linux脚本及检测工具
调试工具ltrace strace ftrace的使用
最近学习了一些调试工具,包括ltrace strace ftrace。这些都属于不同层级的调试工具。 下面是我画的简易的层次关系图。
1 | App |
systemtap是当下功能强大的内核函数追踪工具,我们编写特定的script就可以调试内核函数,由于这个篇幅有限,我将在其他文章中进行介绍。
先从最简单的说起ltrace起。 拿最简单的hello world程序来说,printf调用的lic里面的库函数说白了就是put(),put()函数返回值就是打印字符的个数,包括转移字符\n。
1 | [root@localhost day3]# ltrace -f ./hello |
下面我来说一下strace的功能,追踪system call 与 signal。所谓系统调用,就是内核提供的、功能十分强大的一系列的函数。这些系统调用是在内核中实现的,比如linux中的POSIX标准就是指的这一些。再通过一定的方式把系统调用给用户,一般都通过门(gate)陷入(trap)实现。系统调用是用户程序和内核交互的接口。
1 | [root@localhost day3]# strace -f ./hello |
通过查看上面的system call,我们就会对elf文件载入流程有一个清晰的认识。
流程:
1.调用execve()函数执行载入
2.brk() allocate new space to load the infomation of programmer
3.mmap()把elf头载入virtual address
4.先链接ld.so与ld.so.cache中是否存在之前调用过库函数的绝对地址
5.查看file 状态的fstat(),包括r w x 等
6.读取ELF头,并映射到虚拟地址,进行内存保护mprotect()
7.载入libc.so库函数
8.arch_prctl()设置运行环境的体系结构
9.write()就是内核中写函数,包括发消息给其他的用户,写入设备等。 10.完成调用,退出。
Ftrace 是一个内核中的追踪器,用于帮助系统开发者或设计者查看内核运行情况,它可以被用来调试或者分析延迟/性能问题。最早 ftrace 是一个 function tracer,仅能够记录内核的函数调用流程。如今 ftrace 已经成为一个 framework,采用 plugin 的方式支持开发人员添加更多种类的 trace 功能。
Ftrace需要kernel支持 CONFIG_FUNCTION_TRACER CONFIG_FUNCTION_GRAPH_TRACER CONFIG_CONTEXT_SWITCH_TRACER CONFIG_NOP_TRACER CONFIG_SCHED_TRACER Debugfs 勾选,这样才可以使用ftrace中的一些特定功能。
编译内核完成后,重新开机载入新内核。 ftrace不同于其他的调试工具,他需要debugfs的辅助。debugfs是一种特殊的文件系统,本身无法进行编辑,任何写入信息都要靠echo载入。另外由于是kernel debug,所以需要最高的root权限。 我们要先挂载这个文件系统到特殊的文件目录。这个/mnt/与/sys/kernel/debug/tracing是等同的。
1 | [root@localhost /]# mount -t debugfs debugfs /mnt/ |
Ftrace 的普通使用步骤如下:
- 挂载Debugfs: Ftrace 通过 debugfs 向用户态提供访问接口。配置内核时激活 debugfs 后会创建目录 /sys/kernel/debug ,debugfs 文件系统就是挂载 到该目录。 1.1 运行时挂载: Officially mount method :
1 | # mount -t debugfs nodev /sys/kernel/debug |
1.2 系统启动自动挂载: 要在系统启动自动挂载debugfs,需要将如下内容添加到 /etc/fstab 文件: debugfs /sys/kernel/debug debugfs defaults 0 0
- 选择一种 tracer:
1 | # cat current_tracer |
- 打开关闭追踪(在老的内核上有tracing_enabled,需要给tracing_enabled和tracing_on同时赋1 才能打开追踪,而在新的内核上去掉tracing_enabled只需要控制tracing_on 即可打开关闭追踪)
1 | # echo 1 > tracing_on; run_test; echo 0 > tracing_on |
注:其实ftrace_enabled并不是去掉了,而是从 tracing目录中去掉,我们还是可以在 /proc/sys/kernel/ftrace_enabled 目录下看到他的身影,而且默认已经被设置为1,所以现在我们只需要echo 1到tracing_on 中即可打开追踪。 $ cat /proc/sys/kernel/ftrace_enabled 1
- 查看追踪结果:
ftrace 的输出信息主要保存在 3 个文件中。
- Trace,该文件保存 ftrace 的输出信息,其内容可以直接阅读。
- latency_trace,保存与 trace 相同的信息,不过组织方式略有不同。主要为了用户能方便地分析系统中有关延迟的信息。
- trace_pipe 是一个管道文件,主要为了方便应用程序读取 trace 内容。算是扩展接口吧。
所以可以直接查看 trace 追踪文件,也可以在追踪之前使用trace_pipe 将追踪结果直接导向其他的文件。 比如: # cat trace_pipe > /tmp/log &
1 | # cat /tmp/log |
Ftrace 的进阶使用
使用 echo pid > set_ftrace_pid 来追踪特定的进程!
追踪事件:
2.1 首先查看事件文件夹下面有哪些选项:
1 | # ls events/ |
2.2 追踪一个/若干事件:
1 | # echo 1 > events/sched/sched_wakeup/enable |
2.3 追踪一类事件:
1 | # echo 1 > events/sched/enable |
2.4 追踪所有事件:
1 | # echo 1 > events/enable |
- stack_trace
1 | # echo 1 > /proc/sys/kernel/stack_tracer_enabled |
- 将要跟踪的函数写入文件 set_ftrace_filter ,将不希望跟踪的函数写入文件 set_ftrace_notrace。通常直接操作文件 set_ftrace_filter 就可以了.
============= Ftrace 提供的函数使用=============
内核头文件 include/linux/kernel.h 中描述了 ftrace 提供的工具函数的原型,这些函数包括 trace_printk、tracing_on/tracing_off 等。
