进程组
一个或多个进程的集合

eg:显示子进程与父进程的进程组id1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int main() {
pid_t pid;
if ((pid=fork())<0) {
printf("fork error!");
}else if (pid==0) {
printf("The child process PID is %d.\n",getpid());
printf("The Group ID is %d.\n",getpgrp());
printf("The Group ID is %d.\n",getpgid(0));
printf("The Group ID is %d.\n",getpgid(getpid()));
exit(0);
}
sleep(3);
printf("The parent process PID is %d.\n",getpid());
printf("The Group ID is %d.\n",getpgrp());
return 0;
}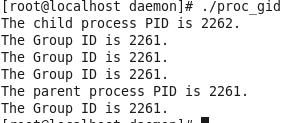
进程组id = 父进程id,即父进程为组长进程
组长进程
- 组长进程标识: 其进程组ID==其进程ID
- 组长进程可以创建一个进程组,创建该进程组中的进程,然后终止
- 只要进程组中有一个进程存在,进程组就存在,与组长进程是否终止无关
- 进程组生存期: 进程组创建到最后一个进程离开(终止或转移到另一个进程组)
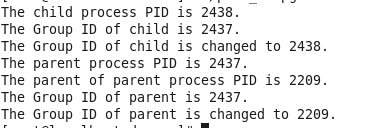
一个进程可以为自己或子进程设置进程组ID,setpgid()加入一个现有的进程组或创建一个新进程组
1 |
|
会话
一个或多个进程组的集合,开始于用户登录,终止与用户退出,此期间所有进程都属于这个会话期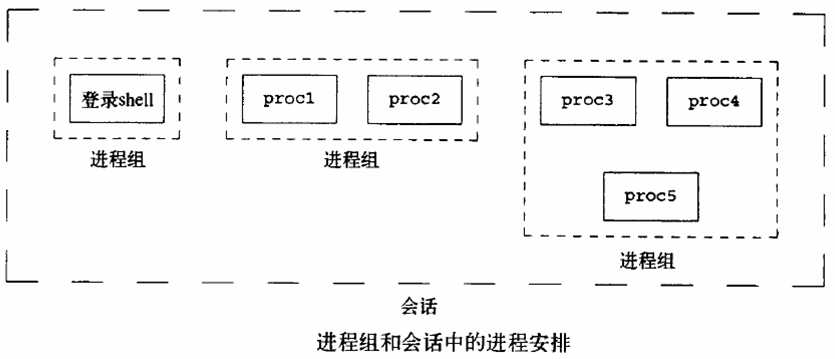
建立新会话:setsid()函数。该调用进程是组长进程,则出错返回,先调用fork, 父进程终止,子进程调用,该调用进程不是组长进程,则创建一个新会话。
- 该进程变成新会话首进程(session header)
- 该进程成为一个新进程组的组长进程。
- 该进程没有控制终端,如果之前有,则会被中断
组长进程不能成为新会话首进程,新会话首进程必定会成为组长进程…
会话ID:会话首进程的进程组ID。获取会话ID: getsid()函数
1 |
|
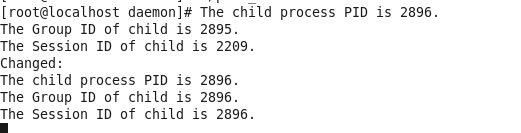
在子进程中调用setsid()后,子进程成为新会话首进程,且成为一个组长进程,其进程组id等于会话id
守护进程
Linux大多数服务都是通过守护进程实现的,完成许多系统任务
- 0: 调度进程,称为交换进程(swapper),内核一部分,系统进程
- 1: init进程, 内核调用,负责内核启动后启动Linux系统
让某个进程不因为用户、终端或者其他的变化而受到影响,那么就必须把这个进程变成一个守护进程
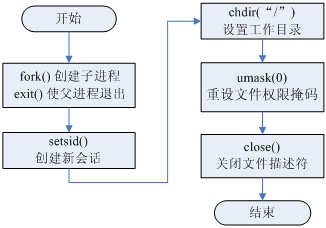
守护进程编程步骤
- 创建子进程,父进程退出
- 所有工作在子进程中进行
- 形式上脱离了控制终端
- 在子进程中创建新会话
- setsid()函数
- 使子进程完全独立出来,脱离控制
- 改变当前目录为根目录
- chdir()函数
- 防止占用可卸载的文件系统
- 也可以换成其它路径
- 重设文件权限掩码
- umask()函数
- 防止继承的文件创建屏蔽字拒绝某些权限
- 增加守护进程灵活性
- 关闭文件描述符
- 继承的打开文件不会用到,浪费系统资源,无法卸载
- getdtablesize()
- 返回所在进程的文件描述符表的项数,即该进程打开的文件数目
1 |
|
因为stdout被关掉了,所以“Never ouput!”不会输出。
查看/tmp/daemon.log,说明该程序一直在运行
fork()
fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制“技术,也就是只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
fork之后内核会通过将子进程放在队列的前面,以让子进程先执行,以免父进程执行导致写时复制,而后子进程执行exec系统调用,因无意义的复制而造成效率的下降。
fork时子进程获得父进程数据空间、堆和栈的复制,所以变量的地址(当然是虚拟地址)也是一样的。
每个进程都有自己的虚拟地址空间,不同进程的相同的虚拟地址显然可以对应不同的物理地址。因此地址相同(虚拟地址)而值不同没什么奇怪。
具体过程是这样的:
fork子进程完全复制父进程的栈空间,也复制了页表,但没有复制物理页面,所以这时虚拟地址相同,物理地址也相同,但是会把父子共享的页面标记为“只读”(类似mmap的private的方式),如果父子进程一直对这个页面是同一个页面,知道其中任何一个进程要对共享的页面“写操作”,这时内核会复制一个物理页面给这个进程使用,同时修改页表。而把原来的只读页面标记为“可写”,留给另外一个进程使用。
这就是所谓的“写时复制”。正因为fork采用了这种写时复制的机制,所以fork出来子进程之后,父子进程哪个先调度呢?内核一般会先调度子进程,因为很多情况下子进程是要马上执行exec,会清空栈、堆。。这些和父进程共享的空间,加载新的代码段。。。,这就避免了“写时复制”拷贝共享页面的机会。如果父进程先调度很可能写共享页面,会产生“写时复制”的无用功。所以,一般是子进程先调度滴。
子进程与父进程之间除了代码是共享的之外,堆栈数据和全局数据均是独立的。
pid = fork()返回两次,第一次父进程,第二次子进程:1
2
3[root@localhost timetest]# ./test
This is parent process: 4016
This is child process: 4017
注意:这里不是绝对的先返回父进程的pid,具体先执行那个进程,要看操作系统的进程调度算法。
操作系统创建一个新的进程(子进程),并且在进程表中相应为它建立一个新的表项。新进程和原有进程的可执行程序是同一个程序;上下文和数据,绝大部分就是原进程(父进程)的拷贝,但它们是两个相互独立的进程!此时程序寄存器pc,在父、子进程的上下文中都声称,这个进程目前执行到fork调用即将返回(此时子进程不占有CPU,子进程的pc不是真正保存在寄存器中,而是作为进程上下文保存在进程表中的对应表项内)。问题是怎么返回,在父子进程中就分道扬镳。
父进程继续执行,操作系统对fork的实现,使这个调用在父进程中返回刚刚创建的子进程的pid(一个正整数),所以下面的if语句中pid<0, pid==0的两个分支都不会执行。所以输出i am the parent process…
子进程在之后的某个时候得到调度,它的上下文被换入,占据 CPU,操作系统对fork的实现,使得子进程中fork调用返回0。所以在这个进程(注意这不是父进程了哦,虽然是同一个程序,但是这是同一个程序的另外一次执行,在操作系统中这次执行是由另外一个进程表示的,从执行的角度说和父进程相互独立)中pid=0。这个进程继续执行的过程中,if语句中 pid<0不满足,但是pid= =0是true。所以输出i am the child process…
为什么看上去程序中互斥的两个分支都被执行了?在一个程序的一次执行中,这当然是不可能的;但是你看到的两行输出是来自两个进程,这两个进程来自同一个程序的两次执行。
fork之后,操作系统会复制一个与父进程完全相同的子进程,虽说是父子关系,但是在操作系统看来,他们更像兄弟关系,这2个进程共享代码空间,但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,但只有一点不同,如果fork成功,子进程中fork的返回值是0,父进程中fork的返回值是子进程的进程号,如果fork不成功,父进程会返回错误。
可以这样想象,2个进程一直同时运行,而且步调一致,在fork之后,他们分别作不同的工作,也就是分岔了。这也是fork为什么叫fork的原因。
在程序段里用了fork()之后程序出了分岔,派生出了两个进程。具体哪个先运行就看该系统的调度算法了。
如果需要父子进程协同,可以通过原语的办法解决。
父进程为什么要创建子进程呢?
前面我们已经说过了Linux是一个多用户操作系统,在同一时间会有许多的用户在争夺系统的资源.有时进程为了早一点完成任务就创建子进程来争夺资源. 一旦子进程被创建,父子进程一起从fork处继续执行,相互竞争系统的资源.有时候我们希望子进程继续执行,而父进程阻塞,直到子进程完成任务.这个时候我们可以调用wait或者waitpid系统调用.
