实验一
操作系统镜像文件ucore.img是如何一步一步生成的?(需要比较详细地解释Makefile中每一条相关命令和命令参数的含义,以及说明命令导致的结果)
用make “V=”看到了所有的编译命令
第178行 create ucore.img,可以看到call函数,
totarget = $(addprefix $(BINDIR)$(SLASH),$(1))
这样就调用了addprefix,把$(BINDIR)$(SLASH)变成$(1)的前缀,在makefile里再把$(1)调用call变成要生成的文件,这里需要bootblock和kernel。
bootblock需要一些.o文件,makefile里的foreach有如下格式:$(foreach < var >,< list >,< text >)
这个函数的意思是,把参数< list >;中的单词逐一取出放到参数< var >所指定的变量中,然后再执行< text>;所包含的表达式。每一次< text >会返回一个字符串,循环过程中,< text >的所返回的每个字符串会以空格分隔,最后当整个循环结束时,< text >所返回的每个字符串所组成的整个字符串(以空格分隔)将会是foreach函数的返回值。
- 通过看makefile生成的编译命令,生成bootasm.o需要bootasm.S
1 | gcc -Iboot/ -fno-builtin -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Os -nostdinc -c boot/bootasm.S -o obj/boot/bootasm.o |
参考:
- -ggdb 生成可供gdb使用的调试信息。这样才能用qemu+gdb来调试bootloader or ucore。
- -m32 生成适用于32位环境的代码。我们用的模拟硬件是32bit的80386,所以ucore也要是32位。
- -gstabs 生成stabs格式的调试信息。这样要ucore的monitor可以显示出便于开发者阅读的函数调用
- -nostdinc 不使用标准库。标准库是给应用程序用的,我们是编译ucore内核,OS内核是提供服务的,所以所有的服务要自给自足。
- -fno-stack-protector 不生成用于检测缓冲区溢出的代码。这是for 应用程序的,我们是编译内核,ucore内核好像还用不到此功能。
- -Os 为减小代码大小而进行优化。根据硬件spec,主引导扇区只有512字节,我们写的简单bootloader的最终大小不能大于510字节。
- -I< dir > 添加搜索头文件的路径
1 | ld -m elf_i386 -nostdlib -N -e start -Ttext 0x7C00 obj/boot/bootasm.o obj/boot/bootmain.o -o obj/bootblock.o |
参考:
- -m
模拟为i386上的连接器 - -nostdlib 不使用标准库
- -N 设置代码段和数据段均可读写
- -e
指定入口 - -Ttext 制定代码段开始位置
1 | kernel = $(call totarget,kernel) |
编译命令:1
gcc -Ikern/trap/ -fno-builtin -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/trap/trapentry.S -o obj/kern/(o文件)
链接器:1
ld -m elf_i386 -nostdlib -T tools/kernel.ld -o bin/kernel obj/kern/init/init.o obj/kern/libs/stdio.o obj/kern/libs/readline.o obj/kern/debug/panic.o obj/kern/debug/kdebug.o obj/kern/debug/kmonitor.o obj/kern/driver/clock.o obj/kern/driver/console.o obj/kern/driver/picirq.o obj/kern/driver/intr.o obj/kern/trap/trap.o obj/kern/trap/vectors.o obj/kern/trap/trapentry.o obj/kern/mm/pmm.o obj/libs/string.o obj/libs/printfmt.o
dd:用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。
注意:指定数字的地方若以下列字符结尾,则乘以相应的数字:b=512;c=1;k=1024;w=2
参数注释:
- if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file >
- of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file >
- ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
- obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
- bs=bytes:同时设置读入/输出的块大小为bytes个字节。
- cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
- skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
- seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
- 注意:通常只用当输出文件是磁盘或磁带时才有效,即备份到磁盘或磁带时才有效。
- count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
- conv=conversion:用指定的参数转换文件。
- ascii:转换ebcdic为ascii
- ebcdic:转换ascii为ebcdic
- ibm:转换ascii为alternate ebcdic
- block:把每一行转换为长度为cbs,不足部分用空格填充
- unblock:使每一行的长度都为cbs,不足部分用空格填充
- lcase:把大写字符转换为小写字符
- ucase:把小写字符转换为大写字符
- swab:交换输入的每对字节
- noerror:出错时不停止
- notrunc:不截短输出文件
- sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
生成一个有10000个块的文件,用0填充(答案中说,每个块默认512字节,但是可能要有bs参数指定或者bs默认就是512?)1
dd if=/dev/zero of=bin/ucore.img count=10000
把bootblock中的内容写到第一个块1
dd if=bin/bootblock of=bin/ucore.img conv=notrunc
从第二个块开始写kernel中的内容1
dd if=bin/kernel of=bin/ucore.img seek=1 conv=notrunc
一个被系统认为是符合规范的硬盘主引导扇区的特征是什么?
上课讲过,合法的主引导扇区最后两个字节有特定值
0x55、0xAA1
2
3buf一共512个字节
buf[510] = 0x55;
buf[511] = 0xAA;
练习2:
1 | file bin/kernel |
在gdb中输入命令,输出2条instruction1
x /2i $pc
跟bootasm.S里的汇编代码一致!amazing1
2
3
4
5
6
7
8
9
10
11
12
13
14(gdb) x /2i $pc
=> 0x7c00: cli
0x7c01: cld
(gdb) x /10i $pc
=> 0x7c00: cli
0x7c01: cld
0x7c02: xor %ax,%ax
0x7c04: mov %ax,%ds
0x7c06: mov %ax,%es
0x7c08: mov %ax,%ss
0x7c0a: in $0x64,%al
0x7c0c: test $0x2,%al
0x7c0e: jne 0x7c0a
0x7c10: mov $0xd1,%al
在Makefile的debug选项中加入-d in_asm -D q.log,可以生成一个q.log里边是执行的汇编命令(部分)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23----------------
IN:
0xfffffff0: ljmp $0xf000,$0xe05b
----------------
IN:
0x000fe05b: cmpl $0x0,%cs:0x6c48
0x000fe062: jne 0xfd2e1
----------------
IN:
0x000fe066: xor %dx,%dx
0x000fe068: mov %dx,%ss
----------------
IN:
0x000fe06a: mov $0x7000,%esp
----------------
IN:
0x000fe070: mov $0xf3691,%edx
0x000fe076: jmp 0xfd165
练习3
分析bootloader进入保护模式的过程。(要求在报告中写出分析)
BIOS将通过读取硬盘主引导扇区到内存,并转跳到对应内存中的位置执行bootloader。请分析bootloader是如何完成从实模式进入保护模式的。1
lab1/boot/bootasm.S
类似之前,从0x7c00进入,首先1
2
3
4
5
6
7
8
9
10.globl start
start:
.code16
cli ;禁止中断发生
cld ;CLD与STD是用来操作方向标志位DF。CLD使DF复位,即D
;F=0,STD使DF置位,即DF=1.用于串操作指令中。
xorw %ax, %ax ;ax置0
movw %ax, %ds ;其他寄存器也清空
movw %ax, %es
movw %ax, %ss
.globl指示告诉汇编器,_start这个符号要被链接器用到,所以要在目标文件的符号表中标记它是一个全局符号(在第 5.1 节 “目标文件”详细解释)。_start就像C程序的main函数一样特殊,是整个程序的入口,链接器在链接时会查找目标文件中的_start符号代表的地址,把它设置为整个程序的入口地址,所以每个汇编程序都要提供一个_start符号并且用.globl声明。如果一个符号没有用.globl声明,就表示这个符号不会被链接器用到。
开启A20:到了80286,系统的地址总线有原来的20根发展为24根,这样能够访问的内存可以达到2^24=16M。Intel在设计80286时提出的目标是向下兼容。所以,在实模式下,系统所表现的行为应该和8086/8088所表现的完全一样,也就是说,在实模式下,80286以及后续系列,应该和8086/8088完全兼容。但最终,80286芯片却存在一个BUG:因为有了80286有A20线,如果程序员访问100000H-10FFEFH之间的内存,系统将实际访问这块内存,而不是象8086/8088一样从0开始。为了解决上述兼容性问题,IBM使用键盘控制器上剩余的一些输出线来管理第21根地址线(从0开始数是第20根) 的有效性,被称为A20 Gate:
如果A20 Gate被打开,则当程序员给出100000H-10FFEFH之间的地址的时候,系统将真正访问这块内存区域;
如果A20 Gate被禁止,则当程序员给出100000H-10FFEFH之间的地址的时候,系统仍然使用8086/8088的方式即取模方式(8086仿真)。绝大多数IBM PC兼容机默认的A20 Gate是被禁止的。现在许多新型PC上存在直接通过BIOS功能调用来控制A20 Gate的功能。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
inb $0x64, %al ;0x64里的数据放到al中,即从I/O端口读取一个字节(BYTE,;HALF-WORD)
testb $0x2, %al ;检测
jnz seta20.1 ;等到这个端口不忙,没有东西传进来
movb $0xd1, %al ; 0xd1 写到 0x64
outb %al, $0x64 ;写8042输出端口
seta20.2:
inb $0x64, %al
testb $0x2, %al
jnz seta20.2 ;等不忙
movb $0xdf, %al ;打开A20 0xdf -> port 0x60
outb %al, $0x60 ;0xdf = 11011111
初始化GDT表并打开保护模式
2
3
4
5
movl %cr0, %eax ;cr0寄存器PE位or置1
orl $CR0_PE_ON, %eax
movl %eax, %cr0
ljmp $PROT_MODE_CSEG, $protcseg ;长跳改cs,基于段机制的寻址
最后初始化堆栈、寄存器,调用bootmain
2
3
4
5
6
7
8
9
10
11
12
13
# 初始化寄存器
movw $PROT_MODE_DSEG, %ax # Our data segment selector
movw %ax, %ds # -> DS: Data Segment
movw %ax, %es # -> ES: Extra Segment
movw %ax, %fs # -> FS
movw %ax, %gs # -> GS
movw %ax, %ss # -> SS: Stack Segment
# Set up the stack pointer and call into C. The stack region is from 0--start(0x7c00)
movl $0x0, %ebp
movl $start, %esp
call bootmain练习四
对于bootmain.c,它唯一的工作就是从硬盘的第一个扇区启动格式为ELF的内核镜像;控制从boot.S文件开始—这个文件设置了保护模式和一个栈,这样C代码就可以运行了,然后再调用bootmain()。
对x86.h头文件有:http://www.codeforge.cn/read/234474/x86.h__html
2
3
4
5
6
7
8
9
10
11
inb(ushort port)
{
uchar data;
asm volatile("in %1,%0" : "=a" (data) : "d" (port));
//对应 in port,data
return data;
}
0x1F7:读 用来存放读操作后的状态
readsect(void *dst, uint32_t secno)从secno扇区读取数据到dst
- 用汇编的方式实现读取1000号逻辑扇区开始的8个扇区
- IDE通道的通讯地址是0x1F0 - 0x1F7
- 其中0x1F3 - 0x1F6 4个字节的端口是用来写入LBA地址的
- LBA就是 logical Block Address
- 1000的16进制就是0x3E8
- 向0x1F3 - 0x1F6写入 0x3E8
- 向0x1F2这个地址写入扇区数量,也就是8
- 向0X1F7写入要执行的操作命令码,对读操作的命令码是 0x20
1 | out 0x1F3 0x00 |
outb的定义在x86.h中,封装out命令,将data输出到port端口1
2
3
4
5
6
7static inline void
outb(ushort port, uchar data)
{
asm volatile("out %0,%1" : : "a" (data), "d" (port));
}
业界共同推出了 LBA48,采用 48 个比特来表示逻辑扇区号。如此一来,就可以管理131072 TB 的硬盘容量了。在这里我们采用将采用 LBA28 来访问硬盘。
第1步:设置要读取的扇区数量。这个数值要写入0x1f2端口。这是个8位端口,因此每次只能读写255个扇区:1
2
3mov dx,0x1f2
mov al,0x01 ;1 个扇区
out dx,al
注意:如果写入的值为 0,则表示要读取 256 个扇区。每读一个扇区,这个数值就减一。因此,如果在读写过程中发生错误,该端口包含着尚未读取的扇区数。
第2步:设置起始LBA扇区号。扇区的读写是连续的,因此只需要给出第一个扇区的编号就可以了。28 位的扇区号太长,需要将其分成 4 段,分别写入端口 0x1f3、0x1f4、0x1f5 和 0x1f6 号端口。其中,0x1f3 号端口存放的是 0~7 位;0x1f4 号端口存放的是 8~15 位;0x1f5 号端口存放的是 16~23 位,最后 4 位在 0x1f6 号端口。
第3步:
向端口 0x1f7 写入 0x20,请求硬盘读。
第4步:等待读写操作完成。端口0x1f7既是命令端口,又是状态端口。在通过这个端口发送读写命令之后,硬盘就忙乎开了。在它内部操作期间,它将 0x1f7 端口的第7位置“1”,表明自己很忙。一旦硬盘系统准备就绪,它再将此位清零,说明自己已经忙完了,同时将第3位置“1”,意思是准备好了,请求主机发送或者接收数据。
第5步:连续取出数据。0x1f0 是硬盘接口的数据端口,而且还是一个16位端口。一旦硬盘控制器空闲,且准备就绪,就可以连续从这个端口写入或者读取数据。
1 | outb(0x1F2, 1); // 读取第一个数据块 |
readseg函数简单包装了readsect,可以从设备读取任意长度的内容。1
2
3
4
5
6
7
8
9
10
11static void readseg(uintptr_t va, uint32_t count, uint32_t offset) {
uintptr_t end_va = va + count;
va -= offset % SECTSIZE;
uint32_t secno = (offset / SECTSIZE) + 1;
// 看是第几块,加1因为0扇区被引导占用,ELF文件从1扇区开始
for (; va < end_va; va += SECTSIZE, secno ++) {
readsect((void *)va, secno);//调用之前的封装函数对每一块进行处理
}
}
对不同的文件,执行file命令如下:1
2
3
4
5
6
7
8
9
10
11file link.o
link.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
file libfoo.so
libfoo.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=871ecaf438d2ccdcd2e54cd8158b9d09a9f971a7, not stripped
file p1
p1: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=37f75ef01273a9c77f4b4739bcb7b63a4545d729, not stripped
file libfoo.so
libfoo.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=871ecaf438d2ccdcd2e54cd8158b9d09a9f971a7, stripped
以下是主函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28bootmain(void) {
// read the 1st page off disk
readseg((uintptr_t)ELFHDR, SECTSIZE * 8, 0);
// 看是不是标准的elf
if (ELFHDR->e_magic != ELF_MAGIC) {
goto bad;
}
struct proghdr *ph, *eph;
// elf头中有elf文件应该加载到什么位置,将表头地址存在ph中
ph = (struct proghdr *)((uintptr_t)ELFHDR + ELFHDR->e_phoff);
eph = ph + ELFHDR->e_phnum;
for (; ph < eph; ph ++) {
readseg(ph->p_va & 0xFFFFFF, ph->p_memsz, ph->p_offset);
}
// 找到内核的入口,这个函数不返回
((void (*)(void))(ELFHDR->e_entry & 0xFFFFFF))();
bad:
outw(0x8A00, 0x8A00);
outw(0x8A00, 0x8E00);
/* do nothing */
while (1);
}
一般的 ELF 文件包括三个索引表:ELF header,Program header table,Section header table。
- ELF header:在文件的开始,保存了路线图,描述了该文件的组织情况。
- Program header table:告诉系统如何创建进程映像。用来构造进程映像的目标文件必须具有程序头部表,可重定位文件不需要这个表。
- Section header table:包含了描述文件节区的信息,每个节区在表中都有一项,每一项给出诸如节区名称、节区大小这类信息。用于链接的目标文件必须包含节区头部表,其他目标文件可以有,也可以没有这个表。
1 | typedef struct |
ELF文件中有很多段,段表(Section Header Table)就是保存这些段的基本信息的结构,包括了段名、段长度、段在文件中的偏移位置、读写权限和其他段属性。
objdump工具可以查看ELF文件基本的段结构1
2
3
4
5
6
7
8
9
10
11
12
13typedef struct
{
Elf64_Word sh_name; /* Section name (string tbl index) */
Elf64_Word sh_type; /* Section type */
Elf64_Xword sh_flags; /* Section flags */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Section size in bytes */
Elf64_Word sh_link; /* Link to another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;
练习五
一个比较简单但很绕的逻辑,找到每个函数调用压栈时的指针,找到这个指针也就找到了上一个函数的部分,再找它之前的函数调用压栈的内容。主要问题是忘记了ebp!=0这个条件,忽视了要用16进制。
- eip是寄存器存放下一个CPU指令存放的内存地址,当CPU执行完当前的指令后,从eip寄存器中读取下一条指令的内存地址,然后继续执行;
- esp是寄存器存放当前线程的栈顶指针;
- ebp存放一个指针,该指针指向系统栈最上面一个栈帧的底部。即EBP寄存器存储的是栈底地址,而这个地址是由ESP在函数调用前传递给EBP的。等到调用结束,EBP会把其地址再次传回给ESP。所以ESP又一次指向了函数调用结束后,栈顶的地址。
1 | void print_stackframe(void) { |
ebp(基指针)寄存器主要通过软件约定与堆栈相关联。 在进入C函数时,函数的初始代码通常将先前函数的基本指针推入堆栈来保存,然后在函数持续时间内将当前esp值复制到ebp中。 如果程序中的所有函数都遵循这个约定,那么在程序执行期间的任何给定点,都可以通过跟踪保存的ebp指针链并确切地确定嵌套的函数调用序列引起这个特定的情况来追溯堆栈。 指向要达到的函数。 例如,当某个特定函数导致断言失败时,因为错误的参数传递给它,但您不确定是谁传递了错误的参数。 堆栈回溯可找到有问题的函数。
最后一行对应的是第一个使用堆栈的函数,所以在栈的最深一层,就是bootmain.c中的bootmain。 bootloader起始的堆栈从0x7c00开始,使用”call bootmain”转入bootmain函数。 call指令压栈,所以bootmain中ebp为0x7bf8。
练习六
一个表项的结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13/*lab1/kern/mm/mmu.h*/
/* Gate descriptors for interrupts and traps */
struct gatedesc {
unsigned gd_off_15_0 : 16; // low 16 bits of offset in segment
unsigned gd_ss : 16; // segment selector
unsigned gd_args : 5; // # args, 0 for interrupt/trap gates
unsigned gd_rsv1 : 3; // reserved(should be zero I guess)
unsigned gd_type : 4; // type(STS_{TG,IG32,TG32})
unsigned gd_s : 1; // must be 0 (system)
unsigned gd_dpl : 2; // descriptor(meaning new) privilege level
unsigned gd_p : 1; // Present
unsigned gd_off_31_16 : 16; // high bits of offset in segment
};
一个表项占用8字节,其中2-3字节是段选择子,0-1字节和6-7字节拼成位移, 两者联合便是中断处理程序的入口地址。(copy from answer)
pic_init:中断控制器的初始化;idt_init:建立中断描述符表,并使能中断,intr_enable()
中断向量表可以认为是一个大数组,产生中断时生成一个中断号,来查这个idt表,找到中断服务例程的地址(段选择子加offset)。
主要是调用SETGATE这个宏对interrupt descriptor table进行初始化,是之前看到的对每个字节进行操作。然后调用lidt进行load idt(sti:使能中断)
建立一个中断描述符
- istrap: 1 是一个trap, 0 代表中断
- sel: 中断处理代码段
- off: 中断处理代码段偏移
- dpl: 描述符的优先级
1 | #define SETGATE(gate, istrap, sel, off, dpl) |
除了系统调用中断(T_SYSCALL)使用陷阱门描述符且权限为用户态权限以外,其它中断均使用特权级(DPL)为0的中断门描述符,权限为内核态权限;
- 中断描述符表(Interrupt Descriptor Table)中断描述符表把每个中断或异常编号和一个指向中断服务例程的描述符联系起来。同GDT一样,IDT是一个8字节的描述符数组,但IDT的第一项可以包含一个描述符。CPU把中断(异常)号乘以8做为IDT的索引。IDT可以位于内存的任意位置,CPU通过IDT寄存器(IDTR)的内容来寻址IDT的起始地址。指令LIDT和SIDT用来操作IDTR。两条指令都有一个显示的操作数:一个6字节表示的内存地址。在保护模式下,最多会存在256个Interrupt/Exception Vectors。
1 | extern uintptr_t __vectors[]; |
对idt中的每一项,调用SETGATE进行设置,第二个是0表明是一个中断,如果是1表明是一个陷阱;GD_KTEXT是SEG_KTEXT(1,全局段编号)乘8,是处理中断的代码段编号,__vectors[i]是作为在代码段中的偏移量,vectors[i]在kern/trap/vectors.S中定义,定义了255个中断服务例程的地址,这里才是入口,且都跳转到__alltraps。在trap中调用了trap_dispatch,这样就根据传进来的进行switch处理。
用户态设置在特权级3,内核态设置在特权级0。
练习七
这个实验实现用户态和内核态的转换,通过看代码基本明白。在init.c中的lab1_switch_to_user函数时一段汇编代码, 触发中断的话,有‘int %0’,就把第二个冒号(输入的数,T_SWITCH_TOK)替换%0, 这样中断号就是T_SWITCH_TOK。
SETGATE设置中断向量表将每个中断处理例程的入口设成vector[i]的值,然后在有中断时,找到中断向量表中这个中断的处理例程,都是跳到alltraps,__alltraps把寄存器(ds es fs gs)压栈,把esp压栈,这样假装构造一个trapframe然后调用trap,trap调用了trap_dispatch
在trap_dispatch中,对从堆栈弹出的段寄存器进行修改,转成User时和转成Kernel时不一样,分别赋值,同时需要修改之前的trapframe,实现中断的恢复。
1 | //LAB1 CHALLENGE 1 : YOUR CODE you should modify below codes. |
实验二
读代码
在bootloader进入保护模式前进行探测物理内存分布和大小,基本方式是通过BIOS中断调用,在实模式下完成,在boot/bootasm.S中从probe_memory处到finish_probe处的代码部分完成。以下应该是检测到的物理内存信息:1
2
3
4
5
6
7
8memory management: default_pmm_manager
e820map:
memory: 0009fc00, [00000000, 0009fbff], type = 1.
memory: 00000400, [0009fc00, 0009ffff], type = 2.
memory: 00010000, [000f0000, 000fffff], type = 2.
memory: 07ee0000, [00100000, 07fdffff], type = 1.
memory: 00020000, [07fe0000, 07ffffff], type = 2.
memory: 00040000, [fffc0000, ffffffff], type = 2.
参考:type是物理内存空间的类型,1是可以使用的,2是暂时不能够使用的。
之前是开启A20的16位地址线,实现20位地址访问。通过写键盘控制器8042的64h端口与60h端口。先转成实模式!
获取的物理内存信息是用这种结构存的(内存映射地址描述符),一共20字节:
1 | struct e820map { |
每探测到一块内存空间,对应的内存映射描述符被写入指定表,以下是通过向INT 15h中断传入e820h参数来探测物理内存空间的信息。”$”美元符号修饰立即数,”%”修饰寄存器。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18probe_memory:
movl $0, 0x8000 #把0这个立即数写入0x8000地址,
xorl %ebx, %ebx #相当于我们设置在0x8000处存放struct e820map, 并清除e820map中的nr_map置0
movw $0x8004, %di #0x8004正好就是第一个内存映射地址描述符的地址,因为nr_map是四个字节
start_probe:
movl $0xE820, %eax #传入0xE820作为参数,
movl $20, %ecx #内存映射地址描述符的大小是20个字节
movl $SMAP, %edx #SMAP之前定义是0x534d4150,不知道何用
int $0x15 #调用INT 15H中断
jnc cont #CF=0,则跳转到cont
movw $12345, 0x8000
jmp finish_probe
cont:
addw $20, %di #设置下一个内存映射地址描述符的地址
incl 0x8000 #E820map中的nr_map加一
cmpl $0, %ebx #如果INT0x15返回的ebx为零,表示探测结束,如果还有就继续找
jnz start_probe
finish_probe:
调用中断int 15h 之前,需要填充如下寄存器:
- eax int 15h 可以完成许多工作,主要有ax的值决定,我们想要获取内存信息,需要将ax赋值为0E820H。
- ebx 放置着“后续值(continuation value)”,第一次调用时ebx必须为0.
- es:di 指向一个地址范围描述结构 ARDS(Address Range Descriptor Structure), BIOS将会填充此结构。
- ecx es:di所指向的地址范围描述结构的大小,以字节为单位。无论es:di所指向的结构如何设置,BIOS最多将会填充ecx字节。不过,通常情况下无论ecx为多大,BIOS只填充20字节,有些BIOS忽略ecx的值,总是填充20字节。
- edx 0534D4150h(‘SMAP’)——BIOS将会使用此标志,对调用者将要请求的系统映像信息进行校验,这些信息被BIOS放置到es:di所指向的结构中。
中断调用之后,结果存放于下列寄存器之中。
- CF CF=0表示没有错误,否则存在错误。
- eax 0534D4150h(‘SMAP’)
- es:di 返回的地址范围描述符结构指针,和输入值相同。
- ecx BIOS填充在地址范围描述符中的字节数量,被BIOS所返回的最小值是20字节。
- ebx 这里放置着为等到下一个地址描述符所需要的后续值,这个值得实际形势依赖于具体的BIOS的实现,调用者不必关心它的具体形式,自需在下一次迭代时将其原封不动地放置到ebx中,就可以通过它获取下一个地址范围描述符。如果它的值为0,并且CF没有进位,表示它是最后一个地址范围描述符。
由于一个物理页需要占用一个Page结构的空间,Page结构在设计时须尽可能小,以减少对内存的占用。1
2
3
4
5
6
7struct Page { // 描述了一个Page
int ref; // 这一页被页表的引用计数,一个页表项设置了一个虚拟页的映射
uint32_t flags; // 描述这个Page的状态,可能每个位表示不同的意思
unsigned int property; // property表示这个块中空闲页的数量,用到此成员变量的这个Page比较特殊,
// 是这个连续内存空闲块地址最小的一页(即头一页, Head Page)。
list_entry_t page_link; // 链接比它地址小和大的其他连续内存空闲块。
};
flag用到了两个bit1
2
总结来说:一个页,里边有各种属性和双向链表的指针段
- ref表示这个页被页表的引用记数,是映射此物理页的虚拟页个数。一旦某页表中有一个页表项设置了虚拟页到这个Page管理的物理页的映射关系,就会把Page的ref加一。反之,若是解除,那就减一。
- flags表示此物理页的状态标记,有两个标志位,第一个表示是否被保留,如果被保留了则设为1(比如内核代码占用的空间)。第二个表示此页是否是free的。如果设置为1,表示这页是free的,可以被分配;如果设置为0,表示这页已经被分配出去了,不能被再二次分配。
- property用来记录某连续内存空闲块的大小,这里需要注意的是用到此成员变量的这个Page一定是连续内存块的开始地址(第一页的地址)。
- page_link是便于把多个连续内存空闲块链接在一起的双向链表指针,连续内存空闲块利用第一个页的成员变量page_link来链接比它地址小和大的其他连续内存空闲块,用到这个成员变量的是这个块的地址最小的一页。
下面简单看看mm/pmm.c中的pmm_init()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56/* pmm_init - initialize the physical memory management */
static void
page_init(void) {
struct e820map *memmap = (struct e820map *)(0x8000 + KERNBASE);
uint64_t maxpa = 0;
cprintf("e820map:\n");
int i;
for (i = 0; i < memmap->nr_map; i ++) {
uint64_t begin = memmap->map[i].addr, end = begin + memmap->map[i].size;
cprintf(" memory: %08llx, [%08llx, %08llx], type = %d.\n",
memmap->map[i].size, begin, end - 1, memmap->map[i].type);
if (memmap->map[i].type == E820_ARM) {
if (maxpa < end && begin < KMEMSIZE) {
maxpa = end;
}
}
}
if (maxpa > KMEMSIZE) {
maxpa = KMEMSIZE;
}
extern char end[];
npage = maxpa / PGSIZE;
//起始物理内存地址位0,所以需要管理的页个数为npage,需要管理的所有页的大小位sizeof(struct Page)*npage
pages = (struct Page *)ROUNDUP((void *)end, PGSIZE);
// pages的地址,最末尾地址按照页大小取整。
for (i = 0; i < npage; i ++) {
SetPageReserved(pages + i);
}
//当前的这些页设置为已占用的
uintptr_t freemem = PADDR((uintptr_t)pages + sizeof(struct Page) * npage);
// 之前设置了占用的页,那空闲的页就是从(pages+sizeof(struct Page)*npage)以上开始的
for (i = 0; i < memmap->nr_map; i ++) {
uint64_t begin = memmap->map[i].addr, end = begin + memmap->map[i].size;
if (memmap->map[i].type == E820_ARM) {
if (begin < freemem) {
begin = freemem;
}
if (end > KMEMSIZE) {
end = KMEMSIZE;
}
if (begin < end) {
begin = ROUNDUP(begin, PGSIZE);
end = ROUNDDOWN(end, PGSIZE);
if (begin < end) {
init_memmap(pa2page(begin), (end - begin) / PGSIZE);
// 通过调用本函数进行空闲的标记
}
}
}
}
}
SetPageReserved表示把物理地址对应的Page结构中的flags标志设置为PG_reserved ,表示这些页已经被使用了,将来不能被用于分配。而init_memmap函数把空闲物理页对应的Page结构中的flags和引用计数ref清零,并加到free_area.free_list指向的双向列表中。1
2
3
4
5
6
7
8
9struct pmm_manager {
const char *name; //物理内存页管理器的名字
void (*init)(void); //初始化内存管理器
void (*init_memmap)(struct Page *base, size_t n); //初始化管理空闲内存页的数据结构
struct Page *(*alloc_pages)(size_t n); //分配n个物理内存页
void (*free_pages)(struct Page *base, size_t n); //释放n个物理内存页
size_t (*nr_free_pages)(void); //返回当前剩余的空闲页数
void (*check)(void); //用于检测分配/释放实现是否正确
};
1 | free_area_t - 维护一个双向链表记录没有用到的Page。 |
1 | typedef struct list_entry list_entry_t; |
练习1 实现first-fit连续物理内存分配算法
重写函数: default_init, default_init_memmap,default_alloc_pages, default_free_pages。
在实现first_fit的回收函数时,注意连续地址空间之间的合并操作。在遍历空闲页块链表时,需要按照空闲块起始地址来排序,形成一个有序的的链表。
首次适应算法(First Fit):该算法从空闲分区链首开始查找,直至找到一个能满足其大小要求的空闲分区为止。然后再按照需求的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链中。多使用内存中低地址部分的空闲区,在高地址部分的空闲区很少被利用,从而保留了高地址部分的空闲区。显然为以后到达的大作业分配大的内存空间创造了条件。但是低地址部分不断被划分,留下许多难以利用、很小的空闲区,每次查找又都从低地址部分开始,会增加查找的开销。
在First Fit算法中,分配器维护一个空闲块列表(free表)。一旦收到内存分配请求,
它遍历列表找到第一个满足的块。如果所选块明显大于请求的块,则分开,其余的空间将被添加到列表中下一个free块中。
- 准备:实现First Fit我们需要使用链表管理空闲块,free_area_t被用来管理free块,首先,找到list.h中的”struct list”。结构”list”是一个简单的双向链表实现。使用”list_init”,”list_add”(”list_add_after”和”list_add_before”),”list_del”,
“list_next”,”list_prev”。有一个棘手的方法是将一般的”list”结构转换为一个特殊结构(如struct”page”),使用以下宏:”le2page”(在memlayout.h中)。 - “default_init”:重用例子中的”default_init”函数来初始化”free_list”并将”nr_free”设置为0。”free_list”用于记录空闲内存块,”nr_free”是可用内存块的总数。
- “default_init_memmap”:调用栈为”kern_init” -> “pmm_init” -> “page_init” -> “init_memmap” -> “pmm_manager” -> “init_memmap”。此函数用于初始化空闲块(使用参数”addr_base”,”page_mumber”)。为了初始化一个空闲块,首先,应该在这个空闲块中初始化每个页面(在memlayout.h中定义)。这个程序包括:
- 设置”p -> flags”的’PG_property’位,表示该页面为有效。在函数”pmm_init”(在pmm.c中),”p-> flags”的位’PG_reserved”已经设置好了。
- 如果此页面是free的且不是free区块的第一页,”p-> property”应该设置为0。
- 如果此页面是free的且是free区块的第一页,”p-> property”应该设置为本空闲块的总页数。
- “default_alloc_pages”:在空闲列表中搜索第一个空闲块(块大小>=n),返回该块的地址作为所需的地址.