- 使用 trace_printk 打印跟踪信息
ftrace 提供了一个用于向 ftrace 跟踪缓冲区输出跟踪信息的工具函数,叫做 trace_printk(),它的使用方式与 printk() 类似。可以通过 trace 文件读取该函数的输出。从头文件 include/linux/kernel.h 中可以看到,在激活配置 CONFIG_TRACING 后,trace_printk() 定义为宏: #define trace_printk(fmt, args…) \ … 所以在使用时:(例子是在一个内核模块中添加打印信息)
1 |
|
- 使用 tracing_on/tracing_off 控制跟踪信息的记录
在跟踪过程中,有时候在检测到某些事件发生时,想要停止跟踪信息的记录,这样,跟踪缓冲区中较新的数据是与该事件有关的。在用户态,可以通过向文件 tracing_on 写入 0 来停止记录跟踪信息,写入 1 会继续记录跟踪信息。而在内核代码中,可以通过函数 tracing_on() 和 tracing_off() 来做到这一点,它们的行为类似于对 /sys/kernel/debug/tracing 下的文件 tracing_on 分别执行写 1 和 写 0 的操作。 使用这两个函数,会对跟踪信息的记录控制地更准确一些,这是因为在用户态写文件 tracing_on 到实际暂停跟踪,中间由于上下文切换、系统调度控制等可能已经经过较长的时间,这样会积累大量的跟踪信息,而感兴趣的那部分可能会被覆盖掉了。
实际代码中,可以通过特定条件(比如检测到某种异常状况,等等)来控制跟踪信息的记录,函数的使用方式类似如下的形式:
1 | if (condition) |
跟踪模块运行状况时,使用 ftrace 命令操作序列在用户态进行必要的设置,而在代码中则可以通过 traceing_on() 控制在进入特定代码区域时开启跟踪信息,并在遇到某些条件时通过 tracing_off() 暂停;读者可以在查看完感兴趣的信息后,将 1 写入 tracing_on 文件以继续记录跟踪信息。实践中,可以通过宏来控制是否将对这些函数的调用编译进内核模块,这样可以在调试时将其开启,在最终发布时将其关闭。 用户态的应用程序可以通过直接读写文件 tracing_on 来控制记录跟踪信息的暂停状态,以便了解应用程序运行期间内核中发生的活动。
如果我们要开启追踪功能。echo 1 > tracing_on echo function_graph >current_tracer 另外我们也可以设置要追踪的pid值 event buffer等
1 | # tracer: function_graph |
ftrace 不仅可以追踪内核中的函数,也可以追踪用户态下的函数是如何trap in kernel 然后ret的。 比如我们写一个fork的demo
1 |
|
然后使用ftrace进行追踪,可以得到一个system call的完整的结果。
Linux性能分析工具汇总
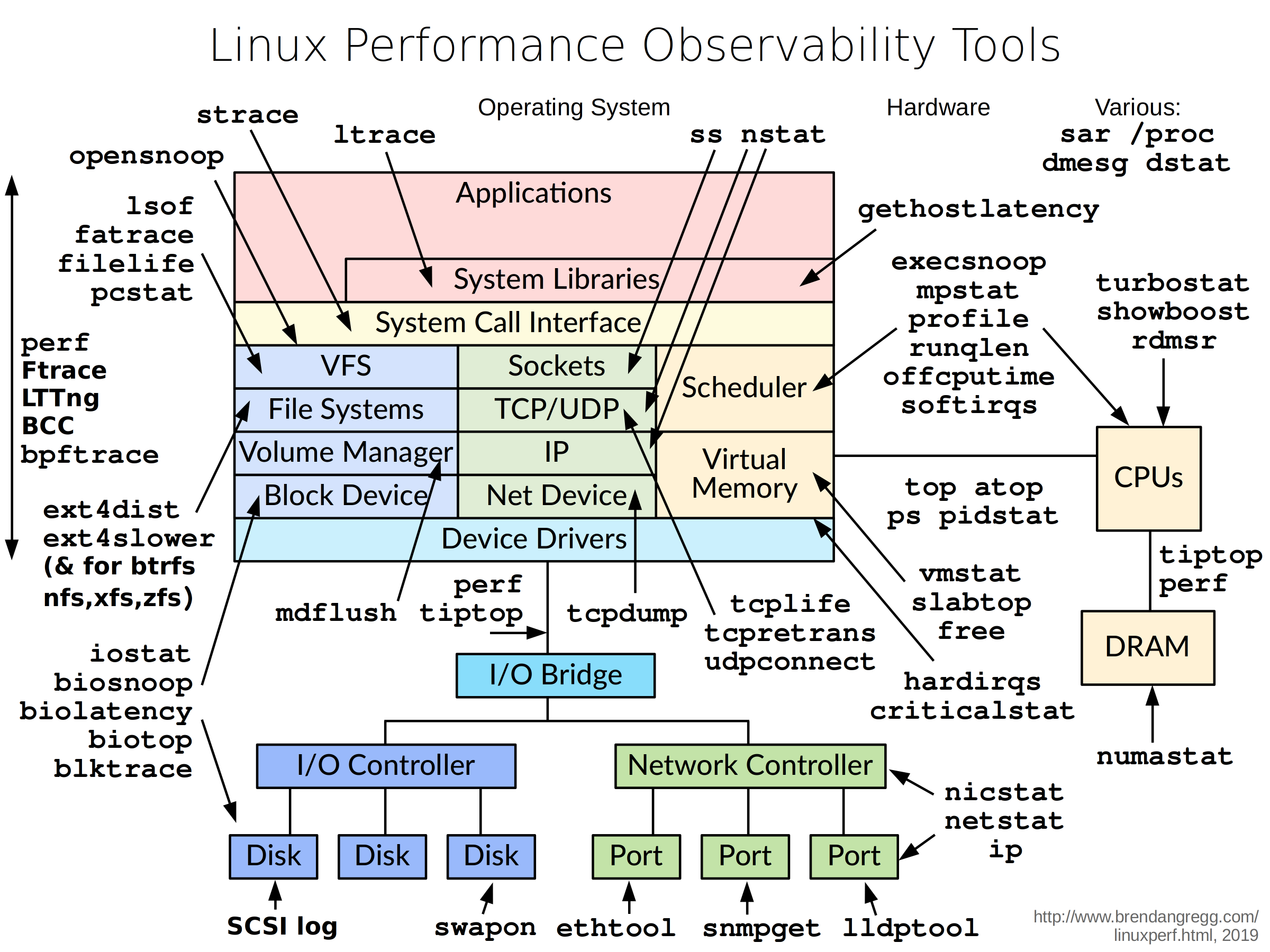
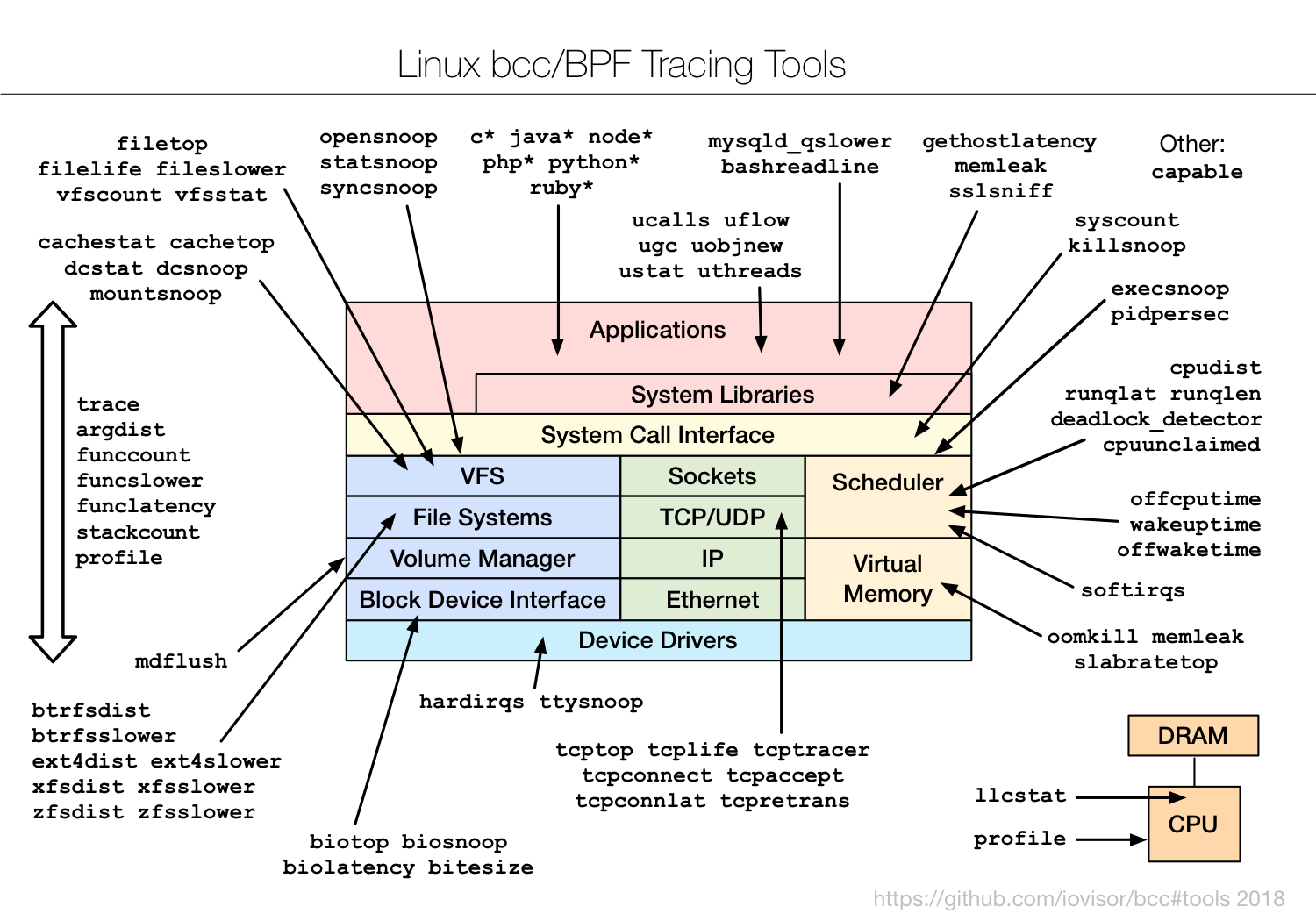
首先来看一张图:
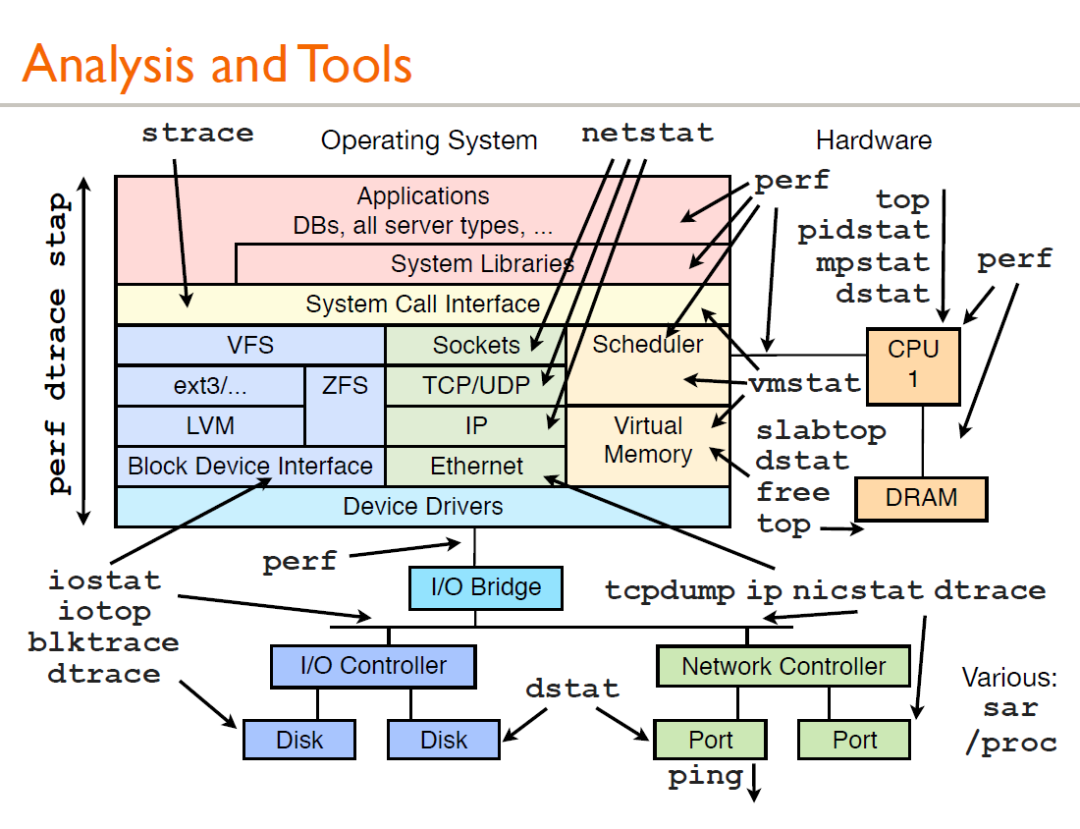
上图是Brendan Gregg 的一次性能分析的分享,这里面的所有工具都可以通过 man 来获得它的帮助文档,下面简单介绍介绍一下常规的用法:
vmstat–虚拟内存统计
vmstat(VirtualMeomoryStatistics,虚拟内存统计)是 Linux 中监控内存的常用工具,可对操作系统的虚拟内存、进程、CPU 等的整体情况进行监视。vmstat 的常规用法:vmstat interval times 即每隔 interval 秒采样一次,共采样 times 次,如果省略 times,则一直采集数据,直到用户手动停止为止。简单举个例子:

可以使用 ctrl+c 停止 vmstat 采集数据。
第一行显示了系统自启动以来的平均值,第二行开始显示现在正在发生的情况,接下来的行会显示每5秒间隔发生了什么,每一列的含义在头部,如下所示:
- procs:r 这一列显示了多少进程在等待cpu,b列显示多少进程正在不可中断的休眠(等待IO)。
- memory:swapd 列显示了多少块被换出了磁盘(页面交换),剩下的列显示了多少块是空闲的(未被使用),多少块正在被用作缓冲区,以及多少正在被用作操作系统的缓存。
- swap:显示交换活动:每秒有多少块正在被换入(从磁盘)和换出(到磁盘)。
- io:显示了多少块从块设备读取(bi)和写出(bo),通常反映了硬盘I/O。
- system:显示每秒中断(in)和上下文切换(cs)的数量。
- cpu:显示所有的cpu时间花费在各类操作的百分比,包括执行用户代码(非内核),执行系统代码(内核),空闲以及等待IO。
内存不足的表现:free memory 急剧减少,回收 buffer 和 cache 也无济于事,大量使用交换分区(swpd),页面交换(swap)频繁,读写磁盘数量(io)增多,缺页中断(in)增多,上下文切换(cs)次数增多,等待IO的进程数(b)增多,大量CPU时间用于等待IO(wa)
iostat–用于报告中央处理器统计信息
iostat 用于报告中央处理器(CPU)统计信息和整个系统、适配器、tty 设备、磁盘和 CD-ROM 的输入/输出统计信息,默认显示了与 vmstat 相同的 cpu 使用信息,使用以下命令显示扩展的设备统计:

第一行显示的是自系统启动以来的平均值,然后显示增量的平均值,每个设备一行。
常见 linux 的磁盘 IO 指标的缩写习惯:rq 是 request,r 是 read,w 是 write,qu 是 queue,sz 是 size,a 是verage,tm 是 time,svc 是 service。
- rrqm/s 和 wrqm/s:每秒合并的读和写请求,“合并的”意味着操作系统从队列中拿出多个逻辑请求合并为一个请求到实际磁盘。
- r/s和w/s:每秒发送到设备的读和写请求数。
- rsec/s和wsec/s:每秒读和写的扇区数。
- avgrq –sz:请求的扇区数。
- avgqu –sz:在设备队列中等待的请求数。
- await:每个IO请求花费的时间。
- svctm:实际请求(服务)时间。
- %util:至少有一个活跃请求所占时间的百分比。
dstat–系统监控工具
dstat 显示了 cpu 使用情况,磁盘 io 情况,网络发包情况和换页情况,输出是彩色的,可读性较强,相对于 vmstat 和iostat 的输入更加详细且较为直观。在使用时,直接输入命令即可,当然也可以使用特定参数。
如下:dstat –cdlmnpsy
img
iotop–LINUX进程实时监控工具
