decltype简介
我们之前使用的typeid运算符来查询一个变量的类型,这种类型查询在运行时进行。RTTI机制为每一个类型产生一个type_info类型的数据,而typeid查询返回的变量相应type_info数据,通过name成员函数返回类型的名称。同时在C++11中typeid还提供了hash_code这个成员函数,用于返回类型的唯一哈希值。RTTI会导致运行时效率降低,且在泛型编程中,我们更需要的是编译时就要确定类型,RTTI并无法满足这样的要求。编译时类型推导的出现正是为了泛型编程,在非泛型编程中,我们的类型都是确定的,根本不需要再进行推导。
而编译时类型推导,除了我们说过的auto关键字,还有本文的decltype。
decltype与auto关键字一样,用于进行编译时类型推导,不过它与auto还是有一些区别的。decltype的类型推导并不是像auto一样是从变量声明的初始化表达式获得变量的类型,而是总是以一个普通表达式作为参数,返回该表达式的类型,而且decltype并不会对表达式进行求值。
decltype用法
推导出表达式类型
1 | int i = 4; |
与using/typedef合用,用于定义类型。
1 | using size_t = decltype(sizeof(0));//sizeof(a)的返回值为size_t类型 |
这样和auto一样,也提高了代码的可读性。
重用匿名类型
在C++中,我们有时候会遇上一些匿名类型,如:1
2
3
4
5struct
{
int d ;
doubel b;
}anon_s;
而借助decltype,我们可以重新使用这个匿名的结构体:1
decltype(anon_s) as ;//定义了一个上面匿名的结构体
泛型编程中结合auto,用于追踪函数的返回值类型
这也是decltype最大的用途了。1
2
3
4
5template <typename _Tx, typename _Ty>
auto multiply(_Tx x, _Ty y)->decltype(_Tx*_Ty)
{
return x*y;
}
decltype推导四规则
- 如果e是一个没有带括号的标记符表达式或者类成员访问表达式,那么的decltype(e)就是e所命名的实体的类型。此外,如果e是一个被重载的函数,则会导致编译错误。
- 否则 ,假设e的类型是T,如果e是一个将亡值,那么decltype(e)为T&&
- 否则,假设e的类型是T,如果e是一个左值,那么decltype(e)为T&。
- 否则,假设e的类型是T,则decltype(e)为T。
标记符指的是除去关键字、字面量等编译器需要使用的标记之外的程序员自己定义的标记,而单个标记符对应的表达式即为标记符表达式。例如:1
int arr[4]
则arr为一个标记符表达式,而arr[3]+0不是。
我们来看下面这段代码:1
2
3int i=10;
decltype(i) a; //a推导为int
decltype((i))b=i;//b推导为int&,必须为其初始化,否则编译错误
仅仅为i加上了(),就导致类型推导结果的差异。这是因为,i是一个标记符表达式,根据推导规则1,类型被推导为int。而(i)为一个左值表达式,所以类型被推导为int&。
通过下面这段代码可以对推导四个规则作进一步了解1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44int i = 4;
int arr[5] = { 0 };
int *ptr = arr;
struct S{ double d; }s ;
void Overloaded(int);
void Overloaded(char);//重载的函数
int && RvalRef();
const bool Func(int);
//规则一:推导为其类型
decltype (arr) var1; //int 标记符表达式
decltype (ptr) var2;//int * 标记符表达式
decltype(s.d) var3;//doubel 成员访问表达式
//decltype(Overloaded) var4;//重载函数。编译错误。
//规则二:将亡值。推导为类型的右值引用。
decltype (RvalRef()) var5 = 1;
//规则三:左值,推导为类型的引用。
decltype ((i))var6 = i; //int&
decltype (true ? i : i) var7 = i; //int& 条件表达式返回左值。
decltype (++i) var8 = i; //int& ++i返回i的左值。
decltype(arr[5]) var9 = i;//int&. []操作返回左值
decltype(*ptr)var10 = i;//int& *操作返回左值
decltype("hello")var11 = "hello"; //const char(&)[9] 字符串字面常量为左值,且为const左值。
//规则四:以上都不是,则推导为本类型
decltype(1) var12;//const int
decltype(Func(1)) var13=true;//const bool
decltype(i++) var14 = i;//int i++返回右值
这里需要提示的是,字符串字面值常量是个左值,且是const左值,而非字符串字面值常量则是个右值。
这么多规则,对于我们写代码的来说难免太难记了,特别是规则三。我们可以利用C++11标准库中添加的模板类is_lvalue_reference来判断表达式是否为左值:1
cout << is_lvalue_reference<decltype(++i)>::value << endl;
结果1表示为左值,结果为0为非右值。
同样的,也有is_rvalue_reference这样的模板类来判断decltype推断结果是否为右值。
几种继承及其特点
public的变量和函数在类的内部外部都可以访问。
protected的变量和函数只能在类的内部和其派生类中访问。
private修饰的元素只能在类内访问。
成员默认属性
- struct的成员默认是公有的
- class的成员默认是私有的
- class继承默认是私有继承
- struct的继承默认是公有的
公有继承方式(public)
注意事项:
- 基类的私有成员,子类不可以访问
- 基类的保护成员,子类可以继承为自己的保护成员,在派生类可以访问,在外部不可以访问。
- 基类的公有成员,子类可以继承为自己的公有成员。在派生类可以访问,在外部也可以访问。
保护继承(protected)
- 基类公有成员,子类中继承为自己的保护成员,在派生类可以访问,在外部不可以访问
- 基类保护成员,子类中继承为自己的保护成员,在派生类可以访问,在外部不可以访问
- 基类私有成员,子类一样不可以访问基类的私有成员。
私有继承(private)
私有继承方式的,就是在继承时,把protected变成private,它需要注意的事项为:
- 基类公有成员,子类中继承为自己的私有成员,在派生类可以访问,在外部不可以访问。
- 基类保护成员,子类中继承为自己的私有成员,在派生类可以访问,在外部不可以访问。
- 基类私有成员,子类一样不可以访问基类的私有成员,
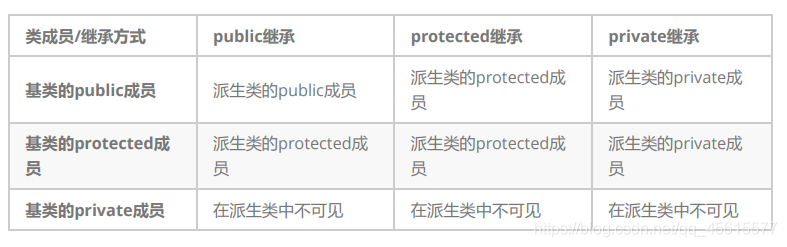
三种继承方式比较
从上面的结果来看,私有继承和保护继承作用完全一样。仔细一想其实还是有区别,区别是如果派生类再一次去派生其它类时,对于刚才的私有继承来说,再派生的类将得不到任何成员。而对于刚才的保护继承,仍能够得到基类的公有和保护成员。
派生类是可以访问基类保护的数据成员,但是还有一些私有数据成员,派生类是无法访问的,并且为提醒类的独立性,我们还是希望通过调用基类的成员函数去初始化这些成员变量,所以派生类是通过调用基类的构造函数,实现对成员变量的初始化。
继承中的作用域
- 在继承体系中基类和派生类都有独立的作用域。
- 子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
- 需要注意的是如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
- 注意在实际中在继承体系里面最好不要定义同名的成员。
什么叫同名隐藏,我们用代码看一下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class Base
{
public:
void fun()
{
cout << "Base::fun()" << endl;
}
};
// 子类 父类
class D :public Base // 继承
{
public:
void fun()
{
cout << "D::fun()" << endl;
}
void show()
{
cout << "D::shoe()" << endl;
}
};
void main()
{
D d;
Base *pb = &d;
pb->fun();// 只能访问子类中父类所有的fun函数
d.fun(); // 只能访问子类自己的fun函数
}
派生类的默认成员函数
- 派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认的构造函 数,则必须在派生类构造函数的初始化列表阶段显示调用。
- 派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
- 派生类的operator=必须要调用基类的operator=完成基类的复制。
- 派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员。因为这样才能保证派生类 对象先清理派生类成员再清理基类成员的顺序。
- 派生类对象初始化先调用基类构造再调派生类构造。
- 派生类对象析构清理先调用派生类析构再调基类的析构
继承与静态成员
基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一个static成员实例 。
同样我们看代码 如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66//继承与静态成员
//基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一个static成员实例 。如下
class Test
{
public:
Test()
{
count++;
}
public:
int GetCount()const
{
return count;
}
//int GetCount()const
//{
// return GetOBJCount();
//}
private:
static int count;// 类的静态成员必须在类外初始化
//因为静态成员属于整个类,而不属于某个对象,如果在类内初始化,会导致每个对象都包含该静态成员,这是矛盾的
};
int Test::count = 0;
class D1 :public Test
{
public:
//int GetCount()const
//{
// return GetOBJCount();
//}
};
class D2 :public Test
{
public:
//int GetCount()const
//{
// return GetOBJCount();
//}
};
class D3 :public Test
{
public:
//int GetCount()const
//{
// return GetOBJCount();
//}
};
class D4 :public Test
{
public:
//int GetCount()const
//{
// return GetOBJCount();
//}
};
void main()
{
D1 d1;
cout << d1.GetCount() << endl;
D2 d2;
cout << d2.GetCount() << endl;
D3 d3;
cout << d3.GetCount() << endl;
D4 d4;
cout << d4.GetCount() << endl;
}
基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一 个static成员实例 。
static修饰的成员,只能在类中进行声明,类外定义,原因是因为静态成员属于整个类,而不属于某个对象,如果在类内初始化,会导致每个对象都包含该静态成员,这是矛盾的。
多态性
(1)解释多态性:函数的多种不同的实现方式即为多态
(2)必要性:在继承中,有时候基类的一些函数在派生类中也是有用的,但是功能不够全或者两者的功能实现方式就是不一样的,这个时候就希望重载那个基类的函数,但是为了不再调用这个函数时,出现不知道调用基类的还是子类的情况出现,于是就提出了多态。如果语言不知多态,则不能称为面向对象的。
(3)多态性是如何实现的:多态是实现是依赖于虚函数来实现的,之所以虚函数可以分清楚当前调用的函数是基类的还是派生类的,主要在于基类和派生类分别有着自己的虚函数表,再调用虚函数时,它们是通过去虚函数表去对应的函数的。
其实虚函数表的本质就是一种迟后联编的过程,正常编译都是先期联编的,但是当代码遇到了virtual时,就会把它当做迟后联编,但是为了迟后编译,就生成了局部变量–虚函数表,这就增大了一些空间上的消耗。(前提是两个函数的返回类型,参数类型,参数个数都得相同,不然就起不到多态的作用)
使用虚函数的一些限制
- 只有类成员函数才能声明为虚函数,这是因为虚函数只适用于有继承关系的类对象中。
- 静态成员函数不能说明为虚函数,因为静态成员函数不受限与某个对象,整个内存中只有一个,所以不会出现混淆的情况
- 内联函数不可以被继承,因为内联函数是不能子啊运行中动态的确认其位置的。
- 构造函数不可以被继承。
- 析构函数可以被继承,而且通常声明为虚函数。
纯虚函数
(1)解释:虚函数是在基类中被声明为virtual,并在派生类中重新定义的成员函数,可实现成员函数的动态重载。纯虚函数的声明有着特殊的语法格式:virtual 返回值类型成员函数名(参数表)=0;
(2)必要性:在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。为了解决上述问题,引入了纯虚函数的概念,将函数定义为纯虚函数(方法:virtual ReturnType Function()= 0;),则编译器要求在派生类中必须予以重载以实现多态性。同时含有纯虚拟函数的类称为抽象类,它不能生成对象。
(3)抽象类的解释:包含纯虚函数的类称为抽象类。由于抽象类包含了没有定义的纯虚函数,所以不能定义抽象类的对象。在C++中,抽象类只能用于被继承而不能直接创建对象的类(Abstract Class)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
using namespace std;
class A
{
public :
virtual void fun() = 0;
};
class B :public A
{
public :
virtual void fun()
{
cout << "B: " << endl;
}
};
int main()
{
B b;
b.fun();
return 0;
}
继承权限
- public继承
- 公有继承的特点是基类的公有成员和保护成员作为派生类的成员时,都保持原有的状态,而基类的私有成员任然是私有的,不能被这个派生类的子类所访问
- protected继承
- 保护继承的特点是基类的所有公有成员和保护成员都成为派生类的保护成员,并且只能被它的派生类成员函数或友元函数访问,基类的私有成员仍然是私有的.
- private继承
- 私有继承的特点是基类的所有公有成员和保护成员都成为派生类的私有成员,并不被它的派生类的子类所访问,基类的成员只能由自己派生类访问,无法再往下继承
模板类的继承
模板类的继承包括四种:
1.(普通类继承模板类)1
2
3
4
5
6
7
8template<class T>
class TBase{
T data;
……
};
class Derived:public TBase<int>{
……
};
2.(模板类继承了普通类(非常常见))1
2
3
4
5
6
7
8class TBase{
……
};
template<class T>
class TDerived:public TBase{
T data;
……
};
3.(类模板继承类模板)1
2
3
4
5
6
7
8
9
10template<class T>
class TBase{
T data1;
……
};
template<class T1,class T2>
class TDerived:public TBase<T1>{
T2 data2;
……
};
4.(模板类继承类模板,即继承模板参数给出的基类)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
using namespace std;
class BaseA{
public:
BaseA(){cout<<"BaseA founed"<<endl;}
};
class BaseB{
public:
BaseB(){cout<<"BaseB founed"<<endl;}
};
template<typename T, int rows>
class BaseC{
private:
T data;
public:
BaseC():data(rows){
cout<<"BaseC founed "<< data << endl;}
};
template<class T>
class Derived:public T{
public:
Derived():T(){cout<<"Derived founed"<<endl;}
};
void main()
{
Derived<BaseA> x;// BaseA作为基类
Derived<BaseB> y;// BaseB作为基类
Derived<BaseC<int, 3> > z; // BaseC<int,3>作为基类
}
reverse函数
C++ < algorithm > 中定义的reverse函数用于反转在[first,last)范围内的顺序1
2template <class BidirectionalIterator>
void reverse (BidirectionalIterator first,BidirectionalIterator last);
例如,交换vector容器中元素的顺序1
2vector<int> v={1,2,3,4,5};
reverse(v.begin(),v.end());//v的值为5,4,3,2,1
当然,你也可以通过它方便的反转string类的字符串1
2string str="C++REVERSE";
reverse(str.begin(),str.end());//str结果为ESREVER++C
该函数等价于通过调用iter_swap来交换元素位置1
2
3
4
5
6
7
8
9template <class BidirectionalIterator>
void reverse (BidirectionalIterator first, BidirectionalIterator last)
{
while ((first!=last)&&(first!=--last))
{
std::iter_swap (first,last);
++first;
}
}
C++中constexpr作用
constexpr 是 C++ 11 标准新引入的关键字,不过在讲解其具体用法和功能之前,读者需要先搞清楚 C++ 常量表达式的含义。
所谓常量表达式,指的就是由多个(≥1)常量组成的表达式。换句话说,如果表达式中的成员都是常量,那么该表达式就是一个常量表达式。这也意味着,常量表达式一旦确定,其值将无法修改。
实际开发中,我们经常会用到常量表达式。以定义数组为例,数组的长度就必须是一个常量表达式:1
2
3
4
5
6
7// 1)
int url[10];//正确
// 2)
int url[6 + 4];//正确
// 3)
int length = 6;
int url[length];//错误,length是变量
上述代码演示了 3 种定义 url 数组的方式,其中第 1、2 种定义 url 数组时,长度分别为 10 和 6+4,显然它们都是常量表达式,可以用于表示数组的长度;第 3 种 url 数组的长度为 length,它是变量而非常量,因此不是一个常量表达式,无法用于表示数组的长度。
常量表达式的应用场景还有很多,比如匿名枚举、switch-case 结构中的 case 表达式等,感兴趣的读者可自行编码测试,这里不再过多举例。
我们知道,C++ 程序的执行过程大致要经历编译、链接、运行这 3 个阶段。值得一提的是,常量表达式和非常量表达式的计算时机不同,非常量表达式只能在程序运行阶段计算出结果;而常量表达式的计算往往发生在程序的编译阶段,这可以极大提高程序的执行效率,因为表达式只需要在编译阶段计算一次,节省了每次程序运行时都需要计算一次的时间。
对于用 C++ 编写的程序,性能往往是永恒的追求。那么在实际开发中,如何才能判定一个表达式是否为常量表达式,进而获得在编译阶段即可执行的“特权”呢?除了人为判定外,C++11 标准还提供有 constexpr 关键字。
constexpr 关键字的功能是使指定的常量表达式获得在程序编译阶段计算出结果的能力,而不必等到程序运行阶段。C++ 11 标准中,constexpr 可用于修饰普通变量、函数(包括模板函数)以及类的构造函数。
注意,获得在编译阶段计算出结果的能力,并不代表 constexpr 修饰的表达式一定会在程序编译阶段被执行,具体的计算时机还是编译器说了算。
constexpr修饰普通变量
C++11 标准中,定义变量时可以用 constexpr 修饰,从而使该变量获得在编译阶段即可计算出结果的能力。
值得一提的是,使用 constexpr 修改普通变量时,变量必须经过初始化且初始值必须是一个常量表达式。举个例子:1
2
3
4
5
6
7
8
9
using namespace std;
int main()
{
constexpr int num = 1 + 2 + 3;
int url[num] = {1,2,3,4,5,6};
couts<< url[1] << endl;
return 0;
}
程序执行结果为:1
2
读者可尝试将 constexpr 删除,此时编译器会提示“url[num] 定义中 num 不可用作常量”。
可以看到,程序第 6 行使用 constexpr 修饰 num 变量,同时将 “1+2+3” 这个常量表达式赋值给 num。由此,编译器就可以在编译时期对 num 这个表达式进行计算,因为 num 可以作为定义数组时的长度。
有读者可能发现,将此示例程序中的 constexpr 用 const 关键字替换也可以正常执行,这是因为 num 的定义同时满足“num 是 const 常量且使用常量表达式为其初始化”这 2 个条件,由此编译器会认定 num 是一个常量表达式。
注意,const 和 constexpr 并不相同,关于它们的区别,我们会在下一节做详细讲解。
另外需要重点提出的是,当常量表达式中包含浮点数时,考虑到程序编译和运行所在的系统环境可能不同,常量表达式在编译阶段和运行阶段计算出的结果精度很可能会受到影响,因此 C++11 标准规定,浮点常量表达式在编译阶段计算的精度要至少等于(或者高于)运行阶段计算出的精度。
constexpr修饰函数
constexpr 还可以用于修饰函数的返回值,这样的函数又称为“常量表达式函数”。
注意,constexpr 并非可以修改任意函数的返回值。换句话说,一个函数要想成为常量表达式函数,必须满足如下 4 个条件。
1) 整个函数的函数体中,除了可以包含 using 指令、typedef 语句以及 static_assert 断言外,只能包含一条 return 返回语句。
举个例子:1
2
3
4constexpr int display(int x) {
int ret = 1 + 2 + x;
return ret;
}
注意,这个函数是无法通过编译的,因为该函数的返回值用 constexpr 修饰,但函数内部包含多条语句。
如下是正确的定义 display() 常量表达式函数的写法:1
2
3
4constexpr int display(int x) {
//可以添加 using 执行、typedef 语句以及 static_assert 断言
return 1 + 2 + x;
}
可以看到,display() 函数的返回值是用 constexpr 修饰的 int 类型值,且该函数的函数体中只包含一个 return 语句。
2) 该函数必须有返回值,即函数的返回值类型不能是 void。
举个例子:1
2
3constexpr void display() {
//函数体
}
像上面这样定义的返回值类型为 void 的函数,不属于常量表达式函数。原因很简单,因为通过类似的函数根本无法获得一个常量。
3) 函数在使用之前,必须有对应的定义语句。我们知道,函数的使用分为“声明”和“定义”两部分,普通的函数调用只需要提前写好该函数的声明部分即可(函数的定义部分可以放在调用位置之后甚至其它文件中),但常量表达式函数在使用前,必须要有该函数的定义。
举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
using namespace std;
//普通函数的声明
int noconst_dis(int x);
//常量表达式函数的声明
constexpr int display(int x);
//常量表达式函数的定义
constexpr int display(int x){
return 1 + 2 + x;
}
int main()
{
//调用常量表达式函数
int a[display(3)] = { 1,2,3,4 };
cout << a[2] << endl;
//调用普通函数
cout << noconst_dis(3) << endl;
return 0;
}
//普通函数的定义
int noconst_dis(int x) {
return 1 + 2 + x;
}
程序执行结果为:1
23
6
读者可自行将 display() 常量表达式函数的定义调整到 main() 函数之后,查看编译器的报错信息。
可以看到,普通函数在调用时,只需要保证调用位置之前有相应的声明即可;而常量表达式函数则不同,调用位置之前必须要有该函数的定义,否则会导致程序编译失败。
4) return 返回的表达式必须是常量表达式,举个例子:1
2
3
4
5
6
7
8
9
10
11
12
using namespace std;
int num = 3;
constexpr int display(int x){
return num + x;
}
int main()
{
//调用常量表达式函数
int a[display(3)] = { 1,2,3,4 };
return 0;
}
该程序无法通过编译,编译器报“display(3) 的结果不是常量”的异常。
常量表达式函数的返回值必须是常量表达式的原因很简单,如果想在程序编译阶段获得某个函数返回的常量,则该函数的 return 语句中就不能包含程序运行阶段才能确定值的变量。
注意,在常量表达式函数的 return 语句中,不能包含赋值的操作(例如 return x=1 在常量表达式函数中不允许的)。另外,用 constexpr 修改函数时,函数本身也是支持递归的,感兴趣的读者可自行尝试编码测试。
constexpr修饰类的构造函数
对于 C++ 内置类型的数据,可以直接用 constexpr 修饰,但如果是自定义的数据类型(用 struct 或者 class 实现),直接用 constexpr 修饰是不行的。
举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
using namespace std;
//自定义类型的定义
constexpr struct myType {
const char* name;
int age;
//其它结构体成员
};
int main()
{
constexpr struct myType mt { "zhangsan", 10 };
cout << mt.name << " " << mt.age << endl;
return 0;
}
此程序是无法通过编译的,编译器会抛出“constexpr不能修饰自定义类型”的异常。
当我们想自定义一个可产生常量的类型时,正确的做法是在该类型的内部添加一个常量构造函数。例如,修改上面的错误示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
//自定义类型的定义
struct myType {
constexpr myType(char *name,int age):name(name),age(age){};
const char* name;
int age;
//其它结构体成员
};
int main()
{
constexpr struct myType mt { "zhangsan", 10 };
cout << mt.name << " " << mt.age << endl;
return 0;
}
程序执行结果为:1
zhangsan 10
可以看到,在 myType 结构体中自定义有一个构造函数,借助此函数,用 constexpr 修饰的 myType 类型的 my 常量即可通过编译。
注意,constexpr 修饰类的构造函数时,要求该构造函数的函数体必须为空,且采用初始化列表的方式为各个成员赋值时,必须使用常量表达式。
前面提到,constexpr 可用于修饰函数,而类中的成员方法完全可以看做是“位于类这个命名空间中的函数”,所以 constexpr 也可以修饰类中的成员函数,只不过此函数必须满足前面提到的 4 个条件。
举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
using namespace std;
//自定义类型的定义
class myType {
public:
constexpr myType(const char *name,int age):name(name),age(age){};
constexpr const char * getname(){
return name;
}
constexpr int getage(){
return age;
}
private:
const char* name;
int age;
//其它结构体成员
};
int main()
{
constexpr struct myType mt { "zhangsan", 10 };
constexpr const char * name = mt.getname();
constexpr int age = mt.getage();
cout << name << " " << age << endl;
return 0;
}
程序执行结果为:1
zhangsan 10
注意,C++11 标准中,不支持用 constexpr 修饰带有 virtual 的成员方法。
constexpr修饰模板函数
C++11 语法中,constexpr 可以修饰模板函数,但由于模板中类型的不确定性,因此模板函数实例化后的函数是否符合常量表达式函数的要求也是不确定的。
针对这种情况下,C++11 标准规定,如果 constexpr 修饰的模板函数实例化结果不满足常量表达式函数的要求,则 constexpr 会被自动忽略,即该函数就等同于一个普通函数。
举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
using namespace std;
//自定义类型的定义
struct myType {
const char* name;
int age;
//其它结构体成员
};
//模板函数
template<typename T>
constexpr T dispaly(T t){
return t;
}
int main()
{
struct myType stu{"zhangsan",10};
//普通函数
struct myType ret = dispaly(stu);
cout << ret.name << " " << ret.age << endl;
//常量表达式函数
constexpr int ret1 = dispaly(10);
cout << ret1 << endl;
return 0;
}
程序执行结果为:1
2zhangsan 10
10
可以看到,示例程序中定义了一个模板函数 display(),但由于其返回值类型未定,因此在实例化之前无法判断其是否符合常量表达式函数的要求:
第 20 行代码处,当模板函数中以自定义结构体 myType 类型进行实例化时,由于该结构体中没有定义常量表达式构造函数,所以实例化后的函数不是常量表达式函数,此时 constexpr 是无效的;
第 23 行代码处,模板函数的类型 T 为 int 类型,实例化后的函数符合常量表达式函数的要求,所以该函数的返回值就是一个常量表达式。
附录
1 |
|
代码说明:
- 以上代码演示了如何在编译期计算3的阶乘。
- 在C++11之前,在编译期进行数值计算必须使用模板元编程技巧。具体来说我们通常需要定义一个内含编译期常量value的类模板(也称作元函数)。这个类模板的定义至少需要分成两部分,分别用于处理一般情况和特殊情况。
- 代码示例中Factorial元函数的定义分为两部分:
- 当模板参数大于0时,利用公式 N!=N*(N-1)! 递归调用自身来计算value的值。
- 当模板参数为0时,将value设为1这个特殊情况下的值。
- 在C++11之后,编译期的数值计算可以通过使用constexpr声明并定义编译期函数来进行。相对于模板元编程,使用constexpr函数更贴近普通的C++程序,计算过程显得更为直接,意图也更明显。
- 但在C++11中constexpr函数所受到的限制较多,比如函数体通常只有一句return语句,函数体内既不能声明变量,也不能使用for语句之类的常规控制流语句。
- 如factorial函数所示,使用C++11在编译期计算阶乘仍然需要利用递归技巧。
- C++14解除了对constexpr函数的大部分限制。在C++14的constexpr函数体内我们既可以声明变量,也可以使用goto和try之外大部分的控制流语句。
- 如factorial2函数所示,使用C++14在编译期计算阶乘只需利用for语句进行常规计算即可。
- 虽说constexpr函数所定义的是编译期的函数,但实际上在运行期constexpr函数也能被调用。事实上,如果使用编译期常量参数调用constexpr函数,我们就能够在编译期得到运算结果;而如果使用运行期变量参数调用constexpr函数,那么在运行期我们同样也能得到运算结果。
- 代码第32行所演示的是在运行期使用变量n调用constexpr函数的结果。
- 准确的说,constexpr函数是一种在编译期和运行期都能被调用并执行的函数。出于constexpr函数的这个特点,在C++11之后进行数值计算时,无论在编译期还是运行期我们都可以统一用一套代码来实现。编译期和运行期在数值计算这点上得到了部分统一。
const的用法
const是不改变的。在C和C++中,我们使用关键字const来使程序元素保持不变。const关键字可以在C++程序的许多上下文中使用。它可以用于:变量、指针、函数参数和返回类型、类数据成员、类成员函数、对象。
- 修饰变量,说明该变量不可以被改变;
- 修饰指针,分为指向常量的指针(pointer to const)和自身是常量的指针(常量指针,const pointer);
- 修饰引用,指向常量的引用(reference to const),用于形参类型,即避免了拷贝,又避免了函数对值的修改;
- 修饰成员函数,说明该成员函数内不能修改成员变量。
下面的声明都是什么意思?1
2
3
4
5const int a; a是一个常整型数
int const a; a是一个常整型数
const int *a; a是一个指向常整型数的指针,整型数是不可修改的,但指针可以
int * const a; a为指向整型数的常指针,指针指向的整型数可以修改,但指针是不可修改的
int const * a const; a是一个指向常整型数的常指针,指针指向的整型数是不可修改的,同时指针也是不可修改的
const变量
如果你用const关键字做任何变量,你就不能改变它的值。同样,必须在声明的时候初始化常数变量。
Example:1
2
3
4
5
6int main
{
const int i = 10;
const int j = i + 10; // works fine
i++; // this leads to Compile time error
}
上面的代码中,我们使 i 成为常量,因此如果我们试图改变它的值,我们将得到编译时错误。尽管我们可以用它来代替其他变量。
指针与const关键字
指针也可以使用const关键字来声明。当我们使用const和指针时,我们可以用两种方式来做:可以把const应用到指针指向的地方,或者我们可以使指针本身成为一个常数。
指向const变量的指针:
意味着指针指向一个const变量。1
const int* u;
这里,表示u是一个指针,可以指向const int类型变量。指针指向的内容不可改变。简称左定值,因为const位于*号的左边。
我们也可以这样写,1
char const* v;
表示v是指向const类型的char的指针。
指向const变量的指针非常有用,因为它可以用来使任何字符串或数组不可变
const指针
为了使指针保持不变,我们必须把const关键字放到右边。对于const指针p其指向的内存地址不能够被改变,但其内容可以改变。简称,右定向。因为const位于*号的右边。1
2int x = 1;
int* const w = &x;
里,w是一个指针,它是const,指向一个int,现在我们不能改变指针,这意味着它总是指向变量x但是可以改变它指向的值,通过改变x的值。
当你想要一个可以在值中改变但不会在内存中移动的存储器时,常量指针指向一个变量是很有用的。因为指针总是指向相同的内存位置,因为它是用const关键字定义的,但是那个内存位置的值可以被更改。
左定值,右定向,const修饰不变量
const函数参数和返回类型
1 | void f(const int i) |
注意几个要点:
①对于内置数据类型,返回const或非const值,不会有任何影响。1
2
3
4
5
6
7
8
9
10const int h()
{
return 1;
}
int main()
{
const int j = h();
int k = h();
}
j和k都将被赋值为1。不会出现错误。
②对于用户定义的数据类型,返回const,将阻止它的修改。此时返回的值不能作为左值使用,既不能被赋值,也不能被修改。const 修饰返回的指针或者引用,是否返回一个指向 const 的指针,取决于我们想让用户干什么。
③在程序执行时创建的临时对象总是const类型。值传递的 const 修饰传递,一般这种情况不需要 const 修饰,因为函数会自动产生临时变量复制实参值。
当 const 参数为指针时,可以防止指针被意外篡改。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using namespace std;
void Cpf(int *const a)
{
cout<<*a<<" ";
*a = 9;
}
int main(void)
{
int a = 8;
Cpf(&a);
cout<<a; // a 为 9
system("pause");
return 0;
}
自定义类型的参数传递,需要临时对象复制参数,对于临时对象的构造,需要调用构造函数,比较浪费时间,因此我们采取 const 外加引用传递的方法。并且对于一般的 int、double 等内置类型,我们不采用引用的传递方式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
using namespace std;
class Test
{
public:
Test(){}
Test(int _m):_cm(_m){}
int get_cm()const
{
return _cm;
}
private:
int _cm;
};
void Cmf(const Test& _tt)
{
cout<<_tt.get_cm();
}
int main(void)
{
Test t(8);
Cmf(t);
system("pause");
return 0;
}
④如果一个函数有一个非const参数,它在发出调用时不能传递const参数。1
2
3
4void t(int*)
{
// function logic
}
如果我们把一个const int参数传递给函数t,会出现错误。
⑤但是,一个具有const类型参数的函数,可以传递一个const类型参数以及一个非const参数。1
2
3
4void g(const int*)
{
// function logic
}
这个函数可以有一个int,也可以有const int类型参数。
const修饰函数返回值
(1)指针传递
如果返回const data,non-const pointer,返回值也必须赋给const data,non-const pointer。因为指针指向的数据是常量不能修改。1
2
3
4
5
6
7
8
9
10
11const int * mallocA(){ ///const data,non-const pointer
int *a=new int(2);
return a;
}
int main()
{
const int *a = mallocA();
///int *b = mallocA(); ///编译错误
return 0;
}
(2)值传递
如果函数返回值采用“值传递方式”,由于函数会把返回值复制到外部临时的存储单元中,加const 修饰没有任何价值。所以,对于值传递来说,加const没有太多意义。
所以:
- 不要把函数
int GetInt(void)写成const int GetInt(void)。 - 不要把函数
A GetA(void)写成const A GetA(void),其中A 为用户自定义的数据类型。
将类数据成员定义为const
这些是类中的数据变量,使用const关键字定义。它们在声明期间未初始化。它们的初始化在构造函数中完成。1
2
3
4
5
6
7
8
9
10
11
12
13
14class Test
{
const int i;
public:
Test (int x) : i(x)
{
}
};
int main()
{
Test t(10);
Test s(20);
}
在这个程序中,i 是一个常量数据成员,在每个对象中它的独立副本将会出现,因此它使用构造函数对每个对象进行初始化。一旦初始化,它的值就不能改变
把类对象定义为const
当一个对象被声明或使用const关键字创建时,它的数据成员在对象的生命周期中永远不会被改变。
语法:1
const class_name object;
例如,如果在上面定义的类测试中,我们想要定义一个常数对象,我们可以这样做:1
const Test r(30);
将类的成员函数定义为const
const成员函数决不会修改对象中的数据成员。注意:const关键字不能与static关键字同时使用,因为static关键字修饰静态成员函数,静态成员函数不含有this指针,即不能实例化,const成员函数必须具体到某一实例。
如果有个成员函数想修改对象中的某一个成员怎么办?这时我们可以使用mutable关键字修饰这个成员,mutable的意思也是易变的,容易改变的意思,被mutable关键字修饰的成员可以处于不断变化中。
const成员函数不能调用非const成员函数,因为非const成员函数可以会修改成员变量。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using namespace std;
class Point{
public :
Point(int _x):x(_x){}
void testConstFunction(int _x) const{
///错误,在const成员函数中,不能修改任何类成员变量
x=_x;
///错误,const成员函数不能调用非onst成员函数,因为非const成员函数可以会修改成员变量
modify_x(_x);
}
void modify_x(int _x){
x=_x;
}
int x;
};
语法:1
return_type function_name() const;
const对象和const成员函数的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class StarWars
{
public:
int i;
StarWars(int x) // constructor
{
i = x;
}
int falcon() const // constant function
{
/*
can do anything but will not
modify any data members
*/
cout << "Falcon has left the Base";
}
int gamma()
{
i++;
}
};
int main()
{
StarWars objOne(10); // non const object
const StarWars objTwo(20); // const object
objOne.falcon(); // No error
objTwo.falcon(); // No error
cout << objOne.i << objTwo.i;
objOne.gamma(); // No error
objTwo.gamma(); // Compile time error
}
输出结果:1
2
3Falcon has left the Base
Falcon has left the Base
10 20
在这里,我们可以看到,const成员函数永远不会改变类的数据成员,并且它可以与const和非const对象一起使用。但是const对象不能与试图改变其数据成员的成员函数一起使用。
关于const的疑问:
const常量的判别标准:
- 只有字面量初始化的const常量才会进入符号表
- 使用其他变量初始化的const常量仍然是只读变量
- 被volatile修饰的const常量不会进入符号表
注意:
- const引用的类型与初始化变量的类型相同时:初始化变量成为只读变量
- const引用的类型与初始化变量的类型不相同时:初生成一个新的只读变量
Example:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
int main()
{
const int x = 1; //字面量初始化,此时x为常量,进入符号表
const int& rx = x; //rx代表只读变量
int& nrx = const_cast<int&>(rx); //去掉rx的只读属性
nrx = 5; //改变了nrx内存空间的值
printf("x = %d\n", x); // 1
printf("rx = %d\n", rx); // 5
printf("nrx = %d\n", nrx); // 5
printf("&x = %p\n", &x); // &x = 002CFD80
printf("&rx = %p\n", &rx); // &x = 002CFD80
printf("&nrx = %p\n", &nrx); // &x = 002CFD80
//输出的地址相同,说明了x、rx、nrx代表同样的内存空间
volatile const int y = 2;//volatile代表易变的
int* p = const_cast<int*>(&y);
*p = 6;
printf("y = %d\n", y); //y = 6
printf("p = %p\n", p); //p = 001BF928
//判别是否是常量是编译器在编译时能不能确认它的值
const int z = y;
p = const_cast<int*>(&z);
*p = 7;
printf("z = %d\n", z); // z = 7
printf("p = %p\n", p); //p = 001BF910
char c = 'c';
char& rc = c;
const int& trc = c;
rc = 'a';
printf("c = %c\n", c); // c = a
printf("rc = %c\n", rc);// rc = a
printf("trc = %c\n", trc);//trc = c
//变量c是char类型,而trc是int类型,所以生成了一个新的只读变量
return 0;
}
输出结果: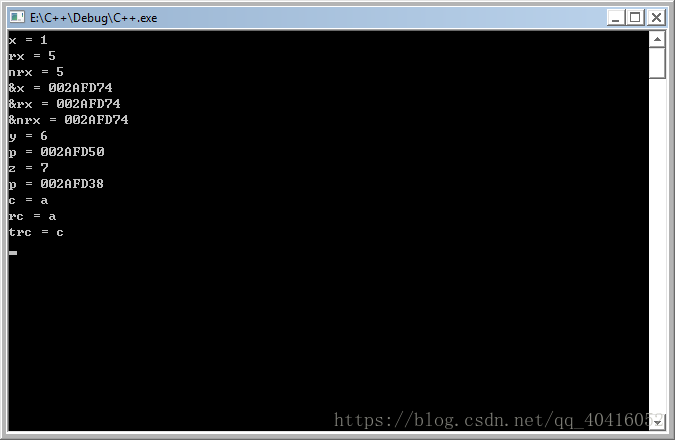
const与#define的区别
- const定义的常量是变量带类型,而#define定义的只是个常数不带类型;
- define只在预处理阶段起作用,简单的文本替换,而const在编译、链接过程中起作用;
- define只是简单的字符串替换没有类型检查。而const是有数据类型的,是要进行判断的,可以避免一些低级错误;
- define预处理后,占用代码段空间,const占用数据段空间;
- const不能重定义,而define可以通过#undef取消某个符号的定义,进行重定义;
- define独特功能,比如可以用来防止文件重复引用。
const重载
可以看下面的代码:
1 | struct A { |
这段代码输出的是这样:
1 | non const |
const修饰的对象调用的是使用const修饰的方法,非const对象调用的是非const的方法。
看下面的这段代码:
1 | A a; |
其实到底层,函数可能会变成这样:
1 | func(A* a); |
函数是在代码段,对象是在数据段,调用不同对象的函数,其实只不过是同一个函数,传递了不同的数据参数而已。
上面的是把对象的this指针传进去。
再回到上面的代码:
1 | struct A { |
可以理解为:
1 | int count(A *); |
咦,这不就是重载吗,难道还有const重载?
还真有,看下这段代码:
1 | struct A { |
输出如下:
1 | const |
所以得出结论:
不只是参数类型和个数不同会产生重载,const修饰的参数也会有重载。
但是只有当const修饰的是指针或者引用类型时才可以,普通的int和const int会编译失败的,具体大家可以自己写代码试试。
宏定义#define的理解与资料整理
利用define来定义 数值宏常量
#define宏定义是个演技非常高超的替身演员,但也会经常耍大牌的,所以我们用它要慎之又慎。它可以出现在代码的任何地方,从本行宏定义开始,以后的代码就就都认识这个宏了;也可以把任何东西定义成宏。因为编译器会在预编译的时候用真身替换替身,而在我们的代码里面却又用常常用替身来帮忙。
看例子:1
在此后的代码中你尽可以使用PI 来代替3.141592654,而且你最好就这么做。不然的话,如果我要把PI 的精度再提高一些,你是否愿意一个一个的去修改这串数呢?你能保证不漏不出错?而使用PI 的话,我们却只需要修改一次(这是十分高效的)。
这种情况还不是最要命的,我们再看一个例子:1
如果你在代码里不用ERROR_POWEROFF 这个宏而用-1,尤其在函数返回错误代码的时候(往往一个开发一个系统需要定义很多错误代码)。肯怕上帝都无法知道-1 表示的是什么意思吧。这个-1,我们一般称为“魔鬼数”,上帝遇到它也会发狂的。所以,我奉劝你代码里一定不要出现“魔鬼数”。(这里是从代码可读性的角度进行考虑!)
但是我们利用define来定义数值类型的数据,一般只是用来定义 常量 ,如果 要定义一些变量,则可以使用c语言中const这个关键字。
我们已经讨论了const 这个关键字,我们知道const 修饰的数据是有类型的,而define 宏定义的数据没有类型。为了安全,我建议你以后在定义一些宏常数的时候用const代替,编译器会给const 修饰的只读变量做类型校验,减少错误的可能。
但一定要注意const修饰的不是常量而是readonly 的变量,const 修饰的只读变量不能用来作为定义数组的维数,也不能放在case 关键字后面。
利用define来定义 字符串宏常量
除了定义宏常数之外,经常还用来定义字符串,尤其是路径:1
2
噢,到底哪一个正确呢?如果路径太长,一行写下来比较别扭怎么办?用反斜杠接续符 ‘\’ 啊:1
还没发现问题?这里用了4 个反斜杠,到底哪个是接续符?回去看看接续符反斜杠。
反斜杠作为接续符时,在本行其后面不能再有任何字符,空格都不行。所以,只有最后一个反斜杠才是接续符。至于A)和B),那要看你怎么用了,既然define 宏只是简单的替换,那给ENG_PATH_1 加上双引号不就成了:“ENG_PATH_1”。
但是请注意:有的系统里规定路径的要用双反斜杠“\\”,比如(这是正确的版本):1
用define 宏定义注释符号
上面对define 的使用都很简单,再看看下面的例子:1
2
3
4
5
BSC my single-line comment
BMC my multi-line comment EMC
D)和E)都错误,为什么呢?因为注释先于预处理指令被处理,当这两行被展开成//…或/…/时,注释已处理完毕,此时再出现//…或/…/自然错误。
因此,试图用宏开始或结束一段注释是不行的。
用define 宏定义表达式
这些都好理解,下面来点有“技术含量”的,定义一年有多少秒:1
这个定义没错吧?很遗憾,很有可能错了,至少不可靠。你有没有考虑在16 位系统下把这样一个数赋给整型变量的时候可能会发生溢出?一年有多少秒也不可能是负数吧。
改一下:1
又出现一个问题,这里的括号到底需不需要呢?继续看一个例子,定义一个宏函数,求x 的平方:1
#define SQR (x) x * x
对不对?试试:假设x 的值为10,SQR (x)被替换后变成10*10。没有问题。
再试试:假设x 的值是个表达式10+1,SQR (x)被替换后变成10+1*10+1。问题来了,这并不是我想要得到的。怎么办?括号括起来不就完了?1
最外层的括号最好也别省了,看例子,求两个数的和:1
如果x 的值是个表达式5*3,而代码又写成这样:SUM (x)* SUM (x)。替换后变成:(5*3)+(5*3)*(5*3)+(5*3)。又错了!所以最外层的括号最好也别省了。我说过define是个演技高超的替身演员,但也经常耍大牌。要搞定它其实很简单,别吝啬括号就行了。
注意这一点:宏函数被调用时是以实参代换形参。而不是“值传送”。
宏定义中的空格
另外还有一个问题需要引起注意,看下面例子:1
编译器认为这是定义了一个宏:SUM,其代表的是(x) (x)+(x)。
为什么会这样呢?其关键问题还是在于SUM 后面的这个空格。所以在定义宏的时候一定要注意什么时候该用空格,什么时候不该用空格。这个空格仅仅在定义的时候有效,在使用这个宏函数的时候,空格会被编译器忽略掉。也就是说,上一节定义好的宏函数SUM(x)在使用的时候在SUM 和(x)之间留有空格是没问题的。比如:SUM(3)和SUM (3)的意思是一样的。
undef
#undef是用来撤销宏定义的,用法如下:1
2
3
4
5
…
// code
//下面的代码就不能用PI 了,它已经被撤销了宏定义。
写好C语言,漂亮的宏定义很重要,使用宏定义可以防止出错,提高可移植性,可读性,方便性 等等。下面列举一些成熟软件中常用得宏定义:
防止一个头文件被重复包含1
2
3
4
5
6
7
//头文件内容
重新定义一些类型
防止由于各种平台和编译器的不同,而产生的类型字节数差异,方便移植。这里已经不是#define的范畴了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20typedef unsigned char boolean; /* Boolean value type. */
typedef unsigned long int uint32; /* Unsigned 32 bit value */
typedef unsigned short uint16; /* Unsigned 16 bit value */
typedef unsigned char uint8; /* Unsigned 8 bit value */
typedef signed long int int32; /* Signed 32 bit value */
typedef signed short int16; /* Signed 16 bit value */
typedef signed char int8; /* Signed 8 bit value */
//下面的不建议使用
typedef unsigned char byte; /* Unsigned 8 bit value type. */
typedef unsigned short word; /* Unsinged 16 bit value type. */
typedef unsigned long dword; /* Unsigned 32 bit value type. */
typedef unsigned char uint1; /* Unsigned 8 bit value type. */
typedef unsigned short uint2; /* Unsigned 16 bit value type. */
typedef unsigned long uint4; /* Unsigned 32 bit value type. */
typedef signed char int1; /* Signed 8 bit value type. */
typedef signed short int2; /* Signed 16 bit value type. */
typedef long int int4; /* Signed 32 bit value type. */
typedef signed long sint31; /* Signed 32 bit value */
typedef signed short sint15; /* Signed 16 bit value */
typedef signed char sint7; /* Signed 8 bit value */
得到指定地址上的一个字节或字1
2
求最大值和最小值1
2
得到一个field在结构体(struct)中的偏移量1
2
得到一个结构体中field所占用的字节数1
按照LSB格式把两个字节转化为一个Word1
按照LSB格式把一个Word转化为两个字节1
2
3
得到一个变量的地址(word宽度)1
2
得到一个字的高位和低位字节1
2
返回一个比X大的最接近的8的倍数1
#define RND8( x ) ((((x) + 7) / 8 ) * 8 )
将一个字母转换为大写1
判断字符是不是10进值的数字1
判断字符是不是16进值的数字1
2
3
防止溢出的一个方法1
返回数组元素的个数1
返回一个无符号数n尾的值MOD_BY_POWER_OF_TWO(X,n)=X%(2^n)1
2
对于IO空间映射在存储空间的结构,输入输出处理1
2
3
4
5
6
使用一些宏跟踪调试
ANSI标准说明了五个预定义的宏名。它们是:1
2
3
4
5__LINE__
__FILE__
__DATE__
__TIME__
__STDC__
可以定义宏,例如:
当定义了_DEBUG,输出数据信息和所在文件所在行1
2
3
4
5
宏定义防止使用错误,用小括号包含。例如:1
用do{}while(0)语句包含多语句防止错误,例如:1
2
应用时:1
2
3if(….)