空闲页管理链表的初始化:把free_list的双向链表中的指针都指向自己,且计数器为01
2
3
4
5
6
7static void default_init(void) {
list_init(&free_list);
nr_free = 0;
}
static inline void list_init(list_entry_t *elm) {
elm->prev = elm->next = elm;
}
初始化空闲页链表,初始化每一个空闲页,然后计算空闲页的总数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17static void default_init_memmap(struct Page *base, size_t n) {
assert(n > 0);
struct Page *p = base;
for (; p != base + n; p ++) {
assert(PageReserved(p));
//这个页是否为保留页,PageReserved(p)返回true才会继续,如果返回true了,说明是保留页
//设置标志位
p->flags = 0;
SetPageProperty(p);
p->property = 0; //应该只有第一个页的这个参数有用
set_page_ref(p, 0);//清空引用,现在是没有虚拟内存引用它的
list_add_before(&free_list, &(p->page_link));//插入空闲页的链表里面
}
nr_free += n; //连续有n个空闲块,空闲链表的个数加n
base->property=n; //连续内存空闲块的大小为n,属于物理页管理链表
//所有的页都在这个双向链表里且只有第0个页有这个块的信息
}
default_alloc_pages从空闲页链表中查找n个空闲页,如果成功,返回第一个页表的地址。遍历空闲链表,一旦发现有大于等于n的连续空闲页块,便将这n个页从空闲页链表中取出,同时使用SetPageReserved和ClearPageProperty表示该页为使用状态,同时如果该连续页的数目大于n,则从第n+1开始截断,之后为截断的块,重新计算相应的property的值。在贴代码之前先说说几个宏。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/* 将这个le转换成一个Page */
/* *
* to_struct - get the struct from a ptr
* @ptr: a struct pointer of member
* @type: the type of the struct this is embedded in
* @member: the name of the member within the struct
* 一般用的时候传进来的type是Page类型的,ptr是这个(Page+双向链表的两个指针)块的双向链表指针的开始地址。offsetof算出了page_link在Page中的偏移值,ptr减去双向链表第一个指针的偏移量得到了这个Page的地址
*/
/* Return the offset of 'member' relative to the beginning of a struct type */
0不代表具体地址,这个offsetof代表这个member在这个type中的偏移值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37static struct Page * default_alloc_pages(size_t n) {
assert(n > 0);
if (n > nr_free) {
return NULL;
}
// n 一定要大于0,且n要小于当前可用的空闲块数
list_entry_t *le, *len;
le = &free_list;
struct Page *p=NULL;
while((le=list_next(le)) != &free_list) {
p = le2page(le, page_link);
if(p->property>=n)
break;
}
//在free_list里遍历每一页,用le2page转换成Page
//如果找到了一个property大于n的就说明找到了这个符合要求的块
if(p != NULL){
int i;
for(i=0;i<n;i++){
len = list_next(le);
struct Page *pp = le2page(le, page_link);
SetPageReserved(pp);
ClearPageProperty(pp);
list_del(le);
le = len;
}
// 如果我现在找到的块是大于n的,那就拆开
if(p->property>n){
(le2page(le,page_link))->property = p->property - n;
}
ClearPageProperty(p);
SetPageReserved(p);
nr_free -= n;
return p;
}
return NULL;
}
default_free_pages将base为起始地址的n个页面放回到free_list中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44static void default_free_pages(struct Page *base, size_t n) {
assert(n > 0);
list_entry_t *le = &free_list;
struct Page *p = base;
//找到比base大的页面地址
while((le=list_next(le)) != &free_list){
p = le2page(le,page_link);
if(p > base)
break;
}
//在找到的p之前逐个插入
for(p = base; p < base + n; p ++){
list_add_before(le,&(p->page_link));
}
base->flags=0;
set_page_ref(base,0);
ClearPageProperty(base);
SetPageProperty(base);
base->property = n;
// 清空flag的信息,清空引用的信息,清空property信息,设置这个Page又是可以被引用的了
// 当前的base又是n个空闲块的头
p = le2page(le,page_link);
if(base+n==p){
base->property+=p->property;
p->property=0;
}
//看是不是可以跟后边的块恰好连在一起,如果连在一起的话就可以合并了
le=list_prev(&(base->page_link));
p = le2page(le, page_link);
//看是不是可以跟前边的连在一起,如果可以的话这个base就可以把property设成0了
if(le!=&free_list && p==base-1){
while(le!=&free_list){
if(p->property){
p->property+=base->property;
base->property=0;
break;
}
le = list_prev(le);
p=le2page(le,page_link);
}
}
nr_free +=n;
cprintf("release %d page,last %d.\n",n,nr_free);
}
运行中出现提示,表明本题成功:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15release 1 page,last 1.
release 1 page,last 2.
release 1 page,last 3.
release 1 page,last 1.
release 1 page,last 32291.
release 1 page,last 32292.
release 1 page,last 32293.
release 3 page,last 3.
release 1 page,last 1.
release 3 page,last 4.
release 1 page,last 4.
release 2 page,last 4.
release 1 page,last 5.
release 5 page,last 32293.
check_alloc_page() succeeded!
first_fit有一种改进,next_fit,第一次找到之后不暂停,第二次找到之后才真正给分配空间。修改比较简单,第一次找到之后记一个flag,下次再找到就可以分配了。
练习二
系统执行中的地址映射。
mooc中讲到了在段页式管理机制下运行这整个过程中,虚拟地址到物理地址的映射产生了多次变化,实现了最终的段页式映射关系:1
virt addr = linear addr = phy addr + 0xC0000000
第一个阶段(开启保护模式,创建启动段表)是bootloader阶段,即从bootloader的start函数(在boot/bootasm.S中)到执行ucore kernel的kern_entry函数之前,其虚拟地址、线性地址以及物理地址之间的映射关系与lab1的一样,即:1
virt addr = linear addr = phy addr
第二个阶段(创建初始页目录表,开启分页模式)从kern_entry函数开始,到pmm_init函数被执行之前。通过几条汇编指令(在kern/init/entry.S中)使能分页机制,主要做了两件事:
- 通过movl %eax, %cr3指令把页目录表的起始地址存入CR3寄存器中;
- 通过movl %eax, %cr0指令把cr0中的CR0_PG标志位设置上。
在此之后,进入了分页机制,地址映射关系如下:1
2virt addr = linear addr = phy addr # 线性地址在0~4MB之内三者的映射关系
virt addr = linear addr = phy addr + 0xC0000000 # 线性地址在0xC0000000~0xC0000000+4MB之内三者的映射关系
仅仅比第一个阶段增加了下面一行的0xC0000000偏移的映射,并且作用范围缩小到了0~4M。在下一个节点,会将作用范围继续扩充到0~KMEMSIZE。
此时的内核(EIP)还在0~4M的低虚拟地址区域运行,而在之后,这个区域的虚拟内存是要给用户程序使用的。为此,需要使用一个绝对跳转来使内核跳转到高虚拟地址(代码在kern/init/entry.S中):1
2
3
4
5
6 # update eip
# now, eip = 0x1.....
leal next, %eax
# set eip = KERNBASE + 0x1.....
jmp *%eax
next:
跳转完毕后,通过把boot_pgdir[0]对应的第一个页目录表项(0~4MB)清零来取消了临时的页映射关系:1
2
3# unmap va 0 ~ 4M, it's temporary mapping
xorl %eax, %eax
movl %eax, __boot_pgdir
最终的地址映射关系如下:1
lab2 stage 2: virt addr = linear addr = phy addr + 0xC0000000 # 线性地址在0~4MB之内三者的映射关系
第三个阶段(完善段表和页表)从pmm_init函数被调用开始。pmm_init函数将页目录表项补充完成(从0~4M扩充到0~KMEMSIZE)。然后,更新了段映射机制,使用了一个新的段表。这个新段表除了包括内核态的代码段和数据段描述符,还包括用户态的代码段和数据段描述符以及TSS(段)的描述符。理论上可以在第一个阶段,即bootloader阶段就将段表设置完全,然后在此阶段继续使用,但这会导致内核的代码和bootloader的代码产生过多的耦合,于是就有了目前的设计。
这时形成了我们期望的虚拟地址、线性地址以及物理地址之间的映射关系:1
lab2 stage 3: virt addr = linear addr = phy addr + 0xC0000000
请描述页目录项(Pag Director Entry)和页表(Page Table Entry)中每个组成部分的含义和以及对ucore而言的潜在用处。
页目录项(Pag Director Entry)每一位的含义:
- 前20位表示4K对齐的该PDE对应的页表起始位置(物理地址,该物理地址的高20位即PDE中的高20位,低12位为0);
- 第9-11位未被CPU使用,可保留给OS使用;
- 接下来的第8位可忽略;
- 第7位用于设置Page大小,0表示4KB;
- 第6位恒为0;
- 第5位用于表示该页是否被使用过;
- 第4位设置为1则表示不对该页进行缓存;
- 第3位设置是否使用write through缓存写策略;
- 第2位表示该页的访问需要的特权级;
- 第1位表示是否允许读写;
- 第0位为该PDE的存在位;
页表项(PTE)中的每项的含义:
- 高20位与PDE相似的,用于表示该PTE指向的物理页的物理地址;
- 9-11位保留给OS使用;
- 7-8位恒为0;
- 第6位表示该页是否为dirty,即是否需要在swap out的时候写回外存;
- 第5位表示是否被访问;
- 3-4位恒为0;
- 0-2位分别表示存在位、是否允许读写、访问该页需要的特权级;
PTE和PDE都有一些保留位供操作系统使用,ucore利用保留位来完成一些其他的内存管理相关的算法。
当ucore执行过程中出现了页访问异常,硬件需要完成的事情分别如下:
- 将发生错误的线性地址保存在cr2寄存器中;
- 在中断栈中依次压入EFLAGS,CS, EIP,以及页访问异常码error code,如果pgfault是发生在用户态,则还需要先压入ss和esp,并且切换到内核栈;
- 根据中断描述符表查询到对应page fault的处理例程地址如后,跳转到对应处执行。
建立虚拟页和物理页帧的地址映射关系
整个页目录表和页表所占空间大小取决与二级页表要管理和映射的物理页数。
假定当前物理内存0~16MB,每物理页(也称Page Frame)大小为4KB,则有4096个物理页,也就意味这有4个页目录项和4096个页表项需要设置。一个页目录项(Page Directory Entry,PDE)和一个页表项(Page Table Entry,PTE)占4B。即使是4个页目录项也需要一个完整的页目录表(占4KB)。而4096个页表项需要16KB(即4096*4B)的空间,也就是4个物理页,16KB的空间。所以对16MB物理页建立一一映射的16MB虚拟页,需要4+1=5个物理页,即20KB的空间来形成二级页表。
把0~KERNSIZE(明确ucore设定实际物理内存不能超过KERNSIZE值,即0x38000000字节,896MB,3670016个物理页)的物理地址一一映射到页目录项和页表项的内容,其大致流程如下:
- 指向页目录表的指针已存储在boot_pgdir变量中。
- 映射0~4MB的首个页表已经填充好。
- 调用boot_map_segment函数进一步建立一一映射关系,具体处理过程以页为单位进行设置,即:
1 | linear addr = phy addr + 0xC0000000 |
设一个32bit线性地址la有一个对应的32bit物理地址pa,如果在以la的高10位为索引值的页目录项中的存在位(PTE_P)为0,表示缺少对应的页表空间,则可通过alloc_page获得一个空闲物理页给页表,页表起始物理地址是按4096字节对齐的,这样填写页目录项的内容为:
页目录项内容 = (页表起始物理地址 & ~0x0FFF) | PTE_U | PTE_W | PTE_P
进一步对于页表中以线性地址la的中10位为索引值对应页表项的内容为:
页表项内容 = (pa & ~0x0FFF) | PTE_P | PTE_W
其中:
PTE_U:位3,表示用户态的软件可以读取对应地址的物理内存页内容
PTE_W:位2,表示物理内存页内容可写
PTE_P:位1,表示物理内存页存在
ucore的内存管理经常需要查找页表:
给定一个虚拟地址,找出这个虚拟地址在二级页表中对应的项。通过更改此项的值可以方便地将虚拟地址映射到另外的页上。可完成此功能的这个函数是get_pte函数。它的原型为1
pte_t *get_pte(pde_t *pgdir, uintptr_t la, bool create)
这里涉及到三个类型pte_t、pde_t和uintptr_t。这三个都是unsigned int类型。
- pde_t:page directory entry,一级页表的表项。
- pte_t:page table entry,表示二级页表的表项。
- uintptr_t:表示为线性地址,由于段式管理只做直接映射,所以它也是逻辑地址。
- pgdir:给出页表起始地址。通过查找这个页表,我们需要给出二级页表中对应项的地址。
可以在需要时再添加对应的二级页表。如果在查找二级页表项时,发现对应的二级页表不存在,则需要根据create参数的值来处理是否创建新的二级页表。如果create参数为0,则get_pte返回NULL;如果create参数不为0,则get_pte需要申请一个新的物理页(通过alloc_page来实现,可在mm/pmm.h中找到它的定义),再在一级页表中添加页目录项指向表示二级页表的新物理页。
注意,新申请的页必须全部设定为零,因为这个页所代表的虚拟地址都没有被映射。
当建立从一级页表到二级页表的映射时,需要注意设置控制位。这里应该设置同时设置上PTE_U、PTE_W和PTE_P(定义可在mm/mmu.h)。如果原来就有二级页表,或者新建立了页表,则只需返回对应项的地址即可。
虚拟地址只有映射上了物理页才可以正常的读写。在完成映射物理页的过程中,除了要在页表的对应表项上填上相应的物理地址外,还要设置正确的控制位。
只有当一级二级页表的项都设置了用户写权限后,用户才能对对应的物理地址进行读写。由于一个物理页可能被映射到不同的虚拟地址上去(譬如一块内存在不同进程间共享),当这个页需要在一个地址上解除映射时,操作系统不能直接把这个页回收,而是要先看看它还有没有映射到别的虚拟地址上。这是通过查找管理该物理页的Page数据结构的成员变量ref(用来表示虚拟页到物理页的映射关系的个数)来实现的,如果ref为0了,表示没有虚拟页到物理页的映射关系了,就可以把这个物理页给回收了,从而这个物理页是free的了,可以再被分配。
page_insert函数将物理页映射在了页表上。可参看page_insert函数的实现来了解ucore内核是如何维护这个变量的。当不需要再访问这块虚拟地址时,可以把这块物理页回收并在将来用在其他地方。取消映射由page_remove来做,这其实是page_insert的逆操作。
建立好一一映射的二级页表结构后,由于分页机制在前一节所述的前两个阶段已经开启,分页机制到此初始化完毕。当执行完毕gdt_init函数后,新的段页式映射已经建立好了。
预备知识copy完了,上练习二和练习三
练习二代码
预备知识不够用了
上mmu.h的代码读读1
2
3
4
5
6
7
8
9
10
11
12
A linear address 'la' has a three-part structure as follows:
+--------10------+-------10-------+---------12----------+
| Page Directory | Page Table | Offset within Page |
| Index | Index | |
+----------------+----------------+---------------------+
\--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/
\----------- PPN(la) -----------/
The PDX, PTX, PGOFF, and PPN macros decompose linear addresses as shown.
To construct a linear address la from PDX(la), PTX(la), and PGOFF(la),
use PGADDR(PDX(la), PTX(la), PGOFF(la)).
1 | //get_pte - get Page Table Entry and return the kernel virtual address of this Page Table Entry for la |
练习三
1 | //page_remove_pte - free an Page sturct which is related linear address la |
问题:1
2
3
4
5
6
7
8数据结构Page的全局变量(其实是一个数组)的每一项与页表中的页目录项和页表项有无对应关系?如果有,其对应关系是啥?
存在对应关系:由于页表项中存放着对应的物理页的物理地址,因此可以通过这个物理地址来获取到对应到的Page数组的对应项,具体做法为将物理地址除以一个页的大小,然后乘上一个Page结构的大小获得偏移量,使用偏移量加上Page数组的基地址皆可以或得到对应Page项的地址;
如果希望虚拟地址与物理地址相等,则需要如何修改lab2,完成此事? 鼓励通过编程来具体完成这个问题。
由于在完全启动了ucore之后,虚拟地址和线性地址相等,都等于物理地址加上0xc0000000,如果需要虚拟地址和物理地址相等,可以考虑更新gdt,更新段映射,使得virtual address = linear address - 0xc0000000,这样的话就可以实现virtual address = physical address;
reference:https://www.jianshu.com/p/abbe81dfe016
实验三
实验内容
在实验二的基础上,借助页表机制和实验一中涉及的中断异常处理机制,完成Pgfault异常处理和FIFO页替换算法的实现,结合磁盘提供的缓存空间,从而能够支持虚存管理,提供一个比实际物理内存空间“更大”的虚拟内存空间给系统使用。
这个实验与实际操作系统中的实现比较起来要简单,不过需要了解实验一和实验二的具体实现。实际操作系统系统中的虚拟内存管理设计与实现是相当复杂的,涉及到与进程管理系统、文件系统等的交叉访问。
简单原理
copy from gitbook
通过内存地址虚拟化,可以使得软件在没有访问某虚拟内存地址时不分配具体的物理内存,而只有在实际访问某虚拟内存地址时,操作系统再动态地分配物理内存,建立虚拟内存到物理内存的页映射关系,这种技术称为按需分页(demand paging)。把不经常访问的数据所占的内存空间临时写到硬盘上,这样可以腾出更多的空闲内存空间给经常访问的数据;当CPU访问到不经常访问的数据时,再把这些数据从硬盘读入到内存中,这种技术称为页换入换出(page swap in/out)。这种内存管理技术给了程序员更大的内存“空间”,从而可以让更多的程序在内存中并发运行。
参考ucore总控函数kern_init的代码,在调用完成虚拟内存初始化的vmm_init函数之前,需要首先调用pmm_init函数完成物理内存的管理,调用pic_init函数完成中断控制器的初始化,调用idt_init函数完成中断描述符表的初始化。
在调用完idt_init函数之后,将进一步调用新函数vmm_init、ide_init、swap_init。
do_pgfault函数会申请一个空闲物理页,并建立好虚实映射关系,从而使得这样的“合法”虚拟页有实际的物理页帧对应。
ide_init就是完成对用于页换入换出的硬盘(简称swap硬盘)的初始化工作。完成ide_init函数后,ucore就可以对这个swap硬盘进行读写操作了。
vmm设计包括两部分:mm_struct(mm)和vma_struct(vma)。mm是具有相同PDT的连续虚拟内存区域集的内存管理器。 vma是一个连续的虚拟内存区域。 vma中存在线性链接列表,mm的vma的redblack链接列表。(redblack是啥?)
建立mm_struct和vma_struct数据结构。当访问内存产生pagefault异常时,可获得访问的内存的方式(读或写)以及具体的虚拟内存地址,这样ucore就可以查询此地址,看是否属于vma_struct数据结构中描述的合法地址范围中,如果在,则可根据具体情况进行请求调页/页换入换出处理;如果不在,则报错。
两种数据结构:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24struct mm_struct {
// 链接所有属于同一页目录表的虚拟内存空间
list_entry_t mmap_list;
// 指向当前正在使用的虚拟内存空间,直接使用这个指针就能找到下一次要用到的虚拟空间
struct vma_struct *mmap_cache;
pde_t *pgdir; // 第一级页表的起始地址,即页目录表项PDT。通过访问pgdir可以查找某虚拟地址对应的页表项是否存在以及页表项的属性等
int map_count; // 记录了链接了的vma_struct个数,共享了几次
void *sm_priv; // 指向记录页访问情况的链表头。
};
struct vma_struct {
// 描述应用程序对虚拟内存“需求”
struct mm_struct *vm_mm; // 指向更高抽象层次的数据结构
// the set of vma using the same PDT
uintptr_t vm_start; // 连续地址虚拟内存空间的起始位置
uintptr_t vm_end; // 连续地址虚拟内存空间的结束位置
uint32_t vm_flags; // 标志属性(读/写/执行)
//link将一系列虚拟内存空间连接起来
list_entry_t list_link;
};
vm_flags:
具体函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// mm_create - alloc a mm_struct & initialize it.
struct mm_struct * mm_create(void) {
struct mm_struct *mm = kmalloc(sizeof(struct mm_struct));
if (mm != NULL) {
list_init(&(mm->mmap_list));
mm->mmap_cache = NULL;
mm->pgdir = NULL;
mm->map_count = 0;
if (swap_init_ok) swap_init_mm(mm);
else mm->sm_priv = NULL;
}
return mm;
}
// mm_destroy - free mm and mm internal fields
void mm_destroy(struct mm_struct *mm) {
list_entry_t *list = &(mm->mmap_list), *le;
while ((le = list_next(list)) != list) {
list_del(le);
kfree(le2vma(le, list_link),sizeof(struct vma_struct)); //kfree vma
}
kfree(mm, sizeof(struct mm_struct)); //kfree mm
mm=NULL;
}
设备驱动程序或者内核模块中动态开辟内存,不是用malloc,而是kmalloc ,vmalloc,
释放内存用的是kfree,vfree,kmalloc函数返回的是虚拟地址(线性地址)。
kmalloc特殊之处在于它分配的内存是物理上连续的,这对于要进行DMA的设备十分重要。
而用vmalloc分配的内存只是线性地址连续,物理地址不一定连续,不能直接用于DMA。vmalloc函数的工作方式类似于kmalloc,只不过前者分配的内存虚拟地址是连续的,而物理地址则无需连续。
通过vmalloc获得的页必须一个一个地进行映射,效率不高, 因此,只在不得已(一般是为了获得大块内存)时使用。vmalloc函数返回一个指针,指向逻辑上连续的一块内存区,其大小至少为size。在发生错误 时,函数返回NULL。1
2
3
4
5
6
7
8
9
10
11// vma_create - 新建一个vma_struct并且初始化(地址范围: vm_start~vm_end)
struct vma_struct * vma_create(uintptr_t vm_start, uintptr_t vm_end, uint32_t vm_flags) {
struct vma_struct *vma = kmalloc(sizeof(struct vma_struct));
if (vma != NULL) {
vma->vm_start = vm_start;
vma->vm_end = vm_end;
vma->vm_flags = vm_flags;
}
return vma;
}
Page Fault异常处理
处理该异常主要用do_pgfault函数,当启动分页机制以后,如果一条指令或数据的虚拟地址所对应的物理页框不在内存中或者访问的类型有错误(比如写一个只读页或用户态程序访问内核态的数据等),就会发生页访问异常。产生页访问异常的原因主要有:
目标页帧不存在(页表项全为0,即该线性地址与物理地址尚未建立映射或者已经撤销);
相应的物理页帧不在内存中(页表项非空,但Present标志位=0,比如在swap分区或磁盘文件上);
不满足访问权限(此时页表项P标志=1,但低权限的程序试图访问高权限的地址空间,或者有程序试图写只读页面)。
当出现上面情况之一,那么就会产生页面page fault(#PF)异常。CPU会把产生异常的线性地址存储在CR2中,并且把表示页访问异常类型的值(简称页访问异常错误码,errorCode)保存在中断栈中。CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址。CR2用于发生页异常时报告出错信息。产生页访问异常后,CPU把引起页访问异常的线性地址装到寄存器CR2中,并给出了出错码errorCode,说明了页访问异常的类型。操作系统中对应的中断服务例程可以检查CR2的内容,从而查出线性地址空间中的哪个页引起本次异常。
CPU在当前内核栈保存当前被打断的程序现场,即依次压入当前被打断程序使用的EFLAGS,CS,EIP,errorCode;由于页访问异常的中断号是0xE,CPU把异常中断号0xE对应的中断服务例程的地址(vectors.S中的标号vector14处)加载到CS和EIP寄存器中,开始执行中断服务例程。
这时ucore开始处理异常中断,首先需要保存硬件没有保存的寄存器。在vectors.S中的标号vector14处先把中断号压入内核栈,然后再在trapentry.S中的标号__alltraps处把DS、ES和其他通用寄存器都压栈。自此,被打断的程序执行现场(context)被保存在内核栈中。接下来,在trap.c的trap函数开始了中断服务例程的处理流程,大致调用关系为:
trap —> trap_dispatch —> pgfault_handler —> do_pgfault
ucore中do_pgfault函数是完成页访问异常处理的主要函数,它根据从CPU的控制寄存器CR2中获取的页访问异常的物理地址以及根据errorCode的错误类型来查找此地址是否在某个VMA的地址范围内以及是否满足正确的读写权限,如果在此范围内并且权限也正确,这认为这是一次合法访问,但没有建立虚实对应关系。所以需要分配一个空闲的内存页,并修改页表完成虚地址到物理地址的映射,刷新TLB,然后调用iret产生软中断,返回到产生页访问异常的指令处重新执行此指令。如果该虚地址不在某VMA范围内,则认为是一次非法访问。
页面置换机制的实现
当缺页中断发生时,操作系统把应用程序当前需要的数据或代码放到内存中来,然后重新执行应用程序产生异常的访存指令。如果在把硬盘中对应的数据或代码调入内存前,操作系统发现物理内存已经没有空闲空间了,这时操作系统必须把它认为“不常用”的页换出到磁盘上去,以腾出内存空闲空间给应用程序所需的数据或代码。
先进先出:选择在内存中驻留时间最久的页予以淘汰。将调入内存的页按照调入的先后顺序链接成一个队列,队列头指向内存中驻留时间最久的页,队列尾指向最近被调入内存的页。因为那些常被访问的页,往往在内存中也停留得最久,结果它们因变“老”而不得不被置换出去。FIFO算法的另一个缺点是,它有一种异常现象(Belady现象),即在增加放置页的页帧的情况下,反而使页访问异常次数增多。
时钟替换算法:是LRU算法的一种近似实现。时钟页替换算法把各个页面组织成环形链表的形式,类似于一个钟的表面。然后把一个指针(简称当前指针)指向最老的那个页面,即最先进来的那个页面。另外,时钟算法需要在页表项(PTE)中设置了一位访问位来表示此页表项对应的页当前是否被访问过。当该页被访问时,CPU中的MMU硬件将把访问位置“1”。当操作系统需要淘汰页时,对当前指针指向的页所对应的页表项进行查询,如果访问位为“0”,则淘汰该页,如果该页被写过,则还要把它换出到硬盘上;如果访问位为“1”,则将该页表项的此位置“0”,继续访问下一个页。该算法近似地体现了LRU的思想,且易于实现,开销少,需要硬件支持来设置访问位。时钟页替换算法在本质上与FIFO算法是类似的,不同之处是在时钟页替换算法中跳过了访问位为1的页。
改进时钟页替换算法:在时钟置换算法中,淘汰一个页面时只考虑了页面是否被访问过,但在实际情况中,还应考虑被淘汰的页面是否被修改过。因为淘汰修改过的页面还需要写回硬盘,使得其置换代价大于未修改过的页面,所以优先淘汰没有修改的页,减少磁盘操作次数。改进的时钟置换算法除了考虑页面的访问情况,还需考虑页面的修改情况。即该算法不但希望淘汰的页面是最近未使用的页,而且还希望被淘汰的页是在主存驻留期间其页面内容未被修改过的。这需要为每一页的对应页表项内容中增加一位引用位和一位修改位。当该页被访问时,CPU中的MMU硬件将把访问位置“1”。当该页被“写”时,CPU中的MMU硬件将把修改位置“1”。这样这两位就存在四种可能的组合情况:(0,0)表示最近未被引用也未被修改,首先选择此页淘汰;(0,1)最近未被使用,但被修改,其次选择;(1,0)最近使用而未修改,再次选择;(1,1)最近使用且修改,最后选择。该算法与时钟算法相比,可进一步减少磁盘的I/O操作次数。
页面置换机制
可以被换出的页
只有映射到用户空间且被用户程序直接访问的页面才能被交换,被内核直接使用的内核空间的页面不能被换出!!!操作系统是执行的关键代码,需要保证运行的高效性和实时性,如果在操作系统执行过程中,发生了缺页现象,则操作系统不得不等很长时间(硬盘的访问速度比内存的访问速度慢2到3个数量级),这将导致整个系统运行低效。
当一个Page Table Entry用来描述一般意义上的物理页时,它维护各种权限和映射关系,以及应该有PTE_P标记;但当它用来描述一个被置换出去的物理页时,它被用来维护该物理页与swap磁盘上扇区的映射关系,并且该PTE不应该由MMU将它解释成物理页映射(即没有 PTE_P 标记)。
与此同时对应的权限则交由mm_struct来维护,当对位于该页的内存地址进行访问的时候,必然导致 page fault,然后ucore能够根据 PTE 描述的swap项将相应的物理页重新建立起来,并根据虚存所描述的权限重新设置好 PTE 使得内存访问能够继续正常进行。
虚存中的页与硬盘上的扇区之间的映射关系
一个页被换出到硬盘,则PTE最低位present位应该是0,表示虚实地址映射关系不存在,接下来7位为保留位,表示页帧号的24位地址用来表示在硬盘上的地址。1
2
3
4\-----------------------------
| offset | reserved | 0 |
\-----------------------------
24 bits 7 bits 1 bit
执行换入换出的时机
当ucore或应用程序访问地址所在的页不在内存时,就会产生page fault异常,引起调用do_pgfault函数,此函数会判断产生访问异常的地址属于check_mm_struct某个vma表示的合法虚拟地址空间,且保存在硬盘swap文件中。
ucore目前大致有两种策略来实现换出操作,即积极换出策略和消极换出策略。积极换出策略是指操作系统周期性地(或在系统不忙的时候)主动把某些认为“不常用”的页换出到硬盘上,从而确保系统中总有一定数量的空闲页存在,这样当需要空闲页时,基本上能够及时满足需求;消极换出策略是指,只是当试图得到空闲页时,发现当前没有空闲的物理页可供分配,这时才开始查找“不常用”页面,并把一个或多个这样的页换出到硬盘上。
页替换算法的数据结构设计
1 | struct Page { |
pra_page_link构造了按页的第一次访问时间进行排序的一个链表,这个链表的开始表示第一次访问时间最近的页,链表结尾表示第一次访问时间最远的页。当然链表头可以就可设置为pra_list_head(定义在swap_fifo.c中),构造的时机是在page fault发生后,进行do_pgfault函数时。pra_vaddr可以用来记录此物理页对应的虚拟页起始地址。
当一个物理页(struct Page)需要被swap出去的时候,首先需要确保它已经分配了一个位于磁盘上的swap page(由连续的8个扇区组成)。这里为了简化设计,在swap_check函数中建立了每个虚拟页唯一对应的swap page,其对应关系设定为:虚拟页对应的PTE的索引值 = swap page的扇区起始位置*8。
1 | struct swap_manager |
map_swappable函数用于记录页访问情况相关属性,swap_out_vistim函数用于挑选需要换出的页。显然第二个函数依赖于第一个函数记录的页访问情况。tick_event函数指针也很重要,结合定时产生的中断,可以实现一种积极的换页策略。
- 准备:为了实现FIFO置换算法,我们应该管理所有可交换的页面,因此我们可以根据时间顺序将这些页面链接到pra_list_head。 使用list.h中的struct list。 struct list是一个简单的双向链表实现,具体函数包括:list_init,list_add(list_add_after),list_add_before,list_del,list_next,list_prev。 将通用列表结构转换为特殊结构(例如结构页面)。可以找到一些宏:le2page(在memlayout.h中),le2vma(在vmm.h中),le2proc(在proc.h中)等;
- _fifo_init_mm:初始化pra_list_head并让mm -> sm_priv指向pra_list_head的addr。 现在,从内存控制struct mm_struct,我们可以调用FIFO算法;
- _fifo_map_swappable:将最近访问的页放到 pra_list_head 队列最后;
- _fifo_swap_out_victim:最早访问的页面从pra_list_head队列中剔除,然后*ptr_page赋值为这一页。
读代码
1 | /* |
练习1:给未被映射的地址映射上物理页
完成do_pgfault(mm/vmm.c)函数,给未被映射的地址映射上物理页。设置访问权限的时候 需要参考页面所在VMA的权限,同时需要注意映射物理页时需要操作内存控制结构所指定的页表,而不是内核的页表。
引入虚拟内存后,可能会出现某一些虚拟内存空间是合法的(在vma中),但是还没有为其分配具体的内存页,这样的话,在访问这些虚拟页的时候就会产生pagefault异常,从而使得OS可以在异常处理时完成对这些虚拟页的物理页分配,在中端返回之后就可以正常进行内存的访问了。将出现了异常的线性地址保存在cr2寄存器中;再到trap_dispatch函数,在该函数中会根据中断号,将page fault的处理交给pgfault_handler函数,进一步交给do_pgfault函数进行处理。产生页面异常的原因主要有:
- 目标页面不存在(页表项全为0,即该线性地址与物理地址尚未建立映射或者已经撤销);
- 相应的物理页面不在内存中(页表项非空,但Present标志位=0,比如在swap分区或磁盘文件上);
- 访问权限不符合(此时页表项P标志=1,比如企图写只读页面)。
1 | do_pgfault - 处理缺页中断的中断处理例程 interrupt handler to process the page fault execption |
调用栈: trap—> trap_dispatch—>pgfault_handler—>do_pgfault
处理器为ucore的do_pgfault函数提供了两项信息,以帮助诊断异常并从中恢复。
(1) CR2寄存器的内容。 处理器使用产生异常的32位线性地址加载CR2寄存器。 do_pgfault可以使用此地址来查找相应的页面目录和页表条目。
(2) 在内核栈中的错误码。缺页错误码与其他异常的错误码不同,错误码可以通知中断处理例程以下信息:
- P flag(bit 0) 表明异常是否是因为一个不存在的页(0)或违反访问权限或使用保留位(1);
- W/R flag(bit 1) 表明引起异常的访存操作是读(0)还是写(1);
- U/S flag (bit 2) 表明引起异常时处理器是在用户态(1)还是内核态(0)
do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr)
第一个是一个mm_struct变量,其中保存了所使用的PDT,合法的虚拟地址空间(使用链表组织),以及与后文的swap机制相关的数据;而第二个参数是产生pagefault的时候硬件产生的error code,可以用于帮助判断发生page fault的原因,而最后一个参数则是出现page fault的线性地址(保存在cr2寄存器中的线性地址)。
- 查询mm_struct中的虚拟地址链表(线性地址对等映射,因此线性地址等于虚拟地址),确定出现page_fault的线性地址是否合法;
- 使用error code(包含了这次内存访问为读/写,对应物理页是否存在)判断是否出现权限问题,如果出现问题则直接返回;
- 根据合法虚拟地址(mm_struct中保存的合法虚拟地址链表中)生成对应产生的物理页的权限;
- 使用get_pte获取出错的线性地址所对应的虚拟页起始地址对应到的页表项,同时使用页表项保存物理地址(P为1)和被换出的物理页在swap中的位置(P为0),并规定swap中第0个页空出来不用于交换。
1 | int do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr) { |
问题:
- 请描述页目录项(Page Director Entry)和页表(Page Table Entry)中组成部分对ucore实现页替换算法的潜在用处。
首先不妨先分析PDE以及PTE中各个组成部分以及其含义;
接下来先描述页目录项的每个组成部分,PDE(页目录项)的具体组成如下图所示;描述每一个组成部分的含义如下:
- 前20位表示4K对齐的该PDE对应的页表起始位置(物理地址,该物理地址的高20位即PDE中的高20位,低12位为0);
- 第9-11位未被CPU使用,可保留给OS使用;
- 接下来的第8位可忽略;
- 第7位用于设置Page大小,0表示4KB;
- 第6位恒为0;
- 第5位用于表示该页是否被使用过;
- 第4位设置为1则表示不对该页进行缓存;
- 第3位设置是否使用write through缓存写策略;
- 第2位表示该页的访问需要的特权级;
- 第1位表示是否允许读写;
- 第0位为该PDE的存在位;
接下来描述页表项(PTE)中的每个组成部分的含义,具体组成如下图所示:
- 高20位与PDE相似的,用于表示该PTE指向的物理页的物理地址;
- 9-11位保留给OS使用;
- 7-8位恒为0;
- 第6位表示该页是否为dirty,即是否需要在swap out的时候写回外存;
- 第5位表示是否被访问;
- 3-4位恒为0;
- 0-2位分别表示存在位、是否允许读写、访问该页需要的特权级;
可以发现无论是PTE还是TDE,都具有着一些保留的位供操作系统使用,也就是说ucore可以利用这些位来完成一些其他的内存管理相关的算法,比如可以在这些位里保存最近一段时间内该页的被访问的次数(仅能表示0-7次),用于辅助近似地实现虚拟内存管理中的换出策略的LRU之类的算法;也就是说这些保留位有利于OS进行功能的拓展;
作者:AmadeusChan
链接:https://www.jianshu.com/p/8d6ce61ac678
来源:简书
如果ucore的缺页服务例程在执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
考虑到ucore的缺页服务例程如果在访问内容中出现了缺页异常,则会有可能导致ucore最终无法完成缺页的处理,因此一般不应该将缺页的ISR以及OS中的其他一些关键代码或者数据换出到外存中,以确保操作系统的正常运行;如果缺页ISR在执行过程中遇到页访问异常,则最终硬件需要完成的处理与正常出现页访问异常的处理相一致,均为:
- 将发生错误的线性地址保存在cr2寄存器中;
- 在中断栈中依次压入EFLAGS,CS, EIP,以及页访问异常码errorcode,由于ISR一定是运行在内核态下的,因此不需要压入ss和esp以及进行栈的切换;
- 根据中断描述符表查询到对应页访问异常的ISR,跳转到对应的ISR处执行,接下来将由软件进行处理;
练习2:补充完成基于FIFO的页面替换算法
维基百科:最简单的页面替换算法(Page Replace Algorithm)是FIFO算法。先进先出页面替换算法是一种低开销算法。这个想法从名称中可以明显看出 - 操作系统跟踪队列中内存中的所有页面,最近到达的放在后面,最早到达的放在前面。当需要更换页面时,会选择队列最前面的页面(最旧的页面)。虽然FIFO开销小且直观,但在实际应用中表现不佳。因此,它很少以未修改的形式使用。该算法存在Belady异常。
FIFO的详细信息
- 准备:为了实现FIFO,我们应该管理所有可交换的页面,这样我们就可以按照时间顺序将这些页面链接到pra_list_head。将通用list换为特殊结构(例如Page);
- _fifo_init_mm:初始化pra_list_head并让mm-> sm_priv指向pra_list_head的addr。 现在,从内存控制struct mm_struct,我们可以访问FIFO;
- _fifo_map_swappable: 最近到达的页需要放到pra_list_head队列的最末尾;
- _fifo_swap_out_victim: 最早到达的页面在pra_list_head队列最前边,我们应该将它踢出去。
1 | 将当前的物理页面插入到FIFO算法中维护的可被交换出去的物理页面链表中的末尾,从而保证该链表中越接近链表头的物理页面在内存中的驻留时间越长; |
1 | static int |
如果在_fifo_map_swappable函数中使用的是list_add_before的话,在_fifo_swap_out_victim中应该使用list_next(head)取得要被删除的页;如果在_fifo_map_swappable函数中使用的是list_add的话,在_fifo_swap_out_victim中应该使用head->prev取得要被删除的页;这个链表是双向循环链表!
