholders::_1是一个占位符,代表这个位置将在函数调用时,被传入的第一个参数所替代。
1 | #include <iostream> |
lambda表达式
lambda表达式有如下优点:
- 声明式编程风格:就地匿名定义目标函数或函数对象,不需要额外写一个命名函数或者函数对象。以更直接的方式去写程序,有更好的可读性和可维护性。
- 简洁:不需要额外再写一个函数或者函数对象,避免了代码膨胀和功能分散,让开发者更加集中精力在手边的问题,同时也获取了更高的生产率。
- 在需要的时间和地点实现功能闭包,使程序更灵活。
lambda表达式的概念和基本用法
lambda表达式定义了一个匿名函数,并且可以捕获一定范围内的变量。 lambda表达式的语法形式可简单归纳如下:1
[capture] (params) opt -> ret { body; }
其中:capture是捕获列表; params是参数表;opt是函数选项;ret是返回值类型;body是函数体。一个完整的lambda表达式看起来像这样:1
2auto f = [](int a)-> int { return a + 1; };
std::cout << f(1) << std::endl;
输出:2。可以看到,上面通过一行代码定义了一个小小的功能闭包,用来将输入加1并返回。
在C++11中,lambda表达式的返回值是通过前面介绍的返回值后置语法来定义的。其实很多时候,lambda表达式的返回值是非常明显的,比如上例。因此,C++中允许省略lambda表达式的返回值定义:1
auto f= [] (int a) return a + 1; };
这样编译器就会根据 return语句自动推导出返回值类型。
另外,lambda表达式在没有参数列表时,参数列表是可以省略的。因此像下面的写法都是正确的:1
2
3auto fl =[](){ return 1; };
auto f2 = []{ return 1; };
//省略空参数表
lambda表达式可以通过捕获列表捕获一定范围内的变量:
- []不捕获任何变量。
- [&]捕获外部作用域中所有变量,并作为引用在函数体中使用(按引用捕获)。
- [=]捕获外部作用域中所有变量,并作为副本在函数体中使用(按值捕获)。
- [=, &foo]按值捕获外部作用域中所有变量,并按引用捕获foo变量。
- [bar]按值捕获bar变量,同时不捕获其他变量。
- [this]捕获当前类中的this指针,让lambda表达式拥有和当前类成员函数同样的访问权限。如果已经使用了&或=,就默认添加此选项。捕获this的目的是可以在lamda中使用当前类的成员函数和成员变量。
1 | class A { |
一个容易出错的细节是,1
2
3
4
5
6int a = 0;
auto f = [=] {return a;};
a += 1;
std::cout << f() << std::endl;
在这个例子中,lambda表达式按值捕获了所有外部变量,在捕获的一瞬间a的值就被复制到f中了,之后a被修改,但此时f中存储的a的值仍然是捕获时候的值,因此,最终输出结果是0。希望修改这些变量的话,我们需使用引用方式捕获。
按值捕获得到的外部变量值是在lambda表达式定义时的值。此时所有外部变量均被复制了一份存储在lambda表达式变量中。此时虽然修改 lambda表达式中的这些外部变量并不会真正影响到外部,我们却仍然无法修改它们。那么如果希望去修改按值捕获的外部变量应当怎么办呢?这时,需要显式指明lambda表达式为 mutable:1
2
3int a = 0;
auto f1 = [=] { return a++; }; // error,修改按值捕获的外部变量
auto f2 = [=]() mutable { return a++; }; // ok
被mutable修饰的lambda表达式就算没有参数也要写明参数列表。
lambda表达式的类型在C++11中被称为“闭包类型”。它是一个特殊的匿名的非nunion的类类型。因此,我们可以认为它是一个带有 operator()的类,即仿函数。因此,我们可以使用std::function和std::bind来存储和操作lambda表达式。1
2std::function<int(int)> f1 = [](int a) { return a; };
std: function<int(void)>f2 = std::bind([](int a) { return a;}, 123);
另外,对于没有捕获任何变量的lambda表达式,还可以被转换成一个普通的函数指针:1
2
3using func_t= int(*)(int);
func_t f = [](int a){ return a; };
f(123);
lambda表达式可以说是就地定义仿函数闭包的“语法糖”。它的捕获列表捕获住的任何外部变量,最终均会变为闭包类型的成员变量。而一个使用了成员变量的类的 operator(),如果能直接被转换为普通的函数指针,那么lambda表达式本身的this指针就丢失掉了。而没有捕获任何外部变量的 lambda表达式则不存在这个问题。
这里也可以很自然地解释为何按值捕获无法修改捕获的外部变量。因为按照C++标准,lambda表达式的operator默认是const的。一个const成员函数是无法修改成员变量的值的。而mutable的作用,就在于取消operator()的const。需要注意的是,没有捕获变量的lambda表达式可以直接转换为函数指针,而捕获变量的lambda表达式则不能转换为函数指针。看看下面的代码:1
2
3
4
5typedef void(*Ptr)(int*);
//正确,没有捕获的lambda表达式可以直接转换为函数指针
Ptr p = [](int* p) {delete p;};
Ptr pl = [&](int* p) {delete p;};
∥错误,有状态的1 ambda不能直接转换为函数指针
上面第二行代码能编译通过,而第三行代码不能编译通过,因为第三行的代码捕获了变量,不能直接转换为函数指针
tuple元组
tuple元组是一个固定大小的不同类型值的集合。1
tuple<const char*, int> tp = make_tuple(sendPack, nSendSize);
等价于一个结构体:1
2
3
4struct A {
char* p;
int len;
};
还有一种方法也可创建元组:1
2
3
4int x = 1;
int y = 2;
string s = "aa";
auto tp = std::tie(x, s, y);
tp的类型是std::tuple<int&, string&, int&>
再看看如何获取元组的值:1
2
3
4//获取第一个值
const char* data = tp.get<0>();
//获取第二个值
int len = tp.get<1>();
还有一种方法也可以获取元组的值,通过std::tie解包tuple1
2
3int x, y;
string a;
std::tie(x, a, y) = tp;
通过tie解包后,tp中3个值会自动赋值给3个变量。解包时,如果只想解某个位置值时,可以用std::ignore占位符来表示不解某个位置的值。比如我们只想解第3个值:1
std::tie(std::ignore, std::ignore, y) = tp;
还有一个创建右值的引用元组方法: forward_as_tuple1
2std::map<int, std::string> m;
m.emplace(std::piecewise_construct, std::forward_as_tuple(10), std::forward_as_tuple (20, 'a));
它实际上创建了一个类似于std::tuple<int&&,std::string&&>类型的tuple。
我们还可以通过tuple_cat连接多个tuple,代码如下:1
2
3
4
5
6
7int main() {
std::tuple<int, std::string, float> t1(10, "Test", 3.14);
int n = 7;
auto t2 = std::tuple_cat(t1, std::make_pair("Foo", "bar"), t1, std::tie(n));
n = 10;
print(t2);
}
结果是:1
(10, Test, 3.14, Foo, bar, 10, Test, 3.14, 10)
总结
本章主要介绍了通过一些C++11的特性简化代码,使代码更方便、简洁和优雅。首先讨论了自动类型推断的两个关键字auto和decltype,通过这两个关键字可以化繁为简,使我们不仅能方便地声明变量,还能获取复杂表达式的类型,将二者和返回值后置组合起来能解决函数的返回值难以推断的难题。
模板别名和模板默认参数可以使我们更方便地定义模板,将复杂的模板定义用一个简短更可读的名称来表示,既减少了烦琐的编码又提高了代码的可读性。
range-based for循环可以用更简洁的方式去遍历数组和容器,它还可以支持自定义的类型,只要自定义类型满足3个条件即可。
初始化列表和统一的初始化使得初始化对象的方式变得更加简单、直接和统一。
std::function不仅是一个函数语义的包装器,还能绑定任意参数,可以更灵活地实现函数的延迟执行。
lambda表达式能更方便地使用STL算法,就地定义的匿名函数免除了维护一大堆函数对象的烦琐,也提高了程序的可读性。
tuple元组可以作为一个灵活的轻量级的小结构体,可以用来替代简单的结构体,它有一个很好的特点就是能容纳任意类型和任意数量的元素,比普通的容器更灵活,功能也更强大。但是它也有复杂的一面, tuple的解析和应用往往需要模板元的一些技巧,对使用者有一定的要求。
使用C++11改进程序性能
右值引用
右值引用标记为T &&。
左值是指表达式结束后仍然存在的持久对象,右值是指表达式结束后就不再存在的临时对象。所有的具名变量或对象都是左值,而右值不具名。在C++11中,右值由两个概念构成,一个是将亡值,另一个则是纯右值。比如,非引用返回的临时变量、运算表达式产生的临时变量、原始字面量和lambda表达式等都是纯右值。而将亡值是C++1l新增的、与右值引用相关的表达式,如将要被移动的对象、T&&函数返回值,std::move返回值。
C+11中所有的值必属于左值、将亡值、纯右值三者之一,将亡值和纯右值都属于右值。区分表达式的左右值属性有一个简便方法:若可对表达式用&符取址,则为左值,否则为右值。比如,简单的赋值语句int i = 0,在这条语句中,i是左值,0是字面量,就是右值。在上面的代码中,i可以被引用,0就不可以了。字面量都是右值。
&&的特性
右值引用就是对一个右值进行引用的类型。因为右值不具名,所以我们只能通过引用的方式找到它。
无论声明左值引用还是右值引用都必须立即进行初始化,因为引用类型本身并不拥有所绑定对象的内存,只是该对象的一个别名。通过右值引用的声明,该右值又“重获新生”,其生命周期与右值引用类型变量的生命周期一样,只要该变量还活着,该右值临时量将会直存活下去。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#include <iostream>
using namespace std;
int g_constructCount = 0;
int g_copyConstructCount = 0;
int g_destructCount = 0;
struct A {
A() {
cout << "construct: " << ++g_constructCount << endl;
}
A(const A& a) {
cout << "copy construct: " << ++g_copyConstructCount << endl;
}
~A() {
cout << "destruct: " << ++g_destructCount << endl;
}
};
A getA() {
return A();
}
int main()
{
A a = getA();
return 0;
}1
2
3
4
5
6
7
8g++ -fno-elide-constructors -std=c++0x -O0 1.cpp -o 1
construct: 1
copy construct: 1
destruct: 1
copy construct: 2
destruct: 2
destruct: 3
在没有返回值优化的情况下,拷贝构造函数调用了两次,一次是getA()函数内部创建的对象返回后构造一个临时对象产生的,一次是在main构造a对象产生的。得如此的destruct是因为临时对象在构造a对象之后就销毁了。修改程序:1
2
3
4
5int main()
{
A&& a = getA();
return 0;
}
输出为:1
2
3
4construct: 1
copy construct: 1
destruct: 1
destruct: 2
通过右值引用,少了一次拷贝构造和一次析构,原因在于右值引用绑定了右值,让临时右值的生命周期延长了。避免临时对象的拷贝构造和析构,事实上,在C++98/03中,也通过常量左值引用来做性能优化。
实际上T&&并不是一定表示右值,它绑定的类型是未定的,既可能是左值又可能是右值。看看这个例子:1
2
3
4
5
6
7
8
9template<typename T>
void f(T&& param);
f(10);
// 10是右值
int x = 10;
f(x);
//x是左值
从这个例子可以看出, param有时是左值,有时是右值,因为在上面的例子中有&&,这表示param实际上是一个未定的引用类型。这个未定的引用类型称为 universal references(可以认为它是一种未定的引用类型),它必须被初始化,它是左值还是右值引用取决于它的初始化,如果&&被一个左值初始化,它就是一个左值;如果它被一个右值初始化,它就是个右值。
需要注意的是,只有当发生自动类型推断时(如函数模板的类型自动推导,或auto关键字),&&才是一个
universal references。1
2
3
4
5
6
7
8
9
10
11template <typename T>
void f(T&& param);
//这里T的类型需要推导,所以&&是一个 universal references
template<typename T>
class Test {
Test(Test&& rhs); // 已经定义了一个特定的类型,没有类型推断
// &&是一个右值引用
};
void f(Test&& param);
// 已经定义了一个确定的类型,没有类型推断,&&是一个右值引用
由于存在T&&这种未定的引用类型,当它作为参数时,有可能被一个左值引用或右值引用的参数初始化,这时经过类型推导的T&&类型,相比右值引用(&&)会发生类型的变化,这种变化被称为引用折叠:
- 所有的右值引用叠加到右值引用上还是一个右值引用;
- 所有的其他引用类型之间的叠加都将变成左值引用。
编译器会将已命名的右值引用视为左值,而将未命名的右值引用视作右值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void PrintValue(int& i) {
std::cout << "lvalue: " << i << std::endl;
}
void PrintValue(int&& i) {
std::cout << "rvalue: " << i << std::endl;
}
void Forward(int&& i) {
PrintValue(i);
}
int main() {
int i = 0;
PrintValue(i);
PrintValue(1);
Forward(2);
return 0;
}
输出:1
2
3lvalue: 0
rvalue: 1
lvalue: 2
Forward函数接收的是一个右值,但是在转发给PrintValue时,因为右值i变成一个命名对象,所以变成了左值。
&&的总结如下:
- 左值和右值是独立于它们的类型的,右值引用类型可能是左值也可能是右值。
- auto&&或函数参数类型自动推导的T&&是一个未定的引用类型,被称为universal references,它可能是左值引用也可能是右值引用类型,取决于初始化的值类型。
- 所有的右值引用叠加到右值引用上仍然是一个右值引用,其他引用折叠都为左值引用,当T&&为模板参数时,输入左值,它会变成左值引用;输入右值时变为具名的右值引用。
- 编译器会将已命名的右值引用视为左值,将未命名的右值引用视为右值。
在编写拷贝函数时,应该提供深拷贝的拷贝构造函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class A {
public:
A() : m_ptr(new int(0)) {
cout << "construct" << endl;
}
A(const A& a) : m_ptr(new int(*a.m_ptr)) {
cout << "copy construct" << endl;
}
~A() {
cout << "destruct" << endl;
delete m_ptr;
}
public:
int* m_ptr;
};
A get(bool flag) {
A a;
A b;
if (flag)
return a;
else
return b;
}
int main()
{
A a = get(false);
}
输出:1
2
3
4
5
6construct
construct
copy construct
destruct
destruct
destruct
这样可以保证拷贝的安全性。但这样的开销很大,get函数返回临时变量,然后通过这个临时变量拷贝构造了新的对象b,临时变量在拷贝完之后就销毁了,可以避免这种性能损耗:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class A {
public:
A() : m_ptr(new int(0)) {