DO(a,b); //产生错误
else
解决方法: 代码就只会执行一次。和直接加花括号有什么区别呢。哦对,不能随便在程序中,任意加{},组成代码块的。1
2
new 操作符
当你写这种代码:1
string *ps = new string("Memory Management");
你使用的new是new操作符。这个操作符就象sizeof一样是语言内置的。你不能改变它的含义,它的功能总是一样的。它要完毕的功能分成两部分。第一部分是分配足够的内存以便容纳所需类型的对象。第二部分是它调用构造函数初始化内存中的对象。new操作符总是做这两件事情,你不能以不论什么方式改变它的行为。
operator new
你所能改变的是怎样为对象分配内存。
new操作符调用一个函数来完毕必需的内存分配,你可以重写或重载这个函数来改变它的行为。new操作符为分配内存所调用函数的名字是operator new。
函数operator new 通常这样声明:1
void * operator new(size_t size);
返回值类型是void*,由于这个函数返回一个未经处理(raw)的指针。未初始化的内存。參数size_t确定分配多少内存。
你能添加额外的參数重载函数operator new,可是第一个參数类型必须是size_t。
你一般不会直接调用operator new,可是一旦这么做。你能够象调用其他函数一样调用它:1
void *rawMemory = operator new(sizeof(string));
操作符operator new将返回一个指针,指向一块足够容纳一个string类型对象的内存。就象malloc一样,operator new的职责仅仅是分配内存。
它对构造函数一无所知。operator new所了解的是内存分配。把operator new 返回的未经处理的指针传递给一个对象是new操作符的工作。当你的编译器遇见这种语句:1
string *ps = new string("Memory Management");
它生成的代码或多或少与以下的代码相似:1
2
3
4void *memory = operator new(sizeof(string)); // 得到未经处理的内存,为String对象
call string::string("Memory Management")
on *memory; // 内存中的对象
string *ps = static_cast<string*>(memory); // 使ps指针指向新的对象
注意第二步包括了构造函数的调用,你做为一个程序猿被禁止这样去做。你的编译器则没有这个约束,它能够做它想做的一切。
因此假设你想建立一个堆对象就必须用new操作符。不能直接调用构造函数来初始化对象。(总结:operator new是用来分配内存的函数,为new操作符调用。能够被重载(有限制))
placement new
有时你确实想直接调用构造函数。在一个已存在的对象上调用构造函数是没有意义的,由于构造函数用来初始化对象。而一个对象只能在给它初值时被初始化一次。
可是有时你有一些已经被分配可是尚未处理的的(raw)内存,你须要在这些内存中构造一个对象。你能够使用一个特殊的operator new ,它被称为placement new。
以下的样例是placement new怎样使用,考虑一下:1
2
3
4
5
6
7
8
9
10class Widget {
public:
Widget(int widgetSize);
...
};
Widget * constructWidgetInBuffer(void *buffer,int widgetSize)
{
return new (buffer) Widget(widgetSize);
}
这个函数返回一个指针。指向一个Widget对象,对象在转递给函数的buffer里分配。
当程序使用共享内存或memory-mapped I/O时这个函数可能实用,由于在这样程序里对象必须被放置在一个确定地址上或一块被例程分配的内存里。
在constructWidgetInBuffer里面。返回的表达式是:new (buffer) Widget(widgetSize)
这初看上去有些陌生,可是它是new操作符的一个使用方法,须要使用一个额外的变量(buffer)。当new操作符隐含调用operator new函数时。把这个变量传递给它。被调用的operator new函数除了带有强制的參数size_t外,还必须接受void*指针參数。指向构造对象占用的内存空间。这个operator new就是placement new,它看上去象这样:1
2
3
4void * operator new(size_t, void *location)
{
return location;
}
这可能比你期望的要简单,可是这就是placement new须要做的事情。毕竟operator new的目的是为对象分配内存然后返回指向该内存的指针。在使用placement new的情况下,调用者已经获得了指向内存的指针。由于调用者知道对象应该放在哪里。placement new必须做的就是返回转递给它的指针。。
(总结:placement new是一种特殊的operator new,作用于一块已分配但未处理或未初始化的raw内存)
小结
让我们从placement new回来片刻,看看new操作符(new operator)与operator new的关系,(new操作符调用operator new)你想在堆上建立一个对象,应该用new操作符。它既分配内存又为对象调用构造函数。假设你只想分配内存,就应该调用operator new函数;它不会调用构造函数。假设你想定制自己的在堆对象被建立时的内存分配过程,你应该写你自己的operator new函数。然后使用new操作符,new操作符会调用你定制的operator new。假设你想在一块已经获得指针的内存里建立一个对象。应该用placement new。
Deletion and Memory Deallocation
为了避免内存泄漏,每一个动态内存分配必须与一个等同相反的deallocation相应。
函数operator delete与delete操作符的关系与operator new与new操作符的关系一样。当你看到这些代码:1
2
3string *ps;
...
delete ps; // 使用delete 操作符
你的编译器会生成代码来析构对象并释放对象占有的内存。
Operator delete用来释放内存。它被这样声明:1
2
3
4
5
6
7void operator delete(void *memoryToBeDeallocated);
···
因此, delete ps; 导致编译器生成类似于这种代码:
```C++
ps->~string(); // call the object's dtor
operator delete(ps); // deallocate the memory the object occupied
这有一个隐含的意思是假设你仅仅想处理未被初始化的内存,你应该绕过new和delete操作符,而调用operator new 获得内存和operator delete释放内存给系统:1
2
3
4
5void *buffer = operator new(50*sizeof(char)); // 分配足够的内存以容纳50个char
//没有调用构造函数
...
operator delete(buffer); // 释放内存
// 没有调用析构函数
这与在C中调用malloc和free等同。
假设你用placement new在内存中建立对象,你应该避免在该内存中用delete操作符。
由于delete操作符调用operator delete来释放内存,可是包括对象的内存最初不是被operator new分配的。placement new仅仅是返回转递给它的指针。谁知道这个指针来自何方?而你应该显式调用对象的析构函数来解除构造函数的影响:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 在共享内存中分配和释放内存的函数 void * mallocShared(size_t size);
void freeShared(void *memory);
void *sharedMemory = mallocShared(sizeof(Widget));
Widget *pw = // 如上所看到的,
constructWidgetInBuffer(sharedMemory, 10); // 使用
// placement new
...
delete pw; // 结果不确定! 共享内存来自
// mallocShared, 而不是operator new
pw->~Widget(); // 正确。 析构 pw指向的Widget,
// 可是没有释放
//包括Widget的内存
freeShared(pw); // 正确。 释放pw指向的共享内存
// 可是没有调用析构函数
如上例所看到的,假设传递给placement new的raw内存是自己动态分配的(通过一些不经常使用的方法),假设你希望避免内存泄漏,你必须释放它。
数组
如何分配数组?会发生什么?1
string *ps = new string[10]; // allocate an array of objects
被使用的new仍然是new操作符,可是建立数组时new操作符的行为与单个对象建立有少许不同。
第一是内存不再用operator new分配,取代以等同的数组分配函数,叫做operator new[](常常被称为array new)。
它与operator new一样能被重载。
在这种编译器下定制数组内存分配是困难的。由于它须要重写全局operator new。这可不是一个能轻易接受的任务。
缺省情况下,全局operator new处理程序中全部的动态内存分配,所以它行为的不论什么改变都将有深入和普遍的影响。并且全局operator new有一个正常的签名(normal signature)。
第二个不同是new操作符调用构造函数的数量。对于数组,在数组里的每个对象的构造函数都必须被调用:1
2
3string *ps = new string[10]; // 调用operator new[]为10个string对象分配内存,
// 然后对每一个数组元素调用string对象的缺省构造函数。
相同当delete操作符用于数组时,它为每一个数组元素调用析构函数,然后调用operator delete来释放内存。
就象你能替换或重载operator delete一样,你也替换或重载operator delete[]。
static关键字
首先说一下内存的五个区:
- 栈(stack):由编译器自动分配释放,存放函数的参数值,局部变量的值(除static),其操作方式类似于数据结构中的栈。
- 堆(heap):一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆(优先队列)是两回事,分配方式倒是类似于链表。
- 全局区(静态区):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域(BSS),程序结束后由系统释放。
- 文字常量区:常量字符串就是放在这里的,如char str[]=”hello”,程序结束后由系统释放,区别const修饰的变量。
- 程序代码区:存放函数体的二进制代码。
作用
- 修饰普通变量,修改变量的存储区域和生命周期,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
- 修饰普通函数,表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定位为 static。
- 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。
- 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员。
- 在函数体,一个被声明为静态的变量在这一函数被调用过程中维持其值不变。
- 在模块内(但在函数体外),一个被声明为静态的变量可以被模块内所用函数访问,但不能被模块外其它函数访问。它是一个本地的全局变量。
- 在模块内,一个被声明为静态的函数只可被这一模块内的其它函数调用。那就是,这个函数被限制在声明它的模块的本地范围内使用
- 类内的static成员变量属于整个类所拥有,不能在类内进行定义,只能在类的作用域内进行定义
- 类内的static成员函数属于整个类所拥有,不能包含this指针,只能调用static成员函数
全局变量和static变量的区别
- 全局变量(外部变量)的说明之前再冠以static就构成了静态的全局变量。
- 全局变量本身就是静态存储方式,静态全局变量当然也是静态存储方式。
- 这两者在存储方式上并无不同。这两者的区别在于非静态全局变量的作用域是整个源程序,当一个源程序由多个原文件组成时,非静态的全局变量在各个源文件中都是有效的。
- 而静态全局变量则限制了其作用域,即只在定义该变量的源文件内有效,在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其他源文件中引起错误。
- static全局变量与普通的全局变量的区别是static全局变量只初始化一次,防止在其他文件单元被引用。
static函数与普通的函数作用域不同。尽在本文件中。只在当前源文件中使用的函数应该说明为内部函数(static),内部函数应该在当前源文件中说明和定义。
对于可在当前源文件以外使用的函数应该在一个头文件中说明,要使用这些函数的源文件要包含这个头文件。static函数与普通函数最主要区别是static函数在内存中只有一份,普通静态函数在每个被调用中维持一份拷贝程序的局部变量存在于(堆栈)中,全局变量存在于(静态区)中,动态申请数据存在于(堆)
static 变量
静态局部变量保存在全局数据区(静态区),而不是保存在栈中,每次的值保持到下一次调用,直到下次赋新值。
- static全局变量与普通的全局变量有什么区别:static全局变量只初使化一次,防止在其他文件单元中被引用;
- static局部变量和普通局部变量有什么区别:static局部变量只被初始化一次,下一次依据上一次结果值;
- static函数与普通函数有什么区别:static函数在内存中只有一份,普通函数在每个被调用中维持一份拷贝
static 成员变量
定义必须在类定义体的外部,在类的内部只是声明,声明必须加static,定义不需要。static类对象必须要在类外进行初始化,static修饰的变量先于对象存在,所以static修饰的变量要在类外初始化;1
2
3
4
5
6
7
8
9
10
11
12class A
{
public:
// 声明static变量,任何声明都不可初始化,如extern外部变量
static int a;
private:
static int b;
};
// 定义static成员变量,可初始化
int A::a = 5;
// 私有静态成员变量,不能直接用类名调用或者对象调用,只能在类内调用
int A::b = 1;
跟类相关的,跟具体的类的对象无关,为所有实例所共享,某个类的实例修改了该静态成员变量,其修改值为该类的其它所有实例所见。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
using namespace std;
class A
{
public:
// 声明static变量,任何声明都不可初始化,如extern外部变量
static int a;
private:
static int b;
public:
static int getAValue()
{
return this.a;
}
};
// 定义static成员变量,可初始化
int A::a = 5;
// 私有静态成员变量,不能直接用类名调用或者对象调用,只能在类内调用
int A::b = 1;
int main(int argc, char *argv[])
{
// new 两个个实例(对象)
A * instanceA = new A();
A * instanceB = new A();
// 改变值,均输出1
instanceA->a = 1;
cout << A::a << endl;
cout << instanceA->getAValue() << endl;
cout << instanceB->getAValue() << endl;
return 0;
}
static 函数
1 |
|
1 |
|
【编译】1
g++ a.cpp b.cpp -o ab.exe
【输出】1
2a = 5
hello world
如果在a.cpp中的int a = 5;定义前面加上static修饰,那么再次去编译,就会b.cpp报未定义错误。如果在a.cpp中的void printHello()函数前加static修饰,再次去编译,一样会报未定义错误。很明显,所有未加static修饰的函数和全局变量具有全局可见性,其他的源文件也能够访问。static修饰函数和变量这一特性可以在不同的文件中定义同名函数和同名变量,而不必担心命名冲突。static可以用作函数和变量的前缀,对于函数来讲,static的作用仅限于隐藏。这有点类似于C++中的名字空间。
static 成员函数
同样的和成员变量一样,跟类相关的,跟具体的类的对象无关,可以通过类名来调用。static成员函数里面不能访问非静态成员变量,也不能调用非静态成员函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
using namespace std;
class A
{
public:
void printStr()
{
printf("hello world");
}
static void print()
{
// 错误,静态成员函数不能调用非静态成员函数
printStr();
}
};
int main(int argc, char *argv[])
{
return 0;
}
静态成员函数没有this隐含指针修饰,存在一种情况,用const修饰类的成员函数(写在函数的最后,不是前面,前面是返回值为常量),表示该函数不能修改该类的状态,如不能在改函数里修改成员变量(除去mutable修饰的外),因为该函数存在一个隐式的this,const修饰后为const this,但是当static修饰成员函数的时候是没有this指针的,所以不能同时用static和const修饰同一个成员函数,不过可以修饰同一个成员变量。
static成员函数不能被virtual修饰,static成员不属于任何对象或实例,所以加上virtual没有任何实际意义;
虚函数的实现是为每一个对象分配一个vptr指针,而vptr是通过this指针调用的,所以不能为virtual
vector和set使用sort方法进行排序
C++中vector和set都是非常方便的容器,
sort方法是algorithm头文件里的一个标准函数,能进行高效的排序,默认是按元素从小到大排序
将sort方法用到vector和set中能实现多种符合自己需求的排序
首先sort方法可以对静态的数组进行排序1
2
3
4
5
6
7
8
9
using namespace std;
int main(){
int a[10] = { 9, 0, 1, 2, 3, 7, 4, 5, 100, 10 };
sort(a, a +10);
for (int i = 0; i < 10; i++)
cout << a[i] << endl;
return 0;
}
运行结果如下: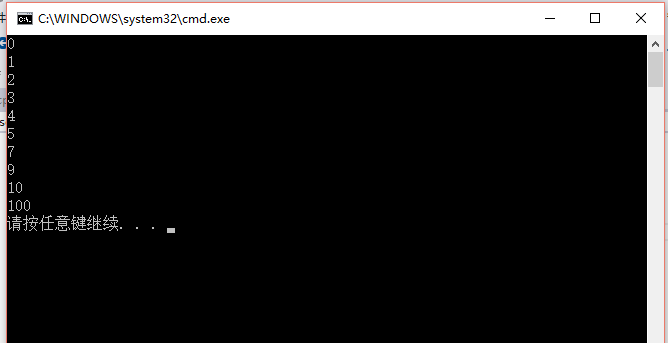
这里可以看到是sort(a,a+10),但是数组a一共只有9个元素,为什么是a+10而不是a+9呢?
因为sort方法实际上最后一位地址对应的数是不取的,
而且vector,set,map这些容器的end()取出来的值实际上并不是最后一个值,而end的前一个才是最后一个值!
需要用prev(xxx.end()),才能取出容器中最后一个元素。
对vector使用sort函数
第一种情形:基本类型,如vector<int>,vector<double>,vector<string>也是可以的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
using namespace std;
int main(){
vector<int> a;
int n = 5;
while (n--){
int score;
cin >> score;
a.push_back(score);
}
//cout <<" a.end()"<< *a.end() << endl; 执行这句话会报错!
cout << " prev(a.end)" << *prev(a.end()) << endl;
sort(a.begin(), a.end());
for (vector<int>::iterator it = a.begin(); it != a.end(); it++){
cout << *it << endl;
}
return 0;
}
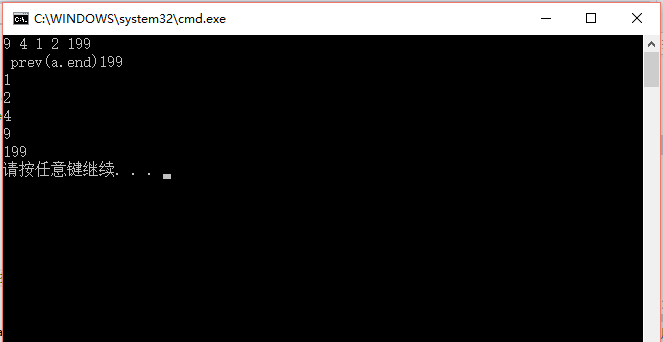
看到了吗,实际上end的前一个指针指向的元素才是插入时的最后一个值!
排序后从小大大。
第二种情形:用自定义的结构体进行sort算法,
这时候需要自己定义个比较函数,因为sort算法是基于容器中的元素是可以两两比较的,然后从小到大排序,所以要自定义怎么样才是小于(’<’)
1 |
|
对于set做类似的操作。
set是一个集合,内部的元素不会重复,同时它会自动进行排序,也是从小到大
而且set的insert方法没有insert(a,cmp)这种重载,所以如果要把结构体插入set中,我们就要重载’<’运算符。
set方法在插入的时候也是从小到大的,那么我们重载一下<运算符让它从大到小排序1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
using namespace std;
struct student{
char name[10];
int score;
};
//自定义“小于”
bool comp(const student &a, const student &b){
return a.score < b.score;
}
bool operator < (const student & stu1,const student &stu2){
return stu1.score > stu2.score;
}
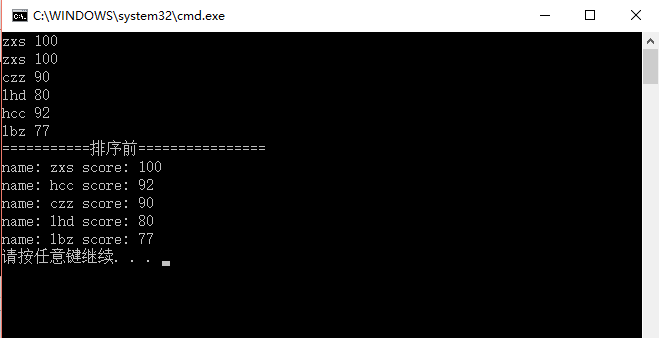
int main(){
//vector<student> vectorStudents;
set<student> setStudents;
//int n = 5;
int n = 6;
while (n--){
student oneStudent;
string name;
int score;
cin >> name >> score;
strcpy(oneStudent.name, name.c_str());
oneStudent.score = score;
setStudents.insert(oneStudent);
}
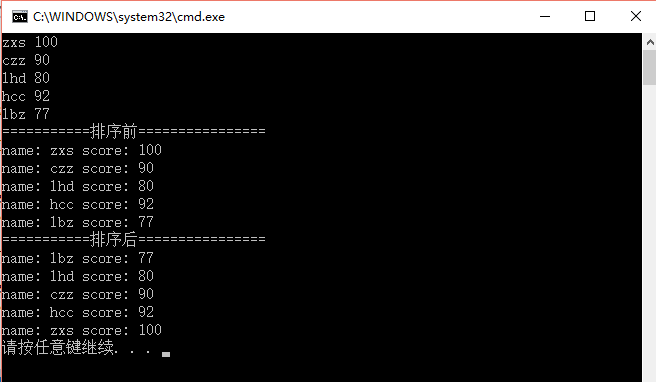
cout << "===========排序前================" << endl;
for (set<student>::iterator it = setStudents.begin(); it != setStudents.end(); it++){
cout << "name: " << it->name << " score: " << it->score << endl;
}
//sort(setStudents.begin(), setStudents.end(), comp);
//cout << "===========排序后================" << endl;
//for (set<student>::iterator it = setStudents.begin(); it != setStudents.end(); it++){
// cout << "name: " << it->name << " score: " << it->score << endl;
//}
return 0;
}
restrict与GCC的编译优化
restrict是C99标准中新添加的关键字,对于从C89标准开始起步学习C语言的同学来说,第一次看到restrict还是相当陌生的。简单说来,restrict关键字是编程者对编译器所做的一个“承诺”:使用restrict修饰过的指针,它所指向的内容只能经由该指针(或从该指针继承而来的指针,如通过该指针赋值或做指针运算而得到的其他指针)修改,而不会被其他不相干的指针所修改。
有了编程者的承诺,编译器便可以对一些通过指针的运算进行大胆的优化了。
观察编译器优化的最好办法当然是查看编译后的汇编代码。Wikipedia上有一个很好的例子,测试环境:Ubuntu 11.04 (x86-64) + Linux 2.6.38 + gcc 4.5.2。测试代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void multi_add(int* restrict p1, int* restrict p2, int* restrict pi)
void multi_add(int* p1, int* p2, int* pi)
{
*p1 += *pi;
*p2 += *pi;
}
int main()
{
int a = 1, b = 2;
int inc = 1;
// increase both a and b by 1
multi_add(&a, &b, &inc);
// print the result
printf("a = %d, b = %d\n", a, b);
}
multi_add函数的功能很简单,将p1和p2指针所指向的内容都加上pi指针的内容。为了测试方便,使用了条件编译指令:如果定义RES宏,则使用带restrict的函数声明。
分别编译出两个版本的程序:1
2gcc restrict.c -o without_restrict
gcc restrict.c -o with_restrict -DRES --std=c99
使用objdump查看目标文件的汇编代码(-d选项表示disassemble):1
objdump -d without_restrict
PS:gcc默认使用的是AT&T汇编,与很多同学在初次学习汇编时接触的Intel x86汇编有些不同
除了表示上的细微符号差别,最大的区别是src/dest的顺序,两者恰好相反:1
2
3Intel : mov eax 2 (先dest后src)
AT&T : mov %2 %eax (先src后dest)
然而这次的结果让人失望:两个版本的程序拥有一模一样的multi_add函数,汇编代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21push %rbp
mov %rsp,%rbp
mov %rdi,-0x8(%rbp)
mov %rsi,-0x10(%rbp)
mov %rdx,-0x18(%rbp)
mov -0x8(%rbp),%rax
mov (%rax),%edx
mov -0x18(%rbp),%rax
mov (%rax),%eax
add %eax,%edx
mov -0x8(%rbp),%rax
mov %edx,(%rax)
mov -0x10(%rbp),%rax
mov (%rax),%edx
mov -0x18(%rbp),%rax
mov (%rax),%eax
add %eax,%edx
mov -0x10(%rbp),%rax
mov %edx,(%rax)
leaveq
retq
其中寄存器rdi存放p1的地址,rsi存放p2的地址,rdx存放的是pi的地址。大段的汇编代码,无非是将寄存器中的内容mov到栈上的临时变量上,再把临时变量的值mov进寄存器进行加法运算。
难道restrict关键字没有任何作用?我怀疑很可能是编辑器优化程度不够。这次,使用-O1重新编译源代码并反汇编,终于观察到差别:
未使用restrict的版本:1
2
3
4mov (%rdx), %eax
add %eax, (%rdi)
mov (%rdx), %eax
add %eax, (%rsi)
使用了restrict的版本:1
2
3mov (%rdx), %eax
add %eax, (%rdi)
add %eax, (%rsi)
可以看出,-O1的编译优化还是很给力的,所有运算直接在寄存器中进行,不再蛋疼地先mov进栈变量,再mov进寄存器进行add运算(在这个简单的例子中,确实没有必要)。
最大的区别在于将rdx寄存器间接引用的值mov进eax的语句只在一开始执行了1次。可以理解,当程序员“承诺”这些指针都是相互独立不再干扰时,pi指针的内容在函数范围内可以视之为常量,只需要load进寄存器一次。
而没有restrict关键字时,即使程序中没有对pi的内容进行操作,编译器仍然不能保证pi的内容在函数范围内是常量:因为有pointer aliasing的可能,即p1和p2指向的内容和pi相关(简单情况:p1和pi实际是同一个指针)。
需要注意的是,restrict是程序员给出的“承诺“,编译器没有指针的合法使用进行检查的职责,也没有这样的能力。
事实上,打开restrict关键字,如果这样调用:1
multi_add(&a, &b, &a);
编译器不会报错。(事实上编译期完全有能力检查出简单alias的pointer)
而使用不同的编译优化级别(不优化,-O1, -O2),则产生了相当不同的结果。
- 不优化 :
a = 2, b = 4 - -O1 :
a = 2, b = 3 - -O2以上:
a = 2, b = 4
前面已经提到,没有开启-O选项时,gcc没有对restrict关键字进行优化(至少在这个例子中),所以应当是正确的行为(尽管此行为可能与编写multi_add函数的初衷不符合)
在O1下,restrict被优化,pi的值一开始即被缓存,所以产生了a和b都增加了1的结果
那么为什么O2以上,行为又开始变得正确了呢?
继续反汇编代码,发现-O2以上时,multi_add函数本身代码保持不变(确实在O1已经优化的相当简洁了),但main函数已经面目全非了:调用multi_add的代码已经改变,准确地说:
multi_add函数已经不再被main调用了
这里不再列出相关的汇编代码,因为这里的优化策略是相当复杂的。在这个例子中,由于a和b都是常量,a和b的值直接在编译期被算了出来,并放入寄存器中进行后续printf的调用。
可以看出,restrict确实是优化的利器。但是如果不仔细使用,它还是相当危险的,甚至能够导致在不同的优化级别下,出现完全不同的程序行为。
volatile
why volatile
volatile 关键词,最早出现于20世纪70年代,被用于处理 MMIO(Memory-mapped I/O) 带来的问题。在引入 MMIO 之后,一块内存地址既有可能是真正的内存,也有可能是映射的一个I/O端口。因此,读/写一个内存地址,既有可能是真正地操作内存,也有可能是读/写一个I/O设备。
那么 MMIO 为什么需要引入 volatile 关键词呢?我们结合下面这段示例代码进行解释:1
2
3
4
5
6
7
8
9unsigned int *p = FunB();
unsigned int a;
unsigned int b;
a = *p; // 语句1
b = *p; // 语句2
*p = a; // 语句3
*p = b; // 语句4
在上述代码片段中,指针p既有可能指向一个内存地址,也有可能指向一个I/O设备。如果指针p指向的是I/O设备,那么语句1和语句2中的变量a和变量b,就会接收到I/O设备的连续两个字节。但是,指针p也有可能指向内存地址,这种情况下,编译器就会进行语句优化,编译器的优化策略会判断变量a和变量b同时从同一个内存地址读取数据,因此在执行完语句1之后,直接将变量a赋值给变量b。对于指针p指向I/O设备的这种情况,就需要防止编译器进行此优化,即不能假设指针b指向的内容不变(对应 volatile 的易变性特性)。
同样,语句3和语句4也有类似的问题,编译器发现将变量a和b同时赋值给指针p是无意义的,因此可能会优化语句3中的赋值操作,而仅仅保留语句4。对于指针p指向I/O设备的情况,也需要防止编译器将类似的写操作给优化消失了(对应 volatile 的不可优化特性)。
对于I/O设备,编译器不能随意交互指令的顺序,因为指令顺序一变,写入I/O设备的内容也就发生变化了(对应 volatile 的顺序性)。
为了满足 MMIO 的这三点需求,就有了 volatile 关键字。
IN C/C++
在C/C++语言中,使用 volatile 关键字声明的变量(或对象)通常具有与优化、多线程相关的特殊属性。通常,volatile 关键字用来阻止(伪)编译器对其认为的、无法“被代码本身”改变的代码(变量或对象)进行优化。如在C/C++中,volatile 关键字可以用来提醒编译器使用 volatile 声明的变量随时有可能改变,因此编译器在代码编译时就不会对该变量进行某些激进的优化,故而编译生成的程序在每次存储或读取该变量时,都会直接从内存地址中读取数据。相反,如果该变量没有使用 volatile 关键字进行声明,则编译器可能会优化读取和存储操作,可能暂时使用寄存器中该变量的值,而如果这个变量由别的程序(线程)更新了的话,就会出现(内存中与寄存器中的)变量值不一致的现象。
定义为volatile的变量是说这变量可能会被意想不到地改变,即在你程序运行过程中一直会变,你希望这个值被正确的处理,每次从内存中去读这个值,而不是因编译器优化从缓存的地方读取,比如读取缓存在寄存器中的数值,从而保证volatile变量被正确的读取。
在单任务的环境中,一个函数体内部,如果在两次读取变量的值之间的语句没有对变量的值进行修改,那么编译器就会设法对可执行代码进行优化。由于访问寄存器的速度要快过RAM(从RAM中读取变量的值到寄存器),以后只要变量的值没有改变,就一直从寄存器中读取变量的值,而不对RAM进行访问。
而在多任务环境中,虽然在一个函数体内部,在两次读取变量之间没有对变量的值进行修改,但是该变量仍然有可能被其他的程序(如中断程序、另外的线程等)所修改。如果这时还是从寄存器而不是从RAM中读取,就会出现被修改了的变量值不能得到及时反应的问题。
因为访问寄存器要比访问内存单元快的多,所以编译器一般都会作减少存取内存的优化,但有可能会读脏数据。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问;如果不使用valatile,则编译器将对所声明的语句进行优化。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错。加了volatile修饰的变量,编译器将不对其相关代码执行优化,而是生成对应代码直接存取原始内存地址)。
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。一般说来,volatile用在如下的几个地方:
- 并行设备的硬件寄存器(如:状态寄存器)
- 中断服务程序中修改的供其它程序检测的变量需要加volatile;
- 多任务环境下各任务间共享的标志应该加volatile;
- 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能有不同意义;
在C/C++语言中,使用 volatile 关键字声明的变量具有三种特性:易变的、不可优化的、顺序执行的。下面分别对这三种特性进行介绍。
易变的
volatile 在词典中的主要释义就是“易变的”。
在 C/C++ 语言中,volatile 的易变性体现在:假设有读、写两条语句,依次对同一个 volatile 变量进行操作,那么后一条的读操作不会直接使用前一条的写操作对应的 volatile 变量的寄存器内容,而是重新从内存中读取该 volatile 变量的值。
上述描述的(部分)示例代码如下:1
2
3
4volatile int nNum = 0; // 将nNum声明为volatile
int nSum = 0;
nNum = FunA(); // nNum被写入的新内容,其值会缓存在寄存器中
nSum = nNum + 1; // 此处会从内存(而非寄存器)中读取nNum的值
不可优化的
在 C/C++ 语言中,volatile 的第二个特性是“不可优化性”。volatile 会告诉编译器,不要对 volatile 声明的变量进行各种激进的优化(甚至将变量直接消除),从而保证程序员写在代码中的指令一定会被执行。
上述描述的(部分)示例代码如下:1
2
3volatile int nNum; // 将nNum声明为volatile
nNum = 1;
printf("nNum is: %d", nNum);
在上述代码中,如果变量 nNum 没有声明为 volatile 类型,则编译器在编译过程中就会对其进行优化,直接使用常量“1”进行替换(这样优化之后,生成的汇编代码很简介,执行时效率很高)。而当我们使用 volatile 进行声明后,编译器则不会对其进行优化,nNum 变量仍旧存在,编译器会将该变量从内存中取出,放入寄存器之中,然后再调用 printf() 函数进行打印。
顺序执行的
在 C/C++ 语言中,volatile 的第三个特性是“顺序执行特性”,即能够保证 volatile 变量间的顺序性,不会被编译器进行乱序优化。
说明:C/C++ 编译器最基本优化原理:保证一段程序的输出,在优化前后无变化。
为了对本特性进行深入了解,下面以两个变量(nNum1 和 nNum2)为例(既然存在“顺序执行”,那描述对象必然大于一个),结合如下示例代码,介绍 volatile 的顺序执行特性。1
2
3
4int nNum1;
int nNum2;
nNum2 = nNum1 + 1; // 语句1
nNum1 = 10; // 语句2
在上述代码中:
- 当 nNum1 和 nNum2 都没有使用 volatile 关键字进行修饰时,编译器会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句2”、再执行“语句1”;
- 当 nNum2 使用 volatile 关键字进行修饰时,编译器也可能会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句2”、再执行“语句1”;
- 当 nNum1 和 nNum2 都使用 volatile 关键字进行修饰时,编译器不会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句1”、再执行“语句2”;
说明:上述论述可通过观察代码的生成的汇编代码进行验证。
volatile与多线程语义
对于多线程编程而言,在临界区内部,可以通过互斥锁(mutex)保证只有一个线程可以访问该临界区的内容,因此临界区内的变量不需要是 volatile 的;而在临界区外部,被多个线程访问的变量应声明为 volatile 的,这也符合了 volatile 的原意:防止编译器缓存(cache)了被多个线程并发用到的变量。
不过,需要注意的是,由于 volatile 关键字的“顺序执行特性”并非会完全保证语句的顺序执行(如 volatile 变量与非volatile 变量之间的操作;又如一些 CPU 也会对语句的执行顺序进行优化),因此导致了对 volatile 变量的操作并不是原子的,也不能用来为线程建立严格的 happens-before 关系。
对于上述描述,示例代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20int nNum1 = 0;
volatile bool flag = false;
thread1()
{
// some code
nNum1 = 666; // 语句1
flag = true; // 语句2
}
thread2()
{
// some code
if (true == flag)
{
// 语句3:按照程序设计的预想,此处的nNum1的值应为666,并据此进行逻辑设计
}
}
在上述代码中,我们的设计思路是先执行 thread1() 中的“语句1”、“语句2”、再执行 thread2() 中的“语句3”,不过实际上程序的执行结果未必如此。根据 volatile 的“顺序性”,非 volatile 变量 nNum1 和 volatile 变量 flag 的执行顺序,可能会被编译器(或 CPU)进行乱序优化,最终导致thread1中的“语句2”先于“语句1”执行,当“语句2”执行完成但“语句1”尚未执行时,此时 thread2 中的判断语句“if (true == flag)”是成立的,但实际上 nNum1 尚未进行赋值为666(语句1尚未执行),所以在判断语句中针对 nNum1 为666的前提下进行的相关操作,就会有问题了。
这是一个在多线程编程中,使用 volatile 不容易发现的问题。
实际上,上述多线程代码想实现的就是一个 happens-before 语义,即保证 thread1 代码块中的所有代码,一定要在 thread2 代码块的第一条代码之前完成。使用互斥锁(mutex)可以保证 happens-before 语义。但是,在 C/C++ 中的 volatile 关键词不能保证这个语义,也就意味着在多线程环境下使用 C/C++ 的 volatile 关键词,如果不够细心,就可能会出现上述问题。
说明:由于 Java 语言的 volatile 关键字支持 Acquire、Release 语义,因此 Java 语言的 volatile 能够用来构建 happens-before 语义。也就是说,前面提到的 C/C++ 中 volatile 在多线程下使用出现的问题,在 Java 语言中是不存在的。
不保证原子性
volatile只保证其“可见性”,不保证其“原子性”。
执行count++;这条语句由3条指令组成:
- 将 count 的值从内存加载到 cpu 的某个 寄存器r;
- 将 寄存器r 的值 +1,结果存放在 寄存器s;
- 将 寄存器s 中的值写回内存。
所以,如果有多个线程同时在执行 count++,在某个线程执行完第(3)步之前,其它线程是看不到它的执行结果的。(这里有疑惑:线程同时执行count++,为了保证其原子性,为何不加mutex lock?而是寻求volatile?)