iotop命令是专门显示硬盘IO的命令,界面风格类似top命令,可以显示IO负载具体是由哪个进程产生的。是一个用来监视磁盘I/O使用状况的top类工具,具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息。
可以以非交互的方式使用:
1 | iotop –bod interval |
查看每个进程的 I/O,可以使用
1 | pidstat,pidstat –d instat |
pidstat–监控系统资源情况
pidstat 主要用于监控全部或指定进程占用系统资源的情况,如 CPU,内存、设备 IO、任务切换、线程等。
使用方法:
1 | pidstat –d interval |
pidstat 还可以用以统计CPU使用信息:
1 | pidstat –u interval |
统计内存信息:
1 | pidstat –r interval |
top
- top 命令的汇总区域显示了五个方面的系统性能信息:
- 负载:时间,登陆用户数,系统平均负载;
- 进程:运行,睡眠,停止,僵尸;
- cpu:用户态,核心态,NICE,空闲,等待IO,中断等;
- 内存:总量,已用,空闲(系统角度),缓冲,缓存;
- 交换分区:总量,已用,空闲
任务区域默认显示:进程 ID,有效用户,进程优先级,NICE 值,进程使用的虚拟内存,物理内存和共享内存,进程状态,CPU 占用率,内存占用率,累计 CPU 时间,进程命令行信息。
htop
htop 是 Linux 系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者X终端中),需要 ncurses。
img
Htop 可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
与 top 相比,htop 有以下优点:
- 可以横向或者纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行。
- 在启动上,比top更快。
- 杀进程时不需要输入进程号。
- htop支持鼠标操作。
mpstat
mpstat 是 Multiprocessor Statistics的缩写,是实时系统监控工具。其报告CPU的一些统计信息,这些信息存放在 /proc/stat 文件中。在多 CPUs 系统里,其不但能查看所有 CPU 的平均状况信息,而且能够查看特定 CPU 的信息。常见用法:
1 | mpstat –P ALL interval times |
netstat
netstat 用于显示与 IP、TCP、UDP和 ICMP 协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
常见用法:
1 | netstat –npl # 可以查看你要打开的端口是否已经打开。 |
ps–显示当前进程的状态
ps 参数太多,具体使用方法可以参考 man ps
常用的方法:
1 | ps aux #hsserver |
杀掉某一程序的方法:
1 | ps aux | grep mysqld | grep –v grep | awk ‘{print $2 }’ xargs kill -9 |
杀掉僵尸进程:
1 | ps –eal | awk ‘{if ($2 == “Z”){print $4}}’ | xargs kill -9 |
strace
跟踪程序执行过程中产生的系统调用及接收到的信号,帮助分析程序或命令执行中遇到的异常情况。
举例:查看 mysqld 在 linux 上加载哪种配置文件,可以通过运行下面的命令:
1 | strace –e stat64 mysqld –print –defaults > /dev/null |
uptime
能够打印系统总共运行了多长时间和系统的平均负载,uptime 命令最后输出的三个数字的含义分别是 1分钟,5分钟,15分钟内系统的平均负荷。
lsof
lsof(list open files)是一个列出当前系统打开文件的工具。通过 lsof 工具能够查看这个列表对系统检测及排错,常见的用法:
查看文件系统阻塞
1 | lsof /boot |
查看端口号被哪个进程占用
1 | lsof -i : 3306 |
查看用户打开哪些文件
1 | lsof –u username |
查看进程打开哪些文件
1 | lsof –p 4838 |
查看远程已打开的网络链接
1 | lsof –i @192.168.34.128 |
perf
perf 是 Linux kernel 自带的系统性能优化工具。优势在于与 Linux Kernel 的紧密结合,它可以最先应用到加入 Kernel 的new feature,用于查看热点函数,查看 cashe miss 的比率,从而帮助开发者来优化程序性能。
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
汇总
结合以上常用的性能测试命令并联系文初的性能分析工具的图,就可以初步了解到性能分析过程中哪个方面的性能使用哪方面的工具(命令)。
常用的性能测试工具
熟练并精通了第二部分的性能分析命令工具,引入几个性能测试的工具,介绍之前先简单了解几个性能测试工具:
- perf_events:一款随 Linux 内核代码一同发布和维护的性能诊断工具,由内核社区维护和发展。Perf 不仅可以用于应用程序的性能统计分析,也可以应用于内核代码的性能统计和分析。
- eBPF tools:一款使用 bcc 进行的性能追踪的工具,eBPF map可以使用定制的 eBPF 程序被广泛应用于内核调优方面,也可以读取用户级的异步代码。重要的是这个外部的数据可以在用户空间管理。这个 k-v 格式的 map 数据体是通过在用户空间调用 bpf 系统调用创建、添加、删除等操作管理的。
- perf-tools:一款基于 perf_events (perf) 和 ftrace 的Linux性能分析调优工具集。Perf-Tools 依赖库少,使用简单。支持Linux 3.2 及以上内核版本。
- bcc(BPF Compiler Collection)::一款使用 eBP F的 perf 性能分析工具。一个用于创建高效的内核跟踪和操作程序的工具包,包括几个有用的工具和示例。利用扩展的BPF(伯克利数据包过滤器),正式称为eBPF,一个新的功能,首先被添加到Linux 3.15。多用途需要Linux 4.1以上BCC。
- ktap:一种新型的linux脚本动态性能跟踪工具。允许用户跟踪Linux内核动态。ktap是设计给具有互操作性,允许用户调整操作的见解,排除故障和延长内核和应用程序。它类似于Linux和Solaris DTrace SystemTap。
- Flame Graphs:是一款使用 perf,system tap,ktap 可视化的图形软件,允许最频繁的代码路径快速准确地识别,可以是使用
github.com/brendangregg/flamegraph中的开发源代码的程序生成。
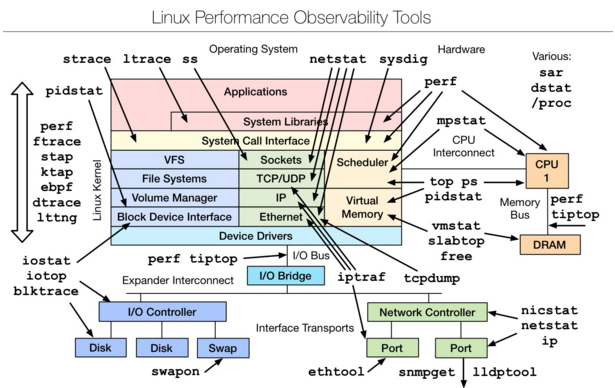
