Leetcode501. Find Mode in Binary Search Tree
Given a binary search tree (BST) with duplicates, find all the mode(s) (the most frequently occurred element) in the given BST. Assume a BST is defined as follows:
For example:1
2
3
4
5
6
7Given BST [1,null,2,2],
1
\
2
/
2
return [2].
Note: If a tree has more than one mode, you can return them in any order.
这道题让我们求二分搜索树中的众数,这里定义的二分搜索树中左根右结点之间的关系是小于等于的,有些题目中是严格小于的,所以一定要看清题目要求。所谓的众数就是出现最多次的数字,可以有多个,那么这道题比较直接点思路就是利用一个哈希表来记录数字和其出现次数之前的映射,然后维护一个变量mx来记录当前最多的次数值,这样在遍历完树之后,根据这个mx值就能把对应的元素找出来。那么用这种方法的话就不需要用到二分搜索树的性质了,随意一种遍历方式都可以。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public:
void inorder(TreeNode* root, unordered_map<int, int>& m, int& mx) {
if(root == NULL)
return;
inorder(root->left, m, mx);
mx = max(mx, ++m[root->val]);
inorder(root->right, m, mx);
}
vector<int> findMode(TreeNode* root) {
vector<int> res;
unordered_map<int, int> m;
int mx = -1;
inorder(root, m, mx);
for(unordered_map<int, int>::iterator p = m.begin(); p != m.end(); p ++) {
if(p->second == mx)
res.push_back(p->first);
}
return res;
}
};
Leetcode502. IPO
Suppose LeetCode will start its IPO soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the IPO. Since it has limited resources, it can only finish at most k distinct projects before the IPO. Help LeetCode design the best way to maximize its total capital after finishing at most k distinct projects.
You are given several projects. For each project i, it has a pure profit Pi and a minimum capital of Ci is needed to start the corresponding project. Initially, you have W capital. When you finish a project, you will obtain its pure profit and the profit will be added to your total capital.
To sum up, pick a list of at most k distinct projects from given projects to maximize your final capital, and output your final maximized capital.
Example 1:1
2
3
4
5
6
7
8
9Input: k=2, W=0, Profits=[1,2,3], Capital=[0,1,1].
Output: 4
Explanation: Since your initial capital is 0, you can only start the project indexed 0.
After finishing it you will obtain profit 1 and your capital becomes 1.
With capital 1, you can either start the project indexed 1 or the project indexed 2.
Since you can choose at most 2 projects, you need to finish the project indexed 2 to get the maximum capital.
Therefore, output the final maximized capital, which is 0 + 1 + 3 = 4.
Note:
- You may assume all numbers in the input are non-negative integers.
- The length of Profits array and Capital array will not exceed 50,000.
- The answer is guaranteed to fit in a 32-bit signed integer.
这道题说初始时我们的资本为0,可以交易k次,并且给了我们提供了交易所需的资本和所能获得的利润,让我们求怎样选择k次交易,使我们最终的资本最大。虽然题目中给我们的资本数组是有序的,但是OJ里的test case肯定不都是有序的,还有就是不一定需要资本大的交易利润就多,该遍历的时候还得遍历。我们可以用贪婪算法来解,每一次都选择资本范围内最大利润的进行交易,那么我们首先应该建立资本和利润对,然后根据资本的大小进行排序,然后我们根据自己当前的资本,用二分搜索法在有序数组中找第一个大于当前资本的交易的位置,然后往前退一步就是最后一个不大于当前资本的交易,然后向前遍历,找到利润最大的那个的进行交易,把利润加入资本W中,然后将这个交易对删除,这样我们就可以保证在进行k次交易后,我们的总资本最大,参见代码如下:
1 | class Solution { |
看论坛上的大神们都比较喜欢用一些可以自动排序的数据结构来做,比如我们可以使用一个最大堆和一个最小堆,把资本利润对放在最小堆中,这样需要资本小的交易就在队首,然后从队首按顺序取出资本小的交易,如果所需资本不大于当前所拥有的资本,那么就把利润资本存入最大堆中,注意这里资本和利润要翻个,因为我们希望把利润最大的交易放在队首,便于取出,这样也能实现我们的目的,参见代码如下:
解法二:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
int findMaximizedCapital(int k, int W, vector<int>& Profits, vector<int>& Capital) {
priority_queue<pair<int, int>> maxH;
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> minH;
for (int i = 0; i < Capital.size(); ++i) {
minH.push({Capital[i], Profits[i]});
}
for (int i = 0; i < k; ++i) {
while (!minH.empty() && minH.top().first <= W) {
auto t = minH.top(); minH.pop();
maxH.push({t.second, t.first});
}
if (maxH.empty()) break;
W += maxH.top().first; maxH.pop();
}
return W;
}
};
Leetcode503. Next Greater Element II
Given a circular array (the next element of the last element is the first element of the array), print the Next Greater Number for every element. The Next Greater Number of a number x is the first greater number to its traversing-order next in the array, which means you could search circularly to find its next greater number. If it doesn’t exist, output -1 for this number.
Example 1:1
2
3
4
5Input: [1,2,1]
Output: [2,-1,2]
Explanation: The first 1's next greater number is 2;
The number 2 can't find next greater number;
The second 1's next greater number needs to search circularly, which is also 2.
我的做法简单粗暴,循环遍历,直到找到正确的最大值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
int i, j, size = nums.size();
vector<int> res;
for(i = 0; i < size; i ++) {
for(j = i+1; j < size*2; j ++) {
if(nums[i] < nums[j%size]) {
res.push_back(nums[j%size]);
break;
}
}
if(j == size*2)
res.push_back(-1);
}
return res;
}
};
也可以在O(n)内完成,它是一个循环找peek问题,但没关系,复制一份同样的数组,放在它的后面就好了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public int[] nextGreaterElements(int[] nums) {
int len = nums.length;
int[] ans = new int[len];
Arrays.fill(ans, -1);
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < 2 * len; i++){
int num = nums[i % len];
while(!stack.isEmpty() && nums[stack.peek()] < num)
ans[stack.pop()] = num;
if (i < len) stack.push(i);
}
return ans;
}
Leetcode504. Base 7
Given an integer, return its base 7 string representation.
Example 1:1
2Input: 100
Output: "202"
Example 2:1
2Input: -7
Output: "-10"
将数字转化为7进制,用字符串形式输出。若是负数,在不考虑正负号的情况下算出7进制表示的数,最后在前面加上负号就行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Solution {
public:
string convertToBase7(int num) {
string res;
int num1 = abs(num);
if(num == 0)
return "0";
while(num1 != 0) {
int temp = num1 % 7;
num1 /= 7;
res = to_string(temp) + res;
}
if(num < 0)
res = "-" + res;
return res;
}
};
Leetcode506. Relative Ranks
Given scores of N athletes, find their relative ranks and the people with the top three highest scores, who will be awarded medals: “Gold Medal”, “Silver Medal” and “Bronze Medal”.
Example 1:1
2
3Input: [5, 4, 3, 2, 1]
Output: ["Gold Medal", "Silver Medal", "Bronze Medal", "4", "5"]
Explanation: The first three athletes got the top three highest scores, so they got "Gold Medal", "Silver Medal" and "Bronze Medal". For the left two athletes, you just need to output their relative ranks according to their scores.
对于给予的得分情况,找出前三名并给予相应的称号,其余以数字作为其名词,记录每个元素的位置和元素值.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution {
public:
vector<string> findRelativeRanks(vector<int>& nums) {
unordered_map<int, int> mp;
for(int i = 0; i < nums.size(); i++) {
mp[nums[i]] = i;
}
sort(nums.begin(), nums.end(), greater<int>());
vector<string> res(nums.size(), "");
for(int i = 0; i < nums.size(); i ++) {
if(i == 0)
res[mp[nums[i]]] = "Gold Medal";
else if(i == 1)
res[mp[nums[i]]] = "Silver Medal";
else if(i == 2)
res[mp[nums[i]]] = "Bronze Medal";
else res[mp[nums[i]]] = to_string(i+1);
}
return res;
}
};
另一种做法:1
2
3
4
5
6
7
8
9
10
11
12
13
14vector<string> findRelativeRanks(vector<int>& nums) {
const int n = nums.size();
vector<string> ans(n);
map<int, int> dict;
for(int i = 0; i < n; i++) dict[-nums[i]] = i;
int cnt = 0;
vector<string> top3{"Gold Medal", "Silver Medal", "Bronze Medal"};
for(auto& [k, i]: dict){
cnt++;
if(cnt <=3) ans[i] = top3[cnt-1];
else ans[i] = to_string(cnt);
}
return ans;
}
Leetcode507. Perfect Number
We define the Perfect Number is a positive integer that is equal to the sum of all its positive divisors except itself.
Now, given an integer n, write a function that returns true when it is a perfect number and false when it is not.
Example:1
2
3Input: 28
Output: True
Explanation: 28 = 1 + 2 + 4 + 7 + 14
把一个数的所有因子找出来然后求和,找一个数的所有因子的时候,并不是从 1 开始直到自身,而是从 1 开始直到 sqrt(自身)1
2
3
4
5
6
7
8
9
10
11
12
13class Solution {
public:
bool checkPerfectNumber(int num) {
int sum = 0;
if(num == 0)
return false;
for(int i = 1; i <= num/2; i ++) {
if(num%i == 0)
sum += i;
}
return sum == num;
}
};
Leetcode508. Most Frequent Subtree Sum
Given the root of a binary tree, return the most frequent subtree sum. If there is a tie, return all the values with the highest frequency in any order.
The subtree sum of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself).
Example 1:1
2Input: root = [5,2,-3]
Output: [2,-3,4]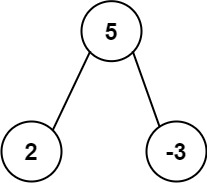
Example 2:1
2Input: root = [5,2,-5]
Output: [2]
这道题给了我们一个二叉树,让我们求出现频率最高的子树之和,求树的结点和并不是很难,就是遍历所有结点累加起来即可。那么这道题的暴力解法就是遍历每个结点,对于每个结点都看作子树的根结点,然后再遍历子树所有结点求和,这样也许可以通过 OJ,但是绝对不是最好的方法。我们想下子树有何特点,必须是要有叶结点,单独的一个叶结点也可以当作是子树,那么子树是从下往上构建的,这种特点很适合使用后序遍历,我们使用一个 HashMap 来建立子树和跟其出现频率的映射,用一个变量 cnt 来记录当前最多的次数,递归函数返回的是以当前结点为根结点的子树结点值之和,然后在递归函数中,我们先对当前结点的左右子结点调用递归函数,然后加上当前结点值,然后更新对应的 HashMap 中的值,然后看此时 HashMap 中的值是否大于等于 cnt,大于的话首先要清空 res,等于的话不用,然后将 sum 值加入结果 res 中即可,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Solution {
public:
vector<int> findFrequentTreeSum(TreeNode* root) {
vector<int> res;
int cnt = 0;
unordered_map<int, int> map;
dfs(root, map, res, cnt);
return res;
}
int dfs(TreeNode* root, unordered_map<int, int> &map, vector<int>& res, int &cnt) {
if (root == NULL)
return 0;
int left = dfs(root->left, map, res, cnt);
int right = dfs(root->right, map, res, cnt);
int sum = left + right + root->val;
map[sum] ++;
if (map[sum] >= cnt) {
if (map[sum] > cnt)
res.clear();
cnt = map[sum];
res.push_back(sum);
}
return sum;
}
};
Leetcode509. Fibonacci Number
The Fibonacci numbers, commonly denoted F(n) form a sequence, called the Fibonacci sequence, such that each number is the sum of the two preceding ones, starting from 0 and 1. That is,
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), for N > 1.
Given N, calculate F(N).
Example 1:1
2
3Input: 2
Output: 1
Explanation: F(2) = F(1) + F(0) = 1 + 0 = 1.
Example 2:1
2
3Input: 3
Output: 2
Explanation: F(3) = F(2) + F(1) = 1 + 1 = 2.
Example 3:1
2
3Input: 4
Output: 3
Explanation: F(4) = F(3) + F(2) = 2 + 1 = 3.
Note:
- 0 ≤ N ≤ 30.
斐波那契,不解释。1
2
3
4
5
6
7
8
9
10class Solution {
public:
int fib(int N) {
if(N==0)
return 0;
if(N==1)
return 1;
return fib(N-1)+fib(N-2);
}
};
另外的解法:动态规划。使用数组存储以前计算的斐波纳契值。Time Complexity - O(N),Space Complexity - O(N)1
2
3
4
5
6
7
8
9
10int fib(int N) {
if(N < 2)
return N;
int memo[N+1];
memo[0] = 0;
memo[1] = 1;
for(int i=2; i<=N; i++)
memo[i] = memo[i-1] + memo[i-2];
return memo[N];
}
Solution 3:使用Imperative方法,我们通过循环并通过在两个变量中仅存储两个先前的斐波那契值来优化空间。Time Complexity - O(N),Space Complexity - O(1)1
2
3
4
5
6
7
8
9
10
11
12int fib(int N) {
if(N < 2)
return N;
int a = 0, b = 1, c = 0;
for(int i = 1; i < N; i++)
{
c = a + b;
a = b;
b = c;
}
return c;
}
Leetcode513. Find Bottom Left Tree Value
Given the root of a binary tree, return the leftmost value in the last row of the tree.
Example 1:1
2Input: root = [2,1,3]
Output: 1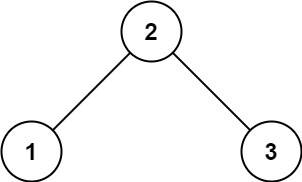
Example 2:1
2Input: root = [1,2,3,4,null,5,6,null,null,7]
Output: 7
这道题让我们求二叉树的最左下树结点的值,也就是最后一行左数第一个值,那么我首先想的是用先序遍历来做,我们维护一个最大深度和该深度的结点值,由于先序遍历遍历的顺序是根-左-右,所以每一行最左边的结点肯定最先遍历到,那么由于是新一行,那么当前深度肯定比之前的最大深度大,所以我们可以更新最大深度为当前深度,结点值res为当前结点值,这样在遍历到该行其他结点时就不会更新结果res了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int findBottomLeftValue(TreeNode* root) {
int res, max_depth = -1;
dfs(root, 0, max_depth, res);
return res;
}
void dfs(TreeNode* root, int depth, int& max_depth, int& res) {
if (root == NULL)
return;
dfs(root->left, depth+1, max_depth, res);
dfs(root->right, depth+1, max_depth, res);
if (depth > max_depth) {
res = root->val;
max_depth = depth;
}
}
};
Leetcode515. Find Largest Value in Each Tree Row
Given the root of a binary tree, return an array of the largest value in each row of the tree (0-indexed).