在没有volatile的时候,执行完count++,执行结果其实是写到CPU缓存中,没有马上写回到内存中,后续在某些情况下(比如CPU缓存不够用)再将CPU缓存中的值flush到内存。因为没有存到内存里,其他线程是不能及时看到执行结果的。
在有volatile的时候,执行完count++,执行结果写入缓存中,并同时写入内存中,所以可以保证其它线程马上看到执行的结果。
但是,volatile 并没有保证原子性,在某个线程执行(1)(2)(3)的时候,volatile 并没有锁定 count 的值,也就是并不能阻塞其他线程也执行(1)(2)(3)。可能有两个线程同时执行(1),所以(2)计算出来一样的结果,然后(3)存回的也是同一个值。
考虑下面一段代码:1
2
3
4
5int some_int = 100;
while(some_int == 100)
{
//your code
}
因为编译器认为some_int没被改变过,一直是100。但是在多线程时,如果执行完第一行,但是还没执行到第三行时,另一个线程修改了some_int,while就不能进入循环了。加了volatile后,阻止了编译器优化,每次读到some_int会从内存中读取,而不是本线程的寄存去(当然这会损失效率)。这就是volatile的作用。
一句话总结:volatile保证线程能读到最新的数据,因为是从内存中读取,且存入内存中。而不是线程各自的寄存器中读写。
inline 内联函数
内联函数和普通函数相比可以加快程序运行的速度,因为不需要中断调用,在编译的时候内联函数可以直接嵌入到目标代码中。
- 相当于把内联函数里面的内容写在调用内联函数处;
- 相当于不用执行进入函数的步骤,直接执行函数体;
- 相当于宏,却比宏多了类型检查,真正具有函数特性;
- 编译器一般不内联包含循环、递归、switch 等复杂操作的内联函数;
- 在类声明中定义的函数,除了虚函数的其他函数都会自动隐式地当成内联函数。
- 作为类成员接口函数来读写类的私有成员或者保护成员,会提高效率
1 | // 声明1(加 inline,建议使用) |
编译器对 inline 函数的处理步骤
- 将 inline 函数体复制到 inline 函数调用点处;
- 为所用 inline 函数中的局部变量分配内存空间;
- 将 inline 函数的的输入参数和返回值映射到调用方法的局部变量空间中;
- 如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)。
优点
- 内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
- 内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换(同普通函数),而宏定义则不会。
- 在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能。
- 内联函数在运行时可调试,而宏定义不可以。
缺点
- 代码膨胀。内联是以代码膨胀(复制)为代价,消除函数调用带来的开销。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
- inline 函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像 non-inline 可以直接链接。
- 是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
内联函数和宏定义的区别
内联函数以代码复杂为代价,它以省去函数调用的开销来提高执行效率。所以一方面如果内联函数体内代码执行时间相比函数调用开销较大,则没有太大的意义;另一方面每一处内联函数的调用都要复制代码,消耗更多的内存空间,因此以下情况不宜使用内联函数:
- 函数体内的代码比较长,将导致内存消耗代价
- 函数体内有循环,函数执行时间要比函数调用开销大
主要区别
- 内联函数在编译时展开,宏在预编译时展开
- 内联函数直接嵌入到目标代码中,宏是简单的做文本替换
- 内联函数有类型、语法判断等功能,而宏没有
- 内联函数是函数,宏不是
- 宏定义时要注意书写(参数要括起来)否则容易出现歧义,内联函数不会产生歧义
- 内联函数代码是被放到符号表中,使用时像宏一样展开,没有调用的开销,效率很高;
- 在使用时,宏只做简单字符串替换(编译前)。而内联函数可以进行参数类型检查(编译时),且具有返回值。
- 内联函数可以作为某个类的成员函数,这样可以使用类的保护成员和私有成员,进而提升效率。而当一个表达式涉及到类保护成员或私有成员时,宏就不能实现了。
union
联合(union)是一种节省空间的特殊的类,一个 union 可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当某个成员被赋值后其他成员变为未定义状态。联合有如下特点:
- 默认访问控制符为 public
- 可以含有构造函数、析构函数
- 不能含有引用类型的成员
- 不能继承自其他类,不能作为基类
- 不能含有虚函数
- 匿名 union 在定义所在作用域可直接访问 union 成员
- 匿名 union 不能包含 protected 成员或 private 成员
- 全局匿名联合必须是静态(static)的
C++11 标准规定,任何非引用类型都可以成为联合体的数据成员,这种联合体也被称为非受限联合体。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14class Student{
public:
Student(bool g, int a): gender(g), age(a) {}
private:
bool gender;
int age;
};
union T{
Student s; // 含有非POD类型的成员,gcc-5.1.0 版本报错
char name[10];
};
int main(){
return 0;
}
上面的代码中,因为 Student 类带有自定义的构造函数,所以是一个非 POD 类型的,这导致编译器报错。这种规定只是 C++ 为了兼容C语言而制定,然而在长期的编程实践中发现,这种规定是没有必要的。
C++11 允许非 POD 类型
C++98 不允许联合体的成员是非 POD 类型,但是 C++11 取消了这种限制。POD 是英文 Plain Old Data 的缩写,用来描述一个类型的属性。POD 类型一般具有以下几种特征(包括 class、union 和 struct等):
- 没有用户自定义的构造函数、析构函数、拷贝构造函数和移动构造函数。
- 不能包含虚函数和虚基类。
- 非静态成员必须声明为 public。
- 类中的第一个非静态成员的类型与其基类不同
- 在类或者结构体继承时,满足以下两种情况之一:
- 派生类中有非静态成员,且只有一个仅包含静态成员的基类;
- 基类有非静态成员,而派生类没有非静态成员。
- 所有非静态数据成员均和其基类也符合上述规则(递归定义),也就是说 POD 类型不能包含非 POD 类型的数据。
- 此外,所有兼容C语言的数据类型都是 POD 类型(struct、union 等不能违背上述规则)。
1 | class B1{}; |
class B2 的第一个非静态成员 b 是基类类型,所以它不是 POD 类型。
1 | class B1 { static int n; }; |
对于 B2,派生类 B2 中有非静态成员,且只有一个仅包含静态成员的基类 B1,所以它是 POD 类型。对于 B3,基类 B2 有非静态成员,而派生类 B3 没有非静态成员,所以它也是 POD 类型。
C++11 允许联合体有静态成员
C++11 删除了联合体不允许拥有静态成员的限制。例如:1
2
3
4
5
6union U {
static int func() {
int n = 3;
return n;
}
};
需要注意的是,静态成员变量只能在联合体内定义,却不能在联合体外使用,这使得该规则很没用。
非受限联合体的赋值注意事项
C++11 规定,如果非受限联合体内有一个非 POD 的成员,而该成员拥有自定义的构造函数,那么这个非受限联合体的默认构造函数将被编译器删除;其他的特殊成员函数,例如默认拷贝构造函数、拷贝赋值操作符以及析构函数等,也将被删除。
这条规则可能导致对象构造失败,请看下面的例子:1
2
3
4
5
6
7
8
9
10
using namespace std;
union U {
string s;
int n;
};
int main() {
U u; // 构造失败,因为 U 的构造函数被删除
return 0;
}
在上面的例子中,因为 string 类拥有自定义的构造函数,所以 U 的构造函数被删除;定义 U 的类型变量 u 需要调用默认构造函数,所以 u 也就无法定义成功。
解决上面问题的一般需要用到 placement new,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
union U {
string s;
int n;
public:
U() { new(&s) string; }
~U() { s.~string(); }
};
int main() {
U u;
return 0;
}
构造时,采用placement new将 s 构造在其地址 &s 上,这里placement new的唯一作用只是调用了一下 string 类的构造函数。注意,在析构时还需要调用 string 类的析构函数。
非受限联合体的匿名声明和“枚举式类”
匿名联合体是指不具名的联合体(也即没有名字的联合体),一般定义如下:1
2
3union U{
union { int x; }; //此联合体为匿名联合体
};
可以看到,联合体 U 内定义了一个不具名的联合体,该联合体包含一个 int 类型的成员变量,我们称这个联合体为匿名联合体。
同样的,非受限联合体也可以匿名,而当非受限的匿名联合体运用于类的声明时,这样的类被称为“枚举式类”。示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
using namespace std;
class Student{
public:
Student(bool g, int a): gender(g), age(a){}
bool gender;
int age;
};
class Singer {
public:
enum Type { STUDENT, NATIVE, FOREIGENR };
Singer(bool g, int a) : s(g, a) { t = STUDENT; }
Singer(int i) : id(i) { t = NATIVE; }
Singer(const char* n, int s) {
int size = (s > 9) ? 9 : s;
memcpy(name , n, size);
name[s] = '\0';
t = FOREIGENR;
}
~Singer(){}
private:
Type t;
union {
Student s;
int id;
char name[10];
};
};
int main() {
Singer(true, 13);
Singer(310217);
Singer("J Michael", 9);
return 0;
}
上面的代码中使用了一个匿名非受限联合体,它作为类 Singer 的“变长成员”来使用,这样的变长成员给类的编写带来了更大的灵活性,这是 C++98 标准中无法达到的。
assert()
断言,是宏,而非函数。assert宏的原型定义在 <assert.h>(C)、<cassert>(C++)中,其作用是如果它的条件返回错误,则终止程序执行。可以通过定义 NDEBUG 来关闭 assert,但是需要在源代码的开头,include <assert.h> 之前。
assert()会对表达式expression进行检测:
- 如果expression的结果为 0(条件不成立),那么断言失败,表明程序出错,
assert()会向标准输出设备(一般是显示器)打印一条错误信息,并调用 abort() 函数终止程序的执行。 - 如果expression的结果为非 0(条件成立),那么断言成功,表明程序正确,
assert()不进行任何操作。
参数:
- expression:要检测的表达式。如果表达式的值为 0,那么断言失败,程序终止执行;如果表达式的值为非 0,那么断言成功,assert() 不进行任何操作。
assert() 的用法和机制
assert()的用法很简单,我们只要传入一个表达式,它会计算这个表达式的结果:如果表达式的结果为“假”,assert()会打印出断言失败的信息,并调用abort()函数终止程序的执行;如果表达式的结果为“真”,assert()就什么也不做,程序继续往后执行。
下面是一个具体的例子:1
2
3
4
5
6
7
8
9
10
int main(){
int m, n, result;
scanf("%d %d", &m, &n);
assert(n != 0); //写作 assert(n) 更加简洁
result = m / n;
printf("result = %d\n", result);
return 0;
}
NDEBUG 宏
如果查看<assert.h>头文件的源码,会发现assert()被定义为下面的样子:1
2
3
4
5
6
这意味着,一旦定义了NDEBUG宏,assert()就无效了。
NDEBUG是”No Debug“的意思,也即“非调试”。有的编译器(例如 Visual Studio)在发布(Release)模式下会定义 NDEBUG 宏,在调试(Debug)模式下不会定义定义这个宏;有的编译器(例如 Xcode)在发布模式和调试模式下都不会定义 NDEBUG 宏,这样当我们以发布模式编译程序时,就必须自己在编译参数中增加NDEBUG宏,或者在包含<assert.h>头文件之前定义NDEBUG宏。
调试模式是程序员在测试代码期间使用的编译模式,发布模式是将程序提供给用户时使用的编译模式。在发布模式下,我们不应该再依赖assert()宏,因为程序一旦出错,assert()会抛出一段用户看不懂的提示信息,并毫无预警地终止程序执行,这样会严重影响软件的用户体验,所以在发布模式下应该让assert()失效。
修改上面的代码,在包含<assert.h>之前定义NDEBUG宏:1
2
3
4
5
6
7
8
9
10
11
int main(){
int m, n, result;
scanf("%d %d", &m, &n);
assert(n);
result = m / n;
printf("result = %d\n", result);
return 0;
}
当以发布模式编译这段代码时,assert()就会失效。如果希望继续以调试模式编译这段代码,去掉NDEBUG宏即可。
注意事项
使用assert()时,被检测的表达式最好不要太复杂,以下面的代码为例:assert( expression1 && expression2 && expression3);
当发生错误时,assert()只会告诉我们expression1 && expression2 && expression3整个表达式为不成立,但是这个大的表达式还包含了三个小的表达式,并且它们之间是&&运算,任何一个小表达式为不成立都会导致整个表达式为不成立,这样我们就无法推断到底是expression1有问题,还是expression2或者expression3有问题,从而给排错带来麻烦。
这里我们应该遵循使用assert()的一个原则:每次断言只能检验一个表达式。根据这个原则,上面的代码应改为:1
2
3assert(expression1);
assert(expression2);
assert(expression3);
如此,一旦程序出错,我们就知道是哪个小的表达式断言失败了,从而快速定位到有问题的代码。
使用assert()的另外一个注意事项是:不要用会改变环境的语句作为断言的表达式。请看下面的代码:1
2
3
4
5
6
7
8
9
10
int main(){
int i = 0;
while(i <= 110){
assert(++i <= 100);
printf("我是第%d行\n",i);
}
return 0;
}
在 Debug 模式下运行,程序循环到第 101 次时,i 的值为 100,++i <= 100不再成立,断言失败,程序终止运行。
在 Release 模式下运行,编译参数中设置了NDEBUG宏(如果编译器没有默认设置,那么需要你自己来设置),assert()会失效,++i <= 100这个表达式也不起作用了,while()无法终止,成为一个死循环。
定义了NDEBUG宏后,assert(++i <= 100)会被替换为((void)0)。
pair类型
pair类型的定义和初始化
pair类型是在有文件utility中定义的,pair类型包含了两个数据值,通常有以下的一些定义和初始化的一些方法:1
2
3pair<T1, T2> p;
pair<T1, T2> p(v1, v2);
make_pair(v1, v2)
上述第一种方法是定义了一个空的pair对象p,第二种方法是定义了包含初始值为v1和v2的pair对象p。第三种方法是以v1和v2值创建的一个新的pair对象。
pair对象的一些操作
除此之外,pair对象还有一些方法,如取出pair对象中的每一个成员的值:1
2p.first
p.second
一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
int main(){
pair<int, string> p1(0, "Hello");
printf("%d, %s\n", p1.first, p1.second.c_str());
pair<int, string> p2 = make_pair(1, "World");
printf("%d, %s\n", p2.first, p2.second.c_str());
return 0;
}
map
标准库map类型是一种以键-值(key-value)存储的数据类型。
- 第一个可以称为关键字(key),每个关键字只能在map中出现一次;
- 第二个可能称为该关键字的值(value);
map以模板(泛型)方式实现,可以存储任意类型的数据,包括使用者自定义的数据类型。Map主要用于资料一对一映射(one-to-one)的情況,map內部的实现自建一颗红黑树,这颗树具有对数据自动排序的功能。在map内部所有的数据都是有序的。
以下分别从以下的几个方面总结:
- map对象的定义和初始化
- map对象的基本操作,主要包括添加元素,遍历等
map对象的定义和初始化
map是键-值对的组合,有以下的一些定义的方法:1
2
3map<k, v> m;
map<k, v> m(m2);
map<k, v> m(b, e);
上述第一种方法定义了一个名为m的空的map对象;第二种方法创建了m2的副本m;第三种方法创建了map对象m,并且存储迭代器b和e范围内的所有元素的副本。
map的value_type是存储元素的键以及值的pair类型,键为const。
使用map得包含map类所在的头文件1
map对象是模板类,需要关键字和存储对象两个模板参数:1
std:map<int, string> personnel;
这样就定义了一个用int作为索引,并拥有相关联的指向string的指针.
为了使用方便,可以对模板类进行一下类型定义,1
typedef aap<int,CString> UDT_MAP_INT_CSTRING;
map共提供了6个构造函数,这块涉及到内存分配器这些东西,略过不表,在下面我们将接触到一些map的构造方法,这里要说下的就是,我们通常用如下方法构造一个map:1
map<int, string> mapStudent;
map中元素的插入
在map中元素有两种插入方法:
- 使用下标
- 使用insert函数
在map中使用下标访问不存在的元素将导致在map容器中添加一个新的元素。
insert函数的插入方法主要有如下:
m.insert(e)m.insert(beg, end)m.insert(iter, e)
上述的e一个value_type类型的值。beg和end标记的是迭代器的开始和结束。
两种插入方法如下面的例子所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using namespace std;
int main(){
map<int, int> mp;
for (int i = 0; i < 10; i ++){
mp[i] = i;
}
for (int i = 10; i < 20; i++){
mp.insert(make_pair(i, i));
}
map<int, int>::iterator it;
for (it = mp.begin(); it != mp.end(); it++){
printf("%d-->%d\n", it->first, it->second);
}
return 0;
}
另外的方法:
1 | // 定义一个map对象 |
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是不能在插入数据的,但是用数组方式就不同了,它可以覆盖以前该关键字对 应的值,用程序说明如下:1
2mapStudent.insert(map<int, string>::value_type (001, "student_one"));
mapStudent.insert(map<int, string>::value_type (001, "student_two"));
map中元素的查找和读取
注意:上述采用下标的方法读取map中元素时,若map中不存在该元素,则会在map中插入。
因此,若只是查找该元素是否存在,可以使用函数count(k),该函数返回的是k出现的次数;若是想取得key对应的值,可以使用函数find(k),该函数返回的是指向该元素的迭代器。
上述的两个函数的使用如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
using namespace std;
int main(){
map<int, int> mp;
for (int i = 0; i < 20; i++){
mp.insert(make_pair(i, i));
}
if (mp.count(0)){
printf("yes!\n");
}else{
printf("no!\n");
}
map<int, int>::iterator it_find;
it_find = mp.find(0);
if (it_find != mp.end()){
it_find->second = 20;
}else{
printf("no!\n");
}
map<int, int>::iterator it;
for (it = mp.begin(); it != mp.end(); it++){
printf("%d->%d\n", it->first, it->second);
}
return 0;
}
从map中删除元素
从map中删除元素的函数是erase(),该函数有如下的三种形式:1
2
3m.erase(k)
m.erase(p)
m.erase(b, e)
第一种方法删除的是m中键为k的元素,返回的是删除的元素的个数;第二种方法删除的是迭代器p指向的元素,返回的是void;第三种方法删除的是迭代器b和迭代器e范围内的元素,返回void。
如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
using namespace std;
int main(){
map<int, int> mp;
for (int i = 0; i < 20; i++){
mp.insert(make_pair(i, i));
}
mp.erase(0);
mp.erase(mp.begin());
map<int, int>::iterator it;
for (it = mp.begin(); it != mp.end(); it++){
printf("%d->%d\n", it->first, it->second);
}
return 0;
}
map的基本操作函数:
C++ maps是一种关联式容器,包含“关键字/值”对
begin()返回指向map头部的迭代器clear()删除所有元素count()返回指定元素出现的次数empty()如果map为空则返回trueend()返回指向map末尾的迭代器equal_range()返回特殊条目的迭代器对erase()删除一个元素find()查找一个元素get_allocator()返回map的配置器insert()插入元素key_comp()返回比较元素key的函数lower_bound()返回键值>=给定元素的第一个位置max_size()返回可以容纳的最大元素个数rbegin()返回一个指向map尾部的逆向迭代器rend()返回一个指向map头部的逆向迭代器size()返回map中元素的个数swap()交换两个mapupper_bound()返回键值>给定元素的第一个位置value_comp()返回比较元素value的函数
stack
| 函数名 | 功能 | 复杂度 |
|---|---|---|
| size() | 返回栈的元素数 | O(1) |
| top() | 返回栈顶的元素 | O(1) |
| pop() | 从栈中取出并删除元素 | O(1) |
| push(x) | 向栈中添加元素x | O(1) |
| empty() | 在栈为空时返回true | O(1) |
贴一些代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
int main()
{
stack<int> S;
S.push(3);
S.push(7);
S.push(1);
cout << S.size() << " ";
cout << S.top() << " ";
S.pop();
cout << S.top() << " ";
S.pop();
cout << S.top() << " ";
S.push(5);
cout << S.top() << " ";
S.pop();
cout << S.top() << endl;
return 0;
}
queues
C++队列是一种容器适配器,它给予程序员一种先进先出(FIFO)的数据结构。
- back() 返回一个引用,指向最后一个元素
- empty() 如果队列空则返回真
- front() 返回第一个元素
- pop() 删除第一个元素
- push() 在末尾加入一个元素
- size() 返回队列中元素的个数
队列可以用线性表(list)或双向队列(deque)来实现(注意vector container 不能用来实现queue,因为vector 没有成员函数pop_front!):1
2queue<list<int>> q1
queue<deque<int>> q2
其成员函数有“判空(empty)” 、“尺寸(Size)” 、“首元(front)” 、“尾元(backt)” 、“加入队列(push)” 、“弹出队列(pop)”等操作。
例:1
2
3
4
5
6
7
8int main()
{
queue<int> q;
q.push(4);
q.push(5);
printf("%d\n",q.front());
q.pop();
}
Priority Queues
C++优先队列类似队列,但是在这个数据结构中的元素按照一定的断言排列有序。
empty()如果优先队列为空,则返回真pop()删除第一个元素push()加入一个元素size()返回优先队列中拥有的元素的个数top()返回优先队列中有最高优先级的元素
优先级队列可以用向量(vector)或双向队列(deque)来实现(注意list container 不能用来实现queue,因为list 的迭代器不是任意存取iterator,而pop 中用到堆排序时是要求randomaccess iterator 的!):
priority_queue<vector<int>, less<int>> pq1; 使用递增less函数对象排序 priority_queue<deque<int>, greater<int>> pq2; 使用递减greater函数对象排序 - 其成员函数有“判空(empty)” 、“尺寸(Size)” 、“栈顶元素(top)” 、“压栈(push)” 、“弹栈(pop)”等。
priority_queue模版类有三个模版参数,元素类型,容器类型,比较算子。其中后两个都可以省略,默认容器为vector,默认算子为less,即小的往前排,大的往后排(出队时序列尾的元素出队)。
初学者在使用priority_queue时,最困难的可能就是如何定义比较算子了。如果是基本数据类型,或已定义了比较运算符的类,可以直接用STL的less算子和greater算子——默认为使用less算子,即小的往前排,大的先出队。如果要定义自己的比较算子,方法有多种,这里介绍其中的一种:重载比较运算符。优先队列试图将两个元素x和y代入比较运算符(对less算子,调用x
例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
using namespace std;
class T {
public:
int x, y, z;
T(int a, int b, int c):x(a), y(b), z(c)
{
}
};
bool operator < (const T &t1, const T &t2)
{
return t1.z < t2.z; // 按照z的顺序来决定t1和t2的顺序
}
int main()
{
priority_queue<T> q;
q.push(T(4,4,3));
q.push(T(2,2,5));
q.push(T(1,5,4));
q.push(T(3,3,6));
while (!q.empty())
{
T t = q.top();
q.pop();
cout << t.x << " " << t.y << " " << t.z << endl;
}
return 1;
}
输出结果为(注意是按照z的顺序从大到小出队的):1
2
3
43 3 6
2 2 5
1 5 4
4 4 3
再看一个按照z的顺序从小到大出队的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
using namespace std;
class T
{
public:
int x, y, z;
T(int a, int b, int c):x(a), y(b), z(c)
{
}
};
bool operator > (const T &t1, const T &t2)
{
return t1.z > t2.z;
}
main()
{
priority_queue<T, vector<T>, greater<T> > q;
q.push(T(4,4,3));
q.push(T(2,2,5));
q.push(T(1,5,4));
q.push(T(3,3,6));
while (!q.empty())
{
T t = q.top();
q.pop();
cout << t.x << " " << t.y << " " << t.z << endl;
}
return 1;
}
输出结果为:1
2
3
44 4 3
1 5 4
2 2 5
3 3 6
vector的内部实现原理及基本用法
本文基于STL vector源代码,但是不考虑分配器allocator,迭代器iterator,异常处理try/catch等内容,同时对_Ucopy()、 _Umove()、 _Ufill()函数也不会过度分析。
vector的定义
1 | template<class _Ty, |
简单理解,就是vector是利用上述三个指针来表示的,基本示意图如下:
两个关键大小:
- 大小:
size=_Mylast - _Myfirst; - 容量:
capacity=_Myend - _Myfirst;
分别对应于resize()、reserve()两个函数。size表示vector中已有元素的个数,容量表示vector最多可存储的元素的个数;为了降低二次分配时的成本,vector实际配置的大小可能比客户需求的更大一些,以备将来扩充,这就是容量的概念。即capacity>=size,当等于时,容器此时已满,若再要加入新的元素时,就要重新进行内存分配,整个vector的数据都要移动到新内存。二次分配成本较高,在实际操作时,应尽量预留一定空间,避免二次分配。
构造与析构
构造
vector的构造函数主要有以下几种:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17vector() : _Mybase()
{ // construct empty vector
_Buy(0);
}
explicit vector(size_type _Count) : _Mybase()
{ // construct from _Count * _Ty()
_Construct_n(_Count, _Ty());
}
vector(size_type _Count, const _Ty& _Val) : _Mybase()
{ // construct from _Count * _Val
_Construct_n(_Count, _Val);
}
vector(const _Myt& _Right) : _Mybase(_Right._Alval)
{ // construct by copying _Right
if (_Buy(_Right.size()))
_Mylast = _Ucopy(_Right.begin(), _Right.end(), _Myfirst);
}
vector优异性能的秘诀之一,就是配置比其所容纳的元素所需更多的内存,一般在使用vector之前,就先预留足够空间,以避免二次分配,这样可以使vector的性能达到最佳。因此元素个数_Count是个远比元素值 _Val重要的参数,因此当构造一个vector时,首要参数一定是元素个数。
由上各构造函数可知,基本上所有构造函数都是基于_Construct _n() 的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19bool _Buy(size_type _Capacity)
{ // allocate array with _Capacity elements
_Myfirst = 0, _Mylast = 0, _Myend = 0;
if (_Capacity == 0) //_Count为0时,直接返回
return (false);
else
{ // nonempty array, allocate storage
_Myfirst = this->_Alval.allocate(_Capacity); //分配内存,并更新成员变量
_Mylast = _Myfirst;
_Myend = _Myfirst + _Capacity;
}
return (true);
}
void _Construct_n(size_type _Count, const _Ty& _Val)
{ // 构造含有_Count个值为_Val的元素的容器
if (_Buy(_Count))
_Mylast = _Ufill(_Myfirst, _Count, _Val);
}
这样就完成了vector容器的构造了。
析构
vector的析构函数很简单,就是先销毁所有已存在的元素,然后释放所有内存1
2
3
4
5
6
7
8
9void _Tidy()
{ // free all storage
if (_Myfirst != 0)
{ // something to free, destroy and deallocate it
_Destroy(_Myfirst, _Mylast);
this->_Alval.deallocate(_Myfirst, _Myend - _Myfirst);
}
_Myfirst = 0, _Mylast = 0, _Myend = 0;
}
插入和删除元素
vector的插入和删除元素是通过push_back ()、pop_back()两个接口来实现的,他们的内部实现也非常简单1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void push_back(const _Ty& _Val)
{ // insert element at end
if (size() < capacity())
_Mylast = _Ufill(_Mylast, 1, _Val);
else
insert(end(), _Val); //空间不足时,就会触发内存的二次分配
}
void pop_back()
{ // erase element at end
if (!empty())
{ // erase last element
_Destroy(_Mylast - 1, _Mylast);
--_Mylast;
}
}
其他接口
reserve()操作。之前提到过reserve(Count) 函数主要是预留Count大小的空间,对应的是容器的容量,目的是保证(_Myend - _Myfirst)>=Count。只有当空间不足时,才会操作,即重新分配一块内存,将原有元素拷贝到新内存,并销毁原有内存1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void reserve(size_type _Count)
{ // determine new minimum length of allocated storage
if (capacity() < _Count)
{ // not enough room, reallocate
pointer _Ptr = this->_Alval.allocate(_Count);
_Umove(begin(), end(), _Ptr);
size_type _Size = size();
if (_Myfirst != 0)
{ // destroy and deallocate old array
_Destroy(_Myfirst, _Mylast);
this->_Alval.deallocate(_Myfirst, _Myend - _Myfirst);
}
_Myend = _Ptr + _Count;
_Mylast = _Ptr + _Size;
_Myfirst = _Ptr;
}
}
resize()操作。resize(Count) 函数主要是用于改变size的,也就是改变vector的大小,最终改变的是(_Mylast - _Myfirst)的值,当size < Count时,就插入元素,当size >Count时,就擦除元素。1
2
3
4
5
6
7void resize(size_type _Newsize, _Ty _Val)
{ // determine new length, padding with _Val elements as needed
if (size() < _Newsize)
_Insert_n(end(), _Newsize - size(), _Val);
else if (_Newsize < size())
erase(begin() + _Newsize, end());
}
_Insert_n()操作。resize()操作和insert()操作都会利用到_Insert_n()这个函数,这个函数非常重要,也比其他函数稍微复杂一点。虽然_Insert_n(_where, _Count, _Val )函数比较长,但是操作都非常简单,主要可以分为以下几种情况:
- _Count == 0,不需要插入,直接返回
- max_size() - size() < _Count,超过系统设置的最大容量,会溢出,造成Xlen()异常
- _Capacity < size() + _Count,vector的容量不足以插入Count个元素,需要进行二次分配,扩大vector的容量。 在VS下,vector容量会扩大50%,即 _Capacity = _Capacity + _Capacity / 2;
若仍不足,则 _Capacity = size() + _Count;
1 | else if (_Capacity < size() + _Count) |
这种情况下,数据从原始容器移动到新分配内存时是从前到后移动的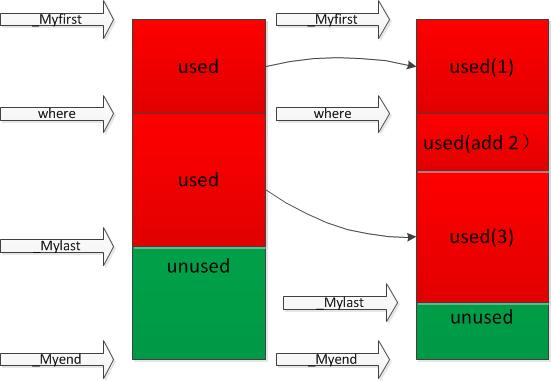
- 空间足够,且被插入元素的位置比较靠近_Mylast,即已有元素的尾部
这种情况下不需要再次进行内存分配,且数据是从后往前操作的。首先是将where~last向后移动,为待插入数据预留Count大小的空间,然后从_Mylast处开始填充,然后将从where处开始填充剩余元素1
2
3
4
5
6
7else if ((size_type)(_Mylast - _VEC_ITER_BASE(_Where)) < _Count)
{ // new stuff spills off end
_Umove(_VEC_ITER_BASE(_Where), _Mylast, _VEC_ITER_BASE(_Where) + _Count); // copy suffix
_Ufill(_Mylast, _Count - (_Mylast - _VEC_ITER_BASE(_Where)), _Val); // insert new stuff off end
_Mylast += _Count;
std::fill(_VEC_ITER_BASE(_Where), _Mylast - _Count, _Val); // insert up to old end
}
- 空间足够,但插入的位置比较靠前
1
2
3
4
5
6
7
8{ // new stuff can all be assigned
_Ty _Tmp = _Val; // in case _Val is in sequence
pointer _Oldend = _Mylast;
_Mylast = _Umove(_Oldend - _Count, _Oldend, _Mylast); // copy suffix
_STDEXT _Unchecked_move_backward(_VEC_ITER_BASE(_Where), _Oldend - _Count, _Oldend); // copy hole
std::fill(_VEC_ITER_BASE(_Where), _VEC_ITER_BASE(_Where) + _Count, _Tmp); // insert into hole
}
erase()操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16iterator erase(const_iterator _First_arg,
const_iterator _Last_arg)
{ // erase [_First, _Last)
iterator _First = _Make_iter(_First_arg);
iterator _Last = _Make_iter(_Last_arg);
if (_First != _Last)
{ // worth doing, copy down over hole
pointer _Ptr = _STDEXT unchecked_copy(_VEC_ITER_BASE(_Last), _Mylast,
_VEC_ITER_BASE(_First));
_Destroy(_Ptr, _Mylast);
_Mylast = _Ptr;
}
return (_First);
}
主要操作就是将后半部分的有效元素向前拷贝,并将后面空间的无效元素析构,并更新_Mylast变量
assign()操作最终都会调用到下面的函数,主要操作是首先擦除容器中已有的全部元素,在从头开始插入Count个Val元素1
2
3
4
5
6void _Assign_n(size_type _Count, const _Ty& _Val)
{ // assign _Count * _Val
_Ty _Tmp = _Val; // in case _Val is in sequence
erase(begin(), end());
insert(begin(), _Count, _Tmp);
}
基本使用
在经过上述对vector内部实现的分析后,再来理解相应接口就变得简单得多。vector对外接口主要可以分为:
构造、析构:1
2
3
4
5
6vector<Elem> c
vector <Elem> c1(c2)
vector <Elem> c(n)
vector <Elem> c(n, elem)
vector <Elem> c(beg,end)
c.~ vector <Elem>()
插入、删除、赋值1
2
3
4
5
6
7
8
9
10c.push_back(elem)
c.pop_back()
c.insert(pos,elem)
c.insert(pos,n,elem)
c.insert(pos,beg,end)
c.erase(pos)
c.erase(beg,end)
c.clear()
c.assign(beg,end)
c.assign(n,elem)
大小相关1
2
3
4
5c.capacity()
c.max_size()
c.resize(num)
c.reserve()
c.size()
获取迭代器1
2
3
4c.begin()
c.end()
c.rbegin()
c.rend()
获取数据1
2
3
4operator[]
c.at(idx)
c.front()
c.back()
size_t
在标准C库中的许多函数使用的参数或者返回值都是表示的用字节表示的对象大小,比如说malloc(n)函数的参数n指明了需要申请的空间大小,还有memcpy(s1, s2, n)的最后一个参数,表明需要复制的内存大小,strlen(s)函数的返回值表明了以’\0’结尾的字符串的长度(不包括’\0’),其返回值并不是该字符串的实际长度,因为要去掉’\0’。
或许你会认为这些参数或者返回值应该被申明为int类型(或者long或者unsigned),但是事实上并不是。C标准中将他们定义为size_t。标准中记载malloc的申明应该出现在,定义为:1
void *malloc(size_t n);
memcpy和strlen的申明应该出现在中:1
2void *memcpy(void *s1, void const *s2, size_t n);
size_t strlen(char const *s);
size_t还经常出现在C++标准库中,此外,C++库中经常会使用一个相似的类型size_type,用的可能比size_t还要多。
可移植性问题
回忆memcpy(s1, s2, n)函数,它将s2指向地址开始的n个字节拷贝到s2指向的地址,返回s1,这个函数可以拷贝任何数据类型,所以参数和返回值的类型应该为可以指向任何类型的void,同时,>源地址不应该被改变,所以第二个参数s2类型应该为`const void`,这些都不是问题。真正的问题在于我们如何申明第三个参数,它代表了源对象的大小,我相信大部分程序员都会选择int:1
void *memcpy(void *s1, void const *s2, int n);
使用int类型在大部分情况下都是可以的,但是我们可以使用unsigned int代替它让第三个参数表示的范围更大。在大部分机器上,unsigned int的最大值要比int的最大值大两倍。使用unsigned int修饰第三个参数的代价与int是相同的:1
void *memcpy(void *s1, void const *s2, unsigned int n);
这样似乎没有问题了,unsigned int可以表示最大类型的对象大小了,这种情况只有在整形和指针类型具有相同大小的情况下,比如说在IP16中,整形和指针都占2个字节(16位),而在IP32上面,整形和指针都占4个字节(32位)。
使用size_t
size_t是一种数据相关的无符号类型,它被设计得足够大以便能够内存中任意对象的大小。在C++中,设计 size_t 就是为了适应多个平台的。ize_t的引入增强了程序在不同平台上的可移植性。
size_t的定义在<stddef.h>,<stdio.h>,<stdlib.h>,<string.h>, <time.h>和<wchar.h>这些标准C头文件中,也出现在相应的C++头文件, 等等中,你应该在你的头文件中至少包含一个这样的头文件在使用size_t之前。包含以上任何C头文件(由C或C++编译的程序)表明将size_t作为全局关键字。根据定义,size_t是sizeof关键字(注:sizeof是关键字,并非运算符)运算结果的类型。所以,应当通过适当的方式声明n来完成赋值:1
n = sizeof(thing);
考虑到可移植性和程序效率,n应该被申明为size_t类型。类似的,下面的foo函数的参数也应当被申明为sizeof:1
foo(sizeof(thing));
参数中带有size_t的函数通常会含有局部变量用来对数组的大小或者索引进行计算,在这种情况下,size_t是个不错的选择。
size_t的大小并非像很多网上描述的那样,其大小是由系统的位数决定的。size_t的大小是由你生成的程序类型决定的,只是生成的程序类型与系统的类型有一定关系。32bits的程序既可以在64bits的系统上运行,也可以在32bits的系统上运行。但是64bits的程序只能在64bits的系统上运行。然而我们编译的程序一般是32bits的,因此size_t的大小也就变成了4个字节。
内存对齐
struct/class/union内存对齐原则有四个:
- 数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员>有子成员,比如说是数组,结构体等)的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储),基本类型不包括struct/class/uinon。
- 结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部”最宽基本类型成员”的整数倍地址开始存储.(struct a里存有struct b,b里有char,int ,double等元素,那b应该从8的整数倍开始存储.)。
- 收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的”最宽基本类型成员”的整数倍.不足的要补齐.(基本类型不包括struct/class/uinon)。
- sizeof(union),以结构里面size最大元素为union的size,因为在某一时刻,union只有一个成员真正存储于该地址。
实例解释:下面以class为代表1
2
3
4
5
6
7No. 1
class Data
{
char c;
int a;
};
cout << sizeof(Data) << endl;
1 | No. 2 |
显然程序No.1 输出的结果为 8, No.2 输出的结果为 16。No.1最大的数据成员是4bytes,1+4=5,补齐为4的倍数,也就是8。而No.2为8bytes,1+8=9,补齐为8的倍数,也就是16。
内存对齐的主要作用是:
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。具体原因稍后解释。
strlen和sizeof区别?
sizeof是运算符,并不是函数,结果在编译时得到而非运行中获得;strlen是字符处理的库函数。
sizeof参数可以是任何数据的类型或者数据(sizeof参数不退化);strlen的参数只能是字符指针且结尾是’\0’的字符串。
因为sizeof值在编译时确定,所以不能用来得到动态分配(运行时分配)存储空间的大小。1
2
3
4
5
6int main(int argc, char const *argv[]){
const char* str = "name";
sizeof(str); // 取的是指针str的长度,是8
strlen(str); // 取的是这个字符串的长度,不包含结尾的 \0。大小是4
return 0;
}
数组在内存中是连续存放的,开辟一块连续的内存空间;数组所占存储空间:sizeof(数组名);数组大小:sizeof(数组名)/sizeof(数组元素数据类型);用运算符sizeof 可以计算出数组的容量(字节数)。sizeof(p),p 为指针得到的是一个指针变量的字节数,而不是p 所指的内存容量。
OFFSETOF
OFFSETOF(s, m)的宏定义,s是结构类型,m是s的成员,求m在s中的偏移量。1
sizeof
sizeof一个类求大小(注意成员变量,函数,虚函数,继承等等对大小的影响)以下运行环境都是一般的,在32位编译环境中。
基本数据类型的sizeof1
2
3
4
5
6
7cout<<sizeof(char)<<endl; 结果是1
cout<<sizeof(int)<<endl; 结果是4
cout<<sizeof(unsigned int)<<endl; 结果是4
cout<<sizeof(long int)<<endl; 结果是4
cout<<sizeof(short int)<<endl; 结果是2
cout<<sizeof(float)<<endl; 结果是4
cout<<sizeof(double)<<endl; 结果是8
指针变量的sizeof1
2
3
4
5
6
7
8
9
10
11
12char *pc ="abc";
sizeof( pc ); // 结果为4
sizeof(*pc); // 结果为1
int *pi;
sizeof( pi ); //结果为4
sizeof(*pi); //结果为4
char **ppc = &pc;
sizeof( ppc ); // 结果为4
sizeof( *ppc ); // 结果为4
sizeof( **ppc ); // 结果为1
void (*pf)();// 函数指针
sizeof( pf );// 结果为4
数组的sizeof数组的sizeof值等于数组所占用的内存字节数,如:1
2
3
4char a1[] = "abc";
int a2[3];
sizeof( a1 ); // 结果为4,字符 末尾还存在一个NULL终止符
sizeof( a2 ); // 结果为3*4=12(依赖于int)
写到这里,提一问,下面的c3,c4值应该是多少呢1
2
3
4
5
6
7
8void foo3(char a3[3])
{
int c3 = sizeof( a3 ); // c3 == 4
}
void foo4(char a4[])
{
int c4 = sizeof( a4 ); // c4 == 4
}
也许当你试图回答c4的值时已经意识到c3答错了,是的,c3!=3。这里函数参数a3已不再是数组类型,而是蜕变成指针,相当于char* a3,为什么仔细想想就不难明白,我们调用函数foo1时,程序会在栈上分配一个大小为3的数组吗不会!数组是“传址”的,调用者只需将实参的地址传递过去,所以a3自然为指针类型char*,c3的值也就为4。
结构体的sizeof1
2
3
4
5
6struct MyStruct
{
double dda1;
char dda;
int type
};
结果为16,为上面的结构分配空间的时候,VC根据成员变量出现的顺序和对齐方式,先为第一个成员dda1分配空间,其起始地址跟结构的起始地址相同(刚好偏移量0刚好为sizeof(double)的倍数),该成员变量占用sizeof(double)=8个字节;接下来为第二个成员dda分配空间,这时下一个可以分配的地址对于结构的起始地址的偏移量为8,是sizeof(char)的倍数,所以把dda存放在偏移量为8的地方满足对齐方式,该成员变量占用sizeof(char)=1个字节;接下来为第三个成员type分配空间,这时下一个可以分配的地址对于结构的起始地址的偏移量为9,不是sizeof(int)=4的倍数,为了满足对齐方式对偏移量的约束问题,VC自动填充3个字节(这三个字节没有放什么东西),这时下一个可以分配的地址对于结构的起始地址的偏移量为12,刚好是sizeof(int)=4的倍数,所以把type存放在偏移量为12的地方,该成员变量占用sizeof(int)=4个字节;这时整个结构的成员变量已经都分配了空间,总的占用的空间大小为:8+1+3+4=16,刚好为结构的字节边界数(即结构中占用最大空间的类型所占用的字节数sizeof(double)=8)的倍数,所以没有空缺的字节需要填充。
含位域结构体的sizeof1
2
3
4
5
6struct BF1
{
char f1 : 3;
char f2 : 4;
char f3 : 5;
};
位域类型为char,第1个字节仅能容纳下f1和f2,所以f2被压缩到第1个字节中,而f3只能从下一个字节开始。因此sizeof(BF1)的结果为2。
含有联合体的结构体的sizeof1
2
3
4
5
6
7
8
9
10struct s1
{
char *ptr,ch;
union A
{
short a,b;
unsigned int c:2, d:1;
};
struct s1* next;
};
这样是8+4=12个字节1
2
3
4
5
6
7
8
9
10struct s1
{
char *ptr,ch;
union //联合体是结构体的成员,占内存,并且最大类型是unsigned int,占4
{
short a,b;
unsigned int c:2, d:1;
};
struct s1* next;
};
这样是8+4+4=16个字节
结构体含有结构体的sizeof1
2
3
4
5
6
7
8
9
10
11
12struct S1
{
char c;
int i;
};
struct S3
{
char c1;
S1 s;
char c2;
};
cout<<sizeof(S3); //S3=16
S1的最宽简单成员的类型为int,S3在考虑最宽简单类型成员时是将S1“打散”看的,所以S3的最宽简单类型为int,这样,通过S3定义的变量,其存储空间首地址需要被4整除,整个sizeof(S3)的值也应该被4整除。
c1的偏移量为0,s的偏移量呢这时s是一个整体,它作为结构体变量也满足前面三个准则,所以其大小为8,偏移量为4,c1与s之间便需要3个填充字节,而c2与s之间就不需要了,所以c2的偏移量为12,算上c2的大小为13,13是不能被4整除的,这样末尾还得补上3个填充字节。最后得到sizeof(S3)的值为16。
带有#pragma pack的sizeof:它是用来调整结构体对齐方式的,不同编译器名称和用法略有不同,VC6中通过#pragma pack实现,也可以直接修改/Zp编译开关。#pragma pack的基本用法为:#pragma pack(n),n为字节对齐数,其取值为1、2、4、8、16,默认是8,如果这个值比结构体成员的sizeof值小,那么该成员的偏移量应该以此值为准,即是说,结构体成员的偏移量应该取二者的最小值,
再看示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
struct S1
{
char c;
int i;
};
struct S3
{
char c1;
S1 s;
char c2
};
计算sizeof(S1)时,min(2, sizeof(i))的值为2,所以i的偏移量为2,加上sizeof(i)等于6,能够被2整除,所以整个S1的大小为6。
同样,对于sizeof(S3),s的偏移量为2,c2的偏移量为8,加上sizeof(c2)等于9,不能被2整除,添加一个填充字节,所以sizeof(S3)等于10。
空结构体的sizeof1
2struct S5 { };
sizeof( S5 ); // 结果为1
类的sizeof
类的sizeof值等于类中成员变量所占用的内存字节数。如:1
2
3
4
5
6
7
8
9
10
11
12
13
14class A
{
public:
int b;
float c;
char d;
};
int main(void)
{
A object;
cout << "sizeof(object) is " << sizeof(object) << endl;
return 0 ;
}
输出结果为12(我的机器上sizeof(float)值为4,字节对其前面已经讲过)。
不过需要注意的是,如果类中存在静态成员变量,结果又会是什么样子呢?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class A
{
public:
static int a;
int b;
float c;
char d;
};
int main()
{
A object;
cout << "sizeof(object) is " << sizeof(object) << endl;
return 0 ;
}
16?不对。结果仍然是12.
因为在程序编译期间,就已经为static变量在静态存储区域分配了内存空间,并且这块内存在程序的整个运行期间都存在。而每次声明了类A的一个对象的时候,为该对象在堆上,根据对象的大小分配内存。
如果类A中包含成员函数,那么又会是怎样的情况呢?看下面的例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class A
{
public:
static int a;
int b;
float c;
char d;
int add(int x,int y)
{
return x+y;
}
};
int main()
{
A object;
cout << "sizeof(object) is " << sizeof(object) << endl;
b = object.add(3,4);
cout << "sizeof(object) is " << sizeof(object) << endl;
return 0 ;
}
结果仍为12。
因为只有非静态类成员变量在新生成一个object的时候才需要自己的副本。所以每个非静态成员变量在生成新object需要内存,而function是不需要的。
标准C++中的string类
相信使用过MFC编程的朋友对CString这个类的印象应该非常深刻吧?的确,MFC中的CString类使用起来真的非常的方便好用。但是如果离开了MFC框架,还有没有这样使用起来非常方便的类呢?答案是肯定的。也许有人会说,即使不用MFC框架,也可以想办法使用MFC中的API,具体的操作方法在本文最后给出操作方法。其实,可能很多人很可能会忽略掉标准C++中string类的使用。标准C++中提供的string类得功能也是非常强大的,一般都能满足我们开发项目时使用。现将具体用法的一部分罗列如下,只起一个抛砖引玉的作用吧,好了,废话少说,直接进入正题吧!