对子进程来说,fork返回给它0,但它的pid绝对不会是0;之所以fork返回0给它,是因为它随时可以调用getpid()来获取自己的pid;
fork之后父子进程除非采用了同步手段,否则不能确定谁先运行,也不能确定谁先结束。认为子进程结束后父进程才从fork返回的,这是不对的,fork不是这样的,vfork才这样。
为什么返回0呢
- 首先必须有一点要清楚,函数的返回值是储存在寄存器eax中的。
- 其次,当fork返回时,新进程会返回0是因为在初始化任务结构时,将eax设置为0;
- 在fork中,把子进程加入到可运行的队列中,由进程调度程序在适当的时机调度运行。也就是从此时开始,当前进程分裂为两个并发的进程。
- 无论哪个进程被调度运行,都将继续执行fork函数的剩余代码,执行结束后返回各自的值。
【NOTE5】
对于fork来说,父子进程共享同一段代码空间,所以给人的感觉好像是有两次返回,其实对于调用fork的父进程来说,如果fork出来的子进程没有得到调度,那么父进程从fork系统调用返回,同时分析sys_fork知道,fork返回的是子进程的id。再看fork出来的子进程,由 copy_process函数可以看出,子进程的返回地址为ret_from_fork(和父进程在同一个代码点上返回),返回值直接置为0。所以当子进程得到调度的时候,也从fork返回,返回值为0。
关键注意两点:
- fork返回后,父进程或子进程的执行位置。(首先会将当前进程eax的值做为返回值)
- 两次返回的pid存放的位置。(eax中)
pid=fork(),当执行这一句时,当前进程进入fork()运行,此时,fork()内会用一段嵌入式汇编进行系统调用:int 0x80。这时进入内核根据此前写入eax的系统调用功能号便会运行sys_fork系统调用。接着,sys_fork中首先会调用C函数find_empty_process产生一个新的进程,然后会调用C函数 copy_process将父进程的内容复制给子进程,但是子进程tss中的eax值赋值为0(这也是为什么子进程中返回0的原因),当赋值完成后, copy_process会返回新进程(该子进程)的pid,这个值会被保存到eax中。这时子进程就产生了,此时子进程与父进程拥有相同的代码空间,程序指针寄存器eip指向相同的下一条指令地址,当fork正常返回调用其的父进程后,因为eax中的值是新创建的子进程号,所以,fork()返回子进程号,执行else(pid > 0);当产生进程切换运行子进程时,首先会恢复子进程的运行环境即装入子进程的tss任务状态段,其中的eax 值(copy_process中置为0)也会被装入eax寄存器,所以,当子进程运行时,fork返回的是0执行if(pid==0)。
多进程
首先,先来讲一下fork之后,发生了什么事情。
由fork创建的新进程被称为子进程(child process)。该函数被调用一次,但返回两次。两次返回的区别是子进程的返回值是0,而父进程的返回值则是新进程(子进程)的进程 id。将子进程id返回给父进程的理由是:因为一个进程的子进程可以多于一个,没有一个函数使一个进程可以获得其所有子进程的进程id。对子进程来说,之所以fork返回0给它,是因为它随时可以调用getpid()来获取自己的pid;也可以调用getppid()来获取父进程的id。(进程id 0总是由交换进程使用,所以一个子进程的进程id不可能为0 )。
fork之后,操作系统会复制一个与父进程完全相同的子进程,虽说是父子关系,但是在操作系统看来,他们更像兄弟关系,这2个进程共享代码空间,但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,子进程拥有父进程当前运行到的位置(两进程的程序计数器pc值相同,也就是说,子进程是从fork返回处开始执行的),但有一点不同,如果fork成功,子进程中fork的返回值是0,父进程中fork的返回值是子进程的进程号,如果fork不成功,父进程会返回错误。
可以这样想象,2个进程一直同时运行,而且步调一致,在fork之后,他们分别作不同的工作,也就是分岔了。这也是fork为什么叫fork的原因
至于哪一个最先运行,可能与操作系统(调度算法)有关,而且这个问题在实际应用中并不重要,如果需要父子进程协同,可以通过原语的办法解决。
常见的通信方式:
- 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
- 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
- 信号(sinal):信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
信号
中断和异常
中断(也称硬件中断)
定义:中断是由其他硬件设备依照CPU时钟周期信号随机产生的。
分类: 可屏蔽中断、非可屏蔽中断
来源:间隔定时器和I/O
异常(也称软件中断)
定义:当指令执行时由CPU控制单元产生的,异常也称为“异步中断”是因为只有在 一条指令终止执行后CPU才会发出中断。
分类: 处理器探测到的异常、故障、陷阱、异常终止、编程异常(也称软中断)、int指令
来源:程序的错误产生的
内核必须处理的异常(例如:缺页和内核服务的请求-int)
异常处理
当发生异常时,CPU控制单元产生一个硬件出错码。CPU根据该中断吗找到中断向量表内的对应向量,根据该向量转到中断处理程序。中断处理程序处理完之后向当前进程发送一个SIG*信号。若进程定义了相应的信号处理程序则转移到相应的程序执行,若没有,则执行内核定义的操作。
中断处理
设备产生中断,PIC(可编程中断控制器)会产生一个对应的中断向量和中断向量表中的每一个中断向量进行比较,转到对应的中断处理程序,中断处理程序进行保存现场,做相关处理,恢复现场,内核调度,返回用户进程。
硬件中断的上半部和下半部及实现方式
硬件中断的分类
- 紧急的 —— 这类中断必须立即执行
- 非紧急的 —— 也必须立即执行
- 非紧急可延迟的 —— 上半部立即执行,下半部延迟执行
硬件中断任务(处理程序)是一个快速、异步、简单地对硬件做出迅速响应并在最短时间内完成必要操作的中断处理程序。硬中断处理程序可以抢占内核任务并且执 行时还会屏蔽同级中断或其它中断,因此中断处理必须要快、不能阻塞。这样一来对于一些要求处理过程比较复杂的任务就不合适在中断任务中一次处理。比如,网卡接收数据的过程中,首先网卡发送中断信号告诉CPU来取数据,然后系统从网卡中读取数据存入系统缓冲区中,再下来解析数据然后送入应用层。这些如果都让中断处理程序来处理显然过程太长,造成新来的中断丢失。因此Linux开发人员将这种任务分割为两个部分,一个叫上底,即中断处理程序,短平快地处理与硬 件相关的操作(如从网卡读数据到系统缓存);而把对时间要求相对宽松的任务(如解析数据的工作)放在另一个部分执行,这个部分就是我们这里要讲的下半底。
下半底是一种推后执行任务,它将某些不那么紧迫的任务推迟到系统更方便的时刻运行。因为并不是非常紧急,通常还是比较耗时的,因此由系统自行安排运行时机,不在中断服务上下文中执行。内核中实现 下半底的手段经过不断演化,目前已经从最原始的BH(bottom thalf)演生出BH、任务队列(Task queues)、软中断(Softirq)、Tasklet、工作队列(Work queues)(2.6内核中新出现的)。
关于软中断和硬中断的其它解析:
软中断一般是指由指令int引起的“伪”中断动作——给CPU制造一个中断的假象;而硬中断则是实实在在由8259的连线触发的中断。因此,严格的 讲,int与IRQ毫无关系,但二者均与中断向量有关系。int引起的中断,CPU是从指令中取得中断向量号;而IRQ引起的中断,CPU必须从数据线上取回中断号,接下来CPU的工作就一样了:保护现场、根据中断号得到中断处理程序地址、执行中断处理、恢复现场继续执行被中断的指令。
在软中断和硬中断之间的区别是什么?
- 硬中断是由外部事件引起的因此具有随机性和突发性;软中断是执行中断指令产生的,无面外部施加中断请求信 号,因此中断的发生不是随机的而是由程序安排好的。
- 硬中断的中断响应周期,CPU需要发中断回合信号(NMI不需要),软中断的中断响应周 期,CPU不需发中断回合信号。
- 硬中断的中断号是由中断控制器提供的(NMI硬中断中断号系统指定为02H);软中断的中断号由指令直接给出, 无需使用中断控制器。
- 硬中断是可屏蔽的(NMI硬中断不可屏蔽),软中断不可屏蔽。
硬中断:
- 硬中断是由硬件产生的,比如,像磁盘,网卡,键盘,时钟等。每个设备或设备集都有它自己的IRQ(中断请求)。基于IRQ,CPU可以将相应的请求分发到对应的硬件驱动上(注:硬件驱动通常是内核中的一个子程序,而不是一个独立的进程)。
- 处理中断的驱动是需要运行在CPU上的,因此,当中断产生的时候,CPU会中断当前正在运行的任务,来处理中断。在有多核心的系统上,一个中断通常只能中断一颗CPU(也有一种特殊的情况,就是在大型主机上是有硬件通道的,它可以在没有主CPU的支持下,可以同时处理多个中断。)。
- 硬中断可以直接中断CPU。它会引起内核中相关的代码被触发。对于那些需要花费一些时间去处理的进程,中断代码本身也可以被其他的硬中断中断。
- 对于时钟中断,内核调度代码会将当前正在运行的进程挂起,从而让其他的进程来运行。它的存在是为了让调度代码(或称为调度器)可以调度多任务。
软中断:
- 软中断的处理非常像硬中断。然而,它们仅仅是由当前正在运行的进程所产生的。
- 通常,软中断是一些对I/O的请求。这些请求会调用内核中可以调度I/O发生的程序。对于某些设备,I/O请求需要被立即处理,而磁盘I/O请求通常可以排队并且可以稍后处理。根据I/O模型的不同,进程或许会被挂起直到I/O完成,此时内核调度器就会选择另一个进程去运行。I/O可以在进程之间产生并且调度过程通常和磁盘I/O的方式是相同。
- 软中断仅与内核相联系。而内核主要负责对需要运行的任何其他的进程进行调度。一些内核允许设备驱动的一些部分存在于用户空间,并且当需要的时候内核也会调度这个进程去运行。
- 软中断并不会直接中断CPU。也只有当前正在运行的代码(或进程)才会产生软中断。这种中断是一种需要内核为正在运行的进程去做一些事情(通常为I/O)的请求。有一个特殊的软中断是Yield调用,它的作用是请求内核调度器去查看是否有一些其他的进程可以运行。
信号本质
软中断信号(signal,又简称为信号)用来通知进程发生了异步事件。在软件层次上是对中断机制的一种模拟,在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。信号是进程间通信机制中唯一的异步通信机制,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。进程之间可以互相通过系统调用kill发送软中断信号。内核也可以因为内部事件而给进程发送信号,通知进程发生了某个事件。信号机制除了基本通知功能外,还可以传递附加信息。
产生信号的条件主要有:
- 用户在终端 按下某些键时,终端驱动程序会发送信号给前台进程,例如Ctrl-C产生SIGINT信 号,Ctrl-/产生SIGQUIT信号,Ctrl-Z产生SIGTSTP信号。
- 硬件异常产生信号,这些条件由硬件检测到并通知内核,然后内核向当前进程发送适当的信号。例如当前进程执行了 除以0的指令,CPU的运算单元会产生异常,内核将这个异常解释为SIGFPE信号发送给进 程。再比如当前进程访问了非法内存地址,,MMU会产生异常,内核将这个异常解释为SIGSEGV信 号发送给进程。
- 一个进程调用kill(2)函数可以发送信 号给另一个进程。
- 可以用kill(1)命令发送信号给某个 进程,kill(1)命令也是调用kill(2)函 数实现的,如果不明确指定信号则发送SIGTERM信号,该信号的默认处理动作是终止进程。
- 当内核检测到某种软件条件发生时也可以通过信号通知进程,例如闹钟超时产生SIGALRM信 号,向读端已关闭的管道写数据时产生SIGPIPE信号。
收到信号的进程对各种信号有不同的处理方法。处理方法可以分为三类:
- 第一种是类似中断的处理程序,对于需要处理的信号,进程可以指定处理函数,由该函数来处理。
- 第二种方法是,忽略某个信号,对该信号不做任何处理,就象未发生过一样。
- 第三种方法是,对该信号的处理保留系统的默认值,这种缺省操作,对大部分的信号的缺省操作是使得进程终止。进程通过系统调用signal来指定进程对某个信号的处理行为。
信号的种类
可以从两个不同的分类角度对信号进行分类:
- 可靠性方面:可靠信号与不可靠信号;
- 与时间的关系上:实时信号与非实时信号。
可靠信号与不可靠信号
Linux信号机制基本上是从Unix系统中继承过来的。早期Unix系统中的信号机制比较简单和原始,信号值小于SIGRTMIN的信号都是不可靠信号。这就是”不可靠信号”的来源。它的主要问题是信号可能丢失。
随着时间的发展,实践证明了有必要对信号的原始机制加以改进和扩充。由于原来定义的信号已有许多应用,不好再做改动,最终只好又新增加了一些信号,并在一开始就把它们定义为可靠信号,这些信号支持排队,不会丢失。
信号值位于SIGRTMIN和SIGRTMAX之间的信号都是可靠信号,可靠信号克服了信号可能丢失的问题。Linux在支持新版本的信号安装函数sigation()以及信号发送函数sigqueue()的同时,仍然支持早期的signal()信号安装函数,支持信号发送函数kill()。
信号的可靠与不可靠只与信号值有关,与信号的发送及安装函数无关。目前linux中的signal()是通过sigation()函数实现的,因此,即使通过signal()安装的信号,在信号处理函数的结尾也不必再调用一次信号安装函数。同时,由signal()安装的实时信号支持排队,同样不会丢失。
对于目前linux的两个信号安装函数:signal()及sigaction()来说,它们都不能把SIGRTMIN以前的信号变成可靠信号(都不支持排队,仍有可能丢失,仍然是不可靠信号),而且对SIGRTMIN以后的信号都支持排队。这两个函数的最大区别在于,经过sigaction安装的信号都能传递信息给信号处理函数,而经过signal安装的信号不能向信号处理函数传递信息。对于信号发送函数来说也是一样的。
实时信号与非实时信号
早期Unix系统只定义了32种信号,前32种信号已经有了预定义值,每个信号有了确定的用途及含义,并且每种信号都有各自的缺省动作。如按键盘的CTRL ^C时,会产生SIGINT信号,对该信号的默认反应就是进程终止。后32个信号表示实时信号,等同于前面阐述的可靠信号。这保证了发送的多个实时信号都被接收。
非实时信号都不支持排队,都是不可靠信号;实时信号都支持排队,都是可靠信号。
信号处理流程
对于一个完整的信号生命周期(从信号发送到相应的处理函数执行完毕)来说,可以分为三个阶段:
- 信号诞生
- 信号在进程中注册
- 信号的执行和注销
信号诞生
信号事件的发生有两个来源:硬件来源(比如我们按下了键盘或者其它硬件故障);软件来源,最常用发送信号的系统函数是kill, raise, alarm和setitimer以及sigqueue函数,软件来源还包括一些非法运算等操作。
这里按发出信号的原因简单分类,以了解各种信号:
- 与进程终止相关的信号。当进程退出,或者子进程终止时,发出这类信号。
- 与进程例外事件相关的信号。如进程越界,或企图写一个只读的内存区域(如程序正文区),或执行一个特权指令及其他各种硬件错误。
- 与在系统调用期间遇到不可恢复条件相关的信号。如执行系统调用exec时,原有资源已经释放,而目前系统资源又已经耗尽。
- 与执行系统调用时遇到非预测错误条件相关的信号。如执行一个并不存在的系统调用。
- 在用户态下的进程发出的信号。如进程调用系统调用kill向其他进程发送信号。