Example 1:1
2Input: root = [1,3,2,5,3,null,9]
Output: [1,3,9]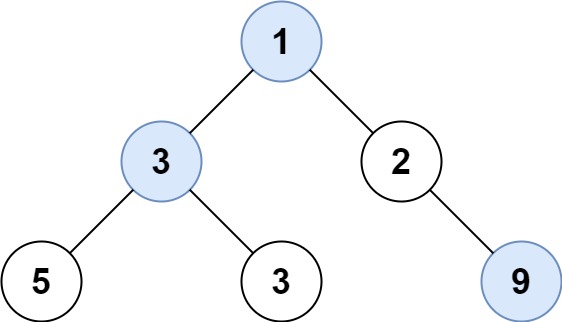
Example 2:1
2Input: root = [1,2,3]
Output: [1,3]
Example 3:1
2Input: root = [1]
Output: [1]
Example 4:1
2Input: root = [1,null,2]
Output: [1,2]
这道题让我们找二叉树每行的最大的结点值,那么实际上最直接的方法就是用层序遍历,然后在每一层中找到最大值,加入结果res中即可,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
vector<int> largestValues(TreeNode* root) {
if (root == NULL)
return {};
queue<TreeNode*> q;
q.push(root);
vector<int> res;
while(!q.empty()) {
int cnt = q.size();
int maxx = INT_MIN;
for (int i = 0; i < cnt; i ++) {
TreeNode* temp = q.front(); q.pop();
maxx = max(maxx, temp->val);
if (temp->left) q.push(temp->left);
if (temp->right) q.push(temp->right);
}
res.push_back(maxx);
}
return res;
}
};
Leetcode516. Longest Palindromic Subsequence
Given a string s, find the longest palindromic subsequence’s length in s. You may assume that the maximum length of s is 1000.
Example 1:1
2
3Input: "bbbab"
Output: 4
One possible longest palindromic subsequence is “bbbb”.
Example 2:1
2
3Input: "cbbd"
Output: 2
One possible longest palindromic subsequence is “bb”.
Constraints:
- 1 <= s.length <= 1000
- s consists only of lowercase English letters.
这道题给了我们一个字符串,让求最大的回文子序列,子序列和子字符串不同,不需要连续。而关于回文串的题之前也做了不少,处理方法上就是老老实实的两两比较吧。像这种有关极值的问题,最应该优先考虑的就是贪婪算法和动态规划,这道题显然使用DP更加合适。这里建立一个二维的DP数组,其中dp[i][j]表示[i,j]区间内的字符串的最长回文子序列,那么对于递推公式分析一下,如果s[i]==s[j],那么i和j就可以增加2个回文串的长度,我们知道中间dp[i + 1][j - 1]的值,那么其加上2就是dp[i][j]的值。如果s[i] != s[j],就可以去掉i或j其中的一个字符,然后比较两种情况下所剩的字符串谁dp值大,就赋给dp[i][j],那么递推公式如下:1
2
3 / dp[i + 1][j - 1] + 2 if (s[i] == s[j])
dp[i][j] =
\ max(dp[i + 1][j], dp[i][j - 1]) if (s[i] != s[j])
1 | class Solution { |
下面是递归形式的解法,memo 数组这里起到了一个缓存已经计算过了的结果,这样能提高运算效率,使其不会 TLE,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
int longestPalindromeSubseq(string s) {
int n = s.size();
vector<vector<int>> memo(n, vector<int>(n, -1));
return helper(s, 0, n - 1, memo);
}
int helper(string& s, int i, int j, vector<vector<int>>& memo) {
if (memo[i][j] != -1) return memo[i][j];
if (i > j) return 0;
if (i == j) return 1;
if (s[i] == s[j]) {
memo[i][j] = helper(s, i + 1, j - 1, memo) + 2;
} else {
memo[i][j] = max(helper(s, i + 1, j, memo), helper(s, i, j - 1, memo));
}
return memo[i][j];
}
};
Leetcode518. Coin Change 2
You are given coins of different denominations and a total amount of money. Write a function to compute the number of combinations that make up that amount. You may assume that you have infinite number of each kind of coin.
Note: You can assume that
- 0 <= amount <= 5000
- 1 <= coin <= 5000
- the number of coins is less than 500
- the answer is guaranteed to fit into signed 32-bit integer
Example 1:1
2
3
4
5
6
7Input: amount = 5, coins = [1, 2, 5]
Output: 4
Explanation: there are four ways to make up the amount:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
Example 2:1
2
3Input: amount = 3, coins = [2]
Output: 0
Explanation: the amount of 3 cannot be made up just with coins of 2.
Example 3:1
2Input: amount = 10, coins = [10]
Output: 1
这道题是之前那道 Coin Change 的拓展,那道题问我们最少能用多少个硬币组成给定的钱数,而这道题问的是组成给定钱数总共有多少种不同的方法。还是要使用 DP 来做,首先来考虑最简单的情况,如果只有一个硬币的话,那么给定钱数的组成方式就最多有1种,就看此钱数能否整除该硬币值。当有两个硬币的话,组成某个钱数的方式就可能有多种,比如可能由每种硬币单独来组成,或者是两种硬币同时来组成,怎么量化呢?比如我们有两个硬币 [1,2],钱数为5,那么钱数的5的组成方法是可以看作两部分组成,一种是由硬币1单独组成,那么仅有一种情况 (1+1+1+1+1);另一种是由1和2共同组成,说明组成方法中至少需要有一个2,所以此时先取出一个硬币2,然后只要拼出钱数为3即可,这个3还是可以用硬币1和2来拼,所以就相当于求由硬币 [1,2] 组成的钱数为3的总方法。是不是不太好理解,多想想。这里需要一个二维的 dp 数组,其中 dp[i][j] 表示用前i个硬币组成钱数为j的不同组合方法,怎么算才不会重复,也不会漏掉呢?我们采用的方法是一个硬币一个硬币的增加,每增加一个硬币,都从1遍历到 amount,对于遍历到的当前钱数j,组成方法就是不加上当前硬币的拼法 dp[i-1][j],还要加上,去掉当前硬币值的钱数的组成方法,当然钱数j要大于当前硬币值,状态转移方程也在上面的分析中得到了:1
dp[i][j] = dp[i - 1][j] + (j >= coins[i - 1] ? dp[i][j - coins[i - 1]] : 0)
注意要初始化每行的第一个位置为0,参见代码如下:
1 | class Solution { |
我们可以对空间进行优化,由于dp[i][j]仅仅依赖于dp[i - 1][j]和dp[i][j - coins[i - 1]]这两项,就可以使用一个一维dp数组来代替,此时的dp[i]表示组成钱数i的不同方法。其实最开始的时候,博主就想着用一维的 dp 数组来写,但是博主开始想的方法是把里面两个 for 循环调换了一个位置,结果计算的种类数要大于正确答案,所以一定要注意 for 循环的顺序不能搞反,参见代码如下:
1 | class Solution { |
在 CareerCup 中,有一道极其相似的题 9.8 Represent N Cents 美分的组成,书里面用的是那种递归的方法,博主想将其解法直接搬到这道题里,但是失败了,博主发现使用那种的递归的解法必须要有值为1的硬币存在,这点无法在这道题里满足。你以为这样博主就没有办法了吗?当然有,博主加了判断,当用到最后一个硬币时,判断当前还剩的钱数是否能整除这个硬币,不能的话就返回0,否则返回1。还有就是用二维数组的 memo 会 TLE,所以博主换成了 map,就可以通过啦~
1 | class Solution { |
Leetcode519. Random Flip Matrix
You are given the number of rows n_rows and number of columns n_cols of a 2D binary matrix where all values are initially 0. Write a function flip which chooses a 0 value uniformly at random, changes it to 1, and then returns the position [row.id, col.id] of that value. Also, write a function reset which sets all values back to 0. Try to minimize the number of calls to system’s Math.random() and optimize the time and space complexity.
Note:
- 1 <= n_rows, n_cols <= 10000
- 0 <= row.id < n_rows and 0 <= col.id < n_cols
- flip will not be called when the matrix has no 0 values left.
- the total number of calls to flip and reset will not exceed 1000.
Example 1:1
2
3
4Input:
["Solution","flip","flip","flip","flip"]
[[2,3],[],[],[],[]]
Output: [null,[0,1],[1,2],[1,0],[1,1]]
Example 2:1
2
3
4
5
6Input:
["Solution","flip","flip","reset","flip"]
[[1,2],[],[],[],[]]
Output: [null,[0,0],[0,1],null,[0,0]]
Explanation of Input Syntax:
The input is two lists: the subroutines called and their arguments. Solution's constructor has two arguments, n_rows and n_cols. flip and resethave no arguments. Arguments are always wrapped with a list, even if there aren't any.
这道题给了一个矩形的长和宽,让每次随机翻转其中的一个点,其中的隐含条件是,之前翻转过的点,下一次不能再翻转回来,而随机生成点是有可能有重复的,一旦很多点都被翻转后,很大概率会重复生成之前的点,所以需要有去重复的操作,而这也是本题的难点所在。可以用一个 HashSet 来记录翻转过了点,这样也方便进行查重操作。所以每次都随机出一个长和宽,然后看这个点是否已经在 HashSe t中了,不在的话,就加入 HashSet,然后返回即可,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Solution {
public:
Solution(int n_rows, int n_cols) {
row = n_rows; col = n_cols;
}
vector<int> flip() {
while (true) {
int x = rand() % row, y = rand() % col;
if (!flipped.count(x * col + y)) {
flipped.insert(x * col + y);
return {x, y};
}
}
}
void reset() {
flipped.clear();
}
private:
int row, col;
unordered_set<int> flipped;
};
Leetcode520. Detect Capital
Given a word, you need to judge whether the usage of capitals in it is right or not.
We define the usage of capitals in a word to be right when one of the following cases holds:
- All letters in this word are capitals, like “USA”.
- All letters in this word are not capitals, like “leetcode”.
- Only the first letter in this word is capital, like “Google”.
- Otherwise, we define that this word doesn’t use capitals in a right way.
Example 1:1
2Input: "USA"
Output: True
Example 2:1
2Input: "FlaG"
Output: False
看一个单词是不是只有第一个字母是大写的,或者是所有字母都是大写/小写。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
bool isbig(char c) {
if(c >= 'A' && c <= 'Z')
return true;
return false;
}
bool detectCapitalUse(string word) {
int flag = false;
if(isbig(word[0]))
flag = isbig(word[1]);
else
flag = false;
for(int i = 1; i < word.length(); i ++)
if(flag != isbig(word[i]))
return false;
return true;
}
};
Leetcode521. Longest Uncommon Subsequence I
Given two strings, you need to find the longest uncommon subsequence of this two strings. The longest uncommon subsequence is defined as the longest subsequence of one of these strings and this subsequence should not be any subsequence of the other string.
A subsequence is a sequence that can be derived from one sequence by deleting some characters without changing the order of the remaining elements. Trivially, any string is a subsequence of itself and an empty string is a subsequence of any string.
The input will be two strings, and the output needs to be the length of the longest uncommon subsequence. If the longest uncommon subsequence doesn’t exist, return -1.
Example 1:1
2
3
4
5
6Input: a = "aba", b = "cdc"
Output: 3
Explanation: The longest uncommon subsequence is "aba",
because "aba" is a subsequence of "aba",
but not a subsequence of the other string "cdc".
Note that "cdc" can be also a longest uncommon subsequence.
Example 2:1
2Input: a = "aaa", b = "bbb"
Output: 3
如果两个元素不等长,那么其中长字符本身就不是另一个字符的子序列,输出长度就行,如果等长,那么如果两个字符串相同,返回-1,不同返回长度,因为一个不是另一个的子序列。1
2
3
4
5
6class Solution {
public:
int findLUSlength(string a, string b) {
return a == b ? -1 : max(a.length(), b.length());
}
};
Leetcode522. Longest Uncommon Subsequence II 题解
Given a list of strings, you need to find the longest uncommon subsequence among them. The longest uncommon subsequence is defined as the longest subsequence of one of these strings and this subsequence should not be any subsequence of the other strings.
A subsequence is a sequence that can be derived from one sequence by deleting some characters without changing the order of the remaining elements. Trivially, any string is a subsequence of itself and an empty string is a subsequence of any string.
The input will be a list of strings, and the output needs to be the length of the longest uncommon subsequence. If the longest uncommon subsequence doesn’t exist, return -1.
Example 1:1
2
3
4
5Input: "aba", "cdc", "eae"
Output: 3
Note:
All the given strings' lengths will not exceed 10.
The length of the given list will be in the range of [2, 50].
由题意知,给定一个装有多个字符串的容器,我们需要找到其中最长的“非公共子序列”的长度。其中,这里的“子序列”是指:对于一个字符串,去掉这个字符串中任意几个字符,但剩余的字符在这个字符串中相对位置不变的字符串。“非公共子序列”是指某字符串与容器中其它任意字符串都不会构成如上定义的“子序列”关系,即某字符串不是其它字符串的“子序列”。
我们用双重for循环遍历的方法来做这道题,对于每个字符串,使其与其它字符串相比较,当两个字符串相同时,直接跳过。如果一个字符串不是其它任意一个字符串的“子序列”,那么这个字符串就是一个如上定义的“非公共子序列”,我们记录下它的长度。最后取最长的“非公共子序列”的长度返回。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class Solution {
public:
int findLUSlength(vector<string>& strs) {
int len = strs.size();
int res = -1;
for (int i = 0; i < len; i ++) {
int j = 0;
for (j = 0; j < len; j ++) {
if (i == j)
continue;
if (issubstr(strs[j], strs[i]))
break;
}
if (j == len)
res = max(res, (int)(strs[i].length()));
}
return res;
}
int issubstr(string& str1, string& str2) {
int p1 = 0, p2 = 0;
int len1 = str1.length(), len2 = str2.length();
while(p1 < len1) {
if (p2 >= len2)
break;
if (str1[p1] == str2[p2])
p2 ++;
p1 ++;
}
return p2 == len2;
}
};
Leetcode523. Continuous Subarray Sum
Given an integer array nums and an integer k, return true if nums has a continuous subarray of size at least two whose elements sum up to a multiple of k, or false otherwise.
An integer x is a multiple of k if there exists an integer n such that x = n * k. 0 is always a multiple of k.
Example 1:1
2
3Input: nums = [23,2,4,6,7], k = 6
Output: true
Explanation: [2, 4] is a continuous subarray of size 2 whose elements sum up to 6.