要想使用标准C++中string类,必须要包含1
2
3
using std::string;
using std::wstring;
或1
using namespace std;
下面你就可以使用string/wstring了,它们两分别对应着char和wchar_t。
string和wstring的用法是一样的,以下只用string作介绍:
string类的构造函数
1 | string(const char *s); //用c字符串s初始化 |
此外,string类还支持默认构造函数和复制构造函数,如string s1;string s2=”hello”;都是正确的写法。当构造的string太长而无法表达时会抛出length_error异常 ;
string类的字符操作
1 | const char &operator[](int n)const; |
operator[]和at()均返回当前字符串中第n个字符的位置,但at函数提供范围检查,当越界时会抛出out_of_range异常,下标运算符[]不提供检查访问。
1 | const char *data()const;//返回一个非null终止的c字符数组 |
string的特性描述
1 | int capacity()const; //返回当前容量(即string中不必增加内存即可存放的元素个数) |
string类的输入输出操作
string类重载运算符operator>>用于输入,同样重载运算符operator<<用于输出操作。
函数getline(istream &in,string &s);用于从输入流in中读取字符串到s中,以换行符’\n’分开。
string的赋值
1 | string &operator=(const string &s);//把字符串s赋给当前字符串 |
string的连接
1 | string &operator+=(const string &s);//把字符串s连接到当前字符串的结尾 |
string的比较
1 | bool operator==(const string &s1,const string &s2)const;//比较两个字符串是否相等 |
运算符”>”,”<”,”>=”,”<=”,”!=”均被重载用于字符串的比较;1
2
3
4
5
6int compare(const string &s) const;//比较当前字符串和s的大小
int compare(int pos, int n,const string &s)const;//比较当前字符串从pos开始的n个字符组成的字符串与s的大小
int compare(int pos, int n,const string &s,int pos2,int n2)const;//比较当前字符串从pos开始的n个字符组成的字符串与s中pos2开始的n2个字符组成的字符串的大小
int compare(const char *s) const;
int compare(int pos, int n,const char *s) const;
int compare(int pos, int n,const char *s, int pos2) const;
compare函数在>时返回1,<时返回-1,==时返回0
string的子串
1 | string substr(int pos = 0,int n = npos) const;//返回pos开始的n个字符组成的字符串 |
string的交换
1 | void swap(string &s2); //交换当前字符串与s2的值 |
string类的查找函数
1 | int find(char c, int pos = 0) const;//从pos开始查找字符c在当前字符串的位置 |
string类的替换函数
1 | string &replace(int p0, int n0,const char *s);//删除从p0开始的n0个字符,然后在p0处插入串s |
string类的插入函数
1 | string &insert(int p0, const char *s); |
string类的删除函数
1 | iterator erase(iterator first, iterator last);//删除[first,last)之间的所有字符,返回删除后迭代器的位置 |
string类的迭代器处理
string类提供了向前和向后遍历的迭代器iterator,迭代器提供了访问各个字符的语法,类似于指针操作,迭代器不检查范围。用string::iterator或string::const_iterator声明迭代器变量,const_iterator不允许改变迭代的内容。常用迭代器函数有:1
2
3
4
5
6
7
8const_iterator begin()const;
iterator begin(); //返回string的起始位置
const_iterator end()const;
iterator end(); //返回string的最后一个字符后面的位置
const_iterator rbegin()const;
iterator rbegin(); //返回string的最后一个字符的位置
const_iterator rend()const;
iterator rend(); //返回string第一个字符位置的前面
rbegin和rend用于从后向前的迭代访问,通过设置迭代器string::reverse_iterator,string::const_reverse_iterator实现
字符串流处理
通过定义ostringstream和istringstream变量实现,#include <sstream>头文件中。例如:1
2
3
4
5
6
7string input("hello,this is a test");
istringstream is(input);
string s1,s2,s3,s4;
is>>s1>>s2>>s3>>s4;//s1="hello,this",s2="is",s3="a",s4="test"
ostringstream os;
os<<s1<<s2<<s3<<s4;
cout<<os.str();
以上就是对C++ string类的一个简要介绍。
string特性描述
可用下列函数来获得string的一些特性:1
2
3
4
5
6int capacity()const; //返回当前容量(即string中不必增加内存即可存放的元素个数)
int max_size()const; //返回string对象中可存放的最大字符串的长度
int size()const; //返回当前字符串的大小
int length()const; //返回当前字符串的长度
bool empty()const; //当前字符串是否为空
void resize(int len,char c); //把字符串当前大小置为len,多去少补,多出的字符c填充不足的部分
测试代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
int main()
{
string str;
if (str.empty())
cout<<"str is NULL."<<endl;
else
cout<<"str is not NULL."<<endl;
str = str + "abcdefg";
cout<<"str is "<<str<<endl;
cout<<"str's size is "<<str.size()<<endl;
cout<<"str's capacity is "<<str.capacity()<<endl;
cout<<"str's max size is "<<str.max_size()<<endl;
cout<<"str's length is "<<str.length()<<endl;
str.resize(20,'c');
cout<<"str is "<<str<<endl;
str.resize(5);
cout<<"str is "<<str<<endl;
return 0;
}
string的查找
由于查找是使用最为频繁的功能之一,string提供了非常丰富的查找函数:(注:string::npos)
size_type find( const basic_string &str, size_type index ); //返回str在字符串中第一次出现的位置(从index开始查找),如果没找到则返回string::npos
size_type find( const char *str, size_type index ); // 同上
size_type find( const char *str, size_type index, size_type length ); //返回str在字符串中第一次出现的位置(从index开始查找,长度为length),如果没找到就返回string::npos
size_type find( char ch, size_type index ); // 返回字符ch在字符串中第一次出现的位置(从index开始查找),如果没找到就返回string::npos
注意:查找字符串a是否包含子串b,不是用 strA.find(strB) > 0 而是 strA.find(strB) != string:npos 这是为什么呢?(初学者比较容易犯的一个错误)本部分参考自web100与luhao1993
先看下面的代码1
2int idx = str.find("abc");
if (idx == string::npos);
上述代码中,idx的类型被定义为int,这是错误的,即使定义为unsigned int 也是错的,它必须定义为 string::size_type。npos 是这样定义的: static const size_type npos = -1; 因为 string::size_type (由字符串配置器 allocator 定义) 描述的是 size,故需为无符号整数型别。因为缺省配置器以型别 size_t 作为 size_type,于是 -1 被转换为无符号整数型别,npos 也就成了该型别的最大无符号值。不过实际数值还是取决于型别 size_type 的实际定义。不幸的是这些最大值都不相同。事实上,(unsigned long)-1 和 (unsigned short)-1 不同(前提是两者型别大小不同)。因此,比较式 idx == string::npos 中,如果 idx 的值为-1,由于 idx 和字符串string::npos 型别不同,比较结果可能得到 false。因此要想判断 find()等查找函数的结果是否为npos,最好的办法是直接比较。
测试代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
using namespace std;
int main(){
int loc;
string s="study hard and make progress everyday! every day!!";
loc=s.rfind("make",10);
cout<<"the word make is at index"<<loc<<endl;//-1表示没找到
loc=s.rfind("make");//缺省状态下,从最后一个往前找
cout<<"the word make is at index"<<loc<<endl;
loc=s.find_first_of("day");
cout<<"the word day(first) is at index "<<loc<<endl;
loc=s.find_first_not_of("study");
cout<<"the first word not of study is at index"<<loc<<endl;
loc=s.find_last_of("day");
cout<<"the last word of day is at index"<<loc<<endl;
loc=s.find("day");//缺陷状态下从第一个往后找
cout<<loc;
return 0;
}
运行结果:
其他常用函数
string &insert(int p,const string &s); //在p位置插入字符串sstring &replace(int p, int n,const char *s); //删除从p开始的n个字符,然后在p处插入串sstring &erase(int p, int n); //删除p开始的n个字符,返回修改后的字符串string substr(int pos = 0,int n = npos) const; //返回pos开始的n个字符组成的字符串void swap(string &s2); //交换当前字符串与s2的值string &append(const char *s); //把字符串s连接到当前字符串结尾void push_back(char c) //当前字符串尾部加一个字符cconst char *data()const; //返回一个非null终止的c字符数组,data():与c_str()类似,用于string转const char*其中它返回的数组是不以空字符终止,const char *c_str()const; //返回一个以null终止的c字符串,即c_str()函数返回一个指向正规C字符串的指针, 内容与本string串相同,用于string转const char*
测试代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
using namespace std;
int main()
{
string str1 = "abc123defg";
string str2 = "swap!";
cout<<str1<<endl;
cout<<str1.erase(3,3)<<endl; //从索引3开始的3个字符,即删除掉了"123"
cout<<str1.insert(0,"123")<<endl; //在头部插入
cout<<str1.append("123")<<endl; //append()方法可以添加字符串
str1.push_back('A'); //push_back()方法只能添加一个字符
cout<<str1<<endl;
cout<<str1.replace(0,3,"hello")<<endl; //即将索引0开始的3个字符替换成"hello"
cout<<str1.substr(5,7)<<endl; //从索引5开始7个字节
str1.swap(str2);
cout<<str1<<endl;
const char* p = str.c_str();
printf("%s\n",p);
return 0;
}
程序执行结果为:1
2
3
4
5
6
7
8
9abc123defg
abcdefg
123abcdefg
123abcdefg123
123abcdefg123A
helloabcdefg123A
abcdefg
swap!
swap!
this指针
this指针的用处
一个对象的this指针并不是对象本身的一部分,不会影响sizeof(对象)的结果。this作用域是在类内部,当在类的非静态成员函数中访问类的非静态成员的时候,编译器会自动将对象本身的地址作为一个隐含参数传递给函数。也就是说,即使你没有写上this指针,编译器在编译的时候也是加上this的,它作为非静态成员函数的隐含形参,对各成员的访问均通过this进行。 例如,调用date.SetMonth(9) <==> SetMonth(&date, 9),this帮助完成了这一转换。
this指针的使用
一种情况就是,在类的非静态成员函数中返回类对象本身的时候,直接使用return *this;另外一种情况是当参数与成员变量名相同时,如this->n = n (不能写成n = n)。
this指针程序示例
this指针存在于类的成员函数中,指向被调用函数所在的类实例的地址。根据以下程序来说明this指针1
2
3
4
5
6
7
8
9
10
11
12
13class Point
{
int x, y;
public:
Point(int a, int b) { x=a; y=b;}
void MovePoint( int a, int b){ x+=a; y+=b;}
void print(){ cout<<"x="<<x<<"y="<<y<<endl;} <="" font="">
};
void main( ) {
Point point1( 10,10);
point1.MovePoint(2,2);
point1.print();
}
当对象point1调用MovePoint(2,2)函数时,即将point1对象的地址传递给了this指针。
MovePoint函数的原型应该是1
void MovePoint( Point *this, int a, int b);
第一个参数是指向该类对象的一个指针,我们在定义成员函数时没看见是因为这个参数在类中是隐含的。这样point1的地址传递给了this,所以在MovePoint函数中便显式的写成:1
void MovePoint(int a, int b) { this->x +=a; this-> y+= b;}
即可以知道,point1调用该函数后,也就是point1的数据成员被调用并更新了值。
即该函数过程可写成1
point1.x+= a; point1. y + = b;
关于this指针的一个经典回答
当你进入一个房子后,你可以看见桌子、椅子、地板等,但是房子你是看不到全貌了。
对于一个类的实例来说,你可以看到它的成员函数、成员变量,但是实例本身呢?this是一个指针,它时时刻刻指向你这个实例本身
类的this指针有以下特点:
(1)this只能在成员函数中使用。全局函数、静态函数都不能使用this。实际上,成员函数默认第一个参数为T * const this。如:1
2
3
4
5
6
7class A
{
public:
int func(int p)
{
}
};
其中,func的原型在编译器看来应该是:1
int func(A * const this,int p);
(2)由此可见,this在成员函数的开始前构造,在成员函数的结束后清除。这个生命周期同任何一个函数的参数是一样的,没有任何区别。当调用一个类的成员函数时,编译器将类的指针作为函数的this参数传递进去。如:1
2A a;
a.func(10);
此处,编译器将会编译成:1
A::func(&a,10);
看起来和静态函数没差别,对吗?不过,区别还是有的。编译器通常会对this指针做一些优化,因此,this指针的传递效率比较高—如VC通常是通过ecx寄存器传递this参数的。
(3)几个this指针的易混问题。
A. this指针是什么时候创建的?
this在成员函数的开始执行前构造,在成员的执行结束后清除。
但是如果class或者struct里面没有方法的话,它们是没有构造函数的,只能当做C的struct使用。采用 TYPE xx的方式定义的话,在栈里分配内存,这时候this指针的值就是这块内存的地址。采用new的方式 创建对象的话,在堆里分配内存,new操作符通过eax返回分配 的地址,然后设置给指针变量。之后去调 用构造函数(如果有构造函数的话),这时将这个内存块的地址传给ecx。
B. this指针存放在何处?堆、栈、全局变量,还是其他?
this指针会因编译器不同而有不同的放置位置。可能是栈,也可能是寄存器,甚至全局变量。在汇编级 别里面,一个值只会以3种形式出现:立即数、寄存器值和内存变量值。不是存放在寄存器就是存放在内 存中,它们并不是和高级语言变量对应的。
C. this指针是如何传递类中的函数的?绑定?还是在函数参数的首参数就是this指针?那么,this指针 又是如何找到“类实例后函数的”?
大多数编译器通过ecx寄存器传递this指针。事实上,这也是一个潜规则。一般来说,不同编译器都会遵从一致的传参规则,否则不同编译器产生的obj就无法匹配了。
在call之前,编译器会把对应的对象地址放到eax中。this是通过函数参数的首参来传递的。this指针在调用之前生成,至于“类实例后函数”,没有这个说法。类在实例化时,只分配类中的变量空间,并没有为函数分配空间。自从类的函数定义完成后,它就在那儿,不会跑的。
D. this指针是如何访问类中的变量的?
如果不是类,而是结构体的话,那么,如何通过结构指针来访问结构中的变量呢?如果你明白这一点的话,就很容易理解这个问题了。
在C++中 ,类和结构是只有一个区别的:类的成员默认是private,而结构是public。
this是类的指针,如果换成结构,那this就是结构的指针了。
E. 我们只有获得一个对象后,才能通过对象使用this指针。如果我们知道一个对象this指针的位置,可以直接使用吗?
this指针只有在成员函数中才有定义。因此,你获得一个对象后,也不能通过对象使用this指针。所以,我们无法知道一个对象的this指针的位置(只有在成员函数里才有this指针的位置)。当然,在成员函数里,你是可以知道this指针的位置的(可以通过&this获得),也可以直接使用它。
F. 每个类编译后,是否创建一个类中函数表保存函数指针,以便用来调用函数?
普通的类函数(不论是成员函数,还是静态函数)都不会创建一个函数表来保存函数指针。只有虚函数才会被放到函数表中。但是,即使是虚函数,如果编译器能明确知道调用的是哪个函数,编译器就不会通过函数表中的指针来间接调用,而是会直接调用该函数。
注意事项
this指针是一个隐含于每一个非静态成员函数中的特殊指针。它指向调用该成员函数的那个对象。- 类内定义的静态方法不能指向实例本身,也就是没有this指针
- 当对一个对象调用成员函数时,编译程序先将对象的地址赋给
this指针,然后调用成员函数,每次成员函数存取数据成员时,都隐式使用this指针。 - 当一个成员函数被调用时,自动向它传递一个隐含的参数,该参数是一个指向这个成员函数所在的对象的指针。
this指针被隐含地声明为:ClassName *const this,这意味着不能给this指针赋值;在ClassName类的const成员函数中,this指针的类型为:const ClassName* const,这说明不能对this指针所指向的这种对象是不可修改的(即不能对这种对象的数据成员进行赋值操作);this并不是一个常规变量,而是个右值,所以不能取得this的地址(不能&this)。- 在以下场景中,经常需要显式引用
this指针:- 为实现对象的链式引用;
- 为避免对同一对象进行赋值操作;
- 在实现一些数据结构时,如
list。
变长参数函数
首先回顾一下较多使用的变长参数函数,最经典的便是printf。1
extern int printf(const char *format, ...);
以上是一个变长参数的函数声明。我们自己定义一个测试函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int testparams(int count, ...)
{
va_list args;
va_start(args, count);
for (int i = 0; i < count; ++i)
{
int arg = va_arg(args, int);
printf("arg %d = %d", i, arg);
}
va_end(args);
return 0;
}
int main()
{
testparams(3, 10, 11, 12);
return 0;
}
变长参数函数的解析,使用到三个宏va_start,va_arg 和va_end,再看va_list的定义typedef char* va_list; 只是一个char指针。
这几个宏如何解析传入的参数呢?
函数的调用,是一个压栈,保存,跳转的过程。简单的流程描述如下:
- 把参数从右到左依次压入栈;
- 调用call指令,把下一条要执行的指令的地址作为返回地址入栈;(被调用函数执行完后会回到该地址继续执行)
- 当前的ebp(基址指针)入栈保存,然后把当前esp(栈顶指针)赋给ebp作为新函数栈帧的基址;
- 执行被调用函数,局部变量等入栈;
- 返回值放入eax,leave,ebp赋给esp,esp所存的地址赋给ebp;(这里可能需要拷贝临时返回对象)
- 从返回地址开始继续执行;(把返回地址所存的地址给eip)
由于开始的时候从右至左把参数压栈,va_start 传入最左侧的参数,往右的参数依次更早被压入栈,因此地址依次递增(栈顶地址最小)。va_arg传入当前需要获得的参数的类型,便可以利用 sizeof 计算偏移量,依次获取后面的参数值。
1 |
上述宏定义中,_INTSIZEOF(n)将地址的低2位指令,做内存的4字节对齐。每次取参数时,调用__crt_va_arg(ap,t),返回t类型参数地址的值,同时将ap偏移到t之后。最后,调用_crt_va_end(ap)将ap置0.
变长参数的函数的使用及其原理看了宏定义是很好理解的。从上文可知,要使用变长参数函数的参数,我们必须知道传入的每个参数的类型。printf中,有format字符串中的特殊字符组合来解析后面的参数类型。但是当传入类的构造函数的参数时,我们并不知道每个参数都是什么类型,虽然参数能够依次传入函数,但无法解析并获取每个参数的数值。因此传统的变长参数函数并不足以解决传入任意构造函数参数的问题。
变长参数模板
我们需要用到C++11的新特性,变长参数模板。
这里举一个使用自定义内存池的例子。定义一个内存池类MemPool.h,以count个类型T为单元分配内存,默认分配一个对象。每当内存内空闲内存不够,则一次申请MEMPOOL_NEW_SIZE个内存对象。内存池本身只负责内存分配,不做初始化工作,因此不需要传入任何参数,只需实例化模板分配相应类型的内存即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
template<typename T, size_t count = 1>
class MemPool
{
private:
union MemObj {
char _obj[1];
MemObj* _freelink;
};
public:
static void* Allocate()
{
if (!_freelist) {
refill();
}
MemObj* alloc_mem = _freelist;
_freelist = _freelist->_freelink;
++_size;
return (void*)alloc_mem;
}
static void DeAllocate(void* p)
{
MemObj* q = (MemObj*)p;
q->_freelink = _freelist;
_freelist = q;
--_size;
}
static size_t TotalSize() {
return _totalsize;
}
static size_t Size() {
return _size;
}
private:
static void refill()
{
size_t size = sizeof(T) * count;
char* new_mem = (char*)malloc(size * MEMPOOL_NEW_SIZE);
for (int i = 0; i < MEMPOOL_NEW_SIZE; ++i) {
MemObj* free_mem = (MemObj*)(new_mem + i * size);
free_mem->_freelink = _freelist;
_freelist = free_mem;
}
_totalsize += MEMPOOL_NEW_SIZE;
}
static MemObj* _freelist;
static size_t _totalsize;
static size_t _size;
};
template<typename T, size_t count>
typename MemPool<T, count>::MemObj* MemPool<T, count>::_freelist = NULL;
template<typename T, size_t count>
size_t MemPool<T, count>::_totalsize = 0;
template<typename T, size_t count>
size_t MemPool<T, count>::_size = 0;
接下来在没有变长参数的情况下,实现通用MemNew和MemDelete函数模板。这里不对函数模板作详细解释,用函数模板我们可以对不同的类型实现同样的内存池分配操作。如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32template<class T>
T *MemNew(size_t count)
{
T *p = (T*)MemPool<T, count>::Allocate();
if (p != NULL)
{
if (!std::is_pod<T>::value)
{
for (size_t i = 0; i < count; ++i)
{
new (&p[i]) T();
}
}
}
return p;
}
template<class T>
T *MemDelete(T *p, size_t count)
{
if (p != NULL)
{
if (!std::is_pod<T>::value)
{
for (size_t i = 0; i < count; ++i)
{
p[i].~T();
}
}
MemPool<T, count>::DeAllocate(p);
}
}
上述实现中,使用placement new对申请的内存进行构造,使用了默认构造函数,当申请内存的类型不具备默认构造函数时,placement new将报错。对于pod类型,可以省去调用构造函数的过程。
引入C++11变长模板参数后MemNew修改为如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16template<class T, class... Args>
T *MemNew(size_t count, Args&&... args)
{
T *p = (T*)MemPool<T, count>::Allocate();
if (p != NULL)
{
if (!std::is_pod<T>::value)
{
for (size_t i = 0; i < count; ++i)
{
new (&p[i]) T(std::forward<Args>(args)...);
}
}
}
return p;
}
以上函数定义包含了多个特性,后面我将一一解释,其中class… Args 表示变长参数模板,函数参数中Args&& 为右值引用。std::forward
C++11中引入了变长参数模板的概念,来解决参数个数不确定的模板。1
2
3
4
5
6
7
8
9
10template<class... T> class Test {};
Test<> test0;
Test<int> test1;
Test<int,int> test2;
Test<int,int,long> test3;
template<class... T> void test(T... args);
test();
test<int>(0);
test<int,int,long>(0,0,0L);
变长参数函数模板
T… args 为形参包,其中args是模式,形参包中可以有0到任意多个参数。调用函数时,可以传任意多个实参。对于函数定义来说,该如何使用参数包呢?在上文的MemNew中,我们使用std::forward依次将参数包传入构造函数,并不关注每个参数具体是什么。如果需要,我们可以用sizeof…(args)操作获取参数个数,也可以把参数包展开,对每个参数做更多的事。展开的方法有两种,递归函数,逗号表达式。
递归函数方式展开,模板推导的时候,一层层递归展开,最后到没有参数时用定义的一般函数终止。1
2
3
4
5
6
7
8
9
10
11
12void test()
{
}
template<class T, class... Args>
void test(T first, Args... args)
{
std::cout << typeid(T).name() << " " << first << std::endl;
test(args...);
}
test<int, int, long>(0, 0, 0L);
output:1
2
3int 0
int 0
long 0
逗号表达式方式展开,利用数组的参数初始化列表和逗号表达式,逐一执行print每个参数。1
2
3
4
5
6
7
8
9
10
11
12
13template<class T>
void print(T arg)
{
std::cout << typeid(T).name() << " " << arg << std::endl;
}
template<class... Args>
void test(Args... args)
{
int arr[] = { (print(args), 0)... };
}
test(0, 0, 0L);
output:1
2
3int 0
int 0
long 0
变长参数类模板
变长参数类模板,一般情况下可以方便我们做一些编译期计算。可以通过偏特化和递归推导的方式依次展开模板参数。
1 | template<class T, class... Types> |
右值引用和完美转发
对于变长参数函数模板,需要将形参包展开逐个处理的需求不多,更多的还是像本文的MemNew这样的需求,最终整个传入某个现有的函数。我们把重点放在参数的传递上。
要理解右值引用,需要先说清楚左值和右值。左值是内存中有确定存储地址的对象的表达式的值;右值则是非左值的表达式的值。const左值不可被赋值,临时对象的右值可以被赋值。左值与右值的根本区别在于是否能用&运算符获得内存地址。1
2
3
4
5
6
7
8
9
10
11
12int i =0;//i 左值
int *p = &i;// i 左值
int& foo();
foo() = 42;// foo() 左值
int* p1 = &foo();// foo() 左值
int foo1();
int j = 0;
j = foo1();// foo 右值
int k = j + 1;// j + 1 右值
int *p2 = &foo1(); // 错误,无法取右值的地址
j = 1;// 1 右值
理解左值和右值之后,再来看引用,对左值的引用就是左值引用,对右值(纯右值和临终值)的引用就是右值引用。
如下函数foo,传入int类型,返回int类型,这里传入函数的参数0和返回值0都是右值(不能用&取得地址)。于是,未做优化的情况下,传入参数0的时候,我们需要把右值0拷贝给param,函数返回的时候需要将0拷贝给临时对象,临时对象再拷贝给res。当然现在的编译器都做了返回值优化,返回对象是直接创建在返回后的左值上的,这里只用来举个例子1
2
3
4
5
6
7int foo(int param)
{
printf("%d", param);
return 0;
}
int res = foo(0);
显然,这里的拷贝都是多余的。可能我们会想要优化,首先将参数int改为int&,传入左值引用,于是0无法传入了,当然我们可以改成const int&,这样终于省去了传参的拷贝。1
2
3
4
5int foo(const int& param)
{
printf("%d", param);
return 0;
}
由于const int& 既可以是左值也可以是右值,传入0或者int变量都能够满足。(但是似乎既然有左值引用的int&类型,就应该有对应的传入右值引用的类型int&&)。另外,这里返回的右值0,似乎不通过拷贝就无法赋值给左值res。
于是有了移动语义,把临时对象的内容直接移动给被赋值的左值对象(std::move)。和右值引用,X&&是到数据类型X的右值引用。1
2
3
4
5
6
7
8
9int result = 0;
int&& foo(int&& param)
{
printf("%d", param);
return std::move(result);
}
int&& res = foo(0);
int *pres = &res;
将foo改为右值引用参数和返回值,返回右值引用,免去拷贝。这里res是具名引用,运算符右侧的右值引用作为左值,可以取地址。右值引用既有左值性质,也有右值性质。
上述例子还只存在于拷贝的性能问题。回到MemNew这样的函数模板。
1 | template<class T> |
上述的前三种方式传参,第一种首先有拷贝消耗,其次有的参数就是需要修改的左值。第二种方式则无法传常数等右值。第三种方式虽然左值右值都能传,却无法对传入的参数进行修改。第四种方式使用右值引用,可以解决参数完美转发的问题。
std::forward能够根据实参的数据类型,返回相应类型的左值和右值引用,将参数完整不动的传递下去。
解释这个原理涉及到引用塌缩规则1
2
3
4T& & ->T&
T& &&->T&
T&& &->T&
T&& &&->T&&
1 | template< class T > struct remove_reference {typedef T type;}; |
对于函数模板1
2
3
4
5template<class T>
T* Test(T&& arg)
{
return new T(std::forward<T>(arg));
}
当传入实参为X类型左值时,T为X&,最后的类型为X&。当实参为X类型右值时,T为X,最后的类型为X&&。
x为左值时:1
2X x;
Test(x);
T为X&,实例化后1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21X& && std::forward(remove_reference<X&>::type& a) noexcept
{
return static_cast<X& &&>(a);
}
X* Test(X& && arg)
{
return new X(std::forward<X&>(arg));
}
// 塌陷后
X& std::forward(X& a)
{
return static_cast<X&>(a);
}
X* Test(X& arg)
{
return new X(std::forward<X&>(arg));
}
x为右值时:1
2X foo();
Test(foo());
T为X,实例化后1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21X&& std::forward(remove_reference<X>::type& a) noexcept
{
return static_cast<X&&>(a);
}
X* Test(X&& arg)
{
return new X(std::forward<X>(arg));
}
// 塌陷后
X&& std::forward(X& a)
{
return static_cast<X&&>(a);
}
X* Test(X&& arg)
{
return new X(std::forward<X>(arg));
}
可以看到最终实参总是被推导为和传入时相同的类型引用。
至此,我们讨论了变长参数模板,讨论了右值引用和函数模板的完美转发,完整的解释了MemNew对任意多个参数的构造函数的参数传递过程。利用变长参数函数模板,右值引用和std::forward,可以完成参数的完美转发。
str相关函数
C语言str系列库函数在不同的库中有不同的实现方法,但原理都是一样的。因为库函数都是没有进行入口参数检查的,并且str系列库函数在面试中经常容易被面试官喊在纸上写某一个函数的实现,因此本文参考了OpenBSD和vc++ 8.0库中的代码,结合自己的编程习惯,部分整理如下:
1、strcpy1
2
3
4
5
6
7
8
9
10
11
12
13char * strcpy(char *dst, const char *src)
{
char *d;
if (dst == NULL || src == NULL)
return dst;
d = dst;
while (*d++ = *src++) // while ((*d++ = *src++) != '\0')
;
return dst;
}
2、strncpy1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//copy at most n characters of src to dst
//Pad with '\0' if src fewer than n characters
char *strncpy(char *dst, const char*src, size_t n)
{
char *d;
if (dst == NULL || src == NULL)
return dst;
d = dst;
while (n != 0 && (*d++ = *src++)) /* copy string */
n--;
if (n != 0)
while (--n != 0)
*d++ == '\0'; /* pad out with zeroes */
return dst;
}
注意n是unsigned int,在进行n—操作时特别要小心。如果不小心写成下面这样就会出错:1
2
3
4while (n-- != 0 && (*d++ = *src++))
;
while (n-- != 0)
*d++ = '\0';
第一个while循环中,当n变为0时,仍然会执行n—一,此时n等于经由-1变成的大正数,导致后面对n的使用出错。
3、strcat1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17char *strcat(char *dst, const char *src)
{
char *d;
if (dst == NULL || src == NULL)
return dst;
d = dst;
while (*d)
d++;
//while (*d++ != 0);
//d--;
while (*d++ = *src++)
;
return dst;
}
4、strncat
写法1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//concatenate at most n characters of src to the end of dst
//terminates dst with '\0'
char *strncat(char *dst, const char *src, size_t n)
{
if (NULL == dst || NULL == src)
return dst;
if (n != 0)
{
char *d = dst;
do
{
if ((*d = *src++) == '\0' )
return dst; //break
d++;
} while (--n != 0);
*d = '\0';
}
return dst;
}
写法2:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27char *strncat(char *dst, const char *src, size_t n)
{
char *d;
if (dst == NULL || src == NULL)
return dst;
d = dst;
while (*d)
d++;
//(1)
while (n != 0)
{
if ((*d++ = *src++) == '\0')
return dst;
n--;
}
//(2)
//while (n--) //这种方式写最后n的值不为0,不过这个n后面不会再被使用
// if ((*d++ == *src++) == '\0')
// return dst;
*d = '\0';
return dst;
}
5、strcmp1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int strcmp(const char *s1, const char *s2)
{
if (s1 == NULL || s2 == NULL)
return 0;
//(1)
//while (*s1 == *s2++)
// if (*s1++ == '\0')
// return 0;
//(2)
for (; *s1 == *s2; s1++, s2++)
if (*s1 == '\0')
return 0;
return *(unsigned char*)s1 - *(unsigned char*)s2;
}
6、strncmp1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27int strncmp(const char *s1, const char *s2, size_t n)
{
if (s1 == NULL || s2 == NULL)
return 0;
if (n == 0)
return 0;
do
{
if (*s1 != *s2++)
return *(unsigned char*)s1 - *(unsigned char*)--s2;
if (*s1++ == '\0')
break;
} while (--n != 0);
//do
//{
// if (*s1 != *s2)
// return *(unsigned char*)s1 - *(unsigned char*)s2;
// if (*s1 == '\0')
// break;
// s1++;
// s2++;
//} while (--n != 0);
return 0;
}
7、strstr
写法1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25//return pointer to first occurrence of find in s
//or NULL if not present
char *strstr(const char *s, const char *find)
{
char *cp = (char*)s;
char *s1, *s2;
if (s == NULL || find == NULL)
return NULL;
while (*cp != '\0')
{
s1 = cp;
s2 = (char*)find;
while (*s1 && *s2 && *s1 == *s2)
s1++, s2++;
if(*s2 == '\0')
return cp;
cp++;
}
return NULL;
}
写法2:参照简单模式匹配算法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16char *strstr(const char *s, const char *find)
{
int i = 0, j = 0;
while (*(s + i) != '\0' && *(find + j) != '\0')
{
if (*(s + i + j) == *(find + j))
j++; //继续比较后一字符
else
{
i++; //开始新一轮比较
j = 0;
}
}
return *(find + j) == '\0' ? (char*)(s + i) : NULL;
}
8、strchr1
2
3
4
5
6
7
8
9
10
11//return pointer to first occurrence of ch in str
//NULL if not present
char *strchr(const char*str, int ch)
{
while (*str != '\0' && *str != (char)ch)
str++;
if(*str == (char)ch)
return (char*)str;
return NULL;
}
9、strrchr1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//return pointer to last occurrence of ch in str
//NULL if not present
char *strrchr(const char *str, int ch)
{
if (str == NULL)
return NULL;
char *s = (char*)str;
while (*s++)
; /* find end of string */
while (--s != str && *s != (char)ch)
; /* search towards front */
if(*s == (char)ch)
return (char*)s;
return NULL;
}
10、strlen1
2
3
4
5
6
7
8
9
10size_t strlen(const char *str)
{
if (str == NULL)
return 0;
const char *eos = str;
while (*eos++)
;
return (eos - 1 - str);
}
RVO
函数如何返回值
函数返回值的传递分为两种情况。
当返回的对象的大小不超过8字节时,通过寄存器(eax edx)返回。
当返回的对象的大小大于8字节时,通过栈返回。但是,如果返回struct/class对象,尽管其大小不大于8字节,也是通过栈返回的。
在通过栈返回的时候,栈上会有一块空间来保存函数的返回值。当函数结束的时候,会把要返回的对象拷贝到这块区域,对于内置类型是直接拷贝,类类型的话是调用copy ctor。这块区域又称为函数返回的临时对象(temporary object)。
下面用代码看一下是不是这样。
首先,编写Base类和func()函数。1
2
3
4
5
6
7
8
9
10
11
12struct Base{
Base() { cout << "default ctor" << endl; };
Base(const Base& b) { cout << "copy ctor " << endl; }
Base& operator=(const Base& b){ cout << "operator=" << endl; a = b.a; return *this;}
~Base(){cout << "dtor " << endl;};
int a = 0;
};
Base func(){
Base a;
return a;
}
调用函数:(为了确保临时对象的存在,我绑定一个const引用到它上面;其实不绑定的话,直接func();也会有临时对象的存在)1
const Base &r = func();
输出1
2default ctor
dtor
按理说,存在临时对象,输出应该是1
2
3
4default ctor
copy ctor
dtor
dtor
因为这里C++做了返回值优化(RVO)。RVO是一种编译器优化的技术,它把要返回的局部变量直接构造在临时对象所在的区域,达到少调用一次copy ctor的目的。
为了避免RVO,把func()重新编写。这样编译器不清楚哪个局部变量会被返回,所以就避免了返回值优化。1
2
3
4
5
6
7
8
9
10Base func(int i){
if(i > 0) {
Base a;
return a;
}
else{
Base b;
return b;
}
}
调用func:1
func(0);
输出1
2
3
4default ctor // 函数内的局部对象
copy ctor //局部对象->临时对象
dtor // 局部对象析构
dtor // 临时对象析构
结果符合预期。
如果这样调用:1
Base a = func(0);
输出:1
2
3
4default ctor // 函数内的局部对象
copy ctor // ?
dtor // 局部对象析构
dtor // ?
为何是这样?不应该是还有一次临时对象到a的copy ctor和a的dtor吗?
这里我猜测进行了另外的优化,将两者合并到了一起,也就是把a的存储区域作为临时对象的区域。
下面这样调用:1
2
3Base a = func(0);
cout << endl;
a = func(0);
输出是:1
2
3
4
5
6
7
8
9
10default ctor // func的局部对象
copy ctor // func的局部对象->临时对象
dtor // func的局部对象析构
default ctor // func的局部对象
copy ctor // func的局部对象->临时对象(也就是a)
dtor // func的局部对象析构
operator= // 临时对象->a
dtor // 临时对象析构
dtor // a析构
输出十分合理!
RVO,是Return Value Optimization。这是在函数返回返回值的时候编译器所做出的优化,是C++11标准的一部分,C++11称之为copy elision。
在第一次编写的func里面,编译器明确知道函数会返回哪一个局部对象,那么编译器会把存储这个局部对象的地址和存储返回值临时对象的地址进行复用,也就是说避免了从局部对象到临时对象的拷贝操作。这就是RVO。
现在把func重新改为:1
2
3
4Base func(){
Base b;
return b;
}
以下面三种方式调用func。1
2
3
4
5func();
cout << endl;
Base a = func();
cout << endl;
a = func();
输出1
2
3
4
5
6
7
8
9default ctor // 局部对象b(也是临时对象)的构造
dtor
default ctor // 局部对象b(也是临时对象,也是要初始化的对象a)的构造
default ctor // 局部对象b(也是临时对象)的构造
operator= // 局部对象b(也是临时对象)-> 对象a
dtor // 局部对象b
dtor // 对象a
输出十分合理!
std::move()
在查阅RVO的资料的时候,看到了这篇博客RVO V.S. std::move,讲的特别好。除了RVO里面还提到了std:move(),为了加深对std::move的理解,我又做了下面几个实验。
重新编写func:1
2
3
4Base func(){
Base b;
return std::move(b);
}
然后向Base添加下面的成员:1
2Base& operator=(Base&& b){ cout << "move operator=" << endl; a = b.a; return *this;}
Base(Base&& b) { cout << "move ctor" << endl;}
调用:1
2
3
4
5func();
cout << endl;
Base a = func();
cout << endl;
a = func();
输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15default ctor // 局部对象b
move ctor // 局部对象b向临时对象的移动
dtor
dtor
default ctor // 局部对象b
move ctor // 局部对象b向临时对象(也是要初始化的对象a)的移动
dtor
default ctor // 局部对象b
move ctor // 局部对象b向临时对象的移动
dtor // 局部对象b析构
move operator= // 临时对象到a的移动,临时对象是右值,所以用move
dtor // 临时对象析构
dtor
func的函数返回类型仍然是Base,而不是Base&&。这意味着函数还是会创建一个Base类的临时对象,只是临时对象是通过右值引用得到的,也就是说通过移动构造函数移动得到的。
把func的返回类型改为Base&&:1
2
3
4Base&& func(){
Base b;
return std::move(b);
}
还是调用,1
2
3
4
5func();
cout << endl;
Base a = func();
cout << endl;
a = func();
输出:1
2
3
4
5
6
7
8
9
10
11default ctor // 局部对象
dtor
default ctor // 局部对象
dtor // 局部对象
move ctor // 局部对象到a的移动(注意:因为这里局部对象已经析构,所以这里的行为是undefined,十分危险)
default ctor // 局部对象
dtor // 局部对象
move operator= // 局部对象到a的移动
dtor
总结:
- 函数的返回类型是类类型,return局部对象,可能会有RVO;
- 函数的返回类型是类类型,return右值引用,肯定不会有RVO;
- 函数的返回类型是右值引用,return右值引用,没有临时对象的消耗,但是仍不可取,因为右值引用的对对象在使用前已经析构了。
cpp的tr1_function使用
介绍
function是一种通用、多态的函数封装。std::function的实例可以对任何可以调用的目标 进行存储、复制、和调用操作,这些目标包括函数、lambda表达式、绑定表达式、以及其它函数对象等。(c++11起的版本可用)
function(和bind一样)可以实现类似函数指针的功能,却比函数指针更加灵活(体现在占位符上面),尤其是在很多成员调用同一个函数(仅仅是参数类型不同)的时候比较方便。
- 可以作为函数和成员函数。
- 可做回调函数,取代函数指针。
- 可作为函数的参数,从外部控制函数内部的行为。
示例代码
先看一下下面这块代码:
1 |
|
Animal类是父类,Fish继承于Animal。测试程序中分别将子类和父类的Move()函数地址赋值给function的指针。调用的结果如下:
1
2I am moving…
I am swimming…
为了体现function可以作为函数的参数传入,我们再写一个函数加到原来的代码中进行测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23void Moving(int option, std::tr1::function<void()> move){
if(option & 1 == 0){ //如果option为偶数,则执行Animal类中的Move方法
move = &Animal::Move;
}
else{
move = &Fish::Move;
}
move();
}
int main(){
std::tr1::function<void()> move = &Animal::Move;
move();
move = &Fish::Move;
move();
std::cout<<"-------------divid line------------\n";
Moving(4,move);
return 0;
}
测试结果如下:
1
2
3
4I am moving…
I am swimming…
————-divid line————
I am moving…
C++函数调用分析
这里以一个简单的C语言代码为例,来分析函数调用过程
代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int func(int param1 ,int param2,int param3)
{
int var1 = param1;
int var2 = param2;
int var3 = param3;
printf("var1=%d,var2=%d,var3=%d",var1,var2,var3);
return var1;
}
int main(int argc, char* argv[])
{
int result = func(1,2,3);
return 0;
}
首先说明,在堆栈中变量分布是从高地址到低地址分布,EBP是指向栈底的指针,在过程调用中不变,又称为帧指针。ESP指向栈顶,程序执行时移动,ESP减小分配空间,ESP增大释放空间,ESP又称为栈指针。
下面来逐步分析函数的调用过程
函数main执行,main各个参数从右向左逐步压入栈中,最后压入返回地址
执行第15行,3个参数以从左向右的顺序压入堆栈,及从param3到param1,栈内分布如下图: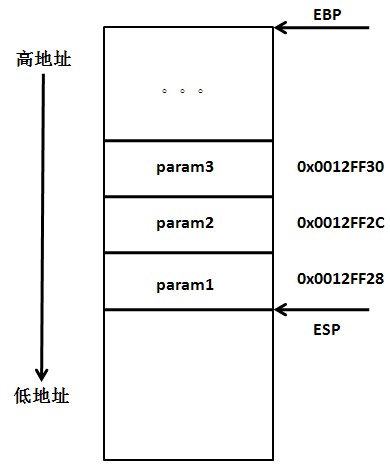
然后是返回地址入栈:此时的栈内分布如下:
第3行函数调用时,通过跳转指令进入函数后,函数地址入栈后,EBP入栈,然后把当前ESP的值给EBP,对应的汇编指令:1
2push ebp
mov ebp esp
此时栈顶和栈底指向同一位置,栈内分布如下: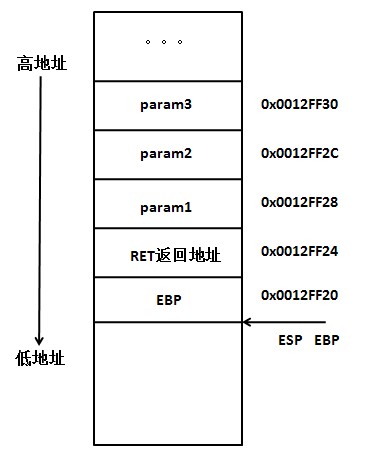
第5行开始执行, int var1 = param1; int var2 = param2; int var3 = param3;按申明顺序依次存储。对应的汇编:1
2mov 0x8(%ebp),%eax
mov %eax,-0x4(%ebp)
其中将[EBP+0x8]地址里的内容赋给EAX,即把param的值赋给EAX,然后把EAX的中的值放到[EBP-4]这个地址里,即把EAX值赋给var1,完成C代码 int var1 = param1,其他变量雷同。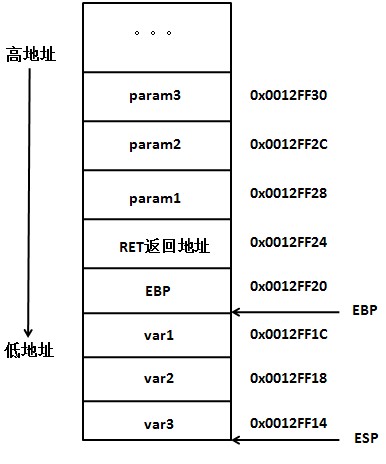
第9行,输出结果,第10行执行 对应的汇编代码:1
mov -0x4(%ebp),%eax
最后通过eax寄存器保存函数的返回值;
调用执行函数完毕,局部变量var3,var2,var1一次出栈,EBP恢复原值,返回地址出栈,找到原执行地址,param1,param2,param3依次出栈,函数调用执行完毕。图略
深入理解C++的动态绑定和静态绑定
为了支持c++的多态性,才用了动态绑定和静态绑定。理解他们的区别有助于更好的理解多态性,以及在编程的过程中避免犯错误。需要理解四个名词:
- 对象的静态类型:对象在声明时采用的类型。是在编译期确定的。
- 对象的动态类型:目前所指对象的类型。是在运行期决定的。对象的动态类型可以更改,但是静态类型无法更改。
关于对象的静态类型和动态类型,看一个示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14class B
{
}
class C : public B
{
}
class D : public B
{
}
D* pD = new D();//pD的静态类型是它声明的类型D*,动态类型也是D*
B* pB = pD;//pB的静态类型是它声明的类型B*,动态类型是pB所指向的对象pD的类型D*
C* pC = new C();
pB = pC;//pB的动态类型是可以更改的,现在它的动态类型是C*
- 静态绑定:绑定的是对象的静态类型,某特性(比如函数)依赖于对象的静态类型,发生在编译期。
- 动态绑定:绑定的是对象的动态类型,某特性(比如函数)依赖于对象的动态类型,发生在运行期。
1 | class B |
让我们看一下,pD->DoSomething()和pB->DoSomething()调用的是同一个函数吗?
不是的,虽然pD和pB都指向同一个对象。因为函数DoSomething是一个no-virtual函数,它是静态绑定的,也就是编译器会在编译期根据对象的静态类型来选择函数。pD的静态类型是D,那么编译器在处理
pD->DoSomething()的时候会将它指向D::DoSomething()。同理,pB的静态类型是B,那pB->DoSomething()调用的就是B::DoSomething()。
让我们再来看一下,pD->vfun()和pB->vfun()调用的是同一个函数吗?
是的。因为vfun是一个虚函数,它动态绑定的,也就是说它绑定的是对象的动态类型,pB和pD虽然静态类型不同,但是他们同时指向一个对象,他们的动态类型是相同的,都是D*,所以,他们的调用的是同一个函数:
D::vfun()。
上面都是针对对象指针的情况,对于引用(reference)的情况同样适用。
指针和引用的动态类型和静态类型可能会不一致,但是对象的动态类型和静态类型是一致的。1
2D D;
D.DoSomething()和D.vfun()永远调用的都是D::DoSomething()和D::vfun()。
我总结了一句话:只有虚函数才使用的是动态绑定,其他的全部是静态绑定。目前我还没有发现不适用这句话的,如果有错误,希望你可以指出来。
特别需要注意的地方
当缺省参数和虚函数一起出现的时候情况有点复杂,极易出错。我们知道,虚函数是动态绑定的,但是为了执行效率,缺省参数是静态绑定的。1
2
3
4
5
6
7
8
9
10
11
12
13class B
{
virtual void vfun(int i = 10);
}
class D : public B
{
virtual void vfun(int i = 20);
}
D* pD = new D();
B* pB = pD;
pD->vfun();
pB->vfun();
有上面的分析可知pD->vfun()和pB->vfun()调用都是函数D::vfun(),但是他们的缺省参数是多少?