- 与终端交互相关的信号。如用户关闭一个终端,或按下break键等情况。
- 跟踪进程执行的信号。
Linux支持的信号列表如下。很多信号是与机器的体系结构相关的
- SIGHUP:当用户退出Shell时,由该Shell启的发所有进程都退接收到这个信号,默认动作为终止进程。
- SIGINT:用户按下
组合键时,用户端时向正在运行中的由该终端启动的程序发出此信号。默认动作为终止进程。 - SIGQUIT:当用户按下
组合键时产生该信号,用户终端向正在运行中的由该终端启动的程序发出此信号。默认动作为终止进程并产生core文件。 - SIGILL :CPU检测到某进程执行了非法指令。默认动作为终止进程并产生core文件。
- SIGTRAP:该信号由断点指令或其他trap指令产生。默认动作为终止进程并产生core文件。
- SIGABRT:调用abort函数时产生该信号。默认动作为终止进程并产生core文件。
- SIGBUS:非法访问内存地址,包括内存地址对齐(alignment)出错,默认动作为终止进程并产生core文件。
- SIGFPE:在发生致命的算术错误时产生。不仅包括浮点运行错误,还包括溢出及除数为0等所有的算术错误。默认动作为终止进程并产生core文件。
- SIGKILL:无条件终止进程。本信号不能被忽略、处理和阻塞。默认动作为终止进程。它向系统管理员提供了一种可以杀死任何进程的方法。
- SIGUSR1:用户定义的信号,即程序可以在程序中定义并使用该信号。默认动作为终止进程。
- SIGSEGV:指示进程进行了无效的内存访问。默认动作为终止进程并使用该信号。默认动作为终止进程。
- SIGUSR2:这是另外一个用户定义信号,程序员可以在程序中定义并使用该信号。默认动作为终止进程。
- SIGPIPE:Broken pipe:向一个没有读端的管道写数据。默认动作为终止进程。
- SIGALRM:定时器超时,超时的时间由系统调用alarm设置。默认动作为终止进程。
- SIGTERM:程序结束(terminate)信号,与SIGKILL不同的是,该信号可以被阻塞和处理。通常用来要求程序正常退出。执行Shell命令kill时,缺少产生这个信号。默认动作为终止进程。
- SIGCHLD:子程序结束时,父进程会收到这个信号。默认动作为忽略该信号。
- SIGCONT:让一个暂停的进程继续执行。
- SIGSTOP:停止(stopped)进程的执行。注意它和SIGTERM以及SIGINT的区别:该进程还未结束,只是暂停执行。本信号不能被忽略、处理和阻塞。默认作为暂停进程。
- SIGTSTP:停止进程的动作,但该信号可以被处理和忽略。按下
组合键时发出该信号。默认动作为暂停进程。 - SIGTTIN:当后台进程要从用户终端读数据时,该终端中的所有进程会收到SIGTTIN信号。默认动作为暂停进程。
- SIGTTOU:该信号类似于SIGTIN,在后台进程要向终端输出数据时产生。默认动作为暂停进程。
- SIGURG:套接字(socket)上有紧急数据时,向当前正在运行的进程发出此信号,报告有紧急数据到达。默认动作为忽略该信号。
- SIGXCPU:进程执行时间超过了分配给该进程的CPU时间,系统产生该信号并发送给该进程。默认动作为终止进程。
- SIGXFSZ:超过文件最大长度的限制。默认动作为yl终止进程并产生core文件。
- SIGVTALRM:虚拟时钟超时时产生该信号。类似于SIGALRM,但是它只计算该进程占有用的CPU时间。默认动作为终止进程。
- SIGPROF:类似于SIGVTALRM,它不仅包括该进程占用的CPU时间还抱括执行系统调用的时间。默认动作为终止进程。
- SIGWINCH:窗口大小改变时发出。默认动作为忽略该信号。
- SIGIO:此信号向进程指示发出一个异步IO事件。默认动作为忽略。
- SIGPWR:关机。默认动作为终止进程。
- SIGRTMIN~SIGRTMAX:Linux的实时信号,它没有固定的含义(或者说可以由用户自由使用)。注意,Linux线程机制使用了前3个实时信号。所有的实时信号的默认动作都是终止进程。
信号在目标进程中注册
在进程表的表项中有一个软中断信号域,该域中每一位对应一个信号。内核给一个进程发送软中断信号的方法,是在进程所在的进程表项的信号域设置对应于该信号的位。如果信号发送给一个正在睡眠的进程,如果进程睡眠在可被中断的优先级上,则唤醒进程;否则仅设置进程表中信号域相应的位,而不唤醒进程。如果发送给一个处于可运行状态的进程,则只置相应的域即可。
进程的task_struct结构中有关于本进程中未决信号的数据成员:struct sigpending pending1
2
3
4struct sigpending{
struct sigqueue *head, *tail;
sigset_t signal;
};
第三个成员是进程中所有未决信号集,第一、第二个成员分别指向一个sigqueue类型的结构链(称之为”未决信号信息链”)的首尾,信息链中的每个sigqueue结构刻画一个特定信号所携带的信息,并指向下一个sigqueue结构:1
2
3
4struct sigqueue{
struct sigqueue *next;
siginfo_t info;
}
信号在进程中注册指的就是信号值加入到进程的未决信号集sigset_t signal(每个信号占用一位)中,并且信号所携带的信息被保留到未决信号信息链的某个sigqueue结构中。只要信号在进程的未决信号集中,表明进程已经知道这些信号的存在,但还没来得及处理,或者该信号被进程阻塞。
当一个实时信号发送给一个进程时,不管该信号是否已经在进程中注册,都会被再注册一次,因此,信号不会丢失,因此,实时信号又叫做”可靠信号”。这意味着同一个实时信号可以在同一个进程的未决信号信息链中占有多个sigqueue结构(进程每收到一个实时信号,都会为它分配一个结构来登记该信号信息,并把该结构添加在未决信号链尾,即所有诞生的实时信号都会在目标进程中注册)。
当一个非实时信号发送给一个进程时,如果该信号已经在进程中注册(通过sigset_t signal指示),则该信号将被丢弃,造成信号丢失。因此,非实时信号又叫做”不可靠信号”。这意味着同一个非实时信号在进程的未决信号信息链中,至多占有一个sigqueue结构。
总之信号注册与否,与发送信号的函数(如kill()或sigqueue()等)以及信号安装函数(signal()及sigaction())无关,只与信号值有关(信号值小于SIGRTMIN的信号最多只注册一次,信号值在SIGRTMIN及SIGRTMAX之间的信号,只要被进程接收到就被注册)
信号的执行和注销
内核处理一个进程收到的软中断信号是在该进程的上下文中,因此,进程必须处于运行状态。当其由于被信号唤醒或者正常调度重新获得CPU时,在其从内核空间返回到用户空间时会检测是否有信号等待处理。如果存在未决信号等待处理且该信号没有被进程阻塞,则在运行相应的信号处理函数前,进程会把信号在未决信号链中占有的结构卸掉。
对于非实时信号来说,由于在未决信号信息链中最多只占用一个sigqueue结构,因此该结构被释放后,应该把信号在进程未决信号集中删除(信号注销完毕);而对于实时信号来说,可能在未决信号信息链中占用多个sigqueue结构,因此应该针对占用sigqueue结构的数目区别对待:如果只占用一个sigqueue结构(进程只收到该信号一次),则执行完相应的处理函数后应该把信号在进程的未决信号集中删除(信号注销完毕)。否则待该信号的所有sigqueue处理完毕后再在进程的未决信号集中删除该信号。
当所有未被屏蔽的信号都处理完毕后,即可返回用户空间。对于被屏蔽的信号,当取消屏蔽后,在返回到用户空间时会再次执行上述检查处理的一套流程。
内核处理一个进程收到的信号的时机是在一个进程从内核态返回用户态时。所以,当一个进程在内核态下运行时,软中断信号并不立即起作用,要等到将返回用户态时才处理。进程只有处理完信号才会返回用户态,进程在用户态下不会有未处理完的信号。
处理信号有三种类型:
- 进程接收到信号后退出;
- 进程忽略该信号;
- 进程收到信号后执行用户设定用系统调用signal的函数。
当进程接收到一个它忽略的信号时,进程丢弃该信号,就象没有收到该信号似的继续运行。如果进程收到一个要捕捉的信号,那么进程从内核态返回用户态时执行用户定义的函数。而且执行用户定义的函数的方法很巧妙,内核是在用户栈上创建一个新的层,该层中将返回地址的值设置成用户定义的处理函数的地址,这样进程从内核返回弹出栈顶时就返回到用户定义的函数处,从函数返回再弹出栈顶时,才返回原先进入内核的地方。这样做的原因是用户定义的处理函数不能且不允许在内核态下执行(如果用户定义的函数在内核态下运行的话,用户就可以获得任何权限)。
信号的安装
如果进程要处理某一信号,那么就要在进程中安装该信号。安装信号主要用来确定信号值及进程针对该信号值的动作之间的映射关系,即进程将要处理哪个信号;该信号被传递给进程时,将执行何种操作。
linux主要有两个函数实现信号的安装:signal()、sigaction()。其中signal()只有两个参数,不支持信号传递信息,主要是用于前32种非实时信号的安装;而sigaction()是较新的函数(由两个系统调用实现:sys_signal以及sys_rt_sigaction),有三个参数,支持信号传递信息,主要用来与 sigqueue() 系统调用配合使用,当然,sigaction()同样支持非实时信号的安装。sigaction()优于signal()主要体现在支持信号带有参数。
signal()
1 | #include <signal.h> |
如果该函数原型不容易理解的话,可以参考下面的分解方式来理解:1
2typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler));
第一个参数指定信号的值,第二个参数指定针对前面信号值的处理,可以忽略该信号(参数设为SIG_IGN);可以采用系统默认方式处理信号(参数设为SIG_DFL);也可以自己实现处理方式(参数指定一个函数地址)。
如果signal()调用成功,返回最后一次为安装信号signum而调用signal()时的handler值;失败则返回SIG_ERR。
传递给信号处理例程的整数参数是信号值,这样可以使得一个信号处理例程处理多个信号。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
void sigroutine(int dunno)
{ /* 信号处理例程,其中dunno将会得到信号的值 */
switch (dunno) {
case 1:
printf("Get a signal -- SIGHUP ");
break;
case 2:
printf("Get a signal -- SIGINT ");
break;
case 3:
printf("Get a signal -- SIGQUIT ");
break;
}
return;
}
int main() {
printf("process id is %d ",getpid());
signal(SIGHUP, sigroutine); //* 下面设置三个信号的处理方法
signal(SIGINT, sigroutine);
signal(SIGQUIT, sigroutine);
for (;;) ;
}
其中信号SIGINT由按下Ctrl-C发出,信号SIGQUIT由按下Ctrl-发出。该程序执行的结果如下:1
2
3
4
5
6
7
8
9
10
11
12localhost:~$ ./sig_test
process id is 463
Get a signal -SIGINT //按下Ctrl-C得到的结果
Get a signal -SIGQUIT //按下Ctrl-得到的结果
//按下Ctrl-z将进程置于后台
[1]+ Stopped ./sig_test
localhost:~$ bg
[1]+ ./sig_test &
localhost:~$ kill -HUP 463 //向进程发送SIGHUP信号
localhost:~$ Get a signal – SIGHUP
kill -9 463 //向进程发送SIGKILL信号,终止进程
localhost:~$
sigaction()
1 | #include <signal.h> |
sigaction函数用于改变进程接收到特定信号后的行为。该函数的第一个参数为信号的值,可以为除SIGKILL及SIGSTOP外的任何一个特定有效的信号(为这两个信号定义自己的处理函数,将导致信号安装错误)。第二个参数是指向结构sigaction的一个实例的指针,在结构sigaction的实例中,指定了对特定信号的处理,可以为空,进程会以缺省方式对信号处理;第三个参数oldact指向的对象用来保存返回的原来对相应信号的处理,可指定oldact为NULL。如果把第二、第三个参数都设为NULL,那么该函数可用于检查信号的有效性。
第二个参数最为重要,其中包含了对指定信号的处理、信号所传递的信息、信号处理函数执行过程中应屏蔽掉哪些信号等等。
sigaction结构定义如下:1
2
3
4
5
6
7
8struct sigaction {
union{
__sighandler_t _sa_handler;
void (*_sa_sigaction)(int,struct siginfo *, void *);
}_u
sigset_t sa_mask;
unsigned long sa_flags;
}
- 联合数据结构中的两个元素_sa_handler以及*_sa_sigaction指定信号关联函数,即用户指定的信号处理函数。除了可以是用户自定义的处理函数外,还可以为SIG_DFL(采用缺省的处理方式),也可以为SIG_IGN(忽略信号)。
- 由_sa_sigaction是指定的信号处理函数带有三个参数,是为实时信号而设的(当然同样支持非实时信号),它指定一个3参数信号处理函数。第一个参数为信号值,第三个参数没有使用,第二个参数是指向siginfo_t结构的指针,结构中包含信号携带的数据值,参数所指向的结构如下:
1 | siginfo_t { |
前面在讨论系统调用sigqueue发送信号时,sigqueue的第三个参数就是sigval联合数据结构,当调用sigqueue时,该数据结构中的数据就将拷贝到信号处理函数的第二个参数中。这样,在发送信号同时,就可以让信号传递一些附加信息。信号可以传递信息对程序开发是非常有意义的。
- sa_mask指定在信号处理程序执行过程中,哪些信号应当被阻塞。缺省情况下当前信号本身被阻塞,防止信号的嵌套发送,除非指定SA_NODEFER或者SA_NOMASK标志位。
注:请注意sa_mask指定的信号阻塞的前提条件,是在由sigaction()安装信号的处理函数执行过程中由sa_mask指定的信号才被阻塞。
- sa_flags中包含了许多标志位,包括刚刚提到的SA_NODEFER及SA_NOMASK标志位。另一个比较重要的标志位是SA_SIGINFO,当设定了该标志位时,表示信号附带的参数可以被传递到信号处理函数中,因此,应该为sigaction结构中的sa_sigaction指定处理函数,而不应该为sa_handler指定信号处理函数,否则,设置该标志变得毫无意义。即使为sa_sigaction指定了信号处理函数,如果不设置SA_SIGINFO,信号处理函数同样不能得到信号传递过来的数据,在信号处理函数中对这些信息的访问都将导致段错误(Segmentation fault)。
信号的发送
发送信号的主要函数有:kill()、raise()、 sigqueue()、alarm()、setitimer()以及abort()。
kill()
1 | #include <sys/types.h> |