Example 2:1
2
3
4Input: nums = [23,2,6,4,7], k = 6
Output: true
Explanation: [23, 2, 6, 4, 7] is an continuous subarray of size 5 whose elements sum up to 42.
42 is a multiple of 6 because 42 = 7 * 6 and 7 is an integer.
Example 3:1
2Input: nums = [23,2,6,4,7], k = 13
Output: false
这道题给了我们一个数组和一个数字k,让求是否存在这样的一个连续的子数组,该子数组的数组之和可以整除k。
下面这种方法用了些技巧,那就是,若数字a和b分别除以数字c,若得到的余数相同,那么 (a-b) 必定能够整除c。用一个集合 HashSet 来保存所有出现过的余数,如果当前的累加和除以k得到的余数在 HashSet 中已经存在了,那么说明之前必定有一段子数组和可以整除k。需要注意的是k为0的情况,由于无法取余,就把当前累加和放入 HashSet 中。还有就是题目要求子数组至少需要两个数字,那么需要一个变量 pre 来记录之前的和,每次存入 HashSet 中的是 pre,而不是当前的累积和,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Solution {
public:
bool checkSubarraySum(vector<int>& nums, int k) {
int n = nums.size(), sum = 0, pre = 0;
unordered_set<int> st;
for (int i = 0; i < n; ++i) {
sum += nums[i];
int t = (k == 0) ? sum : (sum % k);
if (st.count(t)) return true;
st.insert(pre);
pre = t;
}
return false;
}
};
既然 HashSet 可以做,一般来说用 HashMap 也可以做,这里我们建立余数和当前位置之间的映射,由于有了位置信息,就不需要 pre 变量了,之前用保存的坐标和当前位置i比较判断就可以了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Solution {
public:
bool checkSubarraySum(vector<int>& nums, int k) {
int n = nums.size(), sum = 0;
unordered_map<int, int> m{{0,-1}};
for (int i = 0; i < n; ++i) {
sum += nums[i];
int t = (k == 0) ? sum : (sum % k);
if (m.count(t)) {
if (i - m[t] > 1) return true;
} else m[t] = i;
}
return false;
}
};
Leetcode524. Longest Word in Dictionary through Deleting
Given a string and a string dictionary, find the longest string in the dictionary that can be formed by deleting some characters of the given string. If there are more than one possible results, return the longest word with the smallest lexicographical order. If there is no possible result, return the empty string.
Example 1:1
2Input: s = "abpcplea", d = ["ale","apple","monkey","plea"]
Output: "apple"
Example 2:1
2Input: s = "abpcplea", d = ["a","b","c"]
Output: "a"
Note:
- All the strings in the input will only contain lower-case letters.
- The size of the dictionary won’t exceed 1,000.
- The length of all the strings in the input won’t exceed 1,000.
这道题给了我们一个字符串,和一个字典,让我们找到字典中最长的一个单词,这个单词可以通过给定单词通过删除某些字符得到。由于只能删除某些字符,并不能重新排序,所以我们不能通过统计字符出现个数的方法来判断是否能得到该单词,而是只能老老实实的按顺序遍历每一个字符。我们可以给字典排序,通过重写comparator来实现按长度由大到小来排,如果长度相等的就按字母顺序来排。然后我们开始遍历每一个单词,用一个变量i来记录单词中的某个字母的位置,我们遍历给定字符串,如果遍历到单词中的某个字母来,i自增1,如果没有,就继续往下遍历。这样如果最后i和单词长度相等,说明单词中的所有字母都按顺序出现在了字符串s中,由于字典中的单词已经按要求排过序了,所以第一个通过验证的单词一定是正确答案,我们直接返回当前单词即可,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
static bool comp(string& a, string& b) {
if (a.length() == b.length())
return a < b;
return a.length() > b.length();
}
string findLongestWord(string s, vector<string>& dictionary) {
int lens = s.length();
sort(dictionary.begin(), dictionary.end(), comp);
for (int i = 0; i < dictionary.size(); i ++) {
int ps = 0, pd = 0;
for (int j = 0; j < s.length(); j ++)
if (s[j] == dictionary[i][pd])
pd ++;
if (pd == dictionary[i].length())
return dictionary[i];
}
return "";
}
};
Leetcode525. Contiguous Array
Given a binary array nums, return the maximum length of a contiguous subarray with an equal number of 0 and 1.
Example 1:1
2
3Input: nums = [0,1]
Output: 2
Explanation: [0, 1] is the longest contiguous subarray with an equal number of 0 and 1.
Example 2:1
2
3Input: nums = [0,1,0]
Output: 2
Explanation: [0, 1] (or [1, 0]) is a longest contiguous subarray with equal number of 0 and 1.
这道题给了我们一个二进制的数组,让找邻近的子数组使其0和1的个数相等。对于求子数组的问题,需要时刻记着求累积和是一种很犀利的工具,但是这里怎么将子数组的和跟0和1的个数之间产生联系呢?这里需要用到一个 trick,遇到1就加1,遇到0,就减1,这样如果某个子数组和为0,就说明0和1的个数相等。知道了这一点,就用一个 HashMap 建立子数组之和跟结尾位置的坐标之间的映射。如果某个子数组之和在 HashMap 里存在了,说明当前子数组减去 HashMap 中存的那个子数组,得到的结果是中间一段子数组之和,必然为0,说明0和1的个数相等,更新结果 res。注意这里需要在 HashMap 初始化一个 0 -> -1 的映射,这是为了当 sum 第一次出现0的时候,即这个子数组是从原数组的起始位置开始,需要计算这个子数组的长度,而不是建立当前子数组之和 sum 和其结束位置之间的映射。比如就拿例子1来说,nums = [0, 1],当遍历0的时候,sum = -1,此时建立 -1 -> 0 的映射,当遍历到1的时候,此时 sum = 0 了,若 HashMap 中没有初始化一个 0 -> -1 的映射,此时会建立 0 -> 1 的映射,而不是去更新这个满足题意的子数组的长度,所以要这么初始化,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
int findMaxLength(vector<int>& nums) {
map<int, int> m{{0, -1}};
int sum = 0, res = 0;
for (int i = 0;i < nums.size(); i ++) {
if (nums[i] == 1)
sum ++;
else
sum --;
if (m.count(sum))
res = max(res, i-m[sum]);
else
m[sum] = i;
}
return res;
}
};
Leetcode526. Beautiful Arrangement
Suppose you have n integers labeled 1 through n. A permutation of those n integers perm (1-indexed) is considered a beautiful arrangement if for every i (1 <= i <= n), either of the following is true:
- perm[i] is divisible by i.
- i is divisible by perm[i].
Given an integer n, return the number of the beautiful arrangements that you can construct.
Example 1:1
2
3
4
5
6
7
8
9Input: n = 2
Output: 2
Explanation:
The first beautiful arrangement is [1,2]:
- perm[1] = 1 is divisible by i = 1
- perm[2] = 2 is divisible by i = 2
The second beautiful arrangement is [2,1]:
- perm[1] = 2 is divisible by i = 1
- i = 2 is divisible by perm[2] = 1
Example 2:1
2Input: n = 1
Output: 1
这道题给了我们1到N,总共N个正数,然后定义了一种优美排列方式,对于该排列中的所有数,如果数字可以整除下标,或者下标可以整除数字,那么我们就是优美排列,让我们求出所有优美排列的个数。那么对于求种类个数,或者是求所有情况,这种问题通常要用递归来做,递归简直是暴力的不能再暴力的方法了。而递归方法等难点在于写递归函数,如何确定终止条件,还有for循环中变量的起始位置如何确定。那么这里我们需要一个visited数组来记录数字是否已经访问过,因为优美排列中不能有重复数字。我们用变量pos来标记已经生成的数字的个数,如果大于N了,说明已经找到了一组排列,结果res自增1。在for循环中,i应该从1开始,因为我们遍历1到N中的所有数字,如果该数字未被使用过,且满足和坐标之间的整除关系,那么我们标记该数字已被访问过,再调用下一个位置的递归函数,之后不要忘记了恢复初始状态,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public:
int countArrangement(int n) {
int res = 0;
vector<bool> visited(n, false);
dfs(n, 1, visited, res);
return res;
}
void dfs(int n, int cur, vector<bool> visited, int& res) {
if (cur > n) {
res ++;
return ;
}
for (int i = 1; i <= n; i ++) {
if (visited[i-1] || (i%cur != 0 && cur%i != 0))
continue;
visited[i-1] = true;
dfs(n, cur+1, visited, res);
visited[i-1] = false;
}
}
};
Leetcode528. Random Pick with Weight
Given an array w of positive integers, where w[i] describes the weight of index i, write a function pickIndex which randomly picks an index in proportion to its weight.
Note:
- 1 <= w.length <= 10000
- 1 <= w[i] <= 10^5
- pickIndex will be called at most 10000 times.
Example 1:1
2
3
4Input:
["Solution","pickIndex"]
[[[1]],[]]
Output: [null,0]
Example 2:1
2
3
4Input:
["Solution","pickIndex","pickIndex","pickIndex","pickIndex","pickIndex"]
[[[1,3]],[],[],[],[],[]]
Output: [null,0,1,1,1,0]
Explanation of Input Syntax: The input is two lists: the subroutines called and their arguments. Solution‘s constructor has one argument, the array w. pickIndex has no arguments. Arguments are always wrapped with a list, even if there aren’t any.
这道题给了一个权重数组,让我们根据权重来随机取点,现在的点就不是随机等概率的选取了,而是要根据权重的不同来区别选取。比如题目中例子2,权重为 [1, 3],表示有两个点,权重分别为1和3,那么就是说一个点的出现概率是四分之一,另一个出现的概率是四分之三。由于我们的rand()函数是等概率的随机,那么我们如何才能有权重的随机呢,我们可以使用一个trick,由于权重是1和3,相加为4,那么我们现在假设有4个点,然后随机等概率取一个点,随机到第一个点后就表示原来的第一个点,随机到后三个点就表示原来的第二个点,这样就可以保证有权重的随机啦。那么我们就可以建立权重数组的累加和数组,比如若权重数组为 [1, 3, 2] 的话,那么累加和数组为 [1, 4, 6],整个的权重和为6,我们 rand() % 6,可以随机出范围 [0, 5] 内的数,随机到 0 则为第一个点,随机到 1,2,3 则为第二个点,随机到 4,5 则为第三个点,所以我们随机出一个数字x后,然后再累加和数组中查找第一个大于随机数x的数字,使用二分查找法可以找到第一个大于随机数x的数字的坐标,即为所求,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class Solution {
public:
vector<int> cumulative;
int sum;
Solution(vector<int>& w) {
cumulative.resize(w.size(), w[0]);
sum = w[0];
for (int i = 1; i < w.size(); i ++) {
cumulative[i] = cumulative[i-1] + w[i];
sum += w[i];
}
}
int pickIndex() {
int x = rand() % sum;
int left = 0, right = cumulative.size()-1, mid;
while(left < right) {
mid = left + (right-left) / 2;
if (cumulative[mid] <= x)
left = mid + 1;
else
right = mid;
}
return right;
}
};
Leetcode529. Minesweeper
Let’s play the minesweeper game (Wikipedia, online game)!
You are given an m x n char matrix board representing the game board where:
- ‘M’ represents an unrevealed mine,
- ‘E’ represents an unrevealed empty square,
- ‘B’ represents a revealed blank square that has no adjacent mines (i.e., above, below, left, right, and all 4 diagonals),
- digit (‘1’ to ‘8’) represents how many mines are adjacent to this revealed square, and
- ‘X’ represents a revealed mine.
You are also given an integer array click where click = [clickr, clickc] represents the next click position among all the unrevealed squares (‘M’ or ‘E’).
Return the board after revealing this position according to the following rules:
- If a mine ‘M’ is revealed, then the game is over. You should change it to ‘X’.
- If an empty square ‘E’ with no adjacent mines is revealed, then change it to a revealed blank ‘B’ and all of its adjacent unrevealed squares should be revealed recursively.
- If an empty square ‘E’ with at least one adjacent mine is revealed, then change it to a digit (‘1’ to ‘8’) representing the number of adjacent mines.
- Return the board when no more squares will be revealed.