分析一下,缺省参数是静态绑定的,
pD->vfun()时,pD的静态类型是D*,所以它的缺省参数应该是20;同理,pB->vfun()的缺省参数应该是10。编写代码验证了一下,正确。
对于这个特性,估计没有人会喜欢。所以,永远记住:
绝不重新定义继承而来的缺省参数(Never redefine function’s inherited default parameters value.)
mem函数的类型及用法
memccpy函数原型:1
void *memccpy(void *dest, const void *src, int c, size_t n)
函数功能:字符串拷贝,到指定长度或遇到指定字符时停止拷贝
参数说明: src-源字符串指针,c-中止拷贝检查字符,n-长度,dest-拷贝底目的字符串指针
1 |
|
memchr函数原型:1
void *memchr(const void *s, int c, size_t n)
在字符串中第开始n个字符中寻找某个字符c的位置
函数返回: 返回c的位置指针,返回NULL时表示未找到
参数说明: s-要搜索的字符串,c-要寻找的字符,n-指定长度
1 |
|
memcmp函数原型:1
int memcmp(const void *s1, const void *s2, size_t n)
函数功能: 按字典顺序对字符串s1,s2比较,并只比较前n个字符
函数返回: 返回数值表示比较结果
参数说明: s1,s2-要比较的字符串,n-比较的长度
1 |
|
memicmp函数原型:1
int memicmp(const void *s1, const void *s2, size_t n)
函数功能: 按字典顺序、不考虑字母大小写对字符串s1,s2比较,并只比较前n个字符
函数返回: 返回数值表示比较结果
参数说明: s1,s2-要比较的字符串,n-比较的长度
1 |
|
memcpy函数原型:1
void *memcpy(void *dest, const void *src, size_t n)
函数功能: 字符串拷贝
函数返回: 指向dest的指针
参数说明: src-源字符串,n-拷贝的最大长度
1 |
|
memmove函数原型:1
void *memmove(void *dest, const void *src, size_t n)
函数功能: 字符串拷贝
函数返回: 指向dest的指针
参数说明: src-源字符串,n-拷贝的最大长度
1 |
|
memset函数原型:1
void *memset(void *s, int c, size_t n)
函数功能: 字符串中的n个字节内容设置为c
参数说明: s-要设置的字符串,c-设置的内容,n-长度
1 |
|
函数的重载、隐藏和覆盖
函数重载只会发生在同一个类中,函数名相同,只能通过参数类型,参数个数或者有无const来区分。不能通过返回值类型区分,而且virtual也是可有可无的,即虚函数和普通函数在同一类中也可以构成函数重载。
基类和派生类中只能是隐藏或者覆盖。
- 隐藏是指派生类中有函数与基类中函数同名,但是没有构成虚函数覆盖,就是隐藏。隐藏的表现:若基类中函数func()被派生类中函数func()隐藏,那么无法通过派生类对象访问基类中的func() 函数,派生类对象只能访问到派生类中的func()函数。不过基类中的func()确实继承到了派生类中。
- 虚函数也只是在基类和派生类中发挥多态的作用,而在同一类中虚函数也可以重载。
虚函数实现多态的条件:
- 基类中将这些成员声明为virtual。
- 基类和派生类中的这些函数必须同名且参数类型,参数个数,返回值类型必须相同。
- 将派生类的对象赋给基类指针或者引用,实现多态。
缺少任何一条,只会是基类和派生类之间的隐藏,而不是覆盖
如何判断基类和派生类中函数是否是隐藏?当基类和派生类存在同名函数,不论参数类型,参数个数是否相同,派生类中的同名函数都会将基类中的同名函数隐藏掉。
- 基类和派生类都是虚函数,并且同名,但是形参类型或者形参个数不同,多态不满足,但是构成了隐藏,只是没有虚特性。
- 基类中不是虚函数,派生类中定义为虚函数,不构成多态,只是隐藏关系。
- 基类和派生类的两个函数同名,都是虚函数,形参的个数和类型也都相同,但是返回值类型不同,这时编译会报错,因为两个虚函数在隐藏时,返回值类型发生了冲突,因此隐藏发生错误。注意,如果这两个函数不是虚函数,这不会报错,隐藏会成功;同时,如果派生类中是虚函数,基类中不是虚函数,也不过报错,隐藏也是成功的。但是如果基类中为虚函数,派生类中不是,也会报错。这些说明,虚化并隐藏时,返回值类型一定要保持相同。
虚函数要求返回值类型也一样,但是有一种情况允许虚函数返回值时本类对象的引用或者指针,也可以构成覆盖。这个是“协变”规则,具体协变看例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class A:
{
public:
virtual A* func()
{
cout<<"A"<<endl;
return this;
}
};
class B:public A
{
public:
virtual B* func()
{
cout<<"B"<<endl;
return this;
}
};
int main()
{
A *pa=new B;
B* pb=pa->func();//编译无法通过,因为pa是A*类型指针,编译时,对于pa->func()翻译成调用的是A类的函数,返回值为 A*类型。而A*类型无法赋值给派生类指针
B* pb=(B*)pa->func();//正确
B* pb=(B*)(pa->func());//正确
}A *pa=new B;对于虚函数将基类指针指向派生类对象,调用派生类的虚函数。该基类指针能解引用的内存空间是继承到派生类中的基类的内存空间。基类指针调用派生类的虚函数,在虚函数中,this指针指向的是派生类本身,也就是在虚函数中将基类指针强制转换成了派生类指针。其实基类指针pa和派生类中的this指针值相同,都是派生类对象的地址。
协变的存在是为了解决返回值的强制类型转换,真正用途是,通过派生类对象调用虚函数,直接返回派生类指针。若无协变,则会返回基类指针,需要再将基类指针强制转换成派生类指针。具体的意思看例子:
若没有协变,那么上述的代码中派生类中虚函数需要改成以下形式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class B :public A
{
public:
virtual A* func()
{
cout<<"B"<<endl;
return this;//返回值this为B*类型指针,但是因为没有协变,返回的时候将B*类型赋值给了A*类型,然后以A*类型返回到main函数中
}
};
int main()
{
B b;
A *pa=b.func();
B *pb=dynamic<B*> (pa);//将返回的A*类型强制转换成B*类型
}
编译器总是根据类型来调用类成员函数。但是一个派生类的指针可以安全地转化为一个基类的指针。这样删除一个基类的指针的时候,C++不管这个指针指向一个基类对象还是一个派生类的对象,调用的都是基类的析构函数而不是派生类的。如果你依赖于派生类的析构函数的代码来释放资源,而没有重载析构函数,那么会有资源泄漏。所以建议的方式是将析构函数声明为虚函数。
也就是delete a的时候,也会执行派生类的析构函数。
一个函数一旦声明为虚函数,那么不管你是否加上virtual修饰符,它在所有派生类中都成为虚函数。但是由于理解明确起见,建议的方式还是加上virtual修饰符。
构造方法用来初始化类的对象,与父类的其它成员不同,它不能被子类继承(子类可以继承父类所有的成员变量和成员方法,但不继承父类的构造方法)。因此,在创建子类对象时,为了初始化从父类继承来的数据成员,系统需要调用其父类的构造方法。
如果没有显式的构造函数,编译器会给一个默认的构造函数,并且该默认的构造函数仅仅在没有显式地声明构造函数情况下创建。
构造原则如下:
- 如果子类没有定义构造方法,则调用父类的无参数的构造方法。
- 如果子类定义了构造方法,不论是无参数还是带参数,在创建子类的对象的时候,首先执行父类无参数的构造方法,然后执行自己的构造方法。
- 在创建子类对象时候,如果子类的构造函数没有显示调用父类的构造函数,则会调用父类的默认无参构造函数。
- 在创建子类对象时候,如果子类的构造函数没有显示调用父类的构造函数且父类自己提供了无参构造函数,则会调用父类自己的无参构造函数。
- 在创建子类对象时候,如果子类的构造函数没有显示调用父类的构造函数且父类只定义了自己的有参构造函数,则会出错(如果父类只有有参数的构造方法,则子类必须显示调用此带参构造方法)。
- 如果子类调用父类带参数的构造方法,需要用初始化父类成员对象的方式,比如:
1 |
|
强制类型转换运算符
将类型名作为强制类型转换运算符的做法是C语言的老式做法,C++ 为保持兼容而予以保留。
C++ 引入了四种功能不同的强制类型转换运算符以进行强制类型转换:static_cast、reinterpret_cast、const_cast和dynamic_cast。
强制类型转换是有一定风险的,有的转换并不一定安全,如把整型数值转换成指针,把基类指针转换成派生类指针,把一种函数指针转换成另一种函数指针,把常量指针转换成非常量指针等。C++ 引入新的强制类型转换机制,主要是为了克服C语言强制类型转换的以下三个缺点。
- 没有从形式上体现转换功能和风险的不同。例如,将 int 强制转换成 double 是没有风险的,而将常量指针转换成非常量指针,将基类指针转换成派生类指针都是高风险的,而且后两者带来的风险不同(即可能引发不同种类的错误),C语言的强制类型转换形式对这些不同并不加以区分。
- 将多态基类指针转换成派生类指针时不检查安全性,即无法判断转换后的指针是否确实指向一个派生类对象。
- 难以在程序中寻找到底什么地方进行了强制类型转换。
强制类型转换是引发程序运行时错误的一个原因,因此在程序出错时,可能就会想到是不是有哪些强制类型转换出了问题。
如果采用C语言的老式做法,要在程序中找出所有进行了强制类型转换的地方,显然是很麻烦的,因为这些转换没有统一的格式。
而用 C++ 的方式,则只需要查找_cast字符串就可以了。甚至可以根据错误的类型,有针对性地专门查找某一种强制类型转换。例如,怀疑一个错误可能是由于使用了 reinterpret_cast 导致的,就可以只查找reinterpret_cast字符串。
C++ 强制类型转换运算符的用法如下:1
强制类型转换运算符 <要转换到的类型> (待转换的表达式)
例如:1
double d = static_cast <double> (3*5); //将 3*5 的值转换成实数
下面分别介绍四种强制类型转换运算符。
static_cast
static_cast用于进行比较“自然”和低风险的转换,如整型和浮点型、字符型之间的互相转换。另外,如果对象所属的类重载了强制类型转换运算符 T(如 T 是 int、int* 或其他类型名),则 static_cast 也能用来进行对象到 T 类型的转换。
static_cast 不能用于在不同类型的指针之间互相转换,也不能用于整型和指针之间的互相转换,当然也不能用于不同类型的引用之间的转换。因为这些属于风险比较高的转换。
static_cast 用法示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
using namespace std;
class A
{
public:
operator int() { return 1; }
operator char*() { return NULL; }
};
int main()
{
A a;
int n;
char* p = "New Dragon Inn";
n = static_cast <int> (3.14); // n 的值变为 3
n = static_cast <int> (a); //调用 a.operator int,n 的值变为 1
p = static_cast <char*> (a); //调用 a.operator char*,p 的值变为 NULL
n = static_cast <int> (p); //编译错误,static_cast不能将指针转换成整型
p = static_cast <char*> (n); //编译错误,static_cast 不能将整型转换成指针
return 0;
}
reinterpret_cast
reinterpret_cast 用于进行各种不同类型的指针之间、不同类型的引用之间以及指针和能容纳指针的整数类型之间的转换。转换时,执行的是逐个比特复制的操作。
这种转换提供了很强的灵活性,但转换的安全性只能由程序员的细心来保证了。例如,程序员执意要把一个 int 指针、函数指针或其他类型的指针转换成 string 类型的指针也是可以的,至于以后用转换后的指针调用 string 类的成员函数引发错误,程序员也只能自行承担查找错误的烦琐工作:(C++ 标准不允许将函数指针转换成对象指针,但有些编译器,如 Visual Studio 2010,则支持这种转换)。
reinterpret_cast 用法示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
using namespace std;
class A
{
public:
int i;
int j;
A(int n):i(n),j(n) { }
};
int main()
{
A a(100);
int &r = reinterpret_cast<int&>(a); //强行让 r 引用 a
r = 200; //把 a.i 变成了 200
cout << a.i << "," << a.j << endl; // 输出 200,100
int n = 300;
A *pa = reinterpret_cast<A*> ( & n); //强行让 pa 指向 n
pa->i = 400; // n 变成 400
pa->j = 500; //此条语句不安全,很可能导致程序崩溃
cout << n << endl; // 输出 400
long long la = 0x12345678abcdLL;
pa = reinterpret_cast<A*>(la); //la太长,只取低32位0x5678abcd拷贝给pa
unsigned int u = reinterpret_cast<unsigned int>(pa);//pa逐个比特拷贝到u
cout << hex << u << endl; //输出 5678abcd
typedef void (* PF1) (int);
typedef int (* PF2) (int,char *);
PF1 pf1; PF2 pf2;
pf2 = reinterpret_cast<PF2>(pf1); //两个不同类型的函数指针之间可以互相转换
}
程序的输出结果是:1
2
3200, 100
400
5678abed
第 19 行的代码不安全,因为在编译器看来,pa->j 的存放位置就是 n 后面的 4 个字节。 本条语句会向这 4 个字节中写入 500。但这 4 个字节不知道是用来存放什么的,贸然向其中写入可能会导致程序错误甚至崩溃。
上面程序中的各种转换都没有实际意义,只是为了演示 reinteipret_cast 的用法而已。在编写黑客程序、病毒或反病毒程序时,也许会用到这样怪异的转换。
reinterpret_cast体现了 C++ 语言的设计思想:用户可以做任何操作,但要为自己的行为负责。
const_cast
const_cast 运算符仅用于进行去除 const 属性的转换,它也是四个强制类型转换运算符中唯一能够去除 const 属性的运算符。
将 const 引用转换为同类型的非 const 引用,将 const 指针转换为同类型的非 const 指针时可以使用 const_cast 运算符。例如:1
2
3const string s = "Inception";
string& p = const_cast <string&> (s);
string* ps = const_cast <string*> (&s); // &s 的类型是 const string*
dynamic_cast
用 reinterpret_cast 可以将多态基类(包含虚函数的基类)的指针强制转换为派生类的指针,但是这种转换不检查安全性,即不检查转换后的指针是否确实指向一个派生类对象。dynamic_cast专门用于将多态基类的指针或引用强制转换为派生类的指针或引用,而且能够检查转换的安全性。对于不安全的指针转换,转换结果返回 NULL 指针。
dynamic_cast 是通过“运行时类型检查”来保证安全性的。dynamic_cast 不能用于将非多态基类的指针或引用强制转换为派生类的指针或引用——这种转换没法保证安全性,只好用 reinterpret_cast 来完成。
dynamic_cast 示例程序如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
using namespace std;
class Base
{ //有虚函数,因此是多态基类
public:
virtual ~Base() {}
};
class Derived : public Base { };
int main()
{
Base b;
Derived d;
Derived* pd;
pd = reinterpret_cast <Derived*> (&b);
if (pd == NULL)
//此处pd不会为 NULL。reinterpret_cast不检查安全性,总是进行转换
cout << "unsafe reinterpret_cast" << endl; //不会执行
pd = dynamic_cast <Derived*> (&b);
if (pd == NULL) //结果会是NULL,因为 &b 不指向派生类对象,此转换不安全
cout << "unsafe dynamic_cast1" << endl; //会执行
pd = dynamic_cast <Derived*> (&d); //安全的转换
if (pd == NULL) //此处 pd 不会为 NULL
cout << "unsafe dynamic_cast2" << endl; //不会执行
return 0;
}
程序的输出结果是:1
unsafe dynamic_cast1
第 20 行,通过判断 pd 的值是否为 NULL,就能知道第 19 行进行的转换是否是安全的。第 23 行同理。
如果上面的程序中出现了下面的语句:1
Derived & r = dynamic_cast <Derived &> (b);
那该如何判断该转换是否安全呢?不存在空引用,因此不能通过返回值来判断转换是否安全。C++ 的解决办法是:dynamic_cast 在进行引用的强制转换时,如果发现转换不安全,就会拋出一个异常,通过处理异常,就能发现不安全的转换。
attribute二三事
1 | static inline skew_heap_entry_t *skew_heap_insert( |
这个函数是在做uCore的时候发现的,有一个特别的地方attribute((always_inline)),之前从来没见过,于是去查了一下,不查不知道,一查下一跳啊,这竟然是GUN C的一个从来没听过的属性。
当我们用__inline__ __attribute__((always_inline))修饰一个函数的时候,编译器会将我们的代码编译.在调用的地方将我们的函数,插入到调用的地方.
attribute是GNU C特色之一,在iOS用的比较广泛.系统中有许多地方使用到. attribute可以设置函数属性(Function Attribute )、变量属性(Variable Attribute )和类型属性(Type Attribute)等.
函数属性(Function Attribute)
- noreturn
- noinline
- always_inline
- pure
- const
- nothrow
- sentinel
- format
- format_arg
- no_instrument_function
- section
- constructor
- destructor
- used
- unused
- deprecated
- weak
- malloc
- alias
- warn_unused_result
- nonnull
类型属性(Type Attributes)
- aligned
- packed
- transparent_union,
- unused,
- deprecated
- may_alias
变量属性(Variable Attribute)
- aligned
- packed
Clang特有的
- availability
- overloadable
书写格式
书写格式:attribute后面会紧跟一对原括弧,括弧里面是相应的attribute参数1
__attribute__(xxx)
常见的系统用法
format
1 |
format属性可以给被声明的函数加上类似printf或者scanf的特征,它可以使编译器检查函数声明和函数实际调用参数之间的格式化字符串是否匹配。该功能十分有用,尤其是处理一些很难发现的bug。对于format参数的使用如下1
format (archetype, string-index, first-to-check)
第一参数需要传递“archetype”指定是哪种风格,这里是 NSString;“string-index”指定传入函数的第几个参数是格式化字符串;“first-to-check”指定第一个可变参数所在的索引.
noreturn
官方例子: abort() 和 exit()
该属性通知编译器函数从不返回值。当遇到类似函数还未运行到return语句就需要退出来的情况,该属性可以避免出现错误信息。
availability
官方例子:1
2
3
4
5
6
7
8
9
10
11
12
13- (CGSize)sizeWithFont:(UIFont *)font NS_DEPRECATED_IOS(2_0, 7_0, "Use -sizeWithAttributes:") __TVOS_PROHIBITED;
//来看一下 后边的宏
//宏展开以后如下
__attribute__((availability(ios,introduced=2_0,deprecated=7_0,message=""__VA_ARGS__)));
//ios即是iOS平台
//introduced 从哪个版本开始使用
//deprecated 从哪个版本开始弃用
//message 警告的消息
availability属性是一个以逗号为分隔的参数列表,以平台的名称开始,包含一些放在附加信息里的一些里程碑式的声明。
- introduced:第一次出现的版本。
- deprecated:声明要废弃的版本,意味着用户要迁移为其他API
- obsoleted: 声明移除的版本,意味着完全移除,再也不能使用它
- unavailable:在这些平台不可用
- message:一些关于废弃和移除的额外信息,clang发出警告的时候会提供这些信息,对用户使用替代的API非常有用。
- 这个属性支持的平台:ios,macosx。
1 | //如果经常用,建议定义成类似系统的宏 |
visibility
语法:1
__attribute__((visibility("visibility_type")))
其中,visibility_type 是下列值之一:
- default:假定的符号可见性可通过其他选项进行更改。缺省可见性将覆盖此类更改。缺省可见性与外部链接对应。
- hidden:该符号不存放在动态符号表中,因此,其他可执行文件或共享库都无法直接引用它。使用函数指针可进行间接引用。
- internal:除非由特定于处理器的应用二进制接口 (psABI) 指定,否则,内部可见性意味着不允许从另一模块调用该函数。
- protected:该符号存放在动态符号表中,但定义模块内的引用将与局部符号绑定。也就是说,另一模块无法覆盖该符号。
除指定 default 可见性外,此属性都可与在这些情况下具有外部链接的声明结合使用。
您可在 C 和 C++ 中使用此属性。在 C++ 中,还可将它应用于类型、成员函数和命名空间声明。
系统用法:1
2
3
4
5
6// UIKIT_EXTERN extern
nonnull
编译器对函数参数进行NULL的检查,参数类型必须是指针类型(包括对象)1
2
3
4
5
6
7- (int)addNum1:(int *)num1 num2:(int *)num2 __attribute__((nonnull (1,2))){//1,2表示第一个和第二个参数不能为空
return *num1 + *num2;
}
- (NSString *)getHost:(NSURL *)url __attribute__((nonnull (1))){//第一个参数不能为空
return url.host;
}
常见用法
aligned
__attribute((aligned (n))),让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐.例如:
不加修饰的情况1
2
3
4
5
6typedef struct
{
char member1;
int member2;
short member3;
}Family;
输出字节:1
NSLog(@"Family size is %zd",sizeof(Family));
输出结果为:1
2016-07-25 10:28:45.380 Study[917:436064] Family size is 12
修改字节对齐为11
2
3
4
5
6typedef struct
{
char member1;
int member2;
short member3;
}__attribute__ ((aligned (1))) Family;
输出字节:1
NSLog(@"Family size is %zd",sizeof(Family));
输出结果为:1
2016-07-25 10:28:05.315 Study[914:435764] Family size is 12
和上面的结果一致,因为设定的字节对齐为1.而结构体中成员的最大字节数是int 4个字节,1 < 4,按照4字节对齐,和系统默认一致.
修改字节对齐为81
2
3
4
5
6typedef struct
{
char member1;
int member2;
short member3;
}__attribute__ ((aligned (8))) Family;
输出字节:1
NSLog(@"Family size is %zd",sizeof(Family));
输出结果为:1
2016-07-25 10:28:05.315 Study[914:435764] Family size is 16
这里 8 > 4,按照8字节对齐,结果为16。
可是想了半天,也不知道这玩意有什么用,设定值小于系统默认的,和没设定一样,设定大了,又浪费空间,效率也没提高,感觉学习学习就好.
packed
让指定的结构结构体按照一字节对齐,测试:1
2
3
4
5
6
7//不加packed修饰
typedef struct {
char version;
int16_t sid;
int32_t len;
int64_t time;
} Header;
计算长度:1
NSLog(@"size is %zd",sizeof(Header));
输出结果为:1
2016-07-22 11:53:47.728 Study[14378:5523450] size is 16
可以看出,默认系统是按照4字节对齐1
2
3
4
5
6
7//加packed修饰
typedef struct {
char version;
int16_t sid;
int32_t len;
int64_t time;
}__attribute__ ((packed)) Header;
计算长度1
NSLog(@"size is %zd",sizeof(Header));
输出结果为:1
2016-07-22 11:57:46.970 Study[14382:5524502] size is 15
用packed修饰后,变为1字节对齐,这个常用于与协议有关的网络传输中.
noinline & always_inline
内联函数:内联函数从源代码层看,有函数的结构,而在编译后,却不具备函数的性质。内联函数不是在调用时发生控制转移,而是在编译时将函数体嵌入在每一个调用处。编译时,类似宏替换,使用函数体替换调用处的函数名。一般在代码中用inline修饰,但是能否形成内联函数,需要看编译器对该函数定义的具体处理。这两个都是用在函数上
- noinline 不内联
- always_inline 总是内联
内联的本质是用代码块直接替换掉函数调用处,好处是:快减少系统开销.
使用例子:1
2//函数声明
void test(int a) __attribute__((always_inline));
warn_unused_result
当函数或者方法的返回值很重要时,要求调用者必须检查或者使用返回值,否则编译器会发出警告提示1
2
3
4 - (BOOL)availiable __attribute__((warn_unused_result))
{
return 10;
}
constructor / destructor
意思是: 构造器和析构器;constructor修饰的函数会在main函数之前执行,destructor修饰的函数会在程序exit前调用.
示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int main(int argc, char * argv[]) {
@autoreleasepool {
NSLog(@"main");
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
__attribute__((constructor))
void before(){
NSLog(@"before main");
}
__attribute__((destructor))
void after(){
NSLog(@"after main");
}
//在viewController中调用exit
- (void)viewDidLoad {
[super viewDidLoad];
exit(0);
}
输出如下:1
2
32016-07-21 21:49:17.446 Study[14162:5415982] before main
2016-07-21 21:49:17.447 Study[14162:5415982] main
2016-07-21 21:49:17.534 Study[14162:5415982] after main
注意点:
- 程序退出的时候才会调用after函数,经测试,手动退出程序会执行
- 上面两个函数不管写在哪个类里,哪个文件中效果都一样
- 如果存在多个修饰的函数,那么都会执行,顺序不定
- 实际上如果存在多个修饰过的函数,可以它们的调整优先级
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24int main(int argc, char * argv[]) {
@autoreleasepool {
NSLog(@"main");
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
__attribute__((constructor(101)))
void before1(){
NSLog(@"before main - 1");
}
__attribute__((constructor(102)))
void before2(){
NSLog(@"before main - 2");
}
__attribute__((destructor(201)))
void after1(){
NSLog(@"after main - 1");
}
__attribute__((destructor(202)))
void after2(){
NSLog(@"after main - 2");
}
输出结果如下:1
2
3
4
52016-07-21 21:59:35.622 Study[14171:5418393] before main - 1
2016-07-21 21:59:35.624 Study[14171:5418393] before main - 2
2016-07-21 21:59:35.624 Study[14171:5418393] main
2016-07-21 21:59:35.704 Study[14171:5418393] after main - 2
2016-07-21 21:59:35.704 Study[14171:5418393] after main - 1
注意点:
- 括号内的值表示优先级,[0,100]这个返回时系统保留的,自己千万别调用.
- 根据输出结果可以看出,main函数之前的,数值越小,越先调用;main函数之后的数值越大,越先调用.
- 当函数声明和函数实现分开写时,格式如下:
1 | static void before() __attribute__((constructor)); |
讨论:+load,constructor,main的执行顺序,代码如下:1
2
3
4
5
6
7+ (void)load{
NSLog(@"load");
}
__attribute__((constructor))
void before(){
NSLog(@"before main");
}
输出结果如下:1
2
32016-07-21 22:13:58.591 Study[14185:5421811] load
2016-07-21 22:13:58.592 Study[14185:5421811] before main
2016-07-21 22:13:58.592 Study[14185:5421811] main
可以看出执行顺序为:load->constructor->main。为什么呢?
因为 dyld(动态链接器,程序的最初起点)在加载 image(可以理解成 Mach-O 文件)时会先通知 objc runtime 去加载其中所有的类,每加载一个类时,它的 +load 随之调用,全部加载完成后,dyld 才会调用这个 image 中所有的 constructor 方法,然后才调用main函数.
enable_if
用来检查参数是否合法,只能用来修饰函数:1
2
3
4
5void printAge(int age)
__attribute__((enable_if(age > 0 && age < 120, "你丫太监?")))
{
NSLog(@"%d",age);
}
表示只能输入的参数只能是 0 ~ 120左右,否则编译报错.
内存管理
伟大的Bill Gates 曾经失言:
640K ought to be enough for everybody —— Bill Gates 1981
程序员们经常编写内存管理程序,往往提心吊胆。如果不想触雷,唯一的解决办法就是发现所有潜伏的地雷并且排除它们,躲是躲不了的。本文的内容比一般教科书的要深入得多,读者需细心阅读,做到真正地通晓内存管理。
C++内存管理详解
内存分配方式
分配方式简介
在C++中,内存分成5个区,他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。
栈,在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
堆,就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
自由存储区,就是那些由malloc等分配的内存块,他和堆是十分相似的,不过它是用free来结束自己的生命的。
全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改。
明确区分堆与栈
在bbs上,堆与栈的区分问题,似乎是一个永恒的话题,由此可见,初学者对此往往是混淆不清的,所以我决定拿他第一个开刀。
首先,我们举一个例子:
1 | void f() { int* p=new int[5]; } |
这条短短的一句话就包含了堆与栈,看到new,我们首先就应该想到,我们分配了一块堆内存,那么指针p呢?他分配的是一块栈内存,所以这句话的意思就是:在栈内存中存放了一个指向一块堆内存的指针p。在程序会先确定在堆中分配内存的大小,然后调用operator new分配内存,然后返回这块内存的首地址,放入栈中,他在VC6下的汇编代码如下:
1 | 00401028 push 14h |
这里,我们为了简单并没有释放内存,那么该怎么去释放呢?是delete p么?澳,错了,应该是delete []p,这是为了告诉编译器:我删除的是一个数组,VC6就会根据相应的Cookie信息去进行释放内存的工作。
堆和栈究竟有什么区别?
好了,我们回到我们的主题:堆和栈究竟有什么区别?
主要的区别由以下几点:
1.管理方式不同;
2.空间大小不同;
3.能否产生碎片不同;
4.生长方向不同;
5.分配方式不同;
6.分配效率不同;
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
空间大小:一般来讲在32位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M(好像是,记不清楚了)。当然,我们可以修改:
打开工程,依次操作菜单如下:Project->Setting->Link,在Category 中选中Output,然后在Reserve中设定堆栈的最大值和commit。
注意:reserve最小值为4Byte;commit是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。
碎片问题:对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详细的可以参考数据结构,这里我们就不再一一讨论了。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
从这里我们可以看到,堆和栈相比,由于大量new/delete的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和核心态的切换,内存的申请,代价变得更加昂贵。所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址,EBP和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
虽然栈有如此众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,还是用堆好一些。
无论是堆还是栈,都要防止越界现象的发生(除非你是故意使其越界),因为越界的结果要么是程序崩溃,要么是摧毁程序的堆、栈结构,产生以想不到的结果,就算是在你的程序运行过程中,没有发生上面的问题,你还是要小心,说不定什么时候就崩掉,那时候debug可是相当困难的:)
控制C++的内存分配
在嵌入式系统中使用C++的一个常见问题是内存分配,即对new和delete操作符的失控。
具有讽刺意味的是,问题的根源却是C++对内存的管理非常的容易而且安全。具体地说,当一个对象被消除时,它的析构函数能够安全的释放所分配的内存。
这当然是个好事情,但是这种使用的简单性使得程序员们过度使用new和delete,而不注意在嵌入式C++环境中的因果关系。并且,在嵌入式系统中,由于内存的限制,频繁的动态分配不定大小的内存会引起很大的问题以及堆破碎的风险。
作为忠告,保守的使用内存分配是嵌入式环境中的第一原则。
但当你必须要使用new 和delete时,你不得不控制C++中的内存分配。你需要用一个全局的new和delete来代替系统的内存分配符,并且一个类一个类的重载new和delete。
一个防止堆破碎的通用方法是从不同固定大小的内存持中分配不同类型的对象。对每个类重载new 和delete就提供了这样的控制。
重载全局的new和delete操作符
可以很容易地重载new 和 delete 操作符,如下所示:
1 | void * operator new(size_t size) |
这段代码可以代替默认的操作符来满足内存分配的请求。出于解释C++的目的,我们也可以直接调用malloc() 和free()。
也可以对单个类的new 和 delete 操作符重载。这是你能灵活的控制对象的内存分配。
1 | class TestClass { |
所有TestClass 对象的内存分配都采用这段代码。更进一步,任何从TestClass 继承的类也都采用这一方式,除非它自己也重载了new 和 delete 操作符。通过重载new 和 delete 操作符的方法,你可以自由地采用不同的分配策略,从不同的内存池中分配不同的类对象。
为单个的类重载 new[ ]和delete[ ]
必须小心对象数组的分配。你可能希望调用到被你重载过的new 和 delete 操作符,但并不如此。内存的请求被定向到全局的new[ ]和delete[ ] 操作符,而这些内存来自于系统堆。
C++将对象数组的内存分配作为一个单独的操作,而不同于单个对象的内存分配。为了改变这种方式,你同样需要重载new[ ] 和 delete[ ]操作符。
1 | class TestClass { |
但是注意:对于多数C++的实现,new[]操作符中的个数参数是数组的大小加上额外的存储对象数目的一些字节。在你的内存分配机制重要考虑的这一点。你应该尽量避免分配对象数组,从而使你的内存分配策略简单。
常见的内存错误及其对策
发生内存错误是件非常麻烦的事情。编译器不能自动发现这些错误,通常是在程序运行时才能捕捉到。而这些错误大多没有明显的症状,时隐时现,增加了改错的难度。有时用户怒气冲冲地把你找来,程序却没有发生任何问题,你一走,错误又发作了。 常见的内存错误及其对策如下:
- 内存分配未成功,却使用了它。
编程新手常犯这种错误,因为他们没有意识到内存分配会不成功。常用解决办法是,在使用内存之前检查指针是否为NULL。如果指针p是函数的参数,那么在函数的入口处用assert(p!=NULL)进行
检查。如果是用malloc或new来申请内存,应该用if(p==NULL) 或if(p!=NULL)进行防错处理。
- 内存分配虽然成功,但是尚未初始化就引用它。
犯这种错误主要有两个起因:一是没有初始化的观念;二是误以为内存的缺省初值全为零,导致引用初值错误(例如数组)。 内存的缺省初值究竟是什么并没有统一的标准,尽管有些时候为零值,我们宁可信其无不可信其有。所以无论用何种方式创建数组,都别忘了赋初值,即便是赋零值也不可省略,不要嫌麻烦。
- 内存分配成功并且已经初始化,但操作越过了内存的边界。
例如在使用数组时经常发生下标”多1”或者”少1”的操作。特别是在for循环语句中,循环次数很容易搞错,导致数组操作越界。
- 忘记了释放内存,造成内存泄露。
含有这种错误的函数每被调用一次就丢失一块内存。刚开始时系统的内存充足,你看不到错误。终有一次程序突然死掉,系统出现提示:内存耗尽。
动态内存的申请与释放必须配对,程序中malloc与free的使用次数一定要相同,否则肯定有错误(new/delete同理)。
- 释放了内存却继续使用它。
有三种情况:
(1)程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。
(2)函数的return语句写错了,注意不要返回指向”栈内存”的”指针”或者”引用”,因为该内存在函数体结束时被自动销毁。
(3)使用free或delete释放了内存后,没有将指针设置为NULL。导致产生”野指针”。
【规则1】用malloc或new申请内存之后,应该立即检查指针值是否为NULL。防止使用指针值为NULL的内存。
【规则2】不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
【规则3】避免数组或指针的下标越界,特别要当心发生”多1”或者”少1”操作。
【规则4】动态内存的申请与释放必须配对,防止内存泄漏。
【规则5】用free或delete释放了内存之后,立即将指针设置为NULL,防止产生”野指针”。
指针与数组的对比
C++/C程序中,指针和数组在不少地方可以相互替换着用,让人产生一种错觉,以为两者是等价的。
数组要么在静态存储区被创建(如全局数组),要么在栈上被创建。数组名对应着(而不是指向)一块内存,其地址与容量在生命期内保持不变,只有数组的内容可以改变。
指针可以随时指向任意类型的内存块,它的特征是”可变”,所以我们常用指针来操作动态内存。指针远比数组灵活,但也更危险。
下面以字符串为例比较指针与数组的特性。
修改内容
下面示例中,字符数组a的容量是6个字符,其内容为hello。a的内容可以改变,如a[0]= ‘X’。指针p指向常量字符串”world”(位于静态存储区,内容为world),常量字符串的内容是不可以被修改的。从语法上看,编译器并不觉得语句p[0]=’X’有什么不妥,但是该语句企图修改常量字符串的内容而导致运行错误。
1 | char a[] ="hello"; |
内容复制与比较
不能对数组名进行直接复制与比较。若想把数组a的内容复制给数组b,不能用语句 b = a ,否则将产生编译错误。应该用标准库函数strcpy进行复制。同理,比较b和a的内容是否相同,不能用if(b==a) 来判断,应该用标准库函数strcmp进行比较。
语句p = a 并不能把a的内容复制指针p,而是把a的地址赋给了p。要想复制a的内容,可以先用库函数malloc为p申请一块容量为strlen(a)+1个字符的内存,再用strcpy进行字符串复制。同理,语句if(p==a) 比较的不是内容而是地址,应该用库函数strcmp来比较。
1 | // 数组… |
计算内存容量
用运算符sizeof可以计算出数组的容量(字节数)。如下示例中,sizeof(a)的值是12(注意别忘了’’)。指针p指向a,但是sizeof(p)的值却是4。这是因为sizeof(p)得到的是一个指针变量的字节数,相当于sizeof(char*),而不是p所指的内存容量。C++/C语言没有办法知道指针所指的内存容量,除非在申请内存时记住它。
1 | char a[] = "hello world"; |
注意当数组作为函数的参数进行传递时,该数组自动退化为同类型的指针。如下示例中,不论数组a的容量是多少,sizeof(a)始终等于sizeof(char *)。
1 | void Func(char a[100]) |
指针参数是如何传递内存的?
如果函数的参数是一个指针,不要指望用该指针去申请动态内存。如下示例中,Test函数的语句GetMemory(str, 200)并没有使str获得期望的内存,str依旧是NULL,为什么?
1 | void GetMemory(char *p, int num) |
毛病出在函数GetMemory中。编译器总是要为函数的每个参数制作临时副本,指针参数p的副本是 _p,编译器使 _p = p。如果函数体内的程序修改了_p的内容,就导致参数p的内容作相应的修改。这就是指针可以用作输出参数的原因。在本例中,_p申请了新的内存,只是把_p所指的内存地址改变了,但是p丝毫未变。所以函数GetMemory并不能输出任何东西。事实上,每执行一次GetMemory就会泄露一块内存,因为没有用free释放内存。
如果非得要用指针参数去申请内存,那么应该改用“指向指针的指针”,见示例:
1 | void GetMemory2(char **p, int num) |
由于“指向指针的指针”这个概念不容易理解,我们可以用函数返回值来传递动态内存。这种方法更加简单,见示例:
1 | char *GetMemory3(int num) |
用函数返回值来传递动态内存这种方法虽然好用,但是常常有人把return语句用错了。这里强调不要用return语句返回指向”栈内存”的指针,因为该内存在函数结束时自动消亡,见示例:
1 | char *GetString(void) |
用调试器逐步跟踪Test4,发现执行str = GetString语句后str不再是NULL指针,但是str的内容不是“hello world”而是垃圾。
如果把上述示例改写成如下示例,会怎么样?
1 | char *GetString2(void) |
函数Test5运行虽然不会出错,但是函数GetString2的设计概念却是错误的。因为GetString2内的“hello world”是常量字符串,位于静态存储区,它在程序生命期内恒定不变。无论什么时候调用GetString2,它返回的始终是同一个“只读”的内存块。
杜绝“野指针”
“野指针”不是NULL指针,是指向“垃圾”内存的指针。人们一般不会错用NULL指针,因为用if语句很容易判断。但是“野指针”是很危险的,if语句对它不起作用。 “野指针”的成因主要有两种:
- 指针变量没有被初始化。任何指针变量刚被创建时不会自动成为NULL指针,它的缺省值是随机的,它会乱指一气。所以,指针变量在创建的同时应当被初始化,要么将指针设置为NULL,要么让它指向合法的内存。例如
1 | char *p = NULL; |
指针p被free或者delete之后,没有置为NULL,让人误以为p是个合法的指针。
- 指针操作超越了变量的作用域范围。这种情况让人防不胜防,示例程序如下:
1 | class A |
函数Test在执行语句p->Func()时,对象a已经消失,而p是指向a的,所以p就成了”野指针”。但奇怪的是我运行这个程序时居然没有出错,这可能与编译器有关。
有了malloc/free为什么还要new/delete?
malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
对于非内部数据类型的对象而言,光用malloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
因此C++语言需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理与释放内存工作的运算符delete。注意new/delete不是库函数。我们先看一看malloc/free和new/delete如何实现对象的动态内存管理,见示例:
1 | class Obj |
类Obj的函数Initialize模拟了构造函数的功能,函数Destroy模拟了析构函数的功能。函数UseMallocFree中,由于malloc/free不能执行构造函数与析构函数,必须调用成员函数Initialize和Destroy来完成初始化与清除工作。函数UseNewDelete则简单得多。
所以我们不要企图用malloc/free来完成动态对象的内存管理,应该用new/delete。由于内部数据类型的”对象”没有构造与析构的过程,对它们而言malloc/free和new/delete是等价的。
既然new/delete的功能完全覆盖了malloc/free,为什么C++不把malloc/free淘汰出局呢?这是因为C++程序经常要调用C函数,而C程序只能用malloc/free管理动态内存。
如果用free释放”new创建的动态对象”,那么该对象因无法执行析构函数而可能导致程序出错。如果用delete释放”malloc申请的动态内存”,结果也会导致程序出错,但是该程序的可读性很差。所以new/delete必须配对使用,malloc/free也一样。
内存耗尽怎么办?
如果在申请动态内存时找不到足够大的内存块,malloc和new将返回NULL指针,宣告内存申请失败。通常有三种方式处理”内存耗尽”问题。
- 判断指针是否为NULL,如果是则马上用return语句终止本函数。例如:
1 | void Func(void) |
- 判断指针是否为NULL,如果是则马上用exit(1)终止整个程序的运行。例如:
1 | void Func(void) |
- 为new和malloc设置异常处理函数。例如Visual C++可以用_set_new_hander函数为new设置用户自己定义的异常处理函数,也可以让malloc享用与new相同的异常处理函数。详细内容请参考C++使用手册。
上述(1)(2)方式使用最普遍。如果一个函数内有多处需要申请动态内存,那么方式(1)就显得力不从心(释放内存很麻烦),应该用方式(2)来处理。
很多人不忍心用exit(1),问:”不编写出错处理程序,让操作系统自己解决行不行?”