Linux observability tools | Linux 性能观测工具
img
- 首先学习的Basic Tool有如下:uptime、top(htop)、mpstat、isstat、vmstat、free、ping、nicstat、dstat。
- 高级的命令如下:sar、netstat、pidstat、strace、tcpdump、blktrace、iotop、slabtop、sysctl、/proc。
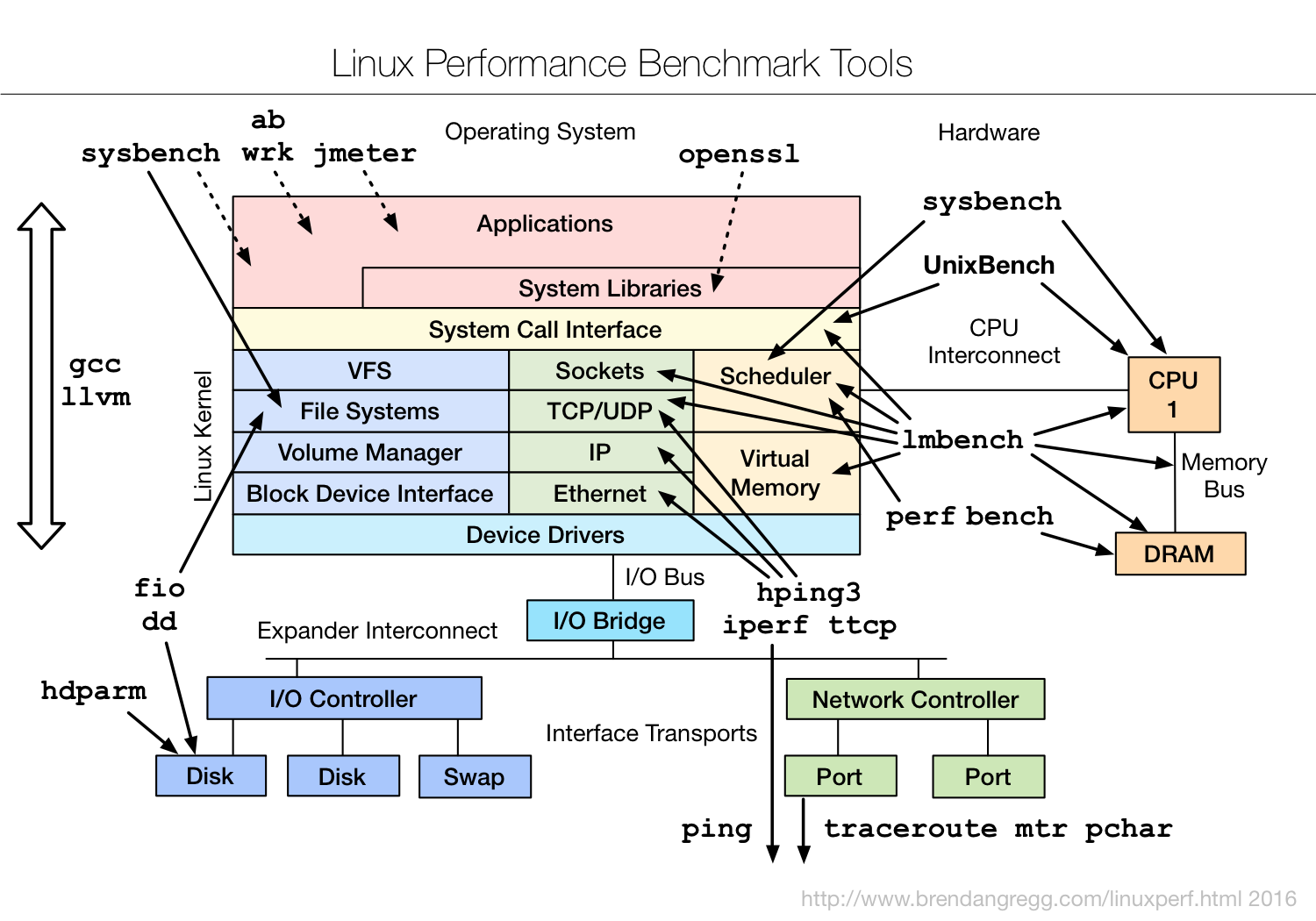
Linux benchmarking tools | Linux 性能测评工具
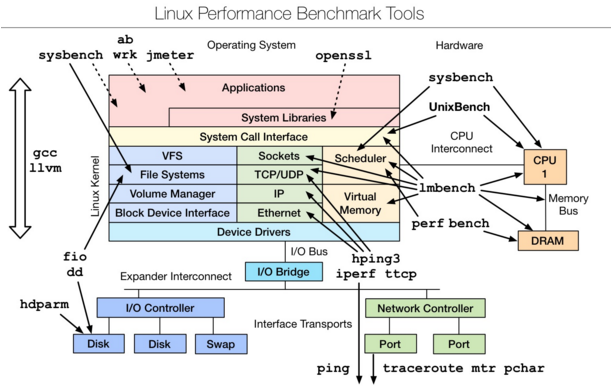
img
是一款性能测评工具,对于不同模块的性能测试可以使用相应的工具,想要深入了解,可以参考最下文的附件文档。
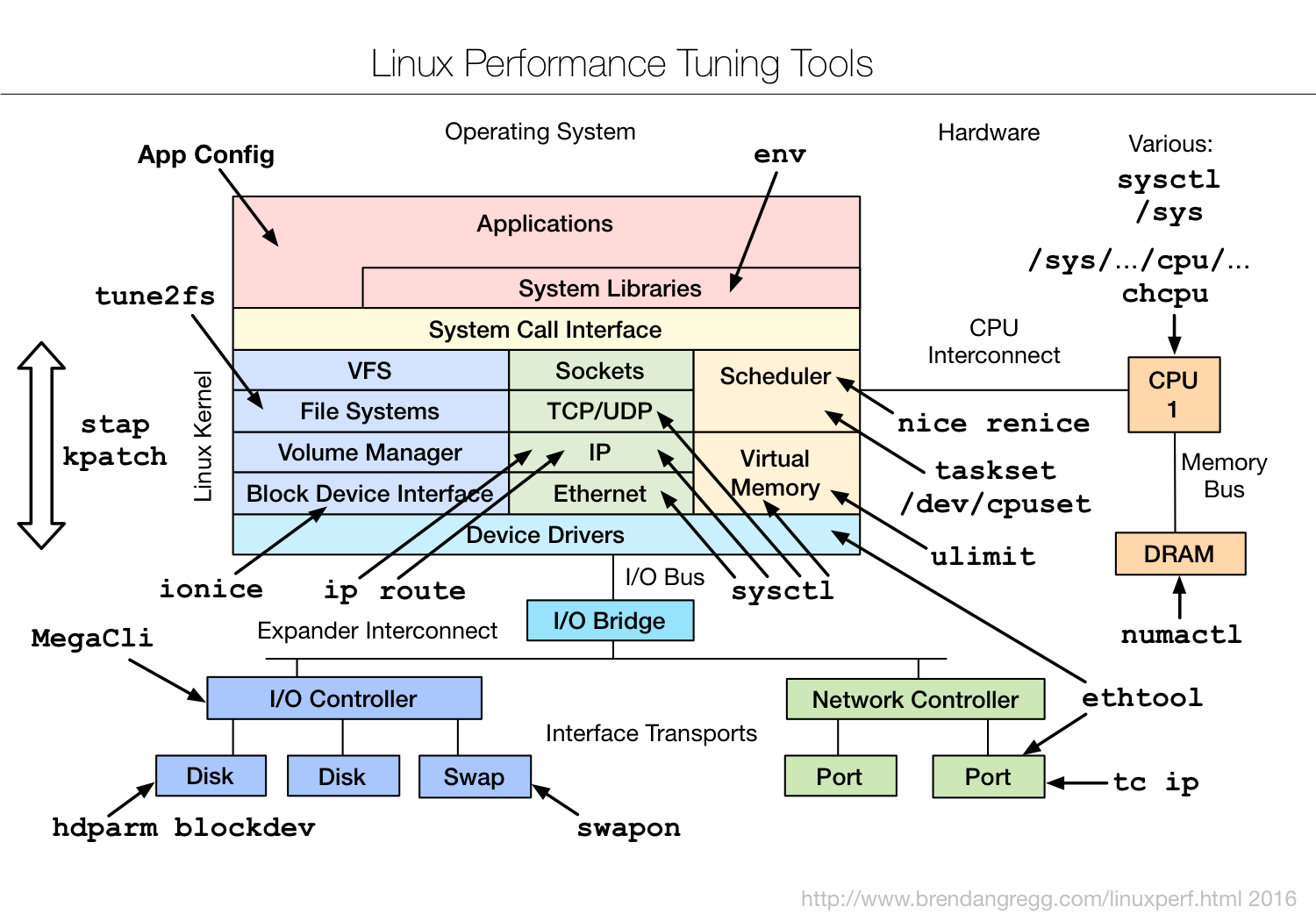
Linux tuning tools | Linux 性能调优工具
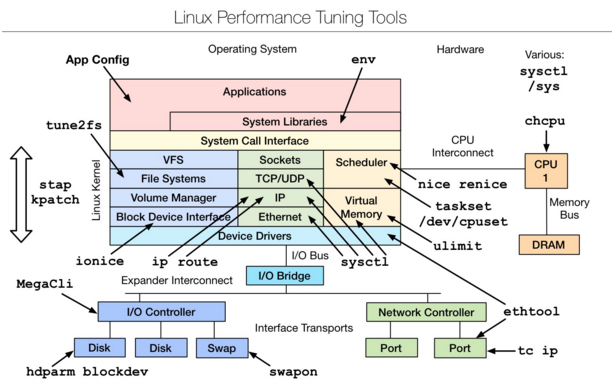
img
是一款性能调优工具,主要是从linux内核源码层进行的调优,想要深入了解,可以参考下文附件文档。
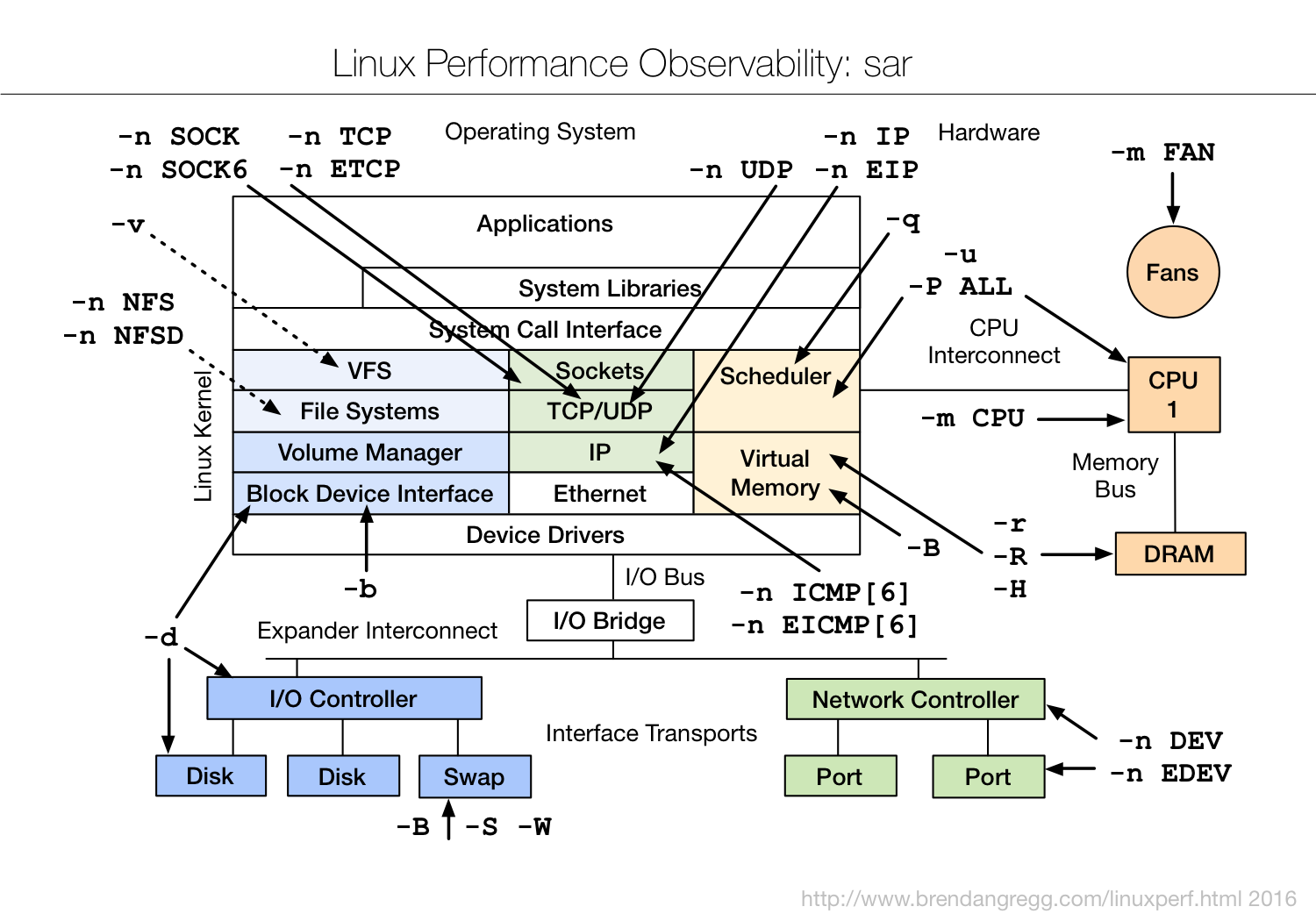
Linux observability sar | linux性能观测工具
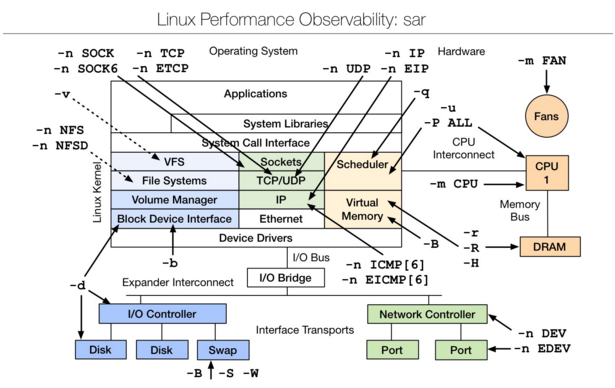
img
sar(System Activity Reporter系统活动情况报告)是目前LINUX上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC 有关的活动等方面。sar 的常规使用方式:
1 | sar [options] [-A] [-o file] t [n] |
其中:t 为采样间隔,n 为采样次数,默认值是1;-o file 表示将命令结果以二进制格式存放在文件中,file 是文件名。options 为命令行选项
Linux命令
文件和目录
cd命令
(它用于切换当前目录,它的参数是要切换到的目录的路径,可以是绝对路径,也可以是相对路径)
cd /home进入 ‘/ home’ 目录cd ..返回上一级目录cd ../..返回上两级目录cd进入个人的主目录cd ~user1进入个人的主目录cd -返回上次所在的目录
pwd命令
pwd 显示工作路径
ls命令
(查看文件与目录的命令,list之意)
- ls 查看目录中的文件
- ls -l 显示文件和目录的详细资料
- ls -a 列出全部文件,包含隐藏文件
- ls -R 连同子目录的内容一起列出(递归列出),等于该目录下的所有文件都会显示出来
- ls [0-9] 显示包含数字的文件名和目录名
- ls -al 长格式显示当前目录下所有文件
- ls -h 文件大小显示为常见大小单位 B KB MB …
- ls -d 显示目录本身,而不是里面的子文件
长格式显示项
1 | -rw------- 1 root root 1190 08-10 23:37 anaconda-ks.cfg |
- 第①项:权限位
- 第②项:引用计数
- 第③项:属主(所有者)
- 第④项:属组
- 第⑤项:大小
- 第⑥项:最后一次修改时间
- 第⑦项:文件名
cp 命令
(用于复制文件,copy之意,它还可以把多个文件一次性地复制到一个目录下)
- -a :将文件的特性一起复制
- -p :连同文件的属性一起复制,而非使用默认方式,与-a相似,常用于备份
- -i :若目标文件已经存在时,在覆盖时会先询问操作的进行
- -r :递归持续复制,用于目录的复制行为
- -u :目标文件与源文件有差异时才会复制
mv命令
(用于移动文件、目录或更名,move之意)
- -f :force强制的意思,如果目标文件已经存在,不会询问而直接覆盖
- -i :若目标文件已经存在,就会询问是否覆盖
- -u :若目标文件已经存在,且比目标文件新,才会更新
rm 命令
(用于删除文件或目录,remove之意)
- -f :就是force的意思,忽略不存在的文件,不会出现警告消息
- -i :互动模式,在删除前会询问用户是否操作
- -r :递归删除,最常用于目录删除,它是一个非常危险的参数
mkdir
- mkdir test 创建名为test的目录
- mkdir -p test1/test2/test3 递归创建
rmdir
删除目录 (只能删除空目录)
查看文件内容
touch
- 命令名称:touch
- 命令所在路径:/bin/touch
- 权限:所有用户
- 能描述:创建空文件 或 修改文件时间
touch test.py 创建空文件,如果文件存在,则修改文件创建时间
more
- 命令所在路径:/bin/more
- 执行权限:所有用户
- 功能描述:分屏显示文件内容
more 文件名 分屏显示文件内容
- 向上翻页 空格键
- 向下翻页 b键
- 退出查看 q键
head
- 命令所在路径:/usr/bin/head
- 执行权限:所有用户
- 功能描述:显示文件头
1 | head 文件名 显示文件头几行(默认显示10行) |
ln
- 命令所在路径:/bin/ln
- 执行权限:所有用户
- 功能描述:链接文件
等同于Windows中的快捷方式,新建的链接,占用不同的硬盘位置,修改一个文件,两边都会改变,删除源文件,软连接文件打不开
ln -s 源文件 目标文件 创建链接文件(文件名都必须写绝对路径)
cat命令
(用于查看文本文件的内容,后接要查看的文件名,通常可用管道与more和less一起使用)
- cat file1 从第一个字节开始正向查看文件的内容
- tac file1 从最后一行开始反向查看一个文件的内容
- cat -n file1 标示文件的行数
- more file1 查看一个长文件的内容
- head -n 2 file1 查看一个文件的前两行
- tail -n 2 file1 查看一个文件的最后两行
- tail -n +1000 file1 从1000行开始显示,显示1000行以后的
- cat filename | head -n 3000 | tail -n +1000 显示1000行到3000行
- cat filename | tail -n +3000 | head -n 1000 从第3000行开始,显示1000(即显示3000~3999行)
文件搜索
find命令
- find / -name file1 从 ‘/‘ 开始进入根文件系统搜索文件和目录
- find / -user user1 搜索属于用户 ‘user1’ 的文件和目录
- find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件
- find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件
