classSolution { public: vector<string> removeInvalidParentheses(string s){ vector<string> res; int cnt1 = 0, cnt2 = 0; for (char c : s) { cnt1 += (c == '('); if (cnt1 == 0) cnt2 += (c == ')'); else cnt1 -= (c == ')'); } helper(s, 0, cnt1, cnt2, res); return res; } voidhelper(string s, int start, int cnt1, int cnt2, vector<string>& res){ if (cnt1 == 0 && cnt2 == 0) { if (isValid(s)) res.push_back(s); return; } for (int i = start; i < s.size(); ++i) { if (i != start && s[i] == s[i - 1]) continue; if (cnt1 > 0 && s[i] == '(') { helper(s.substr(0, i) + s.substr(i + 1), i, cnt1 - 1, cnt2, res); } if (cnt2 > 0 && s[i] == ')') { helper(s.substr(0, i) + s.substr(i + 1), i, cnt1, cnt2 - 1, res); } } } boolisValid(string t){ int cnt = 0; for (int i = 0; i < t.size(); ++i) { if (t[i] == '(') ++cnt; elseif (t[i] == ')' && --cnt < 0) returnfalse; } return cnt == 0; } };
下面这种解法由热心网友 fvglty 提供,应该算是一种暴力搜索的方法,并没有太多的技巧在里面,但是思路直接了当,可以作为为面试中最先提出的解法。思路是先将s放到一个 HashSet 中,然后进行该集合 cur 不为空的 while 循环,此时新建另一个集合 next,遍历之前的集合 cur,若某个字符串是合法的括号,直接加到结果 res 中,并且看若 res 不为空,则直接跳过。跳过的部分实际上是去除括号的操作,由于不知道该去掉哪个半括号,所以只要遇到半括号就都去掉,然后加入另一个集合 next 中,这里实际上保存的是下一层的候选者。当前的 cur 遍历完成后,若 res 不为空,则直接返回,因为这是当前层的合法括号,一定是移除数最少的。若 res 为空,则将 next 赋值给 cur,继续循环,参见代码如下:
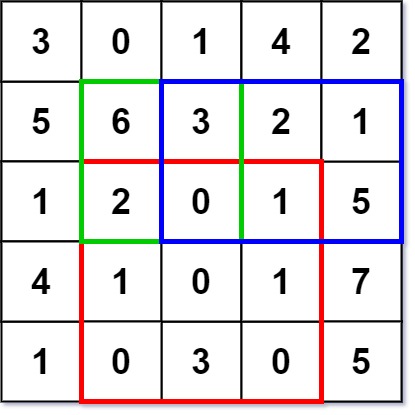
Given a 2D matrix matrix, handle multiple queries of the following type:
Calculate the sum of the elements of matrix inside the rectangle defined by its upper left corner (row1, col1) and lower right corner (row2, col2). Implement the NumMatrix class:
NumMatrix(int[][] matrix) Initializes the object with the integer matrix matrix. int sumRegion(int row1, int col1, int row2, int col2) Returns the sum of the elements of matrix inside the rectangle defined by its upper left corner (row1, col1) and lower right corner (row2, col2).
classNumMatrix { public: vector<vector<int> > dp; NumMatrix(vector<vector<int>>& matrix) { int width = matrix.size(); if (width == 0) return; int height = matrix[0].size(); dp.resize(width+1); for (int i = 0; i < dp.size(); i++) dp[i].resize(height+1, 0); for (int i = 1; i <= width; i ++) for (int j = 1; j <= height; j ++) dp[i][j] = dp[i][j-1] + dp[i-1][j] - dp[i-1][j-1] + matrix[i-1][j-1]; } intsumRegion(int row1, int col1, int row2, int col2){ return dp[row2+1][col2+1] + dp[row1+1][col1+1] - dp[row1-1][col2] - dp[row2][col1-1]; } };
Leetcode305. Number of Islands II
A 2d grid map of m rows and n columns is initially filled with water. We may perform an addLand operation which turns the water at position (row, col) into a land. Given a list of positions to operate, count the number of islands after each addLand operation. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.
Example:
1 2
Input: m = 3, n = 3, positions = [[0,0], [0,1], [1,2], [2,1]] Output: [1,1,2,3]
Explanation:
Initially, the 2d grid grid is filled with water. (Assume 0 represents water and 1 represents land).
1 2 3
0 0 0 0 0 0 0 0 0
Operation 1: addLand(0, 0) turns the water at grid[0][0] into a land.
1 2 3
1 0 0 0 0 0 Number of islands = 1 0 0 0
Operation 2: addLand(0, 1) turns the water at grid[0][1] into a land.
1 2 3
1 1 0 0 0 0 Number of islands = 1 0 0 0
Operation 3: addLand(1, 2) turns the water at grid[1][2] into a land.
1 2 3
1 1 0 0 0 1 Number of islands = 2 0 0 0
Operation 4: addLand(2, 1) turns the water at grid[2][1] into a land.
1 2 3
1 1 0 0 0 1 Number of islands = 3 0 1 0
这道题是之前那道 Number of Islands 的拓展,难度增加了不少,因为这次是一个点一个点的增加,每增加一个点,都要统一一下现在总共的岛屿个数,最开始初始化时没有陆地,如下:
classSolution { public: vector<int> numIslands2(int m, int n, vector<vector<int>>& positions){ vector<int> res; int cnt = 0; vector<int> roots(m * n, -1); vector<vector<int>> dirs{{0, -1}, {-1, 0}, {0, 1}, {1, 0}}; for (auto &pos : positions) { int id = n * pos[0] + pos[1]; if (roots[id] != -1) { res.push_back(cnt); continue; } roots[id] = id; ++cnt; for (auto dir : dirs) { int x = pos[0] + dir[0], y = pos[1] + dir[1], cur_id = n * x + y; if (x < 0 || x >= m || y < 0 || y >= n || roots[cur_id] == -1) continue; int p = findRoot(roots, cur_id), q = findRoot(roots, id); if (p != q) { roots[p] = q; --cnt; } } res.push_back(cnt); } return res; } intfindRoot(vector<int>& roots, int id){ return (id == roots[id]) ? id : findRoot(roots, roots[id]); } };
Leetcode306. Additive Number
Additive number is a string whose digits can form additive sequence.
A valid additive sequence should contain at least three numbers. Except for the first two numbers, each subsequent number in the sequence must be the sum of the preceding two.
Given a string containing only digits ‘0’-‘9’, write a function to determine if it’s an additive number.
Note: Numbers in the additive sequence cannot have leading zeros, so sequence 1, 2, 03 or 1, 02, 3is invalid.
Example 1:
1 2 3 4
Input: "112358" Output: true Explanation: The digits can form an additive sequence: 1, 1, 2, 3, 5, 8. 1 + 1 = 2, 1 + 2 = 3, 2 + 3 = 5, 3 + 5 = 8
这道题是之前那道 Range Sum Query - Immutable 的延伸,之前那道题由于数组的内容不会改变,所以我们只需要建立一个累计数组就可以支持快速的计算区间值了,而这道题说数组的内容会改变,如果我们还是用之前的方法建立累计和数组,那么每改变一个数字,之后所有位置的数字都要改变,这样如果有很多更新操作的话,就会十分不高效,估计很难通过吧。But,被 OJ 分分钟打脸, brute force 完全没有问题啊,这年头,装个比不容易啊。直接就用个数组 data 接住 nums,然后要更新就更新,要求区域和,就遍历求区域和,就这样 naive 的方法还能 beat 百分之二十多啊,这不科学啊,参见代码如下:
classNumArray { public: NumArray(vector<int> nums) { data = nums; } voidupdate(int i, int val){ data[i] = val; } intsumRange(int i, int j){ int sum = 0; for (int k = i; k <= j; ++k) { sum += data[k]; } return sum; } private: vector<int> data; };
classNumArray { public: NumArray(vector<int> nums) { if (nums.empty()) return; data = nums; double root = sqrt(data.size()); len = ceil(data.size() / root); block.resize(len); for (int i = 0; i < data.size(); ++i) { block[i / len] += data[i]; } } voidupdate(int i, int val){ int idx = i / len; block[idx] += val - data[i]; data[i] = val; } intsumRange(int i, int j){ int sum = 0; int start = i / len, end = j / len; if (start == end) { for (int k = i; k <= j; ++k) { sum += data[k]; } return sum; } for (int k = i; k < (start + 1) * len; ++k) { sum += data[k]; } for (int k = start + 1; k < end; ++k) { sum += block[k]; } for (int k = end * len; k <= j; ++k) { sum += data[k]; } return sum; } private: int len; vector<int> data, block; };
Leetcode309. Best Time to Buy and Sell Stock with Cooldown
Say you have an array for which the i th element is the price of a given stock on day i.
Design an algorithm to find the maximum profit. You may complete as many transactions as you like (ie, buy one and sell one share of the stock multiple times) with the following restrictions:
You may not engage in multiple transactions at the same time (ie, you must sell the stock before you buy again).After you sell your stock, you cannot buy stock on next day. (ie, cooldown 1 day)
classSolution { public: intmaxProfit(vector<int>& prices){ int len = prices.size(); if (len == 0) return0; vector<int> buy(len+1, 0), sell(len+1, 0); buy[1] = -prices[0]; for (int i = 2; i < len+1; i ++) { buy[i] = max(sell[i-2]-prices[i-1], buy[i-1]); sell[i] = max(sell[i-1], buy[i-1]+prices[i-1]); } return sell[len]; } };
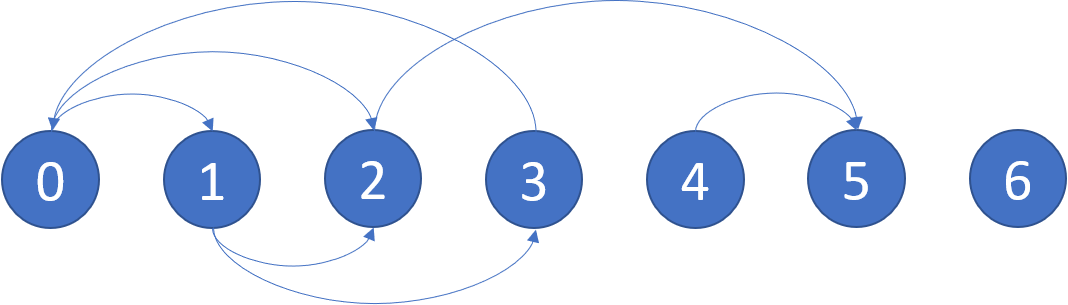
Leetcode310. Minimum Height Trees
A tree is an undirected graph in which any two vertices are connected by exactly one path. In other words, any connected graph without simple cycles is a tree.
Given a tree of n nodes labelled from 0 to n - 1, and an array of n - 1 edges where edges[i] = [ai, bi] indicates that there is an undirected edge between the two nodes ai and bi in the tree, you can choose any node of the tree as the root. When you select a node x as the root, the result tree has height h. Among all possible rooted trees, those with minimum height (i.e. min(h)) are called minimum height trees (MHTs).
Return a list of all MHTs’ root labels. You can return the answer in any order.
The height of a rooted tree is the number of edges on the longest downward path between the root and a leaf.
Example 1:
1 2 3
Input: n = 4, edges = [[1,0],[1,2],[1,3]] Output: [1] Explanation: As shown, the height of the tree is 1 when the root is the node with label 1 which is the only MHT.
Example 2:
1 2
Input: n = 6, edges = [[3,0],[3,1],[3,2],[3,4],[5,4]] Output: [3,4]
classSolution { public: vector<int> findMinHeightTrees(int n, vector<pair<int, int> >& edges){ if (n == 1) return {0}; vector<int> res; vector<unordered_set<int>> adj(n); queue<int> q; for (auto edge : edges) { adj[edge.first].insert(edge.second); adj[edge.second].insert(edge.first); } for (int i = 0; i < n; ++i) { if (adj[i].size() == 1) q.push(i); } while (n > 2) { int size = q.size(); n -= size; for (int i = 0; i < size; ++i) { int t = q.front(); q.pop(); for (auto a : adj[t]) { adj[a].erase(t); if (adj[a].size() == 1) q.push(a); } } } while (!q.empty()) { res.push_back(q.front()); q.pop(); } return res; } };
Leetcode312. Burst Balloons
Given n balloons, indexed from 0 to n-1. Each balloon is painted with a number on it represented by array nums. You are asked to burst all the balloons. If the you burst balloon iyou will get nums[left] * nums[i] * nums[right]coins. Here left and right are adjacent indices of i. After the burst, the left and right then becomes adjacent.
Find the maximum coins you can collect by bursting the balloons wisely.
Note:
You may imagine nums[-1] = nums[n] = 1. They are not real therefore you can not burst them.
classSolution { public: intmaxCoins(vector<int>& nums){ int n = nums.size(); nums.insert(nums.begin(), 1); nums.push_back(1); vector<vector<int>> dp(n + 2, vector<int>(n + 2, 0)); returnburst(nums, dp, 1 , n); } intburst(vector<int>& nums, vector<vector<int>>& dp, int i, int j){ if (i > j) return0; if (dp[i][j] > 0) return dp[i][j]; int res = 0; for (int k = i; k <= j; ++k) { res = max(res, nums[i - 1] * nums[k] * nums[j + 1] + burst(nums, dp, i, k - 1) + burst(nums, dp, k + 1, j)); } dp[i][j] = res; return res; } };
Leetcode313. Super Ugly Number
Write a program to find the nth super ugly number.
Super ugly numbers are positive numbers whose all prime factors are in the given prime list primes of sizek. For example, [1, 2, 4, 7, 8, 13, 14, 16, 19, 26, 28, 32] is the sequence of the first 12 super ugly numbers given primes = [2, 7, 13, 19] of size 4.
Note:
1 is a super ugly number for any given primes.
The given numbers in primes are in ascending order.
0 < k ≤ 100, 0 < n ≤ 106, 0 < primes[i] < 1000.
这道题让我们求超级丑陋数,是之前那两道Ugly Number 丑陋数和Ugly Number II 丑陋数之二的延伸,质数集合可以任意给定,这就增加了难度。但是本质上和Ugly Number II 丑陋数之二没有什么区别,由于我们不知道质数的个数,我们可以用一个idx数组来保存当前的位置,然后我们从每个子链中取出一个数,找出其中最小值,然后更新idx数组对应位置,注意有可能最小值不止一个,要更新所有最小值的位置,参见代码如下:
classSolution { public: intnthSuperUglyNumber(int n, vector<int>& primes){ vector<int> res(1, 1), idx(primes.size(), 0); while (res.size() < n) { vector<int> tmp; int mn = INT_MAX; for (int i = 0; i < primes.size(); ++i) { tmp.push_back(res[idx[i]] * primes[i]); } for (int i = 0; i < primes.size(); ++i) { mn = min(mn, tmp[i]); } for (int i = 0; i < primes.size(); ++i) { if (mn == tmp[i]) ++idx[i]; } res.push_back(mn); } return res.back(); } };
Leetcode315. Count of Smaller Numbers After Self
You are given an integer array nums and you have to return a new counts array. The counts array has the property where counts[i] is the number of smaller elements to the right of nums[i].
Example:
1 2 3 4 5 6 7
Input: [5,2,6,1] Output: [2,1,1,0] Explanation: To the right of 5 there are 2 smaller elements (2 and 1). To the right of 2 there is only 1 smaller element (1). To the right of 6 there is 1 smaller element (1). To the right of 1 there is 0 smaller element.
classSolution { public: vector<int> res; vector<int> idx; voidmerge(vector<int>& nums, int l, int r){ if (l >= r) return; int mid = (l + r) >> 1; merge(nums, l, mid); merge(nums, mid+1, r); vector<int> tmp(r - l + 1); int k = 0, i = l, j = mid+1; while(i <= mid && j <= r) { if (nums[idx[i]] <= nums[idx[j]]) { res[idx[i]] += (j - 1 - mid); tmp[k++] = idx[i ++]; } else tmp[k++] = idx[j ++]; } while(i <= mid) { res[idx[i]] += r - mid; tmp[k++] = idx[i++]; } while(j <= r) tmp[k++] = idx[j++]; for (int i = 0; i < tmp.size(); i ++) idx[l+i] = tmp[i]; } vector<int> countSmaller(vector<int>& nums){ res.assign(nums.size(), 0); idx.assign(nums.size(), 0); for (int i = 0; i < nums.size(); i ++) idx[i] = i; merge(nums, 0, nums.size()-1); return res; } };
Leetcode316. Remove Duplicate Letters
Given a string s, remove duplicate letters so that every letter appears once and only once. You must make sure your result is the smallest in lexicographical order among all possible results.
classSolution { public: string removeDuplicateLetters(string s){ string res = ""; int size = s.length(); unordered_map<char, int> m; unordered_map<char, bool> visited; for (int i = 0; i < size; i ++) { m[s[i]] ++; visited[s[i]] = false; }
for (int i = 0; i < size; i ++) { m[s[i]] --; if (visited[s[i]]) continue; while(!res.empty() && m[res.back()] > 0 && s[i] < res.back()) { visited[res.back()] = false; res.pop_back(); } res += s[i]; visited[s[i]] = true; } return res; } };
Leetcode318. Maximum Product of Word Lengths
Given a string array words, find the maximum value of length(word[i]) * length(word[j]) where the two words do not share common letters. You may assume that each word will contain only lower case letters. If no such two words exist, return 0.
Example 1:
1 2 3
Given ["abcw", "baz", "foo", "bar", "xtfn", "abcdef"] Return 16 The two words can be "abcw", "xtfn".
Example 2:
1 2 3
Given ["a", "ab", "abc", "d", "cd", "bcd", "abcd"] Return 4 The two words can be "ab", "cd".
Example 3:
1 2 3
Given ["a", "aa", "aaa", "aaaa"] Return 0 No such pair of words.
classSolution { public: intmaxProduct(vector<string>& words){ int len = words.size(); vector<int> wordss, lennn; for (int i = 0; i < len; i ++) { int t = 0; for (int j = 0; j < words[i].length(); j ++) { t = t | (1 << (words[i][j]-'a')); } wordss.push_back(t); lennn.push_back(words[i].length()); } int res = -1; for (int i = 0; i < len; i ++) for (int j = i + 1; j < len; j ++) if ((wordss[i] & wordss[j]) == 0) res = max(res, int(lennn[i] * lennn[j])); return res; } };
Leetcode319. Bulb Switcher
There are n bulbs that are initially off. You first turn on all the bulbs. Then, you turn off every second bulb. On the third round, you toggle every third bulb (turning on if it’s off or turning off if it’s on). For the n th round, you only toggle the last bulb. Find how many bulbs are on after n rounds.
Example:
1 2 3 4 5 6 7 8
Given _n_ = 3.
At first, the three bulbs are [off, off, off]. After first round, the three bulbs are [on, on, on]. After second round, the three bulbs are [on, off, on]. After third round, the three bulbs are [on, off, off].
So you should return 1, because there is only one bulb is on.
You are given coins of different denominations and a total amount of money amount. Write a function to compute the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return -1.
Given an integer array nums, return the number of range sums that lie in [lower, upper] inclusive. Range sum S(i, j) is defined as the sum of the elements in nums between indices i and j (i ≤ j), inclusive.
Note: A naive algorithm of O ( n 2) is trivial. You MUST do better than that.
Example:
1 2 3
Input: _nums_ = [-2,5,-1], _lower_ = -2, _upper_ = 2, Output: 3 Explanation: The three ranges are : [0,0], [2,2], [0,2] and their respective sums are: -2, -1, 2.
classSolution { public: intcountRangeSum(vector<int>& nums, int lower, int upper){ int res = 0; longlong sum = 0; multiset<longlong> sums; sums.insert(0); for (int i = 0; i < nums.size(); ++i) { sum += nums[i]; res += distance(sums.lower_bound(sum - upper), sums.upper_bound(sum - lower)); sums.insert(sum); } return res; } };
classSolution { public: intcountRangeSum(vector<int>& nums, int lower, int upper){ vector<long> sums(nums.size() + 1, 0); for (int i = 0; i < nums.size(); ++i) { sums[i + 1] = sums[i] + nums[i]; } returncountAndMergeSort(sums, 0, sums.size(), lower, upper); } intcountAndMergeSort(vector<long>& sums, int start, int end, int lower, int upper){ if (end - start <= 1) return0; int mid = start + (end - start) / 2; int cnt = countAndMergeSort(sums, start, mid, lower, upper) + countAndMergeSort(sums, mid, end, lower, upper); int j = mid, k = mid, t = mid; vector<int> cache(end - start, 0); for (int i = start, r = 0; i < mid; ++i, ++r) { while (k < end && sums[k] - sums[i] < lower) ++k; while (j < end && sums[j] - sums[i] <= upper) ++j; while (t < end && sums[t] < sums[i]) cache[r++] = sums[t++]; cache[r] = sums[i]; cnt += j - k; } copy(cache.begin(), cache.begin() + t - start, sums.begin() + start); return cnt; } };
Leetcode328. Odd Even Linked List
Given the head of a singly linked list, group all the nodes with odd indices together followed by the nodes with even indices, and return the reordered list.
The first node is considered odd, and the second node is even, and so on.
Note that the relative order inside both the even and odd groups should remain as it was in the input.
You must solve the problem in O(1) extra space complexity and O(n) time complexity.
Example 1:
1 2
Given 1->2->3->4->5->NULL, return 1->3->5->2->4->NULL.
Given an integer matrix, find the length of the longest increasing path.
From each cell, you can either move to four directions: left, right, up or down. You may NOT move diagonally or move outside of the boundary (i.e. wrap-around is not allowed).
Example 1:
1 2 3 4 5 6 7 8
Input: nums = [ [9,9,4], [6,6,8], [2,1,1] ] Output: 4 Explanation: The longest increasing path is [1, 2, 6, 9].
Example 2:
1 2 3 4 5 6 7 8
Input: nums = [ [3,4,5], [3,2,6], [2,2,1] ] Output: 4 Explanation: The longest increasing path is [3, 4, 5, 6]. Moving diagonally is not allowed.
classSolution { public: int dirs[4][2] = {{0, -1}, {-1, 0}, {0, 1}, {1, 0}}; int** dp; intlongestIncreasingPath(vector<vector<int>>& matrix){ if (matrix.empty() || matrix[0].empty()) return0; int res = 1, m = matrix.size(), n = matrix[0].size(); dp = (int**)malloc(sizeof(int*)*m); for(int i=0;i<m;i++){ dp[i] = (int*)malloc(sizeof(int)*n); memset(dp[i],0,n*sizeof(int)); } for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { res = max(res, dfs(matrix, i, j)); } } return res; } intdfs(vector<vector<int>>& matrix,int i,int j){ if (dp[i][j]) return dp[i][j]; int mx = 1, m = matrix.size(), n = matrix[0].size(); for(int ii=0;ii<4;ii++){ int x = i + dirs[ii][0], y = j + dirs[ii][1]; if (x < 0 || x >= m || y < 0 || y >= n || matrix[x][y] <= matrix[i][j]) continue; int len = 1 + dfs(matrix, x, y); mx = max(mx, len); } dp[i][j]=mx; return mx; } };
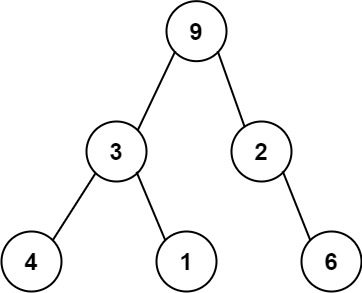
Leetcode331. Verify Preorder Serialization of a Binary Tree
One way to serialize a binary tree is to use preorder traversal. When we encounter a non-null node, we record the node’s value. If it is a null node, we record using a sentinel value such as #.
For example, the above binary tree can be serialized to the string “9,3,4,#,#,1,#,#,2,#,6,#,#“, where # represents a null node.
Given a string of comma-separated values preorder, return true if it is a correct preorder traversal serialization of a binary tree.
It is guaranteed that each comma-separated value in the string must be either an integer or a character # representing null pointer.
You may assume that the input format is always valid.
For example, it could never contain two consecutive commas, such as “1,,3”. Note: You are not allowed to reconstruct the tree.
classSolution { public: boolisValidSerialization(string preorder){ int len = preorder.length(); int i = 0, cnt = 0; while(i < len-1) { if (preorder[i] == '#') { if (cnt == 0) returnfalse; cnt --; i ++; } else { for(; i < len && preorder[i] != ','; i ++) ; cnt ++; } i ++; } return cnt == 0 && preorder[len-1] == '#'; } };
Leetcode334. Increasing Triplet Subsequence
Given an integer array nums, return true if there exists a triple of indices (i, j, k) such that i < j < k and nums[i] < nums[j] < nums[k]. If no such indices exists, return false.
Example 1:
1 2 3
Input: nums = [1,2,3,4,5] Output: true Explanation: Any triplet where i < j < k is valid.
Example 2:
1 2 3
Input: nums = [5,4,3,2,1] Output: false Explanation: No triplet exists.
Example 3:
1 2 3
Input: nums = [2,1,5,0,4,6] Output: true Explanation: The triplet (3, 4, 5) is valid because nums[3] == 0 < nums[4] == 4 < nums[5] == 6.
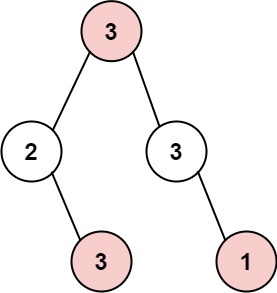
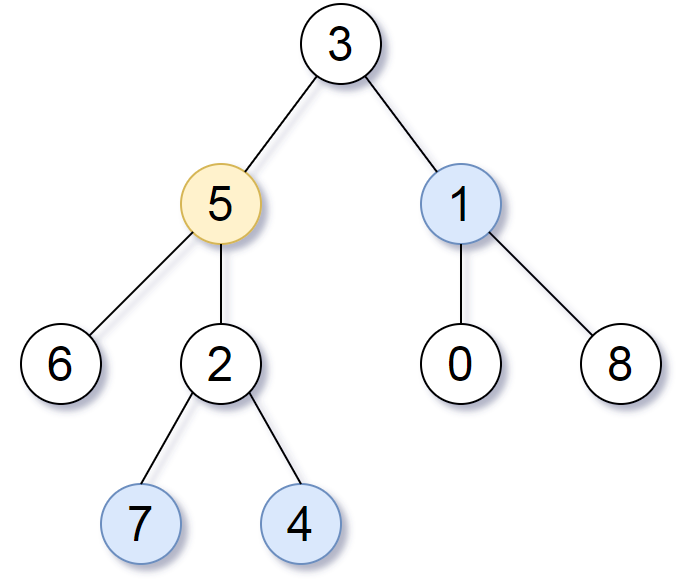
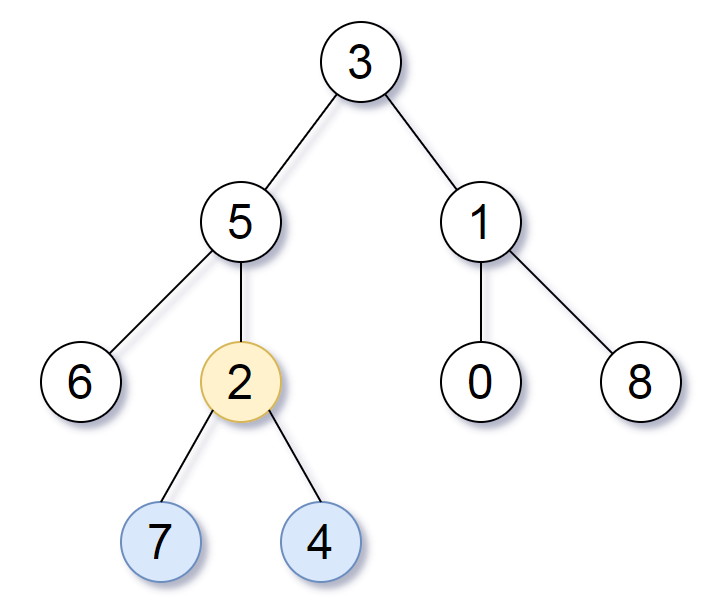
The thief has found himself a new place for his thievery again. There is only one entrance to this area, called root.
Besides the root, each house has one and only one parent house. After a tour, the smart thief realized that all houses in this place form a binary tree. It will automatically contact the police if two directly-linked houses were broken into on the same night.
Given the root of the binary tree, return the maximum amount of money the thief can rob without alerting the police.
Example 1:
1 2 3
Input: root = [3,2,3,null,3,null,1] Output: 7 Explanation: Maximum amount of money the thief can rob = 3 + 3 + 1 = 7.
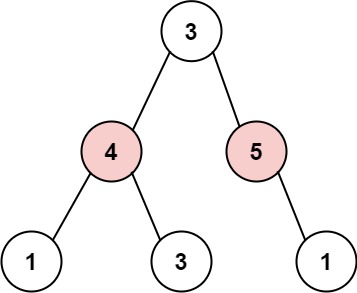
Example 2:
1 2 3
Input: root = [3,4,5,1,3,null,1] Output: 9 Explanation: Maximum amount of money the thief can rob = 4 + 5 = 9.
这道题是之前那两道 House Robber II 和 House Robber 的拓展,这个小偷又偷出新花样了,沿着二叉树开始偷,碉堡了,题目中给的例子看似好像是要每隔一个偷一次,但实际上不一定只隔一个,比如如下这个例子:
下面这种解法思路和解法二有些类似。这里的 helper 函数返回当前结点为根结点的最大 rob 的钱数,里面的两个参数l和r表示分别从左子结点和右子结点开始 rob,分别能获得的最大钱数。在递归函数里面,如果当前结点不存在,直接返回0。否则对左右子结点分别调用递归函数,得到l和r。另外还得到四个变量,ll和lr表示左子结点的左右子结点的最大 rob 钱数,rl 和 rr 表示右子结点的最大 rob 钱数。那么最后返回的值其实是两部分的值比较,其中一部分的值是当前的结点值加上 ll, lr, rl, 和 rr 这四个值,这不难理解,因为抢了当前的房屋,则左右两个子结点就不能再抢了,但是再下一层的四个子结点都是可以抢的;另一部分是不抢当前房屋,而是抢其左右两个子结点,即 l+r 的值,返回两个部分的值中的较大值即可,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution { public: introb(TreeNode* root){ int l = 0, r = 0; returnhelper(root, l, r); } inthelper(TreeNode* node, int& l, int& r){ if (!node) return0; int ll = 0, lr = 0, rl = 0, rr = 0; l = helper(node->left, ll, lr); r = helper(node->right, rl, rr); returnmax(node->val + ll + lr + rl + rr, l + r); } };
Leetcode338. Counting Bits
Given a non negative integer number num. For every numbers i in the range 0 ≤ i ≤ num calculate the number of 1’s in their binary representation and return them as an array.
Example 1:
1 2
Input: 2 Output: [0,1,1]
Example 2:
1 2
Input: 5 Output: [0,1,1,2,1,2]
Follow up: It is very easy to come up with a solution with run time O(n*sizeof(integer)). But can you do it in linear time O(n) /possibly in a single pass? Space complexity should be O(n). Can you do it like a boss? Do it without using any builtin function like __builtin_popcount in c++ or in any other language.
Given a nested list of integers, return the sum of all integers in the list weighted by their depth. Each element is either an integer, or a list – whose elements may also be integers or other lists.
Example 1:
1 2 3
Input: [[1,1],2,[1,1]] Output: 10 Explanation: Four 1's at depth 2, one 2 at depth 1.
Example 2:
1 2 3
Input: [1,[4,[6]]] Output: 27 Explanation: One 1 at depth 1, one 4 at depth 2, and one 6 at depth 3; 1 + 4*2 + 6*3 = 27.
classSolution { public: intdepthSum(vector<NestedInteger>& nestedList){ int res = 0; for (auto a : nestedList) { res += getSum(a, 1); } return res; } intgetSum(NestedInteger ni, int level){ int res = 0; if (ni.isInteger()) return level * ni.getInteger(); for (auto a : ni.getList()) { res += getSum(a, level + 1); } return res; } };
下面这种方法是网上比较流行的一种解法,思路很巧妙,首先根据 Power of Two 中的解法,我们知道 num & (num - 1) 可以用来判断一个数是否为2的次方数,更进一步说,就是二进制表示下,只有最高位是1,那么由于是2的次方数,不一定是4的次方数,比如8,所以我们还要其他的限定条件,我们仔细观察可以发现,4的次方数的最高位的1都是奇数位,那么我们只需与上一个数 (0x55555555) <==> 1010101010101010101010101010101,如果得到的数还是其本身,则可以肯定其为4的次方数:
那么通过观察上面的规律,我们可以看出从5开始,数字都需要先拆出所有的3,一直拆到剩下一个数为2或者4,因为剩4就不用再拆了,拆成两个2和不拆没有意义,而且4不能拆出一个3剩一个1,这样会比拆成 2+2 的乘积小。这样我们就可以写代码了,先预处理n为2和3的情况,然后先将结果 res 初始化为1,然后当n大于4开始循环,结果 res 自乘3,n自减3,根据之前的分析,当跳出循环时,n只能是2或者4,再乘以 res 返回即可:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution { public: intintegerBreak(int n){ if (n == 2 || n == 3) return n - 1; int res = 1; while (n > 4) { res *= 3; n -= 3; } return res * n; } };
直接分别算出能拆出3的个数和最后剩下的余数2或者4,然后直接相乘得到结果,参见代码如下:
1 2 3 4 5 6 7 8 9
classSolution { public: intintegerBreak(int n){ if (n == 2 || n == 3) return n - 1; if (n == 4) return4; n -= 5; return (int)pow(3, (n / 3 + 1)) * (n % 3 + 2); } };
Leetcode344. Reverse String
Write a function that reverses a string. The input string is given as an array of characters char[].
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory. You may assume all the characters consist of printable ascii characters.
You have a number of envelopes with widths and heights given as a pair of integers (w, h). One envelope can fit into another if and only if both the width and height of one envelope is greater than the width and height of the other envelope.
What is the maximum number of envelopes can you Russian doll? (put one inside other)
Example:
1
Given envelopes = [[5,4],[6,4],[6,7],[2,3]], the maximum number of envelopes you can Russian doll is 3 ([2,3] => [5,4] => [6,7]).
classSolution { public: intmaxEnvelopes(vector<pair<int, int>>& envelopes){ int res = 0, n = envelopes.size(); vector<int> dp(n, 1); sort(envelopes.begin(), envelopes.end()); for (int i = 0; i < n; ++i) { for (int j = 0; j < i; ++j) { if (envelopes[i].first > envelopes[j].first && envelopes[i].second > envelopes[j].second) { dp[i] = max(dp[i], dp[j] + 1); } } res = max(res, dp[i]); } return res; } };
Leetcode355. Design Twitter
Design a simplified version of Twitter where users can post tweets, follow/unfollow another user and is able to see the 10 most recent tweets in the user’s news feed. Your design should support the following methods:
postTweet(userId, tweetId) : Compose a new tweet.
getNewsFeed(userId) : Retrieve the 10 most recent tweet ids in the user’s news feed. Each item in the news feed must be posted by users who the user followed or by the user herself. Tweets must be ordered from most recent to least recent.
follow(followerId, followeeId) : Follower follows a followee.
unfollow(followerId, followeeId) : Follower unfollows a followee.
// User 1 posts a new tweet (id = 5). twitter.postTweet(1, 5);
// User 1's news feed should return a list with 1 tweet id -> [5]. twitter.getNewsFeed(1);
// User 1 follows user 2. twitter.follow(1, 2);
// User 2 posts a new tweet (id = 6). twitter.postTweet(2, 6);
// User 1's news feed should return a list with 2 tweet ids -> [6, 5]. // Tweet id 6 should precede tweet id 5 because it is posted after tweet id 5. twitter.getNewsFeed(1);
// User 1 unfollows user 2. twitter.unfollow(1, 2);
// User 1's news feed should return a list with 1 tweet id -> [5], // since user 1 is no longer following user 2. twitter.getNewsFeed(1);
classSolution { public: intcountNumbersWithUniqueDigits(int n){ if (n == 0) return1; int res = 10; for (int i = 2; i <= n; i ++) { int idx = 9; int mul = 9; int count = i; while(count > 1) { mul *= idx; idx --; count --; } res += mul; } return res; } };
Leetcode359. Logger Rate Limiter
Design a logger system that receive stream of messages along with its timestamps, each message should be printed if and only if it is not printed in the last 10 seconds.
Given a message and a timestamp (in seconds granularity), return true if the message should be printed in the given timestamp, otherwise returns false.
It is possible that several messages arrive roughly at the same time.
classSolution { public: boolisPerfectSquare(int num){ if(num == 1) return1; for(int i = 1; i <= num/i; i ++) { if(i * i == num) returntrue; } returnfalse; } };
Leetcode368. Largest Divisible Subset
Given a set of distinct positive integers, find the largest subset such that every pair (S i, Sj) of elements in this subset satisfies: Si % Sj = 0 or Sj % Si = 0.
If there are multiple solutions, return any subset is fine.
classSolution { public: intsuperPow(int a, vector<int>& b){ longlong res = 1; for (int i = 0; i < b.size(); ++i) { res = pow(res, 10) * pow(a, b[i]) % 1337; } return res; } intpow(int x, int n){ if (n == 0) return1; if (n == 1) return x % 1337; returnpow(x % 1337, n / 2) * pow(x % 1337, n - n / 2) % 1337; } };
Leetcode373. Find K Pairs with Smallest Sums
You are given two integer arrays nums1 and nums2 sorted in ascending order and an integer k.
Define a pair (u, v) which consists of one element from the first array and one element from the second array.
Return the k pairs (u1, v1), (u2, v2), …, (uk, vk) with the smallest sums.
Example 1:
1 2 3
Input: nums1 = [1,7,11], nums2 = [2,4,6], k = 3 Output: [[1,2],[1,4],[1,6]] Explanation: The first 3 pairs are returned from the sequence: [1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]
Example 2:
1 2 3
Input: nums1 = [1,1,2], nums2 = [1,2,3], k = 2 Output: [[1,1],[1,1]] Explanation: The first 2 pairs are returned from the sequence: [1,1],[1,1],[1,2],[2,1],[1,2],[2,2],[1,3],[1,3],[2,3]
Example 3:
1 2 3
Input: nums1 = [1,2], nums2 = [3], k = 3 Output: [[1,3],[2,3]] Explanation: All possible pairs are returned from the sequence: [1,3],[2,3]
Constraints:
1 <= nums1.length, nums2.length <= 104
-109 <= nums1[i], nums2[i] <= 109
nums1 and nums2 both are sorted in ascending order.
1 <= k <= 1000
这道题给了我们两个数组,让从每个数组中任意取出一个数字来组成不同的数字对,返回前K个和最小的数字对。那么这道题有多种解法,首先来看 brute force 的解法,这种方法从0循环到数组的个数和k之间的较小值,这样做的好处是如果k远小于数组个数时,不需要计算所有的数字对,而是最多计算 k*k 个数字对,然后将其都保存在 res 里,这时候给 res 排序,用自定义的比较器,就是和的比较,然后把比k多出的数字对删掉即可,参见代码如下:
We are playing the Guess Game. The game is as follows:
I pick a number from 1 to n. You have to guess which number I picked.