如果要在ucore上实现”extended clock页替换算法”请给你的设计方案,现有的swap_manager框架是否足以支持在ucore中实现此算法?如果是,请给你的设计方案。如果不是,请给出你的新的扩展和基此扩展的设计方案。并需要回答如下问题
在现有框架基础上可以支持Extended clock算法。
根据上文中提及到的PTE的组成部分可知,PTE中包含了dirty位和访问位,因此可以确定某一个虚拟页是否被访问过以及写过,但是,考虑到在替换算法的时候是将物理页面进行换出,而可能存在着多个虚拟页面映射到同一个物理页面这种情况,也就是说某一个物理页面是否dirty和是否被访问过是有这些所有的虚拟页面共同决定的,而在原先的实验框架中,物理页的描述信息Page结构中默认只包括了一个对应的虚拟页的地址,应当采用链表的方式,在Page中扩充一个成员,把物理页对应的所有虚拟页都给保存下来;而物理页的dirty位和访问位均为只需要某一个对应的虚拟页对应位被置成1即可置成1;
完成了上述对物理页描述信息的拓展之后,考虑对FIFO算法的框架进行修改得到拓展时钟算法的框架,由于这两种算法都是将所有可以换出的物理页面均按照进入内存的顺序连成一个环形链表,因此初始化,将某个页面置为可以/不可以换出这些函数均不需要进行大的修改(小的修改包括在初始化当前指针等),唯一需要进行重写的函数是选择换出物理页的函数swap_out_victim,对该函数的修改如下:
从当前指针开始,对环形链表进行扫描,根据指针指向的物理页的状态(表示为(access, dirty))来确定应当进行何种修改:如果状态是(0, 0),则将该物理页面从链表上去下,该物理页面记为换出页面,但是由于这个时候这个页面不是dirty的,因此事实上不需要将其写入swap分区;
如果状态是(0,1),则将该物理页对应的虚拟页的PTE中的dirty位都改成0,并且将该物理页写入到外存中,然后指针跳转到下一个物理页;如果状态是(1, 0), 将该物理页对应的虚拟页的PTE中的访问位都置成0,然后指针跳转到下一个物理页面;如果状态是(1, 1),则该物理页的所有对应虚拟页的PTE中的访问为置成0,然后指针跳转到下一个物理页面;
需要被换出的页的特征是什么?
该物理页在当前指针上一次扫过之前没有被访问过;
该物理页的内容与其在外存中保存的数据是一致的, 即没有被修改过;
在ucore中如何判断具有这样特征的页?
在ucore中判断具有这种特征的页的方式已经在上文设计方案中提及过了,具体为:
假如某物理页对应的所有虚拟页中存在一个dirty的页,则认为这个物理页为dirty,否则不这么认为;
假如某物理页对应的所有虚拟页中存在一个被访问过的页,则认为这个物理页为被访问过的,否则不这么认为;
何时进行换入和换出操作?
在产生page fault的时候进行换入操作;
换出操作源于在算法中将物理页的dirty从1修改成0的时候,因此这个时候如果不进行写出到外存,就会造成数据的不一致,具体写出内存的时机是比较细节的问题, 可以在修改dirty的时候写入外存,或者是在这个物理页面上打一个需要写出的标记,到了最终删除这个物理页面的时候,如果发现了这个写出的标记,则在这个时候再写入外存;后者使用一个写延迟标记,有利于多个写操作的合并,从而降低缺页的代价;
实验四
实验目的
了解内核线程创建/执行的管理过程
了解内核线程的切换和基本调度过程
实验内容
当一个程序加载到内存中运行时,首先通过ucore OS的内存管理子系统分配合适的空间,然后就需要考虑如何分时使用CPU来“并发”执行多个程序,让每个运行的程序(这里用线程或进程表示)“感到”它们各自拥有“自己”的CPU。
内核线程是一种特殊的进程,内核线程与用户进程的区别有两个:
- 内核线程只运行在内核态
- 用户进程会在在用户态和内核态交替运行
- 所有内核线程共用ucore内核内存空间,不需为每个内核线程维护单独的内存空间
- 用户进程需要维护各自的用户内存空间
预备知识
内核线程管理
本实验实现了让ucore实现分时共享CPU,实现多条控制流能够并发执行。内核线程是一种特殊的进程,内核线程与用户进程的区别有两个:
- 内核线程只运行在内核态而用户进程会在在用户态和内核态交替运行;
- 所有内核线程直接使用共同的ucore内核内存空间,不需为每个内核线程维护单独的内存空间而用户进程需要维护各自的用户内存空间。
设计管理线程的数据结构,即进程控制块(PCB)。创建内核线程对应的进程控制块,把这些进程控制块通过链表连在一起,便于随时进行插入,删除和查找操作。通过调度器(scheduler)来让不同的内核线程在不同的时间段占用CPU执行,实现对CPU的分时共享。
kern/init/init.c中的kern_init函数中,当完成虚拟内存的初始化工作vmm_init()后,就调用了proc_init函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36void
proc_init(void) {
int i;
list_init(&proc_list);
// initialize the process double linked list
for (i = 0; i < HASH_LIST_SIZE; i ++) {
list_init(hash_list + i);
}
if ((idleproc = alloc_proc()) == NULL) {
panic("cannot alloc idleproc.\n");
}
idleproc->pid = 0;
idleproc->state = PROC_RUNNABLE;
idleproc->kstack = (uintptr_t)bootstack;
idleproc->need_resched = 1;
// 完成了idleproc内核线程创建
set_proc_name(idleproc, "idle");
nr_process ++;
current = idleproc;
int pid = kernel_thread(init_main, "Hello world!!", 0);
if (pid <= 0) {
panic("create init_main failed.\n");
}
initproc = find_proc(pid);
// initproc内核线程的创建
set_proc_name(initproc, "init");
assert(idleproc != NULL && idleproc->pid == 0);
assert(initproc != NULL && initproc->pid == 1);
}
idleproc内核线程的工作就是不停地查询,看是否有其他内核线程可以执行了,如果有,马上让调度器选择那个内核线程执行(请参考cpu_idle函数的实现)。所以idleproc内核线程是在ucore操作系统没有其他内核线程可执行的情况下才会被调用。
接着就是调用kernel_thread函数来创建initproc内核线程。initproc内核线程的工作就是显示“Hello World”,表明自己存在且能正常工作了。
调度器会在特定的调度点上执行调度,完成进程切换。
在lab4中,这个调度点就一处,即在cpu_idle函数中,此函数如果发现当前进程(也就是idleproc)的need_resched置为1(在初始化idleproc的进程控制块时就置为1了),则调用schedule函数,完成进程调度和进程切换。进程调度的过程其实比较简单,就是在进程控制块链表中查找到一个“合适”的内核线程,所谓“合适”就是指内核线程处于“PROC_RUNNABLE”状态。
在接下来的switch_to函数(在后续有详细分析,有一定难度,需深入了解一下)完成具体的进程切换过程。一旦切换成功,那么initproc内核线程就可以通过显示字符串来表明本次实验成功。
进程管理信息用struct proc_struct表示,在kern/process/proc.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct proc_struct {
enum proc_state state; // Process state
int pid; // Process ID
int runs; // the running times of Proces
uintptr_t kstack; // Process kernel stack
volatile bool need_resched; // need to be rescheduled to release CPU?
struct proc_struct *parent; // the parent process
struct mm_struct *mm; // Process's memory management field
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for current interrupt
uintptr_t cr3; // the base addr of Page Directroy Table(PDT)
uint32_t flags; // Process flag
char name[PROC_NAME_LEN + 1]; // Process name
list_entry_t list_link; // Process link list
list_entry_t hash_link; // Process hash list
};
- mm:内存管理的信息。在lab3中有涉及,主要包括内存映射列表、页表指针等。在实际OS中,内核线程常驻内存,不需要考虑swap page问题,在用户进程中考虑进程用户内存空间的swap_page问题时mm才会发挥作用。所以在lab4中mm对于内核线程就没有用了,这样内核线程的proc_struct的成员变量mm=0是合理的。mm里有个很重要的项pgdir,记录的是该进程使用的一级页表的物理地址。由于mm=NULL,所以在proc_struct数据结构中需要有一个代替pgdir项来记录页表起始地址,这就是proc_struct数据结构中的cr3成员变量。
- state:进程所处的状态。
1 | enum proc_state { |
- parent:用户进程的父进程(创建它的进程)。在所有进程中,只有一个进程没有父进程,就是内核创建的第一个内核线程idleproc。内核根据这个父子关系建立一个树形结构,用于维护一些特殊的操作,例如确定某个进程是否可以对另外一个进程进行某种操作等等。
- context:进程的上下文,用于进程切换(参见switch.S)。在uCore中,所有的进程在内核中也是相对独立的(例如独立的内核堆栈以及上下文等等)。使用context保存寄存器的目的就在于在内核态中能够进行上下文之间的切换。实际利用context进行上下文切换的函数是在kern/process/switch.S中定义switch_to。
1
2
3
4
5
6
7
8
9
10
11
12// 在上下文切换时保存寄存器信息,其中有些寄存器貌似不被保存,为了省事
// The 这个结构体的布局要跟switch.S中的switch_to操作对应。
struct context {
uint32_t eip;
uint32_t esp;
uint32_t ebx;
uint32_t ecx;
uint32_t edx;
uint32_t esi;
uint32_t edi;
uint32_t ebp;
}; - tf:中断帧的指针,总是指向内核栈的某个位置:当进程从用户空间跳到内核空间时,中断帧记录了进程在被中断前的状态。当内核需要跳回用户空间时,需要调整中断帧以恢复让进程继续执行的各寄存器值。除此之外,uCore内核允许嵌套中断。因此为了保证嵌套中断发生时tf总是能够指向当前的trapframe,uCore在内核栈上维护了tf的链。
- cr3: cr3 保存页表的物理地址,目的就是进程切换的时候方便直接使用lcr3实现页表切换,避免每次都根据 mm 来计算 cr3。mm数据结构是用来实现用户空间的虚存管理的,但是内核线程没有用户空间,它执行的只是内核中的一小段代码(通常是一小段函数),所以它没有mm结构,也就是NULL。当某个进程是一个普通用户态进程的时候,PCB中的cr3就是mm中页表(pgdir)的物理地址;而当它是内核线程的时候,cr3等于boot_cr3。而boot_cr3指向了uCore启动时建立好的内核虚拟空间的页目录表首地址。
- kstack: 每个线程都有一个内核栈,并且位于内核地址空间的不同位置。对于内核线程,该栈就是运行时的程序使用的栈;而对于普通进程,该栈是发生特权级改变的时候使保存被打断的硬件信息用的栈。uCore在创建进程时分配了 2 个连续的物理页(参见memlayout.h中KSTACKSIZE的定义)作为内核栈的空间。这个栈很小,所以内核中的代码应该尽可能的紧凑,并且避免在栈上分配大的数据结构,以免栈溢出,导致系统崩溃。kstack记录了分配给该进程/线程的内核栈的位置。主要作用有以下几点。
首先,当内核准备从一个进程切换到另一个的时候,需要根据kstack 的值正确的设置好tss,以便在进程切换以后再发生中断时能够使用正确的栈。
其次,内核栈位于内核地址空间,并且是不共享的(每个线程都拥有自己的内核栈),因此不受到 mm 的管理,当进程退出的时候,内核能够根据 kstack 的值快速定位栈的位置并进行回收。uCore 的这种内核栈的设计借鉴的是 linux 的方法(但由于内存管理实现的差异,它实现的远不如 linux 的灵活),它使得每个线程的内核栈在不同的位置,这样从某种程度上方便调试,但同时也使得内核对栈溢出变得十分不敏感,因为一旦发生溢出,它极可能污染内核中其它的数据使得内核崩溃。如果能够通过页表,将所有进程的内核栈映射到固定的地址上去,能够避免这种问题,但又会使得进程切换过程中对栈的修改变得相当繁琐。
为了管理系统中所有的进程控制块,uCore维护了如下全局变量(位于kern/process/proc.c):
- static struct proc *current:当前占用CPU且处于“运行”状态进程控制块指针。通常这个变量是只读的,只有在进程切换的时候才进行修改,并且整个切换和修改过程需要保证操作的原子性,目前至少需要屏蔽中断。可以参考 switch_to 的实现。
- static struct proc *initproc:本实验中,指向一个内核线程。本实验以后,此指针将指向第一个用户态进程。
- static list_entry_t hash_list[HASH_LIST_SIZE]:所有进程控制块的哈希表,proc_struct中的成员变量hash_link将基于pid链接入这个哈希表中。
- list_entry_t proc_list:所有进程控制块的双向线性列表,proc_struct中的成员变量list_link将链接入这个链表中。
创建并执行内核线程
ucore实现了一个简单的进程/线程机制,进程包含独立的地址空间,至少一个线程、内核数据、进程状态、文件等。ucore需要高效地管理所有细节。在ucore,一个线程看成一个特殊的进程(process)。
| 进程状态 | 意义 | 原因 |
|---|---|---|
| PROC_UNINIT | uninitialized | alloc_proc |
| PROC_SLEEPING | sleeping | try_free_pages, do_wait, do_sleep |
| PROC_RUNNABLE | runnable(maybe running) | proc_init, wakeup_proc, |
| PROC_ZOMBIE | almost dead | do_exit |
进程之间的关系:
- parent: proc->parent (proc is children)
- children: proc->cptr (proc is parent)
- older sibling: proc->optr (proc is younger sibling)
- younger sibling: proc->yptr (proc is older sibling)
建立进程控制块(proc.c中的alloc_proc函数)。首先,考虑最简单的内核线程,它通常只是内核中的一小段代码或者函数,没有自己的“专属”空间。这是由于在uCore OS启动后,已经对整个内核内存空间进行了管理,通过设置页表建立了内核虚拟空间(即boot_cr3指向的二级页表描述的空间)。所以uCore OS内核中的所有线程都不需要再建立各自的页表,只需共享这个内核虚拟空间就可以访问整个物理内存了。从这个角度看,内核线程被uCore OS内核这个大“内核进程”所管理。
创建第 0 个内核线程 idleproc
在init.c中的kern_init函数调用了proc.c中的proc_init函数。proc_init函数启动了创建内核线程的步骤。
首先当前的执行上下文(从kern_init启动至今)就可以看成是uCore内核(也可看做是内核进程)中的一个内核线程的上下文。为此,uCore通过给当前执行的上下文分配一个进程控制块以及对它进行相应初始化,将其打造成第0个内核线程——idleproc。具体步骤如下:
- 首先调用alloc_proc函数来通过kmalloc函数获得proc_struct结构的一块内存块,作为第0个进程控制块,并把proc进行初步初始化(即把proc_struct中的各个成员变量清零)。但有些成员变量设置了特殊的值,比如:
1 | proc->state = PROC_UNINIT; 设置进程为“初始”态 |
内核线程共用一个映射内核空间的页表,这表示内核空间对所有内核线程都是“可见”的,所以更精确地说,这些内核线程都应该是从属于同一个唯一的“大内核进程”—uCore内核。
- proc_init函数对idleproc内核线程进行进一步初始化:
1 | idleproc->pid = 0; |
第一条将pid赋值为0,表明idleproc是第0个内核线程。
第二条语句改变了idleproc的状态,使其变为“准备工作”,现在只要uCore调度便可执行。
第三条语句设置了idleproc所使用的内核栈的起始地址。需要注意以后的其他线程的内核栈都需要通过分配获得,因为uCore启动时设置的内核栈就直接分配给idleproc使用了所以这里不用分配。
第四条把idleproc->need_resched设置为“1”,在cpu_idle函数中指明如果进程的need_resched为1那么就可以调度执行其他的了,如果当前idleproc在执行,则只要此标志为1,马上就调用schedule函数要求调度器切换其他进程执行。
创建第 1 个内核线程 initproc
第0个内核线程主要工作是完成内核中各个子系统的初始化。uCore接下来还需创建其他进程来完成各种工作,通过调用kernel_thread函数创建了一个内核线程init_main。1
2
3
4
5
6
7
8// init_main - the second kernel thread used to create user_main kernel threads
static int
init_main(void *arg) {
cprintf("this initproc, pid = %d, name = \"%s\"\n", current->pid, get_proc_name(current));
cprintf("To U: \"%s\".\n", (const char *)arg);
cprintf("To U: \"en.., Bye, Bye. :)\"\n");
return 0;
}
下面我们来分析一下创建内核线程的函数kernel_thread。kernel_thread函数采用了局部变量tf来放置保存内核线程的临时中断帧,并把中断帧的指针传递给do_fork函数,而do_fork函数会调用copy_thread函数来在新创建的进程内核栈上专门给进程的中断帧分配一块空间。给中断帧分配完空间后,就需要构造新进程的中断帧,具体过程是:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16kernel_thread(int (*fn)(void *), void *arg, uint32_t clone_flags)
{
struct trapframe tf;
memset(&tf, 0, sizeof(struct trapframe));
// 给tf进行清零初始化
tf.tf_cs = KERNEL_CS;
tf.tf_ds = tf_struct.tf_es = tf_struct.tf_ss = KERNEL_DS;
// 设置中断帧的代码段(tf.tf_cs)和数据段(tf.tf_ds/tf_es/tf_ss)为内核空间的段(KERNEL_CS/KERNEL_DS)
tf.tf_regs.reg_ebx = (uint32_t)fn;
// fn是函数主体
tf.tf_regs.reg_edx = (uint32_t)arg;
// arg是fn函数的参数
tf.tf_eip = (uint32_t)kernel_thread_entry;
// tf.tf_eip的指出了initproc内核线程从kernel_thread_entry开始执行
return do_fork(clone_flags | CLONE_VM, 0, &tf);
}
kernel_thread_entry是entry.S中实现的汇编函数,它做的事情很简单:1
2
3
4
5kernel_thread_entry:
pushl %edx
call *%ebx
pushl %eax
call do_exit
从上可以看出,kernel_thread_entry函数主要为内核线程的主体fn函数做了一个准备开始和结束运行的“壳”:
- 把函数fn的参数arg(保存在edx寄存器中)压栈;
- 调用fn函数
- 把函数返回值eax寄存器内容压栈
- 调用do_exit函数退出线程执行。
do_fork是创建线程的主要函数。kernel_thread函数通过调用do_fork函数最终完成了内核线程的创建工作。do_fork函数主要做了以下6件事情:
- 分配并初始化进程控制块(alloc_proc函数);
- 分配并初始化内核栈(setup_stack函数);
- 根据clone_flag标志复制或共享进程内存管理结构(copy_mm函数);
- 设置进程在内核(将来也包括用户态)正常运行和调度所需的中断帧和执行上下文(copy_thread函数);
- 把设置好的进程控制块放入hash_list和proc_list两个全局进程链表中;
- 进程已经准备好执行了,把进程状态设置为“就绪”态;设置返回码为子进程的id号。
copy_thread函数代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17static void
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) {
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
// 在内核堆栈的顶部设置中断帧大小的一块栈空间
*(proc->tf) = *tf;
// 拷贝在kernel_thread函数建立的临时中断帧的初始值
proc->tf->tf_regs.reg_eax = 0;
// 设置子进程/线程执行完do_fork后的返回值
proc->tf->tf_esp = esp;
// 设置中断帧中的栈指针esp
proc->tf->tf_eflags |= FL_IF;
// 使能中断
// 以上两句设置中断帧中的栈指针esp和标志寄存器eflags,特别是eflags设置了FL_IF标志,
// 这表示此内核线程在执行过程中,能响应中断,打断当前的执行。
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
}
对于initproc而言,它的中断帧如下所示:1
2
3
4
5
6
7
8
9
10
11//所在地址位置
initproc->tf= (proc->kstack+KSTACKSIZE) – sizeof (struct trapframe);
//具体内容
initproc->tf.tf_cs = KERNEL_CS;
initproc->tf.tf_ds = initproc->tf.tf_es = initproc->tf.tf_ss = KERNEL_DS;
initproc->tf.tf_regs.reg_ebx = (uint32_t)init_main;
initproc->tf.tf_regs.reg_edx = (uint32_t) ADDRESS of "Helloworld!!";
initproc->tf.tf_eip = (uint32_t)kernel_thread_entry;
initproc->tf.tf_regs.reg_eax = 0;
initproc->tf.tf_esp = esp;
initproc->tf.tf_eflags |= FL_IF;
设置好中断帧后,最后就是设置initproc的进程上下文。uCore调度器选择了initproc执行,需要根据initproc->context中保存的执行现场来恢复initproc的执行。这里设置了initproc的执行现场中主要的两个信息:
- 上次停止执行时的下一条指令地址context.eip
- 上次停止执行时的堆栈地址context.esp。
可以看出,由于initproc的中断帧占用了实际给initproc分配的栈空间的顶部,所以initproc就只能把栈顶指针context.esp设置在initproc的中断帧的起始位置。根据context.eip的赋值,可以知道initproc实际开始执行的地方在forkret函数(主要完成do_fork函数返回的处理工作)处。至此,initproc内核线程已经做好准备执行了。
调度并执行内核线程 initproc
在uCore执行完proc_init函数后,就创建好了两个内核线程:idleproc和initproc,这时uCore当前的执行现场就是idleproc,等到执行到init函数的最后一个函数cpu_idle之前,uCore的所有初始化工作就结束了,idleproc将通过执行cpu_idle函数让出CPU,给其它内核线程执行,具体过程如下:1
2
3
4
5
6
7
8void
cpu_idle(void) {
while (1) {
if (current->need_resched) {
schedule();
}
}
}
首先,判断当前内核线程idleproc的need_resched是否不为0,idleproc中的need_resched本就置为1,所以会马上调用schedule函数找其他处于“就绪”态的进程执行。uCore的调度器为FIFO调度器,其核心就是schedule函数。它的执行逻辑很简单:
- 设置当前内核线程current->need_resched为0;
- 在proc_list队列中查找下一个处于“就绪”态的线程或进程;
- 找到这样的进程后,就调用proc_run函数,保存当前进程current的上下文,恢复新进程的执行现场,完成进程切换。
uCore通过proc_run和进一步的switch_to函数完成两个执行现场的切换,具体流程如下:
- 让current指向next内核线程initproc;
- 设置任务状态段ts中特权态0下的栈顶指针esp0为next内核线程initproc的内核栈的栈顶,即next->kstack + KSTACKSIZE;
- 设置CR3寄存器的值为next内核线程initproc的页目录表起始地址next->cr3,这实际上是完成进程间的页表切换;
- 由switch_to函数完成具体的两个线程的执行现场切换,即切换各个寄存器,当switch_to函数执行完“ret”指令后,就切换到initproc执行了。
注意,在第二步设置任务状态段ts中特权态0下的栈顶指针esp0的目的是建立好内核线程或将来用户线程在执行特权态切换(从特权态0<—>特权态3,或从特权态3<—>特权态0)时能够正确定位处于特权态0时进程的内核栈的栈顶,而这个栈顶其实放了一个trapframe结构的内存空间。如果是在特权态3发生了中断/异常/系统调用,则CPU会从特权态3—>特权态0,且CPU从此栈顶(当前被打断进程的内核栈顶)开始压栈来保存被中断/异常/系统调用打断的用户态执行现场;如果是在特权态0发生了中断/异常/系统调用,则CPU会从从当前内核栈指针esp所指的位置开始压栈保存被中断/异常/系统调用打断的内核态执行现场。反之,当执行完对中断/异常/系统调用打断的处理后,最后会执行一个“iret”指令。在执行此指令之前,CPU的当前栈指针esp一定指向上次产生中断/异常/系统调用时CPU保存的被打断的指令地址CS和EIP,“iret”指令会根据ESP所指的保存的址CS和EIP恢复到上次被打断的地方继续执行。
第四步proc_run函数调用switch_to函数,参数是前一个进程和后一个进程的执行现场。
switch.S中的switch_to函数的执行流程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30.globl switch_to
switch_to: # switch_to(from, to)
### save from's registers ###
movl 4(%esp), %eax # eax points to from
popl 0(%eax)
# esp--> return address, so save return addr in FROM’s context
保存前一个进程的执行现场,前两条汇编指令保存了进程在返回switch_to函数后的指令地址到context.eip中
movl %esp, 4(%eax)
……
movl %ebp, 28(%eax)
7条汇编指令完成了保存前一个进程的其他7个寄存器到context中的相应成员变量中
### restore to's registers ###
恢复下一个进程的执行现场,这其实就是上述保存过程的逆执行过程
movl 4(%esp), %eax # not 8(%esp): popped return address already
# eax now points to to
movl 28(%eax), %ebp
……
movl 4(%eax), %esp
从context的高地址的成员变量ebp开始,逐一把相关成员变量的值赋值给对应的寄存器
pushl 0(%eax)
# push TO’s context’s eip, so return addr = TO’s eip
把context中保存的下一个进程要执行的指令地址context.eip放到了堆栈顶
ret
after ret, eip= TO’s eip
把栈顶的内容赋值给EIP寄存器,这样就切换到下一个进程执行了,即当前进程已经是下一个进程了
uCore会执行进程切换,让initproc执行。在对initproc进行初始化时,设置了initproc->context.eip = (uintptr_t)forkret,这样,当执行switch_to函数并返回后,initproc将执行其实际上的执行入口地址forkret。而forkret会调用位于kern/trap/trapentry.S中的forkrets函数执行,具体代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18.globl __trapret
__trapret:
# restore registers from stack
popal
# restore %ds and %es
popl %es
popl %ds
# get rid of the trap number and error code
addl $0x8, %esp
iret
.globl forkrets
forkrets:
# set stack to this new process trapframe
movl 4(%esp), %esp
把esp指向当前进程的中断帧,esp指向了current->tf.tf_eip
jmp __trapret
如果此时执行的是initproc,则current->tf.tf_eip=kernel_thread_entry,initproc->tf.tf_cs = KERNEL_CS,所以当执行完iret后,就开始在内核中执行kernel_thread_entry函数了。
而initproc->tf.tf_regs.reg_ebx = init_main,所以在kernl_thread_entry中执行“call %ebx”后,就开始执行initproc的主体了。Initprocde的主体函数很简单就是输出一段字符串,然后就返回到kernel_tread_entry函数,并进一步调用do_exit执行退出操作了。
练习1:分配并初始化一个进程控制块
alloc_proc函数(位于kern/process/proc.c中)负责分配并返回一个新的struct proc_struct结 构,用于存储新建立的内核线程的管理信息。比较简单,state、pid和cr3需要考虑,其他的无脑赋0和memset一波带走就行1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36static struct proc_struct *
alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
//LAB4:EXERCISE1 YOUR CODE
/*
* below fields in proc_struct need to be initialized
* enum proc_state state; // Process state
* int pid; // Process ID
* int runs; // the running times of Proces
* uintptr_t kstack; // Process kernel stack
* volatile bool need_resched; // bool value: need to be rescheduled to release CPU?
* struct proc_struct *parent; // the parent process
* struct mm_struct *mm; // Process's memory management field
* struct context context; // Switch here to run process
* struct trapframe *tf; // Trap frame for current interrupt
* uintptr_t cr3; // CR3 register: the base addr of Page Directroy Table(PDT)
* uint32_t flags; // Process flag
* char name[PROC_NAME_LEN + 1]; // Process name
*/
proc->state = PROC_UNINIT;
proc->pid = -1;
proc->cr3 = boot_cr3;
proc->runs = 0;
proc->kstack = 0;
proc->need_resched = 0;
proc->parent = NULL;
proc->mm = NULL;
memset(&proc->context, 0, sizeof(struct context));
proc->tf = NULL;
proc->flags = 0;
memset(proc->name, 0, PROC_NAME_LEN);
}
return proc;
}
请说明proc_struct中struct context context和struct trapframe *tf成员变量含义和在本实验中的作用是啥?
结构体中存储了除eax之外的所有通用寄存器以及eip的数值,保存了线程运行的上下文信息;1
2
3
4
5
6
7
8
9
10struct context {
uint32_t eip;
uint32_t esp;
uint32_t ebx;
uint32_t ecx;
uint32_t edx;
uint32_t esi;
uint32_t edi;
uint32_t ebp;
};
context用于内核线程之间切换时,保存原先线程运行的上下文
struct trapframe *tf的作用:
- 在copy_thread函数中对tf进行了设置。在这个函数中,把context变量的esp设置成tf变量的地址,把eip设置成forkret函数指针。
- forkret函数调用了__trapret进行中断返回,tf变量用于构造出新线程时,正确地将控制权转交给新的线程。
练习2:为新创建的内核线程分配资源
创建一个内核线程需要分配和设置好很多资源。kernel_thread函数通过调用do_fork函数完成具体内核线程的创建工作。do_fork函数会调用alloc_proc函数来分配并初始化一个进程控制块,但alloc_proc只是找到了一小块内存用以记录进程的必要信息,并没有实际分配这些资源。
ucore一般通过do_fork实际创建新的内核线程。do_fork的作用是:
创建当前内核线程的一个副本,它们的执行上下文、代码、数据都一样,但是存储位置不同。在这个过程中,需要给新内核线程分配资源,并且复制原进程的状态。为内核线程创建新的线程控制块,并且对控制块中的每个成员变量进行正确的设置,使得之后可以正确切换到对应的线程中执行。练习2完成了在kern/process/proc.c中的do_fork函数中的处理过程。它的大致执行步骤包括:
- 调用alloc_proc,首先获得一块用户信息块。
- 为进程分配一个内核栈。
- 复制原进程的内存管理信息到新进程(但内核线程不必做此事)
- 复制原进程上下文到新进程
- 将新进程添加到进程列表
- 唤醒新进程
- 返回新进程号
1 | /* do_fork - parent process for a new child process |
请说明ucore是否做到给每个新fork的线程一个唯一的id?请说明你的分析和理由。
可以。ucore中为fork的线程分配pid的函数为get_pid:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33// get_pid - alloc a unique pid for process
static int get_pid(void) {
static_assert(MAX_PID > MAX_PROCESS);
struct proc_struct *proc;
list_entry_t *list = &proc_list, *le;
static int next_safe = MAX_PID, last_pid = MAX_PID;
if (++ last_pid >= MAX_PID) {
last_pid = 1;
goto inside;
}
if (last_pid >= next_safe) {
inside:
next_safe = MAX_PID;
repeat:
le = list;
while ((le = list_next(le)) != list) {
proc = le2proc(le, list_link);
if (proc->pid == last_pid) {
if (++ last_pid >= next_safe) {
if (last_pid >= MAX_PID) {
last_pid = 1;
}
next_safe = MAX_PID;
goto repeat;
}
}
else if (proc->pid > last_pid && next_safe > proc->pid) {
next_safe = proc->pid;
}
}
}
return last_pid;
}
如果有严格的next_safe > last_pid + 1,那么可以直接取last_pid + 1作为新的pid(需要last_pid没有超出MAX_PID从而变成1),
如果在进入函数的时候,这两个变量之后没有合法的取值,也就是说next_safe > last_pid + 1不成立,那么进入循环,在循环之中首先通过if(proc->pid == last_pid)这一分支确保了不存在任何进程的pid与last_pid重合,然后再通过if (proc->pid > last_pid && next_safe > proc->pid)这一判断语句保证了不存在任何已经存在的pid满足:last_pid< pid < next_safe,这样就确保了最后能够找到这么一个满足条件的区间,获得合法的pid;
练习3:阅读代码,理解 proc_run 函数和它调用的函数如何完成进程切换的。
唯一调用到这个函数是在线程调度器的schedule函数中,proc_run将proc加载到CPU1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// proc_run - make process "proc" running on cpu
// NOTE: before call switch_to, should load base addr of "proc"'s new PDT
void proc_run(struct proc_struct *proc) {
// 判断需要运行的线程是否是正在运行的线程
if (proc != current) {
bool intr_flag;
struct proc_struct *prev = current, *next = proc;
//如果不是的话,获取到切换前后的两个线程
local_intr_save(intr_flag);
// 关闭中断
{
current = proc;
load_esp0(next->kstack + KSTACKSIZE);
lcr3(next->cr3);
// 设置了TSS和cr3,相当于是切换了页表和栈
switch_to(&(prev->context), &(next->context));
// switch_to恢复要运行的线程的上下文,然后由于恢复的上下文中已经将返回地址(copy_thread函数中完成)修改成了forkret函数的地址(如果这个线程是第一运行的话,否则就是切换到这个线程被切换出来的地址),也就是会跳转到这个函数,最后进一步跳转到了__trapsret函数,调用iret最终将控制权切换到新的线程;
}
local_intr_restore(intr_flag);
// 使能中断
}
}
forkret函数:1
2
3
4
5
6
7// forkret -- the first kernel entry point of a new thread/process
// NOTE: the addr of forkret is setted in copy_thread function
// after switch_to, the current proc will execute here.
static void
forkret(void) {
forkrets(current->tf);
}
在本实验的执行过程中,创建且运行了几个内核线程?