该系统调用可以用来向任何进程或进程组发送任何信号。参数pid的值为信号的接收进程
- pid>0 进程ID为pid的进程
- pid=0 同一个进程组的进程
- pid<0 pid!=-1 进程组ID为 -pid的所有进程
- pid=-1 除发送进程自身外,所有进程ID大于1的进程
Sinno是信号值,当为0时(即空信号),实际不发送任何信号,但照常进行错误检查,因此,可用于检查目标进程是否存在,以及当前进程是否具有向目标发送信号的权限(root权限的进程可以向任何进程发送信号,非root权限的进程只能向属于同一个session或者同一个用户的进程发送信号)。
Kill()最常用于pid>0时的信号发送。该调用执行成功时,返回值为0;错误时,返回-1,并设置相应的错误代码errno。下面是一些可能返回的错误代码:
-EINVAL:指定的信号sig无效。
-ESRCH:参数pid指定的进程或进程组不存在。注意,在进程表项中存在的进程,可能是一个还没有被wait收回,但已经终止执行的僵死进程。
-EPERM: 进程没有权力将这个信号发送到指定接收信号的进程。因为,一个进程被允许将信号发送到进程pid时,必须拥有root权力,或者是发出调用的进程的UID 或EUID与指定接收的进程的UID或保存用户ID(savedset-user-ID)相同。如果参数pid小于-1,即该信号发送给一个组,则该错误表示组中有成员进程不能接收该信号。
sigqueue()
1 | #include <sys/types.h> |
调用成功返回 0;否则,返回 -1。
sigqueue()是比较新的发送信号系统调用,主要是针对实时信号提出的(当然也支持前32种),支持信号带有参数,与函数sigaction()配合使用。
sigqueue的第一个参数是指定接收信号的进程ID,第二个参数确定即将发送的信号,第三个参数是一个联合数据结构union sigval,指定了信号传递的参数,即通常所说的4字节值。1
2
3
4typedef union sigval {
int sival_int;
void *sival_ptr;
}sigval_t;
sigqueue()比kill()传递了更多的附加信息,但sigqueue()只能向一个进程发送信号,而不能发送信号给一个进程组。如果signo=0,将会执行错误检查,但实际上不发送任何信号,0值信号可用于检查pid的有效性以及当前进程是否有权限向目标进程发送信号。
在调用sigqueue时,sigval_t指定的信息会拷贝到对应sig 注册的3参数信号处理函数的siginfo_t结构中,这样信号处理函数就可以处理这些信息了。由于sigqueue系统调用支持发送带参数信号,所以比kill()系统调用的功能要灵活和强大得多。
alarm()
1 | #include <unistd.h> |
系统调用alarm安排内核为调用进程在指定的seconds秒后发出一个SIGALRM的信号。如果指定的参数seconds为0,则不再发送 SIGALRM信号。后一次设定将取消前一次的设定。该调用返回值为上次定时调用到发送之间剩余的时间,或者因为没有前一次定时调用而返回0。
注意,在使用时,alarm只设定为发送一次信号,如果要多次发送,就要多次使用alarm调用。
setitimer()
现在的系统中很多程序不再使用alarm调用,而是使用setitimer调用来设置定时器,用getitimer来得到定时器的状态,这两个调用的声明格式如下:1
2int getitimer(int which, struct itimerval *value);
int setitimer(int which, const struct itimerval *value, struct itimerval *ovalue);
在使用这两个调用的进程中加入以下头文件:1
#include <sys/time.h>
该系统调用给进程提供了三个定时器,它们各自有其独有的计时域,当其中任何一个到达,就发送一个相应的信号给进程,并使得计时器重新开始。三个计时器由参数which指定,如下所示:
TIMER_REAL:按实际时间计时,计时到达将给进程发送SIGALRM信号。
ITIMER_VIRTUAL:仅当进程执行时才进行计时。计时到达将发送SIGVTALRM信号给进程。
ITIMER_PROF:当进程执行时和系统为该进程执行动作时都计时。与ITIMER_VIR-TUAL是一对,该定时器经常用来统计进程在用户态和内核态花费的时间。计时到达将发送SIGPROF信号给进程。
定时器中的参数value用来指明定时器的时间,其结构如下:1
2
3
4struct itimerval {
struct timeval it_interval; /* 下一次的取值 */
struct timeval it_value; /* 本次的设定值 */
};
该结构中timeval结构定义如下:1
2
3
4struct timeval {
long tv_sec; /* 秒 */
long tv_usec; /* 微秒,1秒 = 1000000 微秒*/
};
在setitimer 调用中,参数ovalue如果不为空,则其中保留的是上次调用设定的值。定时器将it_value递减到0时,产生一个信号,并将it_value的值设定为it_interval的值,然后重新开始计时,如此往复。当it_value设定为0时,计时器停止,或者当它计时到期,而it_interval 为0时停止。调用成功时,返回0;错误时,返回-1,并设置相应的错误代码errno:
EFAULT:参数value或ovalue是无效的指针。
EINVAL:参数which不是ITIMER_REAL、ITIMER_VIRT或ITIMER_PROF中的一个。
下面是关于setitimer调用的一个简单示范,在该例子中,每隔一秒发出一个SIGALRM,每隔0.5秒发出一个SIGVTALRM信号:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
int sec;
void sigroutine(int signo) {
switch (signo) {
case SIGALRM:
printf("Catch a signal -- SIGALRM ");
break;
case SIGVTALRM:
printf("Catch a signal -- SIGVTALRM ");
break;
}
return;
}
int main()
{
struct itimerval value,ovalue,value2;
sec = 5;
printf("process id is %d ",getpid());
signal(SIGALRM, sigroutine);
signal(SIGVTALRM, sigroutine);
value.it_value.tv_sec = 1;
value.it_value.tv_usec = 0;
value.it_interval.tv_sec = 1;
value.it_interval.tv_usec = 0;
setitimer(ITIMER_REAL, &value, &ovalue);
value2.it_value.tv_sec = 0;
value2.it_value.tv_usec = 500000;
value2.it_interval.tv_sec = 0;
value2.it_interval.tv_usec = 500000;
setitimer(ITIMER_VIRTUAL, &value2, &ovalue);
for (;;) ;
}
该例子的屏幕拷贝如下:1
2
3
4
5
6
7
8localhost:~$ ./timer_test
process id is 579
Catch a signal – SIGVTALRM
Catch a signal – SIGALRM
Catch a signal – SIGVTALRM
Catch a signal – SIGVTALRM
Catch a signal – SIGALRM
Catch a signal –GVTALRM
abort()
1 | #include <stdlib.h> |
向进程发送SIGABORT信号,默认情况下进程会异常退出,当然可定义自己的信号处理函数。即使SIGABORT被进程设置为阻塞信号,调用abort()后,SIGABORT仍然能被进程接收。该函数无返回值。
raise()
1 | #include <signal.h> |
向进程本身发送信号,参数为即将发送的信号值。调用成功返回 0;否则,返回 -1。
信号集及信号集操作函数:
信号集被定义为一种数据类型:1
2
3typedef struct {
unsigned long sig[_NSIG_WORDS];
} sigset_t
信号集用来描述信号的集合,每个信号占用一位。Linux所支持的所有信号可以全部或部分的出现在信号集中,主要与信号阻塞相关函数配合使用。下面是为信号集操作定义的相关函数:1
2
3
4
5
6
7
8
9
10
11
int sigemptyset(sigset_t *set);
int sigfillset(sigset_t *set);
int sigaddset(sigset_t *set, int signum)
int sigdelset(sigset_t *set, int signum);
int sigismember(const sigset_t *set, int signum);
sigemptyset(sigset_t *set)初始化由set指定的信号集,信号集里面的所有信号被清空;
sigfillset(sigset_t *set)调用该函数后,set指向的信号集中将包含linux支持的64种信号;
sigaddset(sigset_t *set, int signum)在set指向的信号集中加入signum信号;
sigdelset(sigset_t *set, int signum)在set指向的信号集中删除signum信号;
sigismember(const sigset_t *set, int signum)判定信号signum是否在set指向的信号集中。
信号阻塞与信号未决
每个进程都有一个用来描述哪些信号递送到进程时将被阻塞的信号集,该信号集中的所有信号在递送到进程后都将被阻塞。下面是与信号阻塞相关的几个函数:1
2
3
4#include <signal.h>
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset));
int sigpending(sigset_t *set));
int sigsuspend(const sigset_t *mask));
sigprocmask()函数能够根据参数how来实现对信号集的操作,操作主要有三种:
- SIG_BLOCK 在进程当前阻塞信号集中添加set指向信号集中的信号
- SIG_UNBLOCK 如果进程阻塞信号集中包含set指向信号集中的信号,则解除对该信号的阻塞
- SIG_SETMASK 更新进程阻塞信号集为set指向的信号集
sigpending(sigset_t *set))获得当前已递送到进程,却被阻塞的所有信号,在set指向的信号集中返回结果。
sigsuspend(const sigset_t *mask))用于在接收到某个信号之前, 临时用mask替换进程的信号掩码, 并暂停进程执行,直到收到信号为止。sigsuspend 返回后将恢复调用之前的信号掩码。信号处理函数完成后,进程将继续执行。该系统调用始终返回-1,并将errno设置为EINTR。
信号应用实例
linux下的信号应用并没有想象的那么恐怖,程序员所要做的最多只有三件事情:
- 安装信号(推荐使用sigaction());
- 实现三参数信号处理函数,handler(int signal,struct siginfo info, void );
- 发送信号,推荐使用sigqueue()。
实际上,对有些信号来说,只要安装信号就足够了(信号处理方式采用缺省或忽略)。其他可能要做的无非是与信号集相关的几种操作。
实例一:信号发送及处理
实现一个信号接收程序sigreceive(其中信号安装由sigaction())。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
void new_op(int,siginfo_t*,void*);
int main(int argc,char**argv)
{
struct sigaction act;
int sig;
sig=atoi(argv[1]);
sigemptyset(&act.sa_mask);
act.sa_flags=SA_SIGINFO;
act.sa_sigaction=new_op;
if(sigaction(sig,&act,NULL) < 0)
{
printf("install sigal error\n");
}
while(1)
{
sleep(2);
printf("wait for the signal\n");
}
}
void new_op(int signum,siginfo_t *info,void *myact)
{
printf("receive signal %d", signum);
sleep(5);
}
说明,命令行参数为信号值,后台运行sigreceive signo &,可获得该进程的ID,假设为pid,然后再另一终端上运行kill -s signo pid验证信号的发送接收及处理。同时,可验证信号的排队问题。
实例二:信号传递附加信息
主要包括两个实例:
向进程本身发送信号,并传递指针参数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
void new_op(int,siginfo_t*,void*);
int main(int argc,char**argv)
{
struct sigaction act;
union sigval mysigval;
int i;
int sig;
pid_t pid;
char data[10];
memset(data,0,sizeof(data));
for(i=0;i < 5;i++)
data[i]='2';
mysigval.sival_ptr=data;
sig=atoi(argv[1]);
pid=getpid();
sigemptyset(&act.sa_mask);
act.sa_sigaction=new_op;//三参数信号处理函数
act.sa_flags=SA_SIGINFO;//信息传递开关,允许传说参数信息给new_op
if(sigaction(sig,&act,NULL) < 0)
{
printf("install sigal error\n");
}
while(1)
{
sleep(2);
printf("wait for the signal\n");
sigqueue(pid,sig,mysigval);//向本进程发送信号,并传递附加信息
}
}
void new_op(int signum,siginfo_t *info,void *myact)//三参数信号处理函数的实现
{
int i;
for(i=0;i<10;i++)
{
printf("%c\n ",(*( (char*)((*info).si_ptr)+i)));
}
printf("handle signal %d over;",signum);
}
这个例子中,信号实现了附加信息的传递,信号究竟如何对这些信息进行处理则取决于具体的应用。
不同进程间传递整型参数:
把1中的信号发送和接收放在两个程序中,并且在发送过程中传递整型参数。