Every time you guess wrong, I’ll tell you whether the number is higher or lower.
You call a pre-defined API guess(int num) which returns 3 possible results (-1, 1, or 0):
-1 : My number is lower
1 : My number is higher
0 : Congrats! You got it!
Example :
1 2
Input: n = 10, pick = 6 Output: 6
二分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: intguessNumber(int n){ int l = 0, r = n, mid; while(l <= r) { mid = l + (r - l) / 2; if(guess(mid) < 0) r = mid - 1; elseif(guess(mid) > 0) l = mid + 1; elseif(0 == guess(mid)) return mid; } return-1; } };
Leetcode375. Guess Number Higher or Lower II
We are playing the Guessing Game. The game will work as follows:
I pick a number between 1 and n.
You guess a number.
If you guess the right number, you win the game.
If you guess the wrong number, then I will tell you whether the number I picked is higher or lower, and you will continue guessing.
Every time you guess a wrong number x, you will pay x dollars. If you run out of money, you lose the game. Given a particular n, return the minimum amount of money you need to guarantee a win regardless of what number I pick.
Example 1:
1 2
Input: n = 10 Output: 16
Explanation: The winning strategy is as follows:
The range is [1,10]. Guess 7.
If this is my number, your total is $0. Otherwise, you pay $7.
If my number is higher, the range is [8,10]. Guess 9.
If this is my number, your total is $7. Otherwise, you pay $9.
If my number is higher, it must be 10. Guess 10. Your total is $7 + $9 = $16.
If my number is lower, it must be 8. Guess 8. Your total is $7 + $9 = $16.
If my number is lower, the range is [1,6]. Guess 3.
If this is my number, your total is $7. Otherwise, you pay $3.
If my number is higher, the range is [4,6]. Guess 5.
If this is my number, your total is $7 + $3 = $10. Otherwise, you pay $5.
If my number is higher, it must be 6. Guess 6. Your total is $7 + $3 + $5 = $15.
If my number is lower, it must be 4. Guess 4. Your total is $7 + $3 + $5 = $15.
If my number is lower, the range is [1,2]. Guess 1.
If this is my number, your total is $7 + $3 = $10. Otherwise, you pay $1.
If my number is higher, it must be 2. Guess 2. Your total is $7 + $3 + $1 = $11.
The worst case in all these scenarios is that you pay $16. Hence, you only need $16 to guarantee a win.
Example 2:
1 2
Input: n = 1 Output: 0
Explanation: There is only one possible number, so you can guess 1 and not have to pay anything.
Example 3:
1 2
Input: n = 2 Output: 1
Explanation: There are two possible numbers, 1 and 2.
Guess 1.
If this is my number, your total is $0. Otherwise, you pay $1.
If my number is higher, it must be 2. Guess 2. Your total is $1. The worst case is that you pay $1.
classSolution { public: intgetMoneyAmount(int n){ vector<vector<int>> dp(n+1, vector<int>(n+1, 0)); for (int i = 0; i < n + 1; i++) for (int j = 0; j < n + 1; j++) if (i != j) dp[i][j] = INT_MAX; for (int i = 1; i < n; i ++) dp[i][i+1] = i; for(int i = 2; i <= n; i ++) { for (int j = i-1; j >= 1; j --) { int local, minn = INT_MAX; for (int k = j+1; k < i; k ++) { local = max(dp[j][k-1], dp[k+1][i]) + k; minn = min(minn, local); } dp[j][i] = min(minn, dp[j][i]); } } return dp[1][n]; } };
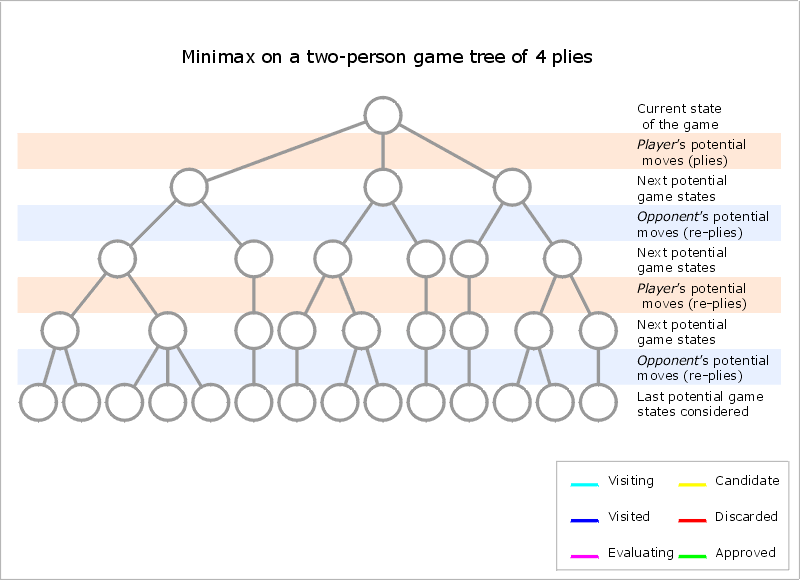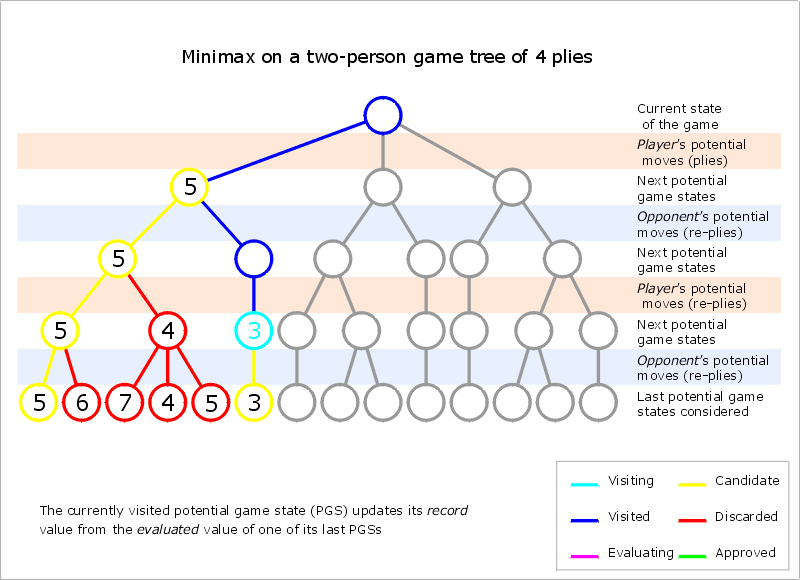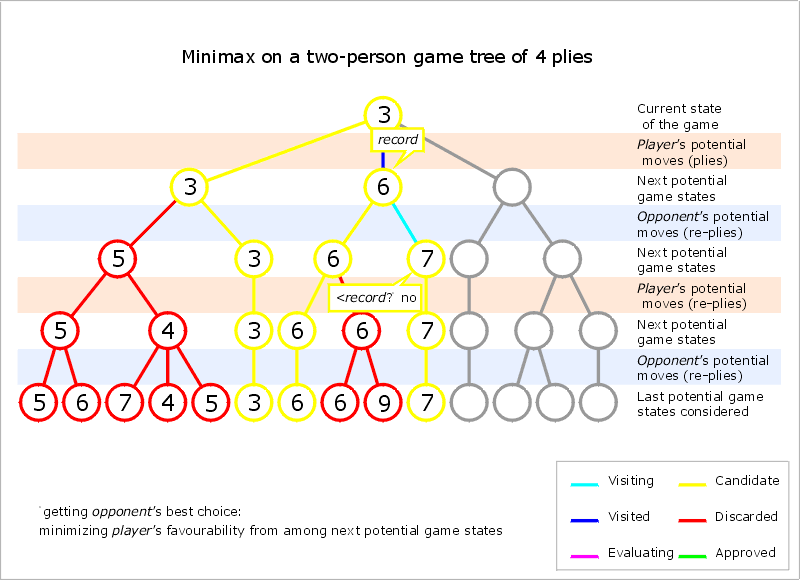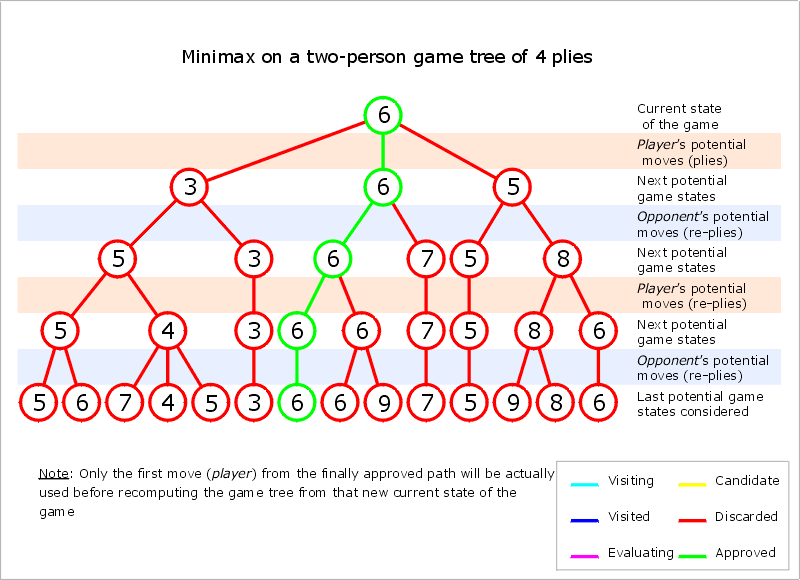
/** * 以'x'的角度来考虑的极小极大算法 */ publicintminimax( char [] board, int depth){ int [] bestMoves = newint [9]; intindex=0; intbestValue= - INFINITY ; for ( int pos=0; pos<9; pos++){ if (board[pos]== empty ){ board[pos] = x ; intvalue= min(board, depth, - INFINITY , + INFINITY ); if (value>bestValue){ bestValue = value; index = 0; bestMoves[index] = pos; } elseif (value==bestValue){ index++; bestMoves[index] = pos; } board[pos] = empty ; } } if (index>1){ index = ( newRandom (System. currentTimeMillis ()).nextInt()>>>1)%index; } return bestMoves[index]; } /** * 对于'x',估值越大对其越有利 */ publicintmax( char [] board, int depth, int alpha, int beta){ intevalValue= gameState (board); booleanisGameOver= (evalValue== WIN || evalValue== LOSE || evalValue== DRAW ); if (beta<=alpha){ return evalValue; } if (depth==0 || isGameOver){ return evalValue; } intbestValue= - INFINITY ; for ( int pos=0; pos<9; pos++){ if (board[pos]== empty ){ // try board[pos] = x ; // maximixing bestValue = Math. max (bestValue, min(board, depth-1, Math. max (bestValue, alpha), beta)); // reset board[pos] = empty ; } } return evalValue; } /** * 对于'o',估值越小对其越有利 */ publicintmin( char [] board, int depth, int alpha, int beta){ intevalValue= gameState (board); booleanisGameOver= (evalValue== WIN || evalValue== LOSE || evalValue== DRAW ); if (alpha>=beta){ return evalValue; } // try if (depth==0 || isGameOver || alpha>=beta){ return evalValue; } intbestValue= + INFINITY ; for ( int pos=0; pos<9; pos++){ if (board[pos]== empty ){ // try board[pos] = o ; // minimixing bestValue = Math.min(bestValue, max(board, depth-1, alpha, Math.min(bestValue, beta))); // reset board[pos] = empty ; } } return evalValue; }
Leetcode376. Wiggle Subsequence
A wiggle sequence is a sequence where the differences between successive numbers strictly alternate between positive and negative. The first difference (if one exists) may be either positive or negative. A sequence with one element and a sequence with two non-equal elements are trivially wiggle sequences.
For example, [1, 7, 4, 9, 2, 5] is a wiggle sequence because the differences (6, -3, 5, -7, 3) alternate between positive and negative. In contrast, [1, 4, 7, 2, 5] and [1, 7, 4, 5, 5] are not wiggle sequences. The first is not because its first two differences are positive, and the second is not because its last difference is zero. A subsequence is obtained by deleting some elements (possibly zero) from the original sequence, leaving the remaining elements in their original order.
Given an integer array nums, return the length of the longest wiggle subsequence of nums.
Example 1:
1 2 3
Input: nums = [1,7,4,9,2,5] Output: 6 Explanation: The entire sequence is a wiggle sequence with differences (6, -3, 5, -7, 3).
Example 2:
1 2 3 4
Input: nums = [1,17,5,10,13,15,10,5,16,8] Output: 7 Explanation: There are several subsequences that achieve this length. One is [1, 17, 10, 13, 10, 16, 8] with differences (16, -7, 3, -3, 6, -8).
classSolution { public: intwiggleMaxLength(vector<int>& nums){ if(nums.size() < 2) return nums.size(); int dir = 0, res = 1; for (int i = 1; i < nums.size(); i ++) { if(nums[i] > nums[i-1]) { if (dir == 0 || dir == -1) { res ++; dir = 1; } } elseif (nums[i] < nums[i-1]) { if (dir == 0 || dir == 1) { res ++; dir = -1; } } } return res; } };
classSolution { public: intwiggleMaxLength(vector<int>& nums){ int len = nums.size(); if(len < 2) return len; vector<vector<int> > dp(len+1, vector<int>(2, 0)); dp[0][0] = 1; dp[0][1] = 1; for (int i = 1; i < len; i ++) { int a = INT_MIN; int b = INT_MIN; for (int k = i-1; k >= 0; k --) { if (nums[i] > nums[k]) a = max(a, dp[k][0]); if (nums[i] < nums[k]) b = max(b, dp[k][1]); } dp[i][1] = a > INT_MIN ? a+1 : 1; dp[i][0] = b > INT_MIN ? b+1 : 1; } returnmax(dp[len-1][0], dp[len-1][1]); } };
Leetcode377. Combination Sum IV
Given an array of distinct integers nums and a target integer target, return the number of possible combinations that add up to target.
The answer is guaranteed to fit in a 32-bit integer.
Leetcode378. Kth Smallest Element in a Sorted Matrix
Given an n x n matrix where each of the rows and columns are sorted in ascending order, return the kth smallest element in the matrix.
Note that it is the kth smallest element in the sorted order, not the kth distinct element.
Example 1:
1 2 3
Input: matrix = [[1,5,9],[10,11,13],[12,13,15]], k = 8 Output: 13 Explanation: The elements in the matrix are [1,5,9,10,11,12,13,13,15], and the 8th smallest number is 13
intkthSmallest(vector<vector<int>>& matrix, int k){ int len = matrix.size(); int left = matrix[0][0], right = matrix[len-1][len-1]; while(left <= right) { int middle = left + (right - left) / 2; if (count(matrix, middle, len) >= k) right = middle - 1; else left = middle + 1; } return left; }
privateintcountSmallerOrEqual(int[][] matrix, int middle, int n){ int i = n - 1; int j = 0; int num = 0; while(i>=0 && j<n){ if(matrix[i][j]<=middle){ num += i+1; j++; }else{ i--; } } return num; }
privateintcountSmallerOrEqual(int[][] matrix, int middle, int n){ int num = 0; for(int i = 0;i<n;i++){ int l = 0, r = n-1; while(l<=r){ int m = l + ((r-l)>>1); if(matrix[i][m]>middle){ r = m - 1; }else{ l = m + 1; } } if(l>=0){ num += l; } } return num; }
Leetcode382. Linked List Random Node
Given a singly linked list, return a random node’s value from the linked list. Each node must have the same probability of being chosen.
Solution solution = new Solution([1, 2, 3]); solution.getRandom(); // return 1 solution.getRandom(); // return 3 solution.getRandom(); // return 2 solution.getRandom(); // return 2 solution.getRandom(); // return 3 // getRandom() should return either 1, 2, or 3 randomly. Each element should have equal probability of returning.
Given an arbitrary ransom note string and another string containing letters from all the magazines, write a function that will return true if the ransom note can be constructed from the magazines ; otherwise, it will return false.
Each letter in the magazine string can only be used once in your ransom note.
Solution solution = new Solution([1, 2, 3]); solution.shuffle(); // Shuffle the array [1,2,3] and return its result. Any permutation of [1,2,3] must be equally likely to be returned. Example: return [3, 1, 2] solution.reset(); // Resets the array back to its original configuration [1,2,3]. Return [1, 2, 3] solution.shuffle(); // Returns the random shuffling of array [1,2,3]. Example: return [1, 3, 2]
/** Resets the array to its original configuration and return it. */ vector<int> reset(){ return v; }
/** Returns a random shuffling of the array. */ vector<int> shuffle(){ vector<int> res = v; for (int i = 0; i < res.size(); ++i) { int t = i + rand() % (res.size() - i); swap(res[i], res[t]); } return res; }
Given a nested list of integers represented as a string, implement a parser to deserialize it.
Each element is either an integer, or a list – whose elements may also be integers or other lists.
Note: You may assume that the string is well-formed:
String is non-empty.
String does not contain white spaces.
String contains only digits 0-9, [, - ,, ].
Example 1:
1 2 3
Given s = "324",
You should return a NestedInteger object which contains a single integer 324.
Example 2:
1 2 3 4 5 6 7 8
Given s = "[123,[456,[789]]]",
Return a NestedInteger object containing a nested list with 2 elements: 1. An integer containing value 123. 2. A nested list containing two elements: i. An integer containing value 456. ii. A nested list with one element: a. An integer containing value 789.
这道题让我们实现一个迷你解析器用来把一个字符串解析成NestInteger类,关于这个嵌套链表类的题我们之前做过三道,Nested List Weight Sum II,Flatten Nested List Iterator,和Nested List Weight Sum。应该对这个类并不陌生了,我们可以先用递归来做,思路是,首先判断s是否为空,为空直接返回,不为空的话看首字符是否为[,不是的话说明s为一个整数,我们直接返回结果。如果首字符是[,且s长度小于等于2,说明没有内容,直接返回结果。反之如果s长度大于2,我们从i=1开始遍历,我们需要一个变量start来记录某一层的其实位置,用cnt来记录跟其实位置是否为同一深度,cnt=0表示同一深度,由于中间每段都是由逗号隔开,所以当我们判断当cnt为0,且当前字符是逗号或者已经到字符串末尾了,我们把start到当前位置之间的字符串取出来递归调用函数,把返回结果加入res中,然后start更新为i+1。如果遇到[,计数器cnt自增1,若遇到],计数器cnt自减1。参见代码如下:
解法一:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: NestedInteger deserialize(string s){ if (s.empty()) returnNestedInteger(); if (s[0] != '[') returnNestedInteger(stoi(s)); if (s.size() <= 2) returnNestedInteger(); NestedInteger res; int start = 1, cnt = 0; for (int i = 1; i < s.size(); ++i) { if (cnt == 0 && (s[i] == ',' || i == s.size() - 1)) { res.add(deserialize(s.substr(start, i - start))); start = i + 1; } elseif (s[i] == '[') ++cnt; elseif (s[i] == ']') --cnt; } return res; } };
Leetcode386. Lexicographical Numbers
Given an integer n, return all the numbers in the range [1, n] sorted in lexicographical order.
You must write an algorithm that runs in O(n) time and uses O(1) extra space.
Example 1:
1 2
Input: n = 13 Output: [1,10,11,12,13,2,3,4,5,6,7,8,9]
Example 2:
1 2
Input: n = 2 Output: [1,2]
给出一个整数 n ,将 1 到 n 的所有整数按照字典顺序排列。例:给出13,返回[1,10,11,12,13,2,3,4,5,6,7,8,9]。注意:尽量使用少的时间和空间复杂度,输入整数大小可能接近5,000,000。
classSolution { public: intfirstUniqChar(string s){ unordered_map<char, int> m; for (char c : s) ++m[c]; for (int i = 0; i < s.size(); ++i) { if(m[s[i]] == 1) return i; } return-1; } };
Leetcode389. Find the Difference
Given two strings s and t which consist of only lowercase letters. String t is generated by random shuffling string s and then add one more letter at a random position. Find the letter that was added in t.
Example:
1 2 3 4 5 6
Input: s = "abcd" t = "abcde" Output: e Explanation: 'e' is the letter that was added.
Given a string s and a string t, check if s is subsequence of t.
You may assume that there is only lower case English letters in both s and t. t is potentially a very long (length ~= 500,000) string, and s is a short string (<=100).
A subsequence of a string is a new string which is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (ie, “ace” is a subsequence of “abcde” while “aec” is not).
Example 1:
1 2
s = "abc", t = "ahbgdc" Return true.
Example 2:
1 2
s = "axc", t = "ahbgdc" Return false.
Follow up: If there are lots of incoming S, say S1, S2, … , Sk where k >= 1B, and you want to check one by one to see if T has its subsequence. In this scenario, how would you change your code?
A character in UTF8 can be from 1 to 4 bytes long, subjected to the following rules:
For 1-byte character, the first bit is a 0, followed by its unicode code. For n-bytes character, the first n-bits are all one’s, the n+1 bit is 0, followed by n-1 bytes with most significant 2 bits being 10. This is how the UTF-8 encoding would work:
Given an array of integers representing the data, return whether it is a valid utf-8 encoding.
Note: The input is an array of integers. Only the least significant 8 bits of each integer is used to store the data. This means each integer represents only 1 byte of data.
Example 1: data = [197, 130, 1], which represents the octet sequence: 11000101 10000010 00000001. Return true.It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
Example 2: data = [235, 140, 4], which represented the octet sequence: 11101011 10001100 00000100. Return false. The first 3 bits are all one’s and the 4th bit is 0 means it is a 3-bytes character. The next byte is a continuation byte which starts with 10 and that’s correct. But the second continuation byte does not start with 10, so it is invalid.
Given an encoded string, return its decoded string.
The encoding rule is: k[encoded_string], where the encoded_string inside the square brackets is being repeated exactly k times. Note that k is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc.
Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, k. For example, there will not be input like 3a or 2[4].
Example 1:
1 2
Input: s = "3[a]2[bc]" Output: "aaabcbc"
Example 2:
1 2
Input: s = "3[a2[c]]" Output: "accaccacc"
Example 3:
1 2
Input: s = "2[abc]3[cd]ef" Output: "abcabccdcdcdef"
classSolution { public: boolis_digit(char c){ return'0' <= c && c <= '9'; } boolis_char(char c){ return'a' <= c && c <= 'z'; } string decodeString(string s){ stack<int> st1; stack<string> st2; int len = s.length(); for (int i = 0; i < len;) { if (is_digit(s[i])) { int t = 0; while(i < len && is_digit(s[i])) t = t*10 + s[i++] - '0'; st1.push(t); } elseif (s[i] == '[') { int t = 0; i ++; while(i+t < len && is_char(s[i+t])) { t ++; } st2.push(s.substr(i, t)); i += t; } elseif (s[i] == ']') { string temp; int t = st1.top(); st1.pop(); string te = st2.top(); st2.pop(); while(t--) temp = temp + te; if (!st2.empty()) {te = st2.top(); st2.pop();st2.push(te + temp);} else st2.push(temp); i ++; } else { string te; int t = 0; while(i+t < len && is_char(s[i+t])) { t ++; } if (!st2.empty()) {te = st2.top(); st2.pop();st2.push(te + s.substr(i, t));} else st2.push(s.substr(i, t)); i += t; } } return st2.top(); } };
Leetcode395. Longest Substring with At Least K Repeating Characters
Find the length of the longest substring T of a given string (consists of lowercase letters only) such that every character in T appears no less than k times.
Example 1:
1 2 3 4 5 6 7
Input: s = "aaabb", k = 3
Output: 3
The longest substring is "aaa", as 'a' is repeated 3 times.
Example 2:
1 2 3 4 5 6 7
Input: s = "ababbc", k = 2
Output: 5
The longest substring is "ababb", as 'a' is repeated 2 times and 'b' is repeated 3 times.
classSolution { public: intlongestSubstring(string s, int k){ int res = 0, n = s.size(); for (int cnt = 1; cnt <= 26; ++cnt) { int start = 0, i = 0, uniqueCnt = 0; vector<int> charCnt(26); while (i < n) { bool valid = true; if (charCnt[s[i++] - 'a']++ == 0) ++uniqueCnt; while (uniqueCnt > cnt) { if (--charCnt[s[start++] - 'a'] == 0) --uniqueCnt; } for (int j = 0; j < 26; ++j) { if (charCnt[j] > 0 && charCnt[j] < k) valid = false; } if (valid) res = max(res, i - start); } } return res; } };
下面这种解法用的分治法 Divide and Conquer 的思想,看起来简洁了不少,但是个人感觉比较难想,这里使用了一个变量 max_idx,是用来分割子串的,实现开始统计好了字符串s的每个字母出现的次数,然后再次遍历每个字母,若当前字母的出现次数小于k了,则从开头到前一个字母的范围内的子串可能是满足题意的,还需要对前面的子串进一步调用递归,用返回值来更新当前结果 res,此时变量 ok 标记为 false,表示当前整个字符串s是不符合题意的,因为有字母出现次数小于k,此时 max_idx 更新为 i+1,表示再从新的位置开始找下一个出现次数小于k的字母的位置,可以对新的范围的子串继续调用递归。当 for 循环结束后,若 ok 是 true,说明整个s串都是符合题意的,直接返回n,否则要对 [max_idx, n-1] 范围内的子串再次调用递归,因为这个区间的子串也可能是符合题意的,还是用返回值跟结果 res 比较,谁大就返回谁,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: intlongestSubstring(string s, int k){ int n = s.size(), max_idx = 0, res = 0; int m[128] = {0}; bool ok = true; for (char c : s) ++m[c]; for (int i = 0; i < n; ++i) { if (m[s[i]] < k) { res = max(res, longestSubstring(s.substr(max_idx, i - max_idx), k)); ok = false; max_idx = i + 1; } } return ok ? n : max(res, longestSubstring(s.substr(max_idx, n - max_idx), k)); } };
Leetcode397. Integer Replacement
Given a positive integer n and you can do operations as follow:
If n is even, replace n with n /2.
If n is odd, you can replace n with either n + 1 or n - 1.
What is the minimum number of replacements needed for n to become 1?
Given an integer array nums with possible duplicates, randomly output the index of a given target number. You can assume that the given target number must exist in the array.
Implement the Solution class:
Solution(int[] nums) Initializes the object with the array nums.
int pick(int target) Picks a random index i from nums where nums[i] == target. If there are multiple valid i’s, then each index should have an equal probability of returning.
Solution solution = new Solution([1, 2, 3, 3, 3]); solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning. solution.pick(1); // It should return 0. Since in the array only nums[0] is equal to 1. solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
这道题指明了我们不能用太多的空间,那么省空间的随机方法只有水塘抽样Reservoir Sampling了,LeetCode之前有过两道需要用这种方法的题目Shuffle an Array和Linked List Random Node。那么如果了解了水塘抽样,这道题就不算一道难题了,我们定义两个变量,计数器cnt和返回结果res,我们遍历整个数组,如果数组的值不等于target,直接跳过;如果等于target,计数器加1,然后我们在[0,cnt)范围内随机生成一个数字,如果这个数字是0,我们将res赋值为i即可,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: Solution(vector<int> nums): v(nums) {} intpick(int target){ int cnt = 0, res = -1; for (int i = 0; i < v.size(); ++i) { if (v[i] != target) continue; ++cnt; if (rand() % cnt == 0) res = i; } return res; } private: vector<int> v; };
Leetcode399. Evaluate Division
You are given an array of variable pairs equations and an array of real numbers values, where equations[i] = [Ai, Bi] and values[i] represent the equation Ai / Bi = values[i]. Each Ai or Bi is a string that represents a single variable.
You are also given some queries, where queries[j] = [Cj, Dj] represents the jth query where you must find the answer for Cj / Dj = ?.
Return the answers to all queries. If a single answer cannot be determined, return -1.0.
Note: The input is always valid. You may assume that evaluating the queries will not result in division by zero and that there is no contradiction.
Example 1:
1 2 3 4 5 6
Input: equations = [["a","b"],["b","c"]], values = [2.0,3.0], queries = [["a","c"],["b","a"],["a","e"],["a","a"],["x","x"]] Output: [6.00000,0.50000,-1.00000,1.00000,-1.00000] Explanation: Given: a / b = 2.0, b / c = 3.0 queries are: a / c = ?, b / a = ?, a / e = ?, a / a = ?, x / x = ? return: [6.0, 0.5, -1.0, 1.0, -1.0 ]
Leetcode1502. Can Make Arithmetic Progression From Sequence
Given an array of numbers arr. A sequence of numbers is called an arithmetic progression if the difference between any two consecutive elements is the same.
Return true if the array can be rearranged to form an arithmetic progression, otherwise, return false.
Example 1:
1 2 3
Input: arr = [3,5,1] Output: true Explanation: We can reorder the elements as [1,3,5] or [5,3,1] with differences 2 and -2 respectively, between each consecutive elements.
Example 2:
1 2 3
Input: arr = [1,2,4] Output: false Explanation: There is no way to reorder the elements to obtain an arithmetic progression.
判断是否可以组成等差数列,将数组排序后,比较两两数字差是否一致。
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: boolcanMakeArithmeticProgression(vector<int>& arr){ sort(arr.begin(), arr.end()); int cha = arr[1] - arr[0]; for(int i = 2; i < arr.size(); i ++) if(arr[i] - arr[i-1] != cha) returnfalse; returntrue; } };
Leetcode1507. Reformat Date
Given a date string in the form Day Month Year, where:
Day is in the set {“1st”, “2nd”, “3rd”, “4th”, …, “30th”, “31st”}.
Month is in the set {“Jan”, “Feb”, “Mar”, “Apr”, “May”, “Jun”, “Jul”, “Aug”, “Sep”, “Oct”, “Nov”, “Dec”}.
Year is in the range [1900, 2100].
Convert the date string to the format YYYY-MM-DD, where:
YYYY denotes the 4 digit year.
MM denotes the 2 digit month.
DD denotes the 2 digit day.
Example 1:
1 2
Input: date = "20th Oct 2052" Output: "2052-10-20"
classSolution { public: string reformatDate(string date){ string res; int count = 0; int day, month, year; vector<string> mon{"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"}; for(int i = 0; i < date.length();) { if(date[i] == ' ') { count ++; i ++; } elseif(count == 0) { day = 0; while('0' <= date[i] && date[i] <= '9') { day = day * 10 + (date[i] - '0'); i ++; } i += 2; } elseif(count == 1) { string months = ""; int ii; while(date[i] != ' ') months += date[i ++]; for(ii = 0; ii < mon.size(); ii ++) if(months == mon[ii]) break; month = ii + 1; } elseif(count == 2) { year = 0; while('0' <= date[i] && date[i] <= '9') { year = year * 10 + (date[i] - '0'); i ++; } } } res = to_string(year) + "-" + (month >= 10 ? "" : "0") + to_string(month) + "-" + (day >= 10 ? "" : "0") + to_string(day); return res; } };
Leetcode1512. Number of Good Pairs
Given an array of integers nums. A pair (i,j) is called good if nums[i] == nums[j] and i < j. Return the number of good pairs.
Example 1:
1 2 3
Input: nums = [1,2,3,1,1,3] Output: 4 Explanation: There are 4 good pairs (0,3), (0,4), (3,4), (2,5) 0-indexed.
Example 2:
1 2 3
Input: nums = [1,1,1,1] Output: 6 Explanation: Each pair in the array are good.
遍历一遍即可。
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: intnumIdenticalPairs(vector<int>& nums){ int res = 0; for(int i = 0; i < nums.size(); i ++) for(int j = i + 1; j < nums.size(); j ++) if(nums[i] == nums[j]) res ++; return res; } };
Leetcode1530. Number of Good Leaf Nodes Pairs
You are given the root of a binary tree and an integer distance. A pair of two different leaf nodes of a binary tree is said to be good if the length of the shortest path between them is less than or equal to distance.
Return the number of good leaf node pairs in the tree.
Example 1:
1 2 3
Input: root = [1,2,3,null,4], distance = 3 Output: 1 Explanation: The leaf nodes of the tree are 3 and 4 and the length of the shortest path between them is 3. This is the only good pair.
Example 2:
1 2 3
Input: root = [1,2,3,4,5,6,7], distance = 3 Output: 2 Explanation: The good pairs are [4,5] and [6,7] with shortest path = 2. The pair [4,6] is not good because the length of ther shortest path between them is 4.
Example 3:
1 2 3
Input: root = [7,1,4,6,null,5,3,null,null,null,null,null,2], distance = 3 Output: 1 Explanation: The only good pair is [2,5].
Constraints:
The number of nodes in the tree is in the range [1, 210].
classSolution { public: int ret; int d; vector<int> dfs(TreeNode* node){ vector<int> cnt(d); if (!node) return cnt; vector<int> lcnt = dfs(node->left); vector<int> rcnt = dfs(node->right); for (int s = 0; s <= d-2; s ++) for (int t = 0; t <= d-2; t ++) { if (s + t + 2 > d) continue; ret += lcnt[s] * rcnt[t]; } for (int i = 0; i < d-1; i ++) cnt[i+1] = lcnt[i] + rcnt[i]; if (!node->left && !node->right) cnt[0] = 1; return cnt; } intcountPairs(TreeNode* root, int distance){ ret = 0; d = distance; dfs(root); return ret; } };
classSolution { public: intmaximumWealth(vector<vector<int>>& accounts){ int res = 0; for (auto& account : accounts) { int sum = 0; for (int i : account) sum += i; res = max(res, sum); } return res; } };
Leetcode1403. Minimum Subsequence in Non-Increasing Order
Given the array nums, obtain a subsequence of the array whose sum of elements is strictly greater than the sum of the non included elements in such subsequence.
If there are multiple solutions, return the subsequence with minimum size and if there still exist multiple solutions, return the subsequence with the maximum total sum of all its elements. A subsequence of an array can be obtained by erasing some (possibly zero) elements from the array.
Note that the solution with the given constraints is guaranteed to be unique. Also return the answer sorted in non-increasing order.
Example 1:
1 2 3
Input: nums = [4,3,10,9,8] Output: [10,9] Explanation: The subsequences [10,9] and [10,8] are minimal such that the sum of their elements is strictly greater than the sum of elements not included, however, the subsequence [10,9] has the maximum total sum of its elements.
classSolution { public: vector<int> minSubsequence(vector<int>& nums){ vector<int> res; sort(nums.begin(), nums.end()); int sum = 0; for(int i : nums) sum += i; sum /= 2; for(int i = nums.size()-1; i >= 0; i --) { if(sum < 0) break; sum -= nums[i]; res.push_back(nums[i]); } return res; } };
Leetcode1408. String Matching in an Array
Given an array of string words. Return all strings in words which is substring of another word in any order. String words[i] is substring of words[j], if can be obtained removing some characters to left and/or right side of words[j].
Example 1:
1 2 3 4
Input: words = ["mass","as","hero","superhero"] Output: ["as","hero"] Explanation: "as" is substring of "mass" and "hero" is substring of "superhero". ["hero","as"] is also a valid answer.
Example 2:
1 2 3
Input: words = ["leetcode","et","code"] Output: ["et","code"] Explanation: "et", "code" are substring of "leetcode".
找到字符串数组中哪些字符串是另一些字符串的子串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: staticboolcmp(string a, string b){ return a.length() < b.length(); } vector<string> stringMatching(vector<string>& words){ set<string> res; sort(words.begin(), words.end(), cmp); int len = words.size(); for(int i = 0; i < len; i ++) for(int j = i + 1; j < len; j ++) if(words[j].find(words[i]) != -1) res.insert(words[i]); returnvector<string>(res.begin(), res.end()); } };
Leetcode1413. Minimum Value to Get Positive Step by Step Sum
Given an array of integers nums, you start with an initial positive value startValue. In each iteration, you calculate the step by step sum of startValue plus elements in nums (from left to right). Return the minimum positive value of startValue such that the step by step sum is never less than 1.
Example 1:
1 2 3 4 5 6 7 8 9 10
Input: nums = [-3,2,-3,4,2] Output: 5 Explanation: If you choose startValue = 4, in the third iteration your step by step sum is less than 1. step by step sum startValue = 4 | startValue = 5 | nums (4 -3 ) = 1 | (5 -3 ) = 2 | -3 (1 +2 ) = 3 | (2 +2 ) = 4 | 2 (3 -3 ) = 0 | (4 -3 ) = 1 | -3 (0 +4 ) = 4 | (1 +4 ) = 5 | 4 (4 +2 ) = 6 | (5 +2 ) = 7 | 2
Example 2:
1 2 3
Input: nums = [1,2] Output: 1 Explanation: Minimum start value should be positive.
classSolution { public: intminStartValue(vector<int>& nums){ int minn = 99999, sum = 0; for(int i = 0; i < nums.size(); i ++) { sum += nums[i]; minn = min(minn, sum); } if(minn < 0) returnabs(minn) + 1; return1; } };
Leetcode1417. Reformat The String
Given alphanumeric string s. (Alphanumeric string is a string consisting of lowercase English letters and digits). You have to find a permutation of the string where no letter is followed by another letter and no digit is followed by another digit. That is, no two adjacent characters have the same type.
Return the reformatted string or return an empty string if it is impossible to reformat the string.
Example 1:
1 2 3
Input: s = "a0b1c2" Output: "0a1b2c" Explanation: No two adjacent characters have the same type in "0a1b2c". "a0b1c2", "0a1b2c", "0c2a1b" are also valid permutations.
Example 2:
1 2 3
Input: s = "leetcode" Output: "" Explanation: "leetcode" has only characters so we cannot separate them by digits.
string reformat(string s){ string res; vector<char> a, b; for(int i = 0; i < s.length(); i ++) { if('0' <= s[i] && s[i] <= '9') a.push_back(s[i]); else b.push_back(s[i]); } int lena = a.size(), lenb = b.size(); int abss = lena - lenb; cout<<abss<<endl; if(abs(abss) > 1) return""; int k = 0; if(lena > lenb) { k = 0; for(char c : a) { s[k] = c; k += 2; } k = 1; for(char c : b) { s[k] = c; k += 2; } } else { k = 0; for(char c : b) { s[k] = c; k += 2; } k = 1; for(char c : a) { s[k] = c; k += 2; } } return s; } };
Leetcode1418. Display Table of Food Orders in a Restaurant
Given the array orders, which represents the orders that customers have done in a restaurant. More specifically orders[i]=[customerNamei,tableNumberi,foodItemi] where customerNamei is the name of the customer, tableNumberi is the table customer sit at, and foodItemi is the item customer orders.
Return the restaurant’s “display table”. The “display table” is a table whose row entries denote how many of each food item each table ordered. The first column is the table number and the remaining columns correspond to each food item in alphabetical order. The first row should be a header whose first column is “Table”, followed by the names of the food items. Note that the customer names are not part of the table. Additionally, the rows should be sorted in numerically increasing order.