Example 1:1
2Input: board = [["E","E","E","E","E"],["E","E","M","E","E"],["E","E","E","E","E"],["E","E","E","E","E"]], click = [3,0]
Output: [["B","1","E","1","B"],["B","1","M","1","B"],["B","1","1","1","B"],["B","B","B","B","B"]]
Example 2:1
2Input: board = [["B","1","E","1","B"],["B","1","M","1","B"],["B","1","1","1","B"],["B","B","B","B","B"]], click = [1,2]
Output: [["B","1","E","1","B"],["B","1","X","1","B"],["B","1","1","1","B"],["B","B","B","B","B"]]
这道题就是经典的扫雷游戏啦,经典到不能再经典,从Win98开始,附件中始终存在的游戏,和纸牌、红心大战、空当接龙一起称为四大天王,曾经消耗了博主太多的时间。小时侯一直不太会玩扫雷,就是瞎点,完全不根据数字分析,每次点几下就炸了,就觉得这个游戏好无聊。后来长大了一些,慢慢的理解了游戏的玩法,才发现这个游戏果然很经典,就像破解数学难题一样,充满了挑战与乐趣。花样百出的LeetCode这次把扫雷出成题,让博主借机回忆了一把小时侯,不错不错,那么来做题吧。题目中图文并茂,相信就算是没玩过扫雷的也能弄懂了,而且规则也说的比较详尽了,那么我们相对应的做法也就明了了。对于当前需要点击的点,我们先判断是不是雷,是的话直接标记X返回即可。如果不是的话,我们就数该点周围的雷个数,如果周围有雷,则当前点变为雷的个数并返回。如果没有的话,我们再对周围所有的点调用递归函数再点击即可。参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34class Solution {
public:
vector<vector<char>> updateBoard(vector<vector<char>>& board, vector<int>& click) {
if (board.empty() || board[0].empty()) return {};
int m = board.size(), n = board[0].size(), row = click[0], col = click[1], cnt = 0;
if (board[row][col] == 'M') {
board[row][col] = 'X';
} else {
for (int i = -1; i < 2; ++i) {
for (int j = -1; j < 2; ++j) {
int x = row + i, y = col + j;
if (x < 0 || x >= m || y < 0 || y >= n) continue;
if (board[x][y] == 'M') ++cnt;
}
}
if (cnt > 0) {
board[row][col] = cnt + '0';
} else {
board[row][col] = 'B';
for (int i = -1; i < 2; ++i) {
for (int j = -1; j < 2; ++j) {
int x = row + i, y = col + j;
if (x < 0 || x >= m || y < 0 || y >= n) continue;
if (board[x][y] == 'E') {
vector<int> nextPos{x, y};
updateBoard(board, nextPos);
}
}
}
}
}
return board;
}
};
下面这种解法跟上面的解法思路基本一样,写法更简洁了一些。可以看出上面的解法中的那两个for循环出现了两次,这样显得代码比较冗余,一般来说对于重复代码是要抽离成函数的,但那样还要多加个函数,也麻烦。我们可以根据第一次找周围雷个数的时候,若此时cnt个数为0并且标识是E的位置记录下来,那么如果最后雷个数确实为0了的话,我们直接遍历我们保存下来为E的位置调用递归函数即可,就不用再写两个for循环了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class Solution {
public:
vector<vector<char>> updateBoard(vector<vector<char>>& board, vector<int>& click) {
if (board.empty() || board[0].empty()) return {};
int m = board.size(), n = board[0].size(), row = click[0], col = click[1], cnt = 0;
if (board[row][col] == 'M') {
board[row][col] = 'X';
} else {
vector<vector<int>> neighbors;
for (int i = -1; i < 2; ++i) {
for (int j = -1; j < 2; ++j) {
int x = row + i, y = col + j;
if (x < 0 || x >= m || y < 0 || y >= n) continue;
if (board[x][y] == 'M') ++cnt;
else if (cnt == 0 && board[x][y] == 'E') neighbors.push_back({x, y});
}
}
if (cnt > 0) {
board[row][col] = cnt + '0';
} else {
for (auto a : neighbors) {
board[a[0]][a[1]] = 'B';
updateBoard(board, a);
}
}
}
return board;
}
};
下面这种方法是上面方法的迭代写法,用queue来存储之后要遍历的位置,这样就不用递归调用函数了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class Solution {
public:
vector<vector<char>> updateBoard(vector<vector<char>>& board, vector<int>& click) {
if (board.empty() || board[0].empty()) return {};
int m = board.size(), n = board[0].size();
queue<pair<int, int>> q({{click[0], click[1]}});
while (!q.empty()) {
int row = q.front().first, col = q.front().second, cnt = 0; q.pop();
vector<pair<int, int>> neighbors;
if (board[row][col] == 'M') board[row][col] = 'X';
else {
for (int i = -1; i < 2; ++i) {
for (int j = -1; j < 2; ++j) {
int x = row + i, y = col + j;
if (x < 0 || x >= m || y < 0 || y >= n) continue;
if (board[x][y] == 'M') ++cnt;
else if (cnt == 0 && board[x][y] == 'E') neighbors.push_back({x, y});
}
}
}
if (cnt > 0) board[row][col] = cnt + '0';
else {
for (auto a : neighbors) {
board[a.first][a.second] = 'B';
q.push(a);
}
}
}
return board;
}
};
Leetcode530. Minimum Absolute Difference in BST
Given a binary search tree with non-negative values, find the minimum absolute difference between values of any two nodes.
Example:1
2
3
4
5
6
7
8Input:
1
\
3
/
2
Output:
1
Explanation:
The minimum absolute difference is 1, which is the difference between 2 and 1 (or between 2 and 3).
这道题给了我们一棵二叉搜索树,让我们求任意个节点值之间的最小绝对差。由于BST的左<根<右的性质可知,如果按照中序遍历会得到一个有序数组,那么最小绝对差肯定在相邻的两个节点值之间产生。所以我们的做法就是对BST进行中序遍历,然后当前节点值和之前节点值求绝对差并更新结果res。这里需要注意的就是在处理第一个节点值时,由于其没有前节点,所以不能求绝对差。这里我们用变量pre来表示前节点值,这里由于题目中说明了所以节点值不为负数,所以我们给pre初始化-1,这样我们就知道pre是否存在。如果没有题目中的这个非负条件,那么就不能用int变量来,必须要用指针,通过来判断是否为指向空来判断前结点是否存在。还好这里简化了问题,用-1就能搞定了,这里我们先来看中序遍历的递归写法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
void inorder(TreeNode* root, int &pre, int &res) {
if(root == NULL)
return;
inorder(root->left, pre, res);
if(pre != -1)
res = min(abs(pre-root->val), res);
pre = root->val;
inorder(root->right, pre, res);
}
int getMinimumDifference(TreeNode* root) {
int res = INT_MAX, pre = -1;
inorder(root, pre, res);
return res;
}
};
Leetcode532. K-diff Pairs in an Array
Given an array of integers and an integer k, you need to find the number of unique k-diff pairs in the array. Here a k-diff pair is defined as an integer pair (i, j), where i and j are both numbers in the array and their absolute difference is k.
Example 1:1
2
3
4Input: [3, 1, 4, 1, 5], k = 2
Output: 2
Explanation: There are two 2-diff pairs in the array, (1, 3) and (3, 5).
Although we have two 1s in the input, we should only return the number of unique pairs.
Example 2:1
2
3Input:[1, 2, 3, 4, 5], k = 1
Output: 4
Explanation: There are four 1-diff pairs in the array, (1, 2), (2, 3), (3, 4) and (4, 5).
Example 3:1
2
3Input: [1, 3, 1, 5, 4], k = 0
Output: 1
Explanation: There is one 0-diff pair in the array, (1, 1).
这道题给了我们一个含有重复数字的无序数组,还有一个整数k,让找出有多少对不重复的数对 (i, j) 使得i和j的差刚好为k。由于k有可能为0,而只有含有至少两个相同的数字才能形成数对,那么就是说需要统计数组中每个数字的个数。可以建立每个数字和其出现次数之间的映射,然后遍历 HashMap 中的数字,如果k为0且该数字出现的次数大于1,则结果 res 自增1;如果k不为0,且用当前数字加上k后得到的新数字也在数组中存在,则结果 res 自增1。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
int findPairs(vector<int>& nums, int k) {
unordered_map<int, int> mp;
int res = 0;
for(int i : nums)
mp[i] ++;
for(auto i : mp) {
if(k == 0 && i.second > 1)
res ++;
if(k > 0 && mp.count(i.first+k)) {
//i.second --;
//mp[i.first+k] --;
// 不需要减1了,因为可以有重复。
res ++;
}
}
return res;
}
};
Leetcode535. Encode and Decode TinyURL
Note: This is a companion problem to the System Design problem: Design TinyURL
TinyURL is a URL shortening service where you enter a URL such as https://leetcode.com/problems/design-tinyurl and it returns a short URL such as http://tinyurl.com/4e9iAk.
Design the encode and decode methods for the TinyURL service. There is no restriction on how your encode/decode algorithm should work. You just need to ensure that a URL can be encoded to a tiny URL and the tiny URL can be decoded to the original URL.
这道题其实不难,给一个url,要求转成一个短字符串,并且能还原出来。为什么专门做这种题呢,其实是想复习C++一些STL的用法,这道题涉及了string和map的用法,先讲题,再专门开两个md谈用法。我的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41class Solution {
public:
map<string, int> map1;
map<int, string> map2;
string s="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
// Encodes a URL to a shortened URL.
string encode(string longUrl) {
map<string,int>::iterator key = map1.find(longUrl);
if(key==map1.end())
{
map1.insert(map<string, int>::value_type (longUrl,map1.size()+1));
map2.insert(map<int, string>::value_type (map2.size()+1,longUrl));
}
int n=map2.size();
string result;
// n is the number of longUrl
while(n>0){
printf("(%d) ",n);
int r = n%62;
n /= 62;
result.append(1,s[r]);
}
//printf("%s\n",result);
return result;
}
// Decodes a shortened URL to its original URL.
string decode(string shortUrl) {
int length = shortUrl.size();
int val=0;
for(int i=0;i<length;i++){
val = val*62+s.find(shortUrl[i]);
}
return map2.find(val)->second;
}
};
// Your Solution object will be instantiated and called as such:
// Solution solution;
// solution.decode(solution.encode(url));
别人的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class Solution {
public:
string alphabet = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
unordered_map<string, string> map;
string key = getRandom();
string getRandom() {
string s;
for (int i = 0; i < 6 ; i++) {
s += alphabet[rand() % 61]; }
return s;
}
// Encodes a URL to a shortened URL.
string encode(string longUrl) {
while(map.count(key)) {
key = getRandom();
}
map.insert(make_pair(key, longUrl));
return "http://tinyurl.com/" + key;
}
// Decodes a shortened URL to its original URL.
string decode(string shortUrl) {
return map.at(shortUrl.replace(0,shortUrl.size()-6,""));
}
};
Leetcode537. Complex Number Multiplication
Given two strings representing two complex numbers. You need to return a string representing their multiplication. Note i2 = -1 according to the definition.
Example 1:1
2
3Input: "1+1i", "1+1i"
Output: "0+2i"
Explanation: (1 + i) * (1 + i) = 1 + i2 + 2 * i = 2i, and you need convert it to the form of 0+2i.
Example 2:1
2
3Input: "1+-1i", "1+-1i"
Output: "0+-2i"
Explanation: (1 - i) * (1 - i) = 1 + i2 - 2 * i = -2i, and you need convert it to the form of 0+-2i.
Note:
- The input strings will not have extra blank.
- The input strings will be given in the form of a+bi, where the integer a and b will both belong to the range of [-100, 100]. - And the output should be also in this form.
复数相乘,简单。两种做法,第一种我写的,自己实现字符串解析,memory用的少但是时间慢一些,第二种用了库,时间短但是memory用的多。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59class Solution {
public:
pair<int,int> cal(string a){
pair<int ,int> aa;
int i;
int temp=0;
for(i=0;i<a.length();i++){
if(i!=0&&(a[i]<'0'||a[i]>'9'))
break;
else if(a[i]>='0'&&a[i]<='9'){
temp=temp*10+(a[i]-'0');
}
}
if(a[0]=='-')
temp=-temp;
int j=i+1,temp2=0;
for(;j<a.length();j++){
if(j!=i+1&&(a[j]<'0'||a[j]>'9'))
break;
else if(a[j]>='0'&&a[j]<='9'){
temp2=temp2*10+(a[j]-'0');
}
}
if(a[i+1]=='-')
temp2=-temp2;
aa.first=temp;
aa.second=temp2;
return aa;
}
string complexNumberMultiply(string a, string b) {
pair<int ,int> aa,bb;
//aa=cal(a);
//bb=cal(b);
//第一种
//第二种
int i;
for(i=0;i<a.length();i++)
if(a[i]=='+')
break;
aa.first=stoi(a.substr(0,i));
aa.second=stoi(a.substr(i+1,a.length()-2-i));
for(i=0;i<b.length();i++)
if(b[i]=='+')
break;
bb.first=stoi(b.substr(0,i));
bb.second=stoi(b.substr(i+1,b.length()-2-i));
int temp1,temp2;
temp1=aa.first*bb.first - aa.second*bb.second;
temp2=aa.first*bb.second + aa.second*bb.first;
string res=to_string(temp1)+"+"+to_string(temp2)+"i";
return res;
}
};
Leetcode538. Convert BST to Greater Tree
Given a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus sum of all keys greater than the original key in BST.
Example:1
2
3
4
5
6
7
8
9Input: The root of a Binary Search Tree like this:
5
/ \
2 13
Output: The root of a Greater Tree like this:
18
/ \
20 13
这道题让我们将二叉搜索树转为较大树,通过题目汇总的例子可以明白,是把每个结点值加上所有比它大的结点值总和当作新的结点值。仔细观察题目中的例子可以发现,2变成了20,而20是所有结点之和,因为2是最小结点值,要加上其他所有结点值,所以肯定就是所有结点值之和。5变成了18,是通过20减去2得来的,而13还是13,是由20减去7得来的,而7是2和5之和。通过看论坛,发现还有更巧妙的方法,不用先求出的所有的结点值之和,而是巧妙的将中序遍历左根右的顺序逆过来,变成右根左的顺序,这样就可以反向计算累加和sum,同时更新结点值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
void inorder(TreeNode* root, int& sum) {
if(root == NULL)
return;
inorder(root->right, sum);
root->val += sum;
sum = root->val;
inorder(root->left, sum);
}
TreeNode* convertBST(TreeNode* root) {
int sum = 0;
inorder(root, sum);
return root;
}
};
Leetcode539. Minimum Time Difference
Given a list of 24-hour clock time points in “Hour:Minutes” format, find the minimum minutes difference between any two time points in the list.
Example 1:1
2Input: ["23:59","00:00"]
Output: 1
Note:
- The number of time points in the given list is at least 2 and won’t exceed 20000.
- The input time is legal and ranges from 00:00 to 23:59.
这道题给了我们一系列无序的时间点,让我们求最短的两个时间点之间的差值。那么最简单直接的办法就是给数组排序,这样时间点小的就在前面了,然后我们分别把小时和分钟提取出来,计算差值,注意唯一的特殊情况就是第一个和末尾的时间点进行比较,第一个时间点需要加上24小时再做差值,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
vector<int> gettime(string& timePoint) {
return {(timePoint[0]-'0')*10 + (timePoint[1]-'0'), (timePoint[3]-'0')*10 + (timePoint[4]-'0')};
}
int findMinDifference(vector<string>& timePoints) {
int n = timePoints.size(), res = INT_MAX, tmp;
sort(timePoints.begin(), timePoints.end());
vector<int> firsttime = gettime(timePoints[0]), secondtime;
for (int i = 0; i < n; i ++) {
secondtime = gettime(timePoints[(i+1) % n]);
tmp = secondtime[1]-firsttime[1] + (secondtime[0]-firsttime[0])*60;
if (i == n-1)
tmp += 24*60;
res = min(res, tmp);
firsttime = secondtime;
}
return res;
}
};
下面这种写法跟上面的大体思路一样,写法上略有不同,是在一开始就把小时和分钟数提取出来并计算总分钟数存入一个新数组,然后再对新数组进行排序,再计算两两之差,最后还是要处理首尾之差,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public:
int gettime(string& timePoint) {
return ((timePoint[0]-'0')*10 + timePoint[1]-'0')*60 + (timePoint[3]-'0')*10 + timePoint[4]-'0';
}
int findMinDifference(vector<string>& timePoints) {
int n = timePoints.size(), res = INT_MAX, tmp;
vector<int> times;
for (int i = 0; i < n; i ++)
times.push_back(gettime(timePoints[i]));
sort(times.begin(), times.end());
for (int i = 0; i < n; i ++) {
tmp = times[(i+1)%n] - times[i];
if (i == n-1)
tmp += 24*60;
res = min(res, tmp);
}
return res;
}
};
Leetcode540. Single Element in a Sorted Array
Given a sorted array consisting of only integers where every element appears twice except for one element which appears once. Find this single element that appears only once.