信号接收程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
void new_op(int,siginfo_t*,void*);
int main(int argc,char**argv)
{
struct sigaction act;
int sig;
pid_t pid;
pid=getpid();
sig=atoi(argv[1]);
sigemptyset(&act.sa_mask);
act.sa_sigaction=new_op;
act.sa_flags=SA_SIGINFO;
if(sigaction(sig,&act,NULL)<0)
{
printf("install sigal error\n");
}
while(1)
{
sleep(2);
printf("wait for the signal\n");
}
}
void new_op(int signum,siginfo_t *info,void *myact)
{
printf("the int value is %d \n",info->si_int);
}
信号发送程序:
命令行第二个参数为信号值,第三个参数为接收进程ID。
1 |
|
注:实例2的两个例子侧重点在于用信号来传递信息,目前关于在linux下通过信号传递信息的实例非常少,倒是Unix下有一些,但传递的基本上都是关于传递一个整数
实例三:信号阻塞及信号集操作
1 |
|
编译该程序,并以后台方式运行。在另一终端向该进程发送信号(运行kill -s 42 pid,SIGRTMIN+10为42),查看结果可以看出几个关键函数的运行机制,信号集相关操作比较简单。
总结
一旦有信号产生,用户进程对信号产生的相应有三种方式:
- 执行默认操作,linux对每种信号都规定了默认操作。
- 捕捉信号,定义信号处理函数,当信号发生时,执行相应的处理函数。
- 忽略信号,当不希望接收到的信号对进程的执行产生影响,而让进程继续执行时,可以忽略该信号,即不对信号进程作任何处理。
有两个信号是应用进程无法捕捉和忽略的,即SIGKILL和SEGSTOP,这是为了使系统管理员能在任何时候中断或结束某一特定的进程。


上图表示了Linux中常见的命令
信号发送:
信号发送的关键使得系统知道向哪个进程发送信号以及发送什么信号。下面是信号操作中常用的函数:
例子:创建子进程,为了使子进程不在父进程发出信号前结束,子进程中使用raise函数发送sigstop信号,使自己暂停;父进程使用信号操作的kill函数,向子进程发送sigkill信号,子进程收到此信号,结束子进程。
信号处理
当某个信号被发送到一个正在运行的进程时,该进程即对次特定的信号注册相应的信号处理函数,以完成所需处理。设置信号处理方式的是signal函数,在程序正常结束前,在应用signal函数恢复系统对信号的默认处理方式。


信号阻塞
有时候既不希望进程在接收到信号时立刻中断进程的执行,也不希望此信号完全被忽略掉,而是希望延迟一段时间再去调用信号处理函数,这个时候就需要信号阻塞来完成。
例子:主程序阻塞了cltr+c的sigint信号。用sigpromask将sigint假如阻塞信号集合。
管道:
管道允许在进程之间按先进先出的方式传送数据,是进程间通信的一种常见方式。
管道是Linux 支持的最初Unix IPC形式之一,具有以下特点:
- 管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道;
- 匿名管道只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程);
- 单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
管道分为pipe(无名管道)和fifo(命名管道)两种,除了建立、打开、删除的方式不同外,这两种管道几乎是一样的。他们都是通过内核缓冲区实现数据传输。
pipe用于相关进程之间的通信,例如父进程和子进程,它通过pipe()系统调用来创建并打开,当最后一个使用它的进程关闭对他的引用时,pipe将自动撤销。
FIFO即命名管道,在磁盘上有对应的节点,但没有数据块——换言之,只是拥有一个名字和相应的访问权限,通过mknode()系统调用或者mkfifo()函数来建立的。一旦建立,任何进程都可以通过文件名将其打开和进行读写,而不局限于父子进程,当然前提是进程对FIFO有适当的访问权。当不再被进程使用时,FIFO在内存中释放,但磁盘节点仍然存在。
管道的实质是一个内核缓冲区,进程以先进先出的方式从缓冲区存取数据:管道一端的进程顺序地将进程数据写入缓冲区,另一端的进程则顺序地读取数据,该缓冲区可以看做一个循环队列,读和写的位置都是自动增加的,一个数据只能被读一次,读出以后再缓冲区都不复存在了。当缓冲区读空或者写满时,有一定的规则控制相应的读进程或写进程是否进入等待队列,当空的缓冲区有新数据写入或慢的缓冲区有数据读出时,就唤醒等待队列中的进程继续读写。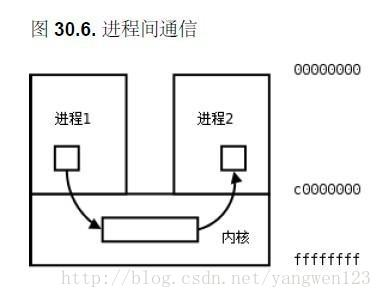
管道的作用是在具有亲缘关系的进程之间传递消息,所谓有亲缘关系,是指有同一个祖先。所以管道并不是只可以用于父子进程通信,也可以在兄弟进程之间还可以用在祖孙之间等,反正只要共同的祖先调用了pipe函数,打开的管道文件就会在fork之后,被各个后代所共享。
不过由于管道是字节流通信,没有消息边界,多个进程同时发送的字节流混在一起,则无法分辨消息,所有管道一般用于2个进程之间通信,另外管道的内容读完后不会保存,管道是单向的,一边要么读,一边要么写,不可以又读又写,想要一边读一边写,那就创建2个管道,如下图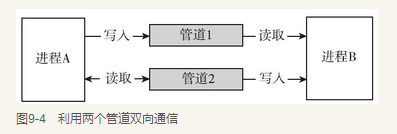
管道是一种文件,可以调用read、write和close等操作文件的接口来操作管道。另一方面管道又不是一种普通的文件,它属于一种独特的文件系统:pipefs。管道的本质是内核维护了一块缓冲区与管道文件相关联,对管道文件的操作,被内核转换成对这块缓冲区内存的操作。下面我们来看一下如何使用管道。1
2
int pipe(int fd[2])
如果成功,则返回值是0,如果失败,则返回值是-1,并且设置errno。
成功调用pipe函数之后,会返回两个打开的文件描述符,一个是管道的读取端描述符pipefd[0],另一个是管道的写入端描述符pipefd[1]。管道没有文件名与之关联,因此程序没有选择,只能通过文件描述符来访问管道,只有那些能看到这两个文件描述符的进程才能够使用管道。那么谁能看到进程打开的文件描述符呢?只有该进程及该进程的子孙进程才能看到。这就限制了管道的使用范围。
成功调用pipe函数之后,可以对写入端描述符pipefd[1]调用write,向管道里面写入数据,代码如下所示:1
write(pipefd[1],wbuf,count);
一旦向管道的写入端写入数据后,就可以对读取端描述符pipefd[0]调用read,读出管道里面的内容。如下所示,管道上的read调用返回的字节数等于请求字节数和管道中当前存在的字节数的最小值。如果当前管道为空,那么read调用会阻塞(如果没有设置O_NONBLOCK标志位的话)。
无名管道:
pipe的例子:父进程创建管道,并在管道中写入数据,而子进程从管道读出数据
命名管道:
和无名管道的主要区别在于,命名管道有一个名字,命名管道的名字对应于一个磁盘索引节点,有了这个文件名,任何进程有相应的权限都可以对它进行访问。
而无名管道却不同,进程只能访问自己或祖先创建的管道,而不能访任意访问已经存在的管道——因为没有名字。
Linux中通过系统调用mknod()或makefifo()来创建一个命名管道。最简单的方式是通过直接使用shell1
mkfifo myfifo
等价于1
mknod myfifo p
以上命令在当前目录下创建了一个名为myfifo的命名管道。用ls -p命令查看文件的类型时,可以看到命名管道对应的文件名后有一条竖线”|”,表示该文件不是普通文件而是命名管道。
使用open()函数通过文件名可以打开已经创建的命名管道,而无名管道不能由open来打开。当一个命名管道不再被任何进程打开时,它没有消失,还可以再次被打开,就像打开一个磁盘文件一样。
可以用删除普通文件的方法将其删除,实际删除的事磁盘上对应的节点信息。
例子:用命名管道实现聊天程序,一个张三端,一个李四端。两个程序都建立两个命名管道,fifo1,fifo2,张三写fifo1,李四读fifo1;李四写fifo2,张三读fifo2。
用select把管道描述符和stdin加入集合,用select进行阻塞,如果有i/o的时候唤醒进程。(粉红色部分为select部分,黄色部分为命名管道部分)



在linux系统中,除了用pipe系统调用建立管道外,还可以使用C函数库中管道函数popen函数来建立管道,使用pclose关闭管道。
例子:设计一个程序用popen创建管道,实现 ls -l |grep main.c的功能
分析:先用popen函数创建一个读管道,调用fread函数将ls -l的结果存入buf变量,用printf函数输出内容,用pclose关闭读管道;
接着用popen函数创建一个写管道,调用fprintf函数将buf的内容写入管道,运行grep命令。
popen的函数原型:1
FILE* popen(const char* command,const char* type);
参数说明:command是子进程要执行的命令,type表示管道的类型,r表示读管道,w代表写管道。如果成功返回管道文件的指针,否则返回NULL。
使用popen函数读写管道,实际上也是调用pipe函数调用建立一个管道,再调用fork函数建立子进程,接着会建立一个shell 环境,并在这个shell环境中执行参数所指定的进程。
消息队列:
消息队列,就是一个消息的链表,是一系列保存在内核中消息的列表。用户进程可以向消息队列添加消息,也可以向消息队列读取消息。
消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
可以把消息看做一个记录,具有特定的格式以及特定的优先级。对消息队列有写权限的进程可以向消息队列中按照一定的规则添加新消息,对消息队列有读权限的进程可以从消息队列中读取消息。
消息队列的常用函数如下表:
进程间通过消息队列通信,主要是:创建或打开消息队列,添加消息,读取消息和控制消息队列。
例子:用函数msget创建消息队列,调用msgsnd函数,把输入的字符串添加到消息队列中,然后调用msgrcv函数,读取消息队列中的消息并打印输出,最后再调用msgctl函数,删除系统内核中的消息队列。(黄色部分是消息队列相关的关键代码,粉色部分是读取stdin的关键代码)


消息队列可以认为是一个链表。进程(线程)可以往里写消息,也可以从里面取出消息。一个进程可以往某个消息队列里写消息,然后终止,另一个进程随时可以从消息队列里取走这些消息。这里也说明了,消息队列具有随内核的持续性,也就是系统不重启,消息队列永久存在。
创建(并打开)、关闭、删除一个消息队列1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
int main()
{
mqd_t posixmq;
int rc = 0;
/*
函数说明:函数创建或打开一个消息队列
返回值:成功返回消息队列描述符,失败返回-1,错误原因存于errno中
*/
posixmq = mq_open(MQ_NAME, MQ_FLAG, FILE_MODE, NULL);
if(-1 == posixmq)
{
perror("创建MQ失败");
exit(1);
}
/*
函数说明:关闭一个打开的消息队列,表示本进程不再对该消息队列读写
返回值:成功返回0,失败返回-1,错误原因存于errno中
*/
rc = mq_close(posixmq);
if(0 != rc)
{
perror("关闭失败");
exit(1);
}
/*
函数说明:删除一个消息队列,好比删除一个文件,其他进程再也无法访问
返回值:成功返回0,失败返回-1,错误原因存于errno中
*/
rc = mq_unlink(MQ_NAME);
if(0 != rc)
{
perror("删除失败");
exit(1);
}
return 0;
}
编译并执行:1
2
3
4
5
6root@linux:/mnt/hgfs/C_libary# gcc -o crtmq crtmq.c
/tmp/ccZ9cTxo.o: In function `main':
crtmq.c:(.text+0x31): undefined reference to `mq_open'
crtmq.c:(.text+0x60): undefined reference to `mq_close'
crtmq.c:(.text+0x8f): undefined reference to `mq_unlink'
collect2: ld returned 1 exit status
因为mq_XXX()函数不是标准库函数,链接时需要指定;库-lrt;1
2root@linux:/mnt/hgfs/C_libary# gcc -o crtmq crtmq.c -lrt
root@linux:/mnt/hgfs/C_libary# ./crtmq
最后程序并没有删除消息队列(消息队列有随内核持续性),如再次执行该程序则会给出错误信息:1
2root@linux:/mnt/hgfs/C_libary# ./crtmq
创建MQ失败: File exit(0)
编译这个程序需要注意几点:
- 消息队列的名字最好使用“/”打头,并且只有一个“/”的名字。否则可能出现移植性问题;(还需保证在根目录有写权限,为了方便我在root权限下测试)
- 创建成功的消息队列不一定能看到,使用一些方法也可以看到,本文不做介绍;
消息队列的名字有如此规定,引用《UNIX网络编程 卷2》的相关描述: mq_open,sem_open,shm_open这三个函数的第一个参数是
一个IPC名字,它可能是某个文件系统中的一个真正存在的路径名,也可能不是。Posix.1是这样描述Posix IPC名字的。
- 它必须符合已有的路径名规则(最多由PATH_MAX个字节构成,包括结尾的空字节)
- 如果它以斜杠开头,那么对这些函数的不同调用将访问同一个队列,否则效果取决于实现(也就是效果没有标准化)
- 名字中的额外的斜杠符的解释由实现定义(同样是没有标准化) 因此,为便于移植起见,Posix IPC名字必须以一个斜杠打头,并且不能再包含任何其他斜杠符。
IPC通信:Posix消息队列读,写
创建消息队列的程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
int main()
{
mqd_t posixmq;
int rc = 0;
/*
函数说明:函数创建或打开一个消息队列
返回值:成功返回消息队列描述符,失败返回-1,错误原因存于errno中
*/
posixmq = mq_open(MQ_NAME, MQ_FLAG, FILE_MODE, NULL);
if(-1 == posixmq)
{
perror("创建MQ失败");
exit(1);
}
/*
函数说明:关闭一个打开的消息队列,表示本进程不再对该消息队列读写
返回值:成功返回0,失败返回-1,错误原因存于errno中
*/
rc = mq_close(posixmq);
if(0 != rc)
{
perror("关闭失败");
exit(1);
}
/*
函数说明:删除一个消息队列,好比删除一个文件,其他进程再也无法访问
返回值:成功返回0,失败返回-1,错误原因存于errno中
*/
rc = mq_unlink(MQ_NAME);
if(0 != rc)