Example 1:
1 2 3 4 5 6 7 8 9 10 11
Input: orders = [["David","3","Ceviche"],["Corina","10","Beef Burrito"],["David","3","Fried Chicken"],["Carla","5","Water"],["Carla","5","Ceviche"],["Rous","3","Ceviche"]] Output: [["Table","Beef Burrito","Ceviche","Fried Chicken","Water"],["3","0","2","1","0"],["5","0","1","0","1"],["10","1","0","0","0"]] Explanation: The displaying table looks like: Table,Beef Burrito,Ceviche,Fried Chicken,Water 3 ,0 ,2 ,1 ,0 5 ,0 ,1 ,0 ,1 10 ,1 ,0 ,0 ,0 For the table 3: David orders "Ceviche" and "Fried Chicken", and Rous orders "Ceviche". For the table 5: Carla orders "Water" and "Ceviche". For the table 10: Corina orders "Beef Burrito".
for(vector<string> a : orders) { if(find(res[0].begin(), res[0].end(), a[2]) == res[0].end()) res[0].push_back(a[2]); mp[stoi(a[1])][a[2]] ++; } sort(res[0].begin(), res[0].end()); for(auto it = mp.begin(); it != mp.end(); it ++) { for(string a : res[0]) if(it->second.find(a) == it->second.end()) it->second.insert(pair<string, int>(a, 0)); } res[0].insert(res[0].begin(), "Table"); for(auto it = mp.begin(); it != mp.end(); it ++) { vector<string> temp; temp.push_back(to_string(it->first)); for(auto itt = it->second.begin(); itt != it->second.end(); itt ++) { temp.push_back(to_string(itt->second)); } res.push_back(temp); } return res; } };
Leetcode1422. Maximum Score After Splitting a String
Given a string s of zeros and ones, return the maximum score after splitting the string into two non-empty substrings (i.e. left substring and right substring).
The score after splitting a string is the number of zeros in the left substring plus the number of ones in the right substring.
Example 1:
1 2 3 4 5 6 7 8 9
Input: s = "011101" Output: 5 Explanation: All possible ways of splitting s into two non-empty substrings are: left = "0" and right = "11101", score = 1 + 4 = 5 left = "01" and right = "1101", score = 1 + 3 = 4 left = "011" and right = "101", score = 1 + 2 = 3 left = "0111" and right = "01", score = 1 + 1 = 2 left = "01110" and right = "1", score = 2 + 1 = 3
Example 2:
1 2 3
Input: s = "00111" Output: 5 Explanation: When left = "00" and right = "111", we get the maximum score = 2 + 3 = 5
classSolution { public: intmaxScore(string s){ int left = 0, right = 0, res = 0; for(int i = 0; i < s.length(); i ++) if(s[i] == '1') right ++; for(int i = 0; i < s.length()-1; i ++) { if(s[i] == '1') { res = max(res, left + right -1); right --; } else { res = max(res, left + right + 1); left ++; } } return res; } };
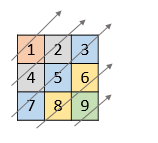
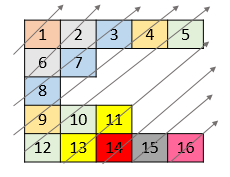
Leetcode1424. Diagonal Traverse II
Given a list of lists of integers, nums, return all elements of nums in diagonal order as shown in the below images.
Given an integer array nums and an integer k, return the maximum sum of a non-empty subsequence of that array such that for every two consecutive integers in the subsequence, nums[i] and nums[j], where i < j, the condition j - i <= k is satisfied.
A subsequence of an array is obtained by deleting some number of elements (can be zero) from the array, leaving the remaining elements in their original order.
Example 1:
1 2 3
Input: nums = [10,2,-10,5,20], k = 2 Output: 37 Explanation: The subsequence is [10, 2, 5, 20].
Example 2:
1 2 3
Input: nums = [-1,-2,-3], k = 1 Output: -1 Explanation: The subsequence must be non-empty, so we choose the largest number.
Example 3:
1 2 3
Input: nums = [10,-2,-10,-5,20], k = 2 Output: 23 Explanation: The subsequence is [10, -2, -5, 20].
classSolution { public: intconstrainedSubsetSum(vector<int>& a, int k){ // 是一个结合了滑动窗口最大值的dp // 使用滑动窗口计算最大值,再使用dp求最大值 int n = a.size(); deque<int> d; int ret = -10000; vector<int> f(n); // f[i] 是考虑前i个元素且选中第i个元素时构造的最大子序列和 for (int i = 0; i < n; i ++) { int l = i - k - 1; // 当前窗口的范围 if (!d.empty() && d.front() == l) d.pop_front(); // 先把上一个窗口的左端点踢出来 f[i] = a[i]; if (!d.empty()) f[i] = max(f[i], f[d.front()] + a[i]); while(!d.empty() && f[d.back()] <= f[i]) d.pop_back(); d.push_back(i); ret = max(ret, f[i]); } return ret; } };
Leetcode1431. Kids With the Greatest Number of Candies
Given the array candies and the integer extraCandies, where candies[i] represents the number of candies that the ith kid has. For each kid check if there is a way to distribute extraCandies among the kids such that he or she can have the greatest number of candies among them. Notice that multiple kids can have the greatest number of candies.
Example 1:
1 2 3 4 5 6 7 8
Input: candies = [2,3,5,1,3], extraCandies = 3 Output: [true,true,true,false,true] Explanation: Kid 1 has 2 candies and if he or she receives all extra candies (3) will have 5 candies --- the greatest number of candies among the kids. Kid 2 has 3 candies and if he or she receives at least 2 extra candies will have the greatest number of candies among the kids. Kid 3 has 5 candies and this is already the greatest number of candies among the kids. Kid 4 has 1 candy and even if he or she receives all extra candies will only have 4 candies. Kid 5 has 3 candies and if he or she receives at least 2 extra candies will have the greatest number of candies among the kids.
classSolution { public: vector<bool> kidsWithCandies(vector<int>& candies, int extraCandies){ vector<bool> res(candies.size(), false); int maxx = -1; for(int i = 0; i < candies.size(); i ++) if(maxx < candies[i]) maxx = candies[i]; for(int i = 0; i < candies.size(); i ++) if(candies[i] + extraCandies >= maxx) res[i] = true; return res; } };
Leetcode1436. Destination City
You are given the array paths, where paths[i] = [cityAi, cityBi] means there exists a direct path going from cityAi to cityBi. Return the destination city, that is, the city without any path outgoing to another city.
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
Example 1:
1 2 3
Input: paths = [["London","New York"],["New York","Lima"],["Lima","Sao Paulo"]] Output: "Sao Paulo" Explanation: Starting at "London" city you will reach "Sao Paulo" city which is the destination city. Your trip consist of: "London" -> "New York" -> "Lima" -> "Sao Paulo".
classSolution { public: string destCity(vector<vector<string>>& paths){ map<string, pair<int, int>> mp; for(int i = 0; i < paths.size(); i ++) { mp[paths[i][0]].first++; mp[paths[i][1]].second++; } for(auto it = mp.begin(); it != mp.end(); it ++) { if(it->second.first == 0 && it->second.second == 1) return it->first; } return""; } };
Leetcode1441. Build an Array With Stack Operations
Given an array target and an integer n. In each iteration, you will read a number from list = {1,2,3…, n}. Build the target array using the following operations:
Push: Read a new element from the beginning list, and push it in the array.
Pop: delete the last element of the array.
If the target array is already built, stop reading more elements. You are guaranteed that the target array is strictly increasing, only containing numbers between 1 to n inclusive.
Return the operations to build the target array. You are guaranteed that the answer is unique.
Example 1:
1 2 3 4 5 6
Input: target = [1,3], n = 3 Output: ["Push","Push","Pop","Push"] Explanation: Read number 1 and automatically push in the array -> [1] Read number 2 and automatically push in the array then Pop it -> [1] Read number 3 and automatically push in the array -> [1,3]
classSolution { public: intcountTriplets(vector<int>& arr){ int ret = 0; int n = arr.size(); vector<int> dp(n, 0); dp[0] = arr[0]; for (int i = 1; i < n; i ++) dp[i] = dp[i-1] ^ arr[i]; int res = 0; for (int i = 0; i < n; i ++) for (int j = i+1; j < n; j ++) { int tmp = i > 0 ? (dp[i-1] ^ dp[j]) : dp[j]; if (tmp == 0) res += (j - i); } return res; } };
Leetcode1446. Consecutive Characters
Given a string s, the power of the string is the maximum length of a non-empty substring that contains only one unique character. Return the power of the string.
Example 1:
1 2 3
Input: s = "leetcode" Output: 2 Explanation: The substring "ee" is of length 2 with the character 'e' only.
Example 2:
1 2 3
Input: s = "abbcccddddeeeeedcba" Output: 5 Explanation: The substring "eeeee" is of length 5 with the character 'e' only.
classSolution { public: intmaxPower(string s){ int count = 1; char c = s[0]; int res = -1; for(int i = 1; i < s.length(); i ++) { if(c == s[i]) { count ++; } else { res = max(res, count); c = s[i]; count = 1; } } res = max(res, count); return res; } };
Leetcode1450. Number of Students Doing Homework at a Given Time
Given two integer arrays startTime and endTime and given an integer queryTime. The ith student started doing their homework at the time startTime[i] and finished it at time endTime[i].
Return the number of students doing their homework at time queryTime. More formally, return the number of students where queryTime lays in the interval [startTime[i], endTime[i]] inclusive.
Example 1:
1 2 3 4 5 6
Input: startTime = [1,2,3], endTime = [3,2,7], queryTime = 4 Output: 1 Explanation: We have 3 students where: The first student started doing homework at time 1 and finished at time 3 and wasn't doing anything at time 4. The second student started doing homework at time 2 and finished at time 2 and also wasn't doing anything at time 4. The third student started doing homework at time 3 and finished at time 7 and was the only student doing homework at time 4.
简单题,无聊,找到在queryTime时写作业的人。
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: intbusyStudent(vector<int>& startTime, vector<int>& endTime, int queryTime){ int res = 0; for(int i = 0; i < startTime.size(); i ++) { if(startTime[i] <= queryTime && queryTime <= endTime[i]) res ++; } return res; } };
Leetcode1455. Check If a Word Occurs As a Prefix of Any Word in a Sentence
Given a sentence that consists of some words separated by a single space, and a searchWord. You have to check if searchWord is a prefix of any word in sentence. Return the index of the word in sentence where searchWord is a prefix of this word (1-indexed).
If searchWord is a prefix of more than one word, return the index of the first word (minimum index). If there is no such word return -1. A prefix of a string S is any leading contiguous substring of S.
Example 1:
1 2 3
Input: sentence = "i love eating burger", searchWord = "burg" Output: 4 Explanation: "burg" is prefix of "burger" which is the 4th word in the sentence.
Example 2:
1 2 3
Input: sentence = "this problem is an easy problem", searchWord = "pro" Output: 2 Explanation: "pro" is prefix of "problem" which is the 2nd and the 6th word in the sentence, but we return 2 as it's the minimal index.
Example 3:
1 2 3
Input: sentence = "i am tired", searchWord = "you" Output: -1 Explanation: "you" is not a prefix of any word in the sentence.
Example 4:
1 2
Input: sentence = "i use triple pillow", searchWord = "pill" Output: 4
classSolution { public: intisPrefixOfWord(string sentence, string searchWord){ int n = int(sentence.length()); int n1 = int(searchWord.length()); int res = 0; int t = 0; for(int i = 0; i < n; i ++) { if(i == 0 || sentence[i - 1] == ' ') { res ++; if(sentence[i] == searchWord[0]) { if(n1 == 1) return res; for(int j = 1; j < n1; j ++) { i++; if(sentence[i] != searchWord[j]) { t = 0; break; } else t = 1; } if(t == 1) return res; } } } return-1; } };
Leetcode1460. Make Two Arrays Equal by Reversing Sub-arrays
Given two integer arrays of equal length target and arr. In one step, you can select any non-empty sub-array of arr and reverse it. You are allowed to make any number of steps. Return True if you can make arr equal to target, or False otherwise.
Example 1:
1 2 3 4 5 6 7
Input: target = [1,2,3,4], arr = [2,4,1,3] Output: true Explanation: You can follow the next steps to convert arr to target: 1- Reverse sub-array [2,4,1], arr becomes [1,4,2,3] 2- Reverse sub-array [4,2], arr becomes [1,2,4,3] 3- Reverse sub-array [4,3], arr becomes [1,2,3,4] There are multiple ways to convert arr to target, this is not the only way to do so.
Example 2:
1 2 3
Input: target = [7], arr = [7] Output: true Explanation: arr is equal to target without any reverses.
Example 3:
1 2
Input: target = [1,12], arr = [12,1] Output: true
判断一个数组能否通过翻转子串变成另一个数组,通过统计每个数字的个数判断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution { public: boolcanBeEqual(vector<int>& target, vector<int>& arr){ vector<int> res(1001, 0); for(int i = 0; i < arr.size(); i ++) res[arr[i]] ++; for(int i = 0; i < target.size(); i ++) { res[target[i]] --; if(res[target[i]] < 0) returnfalse; } returntrue; } };
Leetcode1464. Maximum Product of Two Elements in an Array
Given the array of integers nums, you will choose two different indices i and j of that array. Return the maximum value of (nums[i]-1)*(nums[j]-1).
Example 1:
1 2 3
Input: nums = [3,4,5,2] Output: 12 Explanation: If you choose the indices i=1 and j=2 (indexed from 0), you will get the maximum value, that is, (nums[1]-1)*(nums[2]-1) = (4-1)*(5-1) = 3*4 = 12.
Example 2:
1 2 3
Input: nums = [1,5,4,5] Output: 16 Explanation: Choosing the indices i=1 and j=3 (indexed from 0), you will get the maximum value of (5-1)*(5-1) = 16.
Given the array nums consisting of 2n elements in the form [x1,x2,…,xn,y1,y2,…,yn]. Return the array in the form [x1,y1,x2,y2,…,xn,yn].
Example 1:
1 2 3
Input: nums = [2,5,1,3,4,7], n = 3 Output: [2,3,5,4,1,7] Explanation: Since x1=2, x2=5, x3=1, y1=3, y2=4, y3=7 then the answer is [2,3,5,4,1,7].
Example 2:
1 2
Input: nums = [1,2,3,4,4,3,2,1], n = 4 Output: [1,4,2,3,3,2,4,1]
转换数组。。。。
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: vector<int> shuffle(vector<int>& nums, int n){ vector<int> res; for(int i = 0; i < nums.size()/2; i ++) { res.push_back(nums[i]); res.push_back(nums[i+n]); } return res; } };
Leetcode1475. Final Prices With a Special Discount in a Shop
Given the array prices where prices[i] is the price of the ith item in a shop. There is a special discount for items in the shop, if you buy the ith item, then you will receive a discount equivalent to prices[j] where j is the minimum index such that j > i and prices[j] <= prices[i], otherwise, you will not receive any discount at all.
Return an array where the ith element is the final price you will pay for the ith item of the shop considering the special discount.
Example 1:
1 2 3 4 5 6 7
Input: prices = [8,4,6,2,3] Output: [4,2,4,2,3] Explanation: For item 0 with price[0]=8 you will receive a discount equivalent to prices[1]=4, therefore, the final price you will pay is 8 - 4 = 4. For item 1 with price[1]=4 you will receive a discount equivalent to prices[3]=2, therefore, the final price you will pay is 4 - 2 = 2. For item 2 with price[2]=6 you will receive a discount equivalent to prices[3]=2, therefore, the final price you will pay is 6 - 2 = 4. For items 3 and 4 you will not receive any discount at all.
Given an array nums. We define a running sum of an array as runningSum[i] = sum(nums[0]…nums[i]). Return the running sum of nums.
Example 1:
1 2 3
Input: nums = [1,2,3,4] Output: [1,3,6,10] Explanation: Running sum is obtained as follows: [1, 1+2, 1+2+3, 1+2+3+4].
求前缀和
1 2 3 4 5 6 7 8 9
classSolution { public: vector<int> runningSum(vector<int>& nums){ for(int i = 1; i < nums.size(); i ++) { nums[i] = nums[i] + nums[i-1]; } return nums; } };
Leetcode1486. XOR Operation in an Array
Given an integer n and an integer start. Define an array nums where nums[i] = start + 2*i (0-indexed) and n == nums.length. Return the bitwise XOR of all elements of nums.
Example 1:
1 2 3 4
Input: n = 5, start = 0 Output: 8 Explanation: Array nums is equal to [0, 2, 4, 6, 8] where (0 ^ 2 ^ 4 ^ 6 ^ 8) = 8. Where "^" corresponds to bitwise XOR operator.
求异或和。
1 2 3 4 5 6 7 8 9
classSolution { public: intxorOperation(int n, int start){ int res = start; for(int i = 1; i < n; i ++) res = res ^ (start + i * 2); return res; } };
Leetcode1491. Average Salary Excluding the Minimum and Maximum Salary
Given an array of unique integers salary where salary[i] is the salary of the employee i. Return the average salary of employees excluding the minimum and maximum salary.
Example 1:
1 2 3 4
Input: salary = [4000,3000,1000,2000] Output: 2500.00000 Explanation: Minimum salary and maximum salary are 1000 and 4000 respectively. Average salary excluding minimum and maximum salary is (2000+3000)/2= 2500
去掉最值求平均。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution { public: doubleaverage(vector<int>& salary){ int minn = 1e7, maxx = -1; for(int i = 0; i < salary.size(); i ++) { if(salary[i] > maxx) maxx = salary[i]; if(salary[i] < minn) minn = salary[i]; } int sum = 0, count = 0; for(int i = 0; i < salary.size(); i ++) if(salary[i] != minn && salary[i] != maxx) { sum += salary[i]; count ++; } return (double)sum / count; } };
Leetcode1492. The kth Factor of n
Given two positive integers n and k. A factor of an integer n is defined as an integer i where n % i == 0. Consider a list of all factors of n sorted in ascending order, return the kth factor in this list or return -1 if n has less than k factors.
Example 1:
1 2 3
Input: n = 12, k = 3 Output: 3 Explanation: Factors list is [1, 2, 3, 4, 6, 12], the 3rd factor is 3.
Example 2:
1 2 3
Input: n = 7, k = 2 Output: 7 Explanation: Factors list is [1, 7], the 2nd factor is 7.
找一个数的第k个因子,简单。评测机不稳定,我提交了三次有两次是memory战胜100%。
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: intkthFactor(int n, int k){ int res = 0; for(int i = 1; i <= n; i++){ if(n % i == 0 && --k == 0) return i; } return-1; } };
Leetcode1496. Path Crossing
Given a string path, where path[i] = ‘N’, ‘S’, ‘E’ or ‘W’, each representing moving one unit north, south, east, or west, respectively. You start at the origin (0, 0) on a 2D plane and walk on the path specified by path.
Return True if the path crosses itself at any point, that is, if at any time you are on a location you’ve previously visited. Return False otherwise.
Example 1:
1 2 3
Input: path = "NES" Output: false Explanation: Notice that the path doesn't cross any point more than once.
Given an array of integers arr, write a function that returns true if and only if the number of occurrences of each value in the array is unique.
Example 1:
1 2 3
Input: arr = [1,2,2,1,1,3] Output: true Explanation: The value 1 has 3 occurrences, 2 has 2 and 3 has 1. No two values have the same number of occurrences.
booluniqueOccurrences(vector<int>& arr){ int i; map<int, int> mp; map<int, int> mpp; map<int, int>::iterator it; for(i = 0; i < arr.size(); i ++) { mp[arr[i]] ++; } bool ans = true; for(it = mp.begin(); it != mp.end(); it ++) { if(mpp[it->second] == 1) { ans = false; break; } mpp[it->second] = 1; } return ans; } };
Leetcode1209. Remove All Adjacent Duplicates in String II
You are given a string s and an integer k, a k duplicate removal consists of choosing k adjacent and equal letters from s and removing them, causing the left and the right side of the deleted substring to concatenate together.
We repeatedly make k duplicate removals on s until we no longer can.
Return the final string after all such duplicate removals have been made. It is guaranteed that the answer is unique.
Example 1:
1 2 3
Input: s = "abcd", k = 2 Output: "abcd" Explanation: There's nothing to delete.
Example 2:
1 2 3 4 5
Input: s = "deeedbbcccbdaa", k = 3 Output: "aa" Explanation: First delete "eee" and "ccc", get "ddbbbdaa" Then delete "bbb", get "dddaa" Finally delete "ddd", get "aa"
Example 3:
1 2
Input: s = "pbbcggttciiippooaais", k = 2 Output: "ps"
Constraints:
1 <= s.length <= 105
2 <= k <= 104
s only contains lower case English letters.
这道题是之前那道 Remove All Adjacent Duplicates In String 的拓展,那道题只是让移除相邻的相同字母,而这道题让移除连续k个相同的字母,规则都一样,移除后的空位不保留,断开的位置重新连接,则有可能继续生成可以移除的连续字母。最直接暴力的解法就是多次扫描,每次都移除连续k个字母,然后剩下的字母组成新的字符串,再次进行扫描,但是这种方法现在超时了 Time Limit Exceeded,所以必须要用更加高效的解法。由于多次扫描可能会超时,所以要尽可能的在一次遍历中就完成,对于已经相邻的相同字母容易清除,断开的连续字母怎么一次处理呢?答案是在统计的过程中及时清除连续的字母,由于只能遍历一次,所以清除的操作可以采用字母覆盖的形式的,则这里可以使用双指针 Two Pointers 来操作,i指向的是清除后没有k个连续相同字母的位置,j是当前遍历原字符串的位置,这里还需要一个数组 cnt,其中 cnt[i] 表示字母 s[i] 连续出现的个数。i和j初始化均为0,开始遍历字符串s,用 s[j] 来覆盖 s[i],然后来更新 cnt[i],判断若i大于0,且 s[i - 1] 等于 s[i],说明连续字母的个数增加了一个,用 cnt[i-1] + 1 来更新 cnt[i],否则 cnt[i] 置为1。这样最终前字符串s的前i个字母就是最终移除后剩下的结果,直接返回即可,参见代码如下:
解法一:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution { public: string removeDuplicates(string s, int k){ int i = 0, n = s.size(); vector<int> cnt(n); for (int j = 0; j < n; ++j, ++i) { s[i] = s[j]; cnt[i] = (i > 0 && s[i - 1] == s[i]) ? cnt[i - 1] + 1 : 1; if (cnt[i] == k) i -= k; } return s.substr(0, i); } };
classSolution { public: string removeDuplicates(string s, int k){ string res; vector<pair<int, char>> st{{0, '#'}}; for (char c : s) { if (st.back().second != c) { st.push_back({1, c}); } elseif (++st.back().first == k) { st.pop_back(); } } for (auto &a : st) { res.append(a.first, a.second); } return res; } };
Leetcode1217. Play with Chips
There are some chips, and the i-th chip is at position chips[i].
You can perform any of the two following types of moves any number of times (possibly zero) on any chip:
Move the i-th chip by 2 units to the left or to the right with a cost of 0.
Move the i-th chip by 1 unit to the left or to the right with a cost of 1.
There can be two or more chips at the same position initially. Return the minimum cost needed to move all the chips to the same position (any position).
Example 1:
1 2 3
Input: chips = [1,2,3] Output: 1 Explanation: Second chip will be moved to positon 3 with cost 1. First chip will be moved to position 3 with cost 0. Total cost is 1.
Example 2:
1 2 3
Input: chips = [2,2,2,3,3] Output: 2 Explanation: Both fourth and fifth chip will be moved to position two with cost 1. Total minimum cost will be 2.
classSolution { public: intminCostToMoveChips(vector<int>& chips){ int odd = 0, even = 0; for(int i = 0; i < chips.size(); i ++) { if(chips[i] % 2) odd ++; else even ++; } returnmin(odd, even); } };
Leetcode1221. Split a String in Balanced Strings
Balanced strings are those who have equal quantity of ‘L’ and ‘R’ characters. Given a balanced string s split it in the maximum amount of balanced strings. Return the maximum amount of splitted balanced strings.
Example 1:
1 2 3
Input: s = "RLRRLLRLRL" Output: 4 Explanation: s can be split into "RL", "RRLL", "RL", "RL", each substring contains same number of 'L' and 'R'.
Example 2:
1 2 3
Input: s = "RLLLLRRRLR" Output: 3 Explanation: s can be split into "RL", "LLLRRR", "LR", each substring contains same number of 'L' and 'R'.
Example 3:
1 2 3
Input: s = "LLLLRRRR" Output: 1 Explanation: s can be split into "LLLLRRRR".
Example 4:
1 2 3
Input: s = "RLRRRLLRLL" Output: 2 Explanation: s can be split into "RL", "RRRLLRLL", since each substring contains an equal number of 'L' and 'R'
简单统计L和R的数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution { public: intbalancedStringSplit(string s){ int cur = 0; int len = s.length(); int l = 0, r = 0; for(int i = 0; i < len; i ++) { if(s[i] == 'L') l ++; if(s[i] == 'R') r ++; if(l == r) { l = r = 0; cur ++; } } return cur; } };
Leetcode1222. Queens That Can Attack the King
On an 8x8 chessboard, there can be multiple Black Queens and one White King.
Given an array of integer coordinates queens that represents the positions of the Black Queens, and a pair of coordinates king that represent the position of the White King, return the coordinates of all the queens (in any order) that can attack the King.
Example 1:
1 2 3 4 5 6 7 8 9
Input: queens = [[0,1],[1,0],[4,0],[0,4],[3,3],[2,4]], king = [0,0] Output: [[0,1],[1,0],[3,3]] Explanation: The queen at [0,1] can attack the king cause they're in the same row. The queen at [1,0] can attack the king cause they're in the same column. The queen at [3,3] can attack the king cause they're in the same diagnal. The queen at [0,4] can't attack the king cause it's blocked by the queen at [0,1]. The queen at [4,0] can't attack the king cause it's blocked by the queen at [1,0]. The queen at [2,4] can't attack the king cause it's not in the same row/column/diagnal as the king.
Example 2:
1 2
Input: queens = [[0,0],[1,1],[2,2],[3,4],[3,5],[4,4],[4,5]], king = [3,3] Output: [[2,2],[3,4],[4,4]]
Example 3:
1 2
Input: queens = [[5,6],[7,7],[2,1],[0,7],[1,6],[5,1],[3,7],[0,3],[4,0],[1,2],[6,3],[5,0],[0,4],[2,2],[1,1],[6,4],[5,4],[0,0],[2,6],[4,5],[5,2],[1,4],[7,5],[2,3],[0,5],[4,2],[1,0],[2,7],[0,1],[4,6],[6,1],[0,6],[4,3],[1,7]], king = [3,4] Output: [[2,3],[1,4],[1,6],[3,7],[4,3],[5,4],[4,5]]
classSolution { public: vector<vector<int>> queensAttacktheKing(vector<vector<int>>& queens, vector<int>& king) { int x = king[0], y = king[1]; vector<vector<int>> graph(8, vector<int>(8, 0)); vector<vector<int>> res; for(int i = 0; i < queens.size(); i ++) graph[queens[i][0]][queens[i][1]] = 1; int dy[8] = {0,0,-1,1,-1,1,-1,1}; int dx[8] = {-1,1,0,0,-1,-1,1,1}; int xx, yy; for(int i = 0; i < 8; i ++) { int x = king[0], y = king[1]; xx = x + dx[i]; yy = y + dy[i]; while(0 <= xx && xx <= 7 && 0 <= yy && yy <= 7) { if(graph[xx][yy] == 1) { res.push_back({xx, yy}); break; } xx = xx + dx[i]; yy = yy + dy[i]; } } return res; } };
Leetcode1227. Airplane Seat Assignment Probability
n passengers board an airplane with exactly n seats. The first passenger has lost the ticket and picks a seat randomly. But after that, the rest of passengers will:
Take their own seat if it is still available, Pick other seats randomly when they find their seat occupied What is the probability that the n-th person can get his own seat?
Example 1:
1 2 3
Input: n = 1 Output: 1.00000 Explanation: The first person can only get the first seat.
Example 2:
1 2 3
Input: n = 2 Output: 0.50000 Explanation: The second person has a probability of 0.5 to get the second seat (when first person gets the first seat).
You are given an array coordinates, coordinates[i] = [x, y], where [x, y] represents the coordinate of a point. Check if these points make a straight line in the XY plane.
classSolution { public: staticboolcmp(const vector<int>& a, const vector<int>& b){ if(a[0] > b[0]) returntrue; elseif(a[0] < b[0]) returnfalse; else if(a[1] > b[1]) returntrue; else returnfalse; } boolcheckStraightLine(vector<vector<int>>& coordinates){ sort(coordinates.begin(), coordinates.end(), cmp); int dx = coordinates[1][0] - coordinates[0][0]; int dy = coordinates[1][1] - coordinates[0][1]; if(dx == 0) { for(int i = 1; i < coordinates.size(); i ++) if(coordinates[i][0] != coordinates[0][0]) returnfalse; returntrue; } if(dy == 0) { for(int i = 1; i < coordinates.size(); i ++) if(coordinates[i][1] != coordinates[0][1]) returnfalse; returntrue; } // (y1-y0)/(x1-x0) = (yi-y0)/(xi-x0) //-> (y1-y0)*(xi-x0) = (yi-y0)*(x1-x0) auto &c0 = coordinates[0], &c1 = coordinates[1]; for(int i = 2; i < coordinates.size(); i ++) { auto &c2 = coordinates[i]; if ((c1[1] - c0[1])*(c2[0] - c0[0]) != (c2[1] - c0[1])*(c1[0] - c0[0])) returnfalse; } returntrue; } };
Leetcode1237. Find Positive Integer Solution for a Given Equation
Given a function f(x, y) and a value z, return all positive integer pairs x and y where f(x,y) == z.
The function is constantly increasing, i.e.:
1 2
f(x, y) < f(x + 1, y) f(x, y) < f(x, y + 1)
The function interface is defined like this:
1 2 3 4 5
interface CustomFunction { public: // Returns positive integer f(x, y) for any given positive integer x and y. int f(int x, int y); };
For custom testing purposes you’re given an integer function_id and a target z as input, where function_id represent one function from an secret internal list, on the examples you’ll know only two functions from the list.
You may return the solutions in any order.
Example 1:
1 2 3
Input: function_id = 1, z = 5 Output: [[1,4],[2,3],[3,2],[4,1]] Explanation: function_id = 1 means that f(x, y) = x + y
Example 2:
1 2 3
Input: function_id = 2, z = 5 Output: [[1,5],[5,1]] Explanation: function_id = 2 means that f(x, y) = x * y
/* * // This is the custom function interface. * // You should not implement it, or speculate about its implementation * class CustomFunction { * public: * // Returns f(x, y) for any given positive integers x and y. * // Note that f(x, y) is increasing with respect to both x and y. * // i.e. f(x, y) < f(x + 1, y), f(x, y) < f(x, y + 1) * int f(int x, int y); * }; */
Given n and m which are the dimensions of a matrix initialized by zeros and given an array indices where indices[i] = [ri, ci]. For each pair of [ri, ci] you have to increment all cells in row ri and column ci by 1.
Return the number of cells with odd values in the matrix after applying the increment to all indices.
Example 1:
1 2 3 4 5
Input: n = 2, m = 3, indices = [[0,1],[1,1]] Output: 6 Explanation: Initial matrix = [[0,0,0],[0,0,0]]. After applying first increment it becomes [[1,2,1],[0,1,0]]. The final matrix will be [[1,3,1],[1,3,1]] which contains 6 odd numbers.
Example 2:
1 2 3
Input: n = 2, m = 2, indices = [[1,1],[0,0]] Output: 0 Explanation: Final matrix = [[2,2],[2,2]]. There is no odd number in the final matrix.
classSolution { public: vector<vector<int>> shiftGrid(vector<vector<int>>& grid, int k) { int m = grid.size(), n = grid[0].size(); vector<vector<int>> res(m, vector<int>(n, 0)); for(int i = 0; i < m; i ++) { int x, y; for(int j = 0; j < n; j ++) { y = j + k; x = i; if(y >= n) { int temp; temp = y / n; y = y % n; x = (x + temp) % m; } res[x][y] = grid[i][j]; } } return res; } };
Leetcode1266. Minimum Time Visiting All Points
On a plane there are n points with integer coordinates points[i] = [xi, yi]. Your task is to find the minimum time in seconds to visit all points.
You can move according to the next rules:
In one second always you can either move vertically, horizontally by one unit or diagonally (it means to move one unit vertically and one unit horizontally in one second). You have to visit the points in the same order as they appear in the array.
Example 1:
1 2 3 4 5 6
Input: points = [[1,1],[3,4],[-1,0]] Output: 7 Explanation: One optimal path is [1,1] -> [2,2] -> [3,3] -> [3,4] -> [2,3] -> [1,2] -> [0,1] -> [-1,0] Time from [1,1] to [3,4] = 3 seconds Time from [3,4] to [-1,0] = 4 seconds Total time = 7 seconds
classSolution { public: intminTimeToVisitAllPoints(vector<vector<int>>& points){ int cnt = 0; for(int i = 1; i < points.size(); i ++) { cnt += max(abs(points[i][0] - points[i - 1][0]), abs(points[i][1] - points[i - 1][1])); } return cnt; } };
Leetcode1275. Find Winner on a Tic Tac Toe Game
Tic-tac-toe is played by two players A and B on a 3 x 3 grid.
Return the winner of the game if it exists (A or B), in case the game ends in a draw return “Draw”, if there are still movements to play return “Pending”.
You can assume that moves is valid (It follows the rules of Tic-Tac-Toe), the grid is initially empty and A will play first.
Example 1:
1 2 3 4 5 6
Input: moves = [[0,0],[2,0],[1,1],[2,1],[2,2]] Output: "A" Explanation: "A" wins, he always plays first. "X " "X " "X " "X " "X " " " -> " " -> " X " -> " X " -> " X " " " "O " "O " "OO " "OOX"
Input: moves = [[0,0],[1,1],[2,0],[1,0],[1,2],[2,1],[0,1],[0,2],[2,2]] Output: "Draw" Explanation: The game ends in a draw since there are no moves to make. "XXO" "OOX" "XOX"
Example 4:
1 2 3 4 5 6
Input: moves = [[0,0],[1,1]] Output: "Pending" Explanation: The game has not finished yet. "X " " O " " "
Leetcode1277. Count Square Submatrices with All Ones
Given a m * n matrix of ones and zeros, return how many square submatrices have all ones.
Example 1:
1 2 3 4 5 6 7 8 9 10 11 12
Input: matrix = [ [0,1,1,1], [1,1,1,1], [0,1,1,1] ] Output: 15 Explanation: There are 10 squares of side 1. There are 4 squares of side 2. There is 1 square of side 3. Total number of squares = 10 + 4 + 1 = 15.
Example 2:
1 2 3 4 5 6 7 8 9 10 11
Input: matrix = [ [1,0,1], [1,1,0], [1,1,0] ] Output: 7 Explanation: There are 6 squares of side 1. There is 1 square of side 2. Total number of squares = 6 + 1 = 7.
classSolution { public: intcountSquares(vector<vector<int>>& matrix){ if (matrix.empty() || matrix[0].empty()) return0; int m = matrix.size(), n = matrix[0].size(); int count = 0; int s = std::min(m, n); for (int i = 0; i < m; ++ i) { for (int j = 0; j < n; ++ j) { // 发现为 1 的值, 然后从这个值出发, 访问以这个值为左上角的子方阵 // 子方阵的大小 k 的范围为 [1, s] // 之后访问子方阵中的 matrix[i : i + k, j : j + k] 范围内的每个元素 // 判断是否都是 1, 如果都是 1, 那么最后 is_all_ones 肯定为 true, // 此时累加 count. if (matrix[i][j] == 1) { count ++; bool is_all_ones = true; for (int k = 1; k <= s; ++ k) { if ((i + k >= m) || (j + k >= n)) break; // 越界则不用考虑了 for (int h = i; h <= i + k && is_all_ones; ++ h) { if ((j + k >= n) || (j + k < n && matrix[h][j + k] != 1)) is_all_ones = false; } for (int w = j; w <= j + k && is_all_ones; ++ w) { if ((i + k >= m) || (i + k < m && matrix[i + k][w] != 1)) is_all_ones = false; } if (is_all_ones) count ++; } } } } return count; } };
classSolution { public: intcountSquares(vector<vector<int>>& matrix){ int n = matrix.size(), m = matrix[0].size(); vector<vector<int>> dp1(n+1, vector<int>(m+1, 0)), dp2(n+1, vector<int>(m+1, 0)), dp(n+1, vector<int>(m+1, 0)); for (int r = 1; r <= n; r ++) { for (int c = 1; c <= m; c ++) { if (!matrix[r-1][c-1]) dp1[r][c] = dp2[r][c] = 0; else { dp1[r][c] = dp1[r-1][c] + 1; dp2[r][c] = dp2[r][c-1] + 1; } } } int ret = 0; for (int r = 1; r <= n; r ++) { for (int c = 1; c <= m; c ++) { if (matrix[r-1][c-1]) { dp[r][c] = max(1, min(dp[r-1][c-1]+1, min(dp1[r][c], dp2[r][c]))); ret += dp[r][c]; } } } return ret; } };
优化版本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: intcountSquares(vector<vector<int>>& matrix){ if (matrix.empty() || matrix[0].empty()) return0; int m = matrix.size(), n = matrix[0].size(); int count = 0; for (int i = 0; i < m; ++ i) { for (int j = 0; j < n; ++ j) { if (i > 0 && j > 0 && matrix[i][j] == 1) matrix[i][j] = std::min(matrix[i - 1][j - 1], std::min(matrix[i - 1][j], matrix[i][j - 1])) + 1; count += matrix[i][j]; // 其余情况 } } return count; } };
Leetcode1281. Subtract the Product and Sum of Digits of an Integer
Given an integer number n, return the difference between the product of its digits and the sum of its digits.
Example 1:
1 2 3 4 5 6
Input: n = 234 Output: 15 Explanation: Product of digits = 2 * 3 * 4 = 24 Sum of digits = 2 + 3 + 4 = 9 Result = 24 - 9 = 15
Example 2:
1 2 3 4 5 6
Input: n = 4421 Output: 21 Explanation: Product of digits = 4 * 4 * 2 * 1 = 32 Sum of digits = 4 + 4 + 2 + 1 = 11 Result = 32 - 11 = 21
给定整数n,返回其数字乘积与数字总和之间的差。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution { public: intsubtractProductAndSum(int n){ int he = 0, ji = 1; while(n) { int temp = n % 10; n /= 10; he += temp; ji *= temp; } return ji - he; } };
Leetcode1287. Element Appearing More Than 25% In Sorted Array
Given an integer array sorted in non-decreasing order, there is exactly one integer in the array that occurs more than 25% of the time.
classSolution { public: intfindSpecialInteger(vector<int>& arr){ int step = arr.size() / 4; for(int i = 0; i < arr.size() - step; i ++) { if(arr[i] == arr[i+step]) return arr[i]; } return-1; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
intfindSpecialInteger(vector<int>& arr){ int N = arr.size(); int freq = N / 4;
int pos = 0; for (int i = 1; i < arr.size(); ++i) { if (arr[i] == arr[i - 1]) continue;
if ( (i - pos) > freq) return arr[i-1]; pos = i; }
return arr.back(); }
Leetcode1289. Minimum Falling Path Sum II
Given an n x n integer matrix grid, return the minimum sum of a falling path with non-zero shifts.