cout << "construct" << endl;
}
A(const A& a) : m_ptr(new int(*a.m_ptr)) {
cout << "copy construct" << endl;
}
A(A&& a) : : m_ptr(a.m_ptr) {
a.m_ptr = nullptr;
cout << "move construct: "<< endl;
}
~A() {
cout << "destruct" << endl;
delete m_ptr;
}
public:
int* m_ptr;
};
A get(bool flag) {
A a;
A b;
if (flag)
return a;
else
return b;
}
int main()
{
A a = get(false);
}
输出:1
2
3
4
5
6construct
construct
move construct
destruct
destruct
destruct
上面的代码中没有了拷贝构造,取而代之的是移动构造( Move Construct)。从移动构造函数的实现中可以看到,它的参数是一个右值引用类型的参数A&&,这里没有深拷贝,只有浅拷贝,这样就避免了对临时对象的深拷贝,提高了性能。这里的A&&用来根据参数是左值还是右值来建立分支,如果是临时值,则会选择移动构造函数。移动构造函数只是将临时对象的资源做了浅拷贝,不需要对其进行深拷贝,从而避免了额外的拷贝,提高性能。也就是所谓的移动语义(move语义),右值引用的一个重要目的是用来支持移动语义的。
移动语义可以将资源(堆、系统对象等)通过浅拷贝方式从一个对象转移到另一个对象,这样能够减少不必要的临时对象的创建、拷贝以及销毁,可以大幅度提高C++应用程序的性能,消除临时对象的维护(创建和销毁)对性能的影响。
以代码清单22所示为示例,实现拷贝构造函数和拷贝赋值操作符。
1 | struct Element { |
先构造了一个临时对象t1,这个对象中存放了很多对象,数量可能很多,如果直接将这个t1用 push_back插入到vector中,没有右值版本的构造函数时,会引起大量的拷贝,这种拷贝会造成额外的严重的性能损耗。通过定义右值版本的构造函数以及std::move(t1)就可以避免这种额外的拷贝,从而大幅提高性能。
有了右值引用和移动语义,在设计和实现类时,对于需要动态申请大量资源的类,应该设计右值引用的拷贝构造函数和赋值函数,以提高应用程序的效率。需要注意的是,我们般在提供右值引用的构造函数的同时,也会提供常量左值引用的拷贝构造函数,以保证移动不成还可以使用拷贝构造。
关于左值和右值的定义
左值和右值在C中就存在,不过存在感不高,在C++尤其是C++11中这两个概念比较重要,左值就是有名字的变量(对象),可以被赋值,可以在多条语句中使用,而右值呢,就是临时变量(对象),没有名字,只能在一条语句中出现,不能被赋值。
在 C++11 之前,右值是不能被引用的,最大限度就是用常量引用绑定一个右值,如 :1
const int& i = 3;
在这种情况下,右值不能被修改的。但是实际上右值是可以被修改的,如 :1
T().set().get();
T 是一个类,set 是一个函数为 T 中的一个变量赋值,get 用来取出这个变量的值。在这句中,T() 生成一个临时对象,就是右值,set() 修改了变量的值,也就修改了这个右值。
既然右值可以被修改,那么就可以实现右值引用。右值引用能够方便地解决实际工程中的问题,实现非常有吸引力的解决方案。
右值引用
左值的声明符号为”&”, 为了和左值区分,右值的声明符号为”&&”。
给出一个实例程序如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18#include <iostream>
void process_value(int& i)
{
std::cout << "LValue processed: " << i << std::endl;
}
void process_value(int&& i)
{
std::cout << "RValue processed: " << i << std::endl;
}
int main()
{
int a = 0;
process_value(a);
process_value(1);
}
结果如下1
2
3
4wxl@dev:~$ g++ -std=c++11 test.cpp
wxl@dev:~$ ./a.out
LValue processed: 0
RValue processed: 1
Process_value 函数被重载,分别接受左值和右值。由输出结果可以看出,临时对象是作为右值处理的。
下面涉及到一个问题:
x的类型是右值引用,指向一个右值,但x本身是左值还是右值呢?C++11对此做出了区分:
Things that are declared as rvalue reference can be lvalues or rvalues. The distinguishing criterion is: if it has a name, then it is an lvalue. Otherwise, it is an rvalue.
对上面的程序稍作修改就可以印证这个说法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#include <iostream>
void process_value(int& i)
{
std::cout << "LValue processed: " << i << std::endl;
}
void process_value(int&& i)
{
std::cout << "RValue processed: " << std::endl;
}
int main()
{
int a = 0;
process_value(a);
int&& x = 3;
process_value(x);
}1
2
3
4wxl@dev:~$ g++ -std=c++11 test.cpp
wxl@dev:~$ ./a.out
LValue processed: 0
LValue processed: 3
x 是一个右值引用,指向一个右值3,但是由于x是有名字的,所以x在这里被视为一个左值,所以在函数重载的时候选择为第一个函数。
右值引用的意义
直观意义:为临时变量续命,也就是为右值续命,因为右值在表达式结束后就消亡了,如果想继续使用右值,那就会动用昂贵的拷贝构造函数。(关于这部分,推荐一本书《深入理解C++11》)
右值引用是用来支持转移语义的。转移语义可以将资源 ( 堆,系统对象等 ) 从一个对象转移到另一个对象,这样能够减少不必要的临时对象的创建、拷贝以及销毁,能够大幅度提高 C++ 应用程序的性能。临时对象的维护 ( 创建和销毁 ) 对性能有严重影响。
转移语义是和拷贝语义相对的,可以类比文件的剪切与拷贝,当我们将文件从一个目录拷贝到另一个目录时,速度比剪切慢很多。
通过转移语义,临时对象中的资源能够转移其它的对象里。
在现有的 C++ 机制中,我们可以定义拷贝构造函数和赋值函数。要实现转移语义,需要定义转移构造函数,还可以定义转移赋值操作符。对于右值的拷贝和赋值会调用转移构造函数和转移赋值操作符。如果转移构造函数和转移拷贝操作符没有定义,那么就遵循现有的机制,拷贝构造函数和赋值操作符会被调用。
普通的函数和操作符也可以利用右值引用操作符实现转移语义。
转移语义以及转移构造函数和转移复制运算符
以一个简单的 string 类为示例,实现拷贝构造函数和拷贝赋值操作符。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47class MyString {
private:
char* _data;
size_t _len;
void _init_data(const char *s) {
_data = new char[_len+1];
memcpy(_data, s, _len);
_data[_len] = '\0';
}
public:
MyString() {
_data = NULL;
_len = 0;
}
MyString(const char* p) {
_len = strlen (p);
_init_data(p);
}
MyString(const MyString& str) {
_len = str._len;
_init_data(str._data);
std::cout << "Copy Constructor is called! source: " << str._data << std::endl;
}
MyString& operator=(const MyString& str) {
if (this != &str) {
_len = str._len;
_init_data(str._data);
}
std::cout << "Copy Assignment is called! source: " << str._data << std::endl;
return *this;
}
virtual ~MyString() {
if (_data)
free(_data);
}
};
int main() {
MyString a;
a = MyString("Hello");
std::vector<MyString> vec;
vec.push_back(MyString("World"));
}1
2Copy Assignment is called! source: Hello
Copy Constructor is called! source: World
这个 string 类已经基本满足我们演示的需要。在 main 函数中,实现了调用拷贝构造函数的操作和拷贝赋值操作符的操作。MyString(“Hello”) 和 MyString(“World”) 都是临时对象,也就是右值。虽然它们是临时的,但程序仍然调用了拷贝构造和拷贝赋值,造成了没有意义的资源申请和释放的操作。如果能够直接使用临时对象已经申请的资源,既能节省资源,有能节省资源申请和释放的时间。这正是定义转移语义的目的。
我们先定义转移构造函数。1
2
3
4
5
6
7 MyString(MyString&& str) {
std::cout << "Move Constructor is called! source: " << str._data << std::endl;
_len = str._len;
_data = str._data;
str._len = 0;
str._data = NULL;
}
有下面几点需要对照代码注意:
- 参数(右值)的符号必须是右值引用符号,即“&&”。
- 参数(右值)不可以是常量,因为我们需要修改右值。
- 参数(右值)的资源链接和标记必须修改。否则,右值的析构函数就会释放资源。转移到新对象的资源也就无效了。
现在我们定义转移赋值操作符。1
2
3
4
5
6
7
8
9
10 MyString& operator=(MyString&& str) {
std::cout << "Move Assignment is called! source: " << str._data << std::endl;
if (this != &str) {
_len = str._len;
_data = str._data;
str._len = 0;
str._data = NULL;
}
return *this;
}
这里需要注意的问题和转移构造函数是一样的。
增加了转移构造函数和转移复制操作符后,我们的程序运行结果为 :
由此看出,编译器区分了左值和右值,对右值调用了转移构造函数和转移赋值操作符。节省了资源,提高了程序运行的效率。
有了右值引用和转移语义,我们在设计和实现类时,对于需要动态申请大量资源的类,应该设计转移构造函数和转移赋值函数,以提高应用程序的效率。
但是这几点总结的不错
- std::move执行一个无条件的转化到右值。它本身并不移动任何东西;
- std::forward把其参数转换为右值,仅仅在那个参数被绑定到一个右值时;
- std::move和std::forward在运行时(runtime)都不做任何事。
move语义
std::move将左值转换为右值,从而方便应用移动语义。move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转移没有拷贝。
move实际上并不移动任何东西,它唯一的功能是将一个左值强制转换为一个右值引用,是我们可以通过右值引用使用该值,以用于移动语义。
仅仅转移资源的所有者,将资源的拥有者改为被赋值者。假设一个临时容器很大,赋值给另一个容器:1
2
3
4
5std::list<std::string> tokens;
std::list<std::string> t = tokens;
std::list<std::string> tokens;
std::list<std::string> t = std::move(tokens);
如果不用std::move,拷贝的代价很大,性能较低,使用move几乎没有任何代价,只是转换了资源的所有权,实际上是将左值转换为右值引用,然后应用move语义调用构造函数,就避免了拷贝。
forward和完美转发
需要一种方法能按照参数原来的类型转发到另一个函数,这种转发被称作完美转发,即在函数模板中,完全依照模板的参数的类型(保持参数的左右值特征),将参数传递给函数模板中调用的另一个函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21void PrintT(int& t) {
cout << "lvalue" << endl;
}
void PrintT(int&& t) {
cout << "rvalue" << endl;
}
template<typename T>
void TestForward(T && t) {
PrintT(t);
PrintT(std::forward<T>(t));
PrintT(std::move(t));
}
int main() {
TestForward(1);
int x = 1;
TestForward(x);
TestForward(std::forward<int>(x));
return 0;
}
输出:1
2
3
4
5
6
7
8
9lvalue
rvalue
rvalue
lvalue
lvalue
rvalue
lvalue
rvalue
rvalue
TestForward(1)时,1是右值,所以未定义的引用类型T&& t被一个右值初始化后变成一个右值引用。但是在TestForward中调用PrintT(t)时,t变成一个左值。调用PrintT(std::forward<T>(t))时,std::forward会按照原来的参数类型转发,所以它还是一个右值。
TestForward(x)未定的引用类型T&& t被一个左值初始化后变成一个左值引用,因此,在调用PrintT(std::forward<T>(t))时它会被转发到PrintT(T& t)
emplace_back减少内存拷贝和移动
emplace_back能就地通过参数构造对象,不需要拷贝或者移动内存,相比push_back能更好地避免内存的拷贝与移动,使容器插入元素的性能得到进一步提升。在大多数情况下应该优先使用emplace_back来代替push_back。
所有的标准库容器(array除外,因为它的长度不可改变,不能插入元素)都增加了类似的方法: emplace、 emplace_hint、 emplace_front、emplace_after和emplace_back。
vector的emplace_back的基本用法如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#include <vector>
#include <iostream>
using namespace std;
struct A {
int x;
double y;
A(int a, double b): x(a), y(b);
};
int main() {
vector<A> v;
v.emplace_back(1, 2);
cout<<v.size()<<endl;
return 0;
}
可以看出, emplace_back的用法比较简单,直接通过构造函数的参数就可以构造对象。因此,也要求对象有对应的构造函数,如果没有对应的构造函数,编译器会报错。
其他容器相应的 emplace方法也是类似的。
相对 push_back而言, emplace_back更具性能优势。
在引入右值引用,转移构造函数,转移复制运算符之前,通常使用push_back()向容器中加入一个右值元素(临时对象)的时候,首先会调用构造函数构造这个临时对象,然后需要调用拷贝构造函数将这个临时对象放入容器中。原来的临时变量释放。这样造成的问题是临时变量申请的资源就浪费。
引入了右值引用,转移构造函数(请看这里)后,push_back()右值时就会调用构造函数和转移构造函数。
unordered container无序容器
C++11增加了无序容器 unordered_map/unordered_multimap和unordered_set/unordered_multiset,由于这些容器中的元素是不排序的,因此,比有序容器 map/multimap和set/multiset效率更高。
map和set内部是红黑树,在插入元素时会自动排序,而无序容器内部是散列表( Hash Table),通过哈希(Hash),而不是排序来快速操作元素,使得效率更高。由于无序容器内部是散列表,因此无序容器的key需要提供hash_value函数,其他用法和map/set的用法是一样的。不过对于自定义的key,需要提供Hash函数和比较函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44#include <unordered_map>
#include <vector>
#include <bitset>
#include <string>