不行。如果发生”内存耗尽”这样的事情,一般说来应用程序已经无药可救。如果不用exit(1)把坏程序杀死,它可能会害死操作系统。道理如同:如果不把歹徒击毙,歹徒在老死之前会犯下更多的罪。
有一个很重要的现象要告诉大家。对于32位以上的应用程序而言,无论怎样使用malloc与new,几乎不可能导致”内存耗尽”。我在Windows 98下用Visual C++编写了测试程序,见示例7。这个程序会无休止地运行下去,根本不会终止。因为32位操作系统支持”虚存”,内存用完了,自动用硬盘空间顶替。我只听到硬盘嘎吱嘎吱地响,Window 98已经累得对键盘、鼠标毫无反应。
我可以得出这么一个结论:对于32位以上的应用程序,”内存耗尽”错误处理程序毫无用处。这下可把Unix和Windows程序员们乐坏了:反正错误处理程序不起作用,我就不写了,省了很多麻烦。
我不想误导读者,必须强调:不加错误处理将导致程序的质量很差,千万不可因小失大。
1 | void main(void) |
malloc/free的使用要点
函数malloc的原型如下:
1 | void * malloc(size_t size); |
用malloc申请一块长度为length的整数类型的内存,程序如下:
1 | int *p = (int *) malloc(sizeof(int) * length); |
我们应当把注意力集中在两个要素上:”类型转换”和”sizeof”。
malloc返回值的类型是void ,所以在调用malloc时要显式地进行类型转换,将void 转换成所需要的指针类型。
malloc函数本身并不识别要申请的内存是什么类型,它只关心内存的总字节数。我们通常记不住int, float等数据类型的变量的确切字节数。例如int变量在16位系统下是2个字节,在32位下是4个字节;而float变量在16位系统下是4个字节,在32位下也是4个字节。最好用以下程序作一次测试:
1 | cout << sizeof(char) << endl; |
在malloc的”()”中使用sizeof运算符是良好的风格,但要当心有时我们会昏了头,写出 p = malloc(sizeof(p))这样的程序来。
函数free的原型如下:
1 | void free( void * memblock ); |
为什么free函数不象malloc函数那样复杂呢?这是因为指针p的类型以及它所指的内存的容量事先都是知道的,语句free(p)能正确地释放内存。如果p是NULL指针,那么free对p无论操作多少次都不会出问题。如果p不是NULL指针,那么free对p连续操作两次就会导致程序运行错误。
new/delete的使用要点
运算符new使用起来要比函数malloc简单得多,例如:
1 | int *p1 = (int *)malloc(sizeof(int) * length); |
这是因为new内置了sizeof、类型转换和类型安全检查功能。对于非内部数据类型的对象而言,new在创建动态对象的同时完成了初始化工作。如果对象有多个构造函数,那么new的语句也可以有多种形式。例如
1 | class Obj |
如果用new创建对象数组,那么只能使用对象的无参数构造函数。例如:
1 | Obj *objects = new Obj[100]; // 创建100个动态对象 |
不能写成:
1 | Obj *objects = new Obj[100](1);// 创建100个动态对象的同时赋初值1 |
在用delete释放对象数组时,留意不要丢了符号’[]’。例如:
1 | delete []objects; // 正确的用法 |
后者有可能引起程序崩溃和内存泄漏。
C++中的健壮指针和资源管理
我最喜欢的对资源的定义是:”任何在你的程序中获得并在此后释放的东西?quot;内存是一个相当明显的资源的例子。它需要用new来获得,用delete来释放。同时也有许多其它类型的资源文件句柄、重要的片断、Windows中的GDI资源,等等。将资源的概念推广到程序中创建、释放的所有对象也是十分方便的,无论对象是在堆中分配的还是在栈中或者是在全局作用于内生命的。
对于给定的资源的拥有着,是负责释放资源的一个对象或者是一段代码。所有权分立为两种级别——自动的和显式的(automatic and explicit),如果一个对象的释放是由语言本身的机制来保证的,这个对象的就是被自动地所有。例如,一个嵌入在其他对象中的对象,他的清除需要其他对象来在清除的时候保证。外面的对象被看作嵌入类的所有者。 类似地,每个在栈上创建的对象(作为自动变量)的释放(破坏)是在控制流离开了对象被定义的作用域的时候保证的。这种情况下,作用于被看作是对象的所有者。注意所有的自动所有权都是和语言的其他机制相容的,包括异常。无论是如何退出作用域的————正常流程控制退出、一个break语句、一个return、一个goto、或者是一个throw————自动资源都可以被清除。
到目前为止,一切都很好!问题是在引入指针、句柄和抽象的时候产生的。如果通过一个指针访问一个对象的话,比如对象在堆中分配,C++不自动地关注它的释放。程序员必须明确的用适当的程序方法来释放这些资源。比如说,如果一个对象是通过调用new来创建的,它需要用delete来回收。一个文件是用CreateFile(Win32 API)打开的,它需要用CloseHandle来关闭。用EnterCritialSection进入的临界区(Critical Section)需要LeaveCriticalSection退出,等等。一个”裸”指针,文件句柄,或者临界区状态没有所有者来确保它们的最终释放。基本的资源管理的前提就是确保每个资源都有他们的所有者。
第一条规则(RAII)
一个指针,一个句柄,一个临界区状态只有在我们将它们封装入对象的时候才会拥有所有者。这就是我们的第一规则:在构造函数中分配资源,在析构函数中释放资源。
当你按照规则将所有资源封装的时候,你可以保证你的程序中没有任何的资源泄露。这点在当封装对象(Encapsulating Object)在栈中建立或者嵌入在其他的对象中的时候非常明显。但是对那些动态申请的对象呢?不要急!任何动态申请的东西都被看作一种资源,并且要按照上面提到的方法进行封装。这一对象封装对象的链不得不在某个地方终止。它最终终止在最高级的所有者,自动的或者是静态的。这些分别是对离开作用域或者程序时释放资源的保证。
下面是资源封装的一个经典例子。在一个多线程的应用程序中,线程之间共享对象的问题是通过用这样一个对象联系临界区来解决的。每一个需要访问共享资源的客户需要获得临界区。例如,这可能是Win32下临界区的实现方法。
1 | class CritSect |
这里聪明的部分是我们确保每一个进入临界区的客户最后都可以离开。”进入”临界区的状态是一种资源,并应当被封装。封装器通常被称作一个锁(lock)。
1 | class Lock |
锁一般的用法如下:
1 | void Shared::Act () throw (char *) |
注意无论发生什么,临界区都会借助于语言的机制保证释放。
还有一件需要记住的事情————每一种资源都需要被分别封装。这是因为资源分配是一个非常容易出错的操作,是要资源是有限提供的。我们会假设一个失败的资源分配会导致一个异常————事实上,这会经常的发生。所以如果你想试图用一个石头打两只鸟的话,或者在一个构造函数中申请两种形式的资源,你可能就会陷入麻烦。只要想想在一种资源分配成功但另一种失败抛出异常时会发生什么。因为构造函数还没有全部完成,析构函数不可能被调用,第一种资源就会发生泄露。
这种情况可以非常简单的避免。无论何时你有一个需要两种以上资源的类时,写两个小的封装器将它们嵌入你的类中。每一个嵌入的构造都可以保证删除,即使包装类没有构造完成。
Smart Pointers
我们至今还没有讨论最常见类型的资源————用操作符new分配,此后用指针访问的一个对象。我们需要为每个对象分别定义一个封装类吗?(事实上,C++标准模板库已经有了一个模板类,叫做auto_ptr,其作用就是提供这种封装。我们一会儿在回到auto_ptr。)让我们从一个极其简单、呆板但安全的东西开始。看下面的Smart Pointer模板类,它十分坚固,甚至无法实现。
1 | template <class T> |
为什么要把SmartPointer的构造函数设计为protected呢?如果我需要遵守第一条规则,那么我就必须这样做。资源————在这里是class T的一个对象————必须在封装器的构造函数中分配。但是我不能只简单的调用new T,因为我不知道T的构造函数的参数。因为,在原则上,每一个T都有一个不同的构造函数;我需要为他定义个另外一个封装器。模板的用处会很大,为每一个新的类,我可以通过继承SmartPointer定义一个新的封装器,并且提供一个特定的构造函数。
1 | class SmartItem: public SmartPointer<Item> |
为每一个类提供一个Smart Pointer真的值得吗?说实话————不!他很有教学的价值,但是一旦你学会如何遵循第一规则的话,你就可以放松规则并使用一些高级的技术。这一技术是让SmartPointer的构造函数成为public,但是只是是用它来做资源转换(Resource Transfer)我的意思是用new操作符的结果直接作为SmartPointer的构造函数的参数,像这样:
1 | SmartPointer<Item> item (new Item (i)); |
这个方法明显更需要自控性,不只是你,而且包括你的程序小组的每个成员。他们都必须发誓出了作资源转换外不把构造函数用在人以其他用途。幸运的是,这条规矩很容易得以加强。只需要在源文件中查找所有的new即可。
Resource Transfer
到目前为止,我们所讨论的一直是生命周期在一个单独的作用域内的资源。现在我们要解决一个困难的问题————如何在不同的作用域间安全的传递资源。这一问题在当你处理容器的时候会变得十分明显。你可以动态的创建一串对象,将它们存放至一个容器中,然后将它们取出,并且在最终安排它们。为了能够让这安全的工作————没有泄露————对象需要改变其所有者。
这个问题的一个非常显而易见的解决方法是使用Smart Pointer,无论是在加入容器前还是还找到它们以后。这是他如何运作的,你加入Release方法到Smart Pointer中:
1 | template <class T> |
注意在Release调用以后,Smart Pointer就不再是对象的所有者了————它内部的指针指向空。现在,调用了Release都必须是一个负责的人并且迅速隐藏返回的指针到新的所有者对象中。在我们的例子中,容器调用了Release,比如这个Stack的例子:
1 | void Stack::Push (SmartPointer <Item> & item) throw (char *) |
同样的,你也可以再你的代码中用加强Release的可靠性。
相应的Pop方法要做些什么呢?他应该释放了资源并祈祷调用它的是一个负责的人而且立即作一个资源传递它到一个Smart Pointer?这听起来并不好。
Strong Pointers
资源管理在内容索引(Windows NT Server上的一部分,现在是Windows 2000)上工作,并且,我对这十分满意。然后我开始想……这一方法是在这样一个完整的系统中形成的,如果可以把它内建入语言的本身岂不是一件非常好?我提出了强指针(Strong Pointer)和弱指针(Weak Pointer)。一个Strong Pointer会在许多地方和我们这个SmartPointer相似—它在超出它的作用域后会清除他所指向的对象。资源传递会以强指针赋值的形式进行。也可以有Weak Pointer存在,它们用来访问对象而不需要所有对象—比如可赋值的引用。
任何指针都必须声明为Strong或者Weak,并且语言应该来关注类型转换的规定。例如,你不可以将Weak Pointer传递到一个需要Strong Pointer的地方,但是相反却可以。Push方法可以接受一个Strong Pointer并且将它转移到Stack中的Strong Pointer的序列中。Pop方法将会返回一个Strong Pointer。把Strong Pointer的引入语言将会使垃圾回收成为历史。
这里还有一个小问题—修改C++标准几乎和竞选美国总统一样容易。当我将我的注意告诉给Bjarne Stroutrup的时候,他看我的眼神好像是我刚刚要向他借一千美元一样。
然后我突然想到一个念头。我可以自己实现Strong Pointers。毕竟,它们都很想Smart Pointers。给它们一个拷贝构造函数并重载赋值操作符并不是一个大问题。事实上,这正是标准库中的auto_ptr有的。重要的是对这些操作给出一个资源转移的语法,但是这也不是很难。
1 | template <class T> |
使这整个想法迅速成功的原因之一是我可以以值方式传递这种封装指针!我有了我的蛋糕,并且也可以吃了。看这个Stack的新的实现:
1 | class Stack |
Pop方法强制客户将其返回值赋给一个Strong Pointer,SmartPointer
我马上意识到我已经在某些东西之上了。我开始用了新的方法重写原来的代码。
Parser
我过去有一个老的算术操作分析器,是用老的资源管理的技术写的。分析器的作用是在分析树中生成节点,节点是动态分配的。例如分析器的Expression方法生成一个表达式节点。我没有时间用Strong Pointer去重写这个分析器。我令Expression、Term和Factor方法以传值的方式将Strong Pointer返回到Node中。看下面的Expression方法的实现:
1 | SmartPointer<Node> Parser::Expression() |
最开始,Term方法被调用。他传值返回一个指向Node的Strong Pointer并且立刻把它保存到我们自己的Strong Pointer,pNode中。如果下一个符号不是加号或者减号,我们就简单的把这个SmartPointer以值返回,这样就释放了Node的所有权。另外一方面,如果下一个符号是加号或者减号,我们创建一个新的SumMode并且立刻(直接传递)将它储存到MultiNode的一个Strong Pointer中。这里,SumNode是从MultiMode中继承而来的,而MulitNode是从Node继承而来的。原来的Node的所有权转给了SumNode。
只要是他们在被加号和减号分开的时候,我们就不断的创建terms,我们将这些term转移到我们的MultiNode中,同时MultiNode得到了所有权。最后,我们将指向MultiNode的Strong Pointer向上映射为指向Mode的Strong Pointer,并且将他返回调用着。
我们需要对Strong Pointers进行显式的向上映射,即使指针是被隐式的封装。例如,一个MultiNode是一个Node,但是相同的is-a关系在SmartPointer
1 | template<class To, class From> |
如果你的编译器支持新加入标准的成员模板(member template)的话,你可以为SmartPointer
1 | template <class T> |
这里的这个花招是模板在U不是T的子类的时候就不会编译成功(换句话说,只在U is-a T的时候才会编译)。这是因为uptr的缘故。Release()方法返回一个指向U的指针,并被赋值为_p,一个指向T的指针。所以如果U不是一个T的话,赋值会导致一个编译时刻错误。
1 | std::auto_ptr |
后来我意识到在STL中的auto_ptr模板,就是我的Strong Pointer。在那时候还有许多的实现差异(auto_ptr的Release方法并不将内部的指针清零—你的编译器的库很可能用的就是这种陈旧的实现),但是最后在标准被广泛接受之前都被解决了。
Transfer Semantics
目前为止,我们一直在讨论在C++程序中资源管理的方法。宗旨是将资源封装到一些轻量级的类中,并由类负责它们的释放。特别的是,所有用new操作符分配的资源都会被储存并传递进Strong Pointer(标准库中的auto_ptr)的内部。
这里的关键词是传递(passing)。一个容器可以通过传值返回一个StrongPointer来安全的释放资源。容器的客户只能够通过提供一个相应的Strong Pointer来保存这个资源。任何一个将结果赋给一个”裸”指针的做法都立即会被编译器发现。
1 | auto_ptr<Item> item = stack.Pop (); // ok |
以传值方式被传递的对象有value semantics 或者称为 copy semantics。Strong Pointers是以值方式传递的—但是我们能说它们有copy semantics吗?不是这样的!它们所指向的对象肯定没有被拷贝过。事实上,传递过后,源auto_ptr不在访问原有的对象,并且目标auto_ptr成为了对象的唯一拥有者(但是往往auto_ptr的旧的实现即使在释放后仍然保持着对对象的所有权)。自然而然的我们可以将这种新的行为称作Transfer Semantics。
拷贝构造函数(copy construcor)和赋值操作符定义了auto_ptr的Transfer Semantics,它们用了非const的auto_ptr引用作为它们的参数。
1 | auto_ptr (auto_ptr<T> & ptr); |
这是因为它们确实改变了他们的源—剥夺了对资源的所有权。
通过定义相应的拷贝构造函数和重载赋值操作符,你可以将Transfer Semantics加入到许多对象中。例如,许多Windows中的资源,比如动态建立的菜单或者位图,可以用有Transfer Semantics的类来封装。
Strong Vectors
标准库只在auto_ptr中支持资源管理。甚至连最简单的容器也不支持ownership semantics。你可能想将auto_ptr和标准容器组合到一起可能会管用,但是并不是这样的。例如,你可能会这样做,但是会发现你不能够用标准的方法来进行索引。
1 | vector< auto_ptr<Item> > autoVector; |
这种建造不会编译成功;
1 | Item * item = autoVector [0]; |
另一方面,这会导致一个从autoVect到auto_ptr的所有权转换:
1 | auto_ptr<Item> item = autoVector [0]; |
我们没有选择,只能够构造我们自己的Strong Vector。最小的接口应该如下:
1 | template <class T> |
你也许会发现一个非常防御性的设计态度。我决定不提供一个对vector的左值索引的访问,取而代之,如果你想设定(set)一个值的话,你必须用assign或者assign_direct方法。我的观点是,资源管理不应该被忽视,同时,也不应该在所有的地方滥用。在我的经验里,一个strong vector经常被许多push_back方法充斥着。
Strong vector最好用一个动态的Strong Pointers的数组来实现:
1 | template <class T> |
grow方法申请了一个很大的auto_ptr
auto_vector的其他实现都是十分直接的,因为所有资源管理的复杂度都在auto_ptr中。例如,assign方法简单的利用了重载的赋值操作符来删除原有的对象并转移资源到新的对象:
1 | void assign (size_t i, auto_ptr<T> & p) |
我已经讨论了push_back和pop_back方法。push_back方法传值返回一个auto_ptr,因为它将所有权从auto_vector转换到auto_ptr中。
对auto_vector的索引访问是借助auto_ptr的get方法来实现的,get简单的返回一个内部指针。
1 | T * operator [] (size_t i) |
没有容器可以没有iterator。我们需要一个iterator让auto_vector看起来更像一个普通的指针向量。特别是,当我们废弃iterator的时候,我们需要的是一个指针而不是auto_ptr。我们不希望一个auto_vector的iterator在无意中进行资源转换。
1 | template<class T> |
我们给auto_vect提供了标准的begin和end方法来找回iterator:
1 | class auto_vector |
你也许会问我们是否要利用资源管理重新实现每一个标准的容器?幸运的是,不;事实是strongvector解决了大部分所有权的需求。当你把你的对象都安全的放置到一个strong vector中,你可以用所有其它的容器来重新安排(weak)pointer。
设想,例如,你需要对一些动态分配的对象排序的时候。你将它们的指针保存到一个strongvector中。然后你用一个标准的vector来保存从strong vector中获得的weak指针。你可以用标准的算法对这个vector进行排序。这种中介vector叫做permutation vector。相似的,你也可以用标准的maps, priority queues, heaps, hash tables等等。
Code Inspection
如果你严格遵照资源管理的条款,你就不会再资源泄露或者两次删除的地方遇到麻烦。你也降低了访问野指针的几率。同样的,遵循原有的规则,用delete删除用new申请的德指针,不要两次删除一个指针。你也不会遇到麻烦。但是,那个是更好的注意呢?
这两个方法有一个很大的不同点。就是和寻找传统方法的bug相比,找到违反资源管理的规定要容易的多。后者仅需要一个代码检测或者一个运行测试,而前者则在代码中隐藏得很深,并需要很深的检查。
设想你要做一段传统的代码的内存泄露检查。第一件事,你要做的就是grep所有在代码中出现的new,你需要找出被分配空间地指针都作了什么。你需要确定导致删除这个指针的所有的执行路径。你需要检查break语句,过程返回,异常。原有的指针可能赋给另一个指针,你对这个指针也要做相同的事。
相比之下,对于一段用资源管理技术实现的代码。你也用grep检查所有的new,但是这次你只需要检查邻近的调用:
● 这是一个直接的Strong Pointer转换,还是我们在一个构造函数的函数体中?
● 调用的返回知是否立即保存到对象中,构造函数中是否有可以产生异常的代码。?
● 如果这样的话析构函数中时候有delete?
下一步,你需要用grep查找所有的release方法,并实施相同的检查。
不同点是需要检查、理解单个执行路径和只需要做一些本地的检验。这难道不是提醒你非结构化的和结构化的程序设计的不同吗?原理上,你可以认为你可以应付goto,并且跟踪所有的可能分支。另一方面,你可以将你的怀疑本地化为一段代码。本地化在两种情况下都是关键所在。
在资源管理中的错误模式也比较容易调试。最常见的bug是试图访问一个释放过的strong pointer。这将导致一个错误,并且很容易跟踪。
共享的所有权
为每一个程序中的资源都找出或者指定一个所有者是一件很容易的事情吗?答案是出乎意料的,是!如果你发现了一些问题,这可能说明你的设计上存在问题。还有另一种情况就是共享所有权是最好的甚至是唯一的选择。
共享的责任分配给被共享的对象和它的客户(client)。一个共享资源必须为它的所有者保持一个引用计数。另一方面,所有者再释放资源的时候必须通报共享对象。最后一个释放资源的需要在最后负责free的工作。
最简单的共享的实现是共享对象继承引用计数的类RefCounted:
1 | class RefCounted |
按照资源管理,一个引用计数是一种资源。如果你遵守它,你需要释放它。当你意识到这一事实的时候,剩下的就变得简单了。简单的遵循规则—再构造函数中获得引用计数,在析构函数中释放。甚至有一个RefCounted的smart pointer等价物:
1 | template <class T> |
注意模板中的T不比成为RefCounted的后代,但是它必须有IncRefCount和DecRefCount的方法。当然,一个便于使用的RefPtr需要有一个重载的指针访问操作符。在RefPtr中加入转换语义学(transfer semantics)是读者的工作。
所有权网络
链表是资源管理分析中的一个很有意思的例子。如果你选择表成为链(link)的所有者的话,你会陷入实现递归的所有权。每一个link都是它的继承者的所有者,并且,相应的,余下的链表的所有者。下面是用smart pointer实现的一个表单元:
1 | class Link |
最好的方法是,将连接控制封装到一个弄构进行资源转换的类中。
对于双链表呢?安全的做法是指明一个方向,如forward:
1 | class DoubleLink |
注意不要创建环形链表。
这给我们带来了另外一个有趣的问题—资源管理可以处理环形的所有权吗?它可以,用一个mark-and-sweep的算法。这里是实现这种方法的一个例子:
1 | template<class T> |
注意我们需要用class T来实现方法IsBeingDeleted,就像从CyclPtr继承。对特殊的所有权网络普通化是十分直接的。
将原有代码转换为资源管理代码
如果你是一个经验丰富的程序员,你一定会知道找资源的bug是一件浪费时间的痛苦的经历。我不必说服你和你的团队花费一点时间来熟悉资源管理是十分值得的。你可以立即开始用这个方法,无论你是在开始一个新项目或者是在一个项目的中期。转换不必立即全部完成。下面是步骤。
首先,在你的工程中建立基本的Strong Pointer。然后通过查找代码中的new来开始封装裸指针。
最先封装的是在过程中定义的临时指针。简单的将它们替换为auto_ptr并且删除相应的delete。如果一个指针在过程中没有被删除而是被返回,用auto_ptr替换并在返回前调用release方法。在你做第二次传递的时候,你需要处理对release的调用。注意,即使是在这点,你的代码也可能更加”精力充沛”—你会移出代码中潜在的资源泄漏问题。
下面是指向资源的裸指针。确保它们被独立的封装到auto_ptr中,或者在构造函数中分配在析构函数中释放。如果你有传递所有权的行为的话,需要调用release方法。如果你有容器所有对象,用Strong Pointers重新实现它们。
接下来,找到所有对release的方法调用并且尽力清除所有,如果一个release调用返回一个指针,将它修改传值返回一个auto_ptr。
重复着一过程,直到最后所有new和release的调用都在构造函数或者资源转换的时候发生。这样,你在你的代码中处理了资源泄漏的问题。对其他资源进行相似的操作。
你会发现资源管理清除了许多错误和异常处理带来的复杂性。不仅仅你的代码会变得精力充沛,它也会变得简单并容易维护。
内存泄漏
C++中动态内存分配引发问题的解决方案
假设我们要开发一个String类,它可以方便地处理字符串数据。我们可以在类中声明一个数组,考虑到有时候字符串极长,我们可以把数组大小设为200,但一般的情况下又不需要这么多的空间,这样是浪费了内存。对了,我们可以使用new操作符,这样是十分灵活的,但在类中就会出现许多意想不到的问题,本文就是针对这一现象而写的。现在,我们先来开发一个String类,但它是一个不完善的类。的确,我们要刻意地使它出现各种各样的问题,这样才好对症下药。好了,我们开始吧!
1 | /* String.h */ |
运行结果:
1 | 天极网 |
大家可以看到,以上程序十分正确,而且也是十分有用的。可是,我们不能被表面现象所迷惑!下面,请大家用test_String.cpp文件替换test_right.cpp文件进行编译,看看结果。有的编译器可能就是根本不能进行编译!
test_String.cpp:
1 | #include <iostream> |
运行结果:
1 | 下面分别输入三个范例: |
现在,请大家自己试试运行结果,或许会更加惨不忍睹呢!下面,我为大家一一分析原因。
首先,大家要知道,C++类有以下这些极为重要的函数:
一:复制构造函数。
二:赋值函数。
我们先来讲复制构造函数。什么是复制构造函数呢?比如,我们可以写下这样的代码:String test1(test2);这是进行初始化。我们知道,初始化对象要用构造函数。可这儿呢?按理说,应该有声明为这样的构造函数:String(const String &);可是,我们并没有定义这个构造函数呀?答案是,C++提供了默认的复制构造函数,问题也就出在这儿。
(1):什么时候会调用复制构造函数呢?(以String类为例。)
在我们提供这样的代码:String test1(test2)时,它会被调用;当函数的参数列表为按值传递,也就是没有用引用和指针作为类型时,如:void show_String(const String),它会被调用。其实,还有一些情况,但在这儿就不列举了。
(2):它是什么样的函数。
它的作用就是把两个类进行复制。拿String类为例,C++提供的默认复制构造函数是这样的:
1 | String(const String& a) |
在平时,这样并不会有任何的问题出现,但我们用了new操作符,涉及到了动态内存分配,我们就不得不谈谈浅复制和深复制了。以上的函数就是实行的浅复制,它只是复制了指针,而并没有复制指针指向的数据,可谓一点儿用也没有。打个比方吧!就像一个朋友让你把一个程序通过网络发给他,而你大大咧咧地把快捷方式发给了他,有什么用处呢?我们来具体谈谈:
假如,A对象中存储了这样的字符串:”C++”。它的地址为2000。现在,我们把A对象赋给B对象:String B=A。现在,A和B对象的str指针均指向2000地址。看似可以使用,但如果B对象的析构函数被调用时,则地址2000处的字符串”C++”已经被从内存中抹去,而A对象仍然指向地址2000。这时,如果我们写下这样的代码:cout<<A<<endl;或是等待程序结束,A对象的析构函数被调用时,A对象的数据能否显示出来呢?只会是乱码。而且,程序还会这样做:连续对地址2000处使用两次delete操作符,这样的后果是十分严重的!
本例中,有这样的代码:
1 | String* String1=new String(test1); |
假设test1中str指向的地址为2000,而String中str指针同样指向地址2000,我们删除了2000处的数据,而test1对象呢?已经被破坏了。大家从运行结果上可以看到,我们使用cout<<test1时,一点反应也没有。而在test1的析构函数被调用时,显示是这样:”这个字符串将被删除:”。
再看看这段代码:
1 | cout<<"使用错误的函数:"<<endl; |
show_String函数的参数列表void show_String(const String a)是按值传递的,所以,我们相当于执行了这样的代码:String a=test2;函数执行完毕,由于生存周期的缘故,对象a被析构函数删除,我们马上就可以看到错误的显示结果了:这个字符串将被删除:?=。当然,test2也被破坏了。解决的办法很简单,当然是手工定义一个复制构造函数喽!人力可以胜天!
1 | String::String(const String& a) |
我们执行的是深复制。这个函数的功能是这样的:假设对象A中的str指针指向地址2000,内容为”I am a C++ Boy!”。我们执行代码String B=A时,我们先开辟出一块内存,假设为3000。我们用strcpy函数将地址2000的内容拷贝到地址3000中,再将对象B的str指针指向地址3000。这样,就互不干扰了。
大家把这个函数加入程序中,问题就解决了大半,但还没有完全解决,问题在赋值函数上。我们的程序中有这样的段代码:
1 | String String3; |
经过我前面的讲解,大家应该也会对这段代码进行寻根摸底:凭什么可以这样做:String3=test4???原因是,C++为了用户的方便,提供的这样的一个操作符重载函数:operator=。所以,我们可以这样做。大家应该猜得到,它同样是执行了浅复制,出了同样的毛病。比如,执行了这段代码后,析构函数开始大展神威。由于这些变量是后进先出的,所以最后的String3变量先被删除:这个字符串将被删除:第四个范例。很正常。最后,删除到test4的时候,问题来了:这个字符串将被删除:?=。原因我不用赘述了,只是这个赋值函数怎么写,还有一点儿学问呢!大家请看:
平时,我们可以写这样的代码:x=y=z。(均为整型变量。)而在类对象中,我们同样要这样,因为这很方便。而对象A=B=C就是A.operator=(B.operator=(c))。而这个operator=函数的参数列表应该是:const String& a,所以,大家不难推出,要实现这样的功能,返回值也要是String&,这样才能实现A=B=C。我们先来写写看:
1 | String& String::operator=(const String& a) |
是不是这样就行了呢?我们假如写出了这种代码:A=A,那么大家看看,岂不是把A对象的数据给删除了吗?这样可谓引发一系列的错误。所以,我们还要检查是否为自身赋值。只比较两对象的数据是不行了,因为两个对象的数据很有可能相同。我们应该比较地址。以下是完好的赋值函数:
1 | String& String::operator=(const String& a) |
把这些代码加入程序,问题就完全解决,下面是运行结果:
1 | 下面分别输入三个范例: |
如何对付内存泄漏?
写出那些不会导致任何内存泄漏的代码。很明显,当你的代码中到处充满了new 操作、delete操作和指针运算的话,你将会在某个地方搞晕了头,导致内存泄漏,指针引用错误,以及诸如此类的问题。这和你如何小心地对待内存分配工作其实完全没有关系:代码的复杂性最终总是会超过你能够付出的时间和努力。于是随后产生了一些成功的技巧,它们依赖于将内存分配(allocations)与重新分配(deallocation)工作隐藏在易于管理的类型之后。标准容器(standard containers)是一个优秀的例子。它们不是通过你而是自己为元素管理内存,从而避免了产生糟糕的结果。想象一下,没有string和vector的帮助,写出这个:
1 | #include<vector> |
你有多少机会在第一次就得到正确的结果?你又怎么知道你没有导致内存泄漏呢?
注意,没有出现显式的内存管理,宏,造型,溢出检查,显式的长度限制,以及指针。通过使用函数对象和标准算法(standard algorithm),我可以避免使用指针————例如使用迭代子(iterator),不过对于一个这么小的程序来说有点小题大作了。
这些技巧并不完美,要系统化地使用它们也并不总是那么容易。但是,应用它们产生了惊人的差异,而且通过减少显式的内存分配与重新分配的次数,你甚至可以使余下的例子更加容易被跟踪。早在1981年,我就指出,通过将我必须显式地跟踪的对象的数量从几万个减少到几打,为了使程序正确运行而付出的努力从可怕的苦工,变成了应付一些可管理的对象,甚至更加简单了。
如果你的程序还没有包含将显式内存管理减少到最小限度的库,那么要让你程序完成和正确运行的话,最快的途径也许就是先建立一个这样的库。
模板和标准库实现了容器、资源句柄以及诸如此类的东西,更早的使用甚至在多年以前。异常的使用使之更加完善。
如果你实在不能将内存分配/重新分配的操作隐藏到你需要的对象中时,你可以使用资源句柄(resource handle),以将内存泄漏的可能性降至最低。这里有个例子:我需要通过一个函数,在空闲内存中建立一个对象并返回它。这时候可能忘记释放这个对象。毕竟,我们不能说,仅仅关注当这个指针要被释放的时候,谁将负责去做。使用资源句柄,这里用了标准库中的auto_ptr,使需要为之负责的地方变得明确了。
1 | #include<memory> |
在更一般的意义上考虑资源,而不仅仅是内存。
如果在你的环境中不能系统地应用这些技巧(例如,你必须使用别的地方的代码,或者你的程序的另一部分简直是原始人类(译注:原文是Neanderthals,尼安德特人,旧石器时代广泛分布在欧洲的猿人)写的,如此等等),那么注意使用一个内存泄漏检测器作为开发过程的一部分,或者插入一个垃圾收集器(garbage collector)。
浅谈C/C++内存泄漏及其检测工具
对于一个c/c++程序员来说,内存泄漏是一个常见的也是令人头疼的问题。已经有许多技术被研究出来以应对这个问题,比如Smart Pointer,Garbage Collection等。Smart Pointer技术比较成熟,STL中已经包含支持Smart Pointer的class,但是它的使用似乎并不广泛,而且它也不能解决所有的问题;Garbage Collection技术在Java中已经比较成熟,但是在c/c++领域的发展并不顺畅,虽然很早就有人思考在C++中也加入GC的支持。现实世界就是这样的,作为一个c/c++程序员,内存泄漏是你心中永远的痛。不过好在现在有许多工具能够帮助我们验证内存泄漏的存在,找出发生问题的代码。
内存泄漏的定义
一般我们常说的内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定),使用完后必须显示释放的内存。应用程序一般使用malloc,realloc,new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用,我们就说这块内存泄漏了。以下这段小程序演示了堆内存发生泄漏的情形:
1 | void MyFunction(int nSize) |
当函数GetStringFrom()返回零的时候,指针p指向的内存就不会被释放。这是一种常见的发生内存泄漏的情形。程序在入口处分配内存,在出口处释放内存,但是c函数可以在任何地方退出,所以一旦有某个出口处没有释放应该释放的内存,就会发生内存泄漏。
广义的说,内存泄漏不仅仅包含堆内存的泄漏,还包含系统资源的泄漏(resource leak),比如核心态HANDLE,GDI Object,SOCKET, Interface等,从根本上说这些由操作系统分配的对象也消耗内存,如果这些对象发生泄漏最终也会导致内存的泄漏。而且,某些对象消耗的是核心态内存,这些对象严重泄漏时会导致整个操作系统不稳定。所以相比之下,系统资源的泄漏比堆内存的泄漏更为严重。
GDI Object的泄漏是一种常见的资源泄漏:
1 | void CMyView::OnPaint( CDC* pDC ) |
当函数Something()返回非零的时候,程序在退出前没有把pOldBmp选回pDC中,这会导致pOldBmp指向的HBITMAP对象发生泄漏。这个程序如果长时间的运行,可能会导致整个系统花屏。这种问题在Win9x下比较容易暴露出来,因为Win9x的GDI堆比Win2k或NT的要小很多。
内存泄漏的发生方式
以发生的方式来分类,内存泄漏可以分为4类:
常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。比如例二,如果Something()函数一直返回True,那么pOldBmp指向的HBITMAP对象总是发生泄漏。
偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。比如例二,如果Something()函数只有在特定环境下才返回True,那么pOldBmp指向的HBITMAP对象并不总是发生泄漏。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,但是因为这个类是一个Singleton,所以内存泄漏只会发生一次。另一个例子:
1 | char* g_lpszFileName = NULL; |
如果程序在结束的时候没有释放g_lpszFileName指向的字符串,那么,即使多次调用SetFileName(),总会有一块内存,而且仅有一块内存发生泄漏。
- 隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。举一个例子:
1 | class Connection |
假设在Client从Server端断开后,Server并没有呼叫OnClientDisconnected()函数,那么代表那次连接的Connection对象就不会被及时的删除(在Server程序退出的时候,所有Connection对象会在ConnectionManager的析构函数里被删除)。当不断的有连接建立、断开时隐式内存泄漏就发生了。
从用户使用程序的角度来看,内存泄漏本身不会产生什么危害,作为一般的用户,根本感觉不到内存泄漏的存在。真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积,而隐式内存泄漏危害性则非常大,因为较之于常发性和偶发性内存泄漏它更难被检测到。
检测内存泄漏
检测内存泄漏的关键是要能截获住对分配内存和释放内存的函数的调用。截获住这两个函数,我们就能跟踪每一块内存的生命周期,比如,每当成功的分配一块内存后,就把它的指针加入一个全局的list中;每当释放一块内存,再把它的指针从list中删除。这样,当程序结束的时候,list中剩余的指针就是指向那些没有被释放的内存。这里只是简单的描述了检测内存泄漏的基本原理,详细的算法可以参见Steve Maguire的<
如果要检测堆内存的泄漏,那么需要截获住malloc/realloc/free和new/delete就可以了(其实new/delete最终也是用malloc/free的,所以只要截获前面一组即可)。对于其他的泄漏,可以采用类似的方法,截获住相应的分配和释放函数。比如,要检测BSTR的泄漏,就需要截获SysAllocString/SysFreeString;要检测HMENU的泄漏,就需要截获CreateMenu/ DestroyMenu。(有的资源的分配函数有多个,释放函数只有一个,比如,SysAllocStringLen也可以用来分配BSTR,这时就需要截获多个分配函数)
在Windows平台下,检测内存泄漏的工具常用的一般有三种,MS C-Runtime Library内建的检测功能;外挂式的检测工具,诸如,Purify,BoundsChecker等;利用Windows NT自带的Performance Monitor。这三种工具各有优缺点,MS C-Runtime Library虽然功能上较之外挂式的工具要弱,但是它是免费的;Performance Monitor虽然无法标示出发生问题的代码,但是它能检测出隐式的内存泄漏的存在,这是其他两类工具无能为力的地方。
以下我们详细讨论这三种检测工具:
VC下内存泄漏的检测方法
用MFC开发的应用程序,在DEBUG版模式下编译后,都会自动加入内存泄漏的检测代码。在程序结束后,如果发生了内存泄漏,在Debug窗口中会显示出所有发生泄漏的内存块的信息,以下两行显示了一块被泄漏的内存块的信息:
1 | E:"TestMemLeak"TestDlg.cpp(70) : {59} normal block at 0x00881710, 200 bytes long. |
第一行显示该内存块由TestDlg.cpp文件,第70行代码分配,地址在0x00881710,大小为200字节,{59}是指调用内存分配函数的Request Order,关于它的详细信息可以参见MSDN中_CrtSetBreakAlloc()的帮助。第二行显示该内存块前16个字节的内容,尖括号内是以ASCII方式显示,接着的是以16进制方式显示。
一般大家都误以为这些内存泄漏的检测功能是由MFC提供的,其实不然。MFC只是封装和利用了MS C-Runtime Library的Debug Function。非MFC程序也可以利用MS C-Runtime Library的Debug Function加入内存泄漏的检测功能。MS C-Runtime Library在实现malloc/free,strdup等函数时已经内建了内存泄漏的检测功能。
注意观察一下由MFC Application Wizard生成的项目,在每一个cpp文件的头部都有这样一段宏定义:
1 | #ifdef _DEBUG |
有了这样的定义,在编译DEBUG版时,出现在这个cpp文件中的所有new都被替换成DEBUG_NEW了。那么DEBUG_NEW是什么呢?DEBUG_NEW也是一个宏,以下摘自afx.h,1632行
1 | #define DEBUG_NEW new(THIS_FILE, __LINE__) |
所以如果有这样一行代码:
1 | char* p = new char[200]; |
经过宏替换就变成了:
1 | char* p = new( THIS_FILE, __LINE__)char[200]; |
根据C++的标准,对于以上的new的使用方法,编译器会去找这样定义的operator new:
1 | void* operator new(size_t, LPCSTR, int) |
我们在afxmem.cpp 63行找到了一个这样的operator new 的实现
1 | void* AFX_CDECL operator new(size_t nSize, LPCSTR lpszFileName, int nLine) |
第二个operator new函数比较长,为了简单期间,我只摘录了部分。很显然最后的内存分配还是通过_malloc_dbg函数实现的,这个函数属于MS C-Runtime Library 的Debug Function。这个函数不但要求传入内存的大小,另外还有文件名和行号两个参数。文件名和行号就是用来记录此次分配是由哪一段代码造成的。如果这块内存在程序结束之前没有被释放,那么这些信息就会输出到Debug窗口里。
这里顺便提一下THIS_FILE,FILE和LINE。FILE和LINE都是编译器定义的宏。当碰到FILE时,编译器会把FILE替换成一个字符串,这个字符串就是当前在编译的文件的路径名。当碰到LINE时,编译器会把LINE替换成一个数字,这个数字就是当前这行代码的行号。在DEBUG_NEW的定义中没有直接使用FILE,而是用了THIS_FILE,其目的是为了减小目标文件的大小。假设在某个cpp文件中有100处使用了new,如果直接使用FILE__,那编译器会产生100个常量字符串,这100个字符串都是cpp文件的路径名,显然十分冗余。如果使用THIS_FILE,编译器只会产生一个常量字符串,那100处new的调用使用的都是指向常量字符串的指针。
再次观察一下由MFC Application Wizard生成的项目,我们会发现在cpp文件中只对new做了映射,如果你在程序中直接使用malloc函数分配内存,调用malloc的文件名和行号是不会被记录下来的。如果这块内存发生了泄漏,MS C-Runtime Library仍然能检测到,但是当输出这块内存块的信息,不会包含分配它的的文件名和行号。
要在非MFC程序中打开内存泄漏的检测功能非常容易,你只要在程序的入口处加入以下几行代码:
1 | int tmpFlag = _CrtSetDbgFlag( _CRTDBG_REPORT_FLAG ); |
这样,在程序结束的时候,也就是winmain,main或dllmain函数返回之后,如果还有内存块没有释放,它们的信息会被打印到Debug窗口里。
如果你试着创建了一个非MFC应用程序,而且在程序的入口处加入了以上代码,并且故意在程序中不释放某些内存块,你会在Debug窗口里看到以下的信息:
1 | {47} normal block at 0x00C91C90, 200 bytes long. |
内存泄漏的确检测到了,但是和上面MFC程序的例子相比,缺少了文件名和行号。对于一个比较大的程序,没有这些信息,解决问题将变得十分困难。
为了能够知道泄漏的内存块是在哪里分配的,你需要实现类似MFC的映射功能,把new,maolloc等函数映射到_malloc_dbg函数上。这里我不再赘述,你可以参考MFC的源代码。
由于Debug Function实现在MS C-RuntimeLibrary中,所以它只能检测到堆内存的泄漏,而且只限于malloc,realloc或strdup等分配的内存,而那些系统资源,比如HANDLE,GDI Object,或是不通过C-Runtime Library分配的内存,比如VARIANT,BSTR的泄漏,它是无法检测到的,这是这种检测法的一个重大的局限性。另外,为了能记录内存块是在哪里分配的,源代码必须相应的配合,这在调试一些老的程序非常麻烦,毕竟修改源代码不是一件省心的事,这是这种检测法的另一个局限性。
对于开发一个大型的程序,MS C-Runtime Library提供的检测功能是远远不够的。接下来我们就看看外挂式的检测工具。我用的比较多的是BoundsChecker,一则因为它的功能比较全面,更重要的是它的稳定性。这类工具如果不稳定,反而会忙里添乱。到底是出自鼎鼎大名的NuMega,我用下来基本上没有什么大问题。
使用BoundsChecker检测内存泄漏
BoundsChecker采用一种被称为 Code Injection的技术,来截获对分配内存和释放内存的函数的调用。简单地说,当你的程序开始运行时,BoundsChecker的DLL被自动载入进程的地址空间(这可以通过system-level的Hook实现),然后它会修改进程中对内存分配和释放的函数调用,让这些调用首先转入它的代码,然后再执行原来的代码。BoundsChecker在做这些动作的时,无须修改被调试程序的源代码或工程配置文件,这使得使用它非常的简便、直接。
这里我们以malloc函数为例,截获其他的函数方法与此类似。
需要被截获的函数可能在DLL中,也可能在程序的代码里。比如,如果静态连结C-Runtime Library,那么malloc函数的代码会被连结到程序里。为了截获住对这类函数的调用,BoundsChecker会动态修改这些函数的指令。
以下两段汇编代码,一段没有BoundsChecker介入,另一段则有BoundsChecker的介入:
1 | 126: _CRTIMP void * __cdecl malloc ( |
以下这一段代码有BoundsChecker介入:
1 | 126: _CRTIMP void * __cdecl malloc ( |
当BoundsChecker介入后,函数malloc的前三条汇编指令被替换成一条jmp指令,原来的三条指令被搬到地址01F41EC8处了。当程序进入malloc后先jmp到01F41EC8,执行原来的三条指令,然后就是BoundsChecker的天下了。大致上它会先记录函数的返回地址(函数的返回地址在stack上,所以很容易修改),然后把返回地址指向属于BoundsChecker的代码,接着跳到malloc函数原来的指令,也就是在00403c15的地方。当malloc函数结束的时候,由于返回地址被修改,它会返回到BoundsChecker的代码中,此时BoundsChecker会记录由malloc分配的内存的指针,然后再跳转到到原来的返回地址去。
如果内存分配/释放函数在DLL中,BoundsChecker则采用另一种方法来截获对这些函数的调用。BoundsChecker通过修改程序的DLL Import Table让table中的函数地址指向自己的地址,以达到截获的目的。