Example 1:1
2Input: [1,1,2,3,3,4,4,8,8]
Output: 2
Example 2:1
2Input: [3,3,7,7,10,11,11]
Output: 10
Note: Your solution should run in O(log n) time and O(1) space.
这道题给我们了一个有序数组,说是所有的元素都出现了两次,除了一个元素,让我们找到这个元素。如果没有时间复杂度的限制,我们可以用多种方法来做,最straightforward的解法就是用个双指针,每次检验两个,就能找出落单的。也可以像Single Number里的方法那样,将所有数字亦或起来,相同的数字都会亦或成0,剩下就是那个落单的数字。那么由于有了时间复杂度的限制,需要为O(logn),而数组又是有序的,不难想到要用二分搜索法来做。二分搜索法的难点在于折半了以后,如何判断将要去哪个分支继续搜索,而这道题确实判断条件不明显,比如下面两个例子:
1 1 2 2 3
1 2 2 3 3
这两个例子初始化的时候left=0, right=4一样,mid算出来也一样为2,但是他们要去的方向不同,如何区分出来呢?仔细观察我们可以发现,如果当前数字出现两次的话,我们可以通过数组的长度跟当前位置的关系,计算出右边和当前数字不同的数字的总个数,如果是偶数个,说明落单数左半边,反之则在右半边。有了这个规律就可以写代码了,为啥我们直接就能跟mid+1比呢,不怕越界吗?当然不会,因为left如何跟right相等,就不会进入循环,所以mid一定会比right小,一定会有mid+1存在。当然mid是有可能为0的,所以此时当mid和mid+1的数字不等时,我们直接返回mid的数字就可以了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class Solution {
public:
int singleNonDuplicate(vector<int>& nums) {
int n = nums.size();
int left = 0, right = nums.size()-1, mid;
while(left < right) {
mid = left + (right - left) / 2;
if (nums[mid] == nums[mid+1]) {
if ((n-1-mid) % 2 == 1)
right = mid;
else
left = mid + 1;
}
else {
if (mid == 0 || nums[mid] != nums[mid-1])
return nums[mid];
if ((n-1-mid) % 2 == 1)
left = mid + 1;
else
right = mid;
}
}
return nums[left];
}
};
下面这种解法是对上面的分支进行合并,使得代码非常的简洁。使用到了亦或1这个小技巧,为什么要亦或1呢,原来我们可以将坐标两两归为一对,比如0和1,2和3,4和5等等。而亦或1可以直接找到你的小伙伴,比如对于2,亦或1就是3,对于3,亦或1就是2。如果你和你的小伙伴相等了,说明落单数在右边,如果不等,说明在左边,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
int singleNonDuplicate(vector<int>& nums) {
int left = 0, right = nums.size() - 1;
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == nums[mid ^ 1]) left = mid + 1;
else right = mid;
}
return nums[left];
}
};
Leetcode541. Reverse String II
Given a string and an integer k, you need to reverse the first k characters for every 2k characters counting from the start of the string. If there are less than k characters left, reverse all of them. If there are less than 2k but greater than or equal to k characters, then reverse the first k characters and left the other as original.
Example:1
2Input: s = "abcdefg", k = 2
Output: "bacdfeg"
这是一道字符逆序操作题1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Solution {
public:
string reverseStr(string s, int k) {
int len = s.length();
if(len == 0)
return "";
string sb = "";
int index = 0;
while (index < len){
string tmp = "";
for (int i = index; i < k + index && i < len; i++) {
tmp += s[i];
}
index += k;
reverse(tmp.begin(), tmp.end());
sb = sb + tmp;
for (int i = index; i < k + index && i < len; i++){
sb += s[i];
}
index += k;
}
return sb;
}
};
Leetcode542. 01 Matrix
Given an m x n binary matrix mat, return the distance of the nearest 0 for each cell.
The distance between two adjacent cells is 1.
Example 1:1
2
3
4
5
6
7
8Input: mat = [
[0,0,0],
[0,1,0],
[0,0,0]]
Output: [
[0,0,0],
[0,1,0],
[0,0,0]]
Example 2:1
2Input: mat = [[0,0,0],[0,1,0],[1,1,1]]
Output: [[0,0,0],[0,1,0],[1,2,1]]
这道题给了我们一个只有0和1的矩阵,让我们求每一个1到离其最近的0的距离,其实也就是求一个BFS。我们可以首先遍历一次矩阵,将值为0的点都存入queue,将值为1的点改为INT_MAX。之前像什么遍历迷宫啊,起点只有一个,而这道题所有为0的点都是起点。然后开始BFS遍历,从queue中取出一个数字,遍历其周围四个点,如果越界或者周围点的值小于等于当前值加1,则直接跳过。因为周围点的距离更小的话,就没有更新的必要,否则将周围点的值更新为当前值加1,然后把周围点的坐标加入queue,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Solution {
public:
vector<vector<int>> updateMatrix(vector<vector<int>>& mat) {
int m = mat.size(), n = mat[0].size();
vector<vector<int>> dir = {{-1, 0}, {1, 0}, {0, 1}, {0, -1}};
queue<pair<int, int>> q;
for (int i = 0; i < m; i ++)
for (int j = 0; j < n; j ++)
if (mat[i][j] == 0)
q.push({i, j});
else
mat[i][j] = INT_MAX;
while(!q.empty()) {
pair<int, int> t = q.front();
q.pop();
for (int i = 0; i < 4; i ++) {
int x = t.first + dir[i][0];
int y = t.second + dir[i][1];
if (x < 0 || x >= m || y < 0 || y >= n || mat[x][y] <= mat[t.first][t.second])
continue;
mat[x][y] = mat[t.first][t.second] + 1;
q.push({x, y});
}
}
return mat;
}
};
Leetcode543. Diameter of Binary Tree
Given a binary tree, you need to compute the length of the diameter of the tree. The diameter of a binary tree is the length of the longest path between any two nodes in a tree. This path may or may not pass through the root.
Example:1
2
3
4
5
6
7Given a binary tree
1
/ \
2 3
/ \
4 5
Return 3, which is the length of the path [4,2,1,3] or [5,2,1,3].
递归解题。遍历整个数,根据题意,直径等于左子树深度加上右子树深度,实时更新max,返回值是左右子树较大的深度值加1。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
int dfs(TreeNode* root, int &maxx) {
if(root == NULL)
return 0;
int left = dfs(root->left, maxx);
int right = dfs(root->right, maxx);
maxx = max(right+left, maxx);
return max(right, left) + 1;
}
int diameterOfBinaryTree(TreeNode* root) {
if(root == NULL)
return 0;
int maxx = -1;
dfs(root, maxx);
return maxx;
}
};
Leetcode547. Number of Provinces
There are n cities. Some of them are connected, while some are not. If city a is connected directly with city b, and city b is connected directly with city c, then city a is connected indirectly with city c.
A province is a group of directly or indirectly connected cities and no other cities outside of the group.
You are given an n x n matrix isConnected where isConnected[i][j] = 1 if the ith city and the jth city are directly connected, and isConnected[i][j] = 0 otherwise.
Return the total number of provinces.
Example 1:1
2Input: isConnected = [[1,1,0],[1,1,0],[0,0,1]]
Output: 2
Example 2:1
2Input: isConnected = [[1,0,0],[0,1,0],[0,0,1]]
Output: 3
这道题让我们求省的个数,题目中对于省的定义是可以传递的,比如A和B同省,B和C是同省,那么即使A和C不同省,那么他们三人也属于同省。那么比较直接的解法就是 DFS 搜索,对于某个城市,遍历其临近城市,然后再遍历其邻居的邻居,那么就能把属于同一个省的城市都遍历一遍,同时标记出已经遍历过的城市,然后累积省的个数,再去对于没有遍历到的城市在找临近的城市,这样就能求出个数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
if (isConnected.size() == 0)
return 0;
int res = 0, n = isConnected.size();
vector<int> visited(n, 0);
for (int i = 0; i < n; i ++) {
if (visited[i])
continue;
helper(isConnected, i, n, visited);
res ++;
}
return res;
}
void helper(vector<vector<int>>& isConnected, int i, int n, vector<int>& visited) {
visited[i] = true;
for (int ii = 0; ii < n; ii ++)
if (isConnected[i][ii] && !visited[ii])
helper(isConnected, ii, n, visited);
}
};
Leetcode551. Student Attendance Record I
You are given a string representing an attendance record for a student. The record only contains the following three characters:
- ‘A’ : Absent.
- ‘L’ : Late.
- ‘P’ : Present.
A student could be rewarded if his attendance record doesn’t contain more than one ‘A’ (absent) or more than two continuous ‘L’ (late).
You need to return whether the student could be rewarded according to his attendance record.
Example 1:1
2Input: "PPALLP"
Output: True
Example 2:1
2Input: "PPALLL"
Output: False
简单字符串统计,如果出席记录不包含多于一个“A”(缺席)或超过两个连续的“L”(晚),学生可以获得奖励。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
bool checkRecord(string s) {
int aa[3] = {0};
for(char c : s) {
if(c == 'A') {
aa[0] ++;
aa[1] = 0;
}
if(c == 'L') {
aa[1] ++;
if(aa[1] > 2)
break;
}else {
aa[1] = 0;
}
}
if(aa[0] <= 1 && aa[1] <= 2)
return true;
return false;
}
};
Leetcode553. Optimal Division
You are given an integer array nums. The adjacent integers in nums will perform the float division.
For example, for nums = [2,3,4], we will evaluate the expression “2/3/4”.
However, you can add any number of parenthesis at any position to change the priority of operations. You want to add these parentheses such the value of the expression after the evaluation is maximum.
Return the corresponding expression that has the maximum value in string format.
Note: your expression should not contain redundant parenthesis.
Example 1:1
2
3
4
5
6
7
8
9
10Input: nums = [1000,100,10,2]
Output: "1000/(100/10/2)"
Explanation:
1000/(100/10/2) = 1000/((100/10)/2) = 200
However, the bold parenthesis in "1000/((100/10)/2)" are redundant, since they don't influence the operation priority. So you should return "1000/(100/10/2)".
Other cases:
1000/(100/10)/2 = 50
1000/(100/(10/2)) = 50
1000/100/10/2 = 0.5
1000/100/(10/2) = 2
Example 2:1
2Input: nums = [2,3,4]
Output: "2/(3/4)"
Example 3:1
2Input: nums = [2]
Output: "2"
这道题给了我们一个数组,让我们确定除法的顺序,从而得到值最大的运算顺序,并且不能加多余的括号。刚开始博主没看清题,以为是要返回最大的值,就直接写了个递归的暴力搜索的方法,结果发现是要返回带括号的字符串,尝试的修改了一下,觉得挺麻烦。于是直接放弃抵抗,上网参考大神们的解法,结果大吃一惊,这题原来还可以这么解,完全是数学上的知识啊,太tricky了。数组中n个数字,如果不加括号就是:
x1 / x2 / x3 / … / xn
那么我们如何加括号使得其值最大呢,那么就是将x2后面的除数都变成乘数,比如只有三个数字的情况 a / b / c,如果我们在后两个数上加上括号 a / (b / c),实际上就是a / b * c。而且b永远只能当除数,a也永远只能当被除数。同理,x1只能当被除数,x2只能当除数,但是x3之后的数,只要我们都将其变为乘数,那么得到的值肯定是最大的,所以就只有一种加括号的方式,即:
x1 / (x2 / x3 / … / xn)
这样的话就完全不用递归了,这道题就变成了一个道简单的字符串操作的题目了,这思路,博主服了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
string optimalDivision(vector<int>& nums) {
if (nums.size() == 0)
return "";
int len = nums.size();
string res = "";
res += to_string(nums[0]);
for (int i = 1; i < len; i ++) {
if (i != 1 || len == 2)
res += ("/" + to_string(nums[i]));
else
res += ("/(" + to_string(nums[i]));
}
if (len > 2)
res += ")";
return res;
}
};
Leetcode554. Brick Wall
There is a brick wall in front of you. The wall is rectangular and has several rows of bricks. The bricks have the same height but different width. You want to draw a vertical line from the top to the bottom and cross the leastbricks.
The brick wall is represented by a list of rows. Each row is a list of integers representing the width of each brick in this row from left to right.
If your line go through the edge of a brick, then the brick is not considered as crossed. You need to find out how to draw the line to cross the least bricks and return the number of crossed bricks.
You cannot draw a line just along one of the two vertical edges of the wall, in which case the line will obviously cross no bricks.
Example:1
2
3
4
5
6
7
8Input:
[[1,2,2,1],
[3,1,2],
[1,3,2],
[2,4],
[3,1,2],
[1,3,1,1]]
Output: 2
Note:
- The width sum of bricks in different rows are the same and won’t exceed INT_MAX.
- The number of bricks in each row is in range [1,10,000]. The height of wall is in range [1,10,000]. Total number of bricks of the wall won’t exceed 20,000.
这道题给了我们一个砖头墙壁,上面由不同的长度的砖头组成,让选个地方从上往下把墙劈开,使得被劈开的砖头个数最少,前提是不能从墙壁的两边劈,这样没有什么意义。这里使用一个 HashMap 来建立每一个断点的长度和其出现频率之间的映射,这样只要从断点频率出现最多的地方劈墙,损坏的板砖一定最少。遍历砖墙的每一层,新建一个变量 sum,然后从第一块转头遍历到倒数第二块,将当前转头长度累加到 sum 上,这样每次得到的 sum 就是断点的长度,将其在 HashMap 中的映射值自增1,并且每次都更新下最大的映射值到变量 mx,这样最终 mx 就是出现次数最多的断点值,在这里劈开,绝对损伤的转头数量最少,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
int leastBricks(vector<vector<int>>& wall) {
map<int, int> m;
int res = 0;
for (int i = 0; i < wall.size(); i ++) {
int sum = 0;
for (int j = 0; j < wall[i].size()-1; j ++) {
sum += wall[i][j];
m[sum] ++;
res = max(res, m[sum]);
}
}
for (auto it = m.begin(); it != m.end(); it ++)
res = max(res, it->second);
return wall.size() - res;
}
};
Leetcode556. Next Greater Element III
Given a positive 32-bit integer n, you need to find the smallest 32-bit integer which has exactly the same digits existing in the integer n and is greater in value than n. If no such positive 32-bit integer exists, you need to return -1.