总共创建了两个内核线程,分别为:
- idleproc: 最初的内核线程,在完成新的内核线程的创建以及各种初始化工作之后,进入死循环,用于调度其他线程;
- initproc: 被创建用于打印”Hello World”的线程;
语句 local_intr_save(intr_flag);….local_intr_restore(intr_flag);说明理由在这里有何作用? 请说明理由。
- 关闭中断,使得在这个语句块内的内容不会被中断打断,是一个原子操作;
- 在proc_run函数中,将current指向了要切换到的线程,但是此时还没有真正将控制权转移过去,如果在这个时候出现中断打断这些操作,就会出现current中保存的并不是正在运行的线程的中断控制块,从而出现错误。
实验五
实验目的
了解第一个用户进程创建过程
了解系统调用框架的实现机制
了解ucore如何实现系统调用sys_fork/sys_exec/sys_exit/sys_wait来进行进程管理
实验内容
实验4的线程运行都在内核态。实验5创建了用户进程,让用户进程在用户态执行,且在需要ucore支持时,可通过系统调用来让ucore提供服务。为此需要构造出第一个用户进程,并通过系统调用sys_fork/sys_exec/sys_exit/sys_wait来支持运行不同的应用程序,完成对用户进程的执行过程的基本管理。
预备知识
实验执行流程概述
提供各种操作系统功能的内核线程只能在CPU核心态运行是操作系统自身的要求,操作系统就要呆在核心态,才能管理整个计算机系统。ucore提供了用户态进程的创建和执行机制,给应用程序执行提供一个用户态运行环境。显然,由于进程的执行空间扩展到了用户态空间,且出现了创建子进程执行应用程序等与lab4有较大不同的地方,所以具体实现的不同主要集中在进程管理和内存管理部分。
首先,我们从ucore的初始化部分来看,kern_init中调用的物理内存初始化,进程管理初始化等都有一定的变化。在内存管理部分,与lab4最大的区别就是增加用户态虚拟内存的管理。
- 首先为了管理用户态的虚拟内存,需要对页表的内容进行扩展,能够把部分物理内存映射为用户态虚拟内存。如果某进程执行过程中,CPU在用户态下执行(在CS段寄存器最低两位包含有一个2位的优先级域,如果为0,表示CPU运行在特权态;如果为3,表示CPU运行在用户态。),则可以访问本进程页表描述的用户态虚拟内存,但由于权限不够,不能访问内核态虚拟内存。
- 另一方面,在用户态内存空间和内核态内核空间之间需要拷贝数据,让CPU处在内核态才能完成对用户空间的读或写,为此需要设计专门的拷贝函数(copy_from_user和copy_to_user)完成。但反之则会导致违反CPU的权限管理,导致内存访问异常。
- 在进程管理方面,主要涉及到的是进程控制块中与内存管理相关的部分,包括建立进程的页表和维护进程可访问空间(可能还没有建立虚实映射关系)的信息;
- 加载一个ELF格式的程序到进程控制块管理的内存中的方法;
- 在进程复制(fork)过程中,把父进程的内存空间拷贝到子进程内存空间的技术;
- 另外一部分与用户态进程生命周期管理相关,包括让进程放弃CPU而睡眠等待某事件、让父进程等待子进程结束、一个进程杀死另一个进程、给进程发消息、建立进程的血缘关系链表。
在用户进程管理中,首先,构造出第一个进程idle_proc,作为所有后续进程的祖先;然后,在proc_init函数中,对idle_proc进行进一步初始化,通过alloc把当前ucore的执行环境转变成idle内核线程的执行现场;然后调用kernl_thread来创建第二个内核线程init_main,而init_main内核线程有创建了user_main内核线程。到此,内核线程创建完毕。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// proc_init - set up the first kernel thread idleproc "idle" by itself and
// - create the second kernel thread init_main
void
proc_init(void) {
int i;
list_init(&proc_list);
for (i = 0; i < HASH_LIST_SIZE; i ++) {
list_init(hash_list + i);
}
if ((idleproc = alloc_proc()) == NULL) {
panic("cannot alloc idleproc.\n");
}
idleproc->pid = 0;
idleproc->state = PROC_RUNNABLE;
idleproc->kstack = (uintptr_t)bootstack;
idleproc->need_resched = 1;
set_proc_name(idleproc, "idle");
nr_process ++;
current = idleproc;
int pid = kernel_thread(init_main, NULL, 0);
if (pid <= 0) {
panic("create init_main failed.\n");
}
initproc = find_proc(pid);
set_proc_name(initproc, "init");
assert(idleproc != NULL && idleproc->pid == 0);
assert(initproc != NULL && initproc->pid == 1);
}
接下来是用户进程的创建过程。第一步实际上是通过user_main函数调用kernel_tread创建子进程,通过kernel_execve调用来把某一具体程序的执行内容放入内存。
具体的放置方式是根据ld在此文件上的地址分配为基本原则,把程序的不同部分放到某进程的用户空间中,从而通过此进程来完成程序描述的任务。一旦执行了这一程序对应的进程,就会从内核态切换到用户态继续执行。
以此类推:
CPU在用户空间执行的用户进程,其地址空间不会被其他用户的进程影响,但由于系统调用(用户进程直接获得操作系统服务的唯一通道)、外设中断和异常中断的会随时产生,从而间接推动了用户进程实现用户态到到内核态的切换工作。当进程执行结束后,需回收进程占用和没消耗完毕的设备整个过程,且为新的创建进程请求提供服务。
创建用户进程
应用程序的组成和编译
lab5中新增了一个文件夹user,其中是用于本实验的用户程序。如hello.c1
2
3
4
5
6
7
8
9
int main(void) {
cprintf("Hello world!!.\n");
cprintf("I am process %d.\n", getpid());
cprintf("hello pass.\n");
return 0;
}
按照手册,注释掉Makefile的第六行,编译,(部分)输出如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23gcc -Iuser/ -fno-builtin -Wall -ggdb -m32 -gstabs -nostdinc
-fno-stack-protector -Ilibs/ -Iuser/include/ -Iuser/libs/ -c user/pgdir.c -o obj/user/pgdir.o
ld -m elf_i386 -nostdlib -T tools/user.ld -o obj/__user_pgdir.out
obj/user/libs/panic.o obj/user/libs/syscall.o obj/user/libs/ulib.o
obj/user/libs/initcode.o obj/user/libs/stdio.o obj/user/libs/umain.o
obj/libs/string.o obj/libs/printfmt.o obj/libs/hash.o obj/libs/rand.o obj/user/pgdir.o
+ ld bin/kernel
ld -m elf_i386 -nostdlib -T tools/kernel.ld -o bin/kernel
obj/kern/init/entry.o obj/kern/init/init.o obj/kern/libs/stdio.o
obj/kern/libs/readline.o obj/kern/debug/panic.o obj/kern/debug/kdebug.o
obj/kern/debug/kmonitor.o obj/kern/driver/ide.o obj/kern/driver/clock.o
obj/kern/driver/console.o obj/kern/driver/picirq.o obj/kern/driver/intr.o
obj/kern/trap/trap.o obj/kern/trap/vectors.o obj/kern/trap/trapentry.o
obj/kern/mm/pmm.o obj/kern/mm/swap_fifo.o obj/kern/mm/vmm.o obj/kern/mm/kmalloc.o
obj/kern/mm/swap.o obj/kern/mm/default_pmm.o obj/kern/fs/swapfs.o obj/kern/process/entry.o
obj/kern/process/switch.o obj/kern/process/proc.o obj/kern/schedule/sched.o
obj/kern/syscall/syscall.o obj/libs/string.o obj/libs/printfmt.o obj/libs/hash.o obj/libs/rand.o
-b binary obj/__user_badarg.out obj/__user_forktree.out obj/__user_faultread.out obj/__user_divzero.out
obj/__user_exit.out obj/__user_hello.out obj/__user_waitkill.out obj/__user_softint.out obj/__user_spin.out
obj/__user_yield.out obj/__user_badsegment.out obj/__user_testbss.out obj/__user_faultreadkernel.out
obj/__user_forktest.out obj/__user_pgdir.out
从中可以看出,hello应用程序不仅仅是hello.c,还包含了支持hello应用程序的用户态库:
- user/libs/initcode.S:所有应用程序的起始用户态执行地址“_start”,调整了EBP和ESP后,调用umain函数。
- user/libs/umain.c:实现了umain函数,这是所有应用程序执行的第一个C函数,它将调用应用程序的main函数,并在main函数结束后调用exit函数,而exit函数最终将调用sys_exit系统调用,让操作系统回收进程资源。
- user/libs/ulib.[ch]:实现了最小的C函数库,除了一些与系统调用无关的函数,其他函数是对访问系统调用的包装。
- user/libs/syscall.[ch]:用户层发出系统调用的具体实现。
- user/libs/stdio.c:实现cprintf函数,通过系统调用sys_putc来完成字符输出。
- user/libs/panic.c:实现__panic/__warn函数,通过系统调用sys_exit完成用户进程退出。
在make的最后一步执行了一个ld命令,把hello应用程序的执行码obj/__user_hello.out连接在了ucore kernel的末尾。且ld命令会在kernel中会把__user_hello.out的位置和大小记录在全局变量_binary_obj___user_hello_out_start和_binary_obj___user_hello_out_size中,这样这个hello用户程序就能够和ucore内核一起被 bootloader加载到内存里中,并且通过这两个全局变量定位hello用户程序执行码的起始位置和大小。
用户进程的虚拟地址空间
在tools/user.ld描述了用户程序的用户虚拟空间的执行入口虚拟地址:1
2
3SECTIONS {
/* Load programs at this address: "." means the current address */
. = 0x800020;
在tools/kernel.ld描述了操作系统的内核虚拟空间的起始入口虚拟地址:1
2
3SECTIONS {
/* Load the kernel at this address: "." means the current address */
. = 0xC0100000;
这样ucore把用户进程的虚拟地址空间分了两块:
- 一块与内核线程一样,是所有用户进程都共享的内核虚拟地址空间,映射到同样的物理内存空间中,这样在物理内存中只需放置一份内核代码,使得用户进程从用户态进入核心态时,内核代码可以统一应对不同的内核程序;
- 另外一块是用户虚拟地址空间,虽然虚拟地址范围一样,但映射到不同且没有交集的物理内存空间中。这样当ucore把用户进程的执行代码(即应用程序的执行代码)和数据(即应用程序的全局变量等)放到用户虚拟地址空间中时,确保了各个进程不会“非法”访问到其他进程的物理内存空间。
这样ucore给一个用户进程具体设定的虚拟内存空间(kern/mm/memlayout.h)如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40 Virtual memory map: Permissions
kernel/user
4G ------------------> +---------------------------------+
| |
| Empty Memory (*) |
| |
+---------------------------------+ 0xFB000000
| Cur. Page Table (Kern, RW) | RW/-- PTSIZE
VPT -----------------> +---------------------------------+ 0xFAC00000
| Invalid Memory (*) | --/--
KERNTOP -------------> +---------------------------------+ 0xF8000000
| |
| Remapped Physical Memory | RW/-- KMEMSIZE
| |
KERNBASE ------------> +---------------------------------+ 0xC0000000
| Invalid Memory (*) | --/--
USERTOP -------------> +---------------------------------+ 0xB0000000
| User stack |
+---------------------------------+
| |
: :
| ~~~~~~~~~~~~~~~~ |
| ~~~~~~~~~~~~~~~~ |
: :
| |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| User Program & Heap |
UTEXT ---------------> +---------------------------------+ 0x00800000
| Invalid Memory (*) | --/--
| - - - - - - - - - - - - - - - |
| User STAB Data (optional) |
USERBASE, USTAB------> +---------------------------------+ 0x00200000
| Invalid Memory (*) | --/--
0 -------------------> +---------------------------------+ 0x00000000
(*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
"Empty Memory" is normally unmapped, but user programs may map pages
there if desired.
*/
创建并执行用户进程
在确定了用户进程的执行代码和数据,以及用户进程的虚拟空间布局后,我们可以来创建用户进程了。在本实验中第一个用户进程是由第二个内核线程initproc通过把hello应用程序执行码覆盖到initproc的用户虚拟内存空间来创建的,相关代码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 // kernel_execve - do SYS_exec syscall to exec a user program called by user_main kernel_thread
static int
kernel_execve(const char *name, unsigned char *binary, size_t size) {
int ret, len = strlen(name);
asm volatile (
"int %1;"
: "=a" (ret)
: "i" (T_SYSCALL), "0" (SYS_exec), "d" (name), "c" (len), "b" (binary), "D" (size)
: "memory");
return ret;
}
……
// init_main - the second kernel thread used to create kswapd_main & user_main kernel threads
static int init_main(void *arg) {
KERNEL_EXECVE2(TEST, TESTSTART, TESTSIZE);
KERNEL_EXECVE(hello);
panic("kernel_execve failed.\n");
return 0;
}
##的作用是参数的连接,把“exit”这个字符串连接到这个宏中的x对应位置
#的作用是使一个东西字符串化
Initproc的执行主体是init_main函数,这个函数在缺省情况下是执行宏KERNEL_EXECVE(hello),而这个宏最终是调用kernel_execve函数来调用SYS_exec系统调用,由于ld在链接hello应用程序执行码时定义了两全局变量:1
2_binary_obj___user_hello_out_start:hello执行码的起始位置
_binary_obj___user_hello_out_size中:hello执行码的大小
kernel_execve把这两个变量作为SYS_exec系统调用的参数,让ucore来创建此用户进程。当ucore收到此系统调用后,将依次调用如下函数:1
2vector128(vectors.S) -->
__alltraps(trapentry.S) --> trap(trap.c) --> trap_dispatch(trap.c) --> syscall(syscall.c) --> sys_exec(syscall.c)--> do_execve(proc.c)
最终通过do_execve函数来完成用户进程的创建工作。此函数的主要工作流程如下:
- 为加载新的执行码做好用户态内存空间清空准备。如果mm不为NULL,则设置页表为内核空间页表,且进一步判断mm的引用计数减1后是否为0,如果为0,则表明没有进程再需要此进程所占用的内存空间,为此将根据mm中的记录,释放进程所占用户空间内存和进程页表本身所占空间。最后把当前进程的mm内存管理指针为空。由于此处的initproc是内核线程,所以mm为NULL,整个处理都不会做。
- 加载应用程序执行码到当前进程的新创建的用户态虚拟空间中。这里涉及到读ELF格式的文件,申请内存空间,建立用户态虚存空间,加载应用程序执行码等。load_icode函数完成了整个复杂的工作。
- load_icode函数的主要工作就是给用户进程建立一个能够让用户进程正常运行的用户环境。此函数有一百多行,完成了如下重要工作:
- 调用mm_create函数来申请进程的内存管理数据结构mm所需内存空间,并对mm进行初始化;
- 调用setup_pgdir来申请一个页目录表所需的一个页大小的内存空间,并把描述ucore内核虚空间映射的内核页表(boot_pgdir所指)的内容拷贝到此新目录表中,最后让mm->pgdir指向此页目录表,这就是进程新的页目录表了,且能够正确映射内核虚空间;
- 根据应用程序执行码的起始位置来解析此ELF格式的执行程序,并调用mm_map函数根据ELF格式的执行程序说明的各个段(代码段、数据段、BSS段等)的起始位置和大小建立对应的vma结构,并把vma插入到mm结构中,从而表明了用户进程的合法用户态虚拟地址空间;
- 调用根据执行程序各个段的大小分配物理内存空间,并根据执行程序各个段的起始位置确定虚拟地址,并在页表中建立好物理地址和虚拟地址的映射关系,然后把执行程序各个段的内容拷贝到相应的内核虚拟地址中,至此应用程序执行码和数据已经根据编译时设定地址放置到虚拟内存中了;
- 需要给用户进程设置用户栈,为此调用mm_mmap函数建立用户栈的vma结构,明确用户栈的位置在用户虚空间的顶端,大小为256个页,即1MB,并分配一定数量的物理内存且建立好栈的虚地址<—>物理地址映射关系;
- 至此,进程内的内存管理vma和mm数据结构已经建立完成,于是把mm->pgdir赋值到cr3寄存器中,即更新了用户进程的虚拟内存空间,此时的initproc已经被hello的代码和数据覆盖,成为了第一个用户进程,但此时这个用户进程的执行现场还没建立好;
- 先清空进程的中断帧,再重新设置进程的中断帧,使得在执行中断返回指令“iret”后,能够让CPU转到用户态特权级,并回到用户态内存空间,使用用户态的代码段、数据段和堆栈,且能够跳转到用户进程的第一条指令执行,并确保在用户态能够响应中断;
- 至此,用户进程的用户环境已经搭建完毕。此时initproc将按产生系统调用的函数调用路径原路返回,执行中断返回指令“iret”(位于trapentry.S的最后一句)后,将切换到用户进程hello的第一条语句位置_start处(位于user/libs/initcode.S的第三句)开始执行。
进程退出和等待进程
ucore分了两步来完成进程退出工作,首先,进程本身完成大部分资源的占用内存回收工作,然后父进程完成剩余资源占用内存的回收工作。为何不让进程本身完成所有的资源回收工作呢?这是因为进程要执行回收操作,就表明此进程还存在,还在执行指令,这就需要内核栈的空间不能释放,且表示进程存在的进程控制块不能释放。所以需要父进程来帮忙释放子进程无法完成的这两个资源回收工作。
为此在用户态的函数库中提供了exit函数,此函数最终访问sys_exit系统调用接口让操作系统来帮助当前进程执行退出过程中的部分资源回收。
首先,exit函数会把一个退出码error_code传递给ucore,ucore通过执行内核函数do_exit来完成对当前进程的退出处理,主要工作是回收当前进程所占的大部分内存资源,并通知父进程完成最后的回收工作,具体流程如下:
- 如果current->mm != NULL,表示是用户进程,则开始回收此用户进程所占用的用户态虚拟内存空间;
- 首先执行“lcr3(boot_cr3)”,切换到内核态的页表上,这样当前用户进程目前只能在内核虚拟地址空间执行了,这是为了确保后续释放用户态内存和进程页表的工作能够正常执行;
- 如果当前进程控制块的成员变量mm的成员变量mm_count减1后为0(表明这个mm没有再被其他进程共享,可以彻底释放进程所占的用户虚拟空间了。),则开始回收用户进程所占的内存资源:
- 调用exit_mmap函数释放current->mm->vma链表中每个vma描述的进程合法空间中实际分配的内存,然后把对应的页表项内容清空,最后还把页表所占用的空间释放并把对应的页目录表项清空;
- 调用put_pgdir函数释放当前进程的页目录所占的内存;
- 调用mm_destroy函数释放mm中的vma所占内存,最后释放mm所占内存;
- 此时设置current->mm为NULL,表示与当前进程相关的用户虚拟内存空间和对应的内存管理成员变量所占的内核虚拟内存空间已经回收完毕;
- 这时,设置当前进程的执行状态
current->state=PROC_ZOMBIE,当前进程的退出码current->exit_code=error_code。此时当前进程已经不能被调度了,需要此进程的父进程来做最后的回收工作(即回收描述此进程的内核栈和进程控制块); - 如果当前进程的父进程current->parent处于等待子进程状态:
current->parent->wait_state==WT_CHILD,
则唤醒父进程(即执行“wakup_proc(current->parent)”),让父进程帮助自己完成最后的资源回收; - 如果当前进程还有子进程,则需要把这些子进程的父进程指针设置为内核线程initproc,且各个子进程指针需要插入到initproc的子进程链表中。如果某个子进程的执行状态是PROC_ZOMBIE,则需要唤醒initproc来完成对此子进程的最后回收工作。
- 执行schedule()函数,选择新的进程执行。
那么父进程如何完成对子进程的最后回收工作呢?这要求父进程要执行wait用户函数或wait_pid用户函数,这两个函数的区别是,wait函数等待任意子进程的结束通知,而wait_pid函数等待进程id号为pid的子进程结束通知。这两个函数最终访问sys_wait系统调用接口让ucore来完成对子进程的最后回收工作,即回收子进程的内核栈和进程控制块所占内存空间,具体流程如下:
- 如果pid!=0,表示只找一个进程id号为pid的退出状态的子进程,否则找任意一个处于退出状态的子进程;
- 如果此子进程的执行状态不为PROC_ZOMBIE,表明此子进程还没有退出,则当前进程只好设置自己的执行状态为PROC_SLEEPING,睡眠原因为WT_CHILD(即等待子进程退出),调用schedule()函数选择新的进程执行,自己睡眠等待,如果被唤醒,则重复跳回步骤1处执行;
- 如果此子进程的执行状态为PROC_ZOMBIE,表明此子进程处于退出状态,需要当前进程(即子进程的父进程)完成对子进程的最终回收工作,即首先把子进程控制块从两个进程队列proc_list和hash_list中删除,并释放子进程的内核堆栈和进程控制块。自此,子进程才彻底地结束了它的执行过程,消除了它所占用的所有资源。
系统调用实现
用户进程只能在操作系统给它圈定好的“用户环境”中执行,但“用户环境”限制了用户进程能够执行的指令,即用户进程只能执行一般的指令,无法执行特权指令。如果用户进程想执行一些需要特权指令的任务,比如通过网卡发网络包等,只能让操作系统来代劳了。于是就需要一种机制来确保用户进程不能执行特权指令,但能够请操作系统“帮忙”完成需要特权指令的任务,这种机制就是系统调用。
采用系统调用机制为用户进程提供一个获得操作系统服务的统一接口层:
- 一来可简化用户进程的实现,把一些共性的、繁琐的、与硬件相关、与特权指令相关的任务放到操作系统层来实现,但提供一个简洁的接口给用户进程调用;
- 二来这层接口事先可规定好,且严格检查用户进程传递进来的参数和操作系统要返回的数据,使得让操作系统给用户进程服务的同时,保护操作系统不会被用户进程破坏。
从硬件层面上看,需要硬件能够支持在用户态的用户进程通过某种机制切换到内核态。
初始化系统调用对应的中断描述符
在ucore初始化函数kern_init中调用了idt_init函数来初始化中断描述符表,并设置一个特定中断号的中断门,专门用于用户进程访问系统调用。此事由ide_init函数完成:1
2
3
4
5
6
7
8
9
10void
idt_init(void) {
extern uintptr_t __vectors[];
int i;
for (i = 0; i < sizeof(idt) / sizeof(struct gatedesc); i ++) {
SETGATE(idt[i], 0, GD_KTEXT, __vectors[i], DPL_KERNEL);
}
SETGATE(idt[T_SYSCALL], 1, GD_KTEXT, __vectors[T_SYSCALL], DPL_USER);
lidt(&idt_pd);
}
在上述代码中,可以看到在执行加载中断描述符表lidt指令前,专门设置了一个特殊的中断描述符idt[T_SYSCALL],它的特权级设置为DPL_USER,中断向量处理地址在vectors[T_SYSCALL]处。这样建立好这个中断描述符后,一旦用户进程执行“INT T_SYSCALL”后,由于此中断允许用户态进程产生(注意它的特权级设置为DPL_USER),所以CPU就会从用户态切换到内核态,保存相关寄存器,并跳转到vectors[T_SYSCALL]处开始执行,形成如下执行路径:1
2vector128(vectors.S) -->
__alltraps(trapentry.S) --> trap(trap.c) --> trap_dispatch(trap.c) --> syscall(syscall.c)
建立系统调用的用户库准备
在操作系统中初始化好系统调用相关的中断描述符、中断处理起始地址等后,还需在用户态的应用程序中初始化好相关工作,简化应用程序访问系统调用的复杂性。为此在用户态建立了一个中间层,即简化的libc实现,在user/libs/ulib.[ch]和user/libs/syscall.[ch]中完成了对访问系统调用的封装。用户态最终的访问系统调用函数是syscall,实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24static inline int
syscall(int num, ...) {
va_list ap;
va_start(ap, num);
uint32_t a[MAX_ARGS];
int i, ret;
for (i = 0; i < MAX_ARGS; i ++) {
a[i] = va_arg(ap, uint32_t);
}
va_end(ap);
asm volatile (
"int %1;"
: "=a" (ret)
: "i" (T_SYSCALL),
"a" (num),
"d" (a[0]),
"c" (a[1]),
"b" (a[2]),
"D" (a[3]),
"S" (a[4])
: "cc", "memory");
return ret;
}
从中可以看出,应用程序调用的exit/fork/wait/getpid等库函数最终都会调用syscall函数,只是调用的参数不同而已,如果看最终的汇编代码会更清楚:1
2
3
4
5
6
7
8
9
10……
34: 8b 55 d4 mov -0x2c(%ebp),%edx
37: 8b 4d d8 mov -0x28(%ebp),%ecx
3a: 8b 5d dc mov -0x24(%ebp),%ebx
3d: 8b 7d e0 mov -0x20(%ebp),%edi
40: 8b 75 e4 mov -0x1c(%ebp),%esi
43: 8b 45 08 mov 0x8(%ebp),%eax
46: cd 80 int $0x80
48: 89 45 f0 mov %eax,-0x10(%ebp)
……
可以看到其实是把系统调用号放到EAX,其他5个参数a[0]~a[4]分别保存到EDX/ECX/EBX/EDI/ESI五个寄存器中,及最多用6个寄存器来传递系统调用的参数,且系统调用的返回结果是EAX。比如对于getpid库函数而言,系统调用号(SYS_getpid=18)是保存在EAX中,返回值(调用此库函数的的当前进程号pid)也在EAX中。
与用户进程相关的系统调用
在本实验中,与进程相关的各个系统调用属性如下所示:
|系统调用名 | 含义 | 具体完成服务的函数 |
|——|——|——|
|SYS_exit | process exit | do_exit |
|SYS_fork | create child process, dup mm | do_fork—>wakeup_proc |
|SYS_wait | wait child process | do_wait |
|SYS_exec | after fork, process execute a new program | load a program and refresh the mm |
|SYS_yield | process flag itself need resecheduling | proc->need_sched=1, then scheduler will rescheule this process |
|SYS_kill | kill process | do_kill—>proc->flags |= PF_EXITING, —>wakeup_proc—>do_wait—>do_exit |
|SYS_getpid | get the process’s pid | |
s##### 系统调用的执行过程
与用户态的函数库调用执行过程相比,系统调用执行过程的有四点主要的不同:
- 不是通过“CALL”指令而是通过“INT”指令发起调用;
- 不是通过“RET”指令,而是通过“IRET”指令完成调用返回;
- 当到达内核态后,操作系统需要严格检查系统调用传递的参数,确保不破坏整个系统的安全性;
- 执行系统调用可导致进程等待某事件发生,从而可引起进程切换;
下面我们以getpid系统调用的执行过程大致看看操作系统是如何完成整个执行过程的。当用户进程调用getpid函数,最终执行到INT T_SYSCALL指令后,CPU根据操作系统建立的系统调用中断描述符,转入内核态,并跳转到vector128处(kern/trap/vectors.S),开始了操作系统的系统调用执行过程,函数调用和返回操作的关系如下所示:1
2vector128(vectors.S) -->
__alltraps(trapentry.S) --> trap(trap.c) --> trap_dispatch(trap.c) --> syscall(syscall.c) --> sys_getpid(syscall.c) --> …… --> __trapret(trapentry.S)
在执行trap函数前,软件还需进一步保存执行系统调用前的执行现场,即把与用户进程继续执行所需的相关寄存器等当前内容保存到当前进程的中断帧trapframe中(注意,在创建进程是,把进程的trapframe放在给进程的内核栈分配的空间的顶部)。软件做的工作在vector128和__alltraps的起始部分:1
2
3
4
5
6
7
8
9vectors.S::vector128起始处:
pushl $0
pushl $128
......
trapentry.S::__alltraps起始处:
pushl %ds
pushl %es
pushal
……
自此,用于保存用户态的用户进程执行现场的trapframe的内容填写完毕,操作系统可开始完成具体的系统调用服务。在sys_getpid函数中,简单地把当前进程的pid成员变量做为函数返回值就是一个具体的系统调用服务。完成服务后,操作系统按调用关系的路径原路返回到__alltraps中。然后操作系统开始根据当前进程的中断帧内容做恢复执行现场操作。其实就是把trapframe的一部分内容保存到寄存器内容。恢复寄存器内容结束后,调整内核堆栈指针到中断帧的tf_eip处,这是内核栈的结构如下:1
2
3
4
5
6
7
8
9/* below here defined by x86 hardware */
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
这时执行IRET指令后,CPU根据内核栈的情况回复到用户态,并把EIP指向tf_eip的值,即INT T_SYSCALL后的那条指令。这样整个系统调用就执行完毕了。
读load_icode有感
1 | /* load_icode - load the content of binary program(ELF format) as the new content of current process |
练习1:加载应用程序并执行
do_execv函数调用了load_icode函数(位于kern/process/proc.c中)来加载并解析一个处于内存中的ELF执行文件格式的应用程序,并建立了相应的用户内存空间来存放应用程序的代码段、数据段 等,且要设置好proc_struct结构中的成员变量trapframe中的内容,确保在执行此进程后,能够从应用程序设定的起始执行地址开始执行。
load_icode函数是由do_execve函数调用的,而该函数是exec系统调用的最终处理的函数,功能为将某一个指定的ELF可执行二进制文件加载到当前内存中来,然后当前进程执行这个可执行文件(先前执行的内容全部清空),而load_icode函数的功能则在于为执行新的程序初始化好内存空间,在调用该函数之前,do_execve中已经退出了当前进程的内存空间,改使用了内核的内存空间,这样使得对原先用户态的内存空间的操作成为可能;
由于最终是在用户态下运行的,所以需要将段寄存器初始化为用户态的代码段、数据段、堆栈段;
esp应当指向先前的步骤中创建的用户栈的栈顶;
eip应当指向ELF可执行文件加载到内存之后的入口处;
eflags中应当初始化为中断使能,注意eflags的第1位是恒为1的;
设置ret为0,表示正常返回;
见上边的函数代码。
首先在初始化IDT的时候,设置系统调用对应的中断描述符,使其能够在用户态下被调用,并且设置为trap类型。设置系统调用中断是用户态的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 extern uintptr_t __vectors[];
int i;
for (i = 0; i < sizeof(idt) / sizeof(struct gatedesc); i ++) {
SETGATE(idt[i], 0, GD_KTEXT, __vectors[i], DPL_KERNEL);
}
SETGATE(idt[T_SYSCALL], 1, GD_KTEXT, __vectors[T_SYSCALL], DPL_USER);
lidt(&idt_pd);
/* *
* Set up a normal interrupt/trap gate descriptor
* - istrap: 1 for a trap (= exception) gate, 0 for an interrupt gate
* - sel: Code segment selector for interrupt/trap handler
* - off: Offset in code segment for interrupt/trap handler
* - dpl: Descriptor Privilege Level - the privilege level required
* for software to invoke this interrupt/trap gate explicitly
* using an int instruction.
* */
同样是在trap.c里,设置当计时器到点之后,也就是100个时钟周期之后,这个进程就是可以被重新调度的了,实现多线程的并发执行。1
2
3
4
5
6
7
8
9
10
11
12
13 case IRQ_OFFSET + IRQ_TIMER:
ticks++;
if(ticks>=TICK_NUM){
assert(current != NULL);
current->need_resched = 1;
//print_ticks();
ticks=0;
}
/* LAB5 YOUR CODE */
/* you should upate you lab1 code (just add ONE or TWO lines of code):
* Every TICK_NUM cycle, you should set current process's current->need_resched = 1
*/
-
在proc_alloc函数中,额外对进程控制块中新增加的wait_state, cptr, yptr, optr成员变量进行初始化;
在alloc_proc(void)函数中,对新增的几个变量初始化1
2
3
4
5
6
7
8 //LAB5 YOUR CODE : (update LAB4 steps)
/*
* below fields(add in LAB5) in proc_struct need to be initialized
* uint32_t wait_state; // waiting state
* struct proc_struct *cptr, *yptr, *optr; // relations between processes
*/
proc->wait_state = 0;
proc->cptr = proc->optr = proc->yptr = NULL;
在do_fork函数中,使用set_links函数来完成将fork的线程添加到线程链表中的过程,值得注意的是,该函数中就包括了将其加入list和对进程总数加1这一操作,因此需要将原先的这个操作给删除掉;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50// set_links - set the relation links of process
static void
set_links(struct proc_struct *proc) {
list_add(&proc_list, &(proc->list_link));
proc->yptr = NULL;
if ((proc->optr = proc->parent->cptr) != NULL) {
proc->optr->yptr = proc;
}
proc->parent->cptr = proc;
nr_process ++;
}
//LAB5 YOUR CODE : (update LAB4 steps)
/* Some Functions
* set_links: set the relation links of process. ALSO SEE: remove_links: lean the relation links of process
* -------------------
* update step 1: set child proc's parent to current process, make sure current process's wait_state is 0
* update step 5: insert proc_struct into hash_list && proc_list, set the relation links of process
*/
// 1. call alloc_proc to allocate a proc_struct
proc = alloc_proc();
if(proc == NULL)
goto fork_out;
// 2. call setup_kstack to allocate a kernel stack for child process
proc->parent = current;
assert(current->wait_state == 0);
int status = setup_kstack(proc);
if(status != 0)
goto bad_fork_cleanup_kstack;
// 3. call copy_mm to dup OR share mm according clone_flag
status = copy_mm(clone_flags, proc);
if(status != 0)
goto bad_fork_cleanup_proc;
// 4. call copy_thread to setup tf & context in proc_struct
copy_thread(proc, stack, tf);
// 5. insert proc_struct into hash_list && proc_list
proc->pid = get_pid();
hash_proc(proc);
set_links(proc);
// delete thses two lines !!!