A falling path with non-zero shifts is a choice of exactly one element from each row of grid such that no two elements chosen in adjacent rows are in the same column.
Example 1:
1 2 3 4 5 6 7 8
Input: arr = [[1,2,3],[4,5,6],[7,8,9]] Output: 13 Explanation: The possible falling paths are: [1,5,9], [1,5,7], [1,6,7], [1,6,8], [2,4,8], [2,4,9], [2,6,7], [2,6,8], [3,4,8], [3,4,9], [3,5,7], [3,5,9] The falling path with the smallest sum is [1,5,7], so the answer is 13.
classSolution { public: intminFallingPathSum(vector<vector<int>>& matrix){ int m = matrix.size(), n = matrix[0].size(); vector<int> dp(n, 0), dp2; for (int i = 0; i < n; i ++) dp[i] = matrix[0][i]; for (int i = 1; i < m; i ++) { dp2.assign(n, 0); for (int j = 0; j < n; j ++) { int minn = INT_MAX; for (int k = 0; k < n; k ++) if (k != j) minn = min(minn, dp[k]); dp2[j] = minn + matrix[i][j]; } swap(dp, dp2); } int res = INT_MAX; for (int i = 0; i < n; i ++) res = min(res, dp[i]); return res; } };
Leetcode1290. Convert Binary Number in a Linked List to Integer
Given head which is a reference node to a singly-linked list. The value of each node in the linked list is either 0 or 1. The linked list holds the binary representation of a number.
Return the decimal value of the number in the linked list.
Example 1:
1 2 3
Input: head = [1,0,1] Output: 5 Explanation: (101) in base 2 = (5) in base 10
Example 2:
1 2
Input: head = [0] Output: 0
Example 3:
1 2
Input: head = [1] Output: 1
Example 4:
1 2
Input: head = [1,0,0,1,0,0,1,1,1,0,0,0,0,0,0] Output: 18880
Example 5:
1 2
Input: head = [0,0] Output: 0
二进制链表转换成十进制数
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: intgetDecimalValue(ListNode* head){ int res = 0; while(head) { res = res * 2 + head->val; head = head->next; } return res; } };
Leetcode1295. Find Numbers with Even Number of Digits
Given an array nums of integers, return how many of them contain an even number of digits.
Example 1:
1 2 3 4 5 6 7 8 9
Input: nums = [12,345,2,6,7896] Output: 2 Explanation: 12 contains 2 digits (even number of digits). 345 contains 3 digits (odd number of digits). 2 contains 1 digit (odd number of digits). 6 contains 1 digit (odd number of digits). 7896 contains 4 digits (even number of digits). Therefore only 12 and 7896 contain an even number of digits.
Example 2:
1 2 3 4
Input: nums = [555,901,482,1771] Output: 1 Explanation: Only 1771 contains an even number of digits.
送分题,判断一个数里有几个数字组成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: intfindNumbers(vector<int>& nums){ int digits, result=0; for(int i=0;i<nums.size();i++) { digits=0; int num = nums[i]; while(num) { digits++; num/=10; } if(digits%2==0) result ++; } return result; } };
Leetcode1299. Replace Elements with Greatest Element on Right Side
Given an array arr, replace every element in that array with the greatest element among the elements to its right, and replace the last element with -1.
int setBitToOne(int n, int m) { return n | (1 << (m-1)); }
同理从低位到高位,将n的第m位置0,代码如下
1 2 3 4
int setBitToZero(int n, int m) { return n & ~(1 << (m-1)); }
shl操作 & shr操作
求2的N次方1<<n
高低位交换
1 2
unsigned short a = 34520; a = (a >> 8) | (a << 8);
进行二进制逆序
1 2 3 4 5
unsigned short a = 34520; a = ((a & 0xAAAA) >> 1) | ((a & 0x5555) << 1); a = ((a & 0xCCCC) >> 2) | ((a & 0x3333) << 2); a = ((a & 0xF0F0) >> 4) | ((a & 0x0F0F) << 4); a = ((a & 0xFF00) >> 8) | ((a & 0x00FF) << 8);
获得int型最大最小值
1 2 3 4 5 6 7 8
int getMaxInt() { return (1 << 31) - 1;//2147483647, 由于优先级关系,括号不可省略 } int getMinInt() { return 1 << 31;//-2147483648 }
m的n次方
1 2 3 4 5 6 7 8 9 10 11 12
//自己重写的pow()方法 int pow(int m , int n){ int sum = 1; while(n != 0){ if(n & 1 == 1){ sum *= m; } m *= m; n = n >> 1; } return sum; }
找出不大于N的最大的2的幂指数
1 2 3 4 5 6 7
int findN(int n){ n |= n >> 1; n |= n >> 2; n |= n >> 4; n |= n >> 8 // 整型一般是 32 位,上面我是假设 8 位。 return (n + 1) >> 1; }
二分查找32位整数的前导0个数
1 2 3 4 5 6 7 8 9 10 11 12 13
int nlz(unsigned x) { int n;
if (x == 0) return(32); n = 1; if ((x >> 16) == 0) {n = n +16; x = x <<16;} if ((x >> 24) == 0) {n = n + 8; x = x << 8;} if ((x >> 28) == 0) {n = n + 4; x = x << 4;} if ((x >> 30) == 0) {n = n + 2; x = x << 2;} n = n - (x >> 31); return n; }
位图的操作
将 x 的第 n 位置1,可以通过 x |= (x << n) 来实现set_bit(char x, int n);
将 x 的第 n 位清0,可以通过 x &= ~(1 << n) 来实现clr_bit(char x, int n);
取出 x 的第 n 位的值,可以通过 (x >> n) & 1 来实现get_bit(char x, int n);
publicint[] twoSum(int[] nums, int target) { Map<Integer, Integer> map = newHashMap<>(); for (inti=0; i < nums.length; i++) { map.put(nums[i], i); } for (inti=0; i < nums.length; i++) { intcomplement= target - nums[i]; if (map.containsKey(complement) && map.get(complement) != i) { returnnewint[] { i, map.get(complement) }; } } thrownewIllegalArgumentException("No two sum solution"); }
第三种方法:One-pass Hash Table It turns out we can do it in one-pass. While we iterate and inserting elements into the table, we also look back to check if current element’s complement already exists in the table. If it exists, we have found a solution and return immediately.
1 2 3 4 5 6 7 8 9 10 11
publicint[] twoSum(int[] nums, int target) { Map<Integer, Integer> map = newHashMap<>(); for (inti=0; i < nums.length; i++) { intcomplement= target - nums[i]; if (map.containsKey(complement)) { returnnewint[] { map.get(complement), i }; } map.put(nums[i], i); } thrownewIllegalArgumentException("No two sum solution"); }
反正都是很简单的。。。
Leetcode2. Add Two Numbers
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
Leetcode3. Longest Substring Without Repeating Characters
Given a string, find the length of the longest substring without repeating characters.
Example 1:
1 2 3
Input: "abcabcbb" Output: 3 Explanation: The answer is "abc", with the length of 3.
Example 2:
1 2 3
Input: "bbbbb" Output: 1 Explanation: The answer is "b", with the length of 1.
Example 3:
1 2 3 4
Input: "pwwkew" Output: 3 Explanation: The answer is "wke", with the length of 3. Note that the answer must be a substring, "pwke" is a subsequence and not a substring.
给了我们一个字符串,让求最长的无重复字符的子串,注意这里是子串,不是子序列,所以必须是连续的。先不考虑代码怎么实现,如果给一个例子中的例子 “abcabcbb”,让你手动找无重复字符的子串,该怎么找。博主会一个字符一个字符的遍历,比如 a,b,c,然后又出现了一个a,那么此时就应该去掉第一次出现的a,然后继续往后,又出现了一个b,则应该去掉一次出现的b,以此类推,最终发现最长的长度为3。所以说,需要记录之前出现过的字符,记录的方式有很多,最常见的是统计字符出现的个数,但是这道题字符出现的位置很重要,所以可以使用 HashMap 来建立字符和其出现位置之间的映射。进一步考虑,由于字符会重复出现,到底是保存所有出现的位置呢,还是只记录一个位置?我们之前手动推导的方法实际上是维护了一个滑动窗口,窗口内的都是没有重复的字符,需要尽可能的扩大窗口的大小。由于窗口在不停向右滑动,所以只关心每个字符最后出现的位置,并建立映射。窗口的右边界就是当前遍历到的字符的位置,为了求出窗口的大小,需要一个变量 left 来指向滑动窗口的左边界,这样,如果当前遍历到的字符从未出现过,那么直接扩大右边界,如果之前出现过,那么就分两种情况,在或不在滑动窗口内,如果不在滑动窗口内,那么就没事,当前字符可以加进来,如果在的话,就需要先在滑动窗口内去掉这个已经出现过的字符了,去掉的方法并不需要将左边界 left 一位一位向右遍历查找,由于 HashMap 已经保存了该重复字符最后出现的位置,所以直接移动 left 指针就可以了。维护一个结果 res,每次用出现过的窗口大小来更新结果 res,就可以得到最终结果啦。
这里可以建立一个 HashMap,建立每个字符和其最后出现位置之间的映射,然后需要定义两个变量 res 和 left,其中 res 用来记录最长无重复子串的长度,left 指向该无重复子串左边的起始位置的前一个,由于是前一个,所以初始化就是 -1,然后遍历整个字符串,对于每一个遍历到的字符,如果该字符已经在 HashMap 中存在了,并且如果其映射值大于 left 的话,那么更新 left 为当前映射值。然后映射值更新为当前坐标i,这样保证了 left 始终为当前边界的前一个位置,然后计算窗口长度的时候,直接用 i-left 即可,用来更新结果 res。
这里解释下程序中那个 if 条件语句中的两个条件 m.count(s[i]) && m[s[i]] > left,因为一旦当前字符 s[i] 在 HashMap 已经存在映射,说明当前的字符已经出现过了,而若 m[s[i]] > left 成立,说明之前出现过的字符在窗口内,那么如果要加上当前这个重复的字符,就要移除之前的那个,所以让 left 赋值为 m[s[i]],由于 left 是窗口左边界的前一个位置(这也是 left 初始化为 -1 的原因,因为窗口左边界是从0开始遍历的),所以相当于已经移除出滑动窗口了。举一个最简单的例子 “aa”,当 i=0 时,建立了 a->0 的映射,并且此时结果 res 更新为1,那么当 i=1 的时候,发现a在 HashMap 中,并且映射值0大于 left 的 -1,所以此时 left 更新为0,映射对更新为 a->1,那么此时 i-left 还为1,不用更新结果 res,那么最终结果 res 还为1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: intlengthOfLongestSubstring(string s){ unordered_map<char, int> m; int left = -1, res = 0; for(int i = 0; i < s.length(); i ++) { if(m.count(s[i]) && m[s[i]] > left) { left = m[s[i]]; } m[s[i]] = i; res = max(res, i - left); } return res; } };
Leetcode4. Median of Two Sorted Arrays
Given two sorted arrays nums1 and nums2 of size m and n respectively, return the median of the two sorted arrays.
The overall run time complexity should be O(log (m+n)).
Example 1:
1 2 3
Input: nums1 = [1,3], nums2 = [2] Output: 2.00000 Explanation: merged array = [1,2,3] and median is 2.
Example 2:
1 2 3
Input: nums1 = [1,2], nums2 = [3,4] Output: 2.50000 Explanation: merged array = [1,2,3,4] and median is (2 + 3) / 2 = 2.5.
classSolution { public: string longestPalindrome(string s){ int len = s.length(), lens = len*2+2, id = 0, maxx = 0, reslen = 0; int start;
vector<int> p(lens, 0); string ss(lens, ' '); ss[0] = '$'; ss[1] = '#'; for (int i = 0; i < len; i ++) { ss[i*2+2] = s[i]; ss[i*2+3] = '#'; } for (int i = 1; i < lens; i ++) { if (maxx > i) p[i] = min(p[2*id - i], maxx - i); else p[i] = 1; while(ss[i+p[i]] == ss[i-p[i]]) p[i] ++; if (p[i]+i > maxx) { maxx = p[i] + i; id = i; } if (p[i] > reslen) { reslen = p[i]; start = i; } } return s.substr((start-reslen)/2, reslen-1); } };
Leetcode6. ZigZag Conversion
The string “PAYPALISHIRING” is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
1 2 3
P A H N A P L S I I G Y I R
And then read line by line: “PAHNAPLSIIGYIR”
Write the code that will take a string and make this conversion given a number of rows:
string convert(string s, int numRows); Example 1:
1 2
Input: s = "PAYPALISHIRING", numRows = 3 Output: "PAHNAPLSIIGYIR"
Example 2:
1 2 3 4 5 6 7 8
Input: s = "PAYPALISHIRING", numRows = 4 Output: "PINALSIGYAHRPI" Explanation:
classSolution { public: string convert(string s, int numRows){ if (numRows <= 1) return s; string res; int i = 0, n = s.size(); vector<string> vec(numRows); while(i < n) { for (int pos = 0; pos < numRows && i < n; ++pos) vec[pos] += s[i++]; for (int pos = numRows - 2; pos >= 1 && i < n; --pos) vec[pos] += s[i++]; } for (auto &a : vec) res += a; return res; } };
Leetcode7. Reverse Integer
Given a 32-bit signed integer, reverse digits of an integer.
Example 1:
1 2
Input: 123 Output: 321
Example 2:
1 2
Input: -123 Output: -321
Example 3:
1 2
Input: 120 Output: 21
Note:
Assume we are dealing with an environment which could only store integers within the 32-bit signed integer range: [−231, 231 − 1]. For the purpose of this problem, assume that your function returns 0 when the reversed integer overflows.
翻转数字问题需要注意的就是溢出问题,看了许多网上的解法,由于之前的 OJ 没有对溢出进行测试,所以网上很多人的解法没有处理溢出问题也能通过 OJ。现在 OJ 更新了溢出测试,所以还是要考虑到。为什么会存在溢出问题呢,由于int型的数值范围是 -2147483648~2147483647, 那么如果要翻转 1000000009 这个在范围内的数得到 9000000001,而翻转后的数就超过了范围。博主最开始的想法是,用 long 型数据,其数值范围为 -9223372036854775808~9223372036854775807, 远大于 int 型这样就不会出现溢出问题。但实际上 OJ 给出的官方解答并不需要使用 long,一看比自己的写的更精简一些,它没有特意处理正负号,仔细一想,果然正负号不影响计算,而且没有用 long 型数据,感觉写的更好一些,那么就贴出来吧:
解法一:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution { public: intreverse(int x){ int res = 0; while (x != 0) { if (abs(res) > INT_MAX / 10) return0; res = res * 10 + x % 10; x /= 10; } return res; } };
在贴出答案的同时,OJ 还提了一个问题 To check for overflow/underflow, we could check if ret > 214748364 or ret < –214748364 before multiplying by 10. On the other hand, we do not need to check if ret == 214748364, why? (214748364 即为 INT_MAX / 10)
为什么不用 check 是否等于 214748364 呢,因为输入的x也是一个整型数,所以x的范围也应该在 -2147483648~2147483647 之间,那么x的第一位只能是1或者2,翻转之后 res 的最后一位只能是1或2,所以 res 只能是 2147483641 或 2147483642 都在 int 的范围内。但是它们对应的x为 1463847412 和 2463847412,后者超出了数值范围。所以当过程中 res 等于 214748364 时, 输入的x只能为 1463847412, 翻转后的结果为 2147483641,都在正确的范围内,所以不用 check。
我们也可以用 long 型变量保存计算结果,最后返回的时候判断是否在 int 返回内,但其实题目中说了只能存整型的变量,所以这种方法就只能当个思路扩展了,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: intreverse(int x){ long res = 0; while (x != 0) { res = 10 * res + x % 10; x /= 10; } return (res > INT_MAX || res < INT_MIN) ? 0 : res; } };
Leetcode8. String to Integer (atoi)
Implement atoi which converts a string to an integer.
The function first discards as many whitespace characters as necessary until the first non-whitespace character is found. Then, starting from this character, takes an optional initial plus or minus sign followed by as many numerical digits as possible, and interprets them as a numerical value.
The string can contain additional characters after those that form the integral number, which are ignored and have no effect on the behavior of this function.
If the first sequence of non-whitespace characters in str is not a valid integral number, or if no such sequence exists because either str is empty or it contains only whitespace characters, no conversion is performed.
If no valid conversion could be performed, a zero value is returned.
Note:
Only the space character ‘ ‘ is considered as whitespace character. Assume we are dealing with an environment which could only store integers within the 32-bit signed integer range: [−231, 231 − 1]. If the numerical value is out of the range of representable values, INT_MAX (231 − 1) or INT_MIN (−231) is returned.
Example 1:
1 2
Input: "42" Output: 42
Example 2:
1 2 3 4
Input: " -42" Output: -42 Explanation: The first non-whitespace character is '-', which is the minus sign. Then take as many numerical digits as possible, which gets 42.
Example 3:
1 2 3
Input: "4193 with words" Output: 4193 Explanation: Conversion stops at digit '3' as the next character is not a numerical digit.
Example 4:
1 2 3 4
Input: "words and 987" Output: 0 Explanation: The first non-whitespace character is 'w', which is not a numerical digit or a +/- sign. Therefore no valid conversion could be performed.
Example 5:
1 2 3 4
Input: "-91283472332" Output: -2147483648 Explanation: The number "-91283472332" is out of the range of a 32-bit signed integer. Thefore INT_MIN (−231) is returned.
classSolution { public: boolisPalindrome(int x){ int i=0; if(x<0) returnfalse; int length = 0; int str[100000]; while(x>0){ str[i++]=(x%10); x/=10; } int middle = i/2; int j=0; while(j<middle){ if(str[j]!=str[i-1-j]) returnfalse; j++; } returntrue; } };
Leetcode10. Regular Expression Matching
Given an input string (s) and a pattern (p), implement regular expression matching with support for ‘.’ and ‘*’.
‘.’ Matches any single character.
‘*’ Matches zero or more of the preceding element. The matching should cover the entire input string (not partial).
Note:
s could be empty and contains only lowercase letters a-z.
p could be empty and contains only lowercase letters a-z, and characters like . or *.
Example 1:
1 2 3 4 5
Input: s = "aa" p = "a" Output: false Explanation: "a" does not match the entire string "aa".
Example 2:
1 2 3 4 5
Input: s = "aa" p = "a*" Output: true Explanation: '*' means zero or more of the precedeng element, 'a'. Therefore, by repeating 'a' once, it becomes "aa".
Example 3:
1 2 3 4 5
Input: s = "ab" p = ".*" Output: true Explanation: ".*" means "zero or more (*) of any character (.)".
Example 4:
1 2 3 4 5
Input: s = "aab" p = "c*a*b" Output: true Explanation: c can be repeated 0 times, a can be repeated 1 time. Therefore it matches "aab".
Example 5:
1 2 3 4
Input: s = "mississippi" p = "mis*is*p*." Output: false
Given n non-negative integers a1, a2, …, an , where each represents a point at coordinate (i, ai). n vertical lines are drawn such that the two endpoints of line i is at (i, ai) and (i, 0). Find two lines, which together with x-axis forms a container, such that the container contains the most water.
Note: You may not slant the container and n is at least 2.
The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
Example:
Input: [1,8,6,2,5,4,8,3,7] Output: 49
给定 n 个非负整数 (a1, a2, …, an),每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条竖直线,竖直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
可以看到,这个搜索空间的削减方式和 Two Sum II 问题中的形状如出一辙(其实就是我把上一篇文章里的图直接搬过来了),如果你理解了 Two Sum II 问题,那一定能秒懂这道题。
同样的道理,假设两根柱子是右边的较短,我们就可以排除掉右边的柱子,削减一列的搜索空间,如下图所示。
削减一列的搜索空间
这样,经过 步以后,我们就能排除所有的搜索空间,检查完所有的可能性。
那么,我们最终就写出了这样的双指针代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
publicintmaxArea(int[] height){ int res = 0; int i = 0; int j = height.length - 1; while (i < j) { int area = (j - i) * Math.min(height[i], height[j]); res = Math.max(res, area); if (height[i] < height[j]) { i++; } else { j--; } } return res; }
就比如 167 题的 Two Sum II 和这道题。两者都是用这样的双指针解法,从代码上看非常相似,但它们究竟为何相似呢?实际上,两道题就是因为削减搜索空间的原理相通,解题思路实际上是一模一样的。如果你能洞察这一点,那么距离举一反三也就不远了。
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution { public: intmaxArea(vector<int>& height){ int res = 0, i = 0, j = height.size() - 1; while (i < j) { int h = min(height[i], height[j]); res = max(res, h * (j - i)); while (i < j && h == height[i]) ++i; while (i < j && h == height[j]) --j; } return res; } };
Leetcode12. Integer to Roman
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
1 2 3 4 5 6 7 8
Symbol Value I 1 V 5 X 10 L 50 C 100 D 500 M 1000
For example, two is written as II in Roman numeral, just two one’s added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9.
X can be placed before L (50) and C (100) to make 40 and 90.
C can be placed before D (500) and M (1000) to make 400 and 900.
Given an integer, convert it to a roman numeral. Input is guaranteed to be within the range from 1 to 3999.
Example 1:
1 2
Input: 3 Output: "III"
Example 2:
1 2
Input: 4 Output: "IV"
Example 3:
1 2
Input: 9 Output: "IX"
Example 4:
1 2 3
Input: 58 Output: "LVIII" Explanation: L = 50, V = 5, III = 3.
Example 5:
1 2 3
Input: 1994 Output: "MCMXCIV" Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
classSolution { public: string intToRoman(int num){ string res = ""; vector<char> roman{'M', 'D', 'C', 'L', 'X', 'V', 'I'}; vector<int> value{1000, 500, 100, 50, 10, 5, 1}; for(int i = 0; i < 7; i += 2) { int temp = num / value[i]; num = num % value[i]; if(temp < 4) for(int ii = 0; ii < temp; ii ++) res = res + roman[i]; elseif(temp == 4) { res = res + roman[i] + roman[i-1]; } elseif(temp > 4 && temp < 9) { res = res + roman[i-1]; for(int ii = 6; ii <= temp; ii ++) res = res + roman[i]; } elseif(temp == 9) res = res + roman[i] + roman[i-2]; } return res; } };
Leetcode13. Roman to Integer
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol
Value
I
1
V
5
X
10
L
50
C
100
D
500
M
1000
For example, two is written as II in Roman numeral, just two one’s added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9. X can be placed before L (50) and C (100) to make 40 and 90. C can be placed before D (500) and M (1000) to make 400 and 900. Given a roman numeral, convert it to an integer. Input is guaranteed to be within the range from 1 to 3999.
Example 1:
1 2
Input: "III" Output: 3
Example 2:
1 2
Input: "IV" Output: 4
Example 3:
1 2
Input: "IX" Output: 9
Example 4:
1 2 3
Input: "LVIII" Output: 58 Explanation: L = 50, V= 5, III = 3.
Example 5:
1 2 3
Input: "MCMXCIV" Output: 1994 Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
classSolution { public: string longestCommonPrefix(vector<string>& strs){ if (strs.empty()) return""; sort(strs.begin(), strs.end()); int i = 0, len = min(strs[0].size(), strs.back().size()); while (i < len && strs[0][i] == strs.back()[i]) ++i; return strs[0].substr(0, i); } };
Leetcode15. 3Sum
Given an array nums of n integers, are there elements a, b, c in nums such that a + b + c = 0? Find all unique triplets in the array which gives the sum of zero.
Note: The solution set must not contain duplicate triplets.
Example:
1 2 3 4 5 6 7
Given array nums = [-1, 0, 1, 2, -1, -4],
A solution set is: [ [-1, 0, 1], [-1, -1, 2] ]
给定一个数组A,要求从A中找出这么三个元素a,b,c使得a + b + c = 0,返回由这样的a、b、c构成的三元组,且要保证三元组是唯一的。(即任意的两个三元组,它们里面的元素不能完全相同)
Given an array nums of n integers and an integer target, find three integers in nums such that the sum is closest to target. Return the sum of the three integers. You may assume that each input would have exactly one solution.
Example:
Given array nums = [-1, 2, 1, -4], and target = 1.
The sum that is closest to the target is 2. (-1 + 2 + 1 = 2).
classSolution { public: intthreeSumClosest(vector<int>& nums, int target){ int result = nums[0]+nums[1]+nums[2]; int dis = abs(result - target); int len = nums.size(); if(len < 3) return target; sort(nums.begin(),nums.end()); for (int i = 0; i < len; i ++) { int j = i+1, k = len-1; while ( j < k ) { int temp = abs(nums[i]+nums[j]+nums[k]-target); if (temp < dis) { dis = temp; result = nums[i]+nums[j]+nums[k]; } if (nums[i]+nums[j]+nums[k]<target) j ++; elseif (nums[i]+nums[j]+nums[k]>target) k --; else return target; } } return result; } };
Leetcod17. Letter Combinations of a Phone Number
Given a string containing digits from 2-9 inclusive, return all possible letter combinations that the number could represent.
A mapping of digit to letters (just like on the telephone buttons) is given below. Note that 1 does not map to any letters.
Given an array nums of n integers and an integer target, are there elements a, b, c, and d in nums such that a + b + c + d = target? Find all unique quadruplets in the array which gives the sum of target. The solution set must not contain duplicate quadruplets.
Example:
1 2 3 4 5 6 7
Given array nums = [1, 0, -1, 0, -2, 2], and target = 0. A solution set is: [ [-1, 0, 0, 1], [-2, -1, 1, 2], [-2, 0, 0, 2] ]
题意
中文描述 给定一个数列 S ,包含 n 个整数.在 S 中找到四个元素 a, b, c, d 使得 a + b + c + d = target . 找到所有的独特的满足上述条件的四元组. 注意: 结果集包含的四元组不重复.
classSolution { public: vector<vector<int>> fourSum(vector<int>& nums, int target) { vector<vector<int>> res; sort(nums.begin(), nums.end()); int len = nums.size(); for(int i=0;i<len-3;i++) { for(int j=i+1;j<len-2;j++) { int left = j+1, right = len-1; while(left < right){ int sum = nums[i]+nums[j]+nums[right]+nums[left]; if(sum == target) { vector<int> out{nums[i], nums[j], nums[left], nums[right]}; res.push_back(out); left ++; right--; while(left<right && nums[left]==nums[left-1]) left++; // 很重要的去重! while(left<right && nums[right]==nums[right+1]) right--;// 很重要的去重! } elseif(sum > target) { right --; } else { left ++; } } while(j+1<len-2 && nums[j]==nums[j+1]) j++; } while(i+1<len-3 && nums[i]==nums[i+1]) i++; } return res; } };
Leetcode19. Remove Nth Node From End of List
Given a linked list, remove the n-th node from the end of list and return its head.
Example:
1 2
Given linked list: 1->2->3->4->5, and n = 2. After removing the second node from the end, the linked list becomes 1->2->3->5.
Note: Given n will always be valid.
Follow up: Could you do this in one pass?
这道题让我们移除链表倒数第n个节点,限定n一定是有效的,即n不会大于链表中的元素总数。还有题目要求一次遍历解决问题,那么就得想些比较巧妙的方法了。比如首先要考虑的时,如何找到倒数第n个节点,由于只允许一次遍历,所以不能用一次完整的遍历来统计链表中元素的个数,而是遍历到对应位置就应该移除了。那么就需要用两个指针来帮助解题,pre 和 cur 指针。首先 cur 指针先向前走N步,如果此时 cur 指向空,说明N为链表的长度,则需要移除的为首元素,那么此时返回 head->next 即可,如果 cur 存在,再继续往下走,此时 pre 指针也跟着走,直到 cur 为最后一个元素时停止,此时 pre 指向要移除元素的前一个元素,再修改指针跳过需要移除的元素即可,pre相当于计数器了,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: ListNode* removeNthFromEnd(ListNode* head, int n){ if(!head->next) returnNULL; ListNode* pre = head, *cur = head; for(int i = 0; i < n; i ++) cur = cur->next; if(!cur) return head->next; while(cur->next) { cur = cur->next; pre = pre->next; } pre->next = pre->next->next; return head; } };
Leetcode20. Valid Parentheses
Given a string containing just the characters ‘(‘, ‘)’, ‘{‘, ‘}’, ‘[‘ and ‘]’, determine if the input string is valid.
An input string is valid if:
Open brackets must be closed by the same type of brackets.
Open brackets must be closed in the correct order.
Note that an empty string is also considered valid.
classSolution { public: ListNode* mergeKLists(vector<ListNode*>& lists){ if (lists.empty()) returnNULL; int n = lists.size(); while (n > 1) { int k = (n + 1) / 2; for (int i = 0; i < n / 2; ++i) { lists[i] = mergeTwoLists(lists[i], lists[i + k]); } n = k; } return lists[0]; } ListNode* mergeTwoLists(ListNode* l1, ListNode* l2){ ListNode *dummy = newListNode(-1), *cur = dummy; while (l1 && l2) { if (l1->val < l2->val) { cur->next = l1; l1 = l1->next; } else { cur->next = l2; l2 = l2->next; } cur = cur->next; } if (l1) cur->next = l1; if (l2) cur->next = l2; return dummy->next; } };
Leetcode24. Swap Nodes in Pairs
Given a linked list, swap every two adjacent nodes and return its head. You may not modify the values in the list’s nodes, only nodes itself may be changed.
Example: Given 1->2->3->4, you should return the list as 2->1->4->3.
classSolution { public: ListNode* swapPairs(ListNode* head){ // We use a dummy head node to make handling head operations simpler ListNode *dummy = newListNode(-1), *tail = dummy; // add the dummy node to list tail->next = head; while(head && head->next) { ListNode *nextptr = head->next->next; // swap the adjacent nodes // 2nd node comes to 1st pos tail->next = head->next; // connecting 2nd node to 1st node (head->next)->next = head; // make the 1st node connected to next node on list tail = head; tail->next = nextptr; head = nextptr; } head = dummy->next; delete dummy; return head; } };
Leetcode25. Reverse Nodes in k-Group
Given a linked list, reverse the nodes of a linked list k at a time and return its modified list.
k is a positive integer and is less than or equal to the length of the linked list. If the number of nodes is not a multiple of k then left-out nodes in the end should remain as it is.
Example:
Given this linked list: 1->2->3->4->5
For k = 2, you should return: 2->1->4->3->5
For k = 3, you should return: 3->2->1->4->5
Note:
Only constant extra memory is allowed. You may not alter the values in the list’s nodes, only nodes itself may be changed.
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
把一个很长的链表分成很多个小链表,每一份的长度都是 k (最后一份的长度如果小于 k 则不需要反转),然后对每个小链表进行反转,最后将所有反转后的小链表按之前的顺序拼接在一起。
Given a sorted array nums, remove the duplicates in-place such that each element appear only once and return the new length.
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.
Example 1:
1 2 3 4 5
Given nums = [1,1,2],
Your function should return length = 2, with the first two elements of nums being 1 and 2 respectively.
It doesn't matter what you leave beyond the returned length.
Example 2:
1 2 3 4 5
Given nums = [0,0,1,1,1,2,2,3,3,4],
Your function should return length = 5, with the first five elements of nums being modified to 0, 1, 2, 3, and 4 respectively.
It doesn't matter what values are set beyond the returned length.
Clarification:
Confused why the returned value is an integer but your answer is an array?
Note that the input array is passed in by reference, which means modification to the input array will be known to the caller as well.
Internally you can think of this:
1 2 3 4 5 6 7 8
// nums is passed in by reference. (i.e., without making a copy) int len = removeDuplicates(nums);
// any modification to nums in your function would be known by the caller. // using the length returned by your function, it prints the first len elements. for (int i = 0; i < len; i++) { print(nums[i]); }
classSolution { public: intremoveDuplicates(vector<int>& nums){ if(nums.size() == 0) return0; int prev = nums[0]; int res = 1; for(int i = 1; i < nums.size(); i ++) { if(prev != nums[i]) { prev = nums[i]; nums[res] = nums[i]; res ++; } } return res; } };
Leetcode27. Remove Element
Given an array nums and a value val, remove all instances of that value in-place and return the new length. Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory. The order of elements can be changed. It doesn’t matter what you leave beyond the new length.
Example 1:
1 2 3
Given nums = [3,2,2,3], val = 3, Your function should return length = 2, with the first two elements of nums being 2. It doesn't matter what you leave beyond the returned length.
Example 2:
1 2
Given nums = [0,1,2,2,3,0,4,2], val = 2, Your function should return length = 5, with the first five elements of nums containing 0, 1, 3, 0, and 4.
Note that the order of those five elements can be arbitrary. It doesn’t matter what values are set beyond the returned length.
Clarification: Confused why the returned value is an integer but your answer is an array? Note that the input array is passed in by reference, which means modification to the input array will be known to the caller as well.
Internally you can think of this:
1 2 3 4 5 6 7 8
// nums is passed in by reference. (i.e., without making a copy) int len = removeElement(nums, val);
// any modification to nums in your function would be known by the caller. // using the length returned by your function, it prints the first len elements. for (int i = 0; i < len; i++) { print(nums[i]); }
双指针做法,两个指针分别指向要被删除的值。
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: intremoveElement(vector<int>& nums, int val){ int cur = 0, size = nums.size(); for(int i = 0; i < size; i ++) { if(val != nums[i]) nums[cur++] = nums[i]; } return cur; } };
Leetcode28. Implement strStr()
Implement strStr().
Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
classSolution { public: intstrStr(string haystack, string needle){ int hasize = haystack.size(); int neesize = needle.size(); if(hasize == 0 && neesize == 0) return0; if (hasize < neesize) return-1; int len, j, k; for(int i = 0; i <= hasize - neesize; i ++) { len = 0; for(j = i, k = 0; j < hasize && k < neesize && needle[k] == haystack[j]; j ++, k++) len ++; if(len == neesize) return i; } return-1; } };
Leetcode29. Divide Two Integers
Given two integers dividend and divisor, divide two integers without using multiplication, division and mod operator. Return the quotient after dividing dividend by divisor.
The integer division should truncate toward zero, which means losing its fractional part. For example, truncate(8.345) = 8 and truncate(-2.7335) = -2.
这道题让我们求两数相除,而且规定不能用乘法,除法和取余操作,那么这里可以用另一神器位操作 Bit Manipulation,思路是,如果被除数大于或等于除数,则进行如下循环,定义变量t等于除数,定义计数p,当t的两倍小于等于被除数时,进行如下循环,t扩大一倍,p扩大一倍,然后更新 res 和m。这道题的 OJ 给的一些 test case 非常的讨厌,因为输入的都是 int 型,比如被除数是 -2147483648,在 int 范围内,当除数是 -1 时,结果就超出了 int 范围,需要返回 INT_MAX,所以对于这种情况就在开始用 if 判定,将其和除数为0的情况放一起判定,返回 INT_MAX。然后还要根据被除数和除数的正负来确定返回值的正负,这里采用长整型 long 来完成所有的计算,最后返回值乘以符号即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution { public: intdivide(int dividend, int divisor){ if (dividend == INT_MIN && divisor == -1) return INT_MAX; long m = labs(dividend), n = labs(divisor), res = 0; int sign = ((dividend < 0) ^ (divisor < 0)) ? -1 : 1; if (n == 1) return sign == 1 ? m : -m; while (m >= n) { long t = n, p = 1; while (m >= (t << 1)) { t <<= 1; p <<= 1; } res += p; m -= t; } return sign == 1 ? res : -res; } };
Leetcode30. Substring with Concatenation of All Words
You are given a string s and an array of strings words of the same length. Return all starting indices of substring(s) in s that is a concatenation of each word in words exactly once, in any order, and without any intervening characters.
You can return the answer in any order.
Example 1:
1 2 3 4
Input: s = "barfoothefoobarman", words = ["foo","bar"] Output: [0,9] Explanation: Substrings starting at index 0 and 9 are "barfoo" and "foobar" respectively. The output order does not matter, returning [9,0] is fine too.
Example 2:
1 2
Input: s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"] Output: []
Example 3:
1 2
Input: s = "barfoofoobarthefoobarman", words = ["bar","foo","the"] Output: [6,9,12]
这道题让我们求串联所有单词的子串,就是说给定一个长字符串,再给定几个长度相同的单词,让找出串联给定所有单词的子串的起始位置,还是蛮有难度的一道题。假设 words 数组中有n个单词,每个单词的长度均为 len,那么实际上这道题就让我们出所有长度为 nxlen 的子串,使得其刚好是由 words 数组中的所有单词组成。那么就需要经常判断s串中长度为 len 的子串是否是 words 中的单词,为了快速的判断,可以使用 HashMap,同时由于 words 数组可能有重复单词,就要用 HashMap 来建立所有的单词和其出现次数之间的映射,即统计每个单词出现的次数。
遍历s中所有长度为 nxlen 的子串,当剩余子串的长度小于 nxlen 时,就不用再判断了。所以i从0开始,到 (int)s.size() - nxlen 结束就可以了,注意这里一定要将 s.size() 先转为整型数,再进行解法。一定要形成这样的习惯,一旦 size() 后面要减去数字时,先转为 int 型,因为 size() 的返回值是无符号型,一旦减去一个比自己大的数字,则会出错。对于每个遍历到的长度为 nxlen 的子串,需要验证其是否刚好由 words 中所有的单词构成,检查方法就是每次取长度为 len 的子串,看其是否是 words 中的单词。为了方便比较,建立另一个 HashMap,当取出的单词不在 words 中,直接 break 掉,否则就将其在新的 HashMap 中的映射值加1,还要检测若其映射值超过原 HashMap 中的映射值,也 break 掉,因为就算当前单词在 words 中,但若其出现的次数超过 words 中的次数,还是不合题意的。在 for 循环外面,若j正好等于n,说明检测的n个长度为 len 的子串都是 words 中的单词,并且刚好构成了 words,则将当前位置i加入结果 res 即可,具体参见代码如下:
class Solution { public: vector<int> findSubstring(string s, vector<string>& words) { if (s.empty() || words.empty()) return {}; vector<int> res; int n = s.size(), cnt = words.size(), len = words[0].size(); unordered_map<string, int> m1; for (string w : words) ++m1[w]; for (int i = 0; i < len; ++i) { int left = i, count = 0; unordered_map<string, int> m2; for (int j = i; j <= n - len; j += len) { string t = s.substr(j, len); if (m1.count(t)) { ++m2[t]; if (m2[t] <= m1[t]) { ++count; } else { while (m2[t] > m1[t]) { string t1 = s.substr(left, len); --m2[t1]; if (m2[t1] < m1[t1]) --count; left += len; } } if (count == cnt) { res.push_back(left); --m2[s.substr(left, len)]; --count; left += len; } } else { m2.clear(); count = 0; left = j + len; } } } return res; } };
Leetcode31. Next Permutation
Implement next permutation, which rearranges numbers into the lexicographically next greater permutation of numbers. If such arrangement is not possible, it must rearrange it as the lowest possible order (ie, sorted in ascending order). The replacement must be in-place and use only constant extra memory. Here are some examples. Inputs are in the left-hand column and its corresponding outputs are in the right-hand column.
classSolution { public: intlongestValidParentheses(string s){ int res = 0, n = s.size(); vector<int> dp(n + 1); for (int i = 1; i <= n; ++i) { int j = i - 2 - dp[i - 1]; if (s[i - 1] == '(' || j < 0 || s[j] == ')') { dp[i] = 0; } else { dp[i] = dp[i - 1] + 2 + dp[j]; res = max(res, dp[i]); } } return res; } };
此题还有一种不用额外空间的解法,使用了两个变量 left 和 right,分别用来记录到当前位置时左括号和右括号的出现次数,当遇到左括号时,left 自增1,右括号时 right 自增1。对于最长有效的括号的子串,一定是左括号等于右括号的情况,此时就可以更新结果 res 了,一旦右括号数量超过左括号数量了,说明当前位置不能组成合法括号子串,left 和 right 重置为0。但是对于这种情况 “(()” 时,在遍历结束时左右子括号数都不相等,此时没法更新结果 res,但其实正确答案是2,怎么处理这种情况呢?答案是再反向遍历一遍,采取类似的机制,稍有不同的是此时若 left 大于 right 了,则重置0,这样就可以 cover 所有的情况了,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: intlongestValidParentheses(string s){ int res = 0, left = 0, right = 0, n = s.size(); for (int i = 0; i < n; ++i) { (s[i] == '(') ? ++left : ++right; if (left == right) res = max(res, 2 * right); elseif (right > left) left = right = 0; } left = right = 0; for (int i = n - 1; i >= 0; --i) { (s[i] == '(') ? ++left : ++right; if (left == right) res = max(res, 2 * left); elseif (left > right) left = right = 0; } return res; } };
Leetcode33. Search in Rotated Sorted Array
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.