- whereis halt 显示一个二进制文件、源码或man的位置
- which halt 显示一个二进制文件或可执行文件的完整路径
删除大于50M的文件:
find /var/mail/ -size +50M -exec rm {} \;
文件的权限
-rw-r–r–. 1 root root 44736 7月 18 00:38 install.log
权限位是十位
第一位:代表文件类型
- - 普通文件
- d 目录文件
- l 链接文件
其他九位:代表各用户的权限(前三位=属主权限u 中间三位=属组权限g 其他人权限o)
-r 读 4
-w 写 2
-x 执行 1
权限对文件的含义:
- r:读取文件内容 如:cat、more、head、tail
- w:编辑、新增、修改文件内容 如:vi、echo 但是不包含删除文件
- x:可执行 /tmp/11/22/abc ———
权限对目录的含义:
- r:可以查询目录下文件名 如:ls
- w:具有修改目录结构的权限 如:touch、rm、mv、cp
- x:可以进入目录 如:cd
chmod 命令
ls -lh 显示权限
- chmod ugo+rwx directory1 设置目录的所有人(u)、群组(g)以及其他人(o)以读(r,4 )、写(w,2)和执行(x,1)的权限
- chmod go-rwx directory1 删除群组(g)与其他人(o)对目录的读写执行权限
chown 命令
(改变文件的所有者)
- chown user1 file1 改变一个文件的所有人属性
- chown -R user1 directory1 改变一个目录的所有人属性并同时改变改目录下所有文件的属性
- chown user1:group1 file1 改变一个文件的所有人和群组属性
chgrp 命令
(改变文件所属用户组)
chgrp group1 file1 改变文件的群组
文本处理
grep
grep是一款强大的文本搜索工具,支持正则表达式。全称( global search regular expression(RE) and print out the line)
语法:grep [option]… PATTERN [FILE]…
常用:
1 | usage: grep [-abcDEFGHhIiJLlmnOoqRSsUVvwxZ] [-A num] [-B num] [-C[num]] |
常用参数:
- -v 取反
- -i 忽略大小写
- -c 符合条件的行数
- -n 输出的同时打印行号
- ^* 以*开头
- $ 以结尾
- ^$ 空行
实际使用
准备好一个小故事txt:
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# cat monkey |
直接查找符合条件的行
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# grep moon monkey |
查找反向符合条件的行
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# grep -v moon monkey |
直接查找符合条件的行数
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# grep -c moon monkey |
忽略大小写查找符合条件的行数,先来看一下直接查找的结果
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# grep my monkey |
忽略大小写查看
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# grep -i my monkey |
查找符合条件的行并输出行号
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# grep -n monkey monkey |
查找开头是J的行
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# grep '^J' monkey |
查找结尾是呢的行
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# grep "呢$" monkey |
sed
sed是一种流编辑器,是一款处理文本比较优秀的工具,可以结合正则表达式一起使用。
sed执行过程: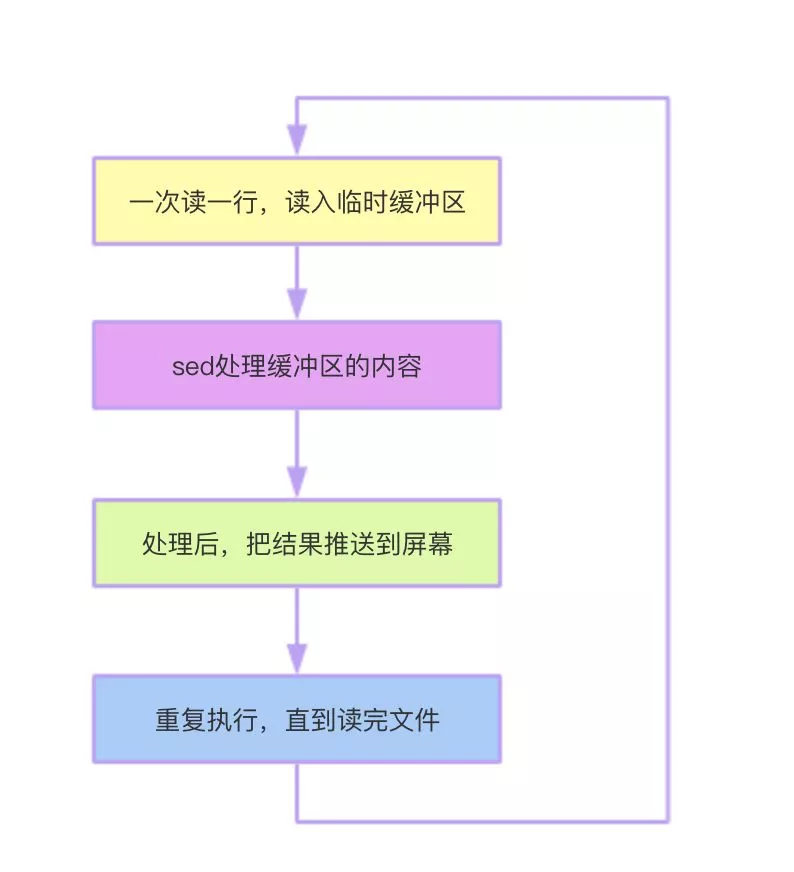
- sed命令: sed
- 语法 : sed [选项]… {命令集} [输入文件]…
常用命令:
- d 删除选择的行
- s 查找
- y 替换
- i 当前行前面插入一行
- a 当前行后面插入一行
- p 打印行
- q 退出
替换符:
- 数字 :替换第几处
- g : 全局替换
- \1: 子串匹配标记,前面搜索可以用元字符集(..)
- &: 保留搜索刀的字符用来替换其他字符
查看文件:
1 | ➜ cat word |
替换:
1 | ➜ sed 's/little/big/' word |
查看文本:
1 | ➜ cat word1 |
全局替换:
1 | ➜ sed 's/to/can/g' word1 |
按行替换(替换2到最后一行)
1 | ➜ sed '2,$s/to/can/' word1 |
删除:
1 | ➜ sed '2d' word |
显示行号:
1 | ➜ sed '=;2d' word |
删除第2行到第四行:
1 | ➜ sed '=;2,4d' word |
向前插入:
1 | ➜ echo "hello" | sed 'i\kitty' |
向后插入:
1 | ➜ echo "kitty" | sed 'i\hello' |
替换第二行为hello kitty
1 | ➜ sed '2c\hello kitty' word |
替换第二行到最后一行为hello kitty
1 | ➜ sed '2,$c\hello kitty' word |
写入行,把带star的行写入c文件中,c提前创建
1 | ➜ sed -n '/star/w c' word |
退出:打印3行后,退出sed
1 | ➜ sed '3q' word |
awk
比起sed和grep,awk不仅仅是一个小工具,也可以算得上一种小型的编程语言了,支持if判断分支和while循环语句还有它的内置函数等,是一个要比grep和sed更强大的文本处理工具,但也就意味着要学习的东西更多了。
下面来说一下awk的一些基础概念以及实际操作。
语法:
- Usage:
awk [POSIX or GNU style options] -f progfile [--] file ... - Usage:
awk [POSIX or GNU style options] [--] 'program' file ...