#include <utility>
struct Key {
std::string first;
std::string second;
};
struct KeyHash {
std::size_t operator()(const Key& k) const {
return std::hash<std::string>()(k.first)^(std::hash<std::string>()(k.second) << 1);
}
};
struct keyEqual {
bool operator()(const Key& lhs, const Key& rhs) const {
return lhs.first == rhs.first && lhs.second == rhs.second;
}
};
int main() {
std::unordered_map<std::string, std::string> m1;
std::unordered_map<int, std::string> m2 = {
{1, "foo"},
{2, "bar"},
{3, "baz"},
};
std::unordered_map<int, std::string> m3 = m2;
std::unordered_map<int, std::string> m4 = std::move(m2);
std::vector<std::pair<std::bitset<8>, int>> v = { {0x12, 1}, {0x01, -1} };
std::unordered_map<std::bitset<8>, double> m5(v.begin(), v.end());
// constructor for a custom type
std::unordered_map<Key, std::string, KeyHash, KeyEqual> m6 = {
{ {"john", "doe"}, "example"},
{ {"mary", "Sue"}, "another"},
};
return 0;
}
使用C++11消除重复,提高代码质量
type_traits——类型萃取
type_traits的类型判断功能在编译期就可以检查出是否是正确的类型,以便能编写更安全的代码。
基本的type_traits
在之前的C++中,在类中定义编译期常量的方法是:
1 | template<typename T> |
在C++11中定义编译期常量,无需自己定义static const int或enum类型,只需要从std::integral_constant派生:
1 | template<typename T> |
将编译期常量包装为一个类型的type_trait——integral_constant:
1 | template<class T, T v> |
常见的用法是从integral_constant派生从而可以通过继承得到value
派生的type_traits可用于检查模板类型是否为某种类型,通过这些trait可以获取编译期检查的bool值结果。
1 | template<class T> |
这是用来检查T是否为bool、char、int、long、long long等整型类型的,派生于std::integral_constant,因此可以通过std::is_xxx::value是否为true判断模板类型是否为目标类型。
1 | #include <iostream> |
C++提供了判断类型之间的关系的traits:
1 | template<class T, class U> |
C++提供了类型转换traits,包括对const的修改,引用的移除和添加,指针和数组的修改等。
1 | template <typename T> |
有时需要添加引用类型,比如从智能指针中获取对象的引用时
1 | #include <iostream> |
移除引用和cv符:
1 | template<typename T> |
先移除引用,再移除cv符,最终获得原始类型,这样可以解决问题,但是较为繁琐,用decay来简化代码:
1 | template<typename T> |
对于普通类型来说,std::decay是移除引用和cv符,大大简化了我们的书写。除了普通类型之外,std::decay还可以用于数组和函数,具体的转换规则如下:
- 先移除T类型的引用,得到类型U,U定义为
remove_reference<T>::type - 如果
is_array<U>::value为true,修改类型type为remove_extent<U>::type* - 否则,如果
is_function<U>::value为true,修改类型type为add_pointer<U>::type - 否则,修改类型type为
remove_cv<U>::type
根据上面的规则,再对照用法示例,就能清楚地理解std::decay的含义了。下面是std::decay的基本用法:
1 | typedef std::decay<int>::type A; // int |
由于std::decay对于函数来说是添加指针,利用这一点,我们可以将函数变成函数指针类型,从而将函数指针变量保存起来,以便在后面延迟执行。
std::conditional在编译期根据一个判断式选择两个类型中的一个,和条件表达式的语义类似,类似一个三元表达式。它的原型如下:
1 | template< bool B, class T, class F> |
std::conditional模板参数中,如果B为true,则conditional::type为T,否则为F。std::conditional测试代码如下:
1 | typedef std::conditional<true, int, float>::type A; // int |
比较两个类型,输出较大的那个类型:
1 | typedef std::conditional<(sizeof(long long) > sizeof(long double)), long long, long double>::type max_size_t; |
将会输出: long double
我们可以通过编译期的判断式来选择类型,这给我们动态选择类型提供了很大的灵活性,在后面经常和其他的C++11特性配合起来使用,是比较常用的特性之一。
有时要获取函数的返回类型是一件比较困难的事情,C++提供了std::result_of,用来在编译期获取一个可调用对象。
1 | std::result_of<A(int)>::type i = 4; |
等价于
1 | decltype(std::declval<A>()(std::declval<int>())); |
std::result_of原型如下:
1 | template<class F, class ... ArgTypes> |
第一个模板参数为可调用对象的类型,第二个模板参数为参数的类型。
1 | int fn(int) { return int(); } |
std::result_of<Fn(ArgTypes...)>要求Fn为一个可调用对象(不能是个函数类型,因为函数类型不是一个可调用对象,因此,下面这种方式是错误的:
1 | typedef std::result_of<decltype(fn)(int)>::type A; |
如果要对某个函数使用std::result_of,要先将函数转换为可调用对象。可以通过以下方式来获取函数返回类型
1 | typedef std::result_of<decltype(fn)&(int)>::type A; |
可变参数模板
声明可变参数模板时需要在typename或class后边带上’…’。
- 声明一个参数包,这个参数包中可以包含0到任意个模板参数
- 在模板定义的右边,可以把参数包展开成一个一个独立的参数
可变参数模板函数
1 | template <class ... T> |
如果要用参数包中的参数,则一定要将参数包展开,有两种展开参数包的方法,一种是递归的模板函数展开,一种是通过逗号表达式和初始化列表方式展开。
通过递归函数展开参数包,需要提供一个参数包展开的函数和一个递归终止函数。
1 | #include <iostream> |
输出:
1 | parameter 1 |
递归终止函数可以写成如下形式:
1 | template<typename T, typename T1, typename T2> |
另一种方法是:
1 | template <class T> |
这种就地展开参数包的方式关键是逗号表达式,它会按顺序执行逗号前边的表达式。expand()函数中的(printarg(args), 0),先执行printarg(args),再得到逗号表达式的结果0。同时用到了初始化列表,通过初始化列表来初始化一个变长数组。{(printargs(args), 0)...}将会展开成((printargs(arg1), 0), (printargs(arg2), 0), (printargs(arg3), 0), etc...),最终会创建一个所有元素为0的数组int arr[sizeof(Args)],会先执行表达式前面的printarg打印出参数。
可变参数模板类
1 | template <class... Types> |
这个可变参数模板类可以携带任意类型任意个数的模板参数:
1 | std::tuple<int> tp1 = std::make_tuple(1); |
模板递归和特化方式展开参数包
可变参数模板类的展开一般需要定义2 ~ 3个类,包含类声明和特化的模板类
1 | template <typename... nums> struct Sum;// 变长模板的声明 |
一个基本的可变参数模板应用类由三部分组成:
第一个是template<typename... Args> struct Sum,这是前向声明,声明这个类是可变参数模板类
第二个是类的定义,它定义了一个部分展开的可变参数模板类,告诉编译器如何递归展开参数包
1 | template <typename First, typename... last> |
第三个是特化的递归终止类,这是在展开到0个参数时终止,也可以在展开到2个时终止。
1 | template<> |
可变参数消除重复代码
1 | template<typename T> |
通过可变模板参数可以消除重复,同时去掉参数个数限制:
1 | template<typename ... Args> |
上边的代码T* Instance(Args... args)的Args是值拷贝的,存在性能损耗,可以通过完美转发来消除损耗:
1 | template<typename ... Args> |
可变参数模板和type_traits的综合应用
optional的实现
C+14中将包含一个std::optional类,它的功能及用法和boost的optional类似。optional<T>内部存储空间可能存储了T类型的值也可能没有存储T类型的值,只有当optional被T初始化之后,这个optional才是有效的,否则是无效的,它实现了未初始化的概念。
optional可以用于解决函数返回无效值的问题,有时根据某个条件去查找对象时,如果查找不到对象,就会返回一个无效值,这不表明函数执行失败,而是表明函数正确执行了,只是结果不是有用的值。这时就可以返回一个未初始化的optional对象,判断这个optional对象是否是有效对象需要判断它是否被初始化,如果没有被初始化就表明这个值是无效的。boost中的optional就实现了这种未初始化的概念。 boost.optional的基本用法很简单:
1 | optional<int> op; |
第一个op由于没有被初始化,所以它是一个无效值,将不会输出打印信息;第二个op被初始化为1,所以它是一个有效值,将会输出1。optional经常用于函数返回值。
由于optionalstd::aligned_storage,原型如下,其中,Len表示所存储类型的size,Align表示该类型内存对齐的大小,通过sizeof(T)可以获取T的size,通过alignof(T)可以获取T内存对齐的大小:
1 | template< std::size_t Len, std::size_t Align = /* default-alignment */ > |
需要注意拷贝和赋值时,内部状态和缓冲区销毁的问题。内部状态用来标示该optional是否被初始化,当已经初始化时需要先将缓冲区清理一下。需要增加右值版本优化效率。
1 | #include <type_traits> |
惰性求值类lazy的实现
惰性求值(Lazy Evaluation)是相对常用的编程语言中的及早求值而言的另一种求值策略,也被称之为按需调用(call-by-need),或者叫延时求值。简单地讲,惰性求值是在谋求一种平衡,一种在节省开发与节约计算资源的一种平衡策略。一个庞大的类实例可能一次只有一小部分会发生更改,如果把其他的东西都盲目的添加进来,就会额外造成不少的计算资源的浪费。因此,在开发时,开发人员不仅要知道高级语言的语法糖,也需要一定的底层 AST 的实现原理,这样能够避免很多不必要的运行时开销。所以,这里的惰性,更多的是指等待的意思:一旦等到了明确的调用命令,自然会把运行结果正确送出。
借助lambda表达式,将函数封装到lambda表达式中,而不是马上求值,是在需要的时候再调用lambda表达式来求值
1 | template<typename T> |
Lazy类用到了std::function和optional,其中std::function用来保存传入的函数,不马上执行,而是延迟到后面需要使用值的时候才执行,函数的返回值被放到一个optional对象中,如果不用optional,则需要增加一个标识符来标识是否已经求值,而使用optional对象可以直接知道对象是否已经求值,用起来更简便。
通过optional对象我们就知道是否已经求值,当发现已经求值时直接返回之前计算的结果,起到缓存的作用。
代码清单后一部分定义了一个辅助函数,该辅助函数的作用是更方便地使用Lazy,因为Lazy类需要一个模板参数来表示返回值类型,而type_traits中的std::result_of可以推断出函数的返回值类型,所以这个辅助函数结合std::result_of就无须显式声明返回类型了,同时可变参数模板消除了重复的模板定义和模板参数的限制,可以满足所有的函数入参,在使用时只需要传入一个函数和其参数就能实现延迟计算。
Lazy内部的std::function
1 | struct BigObject { |
输出:
1 | 8 |
dll帮助类
如果要按照
1 | Ret CallDllFunc(const string& funName, T arg) |
这种方式调用,则首先要把函数指针转换成一种函数对象或泛型函数,这样可以用std::function做这件事。
封装GetProcAddress,将函数指针转换成std::function
1 | template<typename T> |
T是std::function的模板参数,即函数类型的签名。
1 | auto fmax = GetFunction<int(int, int)>("Max"); |
解决函数返回值与入参不一样的问题,通过result_of和可变参数模板解决:
1 | template <typename T, typename ... Args> |
lambda链式调用
将多个函数按照前一个的输出作为下一个输入串起来再推迟到某个时刻计算。
首先创建一个task对象,然后连续调用then的函数,只需要保证前一个函数的输出为后一个的输入即可。最后在需要的时候调用计算结果。
1 | template<typename T> |
输出:
1 | run task result:6 |
any类的实现
boost库有一个Any类,是一个特殊的只能容纳一个元素的容器,他可以擦除类型,给任何类型赋值。
1 | boost::any a = 1; |
vector中可以存放int和double,因为any擦除了int和double的类型,当通过any_cast
any能容纳所有类型的数据,因此,当赋值给any时,需要将值的类型擦除,即以一种通用的方式保存所有类型的数据。这里可以通过继承去擦除类型,基类是不含模板参数的,派生类中才有模板参数,这个模板参数类型正是赋值的类型。在赋值时,将创建的派生类对象赋值给基类指针,基类的派生类携带了数据类型,基类只是原始数据的一个占位符,通过多态的隐式转换擦除了原始数据类型,因此,任何数据类型都可以赋值给它,从而实现能存放所有类型数据的目标。当取数据时需要向下转换成派生类型来获取原始数据,当转换失败时打印详情,并抛出异常。由于向any赋值时需要创建一个派生类对象,所以还需要管理该对象的生命周期,这里用unique_ptr智能指针去管理对象的生命周期。
1 | class Any |
function_traits
可以获得普通函数、函数指针、std::function、函数对象和成员函数的函数类型、返回类型、参数个数和参数的具体类型。
例如:
1 | int func(int a, string b); |
通过function_traits可以很方便地获取所有函数语义类型丰富的信息,对于实际开发很有用。
实现 function_traits的关键技术
实现function_traits关键是要通过模板特化和可变参数模板来获取函数类型和返回类型。
先定义一个基本的function_traits的模板类
1 | template<typename T> |
再通过特化,将返回类型和可变参数模板作为模板参数,就可以获取函数类型、函数返回值和参数的个数了。基本的特化版本如下:
1 | template<typename Ret, typename... Args> |
variant的实现
variant类似于union,它能代表定义的多种类型,允许将不同类型的值赋给它。它的具体类型是在初始化赋值时确定。boost中的variant的基本用法:
1 | typedef variant<int,char, double> vt; |