(i.e., [0,1,2,4,5,6,7] might become [4,5,6,7,0,1,2]).
You are given a target value to search. If found in the array return its index, otherwise return -1.
You may assume no duplicate exists in the array.
Your algorithm’s runtime complexity must be in the order of O(log n).
classSolution { public: intsearch(vector<int>& nums, int target){ int left = 0, right = nums.size() - 1; while(left <= right) { int mid = (left + right) / 2; if(nums[mid] == target) return mid; if(nums[mid] < nums[right]) if(nums[mid] < target && target <= nums[right]) left = mid + 1; else right = mid - 1; else if(nums[left] <= target && target < nums[mid]) right = mid - 1; else left = mid + 1; } return-1; } };
Leetcode34. Find First and Last Position of Element in Sorted Array
Given an array of integers nums sorted in ascending order, find the starting and ending position of a given target value. Your algorithm’s runtime complexity must be in the order of O(log n). If the target is not found in the array, return [-1, -1].
classSolution { public: vector<int> searchRange(vector<int>& nums, int target){ if(nums.size() == 0) return {-1, -1}; if(nums.size() == 1) if(nums[0] == target) return {0, 0}; else return {-1, -1}; int n1 = -1, n2 = -1; int len = nums.size(); int left = 0, right = len-1, mid; while(left <= right) { mid = left + (right - left) / 2; if(nums[mid] > target) right = mid - 1; elseif(nums[mid] < target) left = mid + 1; else break; } if(nums[mid] != target) return {-1, -1}; int i, j; for(i = mid; i < len-1; i ++) { if(nums[i+1] != nums[mid]) break; } for(j = mid; j >= 1; j --) { if(nums[j-1] != nums[mid]) break; } return {j, i}; } };
Leetcode35. Search Insert Position
Given a sorted array and a target value, return the index if the target is found. If not, return the index where it would be if it were inserted in order.
You may assume no duplicates in the array.
Example 1:
1 2
Input: [1,3,5,6], 5 Output: 2
Example 2:
1 2
Input: [1,3,5,6], 2 Output: 1
Example 3:
1 2
Input: [1,3,5,6], 7 Output: 4
Example 4:
1 2
Input: [1,3,5,6], 0 Output: 0
只是搜索需要插入的位置罢了,很简单,遍历或者二分都行。
1 2 3 4 5 6 7 8 9 10 11 12
classSolution { public: intsearchInsert(vector<int>& nums, int target){ if(target <= nums[0]) return0; for(int i = 1; i < nums.size(); i ++) { if(target <= nums[i]) return i; } return nums.size(); } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: intsearchInsert(vector<int>& nums, int target){ if(target <= nums[0]) return0; int l = 0, r = nums.size(), mid; while(l < r) { mid = (l + r) / 2; if(nums[mid] >= target) r = mid; else l = mid + 1; } return r; } };
Leetcode36. Valid Sudoku
Determine if a 9x9 Sudoku board is valid. Only the filled cells need to be validated according to the following rules:
Each row must contain the digits 1-9 without repetition. Each column must contain the digits 1-9 without repetition. Each of the 9 3x3 sub-boxes of the grid must contain the digits 1-9 without repetition.
Explanation: Same as Example 1, except with the 5 in the top left corner being modified to 8. Since there are two 8’s in the top left 3x3 sub-box, it is invalid. Note:
A Sudoku board (partially filled) could be valid but is not necessarily solvable. Only the filled cells need to be validated according to the mentioned rules. The given board contain only digits 1-9 and the character ‘.’. The given board size is always 9x9.
classSolution { public: voidsolveSudoku(vector<vector<char>>& board){ helper(board, 0, 0); } boolhelper(vector<vector<char>>& board, int i, int j){ if(i == 9) returntrue; if (j == 9) returnhelper(board, i+1, 0); if (board[i][j] != '.') returnhelper(board, i, j+1); for (int k = '1'; k <= '9'; k ++) { if (isValid(board, i, j, k)) { board[i][j] = k; if (helper(board, i, j+1)) returntrue; board[i][j] = '.'; } } returnfalse; } boolisValid(vector<vector<char>>& board, int i, int j, char val){ for (int k = 0; k < 9; k ++) if (board[i][k] == val) returnfalse; for (int k = 0; k < 9; k ++) if (board[k][j] == val) returnfalse; i /= 3; i *= 3; j /= 3; j *= 3; for (int k = 0; k < 3; k ++) for (int kk = 0; kk < 3; kk ++) if (board[i+k][j+kk] == val) returnfalse; returntrue; } };
Leetcode38. Count and Say
The count-and-say sequence is the sequence of integers with the first five terms as following:
1
11
21
1211
111221
1 is read off as “one 1” or 11.
11 is read off as “two 1s” or 21.
21 is read off as “one 2, then one 1” or 1211.
Given an integer n where 1 ≤ n ≤ 30, generate the nth term of the count-and-say sequence. You can do so recursively, in other words from the previous member read off the digits, counting the number of digits in groups of the same digit.
Note: Each term of the sequence of integers will be represented as a string.
Example 1:
1 2 3
Input: 1 Output: "1" Explanation: This is the base case.
Example 2:
1 2 3
Input: 4 Output: "1211" Explanation: For n = 3 the term was "21" in which we have two groups "2" and "1", "2" can be read as "12" which means frequency = 1 and value = 2, the same way "1" is read as "11", so the answer is the concatenation of "12" and "11" which is "1211".
classSolution { public: string countAndSay(int n){ if(n == 1) return"1"; string str = countAndSay(n-1) + ' '; int count = 1; string s = ""; for(int i = 0; i < str.length() - 1; i ++){ if(str[i] == str[i+1]){ count++; } else { s = s + to_string(count) + str[i]; count = 1; } } return s; } };
Leetcode39. Combination Sum
Given a set of candidate numbers (candidates) (without duplicates) and a target number (target), find all unique combinations in candidates where the candidate numbers sums to target.
The same repeated number may be chosen from candidates unlimited number of times.
Note:
All numbers (including target) will be positive integers. The solution set must not contain duplicate combinations. Example 1:
1 2 3 4 5 6
Input: candidates = [2,3,6,7], target = 7, A solution set is: [ [7], [2,2,3] ]
Example 2:
1 2 3 4 5 6 7
Input: candidates = [2,3,5], target = 8, A solution set is: [ [2,2,2,2], [2,3,3], [3,5] ]
classSolution { public: vector<vector<int> > result; voiddfs(vector<int>& candidates, vector<int> cur, int start, int target){ if(target == 0) { result.push_back(cur); return; } for(int i = start; i < candidates.size(); i ++) { if(candidates[i] > target) break; cur.push_back(candidates[i]); dfs(candidates, cur, i, target - candidates[i]); cur.pop_back(); } } vector<vector<int>> combinationSum(vector<int>& candidates, int target) { sort(candidates.begin(), candidates.end()); dfs(candidates, vector<int>(), 0, target); return result; } };
Leetcode40. Combination Sum II
Given a collection of candidate numbers (candidates) and a target number (target), find all unique combinations in candidates where the candidate numbers sums to target.
Each number in candidates may only be used once in the combination.
Note:
All numbers (including target) will be positive integers.
The solution set must not contain duplicate combinations.
Example 1:
1 2 3 4 5 6 7 8
Input: candidates = [10,1,2,7,6,1,5], target = 8, A solution set is: [ [1, 7], [1, 2, 5], [2, 6], [1, 1, 6] ]
Example 2:
1 2 3 4 5 6
Input: candidates = [2,5,2,1,2], target = 5, A solution set is: [ [1,2,2], [5] ]
classSolution { public: intfirstMissingPositive(vector<int>& nums){ int n = nums.size(); for(int i = 0;i < n; i ++) { if( nums[i] > 0 && nums[i] < n ) { if( nums[i] != nums[nums[i] - 1]) { swap(nums[i], nums[nums[i] - 1]); i--; } } } for (int j = 0; j < n; j ++) { if (nums[j] - 1 != j) return j + 1; } return n + 1; } };
Leetcode42. Trapping Rain Water
Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining.
The above elevation map is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In this case, 6 units of rain water (blue section) are being trapped. Thanks Marcos for contributing this image!
classSolution { public: // The key idea is based on how we compute the product. // For emaple, 1234 x 123 // 1) we first compute 1234 x 3 and save the results to the string, // 2) then we compute 1234 x 2, and notice that we will start from update // the results from 10th // 3) now 1234 x 1, update from 100th. // To make the code simple, we reverse the input string so that we can use // k = 0, 1 (10th), 2 (100th), 3 (1,000th), ... to update the results. // In the end we just reverse the string. // Time : O(len(num1) * len(num2)) string multiply(string num1, string num2){ if( num1 == "0" || num2 == "0") return"0"; if( num1 == "1") return num2; if( num2 == "1") return num1; std::reverse(num1.begin(), num1.end()); std::reverse(num2.begin(), num2.end()); string ans=""; ans.reserve(num1.size() * num2.size()); int k = 0; for(size_t i=0;i<num2.size();++i,++k){ multiply(num1, num2[i], ans, k); } std::reverse(ans.begin(), ans.end()); return ans; } inttoNumber(char c){ returnint(c - '0');} // multiple a char to a string and updat the result in the resultant string // k: the starting postion that we start to update the resultant string voidmultiply(const string& num, constchar c, std::string& res, int k){ int remain = 0; for(size_t i=0;i<num.size();++i){ int prod = toNumber(num[i]) * toNumber(c) + remain; if(res.size()<=k) { remain = prod / 10; res.push_back((prod - remain * 10)+'0'); } else{ prod += int(res[k] - '0'); remain = prod / 10; res[k] = prod - remain * 10 +'0'; } ++k; } if (remain != 0){ for(size_t i=k;i<res.size();++i){ int sum = int(res[i]-'0') + remain; remain = sum / 10; res[i] = sum - remain * 10+'0'; if (remain == 0){ break; } } if (remain != 0) res.push_back(remain+'0'); } } };
Leetcode44. Wildcard Matching
Given an input string (s) and a pattern (p), implement wildcard pattern matching with support for ‘?’ and ‘*’ where:
‘?’ Matches any single character.
‘*’ Matches any sequence of characters (including the empty sequence).
The matching should cover the entire input string (not partial).
Example 1:
1 2 3
Input: s = "aa", p = "a" Output: false Explanation: "a" does not match the entire string "aa".
Example 2:
1 2 3
Input: s = "aa", p = "*" Output: true Explanation: '*' matches any sequence.
Example 3:
1 2 3
Input: s = "cb", p = "?a" Output: false Explanation: '?' matches 'c', but the second letter is 'a', which does not match 'b'.
Example 4:
1 2 3
Input: s = "adceb", p = "*a*b" Output: true Explanation: The first '*' matches the empty sequence, while the second '*' matches the substring "dce".
classSolution { public: boolisMatch(string s, string p){ int len1 = s.length(), len2 = p.length(); bool dp[len1+1][len2+1]; memset(dp, 0, sizeof(bool)*(len1+1)*(len2+1)); dp[0][0] = true; for (int i = 1; i <= len2; i ++) if (p[i-1] == '*') dp[0][i] = dp[0][i-1]; for (int i = 1; i <= len1; i ++) for (int j = 1; j <= len2; j ++) { if (p[j-1] == '*') dp[i][j] = dp[i-1][j] || dp[i][j-1]; else dp[i][j] = (s[i-1] == p[j-1] || p[j-1] == '?') && dp[i-1][j-1]; } return dp[len1][len2]; } };
Leetcode45. Jump Game II
Given an array of non-negative integers, you are initially positioned at the first index of the array.
Each element in the array represents your maximum jump length at that position.
Your goal is to reach the last index in the minimum number of jumps.
Example:
Input: [2,3,1,1,4] Output: 2 Explanation: The minimum number of jumps to reach the last index is 2. Jump 1 step from index 0 to 1, then 3 steps to the last index. Note:
You can assume that you can always reach the last index.
You are given an n x n 2D matrix representing an image. Rotate the image by 90 degrees (clockwise).
Note: You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation.
Example 1:
1 2 3 4 5 6 7 8 9 10 11 12 13
Given input matrix = [ [1,2,3], [4,5,6], [7,8,9] ],
rotate the input matrix in-place such that it becomes: [ [7,4,1], [8,5,2], [9,6,3] ]
用递归来折半计算,每次把n缩小一半,这样n最终会缩小到0,任何数的0次方都为1,这时候再往回乘,如果此时n是偶数,直接把上次递归得到的值算个平方返回即可,如果是奇数,则还需要乘上个x的值。还有一点需要引起注意的是n有可能为负数,对于n是负数的情况,我可以先用其绝对值计算出一个结果再取其倒数即可,之前是可以的,但是现在 test case 中加了个负2的31次方后,这就不行了,因为其绝对值超过了整型最大值,会有溢出错误,不过可以用另一种写法只用一个函数,在每次递归中处理n的正负,然后做相应的变换即可。
The n-queens puzzle is the problem of placing n queens on an n × n chessboard such that no two queens attack each other.
Given an integer n, return all distinct solutions to the n-queens puzzle.
Each solution contains a distinct board configuration of the n-queens’ placement, where ‘Q’ and ‘.’ both indicate a queen and an empty space respectively.
voidsolveNQueensHelper(int n, int column, vector<string>& board, vector<vector<string>>& res){ if (column == n){// 容易错写成 column == n-1 // base case res.push_back(board); } else { for (int row = 0; row < n; row++){ if (valid_queens(board, column, row)){ // choose board[row][column] = 'Q'; // explore solveNQueensHelper(n, column + 1, board, res); // unchoose board[row][column] = '.'; } } } }
//确定棋盘上皇后位置是不是有效的 boolvalid_queens(vector<string>& board, int column, int row){ int n = board.size(); //1)x = row (横向) for(int i = 0; i < n; i++) if (board[row][i]=='Q') returnfalse;
//2) y = col(纵向):默认true
//3)col + row = y + x;(反对角线) int s = column + row; for( int i = column - 1; i >= 0 && s - i < n; i--) if (board[s-i][i]=='Q') returnfalse;
//4) col - row = y - x;(对角线) s = column - row; for (int i = column - 1; i >= 0 && i - s >= 0; i--) if (board[i-s][i] == 'Q') returnfalse; returntrue; }
Leetcode52. N-Queens II
输出上题中的结果个数。
Leetcode53. Maximum Subarray
Given an integer array nums, find the contiguous subarray (containing at least one number) which has the largest sum and return its sum.
Example:
1 2 3
Input: [-2,1,-3,4,-1,2,1,-5,4], Output: 6 Explanation: [4,-1,2,1] has the largest sum = 6.
这道题让求最大子数组之和,并且要用两种方法来解,分别是 O(n) 的解法,还有用分治法 Divide and Conquer Approach,这个解法的时间复杂度是 O(nlgn),那就先来看 O(n) 的解法,定义两个变量 res 和max_local,其中 res 保存最终要返回的结果,即最大的子数组之和,max_local 初始值为0,每遍历一个数字 num,比较 max_local + num 和 num 中的较大值存入 max_local,然后再把 res 和 max_local 中的较大值存入 res,以此类推直到遍历完整个数组,可得到最大子数组的值存在 res 中。
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution { public: intmaxSubArray(vector<int>& nums){ int res = INT_MIN, sum = 0; int size = nums.size(); int max_local = 0; for(int i = 0; i < size; i ++) { max_local = max(max_local+nums[i], nums[i]); res = max(max_local, res); } return res; } };
题目还要求我们用分治法 Divide and Conquer Approach 来解,这个分治法的思想就类似于二分搜索法,需要把数组一分为二,分别找出左边和右边的最大子数组之和,然后还要从中间开始向左右分别扫描,求出的最大值分别和左右两边得出的最大值相比较取最大的那一个。
classSolution { public: vector<int> spiralOrder(vector<vector<int>>& matrix){ vector<int> res; if(matrix.size() == 0) return res; int count = 0; int x = 0, y = 1, i = 0, j = 0; int m = matrix.size(), n = matrix[0].size(), size = m*n; int left = 0, right = 0, up = 0, down = 0; while(1) { for(int i = left; i < n - right; i ++) res.push_back(matrix[up][i]); up ++; for(int i = up; i < m - down; i ++) res.push_back(matrix[i][n-right-1]); right ++; if(up < m - down) { for(int i = n - right - 1; i >= left; i --) { res.push_back(matrix[m - down - 1][i]); } } down ++; if(left < n - right) { for(int i = m - down - 1; i >= up; i --) res.push_back(matrix[i][left]); } left ++;
if(res.size() >= size) break; } return res; } };
Leetcode55. Jump Game
Given an array of non-negative integers, you are initially positioned at the first index of the array. Each element in the array represents your maximum jump length at that position. Determine if you are able to reach the last index.
Example 1:
1 2 3
Input: nums = [2,3,1,1,4] Output: true Explanation: Jump 1 step from index 0 to 1, then 3 steps to the last index.
Example 2:
1 2 3
Input: nums = [3,2,1,0,4] Output: false Explanation: You will always arrive at index 3 no matter what. Its maximum jump length is 0, which makes it impossible to reach the last index.
classSolution { public: boolcanJump(vector<int>& nums){ int result = 0; for(int i = 0; i < nums.size() && result >= i; i ++) { result = max(nums[i] + i, result); } return result >= nums.size()-1; } };
Leetcode56. Merge Intervals
Given a collection of intervals, merge all overlapping intervals. 一些区间,要求合并重叠的区间,返回一个vector保存结果。
Example 1:
1 2 3
Input: [[1,3],[2,6],[8,10],[15,18]] Output: [[1,6],[8,10],[15,18]] Explanation: Since intervals [1,3] and [2,6] overlaps, merge them into [1,6].
Example 2:
1 2 3
Input: [[1,4],[4,5]] Output: [[1,5]] Explanation: Intervals [1,4] and [4,5] are considered overlapping.
If we draw a graph (with intervals as nodes) that contains undirected edges between all pairs of intervals that overlap, then all intervals in each connected component of the graph can be merged into a single interval.
Algorithm
With the above intuition in mind, we can represent the graph as an adjacency list, inserting directed edges in both directions to simulate undirected edges. Then, to determine which connected component each node is it, we perform graph traversals from arbitrary unvisited nodes until all nodes have been visited. To do this efficiently, we store visited nodes in a Set, allowing for constant time containment checks and insertion. Finally, we consider each connected component, merging all of its intervals by constructing a new Interval with start equal to the minimum start among them and end equal to the maximum end.
This algorithm is correct simply because it is basically the brute force solution. We compare every interval to every other interval, so we know exactly which intervals overlap. The reason for the connected component search is that two intervals may not directly overlap, but might overlap indirectly via a third interval. See the example below to see this more clearly.
Components Example
Although (1, 5) and (6, 10) do not directly overlap, either would overlap with the other if first merged with (4, 7). There are two connected components, so if we merge their nodes, we expect to get the following two merged intervals:
// build a graph where an undirected edge between intervals u and v exists // iff u and v overlap. privatevoidbuildGraph(List<Interval> intervals){ graph = new HashMap<>(); for (Interval interval : intervals) { graph.put(interval, new LinkedList<>()); }
for (Interval interval1 : intervals) { for (Interval interval2 : intervals) { if (overlap(interval1, interval2)) { graph.get(interval1).add(interval2); graph.get(interval2).add(interval1); } } } }
merged = [] for interval in intervals: # if the list of merged intervals is empty or if the current # interval does not overlap with the previous, simply append it. ifnot merged or merged[-1].end < interval.start: merged.append(interval) else: # otherwise, there is overlap, so we merge the current and previous # intervals. merged[-1].end = max(merged[-1].end, interval.end)
return merged
Leetcode57. Insert Interval
Given a set of non-overlapping intervals, insert a new interval into the intervals (merge if necessary). You may assume that the intervals were initially sorted according to their start times.
Input: intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8] Output: [[1,2],[3,10],[12,16]] Explanation: Because the new interval [4,8] overlaps with [3,5],[6,7],[8,10].
NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
这道题让我们在一系列非重叠的区间中插入一个新的区间,可能还需要和原有的区间合并,可以对给定的区间集进行一个一个的遍历比较,那么会有两种情况,重叠或是不重叠,不重叠的情况最好,直接将新区间插入到对应的位置即可,重叠的情况比较复杂,有时候会有多个重叠,需要更新新区间的范围以便包含所有重叠,之后将新区间加入结果 res,最后将后面的区间再加入结果 res 即可。具体思路是,用一个变量 cur 来遍历区间,如果当前 cur 区间的结束位置小于要插入的区间的起始位置的话,说明没有重叠,则将 cur 区间加入结果 res 中,然后 cur 自增1。直到有 cur 越界或有重叠 while 循环退出,然后再用一个 while 循环处理所有重叠的区间,每次用取两个区间起始位置的较小值,和结束位置的较大值来更新要插入的区间,然后 cur 自增1。直到 cur 越界或者没有重叠时 while 循环退出。之后将更新好的新区间加入结果 res,然后将 cur 之后的区间再加入结果 res 中即可,参见代码如下:
Given a string s consists of upper/lower-case alphabets and empty space characters ‘ ‘, return the length of last word (last word means the last appearing word if we loop from left to right) in the string. If the last word does not exist, return 0.
Note: A word is defined as a maximal substring consisting of non-space characters only.
classSolution { public: voidturn(int &x, int &y){ if(x==0 && y==1) x=1,y=0; elseif(x==0 && y==-1) x=-1,y=0; elseif(x==1 && y==0) x=0,y=-1; elseif(x==-1 && y==0) x=0,y=1; } vector<vector<int>> generateMatrix(int n) { int x_dir = 0, y_dir = 1; int x = 0, y = 0; vector<vector<int>> result(n, vector<int>(n, 0)); for(int i = 1; i <= n*n; i ++) { result[x][y] = i; if(x+x_dir<0 || x+x_dir>=n || y+y_dir<0 || y+y_dir>=n || result[x+x_dir][y+y_dir]) turn(x_dir, y_dir); x += x_dir; y += y_dir; } return result; } };
Leetcode60. Permutation Sequence
The set [1,2,3,…,n] contains a total of n! unique permutations. By listing and labeling all of the permutations in order, we get the following sequence for n = 3:
1 2 3 4 5 6
"123" "132" "213" "231" "312" "321"
Given n and k, return the kth permutation sequence.
Note:
Given n will be between 1 and 9 inclusive.
Given k will be between 1 and n! inclusive.
Example 1:
1 2
Input: n = 3, k = 3 Output: "213"
Example 2:
1 2
Input: n = 4, k = 9 Output: "2314"
这道题是让求出n个数字的第k个排列组合,由于其特殊性,我们不用将所有的排列组合的情况都求出来,然后返回其第k个,这里可以只求出第k个排列组合即可,那么难点就在于如何知道数字的排列顺序。首先要知道当 n = 3 时,其排列组合共有 3! = 6 种,当 n = 4 时,其排列组合共有 4! = 24 种,这里就以 n = 4, k = 17 的情况来分析,所有排列组合情况如下:
classSolution { public: string getPermutation(int n, int k){ string res; string num = "123456789"; vector<int> f(n, 1); k --; for(int i = 1; i < n; i ++) { f[i] = f[i-1] * i; } for(int i = n; i >= 1; i --) { int j = k / f[i-1]; k %= f[i - 1]; res.push_back(num[j]); num.erase(j, 1); } return res; } };
Leetcode61. Rotate List
Given a linked list, rotate the list to the right by k places, where k is non-negative.
Example 1:
1 2 3 4 5
Input: 1->2->3->4->5->NULL, k = 2 Output: 4->5->1->2->3->NULL Explanation: rotate 1 steps to the right: 5->1->2->3->4->NULL rotate 2 steps to the right: 4->5->1->2->3->NULL
Example 2:
1 2 3 4 5 6 7
Input: 0->1->2->NULL, k = 4 Output: 2->0->1->NULL Explanation: rotate 1 steps to the right: 2->0->1->NULL rotate 2 steps to the right: 1->2->0->NULL rotate 3 steps to the right: 0->1->2->NULL rotate 4 steps to the right: 2->0->1->NULL
先遍历一次链表,将尾部和头部相连,再进行移动。注意右移k步相当于prehead travel len - k步。
A robot is located at the top-left corner of a m x n grid (marked ‘Start’ in the diagram below).
The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked ‘Finish’ in the diagram below).
How many possible unique paths are there?
Example 1:
1 2
Input: m = 3, n = 2 Output: 3
Explanation: From the top-left corner, there are a total of 3 ways to reach the bottom-right corner:
classSolution { public: intuniquePaths(int m, int n){ int dp[m+1][n+1]; for(int i=0;i<=m;i++) dp[i][0] = 0; for(int i=0;i<=n;i++) dp[0][i] = 0; for(int i = 1; i <= m; ++i) { for(int j = 1; j <= n; ++j) { if(i==1 && j==1) dp[i][j]=1; else dp[i][j] = dp[i-1][j] + dp[i][j - 1]; } } return dp[m][n]; } };
Leetcode63. Unique Paths II
A robot is located at the top-left corner of a m x n grid (marked ‘Start’ in the diagram below).
The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked ‘Finish’ in the diagram below).
Now consider if some obstacles are added to the grids. How many unique paths would there be?
Note: m and n will be at most 100.
Example 1:
1 2 3 4 5 6 7
Input: [ [0,0,0], [0,1,0], [0,0,0] ] Output: 2
Explanation: There is one obstacle in the middle of the 3x3 grid above.
There are two ways to reach the bottom-right corner:
Right -> Right -> Down -> Down
Down -> Down -> Right -> Right
第62题(Unique Paths)的升级版. 现在需要考虑如果表格中存在一些障碍,那么所要求的路径数还有多少条? 在表格表示中,1表示此位置有障碍,0表示没有. 例如在一个3 x 3的表格中存在一个障碍物,
[ [0,0,0], [0,1,0], [0,0,0] ] 求得最终的路径数为2. 注意:m 和 n 均不超过100.
classSolution { public: voiddfs(vector<vector<int>>& grid, int x, int y, int cur, int& res){ int dir[2][2] = {{1, 0}, {0, 1}}; if(x == grid.size() - 1 && y == grid[0].size()-1) { res = min(res, cur); return; } for(int i = 0; i < 2; i ++) { int tmp_x = x + dir[i][0]; int tmp_y = y + dir[i][1]; if(!(0 <= tmp_x && tmp_x < grid.size() && 0 <= tmp_y && tmp_y < grid[0].size() )) continue; cur += grid[tmp_x][tmp_y]; if(cur >= res) { cur -= grid[tmp_x][tmp_y]; continue; } dfs(grid, tmp_x, tmp_y, cur, res); cur -= grid[tmp_x][tmp_y]; } } intminPathSum(vector<vector<int>>& grid){ int res = 999999; dfs(grid, 0, 0, grid[0][0], res); return res; } };
看这情况要上dp了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: intminPathSum(vector<vector<int>>& grid){ int m = grid.size(), n = grid[0].size(); for(int i = 1; i < m; i ++) grid[i][0] += grid[i-1][0]; for(int i = 1; i < n; i ++) grid[0][i] += grid[0][i-1]; for(int i = 1; i < m; i ++) for(int j = 1; j < n; j ++) grid[i][j] = min(grid[i-1][j], grid[i][j-1]) + grid[i][j]; return grid[m-1][n-1]; } };
Leetcode65. Valid Number
A valid number can be split up into these components (in order):
A decimal number or an integer.
(Optional) An ‘e’ or ‘E’, followed by an integer.
A decimal number can be split up into these components (in order):
(Optional) A sign character (either ‘+’ or ‘-‘).
One of the following formats:
One or more digits, followed by a dot ‘.’.
One or more digits, followed by a dot ‘.’, followed by one or more digits.
A dot ‘.’, followed by one or more digits.
An integer can be split up into these components (in order):
(Optional) A sign character (either ‘+’ or ‘-‘).
One or more digits.
For example, all the following are valid numbers: [“2”, “0089”, “-0.1”, “+3.14”, “4.”, “-.9”, “2e10”, “-90E3”, “3e+7”, “+6e-1”, “53.5e93”, “-123.456e789”], while the following are not valid numbers: [“abc”, “1a”, “1e”, “e3”, “99e2.5”, “–6”, “-+3”, “95a54e53”].
Given a string s, return true if s is a valid number.
Given a non-empty array of digits representing a non-negative integer, plus one to the integer.
The digits are stored such that the most significant digit is at the head of the list, and each element in the array contain a single digit. You may assume the integer does not contain any leading zero, except the number 0 itself.
Example 1:
1 2 3
Input: [1,2,3] Output: [1,2,4] Explanation: The array represents the integer 123.
Example 2:
1 2 3
Input: [4,3,2,1] Output: [4,3,2,2] Explanation: The array represents the integer 4321.
classSolution { public: string addBinary(string a, string b){ string res = ""; int aa = a.length() - 1; int bb = b.length() - 1; int carry = 0; int sum = 0; while(aa >= 0 || bb >= 0 || carry) { sum = carry; if(aa >= 0) sum += (a[aa--] - '0'); if(bb >= 0) sum += (b[bb--] - '0'); res = to_string(sum%2) + res; carry = sum / 2; } return res; } };
Leetcode68. Text Justification
Given an array of words and a width maxWidth, format the text such that each line has exactly maxWidth characters and is fully (left and right) justified.
You should pack your words in a greedy approach; that is, pack as many words as you can in each line. Pad extra spaces ‘ ‘ when necessary so that each line has exactly maxWidth characters.
Extra spaces between words should be distributed as evenly as possible. If the number of spaces on a line do not divide evenly between words, the empty slots on the left will be assigned more spaces than the slots on the right.
For the last line of text, it should be left justified and no extra space is inserted between words.
Note:
A word is defined as a character sequence consisting of non-space characters only.
Each word’s length is guaranteed to be greater than 0 and not exceed maxWidth.
The input array words contains at least one word.
Example 1:
1 2 3 4 5 6 7
Input: words = ["This", "is", "an", "example", "of", "text", "justification."], maxWidth = 16 Output: [ "This is an", "example of text", "justification. " ]
Example 2:
1 2 3 4 5 6 7 8 9
Input: words = ["What","must","be","acknowledgment","shall","be"], maxWidth = 16 Output: [ "What must be", "acknowledgment ", "shall be " ] Explanation: Note that the last line is "shall be " instead of "shall be", because the last line must be left-justified instead of fully-justified. Note that the second line is also left-justified becase it contains only one word.
Example 3:
1 2 3 4 5 6 7 8 9 10
Input: words = ["Science","is","what","we","understand","well","enough","to","explain","to","a","computer.","Art","is","everything","else","we","do"], maxWidth = 20 Output: [ "Science is what we", "understand well", "enough to explain to", "a computer. Art is", "everything else we", "do " ]
由于返回的结果是多行的,所以我们在处理的时候也要一行一行的来处理,首先要做的就是确定每一行能放下的单词数,这个不难,就是比较n个单词的长度和加上n - 1个空格的长度跟给定的长度L来比较即可,找到了一行能放下的单词个数,然后计算出这一行存在的空格的个数,是用给定的长度L减去这一行所有单词的长度和。得到了空格的个数之后,就要在每个单词后面插入这些空格,这里有两种情况,比如某一行有两个单词”to” 和 “a”,给定长度L为6,如果这行不是最后一行,那么应该输出”to a”,如果是最后一行,则应该输出 “to a “,所以这里需要分情况讨论,最后一行的处理方法和其他行之间略有不同。最后一个难点就是,如果一行有三个单词,这时候中间有两个空,如果空格数不是2的倍数,那么左边的空间里要比右边的空间里多加入一个空格,那么我们只需要用总的空格数除以空间个数,能除尽最好,说明能平均分配,除不尽的话就多加个空格放在左边的空间里。
classSolution { public: vector<string> fullJustify(vector<string> &words, int L){ vector<string> res; int i = 0; while (i < words.size()) { int j = i, len = 0; while (j < words.size() && len + words[j].size() + j - i <= L) { len += words[j++].size(); } string out; int space = L - len; for (int k = i; k < j; ++k) { out += words[k]; if (space > 0) { int tmp; if (j == words.size()) { if (j - k == 1) tmp = space; else tmp = 1; } else { if (j - k - 1 > 0) { if (space % (j - k - 1) == 0) tmp = space / (j - k - 1); else tmp = space / (j - k - 1) + 1; } else tmp = space; } out.append(tmp, ' '); space -= tmp; } } res.push_back(out); i = j; } return res; } };
Leetcode69. Sqrt(x)
Implement int sqrt(int x). Compute and return the square root of x, where x is guaranteed to be a non-negative integer.
Since the return type is an integer, the decimal digits are truncated and only the integer part of the result is returned.
Example 1:
1 2
Input: 4 Output: 2
Example 2:
1 2 3 4
Input: 8 Output: 2 Explanation: The square root of 8 is 2.82842..., and since the decimal part is truncated, 2 is returned.
进一步优化:根据推导公式不难发现,我们要求的结果就是数组的最后一项,而最后一项又是前面数值叠加起来的,那么我们只需要两个变量保存 i - 1 和 i - 2 的值就可以了.
1 2 3 4 5 6 7 8 9 10 11 12
var climbStairs = function(n) { if (n == 1) { return1; } let first = 1, second = 2; for (let i = 3; i <= n; i++) { let third = first + second; first = second; second = third; } return second; }
复杂度分析
时间复杂度:O(n),单循环到 n。
空间复杂度:O(1),用到了常量的空间。
Leetcode71. Simplify Path
Given an absolute path for a file (Unix-style), simplify it. Or in other words, convert it to the canonical path.
In a UNIX-style file system, a period . refers to the current directory. Furthermore, a double period .. moves the directory up a level.
Note that the returned canonical path must always begin with a slash /, and there must be only a single slash / between two directory names. The last directory name (if it exists) must not end with a trailing /. Also, the canonical path must be the shortest string representing the absolute path.
Example 1:
1 2 3
Input: "/home/" Output: "/home" Explanation: Note that there is no trailing slash after the last directory name.
Example 2:
1 2 3
Input: "/../" Output: "/" Explanation: Going one level up from the root directory is a no-op, as the root level is the highest level you can go.
Example 3:
1 2 3
Input: "/home//foo/" Output: "/home/foo" Explanation: In the canonical path, multiple consecutive slashes are replaced by a single one.
classSolution { public: boolsearchMatrix(vector<vector<int>>& matrix, int target){ if (matrix.empty() || matrix[0].empty()) returnfalse; int m = matrix.size(), n = matrix[0].size(); int left = 0, right = m; while(left < right) { int mid = left + (right - left) / 2; if(matrix[mid][0] == target) returntrue; elseif(matrix[mid][0] >= target) right = mid; else left = mid + 1; } int right1 = right > 0 ? right - 1 : right; left = 0, right = n; while(left < right) { int mid = left + (right - left) / 2; if(matrix[right1][mid] == target) returntrue; elseif(matrix[right1][mid] >= target) right = mid; else left = mid + 1; } returnfalse; } };
Leetcode75. Sort Colors
Given an array with n objects colored red, white or blue, sort them in-place so that objects of the same color are adjacent, with the colors in the order red, white and blue.
Here, we will use the integers 0, 1, and 2 to represent the color red, white, and blue respectively.
Note: You are not suppose to use the library sort function for this problem.
Example:
1 2
Input: [2,0,2,1,1,0] Output: [0,0,1,1,2,2]
Follow up:
A rather straight forward solution is a two-pass algorithm using counting sort.
First, iterate the array counting number of 0s, 1s, and 2s, then overwrite array with total number of 0s, then 1s and followed by 2s.
Could you come up with a one-pass algorithm using only constant space?
voiddfs(int n, int k, int i, vector<int> temp){ if(temp.size() == k) { res.push_back(temp); return; } printf("af");
for(int ii = i + 1; ii <= n; ii ++) { int t = temp.size(); temp.push_back(ii); dfs(n, k, ii, temp); temp.erase(temp.begin()+t); } } vector<vector<int>> combine(int n, int k) { vector<int> temp(0); dfs(n, k, 0, temp); return res; } };
Given a 2D board and a word, find if the word exists in the grid.
The word can be constructed from letters of sequentially adjacent cell, where “adjacent” cells are those horizontally or vertically neighboring. The same letter cell may not be used more than once.
classSolution { public: int m, n; boolsearch(vector<vector<char>>& board, int i, int j, int k, string word, vector<vector<bool>>& visited){ if(word.length() == k) { returntrue; } int m = board.size(), n = board[0].size(); if (i < 0 || j < 0 || i >= m || j >= n || visited[i][j] || board[i][j] != word[k]) returnfalse; visited[i][j] = true; bool res = search(board, i - 1, j, k + 1, word, visited) || search(board, i + 1, j, k + 1, word, visited) || search(board, i, j - 1, k + 1, word, visited) || search(board, i, j + 1, k + 1, word, visited); visited[i][j] = false; return res; } boolexist(vector<vector<char>>& board, string word){ m = board.size(), n = board[0].size(); vector<vector<bool>> visited(m, vector<bool>(n)); for(int i = 0; i < m; i ++) for(int j = 0; j < n; j ++) visited[i][j] = false; for(int i = 0; i < m; i ++) for(int j = 0; j < n; j ++) if(search(board, i, j, 0, word, visited)) returntrue; returnfalse; } };
Leetcode80. Remove Duplicates from Sorted Array II
Given a sorted array nums, remove the duplicates in-place such that duplicates appeared at most twice and return the new length.