域:类似数据库列的概念,但它是按照序号来指定的,比如我要第一个列就是1,第二列就是2,依此类推。$0就是输出整个文本的内容。默认用空格作为分隔符,当然你可以自己通过-F设置适合自己情况的分隔符。
提前自己编了一段数据,学生以及学生成绩数据表。
| 列数 | 名称 | 描述 |
|---|---|---|
| 1 | Name | 姓名 |
| 2 | Math | 数学 |
| 3 | Chinese | 语文 |
| 4 | English | 英语 |
| 5 | History | 历史 |
| 6 | Sport | 体育 |
| 8 | Grade | 班级 |
“Name Math Chinese English History Sport grade 输出整个文本
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '{print $0}' students_store |
输出第一列(姓名列)
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '{print $1}' students_store |
模式&动作
1 | awk '{[pattern] action}' {filenames} |
模式pattern 可以是
- 条件语句
- 正则
模式的两个特殊字段 BEGIN 和 END (不指定时匹配或打印行数)
- BEGIN :一般用来打印列名称。
- END : 一般用来打印总结性质的字符。
动作:action 在{}内指定,一般用来打印,也可以是一个代码段。
示例
给上面的文本加入标题头:
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk 'BEGIN {print "Name Math Chinese English History Sport grade\n----------------------------------------------"} {print $0}' students_store |
仅打印姓名、数学成绩、班级信息,再加一个文尾(再接再厉):
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk 'BEGIN {print "Name Math grade\n---------------------"} {print $1 2 "\t" $7} END {print "continue to exert oneself"}' students_store |
结合正则
使用方法:
1 | 符号 ~ 后接正则表达式 |
此时我们再加入一条后来的新同学,并且没有分班。先来看下现在的数据
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## cat students_store |
模糊匹配|查询已经分班的学生
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '$0 ~/class/' students_store |
精准匹配|查询1班的学生
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '$7=="class-1" {print $0}' students_store |
反向匹配|查询不是1班的学生
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '$7!="class-1" {print $0}' students_store |
比较操作|查询数学大于80的
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '$2>60 {print $0}' students_store |
查询数学大于英语成绩的
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '$2 > $4 {print $0}' students_store |
匹配指定字符中的任意字符,在加一列专业,让我们来看看憨憨们的专业,顺便给最后一个新来的同学分个班吧。然后再来看下此时的数据。
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## cat students_store |
或关系匹配|查询1班和3班的学生
1 | root@iz2ze76ybn73dvwmdij06zz ~]## awk '$0 ~/(class-1|class-3)/' students_store |
任意字符匹配|名字第二个字母是
字符解释:
- ^ : 字段或记录的开头。
- . : 任意字符。
1 | root@iz2ze76ybn73dvwmdij06zz ~]## awk '$0 ~/(class-1|class-3)/' students_store |
复合表达式:&& AND的关系,必同时满足才行哦~
查询数学成绩大于60并且语文成绩也大于60的童鞋。
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '{ if ($2 > 60 && $3 > 60) print $0}' students_store |
|| OR:查询数学大于80或者语文大于80的童鞋。
1 | [root@iz2ze76ybn73dvwmdij06zz ~]## awk '{ if ($2 > 80 || $4 > 80) print $0}' students_store |
printf 格式化输出
除了能达到功能以外,一个好看的格式也是必不可少的,因此格式化的输出看起来会更舒服哦~
语法:
- printf ([格式],参数)
- printf %x(格式) 具体参数 x代表具体格式
| 符号 | 说明 |
|---|---|
| - | 左对齐 |
| Width | 域的步长 |
| .prec | 最大字符串长度或小数点右边位数 |
格式转化符常用格式
| 符号 | 描述 |
|---|---|
| %c | ASCII |
| %d | 整数 |
| %o | 八进制 |
| %x | 十六进制数 |
| %f | 浮点数 |
| %e | 浮点数(科学记数法) |
| %s | 字符串 |
| %g | 决定使用浮点转化e/f |
具体操作示例
ASCII码🐎
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# echo "66" | awk '{printf "%c\n",$0}' |
浮点数
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk 'BEGIN {printf "%f\n",100}' |
16进制数
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk 'BEGIN {printf "%x",996}' |
内置变量
频率较高常用内置变量
- NF :记录浏览域的个数,在记录被读后设置。
- NR :已读的记录数。
- FS : 设置输入域分隔符
- ARGC :命令行参数个数,支持命令行传入。
- RS : 控制记录分隔符
- FIlENAME : awk当前读文件的名称
操作
输出学生成绩表和域个数以及已读记录数。
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk '{print $0, NF , NR}' students_store |
内置函数
常用函数:
- length(s) 返回s长度
- index(s,t) 返回s中字符串t第一次出现的位置
- match (s,r) s中是否包含r字符串
- split(s,a,fs) 在fs上将s分成序列a
- gsub(r,s) 用s代替r,范围全文本
- gsub(r,s,t) 范围t中,s代替r
- substr(s,p) 返回字符串s从第p个位置开始后面的部分(下标是从1 开始算的,大家可以自己试试)
- substr(s,p,n) 返回字符串s从第p个位置开始后面n个字符串的部分
操作
length
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk 'BEGIN {print length(" hello,im xiaoka")}' |
index
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk 'BEGIN {print index("xiaoka","ok")}' |
match
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk 'BEGIN {print match("Java小咖秀","va小")}' |
gsub
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk 'gsub("Xiaoka","xk") {print $0}' students_store |
substr(s,p)
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk 'BEGIN {print substr("xiaoka",3)}' |
substr(s,p,n)
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# awk 'BEGIN {print substr("xiaoka",3,2)}' |
split
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# str="java,xiao,ka,xiu" |
awk脚本
前面说过awk是可以说是一个小型编程语言。如果命令比较短我们可以直接在命令行执行,当命令行比较长的时候,可以使用脚本来处理,比命令行的可读性更高,还可以加上注释。
写一个完整的awk脚本并执行步骤
1.先创建一个awk文件
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# vim printname.awk |
2.脚本第一行要指定解释器
1 | #!/usr/bin/awk -f |
3.编写脚本内容,打印一下名称
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# cat printname.awk |
4.既然是脚本,必不可少的可执行权限安排上~
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# chmod +x printname.awk |
5.有了可执行权限,我们来执行下看结果
1 | [root@iz2ze76ybn73dvwmdij06zz ~]# ./printname.awk |
paste 命令
- paste file1 file2 合并两个文件或两栏的内容
- paste -d ‘+’ file1 file2 合并两个文件或两栏的内容,中间用”+”区分
sort 命令
- sort file1 file2 排序两个文件的内容
- sort file1 file2 | uniq 取出两个文件的并集(重复的行只保留一份)
- sort file1 file2 | uniq -u 删除交集,留下其他的行
- sort file1 file2 | uniq -d 取出两个文件的交集(只留下同时存在于两个文件中的文件)
comm 命令
- comm -1 file1 file2 比较两个文件的内容只删除 ‘file1’ 所包含的内容
- comm -2 file1 file2 比较两个文件的内容只删除 ‘file2’ 所包含的内容
- comm -3 file1 file2 比较两个文件的内容只删除两个文件共有的部分
打包和压缩文件
tar 命令
(对文件进行打包,默认情况并不会压缩,如果指定了相应的参数,它还会调用相应的压缩程序(如gzip和bzip等)进行压缩和解压)
-c :新建打包文件
-t :查看打包文件的内容含有哪些文件名
-x :解打包或解压缩的功能,可以搭配-C(大写)指定解压的目录,注意-c,-t,-x不能同时出现在同一条命令中
-j :通过bzip2的支持进行压缩/解压缩
-z :通过gzip的支持进行压缩/解压缩
-v :在压缩/解压缩过程中,将正在处理的文件名显示出来
-f filename :filename为要处理的文件
-C dir :指定压缩/解压缩的目录dir
压缩:tar -jcv -f filename.tar.bz2 要被处理的文件或目录名称
查询:tar -jtv -f filename.tar.bz2
解压:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
bunzip2 file1.bz2 解压一个叫做 ‘file1.bz2’的文件
bzip2 file1 压缩一个叫做 ‘file1’ 的文件
gunzip file1.gz 解压一个叫做 ‘file1.gz’的文件
gzip file1 压缩一个叫做 ‘file1’的文件
gzip -9 file1 最大程度压缩
rar a file1.rar test_file 创建一个叫做 ‘file1.rar’ 的包
rar a file1.rar file1 file2 dir1 同时压缩 ‘file1’, ‘file2’ 以及目录 ‘dir1’
rar x file1.rar 解压rar包
zip file1.zip file1 创建一个zip格式的压缩包
unzip file1.zip 解压一个zip格式压缩包
zip -r file1.zip file1 file2 dir1 将几个文件和目录同时压缩成一个zip格式的压缩包
系统和关机
- shutdown -h now 关闭系统(1)
- init 0 关闭系统(2)
- telinit 0 关闭系统(3)
- shutdown -h hours:minutes & 按预定时间关闭系统
- shutdown -c 取消按预定时间关闭系统
- shutdown -r now 重启(1)
- reboot 重启(2)
- logout 注销