用variant一个好处是可以擦除类型,不同类型的值都统一成一个variant,虽然这个variant只能存放已定义的类型,但这在很多时候已经够用了。 取值的时候,通过get
打造variant需要解决的问题
第一,要在内部定义一个char缓冲区。缓冲区用来存放variant的值,这个值是variant定义的多种类型中的某种类型的值,因此,这个缓冲区要足够大,能够存放类型最大(sizeof(Type))的值才可以,这个缓冲区的大小还必须在编译期计算出来。因此需要首先要解决的是variant值存放的缓冲区定义的问题。同时注意内存对齐,使用std::aligned_storage作为variant值存放的缓冲区。
第二,要解决赋值的问题。将值赋给vairiant时,需要将该值的类型ID记录下来,以便在后面根据类型取值。将值保存到内部缓冲区时,还需要用palcement new在缓冲区创建对象。另外,还要解决一个问题,就是赋值时需要检查variant中已定义的类型中是否含有该类型,如果没有则编译不通过,以保证赋值是合法的。
variant的赋值函数要做两件事:第一是从原来的variant中取出缓冲区中的对象;第二是通过缓冲区中取出的对象构造出当前variant中的对象。赋值函数的左值和右值的实现如下:
1 | Variant(Variant<Types...>&& old) : m_typeIndex(old.m_typeIndex) { |
第三,解决取值的问题,通过类型取值时,要判断类型是否匹配,如果不匹配,将详情打印出来,方便调试。
打造variant的关键技术:
找出最大的typesize。第一个问题中需要解决的问题是如何找出多种类型中,size最大的那个类型的size。看看如何从多种类型中找出最大类型的size。
1 | template<typename T, typename... Args> |
通过这个MaxType就可以在编译期获取类型中最大的maxsize了:MaxType<Types...>::value。
这里通过继承和递归方式来展开参数包,在展开参数包的过程中将第一个参数的size和后面一个参数的size做比较,获取较大的那个size,直到比较完所有的参数,从而获得所有类型中最大的size,比较的过程和冒泡排序的过程类似。内存对齐的缓冲区aligned_storage需要两个模版参数,第一个是缓冲区大小,第二个是内存对齐的大小。 variant中的aligned_storage中的缓冲区大小就是最大类型的sice,我们已经找出,下一步是找出最大的内存对齐大小。我们可以在MaxType的基础上来获取MaxAligin。
1 | template<typename... Args> |
类型检查和缓冲区中创建对象
第二个问题中需要解决两个问题,1.检查赋值的类型是否在已定义的类型中;2.在缓冲区中创建对象及析构;
1 | template < typename T, typename... List > |
通过bool值Contains
再看看如何在缓冲区中创建对象。
通过placement new在该缓冲区上创建对象,new(data) T(value);,其中data表示一个char缓冲区,T表示某种类型。在缓冲区上创建的对象还必须通过~T去析构,因此还需要一个析构vairiant的帮助类:
1 | template<typename T, typename... Args> |
取值问题
1 | template<typename T> |
测试:
1 | void TestVariant() |
ScopeGuard
ScopeGuard的作用是确保资源面对异常时总能被成功释放,就算没有正常返回。惯用法让我们在构造函数里获取资源,当因为异常或者正常作用域结束,那么在析构函数里释放资源。总是能释放资源。如果没有异常抛出则正常结束,只是有异常发生或者没有正常退出时释放资源。
通过局部变量析构函数来管理资源,根据是否正常退出来确定是否需要清理资源。
1 | template <typename F> |
tuple_helper
std::tuple作为一个泛化的std::pair,它的一个独特特性是能容纳任意个数任意类型的元素。
tuple还需要一些常用操作,比如打印、遍历、根据元素值获取索引位置、反转和应用于函数。
- 打印:由于tuple中的元素是可变参数模板,外面并不知道内部到底是什么数据,有时调试需要知道其具体值,希望能打印出tuple中所有的元素值。
- 根据元素值获取索引位置: tuple接口中有根据索引位置获取元素的接口,根据元素值来获取索引位置是相反的做法。
- 获取索引:在运行期根据索引获取索引位置的元素。
- 遍历:类似于std::for_each算法,可以将函数对象应用于tuple的每个元素。
- 反转:将tuple中的元素逆序。
- 应用于函数:将tuple中的元素进行一定的转换,使之成为函数的入参。
打印tuple
tuple不同于数组和集合,不能通过for循环的方式枚举并打印元素值,需要借助可变参数模板的展开方式来打印出元素值。但是 tuple又不同于可变参数模板不能直接通过展开参数包的方式来展开,因为tuple中的元素需要用std::get<T>(tuple)来获取,展开tuple需要带索引参数。有两种方法可以展开并打印tuple,第一种方法是通过模板类的特化和递归调用结合来展开 tuple;另一种方法是通过一个索引序列来展开tuple。
(1)通过模板特化和递归来展开并打印tuple
因为tuple内部的元素个数和类型是不固定的,如果要打印tuple中的元素,需要在展开tuple时一一打印,展开并打印tuple的代码:
1 | template<class Tuple, std::size_t N> |
模板类TuplePrinter带有一个模板参数std::size_t N,这个N是用来控制递归调用的,每调用一次,这个N就减1,直到减为1为止。 PrintTuple是一个帮助函数,目的是为了更方便地调用TuplePrinter,因为Tupleprinter需要两个参数,一个是tuple,另一个是tuple的size。tuple的size是可以通过sizeof来获取的,在帮助函数中获取tuple的size并调用TuplePrinter,就可以减少外面调用的入参。测试代码如下:
1 | void TestPrint() { |
输出:(1, 2, 3, 'a')
调用过程如下:
1 | Tupleprinter<std::tuplecint, short, double, char>, 4>:: print(tp); |
当递归终止时,打印第一个元素的值:
1 | std::cout << std::get<0>(t); |
接着返回上一层递归打印第二个元素:
1 | std::cout << std::get<1>(t); |
(2)根据索引序列展开并打印tuple
将tuple变为一个可变参数模板需要一个可变索引序列:
1 | template<int...> |
再通过std::get<IndexTuple>(tuple)...来获取参数序列,从而将tuple转换为可变参数模板Args...。
先创建一个索引序列,通过这个索引序列来取tuple中对应位置的元素:
1 | template<int...> |
在生成一个元素对应的索引位置序列之后,就可以通过std::get来获取tuple中的所有元素并将其变为可变参数模板。
1 | template <typename T> |
反转Tuple
1 | template<int I, int... Indexes, typename T, typename... Types> |
应用于函数
1 | template<int...> |
输出:3
使用C++11解决内存泄漏的问题
智能指针可以自动删除分配的内存,是存储指向动态分配(堆)对象指针的累,用于生存期控制,能够确保在离开指针所在作用域时能够自动正确地销毁动态分配的对象,防止内存泄漏。它的一种通用实现技术是引用计数,每使用它一次内部的引用计数加一,每析构一次内部的引用计数减一,减为0时,删除所指向的堆内存。
shared_ptr共享的智能指针
shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向同一个内存,在最后一个shared_ptr析构时,内存才被释放。
基本用法
通过构造函数、std::make_shared<T>辅助函数和reset方法来初始化。
1 | std::shared_ptr<int> p(new int(1)); |
优先使用make_shared来构造智能指针。
不能将一个原始指针直接赋值给一个智能指针:
1 | std::shared_ptr p = new int(1) ; // 编译报错,不允许直接赋值 |
通过get方法来返回原始指针
1 | std::shared_ptr<int> ptr( new int(1) ) ; |
智能指针初始化可以指定删除器
1 | void DeleteIntPtr ( int * p ) { |
当p的引用技术为0时,自动调用删除器来释放对象的内存。删除器也可以是一个lambda表达式,例如:
1 | std::shared_ptr<int> p( new int , [](int * p){delete p} ) ; |
当我们使用shared_ptr管理动态数组时,需要指定删除器,因为std::shared_ptr默认的删除器不能处理数组对象:
1 | std::shared_ptr<int> p(new int[10], [](int* p){delete[] p;}); |
或者通过封装一个make_shared_array方法来让shared_ptr支持数组:
1 | template<typename T> |
不要用一个原始指针初始化多个shared_ptr,以下是错误的。
1 | int* ptr = new int; |
不要在函数实参中创建shared_ptr,在调用函数之前先定义以及初始化它。
不要将this指针作为shared_ptr返回出来,因为this指针是一个裸指针,这样做可能会重复析构。正确返回this的shared_ptr的做法是:让目标类通过派生std::enable_shared_from_this<A>类,然后使用基类的成员函数shared_from_this来返回this的shared_ptr:
1 | class A : public std::enable_shared_from_this<A> { |
要避免循环引用,循环引用会导致内存泄漏。
unique_ptr独占的智能指针
unique_ptr是一个独占的智能指针,他不允许其他的智能指针共享其内部的指针,不允许通过赋值将一个unique_ptr赋值给另外一个unique_ptr,虽然不允许复制,但可以通过函数返回给其他的unique_ptr,还可以通过std::move来转移到其他的unique_ptr,这样它本身就不再拥有原来指针的所有权了。
1 | unique_ptr<T> my_ptr(new T); |
可以自己实现一个make_unique,C++尚未提供这个函数
1 | template<class T, class... Args> inline |
如果不是数组,则直接创建unique_ptr,如果是数组,则先判断是否为定长数组,如果是定长数组则编译不通过,若为非定常数组,则获取数组中的元素类型,再根据入参size创建动态数组的unique_ptr。
unique_ptr还可指向一个数组:
1 | std::unique_ptr<int []> ptr(new int[10]); |
unique_ptr指定删除器需要确定删除器的类型:
1 | std::unique_ptr<int, void(*)(int*)> ptr(new int(1), [](int* p){ delete p; }); |
如果lambda表达式没有捕获变量,这样写是对的,因为可以直接转换成函数指针。捕获了变量后:
1 | std::unique_ptr<int, std::function<void(int*)>> ptr(new int(1), [&](int* p){ delete p; }); |
如果希望只有一个智能指针管理资源或管理数组就用unique_ptr,如果希望多个智能指针管理同一个资源就用shared_ptr。
weak_ptr弱引用的智能指针
弱引用的智能指针weak_ptr是用来监视shared_ptr的,不会使引用计数加一,它不管理shared_ptr内部的指针,主要是为了监视shared_ptr的生命周期,更像是shared_ptr的一个助手。
weak_ptr没有重载运算符*和->,因为它不共享指针,不能操作资源,主要是为了通过shared_ptr获得资源的监测权,它的构造不会增加引用计数,它的析构不会减少引用计数,纯粹只是作为一个旁观者来监视shared_ptr中管理的资源是否存在。weak_ptr还可以用来返回this指针和解决循环引用的问题。
基本用法
通过use_count()获得当前观测资源的引用计数:
1 | shared_ptr<int> sp(new int(10)); |
通过expired()方法判断观测的资源是否已经释放:
1 | shared_ptr<int> sp(new int(10)); |
通过lock方法来获取所监视的shared_ptr:
1 | std::weak_ptr<int> gw; |
之前提到不能直接将this指针返回为shared_ptr,需要通过派生std::enable_shared_from_this类,并通过其方法shared_from_this来返回智能指针,原因是std::enable_shared_from_this类中有一个weak_ptr,这个weak_ptr用来观测this智能指针,调用shared_from_this()方法时,会调用内部这个weak_ptr的lock()方法,将所观测的shared_ptr返回。
1 | struct A : public std::enable_shared_from_this<A> { |
解决循环引用
1 | struct A; |
在这个例子中,由于循环引用导致ap和bp的引用计数都是2,离开作用域后减为1,不会去删除指针,导致内存泄漏,通过weak_ptr解决这个问题。
1 | struct A; |
通过智能指针管理第三方库分配的内存
第三方库分配的内存一般需要通过第三方库提供的释放接口才能释放,由于第三方库返回的指针一般都是原始指针,用完之后如果没有调用第三方库的释放接口,就很容易造成内存泄露。
1 | void *p = GetHandle()->Create(); |
用智能指针来管理第三方库的内存就比较方便,不用担心中途返回或者发生异常导致无法调用释放接口的问题。
1 | void *p = GetHandle()->Create(); |
将其提炼成函数
1 | std::shared_ptr<void> Guard(void*p) |
执行Guard();这句后,函数返回的是一个右值,没有被存储,用完就把p释放了。
可以用宏的方式来解决这个问题:
1 | #define GUARD(p) std::shared_ptr<void> p##p(p, [](void *p){release(p);}) |
也可以用unique_ptr来管理第三方的内存:
1 | #define GUARD(p) std::unique_ptr<void> p##p(p, [](void *p){release(p);}) |
对于宏中的##,其实也很好理解,就是将##前后的字符串连接起来
1 | #define GUARD(p) std::shared_ptr<void> p##p(p, [](void *p){release(p);}) |
为了验证原作者的这些,写一些demo来帮助理解,也有利于更好掌握:
创建一个Base类:
Base.h文件中:
1 | #pragma once |
Base.cpp文件中:
1 | #include "Base.h" |
在main.cpp中:
1 | #include "Base.h" |
此时的输出为:
1 | Base constructor |
【修改一】 当我们对main()中修改为:
1 | int main() |
运行结果:
1 | Base constructor |
发现这时候的p被提前释放了,print something已经是在Base类析构之后做的,此时已经出问题了。
【修改二】将main函数进行修改:
1 | int main() |
运行结果:
1 | Base constructor |
果然如我们所想,一切正常。
使用C++11让多线程开发变得简单
线程
用std::thread创建线程非常简单,只需要提供线程函数或者函数对象即可。
1 | #include <thread> |
函数func会运行于线程对象t中,join函数会阻塞线程,直到线程函数执行结束,如果线程函数有返回值,返回值被忽略。如果不希望线程被阻塞执行,调用detach将线程和线程对象分离,让线程作为后台线程去执行,当前线程也不会阻塞了。需要注意的是detach()之后就无法再和线程发生联系了,比如detach之后就不能通过join来等待线程执行完,线程何时执行完我们也无法控制了。
线程可以接受任意个数的参数。
1 | void func(int i, double d, const std::string& s) { |
std::thread出了作用域后会析构,保证线程函数的生命周期在线程变量的生命周期之内
线程不能复制,但是可以移动:
1 | int main() { |
线程被移动之后,线程对象t就不再代表任何线程。另外可以通过std::bind和lambda表达式来创建线程:
1 | int main() { |
可以将线程存放到容器中,保证线程对象的生命周期:
1 | #include <thread> |
线程可以获取当前线程的ID,还可以获取CPU核心数量:
1 | void func() {} |
互斥量
互斥量是一种同步原语,是一种线程同步的手段,用来保护多线程同时访问的共享数据。
- std::mutex: 独占的互斥量,不能递归使用.