//nr_process ++;
//list_add(&proc_list, &proc->list_link);
// delete thses two lines !!!
// 6. call wakeup_proc to make the new child process RUNNABLE
wakeup_proc(proc);
// 7. set ret vaule using child proc's pid
ret = proc->pid;
请在实验报告中描述当创建一个用户态进程并加载了应用程序后,CPU是如何让这个应用程序最终在用户态执行起来的。即这个用户态进程被ucore选择占用CPU执行(RUNNING态) 到具体执行应用程序第一条指令的整个经过。
- 在经过调度器占用了CPU的资源之后,用户态进程调用了exec系统调用,从而转入到了系统调用的处理例程;
- 调用中断处理例程之后,最终控制权转移到了syscall.c中的syscall函数,然后根据系统调用号转移给了sys_exec函数,在该函数中调用了上文中提及的do_execve函数来完成指定应用程序的加载;
- 在do_execve中进行了若干设置,包括退出当前进程的页表,换用kernel的PDT之后,使用load_icode函数,完成了对整个用户线程内存空间的初始化,包括堆栈的设置以及将ELF可执行文件的加载,之后通过current->tf指针修改了当前系统调用的trapframe,使得最终中断返回的时候能够切换到用户态,并且同时可以正确地将控制权转移到应用程序的入口处;
- 在完成了do_exec函数之后,进行正常的中断返回的流程,由于中断处理例程的栈上面的eip已经被修改成了应用程序的入口处,而cs上的CPL是用户态,因此iret进行中断返回的时候会将堆栈切换到用户的栈,并且完成特权级的切换,并且跳转到要求的应用程序的入口处;
- 接下来开始具体执行应用程序的第一条指令;
练习2:父进程复制自己的内存空间给子进程
创建子进程的函数do_fork在执行中将拷贝当前进程(即父进程)的用户内存地址空间中的合法内容到新进程中(子进程),完成内存资源的复制。具体是通过copy_range函数(位于 kern/mm/pmm.c中)实现的,请补充copy_range的实现,确保能够正确执行。
- 父进程调用fork(),进入中断处理机制,最终交由syscall函数进行处理;
- 在syscall,根据系统调用号,交由sys_fork函数处理;
- 进一步调用do_fork函数,这个函数创建了子进程、并且将父进程的内存空间复制给子进程;
- 在do_fork函数中,调用copy_mm进行内存空间的复制,在该函数中,进一步调用了dup_mmap。dup_mmap中遍历父进程的所有合法虚拟内存空间,并且将这些空间的内容复制到子进程的内存空间中去;
- 在copy_range函数中,对需要复制的内存空间按照页为单位从父进程的内存空间复制到子进程的内存空间中去;
遍历父进程指定的某一段内存空间中的每一个虚拟页,如果这个虚拟页存在,为子进程对应的同一个地址(但是页目录表是不一样的,因此不是一个内存空间)也申请分配一个物理页,然后将前者中的所有内容复制到后者中去,然后为子进程的这个物理页和对应的虚拟地址(事实上是线性地址)建立映射关系;而在本练习中需要完成的内容就是内存的复制和映射的建立,具体流程如下:
- 找到父进程指定的某一物理页对应的内核虚拟地址;
- 找到需要拷贝过去的子进程的对应物理页对应的内核虚拟地址;
- 将前者的内容拷贝到后者中去;
- 为子进程当前分配这一物理页映射上对应的在子进程虚拟地址空间里的一个虚拟页;
1 | /* copy_range - copy content of memory (start, end) of one process A to another process B |
练习3:阅读分析源代码,理解进程执行 fork/exec/wait/exit 的实现,以及系统调用的实现(不需要编码)
fork:在执行了fork系统调用之后,会执行正常的中断处理流程,到中断向量表里查系统调用入口,最终将控制权转移给syscall,之后根据系统调用号执行sys_fork函数,进一步执行了上文中的do_fork函数,新进程的进程控制块进行初始化、设置、以及调用copy_mm将父进程内存中的内容到子进程的内存的复制工作,然后调用wakeup_proc将新创建的进程放入可执行队列(runnable),之后由调度器对子进程进行调度。
exec:在执行了exec系统调用之后,会执行正常的中断处理流程,到中断向量表里查系统调用入口,最终将控制权转移给syscall,之后根据系统调用号执行sys_exec函数,进一步执行了上文中的do_execve函数。在该函数中,会对内存空间进行清空,然后调用load_icode将将要执行的程序加载到内存中,然后调用lcr3(boot_cr4)设置好中断帧,使得最终中断返回之后可以跳转到指定的应用程序的入口处,就可以正确执行了。
wait:在执行了wait系统调用之后,会执行正常的中断处理流程,到中断向量表里查系统调用入口,最终将控制权转移给syscall,之后根据系统调用号执行sys_wait函数,进一步执行了的do_wait函数,在这个函数中,找一个当前进程的处于ZOMBIE状态的子进程,如果有的话直接将其占用的资源释放掉即可;如果找不到,则将我这个进程的状态改成SLEEPING态,并且标记为等待ZOMBIE态的子进程,然后调用schedule函数将其当前线程从CPU占用中切换出去,直到有对应的子进程结束来唤醒这个进程为止。
exit:在执行了exit系统调用之后,会执行正常的中断处理流程,到中断向量表里查系统调用入口,最终将控制权转移给syscall,之后根据系统调用号执行sys_exit函数,进一步执行了的do_exit函数,首先将释放当前进程的大多数资源,然后将其标记为ZOMBIE态,然后调用wakeup_proc函数将其父进程唤醒(如果父进程执行了wait进入SLEEPING态的话),然后调用schedule函数,让出CPU资源,等待父进程进一步完成其所有资源的回收;
问题回答
请分析fork/exec/wait/exit在实现中是如何影响进程的执行状态的?
fork不会影响当前进程的执行状态,但是会将子进程的状态标记为RUNNALB,使得可以在后续的调度中运行起来;
exec不会影响当前进程的执行状态,但是会修改当前进程中执行的程序;
wait系统调用取决于是否存在可以释放资源(ZOMBIE)的子进程,如果有的话不会发生状态的改变,如果没有的话会将当前进程置为SLEEPING态,等待执行了exit的子进程将其唤醒;
exit会将当前进程的状态修改为ZOMBIE态,并且会将父进程唤醒(修改为RUNNABLE),然后主动让出CPU使用权;
实验六
实验目的
- 理解操作系统的调度管理机制
- 熟悉 ucore 的系统调度器框架,以及缺省的Round-Robin 调度算法
- 基于调度器框架实现一个(Stride Scheduling)调度算法来替换缺省的调度算法
实验内容
- 实验五完成了用户进程的管理,可在用户态运行多个进程。
- 之前采用的调度策略是很简单的FIFO调度策略。
- 本次实验,主要是熟悉ucore的系统调度器框架,以及基于此框架的Round-Robin(RR) 调度算法。
- 然后参考RR调度算法的实现,完成Stride Scheduling调度算法。
调度框架和调度算法设计与实现
实验六中的kern/schedule/sched.c只实现了调度器框架,而不再涉及具体的调度算法实现,调度算法在单独的文件(default_sched.[ch])中实现。
在init.c中的kern_init函数中的proc_init之前增加了对sched_init函数的调用。sched_init函数主要完成了对实现特定调度算法的调度类(sched_class,这里是default_sched_class)的绑定,使得ucore在后续的执行中,能够通过调度框架找到实现特定调度算法的调度类并完成进程调度相关工作。
进程状态
1 | struct proc_struct { |
ucore定义的进程控制块struct proc_struct包含了成员变量state,用于描述进程的运行状态,而running和runnable共享同一个状态(state)值(PROC_RUNNABLE。不同之处在于处于running态的进程不会放在运行队列中。进程的正常生命周期如下:
- 进程首先在 cpu 初始化或者 sys_fork 的时候被创建,当为该进程分配了一个进程控制块之后,该进程进入 uninit态(在proc.c 中 alloc_proc)。
- 当进程完全完成初始化之后,该进程转为runnable态。
- 当到达调度点时,由调度器
sched_class根据运行队列run_queue的内容来判断一个进程是否应该被运行,即把处于runnable态的进程转换成running状态,从而占用CPU执行。 - running态的进程通过wait等系统调用被阻塞,进入sleeping态。
- sleeping态的进程被wakeup变成runnable态的进程。
- running态的进程主动 exit 变成zombie态,然后由其父进程完成对其资源的最后释放,子进程的进程控制块成为unused。
- 所有从runnable态变成其他状态的进程都要出运行队列,反之,被放入某个运行队列中。
进程调度实现
内核抢占点
对于用户进程而言,由于有中断的产生,可以随时打断用户进程的执行,转到操作系统内部,从而给了操作系统以调度控制权,让操作系统可以根据具体情况(比如用户进程时间片已经用完了)选择其他用户进程执行。这体现了用户进程的可抢占性。
ucore内核执行是不可抢占的(non-preemptive),即在执行“任意”内核代码时,CPU控制权不可被强制剥夺。这里需要注意,不是在所有情况下ucore内核执行都是不可抢占的,有以下几种“固定”情况是例外:
- 进行同步互斥操作,比如争抢一个信号量、锁(lab7中会详细分析);
- 进行磁盘读写等耗时的异步操作,由于等待完成的耗时太长,ucore会调用shcedule让其他就绪进程执行。
以上两种是因为某个资源(也可称为事件)无法得到满足,无法继续执行下去,从而不得不主动放弃对CPU的控制权。在lab5中有几种情况是调用了schedule函数的。
| 编号 | 位置 | 原因 |
|---|---|---|
| 1 | proc.c:do_exit | 用户线程执行结束,主动放弃CPU |
| 2 | proc.c:do_wait | 用户线程等待着子进程结束,主动放弃CPU |
| 3 | proc.c:init_main | Init_porc内核线程等待所有用户进程结束;所有用户进程结束后回收系统资源 |
| 4 | proc.c:cpu_idle | idleproc内核线程等待处于就绪态的进程或线程,如果有选择一个并切换 |
| 5 | sync.h:lock | 进程无法得到锁,则主动放弃CPU |
| 6 | trap.c:trap | 修改当前进程时间片,若时间片用完,则设置need_resched为1,让当前进程放弃CPU |
第1、2、5处的执行位置体现了由于获取某种资源一时等不到满足、进程要退出、进程要睡眠等原因而不得不主动放弃CPU。第3、4处的执行位置比较特殊,initproc内核线程等待用户进程结束而执行schedule函数;idle内核线程在没有进程处于就绪态时才执行,一旦有了就绪态的进程,它将执行schedule函数完成进程调度。这里只有第6处的位置比较特殊:1
2
3
4
5
6
7if (!in_kernel) {
……
if (current->need_resched) {
schedule();
}
}
只有当进程在用户态执行到“任意”某处用户代码位置时发生了中断,且当前进程控制块成员变量need_resched为1(表示需要调度了)时,才会执行shedule函数。这实际上体现了对用户进程的可抢占性。如果没有第一行的if语句,那么就可以体现对内核代码的可抢占性。但如果要把这一行if语句去掉,我们就不得不实现对ucore中的所有全局变量的互斥访问操作,以防止所谓的race-condition现象,这样ucore的实现复杂度会增加不少。
Race condition旨在描述一个系统或者进程的输出依赖于不受控制的事件出现顺序或者出现时机。此词源自于两个信号试着彼此竞争,来影响谁先输出。 举例来说,如果计算机中的两个进程同时试图修改一个共享内存的内容,在没有并发控制的情况下,最后的结果依赖于两个进程的执行顺序与时机。而且如果发生了并发访问冲突,则最后的结果是不正确的。从维基百科的定义来看,race condition不仅仅是出现在程序中。以下讨论的race conditon全是计算机中多个进程同时访问一个共享内存,共享变量的例子。
要阻止出现race condition情况的关键就是不能让多个进程同时访问那块共享内存。访问共享内存的那段代码就是critical section。所有的解决方法都是围绕这个critical section来设计的。想要成功的解决race condition问题,并且程序还可以正确运行,从理论上应该满足以下四个条件:
- 不会有两个及以上进程同时出现在他们的critical section。
- 不要做任何关于CPU速度和数量的假设。
- 任何进程在运行到critical section之外时都不能阻塞其他进程。
- 不会有进程永远等在critical section之前。
进程切换过程
进程调度函数schedule选择了下一个将占用CPU执行的进程后,将调用进程切换,从而让新的进程得以执行。
两个用户进程,在二者进行进程切换的过程中,具体的步骤如下:
- 首先在执行某进程A的用户代码时,出现了一个
trap,这个时候就会从进程A的用户态切换到内核态(过程(1)),并且保存好进程A的trapframe;当内核态处理中断时发现需要进行进程切换时,ucore要通过schedule函数选择下一个将占用CPU执行的进程(即进程B),然后会调用proc_run函数,proc_run函数进一步调用switch_to函数,切换到进程B的内核态(过程(2)),继续进程B上一次在内核态的操作,并通过iret指令,最终将执行权转交给进程B的用户空间(过程(3))。 - 当进程B由于某种原因发生中断之后(过程(4)),会从进程B的用户态切换到内核态,并且保存好进程B的trapframe;当内核态处理中断时发现需要进行进程切换时,即需要切换到进程A,ucore再次切换到进程A(过程(5)),会执行进程A上一次在内核调用schedule函数返回后的下一行代码,这行代码当然还是在进程A的上一次中断处理流程中。最后当进程A的中断处理完毕的时候,执行权又会反交给进程A的用户代码(过程(6))。这就是在只有两个进程的情况下,进程切换间的大体流程。
调度框架和调度算法
设计思路
在操作方面,如果需要选择一个就绪进程,就可以从基于某种组织方式的就绪进程集合中选择出一个进程执行。选择是在集合中挑选一个“合适”的进程,出意味着离开就绪进程集合。
另外考虑到一个处于运行态的进程还会由于某种原因(比如时间片用完了)回到就绪态而不能继续占用CPU执行,这就会重新进入到就绪进程集合中。这两种情况就形成了调度器相关的三个基本操作:在就绪进程集合中选择、进入就绪进程集合和离开就绪进程集合。这三个操作属于调度器的基本操作。
在进程的执行过程中,就绪进程的等待时间和执行进程的执行时间是影响调度选择的重要因素。这些进程状态变化的情况需要及时让进程调度器知道,便于选择更合适的进程执行。所以这种进程变化的情况就形成了调度器相关的一个变化感知操作:timer时间事件感知操作。这样在进程运行或等待的过程中,调度器可以调整进程控制块中与进程调度相关的属性值(比如消耗的时间片、进程优先级等),并可能导致对进程组织形式的调整(比如以时间片大小的顺序来重排双向链表等),并最终可能导致调选择新的进程占用CPU运行。这个操作属于调度器的进程调度属性调整操作。
数据结构
- 在 ucore 中,调度器引入 run-queue(简称rq,即运行队列)的概念,通过链表结构管理进程。
- 由于目前 ucore 设计运行在单CPU上,其内部只有一个全局的运行队列,用来管理系统内全部的进程。
- 运行队列通过链表的形式进行组织。链表的每一个节点是一个list_entry_t,每个list_entry_t 又对应到了
struct proc_struct *,这其间的转换是通过宏le2proc来完成。 - 具体来说,我们知道在
struct proc_struct中有一个叫run_link的list_entry_t,因此可以通过偏移量逆向找到对因某个run_list的struct proc_struct。即进程结构指针proc = le2proc(链表节点指针, run_link)。
1 | // The introduction of scheduling classes is borrrowed from Linux, and makes the |
proc.h 中的 struct proc_struct 中也记录了一些调度相关的信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34struct proc_struct {
enum proc_state state; // Process state
int pid; // Process ID
int runs; // the running times of Proces
uintptr_t kstack; // Process kernel stack
volatile bool need_resched; // bool value: need to be rescheduled to release CPU?
struct proc_struct *parent; // the parent process
struct mm_struct *mm; // Process's memory management field
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for current interrupt
uintptr_t cr3; // CR3 register: the base addr of Page Directroy Table(PDT)
uint32_t flags; // Process flag
char name[PROC_NAME_LEN + 1]; // Process name
list_entry_t list_link; // Process link list
list_entry_t hash_link; // Process hash list
int exit_code; // exit code (be sent to parent proc)
uint32_t wait_state; // waiting state
struct proc_struct *cptr, *yptr, *optr; // relations between processes
struct run_queue *rq; // running queue contains Process
list_entry_t run_link; // the entry linked in run queue
// 该进程的调度链表结构,该结构内部的连接组成了 运行队列 列表
int time_slice; // time slice for occupying the CPU
// 进程剩余的时间片
skew_heap_entry_t lab6_run_pool; // FOR LAB6 ONLY: the entry in the run pool
//在优先队列中用到的
uint32_t lab6_stride; // FOR LAB6 ONLY: the current stride of the process
// 步进值
uint32_t lab6_priority; // FOR LAB6 ONLY: the priority of process, set by lab6_set_priority(uint32_t)
// 优先级
};
RR调度算法在RR_sched_class调度策略类中实现。
通过数据结构 struct run_queue 来描述完整的 run_queue(运行队列)。它的主要结构如下:1
2
3
4
5
6
7
8
9
10struct run_queue {
//其运行队列的哨兵结构,可以看作是队列头和尾
list_entry_t run_list;
//优先队列形式的进程容器,只在 LAB6 中使用
skew_heap_entry_t *lab6_run_pool;
//表示其内部的进程总数
unsigned int proc_num;
//每个进程一轮占用的最多时间片
int max_time_slice;
};
在 ucore 框架中,运行队列存储的是当前可以调度的进程,所以,只有状态为runnable的进程才能够进入运行队列。当前正在运行的进程并不会在运行队列中。
调度点的相关关键函数
如果我们能够让wakup_proc、schedule、run_timer_list这三个调度相关函数的实现与具体调度算法无关,那么就可以认为ucore实现了一个与调度算法无关的调度框架。
wakeup_proc函数完成了把一个就绪进程放入到就绪进程队列中的工作,为此还调用了一个调度类接口函数sched_class_enqueue,这使得wakeup_proc的实现与具体调度算法无关。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void wakeup_proc(struct proc_struct *proc) {
assert(proc->state != PROC_ZOMBIE);
bool intr_flag;
local_intr_save(intr_flag);
{
if (proc->state != PROC_RUNNABLE) {
proc->state = PROC_RUNNABLE;
proc->wait_state = 0;
if (proc != current) {
sched_class_enqueue(proc);
}
}
else {
warn("wakeup runnable process.\n");
}
}
local_intr_restore(intr_flag);
}
schedule函数完成了与调度框架和调度算法相关三件事情:
- 把当前继续占用CPU执行的运行进程放放入到就绪进程队列中;
- 从就绪进程队列中选择一个“合适”就绪进程;
- 把这个“合适”的就绪进程从就绪进程队列中取出;
- 如果没有的话,说明现在没有合适的进程可以执行,就执行idle_proc;
- 加了一个runs,表明这个进程运行过几次了;
1 | void schedule(void) { |
run_time_list在lab6中并没有涉及,是在lab7中的。
通过调用三个调度类接口函数sched_class_enqueue、sched_class_pick_next、sched_class_enqueue来使得完成这三件事情与具体的调度算法无关。run_timer_list函数在每次timer中断处理过程中被调用,从而可用来调用调度算法所需的timer时间事件感知操作,调整相关进程的进程调度相关的属性值。通过调用调度类接口函数sched_class_proc_tick使得此操作与具体调度算法无关。
这里涉及了一系列调度类接口函数:
- sched_class_enqueue
- sched_class_dequeue
- sched_class_pick_next
- sched_class_proc_tick
这4个函数的实现其实就是调用某基于sched_class数据结构的特定调度算法实现的4个指针函数。采用这样的调度类框架后,如果我们需要实现一个新的调度算法,则我们需要定义一个针对此算法的调度类的实例,一个就绪进程队列的组织结构描述就行了,其他的事情都可交给调度类框架来完成。
RR调度算法
RR调度算法的调度思想是让所有runnable态的进程分时轮流使用CPU时间。
RR调度器维护当前runnable进程的有序运行队列。当前进程的时间片用完之后,调度器将当前进程放置到运行队列的尾部,再从其头部取出进程进行调度。
RR调度算法的就绪队列在组织结构上也是一个双向链表,只是增加了一个成员变量,表明在此就绪进程队列中的最大执行时间片。而且在进程控制块proc_struct中增加了一个成员变量time_slice,用来记录进程当前的可运行时间片段。这是由于RR调度算法需要考虑执行进程的运行时间不能太长。在每个timer到时的时候,操作系统会递减当前执行进程的time_slice,当time_slice为0时,就意味着这个进程运行了一段时间(这个时间片段称为进程的时间片),需要把CPU让给其他进程执行,于是操作系统就需要让此进程重新回到rq的队列尾,且重置此进程的时间片为就绪队列的成员变量最大时间片max_time_slice值,然后再从rq的队列头取出一个新的进程执行。
RR_enqueue的函数实现如下表所示。即把某进程的进程控制块指针放入到rq队列末尾,且如果进程控制块的时间片为0,则需要把它重置为rq成员变量max_time_slice。这表示如果进程在当前的执行时间片已经用完,需要等到下一次有机会运行时,才能再执行一段时间。1
2
3
4
5
6
7
8
9static void RR_enqueue(struct run_queue *rq, struct proc_struct *proc) {
assert(list_empty(&(proc->run_link)));
list_add_before(&(rq->run_list), &(proc->run_link));
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {
proc->time_slice = rq->max_time_slice;
}
proc->rq = rq;
rq->proc_num ++;
}
RR_pick_next的函数实现如下表所示。即选取就绪进程队列rq中的队头队列元素,并把队列元素转换成进程控制块指针。1
2
3
4
5
6
7
8static struct proc_struct *
RR_pick_next(struct run_queue *rq) {
list_entry_t *le = list_next(&(rq->run_list));
if (le != &(rq->run_list)) {
return le2proc(le, run_link);
}
return NULL;
}
RR_dequeue的函数实现如下表所示。即把就绪进程队列rq的进程控制块指针的队列元素删除,并把表示就绪进程个数的proc_num减一。1
2
3
4
5static void RR_dequeue(struct run_queue *rq, struct proc_struct *proc) {
assert(!list_empty(&(proc->run_link)) && proc->rq == rq);
list_del_init(&(proc->run_link));
rq->proc_num --;
}
RR_proc_tick的函数实现如下表所示。每次timer到时后,trap函数将会间接调用此函数来把当前执行进程的时间片time_slice减一。如果time_slice降到零,则设置此进程成员变量need_resched标识为1,这样在下一次中断来后执行trap函数时,会由于当前进程程成员变量need_resched标识为1而执行schedule函数,从而把当前执行进程放回就绪队列末尾,而从就绪队列头取出在就绪队列上等待时间最久的那个就绪进程执行。1
2
3
4
5
6
7
8
9static void
RR_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
if (proc->time_slice > 0) {
proc->time_slice --;
}
if (proc->time_slice == 0) {
proc->need_resched = 1;
}
}
Stride Scheduling
基本思路
- 为每个runnable的进程设置一个当前状态stride,表示该进程当前的调度权,也可以表示这个进程执行了多久了。另外定义其对应的pass值,表示对应进程在调度后,stride 需要进行的累加值。
- 每次需要调度时,从当前 runnable 态的进程中选择stride最小的进程调度。
- 对于获得调度的进程P,将对应的stride加上其对应的步长pass(只与进程的优先权有关系)。
- 在一段固定的时间之后,回到2步骤,重新调度当前stride最小的进程。
可以证明,如果令P.pass =BigStride / P.priority,其中P.priority表示进程的优先权(大于 1),而 BigStride 表示一个预先定义的大常数,则该调度方案为每个进程分配的时间将与其优先级成正比。
将该调度器应用到 ucore 的调度器框架中来,则需要将调度器接口实现如下:
- init:
- 初始化调度器类的信息(如果有的话)。
- 初始化当前的运行队列为一个空的容器结构。(比如和RR调度算法一样,初始化为一个有序列表)
- enqueue
- 初始化刚进入运行队列的进程 proc的stride属性。
- 将 proc插入放入运行队列中去(注意:这里并不要求放置在队列头部)。
- dequeue
- 从运行队列中删除相应的元素。
- pick next
- 扫描整个运行队列,返回其中stride值最小的对应进程。
- 更新对应进程的stride值,即pass = BIG_STRIDE / P->priority; P->stride += pass。
- proc tick:
- 检测当前进程是否已用完分配的时间片。如果时间片用完,应该正确设置进程结构的相关标记来引起进程切换。
- 一个 process 最多可以连续运行 rq.max_time_slice个时间片。
使用优先队列实现 Stride Scheduling
使用优化的优先队列数据结构实现该调度。
优先队列是这样一种数据结构:使用者可以快速的插入和删除队列中的元素,并且在预先指定的顺序下快速取得当前在队列中的最小(或者最大)值及其对应元素。可以看到,这样的数据结构非常符合 Stride 调度器的实现。
libs/skew_heap.h中是优先队列的一个实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17static inline void skew_heap_init(skew_heap_entry_t *a) __attribute__((always_inline));
// 初始化一个队列节点
static inline skew_heap_entry_t *skew_heap_merge(
skew_heap_entry_t *a, skew_heap_entry_t *b,
compare_f comp);
// 合并两个优先队列
static inline skew_heap_entry_t *skew_heap_insert(
skew_heap_entry_t *a, skew_heap_entry_t *b,
compare_f comp) __attribute__((always_inline));
// 将节点 b 插入至以节点 a 为队列头的队列中去,返回插入后的队列
static inline skew_heap_entry_t *skew_heap_remove(
skew_heap_entry_t *a, skew_heap_entry_t *b,
compare_f comp) __attribute__((always_inline));
// 将节点 b 插入从以节点 a 为队列头的队列中去,返回删除后的队列
当使用优先队列作为Stride调度器的实现方式之后,运行队列结构也需要作相关改变,其中包括:
struct run_queue中的lab6_run_pool指针,在使用优先队列的实现中表示当前优先队列的头元素,如果优先队列为空,则其指向空指针(NULL)。struct proc_struct中的lab6_run_pool结构,表示当前进程对应的优先队列节点。本次实验已经修改了系统相关部分的代码,使得其能够很好地适应LAB6新加入的数据结构和接口。而在实验中我们需要做的是用优先队列实现一个正确和高效的Stride调度器,如果用较简略的伪代码描述,则有:
- init(rq):
- Initialize rq->run_list
- Set rq->lab6_run_pool to NULL
- Set rq->proc_num to 0
- enqueue(rq, proc)
- Initialize proc->time_slice
- Insert proc->lab6_run_pool into rq->lab6_run_pool
- rq->proc_num ++
- dequeue(rq, proc)
- Remove proc->lab6_run_pool from rq->lab6_run_pool
- rq->proc_num —
- pick_next(rq)
- If rq->lab6_run_pool == NULL, return NULL
- Find the proc corresponding to the pointer rq->lab6_run_pool
- proc->lab6_stride += BIG_STRIDE / proc->lab6_priority
- Return proc
- proc_tick(rq, proc):
- If proc->time_slice > 0, proc->time_slice —
– If proc->time_slice == 0, set the flag proc->need_resched
- If proc->time_slice > 0, proc->time_slice —
练习1: 使用 Round Robin 调度算法(不需要编码)
与之前相比,新增了斜堆数据结构的实现;新增了调度算法Round Robin的实现,具体为调用sched.c文件中的sched_class的一系列函数,主要有enqueue、dequeue、pick_next等。之后,这些函数进一步调用调度器中的相应函数,默认该调度器为Round Robin调度器,这是在default_sched.[c|h]中定义的;新增了set_priority,get_time等函数;
首先在init.c中调用了sched_init函数,在这里把sched_class赋值为default_sched_class,也就是RR,如下:1
2
3
4
5
6
7
8
9
10void
sched_init(void) {
list_init(&timer_list);
sched_class = &default_sched_class;
rq = &__rq;
rq->max_time_slice = MAX_TIME_SLICE;
sched_class->init(rq);
cprintf("sched class: %s\n", sched_class->name);
}
- RR_init函数:这个函数会被封装为sched_init函数,用于调度算法的初始化,它是在ucore的init.c里面被调用进行初始化,主要完成了计时器list、run_queue的run_list的初始化;
- enqueue函数:将某个进程放入调用算法中的可执行队列中,被封装成sched_class_enqueue函数,这个函数仅在wakeup_proc和schedule函数中被调用,wakeup_proc将某个不是RUNNABLE的进程改成RUNNABLE的并调用enqueue加入可执行队列,而后者是将正在执行的进程换出到可执行队列中去并取出一个可执行进程;
- dequeue函数:将某个在队列中的进程取出,sched_class_dequeue将其封装并在schedule中被调用,将调度算法选择的进程从等待的可执行进程队列中取出;
- pick_next函数:根据调度算法选择下一个要执行的进程,仅在schedule中被调用;
- proc_tick函数:在时钟中断时执行的操作,时间片减一,当时间片为0时,说明这个进程需要重新调度了。仅在进行时间中断的ISR中调用;
请理解并分析sched_calss中各个函数指针的用法,并接合Round Robin 调度算法描述ucore的调度执行过程:
- ucore中的调度主要通过schedule和wakeup_proc函数完成,schedule主要把当前执行的进程入队,调用sched_class_pick_next选择下一个执行的进程并将其出队,开始执行。scheduleha函数把当前的进程入队,挑选一个进程将其出队并开始执行。
- 当需要将某一个进程加入就绪进程队列中,需要调用enqueue,将其插入到使用链表组织run_queue的队尾,将这个进程的能够使用的时间片初始化为max_time_slice;
- 当需要将某一个进程从就绪队列中取出,需要调用dequeue,调用list_del_init将其直接删除即可;
- 当需要取出执行的下一个进程时,只需调用pick_next将就绪队列run_queue的队头取出即可;
- 在一个时钟中断中,调用proc_tick将当前执行的进程的剩余可执行时间减1,一旦减到了0,则这个进程的need_resched为1,设成可以被调度的,这样之后就会调用schedule函数将这个进程切换出去;
请在实验报告中简要说明如何设计实现”多级反馈队列调度算法“,给出概要设计,鼓励给出详细设计;
调度机制:
- 进程在进入待调度的队列等待时,首先进入优先级最高的Q1等待。
- 设置多个就绪队列。在系统中设置多个就绪队列,并为每个队列赋予不同的优先级,从第一个开始逐个降低。不同队列进程中所赋予的执行时间也不同,优先级越高,时间片越小。
- 每个队列都采用FCFS(先来先服务)算法。轮到该进程执行时,若在该时间片内完成,便撤离操作系统,否则调度程序将其转入第二队列的末尾等待调度,…….。若进程最后被调到第N队列中时,便采用RR方式运行。
- 按队列优先级调度。调度按照优先级最高队列中诸进程运行,仅当第一队列空闲时才调度第二队列进程执行。若低优先级队列执行中有优先级高队列进程执行,应立刻将此进程放入队列末尾,把处理机分配给新到高优先级进程。
- 设置N个多级反馈队列的入口,Q0,Q1,Q2,Q3,…,编号越靠前的队列优先级越低,优先级越低的队列上时间片的长度越大;
- 调用sched_init对调度算法初始化的时候需要同时对N个队列进行初始化;
- 在将进程加入到就绪进程集合的时候,观察这个进程的时间片有没有使用完,如果使用完了,就将所在队列的优先级调低,加入到优先级低一级的队列中去,如果没有使用完时间片,则加入到当前优先级的队列中去;
- 在同一个优先级的队列内使用时间片轮转算法;
- 在选择下一个执行的进程的时候,先考虑更高优先级的队列中是否存在任务,如果不存在在去找较低优先级的队列;
- 从就绪进程集合中删除某一个进程的话直接在对应队列中删除;
练习2:实现 Stride Scheduling 调度算法(需要编码)
啊啊啊忘了在trap.c里改怪不得怎么都搞不对啊啊啊啊啊啊啊啊啊这下子总算有170了!!!
还是先看看代码里斜堆(skew heap)的实现吧,好多地方要用到这个结构,具体可以在yuhao0102.github.io里仔细看。
在libs/skew.h中定义了skew heap。
猜测这只是一个入口,类似链表那种实现,不包括数据,只有指针。1
2
3struct skew_heap_entry {
struct skew_heap_entry *parent, *left, *right;
};
proc_stride_comp_f函数是用来比较这两个进程的stride的,a比b大返回1,相等返回0,a比b小返回-1。1
2
3
4
5
6
7
8
9
10
11/* The compare function for two skew_heap_node_t's and the
* corresponding procs*/
static int proc_stride_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, lab6_run_pool);
struct proc_struct *q = le2proc(b, lab6_run_pool);
int32_t c = p->lab6_stride - q->lab6_stride;
if (c > 0) return 1;
else if (c == 0) return 0;
else return -1;
}
这是初始化的函数,把三个指针初始化为NULL1
2
3
4
5static inline void
skew_heap_init(skew_heap_entry_t *a)
{
a->left = a->right = a->parent = NULL;
}
这个是把两个堆merge在一起的操作,强行内联hhh,这个是递归的!1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34static inline skew_heap_entry_t *
skew_heap_merge(skew_heap_entry_t *a, skew_heap_entry_t *b,
compare_f comp)
{
if (a == NULL) return b;
else if (b == NULL) return a;
// 如果a或b有一个为空,则返回另一个
skew_heap_entry_t *l, *r;
if (comp(a, b) == -1)
{
r = a->left;
l = skew_heap_merge(a->right, b, comp);
a->left = l;
a->right = r;
if (l) l->parent = a;
return a;
// 否则判断a和b的值哪个大,如果a比b小,则a的右子树和b合并,a作为堆顶
}
else
{
r = b->left;
l = skew_heap_merge(a, b->right, comp);
b->left = l;
b->right = r;
if (l)
l->parent = b;
return b;
// 另一种情况
}
}
insert就是把一个单节点的堆跟大堆合并1
2
3
4
5
6
7static inline skew_heap_entry_t *
skew_heap_insert(skew_heap_entry_t *a, skew_heap_entry_t *b,
compare_f comp)
{
skew_heap_init(b);
return skew_heap_merge(a, b, comp);
}
删除就是把节点的左右子树进行merge,比较简单,记得删掉这个节点之后补充它的parent即可1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17static inline skew_heap_entry_t *
skew_heap_remove(skew_heap_entry_t *a, skew_heap_entry_t *b,
compare_f comp)
{
skew_heap_entry_t *p = b->parent;
skew_heap_entry_t *rep = skew_heap_merge(b->left, b->right, comp);
if (rep) rep->parent = p;
if (p)
{
if (p->left == b)
p->left = rep;
else p->right = rep;
return a;
}
else return rep;
}
首先把default_sched.c中设置RR调度器为默认调度器的部分注释掉,然后把default_sched_stride_c改成default_sched_stride.c,这里对默认调度器进行了重新定义。1
2
3
4
5
6
7
8struct sched_class default_sched_class = {
.name = "stride_scheduler",
.init = stride_init,
.enqueue = stride_enqueue,
.dequeue = stride_dequeue,
.pick_next = stride_pick_next,
.proc_tick = stride_proc_tick,
};
针对PCB的初始化,代码如下,综合了几个实验的初始化代码,也是一个总结:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54//LAB4:EXERCISE1 YOUR CODE
/*
* below fields in proc_struct need to be initialized
* enum proc_state state; // Process state
* int pid; // Process ID
* int runs; // the running times of Proces
* uintptr_t kstack; // Process kernel stack
* volatile bool need_resched; // bool value: need to be rescheduled to release CPU?