Example 1:1
2Input: 12
Output: 21
Example 2:1
2Input: 21
Output: -1
这道题给了我们一个数字,让我们对各个位数重新排序,求出刚好比给定数字大的一种排序,如果不存在就返回-1。这道题给的例子的数字都比较简单,我们来看一个复杂的,比如12443322,这个数字的重排序结果应该为13222344,如果我们仔细观察的话会发现数字变大的原因是左数第二位的2变成了3,细心的童鞋会更进一步的发现后面的数字由降序变为了升序,这也不难理解,因为我们要求刚好比给定数字大的排序方式。那么我们再观察下原数字,看看2是怎么确定的,我们发现,如果从后往前看的话,2是第一个小于其右边位数的数字,因为如果是个纯降序排列的数字,做任何改变都不会使数字变大,直接返回-1。知道了找出转折点的方法,再来看如何确定2和谁交换,这里2并没有跟4换位,而是跟3换了,那么如何确定的3?其实也是从后往前遍历,找到第一个大于2的数字交换,然后把转折点之后的数字按升序排列就是最终的结果了。最后记得为防止越界要转为长整数型,然后根据结果判断是否要返回-1即可,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class Solution {
public:
static bool comp(int &a, int &b) {
return a > b;
}
int nextGreaterElement(int n) {
vector<int> nums;
while(n > 0) {
nums.push_back(n%10);
n /= 10;
}
int len = nums.size();
int j, i = len-1;
for (i = 0; i < len-1; i ++)
if (nums[i] > nums[i+1])
break;
if (i == len-1)
return -1;
i ++;
for (j = 0; j < len-1; j ++)
if (nums[j] > nums[i])
break;
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
sort(nums.begin(), nums.begin()+i, comp);
long int res = 0;
for (i = len-1; i >= 0; i --) {
res = res * 10 + nums[i];
if (res > INT_MAX)
return -1;
}
return res;
}
};
Leetcode557. Reverse Words in a String III
Given a string, you need to reverse the order of characters in each word within a sentence while still preserving whitespace and initial word order.
Example 1:
Input: “Let’s take LeetCode contest”
Output: “s’teL ekat edoCteeL tsetnoc”
Note: In the string, each word is separated by single space and there will not be any extra space in the string.
1 | class Solution { |
另一种方法:1
2
3
4
5
6
7
8
9string reverseWords(string s) {
size_t front = 0;
for(int i = 0; i <= s.length(); ++i){
if(i == s.length() || s[i] == ' '){
reverse(&s[front], &s[i]);
front = i + 1;
}
}
return s;
用python一行就可以搞定1
return " ".join([i[::-1] for i in s.split()])
Leetcode558. Quad Tree Intersection
A quadtree is a tree data in which each internal node has exactly four children: topLeft, topRight, bottomLeft and bottomRight. Quad trees are often used to partition a two-dimensional space by recursively subdividing it into four quadrants or regions.
We want to store True/False information in our quad tree. The quad tree is used to represent a N * N boolean grid. For each node, it will be subdivided into four children nodes until the values in the region it represents are all the same. Each node has another two boolean attributes : isLeaf and val. isLeafis true if and only if the node is a leaf node. The val attribute for a leaf node contains the value of the region it represents.
For example, below are two quad trees A and B:
A:1
2
3
4
5
6
7
8
9
10
11
12
13+-------+-------+ T: true
| | | F: false
| T | T |
| | |
+-------+-------+
| | |
| F | F |
| | |
+-------+-------+
topLeft: T
topRight: T
bottomLeft: F
bottomRight: F
B:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17+-------+---+---+
| | F | F |
| T +---+---+
| | T | T |
+-------+---+---+
| | |
| T | F |
| | |
+-------+-------+
topLeft: T
topRight:
topLeft: F
topRight: F
bottomLeft: T
bottomRight: T
bottomLeft: T
bottomRight: F
Your task is to implement a function that will take two quadtrees and return a quadtree that represents the logical OR (or union) of the two trees.1
2
3
4
5
6
7
8
9
10A: B: C (A or B):
+-------+-------+ +-------+---+---+ +-------+-------+
| | | | | F | F | | | |
| T | T | | T +---+---+ | T | T |
| | | | | T | T | | | |
+-------+-------+ +-------+---+---+ +-------+-------+
| | | | | | | | |
| F | F | | T | F | | T | F |
| | | | | | | | |
+-------+-------+ +-------+-------+ +-------+-------+
Note:
- Both A and B represent grids of size N * N.
- N is guaranteed to be a power of 2.
- If you want to know more about the quad tree, you can refer to its wiki.
- The logic OR operation is defined as this: “A or B” is true if A is true, or if B is true, or if both A and B are true.
这道题又是一道四叉树的题,说是给了我们两个四叉树,然后让我们将二棵树相交形成了一棵四叉树,相交的机制采用的是或,即每个自区域相‘或’,题目中给的例子很好的说明了一些相‘或’的原则,比如我们看A和B中的右上结点,我们发现A树的右上结点已经是一个值为true的叶结点,而B的右上结点还是一个子树,那么此时不论子树里有啥内容,我们相交后的树的右上结点应该跟A树的右上结点保持一致,假如A树的右上结点值是false的话,相‘或’起不到任何作用,那么相交后的树的右上结点应该跟B树的右上结点保持一致。那么我们可以归纳出,只有某一个结点是叶结点了,我们看其值,如果是true,则相交后的结点和此结点保持一致,否则跟另一个结点保持一致。比较麻烦的情况是当两个结点都不是叶结点的情况,此时我们需要对相对应的四个子结点分别调用递归函数,调用之后还需要进行进一步处理,因为一旦四个子结点的值相同,且都是叶结点的话,那么此时应该合并为一个大的叶结点,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
Node* intersect(Node* quadTree1, Node* quadTree2) {
if (quadTree1->isLeaf) return quadTree1->val ? quadTree1 : quadTree2;
if (quadTree2->isLeaf) return quadTree2->val ? quadTree2 : quadTree1;
Node *tl = intersect(quadTree1->topLeft, quadTree2->topLeft);
Node *tr = intersect(quadTree1->topRight, quadTree2->topRight);
Node *bl = intersect(quadTree1->bottomLeft, quadTree2->bottomLeft);
Node *br = intersect(quadTree1->bottomRight, quadTree2->bottomRight);
if (tl->val == tr->val && tl->val == bl->val && tl->val == br->val && tl->isLeaf && tr->isLeaf && bl->isLeaf && br->isLeaf) {
return new Node(tl->val, true, NULL, NULL, NULL, NULL);
} else {
return new Node(false, false, tl, tr, bl, br);
}
}
};
Leetcode559. Maximum Depth of N-ary Tree
Given a n-ary tree, find its maximum depth.
The maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.
For example, given a 3-ary tree: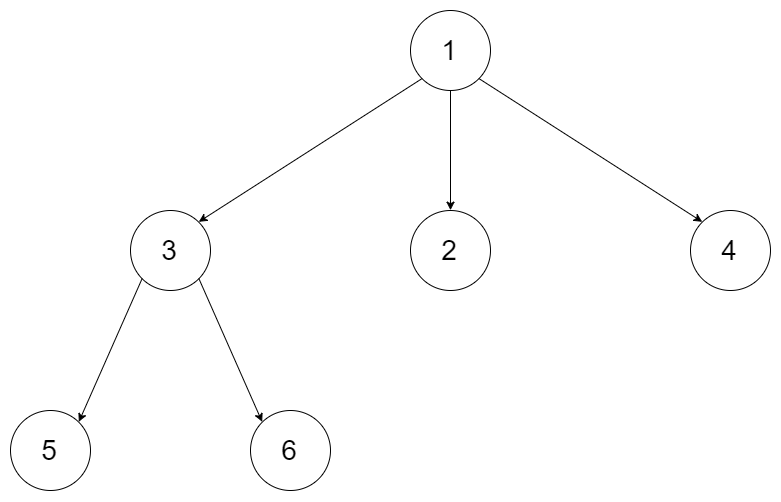
We should return its max depth, which is 3.
Note:
The depth of the tree is at most 1000.
The total number of nodes is at most 5000.
多叉树最大深度1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
int maxDepth(Node* root) {
if(root == NULL)
return 0;
if(root->children.size() == 0)
return 1;
int maxx = -1;
for(int i = 0; i < root->children.size(); i ++){
int temp = maxDepth(root->children[i]);
if(maxx < temp)
maxx = temp;
}
return maxx+1;
}
};
Leetcode560. Subarray Sum Equals K
Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.
Example 1:1
2Input:nums = [1,1,1], k = 2
Output: 2
Note:
- The length of the array is in range [1, 20,000].
- The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].
这道题给了我们一个数组,让求和为k的连续子数组的个数,博主最开始看到这道题想着肯定要建立累加和数组啊,然后遍历累加和数组的每个数字,首先看其是否为k,是的话结果 res 自增1,然后再加个往前的循环,这样可以快速求出所有的子数组之和,看是否为k,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
int res = 0, n = nums.size();
vector<int> sums = nums;
for (int i = 1; i < n; ++i) {
sums[i] = sums[i - 1] + nums[i];
}
for (int i = 0; i < n; ++i) {
if (sums[i] == k) ++res;
for (int j = i - 1; j >= 0; --j) {
if (sums[i] - sums[j] == k) ++res;
}
}
return res;
}
};
用一个 HashMap 来建立连续子数组之和跟其出现次数之间的映射,初始化要加入 {0,1} 这对映射,这是为啥呢,因为解题思路是遍历数组中的数字,用 sum 来记录到当前位置的累加和,建立 HashMap 的目的是为了可以快速的查找 sum-k 是否存在,即是否有连续子数组的和为 sum-k,如果存在的话,那么和为k的子数组一定也存在,这样当 sum 刚好为k的时候,那么数组从起始到当前位置的这段子数组的和就是k,满足题意,如果 HashMap 中事先没有 m[0] 项的话,这个符合题意的结果就无法累加到结果 res 中,这就是初始化的用途。上面讲解的内容顺带着也把 for 循环中的内容解释了,这里就不多阐述了,有疑问的童鞋请在评论区留言哈,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
int res = 0, sum = 0, n = nums.size();
unordered_map<int, int> m{{0, 1}};
for (int i = 0; i < n; ++i) {
sum += nums[i];
res += m[sum - k];
++m[sum];
}
return res;
}
};
Leetcode561. Array Partition I
Given an array of 2n integers, your task is to group these integers into n pairs of integer, say (a1, b1), (a2, b2), …, (an, bn) which makes sum of min(ai, bi) for all i from 1 to n as large as possible.
Example 1:1
2Input: [1,4,3,2]
Output: 4
Explanation: n is 2, and the maximum sum of pairs is 4 = min(1, 2) + min(3, 4).
Note:
n is a positive integer, which is in the range of [1, 10000].
All the integers in the array will be in the range of [-10000, 10000].
这道题目给了我们一个数组有2n integers, 需要我们把这个数组分成n对,然后从每一对里面拿小的那个数字,把所有的加起来,返回这个sum。并且要使这个sum 尽量最大。如何让sum 最大化呢,我们想一下,如果是两个数字,一个很小,一个很大,这样的话,取一个小的数字,就浪费了那个大的数字。所以我们要使每一对的两个数字尽可能接近。我们先把nums sort 一下,让它从小到大排列,接着每次把index: 0, 2, 4…偶数位的数字加起来就可以了。1
2
3
4
5
6
7
8
9
10
11class Solution {
public:
int arrayPairSum(vector<int>& nums) {
sort(nums.begin(),nums.end());
int sum=0;
for(int i=0;i<nums.size();i+=2)
sum+=nums[i];
return sum;
}
};
Leetcode563. Binary Tree Tilt
Given a binary tree, return the tilt of the whole tree.
The tilt of a tree node is defined as the absolute difference between the sum of all left subtree node values and the sum of all right subtree node values. Null node has tilt 0.
The tilt of the whole tree is defined as the sum of all nodes’ tilt.
Example:1
2
3
4
5
6
7
8
9
10Input:
1
/ \
2 3
Output: 1
Explanation:
Tilt of node 2 : 0
Tilt of node 3 : 0
Tilt of node 1 : |2-3| = 1
Tilt of binary tree : 0 + 0 + 1 = 1
这道题其实是要求 求出各个节点左右子树的差的绝对值,将这些绝对值求和并返回。左右子树的差 = | 左子树所有节点的值的和 - 右子树所有节点的值的和 |。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
int dfs(TreeNode* root, int& ans) {
if(root == NULL)
return 0;
int left, right;
left = dfs(root->left, ans);
right = dfs(root->right, ans);
int tilt = abs(left - right);
ans += tilt;
return left + right + root->val;
}
int findTilt(TreeNode* root) {
int ans = 0;
dfs(root, ans);
return ans;
}
};
Leetcode565. Array Nesting
A zero-indexed array A of length N contains all integers from 0 to N-1. Find and return the longest length of set S, where S[i] = {A[i], A[A[i]], A[A[A[i]]], … } subjected to the rule below.
Suppose the first element in S starts with the selection of element A[i] of index = i, the next element in S should be A[A[i]], and then A[A[A[i]]]… By that analogy, we stop adding right before a duplicate element occurs in S.
Example 1:1
2
3
4
5
6
7Input: A = [5,4,0,3,1,6,2]
Output: 4
Explanation:
A[0] = 5, A[1] = 4, A[2] = 0, A[3] = 3, A[4] = 1, A[5] = 6, A[6] = 2.
One of the longest S[K]:
S[0] = {A[0], A[5], A[6], A[2]} = {5, 6, 2, 0}
Note:
- N is an integer within the range [1, 20,000].
- The elements of A are all distinct.
- Each element of A is an integer within the range [0, N-1].
这道题让我们找嵌套数组的最大个数,给的数组总共有n个数字,范围均在 [0, n-1] 之间,题目中也把嵌套数组的生成解释的很清楚了,其实就是值变成坐标,得到的数值再变坐标。那么实际上当循环出现的时候,嵌套数组的长度也不能再增加了,而出现的这个相同的数一定是嵌套数组的首元素。其实对于遍历过的数字,我们不用再将其当作开头来计算了,而是只对于未遍历过的数字当作嵌套数组的开头数字,不过在进行嵌套运算的时候,并不考虑中间的数字是否已经访问过,而是只要找到和起始位置相同的数字位置,然后更新结果 res,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class Solution {
public:
int arrayNesting(vector<int>& nums) {
int len = nums.size();
vector<bool> visited(len, false);
int res = 0;
for (int i = 0; i < len; i ++) {
if (visited[i])
continue;
res = max(res, helper(nums, i, visited));
}
return res;
}
int helper(vector<int>& nums, int start, vector<bool> &visited) {
int len = nums.size();
int res = 0;
while(start < len && !visited[start]) {
visited[start] = true;
res ++;
start = nums[start];
}
return res;
}
};
Leetcode566. Reshape the Matrix
In MATLAB, there is a very useful function called ‘reshape’, which can reshape a matrix into a new one with different size but keep its original data.