- time 测算一个命令(即程序)的执行时间
进程相关的命令
jps命令
(显示当前系统的java进程情况,及其id号)
- jps(Java Virtual Machine Process Status Tool)是JDK 1.5提供的一个显示当前所有java进程pid的命令,简单实用,非常适合在linux/unix平台上简单察看当前java进程的一些简单情况。
ps命令
(用于将某个时间点的进程运行情况选取下来并输出,process之意)
-A :所有的进程均显示出来
-a :不与terminal有关的所有进程
-u :有效用户的相关进程
-x :一般与a参数一起使用,可列出较完整的信息
-l :较长,较详细地将PID的信息列出
ps aux # 查看系统所有的进程数据
ps ax # 查看不与terminal有关的所有进程
ps -lA # 查看系统所有的进程数据
ps axjf # 查看连同一部分进程树状态
kill命令
(用于向某个工作(%jobnumber)或者是某个PID(数字)传送一个信号,它通常与ps和jobs命令一起使用)
killall命令
(向一个命令启动的进程发送一个信号)
top命令
是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
如何杀死进程:
- 图形化界面的方式
- kill -9 pid (-9表示强制关闭)
- killall -9 程序的名字
- pkill 程序的名字
查看进程端口号:
netstat -tunlp|grep 端口号
普通文件和目录文件的区别
普通文件和目录文件
- 普通文件:存储普通数据,一般就是字符串。
- 目录文件:存储了一张表,该表就是该目录文件下,所有文件名和inode的映射关系。
权限的区别
对于普通文件来说,rwx的意义是:
- r:可以获得这个普通文件的名字和内容。
- w:可以修改这个文件的内容和文件名。可以删除该文件。
- x:该文件是否具有被执行的权限。
对于目录文件来说,rwx的意义是:
- r:表示具有读取目录结构列表的权限,所以当你具有读取(r)一个目录的权限时,表示你可以查询该目录下的文件名。 就可以利用 ls 这个命令将该目录的内容列表显示出来, 必须这个目录有x的权限,才可以进入这个目录。
- w:移动该目录结构列表的权限(建立新的文件与目录、删除已经存在的文件与目录、更名、移动位置)。
- x:目录不可以被执行,目录的x代表的是用户能否进入该目录成为工作目录。
Linux 常见目录
/根目录/bin命令保存目录(普通用户就可以读取的命令)/boot启动目录,启动相关文件/dev设备文件保存目录/etc配置文件保存目录/home普通用户的家目录/lib系统库保存目录/mnt系统挂载目录/media挂载目录/root超级用户的家目录/tmp临时目录/sbin命令保存目录(超级用户才能使用的目录)/proc直接写入内存的/sys将内核的一些信息映射,可供应用程序所用/usr系统软件资源目录/usr/bin/系统命令(普通用户)/usr/sbin/系统命令(超级用户)/var系统相关文档内容/var/log/系统日志位置/var/spool/mail/系统默认邮箱位置/var/lib/默认安装的库文件目录
nohup
在应用Unix/Linux时,我们一般想让某个程序在后台运行,于是我们将常会用 & 在程序结尾来让程序自动运行。比如我们要运行mysql在后台: /usr/local/mysql/bin/mysqld_safe –user=mysql &。可是有很多程序并不想mysqld一样,这样我们就需要nohup命令,怎样使用nohup命令呢?这里讲解nohup命令的一些用法。
1 | nohup /root/start.sh & |
在shell中回车后提示:
1 | [~]$ appending output to nohup.out |
原程序的的标准输出被自动改向到当前目录下的nohup.out文件,起到了log的作用。
但是有时候在这一步会有问题,当把终端关闭后,进程会自动被关闭,察看nohup.out可以看到在关闭终端瞬间服务自动关闭。
咨询红旗Linux工程师后,他也不得其解,在我的终端上执行后,他启动的进程竟然在关闭终端后依然运行。
在第二遍给我演示时,我才发现我和他操作终端时的一个细节不同:他是在当shell中提示了nohup成功后还需要按终端上键盘任意键退回到shell输入命令窗口,然后通过在shell中输入exit来退出终端;而我是每次在nohup执行成功后直接点关闭程序按钮关闭终端.。所以这时候会断掉该命令所对应的session,导致nohup对应的进程被通知需要一起shutdown。
这个细节有人和我一样没注意到,所以在这儿记录一下了。
nohup 命令
用途:不挂断地运行命令。
语法:nohup Command [ Arg … ] [ & ]
描述:nohup 命令运行由 Command 参数和任何相关的 Arg 参数指定的命令,忽略所有挂断(SIGHUP)信号。在注销后使用 nohup 命令运行后台中的程序。要运行后台中的 nohup 命令,添加 & ( 表示”and”的符号)到命令的尾部。
无论是否将 nohup 命令的输出重定向到终端,输出都将附加到当前目录的 nohup.out 文件中。如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。如果没有文件能创建或打开以用于追加,那么 Command 参数指定的命令不可调用。如果标准错误是一个终端,那么把指定的命令写给标准错误的所有输出作为标准输出重定向到相同的文件描述符。
退出状态:该命令返回下列出口值:
- 126 可以查找但不能调用 Command 参数指定的命令。
- 127 nohup 命令发生错误或不能查找由 Command 参数指定的命令。
否则,nohup 命令的退出状态是 Command 参数指定命令的退出状态。
nohup命令及其输出文件
nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思( n ohang up)。
该命令的一般形式为:nohup command &
使用nohup命令提交作业
如果使用nohup命令提交作业,那么在缺省情况下该作业的所有输出都被重定向到一个名为nohup.out的文件中,除非另外指定了输出文件:
nohup command > myout.file 2>&1 &
在上面的例子中,输出被重定向到myout.file文件中。
使用 jobs 查看任务。
使用 fg %n 关闭。
环境变量设置
简介
环境变量是在操作系统中一个具有特定名字的对象,它包含了一个或多个应用程序将使用到的信息。Linux是一个多用户的操作系统,每个用户登录系统时都会有一个专用的运行环境,通常情况下每个用户的默认的环境都是相同的。这个默认环境就是一组环境变量的定义。每个用户都可以通过修改环境变量的方式对自己的运行环境进行配置。
分类
根据环境变量的生命周期我们可以将其分为永久性变量和临时性变量,根据用户等级的不同又可以将其分为系统级变量和用户级变量。怎么分都无所谓,主要是对它的理解。
对所有用户生效的永久性变量(系统级)
这类变量对系统内的所有用户都生效,所有用户都可以使用这类变量。作用范围是整个系统。
设置方式: 用vim在/etc/profile文件中添加我们想要的环境变量。
当然,这个文件只有在root(超级用户)下才能修改。我们可以在etc目录下使用ls -l查看这个文件的用户及权限。
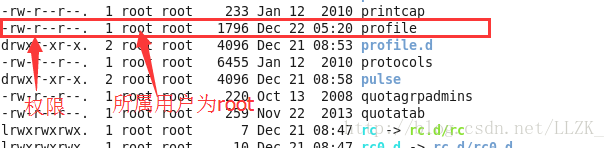
利用vim打开/etc/ profile文件,用export指令添加环境变量。
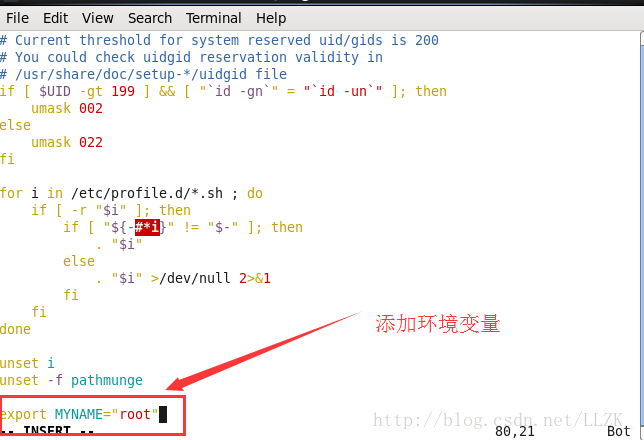
【注意】:添加完成后新的环境变量不会立即生效,除非你调用source /etc/profile 该文件才会生效。否则只能在下次重进此用户时才能生效。

对单一用户生效的永久性变量(用户级)
该类环境变量只对当前的用户永久生效。也就是说假如用户A设置了此类环境变量,这个环境变量只有A可以使用。而对于其他的B,C,D,E….用户等等,这个变量是不存在的。
设置方法:在用户主目录”~”下的隐藏文件 “.bash_profile”中添加自己想要的环境变量。
查看隐藏文件: ls -a或ls -al

利用vim打开文件,利用export添加环境变量。与上相同。同样注意,添加完成后新的环境变量不会立即生效,除非你调用source ./.bash_profile 该文件才会生效。否则只能在下次重进此用户时才能生效。
可以看到我在上图中用红框框住了两个文件,.bashrc和.bash_profile。原则上来说设置此类环境变量时在这两个文件任意一个里面添加都是可以的。
~/.bash_profile是交互式login方式进入bash shell运行。
~/ .bashrc是交互式non-login方式进入bash shell运行。
二者设置大致相同。通俗点说,就是.bash_profile文件只会在用户登录的时候读取一次,而.bashrc在每次打开终端进行一次新的会话时都会读取。
临时有效的环境变量(只对当前shell有效)
此类环境变量只对当前的shell有效。当我们退出登录或者关闭终端再重新打开时,这个环境变量就会消失。是临时的。
设置方法:直接使用export指令添加。
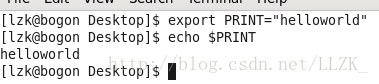
设置环境变量常用的几个指令
echo
查看显示环境变量,使用时要加上符号“”例:echo”例:echoPATH
export
设置新的环境变量
export 新环境变量名=内容
例:export MYNAME=”LLZZ”
修改环境变量
修改环境变量没有指令,可以直接使用环境变量名进行修改。
例:MYNAME=”ZZLL”
env
查看所有环境变量
set
查看本地定义的所有shell变量
unset
删除一个环境变量
例 unset MYNAME
readonly
设置只读环境变量。
例:readonly MYNAME
常用的几个环境变量
PATH
指定命令的搜索路径。通过设置环境变量PATH可以让我们运行程序或指令更加方便。
echo $PATH 查看环境变量PATH。
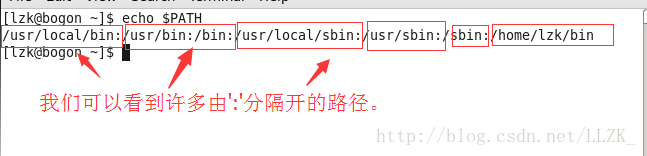
每一个冒号都是一个路径,这些搜索路径都是一些可以找到可执行程序的目录列表。当我们输入一个指令时,shell会先检查命令是否是内部命令,不是的话会再检查这个命令是否是一个应用程序。然后shell会试着从这些搜索路径,即PATH(上图中路径)中寻找这些应用程序。如果shell在这些路径目录里没有找到可执行文件。则会报错。若找到,shell内部命令或应用程序将被分解为系统调用并传给Linux内核。
举个例子:
现在有一个c程序test.c通过gcc编译生成的可执行文件a.out(功能:输出helloworld)。我们平常执行这个a.out的时候是使用
①相对路径调用方式: ./a.out (”.”代表当前目录,”/”分隔符)。
②还可以使用绝对路径调用方式:将其全部路径写出:/home/lzk/test/a.out(此路径是我的工作目录路径,只是个例子,仅供参考)
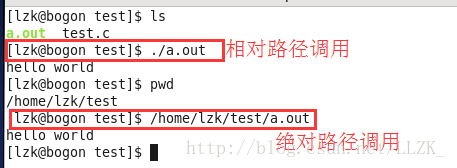
③通过设置PATH环境变量,直接用文件名调用:
在没设置PATH前,我们直接使用a.out调用程序会报错,因为shell并没有从PATH已拥有的搜索路径目录中找到a.out这个可执行程序。

使用export指令,将a.out的路径添加到搜索路径当中,export PATH=$PATH:路径
我们就可以使用a.out直接执行程序。
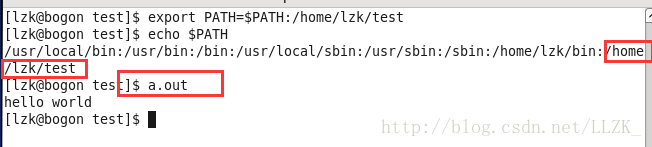
HOME
指定用户的主工作目录,即为用户登录到Linux系统中时的默认目录,即“~”。
LOGNAME
指当前用户的登录名
HOSTNAME
指主机的名称。
SHELL
指当前用户用的是哪种shell
LANG/LANGUGE
和语言相关的环境变量,使用多种语言的用户可以修改此环境变量。
指当前用户的邮件存放目录
PS1
命令提示符,root用户是#,普通用户是$
PS2
附属提示符,默认是“>”
SECONDS
从当前shell开始运行所流逝的秒数
总结
环境变量是和shell紧密相关的,用户登录系统后就启动了一个shell,对于Linux来说一般是bash(Bourne Again shell,Bourne shell(sh)的扩展),也可以切换到其他版本的shell。bash有两个基本的系统级配置文件:/etc/bashrc和/etc/profile。这些配置文件包含了两组不同的变量:shell变量和环境变量。shell变量是局部的,而环境变量是全局的。环境变量是通过shell命令来设置。设置好的环境变量又可以被所以当前用户的程序使用。
Linux检测工具
- 静态代码检测工具:cppcheck、Clang-Tidy、PC-lint、SonarQube+sonar-cxx、Facebook的infer、Clang Static Analyzer。
- 内存泄漏检测工具:valgrind、ASan、mtrace、ccmalloc、debug_new。
- profiling工具:gperftools、perf、intel VTune、AMD CodeAnalyst、gnu prof、Quantify
https://www.brendangregg.com/linuxperf.html
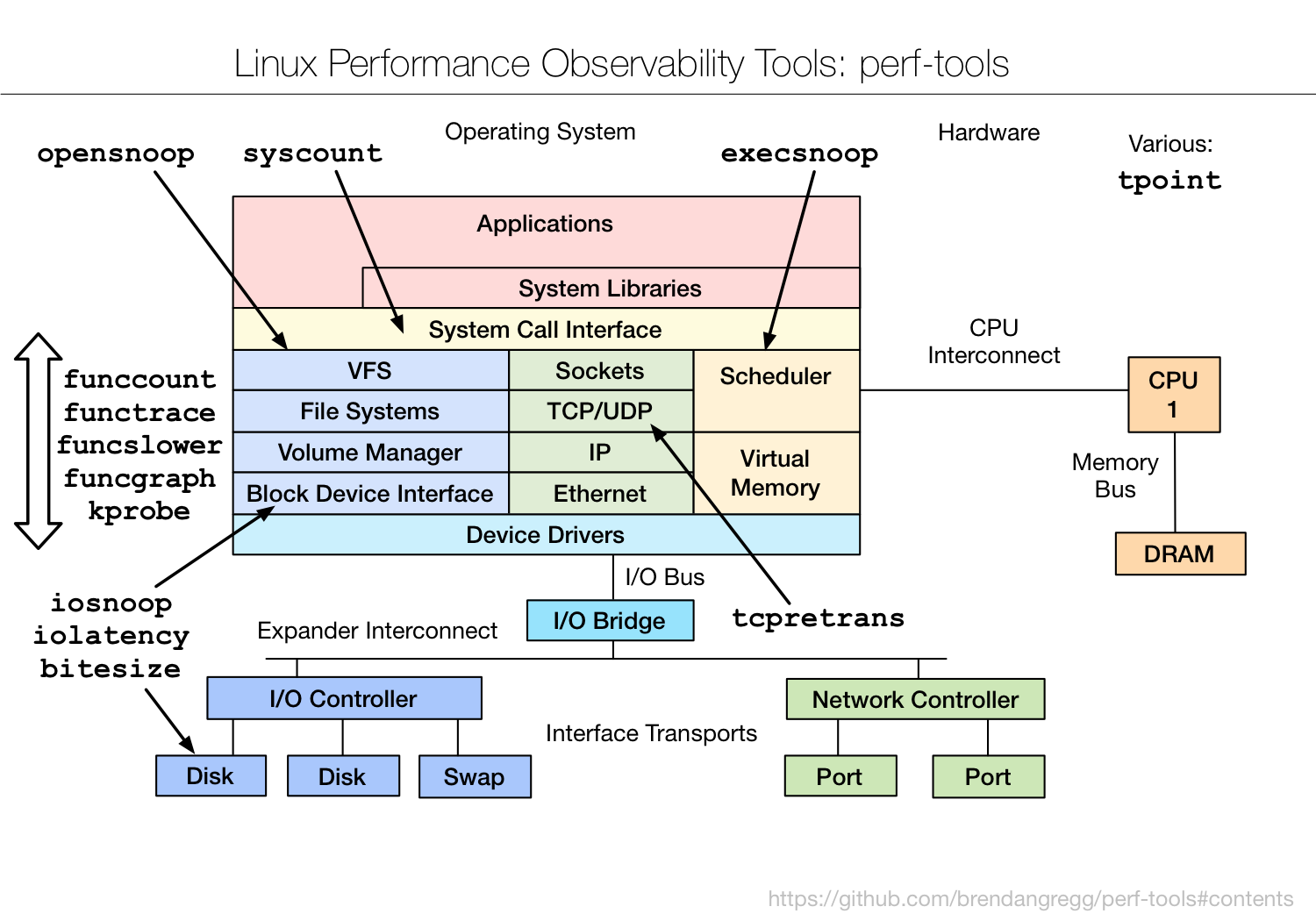
Linux shell脚本
入参和默认变量
对于shell脚本而言,有些内容是专门用于处理参数的,它们都有特定的含义,例如:
- /home/shouwang/test.sh para1 para2 para3
- $0 $1 $2 $3
- 脚本名 第一个参数 第三个参数
除此之外,还有一些其他的默认变量,例如:
$#代表脚本后面跟的参数个数,前面的例子中有3个参数$@代表了所有参数,并且可以被遍历$*代表了所有参数,且作为整体,和$@很像,但是有区别$$代表了当前脚本的进程ID$?代表了上一条命令的退出状态
变量
给变量赋值,使用等号即可,但是等号两边千万不要有空格,等号右边有空格的字符串也必须用引号引起来:para1="hello world"表示字符串直接赋给变量para1
unset用于取消变量。例如:unset para1
如何使用变量呢?使用变量时,需要在变量前加$.