* struct proc_struct *parent; // the parent process
* struct mm_struct *mm; // Process's memory management field
* struct context context; // Switch here to run process
* struct trapframe *tf; // Trap frame for current interrupt
* uintptr_t cr3; // CR3 register: the base addr of Page Directroy Table(PDT)
* uint32_t flags; // Process flag
* char name[PROC_NAME_LEN + 1]; // Process name
*/
proc->state = PROC_UNINIT;
proc->pid = -1;
proc->cr3 = boot_cr3;
proc->runs = 0;
proc->kstack = 0;
proc->need_resched = 0;
proc->parent = NULL;
proc->mm = NULL;
memset(&proc->context, 0, sizeof(struct context));
proc->tf = NULL;
proc->flags = 0;
memset(proc->name, 0, PROC_NAME_LEN);
//LAB5 YOUR CODE : (update LAB4 steps)
/*
* below fields(add in LAB5) in proc_struct need to be initialized
* uint32_t wait_state; // waiting state
* struct proc_struct *cptr, *yptr, *optr; // relations between processes
*/
proc->wait_state = 0;
proc->cptr = proc->optr = proc->yptr = NULL;
//LAB6 YOUR CODE : (update LAB5 steps)
/*
* below fields(add in LAB6) in proc_struct need to be initialized
* struct run_queue *rq; // running queue contains Process
* list_entry_t run_link; // the entry linked in run queue
* int time_slice; // time slice for occupying the CPU
* skew_heap_entry_t lab6_run_pool; // FOR LAB6 ONLY: the entry in the run pool
* uint32_t lab6_stride; // FOR LAB6 ONLY: the current stride of the process
* uint32_t lab6_priority; // FOR LAB6 ONLY: the priority of process, set by lab6_set_priority(uint32_t)
*/
proc->rq = NULL;
memset(&proc->run_link, 0, sizeof(list_entry_t));
proc->time_slice = 0;
memset(&proc->lab6_run_pool,0,sizeof(skew_heap_entry_t));
proc->lab6_stride=0;
proc->lab6_priority=1;
主要就是在vim kern/schedule/default_sched_stride.c里的修改。1
BIG_STRIDE应该设置成小于2^32-1的一个常数。
这个函数用来对run_queue进行初始化等操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/*
* stride_init initializes the run-queue rq with correct assignment for
* member variables, including:
*
* - run_list: should be a empty list after initialization.
* - lab6_run_pool: NULL
* - proc_num: 0
* - max_time_slice: no need here, the variable would be assigned by the caller.
*
* hint: see libs/list.h for routines of the list structures.
*/
static void
stride_init(struct run_queue *rq) {
/* LAB6: YOUR CODE
* (1) init the ready process list: rq->run_list
* (2) init the run pool: rq->lab6_run_pool
* (3) set number of process: rq->proc_num to 0
*/
list_init(&rq->run_list);
rq->lab6_run_pool = NULL;
rq->proc_num = 0;
}
1 | /* |
做删除操作,把这个进程从run_pool里删除,并且将run_queue里的进程数减一。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/*
* stride_dequeue removes the process ``proc'' from the run-queue
* ``rq'', the operation would be finished by the skew_heap_remove
* operations. Remember to update the ``rq'' structure.
*
* hint: see libs/skew_heap.h for routines of the priority
* queue structures.
*/
static void
stride_dequeue(struct run_queue *rq, struct proc_struct *proc) {
/* LAB6: YOUR CODE
* (1) remove the proc from rq correctly
* NOTICE: you can use skew_heap or list. Important functions
* skew_heap_remove: remove a entry from skew_heap
* list_del_init: remove a entry from the list
*/
rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool, &proc->lab6_run_pool, proc_stride_comp_f);
rq->proc_num --;
}
pick_next从run_queue中选择stride值最小的进程,即斜堆的根节点对应的进程,并且返回这个proc,同时更新这个proc的stride1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/*
* stride_pick_next pick the element from the ``run-queue'', with the
* minimum value of stride, and returns the corresponding process
* pointer. The process pointer would be calculated by macro le2proc,
* see kern/process/proc.h for definition. Return NULL if
* there is no process in the queue.
*
* When one proc structure is selected, remember to update the stride
* property of the proc. (stride += BIG_STRIDE / priority)
*
* hint: see libs/skew_heap.h for routines of the priority
* queue structures.
*/
static struct proc_struct *
stride_pick_next(struct run_queue *rq) {
/* LAB6: YOUR CODE
* (1) get a proc_struct pointer p with the minimum value of stride
(1.1) If using skew_heap, we can use le2proc get the p from rq->lab6_run_poll
(1.2) If using list, we have to search list to find the p with minimum stride value
* (2) update p;s stride value: p->lab6_stride
* (3) return p
*/
if (rq->lab6_run_pool == NULL)
return NULL;
struct proc_struct *p = le2proc(rq->lab6_run_pool, lab6_run_pool);
p->lab6_stride += BIG_STRIDE/p->lab6_priority;
return p;
}
要在trap的时候调用!!!!如果这个proc的时间片还有的话,就减一,如果这个时间片为0了,就把它设成可调度的,参与调度。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/*
* stride_proc_tick works with the tick event of current process. You
* should check whether the time slices for current process is
* exhausted and update the proc struct ``proc''. proc->time_slice
* denotes the time slices left for current
* process. proc->need_resched is the flag variable for process
* switching.
*/
static void
stride_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
/* LAB6: YOUR CODE */
if (proc->time_slice > 0) {
proc->time_slice --;
}
if (proc->time_slice == 0) {
proc->need_resched = 1;
}
}
实验七
实验目的
- 理解操作系统的同步互斥的设计实现;
- 理解底层支撑技术:禁用中断、定时器、等待队列;
- 在ucore中理解信号量(semaphore)机制的具体实现;
- 理解管程机制,在ucore内核中增加基于管程(monitor)的条件变量(condition variable)的支持;
- 了解经典进程同步问题,并能使用同步机制解决进程同步问题。
实验内容
lab6已经可以调度运行多个进程,如果多个进程需要协同操作或访问共享资源,则存在如何同步和有序竞争的问题。本次实验,主要是熟悉ucore的进程同步机制—信号量(semaphore)机制,以及基于信号量的哲学家就餐问题解决方案。然后掌握管程的概念和原理,并参考信号量机制,实现基于管程的条件变量机制和基于条件变量来解决哲学家就餐问题。
在本次实验中,在kern/sync/check_sync.c中提供了一个基于信号量的哲学家就餐问题解法。同时还需完成练习,即实现基于管程(主要是灵活运用条件变量和互斥信号量)的哲学家就餐问题解法。
哲学家就餐问题描述如下:有五个哲学家,他们的生活方式是交替地进行思考和进餐。哲学家们公用一张圆桌,周围放有五把椅子,每人坐一把。在圆桌上有五个碗和五根筷子,当一个哲学家思考时,他不与其他人交谈,饥饿时便试图取用其左、右最靠近他的筷子,但他可能一根都拿不到。只有在他拿到两根筷子时,方能进餐,进餐完后,放下筷子又继续思考。
同步互斥的设计与实现
实验执行流程概述
互斥是指某一资源同时只允许一个进程对其进行访问,具有唯一性和排它性,但互斥不用限制进程对资源的访问顺序,即访问可以是无序的。同步是指在进程间的执行必须严格按照规定的某种先后次序来运行,即访问是有序的,这种先后次序取决于要系统完成的任务需求。在进程写资源情况下,进程间要求满足互斥条件。在进程读资源情况下,可允许多个进程同时访问资源。
实验七设计实现了多种同步互斥手段,包括时钟中断管理、等待队列、信号量、管程机制(包含条件变量设计)等,并基于信号量实现了哲学家问题的执行过程。而本次实验的练习是要求用管程机制实现哲学家问题的执行过程。在实现信号量机制和管程机制时,需要让无法进入临界区的进程睡眠,为此在ucore中设计了等待队列wait_queue。当进程无法进入临界区(即无法获得信号量)时,可让进程进入等待队列,这时的进程处于等待状态(也可称为阻塞状态),从而会让实验六中的调度器选择一个处于就绪状态(即RUNNABLE_STATE)的进程,进行进程切换,让新进程有机会占用CPU执行,从而让整个系统的运行更加高效。
lab7/kern/sync/check_sync.c中的check_sync函数可以理解为是实验七的起始执行点,是实验七的总控函数。进一步分析此函数,可以看到这个函数主要分为了两个部分,第一部分是实现基于信号量的哲学家问题,第二部分是实现基于管程的哲学家问题。
- 对于check_sync函数的第一部分,首先实现初始化了一个互斥信号量,然后创建了对应5个哲学家行为的5个信号量,并创建5个内核线程代表5个哲学家,每个内核线程完成了基于信号量的哲学家吃饭睡觉思考行为实现。
- 对于check_sync函数的第二部分,首先初始化了管程,然后又创建了5个内核线程代表5个哲学家,每个内核线程要完成基于管程的哲学家吃饭、睡觉、思考的行为实现。
同步互斥的底层支撑
由于调度的存在,且进程在访问某类资源暂时无法满足的情况下会进入等待状态,导致了多进程执行时序的不确定性和潜在执行结果的不确定性。为了确保执行结果的正确性,本试验需要设计更加完善的进程等待和互斥的底层支撑机制,确保能正确提供基于信号量和条件变量的同步互斥机制。
由于有定时器、屏蔽/使能中断、等待队列wait_queue支持test_and_set_bit等原子操作机器指令(在本次实验中没有用到)的存在,使得我们在实现进程等待、同步互斥上得到了极大的简化。下面将对定时器、屏蔽/使能中断和等待队列进行进一步讲解。
定时器
在传统的操作系统中,定时器提供了基于时间事件的调度机制。在ucore中,两次时间中断之间的时间间隔为一个时间片,timer splice。
基于此时间单位,操作系统得以向上提供基于时间点的事件,并实现基于时间长度的睡眠等待和唤醒机制。在每个时钟中断发生时,操作系统产生对应的时间事件。
sched.h, sched.c定义了有关timer的各种相关接口来使用 timer 服务,其中主要包括:
typedef struct {……} timer_t:定义了 timer_t 的基本结构,其可以用 sched.h 中的timer_init函数对其进行初始化。void timer_init(timer t *timer, struct proc_struct *proc, int expires): 对某定时器进行初始化,让它在expires时间片之后唤醒proc进程。void add_timer(timer t *timer):向系统添加某个初始化过的timer_t,该定时器在指定时间后被激活,并将对应的进程唤醒至runnable(如果当前进程处在等待状态)。void del_timer(timer_t *time):向系统删除(或者说取消)某一个定时器。该定时器在取消后不会被系统激活并唤醒进程。void run_timer_list(void):更新当前系统时间点,遍历当前所有处在系统管理内的定时器,找出所有应该激活的计数器,并激活它们。该过程在且只在每次定时器中断时被调用。在ucore中,其还会调用调度器事件处理程序。
一个 timer_t 在系统中的存活周期可以被描述如下:
- timer_t在某个位置被创建和初始化,并通过add_timer加入系统管理列表中;
- 系统时间被不断累加,直到 run_timer_list 发现该 timer_t到期;
- run_timer_list更改对应的进程状态,并从系统管理列表中移除该timer_t;
屏蔽与使能中断
之前用过,这里简单看看。
在ucore中提供的底层机制包括中断屏蔽/使能控制等。kern/sync.c有开关中断的控制函数local_intr_save(x)和local_intr_restore(x),它们是基于kern/driver文件下的intr_enable()、intr_disable()函数实现的。具体调用关系为:
关中断:
local_intr_save—>__intr_save—>intr_disable—>cli
开中断:local_intr_restore—>__intr_restore—>intr_enable—>sti
最终的cli和sti是x86的机器指令,最终实现了关(屏蔽)中断和开(使能)中断,即设置了eflags寄存器中与中断相关的位。通过关闭中断,可以防止对当前执行的控制流被其他中断事件处理所打断。既然不能中断,那也就意味着在内核运行的当前进程无法被打断或被重新调度,即实现了对临界区的互斥操作。所以在单处理器情况下,可以通过开关中断实现对临界区的互斥保护,需要互斥的临界区代码的一般写法为:1
2
3
4
5local_intr_save(intr_flag);
{
临界区代码
}
local_intr_restore(intr_flag);
但是,在多处理器情况下,这种方法是无法实现互斥的,因为屏蔽了一个CPU的中断,只能阻止本地CPU上的进程不会被中断或调度,并不意味着其他CPU上执行的进程不能执行临界区的代码。所以,开关中断只对单处理器下的互斥操作起作用。
等待队列
在课程中提到用户进程或内核线程可以转入等待状态以等待某个特定事件(比如睡眠,等待子进程结束,等待信号量等),当该事件发生时这些进程能够被再次唤醒。内核实现这一功能的一个底层支撑机制就是等待队列wait_queue,等待队列和每一个事件(睡眠结束、时钟到达、任务完成、资源可用等)联系起来。需要等待事件的进程在转入休眠状态后插入到等待队列中。当事件发生之后,内核遍历相应等待队列,唤醒休眠的用户进程或内核线程,并设置其状态为就绪状态(PROC_RUNNABLE),并将该进程从等待队列中清除。
ucore在kern/sync/{ wait.h, wait.c }中实现了等待项wait结构和等待队列wait queue结构以及相关函数),这是实现ucore中的信号量机制和条件变量机制的基础,进入wait queue的进程会被设为等待状态(PROC_SLEEPING),直到他们被唤醒。
数据结构定义1
2
3
4
5
6
7
8
9
10
11
12typedef struct {
struct proc_struct *proc; //等待进程的指针
uint32_t wakeup_flags; //进程被放入等待队列的原因标记
wait_queue_t *wait_queue; //指向此wait结构所属于的wait_queue
list_entry_t wait_link; //用来组织wait_queue中wait节点的连接
} wait_t;
typedef struct {
list_entry_t wait_head; //wait_queue的队头
} wait_queue_t;
le2wait(le, member) //实现wait_t中成员的指针向wait_t 指针的转化
相关函数说明
与wait和wait queue相关的函数主要分为两层,底层函数是对wait queue的初始化、插入、删除和查找操作,相关函数如下:
wait_init:初始化wait结构,将放入等待队列的原因标记设置为WT_INTERRUPTED,意为可以被打断等待状态1
2
3
4
5
6void
wait_init(wait_t *wait, struct proc_struct *proc) {
wait->proc = proc;
wait->wakeup_flags = WT_INTERRUPTED;
list_init(&(wait->wait_link));
}
wait_in_queue:wait是否在wait queue中1
2
3
4bool
wait_in_queue(wait_t *wait) {
return !list_empty(&(wait->wait_link));
}
wait_queue_init:初始化wait_queue结构1
2
3
4void
wait_queue_init(wait_queue_t *queue) {
list_init(&(queue->wait_head));
}
wait_queue_add:设置当前等待项wait的等待队列,并把wait前插到wait queue中1
2
3
4
5
6void
wait_queue_add(wait_queue_t *queue, wait_t *wait) {
assert(list_empty(&(wait->wait_link)) && wait->proc != NULL);
wait->wait_queue = queue;
list_add_before(&(queue->wait_head), &(wait->wait_link));
}
wait_queue_del:从wait queue中删除wait1
2
3
4
5void
wait_queue_del(wait_queue_t *queue, wait_t *wait) {
assert(!list_empty(&(wait->wait_link)) && wait->wait_queue == queue);
list_del_init(&(wait->wait_link));
}
wait_queue_next:取得wait_queue中wait等待项的后一个链接指针1
2
3
4
5
6
7
8
9wait_t *
wait_queue_next(wait_queue_t *queue, wait_t *wait) {
assert(!list_empty(&(wait->wait_link)) && wait->wait_queue == queue);
list_entry_t *le = list_next(&(wait->wait_link));
if (le != &(queue->wait_head)) {
return le2wait(le, wait_link);
}
return NULL;
}
wait_queue_prev:取得wait_queue中wait等待项的前一个链接指针1
2
3
4
5
6
7
8
9wait_t *
wait_queue_prev(wait_queue_t *queue, wait_t *wait) {
assert(!list_empty(&(wait->wait_link)) && wait->wait_queue == queue);
list_entry_t *le = list_prev(&(wait->wait_link));
if (le != &(queue->wait_head)) {
return le2wait(le, wait_link);
}
return NULL;
}
wait_queue_first:取得wait queue的第一个wait1
2
3
4
5
6
7
8wait_t *
wait_queue_first(wait_queue_t *queue) {
list_entry_t *le = list_next(&(queue->wait_head));
if (le != &(queue->wait_head)) {
return le2wait(le, wait_link);
}
return NULL;
}
wait_queue_last:取得wait queue的最后一个wait1
2
3
4
5
6
7
8wait_t *
wait_queue_last(wait_queue_t *queue) {
list_entry_t *le = list_prev(&(queue->wait_head));
if (le != &(queue->wait_head)) {
return le2wait(le, wait_link);
}
return NULL;
}
bool wait_queue_empty:wait queue是否为空1
2
3
4bool
wait_queue_empty(wait_queue_t *queue) {
return list_empty(&(queue->wait_head));
}
高层函数基于底层函数实现了让进程进入等待队列—wait_current_set,以及从等待队列中唤醒进程—wakeup_wait,相关函数如下:
wait_current_set:进程进入等待队列,当前进程的状态设置成睡眠1
2
3
4
5
6
7
8void
wait_current_set(wait_queue_t *queue, wait_t *wait, uint32_t wait_state) {
assert(current != NULL);
wait_init(wait, current);
current->state = PROC_SLEEPING;
current->wait_state = wait_state;
wait_queue_add(queue, wait);
}
wait_current_del:把与当前进程关联的wait从等待队列queue中删除1
2
3
4
5
6
wakeup_wait:唤醒等待队列上的wait所关联的进程1
2
3
4
5
6
7
8void
wakeup_wait(wait_queue_t *queue, wait_t *wait, uint32_t wakeup_flags, bool del) {
if (del) {
wait_queue_del(queue, wait);
}
wait->wakeup_flags = wakeup_flags;
wakeup_proc(wait->proc);
}
void wakeup_first:唤醒等待队列上第一个的等待的进程1
2
3
4
5
6
7void
wakeup_first(wait_queue_t *queue, uint32_t wakeup_flags, bool del) {
wait_t *wait;
if ((wait = wait_queue_first(queue)) != NULL) {
wakeup_wait(queue, wait, wakeup_flags, del);
}
}
wakeup_queue:唤醒等待队列上的所有等待进程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void
wakeup_queue(wait_queue_t *queue, uint32_t wakeup_flags, bool del) {
wait_t *wait;
if ((wait = wait_queue_first(queue)) != NULL) {
if (del) {
do {
wakeup_wait(queue, wait, wakeup_flags, 1);
} while ((wait = wait_queue_first(queue)) != NULL);
}
else {
do {
wakeup_wait(queue, wait, wakeup_flags, 0);
} while ((wait = wait_queue_next(queue, wait)) != NULL);
}
}
}
信号量
信号量是一种同步互斥机制的实现,普遍存在于现在的各种操作系统内核里。相对于spinlock 的应用对象,信号量的应用对象是在临界区中运行的时间较长的进程。等待信号量的进程需要睡眠来减少占用 CPU 的开销。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20struct semaphore {
int count;
queueType queue;
};
void semWait(semaphore s)
{
s.count--;
if (s.count < 0) {
/* place this process in s.queue */;
/* block this process */;
}
}
void semSignal(semaphore s)
{
s.count++;
if (s.count<= 0) {
/* remove a process P from s.queue */;
/* place process P on ready list */;
}
}
基于上诉信号量实现可以认为,当多个(>1)进程可以进行互斥或同步合作时,一个进程会由于无法满足信号量设置的某条件而在某一位置停止,直到它接收到一个特定的信号(表明条件满足了)。为了发信号,需要使用一个称作信号量的特殊变量。为通过信号量s传送信号,信号量的V操作采用进程可执行原语semSignal(s);为通过信号量s接收信号,信号量的P操作采用进程可执行原语semWait(s);如果相应的信号仍然没有发送,则进程被阻塞或睡眠,直到发送完为止。
ucore中信号量参照上述原理描述,建立在开关中断机制和wait_queue的基础上进行了具体实现。信号量的数据结构定义如下:1
2
3
4typedef struct {
int value; //信号量的当前值
wait_queue_t wait_queue; //信号量对应的等待队列
} semaphore_t;semaphore_t是最基本的记录型信号量(record semaphore)结构,包含了用于计数的整数值value,和一个进程等待队列wait_queue,一个等待的进程会挂在此等待队列上。
在ucore中最重要的信号量操作是P操作函数down(semaphore_t *sem)和V操作函数up(semaphore_t *sem)。但这两个函数的具体实现是__down(semaphore_t *sem, uint32_t wait_state)函数和__up(semaphore_t *sem, uint32_t wait_state)函数,二者的具体实现描述如下:
__down(semaphore_t *sem, uint32_t wait_state, timer_t *timer):具体实现信号量的P操作,首先关掉中断,然后判断当前信号量的value是否大于0。如果是>0,则表明可以获得信号量,故让value减一,并打开中断返回即可;如果不是>0,则表明无法获得信号量,故需要将当前的进程加入到等待队列中,并打开中断,然后运行调度器选择另外一个进程执行。如果被V操作唤醒,则把自身关联的wait从等待队列中删除(此过程需要先关中断,完成后开中断)。
__up(semaphore_t *sem, uint32_t wait_state):具体实现信号量的V操作,首先关中断,如果信号量对应的wait queue中没有进程在等待,直接把信号量的value加一,然后开中断返回;如果有进程在等待且进程等待的原因是semophore设置的,则调用wakeup_wait函数将waitqueue中等待的第一个wait删除,且把此wait关联的进程唤醒,最后开中断返回。
对照信号量的原理性描述和具体实现,可以发现二者在流程上基本一致,只是具体实现采用了关中断的方式保证了对共享资源的互斥访问,通过等待队列让无法获得信号量的进程睡眠等待。另外,我们可以看出信号量的计数器value具有有如下性质:
- value>0,表示共享资源的空闲数
- vlaue<0,表示该信号量的等待队列里的进程数
- value=0,表示等待队列为空
管程和条件变量
原理回顾
引入了管程是为了将对共享资源的所有访问及其所需要的同步操作集中并封装起来。Hansan为管程所下的定义:“一个管程定义了一个数据结构和能为并发进程所执行(在该数据结构上)的一组操作,这组操作能同步进程和改变管程中的数据”。有上述定义可知,管程由四部分组成:
- 管程内部的共享变量;
- 管程内部的条件变量;
- 管程内部并发执行的进程;
- 对局部于管程内部的共享数据设置初始值的语句。
局限在管程中的数据结构,只能被局限在管程的操作过程所访问,任何管程之外的操作过程都不能访问它;另一方面,局限在管程中的操作过程也主要访问管程内的数据结构。由此可见,管程相当于一个隔离区,它把共享变量和对它进行操作的若干个过程围了起来,所有进程要访问临界资源时,都必须经过管程才能进入,而管程每次只允许一个进程进入管程,从而需要确保进程之间互斥。
但在管程中仅仅有互斥操作是不够用的。进程可能需要等待某个条件Cond为真才能继续执行。如果采用忙等(busy waiting)方式:1
while not( Cond ) do {}
在单处理器情况下,将会导致所有其它进程都无法进入临界区使得该条件Cond为真,该管程的执行将会发生死锁。为此,可引入条件变量(Condition Variables,简称CV)。一个条件变量CV可理解为一个进程的等待队列,队列中的进程正等待某个条件Cond变为真。每个条件变量关联着一个条件,如果条件Cond不为真,则进程需要等待,如果条件Cond为真,则进程可以进一步在管程中执行。需要注意当一个进程等待一个条件变量CV(即等待Cond为真),该进程需要退出管程,这样才能让其它进程可以进入该管程执行,并进行相关操作,比如设置条件Cond为真,改变条件变量的状态,并唤醒等待在此条件变量CV上的进程。因此对条件变量CV有两种主要操作:
- wait_cv: 被一个进程调用,以等待断言Pc被满足后该进程可恢复执行. 进程挂在该条件变量上等待时,不被认为是占用了管程。
- signal_cv:被一个进程调用,以指出断言Pc现在为真,从而可以唤醒等待断言Pc被满足的进程继续执行。
“哲学家就餐”实例
有了互斥和信号量支持的管程就可用用了解决各种同步互斥问题。“用管程解决哲学家就餐问题”如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32monitor dp
{
enum {THINKING, HUNGRY, EATING} state[5];
condition self[5];
void pickup(int i) {
state[i] = HUNGRY;
test(i);
if (state[i] != EATING)
self[i].wait_cv();
}
void putdown(int i) {
state[i] = THINKING;
test((i + 4) % 5);
test((i + 1) % 5);
}
void test(int i) {
if ((state[(i + 4) % 5] != EATING) &&
(state[i] == HUNGRY) &&
(state[(i + 1) % 5] != EATING)) {
state[i] = EATING;
self[i].signal_cv();
}
}
initialization code() {
for (int i = 0; i < 5; i++)
state[i] = THINKING;
}
}
关键数据结构
虽然大部分教科书上说明管程适合在语言级实现比如java等高级语言,没有提及在采用C语言的OS中如何实现。下面我们将要尝试在ucore中用C语言实现采用基于互斥和条件变量机制的管程基本原理。
ucore中的管程机制是基于信号量和条件变量来实现的。ucore中的管程的数据结构monitor_t定义如下:1
2
3
4
5
6
7
8
9typedef struct monitor{
semaphore_t mutex; // the mutex lock for going into the routines in monitor, should be initialized to 1
// the next semaphore is used to
// (1) procs which call cond_signal funciton should DOWN next sema after UP cv.sema
// OR (2) procs which call cond_wait funciton should UP next sema before DOWN cv.sema
semaphore_t next;
int next_count; // the number of of sleeped procs which cond_signal funciton
condvar_t *cv; // the condvars in monitor
} monitor_t;
管程中的成员变量mutex是一个二值信号量,是实现每次只允许一个进程进入管程的关键元素,确保了互斥访问性质。管程中的条件变量cv通过执行wait_cv,会使得等待某个条件Cond为真的进程能够离开管程并睡眠,且让其他进程进入管程继续执行;而进入管程的某进程设置条件Cond为真并执行signal_cv时,能够让等待某个条件Cond为真的睡眠进程被唤醒,从而继续进入管程中执行。
注意:管程中的成员变量信号量next和整型变量next_count是配合进程对条件变量cv的操作而设置的,这是由于发出signal_cv的进程A会唤醒由于wait_cv而睡眠的进程B,由于管程中只允许一个进程运行,所以进程B执行会导致唤醒进程B的进程A睡眠,直到进程B离开管程,进程A才能继续执行,这个同步过程是通过信号量next完成的;而next_count表示了由于发出singal_cv而睡眠的进程个数。
管程中的条件变量的数据结构condvar_t定义如下:1
2
3
4
5typedef struct condvar{
semaphore_t sem; // the sem semaphore is used to down the waiting proc, and the signaling proc should up the waiting proc
int count; // the number of waiters on condvar
monitor_t * owner; // the owner(monitor) of this condvar
} condvar_t;
条件变量的定义中也包含了一系列的成员变量,信号量sem用于让发出wait_cv操作的等待某个条件Cond为真的进程睡眠,而让发出signal_cv操作的进程通过这个sem来唤醒睡眠的进程。count表示等在这个条件变量上的睡眠进程的个数。owner表示此条件变量的宿主是哪个管程。
条件变量的signal和wait的设计
理解了数据结构的含义后,我们就可以开始管程的设计实现了。ucore设计实现了条件变量wait_cv操作和signal_cv操作对应的具体函数,即cond_wait函数和cond_signal函数,此外还有cond_init初始化函数。
首先来看wait_cv的原理实现:1
2
3
4
5
6
7cv.count++;
if(monitor.next_count > 0)
sem_signal(monitor.next);
else
sem_signal(monitor.mutex);
sem_wait(cv.sem);
cv.count -- ;
对照着可分析出cond_wait函数的具体执行过程。可以看出如果进程A执行了cond_wait函数,表示此进程等待某个条件Cond不为真,需要睡眠。因此表示等待此条件的睡眠进程个数cv.count要加一。接下来会出现两种情况。
情况一:如果monitor.next_count如果大于0,表示有大于等于1个进程执行cond_signal函数且睡了,就睡在了monitor.next信号量上(假定这些进程挂在monitor.next信号量相关的等待队列S上),因此需要唤醒等待队列S中的一个进程B;然后进程A睡在cv.sem上。如果进程A醒了,则让cv.count减一,表示等待此条件变量的睡眠进程个数少了一个,可继续执行了!
这里隐含这一个现象,即某进程A在时间顺序上先执行了cond_signal,而另一个进程B后执行了cond_wait,这会导致进程A没有起到唤醒进程B的作用。
问题: 在cond_wait有sem_signal(mutex),但没有看到哪里有sem_wait(mutex),这好像没有成对出现,是否是错误的? 答案:其实在管程中的每一个函数的入口处会有wait(mutex),这样二者就配好对了。
情况二:如果monitor.next_count如果小于等于0,表示目前没有进程执行cond_signal函数且睡着了,那需要唤醒的是由于互斥条件限制而无法进入管程的进程,所以要唤醒睡在monitor.mutex上的进程。然后进程A睡在cv.sem上,如果睡醒了,则让cv.count减一,表示等待此条件的睡眠进程个数少了一个,可继续执行了!
然后来看signal_cv的原理实现:1
2
3
4
5
6if( cv.count > 0) {
monitor.next_count ++;
sem_signal(cv.sem);
sem_wait(monitor.next);
monitor.next_count -- ;
}
对照着可分析出cond_signal函数的具体执行过程。首先进程B判断cv.count,如果不大于0,则表示当前没有执行cond_wait而睡眠的进程,因此就没有被唤醒的对象了,直接函数返回即可;如果大于0,这表示当前有执行cond_wait而睡眠的进程A,因此需要唤醒等待在cv.sem上睡眠的进程A。由于只允许一个进程在管程中执行,所以一旦进程B唤醒了别人(进程A),那么自己就需要睡眠。故让monitor.next_count加一,且让自己(进程B)睡在信号量monitor.next上。如果睡醒了,这让monitor.next_count减一。
管程中函数的入口出口设计
为了让整个管程正常运行,还需在管程中的每个函数的入口和出口增加相关操作,即:1
2
3
4
5
6
7
8
9
10
11function_in_monitor (…)
{
sem.wait(monitor.mutex);
//-----------------------------
the real body of function;
//-----------------------------
if(monitor.next_count > 0)
sem_signal(monitor.next);
else
sem_signal(monitor.mutex);
}
这样带来的作用有两个,(1)只有一个进程在执行管程中的函数。(2)避免由于执行了cond_signal函数而睡眠的进程无法被唤醒。对于第二点,如果进程A由于执行了cond_signal函数而睡眠(这会让monitor.next_count大于0,且执行sem_wait(monitor.next)),则其他进程在执行管程中的函数的出口,会判断monitor.next_count是否大于0,如果大于0,则执行sem_signal(monitor.next),从而执行了cond_signal函数而睡眠的进程被唤醒。上诉措施将使得管程正常执行。
练习1:理解内核级信号量的实现和基于内核级信号量的哲学家就餐问题
首先把trap.c中处理时钟中断的时候调用的sched_class_proc_tick函数替换为run_timer_list函数(后者中已经包括了前者),用于支持定时器机制;
在sem.c定义了内核级信号量机制的函数,先来学习这个文件。sem.h中是定义,这个semphore_t结构体就是信号量的定义了。里边有一个value和一个队列。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
typedef struct {
int value;
wait_queue_t wait_queue;
} semaphore_t;
void sem_init(semaphore_t *sem, int value);
void up(semaphore_t *sem);
void down(semaphore_t *sem);
bool try_down(semaphore_t *sem);
sem_init对信号量进行初始化,信号量包括了一个整型数值变量和一个等待队列,该函数将该变量设置为指定的初始值(有几个资源),并且将等待队列初始化即可;wait_queue_init是把这个队列初始化。1
2
3
4
5
6
7
8
9
10void
sem_init(semaphore_t *sem, int value) {
sem->value = value;
wait_queue_init(&(sem->wait_queue));
}
void
wait_queue_init(wait_queue_t *queue) {
list_init(&(queue->wait_head));
}
__up: 这个函数是释放一个该信号量对应的资源,如果它的等待队列中没有等待的请求,则直接把资源数加一,返回即可;如果在等待队列上有等在这个信号量上的进程,则调用wakeup_wait将其唤醒执行;在函数中禁用了中断,保证了操作的原子性,函数中操作的具体流程为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19static __noinline void __up(semaphore_t *sem, uint32_t wait_state) {
bool intr_flag;
local_intr_save(intr_flag);
{
wait_t *wait;
//查询等待队列是否为空
if ((wait = wait_queue_first(&(sem->wait_queue))) == NULL) {
sem->value ++;
//如果是空的话,没有等待的线程,给整型变量加1;
}
else {
//如果等待队列非空,有等待的线程,取出其中的一个进程唤醒;
assert(wait->proc->wait_state == wait_state);
wakeup_wait(&(sem->wait_queue), wait, wait_state, 1);
//这个函数找到等待的线程并唤醒
}
}
local_intr_restore(intr_flag);
}
__down: 是原理课中的P操作,表示请求一个该信号量对应的资源,同样禁用中断,保证原子性。首先查询整型变量看是否大于0,如果大于0则表示存在可分配的资源,整型变量减1,直接返回;如果整型变量小于等于0,表示没有可用的资源,那么当前进程的需求得不到满足,因此在wait_current_set中将其状态改为SLEEPING态,然后调用wait_queue_add将其挂到对应信号量的等待队列中,调用schedule函数进行调度,让出CPU,在资源得到满足,重新被唤醒之后,将自身从等待队列上删除掉;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34static __noinline uint32_t __down(semaphore_t *sem, uint32_t wait_state) {
bool intr_flag;
local_intr_save(intr_flag);
if (sem->value > 0) {
sem->value --;
local_intr_restore(intr_flag);
return 0;
}
wait_t __wait, *wait = &__wait;
wait_current_set(&(sem->wait_queue), wait, wait_state);
// 挂起这个等待线程并加入等待队列
local_intr_restore(intr_flag);
schedule();
local_intr_save(intr_flag);
wait_current_del(&(sem->wait_queue), wait);
local_intr_restore(intr_flag);
// 有可能当前线程被唤醒的原因跟之前等待的原因不一致
// 要把原因返回,由高层判断是否是合理状态。
if (wait->wakeup_flags != wait_state) {
return wait->wakeup_flags;
}
return 0;
}
void
wait_current_set(wait_queue_t *queue, wait_t *wait, uint32_t wait_state) {
assert(current != NULL);
wait_init(wait, current);
current->state = PROC_SLEEPING;
current->wait_state = wait_state;
wait_queue_add(queue, wait);
}try_down: 简化版的P操作,如果资源数大于0则分配,资源数小于0也不进入等待队列,即使获取资源失败也不会堵塞当前进程;1
2
3
4
5
6
7
8
9bool try_down(semaphore_t *sem) {
bool intr_flag, ret = 0;
local_intr_save(intr_flag);
if (sem->value > 0) {
sem->value --, ret = 1;
}
local_intr_restore(intr_flag);
return ret;
}
请在实验报告中给出给用户态进程/线程提供信号量机制的设计方案,并比较说明给内核级提供信号量机制的异同。
用于保证操作原子性的禁用中断机制、以及CPU提供的Test and Set指令机制都只能在用户态下运行,为了方便起见,可以将信号量机制的实现放在OS中来提供,然后使用系统调用的方法统一提供出若干个管理信号量的系统调用,分别如下所示:
- 申请创建一个信号量的系统调用,可以指定初始值,返回一个信号量描述符(类似文件描述符);
- 将指定信号量执行P操作;
- 将指定信号量执行V操作;
- 将指定信号量释放掉;
给内核级线程提供信号量机制和给用户态进程/线程提供信号量机制的异同点在于:
相同点:
提供信号量机制的代码实现逻辑是相同的;
不同点:
由于实现原子操作的中断禁用、Test and Set指令等均需要在内核态下运行,因此提供给用户态进程的信号量机制是通过系统调用来实现的,而内核级线程只需要直接调用相应的函数就可以了;
练习2: 完成内核级条件变量和基于内核级条件变量的哲学家就餐问题
首先掌握管程机制,然后基于信号量实现完成条件变量实现,然后用管程机制实现哲学家就餐问题的解决方案(基于条件变量)。
In [OS CONCEPT] 7.7 section, the accurate define and approximate implementation of MONITOR was introduced.