You’re given a matrix represented by a two-dimensional array, and two positive integers r and c representing the row number and column number of the wanted reshaped matrix, respectively.
The reshaped matrix need to be filled with all the elements of the original matrix in the same row-traversing order as they were.
If the ‘reshape’ operation with given parameters is possible and legal, output the new reshaped matrix; Otherwise, output the original matrix.
Example 1:1
2
3
4
5
6
7
8
9Input:
nums =
[[1,2],
[3,4]]
r = 1, c = 4
Output:
[[1,2,3,4]]
Explanation:
The row-traversing of nums is [1,2,3,4]. The new reshaped matrix is a 1 * 4 matrix, fill it row by row by using the previous list.
Example 2:1
2
3
4
5
6
7
8
9
10Input:
nums =
[[1,2],
[3,4]]
r = 2, c = 4
Output:
[[1,2],
[3,4]]
Explanation:
There is no way to reshape a 2 * 2 matrix to a 2 * 4 matrix. So output the original matrix.
把矩阵换个样子输出出来,效率还挺高的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution {
public:
vector<vector<int>> matrixReshape(vector<vector<int>>& nums, int r, int c) {
int m = nums.size(), n = nums[0].size();
if(m*n != r*c)
return nums;
vector<vector<int>> res(r, vector<int>(c, 0));
int ii = 0, jj = 0;
for(int i = 0; i < m; i ++)
for(int j = 0; j < n; j ++) {
res[ii][jj] = nums[i][j];
if(jj == c - 1) {
ii ++;
jj = 0;
}
else
jj ++;
}
return res;
}
};
Leetcode567. Permutation in String
Given two strings s1 and s2, write a function to return true if s2 contains the permutation of s1. In other words, one of the first string’s permutations is the substring of the second string.
Example 1:1
2
3Input:s1 = "ab" s2 = "eidbaooo"
Output:True
Explanation: s2 contains one permutation of s1 ("ba").
Example 2:1
2Input:s1= "ab" s2 = "eidboaoo"
Output: False
Note:
- The input strings only contain lower case letters.
- The length of both given strings is in range [1, 10,000].
这道题给了两个字符串s1和s2,问我们s1的全排列的字符串任意一个是否为s2的字串。这道题的正确做法应该是使用滑动窗口Sliding Window的思想来做,可以使用两个哈希表来做,或者是使用一个哈希表配上双指针来做。我们先来看使用两个哈希表来做的情况,我们先来分别统计s1和s2中前n1个字符串中各个字符出现的次数,其中n1为字符串s1的长度,这样如果二者字符出现次数的情况完全相同,说明s1和s2中前n1的字符互为全排列关系,那么符合题意了,直接返回true。如果不是的话,那么我们遍历s2之后的字符,对于遍历到的字符,对应的次数加1,由于窗口的大小限定为了n1,所以每在窗口右侧加一个新字符的同时就要在窗口左侧去掉一个字符,每次都比较一下两个哈希表的情况,如果相等,说明存在,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class Solution {
public:
bool checkInclusion(string s1, string s2) {
int len1 = s1.length(), len2 = s2.length();
if (len1 > len2)
return false;
unordered_map<char, int>::iterator it;
unordered_map<char, int> m1, m2;
for (int i = 0; i < len1; i ++) {
m1[s1[i]] ++;
m2[s2[i]] ++;
}
for (int i = len1; i < len2; i ++) {
for (it = m1.begin(); it != m1.end(); it ++) {
if (it->second != m2[it->first])
break;
}
if (it == m1.end())
return true;
m2[s2[i-len1]] --;
m2[s2[i]] ++;
}
for (it = m1.begin(); it != m1.end(); it ++) {
if (it->second != m2[it->first])
break;
}
if (it == m1.end())
return true;
return false;
}
};
Leetcode572. Subtree of Another Tree
Given two non-empty binary trees s and t, check whether tree t has exactly the same structure and node values with a subtree of s. A subtree of s is a tree consists of a node in s and all of this node’s descendants. The tree s could also be considered as a subtree of itself.
Example 1:1
2
3
4
5
6
7
8
9
10
11Given tree s:
3
/ \
4 5
/ \
1 2
Given tree t:
4
/ \
1 2
Return true, because t has the same structure and node values with a subtree of s.
Example 2:1
2
3
4
5
6
7
8
9
10
11
12
13Given tree s:
3
/ \
4 5
/ \
1 2
/
0
Given tree t:
4
/ \
1 2
Return false.
这道题让我们求一个数是否是另一个树的子树,从题目中的第二个例子中可以看出,子树必须是从叶结点开始的,中间某个部分的不能算是子树,那么我们转换一下思路,是不是从s的某个结点开始,跟t的所有结构都一样,那么问题就转换成了判断两棵树是否相同,也就是Same Tree的问题了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
bool issame(TreeNode* s, TreeNode* t) {
if(!s && !t)
return true;
if(!s || !t)
return false;
if(s->val != t->val)
return false;
return issame(s->left, t->left) && issame(s->right, t->right);
}
bool isSubtree(TreeNode* s, TreeNode* t) {
if (!s) return false;
if (issame(s, t)) return true;
return isSubtree(s->left, t) || isSubtree(s->right, t);
}
};
Leetcode575. Distribute Candies
Given an integer array with even length, where different numbers in this array represent different kinds of candies. Each number means one candy of the corresponding kind. You need to distribute these candies equally in number to brother and sister. Return the maximum number of kinds of candies the sister could gain.
Example 1:1
2
3
4
5
6Input: candies = [1,1,2,2,3,3]
Output: 3
Explanation:
There are three different kinds of candies (1, 2 and 3), and two candies for each kind.
Optimal distribution: The sister has candies [1,2,3] and the brother has candies [1,2,3], too.
The sister has three different kinds of candies.
Example 2:1
2
3
4Input: candies = [1,1,2,3]
Output: 2
Explanation: For example, the sister has candies [2,3] and the brother has candies [1,1].
The sister has two different kinds of candies, the brother has only one kind of candies.
记录糖果种类,若糖果种类大于数组的一半,妹妹最多得到candies.size()/2种糖果,否则每种糖果都可以得到1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
int distributeCandies(vector<int>& candies) {
int len = candies.size();
int unique = 0;
sort(candies.begin(), candies.end());
for(int i = 0; i < len; i ++)
if(i == 0 || candies[i] != candies[i-1])
unique ++;
return min(unique, len/2);
}
};
LeetCode576. Out of Boundary Paths
There is an m by n grid with a ball. Given the start coordinate (i,j) of the ball, you can move the ball to adjacent cell or cross the grid boundary in four directions (up, down, left, right). However, you can at most move N times. Find out the number of paths to move the ball out of grid boundary. The answer may be very large, return it after mod 109 + 7.
Example 1:1
2Input:m = 2, n = 2, N = 2, i = 0, j = 0
Output: 6
Example 2:1
2Input:m = 1, n = 3, N = 3, i = 0, j = 1
Output: 12
Note:
- Once you move the ball out of boundary, you cannot move it back.
- The length and height of the grid is in range [1,50].
- N is in range [0,50].
这道题给了我们一个二维的数组,某个位置放个足球,每次可以在上下左右四个方向中任意移动一步,总共可以移动N步,问我们总共能有多少种移动方法能把足球移除边界,由于结果可能是个巨大的数,所以让我们对一个大数取余。那么我们知道对于这种结果很大的数如果用递归解法很容易爆栈,所以最好考虑使用DP来解。那么我们使用一个三维的DP数组,其中dp[k][i][j]表示总共走k步,从(i,j)位置走出边界的总路径数。那么我们来找递推式,对于dp[k][i][j],走k步出边界的总路径数等于其周围四个位置的走k-1步出边界的总路径数之和,如果周围某个位置已经出边界了,那么就直接加上1,否则就在dp数组中找出该值,这样整个更新下来,我们就能得出每一个位置走任意步数的出界路径数了,最后只要返回dp[N][i][j]就是所求结果了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
int findPaths(int m, int n, int maxMove, int startRow, int startColumn) {
vector<vector<vector<int>>> dp(maxMove+1, vector<vector<int>>(m, vector<int>(n, 0)));
for (int k = 1; k <= maxMove; k ++)
for (int i = 0; i < m; i ++)
for (int j = 0; j < n; j ++) {
long long int x1 = j == n-1 ? 1 : dp[k-1][i][j+1];
long long int x2 = j == 0 ? 1 : dp[k-1][i][j-1];
long long int x3 = i == m-1 ? 1 : dp[k-1][i+1][j];
long long int x4 = i == 0 ? 1 : dp[k-1][i-1][j];
dp[k][i][j] = (x1+x2+x3+x4) % 1000000007;
}
return dp[maxMove][startRow][startColumn];
}
};
Leetcode581. Shortest Unsorted Continuous Subarray
Given an integer array, you need to find one continuous subarray that if you only sort this subarray in ascending order, then the whole array will be sorted in ascending order, too.
You need to find the shortest such subarray and output its length.
Example 1:1
2
3Input: [2, 6, 4, 8, 10, 9, 15]
Output: 5
Explanation: You need to sort [6, 4, 8, 10, 9] in ascending order to make the whole array sorted in ascending order.
这道题是要找出最短的子数组,如果此子数组按照升序排列,则整个数组按照升序排列。先用一个数组temp保存nums,然后对temp排序,然后用两个变量start和end去找两个数组出现不同之处的第一个位置和最后一个位置,最后返回end-start+1就是要找的数组长度。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
int findUnsortedSubarray(vector<int>& nums) {
vector<int> temp(nums);
sort(nums.begin(), nums.end());
int start, end;
for(start = 0; start < nums.size(); start ++) {
if(temp[start] != nums[start]) {
break;
}
}
for(end = nums.size()-1; end >= start; end --) {
if(temp[end] != nums[end]) {
break;
}
}
return end - start + 1;
}
};
Leetcode583. Delete Operation for Two Strings
Given two words word1 and word2 , find the minimum number of steps required to make word1 and word2 the same, where in each step you can delete one character in either string.
Example 1:1
2
3Input: "sea", "eat"
Output: 2
Explanation: You need one step to make "sea" to "ea" and another step to make "eat" to "ea".
Note:
- The length of given words won’t exceed 500.
- Characters in given words can only be lower-case letters.
这道题给了我们两个单词,问最少需要多少步可以让两个单词相等,每一步可以在任意一个单词中删掉一个字符。那么来分析怎么能让步数最少呢,是不是知道两个单词最长的相同子序列的长度,并乘以2,被两个单词的长度之和减,就是最少步数了。
定义一个二维的 dp 数组,其中dp[i][j]表示 word1 的前i个字符和 word2 的前j个字符组成的两个单词的最长公共子序列的长度。下面来看状态转移方程dp[i][j]怎么求,首先来考虑dp[i][j]和dp[i-1][j-1]之间的关系,可以发现,如果当前的两个字符相等,那么dp[i][j] = dp[i-1][j-1] + 1,这不难理解吧,因为最长相同子序列又多了一个相同的字符,所以长度加1。由于 dp 数组的大小定义的是(n1+1) x (n2+1),所以比较的是word1[i-1]和word2[j-1]。如果这两个字符不相等呢,难道直接将dp[i-1][j-1]赋值给dp[i][j]吗,当然不是,这里还要错位相比嘛,比如就拿题目中的例子来说,”sea” 和 “eat”,当比较第一个字符,发现 ‘s’ 和 ‘e’ 不相等,下一步就要错位比较啊,比较 sea 中第一个 ‘s’ 和 eat 中的 ‘a’,sea 中的 ‘e’ 跟 eat 中的第一个 ‘e’ 相比,这样dp[i][j]就要取dp[i-1][j]跟dp[i][j-1]中的较大值了,最后求出了最大共同子序列的长度,就能直接算出最小步数了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14class Solution {
public:
int minDistance(string word1, string word2) {
int m = word1.length(), n = word2.length();
vector<vector<int>> dp(m+1, vector(n+1, 0));
for (int i = 1; i <= m; i ++)
for (int j = 1; j <= n; j ++)
if (word1[i-1] == word2[j-1])
dp[i][j] = dp[i-1][j-1] + 1;
else
dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
return m + n - 2 * dp[m][n];
}
};
Leetcode589. N-ary Tree Preorder Traversal
Given an n-ary tree, return the preorder traversal of its nodes’ values.
For example, given a 3-ary tree: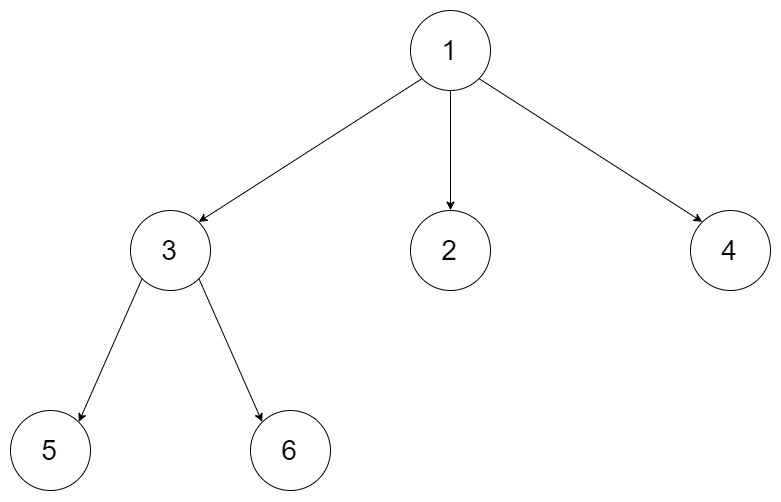
Return its preorder traversal as: [1,3,5,6,2,4].
Note:
Recursive solution is trivial, could you do it iteratively?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Solution {
public:
vector<int> res;
void des(Node* root){
if(root==NULL)
return ;
res.push_back(root->val);
for(int i=0;i<root->children.size();i++)
des(root->children[i]);
return;
}
vector<int> preorder(Node* root) {
des(root);
return res;
}
};
Leetcode590. N-ary Tree Postorder Traversal
Given an n-ary tree, return the postorder traversal of its nodes’ values.
For example, given a 3-ary tree:
Return its postorder traversal as: [5,6,3,2,4,1].
Note:
Recursive solution is trivial, could you do it iteratively?
遍历一棵n叉树。
1 | class Solution { |
Leetcode592. Fraction Addition and Subtraction
Given a string expression representing an expression of fraction addition and subtraction, return the calculation result in string format.