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.
Example 1: Given nums = [1,1,1,2,2,3], Your function should return length = 5, with the first five elements of nums being 1, 1, 2, 2 and 3 respectively. It doesn not matter what you leave beyond the returned length.
Example 2: Given nums = [0,0,1,1,1,1,2,3,3], Your function should return length = 7, with the first seven elements of nums being modified to 0, 0, 1, 1, 2, 3 and 3 respectively.
Clarification: Confused why the returned value is an integer but your answer is an array? Note that the input array is passed in by reference, which means modification to the input array will be known to the caller as well. Internally you can think of this:
1 2 3 4 5 6 7 8
// nums is passed in by reference. (i.e., without making a copy) int len = removeDuplicates(nums);
// any modification to nums in your function would be known by the caller. // using the length returned by your function, it prints the first len elements. for (int i = 0; i < len; i++) { print(nums[i]); }
Given n non-negative integers representing the histogram’s bar height where the width of each bar is 1, find the area of largest rectangle in the histogram.
Above is a histogram where width of each bar is 1, given height = [2,1,5,6,2,3].
The largest rectangle is shown in the shaded area, which has area = 10 unit.
Example:
1 2
Input: [2,1,5,6,2,3] Output: 10
这里维护一个栈,用来保存递增序列,相当于上面那种方法的找局部峰值。我们可以看到,直方图矩形面积要最大的话,需要尽可能的使得连续的矩形多,并且最低一块的高度要高。有点像木桶原理一样,总是最低的那块板子决定桶的装水量。那么既然需要用单调栈来做,首先要考虑到底用递增栈,还是用递减栈来做。我们想啊,递增栈是维护递增的顺序,当遇到小于栈顶元素的数就开始处理,而递减栈正好相反,维护递减的顺序,当遇到大于栈顶元素的数开始处理。那么根据这道题的特点,我们需要按从高板子到低板子的顺序处理,先处理最高的板子,宽度为1,然后再处理旁边矮一些的板子,此时长度为2,因为之前的高板子可组成矮板子的矩形 ,因此我们需要一个递增栈,当遇到大的数字直接进栈,而当遇到小于栈顶元素的数字时,就要取出栈顶元素进行处理了,那取出的顺序就是从高板子到矮板子了,于是乎遇到的较小的数字只是一个触发,表示现在需要开始计算矩形面积了,为了使得最后一块板子也被处理,这里用了个小 trick,在高度数组最后面加上一个0,这样原先的最后一个板子也可以被处理了。由于栈顶元素是矩形的高度,那么关键就是求出来宽度,那么跟之前那道 Trapping Rain Water 一样,单调栈中不能放高度,而是需要放坐标。由于我们先取出栈中最高的板子,那么就可以先算出长度为1的矩形面积了,然后再取下一个板子,此时根据矮板子的高度算长度为2的矩形面积,以此类推,知道数字大于栈顶元素为止,再次进栈。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution { public: intlargestRectangleArea(vector<int>& heights){ stack<int> s; int res = 0; heights.push_back(0); for(int i = 0; i < heights.size(); i ++) { if(s.empty() || heights[s.top()] < heights[i]) s.push(i); else { int cur = s.top(); s.pop(); res = max(res, heights[cur]*(s.empty() ? i : (i - s.top() - 1))); i --; } } return res; } };
classSolution { public: intlargestRectangleArea(vector<int>& heights){ int res = 0; for(int i = 0; i < heights.size(); i ++) { if(i + 1 < heights.size() && heights[i] <= heights[i+1]) continue; int minn = heights[i]; for(int k = i; k >= 0; k --) { minn = min(heights[k], minn); int area = minn * (i - k + 1); res = max(res, area); } } return res; } };
//解法3:动态规划2:时间复杂度O(NM)[],空间复杂度O(N) intmaximalRectangle(vector<vector<char>>& matrix){ if (matrix.size() == 0) return0; int m = matrix.size(); int n = matrix[0].size(); //分别存储每一行上元素对应的最大矩形的高度以及左右区间 vector<int> left(n, 0);//最大的左边界为左端 vector<int> right(n, n);//最大的有边界为右端 vector<int> height(n, 0);
int maxarea = 0; for (int i = 0; i < m; i++) { int cur_left = 0, cur_right = n; //更新高度,最后存储在height数组的就是每一列‘1’的个数 for (int j = 0; j < n; j++) { if (matrix[i][j] == '1') height[j]++; else height[j] = 0; } //更新左边界, for (int j = 0; j < n; j++) { if (matrix[i][j] == '1') left[j] = max(left[j], cur_left); else { left[j] = 0; cur_left = j + 1; } } //更新右边界 for (int j = n - 1; j >= 0; j--) { if (matrix[i][j] == '1') right[j] = min(right[j], cur_right); else { right[j] = n; cur_right = j; } } for (int j = 0; j < n; j++) { maxarea = max(maxarea, (right[j] - left[j]) * height[j]); } } return maxarea; }
Leetcode86. Partition List
Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x. You should preserve the original relative order of the nodes in each of the two partitions.
Example:
1 2
Input: head = 1->4->3->2->5->2, x = 3 Output: 1->2->2->4->3->5
Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array.
Note:
The number of elements initialized in nums1 and nums2 are m and n respectively. You may assume that nums1 has enough space (size that is greater or equal to m + n) to hold additional elements from nums2. Example:
Input: nums1 = [1,2,3,0,0,0], m = 3 nums2 = [2,5,6], n = 3
classSolution { public: voidmerge(vector<int>& nums1, int m, vector<int>& nums2, int n){ if(n==0) return; if(m==0) { for(int i=0;i<n;i++) nums1[i] = nums2[i]; return ; } int pointer = 0; for(int i = 0; i < n; i ++) { for(; pointer < m; pointer ++) if(nums2[i] < nums1[pointer]) break; for(int ii = m; ii > pointer; ii --) nums1[ii] = nums1[ii - 1]; m++; nums1[pointer] = nums2[i]; } } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: voidmerge(vector<int>& nums1, int m, vector<int>& nums2, int n){ int i = m - 1; int j = n - 1; int k = m + n - 1; while(i >= 0 && j >= 0) { if(nums1[i] >= nums2[j]) nums1[k--] = nums1[i--]; else nums1[k--] = nums2[j--]; } while(j >= 0) nums1[k--] = nums2[j--]; } };
Leetcode89. Gray Code
The gray code is a binary numeral system where two successive values differ in only one bit.
Given a non-negative integer n representing the total number of bits in the code, print the sequence of gray code. A gray code sequence must begin with 0.
For a given n, a gray code sequence may not be uniquely defined. For example, [0,2,3,1] is also a valid gray code sequence.
00 - 0 10 - 2 11 - 3 01 - 1
Example 2:
1 2 3 4 5
Input: 0 Output: [0] Explanation: We define the gray code sequence to begin with 0. A gray code sequence of n has size = 2n, which for n = 0 the size is 20 = 1. Therefore, for n = 0 the gray code sequence is [0].
蓝色部分由于最高位加的是 0 ,所以它的数值和 n = 2 的所有解的情况一样。而橙色部分由于最高位加了 1,所以值的话,就是在其对应的值上加 4,也就是 [公式] ,即 [公式] ,也就是 1 << ( n - 1) 。所以我们的算法可以用迭代求出来了。
classSolution { public: ListNode* reverseBetween(ListNode* head, int m, int n){ int count = 0; ListNode *res = newListNode(-1, head); ListNode *pre = res, *cur = pre; for(count = 0; count < m; count ++) { pre = cur; cur = cur->next; } for(count = m; count < n; count ++) { ListNode *temp = cur->next; cur->next = temp->next; temp->next = pre->next; pre->next = temp; } return res->next; } };
Leetcode93. Restore IP Addresses
Given a string containing only digits, restore it by returning all possible valid IP address combinations. A valid IP address consists of exactly four integers (each integer is between 0 and 255) separated by single points.
Explanation: The above output corresponds to the 5 unique BST’s shown below:
1 2 3 4 5
1 3 3 2 1 \ / / / \ \ 3 2 1 1 3 2 / / \ \ 2 1 2 3
这种建树问题一般来说都是用递归来解,这道题也不例外,划分左右子树,递归构造。这个其实是用到了大名鼎鼎的分治法 Divide and Conquer,类似的题目还有之前的那道 Different Ways to Add Parentheses 用的方法一样,用递归来解,划分左右两个子数组,递归构造。刚开始时,将区间 [1, n] 当作一个整体,然后需要将其中的每个数字都当作根结点,其划分开了左右两个子区间,然后分别调用递归函数,会得到两个结点数组,接下来要做的就是从这两个数组中每次各取一个结点,当作当前根结点的左右子结点,然后将根结点加入结果 res 数组中即可。
Given a binary tree, determine if it is a valid binary search tree (BST).
Assume a BST is defined as follows:
The left subtree of a node contains only nodes with keys less than the node’s key. The right subtree of a node contains only nodes with keys greater than the node’s key. Both the left and right subtrees must also be binary search trees.
Example 1:
1 2 3 4 5
2 / \ 1 3 Input: [2,1,3] Output: true
Example 2:
1 2 3 4 5 6 7 8
5 / \ 1 4 / \ 3 6 Input: [5,1,4,null,null,3,6] Output: false Explanation: The root node's value is 5 but its right child's value is 4.
You are given the root of a binary search tree (BST), where exactly two nodes of the tree were swapped by mistake. Recover the tree without changing its structure.
Follow up: A solution using O(n) space is pretty straight forward. Could you devise a constant space solution?
Example 1:
1 2 3
Input: root = [1,3,null,null,2] Output: [3,1,null,null,2] Explanation: 3 cannot be a left child of 1 because 3 > 1. Swapping 1 and 3 makes the BST valid.
Example 2:
1 2 3
Input: root = [3,1,4,null,null,2] Output: [2,1,4,null,null,3] Explanation: 2 cannot be in the right subtree of 3 because 2 < 3. Swapping 2 and 3 makes the BST valid.
这道题要求我们复原一个二叉搜索树,说是其中有两个的顺序被调换了。用双指针来代替一维向量的,但是这种方法用到了递归,也不是 O(1) 空间复杂度的解法,这里需要三个指针,first,second 分别表示第一个和第二个错乱位置的节点,pre 指向当前节点的中序遍历的前一个节点。这里用传统的中序遍历递归来做,不过再应该输出节点值的地方,换成了判断 pre 和当前节点值的大小,如果 pre 的大,若 first 为空,则将 first 指向 pre 指的节点,把 second 指向当前节点。这样中序遍历完整个树,若 first 和 second 都存在,则交换它们的节点值即可。这个算法的空间复杂度仍为 O(n),n为树的高度。
Given two binary trees, write a function to check if they are the same or not. Two binary trees are considered the same if they are structurally identical and the nodes have the same value.
We start at some node in a directed graph, and every turn, we walk along a directed edge of the graph. If we reach a terminal node (that is, it has no outgoing directed edges), we stop.
We define a starting node to be safe if we must eventually walk to a terminal node. More specifically, there is a natural number k, so that we must have stopped at a terminal node in less than k steps for any choice of where to walk.
Return an array containing all the safe nodes of the graph. The answer should be sorted in ascending order.
The directed graph has n nodes with labels from 0 to n - 1, where n is the length of graph. The graph is given in the following form: graph[i] is a list of labels j such that (i, j) is a directed edge of the graph, going from node i to node j.
Example 1:
1 2 3 4
Illustration of graph Input: graph = [[1,2],[2,3],[5],[0],[5],[],[]] Output: [2,4,5,6] Explanation: The given graph is shown above.
classSolution { public: // -1: unknow, 1: safe, 2: visiting, 3: unsafe vector<int> eventualSafeNodes(vector<vector<int>>& graph){ int size = graph.size(); vector<int> safe(size, -1); vector<int> res; for (int i = 0; i < size; i ++) { if (helper(graph, safe, i) == 1) res.push_back(i); } return res; } inthelper(vector<vector<int>>& graph, vector<int>& safe, int cur){ if (safe[cur] == 2) return safe[cur] = 3; if (safe[cur] != -1) return safe[cur]; safe[cur] = 2; for (int i = 0; i < graph[cur].size(); i ++) if (helper(graph, safe, graph[cur][i]) == 3) return safe[cur] = 3; return safe[cur] = 1; } };
Leetcode804. Unique Morse Code Words
International Morse Code defines a standard encoding where each letter is mapped to a series of dots and dashes, as follows: “a” maps to “.-“, “b” maps to “-…”, “c” maps to “-.-.”, and so on.
For convenience, the full table for the 26 letters of the English alphabet is given below:
[“.-“,”-…”,”-.-.”,”-..”,”.”,”..-.”,”–.”,”….”,”..”,”.—“,”-.-“,”.-..”,”–”,”-.”,”—“,”.–.”,”–.-“,”.-.”,”…”,”-“,”..-“,”…-“,”.–”,”-..-“,”-.–”,”–..”] Now, given a list of words, each word can be written as a concatenation of the Morse code of each letter. For example, “cba” can be written as “-.-..–…”, (which is the concatenation “-.-.” + “-…” + “.-“). We’ll call such a concatenation, the transformation of a word.
Return the number of different transformations among all words we have.
Example:
1 2 3 4 5 6 7 8
Input: words = ["gin", "zen", "gig", "msg"] Output: 2 Explanation: The transformation of each word is: "gin" -> "--...-." "zen" -> "--...-." "gig" -> "--...--." "msg" -> "--...--."
There are 2 different transformations, “–…-.” and “–…–.”. Note:
We are to write the letters of a given string S, from left to right into lines. Each line has maximum width 100 units, and if writing a letter would cause the width of the line to exceed 100 units, it is written on the next line. We are given an array widths, an array where widths[0] is the width of ‘a’, widths[1] is the width of ‘b’, …, and widths[25] is the width of ‘z’.
Now answer two questions: how many lines have at least one character from S, and what is the width used by the last such line? Return your answer as an integer list of length 2.
Example :
1 2 3 4 5 6 7
Input: widths = [10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10] S = "abcdefghijklmnopqrstuvwxyz" Output: [3, 60] Explanation: All letters have the same length of 10. To write all 26 letters, we need two full lines and one line with 60 units.
Example :
1 2 3 4 5 6 7 8 9 10
Input: widths = [4,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10] S = "bbbcccdddaaa" Output: [2, 4] Explanation: All letters except 'a' have the same length of 10, and "bbbcccdddaa" will cover 9 * 10 + 2 * 4 = 98 units. For the last 'a', it is written on the second line because there is only 2 units left in the first line. So the answer is 2 lines, plus 4 units in the second line.
classSolution { public: vector<int> numberOfLines(vector<int>& widths, string S){ int res=1; int cur=0; for(int i=0;i<S.length();i++){ int width = widths[S[i]-'a']; res = cur + width > 100 ? res+1 : res; cur = cur + width > 100 ? width : cur+width; } return {res,cur}; } };
Leetcode807. Max Increase to Keep City Skyline
In a 2 dimensional array grid, each value grid[i][j] represents the height of a building located there. We are allowed to increase the height of any number of buildings, by any amount (the amounts can be different for different buildings). Height 0 is considered to be a building as well.
At the end, the “skyline” when viewed from all four directions of the grid, i.e. top, bottom, left, and right, must be the same as the skyline of the original grid. A city’s skyline is the outer contour of the rectangles formed by all the buildings when viewed from a distance. See the following example.
What is the maximum total sum that the height of the buildings can be increased?
classSolution { public: intmaxIncreaseKeepingSkyline(vector<vector<int>>& grid){ int length = grid[0].size(); int* topmax,*leftmax; topmax = (int*)malloc(sizeof(int)*length); leftmax = (int*)malloc(sizeof(int)*length); for(int i = 0; i < length; i ++) topmax[i] = leftmax[i] = 0; for(int i = 0; i < length; i ++) for(int j = 0; j < length; j ++){ if(grid[i][j] > topmax[i]) topmax[i] = grid[i][j]; if(grid[i][j] > leftmax[j]) leftmax[j] = grid[i][j]; } int result = 0; for(int i = 0; i < length; i ++) for(int j = 0; j < length; j ++) result += ((leftmax[j] > topmax[i] ? topmax[i] : leftmax[j]) - grid[i][j]); return result; } };
Leetcode808. Soup Servings
There are two types of soup: type A and type B. Initially we have N ml of each type of soup. There are four kinds of operations:
Serve 100 ml of soup A and 0 ml of soup B
Serve 75 ml of soup A and 25 ml of soup B
Serve 50 ml of soup A and 50 ml of soup B
Serve 25 ml of soup A and 75 ml of soup B
When we serve some soup, we give it to someone and we no longer have it. Each turn, we will choose from the four operations with equal probability 0.25. If the remaining volume of soup is not enough to complete the operation, we will serve as much as we can. We stop once we no longer have some quantity of both types of soup.
Note that we do not have the operation where all 100 ml’s of soup B are used first.
Return the probability that soup A will be empty first, plus half the probability that A and B become empty at the same time.
Example:
1 2 3 4
Input: N = 50 Output: 0.625 Explanation: If we choose the first two operations, A will become empty first. For the third operation, A and B will become empty at the same time. For the fourth operation, B will become empty first. So the total probability of A becoming empty first plus half the probability that A and B become empty at the same time, is 0.25 * (1 + 1 + 0.5 + 0) = 0.625.
Notes:
0 <= N <= 10^9.
Answers within 10^-6 of the true value will be accepted as correct.
自己当初写的代码的思路是对的,但是细节实现上没考虑周全。这里还是参考了网上代码的总结:
我们在这里采用的方法严格来讲是DFS + memorization,也就是需要计算一个子问题的时候,我们首先在表格中查找,看看原来有没有被计算过,如果被计算过,则直接返回结果,否则就再重新计算,并将结果保存在表格中。这样的好处是没必要计算每个子问题,只计算递归过程中用到的子问题。如果我们定义f(a, b)表示有a毫升的A和b毫升的B时符合条件的概率,那么容易知道递推公式就是:f(a, b) = 0.25 * (f(a - 4, b) + f(a - 3, b - 1) + f(a - 2, b - 2) + f(a - 1, b - 3)),其中平凡条件是:
classSolution { public: doublesoupServings(int N){ int n = ceil(N / 25.0); return N >= 4800 ? 1.0 : f(n, n); } private: doublef(int a, int b){ if (a <= 0 && b <= 0) { return0.5; } if (a <= 0) { return1; } if (b <= 0) { return0; } if (memo[a][b] > 0) { return memo[a][b]; } memo[a][b] = 0.25 * (f(a - 4, b) + f(a - 3, b - 1) + f(a - 2, b - 2) + f(a - 1, b - 3)); return memo[a][b]; } double memo[200][200]; };
Leetcode809. Expressive Words
Sometimes people repeat letters to represent extra feeling. For example:
1 2
"hello" -> "heeellooo" "hi" -> "hiiii"
In these strings like “heeellooo”, we have groups of adjacent letters that are all the same: “h”, “eee”, “ll”, “ooo”.
You are given a string s and an array of query strings words. A query word is stretchy if it can be made to be equal to s by any number of applications of the following extension operation: choose a group consisting of characters c, and add some number of characters c to the group so that the size of the group is three or more.
For example, starting with “hello”, we could do an extension on the group “o” to get “hellooo”, but we cannot get “helloo” since the group “oo” has a size less than three. Also, we could do another extension like “ll” -> “lllll” to get “helllllooo”. If s = “helllllooo”, then the query word “hello” would be stretchy because of these two extension operations: query = “hello” -> “hellooo” -> “helllllooo” = s. Return the number of query strings that are stretchy.
Example 1:
1 2 3 4 5
Input: s = "heeellooo", words = ["hello", "hi", "helo"] Output: 1 Explanation: We can extend "e" and "o" in the word "hello" to get "heeellooo". We can't extend "helo" to get "heeellooo" because the group "ll" is not size 3 or more.
Example 2:
1 2
Input: s = "zzzzzyyyyy", words = ["zzyy","zy","zyy"] Output: 3
classSolution { public: intexpressiveWords(string s, vector<string>& words){ int res = 0; bool legal = true; int len = s.length(); for (string word : words) { int len2 = word.length(); legal = true; if (len < len2) continue; int p1 = 0, p2 = 0; while (p1 < len && p2 < len2) { if (s[p1] == word[p2]) { int t1 = 1, t2 = 1; while (p1 < len-1 && s[p1] == s[p1+1]) { t1 ++; p1 ++; } while (p2 < len2-1 && word[p2] == word[p2+1]) { t2 ++; p2 ++; } if (t1 == 2 && t1 - t2 == 1) legal = false; if ((t1 < 3 && t1 != t2) || t1 < t2) break; } else break; p1 ++; p2 ++; } if (p1 == len && p2 == word.size() && legal) res ++; } return res; } };
Leetcode811. Subdomain Visit Count
A website domain like “discuss.leetcode.com” consists of various subdomains. At the top level, we have “com”, at the next level, we have “leetcode.com”, and at the lowest level, “discuss.leetcode.com”. When we visit a domain like “discuss.leetcode.com”, we will also visit the parent domains “leetcode.com” and “com” implicitly.
Now, call a “count-paired domain” to be a count (representing the number of visits this domain received), followed by a space, followed by the address. An example of a count-paired domain might be “9001 discuss.leetcode.com”.
We are given a list cpdomains of count-paired domains. We would like a list of count-paired domains, (in the same format as the input, and in any order), that explicitly counts the number of visits to each subdomain.
Example 1:
1 2 3 4 5 6
Input: ["9001 discuss.leetcode.com"] Output: ["9001 discuss.leetcode.com", "9001 leetcode.com", "9001 com"] Explanation: We only have one website domain: "discuss.leetcode.com". As discussed above, the subdomain "leetcode.com" and "com" will also be visited. So they will all be visited 9001 times.
Example 2:
1 2 3 4 5 6
Input: ["900 google.mail.com", "50 yahoo.com", "1 intel.mail.com", "5 wiki.org"] Output: ["901 mail.com","50 yahoo.com","900 google.mail.com","5 wiki.org","5 org","1 intel.mail.com","951 com"] Explanation: We will visit "google.mail.com" 900 times, "yahoo.com" 50 times, "intel.mail.com" once and "wiki.org" 5 times. For the subdomains, we will visit "mail.com" 900 + 1 = 901 times, "com" 900 + 50 + 1 = 951 times, and "org" 5 times.
classSolution(object): defsubdomainVisits(self, cpdomains): ans = collections.Counter() for domain in cpdomains: count, domain = domain.split() count = int(count) frags = domain.split('.') for i in xrange(len(frags)): ans[".".join(frags[i:])] += count return ["{} {}".format(ct, dom) for dom, ct in ans.items()]
Leetcode812. Largest Triangle Area
You have a list of points in the plane. Return the area of the largest triangle that can be formed by any 3 of the points.
classSolution { public: doublegetLength(int x1, int x2, int y1, int y2){ returnsqrt((double)(x1-x2)*(x1-x2)+(double)(y1-y2)*(y1-y2)); } doublelargestTriangleArea(vector<vector<int>>& points){ double result = 0.0; double a, b, c, q; int n = points.size(); for( int i = 0; i < n; i ++) for( int j = 0; j < n; j ++) for(int k = 0; k < n; k ++) { double area = 0.5 * abs(points[i][0] * points[j][1] + points[j][0] * points[k][1] + points[k][0] * points[i][1] -points[i][0] * points[k][1] - points[k][0] * points[j][1] - points[j][0] * points[i][1]); result = max(result, area); } return result; } };
Leetcode813. Largest Sum of Averages
We partition a row of numbers A into at most K adjacent (non-empty) groups, then our score is the sum of the average of each group. What is the largest score we can achieve?
Note that our partition must use every number in A, and that scores are not necessarily integers.
Example:
1 2 3 4 5 6 7 8
Input: A = [9,1,2,3,9] K = 3 Output: 20 Explanation: The best choice is to partition A into [9], [1, 2, 3], [9]. The answer is 9 + (1 + 2 + 3) / 3 + 9 = 20. We could have also partitioned A into [9, 1], [2], [3, 9], for example. That partition would lead to a score of 5 + 2 + 6 = 13, which is worse.
Note:
1 <= A.length <= 100.
1 <= A[i] <= 10000.
1 <= K <= A.length.
Answers within 10^-6 of the correct answer will be accepted as correct.
classSolution { public: doublelargestSumOfAverages(vector<int>& A, int K){ int n = A.size(); vector<vector<double>> memo(101, vector<double>(101)); double cur = 0; for (int i = 0; i < n; ++i) { cur += A[i]; memo[i + 1][1] = cur / (i + 1); } returnhelper(A, K, n, memo); } doublehelper(vector<int>& A, int k, int j, vector<vector<double>>& memo){ if (memo[j][k] > 0) return memo[j][k]; double cur = 0; for (int i = j - 1; i > 0; --i) { cur += A[i]; memo[j][k] = max(memo[j][k], helper(A, k - 1, i, memo) + cur / (j - i)); } return memo[j][k]; } };
Leetcode814. Binary Tree Pruning
We are given the head node root of a binary tree, where additionally every node’s value is either a 0 or a 1.
Return the same tree where every subtree (of the given tree) not containing a 1 has been removed.
(Recall that the subtree of a node X is X, plus every node that is a descendant of X.)
Example 1:
1 2
Input: [1,null,0,0,1] Output: [1,null,0,null,1]
Explanation: Only the red nodes satisfy the property “every subtree not containing a 1”. The diagram on the right represents the answer.
We had some 2-dimensional coordinates, like “(1, 3)” or “(2, 0.5)”. Then, we removed all commas, decimal points, and spaces, and ended up with the string S. Return a list of strings representing all possibilities for what our original coordinates could have been.
Our original representation never had extraneous zeroes, so we never started with numbers like “00”, “0.0”, “0.00”, “1.0”, “001”, “00.01”, or any other number that can be represented with less digits. Also, a decimal point within a number never occurs without at least one digit occuring before it, so we never started with numbers like “.1”.
The final answer list can be returned in any order. Also note that all coordinates in the final answer have exactly one space between them (occurring after the comma.)
if S == “”: return [] if S == “0”: return [S] if S == “0XXX0”: return [] if S == “0XXX”: return [“0.XXX”] if S == “XXX0”: return [S] return [S, “X.XXX”, “XX.XX”, “XXX.X”…]
classSolution { public: vector<string> ambiguousCoordinates(string S){ vector<string> res; int n = S.size(); for (int i = 1; i < n - 2; ++i) { vector<string> A = findAll(S.substr(1, i)), B = findAll(S.substr(i + 1, n - 2 - i)); for (auto &a : A) { for (auto &b : B) { res.push_back("(" + a + ", " + b + ")"); } } } return res; } vector<string> findAll(string S){ int n = S.size(); if (n == 0 || (n > 1 && S[0] == '0' && S[n - 1] == '0')) return {}; if (n > 1 && S[0] == '0') return {"0." + S.substr(1)}; if (S[n - 1] == '0') return {S}; vector<string> res{S}; for (int i = 1; i < n; ++i) res.push_back(S.substr(0, i) + "." + S.substr(i)); return res; } };
Leetcode817. Linked List Components
We are given head, the head node of a linked list containing unique integer values.
We are also given the list G, a subset of the values in the linked list.
Return the number of connected components in G, where two values are connected if they appear consecutively in the linked list.
Example 1:
1 2 3 4 5 6
Input: head: 0->1->2->3 G = [0, 1, 3] Output: 2 Explanation: 0 and 1 are connected, so [0, 1] and [3] are the two connected components.
Example 2:
1 2 3 4 5 6
Input: head: 0->1->2->3->4 G = [0, 3, 1, 4] Output: 2 Explanation: 0 and 1 are connected, 3 and 4 are connected, so [0, 1] and [3, 4] are the two connected components.
Note:
If N is the length of the linked list given by head, 1 <= N <= 10000.
The value of each node in the linked list will be in the range [0, N - 1].
classSolution { public: intnumComponents(ListNode* head, vector<int>& G){ int res = 0; unordered_set<int> nodeSet(G.begin(), G.end()); while (head) { if (!nodeSet.count(head->val)) { head = head->next; continue; } ++res; while (head && nodeSet.count(head->val)) { head = head->next; } } return res; } };
Leetcode819. Most Common Word
Given a paragraph and a list of banned words, return the most frequent word that is not in the list of banned words. It is guaranteed there is at least one word that isn’t banned, and that the answer is unique.
Words in the list of banned words are given in lowercase, and free of punctuation. Words in the paragraph are not case sensitive. The answer is in lowercase.
Example:
1 2 3 4
Input: paragraph = "Bob hit a ball, the hit BALL flew far after it was hit." banned = ["hit"] Output: "ball"
Explanation: “hit” occurs 3 times, but it is a banned word. “ball” occurs twice (and no other word does), so it is the most frequent non-banned word in the paragraph. Note that words in the paragraph are not case sensitive, that punctuation is ignored (even if adjacent to words, such as “ball,”), and that “hit” isn’t the answer even though it occurs more because it is banned.
classSolution { public: string mostCommonWord(string paragraph, vector<string>& banned){ unordered_map<string, int>m; for(int i = 0; i < paragraph.size();){ string s = ""; while(i < paragraph.size() && isalpha(paragraph[i])) s.push_back(tolower(paragraph[i++])); while(i < paragraph.size() && !isalpha(paragraph[i])) i++; m[s]++; } for(auto x: banned) m[x] = 0; string res = ""; int count = 0; for(auto x: m) if(x.second > count) res = x.first, count = x.second; return res; } };
Leetcode820. Short Encoding of Words
A valid encoding of an array of words is any reference string s and array of indices indices such that:
words.length == indices.length
The reference string s ends with the ‘#’ character.
For each index indices[i], the substring of s starting from indices[i] and up to (but not including) the next ‘#’ character is equal to words[i].
Given an array of words, return the length of the shortest reference string s possible of any valid encoding of words.
Example 1:
1 2 3 4 5 6
Input: words = ["time", "me", "bell"] Output: 10 Explanation: A valid encoding would be s = "time#bell#" and indices = [0, 2, 5]. words[0] = "time", the substring of s starting from indices[0] = 0 to the next '#' is underlined in "time#bell#" words[1] = "me", the substring of s starting from indices[1] = 2 to the next '#' is underlined in "time#bell#" words[2] = "bell", the substring of s starting from indices[2] = 5 to the next '#' is underlined in "time#bell#"
Example 2:
1 2 3
Input: words = ["t"] Output: 2 Explanation: A valid encoding would be s = "t#" and indices = [0].
classSolution { public: vector<int> shortestToChar(string S, char C){ vector<int> res(S.size(), S.size()); for (int i = 0; i < S.size(); ++i) { if (S[i] == C) res[i] = 0; elseif (i > 0) res[i] = res[i - 1] + 1; } for (int i = (int)S.size() - 2; i >= 0; --i) { res[i] = min(res[i], res[i + 1] + 1); } return res; } };
Leetcode822. Card Flipping Game
On a table are N cards, with a positive integer printed on the front and back of each card (possibly different).
We flip any number of cards, and after we choose one card.
If the number X on the back of the chosen card is not on the front of any card, then this number X is good.
What is the smallest number that is good? If no number is good, output 0.
Here, fronts[i] and backs[i] represent the number on the front and back of card i.
A flip swaps the front and back numbers, so the value on the front is now on the back and vice versa.
Example:
1 2 3 4
Input: fronts = [1,2,4,4,7], backs = [1,3,4,1,3] Output: 2 Explanation: If we flip the second card, the fronts are [1,3,4,4,7] and the backs are [1,2,4,1,3]. We choose the second card, which has number 2 on the back, and it isn't on the front of any card, so 2 is good.
classSolution { public: intflipgame(vector<int>& fronts, vector<int>& backs){ int res = INT_MAX, n = fronts.size(); unordered_set<int> same; for (int i = 0; i < n; ++i) { if (fronts[i] == backs[i]) same.insert(fronts[i]); } for (int front : fronts) { if (!same.count(front)) res = min(res, front); } for (int back : backs) { if (!same.count(back)) res = min(res, back); } return (res == INT_MAX) ? 0 : res; } };
Leetcode823. Binary Trees With Factors
Given an array of unique integers, each integer is strictly greater than 1.
We make a binary tree using these integers and each number may be used for any number of times.
Each non-leaf node’s value should be equal to the product of the values of it’s children.
How many binary trees can we make? Return the answer modulo 10 ** 9 + 7.
Example 1:
1 2 3
Input: A = [2, 4] Output: 3 Explanation: We can make these trees: [2], [4], [4, 2, 2]
Example 2:
1 2 3
Input: A = [2, 4, 5, 10] Output: 7 Explanation: We can make these trees: [2], [4], [5], [10], [4, 2, 2], [10, 2, 5], [10, 5, 2].
Note:
1 <= A.length <= 1000.
2 <= A[i] <= 10 ^ 9.
两个难点,定义dp表达式跟推导状态转移方程。怎么简单怎么来呗,我们用一个一维dp数组,其中dp[i]表示值为i的结点做根结点时,能够形成的符合题意的二叉树的个数。这样我们将数组A中每个结点的dp值都累加起来就是最终的结果了。好了,有了定义式,接下来就是最大的难点了,推导状态转移方程。题目中的要求是根结点的值必须是左右子结点值的乘积,那么根结点的dp值一定是跟左右子结点的dp值有关的,是要加上左右子结点的dp值的乘积的,为啥是乘呢,比如有两个球,一个有2种颜色,另一个有3种颜色,问两个球放一起总共能有多少种不同的颜色组合,当然是相乘啦。每个结点的dp值初始化为1,因为就算是当个光杆司令的叶结点,也是符合题意的,所以至少是1。然后就要找其左右两个子结点了,怎么找,有点像 Two Sum 的感觉,先确定一个,然后在HashMap中快速定位另一个,想到了这一层的话,我们的dp定义式就需要做个小修改,之前说的是用一个一维dp数组,现在看来就不太合适了,因为我们需要快速查找某个值,所以这里我们用一个HashMap来定义dp。好,继续,既然要先确定一个结点,由于都是大于1的正数,那么这个结点肯定要比根结点值小,为了遍历方便,我们想把小的放前面,那么我们就需要给数组A排个序,这样就可以遍历之前较小的数字了,那么如何快速定位另一个子结点呢,我们只要用根结点值对遍历值取余,若为0,说明可以整除,然后再在HashMap中查找这个商是否存在,在的话,说明存在这样的两个结点,其结点值之积等于结点A[i],然后我们将这两个结点值之积加到dp[A[i]]中即可,注意还要对超大数取余,防止溢出。最后当所有结点的dp值都更新完成了,将其和算出来返回即可,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: intnumFactoredBinaryTrees(vector<int>& A){ long res = 0, M = 1e9 + 7; unordered_map<int, long> dp; sort(A.begin(), A.end()); for (int i = 0; i < A.size(); ++i) { dp[A[i]] = 1; for (int j = 0; j < i; ++j) { if (A[i] % A[j] == 0 && dp.count(A[i] / A[j])) { dp[A[i]] = (dp[A[i]] + dp[A[j]] * dp[A[i] / A[j]]) % M; } } } for (auto a : dp) res = (res + a.second) % M; return res; } };
Leetcode824. Goat Latin
A sentence S is given, composed of words separated by spaces. Each word consists of lowercase and uppercase letters only.
We would like to convert the sentence to “Goat Latin” (a made-up language similar to Pig Latin.)
The rules of Goat Latin are as follows:
If a word begins with a vowel (a, e, i, o, or u), append “ma” to the end of the word. For example, the word ‘apple’ becomes ‘applema’.
If a word begins with a consonant (i.e. not a vowel), remove the first letter and append it to the end, then add “ma”. For example, the word “goat” becomes “oatgma”.
Add one letter ‘a’ to the end of each word per its word index in the sentence, starting with 1. For example, the first word gets “a” added to the end, the second word gets “aa” added to the end and so on. Return the final sentence representing the conversion from S to Goat Latin.
Example 1:
1 2
Input: "I speak Goat Latin" Output: "Imaa peaksmaaa oatGmaaaa atinLmaaaaa"
Example 2:
1 2
Input: "The quick brown fox jumped over the lazy dog" Output: "heTmaa uickqmaaa rownbmaaaa oxfmaaaaa umpedjmaaaaaa overmaaaaaaa hetmaaaaaaaa azylmaaaaaaaaa ogdmaaaaaaaaaa"
Notes:
S contains only uppercase, lowercase and spaces. Exactly one space between each word.
classSolution { public: intnumFriendRequests(vector<int>& ages){ int res = 0, n = ages.size(); sort(ages.begin(), ages.end()); for (int i = n - 1; i >= 1; --i) { for (int j = i - 1; j >= 0; --j) { if (ages[j] <= 0.5 * ages[i] + 7) continue; if (ages[i] == ages[j]) ++res; ++res; } } return res; } };
这个方法会超时。
我们可以来优化一下上面的解法,根据上面的分析,其实题目给的这三个条件可以归纳成一个条件,若A想加B的好友,那么B的年龄必须在 (A*0.5+7, A] 这个范围内,由于区间要有意义的话,A0.5+7 < A 必须成立,解出 A > 14,那么A最小就只能取15了。意思说你不能加小于15岁的好友(青少年成长保护???)。我们的优化思路是对于每一个年龄,我们都只要求出上面那个区间范围内的个数,就是符合题意的。那么既然是求区域和,建立累加数组就是一个很好的选择了,首先我们先建立一个统计数组numInAge,范围是[0, 120],用来统计在各个年龄点上有多少人,然后再建立累加和数组sumInAge。这个都建立好了以后,我们就可以开始遍历,由于之前说了不能加小于15的好友,所以我们从15开始遍历,如果某个年龄点没有人,直接跳过。然后就是统计出 (A*0.5+7, A] 这个范围内有多少人,可以通过累计和数组来快速求的,由于当前时间点的人可以跟这个区间内的所有发好友申请,而当前时间点可能还有多人,所以二者相乘,但由于我们但区间里还包括但当前年龄点本身,所以还要减去当前年龄点上的人数,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: intnumFriendRequests(vector<int>& ages){ int res = 0; vector<int> numInAge(121), sumInAge(121); for (int age : ages) ++numInAge[age]; for (int i = 1; i <= 120; ++i) { sumInAge[i] = numInAge[i] + sumInAge[i - 1]; } for (int i = 15; i <= 120; ++i) { if (numInAge[i] == 0) continue; int cnt = sumInAge[i] - sumInAge[i * 0.5 + 7]; res += cnt * numInAge[i] - numInAge[i]; } return res; } };
Leetcode826. Most Profit Assigning Work
You have n jobs and m workers. You are given three arrays: difficulty, profit, and worker where:
difficulty[i]and profit[i] are the difficulty and the profit of the ith job, and worker[j] is the ability of jth worker (i.e., the jth worker can only complete a job with difficulty at most worker[j]).
Every worker can be assigned at most one job, but one job can be completed multiple times.