通常,管程是一种语言结构,编译器通常会强制执行互斥。 将其与信号量进行比较,信号量通常是OS构造。
- DEFNIE & CHARACTERISTIC:
- 管程是组合在一起的过程、变量和数据结构的集合。
- 进程可以调用监视程序但无法访问内部数据结构。
- 管程中一次只能有一个进程处于活动状态。
- 条件变量允许阻塞和解除阻塞。
- cv.wait() 阻塞一个进程
- 该过程等待条件变量cv。
- cv.signal() (也视为 cv.notify) 解除一个等待条件变量cv的进程的阻塞状态。
发生这种情况时,我们仍然需要在管程中只有一个进程处于活动状态。 这可以通过以下几种方式完成:- 在某些系统上,旧进程(执行信号的进程)离开管程,新进程进入
- 在某些系统上,信号必须是管程内执行的最后一个语句。
- 在某些系统上,旧进程将阻塞,直到管程再次可用。
- 在某些系统上,新进程(未被信号阻止的进程)将保持阻塞状态,直到管程再次可用。
- cv.wait() 阻塞一个进程
- 如果在没有人等待的情况下发出条件变量信号,则信号丢失。 将此与信号量进行比较,其中信号将允许将来执行等待的进程无阻塞。
- 不应该将条件变量视为传统意义上的变量。
- 它没有价值。
- 将其视为OOP意义上的对象。
- 它有两种方法,wait和signal来操纵调用过程。
- 定义如下,mutex保证对操作的互斥访问,这些访问主要是对共享变量的访问,所以需要互斥;cv是条件变量。
1 | monitor mt { |
实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13typedef struct condvar{
semaphore_t sem; // the sem semaphore is used to down the waiting proc,
// and the signaling proc should up the waiting proc
int count; // the number of waiters on condvar
monitor_t * owner; // the owner(monitor) of this condvar
} condvar_t;
typedef struct monitor{
semaphore_t mutex; // the mutex lock for going into the routines in monitor, should be initialized to 1 semaphore_t next; // the next semaphore is used to down the signaling proc itself,
// and the other OR wakeuped waiting proc should wake up the sleeped signaling proc.
int next_count; // the number of of sleeped signaling proc
condvar_t *cv; // the condvars in monitor
} monitor_t;
这是一个管程里的操作,首先在操作开始和结束有wait和signal,保证对中间的访问是互斥的,条件不满足则执行wait执行等待。特殊信号量next和后边的if-else是有对应关系的。1
2
3
4
5
6
7
8
9
10
11--------routines in monitor---------------
routineA_in_mt () {
wait(mt.mutex);
...
real body of routineA
...
if(next_count>0)
signal(mt.next);
else
signal(mt.mutex);
}
条件变量是管程的重要组成部分。
cond_wait: 一个条件得不到满足,则睡眠,如果这个条件得到满足,则另一个进程调用signal唤醒这个进程。该函数的功能为将当前进程等待在指定信号量上。等待队列的计数加1,然后释放管程的锁或者唤醒一个next上的进程来释放锁(否则会造成管程被锁死无法继续访问,同时这个操作不能和前面的等待队列计数加1的操作互换顺序,要不不能保证共享变量访问的互斥性),然后把自己等在条件变量的等待队列上,直到有signal信号将其唤醒,正常退出函数;1
2
3
4
5
6
7
8
9
10--------condvar wait/signal---------------
cond_wait (cv) {
cv.count ++;
if(mt.next_count>0)
signal(mt.next)
else
signal(mt.mutex);
wait(cv.sem);//由于条件不满足,则wait,这里时cv的sem
cv.count --;
}
实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Suspend calling thread on a condition variable waiting for condition Atomically unlocks
// mutex and suspends calling thread on conditional variable after waking up locks mutex. Notice: mp is mutex semaphore for monitor's procedures
void
cond_wait (condvar_t *cvp) {
//LAB7 EXERCISE1: YOUR CODE
cprintf("cond_wait begin: cvp %x, cvp->count %d, cvp->owner->next_count %d\n", cvp, cvp->count, cvp->owner
->next_count);
cvp->count ++;
if (cvp->owner->next_count > 0) {
up(&cvp->owner->next);
} else {
up(&cvp->owner->mutex);
}
down(&cvp->sem);
cvp->count --;
cprintf("cond_wait end: cvp %x, cvp->count %d, cvp->owner->next_count %d\n", cvp, cvp->count, cvp->owner->
next_count);
}
cond_signal: 将指定条件变量上等待队列中的一个线程进行唤醒,并且将控制权转交给这个进程。判断当前的条件变量的等待队列是否大于0,即队列上是否有正在等待的进程,如果没有则不需要进行任何操作;如果有正在等待的进程,则将其中的一个唤醒,这里的等待队列是使用了一个信号量来进行实现的,由于信号量中已经包括了对等待队列的操作,因此要进行唤醒只需要对信号量执行up操作即可;接下来当前进程为了将控制权转交给被唤醒的进程,将自己等待到了这个条件变量所述的管程的next信号量上,这样的话就可以切换到被唤醒的进程。
有线程处于等待时,它的cv.count大于0,会有进一步的操作,唤醒其他进程,自身处于睡眠状态。上边的wait如果A进程中monitor.next_count大于0,那么可以唤醒monitor.next,正好与这里的wait对应。
如果cv.count大于0,有线程正在等待,把线程A从等待队列中移除,并唤醒线程A。在A的real_body之后的那个signal是唤醒B的实际函数。这里的next_count是发出条件变量signal的线程的个数。当B发出了条件变量signal操作,且把自身置成睡眠状态,使得被唤醒的A有机会在它自己退出的时候唤醒B。这是因为A和B都是在管程中执行的函数,都会涉及到对共享变量的访问,但是只允许一个进程对共享变量访问,保证互斥!
1 | cond_signal(cv) { |
实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// Unlock one of threads waiting on the condition variable.
void
cond_signal (condvar_t *cvp) {
//LAB7 EXERCISE1: YOUR CODE
cprintf("cond_signal begin: cvp %x, cvp->count %d, cvp->owner->next_count %d\n", cvp, cvp->count, cvp->owner
->next_count);
if(cvp->count>0) {
cvp->owner->next_count ++;
up(&cvp->sem);
down(&cvp->owner->next);
cvp->owner->next_count --;
}
cprintf("cond_signal end: cvp %x, cvp->count %d, cvp->owner->next_count %d\n", cvp, cvp->count, cvp->owner->
next_count);
}
哲学家就餐问题:
phi_take_forks_condvar表示指定的哲学家尝试获得自己所需要进餐的两把叉子,如果不能获得则阻塞。首先给管程上锁,将哲学家的状态修改为HUNGER,判断当前哲学家是否可以获得足够的资源进行就餐,即判断与之相邻的哲学家是否正在进餐;如果能够进餐,将自己的状态修改成EATING,然后释放锁,离开管程即可;如果不能进餐,等待在自己对应的条件变量上,等待相邻的哲学家释放资源的时候将自己唤醒;
最终具体的代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void phi_take_forks_condvar(int i) {
//--------into routine in monitor--------------
// LAB7 EXERCISE1: YOUR CODE
// I am hungry
// try to get fork
//--------leave routine in monitor--------------
down(&(mtp->mutex));
state_condvar[i]=HUNGRY;
if(state_condvar[(i+4)%5]!=EATING && state_condvar[(i+1)%5]!=EATING){
state_condvar[i]=EATING;
}
else
{
cprintf("phi_take_forks_condvar: %d didn’t get fork and will wait\n", i);
cond_wait(mtp->cv + i);
}
if(mtp->next_count>0)
up(&(mtp->next));
else
up(&(mtp->mutex));
}
phi_put_forks_condvar函数则是释放当前哲学家占用的叉子,并且唤醒相邻的因为得不到资源而进入等待的哲学家。首先获取管程的锁,将自己的状态修改成THINKING,检查相邻的哲学家是否在自己释放了叉子的占用之后满足了进餐的条件,如果满足,将其从等待中唤醒(使用cond_signal);释放锁,离开管程;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void phi_put_forks_condvar(int i) {
//--------into routine in monitor--------------
// LAB7 EXERCISE1: YOUR CODE
// I ate over
// test left and right neighbors
//--------leave routine in monitor--------------
down(&(mtp->mutex));
state_condvar[i] = THINKING;
cprintf("phi_put_forks_condvar: %d finished eating\n", i);
phi_test_condvar((i + N - 1) % N);
phi_test_condvar((i + 1) % N);
if(mtp->next_count>0)
up(&(mtp->next));
else
up(&(mtp->mutex));
}
phi_test_sema检查了第i个哲学家左右两边的人是不是处于EATING状态,如果都不是的话,而且第i个人又是HUNGRY的,则唤醒第i个。1
2
3
4
5
6
7
8
9
10
11
12#define LEFT (i-1+N)%N /* i的左邻号码 */
#define RIGHT (i+1)%N /* i的右邻号码 */
void phi_test_sema(i) /* i:哲学家号码从0到N-1 */
{
if(state_sema[i]==HUNGRY&&state_sema[LEFT]!=EATING
&&state_sema[RIGHT]!=EATING)
{
state_sema[i]=EATING;
up(&s[i]);
}
}
请在实验报告中给出给用户态进程/线程提供条件变量机制的设计方案,并比较说明给内核级 提供条件变量机制的异同。
本实验中管程的实现中互斥访问的保证是完全基于信号量的,如果根据上文中的说明使用系统调用实现用户态的信号量的实现机制,那么就可以按照相同的逻辑在用户态实现管程机制和条件变量机制;
实验八
实验目的
通过完成本次实验,希望能达到以下目标:
- 了解基本的文件系统系统调用的实现方法;
- 了解一个基于索引节点组织方式的Simple FS文件系统的设计与实现;
- 了解文件系统抽象层-VFS的设计与实现;
实验内容
本次实验涉及的是文件系统,通过分析了解ucore文件系统的总体架构设计,完善读写文件操作,从新实现基于文件系统的执行程序机制(即改写do_execve),从而可以完成执行存储在磁盘上的文件和实现文件读写等功能。
文件系统设计与实现
ucore 文件系统总体介绍
UNIX提出了四个文件系统抽象概念:文件(file)、目录项(dentry)、索引节点(inode)和安装点(mount point)
- 文件:文件中的内容可理解为是一有序字节,文件有一个方便应用程序识别的文件名称(也称文件路径名)。典型的文件操作有读、写、创建和删除等。
- 目录项:目录项不是目录(又称文件路径),而是目录的组成部分。在UNIX中目录被看作一种特定的文件,而目录项是文件路径中的一部分。如一个文件路径名是“/test/testfile”,则包含的目录项为:
- 根目录“/”,
- 目录“test”和文件“testfile”
- 这三个都是目录项。
- 一般而言,目录项包含目录项的名字(文件名或目录名)和目录项的索引节点位置。
- 索引节点:UNIX将文件的相关元数据信息(如访问控制权限、大小、拥有者、创建时间、数据内容等等信息)存储在一个单独的数据结构中,该结构被称为索引节点。
- 安装点:在UNIX中,文件系统被安装在一个特定的文件路径位置,这个位置就是安装点。所有的已安装文件系统都作为根文件系统树中的叶子出现在系统中。
ucore模仿了UNIX的文件系统设计,ucore的文件系统架构主要由四部分组成:
- 通用文件系统访问接口层:该层提供了一个从用户空间到文件系统的标准访问接口。这一层访问接口让应用程序能够通过一个简单的接口获得ucore内核的文件系统服务。
- 文件系统抽象层:向上提供一个一致的接口给内核其他部分(文件系统相关的系统调用实现模块和其他内核功能模块)访问。向下提供一个同样的抽象函数指针列表和数据结构屏蔽不同文件系统的实现细节。
- Simple FS文件系统层:一个基于索引方式的简单文件系统实例。向上通过各种具体函数实现以对应文件系统抽象层提出的抽象函数。向下访问外设接口
- 外设接口层:向上提供device访问接口屏蔽不同硬件细节。向下实现访问各种具体设备驱动的接口,比如disk设备接口/串口设备接口/键盘设备接口等。
假如应用程序操作文件(打开/创建/删除/读写):
- 通过文件系统的通用文件系统访问接口层为用户空间提供的访问接口进入文件系统内部;
- 文件系统抽象层把访问请求转发给某一具体文件系统(比如SFS文件系统);
- 具体文件系统(Simple FS文件系统层)把应用程序的访问请求转化为对磁盘上的block的处理请求,并通过外设接口层交给磁盘驱动例程来完成具体的磁盘操作。
- 通用文件系统访问接口
- 文件系统相关用户库
- write::usr/libs/file.c
- 用户态文件系统相关系统调用访问接口
- sys_write/sys_call::/usr/libs/syscall.c
- 内核态文件系统相关系统调用实现
- sys_write::/kern/syscall/syscall.c
- 文件系统相关用户库
- 文件系统抽象层VFS
- dir接口
- file接口
- inode接口
- etc…
- sysfile_write::kern/fs/sysfile.c
- file_write::/kern/fs/file.c
- vop_write::/kern/fs/vfs/inode.h
- Simple FS文件系统实现
- sfs的inode实现
- sfs的外设访问接口
- sfs_write::kern/fs/sfs/sfs_inode.c
- sfs_wbuf::/kern/fs/sfs/sfs_io.c
- 文件系统IO设备接口
- device访问接口
- stdin/stdout访问接口
- etc…
- dop_io::/kern/fs/devs/dev.h
- disk0_io::/kern/fs/devs/dev_disk0.c
- 硬盘驱动、串口驱动
- ide_write_secs::/kern/driver/ide.c
ucore文件系统总体结构
从ucore操作系统不同的角度来看,ucore中的文件系统架构包含四类主要的数据结构, 它们分别是:
- 超级块(SuperBlock),它主要从文件系统的全局角度描述特定文件系统的全局信息。它的作用范围是整个OS空间。
- 索引节点(inode):它主要从文件系统的单个文件的角度描述了文件的各种属性和数据所在位置。它的作用范围是整个OS空间。
- 目录项(dentry):它主要从文件系统的文件路径的角度描述了文件路径中的一个特定的目录项(注:一系列目录项形成目录/文件路径)。它的作用范围是整个OS空间。
- 对于SFS而言,inode(具体为struct sfs_disk_inode)对应于物理磁盘上的具体对象,
- dentry(具体为struct sfs_disk_entry)是一个内存实体,其中的ino成员指向对应的inode number,另外一个成员是file name(文件名).
- 文件(file),它主要从进程的角度描述了一个进程在访问文件时需要了解的文件标识,文件读写的位置,文件引用情况等信息。它的作用范围是某一具体进程。
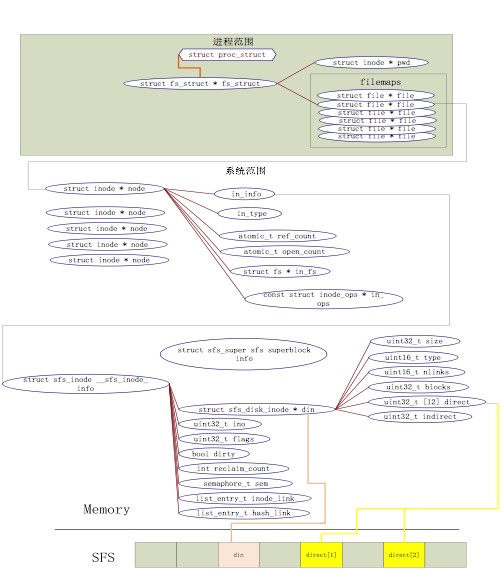
通用文件系统访问接口
文件和目录相关用户库函数
在文件操作方面,最基本的相关函数是open、close、read、write。
- 在读写一个文件之前,首先要用open系统调用将其打开。
- open的第一个参数指定文件的路径名,可使用绝对路径名;
- 第二个参数指定打开的方式,可设置为O_RDONLY、O_WRONLY、O_RDWR,分别表示只读、只写、可读可写。
- 在打开一个文件后,就可以使用它返回的文件描述符fd对文件进行相关操作。
- 在使用完一个文件后,还要用close系统调用把它关闭,其参数就是文件描述符fd。这样它的文件描述符就可以空出来,给别的文件使用。
- 读写文件内容的系统调用是read和write。read系统调用有三个参数:
- 一个指定所操作的文件描述符,一个指定读取数据的存放地址,最后一个指定读多少个字节。在C程序中调用该系统调用的方法如下:
count = read(filehandle, buffer, nbytes);。 - 该系统调用会把实际读到的字节数返回给count变量。在正常情形下这个值与nbytes相等,但有时可能会小一些。例如,在读文件时碰上了文件结束符,从而提前结束此次读操作。
- 一个指定所操作的文件描述符,一个指定读取数据的存放地址,最后一个指定读多少个字节。在C程序中调用该系统调用的方法如下:
对于目录而言,最常用的操作是跳转到某个目录,这里对应的用户库函数是chdir。然后就需要读目录的内容了,即列出目录中的文件或目录名,这在处理上与读文件类似,即需要:通过opendir函数打开目录,通过readdir来获取目录中的文件信息,读完后还需通过closedir函数来关闭目录。由于在ucore中把目录看成是一个特殊的文件,所以opendir和closedir实际上就是调用与文件相关的open和close函数。只有readdir需要调用获取目录内容的特殊系统调用sys_getdirentry。而且这里没有写目录这一操作。在目录中增加内容其实就是在此目录中创建文件,需要用到创建文件的函数。
文件和目录访问相关系统调用
与文件相关的open、close、read、write用户库函数对应的是sys_open、sys_close、sys_read、sys_write四个系统调用接口。与目录相关的readdir用户库函数对应的是sys_getdirentry系统调用。这些系统调用函数接口将通过syscall函数来获得ucore的内核服务。当到了ucore内核后,在调用文件系统抽象层的file接口和dir接口。
文件系统抽象层 - VFS
文件系统抽象层是把不同文件系统的对外共性接口提取出来,形成一个函数指针数组,这样,通用文件系统访问接口层只需访问文件系统抽象层,而不需关心具体文件系统的实现细节和接口。
file & dir接口
file&dir接口层定义了进程在内核中直接访问的文件相关信息,这定义在file数据结构中,具体描述如下:1
2
3
4
5
6
7
8
9
10
11struct file {
enum {
FD_NONE, FD_INIT, FD_OPENED, FD_CLOSED,
} status; //访问文件的执行状态
bool readable; //文件是否可读
bool writable; //文件是否可写
int fd; //文件在filemap中的索引值
off_t pos; //访问文件的当前位置
struct inode *node; //该文件对应的内存inode指针
int open_count; //打开此文件的次数
};
而在kern/process/proc.h中的proc_struct结构中描述了进程访问文件的数据接口files_struct,其数据结构定义如下:1
2
3
4
5
6struct files_struct {
struct inode *pwd; //进程当前执行目录的内存inode指针
struct file *fd_array; //进程打开文件的数组
atomic_t files_count; //访问此文件的线程个数
semaphore_t files_sem; //确保对进程控制块中fs_struct的互斥访问
};
当创建一个进程后,该进程的files_struct将会被初始化或复制父进程的files_struct。当用户进程打开一个文件时,将从fd_array数组中取得一个空闲file项,然后会把此file的成员变量node指针指向一个代表此文件的inode的起始地址。
inode 接口
index node是位于内存的索引节点,它是VFS结构中的重要数据结构,因为它实际负责把不同文件系统的特定索引节点信息(甚至不能算是一个索引节点)统一封装起来,避免了进程直接访问具体文件系统。其定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14struct inode {
union { //包含不同文件系统特定inode信息的union成员变量
struct device __device_info; //设备文件系统内存inode信息
struct sfs_inode __sfs_inode_info; //SFS文件系统内存inode信息
} in_info;
enum {
inode_type_device_info = 0x1234,
inode_type_sfs_inode_info,
} in_type; //此inode所属文件系统类型
atomic_t ref_count; //此inode的引用计数
atomic_t open_count; //打开此inode对应文件的个数
struct fs *in_fs; //抽象的文件系统,包含访问文件系统的函数指针
const struct inode_ops *in_ops; //抽象的inode操作,包含访问inode的函数指针
};
在inode中,有一成员变量为in_ops,这是对此inode的操作函数指针列表,其数据结构定义如下:1
2
3
4
5
6
7
8
9
10
11struct inode_ops {
unsigned long vop_magic;
int (*vop_open)(struct inode *node, uint32_t open_flags);
int (*vop_close)(struct inode *node);
int (*vop_read)(struct inode *node, struct iobuf *iob);
int (*vop_write)(struct inode *node, struct iobuf *iob);
int (*vop_getdirentry)(struct inode *node, struct iobuf *iob);
int (*vop_create)(struct inode *node, const char *name, bool excl, struct inode **node_store);
int (*vop_lookup)(struct inode *node, char *path, struct inode **node_store);
……
};
参照上面对SFS中的索引节点操作函数的说明,可以看出inode_ops是对常规文件、目录、设备文件所有操作的一个抽象函数表示。对于某一具体的文件系统中的文件或目录,只需实现相关的函数,就可以被用户进程访问具体的文件了,且用户进程无需了解具体文件系统的实现细节。
Simple FS 文件系统
ucore内核把所有文件都看作是字节流,任何内部逻辑结构都是专用的,由应用程序负责解释。但是ucore区分文件的物理结构。ucore目前支持如下几种类型的文件:
- 常规文件:文件中包括的内容信息是由应用程序输入。SFS文件系统在普通文件上不强加任何内部结构,把其文件内容信息看作为字节。
- 目录:包含一系列的entry,每个entry包含文件名和指向与之相关联的索引节点(index node)的指针。目录是按层次结构组织的。
- 链接文件:实际上一个链接文件是一个已经存在的文件的另一个可选择的文件名。
- 设备文件:不包含数据,但是提供了一个映射物理设备(如串口、键盘等)到一个文件名的机制。可通过设备文件访问外围设备。
- 管道:管道是进程间通讯的一个基础设施。管道缓存了其输入端所接受的数据,以便在管道输出端读的进程能一个先进先出的方式来接受数据。
SFS文件系统中目录和常规文件具有共同的属性,而这些属性保存在索引节点中。SFS通过索引节点来管理目录和常规文件,索引节点包含操作系统所需要的关于某个文件的关键信息,比如文件的属性、访问许可权以及其它控制信息都保存在索引节点中。可以有多个文件名可指向一个索引节点。
文件系统的布局
文件系统通常保存在磁盘上。在本实验中,第三个磁盘(即disk0,前两个磁盘分别是ucore.img和swap.img)用于存放一个SFS文件系统(Simple Filesystem)。通常文件系统中,磁盘的使用是以扇区(Sector)为单位的,但是为了实现简便,SFS 中以 block (4K,与内存 page 大小相等)为基本单位。
SFS文件系统的布局如下图所示。superblock -> root-dir inode -> freemap -> inode/file_data/dir_data_blocks
第0个块(4K)是超级块(superblock),它包含了关于文件系统的所有关键参数,当计算机被启动或文件系统被首次接触时,超级块的内容就会被装入内存。其定义如下:1
2
3
4
5
6struct sfs_super {
uint32_t magic; /* magic number, should be SFS_MAGIC */
uint32_t blocks; /* # of blocks in fs */
uint32_t unused_blocks; /* # of unused blocks in fs */
char info[SFS_MAX_INFO_LEN + 1]; /* infomation for sfs */
};
可以看到,包含:
- 成员变量魔数magic,其值为
0x2f8dbe2a,内核通过它来检查磁盘镜像是否是合法的 SFS img; - 成员变量blocks记录了SFS中所有block的数量,即 img 的大小;
- 成员变量unused_block记录了SFS中还没有被使用的block的数量;
- 成员变量info包含了字符串”simple file system”。
第1个块放了一个root-dir的inode,用来记录根目录的相关信息。有关inode还将在后续部分介绍。通过这个root-dir的inode信息就可以定位并查找到根目录下的所有文件信息。
从第2个块开始,根据SFS中所有块的数量,用1个bit来表示一个块的占用和未被占用的情况。这个区域称为SFS的freemap区域,这将占用若干个块空间。为了更好地记录和管理freemap区域,专门提供了两个文件kern/fs/sfs/bitmap.[ch]来完成根据一个块号查找或设置对应的bit位的值。1
2
3
4
5struct bitmap {
uint32_t nbits;
uint32_t nwords;
WORD_TYPE *map;
};
最后在剩余的磁盘空间中,存放了所有其他目录和文件的inode信息和内容数据信息。需要注意的是虽然inode的大小小于一个块的大小(4096B),但为了实现简单,每个 inode 都占用一个完整的 block。
在sfs_fs.c文件中的sfs_do_mount函数中,完成了加载位于硬盘上的SFS文件系统的超级块superblock和freemap的工作。这样,在内存中就有了SFS文件系统的全局信息。
在fs_init中分别调用了vfs_init(),dev_init()和sfs_init(),sfs_init()中调用了sfs_mount("disk0"),sfs_mount中调用了vfs_mount(devname, sfs_do_mount);,vfs_mount()中从设备列表中找到一个名字相同的设备,这个设备的fs应该是NULL,即它是没有被挂载到某个文件系统的。找到这个设备的inode中in_info,调用传进来的mountfunc,即sfs_do_mount1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111/*
* sfs_do_mount - mount sfs file system.