截获住这些分配和释放函数,BoundsChecker就能记录被分配的内存或资源的生命周期。接下来的问题是如何与源代码相关,也就是说当BoundsChecker检测到内存泄漏,它如何报告这块内存块是哪段代码分配的。答案是调试信息(Debug Information)。当我们编译一个Debug版的程序时,编译器会把源代码和二进制代码之间的对应关系记录下来,放到一个单独的文件里(.pdb)或者直接连结进目标程序,通过直接读取调试信息就能得到分配某块内存的源代码在哪个文件,哪一行上。使用Code Injection和Debug Information,使BoundsChecker不但能记录呼叫分配函数的源代码的位置,而且还能记录分配时的Call Stack,以及Call Stack上的函数的源代码位置。这在使用像MFC这样的类库时非常有用,以下我用一个例子来说明:
1 | void ShowXItemMenu() |
当调用ShowYItemMenu()时,我们故意造成HMENU的泄漏。但是,对于BoundsChecker来说被泄漏的HMENU是在class CMenu::CreatePopupMenu()中分配的。假设的你的程序有许多地方使用了CMenu的CreatePopupMenu()函数,如CMenu::CreatePopupMenu()造成的,你依然无法确认问题的根结到底在哪里,在ShowXItemMenu()中还是在ShowYItemMenu()中,或者还有其它的地方也使用了CreatePopupMenu()?有了Call Stack的信息,问题就容易了。BoundsChecker会如下报告泄漏的HMENU的信息:
1 | Function |
这里省略了其他的函数调用
如此,我们很容易找到发生问题的函数是ShowYItemMenu()。当使用MFC之类的类库编程时,大部分的API调用都被封装在类库的class里,有了Call Stack信息,我们就可以非常容易的追踪到真正发生泄漏的代码。
记录Call Stack信息会使程序的运行变得非常慢,因此默认情况下BoundsChecker不会记录Call Stack信息。可以按照以下的步骤打开记录Call Stack信息的选项开关:
- 打开菜单:BoundsChecker|Setting…
- 在Error Detection页中,在Error Detection Scheme的List中选择Custom
- 在Category的Combox中选择 Pointer and leak error check
- 钩上Report Call Stack复选框
- 点击Ok
基于Code Injection,BoundsChecker还提供了API Parameter的校验功能,memory over run等功能。这些功能对于程序的开发都非常有益。由于这些内容不属于本文的主题,所以不在此详述了。
尽管BoundsChecker的功能如此强大,但是面对隐式内存泄漏仍然显得苍白无力。所以接下来我们看看如何用Performance Monitor检测内存泄漏。
使用Performance Monitor检测内存泄漏
NT的内核在设计过程中已经加入了系统监视功能,比如CPU的使用率,内存的使用情况,I/O操作的频繁度等都作为一个个Counter,应用程序可以通过读取这些Counter了解整个系统的或者某个进程的运行状况。Performance Monitor就是这样一个应用程序。
为了检测内存泄漏,我们一般可以监视Process对象的Handle Count,Virutal Bytes 和Working Set三个Counter。Handle Count记录了进程当前打开的HANDLE的个数,监视这个Counter有助于我们发现程序是否有Handle泄漏;Virtual Bytes记录了该进程当前在虚地址空间上使用的虚拟内存的大小,NT的内存分配采用了两步走的方法,首先,在虚地址空间上保留一段空间,这时操作系统并没有分配物理内存,只是保留了一段地址。然后,再提交这段空间,这时操作系统才会分配物理内存。所以,Virtual Bytes一般总大于程序的Working Set。监视Virutal Bytes可以帮助我们发现一些系统底层的问题; Working Set记录了操作系统为进程已提交的内存的总量,这个值和程序申请的内存总量存在密切的关系,如果程序存在内存的泄漏这个值会持续增加,但是Virtual Bytes却是跳跃式增加的。
监视这些Counter可以让我们了解进程使用内存的情况,如果发生了泄漏,即使是隐式内存泄漏,这些Counter的值也会持续增加。但是,我们知道有问题却不知道哪里有问题,所以一般使用Performance Monitor来验证是否有内存泄漏,而使用BoundsChecker来找到和解决。
当Performance Monitor显示有内存泄漏,而BoundsChecker却无法检测到,这时有两种可能:第一种,发生了偶发性内存泄漏。这时你要确保使用Performance Monitor和使用BoundsChecker时,程序的运行环境和操作方法是一致的。第二种,发生了隐式的内存泄漏。这时你要重新审查程序的设计,然后仔细研究Performance Monitor记录的Counter的值的变化图,分析其中的变化和程序运行逻辑的关系,找到一些可能的原因。这是一个痛苦的过程,充满了假设、猜想、验证、失败,但这也是一个积累经验的绝好机会。
探讨C++内存回收
C++内存对象大会战
如果一个人自称为程序高手,却对内存一无所知,那么我可以告诉你,他一定在吹牛。用C或C++写程序,需要更多地关注内存,这不仅仅是因为内存的分配是否合理直接影响着程序的效率和性能,更为主要的是,当我们操作内存的时候一不小心就会出现问题,而且很多时候,这些问题都是不易发觉的,比如内存泄漏,比如悬挂指针。笔者今天在这里并不是要讨论如何避免这些问题,而是想从另外一个角度来认识C++内存对象。
我们知道,C++将内存划分为三个逻辑区域:堆、栈和静态存储区。既然如此,我称位于它们之中的对象分别为堆对象,栈对象以及静态对象。那么这些不同的内存对象有什么区别了?堆对象和栈对象各有什么优劣了?如何禁止创建堆对象或栈对象了?这些便是今天的主题。
基本概念
先来看看栈。栈,一般用于存放局部变量或对象,如我们在函数定义中用类似下面语句声明的对象:
1 | Type stack_object ; |
stack_object便是一个栈对象,它的生命期是从定义点开始,当所在函数返回时,生命结束。
另外,几乎所有的临时对象都是栈对象。比如,下面的函数定义:
1 | Type fun(Type object); |
这个函数至少产生两个临时对象,首先,参数是按值传递的,所以会调用拷贝构造函数生成一个临时对象object_copy1 ,在函数内部使用的不是使用的不是object,而是object_copy1,自然,object_copy1是一个栈对象,它在函数返回时被释放;还有这个函数是值返回的,在函数返回时,如果我们不考虑返回值优化(NRV),那么也会产生一个临时对象object_copy2,这个临时对象会在函数返回后一段时间内被释放。比如某个函数中有如下代码:
1 | Type tt ,result ; //生成两个栈对象 |
上面的第二个语句的执行情况是这样的,首先函数fun返回时生成一个临时对象object_copy2 ,然后再调用赋值运算符执行
1 | tt = object_copy2 ; //调用赋值运算符 |
看到了吗?编译器在我们毫无知觉的情况下,为我们生成了这么多临时对象,而生成这些临时对象的时间和空间的开销可能是很大的,所以,你也许明白了,为什么对于”大”对象最好用const引用传递代替按值进行函数参数传递了。
接下来,看看堆。堆,又叫自由存储区,它是在程序执行的过程中动态分配的,所以它最大的特性就是动态性。在C++中,所有堆对象的创建和销毁都要由程序员负责,所以,如果处理不好,就会发生内存问题。如果分配了堆对象,却忘记了释放,就会产生内存泄漏;而如果已释放了对象,却没有将相应的指针置为NULL,该指针就是所谓的”悬挂指针”,再度使用此指针时,就会出现非法访问,严重时就导致程序崩溃。
那么,C++中是怎样分配堆对象的?唯一的方法就是用new(当然,用类malloc指令也可获得C式堆内存),只要使用new,就会在堆中分配一块内存,并且返回指向该堆对象的指针。
再来看看静态存储区。所有的静态对象、全局对象都于静态存储区分配。关于全局对象,是在main()函数执行前就分配好了的。其实,在main()函数中的显示代码执行之前,会调用一个由编译器生成的_main()函数,而_main()函数会进行所有全局对象的的构造及初始化工作。而在main()函数结束之前,会调用由编译器生成的exit函数,来释放所有的全局对象。比如下面的代码:
1 | void main(void) |
实际上,被转化成这样:
1 | void main(void) |
所以,知道了这个之后,便可以由此引出一些技巧,如,假设我们要在main()函数执行之前做某些准备工作,那么我们可以将这些准备工作写到一个自定义的全局对象的构造函数中,这样,在main()函数的显式代码执行之前,这个全局对象的构造函数会被调用,执行预期的动作,这样就达到了我们的目的。 刚才讲的是静态存储区中的全局对象,那么,局部静态对象了?局部静态对象通常也是在函数中定义的,就像栈对象一样,只不过,其前面多了个static关键字。局部静态对象的生命期是从其所在函数第一次被调用,更确切地说,是当第一次执行到该静态对象的声明代码时,产生该静态局部对象,直到整个程序结束时,才销毁该对象。
还有一种静态对象,那就是它作为class的静态成员。考虑这种情况时,就牵涉了一些较复杂的问题。
第一个问题是class的静态成员对象的生命期,class的静态成员对象随着第一个class object的产生而产生,在整个程序结束时消亡。也就是有这样的情况存在,在程序中我们定义了一个class,该类中有一个静态对象作为成员,但是在程序执行过程中,如果我们没有创建任何一个该class object,那么也就不会产生该class所包含的那个静态对象。还有,如果创建了多个class object,那么所有这些object都共享那个静态对象成员。
第二个问题是,当出现下列情况时:
1 | class Base |
请注意上面标为黑体的三条语句,它们所访问的s_object是同一个对象吗?答案是肯定的,它们的确是指向同一个对象,这听起来不像是真的,是吗?但这是事实,你可以自己写段简单的代码验证一下。我要做的是来解释为什么会这样? 我们知道,当一个类比如Derived1,从另一个类比如Base继承时,那么,可以看作一个Derived1对象中含有一个Base型的对象,这就是一个subobject。一个Derived1对象的大致内存布局如下:
让我们想想,当我们将一个Derived1型的对象传给一个接受非引用Base型参数的函数时会发生切割,那么是怎么切割的呢?相信现在你已经知道了,那就是仅仅取出了Derived1型的对象中的subobject,而忽略了所有Derived1自定义的其它数据成员,然后将这个subobject传递给函数(实际上,函数中使用的是这个subobject的拷贝)。
所有继承Base类的派生类的对象都含有一个Base型的subobject(这是能用Base型指针指向一个Derived1对象的关键所在,自然也是多态的关键了),而所有的subobject和所有Base型的对象都共用同一个s_object对象,自然,从Base类派生的整个继承体系中的类的实例都会共用同一个s_object对象了。上面提到的example、example1、example2的对象布局如下图所示:
三种内存对象的比较
栈对象的优势是在适当的时候自动生成,又在适当的时候自动销毁,不需要程序员操心;而且栈对象的创建速度一般较堆对象快,因为分配堆对象时,会调用operator new操作,operator new会采用某种内存空间搜索算法,而该搜索过程可能是很费时间的,产生栈对象则没有这么麻烦,它仅仅需要移动栈顶指针就可以了。但是要注意的是,通常栈空间容量比较小,一般是1MB~2MB,所以体积比较大的对象不适合在栈中分配。特别要注意递归函数中最好不要使用栈对象,因为随着递归调用深度的增加,所需的栈空间也会线性增加,当所需栈空间不够时,便会导致栈溢出,这样就会产生运行时错误。
堆对象,其产生时刻和销毁时刻都要程序员精确定义,也就是说,程序员对堆对象的生命具有完全的控制权。我们常常需要这样的对象,比如,我们需要创建一个对象,能够被多个函数所访问,但是又不想使其成为全局的,那么这个时候创建一个堆对象无疑是良好的选择,然后在各个函数之间传递这个堆对象的指针,便可以实现对该对象的共享。另外,相比于栈空间,堆的容量要大得多。实际上,当物理内存不够时,如果这时还需要生成新的堆对象,通常不会产生运行时错误,而是系统会使用虚拟内存来扩展实际的物理内存。
接下来看看static对象。
首先是全局对象。全局对象为类间通信和函数间通信提供了一种最简单的方式,虽然这种方式并不优雅。一般而言,在完全的面向对象语言中,是不存在全局对象的,比如C#,因为全局对象意味着不安全和高耦合,在程序中过多地使用全局对象将大大降低程序的健壮性、稳定性、可维护性和可复用性。C++也完全可以剔除全局对象,但是最终没有,我想原因之一是为了兼容C。
其次是类的静态成员,上面已经提到,基类及其派生类的所有对象都共享这个静态成员对象,所以当需要在这些class之间或这些class objects之间进行数据共享或通信时,这样的静态成员无疑是很好的选择。
接着是静态局部对象,主要可用于保存该对象所在函数被屡次调用期间的中间状态,其中一个最显著的例子就是递归函数,我们都知道递归函数是自己调用自己的函数,如果在递归函数中定义一个nonstatic局部对象,那么当递归次数相当大时,所产生的开销也是巨大的。这是因为nonstatic局部对象是栈对象,每递归调用一次,就会产生一个这样的对象,每返回一次,就会释放这个对象,而且,这样的对象只局限于当前调用层,对于更深入的嵌套层和更浅露的外层,都是不可见的。每个层都有自己的局部对象和参数。
在递归函数设计中,可以使用static对象替代nonstatic局部对象(即栈对象),这不仅可以减少每次递归调用和返回时产生和释放nonstatic对象的开销,而且static对象还可以保存递归调用的中间状态,并且可为各个调用层所访问。
使用栈对象的意外收获
前面已经介绍到,栈对象是在适当的时候创建,然后在适当的时候自动释放的,也就是栈对象有自动管理功能。那么栈对象会在什么会自动释放了?第一,在其生命期结束的时候;第二,在其所在的函数发生异常的时候。你也许说,这些都很正常啊,没什么大不了的。是的,没什么大不了的。但是只要我们再深入一点点,也许就有意外的收获了。
栈对象,自动释放时,会调用它自己的析构函数。如果我们在栈对象中封装资源,而且在栈对象的析构函数中执行释放资源的动作,那么就会使资源泄漏的概率大大降低,因为栈对象可以自动的释放资源,即使在所在函数发生异常的时候。实际的过程是这样的:函数抛出异常时,会发生所谓的stack_unwinding(堆栈回滚),即堆栈会展开,由于是栈对象,自然存在于栈中,所以在堆栈回滚的过程中,栈对象的析构函数会被执行,从而释放其所封装的资源。除非,除非在析构函数执行的过程中再次抛出异常――而这种可能性是很小的,所以用栈对象封装资源是比较安全的。基于此认识,我们就可以创建一个自己的句柄或代理来封装资源了。智能指针(auto_ptr)中就使用了这种技术。在有这种需要的时候,我们就希望我们的资源封装类只能在栈中创建,也就是要限制在堆中创建该资源封装类的实例。
禁止产生堆对象
上面已经提到,你决定禁止产生某种类型的堆对象,这时你可以自己创建一个资源封装类,该类对象只能在栈中产生,这样就能在异常的情况下自动释放封装的资源。
那么怎样禁止产生堆对象了?我们已经知道,产生堆对象的唯一方法是使用new操作,如果我们禁止使用new不就行了么。再进一步,new操作执行时会调用operator new,而operator new是可以重载的。方法有了,就是使new operator 为private,为了对称,最好将operator delete也重载为private。现在,你也许又有疑问了,难道创建栈对象不需要调用new吗?是的,不需要,因为创建栈对象不需要搜索内存,而是直接调整堆栈指针,将对象压栈,而operator new的主要任务是搜索合适的堆内存,为堆对象分配空间,这在上面已经提到过了。好,让我们看看下面的示例代码:
1 | #include <stdlib.h> //需要用到C式内存分配函数 |
NoHashObject现在就是一个禁止堆对象的类了,如果你写下如下代码:
1 | NoHashObject* fp = new NoHashObject() ; //编译期错误! |
上面代码会产生编译期错误。好了,现在你已经知道了如何设计一个禁止堆对象的类了,你也许和我一样有这样的疑问,难道在类NoHashObject的定义不能改变的情况下,就一定不能产生该类型的堆对象了吗?不,还是有办法的,我称之为”暴力破解法”。C++是如此地强大,强大到你可以用它做你想做的任何事情。这里主要用到的是技巧是指针类型的强制转换。
1 | void main(void) |
上面的实现是麻烦的,而且这种实现方式几乎不会在实践中使用,但是我还是写出来路,因为理解它,对于我们理解C++内存对象是有好处的。对于上面的这么多强制类型转换,其最根本的是什么了?我们可以这样理解:
某块内存中的数据是不变的,而类型就是我们戴上的眼镜,当我们戴上一种眼镜后,我们就会用对应的类型来解释内存中的数据,这样不同的解释就得到了不同的信息。
所谓强制类型转换实际上就是换上另一副眼镜后再来看同样的那块内存数据。
另外要提醒的是,不同的编译器对对象的成员数据的布局安排可能是不一样的,比如,大多数编译器将NoHashObject的ptr指针成员安排在对象空间的头4个字节,这样才会保证下面这条语句的转换动作像我们预期的那样执行:
1 | Resource* rp = (Resource*)obj_ptr ; |
但是,并不一定所有的编译器都是如此。
既然我们可以禁止产生某种类型的堆对象,那么可以设计一个类,使之不能产生栈对象吗?当然可以。
禁止产生栈对象
前面已经提到了,创建栈对象时会移动栈顶指针以”挪出”适当大小的空间,然后在这个空间上直接调用对应的构造函数以形成一个栈对象,而当函数返回时,会调用其析构函数释放这个对象,然后再调整栈顶指针收回那块栈内存。在这个过程中是不需要operator new/delete操作的,所以将operator new/delete设置为private不能达到目的。当然从上面的叙述中,你也许已经想到了:将构造函数或析构函数设为私有的,这样系统就不能调用构造/析构函数了,当然就不能在栈中生成对象了。
这样的确可以,而且我也打算采用这种方案。但是在此之前,有一点需要考虑清楚,那就是,如果我们将构造函数设置为私有,那么我们也就不能用new来直接产生堆对象了,因为new在为对象分配空间后也会调用它的构造函数啊。所以,我打算只将析构函数设置为private。再进一步,将析构函数设为private除了会限制栈对象生成外,还有其它影响吗?是的,这还会限制继承。
如果一个类不打算作为基类,通常采用的方案就是将其析构函数声明为private。
为了限制栈对象,却不限制继承,我们可以将析构函数声明为protected,这样就两全其美了。如下代码所示:
1 | class NoStackObject |
接着,可以像这样使用NoStackObject类:
1 | NoStackObject* hash_ptr = new NoStackObject() ; |
呵呵,是不是觉得有点怪怪的,我们用new创建一个对象,却不是用delete去删除它,而是要用destroy方法。很显然,用户是不习惯这种怪异的使用方式的。所以,我决定将构造函数也设为private或protected。这又回到了上面曾试图避免的问题,即不用new,那么该用什么方式来生成一个对象了?我们可以用间接的办法完成,即让这个类提供一个static成员函数专门用于产生该类型的堆对象。(设计模式中的singleton模式就可以用这种方式实现。)让我们来看看:
1 | class NoStackObject |
现在可以这样使用NoStackObject类了:
1 | NoStackObject* hash_ptr = NoStackObject::creatInstance() ; |
现在感觉是不是好多了,生成对象和释放对象的操作一致了。
浅议C++ 中的垃圾回收方法
许多 C 或者 C++ 程序员对垃圾回收嗤之以鼻,认为垃圾回收肯定比自己来管理动态内存要低效,而且在回收的时候一定会让程序停顿在那里,而如果自己控制内存管理的话,分配和释放时间都是稳定的,不会导致程序停顿。最后,很多 C/C++ 程序员坚信在C/C++ 中无法实现垃圾回收机制。这些错误的观点都是由于不了解垃圾回收的算法而臆想出来的。
其实垃圾回收机制并不慢,甚至比动态内存分配更高效。因为我们可以只分配不释放,那么分配内存的时候只需要从堆上一直的获得新的内存,移动堆顶的指针就够了;而释放的过程被省略了,自然也加快了速度。现代的垃圾回收算法已经发展了很多,增量收集算法已经可以让垃圾回收过程分段进行,避免打断程序的运行了。而传统的动态内存管理的算法同样有在适当的时间收集内存碎片的工作要做,并不比垃圾回收更有优势。
而垃圾回收的算法的基础通常基于扫描并标记当前可能被使用的所有内存块,从已经被分配的所有内存中把未标记的内存回收来做的。C/C++ 中无法实现垃圾回收的观点通常基于无法正确扫描出所有可能还会被使用的内存块,但是,看似不可能的事情实际上实现起来却并不复杂。首先,通过扫描内存的数据,指向堆上动态分配出来内存的指针是很容易被识别出来的,如果有识别错误,也只能是把一些不是指针的数据当成指针,而不会把指针当成非指针数据。这样,回收垃圾的过程只会漏回收掉而不会错误的把不应该回收的内存清理。其次,如果回溯所有内存块被引用的根,只可能存在于全局变量和当前的栈内,而全局变量(包括函数内的静态变量)都是集中存在于 bss 段或 data段中。
垃圾回收的时候,只需要扫描 bss 段, data 段以及当前被使用着的栈空间,找到可能是动态内存指针的量,把引用到的内存递归扫描就可以得到当前正在使用的所有动态内存了。
如果肯为你的工程实现一个不错的垃圾回收器,提高内存管理的速度,甚至减少总的内存消耗都是可能的。如果有兴趣的话,可以搜索一下网上已有的关于垃圾回收的论文和实现了的库,开拓视野对一个程序员尤为重要。
C++虚继承
概念
为了解决从不同途径继承来的同名的数据成员在内存中有不同的拷贝造成数据不一致问题,将共同基类设置为虚基类。这时从不同的路径继承过来的同名数据成员在内存中就只有一个拷贝,同一个函数名也只有一个映射。这样不仅就解决了二义性问题,也节省了内存,避免了数据不一致的问题。
class 派生类名:virtual 继承方式 基类名
virtual是关键字,声明该基类为派生类的虚基类。
在多继承情况下,虚基类关键字的作用范围和继承方式关键字相同,只对紧跟其后的基类起作用。
声明了虚基类之后,虚基类在进一步派生过程中始终和派生类一起,维护同一个基类子对象的拷贝。
底层实现原理与编译器相关,一般通过虚基类指针和虚基类表实现,每个虚继承的子类都有一个虚基类指针(占用一个指针的存储空间,4字节)和虚基类表(不占用类对象的存储空间)(需要强调的是,虚基类依旧会在子类里面存在拷贝,只是仅仅最多存在一份而已,并不是不在子类里面了);当虚继承的子类被当做父类继承时,虚基类指针也会被继承。
实际上,vbptr 指的是虚基类表指针(virtual base table pointer),该指针指向了一个虚基类表(virtual table),虚表中记录了虚基类与本类的偏移地址;通过偏移地址,这样就找到了虚基类成员,而虚继承也不用像普通多继承那样维持着公共基类(虚基类)的两份同样的拷贝,节省了存储空间。
执行顺序
首先执行虚基类的构造函数,多个虚基类的构造函数按照被继承的顺序构造;
执行基类的构造函数,多个基类的构造函数按照被继承的顺序构造;
执行成员对象的构造函数,多个成员对象的构造函数按照申明的顺序构造;
执行派生类自己的构造函数;
析构以与构造相反的顺序执行;
mark
从虚基类直接或间接派生的派生类中的构造函数的成员初始化列表中都要列出对虚基类构造函数的调用。但只有用于建立对象的最派生类的构造函数调用虚基类的构造函数,而该派生类的所有基类中列出的对虚基类的构造函数的调用在执行中被忽略,从而保证对虚基类子对象只初始化一次。
在一个成员初始化列表中同时出现对虚基类和非虚基类构造函数的调用时,虚基类的构造函数先于非虚基类的构造函数执行。
虚继承与继承的差异
首先,虚拟继承与普通继承的区别有:
假设derived 继承自base类,那么derived与base是一种“is a”的关系,即derived类是base类,而反之错误;
假设derived 虚继承自base类,那么derivd与base是一种“has a”的关系,即derived类有一个指向base类的vptr。(貌似有些牵强!某些编译器确实如此,关于虚继承与普通继承的差异见:c++ 虚继承与继承的差异 )
因此虚继承可以认为不是一种继承关系,而可以认为是一种组合的关系。正是因为这样的区别,下面我们针对虚拟继承来具体分析。虚拟继承中遇到最广泛的是菱形结构。下面从菱形虚继承结构说起吧:
1 | class stream |
程序运行的输出结果为:
1 | stream::stream()! |
输出这样的结果是毫无悬念的!本来虚拟继承的目的就是当多重继承出现重复的基类时,其只保存一份基类。减少内存开销。其继承结构为:
1 | stream |
这样子的菱形结构,使公共基类只产生一个拷贝。
从基类 stream 派生新类时,使用 virtual 将类stream说明为虚基类,这时派生类istream、ostream包含一个指向虚基类的vptr,而不会产生实际的stream空间。所以最终iiostream也含有一个指向虚基类的vptr,调用stream中的成员方法时,通过vptr去调用,不会产生二义性。
而现在我们换种方式使用虚继承:
1 | class stream |
其输出结果为:
1 | stream::stream()! |
从结果可以看到,其构造过程中重复出现基类stream的构造过程。这样就完全没有达到虚拟继承的目的。其继承结构为:
1 | stream stream |
从继承结构可以看出,如果iiostream对象调用基类stream中的成员方法,会导致方法的二义性。因为iiostream含有指向其虚继承基类 istream,ostream的vptr。而 istream,ostream包含了stream的空间,所以导致iiostream不知道导致是调用那个stream的方法。要解决改问题,可以指定vptr,即在调用成员方法是需要加上作用域,例如
1 | class stream |
编译器提示调用f方法错误。而采用
1 | ii.istream::f(); |
编译通过,并且会调用istream类vptr指向的f()方法。 前面说了这么多,在实际的应用中虚拟继承的胡乱使用,更是会导致继承顺序以及基类构造顺序的混乱。如下面的代码:
1 | class B1 |
上面的代码是来自《Exceptional C++ Style》中关于继承顺序的一段代码。可以看到,上面的代码继承关系非常复杂,而且层次不是特别的清楚。而虚继承的加入更是让继承结构更加无序。不管怎么样,我们还是可以根据c++的标准来分析上面代码的构造顺序。c++对于创建一个类类型的初始化顺序是这样子的:
- 最上层派生类的构造函数负责调用虚基类子对象的构造函数。所有虚基类子对象会按照深度优先、从左到右的顺序进行初始化;
- 直接基类子对象按照它们在类定义中声明的顺序被一一构造起来;
- 非静态成员子对象按照它们在类定义体中的声明的顺序被一一构造起来;
- 最上层派生类的构造函数体被执行。
根据上面的规则,可以看出,最先构造的是虚继承基类的构造函数,并且是按照深度优先,从左往右构造。因此,我们需要将继承结构划分层次。显然上面的代码可以认为是4层继承结构。其中最顶层的是B1,B2类。第二层是V1,V2,V3。第三层是D1,D2.最底层是X。而D1虚继承V1,D2虚继承V2,且D1和D2在同一层。所以V1最先构造,其次是V2.在V2构造顺序中,B1先于B2.虚基类构造完成后,接着是直接基类子对象构造,其顺序为D1,D2.最后为成员子对象的构造,顺序为声明的顺序。构造完毕后,开始按照构造顺序执行构造函数体了。所以其最终的输出结果为:
1 | B1::B1()!< |
从结果也可以看出其构造顺序完全符合上面的标准。而在结果中,可以看到B1重复构造。还是因为没有按照要求使用virtual继承导致的结果。要想只构造B1一次,可以将virtual全部改在B1上,如下面的代码:
1 | class B1 |
根据上面的代码,其输出结果为:
1 | B1::B1()!< |
由于虚继承导致其构造顺序发生比较大的变化。不管怎么,分析的规则还是一样。
上面分析了这么多,我们知道了虚继承有一定的好处,但是虚继承会增大占用的空间。这是因为每一次虚继承会产生一个vptr指针。空间因素在编程过程中,我们很少考虑,而构造顺序却需要小心,因此使用未构造对象的危害是相当大的。因此,我们需要小心的使用继承,更要确保在使用继承的时候保证构造顺序不会出错。下面我再着重强调一下基类的构造顺序规则:
- 最上层派生类的构造函数负责调用虚基类子对象的构造函数。所有虚基类子对象会按照深度优先、从左到右的顺序进行初始化;
- 直接基类子对象按照它们在类定义中声明的顺序被一一构造起来;
- 非静态成员子对象按照它们在类定义体中的声明的顺序被一一构造起来;
- 最上层派生类的构造函数体被执行。
C++中虚函数
概念
在某基类中声明为 virtual 并在一个或多个派生类中被重新定义的成员函数,用法格式为:virtual 函数返回类型 函数名(参数表) {函数体};实现多态性,通过指向派生类的基类指针或引用,访问派生类中同名覆盖成员函数。
定义
简单地说,那些被virtual关键字修饰的成员函数,就是虚函数。虚函数的作用,用专业术语来解释就是实现多态性(Polymorphism),多态性是将接口与实现进行分离;用形象的语言来解释就是实现以共同的方法,但因个体差异,而采用不同的策略。多态性底层的原理是什么?这里需要引出虚表和虚基表指针的概念。
- 虚表:虚函数表的缩写,类中含有virtual关键字修饰的方法时,编译器会自动生成虚表
- 虚函数表是全局共享的元素,即全局仅有一个,在编译时就构造完成
- 虚函数表类似一个数组,类对象中存储vptr指针,指向虚函数表,即虚函数表不是函数,不是程序代码,不可能存储在代码段
- 虚函数表存储虚函数的地址,即虚函数表的元素是指向类成员函数的指针,而类中虚函数的个数在编译时期可以确定,即虚函数表的大小可以确定,即大小是在编译时期确定的,不必动态分配内存空间存储虚函数表,所以不在堆中
- 虚表指针:在含有虚函数的类实例化对象时,对象地址的前四个字节存储的指向虚表的指针
C++中虚函数表位于只读数据段(.rodata),也就是C++内存模型中的常量区;而虚函数则位于代码段(.text),也就是C++内存模型中的代码区。
由于虚表指针vptr跟虚函数密不可分,对于有虚函数或者继承于拥有虚函数的基类,对该类进行实例化时,在构造函数执行时会对虚表指针进行初始化,并且存在对象内存布局的最前面。
生成
编译器在发现基类中有虚函数时,会自动为每个含有虚函数的类生成一份虚表,该表是一个一维数组,虚表里保存了虚函数的入口地址。
编译器会在每个对象的前四个字节中保存一个虚表指针,即vptr,指向对象所属类的虚表。在构造时,根据对象的类型去初始化虚指针vptr,从而让vptr指向正确的虚表,从而在调用虚函数时,能找到正确的函数
在派生类定义对象时,程序运行会自动调用构造函数,在构造函数中创建虚表并对虚表初始化。在构造子类对象时,会先调用父类的构造函数,此时,编译器只“看到了”父类,并为父类对象初始化虚表指针,令它指向父类的虚表;当调用子类的构造函数时,为子类对象初始化虚表指针,令它指向子类的虚表
当派生类对基类的虚函数没有重写时,派生类的虚表指针指向的是基类的虚表;当派生类对基类的虚函数重写时,派生类的虚表指针指向的是自身的虚表;当派生类中有自己的虚函数时,在自己的虚表中将此虚函数地址添加在后面。这样指向派生类的基类指针在运行时,就可以根据派生类对虚函数重写情况动态的进行调用,从而实现多态性。
构造函数/析构函数能否声明为虚函数或者纯虚函数
析构函数:析构函数可以为虚函数,并且一般情况下基类析构函数要定义为虚函数。
只有在基类析构函数定义为虚函数时,调用操作符delete销毁指向对象的基类指针时,才能准确调用派生类的析构函数(从该级向上按序调用虚函数),才能准确销毁数据。
析构函数可以是纯虚函数,含有纯虚函数的类是抽象类,此时不能被实例化。但派生类中可以根据自身需求重新改写基类中的纯虚函数。
构造函数不能定义为虚函数。
- 创建一个对象时需要确定对象的类型,而虚函数是在运行时动态确定其类型的。在构造一个对象时,由于对象还未创建成功,编译器无法知道对象的实际类型
- 虚函数的调用需要虚函数表指针vptr,而该指针存放在对象的内存空间中,若构造函数声明为虚函数,那么由于对象还未创建,还没有内存空间,更没有虚函数表vtable地址用来调用虚构造函数了
- 虚函数的作用在于通过父类的指针或者引用调用它的时候能够变成调用子类的那个成员函数。而构造函数是在创建对象时自动调用的,不可能通过父类或者引用去调用,因此就规定构造函数不能是虚函数
将构造函数和析构函数声明为inline是没有什么意义的,即编译器并不真正对声明为inline的构造和析构函数进行内联操作,因为编译器会在构造和析构函数中添加额外的操作(申请/释放内存,构造/析构对象等),致使构造函数/析构函数并不像看上去的那么精简。
有的人认为虚函数被声明为inline,但是编译器并没有对其内联,他们给出的理由是inline是编译期决定的,而虚函数是运行期决定的,即在不知道将要调用哪个函数的情况下,如何将函数内联呢?
上述观点看似正确,其实不然,如果虚函数在编译器就能够决定将要调用哪个函数时,就能够内联。当是指向派生类的指针(多态性)调用声明为inline的虚函数时,不会内联展开;当是对象本身调用虚函数时,会内联展开,当然前提依然是函数并不复杂的情况下
目的
直接的讲,C++中基类采用virtual虚析构函数是为了防止内存泄漏。
具体地说,如果派生类中申请了内存空间,并在其析构函数中对这些内存空间进行释放。假设基类中采用的是非虚析构函数,当删除基类指针指向的派生类对象时就不会触发动态绑定,因而只会调用基类的析构函数,而不会调用派生类的析构函数。那么在这种情况下,派生类中申请的空间就得不到释放从而产生内存泄漏。
所以,为了防止这种情况的发生,C++中基类的析构函数应采用virtual虚析构函数。
构造函数和析构函数可以调用虚函数吗,为什么
- 在C++中,提倡不在构造函数和析构函数中调用虚函数;
- 构造函数和析构函数调用虚函数时都不使用动态联编,如果在构造函数或析构函数中调用虚函数,则运行的是为构造函数或析构函数自身类型定义的版本;
- 因为父类对象会在子类之前进行构造,此时子类部分的数据成员还未初始化,因此调用子类的虚函数时不安全的,故而C++不会进行动态联编;
- 析构函数是用来销毁一个对象的,在销毁一个对象时,先调用子类的析构函数,然后再调用基类的析构函数。所以在调用基类的析构函数时,派生类对象的数据成员已经销毁,这个时候再调用子
类的虚函数没有任何意义。
虚析构函数的作用,父类的析构函数是否要设置为虚函数?
1) C++中基类采用virtual虚析构函数是为了防止内存泄漏。
具体地说,如果派生类中申请了内存空间,并在其析构函数中对这些内存空间进行释放。
假设基类中采用的是非虚析构函数,当删除基类指针指向的派生类对象时就不会触发动态绑定,因而只会调用基类的析构函数,而不会调用派生类的析构函数。
那么在这种情况下,派生类中申请的空间就得不到释放从而产生内存泄漏。所以,为了防止这种情况的发生,C++中基类的析构函数应采用virtual虚析构函数。
2) 纯虚析构函数一定得定义,因为每一个派生类析构函数会被编译器加以扩张,以静态调用的方式调用其每一个虚基类以及上一层基类的析构函数。因此,缺乏任何一个基类析构函数的定义,就会导致链接失败,最好不要把虚析构函数定义为纯虚析构函数。
纯虚函数
定义
纯虚函数是一种特殊的虚函数,它的一般格式如下:
1 | class <类名> |
在许多情况下,在基类中不能对虚函数给出有意义的实现,而把它声明为纯虚函数,它的实现留给该基类的派生类去做。这就是纯虚函数的作用。
纯虚函数可以让类先具有一个操作名称,而没有操作内容,让派生类在继承时再去具体地给出定义。
凡是含有纯虚函数的类叫做抽象类。这种类不能声明对象,只是作为基类为派生类服务。除非在派生类中完全实现基类中所有的的纯虚函数,否则,派生类也变成了抽象类,不能实例化对象。
抽象类
抽象类是一种特殊的类,它是为了抽象和设计的目的为建立的,它处于继承层次结构的较上层。
(1)抽象类的定义:称带有纯虚函数的类为抽象类。
(2)抽象类的作用:抽象类的主要作用是将有关的操作作为结果接口组织在一个继承层次结构中,由它来为派生类提供一个公共的根,派生类将具体实现在其基类中作为接口的操作。所以派生类实际上刻画了一组子类的操作接口的通用语义,这些语义也传给子类,子类可以具体实现这些语义,也可以再将这些语义传给自己的子类。
(3)使用抽象类时注意:抽象类只能作为基类来使用,其纯虚函数的实现由派生类给出。如果派生类中没有重新定义纯虚函数,而只是继承基类的纯虚函数,则这个派生类仍然还是一个抽象类。如果派生类中给出了基类纯虚函数的实现,则该派生类就不再是抽象类了,它是一个可以建立对象的具体的类。
抽象类是不能定义对象的。一个纯虚函数不需要(但是可以)被定义。
虚函数的代价?
- 带有虚函数的类,每一个类会产生一个虚函数表,用来存储指向虚成员函数的指针,增大类;
- 带有虚函数的类的每一个对象,都会有有一个指向虚表的指针,会增加对象的空间大小;
- 不能再是内敛的函数,因为内敛函数在编译阶段进行替代,而虚函数表示等待,在运行阶段才能确定到低是采用哪种函数,虚函数不能是内敛函数。
哪些函数不能是虚函数?
- 构造函数,构造函数初始化对象,派生类必须知道基类函数干了什么,才能进行构造;当有虚函数时,每一个类有一个虚表,每一个对象有一个虚表指针,虚表指针在构造函数中初始化;
- 内联函数,内联函数表示在编译阶段进行函数体的替换操作,而虚函数意味着在运行期间进行类型确定,所以内联函数不能是虚函数;
- 静态函数,静态函数不属于对象属于类,静态成员函数没有this指针,因此静态函数设置为虚函数没有任何意义。
- 友元函数,友元函数不属于类的成员函数,不能被继承。对于没有继承特性的函数没有虚函数的说法。
- 普通函数,普通函数不属于类的成员函数,不具有继承特性,因此普通函数没有虚函数。
C++中手动获取调用堆栈
原文链接;https://blog.csdn.net/kevinlynx/article/details/39269507
要了解调用栈,首先需要了解函数的调用过程,下面用一段代码作为例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14#include <stdio.h>
int add(int a, int b) {
int result = 0;
result = a + b;
return result;
}
int main(int argc, char *argv[]) {
int result = 0;
result = add(1, 2);
printf("result = %d \r\n", result);
return 0;
}
使用gcc编译,然后gdb反汇编main函数,看看它是如何调用add函数的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19(gdb) disassemble main
Dump of assembler code for function main:
0x08048439 <+0>: push %ebp
0x0804843a <+1>: mov %esp,%ebp
0x0804843c <+3>: and $0xfffffff0,%esp
0x0804843f <+6>: sub $0x20,%esp
0x08048442 <+9>: movl $0x0,0x1c(%esp) # 给result变量赋0值
0x0804844a <+17>: movl $0x2,0x4(%esp) # 将第2个参数压栈(该参数偏移为esp+0x04)
0x08048452 <+25>: movl $0x1,(%esp) # 将第1个参数压栈(该参数偏移为esp+0x00)
0x08048459 <+32>: call 0x804841c <add> # 调用add函数
0x0804845e <+37>: mov %eax,0x1c(%esp) # 将add函数的返回值赋给result变量
0x08048462 <+41>: mov 0x1c(%esp),%eax
0x08048466 <+45>: mov %eax,0x4(%esp)
0x0804846a <+49>: movl $0x8048510,(%esp)
0x08048471 <+56>: call 0x80482f0 <printf@plt>
0x08048476 <+61>: mov $0x0,%eax
0x0804847b <+66>: leave
0x0804847c <+67>: ret
End of assembler dump.
可以看到,参数是在add函数调用前压栈,换句话说,参数压栈由调用者进行,参数存储在调用者的栈空间中,下面再看一下进入add函数后都做了什么:1
2
3
4
5
6
7
8
9
10
11
12
13
14(gdb) disassemble add
Dump of assembler code for function add:
0x0804841c <+0>: push %ebp # 将ebp压栈(保存函数调用者的栈基址)
0x0804841d <+1>: mov %esp,%ebp # 将ebp指向栈顶esp(设置当前函数的栈基址)
0x0804841f <+3>: sub $0x10,%esp # 分配栈空间(栈向低地址方向生长)
0x08048422 <+6>: movl $0x0,-0x4(%ebp) # 给result变量赋0值(该变量偏移为ebp-0x04)
0x08048429 <+13>: mov 0xc(%ebp),%eax # 将第2个参数的值赋给eax(准备运算)
0x0804842c <+16>: mov 0x8(%ebp),%edx # 将第1个参数的值赋给edx(准备运算)
0x0804842f <+19>: add %edx,%eax # 加法运算(edx+eax),结果保存在eax中
0x08048431 <+21>: mov %eax,-0x4(%ebp) # 将运算结果eax赋给result变量
0x08048434 <+24>: mov -0x4(%ebp),%eax # 将result变量的值赋给eax(eax将作为函数返回值)
0x08048437 <+27>: leave # 恢复函数调用者的栈基址(pop %ebp)
0x08048438 <+28>: ret # 返回(准备执行下条指令)
End of assembler dump.
进入add函数后,首先进行的操作是将当前的栈基址ebp压栈(此栈基址是调用者main函数的),然后将ebp指向栈顶esp,接下来再进行函数内的处理流程。函数结束前,会将函数调用者的栈基址恢复,然后返回准备执行下一指令。这个过程中,栈上的空间会是下面的样子:
可以发现,每调用一次函数,都会对调用者的栈基址(ebp)进行压栈操作,并且由于栈基址是由当时栈顶指针(esp)而来,会发现,各层函数的栈基址很巧妙的构成了一个链,即当前的栈基址指向下一层函数栈基址所在的位置,如下图所示:
了解了函数的调用过程,想要回溯调用栈也就很简单了,首先获取当前函数的栈基址(寄存器ebp)的值,然后获取该地址所指向的栈的值,该值也就是下层函数的栈基址,找到下层函数的栈基址后,重复刚才的动作,即可以将每一层函数的栈基址都找出来,这也就是我们所需要的调用栈了。
下面是根据原理实现的一段获取函数调用栈的代码,供参考。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59#include <stdio.h>
/* 打印调用栈的最大深度 */
#define DUMP_STACK_DEPTH_MAX 16
/* 获取寄存器ebp的值 */
void get_ebp(unsigned long *ebp) {
__asm__ __volatile__ (
"mov %%ebp, %0"
:"=m"(*ebp)
::"memory");
}
/* 获取调用栈 */
int dump_stack(void **stack, int size) {
unsigned long ebp = 0;
int depth = 0;
/* 1.得到首层函数的栈基址 */
get_ebp(&ebp);
/* 2.逐层回溯栈基址 */
for (depth = 0; (depth < size) && (0 != ebp) && (0 != *(unsigned long *)ebp) && (ebp != *(unsigned long *)ebp); ++depth) {
stack[depth] = (void *)(*(unsigned long *)(ebp + sizeof(unsigned long)));
ebp = *(unsigned long *)ebp;
}
return depth;
}
/* 测试函数 2 */
void test_meloner() {
void *stack[DUMP_STACK_DEPTH_MAX] = {0};
int stack_depth = 0;
int i = 0;
/* 获取调用栈 */
stack_depth = dump_stack(stack, DUMP_STACK_DEPTH_MAX);
/* 打印调用栈 */
printf(" Stack Track: \r\n");
for (i = 0; i < stack_depth; ++i) {
printf(" [%d] %p \r\n", i, stack[i]);
}
return;
}
/* 测试函数 1 */
void test_hutaow() {
test_meloner();
return;
}
/* 主函数 */
int main(int argc, char *argv[]) {
test_hutaow();
return 0;
}
需要知道的信息:
- 函数调用对应的call指令本质上是先压入下一条指令的地址到堆栈,然后跳转到目标函数地址
- 函数返回指令ret则是从堆栈取出一个地址,然后跳转到该地址
- EBP寄存器始终指向当前执行函数相关信息(局部变量)所在栈中的位置,ESP则始终指向栈顶
- 每一个函数入口都会保存调用者的EBP值,在出口处都会重设EBP值,从而实现函数调用的现场保存及现场恢复
- 64位机器增加了不少寄存器,从而使得函数调用的参数大部分时候可以通过寄存器传递;同时寄存器名字发生改变,例如EBP变为RBP
在函数调用中堆栈的情况可用下图说明:
将代码对应起来:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void g() {
int *p = 0;
long a = 0x1234;
printf("%p %x\n", &a, a);
printf("%p %x\n", &p, p);
f();
*p = 1;
}
void b(int argc, char **argv) {
printf("%p %p\n", &argc, &argv);
g();
}
int main(int argc, char **argv) {
b(argc, argv);
return 0;
}
在函数g()中断点,看看堆栈中的内容(64位机器):1
2
3
4
5
6
7
8
9
10
11(gdb) p $rbp
$2 = (void *) 0x7fffffffe370
(gdb) p &p
$3 = (int **) 0x7fffffffe368
(gdb) p $rsp
$4 = (void *) 0x7fffffffe360
(gdb) x/8ag $rbp-16
0x7fffffffe360: 0x1234 0x0
0x7fffffffe370: 0x7fffffffe390 0x400631 <b(int, char**)+43>
0x7fffffffe380: 0x7fffffffe498 0x1a561cbc0
0x7fffffffe390: 0x7fffffffe3b0 0x40064f <main(int, char**)+27>
对应的堆栈图: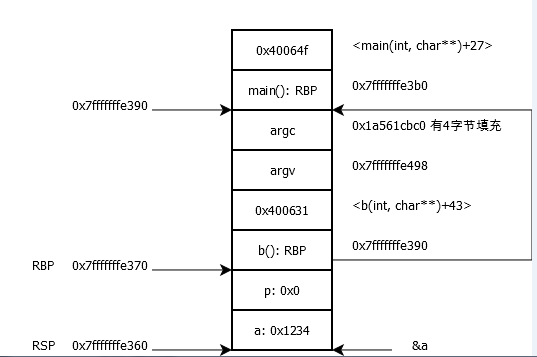
可以看看例子中0x400631 <b(int, char**)+43>和0x40064f <main(int, char**)+27>中的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15(gdb) disassemble 0x400631
...
0x0000000000400627 <b(int, char**)+33>: callq 0x400468 <printf@plt>
0x000000000040062c <b(int, char**)+38>: callq 0x4005ae <g()>
0x0000000000400631 <b(int, char**)+43>: leaveq # call的下一条指令
...
(gdb) disassemble 0x40064f
...
0x000000000040063f <main(int, char**)+11>: mov %rsi,-0x10(%rbp)
0x0000000000400643 <main(int, char**)+15>: mov -0x10(%rbp),%rsi
0x0000000000400647 <main(int, char**)+19>: mov -0x4(%rbp),%edi
0x000000000040064a <main(int, char**)+22>: callq 0x400606 <b(int, char**)>
0x000000000040064f <main(int, char**)+27>: mov $0x0,%eax # call的下一条指令
...