例如要打印前面para1的内容:echo "para1 is $para1",将会输出 para1 is hello world。或者变量名两边添加大括号:echo "para1 is ${para1}!",将会输出para1 is hello world!
命令执行在shell中执行命令通常只需要像在终端一样执行命令即可,不过,如果想要命令结果打印出来的时候,这样的方式就行不通了。因此,shell的命令方式常有:
1 | a=`ls` |
“`“是左上角~键,不是单引号。
或者使用$,后面括号内是执行的命令:echo "current path is $(pwd)" 。
另外,前面两种方式对于计算表达式也是行不通的,而要采取下面的方式:echo "1+1=$((1+1))",打印:1+1=2,即$后面用两重括号将要计算的表达式包裹起来。那如果要执行的命令存储在变量中呢?前面的方法都不可行了,当然括号内的内容被当成命令执行还是成立的。要使用下面的方式,例如:
a="ls"echo "$($a)"
但是如果字符串时多条命令的时候,上面的方式又不可行了,而要采用下面的方式:
a="ls;pwd"echo "$(eval $a)"
这是使用了eval,将a的内容都作为命令来执行。
条件分支
一般说明,如果命令执行成功,则其返回值为0,否则为非0,因此,可以通过下面的方式判断上条命令的执行结果:
1 | if [ $? -eq 0 ]then |
case语句使用方法如下:
1 | name="aa" |
初学者特别需要注意以下几点:
- []前面要有空格,它里面是逻辑表达式
- if elif后面要跟then,然后才是要执行的语句
- 如果想打印上一条命令的执行结果,最好的做法是将
$?赋给一个变量,因为一旦执行了一条命令$?的值就可能会变。 - case每个分支最后以两个分号结尾,最后是case反过来写,即esac。
多个条件如何使用呢,两种方式,方式一:
1 | if [ 10 -gt 5 -o 10 -gt 4 ];then |
方式二:
1 | if [ 10 -gt 5 ] || [ 10 -gt 4 ];then |
其中-o或者||表示或。这里也有一些常见的条件判定。总结如下:
-oor或者,同||-aand与,同&&!非
整数判断:
-eq两数是否相等-ne两数是否不等-gt前者是否大于后者(greater then)-lt前面是否小于后者(less than)-ge前者是否大于等于后者(greater then or equal)-le前者是否小于等于后者(less than or equal)
字符串判断str1 exp str2:
-z "$str1"str1是否为空字符串-n "$str1"str1是否不是空字符串"$str1" == "$str2"str1是否与str2相等"$str1" != "$str2"str1是否与str2不等"$str1" =~ "str2"str1是否包含str2
特别注意,字符串变量最好用引号引起来,因为一旦字符串中有空格,这个表达式就错了,有兴趣的可以尝试当str1=”hello world”,而str2=”hello”的时候进行比较。
文件目录判断:filename
-f $filename是否为文件-e $filename是否存在-d $filename是否为目录-s $filename文件存在且不为空! -s $filename文件是否为空
循环
循环形式一,和Python的for in很像:
1 | #遍历输出脚本的参数 |
循环形式二,和C语言风格很像:
1 | for ((i = 0 ; i < 10 ; i++)); |
循环形式三:
1 | for i in {1..5}; |
循环方式四:
1 | while [ "$ans" != "yes" ] |
只有当输入yes时,循环才会退出。即条件满足时,就进行循环。
循环方式五:
1 | ans=yes |
这里表示,只有当ans不是yes时,循环就终止。
循环方式六:
1 | for i in {5..15..3}; |
每隔5打印一次,即打印5,8,11,14。
函数
定义函数方式如下:
1 | myfunc() |
或者:
1 | function myfunc() |
函数调用:
1 | para1="shouwang" |
返回值
通常函数的return返回值只支持0-255,因此想要获得返回值,可以通过下面的方式。
1 | function myfunc() |
通过return的方式适用于判断函数的执行是否成功:
1 | function myfunc() |
日志保存
脚本执行后免不了要记录日志,最常用的方法就是重定向。以下面的脚本为例:
1 | #!/bin/bash |
方式一,将标准输出保存到文件中,打印标准错误:
1 | ./test.sh > log.dat |
这种情况下,如果命令执行出错,错误将会打印到控制台。所以如果你在程序中调用,这样将不会讲错误信息保存在日志中。
方式二,标准输出和标准错误都保存到日志文件中:
1 | ./test.sh > log.dat 2>&1 |
2>&1的含义可以参考《如何理解linuxshell中的2>&1》
方式三,保存日志文件的同时,也输出到控制台:
1 | ./test.sh |tee log.dat |
脚本执行
最常见的执行方式前面已经看到了:
1 | ./test.sh |
其它执行方式:
sh test.sh,在子进程中执行sh -x test.sh,会在终端打印执行到命令,适合调试source test.sh,test.sh在父进程中执行. test.sh,不需要赋予执行权限,临时执行脚本
退出码
很多时候我们需要获取脚本的执行结果,即退出状态,通常0表示执行成功,而非0表示失败。为了获得退出码,我们需要使用exit。例如:
1 | #!/bin/bash |
这里需要特别注意的一点是,使用
1 | returnVal=`myfun aa` |
这样的句子执行函数,即便函数里面有exit,它也不会退出脚本执行,而只是会退出该函数,这是因为exit是退出当前进程,而这种方式执行函数,相当于fork了一个子进程,因此不会退出当前脚本。最终结果就会看到,无论你的函数参数是什么最后end shell都会打印。
1 | ./test.sh;echo $? |
1 | 0 |
这里的0就是脚本的执行结果。
bash命令逻辑
cmd1&&cmd2:如果cmd1成功则执行cmd2cmd1||cmd2:如果cmd1不成功则执行cmd2cmd1|cmd2:这个是管道,把cmd1的输出作为cmd2的输入cmd1;cmd2:连续执行两条命令,先cmd1,然后cmd2
逻辑运算符
-f 常用!侦测『档案』是否存在 eg: if [ -f filename ]
-d 常用!侦测『目录』是否存在
-b 侦测是否为一个『 block 档案』
-c 侦测是否为一个『 character 档案』
-S 侦测是否为一个『 socket 标签档案』
-L 侦测是否为一个『 symbolic link 的档案』
-e 侦测『某个东西』是否存在!
关于程序的逻辑卷标
-G 侦测是否由 GID 所执行的程序所拥有
-O 侦测是否由 UID 所执行的程序所拥有
-p 侦测是否为程序间传送信息的 name pipe 或是 FIFO (老实说,这个不太懂!)
关于档案的属性侦测
-r 侦测是否为可读的属性
-w 侦测是否为可以写入的属性
-x 侦测是否为可执行的属性
-s 侦测是否为『非空白档案』
-u 侦测是否具有『 SUID 』的属性
-g 侦测是否具有『 SGID 』的属性
-k 侦测是否具有『 sticky bit 』的属性
两个档案之间的判断与比较 ;例如[ test file1 -nt file2 ]
-nt 第一个档案比第二个档案新
-ot 第一个档案比第二个档案旧
-ef 第一个档案与第二个档案为同一个档案( link 之类的档案)
逻辑的『和(and)』『或(or)』
&& 逻辑的 AND 的意思
|| 逻辑的 OR 的意思
运算符号 代表意义
= 等于 应用于:整型或字符串比较 如果在[] 中,只能是字符串
!=不等于 应用于:整型或字符串比较 如果在[] 中,只能是字符串
< 小于 应用于:整型比较 在[] 中,不能使用 表示字符串
> 大于 应用于:整型比较 在[] 中,不能使用 表示字符串
-eq 等于 应用于:整型比较
-ne 不等于 应用于:整型比较
-lt 小于 应用于:整型比较
-gt 大于 应用于:整型比较
-le 小于或等于 应用于:整型比较
-ge 大于或等于 应用于:整型比较
-a 双方都成立(and) 逻辑表达式 –a 逻辑表达式
-o 单方成立(or) 逻辑表达式 –o 逻辑表达式
-z 空字符串
-n 非空字符串
逻辑表达式
test 命令
使用方法:test EXPRESSION
如:
1 | [root@localhost ~]# test 1 = 1 && echo 'ok' |
注意:所有字符 与逻辑运算符直接用“空格”分开,不能连到一起。
精简表达式
[] 表达式
1 | [root@localhost ~]# [ 1 -eq 1 ] && echo 'ok' |
注意:在[] 表达式中,常见的>,<需要加转义字符,表示字符串大小比较,以acill码 位置作为比较。 不直接支持<>运算符,还有逻辑运算符|| && 它需要用-a[and] –o[or]表示
[[]] 表达式
1 | [root@localhost ~]# [ 1 -eq 1 ] && echo 'ok' |
注意:[[]] 运算符只是[]运算符的扩充。能够支持<,>符号运算不需要转义符,它还是以字符串比较大小。里面支持逻辑运算符:|| &&
性能比较
bash的条件表达式中有三个几乎等效的符号和命令:test,[]和[[]]。通常,大家习惯用if [];then这样的形式。而[[]]的出现,根据ABS所说,是为了兼容><之类的运算符。以下是比较它们性能,发现[[]]是最快的。
1 | $ time (for m in {1..100000}; do test -d .;done;) |
不考虑对低版本bash和对sh的兼容的情况下,用[[]]是兼容性强,而且性能比较快,在做条件运算时候,可以使用该运算符。