- std::timed_mutex: 带超时的独占互斥量,不能递归使用.
- std::recursive_mutex: 递归互斥量,不带超时功能.
- std::recursive_timed_mutex: 带超时的递归互斥量.
这些互斥量的基本接口十分相近,都是通过lock()来阻塞线程,直到获得互斥量的所有权为止。在线程获得互斥量并完成任务后,就必须使用unlock()来解除对互斥量的占用,lock和unlock必须成对出现。try_lock()尝试锁定互斥量,成功返回true,失败返回false,他是非阻塞的。
1 | std::mutex g_lock; |
使用lock_guard可以简化lock/unlock的写法,因为lock_guard在构造时可以自动锁定互斥量,在退出作用域后进行析构时会自动解锁,从而保证了互斥量的正确操作。
1 | void f_lock_guard() |
递归的独占互斥量std::recursive_mutex允许同一线程多次获得该互斥锁,可以用来解决同一线程需要多次获取互斥量时死锁的问题,来获得对互斥量对象的多层所有权,std::recursive_mutex 释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),可理解为 lock() 次数和 unlock() 次数相同,除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
1 | struct Complex { |
尽量不要使用递归锁,因为:
- 需要用到递归锁定的多线程互斥处理往往本身就是可以简化的,允许递归互斥很容易放纵复杂逻辑的产生,从而导致一些多线程同步引起的晦涩问题
- 递归锁比起非递归锁,效率会低一些。
- 递归锁虽然允许同一个线程多次获得同一个互斥量,可重复获得的最大次数并未具体说明,一旦超过一定次数,再对lock进行调用就会抛出
std::system错误。
带超时的互斥量std::timed_mutex和std::recursive_timed_mutex。std::timed_mutex是超时的独占锁,std::recursive_timed_mutex是超时的递归锁,主要用在获取锁时增加超时等待功能,因为有时不知道获取锁需要多久,为了不至于一直在等待获取互斥量,就设置一个等待超时时间,在超时后还可以做其他的事情。
std::timed_mutex比std::mutex多了两个超时获取锁的接口:try_lock_for和try_lock_until,这两个接口是用来设置获取互斥量的超时时间,使用时可以用一个while循环去不断地获取互斥量。
1 | std::timed_mutex mutex; |
条件变量
<condition_variable>头文件主要包含了与条件变量相关的类和函数。相关的类包括std::condition_variable和std::condition_variable_any,还有枚举类型std::cv_status。另外还包括函数std::notify_all_at_thread_exit()。
condition_variable配合std::unique_lock<std::mutex>进行wait操作。condition_variable_any,和任意带有lock、unlock语义的mutex搭配使用,比较灵活,但效率比condition_variable差一些。条件变量的使用过程如下:
- 拥有条件变量的线程获取互斥量。
- 循环检查某个条件,如果条件不满足,则阻塞直到条件满足;如果条件满足,则向下执行。
- 某个线程满足条件执行完之后调用
notify_one或notify_all唤醒一个或者所有的等待线程。
1 | template<typename T> |
这个同步队列在没有满的情况下可以插入数据,如果满了,则会调用m_notFull阻塞等待,待消费线程取出数据之后发一个未满的通知,然后前面阻塞的线程就会被唤醒继续往下执行;如果队列为空,就不能取数据,会调用m_notEmpty条件变量阻塞,等待插入数据的线程发出不为空的通知时,才能继续往下执行。以上过程是同步队列的工作过程。
当std::condition_variable对象的某个 wait 函数被调用的时候,它使用std::unique_lock(通过std::mutex) 来锁住当前线程。当前线程会一直被阻塞,直到另外一个线程在相同的std::condition_variable对象上调用了 notification 函数来唤醒当前线程。
std::condition_variable对象通常使用std::unique_lock<std::mutex>来等待,如果需要使用另外的lockable类型,可以使用std::condition_variable_any类,本文后面会讲到std::condition_variable_any的用法。
首先我们来看一个简单的例子
1 | #include <iostream> // std::cout |
执行结果如下:
1 | 10 threads ready to race... |
好了,对条件变量有了一个基本的了解之后,我们来看看std::condition_variable的各个成员函数。
std::condition_variable提供了两种 wait() 函数。当前线程调用 wait() 后将被阻塞(此时当前线程应该获得了锁(mutex),不妨设获得锁 lck),直到另外某个线程调用notify_*唤醒了当前线程。
在线程被阻塞时,该函数会自动调用lck.unlock()释放锁,使得其他被阻塞在锁竞争上的线程得以继续执行。另外,一旦当前线程获得通知(notified,通常是另外某个线程调用notify_*唤醒了当前线程),wait() 函数也是自动调用lck.lock(),使得 lck 的状态和 wait 函数被调用时相同。
在第二种情况下(即设置了 Predicate),只有当 pred 条件为 false 时调用 wait() 才会阻塞当前线程,并且在收到其他线程的通知后只有当 pred 为 true 时才会被解除阻塞。因此第二种情况类似以下代码:
1 | while (!pred()) wait(lck); |
请看下面例子(参考):
1 | #include <iostream> // std::cout |
程序执行结果如下:
1 | concurrency ) ./ConditionVariable-wait |
std::condition_variable::wait_for() 介绍
unconditional (1):
1 | template <class Rep, class Period> |
predicate (2)
1 | template <class Rep, class Period, class Predicate> |
与 std::condition_variable::wait() 类似,不过 wait_for 可以指定一个时间段,在当前线程收到通知或者指定的时间 rel_time 超时之前,该线程都会处于阻塞状态。而一旦超时或者收到了其他线程的通知,wait_for 返回,剩下的处理步骤和 wait() 类似。
另外,wait_for 的重载版本(predicte(2))的最后一个参数 pred 表示 wait_for 的预测条件,只有当 pred 条件为 false 时调用 wait() 才会阻塞当前线程,并且在收到其他线程的通知后只有当 pred 为 true 时才会被解除阻塞,因此相当于如下代码:
1 | return wait_until (lck, chrono::steady_clock::now() + rel_time, std::move(pred)); |
请看下面的例子(参考),下面的例子中,主线程等待 th 线程输入一个值,然后将 th 线程从终端接收的值打印出来,在 th 线程接受到值之前,主线程一直等待,每个一秒超时一次,并打印一个 “.”:
1 | #include <iostream> // std::cout |
std::condition_variable::wait_until 介绍
unconditional (1)
1 | template <class Clock, class Duration> |
predicate (2)
1 | template <class Clock, class Duration, class Predicate> |
与std::condition_variable::wait_for类似,但是 wait_until 可以指定一个时间点,在当前线程收到通知或者指定的时间点 abs_time 超时之前,该线程都会处于阻塞状态。而一旦超时或者收到了其他线程的通知,wait_until 返回,剩下的处理步骤和 wait_until() 类似。
另外,wait_until 的重载版本(predicte(2))的最后一个参数 pred 表示 wait_until 的预测条件,只有当 pred 条件为 false 时调用 wait() 才会阻塞当前线程,并且在收到其他线程的通知后只有当 pred 为 true 时才会被解除阻塞,因此相当于如下代码:
1 | while (!pred()) |
std::condition_variable::notify_one() 介绍
唤醒某个等待(wait)线程。如果当前没有等待线程,则该函数什么也不做,如果同时存在多个等待线程,则唤醒某个线程是不确定的(unspecified)。
请看下例(参考):
1 | #include <iostream> // std::cout |
std::condition_variable::notify_all() 介绍
唤醒所有的等待(wait)线程。如果当前没有等待线程,则该函数什么也不做。请看下面的例子:
1 | #include <iostream> // std::cout |
std::condition_variable_any 介绍
与std::condition_variable类似,只不过std::condition_variable_any的 wait 函数可以接受任何 lockable 参数,而std::condition_variable只能接受std::unique_lock<std::mutex>类型的参数,除此以外,和std::condition_variable几乎完全一样。
std::cv_status 枚举类型介绍
cv_status::no_timeout:wait_for 或者 wait_until 没有超时,即在规定的时间段内线程收到了通知。cv_status::timeout:wait_for 或者 wait_until 超时。
std::notify_all_at_thread_exit
函数原型为:
1 | void notify_all_at_thread_exit (condition_variable& cond, unique_lock<mutex> lck); |
当调用该函数的线程退出时,所有在 cond 条件变量上等待的线程都会收到通知。请看下例(参考):
1 | #include <iostream> // std::cout |
原子变量
C++11提供了一个原子类型std::atomic
1 | int value; |
可以改成:
1 | std::atmoic<int> value; |
call_once/once_flag的使用
为了保证在多线程环境中某个函数仅被调用一次,比如,需要初始化某个对象,而这个对象只能初始化一次时,就可以用std::call_once来保证函数在多线程环境中只被调用一次。使用std::call_once时,需要一个once_flag作为call_one的入参,它的用法比较简单。
1 | #include<iostream> |
运行结果:
1 | Called once |
异步操作类
C++11 提供了异步操作相关的类:
std::future作为异步结果的传输通道,用于获取线程函数的的返回值;std::promise用于包装一个值,将数据和future绑定起来,方便线程赋值;std::package_task将函数和future绑定起来,以便异步调用。
std::future
thread库提供了future用来访问异步操作的结果,因为一个异步操作的结果不能马上获取,只能在未来某个时候从某个地方获取,这个异步操作的结果是一个未来的期待值,所以被称为future,future提供了获取异步操作结果的通道。可以以同步等待的方式获取结果,可以通过查询future的状态(future_status)来获取异步操作的结果。future_status有如下3种状态:
- Deferred:异步操作还没开始
- Ready:异步操作已经完成
- Timeout:异步操作超时
我们可以查询future状态,通过它内部的状态可以知道异步任务的执行情况:
1 | std::future_status status; |
获取future结果有三种方式:
- get: 等待异步操作结束并返回结果
- wait:只是等待异步操作完成,没有返回值
- wait_for:是超时等待返回结果
std::promise
std::promise将数据和future绑定起来,在线程函数中为外面传进来的promise赋值,在线程函数执行完之后就可以通过promise的future获取该值了。取值是间接地通过promise内部提供的future来获取的。
1 | std::promise<int> pr; |
std::packaged_task
std::packaged_task包装了一个可调用对象的包装类(如function、lambda expression、bind expression和another function object),将函数和future绑定起来,以便异步调用,它和std::promise在某种程度上有点像,promise保存了一个共享状态的值,而packaged_task保存的是一个函数。
1 | std::packaged_task<int()> task([](){return 7;}); |
std::promise、std::packaged_task和std::future三者之间的关系
std::future提供了一个访问异步操作结果的机制,它和线程是一个级别的,属于低层次的对象。std::promise和std::packaged_task,它们内部都有future以便访问异步操作结果,std::packaged_task包装的是一个异步操作,而std::promise包装的是一个值,都是为了方便异步操作的返回值。
std::promise:需要获取线程中的某个值std::packaged_task:需要获取一个异步操作的返回值