For example, if three workers attempt the same job that pays $1, then the total profit will be $3. If a worker cannot complete any job, their profit is $0. Return the maximum profit we can achieve after assigning the workers to the jobs.
Example 1:
1 2 3
Input: difficulty = [2,4,6,8,10], profit = [10,20,30,40,50], worker = [4,5,6,7] Output: 100 Explanation: Workers are assigned jobs of difficulty [4,4,6,6] and they get a profit of [20,20,30,30] separately.
classSolution { public: intmaxProfitAssignment(vector<int>& difficulty, vector<int>& profit, vector<int>& worker){ int res = 0, curmax = 0, curwork = 0; int len = difficulty.size(); vector<pair<int, int>> v; for (int i = 0; i < len; i ++) v.push_back(make_pair(difficulty[i], profit[i])); sort(v.begin(), v.end(), [](pair<int, int>& a,pair<int, int>& b){ return a.first < b.first; }); sort(worker.begin(), worker.end()); int j = 0; for (int i = 0; i < worker.size(); i ++) { while (j < len) { if (worker[i] < v[j].first) break; curmax = max(curmax, v[j].second); j ++; } res += curmax; } return res; } };
Leetcode830. Positions of Large Groups
In a string S of lowercase letters, these letters form consecutive groups of the same character. For example, a string like S = “abbxxxxzyy” has the groups “a”, “bb”, “xxxx”, “z” and “yy”.
Call a group large if it has 3 or more characters. We would like the starting and ending positions of every large group. The final answer should be in lexicographic order.
Example 1:
1 2 3
Input: "abbxxxxzzy" Output: [[3,6]] Explanation: "xxxx" is the single large group with starting 3 and ending positions 6.
Example 2:
1 2 3
Input: "abc" Output: [] Explanation: We have "a","b" and "c" but no large group.
找到长度大于3的子串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: vector<vector<int>> largeGroupPositions(string S) { vector<vector<int>> res; int len = S.length(); int begin, end; for(int i = 0; i < len; i ++) { begin = i; while(i < len-1 && S[i] == S[i+1]) i ++; if(i - begin + 1 >= 3) res.push_back({begin, i}); } return res; } };
Leetcode831. Masking Personal Information
We are given a personal information string S, which may represent either an email address or a phone number.
We would like to mask this personal information according to the following rules:
Email address:
We define a name to be a string of length ≥ 2consisting of only lowercase letters a-z or uppercase letters A-Z.
An email address starts with a name, followed by the symbol ‘@’, followed by a name, followed by the dot ‘.’ and followed by a name.
All email addresses are guaranteed to be valid and in the format of “name1@name2.name3“.
To mask an email, all names must be converted to lowercase and all letters between the first and last letter of the first name must be replaced by 5 asterisks ‘*’.
Phone number:
A phone number is a string consisting of only the digits 0-9or the characters from the set {‘+’, ‘-‘, ‘(‘, ‘)’, ‘ ‘}. You may assume a phone number contains 10 to 13 digits.
The last 10 digits make up the local number, while the digits before those make up the country code. Note that the country code is optional. We want to expose only the last 4 digits and mask all other digits.
The local number should be formatted and masked as ***-***-1111, where 1 represents the exposed digits.
To mask a phone number with country code like +111 111 111 1111, we write it in the form +***-***-***-1111. The ‘+’ sign and the first ‘-‘ sign before the local number should only exist if there is a country code. For example, a 12 digit phone number mask should start with “+**-“.
Note that extraneous characters like “(“, “)”, “ “, as well as extra dashes or plus signs not part of the above formatting scheme should be removed.
Return the correct “mask” of the information provided.
Example 1:
1 2 3 4 5
Input: "LeetCode@LeetCode.com" Output: "l*****e@leetcode.com" Explanation: All names are converted to lowercase, and the letters between the first and last letter of the first name is replaced by 5 asterisks. Therefore, "leetcode" -> "l*****e".
Example 2:
1 2 3 4
Input: "AB@qq.com" Output: "a*****b@qq.com" Explanation: There must be 5 asterisks between the first and last letter of the first name "ab". Therefore, "ab" -> "a*****b".
Example 3:
1 2 3
Input: "1(234)567-890" Output: "***-***-7890" Explanation: 10 digits in the phone number, which means all digits make up the local number.
Example 4:
1 2 3
Input: "86-(10)12345678" Output: "+**-***-***-5678" Explanation: 12 digits, 2 digits for country code and 10 digits for local number.
classSolution { public: chartolower(char c){ if ('A' <= c && c <= 'Z') return c + ('a'-'A'); else return c; } string maskPII(string s){ string t, res = ""; bool is_email = false; int _size = 0; int aa = 0, bb = -1; for (int i = 0; i < s.length(); i ++) { if ('@' == s[i]) { is_email = true; aa = i-1; } if ('-' == s[i]) _size ++; if (_size == 1 && bb == -1 && '-' == s[i]) bb = i; if ('+' == s[i] || '-' == s[i] || '(' == s[i] || ')' == s[i] || ' ' == s[i]) continue; t.push_back(tolower(s[i])); } if (is_email) { for (int i = 0; i < t.length(); i ++) { if (i == 0) { res += t[i]; res += "*****"; } elseif (i >= aa) res += t[i]; } } else { int length = t.length(); if (length > 10) { res += "+"; res += string(length-10, '*'); res += "-"; } res += "***-***-"; for (int i = length-4; i < length; i ++) res += t[i]; } return res; } };
Leetcode832. Flipping an Image
Given a binary matrix A, we want to flip the image horizontally, then invert it, and return the resulting image.
To flip an image horizontally means that each row of the image is reversed. For example, flipping [1, 1, 0] horizontally results in [0, 1, 1].
To invert an image means that each 0 is replaced by 1, and each 1 is replaced by 0. For example, inverting [0, 1, 1] results in [1, 0, 0].
Example 1:
1 2 3 4
Input: [[1,1,0],[1,0,1],[0,0,0]] Output: [[1,0,0],[0,1,0],[1,1,1]] Explanation: First reverse each row: [[0,1,1],[1,0,1],[0,0,0]]. Then, invert the image: [[1,0,0],[0,1,0],[1,1,1]]
Example 2:
1 2 3 4
Input: [[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]] Output: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]] Explanation: First reverse each row: [[0,0,1,1],[1,0,0,1],[1,1,1,0],[0,1,0,1]]. Then invert the image: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
没啥好说的,普通的矩阵操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: vector<vector<int> > flipAndInvertImage(vector<vector<int> >& A) { for(int i = 0; i < A.size(); i ++){ for(int j = 0, k = A[i].size()-1; j < A[i].size() / 2; j ++, k --){ int temp = A[i][j]; A[i][j] = A[i][k]; A[i][k] = temp; } for(int j = 0, k = A[i].size()-1; j < A[i].size(); j ++, k --){ A[i][j] = 1 - A[i][j]; } } return A; } };
Leetcode833. Find And Replace in String
To some string S, we will perform some replacement operations that replace groups of letters with new ones (not necessarily the same size).
Each replacement operation has 3 parameters: a starting index i, a source word x and a target word y. The rule is that if x starts at position i in the original string S, then we will replace that occurrence of x with y. If not, we do nothing.
For example, if we have S = “abcd” and we have some replacement operation i = 2, x = “cd”, y = “ffff”, then because “cd” starts at position 2 in the original string S, we will replace it with “ffff”.
Using another example on S = “abcd”, if we have both the replacement operation i = 0, x = “ab”, y = “eee”, as well as another replacement operation i = 2, x = “ec”, y = “ffff”, this second operation does nothing because in the original string S[2] = ‘c’, which doesn’t match x[0] = ‘e’.
All these operations occur simultaneously. It’s guaranteed that there won’t be any overlap in replacement: for example, S = “abc”, indexes = [0, 1], sources = [“ab”,”bc”] is not a valid test case.
Example 1:
1 2 3 4
Input: S = "abcd", indexes = [0,2], sources = ["a","cd"], targets = ["eee","ffff"] Output: "eeebffff" Explanation: "a" starts at index 0 in S, so it's replaced by "eee". "cd" starts at index 2 in S, so it's replaced by "ffff".
Example 2:
1 2 3 4
Input: S = "abcd", indexes = [0,2], sources = ["ab","ec"], targets = ["eee","ffff"] Output: "eeecd" Explanation: "ab" starts at index 0 in S, so it's replaced by "eee". "ec" doesn't starts at index 2 in the original S, so we do nothing.
classSolution { public: string findReplaceString(string s, vector<int>& indices, vector<string>& sources, vector<string>& targets){ vector<pair<int, int>> v; for (int i = 0; i < indices.size(); ++i) { v.push_back({indices[i], i}); } sort(v.begin(), v.end());
int len = s.length(); string res = ""; int p1 = 0, p2 = 0, i = 0; while(i < len && p1 < v.size()) { int tmp = i, j = 0; if (i > indices[v[p1].second]) p1 ++; elseif (i == indices[v[p1].second]) { int len2 = sources[v[p1].second].length(); while(j < len2 && tmp < len) { if (sources[v[p1].second][j] != s[tmp]) break; j ++; tmp++; } if (j == len2) { res += targets[v[p1].second]; p1 ++; i += len2; } else res += s[i++]; } elseif (i < len) res += s[i++]; } while(i < len) res += s[i++]; return res; } };
Leetcode835. Image Overlap
You are given two images, img1 and img2, represented as binary, square matrices of size n x n. A binary matrix has only 0s and 1s as values.
We translate one image however we choose by sliding all the 1 bits left, right, up, and/or down any number of units. We then place it on top of the other image. We can then calculate the overlap by counting the number of positions that have a 1 in both images.
Note also that a translation does not include any kind of rotation. Any 1 bits that are translated outside of the matrix borders are erased.
classSolution { public: intlargestOverlap(vector<vector<int>>& A, vector<vector<int>>& B){ int res = 0, n = A.size(); vector<vector<int>> m_map(2*n+1, vector<int>(2*n+1, 0)); for (int i = 0; i < n; ++i) { for (int j = 0; j < n; ++j) { if (A[i][j] == 1) { for (int ii = 0; ii < n; ++ii) { for (int jj = 0; jj < n; ++jj) { if (B[ii][jj] == 1) ++m_map[i-ii+n][j-jj+n]; } } } } } for (int i = 0; i < m_map.size(); i ++) for (int j = 0; j < m_map[0].size(); j++) res = max(m_map[i][j], res); return res; } };
Leetcode836. Rectangle Overlap
A rectangle is represented as a list [x1, y1, x2, y2], where (x1, y1) are the coordinates of its bottom-left corner, and (x2, y2) are the coordinates of its top-right corner.
Two rectangles overlap if the area of their intersection is positive. To be clear, two rectangles that only touch at the corner or edges do not overlap.
Given two (axis-aligned) rectangles, return whether they overlap.
There are N dominoes in a line, and we place each domino vertically upright.
In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left.
Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
Given a string “S” representing the initial state. S[i] = ‘L’, if the i-th domino has been pushed to the left; S[i] = ‘R’, if the i-th domino has been pushed to the right; S[i] = ‘.’, if the i-th domino has not been pushed.
Return a string representing the final state.
Example 1:
1 2
Input: ".L.R...LR..L.." Output: "LL.RR.LLRRLL.."
Example 2:
1 2 3
Input: "RR.L" Output: "RR.L" Explanation: The first domino expends no additional force on the second domino.
There are N rooms and you start in room 0. Each room has a distinct number in 0, 1, 2, …, N-1, and each room may have some keys to access the next room.
Formally, each room i has a list of keys rooms[i], and each key rooms[i][j] is an integer in [0, 1, …, N-1] where N = rooms.length. A key rooms[i][j] = v opens the room with number v.
Initially, all the rooms start locked (except for room 0).
You can walk back and forth between rooms freely.
Return true if and only if you can enter every room.
Example 1:
1 2 3 4 5 6 7
Input: [[1],[2],[3],[]] Output: true Explanation: We start in room 0, and pick up key 1. We then go to room 1, and pick up key 2. We then go to room 2, and pick up key 3. We then go to room 3. Since we were able to go to every room, we return true.
Example 2:
1 2 3
Input: [[1,3],[3,0,1],[2],[0]] Output: false Explanation: We can't enter the room with number 2.
Note:
1 <= rooms.length <= 1000
0 <= rooms[i].length <= 1000
The number of keys in all rooms combined is at most 3000.
classSolution { public: boolcanVisitAllRooms(vector<vector<int>>& rooms){ int len = rooms.size(); vector<int> visited(len, 0);
queue<int> q; q.push(0); while(!q.empty()) { int t = q.front(); q.pop(); visited[t] = true; for (int i = 0; i < rooms[t].size(); i ++) { if (visited[rooms[t][i]]) continue; q.push(rooms[t][i]); } } for (int i = 0; i < len; i ++) if (!visited[i]) returnfalse; returntrue; } };
Leetcode844. Backspace String Compare
Given two strings S and T, return if they are equal when both are typed into empty text editors. # means a backspace character.
Note that after backspacing an empty text, the text will continue empty.
Example 1:
1 2 3
Input: S = "ab#c", T = "ad#c" Output: true Explanation: Both S and T become "ac".
Example 2:
1 2 3
Input: S = "ab##", T = "c#d#" Output: true Explanation: Both S and T become "".
Example 3:
1 2 3
Input: S = "a##c", T = "#a#c" Output: true Explanation: Both S and T become "c".
Example 4:
1 2 3
Input: S = "a#c", T = "b" Output: false Explanation: S becomes "c" while T becomes "b".
Let’s call any (contiguous) subarray B (of A) a mountain if the following properties hold:
1
B.length >= 3
There exists some 0 < i < B.length - 1 such that B[0] < B[1] < ... B[i-1] < B[i] > B[i+1] > ... > B[B.length - 1] (Note that B could be any subarray of A, including the entire array A.)
Given an array A of integers, return the length of the longest mountain.
Return 0 if there is no mountain.
Example 1:
1 2 3
Input: [2,1,4,7,3,2,5] Output: 5 Explanation: The largest mountain is [1,4,7,3,2] which has length 5.
Example 2:
1 2 3
Input: [2,2,2] Output: 0 Explanation: There is no mountain.
Note:
0 <= A.length <= 10000
0 <= A[i] <= 10000
这道题给了我们一个数组,然后定义了一种像山一样的子数组,就是先递增再递减的子数组,注意这里是强行递增或者递减的,并不存在相等的情况。那么实际上这道题就是让在数组中寻找一个位置,使得以此位置为终点的递增数组和以此位置为起点的递减数组的长度最大。而以某个位置为起点的递减数组,如果反个方向来看,其实就是就该位置为终点的递增数列,那么既然都是求最长的递增数列,我们可以分别用两个 dp 数组 up 和 down,其中up[i]表示以i位置为终点的最长递增数列的个数,down[i]表示以i位置为起点的最长递减数列的个数,这样我们正向更新up数组,反向更新down数组即可。先反向更新好了down之后,在正向更新up数组的同时,也可以更新结果res,当某个位置的up[i]和down[i]均大于0的时候,那么就可以用up[i] + down[i] + 1来更新结果res了,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: intlongestMountain(vector<int>& A){ int res = 0, n = A.size(); vector<int> up(n), down(n); for (int i = n - 2; i >= 0; --i) { if (A[i] > A[i + 1]) down[i] = down[i + 1] + 1; } for (int i = 1; i < n; ++i) { if (A[i] > A[i - 1]) up[i] = up[i - 1] + 1; if (up[i] > 0 && down[i] > 0) res = max(res, up[i] + down[i] + 1); } return res; } };
我们可以对空间进行优化,不必使用两个数组来记录所有位置的信息,而是只用两个变量 up 和 down 来分别记录以当前位置为终点的最长递增数列的长度,和以当前位置为终点的最长递减数列的长度。 我们从 i=1 的位置开始遍历,因为山必须要有上坡和下坡,所以 i=0 的位置永远不可能成为 peak。此时再看,如果当前位置跟前面的位置相等了,那么当前位置的 up 和 down 都要重置为0,从当前位置开始找新的山,和之前的应该断开。或者是当 down 不为0,说明此时是在下坡,如果当前位置大于之前的了,突然变上坡了,那么之前的累计也需要重置为0。然后当前位置再进行判断,若大于前一个位置,则是上坡,up 自增1,若小于前一个位置,是下坡,down 自增1。当 up 和 down 同时为正数,则用 up+down+1 来更新结果 res 即可,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: intlongestMountain(vector<int>& A){ int res = 0, up = 0, down = 0, n = A.size(); for (int i = 1; i < n; ++i) { if ((down && A[i - 1] < A[i]) || (A[i - 1] == A[i])) { up = down = 0; } if (A[i - 1] < A[i]) ++up; if (A[i - 1] > A[i]) ++down; if (up > 0 && down > 0) res = max(res, up + down + 1); } return res; } };
Leetcode848. Shifting Letters
You are given a string s of lowercase English letters and an integer array shifts of the same length.
Call the shift() of a letter, the next letter in the alphabet, (wrapping around so that ‘z’ becomes ‘a’).
For example, shift(‘a’) = ‘b’, shift(‘t’) = ‘u’, and shift(‘z’) = ‘a’. Now for each shifts[i] = x, we want to shift the first i + 1 letters of s, x times.
Return the final string after all such shifts to s are applied.
Example 1:
1 2 3 4 5 6
Input: s = "abc", shifts = [3,5,9] Output: "rpl" Explanation: We start with "abc". After shifting the first 1 letters of s by 3, we have "dbc". After shifting the first 2 letters of s by 5, we have "igc". After shifting the first 3 letters of s by 9, we have "rpl", the answer.
classSolution { public: string shiftingLetters(string s, vector<int>& shifts){ int len = shifts.size(); if (shifts.size() == 0 || s == "") return s; vector<int> sums(len, 0); for (int i = len-2; i >= 0; i --) shifts[i] = (shifts[i+1]%26 + shifts[i]%26) %26; for (int i = len-1; i >= 0; i --) s[i] = 'a' + (s[i] - 'a' + shifts[i]%26) % 26; return s; } };
Leetcode849. Maximize Distance to Closest Person
In a row of seats, 1 represents a person sitting in that seat, and 0 represents that the seat is empty.
There is at least one empty seat, and at least one person sitting.
Alex wants to sit in the seat such that the distance between him and the closest person to him is maximized.
Return that maximum distance to closest person.
Example 1:
1 2 3 4 5 6
Input: [1,0,0,0,1,0,1] Output: 2 Explanation: If Alex sits in the second open seat (seats[2]), then the closest person has distance 2. If Alex sits in any other open seat, the closest person has distance 1. Thus, the maximum distance to the closest person is 2.
Example 2:
1 2 3 4 5
Input: [1,0,0,0] Output: 3 Explanation: If Alex sits in the last seat, the closest person is 3 seats away. This is the maximum distance possible, so the answer is 3.
Note:
1 <= seats.length <= 20000
seats contains only 0s or 1s, at least one 0, and at least one 1.
这道题给了我们一个只有0和1且长度为n的数组,代表n个座位,其中0表示空座位,1表示有人座。现在说是爱丽丝想找个位置坐下,但是希望能离最近的人越远越好,这个不难理解,就是想左右两边尽量跟人保持距离,让我们求这个距离最近的人的最大距离。来看题目中的例子1,有三个空位连在一起,那么爱丽丝肯定是坐在中间的位置比较好,这样跟左右两边人的距离都是2。例子2有些特别,当空位连到了末尾的时候,这里可以想像成靠墙,那么靠墙坐肯定离最远啦,所以例子2中爱丽丝坐在最右边的位子上距离左边的人距离最远为3。那么不难发现,爱丽丝肯定需要先找出最大的连续空位长度,若连续空位靠着墙了,那么就直接挨着墙坐,若两边都有人,那么就坐到空位的中间位置。如何能快速知道连续空位的长度呢,只要知道了两边人的位置,相减就是中间连续空位的个数。所以博主最先使用的方法是用一个数组来保存所有1的位置,即有人坐的位置,然后用相邻的两个位置相减,就可以得到连续空位的长度。当然,靠墙这种特殊情况要另外处理一下。当把所有1位置存入数组 nums 之后,开始遍历 nums 数组,第一个人的位置有可能不靠墙,那么他的位置坐标就是他左边靠墙的连续空位个数,直接更新结果 res 即可,因为靠墙连续空位的个数就是离右边人的最远距离。然后对于其他的位置,我们减去前一个人的位置坐标,然后除以2,更新结果 res。还有最右边靠墙的情况也要处理一下,就用 n-1 减去最后一个人的位置坐标,然后更新结果 res 即可,参见代码如下:
解法一:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: intmaxDistToClosest(vector<int>& seats){ int n = seats.size(), res = 0; vector<int> nums; for (int i = 0; i < n; ++i) { if (seats[i] == 1) nums.push_back(i); } for (int i = 0; i < nums.size(); ++i) { if (i == 0) res = max(res, nums[0]); else res = max(res, (nums[i] - nums[i - 1]) / 2); } if (!nums.empty()) res = max(res, n - 1 - nums.back()); return res; } };
classSolution { public: intmaxDistToClosest(vector<int>& seats){ int n = seats.size(), start = 0, res = 0; for (int i = 0; i < n; ++i) { if (seats[i] != 1) continue; if (start == 0) res = max(res, i - start); else res = max(res, (i - start + 1) / 2); start = i + 1; } res = max(res, n - start); return res; } };
讨论:这道题的一个很好的 follow up 是让我们返回爱丽丝坐下的位置,那么要在结果 res 可以被更新的时候,同时还应该记录下连续空位的起始位置 start,这样有了 start 和 最大距离 res,那么就可以定位出爱丽丝的座位了。
Leetcode851. Loud and Rich
There is a group of n people labeled from 0 to n - 1 where each person has a different amount of money and a different level of quietness.
You are given an array richer where richer[i] = [ai, bi] indicates that ai has more money than bi and an integer array quiet where quiet[i] is the quietness of the ith person. All the given data in richer are logically correct (i.e., the data will not lead you to a situation where x is richer than y and y is richer than x at the same time).
Return an integer array answer where answer[x] = y if y is the least quiet person (that is, the person y with the smallest value of quiet[y]) among all people who definitely have equal to or more money than the person x.
Example 1:
1 2 3 4 5 6 7 8 9
Input: richer = [[1,0],[2,1],[3,1],[3,7],[4,3],[5,3],[6,3]], quiet = [3,2,5,4,6,1,7,0] Output: [5,5,2,5,4,5,6,7] Explanation: answer[0] = 5. Person 5 has more money than 3, which has more money than 1, which has more money than 0. The only person who is quieter (has lower quiet[x]) is person 7, but it is not clear if they have more money than person 0. answer[7] = 7. Among all people that definitely have equal to or more money than person 7 (which could be persons 3, 4, 5, 6, or 7), the person who is the quietest (has lower quiet[x]) is person 7. The other answers can be filled out with similar reasoning.
Example 2:
1 2
Input: richer = [], quiet = [0] Output: [0]
有n 个人,编号0 ∼ n − 1 ,它们有两个属性,财富和安静,给定两个数组r和q,r里面的元素都是数对,(a , b)表示a比b财富严格更多,而q qq存的是每个人的安静值。要求返回一个数组c,使得c[i]表示对于编号i的这个人,财富不少于他的所有人里安静值最小的人的编号。题目保证财富比较的传递关系没有环。
classSolution { public: vector<int> loudAndRich(vector<vector<int>>& richer, vector<int>& quiet){ int len = quiet.size(); vector<int> res(len, -1); unordered_map<int, vector<int>> m; for (auto a : richer) m[a[1]].push_back(a[0]); for (int i = 0; i < len; i ++) helper(m, quiet, i, res); return res; } voidhelper(unordered_map<int, vector<int>>& m, vector<int>& quiet, int i, vector<int>& res){ if (res[i] > 0) return; res[i] = i; for (int ii : m[i]) { helper(m, quiet, ii, res); if (quiet[res[i]] > quiet[res[ii]]) res[i] = res[ii]; } } };
Leetcode852. Peak Index in a Mountain Array
Let’s call an array A a mountain if the following properties hold:
A.length >= 3 There exists some 0 < i < A.length - 1 such that A[0] < A[1] < … A[i-1] < A[i] > A[i+1] > … > A[A.length - 1] Given an array that is definitely a mountain, return any i such that A[0] < A[1] < … A[i-1] < A[i] > A[i+1] > … > A[A.length - 1].
Example 1:
1 2
Input: [0,1,0] Output: 1
Example 2:
1 2
Input: [0,2,1,0] Output: 1
Note:
3 <= A.length <= 10000 0 <= A[i] <= 10^6 A is a mountain, as defined above.
classSolution { publicintpeakIndexInMountainArray(int[] A){ int lo = 0, hi = A.length - 1; while (lo < hi) { int mi = lo + (hi - lo) / 2; if (A[mi] < A[mi + 1]) lo = mi + 1; else hi = mi; } return lo; }
Leetcode853. Car Fleet
N cars are going to the same destination along a one lane road. The destination is target miles away. Each car i has a constant speed speed[i] (in miles per hour), and initial position position[i] miles towards the target along the road.
A car can never pass another car ahead of it, but it can catch up to it, and drive bumper to bumper at the same speed.
The distance between these two cars is ignored - they are assumed to have the same position.
A car fleet is some non-empty set of cars driving at the same position and same speed. Note that a single car is also a car fleet.
If a car catches up to a car fleet right at the destination point, it will still be considered as one car fleet. How many car fleets will arrive at the destination?
Example 1:
1 2 3 4 5 6 7
Input: target = 12, position = [10,8,0,5,3], speed = [2,4,1,1,3] Output: 3 Explanation: The cars starting at 10 and 8 become a fleet, meeting each other at 12. The car starting at 0 doesn't catch up to any other car, so it is a fleet by itself. The cars starting at 5 and 3 become a fleet, meeting each other at 6. Note that no other cars meet these fleets before the destination, so the answer is 3.
Note:
0 <= N <= 10 ^ 4
0 < target <= 10 ^ 6
0 < speed[i] <= 10 ^ 6
0 <= position[i] < target
All initial positions are different.
这道题说是路上有一系列的车,车在不同的位置,且分别有着不同的速度,但行驶的方向都相同。如果后方的车在到达终点之前追上前面的车了,那么它就会如痴汉般尾随在其后,且速度降至和前面的车相同,可以看作是一个车队,当然,单独的一辆车也可以看作是一个车队,问我们共有多少个车队到达终点。这道题是小学时候的应用题的感觉,什么狗追人啊,人追狗啊之类的。这道题的正确解法的思路其实不太容易想,因为我们很容易把注意力都集中到每辆车,去计算其每个时刻所在的位置,以及跟前面的车相遇的位置,这其实把这道题想复杂了,其实并不需要知道车的相遇位置,只关心是否能组成车队一同经过终点线,那么如何才能知道是否能一起过线呢,最简单的方法就是看时间,假如车B在车A的后面,而车B到终点线的时间小于等于车A,那么就知道车A和B一定会组成车队一起过线。这样的话,就可以从离终点最近的一辆车开始,先算出其撞线的时间,然后再一次遍历身后的车,若后面的车撞线的时间小于等于前面的车的时间,则会组成车队。反之,若大于前面的车的时间,则说明无法追上前面的车,于是自己会形成一个新的车队,且是车头,则结果 res 自增1即可。 思路有了,就可以具体实现了,使用一个 TreeMap 来建立小车位置和其到达终点时间之间的映射,这里的时间使用 double 型,通过终点位置减去当前位置,并除以速度来获得。我们希望能从 position 大的小车开始处理,而 TreeMap 是把小的数字排在前面,这里使用了个小 trick,就是映射的时候使用的是 position 的负数,这样就能先处理原来 position 大的车,从而统计出正确的车队数量,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: intcarFleet(int target, vector<int>& position, vector<int>& speed){ int res = 0; double cur = 0; map<int, double> pos2time; for (int i = 0; i < position.size(); ++i) { pos2time[-position[i]] = (double)(target - position[i]) / speed[i]; } for (auto a : pos2time) { if (a.second <= cur) continue; cur = a.second; ++res; } return res; } };
Leetcode855. Exam Room
In an exam room, there are N seats in a single row, numbered 0, 1, 2, …, N-1.
When a student enters the room, they must sit in the seat that maximizes the distance to the closest person. If there are multiple such seats, they sit in the seat with the lowest number. (Also, if no one is in the room, then the student sits at seat number 0.)
Return a class ExamRoom(int N) that exposes two functions: ExamRoom.seat() returning an int representing what seat the student sat in, and ExamRoom.leave(int p) representing that the student in seat number p now leaves the room. It is guaranteed that any calls to ExamRoom.leave(p) have a student sitting in seat p.
Example 1:
1 2 3 4 5 6 7 8 9 10
Input: ["ExamRoom","seat","seat","seat","seat","leave","seat"], [[10],[],[],[],[],[4],[]] Output: [null,0,9,4,2,null,5] Explanation: ExamRoom(10) -> null seat() -> 0, no one is in the room, then the student sits at seat number 0. seat() -> 9, the student sits at the last seat number 9. seat() -> 4, the student sits at the last seat number 4. seat() -> 2, the student sits at the last seat number 2. leave(4) -> null seat() -> 5, the student sits at the last seat number 5.
Note:
1 <= N <= 10^9
ExamRoom.seat() and ExamRoom.leave() will be called at most 10^4 times across all test cases.
Calls to ExamRoom.leave(p) are guaranteed to have a student currently sitting in seat number p.
classSolution { public: intscoreOfParentheses(string S){ int res = 0, cnt = 0, n = S.size(); for (int i = 0; i < n; ++i) { (S[i] == '(') ? ++cnt : --cnt; if (S[i] == ')' && S[i - 1] == '(') res += (1 << cnt); } return res; } };
Leetcode858. Mirror Reflection
There is a special square room with mirrors on each of the four walls. Except for the southwest corner, there are receptors on each of the remaining corners, numbered 0, 1, and 2.
The square room has walls of length p, and a laser ray from the southwest corner first meets the east wall at a distance q from the 0th receptor.
Return the number of the receptor that the ray meets first. (It is guaranteed that the ray will meet a receptor eventually.)
Example 1:
1 2 3
Input: p = 2, q = 1 Output: 2 Explanation: The ray meets receptor 2 the first time it gets reflected back to the left wall.
题目大意:
存在一个方形空间,如上图所示,一束光从左下角射出,方形空间的四条边都会反射,在0,1,2处存在3个接收器,问,给定方形空间的边长 p 和第一次到达右边界时距离0号接收器的距离,这束光最终会落到哪个接收器上?
classSolution { public: intgcd(int m, int n){ int temp; while(n != 0) { temp = m % n; m = n; n = temp; } return m; } intmirrorReflection(int p, int q){ int temp = gcd(p, q); p = p / temp; q = q / temp; if(p%2==0) return2; elseif(q%2==0) return0; else return1; } };
Leetcode859. Buddy Strings
Given two strings A and B of lowercase letters, return true if and only if we can swap two letters in A so that the result equals B.
Example 1:
1 2
Input: A = "ab", B = "ba" Output: true
Example 2:
1 2
Input: A = "ab", B = "ab" Output: false
Example 3:
1 2
Input: A = "aa", B = "aa" Output: true
Example 4:
1 2
Input: A = "aaaaaaabc", B = "aaaaaaacb" Output: true
Customers are standing in a queue to buy from you, and order one at a time (in the order specified by bills).
Each customer will only buy one lemonade and pay with either a $5, $10, or $20 bill. You must provide the correct change to each customer, so that the net transaction is that the customer pays $5.
Note that you don’t have any change in hand at first.
Return true if and only if you can provide every customer with correct change.
Example 1:
1 2
Input: [5,5,5,10,20] Output: true
Explanation:
From the first 3 customers, we collect three $5 bills in order.
From the fourth customer, we collect a $10 bill and give back a $5.
From the fifth customer, we give a $10 bill and a $5 bill.
Since all customers got correct change, we output true.
Example 2:
1 2
Input: [5,5,10] Output: true
Example 3:
1 2
Input: [10,10] Output: false
Example 4:
1 2
Input: [5,5,10,10,20] Output: false
Explanation:
From the first two customers in order, we collect two $5 bills.
For the next two customers in order, we collect a $10 bill and give back a $5 bill.
For the last customer, we can’t give change of $15 back because we only have two $10 bills.
Since not every customer received correct change, the answer is false.
Notice that a 1 in the i’th column from the right, contributes 2^i to the score.
Say we are finished toggling the rows in some configuration. Then for each column, (to maximize the score), we’ll toggle the column if it would increase the number of 1s.
We can brute force over every possible way to toggle rows.
Say the matrix has R rows and C columns.
For each state, the transition trans = state ^ (state-1) represents the rows that must be toggled to get into the state of toggled rows represented by (the bits of) state.
We’ll toggle them, and also maintain the correct column sums of the matrix on the side.
Afterwards, we’ll calculate the score. If for example the last column has a column sum of 3, then the score is max(3, R-3), where R-3 represents the score we get from toggling the last column.
In general, the score is increased by max(col_sum, R - col_sum) * (1 << (C-1-c)), where the factor (1 << (C-1-c)) is the power of 2 that each 1 contributes.
Note that this approach may not run in the time allotted.
classSolution { publicintmatrixScore(int[][] A){ int R = A.length, C = A[0].length; int[] colsums = newint[C]; for (int r = 0; r < R; ++r) for (int c = 0; c < C; ++c) colsums[c] += A[r][c];
int ans = 0; for (int state = 0; state < (1<<R); ++state) { // Toggle the rows so that after, 'state' represents // the toggled rows. if (state > 0) { int trans = state ^ (state-1); for (int r = 0; r < R; ++r) { if (((trans >> r) & 1) > 0) { for (int c = 0; c < C; ++c) { colsums[c] += A[r][c] == 1 ? -1 : 1; A[r][c] ^= 1; } } } }
// Calculate the score with the rows toggled by 'state' int score = 0; for (int c = 0; c < C; ++c) score += Math.max(colsums[c], R - colsums[c]) * (1 << (C-1-c)); ans = Math.max(ans, score); } return ans; } }
Leetcode863. All Nodes Distance K in Binary Tree
Given the root of a binary tree, the value of a target node target, and an integer k, return an array of the values of all nodes that have a distance k from the target node.
You can return the answer in any order.
Example 1:
1 2 3
Input: root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, k = 2 Output: [7,4,1] Explanation: The nodes that are a distance 2 from the target node (with value 5) have values 7, 4, and 1.
在递归函数中,首先判断若当前结点为空,则直接返回0。然后判断 dist 是否为k,是的话,说目标结点距离当前结点的距离为K,是符合题意的,需要加入结果 res 中,并返回0,注意这里返回0是为了剪枝。否则判断,若当前结点正好就是目标结点,或者已经遍历过了目标结点(表现为 dist 大于0),那么对左右子树分别调用递归函数,并将返回值分别存入 left 和 right 两个变量中。注意此时应带入 dist+1,因为是先序遍历,若目标结点之前被遍历到了,那么说明目标结点肯定不在当前结点的子树中,当前要往子树遍历的话,肯定离目标结点又远了一些,需要加1。若当前结点不是目标结点,也还没见到目标结点时,同样也需要对左右子结点调用递归函数,但此时 dist 不加1,因为不确定目标结点的位置。若 left 或者 right 值等于K,则说明目标结点在子树中,且距离当前结点为K(为啥呢?因为目标结点本身是返回1,所以当左右子结点返回K时,和当前结点距离是K)。接下来判断,若当前结点是目标结点,直接返回1,这个前面解释过了。然后再看 left 和 right 的值是否大于0,若 left 值大于0,说明目标结点在左子树中,我们此时就要对右子结点再调用一次递归,并且 dist 带入 left+1,同理,若 right 值大于0,说明目标结点在右子树中,我们此时就要对左子结点再调用一次递归,并且 dist 带入 right+1。这两步很重要,是之所以能不建立邻接链表的关键所在。若 left 大于0,则返回 left+1,若 right 大于0,则返回 right+1,否则就返回0,参见代码如下:
classSolution { public: vector<int> distanceK(TreeNode* root, TreeNode* target, int K){ if (K == 0) return {target->val}; vector<int> res; helper(root, target, K, 0, res); return res; } inthelper(TreeNode* node, TreeNode* target, int k, int dist, vector<int>& res){ if (!node) return0; if (dist == k) {res.push_back(node->val); return0;} int left = 0, right = 0; if (node->val == target->val || dist > 0) { left = helper(node->left, target, k, dist + 1, res); right = helper(node->right, target, k, dist + 1, res); } else { left = helper(node->left, target, k, dist, res); right = helper(node->right, target, k, dist, res); } if (left == k || right == k) {res.push_back(node->val); return0;} if (node->val == target->val) return1; if (left > 0) helper(node->right, target, k, left + 1, res); if (right > 0) helper(node->left, target, k, right + 1, res); if (left > 0 || right > 0) return left > 0 ? left + 1 : right + 1; return0; } };
Leetcode865. Smallest Subtree with all the Deepest Nodes
Given the root of a binary tree, the depth of each node is the shortest distance to the root.
Return the smallest subtree such that it contains all the deepest nodes in the original tree.
A node is called the deepest if it has the largest depth possible among any node in the entire tree.
The subtree of a node is tree consisting of that node, plus the set of all descendants of that node.
Example 1:
1 2 3 4 5
Input: root = [3,5,1,6,2,0,8,null,null,7,4] Output: [2,7,4] Explanation: We return the node with value 2, colored in yellow in the diagram. The nodes coloured in blue are the deepest nodes of the tree. Notice that nodes 5, 3 and 2 contain the deepest nodes in the tree but node 2 is the smallest subtree among them, so we return it.
Example 2:
1 2 3
Input: root = [1] Output: [1] Explanation: The root is the deepest node in the tree.
Example 3:
1 2 3
Input: root = [0,1,3,null,2] Output: [2] Explanation: The deepest node in the tree is 2, the valid subtrees are the subtrees of nodes 2, 1 and 0 but the subtree of node 2 is the smallest.
classSolution { public: vector<vector<int>> transpose(vector<vector<int>>& A) { int m = A.size(), n = A[0].size(); vector<vector<int>> result(n, vector<int>(m, 0)); for(int i = 0; i < m; i ++) for(int j = 0; j < n; j ++) result[j][i] = A[i][j]; return result; } };
Leetcode868. Binary Gap
Given a positive integer N, find and return the longest distance between two consecutive 1’s in the binary representation of N.
If there aren’t two consecutive 1’s, return 0.
Example 1:
1 2 3 4 5 6 7 8
Input: 22 Output: 2 Explanation: 22 in binary is 0b10110. In the binary representation of 22, there are three ones, and two consecutive pairs of 1's. The first consecutive pair of 1's have distance 2. The second consecutive pair of 1's have distance 1. The answer is the largest of these two distances, which is 2.
Example 2:
1 2 3 4
Input: 5 Output: 2 Explanation: 5 in binary is 0b101.
Example 3:
1 2 3 4
Input: 6 Output: 1 Explanation: 6 in binary is 0b110.
Example 4:
1 2 3 4 5
Input: 8 Output: 0 Explanation: 8 in binary is 0b1000. There aren't any consecutive pairs of 1's in the binary representation of 8, so we return 0.