*
* @dev: the block device contains sfs file system
* @fs_store: the fs struct in memroy
*/
static int
sfs_do_mount(struct device *dev, struct fs **fs_store) {
static_assert(SFS_BLKSIZE >= sizeof(struct sfs_super));
static_assert(SFS_BLKSIZE >= sizeof(struct sfs_disk_inode));
static_assert(SFS_BLKSIZE >= sizeof(struct sfs_disk_entry));
if (dev->d_blocksize != SFS_BLKSIZE) {
return -E_NA_DEV;
}
/* 分配一个fs的结构 */
struct fs *fs;
if ((fs = alloc_fs(sfs)) == NULL) {
return -E_NO_MEM;
}
/* 获取这个sfs的sfs_fs */
struct sfs_fs *sfs = fsop_info(fs, sfs);
sfs->dev = dev;
int ret = -E_NO_MEM;
void *sfs_buffer;
if ((sfs->sfs_buffer = sfs_buffer = kmalloc(SFS_BLKSIZE)) == NULL) {
goto failed_cleanup_fs;
}
/* 专门用来读超级块的 */
if ((ret = sfs_init_read(dev, SFS_BLKN_SUPER, sfs_buffer)) != 0) {
goto failed_cleanup_sfs_buffer;
}
ret = -E_INVAL;
struct sfs_super *super = sfs_buffer;
if (super->magic != SFS_MAGIC) {
// 开头一定要是魔数
cprintf("sfs: wrong magic in superblock. (%08x should be %08x).\n",
super->magic, SFS_MAGIC);
goto failed_cleanup_sfs_buffer;
}
if (super->blocks > dev->d_blocks) {
cprintf("sfs: fs has %u blocks, device has %u blocks.\n",
super->blocks, dev->d_blocks);
goto failed_cleanup_sfs_buffer;
}
super->info[SFS_MAX_INFO_LEN] = '\0';
sfs->super = *super;
ret = -E_NO_MEM;
uint32_t i;
/* alloc and initialize hash list, 用于inode */
list_entry_t *hash_list;
if ((sfs->hash_list = hash_list = kmalloc(sizeof(list_entry_t) * SFS_HLIST_SIZE)) == NULL) {
goto failed_cleanup_sfs_buffer;
}
for (i = 0; i < SFS_HLIST_SIZE; i ++) {
list_init(hash_list + i);
}
/* load and check freemap */
struct bitmap *freemap;
uint32_t freemap_size_nbits = sfs_freemap_bits(super);
if ((sfs->freemap = freemap = bitmap_create(freemap_size_nbits)) == NULL) {
goto failed_cleanup_hash_list;
}
uint32_t freemap_size_nblks = sfs_freemap_blocks(super);
if ((ret = sfs_init_freemap(dev, freemap, SFS_BLKN_FREEMAP, freemap_size_nblks, sfs_buffer)) != 0) {
goto failed_cleanup_freemap;
}
uint32_t blocks = sfs->super.blocks, unused_blocks = 0;
for (i = 0; i < freemap_size_nbits; i ++) {
if (bitmap_test(freemap, i)) {
unused_blocks ++;
}
}
assert(unused_blocks == sfs->super.unused_blocks);
/* and other fields */
sfs->super_dirty = 0;
sem_init(&(sfs->fs_sem), 1);
sem_init(&(sfs->io_sem), 1);
sem_init(&(sfs->mutex_sem), 1);
list_init(&(sfs->inode_list));
cprintf("sfs: mount: '%s' (%d/%d/%d)\n", sfs->super.info,
blocks - unused_blocks, unused_blocks, blocks);
/* link addr of sync/get_root/unmount/cleanup funciton fs's function pointers*/
fs->fs_sync = sfs_sync;
fs->fs_get_root = sfs_get_root;
fs->fs_unmount = sfs_unmount;
fs->fs_cleanup = sfs_cleanup;
*fs_store = fs;
return 0;
failed_cleanup_freemap:
bitmap_destroy(freemap);
failed_cleanup_hash_list:
kfree(hash_list);
failed_cleanup_sfs_buffer:
kfree(sfs_buffer);
failed_cleanup_fs:
kfree(fs);
return ret;
}
索引节点
在SFS文件系统中,需要记录文件内容的存储位置以及文件名与文件内容的对应关系。
- sfs_disk_inode记录了文件或目录的内容存储的索引信息,该数据结构在硬盘里储存,需要时读入内存。
- sfs_disk_entry表示一个目录中的一个文件或目录,包含该项所对应inode的位置和文件名,同样也在硬盘里储存,需要时读入内存。
磁盘索引节点
SFS中的磁盘索引节点代表了一个实际位于磁盘上的文件。首先我们看看在硬盘上的索引节点的内容:1
2
3
4
5
6
7
8struct sfs_disk_inode {
uint32_t size; 如果inode表示常规文件,则size是文件大小
uint16_t type; inode的文件类型
uint16_t nlinks; 此inode的硬链接数
uint32_t blocks; 此inode的数据块数的个数
uint32_t direct[SFS_NDIRECT]; 此inode的直接数据块索引值(有SFS_NDIRECT个)
uint32_t indirect; 此inode的一级间接数据块索引值
};
通过上表可以看出,如果inode表示的是文件,则成员变量direct[]直接指向了保存文件内容数据的数据块索引值。indirect间接指向了保存文件内容数据的数据块,indirect指向的是间接数据块(indirect_block),此数据块实际存放的全部是数据块索引,这些数据块索引指向的数据块才被用来存放文件内容数据。
默认的,ucore 里 SFS_NDIRECT 是 12,即直接索引的数据页大小为 12 4k = 48k;当使用一级间接数据块索引时,ucore 支持最大的文件大小为 12 4k + 1024 * 4k = 48k + 4m。数据索引表内,0 表示一个无效的索引,inode 里 blocks 表示该文件或者目录占用的磁盘的 block 的个数。indiret 为 0 时,表示不使用一级索引块。(因为 block 0 用来保存 super block,它不可能被其他任何文件或目录使用,所以这么设计也是合理的)。
对于普通文件,索引值指向的 block 中保存的是文件中的数据。而对于目录,索引值指向的数据保存的是目录下所有的文件名以及对应的索引节点所在的索引块(磁盘块)所形成的数组。数据结构如下:1
2
3
4
5/* file entry (on disk) */
struct sfs_disk_entry {
uint32_t ino; 索引节点所占数据块索引值
char name[SFS_MAX_FNAME_LEN + 1]; 文件名
};
操作系统中,每个文件系统下的 inode 都应该分配唯一的 inode 编号。SFS 下,为了实现的简便,每个 inode 直接用他所在的磁盘 block 的编号作为 inode 编号。比如,root block 的 inode 编号为 1;每个 sfs_disk_entry 数据结构中,name 表示目录下文件或文件夹的名称,ino 表示磁盘 block 编号,通过读取该 block 的数据,能够得到相应的文件或文件夹的 inode。ino 为0时,表示一个无效的 entry。
此外,和 inode 相似,每个 sfs_dirent_entry 也占用一个 block。
内存中的索引节点
1 | /* inode for sfs */ |
可以看到SFS中的内存inode包含了SFS的硬盘inode信息,而且还增加了其他一些信息,这属于是便于进行是判断否改写、互斥操作、回收和快速地定位等作用。需要注意,一个内存inode是在打开一个文件后才创建的,如果关机则相关信息都会消失。而硬盘inode的内容是保存在硬盘中的,只是在进程需要时才被读入到内存中,用于访问文件或目录的具体内容数据
为了方便实现上面提到的多级数据的访问以及目录中 entry 的操作,对 inode SFS实现了一些辅助的函数:
- sfs_bmap_load_nolock:将对应 sfs_inode 的第 index 个索引指向的 block 的索引值取出存到相应的指针指向的单元(ino_store)。该函数只接受 index <= inode->blocks 的参数。当 index == inode->blocks 时,该函数理解为需要为 inode 增长一个 block。并标记 inode 为 dirty(所有对 inode 数据的修改都要做这样的操作,这样,当 inode 不再使用的时候,sfs 能够保证 inode 数据能够被写回到磁盘)。sfs_bmap_load_nolock 调用的 sfs_bmap_get_nolock 来完成相应的操作,阅读 sfs_bmap_get_nolock,了解他是如何工作的。(sfs_bmap_get_nolock 只由 sfs_bmap_load_nolock 调用)
1 | /* |
- sfs_bmap_truncate_nolock:将多级数据索引表的最后一个 entry 释放掉。他可以认为是 sfs_bmap_load_nolock 中,index == inode->blocks 的逆操作。当一个文件或目录被删除时,sfs 会循环调用该函数直到 inode->blocks 减为 0,释放所有的数据页。函数通过 sfs_bmap_free_nolock 来实现,他应该是 sfs_bmap_get_nolock 的逆操作。和 sfs_bmap_get_nolock 一样,调用 sfs_bmap_free_nolock 也要格外小心。
- sfs_dirent_read_nolock:将目录的第 slot 个 entry 读取到指定的内存空间。他通过上面提到的函数来完成。
- sfs_dirent_search_nolock:是常用的查找函数。他在目录下查找 name,并且返回相应的搜索结果(文件或文件夹)的 inode 的编号(也是磁盘编号),和相应的 entry 在该目录的 index 编号以及目录下的数据页是否有空闲的 entry。(SFS 实现里文件的数据页是连续的,不存在任何空洞;而对于目录,数据页不是连续的,当某个 entry 删除的时候,SFS 通过设置 entry->ino 为0将该 entry 所在的 block 标记为 free,在需要添加新 entry 的时候,SFS 优先使用这些 free 的 entry,其次才会去在数据页尾追加新的 entry。
注意,这些后缀为 nolock 的函数,只能在已经获得相应 inode 的semaphore才能调用。
inode的文件操作函数1
2
3
4
5
6
7
8static const struct inode_ops sfs_node_fileops = {
.vop_magic = VOP_MAGIC,
.vop_open = sfs_openfile,
.vop_close = sfs_close,
.vop_read = sfs_read,
.vop_write = sfs_write,
……
};
上述sfs_openfile、sfs_close、sfs_read和sfs_write分别对应用户进程发出的open、close、read、write操作。其中sfs_openfile不用做什么事;sfs_close需要把对文件的修改内容写回到硬盘上,这样确保硬盘上的文件内容数据是最新的;sfs_read和sfs_write函数都调用了一个函数sfs_io,并最终通过访问硬盘驱动来完成对文件内容数据的读写。
inode的目录操作函数
1 | static const struct inode_ops sfs_node_dirops = { |
对于目录操作而言,由于目录也是一种文件,所以sfs_opendir、sys_close对应户进程发出的open、close函数。相对于sfs_open,sfs_opendir只是完成一些open函数传递的参数判断,没做其他更多的事情。目录的close操作与文件的close操作完全一致。由于目录的内容数据与文件的内容数据不同,所以读出目录的内容数据的函数是sfs_getdirentry,其主要工作是获取目录下的文件inode信息。
设备层文件 IO 层
在本实验中,为了统一地访问设备,我们可以把一个设备看成一个文件,通过访问文件的接口来访问设备。目前实现了stdin设备文件文件、stdout设备文件、disk0设备。stdin设备就是键盘,stdout设备就是CONSOLE(串口、并口和文本显示器),而disk0设备是承载SFS文件系统的磁盘设备。下面我们逐一分析ucore是如何让用户把设备看成文件来访问。
关键数据结构
为了表示一个设备,需要有对应的数据结构,ucore为此定义了struct device,其描述如下:1
2
3
4
5
6
7
8struct device {
size_t d_blocks; //设备占用的数据块个数
size_t d_blocksize; //数据块的大小
int (*d_open)(struct device *dev, uint32_t open_flags); //打开设备的函数指针
int (*d_close)(struct device *dev); //关闭设备的函数指针
int (*d_io)(struct device *dev, struct iobuf *iob, bool write); //读写设备的函数指针
int (*d_ioctl)(struct device *dev, int op, void *data); //用ioctl方式控制设备的函数指针
};
这个数据结构能够支持对块设备(比如磁盘)、字符设备(比如键盘、串口)的表示,完成对设备的基本操作。ucore虚拟文件系统为了把这些设备链接在一起,还定义了一个设备链表,即双向链表vdev_list,这样通过访问此链表,可以找到ucore能够访问的所有设备文件。
但这个设备描述没有与文件系统以及表示一个文件的inode数据结构建立关系,为此,还需要另外一个数据结构把device和inode联通起来,这就
是vfs_dev_t数据结构:1
2
3
4
5
6
7
8// device info entry in vdev_list
typedef struct {
const char *devname;
struct inode *devnode;
struct fs *fs;
bool mountable;
list_entry_t vdev_link;
} vfs_dev_t;
利用vfs_dev_t数据结构,就可以让文件系统通过一个链接vfs_dev_t结构的双向链表找到device对应的inode数据结构,一个inode节点的成员变量in_type的值是0x1234,则此 inode的成员变量in_info将成为一个device结构。这样inode就和一个设备建立了联系,这个inode就是一个设备文件。
stdout设备文件
初始化
既然stdout设备是设备文件系统的文件,自然有自己的inode结构。在系统初始化时,即只需如下处理过程1
2
3
4
5
6
7kern_init ——>
fs_init ——>
dev_init ——>
dev_init_stdout ——>
dev_create_inode ——>
stdout_device_init ——>
vfs_add_dev
在dev_init_stdout中完成了对stdout设备文件的初始化。即首先创建了一个inode,然后通过stdout_device_init完成对inode中的成员变量inode->__device_info进行初始:
这里的stdout设备文件实际上就是指的console外设(它其实是串口、并口和CGA的组合型外设)。这个设备文件是一个只写设备,如果读这个设备,就会出错。接下来我们看看stdout设备的相关处理过程。
初始化
stdout设备文件的初始化过程主要由stdout_device_init完成,其具体实现如下:1
2
3
4
5
6
7
8
9static void
stdout_device_init(struct device *dev) {
dev->d_blocks = 0;
dev->d_blocksize = 1;
dev->d_open = stdout_open;
dev->d_close = stdout_close;
dev->d_io = stdout_io;
dev->d_ioctl = stdout_ioctl;
}
可以看到,stdout_open函数完成设备文件打开工作,如果发现用户进程调用open函数的参数flags不是只写(O_WRONLY),则会报错。1
2
3
4
5
6
7static int
stdout_open(struct device *dev, uint32_t open_flags) {
if (open_flags != O_WRONLY) {
return -E_INVAL;
}
return 0;
}
访问操作实现
stdout_io函数完成设备的写操作工作,具体实现如下:1
2
3
4
5
6
7
8
9
10
11static int
stdout_io(struct device *dev, struct iobuf *iob, bool write) {
if (write) {
char *data = iob->io_base;
for (; iob->io_resid != 0; iob->io_resid --) {
cputchar(*data ++);
}
return 0;
}
return -E_INVAL;
}
可以看到,要写的数据放在iob->io_base所指的内存区域,一直写到iob->io_resid的值为0为止。每次写操作都是通过cputchar来完成的,此函数最终将通过console外设驱动来完成把数据输出到串口、并口和CGA显示器上过程。另外,也可以注意到,如果用户想执行读操作,则stdout_io函数直接返回错误值-E_INVAL。
stdin 设备文件
这里的stdin设备文件实际上就是指的键盘。这个设备文件是一个只读设备,如果写这个设备,就会出错。接下来我们看看stdin设备的相关处理过程。
初始化
stdin设备文件的初始化过程主要由stdin_device_init完成了主要的初始化工作,具体实现如下:1
2
3
4
5
6
7
8
9
10
11
12static void
stdin_device_init(struct device *dev) {
dev->d_blocks = 0;
dev->d_blocksize = 1;
dev->d_open = stdin_open;
dev->d_close = stdin_close;
dev->d_io = stdin_io;
dev->d_ioctl = stdin_ioctl;
p_rpos = p_wpos = 0;
wait_queue_init(wait_queue);
}
相对于stdout的初始化过程,stdin的初始化相对复杂一些,多了一个stdin_buffer缓冲区,描述缓冲区读写位置的变量p_rpos、p_wpos以及用于等待缓冲区的等待队列wait_queue。在stdin_device_init函数的初始化中,也完成了对p_rpos、p_wpos和wait_queue的初始化。
访问操作实现
stdin_io函数负责完成设备的读操作工作,具体实现如下:1
2
3
4
5
6
7
8
9
10
11static int
stdin_io(struct device *dev, struct iobuf *iob, bool write) {
if (!write) {
int ret;
if ((ret = dev_stdin_read(iob->io_base, iob->io_resid)) > 0) {
iob->io_resid -= ret;
}
return ret;
}
return -E_INVAL;
}
可以看到,如果是写操作,则stdin_io函数直接报错返回。所以这也进一步说明了此设备文件是只读文件。如果此读操作,则此函数进一步调用dev_stdin_read函数完成对键盘设备的读入操作。dev_stdin_read函数的实现相对复杂一些,主要的流程如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30static int
dev_stdin_read(char *buf, size_t len) {
int ret = 0;
bool intr_flag;
local_intr_save(intr_flag);
{
for (; ret < len; ret ++, p_rpos ++) {
try_again:
if (p_rpos < p_wpos) {
*buf ++ = stdin_buffer[p_rpos % stdin_BUFSIZE];
}
else {
wait_t __wait, *wait = &__wait;
wait_current_set(wait_queue, wait, WT_KBD);
local_intr_restore(intr_flag);
schedule();
local_intr_save(intr_flag);
wait_current_del(wait_queue, wait);
if (wait->wakeup_flags == WT_KBD) {
goto try_again;
}
break;
}
}
}
local_intr_restore(intr_flag);
return ret;
}
在上述函数中可以看出,如果p_rpos < p_wpos,则表示有键盘输入的新字符在stdin_buffer中,于是就从stdin_buffer中取出新字符放到iobuf指向的缓冲区中;如果p_rpos >=p_wpos,则表明没有新字符,这样调用read用户态库函数的用户进程就需要采用等待队列的睡眠操作进入睡眠状态,等待键盘输入字符的产生。
当识别出中断是键盘中断(中断号为IRQ_OFFSET + IRQ_KBD)时,会调用dev_stdin_write函数,来把字符写入到stdin_buffer中,且会通过等待队列的唤醒操作唤醒正在等待键盘输入的用户进程。
实验执行流程概述
kern_init函数增加了对fs_init函数的调用。fs_init函数就是文件系统初始化的总控函数,它进一步调用了虚拟文件系统初始化函数vfs_init,与文件相关的设备初始化函数dev_init和Simple FS文件系统的初始化函数sfs_init。这三个初始化函数联合在一起,协同完成了整个虚拟文件系统、SFS文件系统和文件系统对应的设备(键盘、串口、磁盘)的初始化工作。其函数调用关系图如下所示:
vfs_init如下所示:1
2
3
4
5
6// vfs_init - vfs initialize
void
vfs_init(void) {
sem_init(&bootfs_sem, 1);
vfs_devlist_init();
}
sem_init函数主要是初始化了信号量和等待队列:1
2
3
4
5void
sem_init(semaphore_t *sem, int value) {
sem->value = value;
wait_queue_init(&(sem->wait_queue));
}
vfs_devlist_init主要是初始化设备列表,建立了一个device list双向链表vdev_list,为后续具体设备(键盘、串口、磁盘)以文件的形式呈现建立查找访问通道1
2
3
4
5void
vfs_devlist_init(void) {
list_init(&vdev_list);
sem_init(&vdev_list_sem, 1);
}
dev_init函数通过进一步调用disk0/stdin/stdout_device_init完成对具体设备的初始化,把它们抽象成一个设备文件,并建立对应的inode数据结构,最后把它们链入到vdev_list中。这样通过虚拟文件系统就可以方便地以文件的形式访问这些设备了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
/* dev_init - Initialization functions for builtin vfs-level devices. */
void
dev_init(void) {
// init_device(null);
init_device(stdin);
init_device(stdout);
init_device(disk0);
}1
2
3
4
5
6
7
8
9
10
11
12
13void
dev_init_disk0(void) {
struct inode *node;
if ((node = dev_create_inode()) == NULL) {
panic("disk0: dev_create_node.\n");
}
disk0_device_init(vop_info(node, device));
int ret;
if ((ret = vfs_add_dev("disk0", node, 1)) != 0) {
panic("disk0: vfs_add_dev: %e.\n", ret);
}
}1
2
3
4
5
6
7
8
9
10
11
12dev_init_stdin(void) {
struct inode *node;
if ((node = dev_create_inode()) == NULL) {
panic("stdin: dev_create_node.\n");
}
stdin_device_init(vop_info(node, device));
int ret;
if ((ret = vfs_add_dev("stdin", node, 0)) != 0) {
panic("stdin: vfs_add_dev: %e.\n", ret);
}
}1
2
3
4
5
6
7
8
9
10
11
12
13void
dev_init_stdout(void) {
struct inode *node;
if ((node = dev_create_inode()) == NULL) {
panic("stdout: dev_create_node.\n");
}
stdout_device_init(vop_info(node, device));
int ret;
if ((ret = vfs_add_dev("stdout", node, 0)) != 0) {
panic("stdout: vfs_add_dev: %e.\n", ret);
}
}
sfs_init是完成对Simple FS的初始化工作,并把此实例文件系统挂在虚拟文件系统中,从而让ucore的其他部分能够通过访问虚拟文件系统的接口来进一步访问到SFS实例文件系统。1
2
3
4
5
6
7
8
9
10
11
12
13/*
* sfs_init - mount sfs on disk0
*
* CALL GRAPH:
* kern_init-->fs_init-->sfs_init
*/
void
sfs_init(void) {
int ret;
if ((ret = sfs_mount("disk0")) != 0) {
panic("failed: sfs: sfs_mount: %e.\n", ret);
}
}
在sfs_init中调用了sfs_mount —> vfs_mount 进行挂载:1
2
3
4int
sfs_mount(const char *devname) {
return vfs_mount(devname, sfs_do_mount);
}
vfs_mount把一个文件系统挂载到系统上1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34/*
* vfs_mount - Mount a filesystem. Once we've found the device, call MOUNTFUNC to
* set up the filesystem and hand back a struct fs.
*
* The DATA argument is passed through unchanged to MOUNTFUNC.
*/
int
vfs_mount(const char *devname, int (*mountfunc)(struct device *dev, struct fs **fs_store)) {
int ret;
lock_vdev_list();
// 信号量操作
vfs_dev_t *vdev;
if ((ret = find_mount(devname, &vdev)) != 0) {
// 找一个同名设备
goto out;
}
if (vdev->fs != NULL) {
ret = -E_BUSY;
// 如果这个设备已经被挂载到一个文件系统上了,就不能被再挂载
goto out;
}
assert(vdev->devname != NULL && vdev->mountable);
struct device *dev = vop_info(vdev->devnode, device);
if ((ret = mountfunc(dev, &(vdev->fs))) == 0) {
assert(vdev->fs != NULL);
cprintf("vfs: mount %s.\n", vdev->devname);
}
out:
unlock_vdev_list();
// 解锁
return ret;
}
对于vop_info:1
2
3
4
5
6
7
8
9__##type##_info是一个struct device或struct sfs_inode的结构体,一般调用vop_info的时候都是给一个变量赋值为一个设备的结构体。
mountfunc竟然是一个参数,流批流批。。。溯源的话有sfs_do_mount作为参数,下文介绍sfs_do_mount,太多了。。。
文件操作实现
打开文件
有了上述分析后,我们可以看看如果一个用户进程打开文件会做哪些事情?首先假定用户进程需要打开的文件已经存在在硬盘上。以user/sfs_filetest1.c为例,首先用户进程会调用在main函数中的如下语句:1
int fd1 = safe_open("sfs\_filetest1", O_RDONLY);
如果ucore能够正常查找到这个文件,就会返回一个代表文件的文件描述符fd1,这样在接下来的读写文件过程中,就直接用这样fd1来代表就可以了。
safe_open实现如下,在open中调用了sys_open,接着调用了syscall,执行系统调用:1
2
3
4
5
6
7static int safe_open(const char *path, int open_flags)
{
int fd = open(path, open_flags);
printf("fd is %d\n",fd);
assert(fd >= 0);
return fd;
}
通用文件访问接口层的处理流程
进一步调用如下用户态函数: open->sys_open->syscall,从而引起系统调用进入到内核态。到了内核态后,通过中断处理例程,会调用到sys_open内核函数,并进一步调用sysfile_open内核函数。到了这里,需要把位于用户空间的字符串”sfs_filetest1”拷贝到内核空间中的字符串path中,这里copy_path完成了本功能,这里不再列出。进入到文件系统抽象层的处理流程完成进一步的打开文件操作中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19static int
sys_open(uint32_t arg[]) {
const char *path = (const char *)arg[0];
uint32_t open_flags = (uint32_t)arg[1];
return sysfile_open(path, open_flags);
}
/* sysfile_open - open file */
int
sysfile_open(const char *__path, uint32_t open_flags) {
int ret;
char *path;
if ((ret = copy_path(&path, __path)) != 0) {
return ret;
}
ret = file_open(path, open_flags);
kfree(path);
return ret;
}
文件系统抽象层的处理流程
分配一个空闲的file数据结构变量file。
- 在文件系统抽象层的处理中,首先调用的是file_open函数,它要给这个即将打开的文件分配一个file数据结构的变量,这个变量其实是当前进程的打开文件数组
current->fs_struct->filemap[]中的一个空闲元素(即还没用于一个打开的文件),而这个元素的索引值就是最终要返回到用户进程并赋值给变量fd1。到了这一步还仅仅是给当前用户进程分配了一个file数据结构的变量,还没有找到对应的文件索引节点。
- 在文件系统抽象层的处理中,首先调用的是file_open函数,它要给这个即将打开的文件分配一个file数据结构的变量,这个变量其实是当前进程的打开文件数组
调用
vfs_open函数来找到path指出的文件所对应的基于inode数据结构的VFS索引节点node。vfs_open函数需要完成:- 确定读写权限;
- 通过vfs_lookup找到path对应文件的inode;首先是调用get_device,先对路径字符串进行判断,看是不是声明了设备(有:)或者是绝对路径(有/)。如果是相对路径,调用vfs_get_curdir获得当前的路径。如果有设备名,则根据路径中的设备名在设备list中找到这个设备,返回一个inode。如果是绝对路径,则返回根目录。如果开头有个‘:’,说明是在当前文件系统中,返回的是当前目录。
- 找到文件设备的根目录“/”的索引节点需要注意,这里的
vfs_lookup函数是一个针对目录的操作函数,它会调用vop_lookup函数来找到SFS文件系统中的“/”目录下的“sfs_filetest1”文件。为此,vfs_lookup函数首先调用get_device函数,并进一步调用vfs_get_bootfs函数来找到根目录“/”对应的inode。这个inode就是位于vfs.c中的inode变量bootfs_node。这个变量在init_main函数(位于kern/process/proc.c)执行时获得了赋值。 - 通过调用vop_lookup函数来查找到根目录“/”下对应文件sfs_filetest1的索引节点,如果找到就返回此索引节点。
- 调用vop_open函数打开文件。
- 调用了vop_truncate(应该是这个sfs_truncfile),调整文件大小到适当的大小(按照块个数计算)
- 调用了vfs_fsync,如果发生了什么使得这个块变成dirty了,就调用d_io把它写进去。
把file和node建立联系,设置file的读写权限,如果是append模式的话还要把file的pos设置到末尾。完成后,将返回到file_open函数中,通过执行语句“file->node=node;”,就把当前进程的current->fs_struct->filemap[fd](即file所指变量)的成员变量node指针指向了代表sfs_filetest1文件的索引节点inode。
- 这时返回fd。经过重重回退,通过系统调用返回,用户态的syscall->sys_open->open->safe_open等用户函数的层层函数返回,最终把fd赋值给fd1。自此完成了打开文件操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46// open file
int
file_open(char *path, uint32_t open_flags) {
bool readable = 0, writable = 0;
switch (open_flags & O_ACCMODE) {
case O_RDONLY: readable = 1; break;
case O_WRONLY: writable = 1; break;
case O_RDWR:
readable = writable = 1;
break;
default:
return -E_INVAL;
}
int ret;
struct file *file;
if ((ret = fd_array_alloc(NO_FD, &file)) != 0) {
return ret;
}
//分配一个file数据结构的变量
struct inode *node;
if ((ret = vfs_open(path, open_flags, &node)) != 0) {
fd_array_free(file);
return ret;
}
//找到path指出的文件所对应的基于inode数据结构的VFS索引节点node
file->pos = 0;
if (open_flags & O_APPEND) {
struct stat __stat, *stat = &__stat;
if ((ret = vop_fstat(node, stat)) != 0) {
vfs_close(node);
fd_array_free(file);
return ret;
}
file->pos = stat->st_size;
}
// 根据open_flags找当前指针应该指在文件的什么位置
file->node = node;
file->readable = readable;
file->writable = writable;
fd_array_open(file);
return file->fd;
}
SFS文件系统层的处理流程
在sfs_inode.c中的sfs_node_dirops变量定义了“.vop_lookup = sfs_lookup”,所以我们重点分析sfs_lookup的实现。
sfs_lookup有三个参数:node,path,node_store。其中node是根目录“/”所对应的inode节点;path是文件sfs_filetest1的绝对路径/sfs_filetest1,而node_store是经过查找获得的sfs_filetest1所对应的inode节点。
sfs_lookup函数以“/”为分割符,从左至右逐一分解path获得各个子目录和最终文件对应的inode节点。在本例中是调用sfs_lookup_once查找以根目录下的文件sfs_filetest1所对应的inode节点。当无法分解path后,就意味着找到了sfs_filetest1对应的inode节点,就可顺利返回了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/*
* sfs_lookup - Parse path relative to the passed directory
* DIR, and hand back the inode for the file it
* refers to.
*/
static int
sfs_lookup(struct inode *node, char *path, struct inode **node_store) {
struct sfs_fs *sfs = fsop_info(vop_fs(node), sfs);
assert(*path != '\0' && *path != '/');
vop_ref_inc(node);
struct sfs_inode *sin = vop_info(node, sfs_inode);
// 找到sfs_inode __sfs_inode_info。
if (sin->din->type != SFS_TYPE_DIR) {
vop_ref_dec(node);
return -E_NOTDIR;
}
struct inode *subnode;
int ret = sfs_lookup_once(sfs, sin, path, &subnode, NULL);
// 找到与路径相符的inode并加载到subnode里。
vop_ref_dec(node);
if (ret != 0) {
return ret;
}
*node_store = subnode;
return 0;
}
读文件
用户进程有如下语句:1
read(fd, data, len);
即读取fd对应文件,读取长度为len,存入data中。下面来分析一下读文件的实现。
通用文件访问接口层的处理流程
进一步调用如下用户态函数:read->sys_read->syscall,从而引起系统调用进入到内核态。到了内核态以后,通过中断处理例程,会调用到sys_read内核函数,并进一步调用sysfile_read内核函数,进入到文件系统抽象层处理流程完成进一步读文件的操作。1
2
3
4
5
6
7static int
sys_read(uint32_t arg[]) {
int fd = (int)arg[0];
void *base = (void *)arg[1];
size_t len = (size_t)arg[2];
return sysfile_read(fd, base, len);
}
文件系统抽象层的处理流程
- 检查错误,即检查读取长度是否为0和文件是否可读。
- 分配buffer空间,即调用kmalloc函数分配4096字节的buffer空间。
- 读文件过程
- 实际读文件。
- 循环读取文件,每次读取buffer大小。
- 每次循环中,先检查剩余部分大小,若其小于4096字节,则只读取剩余部分的大小。
- 调用file_read函数(详细分析见后)将文件内容读取到buffer中,alen为实际大小。
- 调用copy_to_user函数将读到的内容拷贝到用户的内存空间中。
- 调整各变量以进行下一次循环读取,直至指定长度读取完成。
- 最后函数调用层层返回至用户程序,用户程序收到了读到的文件内容。
- file_read函数
- 这个函数是读文件的核心函数。函数有4个参数,
- fd是文件描述符,
- base是缓存的基地址,
- len是要读取的长度,
- copied_store存放实际读取的长度。
- 函数首先调用
fd2file函数找到对应的file结构,并检查是否可读。 - 调用
filemap_acquire函数使打开这个文件的计数加1。 - 调用vop_read函数将文件内容读到iob中(详细分析见后)。
- 调整文件指针偏移量pos的值,使其向后移动实际读到的字节数iobuf_used(iob)。
- 调用filemap_release函数使打开这个文件的计数减1,若打开计数为0,则释放file。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54/* sysfile_read - read file */
int
sysfile_read(int fd, void *base, size_t len) {
struct mm_struct *mm = current->mm;
if (len == 0) {
return 0;
}
if (!file_testfd(fd, 1, 0)) {
return -E_INVAL;
}
// 检查读取长度是否为0和文件是否可读
void *buffer;
if ((buffer = kmalloc(IOBUF_SIZE)) == NULL) {
return -E_NO_MEM;
}
// 调用kmalloc函数分配4096字节的buffer空间
int ret = 0;
size_t copied = 0, alen;
while (len != 0) {
if ((alen = IOBUF_SIZE) > len) {
alen = len;
}
ret = file_read(fd, buffer, alen, &alen);
// 将文件内容读取到buffer中,alen为实际大小
if (alen != 0) {
lock_mm(mm);
{
if (copy_to_user(mm, base, buffer, alen)) {
// copy_to_user在vmm.c中,检查权限后memcpy
assert(len >= alen);
base += alen, len -= alen, copied += alen;
}
// 调用copy_to_user函数将读到的内容拷贝到用户的内存空间中
// 调整各变量以进行下一次循环读取,直至指定长度读取完成
else if (ret == 0) {
ret = -E_INVAL;
}
}
unlock_mm(mm);
}
if (ret != 0 || alen == 0) {
goto out;
}
}
out:
kfree(buffer);
if (copied != 0) {
return copied;
}
return ret;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// read file
int
file_read(int fd, void *base, size_t len, size_t *copied_store) {
int ret;
struct file *file;
*copied_store = 0;
if ((ret = fd2file(fd, &file)) != 0) {
return ret;
}
// 找到对应的file结构
if (!file->readable) {
return -E_INVAL;
}
fd_array_acquire(file);
// 打开这个文件的计数加1
struct iobuf __iob, *iob = iobuf_init(&__iob, base, len, file->pos);
ret = vop_read(file->node, iob);
// 文件内容读到iob中,通过sfs_read --> sfs_io,获取到inode,执行sfs_io_nolock。
size_t copied = iobuf_used(iob);
if (file->status == FD_OPENED) {
file->pos += copied;
}
*copied_store = copied;
fd_array_release(file);
return ret;
}
- 这个函数是读文件的核心函数。函数有4个参数,
- 实际读文件。
SFS文件系统层的处理流程
vop_read函数实际上是对sfs_read的包装。在sfs_inode.c中sfs_node_fileops变量定义了.vop_read = sfs_read,所以下面来分析sfs_read函数的实现。
- sfs_read函数调用sfs_io函数。
- 它有三个参数,node是对应文件的inode,iob是缓存,write表示是读还是写的布尔值(0表示读,1表示写),这里是0。
- 函数先找到inode对应sfs和sin,
- 然后调用sfs_io_nolock函数进行读取文件操作,
- 最后调用iobuf_skip函数调整iobuf的指针。
1 | /* |
练习1: 完成读文件操作的实现
首先完成proc.c中process控制块的初始化,在static struct proc_struct *alloc_proc(void)中添加:1
proc->filesp = NULL;
如果调用了read系统调用,继续调用sys_read函数,和sysfile_read函数,在这个函数中,创建了缓冲区,进一步复制到用户空间的指定位置去;从文件读取数据的函数是file_read。
在file_read函数中,通过文件描述符找到相应文件对应的内存中的inode信息,调用vop_read进行读取处理,vop_read继续调用sfs_read函数,然后调用sfs_io函数和sfs_io_nolock函数。
- 在sfs_io_nolock函数中,
- 先计算一些辅助变量,并处理一些特殊情况(比如越界),
- 然后有
sfs_buf_op = sfs_rbuf,sfs_block_op = sfs_rblock,设置读取的函数操作。 - 先处理起始的没有对齐到块的部分,再以块为单位循环处理中间的部分,最后处理末尾剩余的部分。
- 每部分中都调用sfs_bmap_load_nolock函数得到blkno对应的inode编号,
- 并调用
sfs_rbuf或sfs_rblock函数读取数据(中间部分调用sfs_rblock,起始和末尾部分调用sfs_rbuf),调整相关变量。 - 完成后如果
offset + alen > din->fileinfo.size(写文件时会出现这种情况,读文件时不会出现这种情况,alen为实际读写的长度),则调整文件大小为offset + alen并设置dirty变量。
sfs_bmap_load_nolock函数将对应sfs_inode的第index个索引指向的block的索引值取出存到相应的指针指向的单元(ino_store)。- 调用sfs_bmap_get_nolock来完成相应的操作。
- sfs_rbuf和sfs_rblock函数最终都调用sfs_rwblock_nolock函数完成操作,
- 而sfs_rwblock_nolock函数调用dop_io->disk0_io->disk0_read_blks_nolock->ide_read_secs完成对磁盘的操作。
1 | /* |
- 请在实验报告中给出设计实现”UNIX的PIPE机制“的概要设方案,鼓励给出详细设计方案。
- PIPE机制可以看成是一个缓冲区,可以在磁盘上(或内存中?)保留一部分空间作为pipe机制的缓冲区。当两个进程之间要求建立pipe时,在两个进程的进程控制块上修改某些属性表明这个进程是管道数据的发送方还是接受方,这样就可以将stdin或stdout重定向到生成的临时文件里,在两个进程中打开这个临时文件。
- 当进程A使用stdout写时,查询PCB中的相关变量,把这些stdout数据输出到临时文件中;
- 当进程B使用stdin的时候,查询PCB中的信息,从临时文件中读取数据;
练习2: 完成基于文件系统的执行程序机制的实现
改写proc.c中的load_icode函数和其他相关函数,实现基于文件系统的执行程序机制。首先是在do_execve中进行文件名和命令行参数的复制,执行sysfie_open打开相关文件,fd是已经打开的这个文件。执行: make qemu。如果能看看到sh用户程序的执行界面,则基本成功了。如果在sh用户界面上可 以执行”ls”,”hello”等其他放置在sfs文件系统中的其他执行程序,则可以认为本实验基本成功。
- 给要执行的用户进程创建一个新的内存管理结构mm,
- 创建用户内存空间的新的页目录表;
- 将磁盘上的ELF文件的TEXT/DATA/BSS段正确地加载到用户空间中;
- 从磁盘中读取elf文件的header;
- 根据elfheader中的信息,获取到磁盘上的program header;
- 对于每一个program header:
- 为TEXT/DATA段在用户内存空间上的保存分配物理内存页,同时建立物理页和虚拟页的映射关系;
- 从磁盘上读取TEXT/DATA段,并且复制到用户内存空间上去;
- 根据program header得知是否需要创建BBS段,如果是,则分配相应的内存空间,并且全部初始化成0,并且建立物理页和虚拟页的映射关系;
- 将用户栈的虚拟空间设置为合法,并且为栈顶部分先分配4个物理页,建立好映射关系;
- 切换到用户地址空间;
- 设置好用户栈上的信息,即需要传递给执行程序的参数;
- 设置好中断帧;
1 | static int |
UNIX的硬链接和软链接机制:
硬链接:
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
软链接:
- 软链接有自己的文件属性及权限等;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 软链接可对文件或目录创建;
- 创建软链接时,链接计数 i_nlink 不会增加;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接
硬链接: 与普通文件没什么不同,inode 都指向同一个文件在硬盘中的区块
软链接: 保存了其代表的文件的绝对路径,是另外一种文件,在硬盘上有独立的区块,访问时替换自身路径。
sfs_disk_inode结构体中有一个nlinks变量,如果要创建一个文件的软链接,这个软链接也要创建inode,只是它的类型是链接,找一个域设置它所指向的文件inode,如果文件是一个链接,就可以通过保存的inode位置进行操作;当删除一个软链接时,直接删掉inode即可;
硬链接与文件是共享inode的,如果创建一个硬链接,需要将源文件中的被链接的计数加1;当删除一个硬链接的时候,除了需要删掉inode之外,还需要将硬链接指向的文件的被链接计数减1,如果减到了0,则需要将A删除掉;