{
perror("删除失败");
exit(1);
}
return 0;
}
编译并执行:1
2root@linux:/mnt/hgfs/C_libary# gcc -o crtmq crtmq.c -lrt
root@linux:/mnt/hgfs/C_libary# ./crtmq
程序并没有删除消息队列(消息队列有随内核持续性),如再次执行该程序则会给出错误信息:1
2root@linux:/mnt/hgfs/C_libary# ./crtmq
创建MQ失败: File exit(0)
向消息队列写消息的程序:
消息队列的读写主要使用下面两个函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/*头文件*/
/*返回:若成功则为消息中字节数,若出错则为-1 */
int mq_send(mqd_t mqdes, const char *msg_ptr, size_t msg_len, unsigned msg_prio);
/*返回:若成功则为0, 若出错则为-1*/
ssize_t mq_receive(mqd_t mqdes, char *msg_ptr, size_t msg_len, unsigned *msg_prio);
/*消息队列属性结构体*/
struct mq_attr {
long mq_flags; /* Flags: 0 or O_NONBLOCK */
long mq_maxmsg; /* Max. # of messages on queue */
long mq_msgsize; /* Max. message size (bytes) */
long mq_curmsgs; /* # of messages currently in queue */
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
/*向消息队列发送消息,消息队列名及发送的信息通过参数传递*/
int main(int argc, char *argv[])
{
mqd_t mqd;
char *ptr;
size_t len;
unsigned int prio;
int rc;
if(argc != 4)
{
printf("Usage: sendmq <name> <bytes> <priority>\n");
exit(1);
}
len = atoi(argv[2]);
prio = atoi(argv[3]);
//只写模式找开消息队列
mqd = mq_open(argv[1], O_WRONLY);
if(-1 == mqd)
{
perror("打开消息队列失败");
exit(1);
}
// 动态申请一块内存
ptr = (char *) calloc(len, sizeof(char));
if(NULL == ptr)
{
perror("申请内存失败");
mq_close(mqd);
exit(1);
}
/*向消息队列写入消息,如消息队列满则阻塞,直到消息队列有空闲时再写入*/
rc = mq_send(mqd, ptr, len, prio);
if(rc < 0)
{
perror("写入消息队列失败");
mq_close(mqd);
exit(1);
}
// 释放内存
free(ptr);
return 0;
}
编译并执行:1
2
3
4
5root@linux:/mnt/hgfs/C_libary# gcc -o sendmq sendmq.c -lrt
root@linux:/mnt/hgfs/C_libary# ./sendmq /tmp 30 15
root@linux:/mnt/hgfs/C_libary# ./sendmq /tmp 30 16
root@linux:/mnt/hgfs/C_libary# ./sendmq /tmp 30 17
root@linux:/mnt/hgfs/C_libary# ./sendmq /tmp 30 18
上面先后向消息队列“/tmp”写入了四条消息,因为先前创建的消息队列只允许存放3条消息,本次第四次写入时程序会阻塞。直到有另外进程从消息队列取走消息后本次写入才成功返回。
读消息队列:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
/*读取某消息队列,消息队列名通过参数传递*/
int main(int argc, char *argv[])
{
mqd_t mqd;
struct mq_attr attr;
char *ptr;
unsigned int prio;
size_t n;
int rc;
if(argc != 2)
{
printf("Usage: readmq <name>\n");
exit(1);
}
/*只读模式打开消息队列*/
mqd = mq_open(argv[1], O_RDONLY);
if(mqd < 0)
{
perror("打开消息队列失败");
exit(1);
}
// 取得消息队列属性,根据mq_msgsize动态申请内存
rc = mq_getattr(mqd, &attr);
if(rc < 0)
{
perror("取得消息队列属性失败");
exit(1);
}
/*动态申请保证能存放单条消息的内存*/
ptr = calloc(attr.mq_msgsize, sizeof(char));
if(NULL == ptr)
{
printf("动态申请内存失败\n");
mq_close(mqd);
exit(1);
}
/*接收一条消息*/
n = mq_receive(mqd, ptr, attr.mq_msgsize, &prio);
if(n < 0)
{
perror("读取失败");
mq_close(mqd);
free(ptr);
exit(1);
}
printf("读取 %ld 字节\n 优先级为 %u\n", (long)n, prio);
return 0;
}
编译并执行:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16root@linux:/mnt/hgfs/C_libary# vi readmq.c
root@linux:/mnt/hgfs/C_libary# vi readmq.c
root@linux:/mnt/hgfs/C_libary# gcc -o readmq readmq.c -lrt
root@linux:/mnt/hgfs/C_libary# ./readmq /tmp
读取 30 字节
优先级为 18
root@linux:/mnt/hgfs/C_libary# ./readmq /tmp
读取 30 字节
优先级为 17
root@linux:/mnt/hgfs/C_libary# ./readmq /tmp
读取 30 字节
优先级为 16
root@linux:/mnt/hgfs/C_libary# ./readmq /tmp
读取 30 字节
优先级为 15
root@linux:/mnt/hgfs/C_libary# ./readmq /tmp
程序执行五次,第一次执行完,先前阻塞在写处的程序成功返回。第五次执行,因为消息队列已经为空,程序阻塞。直到另外的进程向消息队列写入一条消息。另外,还可以看出Posix消息队列每次读出的都是消息队列中优先级最高的消息。
IPC通信:Posix消息队列的属性设置
Posix消息队列的属性使用如下结构存放:1
2
3
4
5
6
7struct mq_attr
{
long mq_flags; /*阻塞标志位,0为非阻塞(O_NONBLOCK)*/
long mq_maxmsg; /*队列所允许的最大消息条数*/
long mq_msgsize; /*每条消息的最大字节数*/
long mq_curmsgs; /*队列当前的消息条数*/
};
队列可以在创建时由mq_open()函数的第四个参数指定mq_maxmsg,mq_msgsize。 如创建时没有指定则使用默认值,一旦创建,则不可再改变。
队列可以在创建后由mq_setattr()函数设置mq_flags1
2
3
4
5
6
7
8
9
/*取得消息队列属性,放到mqstat地fh*/
int mq_getattr(mqd_t mqdes, struct mq_attr *mqstat);
/*设置消息队列属性,设置值由mqstat提供,原先值写入omqstat*/
int mq_setattr(mqd_t mqdes, const struct mq_attr *mqstat, struct mq_attr *omqstat);
均返回:若成功则为0,若出错为-1
程序获取和设置消息队列的默认属性:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
int main()
{
mqd_t posixmq;
int rc = 0;
struct mq_attr mqattr;
// 创建默认属性的消息队列
posixmq = mq_open(MQ_NAME, MQ_FLAG, FILE_MODE, NULL);
if(-1 == posixmq)
{
perror("创建MQ失败");
exit(1);
}
// 获取消息队列的默认属性
rc = mq_getattr(posixmq, &mqattr);
if(-1 == rc)
{
perror("获取消息队列属性失败");
exit(1);
}
printf("队列阻塞标志位:%ld\n", mqattr.mq_flags);
printf("队列允许最大消息数:%ld\n", mqattr.mq_maxmsg);
printf("队列消息最大字节数:%ld\n", mqattr.mq_msgsize);
printf("队列当前消息条数:%ld\n", mqattr.mq_curmsgs);
rc = mq_close(posixmq);
if(0 != rc)
{
perror("关闭失败");
exit(1);
}
rc = mq_unlink(MQ_NAME);
if(0 != rc)
{
perror("删除失败");
exit(1);
}
return 0;
}
编译并执行:1
2
3
4
5
6
7root@linux:/mnt/hgfs/C_libary# gcc -o attrmq attrmq.c -lrt
root@linux:/mnt/hgfs/C_libary# ./attrmq
队列阻塞标志位:0
队列允许最大消息数:10
队列消息最大字节数:8192
队列当前消息条数:0
root@linux:/mnt/hgfs/C_libary#
设置消息队列的属性:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
int main()
{
mqd_t posixmq;
int rc = 0;
struct mq_attr mqattr;
// 创建默认属性的消息队列
mqattr.mq_maxmsg = 5; // 注意不能超过系统最大限制
mqattr.mq_msgsize = 8192;
//posixmq = mq_open(MQ_NAME, MQ_FLAG, FILE_MODE, NULL);
posixmq = mq_open(MQ_NAME, MQ_FLAG, FILE_MODE, &mqattr);
if(-1 == posixmq)
{
perror("创建MQ失败");
exit(1);
}
mqattr.mq_flags = 0;
mq_setattr(posixmq, &mqattr, NULL);// mq_setattr()只关注mq_flags,adw
// 获取消息队列的属性
rc = mq_getattr(posixmq, &mqattr);
if(-1 == rc)
{
perror("获取消息队列属性失败");
exit(1);
}
printf("队列阻塞标志位:%ld\n", mqattr.mq_flags);
printf("队列允许最大消息数:%ld\n", mqattr.mq_maxmsg);
printf("队列消息最大字节数:%ld\n", mqattr.mq_msgsize);
printf("队列当前消息条数:%ld\n", mqattr.mq_curmsgs);
rc = mq_close(posixmq);
if(0 != rc)
{
perror("关闭失败");
exit(1);
}
rc = mq_unlink(MQ_NAME);
if(0 != rc)
{
perror("删除失败");
exit(1);
}
return 0;
}
编译运行:1
2
3
4
5
6root@linux:/mnt/hgfs/C_libary# gcc -o setattrmq setattrmq.c -lrt
root@linux:/mnt/hgfs/C_libary# ./setattrmq
队列阻塞标志位:0
队列允许最大消息数:5
队列消息最大字节数:8192
队列当前消息条数:0
共享内存:
共享内存允许两个或多个进程共享一个给定的存储区,这一段存储区可以被两个或两个以上的进程映射至自身的地址空间中,一个进程写入共享内存的信息,可以被其他使用这个共享内存的进程,通过一个简单的内存读取错做读出,从而实现了进程间的通信。
采用共享内存进行通信的一个主要好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝,对于像管道和消息队里等通信方式,则需要再内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次:一次从输入文件到共享内存区,另一次从共享内存到输出文件。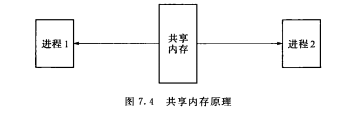
一般而言,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时在重新建立共享内存区域;而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件,因此,采用共享内存的通信方式效率非常高。
共享内存有两种实现方式:1、内存映射 2、共享内存机制
什么是共享内存
顾名思义,共享内存就是允许两个不相关的进程访问同一个逻辑内存。共享内存是在两个正在运行的进程之间共享和传递数据的一种非常有效的方式。不同进程之间共享的内存通常安排为同一段物理内存。进程可以将同一段共享内存连接到它们自己的地址空间中,所有进程都可以访问共享内存中的地址,就好像它们是由用C语言函数malloc分配的内存一样。而如果某个进程向共享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程。
特别提醒:共享内存并未提供同步机制,也就是说,在第一个进程结束对共享内存的写操作之前,并无自动机制可以阻止第二个进程开始对它进行读取。所以我们通常需要用其他的机制来同步对共享内存的访问,例如前面说到的信号量。
共享内存的使得
与信号量一样,在Linux中也提供了一组函数接口用于使用共享内存,而且使用共享共存的接口还与信号量的非常相似,而且比使用信号量的接口来得简单。它们声明在头文件 sys/shm.h中。
shmget函数
该函数用来创建共享内存,它的原型为:1
int shmget(key_t key, size_t size, int shmflg);
第一个参数,与信号量的semget函数一样,程序需要提供一个参数key(非0整数),它有效地为共享内存段命名,shmget函数成功时返回一个与key相关的共享内存标识符(非负整数),用于后续的共享内存函数。调用失败返回-1.