future被promise和packaged_task用来作为异步操作或者异步结果的连接通道,用std::future和std::shared_future来获取异步调用的结果。future是不可拷贝的,只能移动,shared_future是可以拷贝的,当需要将future放到容器中则需要用shared_future。
1 | #include <iostream> |
1 | #include <iostream> |
输出:
1 | The result is 4 |
线程异步操作函数async
std::async比std::promise、std::package_task和std::thread更上层,它可以用来直接创建异步的task,异步任务返回的结果保存在future中,当需要获取线程执行的结果,可以通过future.get()来获取,如果不关注异步任务的结果,只是简单的等待任务执行完成,则调用future.wait()即可。
std::async是更高层次的异步操作,使我们不关心线程创建的内部细节,就能方便的获取线程异步执行的结果,还可以指定线程创建策略,更多的时候应该使用 std::async来创建线程,成为异步操作的首选。
std::async原型为
1 | std::async(std::launch::async | std::launch::deferred,f,args...) |
第一个参数为线程的创建策略,第二个为线程函数,其他的为线程函数的参数。
关于创建策略有两种:
std::launch::async:在调用async就开始创建线程;std::launch::deferred:延迟加载的方式创建线程,调用async的时候不创建线程,直到调用了future的get或者wait方法来创建线程。
1 | #include <thread> |
- 线程的创建和使用简单方便,可以通过多种方式创建,还可以根据需要获取线程的一些信息及休眠线程。
- 互斥量可以通过多种方式来保证线程安全,既可以用独占的互斥量保证线程安全,又可以通过递归的互斥量来保护共享资源以避免死锁,还可以设置获取互斥量的超时时间,避免一直阻塞等待。
- 条件变量提供了另外一种用于等待的同步机制,它能阻塞一个或多个线程,直到收到另外一个线程发出的通知或者超时,才会唤醒当前阻塞的线程。条件变量的使用需要配合互斥量。
- 原子变量可以更方便地实现线程保护。
- call_once保证在多线程情况下函数只被调用一次,可以用在在某些只能初始化一次的场景中。
- future、promise和std::package_task用于异步调用的包装和返回值。
- async更方便地实现了异步调用,应该优先使用async取代线程的创建。
使用C++11中的便利工具
处理日期和时间的chrono库
chrono库主要包含了三种类型:时间间隔Duration、时钟Clocks和时间点Time point。
记录时长的duration
duration表示一段时间间隔,用来记录时间长度,可以表示几秒钟、几分钟或者几个小时的时间间隔,duration的原型是:
1 | template<class Rep, class Period = std::ratio<1>> class duration; |
第一个模板参数Rep是一个数值类型,表示时钟个数;第二个模板参数是一个默认模板参数std::ratio,它的原型是:
1 | template<std::intmax_t Num, std::intmax_t Denom = 1> class ratio; |
它表示每个时钟周期的秒数,其中第一个模板参数Num代表分子,Denom代表分母,分母默认为1,ratio代表的是一个分子除以分母的分数值,比如ratio<2>代表一个时钟周期是两秒,ratio<60>代表了一分钟,ratio<60*60>代表一个小时,ratio<60*60*24>代表一天。而ratio<1, 1000>代表的则是1/1000秒即一毫秒,ratio<1, 1000000>代表一微秒,ratio<1, 1000000000>代表一纳秒。标准库为了方便使用,就定义了一些常用的时间间隔,如时、分、秒、毫秒、微秒和纳秒,在chrono命名空间下,它们的定义如下:
1 | typedef duration <Rep, ratio<3600,1>> hours; |
通过定义这些常用的时间间隔类型,我们能方便的使用它们,比如线程的休眠:
1 | std::this_thread::sleep_for(std::chrono::seconds(3)); //休眠三秒 |
chrono还提供了获取时间间隔的时钟周期个数的方法count(),它的基本用法:
1 | #include <chrono> |
输出:
1 | 3 ms duration has 3 ticks |
时间间隔之间可以做运算,比如下面的例子中计算两端时间间隔的差值:
1 | std::chrono::minutes t1( 10 ); |
其中,t1 是代表 10 分钟、 t2 是代表 60 秒,t3 则是 t1 減去 t2,也就是 600 - 60 = 540 秒。通过t1-t2的count输出差值为540个时钟周期即540秒(因为每个时钟周期为一秒)。我们还可以通过duration_cast<>()来将当前的时钟周期转换为其它的时钟周期,比如我可以把秒的时钟周期转换为分钟的时钟周期,然后通过count来获取转换后的分钟时间间隔:
1 | cout << chrono::duration_cast<chrono::minutes>( t3 ).count() <<” minutes”<< endl; |
将会输出:
1 | 9 minutes |
Time point
time_point表示一个时间点,用来获取1970.1.1以来的秒数和当前的时间, 可以做一些时间的比较和算术运算,可以和ctime库结合起来显示时间。time_point必须要clock来计时,time_point有一个函数time_since_epoch()用来获得1970年1月1日到time_point时间经过的duration。下面的例子计算当前时间距离1970年1月一日有多少天:
1 | #include <iostream> |
time_point还支持一些算术元算,比如两个time_point的差值时钟周期数,还可以和duration相加减。下面的例子输出前一天和后一天的日期:
1 | #include <iostream> |
输出:
1 | One day ago, the time was 2014-3-2622:38:27 |
Clocks
表示当前的系统时钟,内部有time_point, duration, Rep, Period等信息,它主要用来获取当前时间,以及实现time_t和time_point的相互转换。Clocks包含三种时钟:
- system_clock:从系统获取的时钟;
- steady_clock:不能被修改的时钟;
- high_resolution_clock:高精度时钟,实际上是system_clock或者steady_clock的别名。
可以通过now()来获取当前时间点:
1 | #include <iostream> |
输出:
1 | Hello World |
通过时钟获取两个时间点之相差多少个时钟周期,我们可以通过duration_cast将其转换为其它时钟周期的duration:
1 | cout << std::chrono::duration_cast<std::chrono::microseconds>( t2-t1 ).count() <<” microseconds”<< endl; |
输出:
1 | 20 microseconds |
system_clock的to_time_t方法可以将一个time_point转换为ctime:
1 | std::time_t now_c = std::chrono::system_clock::to_time_t(time_point); |
而from_time_t方法则是相反的,它将ctime转换为time_point。
steady_clock可以获取稳定可靠的时间间隔,后一次调用now()的值和前一次的差值是不因为修改了系统时间而改变,它保证了稳定的时间间隔。它的用法和system用法一样。
system_clock和std::put_time配合起来使用可以格式化日期的输出,std::put_time能将日期格式化输出。下面的例子是将当前时间格式化输出:
1 | #include <chrono> |
上面的例子将输出:
1 | 2014-3-27 22:11:49 |
timer
可以利用high_resolution_clock来实现一个类似于boost.timer的定时器,这样的timer在测试性能时会经常用到,经常用它来测试函数耗时,它的基本用法是这样的:
1 | void fun() |
c++11中增加了chrono库,现在用来实现一个定时器是很简单的事情,还可以移除对boost的依赖。它的实现比较简单,下面是具体实现:
1 | #include<chrono> |
测试代码:
1 | void fun() |
数值类型和字符串的相互转换
C++11提供了to_string方法,可以方便地将各种数值类型转换为字符串类型
1 | std::string to_string(int value); |
还提供了stoxxx方法,将string转换为各种类型的数据:
1 | std::string str = "1000"; |
c++11还提供了字符串(char*)转换为整数和浮点类型的方法:
- atoi: 将字符串转换为 int
- atol: 将字符串转换为long
- atoll:将字符串转换为 long long
- atof: 将字符串转换为浮点数
宽窄字符转换
c++11增加了unicode字面量的支持,可以通过L来定义宽字符。
1 | std::wstring wide_str = L"中国人"; //定义了宽字符字符串 |
将宽字符转换为窄字符需要用到condecvt库中的std::wstring_convert,它需要如下几个转换器:
std::codecvt_utf8,封装了UTF-8与UCS2及UTF-8与UCS4的编码转换;std::codecvt_utf16,封装了UTF-16与UCS2及UTF-16与UCS4的编码转换;std::codecvt_utf8_utf16,封装了UTF-8与UTF-16的编码转换;
std::wstring_convert使std::string和std::wstring之间的相互转换变得很方便,如代码:
1 | std::wstring wide_str = L"中国人"; |
输出:
1 | 中国人 |
C++11的其他特性
委托构造函数和继承构造函数
委托构造函数允许在同一个类中一个构造函数可以调用另一个构造函数,从而可以在初始化时简化变量的初始化。
1 | class class_c { |
通过委托构造函数简化:
1 | class class_c { |
需要注意,如果使用了委托构造函数,则不能使用类成员初始化,比如:
1 | class A{ |
如果一个派生类继承自一个基类,如果其构造函数想要使用和基类相同的构造函数,如果构造函数有多个,则在派生类中要写多个构造函数,每个都用基类构造, 在c++11中,可以使用继承构造函数来简化这一操作。
1 | class Base{ |
原始的字面量
原始字面量可以直接表示字符串的实际含义,因为有些字符串带一些特殊字符,比如在转义字符串中,我们往往要专门处理。如windows路径名:D:\A\B\test.txt
在c++11中,使用R"xx(string)xx"来获得括号中的string部分的字符串形式,不需要使用转义字符等附加字符,比如:
1 | string a = R"(D:\A\B\test.txt)" |
注意,R"xxx(raw string)xxx",其中原始字符串必须用括号()括起来,括号前后可以加其他字符串,所加的字符串是会被忽略的,而且加的字符串必须在括号两边同时出现。
1 | string str = R"test(D:A\B\test.test)test"; |
final和override标识符
c++11中增加了final关键字来限制某个类不能被继承(类似java)或者某个虚函数不能别重写(类似c#中的sealed)。如果修饰函数,final只能修饰虚函数,并且要放到类或者函数的后面。
1 | struct A{ |
c++11中还增加了override关键字确保在派生类中声明的重写函数与基类的虚函数有相同的签名,同时也明确表明将会重写基类的虚函数,还可以防止因疏忽把原来想重写基类的虚函数声明为重载。override关键字要放到方法的后面
1 | struct A{ |
内存对齐
内存对齐介绍
cpu访问内存的时候,起始地址并不是随意的,例如有些cpu访问内存起始地址要是4的倍数,因为内存总线的宽度为32位,每次读写操作都4个字节4个字节进行。如果某个数据在内存中不是字节对齐的,则会在访问的时候比较麻烦,比如4字节的int32类型,没有4字节对齐,则需要访问两次内存才能读到完整的数据。因此,内存对齐可以提高程序的效率。
因为有了内存对齐,所以数据在内存中的存放就不是紧挨着的,而是会出现一些空隙。C++数据内存对齐的含义是,数据在内存中的起始地址是数据size的倍数。c++结构体内存对齐的原则是:结构体内的每个变量都自身对齐,按照字节对齐,中间加入padding,;整个结构体按照结构体内的最大size变量的对齐方式对齐,比如:
1 | struct{ |
结构体按照最大size的变量对齐,即按照double的8字节对齐。
堆内存的内存对齐
malloc一般使用当前平台默认的最大内存对齐数对齐内存。当我们需要分配一块特定内存对齐的内存块时,使用memalign等函数。
1 | #include <assert.h> |
利用alignas指定内存对齐大小
1 | alignas(32) long long a = 0; |
指定a为32字节对齐。 alignas可以将内存对齐改大,而不能改小,因此,可以有 alignas(32) long long a; 而不能有alignas(1) long long a;
1 | #define XX 1 |
指定为1字节对齐,因为MyStruct内部没有数据,自然为1字节对齐。如果内部含有int类型数据,则alignas只能将对齐方式改大不能改小,故不能为1字节对齐。
1 | alignas(int) char c; |
这个char就按照int的方式对齐了。
利用alignof和std::alignment_of获取内存对齐大小
alignof用来获取内存对齐大小,只能返回size_t。