The final result should be an irreducible fraction. If your final result is an integer, say 2, you need to change it to the format of a fraction that has a denominator 1. So in this case, 2 should be converted to 2/1.
Example 1:1
2Input: expression = "-1/2+1/2"
Output: "0/1"
Example 2:1
2Input: expression = "-1/2+1/2+1/3"
Output: "1/3"
Example 3:1
2Input: expression = "1/3-1/2"
Output: "-1/6"
Example 4:1
2Input: expression = "5/3+1/3"
Output: "2/1"
这道题让我们做分数的加减法,给了我们一个分数加减法式子的字符串,然我们算出结果,结果当然还是用分数表示了。那么其实这道题主要就是字符串的拆分处理,再加上一点中学的数学运算的知识就可以了。中学数学告诉我们必须将分母变为同一个数,分子才能相加,为了简便,我们不求最小公倍数,而是直接乘上另一个数的分母,然后相加。不过得到的结果需要化简一下,我们求出分子分母的最大公约数,记得要取绝对值,然后分子分母分别除以这个最大公约数就是最后的结果了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66class Solution {
public:
int fun(int m, int n){
if (m < 0)
m = -m;
if (n < 0)
n = -n;
if (m < n) {
int tmp = m;
m = n;
n = tmp;
}
int rem;
while(n > 0){
rem = m % n;
m = n;
n = rem;
}
return m;
}
int get_num(string e, int &i, int len) {
int tmp = 0, flag = 1;
if (e[i] == '-') {
flag = -1;
i ++;
}
else if (e[i] == '+' || e[i] == '/')
i ++;
while(i < len && '0' <= e[i] && e[i] <= '9') {
tmp = tmp*10 + e[i] - '0';
i ++;
}
return tmp*flag;
}
string fractionAddition(string expression) {
int len = expression.length(), i = 0;
vector<int> res;
while(i < len) {
if (res.size() == 0) {
res.push_back(get_num(expression, i, len));
res.push_back(get_num(expression, i, len));
}
else {
int res0 = get_num(expression, i, len);
int res1 = get_num(expression, i, len);
res0 = res0 * res[1];
res[0] = res[0] * res1 + res0;
res[1] = res[1] * res1;
}
}
if (res[0] == 0)
return "0/1";
else {
int t = fun(res[0], res[1]);
res[0] /= t;
res[1] /= t;
return to_string(res[0]) + "/" + to_string(res[1]);
}
return "";
}
};
Leetcode593. Valid Square
Given the coordinates of four points in 2D space p1, p2, p3 and p4, return true if the four points construct a square.
The coordinate of a point pi is represented as [xi, yi]. The input is not given in any order.
A valid square has four equal sides with positive length and four equal angles (90-degree angles).
Example 1:1
2Input: p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,1]
Output: true
Example 2:1
2Input: p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,12]
Output: false
Example 3:1
2Input: p1 = [1,0], p2 = [-1,0], p3 = [0,1], p4 = [0,-1]
Output: true
这道题给了我们四个点,让验证这四个点是否能组成一个正方形,刚开始博主考虑的方法是想判断四个角是否是直角,但即便四个角都是直角,也不能说明一定就是正方形,还有可能是矩形。还得判断各边是否相等。其实这里可以仅通过边的关系的来判断是否是正方形,根据初中几何的知识可以知道正方形的四条边相等,两条对角线相等,满足这两个条件的四边形一定是正方形。那么这样就好办了,只需要对四个点,两两之间算距离,如果计算出某两个点之间距离为0,说明两点重合了,直接返回 false,如果不为0,那么就建立距离和其出现次数之间的映射,最后如果我们只得到了两个不同的距离长度,那么就说明是正方形了,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
bool validSquare(vector<int>& p1, vector<int>& p2, vector<int>& p3, vector<int>& p4) {
unordered_map<int, int> m;
vector<vector<int>> v{p1, p2, p3, p4};
for (int i = 0; i < 4; ++i) {
for (int j = i + 1; j < 4; ++j) {
int x1 = v[i][0], y1 = v[i][1], x2 = v[j][0], y2 = v[j][1];
int dist = (x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2);
if (dist == 0) return false;
++m[dist];
}
}
return m.size() == 2;
}
};
Leetcode594. Longest Harmonious Subsequence
We define a harmounious array as an array where the difference between its maximum value and its minimum value is exactly 1. Now, given an integer array, you need to find the length of its longest harmonious subsequence among all its possible subsequences.
Example 1:1
2
3Input: [1,3,2,2,5,2,3,7]
Output: 5
Explanation: The longest harmonious subsequence is [3,2,2,2,3].
由于所需子序列有且只有两种元素,且相差为1,所以可以用map将所有数字的个数记录下来,再遍历map,如果对于一个key,如果key+1也存在于map中,则存在以key和key+1两个数字组成的和谐子序列,长度为两个数字的个数之和。1
2
3
4
5
6
7
8
9
10
11
12
13
14class Solution {
public:
int findLHS(vector<int>& nums) {
int res = 0;
unordered_map<int, int> mp;
for(int i = 0; i < nums.size(); i ++)
mp[nums[i]] ++;
for(auto i = mp.begin(); i != mp.end(); i ++) {
if(mp.count(i->first+1))
res = max(res, i->second + mp[i->first+1]);
}
return res;
}
};
Leetcode595. Big Countries
We define a harmonious array is an array where the difference between its maximum value and its minimum value is exactly 1.
Now, given an integer array, you need to find the length of its longest harmonious subsequence among all its possible subsequences.
Example 1:1
2
3Input: [1,3,2,2,5,2,3,7]
Output: 5
Explanation: The longest harmonious subsequence is [3,2,2,2,3].
这道题给了我们一个数组,让我们找出最长的和谐子序列,关于和谐子序列就是序列中数组的最大最小差值均为1。由于这里只是让我们求长度,并不需要返回具体的子序列。所以我们可以对数组进行排序,那么实际上我们只要找出来相差为1的两个数的总共出现个数就是一个和谐子序列的长度了。明白了这一点,我们就可以建立一个数字和其出现次数之间的映射,利用 TreeMap 的自动排序的特性,那么我们遍历 TreeMap 的时候就是从小往大开始遍历,我们从第二个映射对开始遍历,每次跟其前面的映射对比较,如果二者的数字刚好差1,那么就把二个数字的出现的次数相加并更新结果 res 即可,参见代码如下:
1 | class Solution { |
Leetcode596. Classes More Than 5 Students
There is a table courses with columns: student and class Please list out all classes which have more than or equal to 5 students. For example, the table:1
2
3
4
5
6
7
8
9
10
11
12
13+---------+------------+
| student | class |
+---------+------------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
+---------+------------+
Should output:1
2
3
4
5+---------+
| class |
+---------+
| Math |
+---------+1
2
3SELECT class FROM courses
GROUP BY class
HAVING COUNT(DISTINCT(student)) >= 5
Leetcode598. Range Addition II
Given an m * n matrix M initialized with all 0’s and several update operations.
Operations are represented by a 2D array, and each operation is represented by an array with two positive integers a and b, which means M[i][j] should be added by one for all 0 <= i < a and 0 <= j < b.
You need to count and return the number of maximum integers in the matrix after performing all the operations.
Example 1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21Input:
m = 3, n = 3
operations = [[2,2],[3,3]]
Output: 4
Explanation:
Initially, M =
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]
After performing [2,2], M =
[[1, 1, 0],
[1, 1, 0],
[0, 0, 0]]
After performing [3,3], M =
[[2, 2, 1],
[2, 2, 1],
[1, 1, 1]]
So the maximum integer in M is 2, and there are four of it in M. So return 4.
求ops[0 .. len][0]和ops[0 .. len][1]的最小值,矩阵越靠近左上角的元素值越大,因为要加1的元素 行和列索引是从0开始的。那么只需要找到操作次数最多的元素位置即可。而操作次数最多的元素肯定是偏向于靠近矩阵左上角的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
int maxCount(int m, int n, vector<vector<int>>& ops) {
if(ops.size() == 0)
return m * n;
int res = 0;
int min1 = 99999, min2 = 99999;
for(int i = 0; i < ops.size(); i ++) {
if(min1 > ops[i][0])
min1 = ops[i][0];
if(min2 > ops[i][1])
min2 = ops[i][1];
}
return min1 * min2;
}
};
Leetcode599. Minimum Index Sum of Two Lists
Suppose Andy and Doris want to choose a restaurant for dinner, and they both have a list of favorite restaurants represented by strings.
You need to help them find out their common interest with the least list index sum. If there is a choice tie between answers, output all of them with no order requirement. You could assume there always exists an answer.
Example 1:1
2
3
4
5Input:
["Shogun", "Tapioca Express", "Burger King", "KFC"]
["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"]
Output: ["Shogun"]
Explanation: The only restaurant they both like is "Shogun".
Example 2:1
2
3
4
5Input:
["Shogun", "Tapioca Express", "Burger King", "KFC"]
["KFC", "Shogun", "Burger King"]
Output: ["Shogun"]
Explanation: The restaurant they both like and have the least index sum is "Shogun" with index sum 1 (0+1).
如果两者只有一个共同喜欢的餐馆,直接将其返回;如果不止一个,则返回下标之和最小的一个。两个列表均没有重复元素,长度均在[1, 1000]范围内,其中的元素长度均在[1, 30]范围内。万一有多个答案的话?如果index之和的最小值大于等于当前这一组index之和,那有两种情况,一个是大于,那么更新结果vector,另一种是等于,那么直接把当前字符串加入结果vector。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
vector<string> findRestaurant(vector<string>& list1, vector<string>& list2) {
unordered_map<string, int> mp;
vector<string> ans;
int res = 9999999;
for(int i = 0; i < list1.size(); i ++)
mp[list1[i]] = i;
for(int i = 0; i < list2.size(); i ++) {
auto temp = mp.find(list2[i]);
if(temp != mp.end())
if(res >= i + temp->second) {
if(res > i + temp->second) {
ans.clear();
res = i + temp->second;
}
ans.push_back(temp->first);
}
}
return ans;
}
};
Leetcode600. Non-negative Integers without Consecutive Ones
Given a positive integer n, find the number of non-negative integers less than or equal to n, whose binary representations do NOT contain consecutive ones.
Example 1:1
2
3
4
5
6
7
8
9
10
11Input: 5
Output: 5
Explanation:
Here are the non-negative integers <= 5 with their corresponding binary representations:
0 : 0
1 : 1
2 : 10
3 : 11
4 : 100
5 : 101
Among them, only integer 3 disobeys the rule (two consecutive ones) and the other 5 satisfy the rule.
这道题给了我们一个数字,让我们求不大于这个数字的所有数字中,其二进制的表示形式中没有连续1的个数。根据题目中的例子也不难理解题意。我们首先来考虑二进制的情况,对于1来说,有0和1两种,对于11来说,有00,01,10,三种情况,那么有没有规律可寻呢,其实是有的,我们可以参见这个帖子,这样我们就可以通过DP的方法求出长度为k的二进制数的无连续1的数字个数。由于题目给我们的并不是一个二进制数的长度,而是一个二进制数,比如100,如果我们按长度为3的情况计算无连续1点个数个数,就会多计算101这种情况。所以我们的目标是要将大于num的情况去掉。下面从头来分析代码,首先我们要把十进制数转为二进制数,将二进制数存在一个字符串中,并统计字符串的长度。然后我们利用这个帖子中的方法,计算该字符串长度的二进制数所有无连续1的数字个数,然后我们从倒数第二个字符开始往前遍历这个二进制数字符串,如果当前字符和后面一个位置的字符均为1,说明我们并没有多计算任何情况,不明白的可以带例子来看。
如果当前字符和后面一个位置的字符均为0,说明我们有多计算一些情况,就像之前举的100这个例子,我们就多算了101这种情况。我们怎么确定多了多少种情况呢,假如给我们的数字是8,二进制为1000,我们首先按长度为4算出所有情况,共8种。仔细观察我们十进制转为二进制字符串的写法,发现转换结果跟真实的二进制数翻转了一下,所以我们的t为”0001”,那么我们从倒数第二位开始往前遍历,到i=1时,发现有两个连续的0出现,那么i=1这个位置上能出现1的次数,就到one数组中去找,那么我们减去1,减去的就是0101这种情况,再往前遍历,i=0时,又发现两个连续0,那么i=0这个位置上能出1的次数也到one数组中去找,我们再减去1,减去的是1001这种情况,参见代码如下:
解法一:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Solution {
public:
int findIntegers(int num) {
int cnt = 0, n = num;
string t = "";
while (n > 0) {
++cnt;
t += (n & 1) ? "1" : "0";
n >>= 1;
}
vector<int> zero(cnt), one(cnt);
zero[0] = 1; one[0] = 1;
for (int i = 1; i < cnt; ++i) {
zero[i] = zero[i - 1] + one[i - 1];
one[i] = zero[i - 1];
}
int res = zero[cnt - 1] + one[cnt - 1];
for (int i = cnt - 2; i >= 0; --i) {
if (t[i] == '1' && t[i + 1] == '1') break;
if (t[i] == '0' && t[i + 1] == '0') res -= one[i];
}
return res;
}
};
下面这种解法其实蛮有意思的,其实长度为k的二进制数字符串没有连续的1的个数是一个斐波那契数列f(k)。比如当k=5时,二进制数的范围是00000-11111,我们可以将其分为两个部分,00000-01111和10000-10111,因为任何大于11000的数字都是不成立的,因为有开头已经有了两个连续1。而我们发现其实00000-01111就是f(4),而10000-10111就是f(3),所以f(5) = f(4) + f(3),这就是一个斐波那契数列啦。那么我们要做的首先就是建立一个这个数组,方便之后直接查值。我们从给定数字的最高位开始遍历,如果某一位是1,后面有k位,就加上f(k),因为如果我们把当前位变成0,那么后面k位就可以直接从斐波那契数列中取值了。然后标记pre为1,再往下遍历,如果遇到0位,则pre标记为0。如果当前位是1,pre也是1,那么直接返回结果。最后循环退出后我们要加上数字本身这种情况,参见代码如下:
解法二:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
int findIntegers(int num) {
int res = 0, k = 31, pre = 0;
vector<int> f(32, 0);
f[0] = 1; f[1] = 2;
for (int i = 2; i < 31; ++i) {
f[i] = f[i - 2] + f[i - 1];
}
while (k >= 0) {
if (num & (1 << k)) {
res += f[k];
if (pre) return res;
pre = 1;
} else pre = 0;
--k;
}
return res + 1;
}
};