不相关的进程可以通过该函数的返回值访问同一共享内存,它代表程序可能要使用的某个资源,程序对所有共享内存的访问都是间接的,程序先通过调用shmget函数并提供一个键,再由系统生成一个相应的共享内存标识符(shmget函数的返回值),只有shmget函数才直接使用信号量键,所有其他的信号量函数使用由semget函数返回的信号量标识符。
第二个参数,size以字节为单位指定需要共享的内存容量
第三个参数,shmflg是权限标志,它的作用与open函数的mode参数一样,如果要想在key标识的共享内存不存在时,创建它的话,可以与IPC_CREAT做或操作。共享内存的权限标志与文件的读写权限一样,举例来说,0644,它表示允许一个进程创建的共享内存被内存创建者所拥有的进程向共享内存读取和写入数据,同时其他用户创建的进程只能读取共享内存。
shmat函数
第一次创建完共享内存时,它还不能被任何进程访问,shmat函数的作用就是用来启动对该共享内存的访问,并把共享内存连接到当前进程的地址空间。它的原型如下:1
void *shmat(int shm_id, const void *shm_addr, int shmflg);
第一个参数,shm_id是由shmget函数返回的共享内存标识。
第二个参数,shm_addr指定共享内存连接到当前进程中的地址位置,通常为空,表示让系统来选择共享内存的地址。
第三个参数,shm_flg是一组标志位,通常为0。
调用成功时返回一个指向共享内存第一个字节的指针,如果调用失败返回-1.
shmdt函数
该函数用于将共享内存从当前进程中分离。注意,将共享内存分离并不是删除它,只是使该共享内存对当前进程不再可用。它的原型如下:
int shmdt(const void *shmaddr);
参数shmaddr是shmat函数返回的地址指针,调用成功时返回0,失败时返回-1.
shmctl函数
与信号量的semctl函数一样,用来控制共享内存,它的原型如下:1
int shmctl(int shm_id, int command, struct shmid_ds *buf);
第一个参数,shm_id是shmget函数返回的共享内存标识符。
第二个参数,command是要采取的操作,它可以取下面的三个值 :
- IPC_STAT:把shmid_ds结构中的数据设置为共享内存的当前关联值,即用共享内存的当前关联值覆盖shmid_ds的值。
- IPC_SET:如果进程有足够的权限,就把共享内存的当前关联值设置为shmid_ds结构中给出的值
- IPC_RMID:删除共享内存段
第三个参数,buf是一个结构指针,它指向共享内存模式和访问权限的结构。
shmid_ds结构至少包括以下成员:1
2
3
4
5
6struct shmid_ds
{
uid_t shm_perm.uid;
uid_t shm_perm.gid;
mode_t shm_perm.mode;
};
使用共享内存进行进程间通信
说了这么多,又到了实战的时候了。下面就以两个不相关的进程来说明进程间如何通过共享内存来进行通信。其中一个文件shmread.c创建共享内存,并读取其中的信息,另一个文件shmwrite.c向共享内存中写入数据。为了方便操作和数据结构的统一,为这两个文件定义了相同的数据结构,定义在文件shmdata.c中。结构shared_use_st中的written作为一个可读或可写的标志,非0:表示可读,0表示可写,text则是内存中的文件。
shmdata.h的源代码如下:1
2
3
4
5
6
7
8
9
10
11
12
struct shared_use_st
{
int written;//作为一个标志,非0:表示可读,0表示可写
char text[TEXT_SZ];//记录写入和读取的文本
};
源文件shmread.c的源代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
int main()
{
int running = 1;//程序是否继续运行的标志
void *shm = NULL;//分配的共享内存的原始首地址
struct shared_use_st *shared;//指向shm
int shmid;//共享内存标识符
//创建共享内存
shmid = shmget((key_t)1234, sizeof(struct shared_use_st), 0666|IPC_CREAT);
if(shmid == -1)
{
fprintf(stderr, "shmget failed\n");
exit(EXIT_FAILURE);
}
//将共享内存连接到当前进程的地址空间
shm = shmat(shmid, 0, 0);
if(shm == (void*)-1)
{
fprintf(stderr, "shmat failed\n");
exit(EXIT_FAILURE);
}
printf("\nMemory attached at %X\n", (int)shm);
//设置共享内存
shared = (struct shared_use_st*)shm;
shared->written = 0;
while(running)//读取共享内存中的数据
{
//没有进程向共享内存定数据有数据可读取
if(shared->written != 0)
{
printf("You wrote: %s", shared->text);
sleep(rand() % 3);
//读取完数据,设置written使共享内存段可写
shared->written = 0;
//输入了end,退出循环(程序)
if(strncmp(shared->text, "end", 3) == 0)
running = 0;
}
else//有其他进程在写数据,不能读取数据
sleep(1);
}
//把共享内存从当前进程中分离
if(shmdt(shm) == -1)
{
fprintf(stderr, "shmdt failed\n");
exit(EXIT_FAILURE);
}
//删除共享内存
if(shmctl(shmid, IPC_RMID, 0) == -1)
{
fprintf(stderr, "shmctl(IPC_RMID) failed\n");
exit(EXIT_FAILURE);
}
exit(EXIT_SUCCESS);
}
源文件shmwrite.c的源代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
int main()
{
int running = 1;
void *shm = NULL;
struct shared_use_st *shared = NULL;
char buffer[BUFSIZ + 1];//用于保存输入的文本
int shmid;
//创建共享内存
shmid = shmget((key_t)1234, sizeof(struct shared_use_st), 0666|IPC_CREAT);
if(shmid == -1)
{
fprintf(stderr, "shmget failed\n");
exit(EXIT_FAILURE);
}
//将共享内存连接到当前进程的地址空间
shm = shmat(shmid, (void*)0, 0);
if(shm == (void*)-1)
{
fprintf(stderr, "shmat failed\n");
exit(EXIT_FAILURE);
}
printf("Memory attached at %X\n", (int)shm);
//设置共享内存
shared = (struct shared_use_st*)shm;
while(running)//向共享内存中写数据
{
//数据还没有被读取,则等待数据被读取,不能向共享内存中写入文本
while(shared->written == 1)
{
sleep(1);
printf("Waiting...\n");
}
//向共享内存中写入数据
printf("Enter some text: ");
fgets(buffer, BUFSIZ, stdin);
strncpy(shared->text, buffer, TEXT_SZ);
//写完数据,设置written使共享内存段可读
shared->written = 1;
//输入了end,退出循环(程序)
if(strncmp(buffer, "end", 3) == 0)
running = 0;
}
//把共享内存从当前进程中分离
if(shmdt(shm) == -1)
{
fprintf(stderr, "shmdt failed\n");
exit(EXIT_FAILURE);
}
sleep(2);
exit(EXIT_SUCCESS);
}
再来看看运行的结果: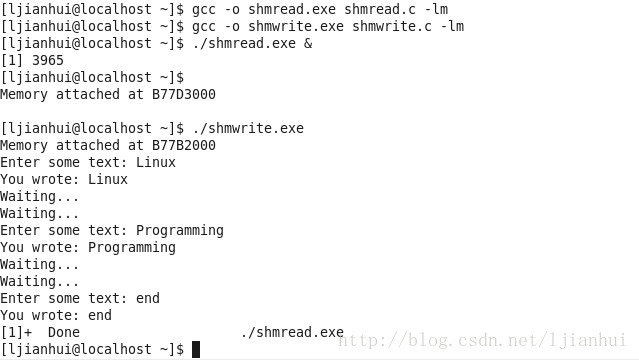
分析:
程序shmread创建共享内存,然后将它连接到自己的地址空间。在共享内存的开始处使用了一个结构struct_use_st。该结构中有个标志written,当共享内存中有其他进程向它写入数据时,共享内存中的written被设置为0,程序等待。当它不为0时,表示没有进程对共享内存写入数据,程序就从共享内存中读取数据并输出,然后重置设置共享内存中的written为0,即让其可被shmwrite进程写入数据。
程序shmwrite取得共享内存并连接到自己的地址空间中。检查共享内存中的written,是否为0,若不是,表示共享内存中的数据还没有被完,则等待其他进程读取完成,并提示用户等待。若共享内存的written为0,表示没有其他进程对共享内存进行读取,则提示用户输入文本,并再次设置共享内存中的written为1,表示写完成,其他进程可对共享内存进行读操作。
关于前面的例子的安全性讨论
这个程序是不安全的,当有多个程序同时向共享内存中读写数据时,问题就会出现。可能你会认为,可以改变一下written的使用方式,例如,只有当written为0时进程才可以向共享内存写入数据,而当一个进程只有在written不为0时才能对其进行读取,同时把written进行加1操作,读取完后进行减1操作。这就有点像文件锁中的读写锁的功能。咋看之下,它似乎能行得通。但是这都不是原子操作,所以这种做法是行不能的。试想当written为0时,如果有两个进程同时访问共享内存,它们就会发现written为0,于是两个进程都对其进行写操作,显然不行。当written为1时,有两个进程同时对共享内存进行读操作时也是如些,当这两个进程都读取完是,written就变成了-1.