1 | MyStruct xx; |
alignment_of继承自std::integral_constant,因此拥有value_type、type和value成员
1 | cout << std::alignment_of<MyStruct>::value << std::endl; |
内存对齐的类型std::aligned_storage
aligned_storage可以看成一个内存对齐的缓冲区,原型如下:
1 | template<std::size_t Len, std::size_t Align = /*default-alignment*/> |
Len代表所存储类型的size,Align代表所存储类型的对齐大小,通过sizeof(T)获取T的size,通过alignof(T)获取T内存对齐的大小,所以std::aligned_storage的声明是这样的:std::aligned_storage<sizeof(T), align(T)>或者std::aligned_storage<sizeof(T), std::alignment_of(T)::value>。
1 | struct A{ |
为什么要使用std::aligned_storage呢?很多时候需要分配一块单纯的内存块,之后再使用placement new在这块内存上构建对象:
1 | char xx[32]; |
但是char[32]是1字节对齐的,xx很有可能不在指定的对齐位置上,这是调用placement new构造内存块引起效率问题,所以应该使用std::aligned_storage构造内存块:
1 | typedef std::aligned_storage<sizeof<A>, alignof(A)>::type Aligned_A; |
std::max_align_t和std::align操作符
std::max_align_t返回当前平台的最大默认内存对齐类型。通过下面这个方式获得当前平台的默认最大内存对齐数:
1 | cout << alignof(std::max_align_t) << endl; |
std::align用来在一大块内存中获取一个符合指定内存要求的地址。
1 | char buffer[] = "---------------"; |
在buffer这个大内存中,指定内存对齐为align(int),找一块sizeof(char)大小的内存,并在找到这块内存后把地址放入pt中。
新增的便利算法
all_of、any_of、none_of
算法库新增了三个用于判断的算法all_of、any_of和none_of:
1 | template< class InputIt, class UnaryPredicate > |
- all_of:检查区间[first, last)中是否所有的元素都满足一元判断式p,所有的元素都满足条件返回true,否则返回false。
- any_of:检查区间[first, last)中是否至少有一个元素都满足一元判断式p,只要有一个元素满足条件就返回true,否则返回true。
- none_of:检查区间[first, last)中是否所有的元素都不满足一元判断式p,所有的元素都不满足条件返回true,否则返回false。
下面是这几个算法的示例:
1 | #include <iostream> |
输出:
1 | all is odd |
find_if_not
算法库的查找算法新增了一个find_if_not,它的含义和find_if是相反的,即查找不符合某个条件的元素,find_if也可以实现find_if_not的功能,只需要将判断式改为否定的判断式即可,现在新增了find_if_not之后,就不需要再写否定的判断式了,可读性也变得更好。下面是它的基本用法:
1 | #include <iostream> |
将输出:
1 | the first even is 4 |
可以看到使用find_if_not不需要再定义新的否定含义的判断式了,更简便了。
copy_if
算法库还增加了一个copy_if算法,它相比原来的copy算法多了一个判断式,用起来更方便了,下面是它的基本用法:
1 | #include <iostream> |
iota
算法库新增了iota用来方便的生成有序序列,比如我们需要一个定长数组,这个数组中的元素都是在某一个数值的基础之上递增的,那么用iota可以很方便的生成这个数组了。下面是它的基本用法:
1 | #include <numeric> |
将输出:
1 | 1 2 3 4 |
可以看到使用iota比遍历赋值来初始化数组更简洁,需要注意的是iota初始化的序列需要指定大小,如果上面的代码中:vector
minmax_element
算法库还新增了一个同时获取最大值和最小值的算法minmax_element,这样我们如果想获取最大值和最小值的时候就不用分别调用max_element和max_element算法了,用起来会更方便,minmax_element会将最小值和最大值的迭代器放到一个pair中返回,下面是它的基本用法:
1 | #include <iostream> |
将输出:
1 | 1 9 |
is_sorted和is_sorted_until
算法库新增了is_sorted和is_sorted_until算法,is_sort用来判断某个序列是否是排好序的,is_sort_until则用来返回序列中前面已经排好序的部分序列。下面是它们的基本用法:
1 | #include <iostream> |
将输出:
1 | 1 2 5 7 9 |
总结:这些新增的算法让我们用起来更加简便,也增强了代码的可读性。
C++11改进我们的模式
改进单例模式
单例模式保证一个类仅有一个实例,并提供一个访问它的全局访问点。在c++11之前,我们写单例模式的时候会遇到一个问题,就是多种类型的单例可能需要创建多个类型的单例,主要是因为创建单例对象的构造函数无法统一,各个类型的形参不尽相同,导致我们不容易做一个所有类型都通用的单例。现在c+11帮助我们解决了这个问题,解决这个问题靠的是c++11的可变模板参数。
将原有的多个构造函数合并:
1 | template <typename T0, typename T1, typename T2, typename T3, typename T4, typename T5> |
改为
1 | template <typename T> |
/*更新说明**/
由于原来的接口中,单例对象的初始化和取值都是一个接口,可能会遭到误用,更新之后,初始化和取值分为两个接口,单例的用法为:先初始化,后面取值,如果中途销毁单例的话,需要重新取值。如果没有初始化就取值则会抛出一个异常。
增加Multiton的实现
1 | #include <map> |
改进观察者模式
观察者模式定义对象间一种一对多关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。和单例模式面临的是同样的问题,主题更新的接口难以统一,很难做出一个通用的观察者模式,还是用到可变模板参数解决这个问题,其次还用到了右值引用,避免多余的内存移动。c++11版本的观察者模式支持注册的观察者为函数、函数对象和lamda表达式,也避免了虚函数调用,更简洁更通用。
主要改进的地方有两个:通过被通知接口参数化和std::function来代替继承,通过可变参数模板和完美转发来消除接口变化产生的影响。直接看代码。
1 | class NonCopyable { |
增加了+=和-=运算符,使用法更接近c#,这里+=会返回一个key,这个key用来-=删除委托时用到,这种做法不太好,只是一个简单的处理。如果内部用vector的话,-=时,根据function去删除指定的委托的话,用法就和c#完全一致了,不过,这里遇到的问题是function不支持比较操作,导致将function存入容器后,后面再根据function去删除时就找不到对应的function了。
改进访问者模式
访问者表示一个作用于某对象结构中的各元素的操作,可用于不改变各元素的类的前提下定义作用于这些元素的新操作。
访问者模式需要注意定义对象结构的类很少改变,但经常需要在此结构上定义新的操作。改变对象结构类需要重定义对所有访问者的接口,这可能需要很大的代价。定义一个稳定的访问者接口层,即不会因为增加新的被访问者而修改接口层。通过可变参数模板实现一个稳定的接口层,利用可变参数模板可以支持任意个数的参数的特点,可以让访问者接口层访问任意个数的被访问者。
访问者模式是GOF23个设计模式中比较复杂的模式之一,但是它的功能也很强大,非常适合稳定的继承层次中对象的访问,可以在不修改被访问对象的情况下,动态添加职责,这正是访问者模式强大的地方,但是它的实现又造成了两个继承层次的强烈耦合,这也是被人诟病的地方,可以说是让人爱又让人恨的模式。c++11实现的访问者模式将会解决这个问题。我们将在c++11版本的访问者模式中看到,定义新的访问者是很容易的,扩展性很好,被访问者的继承层次也不用做任何修改。具体代码:
1 | template<typename... Types> |
上面的代码为每个类型都定义了一个纯虚函数Visit。
下面看看被访问的继承体系如何使用Visitor访问该继承体系的对象。
1 | struct stA; |
测试代码:
1 | void TestVisitor() |
测试结果:
1 | from stA: 8.97 |
typedef Visitor<stA, stB> MytVisitor;会自动生成stA和stB的visit虚函数:
1 | struct Visitor<stA, stB> { |
当被访者需要增加stC、stD时,增加就行:
1 | `typedef Visitor<stA, stB, stC, stD> MytVisitor; |
类型自动生成接口:
1 | struct Visitor<stA, stB, stC, stD> { |
改进命令模式
命令模式的作用是将请求封装为一个对象,将请求的发起者和执行者解耦,支持对请求排队以及撤销和重做。将请求封装成一个个命令对象,使得我们可以集中处理或延迟处理这些命令请求,而且不同的客户对象可以共享命令,控制请求的优先级、排队、支持请求命令撤销和重做。
命令模式的这些好处是显而易见的,但是,在实际使用过程中它的问题也暴露出来了。随着请求的增多,请求的封装类—命令类也会越来越多,尤其是GUI应用中,请求是非常多的。越来越多的命令类会导致类爆炸,难以管理。关于类爆炸这个问题,GOF很早就意识到了,他们提出了一个解决方法:对于简单的不能取消和不需要参数的命令,可以用一个命令类模板来参数化该命令的接收者,用接收者类型来参数化命令类,并维护一个接收者对象和一个动作之间的绑定,而这一动作是用指向同一个成员函数的指针存储的。具体代码是这样的:
简单命令类的定义:
1 | template <class Receiver> |
测试代码如下:
1 | class MyClass { |
通过一个泛型的简单命令类来避免不断创建新的命令类,是一个不错的办法,但是,这个办法不完美,即它只能是简单的命令类,不能对复杂的,甚至所有的命令类泛化,这是它的缺陷,所以,它只是部分的解决了问题。我想我可以改进这个办法缺陷,完美的解决类爆炸的问题。在c++11之前我不知道有没有人解决过这个问题,至少我没看到过。现在可以通过c++11来完美的解决这个问题了。
要完美的解决命令模式类爆炸问题的关键是如何定义个通用的泛化的命令类,这个命令类可以泛化所有的命令,而不是GOF提到的简单命令。我们再回过头来看看GOF中那个简单的命令类的定义,它只是泛化了没有参数和返回值的命令类,命令类内部引用了一个接收者和接收者的函数指针,如果接收者的行为函数指针有参数就不能通用了,所以我们要解决的关键问题是如何让命令类能接受所有的成员函数指针或者函数对象。
我们需要一个函数包装器,它可以接受所有的函数对象、fucntion和lamda表达式等。接受function、函数对象、lamda和普通函数的包装器:
1 | template< class F, class... Args, class = typename std::enable_if<!std::is_member_function_pointer<F>::value>::type> |
接受成员函数的包装器:
1 | template<class R, class C, class... DArgs, class P, class... Args> |
通过重载的Wrap让它能接收成员函数。这样一个真正意义上的万能的函数包装器就完成了。现在再来看,它是如何应用到命令模式中,完美的解决类爆炸的问题。
一个通用的泛化的命令类:
1 | #include <functional> |
测试代码:
1 | struct STA |
我们在通用的命令类内部定义了一个万能的函数包装器,使得我们可以封装所有的命令,增加新的请求都不需要重新定义命令了,完美的解决了命令类爆炸的问题。
改进对象池模式
对象池对于创建比较大的对象来说很有意义,为了避免重复创建开销比较大的对象,可以通过对象池来优化,实现创建好一批对象,放到一个集合里,每当程序需要新对象时,就从对象池中获取,程序用完该对象后会把对象归还给对象池。
1 | #include <string> |
使用C++11实现一个半同步半异步线程池
实际中,主要有两种方法处理大量的并发任务,一种是一个请求由系统产生一个相应的处理请求的线程(一对一);另外一种是系统预先生成一些用于处理请求的进程,当请求的任务来临时,先放入同步队列中,分配一个处理请求的进程去处理任务,线程处理完任务后还可以重用,不会销毁,而是等待下次任务的到来。(一对多的线程池技术)线程池技术,能避免大量线程的创建和销毁动作,节省资源,对于多核处理器,由于线程被分派配到多个cpu,会提高并行处理的效率。线程池技术分为半同步半异步线程池和领导者追随者线程池。
一个半同步半异步线程池分为三层。
- 同步服务层:它处理来自上层的任务请求,上层的请求可能是并发的,这些请求不是马上就会被处理的,而是将这些任务放到一个同步排队层中,等待处理。
- 同步排队层: 来自上层的任务请求都会加到排队层中等待处理,排队层实际就是一个std::queue。
- 异步服务层: 这一层中会有多个线程同时处理排队层中的任务,异步服务层从同步排队层中取出任务并行的处理。
上层只需要将任务丢到同步队列中,主线程也不会阻塞,还能继续发起新的请求。排队曾居于核心地位,实现时,排队曾就是一个同步队列,允许多个线程同时去添加或取出任务。线程池有两个活动过程,一个是往同步队列中添加任务的过程,一个是从同步队列中取任务的过程。