顺带一提,每个函数入口和出口,对应的设置RBP代码为:1
2
3
4
5
6
7
8(gdb) disassemble g
...
0x00000000004005ae <g()+0>: push %rbp # 保存调用者的RBP到堆栈
0x00000000004005af <g()+1>: mov %rsp,%rbp # 设置自己的RBP
...
0x0000000000400603 <g()+85>: leaveq # 等同于:movq %rbp, %rsp
# popq %rbp
0x0000000000400604 <g()+86>: retq
由以上可见,通过当前的RSP或RBP就可以找到调用堆栈中所有函数的RBP;找到了RBP就可以找到函数地址。因为,任何时候的RBP指向的堆栈位置就是上一个函数的RBP;而任何时候RBP所在堆栈中的前一个位置就是函数返回地址。
由此我们可以自己构建一个导致gdb无法取得调用堆栈的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24void f() {
long *p = 0;
p = (long*) (&p + 1); // 取得g()的RBP
*p = 0; // 破坏g()的RBP
}
void g() {
int *p = 0;
long a = 0x1234;
printf("%p %x\n", &a, a);
printf("%p %x\n", &p, p);
f();
*p = 1; // 写0地址导致一次core
}
void b(int argc, char **argv) {
printf("%p %p\n", &argc, &argv);
g();
}
int main(int argc, char **argv) {
b(argc, argv);
return 0;
}
使用gdb运行该程序:1
2
3
4
5
6
7Program received signal SIGSEGV, Segmentation fault.
g () at ebp.c:37
37 *p = 1;
(gdb) bt
Cannot access memory at address 0x8
(gdb) p $rbp
$1 = (void *) 0x0
bt无法获取堆栈,在函数g()中RBP被改写为0,gdb从0偏移一个地址长度即0x8,尝试从0x8内存位置获取函数地址,然后提示Cannot access memory at address 0x8。
RBP出现了问题,我们就可以通过RSP来手动获取调用堆栈。因为RSP是不会被破坏的,要通过RSP获取调用堆栈则需要偏移一些局部变量所占的空间:1
2
3
4
5
6
7(gdb) p $rsp
$2 = (void *) 0x7fffffffe360
(gdb) x/8ag $rsp+16 # g()中局部变量占16字节
0x7fffffffe370: 0x7fffffffe390 0x400631 <b(int, char**)+43>
0x7fffffffe380: 0x7fffffffe498 0x1a561cbc0
0x7fffffffe390: 0x7fffffffe3b0 0x40064f <main(int, char**)+27>
0x7fffffffe3a0: 0x7fffffffe498 0x100000000
基于以上就可以手工找到调用堆栈:1
2
3g()
0x400631 <b(int, char**)+43>
0x40064f <main(int, char**)+27>
上面的例子本质上也是破坏堆栈,并且仅仅破坏了保存了的RBP。在实际情况中,堆栈可能会被破坏得更多,则可能导致手动定位也较困难。
堆栈被破坏还可能导致更多的问题,例如覆盖了函数返回地址,则会导致RIP错误;例如堆栈的不平衡。导致堆栈被破坏的原因也有很多,例如局部数组越界;delete/free栈上对象等。
omit-frame-pointer
使用RBP获取调用堆栈相对比较容易。但现在编译器都可以设置不使用RBP(gcc使用-fomit-frame-pointer,msvc使用/Oy),对于函数而言不设置其RBP意味着可以节省若干条指令。在函数内部则完全使用RSP的偏移来定位局部变量,包括嵌套作用域里的局部变量,即使程序实际运行时不会进入这个作用域。
例如:1
2
3
4
5
6
7void f2() {
int a = 0x1234;
if (a > 0) {
int b = 0xff;
b = a;
}
}
gcc中使用-fomit-frame-pointer生成的代码为:1
2
3
4
5
6
7
8
9(gdb) disassemble f2
Dump of assembler code for function f2:
0x00000000004004a5 <f2+0>: movl $0x1234,-0x8(%rsp) # int a = 0x1234
0x00000000004004ad <f2+8>: cmpl $0x0,-0x8(%rsp)
0x00000000004004b2 <f2+13>: jle 0x4004c4 <f2+31>
0x00000000004004b4 <f2+15>: movl $0xff,-0x4(%rsp) # int b = 0xff
0x00000000004004bc <f2+23>: mov -0x8(%rsp),%eax
0x00000000004004c0 <f2+27>: mov %eax,-0x4(%rsp)
0x00000000004004c4 <f2+31>: retq
C++智能指针
智能指针的作用
1) C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。
2) 智能指针在C++11版本之后提供,包含在头文件中,shared_ptr、unique_ptr、weak_pptr。shared_ptr多个指针指向相同的对象。shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,自动删除所指向的堆内存。shared_ptr内部的引用计数是线程安全的,但是对象的读取需要加锁。
3) 初始化。智能指针是个模板类,可以指定类型,传入指针通过构造函数初始化。也可以使用make_shared函数初始化。不能将指针直接赋值给一个智能指针,一个是类,一个是指针。例如std::shared_ptrp4 = new int(1);的写法是错误的
4) unique_ptr“唯一”拥有其所指对象,同一时刻只能有一个unique_ptr指向给定对象(通过禁止拷贝语义、只有移动语义来实现)。相比与原始指针unique_ptr用于其RAII的特性,使得在出现异常的情况下,动态资源能得到释放。unique_ptr指针本身的生命周期:从unique_ptr指针创建时开始,直到离开作用域。离开作用域时,若其指向对象,则将其所指对象销毁(默认使用delete操作符,用户可指定其他操作)。unique_ptr指针与其所指对象的关系:在智能指针生命周期内,可以改变智能指针所指对象,如创建智能指针时通过构造函数指定、通过reset方法重新指定、通过release方法释放所有权、通过移动语义转移所有权。
5) 智能指针类将一个计数器与类指向的对象相关联,引用计数跟踪该类有多少个对象共享同一指针。每次创建类的新对象时,初始化指针并将引用计数置为1;当对象作为另一对象的副本而创建时,拷贝构造函数拷贝指针并增加与之相应的引用计数;对一个对象进行赋值时,赋值操作符减少左操作数所指对象的引用计数(如果引用计数为减至0,则删除对象),并增加右操作数所指对象的引用计数;调用析构函数时,构造函数减少引用计数(如果引用计数减至0,则删除基础对象)。
6) weak_ptr 是一种不控制对象生命周期的智能指针, 它指向一个 shared_ptr 管理的对象. 进行该对象的内存管理的是那个强引用的 shared_ptr。 weak_ptr只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作, 它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少.
说说你了解的auto_ptr作用
- auto_ptr的出现,主要是为了解决“有异常抛出时发生内存泄漏”的问题;抛出异常,将导致指针p所指向的空间得不到释放而导致内存泄漏;
- auto_ptr构造时取得某个对象的控制权,在析构时释放该对象。我们实际上是创建一个auto_ptr类型的局部对象,该局部对象析构时,会将自身所拥有的指针空间释放,所以不会有内存泄漏;
- auto_ptr的构造函数是explicit,阻止了一般指针隐式转换为 auto_ptr的构造,所以不能直接将一般类型的指针赋值给auto_ptr类型的对象,必须用auto_ptr的构造函数创建对象;
- 由于auto_ptr对象析构时会删除它所拥有的指针,所以使用时避免多个auto_ptr对象管理同一个指针;
- auto_ptr内部实现,析构函数中删除对象用的是delete而不是delete[],所以auto_ptr不能管理数组;
- auto_ptr支持所拥有的指针类型之间的隐式类型转换。
- 可以通过*和->运算符对auto_ptr所有用的指针进行提领操作;
- T get(),获得auto_ptr所拥有的指针;T release(),释放auto_ptr的所有权,并将所
有用的指针返回。
智能指针的循环引用
循环引用是指使用多个智能指针share_ptr时,出现了指针之间相互指向,从而形成环的情况,有点类似于死锁的情况,这种情况下,智能指针往往不能正常调用对象的析构函数,从而造成内存泄漏。举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
using namespace std;
template <typename T>
class Node
{
public:
Node(const T& value)
:_pPre(NULL)
, _pNext(NULL)
, _value(value)
{
cout << "Node()" << endl;
}
~Node()
~Node()
{
cout << "~Node()" << endl;
cout << "this:" << this << endl;
}
shared_ptr<Node<T>> _pPre;
shared_ptr<Node<T>> _pNext;
T _value;
};
void Funtest()
{
shared_ptr<Node<int>> sp1(new Node<int>(1));
shared_ptr<Node<int>> sp2(new Node<int>(2));
cout << "sp1.use_count:" << sp1.use_count() << endl;
cout << "sp2.use_count:" << sp2.use_count() << endl;
sp1->_pNext = sp2; //sp1的引用+1
sp2->_pPre = sp1; //sp2的引用+1
cout << "sp1.use_count:" << sp1.use_count() << endl;
cout << "sp2.use_count:" << sp2.use_count() << endl;
}
int main()
{
Funtest();
system("pause");
return 0;
}
//输出结果
//Node()
//Node()
//sp1.use_count:1
//sp2.use_count:1
//sp1.use_count:2
//sp2.use_count:2
从上面shared_ptr的实现中我们知道了只有当引用计数减减之后等于0,析构时才会释放对象,而上述情况造成了一个僵局,那就是析构对象时先析构sp2,可是由于sp2的空间sp1还在使用中,所以sp2.use_count减减之后为1,不释放,sp1也是相同的道理,由于sp1的空间sp2还在使用中,所以sp1.use_count减减之后为1,也不释放。sp1等着sp2先释放,sp2等着sp1先释放,二者互不相让,导致最终都没能释放,内存泄漏。
在实际编程过程中,应该尽量避免出现智能指针之间相互指向的情况,如果不可避免,可以使用弱指针—weak_ptr,它不增加引用计数,只要出了作用域就会自动析构。
使用智能指针管理内存资源,RAII是怎么回事?
RAII全称是“Resource Acquisition is Initialization”,直译过来是“资源获取即初始化”,也就是说在构造函数中申请分配资源,在析构函数中释放资源。
因为C++的语言机制保证了,当一个对象创建的时候,自动调用构造函数,当对象超出作用域的时候会自动调用析构函数。所以,在RAII的指导下,我们应该使用类来管理资源,将资源和对象的生命周期绑定。
智能指针(std::shared_ptr和std::unique_ptr)即RAII最具代表的实现,使用智能指针,可以实现自动的内存管理,再也不需要担心忘记delete造成的内存泄漏。
毫不夸张的来讲,有了智能指针,代码中几乎不需要再出现delete了。
智能指针背后的设计思想
无智能指针造成内存泄漏的例子
1 | void remodel(std::string & str) |
当出现异常时(weird_thing()返回true),delete将不被执行,因此将导致内存泄露 。
常规解决方案:
- 在throw exception()之前添加delete ps;
- 不要忘了最后一个delete ps;
智能指针的设计思想
仿照本地变量能够自动从栈内存中删除的思想,对指针设计一个析构函数,该析构函数将在指针过期时自动释放它指向的内存,总结来说就是:将基本类型指针封装为类对象指针(这个类肯定是个模板,以适应不同基本类型的需求),并在析构函数中编写delete语句以用来删除指针指向的内存空间。
转换remodel()函数的步骤:
- 包含头文件memory(智能指针所在的头文件);
- 将指向string的指针替换为指向string的智能指针对象;
- 删除delete语句。
使用auto_ptr修改该函数的结果:1
2
3
4
5
6
7
8
9
10
11
void remodel (std::string & str)
{
std::auto_ptr<std::string> ps (new std::string(str));
...
if (weird_thing ())
throw exception();
str = *ps;
// delete ps; NO LONGER NEEDED
return;
}
C++智能指针简单介绍
STL一共给我们提供了四种智能指针:auto_ptr、unique_ptr、shared_ptr和weak_ptr。
其中:auto_ptr在C++11中已将其摒弃。
使用注意点:
所有的智能指针类都有一个explicit构造函数,以指针作为参数。比如auto_ptr的类模板原型为:1
2
3
4
5templet<class T>
class auto_ptr {
explicit auto_ptr(X* p = 0) ;
...
};
因此不能自动将指针转换为智能指针对象,必须显示调用:1
2
3
4
5
6shared_ptr<double> pd;
double *p_reg = new double;
pd = p_reg;//NOT ALLOWED(implicit conversion)
pd = shared_ptr<double>(p_reg);// ALLOWED (explicit conversion)
shared_ptr<double> pshared = p_reg;//NOT ALLOWED (implicit conversion)
shared_ptr<double> pshared(p_reg);//ALLOWED (explicit conversion)
对全部三种智能指针都应避免的一点:1
2string vacation("I wandered lonely as a child."); //heap param
shared_ptr<string> pvac(&vacation);//NO!!
pvac过期时,程序将把delete运算符用于非堆(栈)内存,这是错误的!
使用实例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
class report
{
private:
std::string str;
public:
report(const std::string s) : str(s){
std::cout<<"Object created.\n";
}
~report(){
std::cout<<"Object deleted.\n";
}
void comment() const {
std::cout<<str<<"\n";
}
};
int main(){
{
std::auto_ptr<report> ps(new report("using auto ptr"));
ps->comment();
}//auto_ptr 作用域结束
{
std::shared_ptr<report> ps(new report("using shared_ptr"));
ps->comment();
}//shared_ptr 作用域结束
{
std::unique_ptr<report> ps(new report("using unique ptr"));
ps->comment();
}//unique_ptr 作用域结束
return 0;
}
为什么摒弃auto_ptr?
问题来源:1
2
3auto_ptr<string> ps (new string("I reigned lonely as a cloud."));
auto_ptr<string> vocation;
vocation = ps;
如果ps和vocation是常规指针,则两个指针指向同一个string对象,当指针过期时,则程序会试图删除同一个对象,要避免这种问题,解决办法:
定义赋值运算符,使之执行深复制。这样两个指针将指向不同的对象,其中的一个对象是另一个对象的副本,缺点是浪费空间,所以智能指针都未采取此方案。
建立所有权(ownership)概念。对于特定的对象,智能有一个智能对象可拥有,这样只能拥有对象的智能指针的析构函数会删除该对象。然后让赋值操作转让所有权。这就是用于auto_ptr和unique_ptr的策略,但unique_ptr的策略更严格。
创建智能更高的指针,跟踪引用特定对象的智能指针数。这称为引用计数。例如,赋值时,计数将加1,而指针过期时,计数将减1,当减为0时才调用delete。这是shared_ptr采用的策略。同样的策略也适用于复制构造函数。
摒弃auto_ptr的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
using namespace std;
int main(){
auto_ptr<string> films[5] = {
auto_ptr<string> (new string("Fowl Balls")),
auto_ptr<string> (new string("Duck Walks")),
auto_ptr<string> (new string("Chicken Runs")),
auto_ptr<string> (new string("Turkey Errors")),
auto_ptr<string> (new string("Goose Eggs"))
};
auto_ptr<string> pwin;
pwin = films[2];//films[2] loses owership,将所有权从films[2]转让给pwin,此时films[2]不再引用该字符串从而变成空指针
cout<<"The nominees for best avian baseball film are\n";
for(int i = 0;i < 5;++i)
{
cout<< *films[i]<<endl;
}
cout<<"The winner is "<<*pwin<<endl;
cin.get();
return 0;
}
运行下发现程序崩溃了,原因是films[2]已经是空指针了,输出空指针就会崩溃。如果把auto_ptr换成shared_ptr或unique_ptr后,程序就不会崩溃,原因如下:
适用shared_ptr时运行正常,因为shared_ptr采用引用计数,pwin和films[2]都指向同一块内存,在释放空间时因为事先要判断引用计数值的大小,因此不会出现多次删除一个对象的错误。
适用unique_ptr时编译出错,与auto_ptr一样,unique_ptr也采用所有权模型,但在适用unique_ptr时,程序不会等到运行阶段崩溃,在编译阶段下属代码就会出现错误:1
2unique_ptr<string> pwin;
pwin = films[2];//films[2] loses ownership
这就是为何摒弃auto_ptr的原因:避免潜在的内存泄漏问题。
unique_ptr为何优于auto_ptr?
使用规则更严格
1 | auto_ptr<string> p1(new string("auto")); //#1 |
在语句#3中,p2接管string对象的所有权后,p1的所有权将被剥夺。–>可防止p1和p2的析构函数试图删除同一个对象。但如果随后试图使用p1,则会出现错误。1
2
3unique_ptr<string> p3(new string("auto"));//#4
unique_ptr<string> p4;//#5
p4=p3;//#6
编译器会认为#6语句为非法,可以避免上述问题。
对悬挂指针的操作更智能
总体来说:允许临时悬挂指针的赋值,禁止其他情况的出现。
示例:函数定义如下:1
2
3
4unique_ptr<string> demo(const char *s){
unique_ptr<string> temp (new string(a));
return temp;
}
在程序中调用函数:1
2unique_ptr<string> ps;
ps = demo("unique special");
编译器允许此种赋值方式。总之:当程序试图将一个unique_ptr赋值给另一个时,如果源unique_ptr是个临时右值,编译器允许这么做;如果源unique_ptr将存在一段时间,编译器将禁止这么做。1
2
3
4
5unique_ptr<string> pu1(new string("hello world"));
unique_ptr<string> pu2;
pu2 = pu1;//#1 not allowed
unique_ptr<string> pu3;
pu3 = unique_ptr<string>(new string("you"));//#2 allowed
如果确实想执行类似#1的操作,仅当以非智能的方式使用摒弃的智能指针时(如解除引用时),这种赋值才不安全。要安全的重用这种指针,可给它赋新值。C++有一个标准库函数std::move(),可以将原来的指针转让所有权变成空指针,可以对其重新赋值。1
2
3
4
5unque_ptr<string> ps1,ps2;
ps1 = demo("hello");
ps2 = move(ps1);
ps1 = demo("alexia");
cout<<*ps2<<*ps1<<endl;
如何选择智能指针
使用指南:
如果程序要使用多个指向同一个对象的指针,应选用shared_ptr。这样的情况包括:
- 有一个指针数组,并使用一些辅助指针来标示特定的元素,如最大的元素和最小的元素;
- 连个对象包含指向第三个对象的指针;
- STL容器包含指针。很多STL算法都支持复制和赋值操作,这些操作可用于shared_ptr,但不能用于unique_ptr(编译器发出warning)和auto_ptr(行为不确定)。如果你的编译器没有提供shared_ptr,可使用Boost库提供的shared_ptr。
如果程序不需要多个指向同一个对象的指针,则可使用unique_ptr。如果函数使用new分配内存,并返还指向该内存的指针,将其返回类型声明为unique_ptr是不错的选择。这样,所有权转让给接受返回值的unique_ptr,而该智能指针将负责调用delete。可将unique_ptr储存到STL容器中,只要不调用将unique_ptr复制或赋值给另一个算法(如sort())。例如,可在程序中使用类似于下面的代码段:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15unique_ptr<int> make_int(int n){
return unique_ptr<int>(new int(n));
}
void show(unique_ptr<int> &p1){
cout<<*a<<' ';
}
int main(){
...
vector<unique_ptr<int>> vp(size);
for(int i=0; i<vp.size();i++){
vp[i] = make_int(rand() %1000);//copy temporary unique_ptr
}
vp.push_back(make_int(rand()%1000));// ok because arg is temporary
for_each(vp.begin(),vp.end(),show); //use for_each();
}
其中push_back调用没有问题,因为它返回一个临时unique_ptr,该unique_ptr被赋值给vp中的一个unique_ptr。另外,如果按值而不是按引用给show()传递对象,for_each()将非法,因为这将导致使用一个来自vp的非临时unique_ptr初始化p1,而这是不允许的。前面说过,编译器将发现错误使用unique_ptr的企图。
在unique_ptr为右值时,可将其赋给shared_ptr,这与将一个unique_ptr赋给一个需要满足的条件相同。与前面一样,在下面的代码中,make_int()的返回类型为unique_ptr<int>:1
2
3unique_ptr<int> pup(make_int(rand() % 1000)); // ok
shared_ptr<int> spp(pup); // not allowed, pup as lvalue
shared_ptr<int> spr(make_int(rand() % 1000)); // ok
模板shared_ptr包含一个显式构造函数,可用于将右值unique_ptr转换为shared_ptr。shared_ptr将接管原来归unique_ptr所有的对象。
在满足unique_ptr要求的条件时,也可使用auto_ptr,但unique_ptr是更好的选择。如果你的编译器没有unique_ptr,可考虑使用Boost库提供的scoped_ptr,它与unique_ptr类似。
弱引用智能指针 weak_ptr
设计weak_ptr的原因:解决使用shared_ptr因循环引用而不能释放资源的问题。
空悬指针问题

有两个指针p1和p2,指向堆上的同一个对象Object,p1和p2位于不同的线程中。假设线程A通过p1指针将对象销毁了(尽管把p1置为NULL),那p2就成了空悬指针。这是一种典型的C/C++内存错误。
使用weak_ptr能够帮助我们轻松解决上述的空悬指针问题(直接使用shared_ptr也是可以的)。
weak_ptr不控制对象的生命期,但是它知道对象是否还活着,如果对象还活着,那么它可以提升为有效的shared_ptr(提升操作通过lock()函数获取所管理对象的强引用指针);如果对象已经死了,提升会失败,返回一个空的shared_ptr。
举个栗子 :1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
int main()
{
// OLD, problem with dangling pointer
// PROBLEM: ref will point to undefined data!
int* ptr = new int(10);
int* ref = ptr;
delete ptr;
// NEW
// SOLUTION: check expired() or lock() to determine if pointer is valid
// empty definition
std::shared_ptr<int> sptr;
// takes ownership of pointer
sptr.reset(new int);
*sptr = 10;
// get pointer to data without taking ownership
std::weak_ptr<int> weak1 = sptr;
// deletes managed object, acquires new pointer
sptr.reset(new int);
*sptr = 5;
// get pointer to new data without taking ownership
std::weak_ptr<int> weak2 = sptr;
// weak1 is expired!
if(auto tmp = weak1.lock())
std::cout << *tmp << '\n';
else
std::cout << "weak1 is expired\n";
// weak2 points to new data (5)
if(auto tmp = weak2.lock())
std::cout << *tmp << '\n';
else
std::cout << "weak2 is expired\n";
}
循环引用问题
栗子 大法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
using namespace std;
using namespace boost;
class BB;
class AA
{
public:
AA() { cout << "AA::AA() called" << endl; }
~AA() { cout << "AA::~AA() called" << endl; }
shared_ptr<BB> m_bb_ptr; //!
};
class BB
{
public:
BB() { cout << "BB::BB() called" << endl; }
~BB() { cout << "BB::~BB() called" << endl; }
shared_ptr<AA> m_aa_ptr; //!
};
int main()
{
shared_ptr<AA> ptr_a (new AA);
shared_ptr<BB> ptr_b ( new BB);
cout << "ptr_a use_count: " << ptr_a.use_count() << endl;
cout << "ptr_b use_count: " << ptr_b.use_count() << endl;
//下面两句导致了AA与BB的循环引用,结果就是AA和BB对象都不会析构
ptr_a->m_bb_ptr = ptr_b;
ptr_b->m_aa_ptr = ptr_a;
cout << "ptr_a use_count: " << ptr_a.use_count() << endl;
cout << "ptr_b use_count: " << ptr_b.use_count() << endl;
}
运行结果:
可以看到由于AA和BB内部的shared_ptr各自保存了对方的一次引用,所以导致了ptr_a和ptr_b销毁的时候都认为内部保存的指针计数没有变成0,所以AA和BB的析构函数不会被调用。解决方法就是把一个shared_ptr替换成weak_ptr。
可以看到由于AA和BB内部的shared_ptr各自保存了对方的一次引用,所以导致了ptr_a和ptr_b销毁的时候都认为内部保存的指针计数没有变成0,所以AA和BB的析构函数不会被调用。解决方法就是把一个shared_ptr替换成weak_ptr。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
using namespace std;
using namespace boost;
class BB;
class AA
{
public:
AA() { cout << "AA::AA() called" << endl; }
~AA() { cout << "AA::~AA() called" << endl; }
weak_ptr<BB> m_bb_ptr; //!
};
class BB
{
public:
BB() { cout << "BB::BB() called" << endl; }
~BB() { cout << "BB::~BB() called" << endl; }
shared_ptr<AA> m_aa_ptr; //!
};
int main()
{
shared_ptr<AA> ptr_a (new AA);
shared_ptr<BB> ptr_b ( new BB);
cout << "ptr_a use_count: " << ptr_a.use_count() << endl;
cout << "ptr_b use_count: " << ptr_b.use_count() << endl;
//下面两句导致了AA与BB的循环引用,结果就是AA和BB对象都不会析构
ptr_a->m_bb_ptr = ptr_b;
ptr_b->m_aa_ptr = ptr_a;
cout << "ptr_a use_count: " << ptr_a.use_count() << endl;
cout << "ptr_b use_count: " << ptr_b.use_count() << endl;
}
运行结果:
最后值得一提的是,虽然通过弱引用指针可以有效的解除循环引用,但这种方式必须在能预见会出现循环引用的情况下才能使用,即这个仅仅是一种编译期的解决方案,如果程序在运行过程中出现了循环引用,还是会造成内存泄漏的。因此,不要认为只要使用了智能指针便能杜绝内存泄漏。
智能指针源码解析
在介绍智能指针源码前,需要明确的是,智能指针本身是一个栈上分配的对象。根据栈上分配的特性,在离开作用域后,会自动调用其析构方法。智能指针根据这个特性实现了对象内存的管理和自动释放。
本文所分析的智能指针源码基于 Android ndk-16b 中 llvm-libc++的 memory 文件。
unique_ptr
先看下 unique_ptr的声明。unique_ptr有两个模板参数,分别为_Tp和_Dp。
- _Tp表示原生指针的类型。
- _Dp则表示析构器,开发者可以自定义指针销毁的代码。其拥有一个默认值default_delete<_Tp>,其实就是标准的delete函数。
函数声明中typename __pointer_type<_Tp, deleter_type>::type可以简单理解为_Tp*,即原生指针类型。1
2
3
4
5
6
7
8template <class _Tp, class _Dp = default_delete<_Tp> >
class _LIBCPP_TEMPLATE_VIS unique_ptr {
public:
typedef _Tp element_type;
typedef _Dp deleter_type;
typedef typename __pointer_type<_Tp, deleter_type>::type pointer;
//...
}
unique_ptr中唯一的数据成员就是原生指针和析构器的 pair。1
2private:
__compressed_pair<pointer, deleter_type> __ptr_;
下面看下unique_ptr的构造函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37template <class _Tp, class _Dp = default_delete<_Tp> >
class _LIBCPP_TEMPLATE_VIS unique_ptr {
public:
// 默认构造函数,用pointer的默认构造函数初始化__ptr_
constexpr unique_ptr() noexcept : __ptr_(pointer()) {}
// 空指针的构造函数,同上
constexpr unique_ptr(nullptr_t) noexcept : __ptr_(pointer()) {}
// 原生指针的构造函数,用原生指针初始化__ptr_
explicit unique_ptr(pointer __p) noexcept : __ptr_(__p) {}
// 原生指针和析构器的构造函数,用这两个参数初始化__ptr_,当前析构器为左值引用
unique_ptr(pointer __p, _LValRefType<_Dummy> __d) noexcept
: __ptr_(__p, __d) {}
// 原生指针和析构器的构造函数,析构器使用转移语义进行转移
unique_ptr(pointer __p, _GoodRValRefType<_Dummy> __d) noexcept
: __ptr_(__p, _VSTD::move(__d)) {
static_assert(!is_reference<deleter_type>::value,
"rvalue deleter bound to reference");
}
// 移动构造函数,取出原有unique_ptr的指针和析构器进行构造
unique_ptr(unique_ptr&& __u) noexcept
: __ptr_(__u.release(), _VSTD::forward<deleter_type>(__u.get_deleter())) {
}
// 移动赋值函数,取出原有unique_ptr的指针和析构器进行构造
unique_ptr& operator=(unique_ptr&& __u) _NOEXCEPT {
reset(__u.release());
__ptr_.second() = _VSTD::forward<deleter_type>(__u.get_deleter());
return *this;
}
}
再看下unique_ptr几个常用函数的实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28template <class _Tp, class _Dp = default_delete<_Tp> >
class _LIBCPP_TEMPLATE_VIS unique_ptr {
// 返回原生指针
pointer get() const _NOEXCEPT {
return __ptr_.first();
}
// 判断原生指针是否为空
_LIBCPP_EXPLICIT operator bool() const _NOEXCEPT {
return __ptr_.first() != nullptr;
}
// 将__ptr置空,并返回原有的指针
pointer release() _NOEXCEPT {
pointer __t = __ptr_.first();
__ptr_.first() = pointer();
return __t;
}
// 重置原有的指针为新的指针,如果原有指针不为空,对原有指针所指对象进行销毁
void reset(pointer __p = pointer()) _NOEXCEPT {
pointer __tmp = __ptr_.first();
__ptr_.first() = __p;
if (__tmp)
__ptr_.second()(__tmp);
}
}
再看下unique_ptr指针特性的两个方法。1
2
3
4
5
6
7
8
9// 返回原生指针的引用
typename add_lvalue_reference<_Tp>::type
operator*() const {
return *__ptr_.first();
}
// 返回原生指针
pointer operator->() const _NOEXCEPT {
return __ptr_.first();
}
最后再看下unique_ptr的析构函数。1
2// 通过reset()方法进行对象的销毁
~unique_ptr() { reset(); }
shared_ptr
shared_ptr 与unique_ptr最核心的区别就是比unique_ptr多了一个引用计数,并由于引用计数的加入,可以支持拷贝。
先看下shared_ptr的声明。shared_ptr主要有两个成员变量,一个是原生指针,一个是控制块的指针,用来存储这个原生指针的shared_ptr和weak_ptr的数量。1
2
3
4
5
6
7
8
9
10
11template<class _Tp>
class shared_ptr
{
public:
typedef _Tp element_type;
private:
element_type* __ptr_;
__shared_weak_count* __cntrl_;
//...
}
我们重点看下__shared_weak_count的定义。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76// 共享计数类
class __shared_count
{
__shared_count(const __shared_count&);
__shared_count& operator=(const __shared_count&);
protected:
// 共享计数
long __shared_owners_;
virtual ~__shared_count();
private:
// 引用计数变为0的回调,一般是进行内存释放
virtual void __on_zero_shared() _NOEXCEPT = 0;
public:
// 构造函数,需要注意内部存储的引用计数是从0开始,外部看到的引用计数其实为1
explicit __shared_count(long __refs = 0) _NOEXCEPT
: __shared_owners_(__refs) {}
// 增加共享计数
void __add_shared() _NOEXCEPT {
__libcpp_atomic_refcount_increment(__shared_owners_);
}
// 释放共享计数,如果共享计数为0(内部为-1),则调用__on_zero_shared进行内存释放
bool __release_shared() _NOEXCEPT {
if (__libcpp_atomic_refcount_decrement(__shared_owners_) == -1) {
__on_zero_shared();
return true;
}
return false;
}
// 返回引用计数,需要对内部存储的引用计数+1处理
long use_count() const _NOEXCEPT {
return __libcpp_relaxed_load(&__shared_owners_) + 1;
}
};
class __shared_weak_count
: private __shared_count
{
// weak ptr计数
long __shared_weak_owners_;
public:
// 内部共享计数和weak计数都为0
explicit __shared_weak_count(long __refs = 0) _NOEXCEPT
: __shared_count(__refs),
__shared_weak_owners_(__refs) {}
protected:
virtual ~__shared_weak_count();
public:
// 调用通过父类的__add_shared,增加共享引用计数
void __add_shared() _NOEXCEPT {
__shared_count::__add_shared();
}
// 增加weak引用计数
void __add_weak() _NOEXCEPT {
__libcpp_atomic_refcount_increment(__shared_weak_owners_);
}
// 调用父类的__release_shared,如果释放了原生指针的内存,还需要调用__release_weak,因为内部weak计数默认为0
void __release_shared() _NOEXCEPT {
if (__shared_count::__release_shared())
__release_weak();
}
// weak引用计数减1
void __release_weak() _NOEXCEPT;
// 获取共享计数
long use_count() const _NOEXCEPT {return __shared_count::use_count();}
__shared_weak_count* lock() _NOEXCEPT;
private:
// weak计数为0的处理
virtual void __on_zero_shared_weak() _NOEXCEPT = 0;
};
其实__shared_weak_count也是虚类,具体使用的是__shared_ptr_pointer。__shared_ptr_pointer中有一个成员变量__data_,用于存储原生指针、析构器、分配器。__shared_ptr_pointer继承了__shared_weak_count,因此它就主要负责内存的分配、销毁,引用计数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class __shared_ptr_pointer
: public __shared_weak_count
{
__compressed_pair<__compressed_pair<_Tp, _Dp>, _Alloc> __data_;
public:
_LIBCPP_INLINE_VISIBILITY
__shared_ptr_pointer(_Tp __p, _Dp __d, _Alloc __a)
: __data_(__compressed_pair<_Tp, _Dp>(__p, _VSTD::move(__d)), _VSTD::move(__a)) {}
virtual const void* __get_deleter(const type_info&) const _NOEXCEPT;
private:
virtual void __on_zero_shared() _NOEXCEPT;
virtual void __on_zero_shared_weak() _NOEXCEPT;
};
了解了引用计数的基本原理后,再看下shared_ptr的实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// 使用原生指针构造shared_ptr时,会构建__shared_ptr_pointer的控制块
shared_ptr<_Tp>::shared_ptr(_Yp* __p,
typename enable_if<is_convertible<_Yp*, element_type*>::value, __nat>::type)
: __ptr_(__p)
{
unique_ptr<_Yp> __hold(__p);
typedef typename __shared_ptr_default_allocator<_Yp>::type _AllocT;
typedef __shared_ptr_pointer<_Yp*, default_delete<_Yp>, _AllocT > _CntrlBlk;
__cntrl_ = new _CntrlBlk(__p, default_delete<_Yp>(), _AllocT());
__hold.release();
__enable_weak_this(__p, __p);
}
// 如果进行shared_ptr的拷贝,会增加引用计数
template<class _Tp>
inline
shared_ptr<_Tp>::shared_ptr(const shared_ptr& __r) _NOEXCEPT
: __ptr_(__r.__ptr_),
__cntrl_(__r.__cntrl_)
{
if (__cntrl_)
__cntrl_->__add_shared();
}
// 销毁shared_ptr时,会使共享引用计数减1,如果减到0会销毁内存
template<class _Tp>
shared_ptr<_Tp>::~shared_ptr()
{
if (__cntrl_)
__cntrl_->__release_shared();
}
weak_ptr
了解完shared_ptr,weak_ptr也就比较简单了。weak_ptr也包括两个对象,一个是原生指针,一个是控制块。虽然weak_ptr内存储了原生指针,不过由于未实现operator->因此不能直接使用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class _LIBCPP_TEMPLATE_VIS weak_ptr
{
public:
typedef _Tp element_type;
private:
element_type* __ptr_;
__shared_weak_count* __cntrl_;
}
// 通过shared_ptr构造weak_ptr。会将shared_ptr的成员变量地址进行复制。增加weak引用计数
weak_ptr<_Tp>::weak_ptr(shared_ptr<_Yp> const& __r,
typename enable_if<is_convertible<_Yp*, _Tp*>::value, __nat*>::type)
_NOEXCEPT
: __ptr_(__r.__ptr_),
__cntrl_(__r.__cntrl_)
{
if (__cntrl_)
__cntrl_->__add_weak();
}
// weak_ptr析构器
template<class _Tp>
weak_ptr<_Tp>::~weak_ptr()
{
if (__cntrl_)
__cntrl_->__release_weak();
}
MSVC C++ STL 源码解析系列介绍
std::unique_ptr是 c++ 11 添加的智能指针之一,是裸指针的封装,我们可以直接使用裸指针来构造std::unique_ptr:
1 | struct TestStruct { |
在 c++ 14 及以上,可以使用std::make_unique来更方便地构造std::unique_ptr,参数列表需匹配创建对象的构造函数:
1 | std::unique_ptr<int> p0 = std::make_unique<int>(1); |
除了保存普通对象,std::unique_ptr还能保存数组,这时std::make_unique的参数表示数组的长度:
1 | std::unique_ptr<int[]> p0 = std::make_unique<int[]>(1); |
std::unique_ptr重载了operator->,你可以像使用普通指针一样使用它:
1 | std::unique_ptr<TestStruct> p = std::make_unique<TestStruct>(TestStruct { 1, 2 }); |
当然,直接使用nullptr对其赋值,或者拿std::unique_ptr与nullptr进行比较,都是可以的:
1 | std::unique_ptr<TestClass> p = nullptr; |
std::unique_ptr在离开其作用域时,所保存的对象会自动销毁:
1 | std::cout << "block begin" << std::endl; |
比较重要的一点是std::unique_ptr删除了拷贝构造,所有它对对象的所有权是独享的,你没有办法直接将std::unique_ptr相互拷贝,而只能通过std::move来转移所有权:
1 | auto p1 = std::make_unique<TestClass>(); |
正确的做法是:
1 | auto p1 = std::make_unique<TestClass>(); |
因为触发了移动语义,转移所有权期间,对象不会重新构造。
除了上面这些特性,std::unique_ptr还提供了一些与裸指针相关的成员函数,你可以使用get()来直接获取裸指针:
1 | auto p = std::make_unique<TestClass>(); |
也可以使用release()来释放裸指针,在释放后,原来的std::unique_ptr会变成nullptr:
1 | auto p = std::make_unique<TestClass>(); |
要注意的是,get()和release()都不会销毁原有对象,只是单纯对裸指针进行操作而已。
在实际编程实践中,std::unique_ptr要比std::shared_ptr更实用,因为std::unique_ptr对对象的所有权是明确的,销毁时机也是明确的,可以很好地避免使用 new。
源码解析
下面的源码解析基于 MSVC 16 2019 (64-Bit),其他编译器可能有所不同。
_Compressed_pair
_Compressed_pair是std::unique_ptr内部用于存储 deleter 和裸指针的工具,从字面意思来看,它实现的功能和std::pair是类似的,但是有所差异的一点是在某些场景下,_Compressed_pair相比std::pair做了额外的压缩,我们先来看看源码:
1 | struct _Zero_then_variadic_args_t { |
可以看到,_Compressed_pair在满足条件is_empty_v<_Ty1> && !is_final_v<_Ty1>时,会走上面的定义,使用 Empty base optimization 即空基类优化,不满足时,则走下面的特化,退化成普通的pair,我们来通过一段示例代码看一下压缩效果:
1 | std::cout << sizeof(std::pair<A, int>) << std::endl; |
当 A 为空类时,由于 c++ 的机制,会为其保留 1 字节的空间,A 和 int 联合存放在std::pair里时,因为需要进行对齐,就变成了 4 + 4 字节,而_Compressed_pair则通过空基类优化避免了这个问题。
unique_ptr
先来看看保存普通对象的std::unique_ptr的定义:
1 | template <class _Ty, class _Dx = default_delete<_Ty>> |
这里的模板参数_Ty是保存的对象类型,_Dx是删除器类型,默认为default_delete<_Ty>,下面是具体的定义:
1 | template <class _Ty> |
很简单,只是一个重载了operator()的结构体而已,operator()中则直接调用delete。
std::unique_ptr中定义了几个 using:
1 | template <class _Ty, class _Dx_noref, class = void> |
这里element_type为元素类型,deleter_type为删除器类型,我们主要关注pointer,pointer的类型由_Get_deleter_pointer_type决定,我们可以发现它有两个定义,前者是默认定义,当删除器中没有定义pointer时会fallback到这个定义,如果删除器定义了pointer,则会使用删除器中的pointer类型。下面是一段实验代码:
1 | template <class Ty> |
输出结果:
1 | struct A * __ptr64 |
然后我们来看一下std::unique_ptr的 private block:
1 | private: |
只是定义了一个_Compressed_pair来同时保存删除器和裸指针,这里要注意的是,pair中保存的顺序,first是删除器,second是pointer。
接下来看一下std::unique_ptr的各种构造和operator=,首先是默认构造:
1 | template <class _Dx2 = _Dx, _Unique_ptr_enable_default_t<_Dx2> = 0> |
这里的_Zero_then_variadic_args_t在上面也出现过,是一个空结构体,作用于用于标记参数数量,然后决定具体使用_Compressed_pair的哪一个构造。
接下来是nullptr_t的构造和operator=:
1 | template <class _Dx2 = _Dx, _Unique_ptr_enable_default_t<_Dx2> = 0> |
主要是针对空指针的处理,当使用空指针进行构造和赋值的时候,相当于把std::unique_ptr重置。
接下来是更常用的构造:
1 | template <class _Dx2> |
单参数的构造只传入指针,当满足删除器类型不是指针而且可默认构造的情况下启用,直接把传入的裸指针存入pair,这时候由于删除器是可默认构造的,pair中保存的删除器会被直接默认构造。另外的三个也需要满足一定条件,这时可以从外部传入删除器,并将其保存至pair中。
然后是移动构造:
1 | template <class _Dx2 = _Dx, enable_if_t<is_move_constructible_v<_Dx2>, int> = 0> |
条件判断比较多,不过归根到底都是直接移动删除器,然后调用原std::unique_ptr的release()释放裸指针,再将裸指针填入新的pair中。
最后,有关构造和赋值比较重要的是被删除的两个方法:
1 | unique_ptr(const unique_ptr&) = delete; |
这直接决定了std::unique_ptr没办法复制与相互赋值,这是语义上独享内存所有权的基石。
我们再看析构:
1 | ~unique_ptr() noexcept { |
比较简单,先判断pair中保存的裸指针是否为空,不为空的话则调用pair中保存的deleter来释放内存。
std::unique_ptr和大部分 stl 类一样提供了swap()方法:
1 | void swap(unique_ptr& _Right) noexcept { |
有关删除器,std::unique_ptr还提供了getter方法来获取删除器:
1 | _NODISCARD _Dx& get_deleter() noexcept { |
接下来看与指针息息相关的几个操作符重载:
1 | _NODISCARD add_lvalue_reference_t<_Ty> operator*() const noexcept /* strengthened */ { |
这使得我们可以像使用普通指针一样使用std::unique_ptr。
最后是三个对裸指针的直接操作:
1 | _NODISCARD pointer get() const noexcept { |
从代码上可以看出来,get()和release()并不会触发内存销毁,而reset()的内存销毁也是有条件的,只有reset()为空指针时才会触发销毁。
整体上来看std::unique_ptr的代码并不算复杂,只是裸指针的一层封装而已。
1 | unique_ptr<_Ty[], _Dx> |
std::unique_ptr还有另外一个定义,即:
1 | template <class _Ty, class _Dx> |
这个定义是针对数组的。大部分代码其实都跟前面相同,我们主要关注不一样的地方,首先是default_delete的特化:
1 | template <class _Ty> |
针对数组,这里的operator()的实现由delete改成了delete[]。
然后是一些操作符重载上的不同:
1 | _NODISCARD _Ty& operator[](size_t _Idx) const noexcept /* strengthened */ { |
与普通的std::unique_ptr不同的是,它不再提供operator*和operator->,取而代之的是operator[],这也与普通数组的操作一致。
其他的一些代码,主要是构造、析构、operator=,基本都与普通的定义一致,就不再赘述了。
make_unique
std::make_unique的用法在前面也说过了,主要是用于更优雅地构造std::unique_ptr的,代码其实也很简单,只是一层简单的透传:
1 | // FUNCTION TEMPLATE make_unique |
在 C++ 20 之后,标准库还提供了std::make_unique_for_overwrite来构造std::unique_ptr,与std::make_unique的区别在于,它不需要传递额外参数,直接使用目标类型的默认构造,下面是源码:
1 |
|
也很简单,透传而已。
总结
std::unique_ptr有两个定义,分别针对普通类型和数组类型std::unique_ptr第二个模板参数是删除器,不传递的情况下使用的是default_deletestd::unique_ptr重载了指针、数组相关的操作符,实现与裸指针类似的操作std::unique_ptr不允许拷贝,语义上表示一段内存的所有权,转移所有权需要使用std::move产生移动语义std::unique_ptr提供了get()和release()来直接对裸指针进行操作std::unqiue_ptr可以直接与nullptr比较,也可以使用nullptr赋值- 可以使用
std::make_unique和std::make_unique_for_overwrite来更方便地构造std::unique_ptr