要想让程序安全地执行,就要有一种进程同步的进制,保证在进入临界区的操作是原子操作。例如,可以使用前面所讲的信号量来进行进程的同步。因为信号量的操作都是原子性的。
使用共享内存的优缺点
优点:我们可以看到使用共享内存进行进程间的通信真的是非常方便,而且函数的接口也简单,数据的共享还使进程间的数据不用传送,而是直接访问内存,也加快了程序的效率。同时,它也不像匿名管道那样要求通信的进程有一定的父子关系。
缺点:共享内存没有提供同步的机制,这使得我们在使用共享内存进行进程间通信时,往往要借助其他的手段来进行进程间的同步工作。
内存映射
内存映射 memory map机制使进程之间通过映射同一个普通文件实现共享内存,通过mmap()系统调用实现。普通文件被映射到进程地址空间后,进程可以
像访问普通内存一样对文件进行访问,不必再调用read/write等文件操作函数。
例子:创建子进程,父子进程通过匿名映射实现共享内存。
分析:主程序中先调用mmap映射内存,然后再调用fork函数创建进程。那么在调用fork函数之后,子进程继承父进程匿名映射后的地址空间,同样也继承mmap函数的返回地址,这样,父子进程就可以通过映射区域进行通信了。

UNIX System V共享内存机制
IPC的共享内存指的是把所有的共享数据放在共享内存区域(IPC shared memory region),任何想要访问该数据的进程都必须在本进程的地址空间新增一块内存区域,用来映射存放共享数据的物理内存页面。
和前面的mmap系统调用通过映射一个普通文件实现共享内存不同,UNIX system V共享内存是通过映射特殊文件系统shm中的文件实现进程间的共享内存通信。
例子:设计两个程序,通过unix system v共享内存机制,一个程序写入共享区域,另一个程序读取共享区域。
分析:一个程序调用fotk函数产生标准的key,接着调用shmget函数,获取共享内存区域的id,调用shmat函数,映射内存,循环计算年龄,另一个程序读取共享内存。
(fotk函数在消息队列部分已经用过了,根据pathname指定的文件(或目录)名称,以及proj参数指定的数字,ftok函数为IPC对象生成一个唯一性的键值。)1
key_t ftok(char* pathname,char proj)


信号量
POSIX信号量是属于POSIX标准系统接口定义的实时扩展部分。在SUS(Single UNIX Specification)单一规范中,定义的XSI IPC中也同样定义了人们通常称为System V信号量的系统接口。信号量作为进程间同步的工具是很常用的一种同步IPC类型。
信号量是一种用于不同进程间进行同步的工具,当然对于进程安全的对于线程也肯定是安全的,所以信号量也理所当然可以用于同一进程内的不同线程的同步。
有了互斥量和条件变量还提供信号量的原因是:信号量的主要目的是提供一种进程间同步的方式。这种同步的进程可以共享也可以不共享内存区。虽然信号量的意图在于进程间的同步,互斥量和条件变量的意图在于线程间同步,但信号量也可用于线程间同步,互斥量和条件变量也可通过共享内存区进行进程间同步。但应该根据具体应用考虑到效率和易用性进行具体的选择。
POSIX信号量的操作
POSIX信号量有两种:有名信号量和无名信号量,无名信号量也被称作基于内存的信号量。有名信号量通过IPC名字进行进程间的同步,而无名信号量如果不是放在进程间的共享内存区中,是不能用来进行进程间同步的,只能用来进行线程同步。
POSIX信号量有三种操作:
(1)创建一个信号量。创建的过程还要求初始化信号量的值。
根据信号量取值(代表可用资源的数目)的不同,POSIX信号量还可以分为:
二值信号量:信号量的值只有0和1,这和互斥量很类型,若资源被锁住,信号量的值为0,若资源可用,则信号量的值为1;
计数信号量:信号量的值在0到一个大于1的限制值(POSIX指出系统的最大限制值至少要为32767)。该计数表示可用的资源的个数。
(2)等待一个信号量(wait)。该操作会检查信号量的值,如果其值小于或等于0,那就阻塞,直到该值变成大于0,然后等待进程将信号量的值减1,进程获得共享资源的访问权限。这整个操作必须是一个原子操作。该操作还经常被称为P操作(荷兰语Proberen,意为:尝试)。
(3)挂出一个信号量(post)。该操作将信号量的值加1,如果有进程阻塞着等待该信号量,那么其中一个进程将被唤醒。该操作也必须是一个原子操作。该操作还经常被称为V操作(荷兰语Verhogen,意为:增加)
下面演示经典的生产者消费者问题,单个生产者和消费者共享一个缓冲区;
下面是生产者和消费者同步的伪代码:
1 | //信号量的初始化 |
上面的代码大致流程如下:当生产者和消费者开始都运行时,生产者获取put信号量,此时put为1表示有资源可用,生产者进入共享缓冲区,进行修改。而消费者获取get信号量,而此时get为0,表示没有资源可读,于是消费者进入等待序列,直到生产者生产出一个数据,然后生产者通过挂出get信号量来通知等待的消费者,有数据可以读。
很多时候信号量和互斥量,条件变量三者都可以在某种应用中使用,那这三者的差异有哪些呢,下面列出了这三者之间的差异:
互斥量必须由给它上锁的线程解锁。而信号量不需要由等待它的线程进行挂出,可以在其他进程进行挂出操作。
互斥量要么被锁住,要么是解开状态,只有这两种状态。而信号量的值可以支持多个进程成功进行wait操作。
信号量的挂出操作总是被记住,因为信号量有一个计数值,挂出操作总会将该计数值加1,然而当向条件变量发送一个信号时,如果没有线程等待在条件变量,那么该信号会丢失。
POSIX信号量函数接口
POSIX信号量的函数接口如下图所示:
有名信号量的创建和删除
1 |
|
sem_open用于创建或打开一个信号量,信号量是通过name参数即信号量的名字来进行标识的。关于POSX IPC的名字可以参考《UNIX网络编程 卷2:进程间通信》P14。
oflag参数可以为:0,O_CREAT,O_EXCL。如果为0表示打开一个已存在的信号量,如果为O_CREAT,表示如果信号量不存在就创建一个信号量,如果存在则打开被返回。此时mode和value需要指定。如果为O_CREAT | O_EXCL,表示如果信号量已存在会返回错误。
mode参数用于创建信号量时,表示信号量的权限位,和open函数一样包括:S_IRUSR,S_IWUSR,S_IRGRP,S_IWGRP,S_IROTH,S_IWOTH。
value表示创建信号量时,信号量的初始值。1
2
3
4
5
int sem_close(sem_t *sem);
int sem_unlink(const char *name);
//成功返回0,失败返回-1
sem_close用于关闭打开的信号量。当一个进程终止时,内核对其上仍然打开的所有有名信号量自动执行这个操作。调用sem_close关闭信号量并没有把它从系统中删除它,POSIX有名信号量是随内核持续的。即使当前没有进程打开某个信号量它的值依然保持。直到内核重新自举或调用sem_unlink()删除该信号量。
sem_unlink用于将有名信号量立刻从系统中删除,但信号量的销毁是在所有进程都关闭信号量的时候。
信号量的P操作
1 |
|
sem_wait()用于获取信号量,首先会测试指定信号量的值,如果大于0,就会将它减1并立即返回,如果等于0,那么调用线程会进入睡眠,指定信号量的值大于0.
sem_trywait和sem_wait的差别是,当信号量的值等于0的,调用线程不会阻塞,直接返回,并标识EAGAIN错误。
sem_timedwait和sem_wait的差别是当信号量的值等于0时,调用线程会限时等待。当等待时间到后,信号量的值还是0,那么就会返回错误。其中struct timespec *abs_timeout是一个绝对时间,具体可以参考条件变量关于等待时间的使用
信号量的V操作
1 |
|
当一个线程使用完某个信号量后,调用sem_post,使该信号量的值加1,如果有等待的线程,那么会唤醒等待的一个线程。
获取当前信号量的值
1 |
|
该函数返回当前信号量的值,通过sval输出参数返回,如果当前信号量已经上锁(即同步对象不可用),那么返回值为0,或为负数,其绝对值就是等待该信号量解锁的线程数。
下面测试在Linux下的信号量是否会出现负值:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
using namespace std;
sem_t *pSem;
void * testThread (void *ptr)
{
sem_wait(pSem);
sleep(10);
sem_close(pSem);
}
int main()
{
pSem = sem_open(SEM_NAME, O_CREAT, 0666, 5);
pthread_t pid;
int semVal;
for (int i = 0; i < 7; ++i)
{
pthread_create(&pid, NULL, testThread, NULL);
sleep(1);
sem_getvalue(pSem, &semVal);
cout<<"semaphore value:"<<semVal<<endl;
}
sem_close(pSem);
sem_unlink(SEM_NAME);
}
执行结果如下:1
2
3
4
5
6
7semaphore value:4
semaphore value:3
semaphore value:2
semaphore value:1
semaphore value:0
semaphore value:0
semaphore value:0
这说明在Linux 2.6.18中POSIX信号量是不会出现负值的。
无名信号量的创建和销毁
1 |
|
sem_init()用于无名信号量的初始化。无名信号量在初始化前一定要在内存中分配一个sem_t信号量类型的对象,这就是无名信号量又称为基于内存的信号量的原因。
sem_init()第一个参数是指向一个已经分配的sem_t变量。第二个参数pshared表示该信号量是否由于进程间通步,当pshared = 0,那么表示该信号量只能用于进程内部的线程间的同步。当pshared != 0,表示该信号量存放在共享内存区中,使使用它的进程能够访问该共享内存区进行进程同步。第三个参数value表示信号量的初始值。
这里需要注意的是,无名信号量不使用任何类似O_CREAT的标志,这表示sem_init()总是会初始化信号量的值,所以对于特定的一个信号量,我们必须保证只调用sem_init()进行初始化一次,对于一个已初始化过的信号量调用sem_init()的行为是未定义的。如果信号量还没有被某个线程调用还好,否则基本上会出现问题。
使用完一个无名信号量后,调用sem_destroy摧毁它。这里要注意的是:摧毁一个有线程阻塞在其上的信号量的行为是未定义的。
有名和无名信号量的持续性
有名信号量是随内核持续的。当有名信号量创建后,即使当前没有进程打开某个信号量它的值依然保持。直到内核重新自举或调用sem_unlink()删除该信号量。
无名信号量的持续性要根据信号量在内存中的位置:
如果无名信号量是在单个进程内部的数据空间中,即信号量只能在进程内部的各个线程间共享,那么信号量是随进程的持续性,当进程终止时它也就消失了。
如果无名信号量位于不同进程的共享内存区,因此只要该共享内存区仍然存在,该信号量就会一直存在。所以此时无名信号量是随内核的持续性。
信号量的继承
对于有名信号量在父进程中打开的任何有名信号量在子进程中仍是打开的。即下面代码是正确的:1
2
3
4
5
6
7
8
9sem_t *pSem;
pSem = sem_open(SEM_NAME, O_CREAT, 0666, 5);
if(fork() == 0)
{
//...
sem_wait(pSem);
//...
}
对于无名信号量的继承要根据信号量在内存中的位置:
如果无名信号量是在单个进程内部的数据空间中,那么信号量就是进程数据段或者是堆栈上,当fork产生子进程后,该信号量只是原来的一个拷贝,和之前的信号量是独立的。下面是测试代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30int main()
{
sem_t mSem;
sem_init(&mSem, 0, 3);
int val;
sem_getvalue(&mSem, &val);
cout<<"parent:semaphore value:"<<val<<endl;
sem_wait(&mSem);
sem_getvalue(&mSem, &val);
cout<<"parent:semaphore value:"<<val<<endl;
if(fork() == 0)
{
sem_getvalue(&mSem, &val);
cout<<"child:semaphore value:"<<val<<endl;
sem_wait(&mSem);
sem_getvalue(&mSem, &val);
cout<<"child:semaphore value:"<<val<<endl;
exit(0);
}
sleep(1);
sem_getvalue(&mSem, &val);
cout<<"parent:semaphore value:"<<val<<endl;
}
测试结果如下:1
2
3
4
5parent:semaphore value:3
parent:semaphore value:2
child:semaphore value:2
child:semaphore value:1
parent:semaphore value:2
如果无名信号量位于不同进程的共享内存区,那么fork产生的子进程中的信号量仍然会存在该共享内存区,所以该信号量仍然保持着之前的状态。
信号量的销毁
对于有名信号量,当某个持有该信号量的进程没有解锁该信号量就终止了,内核并不会将该信号量解锁。这跟记录锁不一样。
对于无名信号量,如果信号量位于进程内部的内存空间中,当进程终止后,信号量也就不存在了,无所谓解锁了。如果信号量位于进程间的共享内存区中,当进程终止后,内核也不会将该信号量解锁。
下面是测试代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24int main()
{
sem_t *pSem;
pSem = sem_open(SEM_NAME, O_CREAT, 0666, 5);
int val;
sem_getvalue(pSem, &val);
cout<<"parent:semaphore value:"<<val<<endl;
if(fork() == 0)
{
sem_wait(pSem);
sem_getvalue(pSem, &val);
cout<<"child:semaphore value:"<<val<<endl;
exit(0);
}
sleep(1);
sem_getvalue(pSem, &val);
cout<<"parent:semaphore value:"<<val<<endl;
sem_unlink(SEM_NAME);
}
下面是测试结果:1
2
3parent:semaphore value:5
child:semaphore value:4
parent:semaphore value:4
信号量代码测试
对于有名信号量在父进程中打开的任何有名信号量在子进程中仍是打开的。即下面代码是正确的:
对于信号量用于进程间同步的代码的测试,我没有采用经典的生产者和消费者问题,原因是这里会涉及到共享内存的操作。我只是简单的用一个同步文件操作的例子进行描述。 在下面的测试代码中,POSIX有名信号量初始值为2,允许两个进程获得文件的操作权限。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
using namespace std;
void semTest(int flag)
{
sem_t *pSem;
pSem = sem_open(SEM_NAME, O_CREAT, 0666, 2);
sem_wait(pSem);
ofstream fileStream("./test.txt", ios_base::app);
for (int i = 0; i < 5; ++i)
{
sleep(1);
fileStream<<flag;
fileStream<<' '<<flush;
}
sem_post(pSem);
sem_close(pSem);
}
int main()
{
for (int i = 1; i <= 3; ++i)
{
if (fork() == 0)
{
semTest(i);
sleep(1);
exit(0);
}
}
}
程序的运行结果,“./test.txt”文件的内容如下:1
2//./test.txt
1 2 1 2 1 2 1 2 1 2 3 3 3 3 3
线程之间的通信方式
- 锁机制:包括互斥锁/量(mutex)、读写锁(reader-writer lock)、自旋锁(spin lock)、条件变量(condition)
- 互斥锁/量(mutex):提供了以排他方式防止数据结构被并发修改的方法。
- 读写锁(reader-writer lock):允许多个线程同时读共享数据,而对写操作是互斥的。
- 自旋锁(spin lock)与互斥锁类似,都是为了保护共享资源。互斥锁是当资源被占用,申请者进入睡眠状态;而自旋锁则循环检测保持者是否已经释放锁。
- 条件变量(condition):可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
- 信号量机制(Semaphore)
- 无名线程信号量
- 命名线程信号量
- 信号机制(Signal):类似进程间的信号处理
- 屏障(barrier):屏障允许每个线程等待,直到所有的合作线程都达到某一点,然后从该点继续执行。
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制