一开始线程池会启动一定数量的线程,这些线程属于异步层,主要用来并行处理排队层中的任务,如果排队层中的任务数为空,则这些线程等待任务的到来,如果发现排队层中有任务了,线程池则会从等待的这些线程中唤醒一个来处理新任务。同步服务层则会不断地将新的任务添加到同步排队层中,这里有个问题值得注意,有可能上层的任务非常多,而任务又是非常耗时的,这时,异步层中的线程处理不过来,则同步排队层中的任务会不断增加,如果同步排队层不加上
限控制,则可能会导致排队层中的任务过多,内存暴涨的问题。因此,排队层需要加上限的控制,当排队层中的任务数达到上限时,就不让上层的任务添加进来,起到限制和保护的作用。
同步队列即为线程中三层结构中的中间那一层,它的主要作用是保证队列中共享数据线程安全,还为上一层同步服务层提供添加新任务的接口,以及为下一层异步服务层提供取任务的接口。同时,还要限制任务数的上限,避免任务过多导致内存暴涨的问题。同步队列的实现比较简单,我们会用到C++11的锁、条件变量、右值引用、std::move以及std::forwardo。move是为了实现移动语义,forward是为了实现完美转发。同步队列的锁是用来线程同步的,条件变量是用来实现线程通信的,即线程池空了就要等待,不为空就通知一个线程去处理;线程池满了就等待,直到没有满的时候才通知上层添加新任务。
这三个层次之间需要使用std::mutex、std::condition_variable来进行事件同步,线程池的实现代码如下。
1 | #include <list> |
Take函数先创建一个unique_lock获取,然后再通过条件变量m_notEmpty来等待判断式,判断式由两个条件组成,一个是停止的标志,另一个是不为空的条件,当不满足任何一个条件时,条件变量会释放mutex并将线程置于waiting状态,等待其他线程调用notify_one/notify-all将其唤醒;当满足任何一个条件时,则继续往下执行后面的逻辑,即将队列中的任务取出,并唤醒一个正处于等待状态的添加任务的线程去添加任务。当处于waiting状态的线程被或notify_all唤醒时,条件变量会先重新获取mutex,然后再检查条件是否满足,如果满足,则往下执行,如果不满足,则释放mutex继续等待。
Add函数的过程与Take类似,先获取mutex,不满足条件时,释放继续等待,如果满足条件,则将新的任务插人到队列中,并唤醒取任的线程去取数据。
Stop函数先获取mutex,然后将停止标志置为true。注意,为了保证线程安全,这里需要先获取mutex,在将其标志置为之后,再唤醒所有等待的线程,因为等待的条件是m_needStop,并且满足条件,所以线程会继续往下执行。由于线程在m_needStop为true时会退出,所以所有的等待线程会相继退出。另外一个值得注意的地方是,我们把m_notFull.notify_all()放到lock_guard保护范围之外了,这里也可以将m_notFull.notify_all()放到lock_guard保护范围之内,放到外面是为了做一点优化。因为notify-one或notify-all会唤醒一个在等待的线程,线程被唤醒后会先获取mutex再检查条件是否满足,如果这时被lock_guard保护,被唤醒的线程则需要lock_guard析构释放mutex才能获取。如果在lock_guard之外notify_one或notify_all,被唤醒的线程获取锁的时候不需要等待lock-guard释放锁,性能会
好一点,所以在执行notify-one或notify-all时不需要加锁保护。
线程池:
一个完整的线程池包括三层:同步服务层、排队层和异步服务层,其实这也是一种生产者一消费者模式,同步层是生产者,不断将新任务丢到排队层中,因此,线程池需要提供一个添加新任务的接口供生产者使用;消费者是异步层,具体是由线程池中预先创建的线程去处理排队层中的任务。排队层是一个同步队列,它内部保证了上下两层对共享数据的安全访问,同时还要保证队列不会被无限制地添加任务导致内存暴涨,这个同步队列将使用上一节中实现的线程池。另外,线程池还要提供一个停止的接口,让用户能够在需要的时候停止线程池的运行。
1 | const int MaxTaskCount = 100; |
C++11实现一个轻量级的AOP框架
AOP(Aspect-Oriented Programming,面向方面编程),可以解决面向对象编程中的一些问题,是OOP的一种有益补充。面向对象编程中的继承是一种从上而下的关系,不适合定义从左到右的横向关系,如果继承体系中的很多无关联的对象都有一些公共行为,这些公共行为可能分散在不同的组件、不同的对象之中,通过继承方式提取这些公共行为就不太合适了。使用AOP还有一种情况是为了提高程序的可维护性,AOP将程序的非核心逻辑都“横切”出来,将非核心逻辑和核心逻辑分离,使我们能集中精力在核心逻辑上,如图所示的这种情况。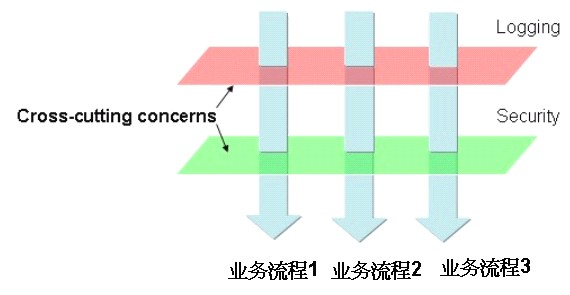
在图中,每个业务流程都有日志和权限验证的功能,还有可能增加新的功能,实际上我们只关心核心逻辑,其他的一些附加逻辑,如日志和权限,我们不需要关注,这时,就可以将日志和权限等非核心逻辑“横切”出来,使核心逻辑尽可能保持简洁和清晰,方便维护。这样“横切”的另外一个好处是,这些公共的非核心逻辑被提取到多个切面中了,使它们可以被其他组件或对象复用,消除了重复代码。
AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,它们经常发生在核心关注点的多处,而各处都基本相似,比如权限认证、日志、事务处理。AOP 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
实现AOP的技术分为:静态织入和动态织入。静态织入一般采用抓们的语法创建“方面”,从而使编译器可以在编译期间织入有关“方面”的代码,AspectC++就是采用的这种方式。这种方式还需要专门的编译工具和语法,使用起来比较复杂。我将要介绍的AOP框架正是基于动态织入的轻量级AOP框架。动态织入一般采用动态代理的方式,在运行期对方法进行拦截,将切面动态织入到方法中,可以通过代理模式来实现。
1 | #include<memory> |
测试代码将输出:
1 | Before real Output |
可以看到我们通过HelloProxy代理对象实现了对Output方法的拦截,这里Hello::Output就是核心逻辑,HelloProxy实际上就是一个切面,我们可以把一些非核心逻辑放到里面,比如在核心逻辑之前的一些校验,在核心逻辑执行之后的一些日志等。
要实现灵活组合各种切面,一个比较好的方法是将切面作为模板的参数,这个参数是可变的,支持1到N(N>0)切面,先执行核心逻辑之前的切面逻辑,执行完之后再执行核心逻辑,然后再执行核心逻辑之后的切面逻辑。这里,我们可以通过可变参数模板来支持切面的组合。AOP实现的关键是动态织入,实现技术就是拦截目标方法,只要拦截了目标方法,我们就可以在目标方法执行前后做一些非核心逻辑,通过继承方式来实现拦截,需要派生基类并实现基类接口,这使程序的耦合性增加了。为了降低耦合性,这里通过模板来做解耦,即每个切面对象需要提供Before(Args…)或After(Args…)方法,用来处理核心逻辑执行前后的非核心逻辑。
为了实现切面的充分解耦合,我们的切面不必通过继承方式实现,而且也不必要求切面必须具备Before和After方法,只要具备任意一个方法即可,给使用者提供最大的便利性和灵活性。实现这个功能稍微有点复杂,复杂的地方在于切面可能具有某个方法也可能不具有某个方法,具有就调用,不具有也不会出错。问题的本质上是需要检查类型是否具有某个方法,在C++中是无法在运行期做到这个事情的,因为C++像不托管语言c#或java那样具备反射功能,然而,我们可以在编译期检查类型是否具有某个方法。
1 | #define HAS_MEMBER(member)\ |
实现思路很简单,将需要动态织入的函数保存起来,然后根据参数化的切面来执行Before(Args…)处理核心逻辑之前的一些非核心逻辑,在核心逻辑执行完之后,再执行After(Args…)来处理核心逻辑之后的一些非核心逻辑。上面的代码中的has_member_Before和has_member_After这两个traits是为了让使用者用起来更灵活,使用者可以自由的选择Before和After,可以仅仅有Before或After,也可以二者都有。
需要注意的是切面中的约束,因为通过模板参数化切面,要求切面必须有Before或After函数,这两个函数的入参必须和核心逻辑的函数入参保持一致,如果切面函数和核心逻辑函数入参不一致,则会报编译错误。从另外一个角度来说,也可以通过这个约束在编译期就检查到某个切面是否正确。
下面看一个简单的测试AOP的例子,这个例子中我们将记录目标函数的执行时间并输出日志,其中计时和日志都放到切面中。在执行函数之前输出日志,在执行完成之后也输出日志,并对执行的函数进行计时。
1 | struct TimeElapsedAspect |
使用C++开发一个轻量级的IoC容器
让对象不再直接依赖于外部对象的创建,而是依赖于某种机制,这种机制可以让对象之间的关系在外面组装,外界可以根据需求灵活地配置这种机制的对象创建策略,从而获得想要的目标对象,这种机制被称为控制反转。控制反转就是应用本身不负责依赖对象的创建和维护,而交给一个外部容器来负责。这样控制权就由应用转移到了外部容器,即实现了所谓的控制反转。IoC用来降低对象之间直接依赖产生的耦合性。
具体做法是将对象的依赖关系从代码中移出去,放到一个统一的配置文件中或者在IoC容器中配置这种依赖关系,由容器来管理对象的依赖关系。比如可以这样来初始化:
1 | void IocSample() { |
在上面的例子中,我们在外面通过IoC容器配置了A和Base对象的关系,然后由IoC容器去创建A对象,这里A对象的创建不再依赖于工厂或者Base对象,彻底解耦了二者之间的关系。
IoC使得我们在对象创建上获得了最大的灵活性,大大降低了依赖对象创建时的耦合性,即使需求变化了,也只需要修改配置文件就可以创建想要的对象,而不需要修改代码了。我们一般是通过依赖注人(Dependency Injection)来将对象创建的依赖关系注人到目标类型的构造函数中。
IoC容器实际上具备两种能力,一种是对象工厂的能力,不仅可以创建所有的对象,还能根据配置去创建对象;另一种能力是可以去创建依赖对象,应用不需要直接创建依赖对象,由IoC容器去创建,实现控制反转。
IoC创建对象
因为IoC容器本质上是为了创建对象及依赖的对象,所以实现loc容器第一个要解决的问题是如何创建对象。IoC容器要创建所有类型对象的能力,并且还能根据配置来创建依赖对象。我们先看看如何实现一个可配置的对象工厂。
一个可配置的对象工厂实现思路如下:先注册可能需要创建的对象类型的构造函数,将其放到一个内部关联容器中,设置键为类型的名称或者某个唯一的标识,值为类型的构造函数,然后在创建的时候根据类型名称或某个唯一标识来查找对应的构造函数并最终创建出目标对象。对于外界来说,不需要关心对象具体是如何创建的,只需要告诉工厂要创建的类型名称即可,工厂获取了类型名称或唯一标识之后就可以创建需要的对象了。由于工厂是根据唯一标识来创建对象,所以这个唯一标识是可以写到配置文件中的,这样就可以根据配置动态生成所需要的对象了,我们一般是将类型的名称作为这个唯一标识。
类型擦除就是将原有类型消除或者隐藏。为什么要擦除类型?因为很多时候我们不关心只体类型是什么或者根本就不需要这个类型。类型擦除可以获取很多好处,比如使得程序有更好的扩展性,还能消除耦合以及消除一些重复行为,使程序更加简洁高效。下面是一些常用的类型擦除方式:
- 通过多态来擦除类型。
- 通过模板来擦除类型。
- 通过某种类型容器来擦除类型。
- 通过某种通用类型来擦除类型。
- 通过闭包来擦除类型。
第一种类型擦除方式是最简单的,也是经常用的,通过将派生类型隐式转换成基类型,再通过基类去调用虚函数。在这种情况下,我们不用关心派生类的具体类型,只需要以一种统一的方式去做不同的事情,所以就把派生类型转成基类型隐藏起来,这样不仅可以多态调用,还使程序具有良好的可扩展性。然而这种方式的类型擦除仅是将部分类型擦除,因为基类型仍然存在,而且这种类型擦除的方式还必须继承这种强耦合的方式。正是因为这些缺点,通过多态来擦除类型的方式有较多局限性,并且效果也不好。这时通过第二种方式来擦除类型,可以以解决第一种方式的一些问题。通过模板来擦除类型,本质上是把不同类型的共同行为进行了抽象,这时不同类型彼此之间不需要通过继承这种强耦合的方式去获得共同的行为,仅仅是通过模板就能获取共同行为,降低了不同类型之间的耦合,是一种很好的类型擦除方式。然而,第二种方式虽然降低了对象间的耦合,但是还有一个问题没解决,就是基本类型始终需要指定,并没有消除基本类型,例如,不可能把一个T本身作为容器元素,必须在容器初始化时指定T为某个具体类型。
有时,希望有一种通用的类型,可以让容器容纳所有的类型,作为所有类型的基类,可以当作一种通用的类型。之前实现的Variant类可以把不同的类型抱起来,获得一种统一的类型,而且不同类型之间没有耦合关系。比如,可以通过Variant这样来擦除类型:
1 | //定义通用的类型,这个类型可能容纳多种类型 |
上面的代码擦除了不同类型,使得不同的类型都可以放到一个容器中了,如果要取出来就很简单,通过Get
纳声明的那些类型,是有限的,超出定义的范围就不行了。
通过某种通用类型来擦除原有类型的方式可以消除这个缺点,这种通用类型就是Any类型,下面介绍怎么用Any来擦除类型。
1 | vector<Any> v; |
在上面的代码中,不需要预先定义类型的范围,允许任何类型的对象都赋值给Any对象,消除了Variant类型只支持有限类型的问题,但是Any的缺点是:在取值的时候仍然需要具体的类型。
1 | #include <string> |
这样仍然不太方便,但是可以改进,可以借助闭包,将一些类型信息保存在闭包中,闭包将类型隐藏起来了,从而实现了类型擦除的目的。由于闭包本身的类型是确定的,所以能放到普通的容器中,在需要的时候从闭包中取出具体的类型。下面看看如何通过闭包来擦除类型,代码如下:
1 | template<typename T> |
最后的可变参数模板改进IoC容器,支持带参数对象的创建。
1 | #include <string> |
类型注册分成三种方式注册,一种是简单方式注册,它只需要具体类型信息和key,类型的构造函数中没有参数,从容器中取也只需要类型和key;另外一种简单注册方式需要接口类型和具体类型,返回实例时,可以通过接口类型和key来得到具体对象;第三种是构造函数中带参数的类型注册,需要接口类型、key和参数类型,获取对象时需要接口类型、key和参数。返回的实例可以是普通的指针也可以是智能指针。需要注意的是key是唯一的,如果不唯一,会产生一个断言错误,推荐用类型的名称作为key,可以保证唯一性,std::string strKey = typeid(T).name()。