找到一个数的二进制表示中最远的两个1的距离。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution { public: intbinaryGap(int N){ int res = 0, prev = -1, cur = -1; int count = 0; while(N) { int temp = N & 1; if(temp == 1) { prev = cur; cur = count; if(prev != -1 && cur != -1) res = max(res, cur - prev); } count ++; N = N >> 1; } return res; } };
LeetCode869. Reordered Power of 2
Starting with a positive integer N, we reorder the digits in any order (including the original order) such that the leading digit is not zero. Return true if and only if we can do this in a way such that the resulting number is a power of 2.
classSolution { public: boolreorderedPowerOf2(int N){ long sum = helper(N); for (int i = 0; i < 31; i++) { if (helper(1 << i) == sum) returntrue; } returnfalse; } longhelper(int N){ long res = 0; for (; N; N /= 10) res += pow(10, N % 10); return res; } };
Leetcode870. Advantage Shuffle
Given two arrays A and B of equal size, the advantage of A with respect to B is the number of indices i for which A[i] > B[i].
Return any permutation of A that maximizes its advantage with respect to B.
Example 1:
1 2
Input: A = [2,7,11,15], B = [1,10,4,11] Output: [2,11,7,15]
Example 2:
1 2
Input: A = [12,24,8,32], B = [13,25,32,11] Output: [24,32,8,12]
Note:
1 <= A.length = B.length <= 10000
0 <= A[i] <= 10^9
0 <= B[i] <= 10^9
这道题给了我们两个数组A和B,让对A进行重排序,使得每个对应对位置上A中的数字尽可能的大于B。这不就是大名鼎鼎的田忌赛马么,但想出高招并不是田忌,而是孙膑,就是孙子兵法的作者,但这 credit 好像都给了田忌,让人误以为是田忌的智慧,不禁想起了高富帅重金买科研成果的冠名权的故事。孙子原话是,“今以君之下驷与彼上驷,取君上驷与彼中驷,取君中驷与彼下驷”。就是自己的下马跟人上马比,稳输不用管,上马跟其中马跑,稳赢,中马跟其下马跑,还是稳赢。那我还全马跟其半马跑,能赢否?不过说的,今天博主所在的城市还真有马拉松比赛,而且博主还报了半马,但是由于身不由己的原因无法去跑,实在是可惜,没事,来日方长,总是有机会的。扯了这么久的犊子,赶紧拉回来做题吧。其实这道题的思路还真是田忌赛马的智慧一样,既然要想办法大过B中的数,那么对于B中的每个数(可以看作每匹马),先在A中找刚好大于该数的数字(这就是为啥中马跟其下马比,而不是上马跟其下马比),用太大的数字就浪费了,而如果A中没有比之大的数字,就用A中最小的数字(用下马跟其上马比,不过略有不同的是此时我们没有上马)。就用这种贪婪算法的思路就可以成功解题了,为了方便起见,就是用一个 MultiSet 来做,相当于一个允许重复的 TreeSet,既允许重复又自带排序功能,岂不美哉!那么遍历B中每个数字,在A进行二分搜索第一个大于的数字,这里使用了 STL 自带的 upper_bound 来做,当然想自己写二分也没问题。然后看,若不存在,则将A中最小的数字加到结果 res 中,否则就将第一个大于的数字加入结果 res 中,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution { public: vector advantageCount(vector& A, vector& B){ vector<int> res; multiset<int> st(A.begin(), A.end()); for (int i = 0; i < B.size(); ++i) { auto it = (*st.rbegin() <= B[i]) ? st.begin() : st.upper_bound(B[i]); res.push_back(*it); st.erase(it); } return res; } };
当两个数组都是有序的时候,我们就能快速的直到各自的最大值与最小值,问题就变得容易很多了。比如可以先从B的最大值开始,这是就看A的最大值能否大过B,能的话,就移动到对应位置,不能的话就用最小值,然后再看B的次大值,这样双指针就可以解决问题。所以可以先给A按从小到大的顺序,对于B的话,不能直接排序,因为这样的话原来的顺序就完全丢失了,所以将B中每个数字和其原始坐标位置组成一个 pair 对儿,加入到一个最大堆中,这样B中的最大值就会最先被取出来,再进行上述的操作,这时候就可以发现保存的原始坐标就发挥用处了,根据其坐标就可以直接更新结果 res 中对应的位置了,参见代码如下: 解法二:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: vector advantageCount(vector& A, vector& B){ int n = A.size(), left = 0, right = n - 1; vector<int> res(n); sort(A.begin(), A.end()); priority_queue<pair<int, int>> q; for (int i = 0; i < n; ++i) q.push({B[i], i}); while (!q.empty()) { int val = q.top().first, idx = q.top().second; q.pop(); if (A[right] > val) res[idx] = A[right--]; else res[idx] = A[left++]; } return res; } };
Leetcode871. Minimum Number of Refueling Stops
A car travels from a starting position to a destination which is target miles east of the starting position.
Along the way, there are gas stations. Each station[i] represents a gas station that is station[i][0] miles east of the starting position, and has station[i][1] liters of gas.
The car starts with an infinite tank of gas, which initially has startFuel liters of fuel in it. It uses 1 liter of gas per 1 mile that it drives.
When the car reaches a gas station, it may stop and refuel, transferring all the gas from the station into the car.
What is the least number of refueling stops the car must make in order to reach its destination? If it cannot reach the destination, return -1.
Note that if the car reaches a gas station with 0 fuel left, the car can still refuel there. If the car reaches the destination with 0 fuel left, it is still considered to have arrived.
Example 1:
1 2 3
Input: target = 1, startFuel = 1, stations = [] Output: 0 Explanation: We can reach the target without refueling.
Example 2:
1 2 3
Input: target = 100, startFuel = 1, stations = [[10,100]] Output: -1 Explanation: We can't reach the target (or even the first gas station).
Example 3:
1 2 3 4 5 6 7 8
Input: target = 100, startFuel = 10, stations = [[10,60],[20,30],[30,30],[60,40]] Output: 2 Explanation: We start with 10 liters of fuel. We drive to position 10, expending 10 liters of fuel. We refuel from 0 liters to 60 liters of gas. Then, we drive from position 10 to position 60 (expending 50 liters of fuel), and refuel from 10 liters to 50 liters of gas. We then drive to and reach the target. We made 2 refueling stops along the way, so we return 2.
classSolution { public: intminRefuelStops(int target, int startFuel, vector<vector>& stations){ int n = stations.size(); vector<long> dp(n + 1, startFuel); for (int k = 0; k < n; ++k) { for (int i = k; i >= 0 && dp[i] >= stations[k][0]; --i) { dp[i + 1] = max(dp[i + 1], dp[i] + stations[k][1]); } } for (int i = 0; i <= n; ++i) { if (dp[i] >= target) return i; } return-1; } };
这道题还有一个标签是 Heap,说明还可以用堆来做,这里是用最大堆。因为之前也分析了,我们关心的是在最小的加油次数下能达到的最远距离,那么每个加油站的油量就是关键因素,可以将所有能到达的加油站根据油量的多少放入最大堆,这样每一次都选择油量最多的加油站去加油,才能尽可能的到达最远的地方(如果骄傲没被现实大海冷冷拍下,又怎会懂得要多努力,才走得到远方。。。打住打住,要唱起来了 ^o^)。这里需要一个变量i来记录当前遍历到的加油站的位置,外层循环的终止条件是 startFuel 小于 target,然后在内部也进行循环,若当前加油站的距离小于等于 startFuel,说明可以到达,则把该加油站油量存入最大堆,这个 while 循环的作用就是把所有当前能到达的加油站的油量都加到最大堆中。这样取出的堆顶元素就是最大的油量,也是我们下一步需要去的地方(最想要去的地方,怎么能在半路就返航?!),假如此时堆为空,则直接返回 -1,表示无法到达 target。否则就把堆顶元素加到 startFuel 上,此时的startFuel 就表示当前能到的最远距离,是不是跟上面的 DP 解法核心思想很类似。由于每次只能去一个加油站,此时结果 res 也自增1,当 startFuel 到达 target 时,结果 res 就是最小的加油次数,参见代码如下: 解法二:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: intminRefuelStops(int target, int startFuel, vector<vector>& stations){
int res = 0, i = 0, n = stations.size(); priority_queue<int> pq; for (; startFuel < target; ++res) { while (i < n && stations[i][0] <= startFuel) { pq.push(stations[i++][1]); } if (pq.empty()) return-1; startFuel += pq.top(); pq.pop(); } return res; } };
Leetcode872. Leaf-Similar Trees
Consider all the leaves of a binary tree. From left to right order, the values of those leaves form a leaf value sequence.
For example, in the given tree above, the leaf value sequence is (6, 7, 4, 9, 8). Two binary trees are considered leaf-similar if their leaf value sequence is the same. Return true if and only if the two given trees with head nodes root1 and root2 are leaf-similar.
Leetcode873. Length of Longest Fibonacci Subsequence
A sequence x1, x2, …, xn is Fibonacci-like if:
1 2
n >= 3 xi + xi+1 == xi+2 for all i + 2 <= n
Given a strictly increasing array arr of positive integers forming a sequence, return the length of the longest Fibonacci-like subsequence of arr. If one does not exist, return 0.
A subsequence is derived from another sequence arr by deleting any number of elements (including none) from arr, without changing the order of the remaining elements. For example, [3, 5, 8] is a subsequence of [3, 4, 5, 6, 7, 8].
Example 1:
1 2 3
Input: arr = [1,2,3,4,5,6,7,8] Output: 5 Explanation: The longest subsequence that is fibonacci-like: [1,2,3,5,8].
Example 2:
1 2 3
Input: arr = [1,3,7,11,12,14,18] Output: 3 Explanation: The longest subsequence that is fibonacci-like: [1,11,12], [3,11,14] or [7,11,18].
classSolution { public: introbotSim(vector<int>& commands, vector<vector<int>>& obstacles){ set<pair<int, int>> obs; for(int i = 0; i < obstacles.size(); i++) obs.insert(make_pair(obstacles[i][0], obstacles[i][1])); int coord[2] = {0, 0}, dir = 1; // x-y coordinate 0: x, 1: y, 2: -x, 3: -y int result = 0; for(int i = 0; i < commands.size(); i ++) { if(commands[i] == -2) dir = (dir+1) % 4; elseif(commands[i] == -1) dir = (dir+3) % 4; else { int axis, forward; switch(dir) { case0: axis = 0; forward = 1; break; case1: axis = 1; forward = 1; break; case2: axis = 0; forward = -1; break; case3: axis = 1; forward = -1; break; default: break; } for(int m = 0; m < commands[i]; m ++) { coord[axis] += forward; if(obs.find(make_pair(coord[0], coord[1])) != obs.end()) { coord[axis] -= forward; break; } result = max(result, coord[0]*coord[0] + coord[1]*coord[1]); } } } return result; } };
Leetcode875. Koko Eating Bananas
Koko loves to eat bananas. There are N piles of bananas, the i-th pile has piles[i] bananas. The guards have gone and will come back in H hours. Koko can decide her bananas-per-hour eating speed of K. Each hour, she chooses some pile of bananas, and eats K bananas from that pile. If the pile has less than K bananas, she eats all of them instead, and won’t eat any more bananas during this hour.
Koko likes to eat slowly, but still wants to finish eating all the bananas before the guards come back.
Return the minimum integer K such that she can eat all the bananas within Hhours.
Example 1:
1 2
Input: piles = [3,6,7,11], H = 8 Output: 4
Example 2:
1 2
Input: piles = [30,11,23,4,20], H = 5 Output: 30
Example 3:
1 2
Input: piles = [30,11,23,4,20], H = 6 Output: 23
Note:
1 <= piles.length <= 10^4
piles.length <= H <= 10^9
1 <= piles[i] <= 10^9
这道题说有一只叫科科的猩猩,非常的喜欢吃香蕉,现在有N堆香蕉,每堆的个数可能不同,科科有H小时的时间来吃。要求是,每个小时内,科科只能选某一堆香蕉开始吃,若科科的吃速固定为K,即便在一小时内科科已经吃完了该堆的香蕉,也不能换堆,直到下一个小时才可以去另一堆吃。为了健康,科科想尽可能的吃慢一些,但同时也想在H小时内吃完所有的N堆香蕉,让我们找出一个最小的吃速K值。那么首先来想,既然每个小时只能吃一堆,总共要在H小时内吃完N堆,那么H一定要大于等于N,不然一定没法吃完N堆,这个条件题目中给了,所以就不用再 check 了。我们想一下K的可能的取值范围,当H无穷大的时候,科科有充足的时间去吃,那么就可以每小时只吃一根,也可以吃完,所以K的最小取值是1。那么当H最小,等于N时,那么一个小时内必须吃完任意一堆,那么K值就应该是香蕉最多的那一堆的个数,题目中限定了不超过 1e9,这就是最大值。所以要求的K值的范围就是 [1, 1e9],固定的范围内查找数字,当然,最暴力的方法就是一个一个的试,凭博主多年与 OJ 抗衡的经验来说,基本可以不用考虑的。那么二分查找法就是不二之选了,我们知道经典的二分查找法,是要求数组有序的,而这里香蕉个数数组又不一定是有序的。这是一个很好的观察,但是要弄清楚到底是什么应该是有序的,要查找的K是吃速,跟香蕉堆的个数并没有直接的关系,而K所在的数组其实应该是 [1, 1e9] 这个数组,其本身就是有序的,所以二分查找没有问题。当求出了 mid 之后,需要统计用该速度吃完所有的香蕉堆所需要的时间,统计的方法就是遍历每堆的香蕉个数,然后算吃完该堆要的时间。比如 K=4,那么假如有3个香蕉,需要1个小时,有4香蕉,还是1个小时,有5个香蕉,就需要两个小时,如果将三种情况融合为一个式子呢,就是用吃速加上香蕉个数减去1,再除以吃速即可,即 (pile+mid-1)/mid,大家可以自行带数字检验,是没有问题的。算出需要的总时间后去跟H比较,若小于H,说明吃的速度慢了,需要加快速度,所以 left 更新为 mid+1,否则 right 更新为 mid,最后返回 right 即可,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution { public: intminEatingSpeed(vector<int>& piles, int H){ int left = 1, right = 1e9; while (left < right) { int mid = left + (right - left) / 2, cnt = 0; for (int pile : piles) cnt += (pile + mid - 1) / mid; if (cnt > H) left = mid + 1; else right = mid; } return right; } };
Leetcode876. Middle of the Linked List
Given a non-empty, singly linked list with head node head, return a middle node of linked list.
If there are two middle nodes, return the second middle node.
Example 1:
1 2 3 4 5
Input: [1,2,3,4,5] Output: Node 3 from this list (Serialization: [3,4,5]) The returned node has value 3. (The judge's serialization of this node is [3,4,5]). Note that we returned a ListNode object ans, such that: ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, and ans.next.next.next = NULL.
Example 2:
1 2 3
Input: [1,2,3,4,5,6] Output: Node 4 from this list (Serialization: [4,5,6]) Since the list has two middle nodes with values 3 and 4, we return the second one.
Note: The number of nodes in the given list will be between 1 and 100.
Alex and Lee play a game with piles of stones. There are an even number of piles arranged in a row, and each pile has a positive integer number of stones piles[i].
The objective of the game is to end with the most stones. The total number of stones is odd, so there are no ties.
Alex and Lee take turns, with Alex starting first. Each turn, a player takes the entire pile of stones from either the beginning or the end of the row. This continues until there are no more piles left, at which point the person with the most stones wins.
Assuming Alex and Lee play optimally, return True if and only if Alex wins the game.
Example 1:
1 2 3 4 5 6 7 8
Input: [5,3,4,5] Output: true Explanation: Alex starts first, and can only take the first 5 or the last 5. Say he takes the first 5, so that the row becomes [3, 4, 5]. If Lee takes 3, then the board is [4, 5], and Alex takes 5 to win with 10 points. If Lee takes the last 5, then the board is [3, 4], and Alex takes 4 to win with 9 points. This demonstrated that taking the first 5 was a winning move for Alex, so we return true.
Note:
2 <= piles.length <= 500
piles.length is even.
1 <= piles[i] <= 500
sum(piles) is odd.
这道题说是有偶数堆的石子,每堆的石子个数可能不同,但石子总数是奇数个。现在 Alex 和 Lee (不应该是 Alice 和 Bob 么??)两个人轮流选石子堆,规则是每次只能选开头和末尾中的一堆,最终获得石子总数多的人获胜。若 Alex 先选,两个人都会一直做最优选择,问我们最终 Alex 是否能获胜。博主最先想到的方法是像 Predict the Winner 中的那样,用个 player 变量来记录当前是哪个玩家在操作,若为0,表示 Alex 在选,那么他只有两种选择,要么拿首堆,要么拿尾堆,两种情况分别调用递归,两个递归函数只要有一个能返回 true,则表示 Alex 可以获胜,还需要用个变量 cur0 来记录当前 Alex 的石子总数。同理,若 Lee 在选,即 player 为1的时候,也是只有两种选择,分别调用递归,两个递归函数只要有一个能返回 true,则表示 Lee 可以获胜,用 cur1 来记录当前 Lee 的石子总数。需要注意的是,当首堆或尾堆被选走了后,我们需要标记,这里就有两种方法,一种是从原 piles 中删除选走的堆(或者是新建一个不包含选走堆的数组),但是这种方法会包括大量的拷贝运算,无法通过 OJ。另一种方法是用两个指针 left 和 right,分别指向首尾的位置。当选取了首堆时,则 left 自增1,若选了尾堆时,则 right 自减1。这样就不用执行删除操作,或是拷贝数组了,大大的提高了运行效率,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution { public: boolstoneGame(vector<int>& piles){ returnhelper(piles, 0, 0, 0, (int)piles.size() - 1, 0); } boolhelper(vector<int>& piles, int cur0, int cur1, int left, int right, int player){ if (left > right) return cur0 > cur1; if (player == 0) { returnhelper(piles, cur0 + piles[left], cur1, left + 1, right, 1) || helper(piles, cur0 + piles[right], cur1, left + 1, right, 1); } else { returnhelper(piles, cur0, cur1 + piles[left], left, right - 1, 0) || helper(piles, cur0, cur1 + piles[right], left, right - 1, 0); } } };
这道题也可以使用动态规划 Dynamic Programming 来做,由于玩家获胜的规则是拿到的石子数多,那么多的石子数就可以量化为 dp 值。所以我们用一个二维数组,其中dp[i][j]表示在区间[i, j]内 Alex 比 Lee 多拿的石子数,若为正数,说明 Alex 拿得多,若为负数,则表示 Lee 拿得多。则最终只要看dp[0][n-1]的值,若为正数,则 Alex 能获胜。现在就要找状态转移方程了,我们想,在区间[i, j]内要计算 Alex 比 Lee 多拿的石子数,在这个区间内,Alex 只能拿i或者j位置上的石子,那么当 Alex 拿了piles[i]的话,等于 Alex 多了piles[i]个石子,此时区间缩小成了[i+1, j],此时应该 Lee 拿了,此时根据我们以往的 DP 经验,应该调用子区间的 dp 值,没错,但这里dp[i+1][j]表示是在区间[i+1, j]内 Alex 多拿的石子数,但是若区间[i+1, j]内 Lee 先拿的话,其多拿的石子数也应该是dp[i+1][j],因为两个人都要最优化拿,那么dp[i][j]的值其实可以被piles[i] - dp[i+1][j]更新,因为 Alex 拿了piles[i],减去 Lee 多出的dp[i+1][j],就是区间[i, j]中 Alex 多拿的石子数。同理,假如 Alex 先拿piles[j],那么就用piles[j] - dp[i][j-1]来更新dp[i][j],则我们用二者的较大值来更新即可。注意开始的时候要把dp[i][i]都初始化为piles[i],还需要注意的是,这里的更新顺序很重要,是从小区间开始更新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: boolstoneGame(vector<int>& piles){ int n = piles.size(); vector<vector<int>> dp(n, vector<int>(n)); for (int i = 0; i < n; ++i) dp[i][i] = piles[i]; for (int len = 1; len < n; ++len) { for (int i = 0; i < n - len; ++i) { int j = i + len; dp[i][j] = max(piles[i] - dp[i + 1][j], piles[j] - dp[i][j - 1]); } } return dp[0][n - 1] > 0; } };
其实这道题是一道脑筋急转弯题,跟之前那道 Nim Game 有些像。原因就在于题目中的一个条件,那就是总共有偶数堆,那么就是可以分为堆数相等的两堆,比如我们按奇偶分为两堆。题目还说了石子总数为奇数个,那么分出的这两堆的石子总数一定是不相等的,那么我们只要每次一直取石子总数多的奇数堆或者偶数堆,Alex 就一定可以躺赢,所以最叼的方法就是直接返回 true。
You are given an array people where people[i] is the weight of the ith person, and an infinite number of boats where each boat can carry a maximum weight of limit. Each boat carries at most two people at the same time, provided the sum of the weight of those people is at most limit.
Return the minimum number of boats to carry every given person.
这道题让我们载人过河,说是每个人的体重不同,每条船承重有个限度 limit(限定了这个载重大于等于最重人的体重),同时要求每条船不能超过两人,问我们将所有人载到对岸最少需要多少条船。从题目中的例子2可以看出,最肥的人有可能一人占一条船,当然如果船的载量够大的话,可能还能挤上一个瘦子,那么最瘦的人是最可能挤上去的,所以策略就是胖子加瘦子的上船组合。那么这就是典型的贪婪算法的适用场景啊,首先要给所有人按体重排个序,从瘦子到胖子,这样我们才能快速的知道当前最重和最轻的人。然后使用双指针,left 指向最瘦的人,right 指向最胖的人,当 left 小于等于 right 的时候,进行 while 循环。在循环中,胖子是一定要上船的,所以 right 自减1是肯定有的,但是还是要看能否再带上一个瘦子,能的话 left 自增1。然后结果 res 一定要自增1,因为每次都要用一条船,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: intnumRescueBoats(vector<int>& people, int limit){ int n = people.size(), res = 0; int left = 0, right = n-1; sort(people.begin(), people.end()); while(left <= right) { if (people[left] + people[right] > limit) right --; else { right --; left ++; } res ++; } return res; } };
Leetcode883. Projection Area of 3D Shapes
On a N * N grid, we place some 1 * 1 * 1 cubes that are axis-aligned with the x, y, and z axes. Each value v = grid[i][j] represents a tower of v cubes placed on top of grid cell (i, j). Now we view the projection of these cubes onto the xy, yz, and zx planes. A projection is like a shadow, that maps our 3 dimensional figure to a 2 dimensional plane.
Here, we are viewing the “shadow” when looking at the cubes from the top, the front, and the side. Return the total area of all three projections.
Example 1:
1 2
Input: [[2]] Output: 5
Example 2:
1 2 3 4
Input: [[1,2],[3,4]] Output: 17 Explanation: Here are the three projections ("shadows") of the shape made with each axis-aligned plane.
classSolution { public: intprojectionArea(vector<vector<int>>& grid){ int x = grid.size(); int y = grid[0].size(); int res = 0; int max; for(int i = 0; i < x; i ++) for(int j = 0; j < y; j ++) if(grid[i][j] != 0) res ++; for(int i = 0; i < x; i ++){ max = -1; for(int j = 0; j < y; j ++) if(grid[i][j] > max) max = grid[i][j]; res += max; } for(int i = 0; i < y; i ++){ max = -1; for(int j = 0; j < x; j ++) if(grid[j][i] > max) max = grid[j][i]; res += max; } return res; } };
classSolution { public: intprojectionArea(vector<vector<int>>& grid){ int N = grid.size(); int ans = 0;
for (int i = 0; i < N; ++i) { int bestRow = 0; // largest of grid[i][j] int bestCol = 0; // largest of grid[j][i] for (int j = 0; j < N; ++j) { if (grid[i][j] > 0) ans++; // top shadow bestRow = max(bestRow, grid[i][j]); bestCol = max(bestCol, grid[j][i]); } ans += bestRow + bestCol; }
return ans; } };
Leetcode884. Uncommon Words from Two Sentences
We are given two sentences A and B. (A sentence is a string of space separated words. Each word consists only of lowercase letters.)
A word is uncommon if it appears exactly once in one of the sentences, and does not appear in the other sentence.
Return a list of all uncommon words.
You may return the list in any order.
Example 1:
1 2
Input: A = "this apple is sweet", B = "this apple is sour" Output: ["sweet","sour"]
Example 2:
1 2
Input: A = "apple apple", B = "banana" Output: ["banana"]
Note:
0 <= A.length <= 200
0 <= B.length <= 200
A and B both contain only spaces and lowercase letters.
classSolution { public: vector<string> uncommonFromSentences(string A, string B){ unordered_map<string, int> count; istringstream iss(A + " " + B); while (iss >> A) count[A]++; vector<string> res; for (auto w: count) if (w.second == 1) res.push_back(w.first); return res; } };
Leetcode885. Spiral Matrix III
On a 2 dimensional grid with R rows and C columns, we start at (r0, c0) facing east. Here, the north-west corner of the grid is at the first row and column, and the south-east corner of the grid is at the last row and column. Now, we walk in a clockwise spiral shape to visit every position in this grid.
Whenever we would move outside the boundary of the grid, we continue our walk outside the grid (but may return to the grid boundary later.) Eventually, we reach all R * C spaces of the grid. Return a list of coordinates representing the positions of the grid in the order they were visited.
Example 1:
1 2
Input: R = 1, C = 4, r0 = 0, c0 = 0 Output: [[0,0],[0,1],[0,2],[0,3]]
Example 2:
1 2
Input: R = 5, C = 6, r0 = 1, c0 = 4 Output: [[1,4],[1,5],[2,5],[2,4],[2,3],[1,3],[0,3],[0,4],[0,5],[3,5],[3,4],[3,3],[3,2],[2,2],[1,2],[0,2],[4,5],[4,4],[4,3],[4,2],[4,1],[3,1],[2,1],[1,1],[0,1],[4,0],[3,0],[2,0],[1,0],[0,0]]
classSolution { public: vector<vector<int>> spiralMatrixIII(int R, int C, int r0, int c0) { vector<vector<int>> res; int step = 1; while (res.size() < R * C) { for (int i = 0; i < step; ++i) add(R, C, r0, c0++, res); for (int i = 0; i < step; ++i) add(R, C, r0++, c0, res); ++step; for (int i = 0; i < step; ++i) add(R, C, r0, c0--, res); for (int i = 0; i < step; ++i) add(R, C, r0--, c0, res); ++step; } return res; } voidadd(int R, int C, int x, int y, vector<vector<int>>& res){ if (x >= 0 && x < R && y >= 0 && y < C) res.push_back({x, y}); } };
可以用两个数组 dirX 和 dirY 来控制下一个方向,就像迷宫遍历中的那样,这样只需要一个变量 cur,来分别到 dirX 和 dirY 中取值,初始化为0,表示向右的方向。从螺旋遍历的机制可以看出,每当向右或者向左前进时,步长就要加1,那么我们只要判断当 cur 为0或者2的时候,step 就自增1。由于 cur 初始化为0,所以刚开始 step 就会增1,那么就可以将 step 初始化为0,同时还需要把起始位置提前加入结果 res 中。此时在 while 循环中只需要一个 for 循环即可,朝当前的 cur 方向前进 step 步,r0 加上 dirX[cur],c0 加上 dirY[cur],若没有越界,则加入结果 res 中即可。之后记得 cur 要自增1,为了防止越界,对4取余,就像循环数组一样的操作,参见代码如下:
解法二:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: vector<vector<int>> spiralMatrixIII(int R, int C, int r0, int c0) { vector<vector<int>> res{{r0, c0}}; vector<int> dirX{0, 1, 0, -1}, dirY{1, 0, -1, 0}; int step = 0, cur = 0; while (res.size() < R * C) { if (cur == 0 || cur == 2) ++step; for (int i = 0; i < step; ++i) { r0 += dirX[cur]; c0 += dirY[cur]; if (r0 >= 0 && r0 < R && c0 >= 0 && c0 < C) res.push_back({r0, c0}); } cur = (cur + 1) % 4; } return res; } };
classSolution { public: vector<vector<int>> spiralMatrixIII(int R, int C, int r0, int c0) { vector<vector<int>> res{{r0, c0}}; int x = 0, y = 1, t = 0; for (int k = 0; res.size() < R * C; ++k) { for (int i = 0; i < k / 2 + 1; ++i) { r0 += x; c0 += y; if (r0 >= 0 && r0 < R && c0 >= 0 && c0 < C) res.push_back({r0, c0}); } t = x; x = y; y = -t; } return res; } };
LeetCode886. Possible Bipartition
Given a set of N people (numbered 1, 2, …, N), we would like to split everyone into two groups of any size.
Each person may dislike some other people, and they should not go into the same group.
Formally, if dislikes[i] = [a, b], it means it is not allowed to put the people numbered a and b into the same group.
Return true if and only if it is possible to split everyone into two groups in this way.
classSolution { public: boolpossibleBipartition(int n, vector<vector<int>>& dislikes){ vector<vector<int> > g(n+1, vector<int>(n+1, 0)); vector<int> color(n+1, 0); for (int i = 0; i < dislikes.size(); i ++) { g[dislikes[i][0]][dislikes[i][1]] = 1; g[dislikes[i][1]][dislikes[i][0]] = 1; } for(int i = 1; i <= n; i ++) if (color[i] == 0 && !helper(g, i, color, 1)) returnfalse; returntrue; } boolhelper(vector<vector<int> >& g, int cur, vector<int>& color, int col){ color[cur] = col; for (int i = 0; i < g.size(); i ++) { if (g[cur][i] == 1) { if (color[i] == col) returnfalse; if (color[i] == 0 && !helper(g, i, color, -col)) returnfalse; } } returntrue; } };
Leetcode888. Fair Candy Swap
Alice and Bob have candy bars of different sizes: A[i] is the size of the i-th bar of candy that Alice has, and B[j] is the size of the j-th bar of candy that Bob has.
Since they are friends, they would like to exchange one candy bar each so that after the exchange, they both have the same total amount of candy. (The total amount of candy a person has is the sum of the sizes of candy bars they have.)
Return an integer array ans where ans[0] is the size of the candy bar that Alice must exchange, and ans[1] is the size of the candy bar that Bob must exchange.
If there are multiple answers, you may return any one of them. It is guaranteed an answer exists.
Example 1:
1 2
Input: A = [1,1], B = [2,2] Output: [1,2]
Example 2:
1 2
Input: A = [1,2], B = [2,3] Output: [1,2]
Example 3:
1 2
Input: A = [2], B = [1,3] Output: [2,3]
Example 4:
1 2
Input: A = [1,2,5], B = [2,4] Output: [5,4]
Note:
1 <= A.length <= 10000
1 <= B.length <= 10000
1 <= A[i] <= 100000
1 <= B[i] <= 100000
It is guaranteed that Alice and Bob have different total amounts of candy.
vector<int> fairCandySwap(vector<int>& A, vector<int>& B) { sort(A.begin(),A.end());//升序排序 sort(B.begin(),B.end());//升序排序 int sum1=0,sum2=0,sum3,cha,cha1; for(int i:A)//sum1存储A中的总量 sum1+=i; for(int i:B)//sum2存储B中的总量 sum2+=i; sum3=(sum1+sum2)/2;//sum3是平均值 cha=sum1-sum3;//cha表示A和平均值之间的差,如果大于0,说明A要在B中找一个小cha这个数值的,如果小于0,同理 int i=0,j=0; while(i<A.size()&&j<B.size())//i和j两个索引不断地向后走 { cha1=A[i]-B[j]; if(cha1==cha)//如果刚好等于,那么返回两个数值 return {A[i],B[j]}; elseif(cha1<cha)//如果小于,那么说明A[i]数值太小,应该更大一点 i++; else//如果大于,那么说明B[j]数值太小,应该更大一点 j++; } }
Leetcode889. Construct Binary Tree from Preorder and Postorder Traversal
Return any binary tree that matches the given preorder and postorder traversals.
Values in the traversals pre and post are distinct positive integers.
Example 1:
1 2
Input: pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1] Output: [1,2,3,4,5,6,7]
Note:
1 <= pre.length == post.length <= 30
pre[] and post[] are both permutations of 1, 2, …, pre.length.
It is guaranteed an answer exists. If there exists multiple answers, you can return any of them.
这道题给了一棵树的先序遍历和后序遍历的数组,让我们根据这两个数组来重建出原来的二叉树。之前也做过二叉树的先序遍历 Binary Tree Preorder Traversal 和 后序遍历 Binary Tree Postorder Traversal,所以应该对其遍历的顺序并不陌生。其实二叉树最常用的三种遍历方式,先序,中序,和后序遍历,只要知道其中的任意两种遍历得到的数组,就可以重建出原始的二叉树,而且正好都在 LeetCode 中有出现,其他两道分别是 Construct Binary Tree from Inorder and Postorder Traversal 和 Construct Binary Tree from Preorder and Inorder Traversal。如果做过之前两道题,那么这道题就没有什么难度了,若没有的话,可能还是有些 tricky 的,虽然这仅仅只是一道 Medium 的题。
classSolution { public: TreeNode* constructFromPrePost(vector<int>& pre, vector<int>& post){ returnhelper(pre, 0, (int)pre.size() - 1, post, 0, (int)post.size() - 1); } TreeNode* helper(vector<int>& pre, int preL, int preR, vector<int>& post, int postL, int postR){ if (preL > preR || postL > postR) returnnullptr; TreeNode *node = newTreeNode(pre[preL]); if (preL == preR) return node; int idx = -1; for (idx = postL; idx <= postR; ++idx) { if (pre[preL + 1] == post[idx]) break; } node->left = helper(pre, preL + 1, preL + 1 + (idx - postL), post, postL, idx); node->right = helper(pre, preL + 1 + (idx - postL) + 1, preR, post, idx + 1, postR - 1); return node; } };
Leetcode890. Find and Replace Pattern
You have a list of words and a pattern, and you want to know which words in words matches the pattern.
A word matches the pattern if there exists a permutation of letters p so that after replacing every letter x in the pattern with p(x), we get the desired word.
(Recall that a permutation of letters is a bijection from letters to letters: every letter maps to another letter, and no two letters map to the same letter.)
Return a list of the words in words that match the given pattern.
You may return the answer in any order.
Example 1:
1 2 3 4 5
Input: words = ["abc","deq","mee","aqq","dkd","ccc"], pattern = "abb" Output: ["mee","aqq"] Explanation: "mee" matches the pattern because there is a permutation {a -> m, b -> e, ...}. "ccc" does not match the pattern because {a -> c, b -> c, ...} is not a permutation, since a and b map to the same letter.
classSolution { public: intsurfaceArea(vector<vector<int>>& grid){ int n =grid.size(), res = 0; for(int i = 0 ; i < n; i ++) for(int j = 0; j < n; j ++) { if(grid[i][j] > 0) { res += 4 * grid[i][j] + 2; if(i > 0) res -= min(grid[i][j], grid[i-1][j]) * 2; if(j > 0) res -= min(grid[i][j], grid[i][j-1]) * 2; } } return res; } };
Leetcode893. Groups of Special-Equivalent Strings
You are given an array A of strings.
A move onto S consists of swapping any two even indexed characters of S, or any two odd indexed characters of S.
Two strings S and T are special-equivalent if after any number of moves onto S, S == T.
For example, S = “zzxy” and T = “xyzz” are special-equivalent because we may make the moves “zzxy” -> “xzzy” -> “xyzz” that swap S[0] and S[2], then S[1] and S[3].
Now, a group of special-equivalent strings from A is a non-empty subset of A such that:
Every pair of strings in the group are special equivalent, and; The group is the largest size possible (ie., there isn’t a string S not in the group such that S is special equivalent to every string in the group) Return the number of groups of special-equivalent strings from A.
Example 1:
1 2 3 4 5 6
Input: ["abcd","cdab","cbad","xyzz","zzxy","zzyx"] Output: 3 Explanation: One group is ["abcd", "cdab", "cbad"], since they are all pairwise special equivalent, and none of the other strings are all pairwise special equivalent to these.
The other two groups are ["xyzz", "zzxy"] and ["zzyx"]. Note that in particular, "zzxy" is not special equivalent to "zzyx".
classSolution { public: vector<TreeNode*> allPossibleFBT(int N){ N--; vector<TreeNode*> res; if(N==0){ res.push_back(newTreeNode(0)); return res; } for (int i = 1; i < N; i += 2) { for (auto& left : allPossibleFBT(i)) { for (auto& right : allPossibleFBT(N - i)) { TreeNode* root = newTreeNode(0); root->left = left; root->right = right; res.push_back(root); } } } return res; } };
Leetcode896. Monotonic Array
An array is monotonic if it is either monotone increasing or monotone decreasing.
An array A is monotone increasing if for all i <= j, A[i] <= A[j]. An array A is monotone decreasing if for all i <= j, A[i] >= A[j].
Return true if and only if the given array A is monotonic.
判断数组是否单调。
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: boolisMonotonic(vector<int>& A){ bool inc=true, dec=true; for(int i = 0; i < A.size()-1; i ++) { if(A[i] > A[i+1]) inc = false; if(A[i] < A[i+1]) dec = false; } return inc || dec; } };
Leetcode897. Increasing Order Search Tree
Given a binary search tree, rearrange the tree in in-order so that the leftmost node in the tree is now the root of the tree, and every node has no left child and only 1 right child.
Example 1: Input: [5,3,6,2,4,null,8,1,null,null,null,7,9]
Write an iterator that iterates through a run-length encoded sequence.
The iterator is initialized by RLEIterator(int[] A), where A is a run-length encoding of some sequence. More specifically, for all even i, A[i] tells us the number of times that the non-negative integer value A[i+1] is repeated in the sequence.
The iterator supports one function: next(int n), which exhausts the next n elements (n >= 1) and returns the last element exhausted in this way. If there is no element left to exhaust, next returns -1instead.
For example, we start with A = [3,8,0,9,2,5], which is a run-length encoding of the sequence [8,8,8,5,5]. This is because the sequence can be read as “three eights, zero nines, two fives”.
Example 1:
1 2 3 4 5 6 7 8 9 10 11
Input: ["RLEIterator","next","next","next","next"], [[[3,8,0,9,2,5]],[2],[1],[1],[2]] Output: [null,8,8,5,-1] Explanation: RLEIterator is initialized with RLEIterator([3,8,0,9,2,5]). This maps to the sequence [8,8,8,5,5]. RLEIterator.next is then called 4 times:
.next(2) exhausts 2 terms of the sequence, returning 8. The remaining sequence is now [8, 5, 5]. .next(1) exhausts 1 term of the sequence, returning 8. The remaining sequence is now [5, 5]. .next(1) exhausts 1 term of the sequence, returning 5. The remaining sequence is now [5]. .next(2) exhausts 2 terms, returning -1. This is because the first term exhausted was 5, but the second term did not exist. Since the last term exhausted does not exist, we return -1.
Note:
0 <= A.length <= 1000
A.length is an even integer.
0 <= A[i] <= 10^9
这道题给了我们一种 Run-Length Encoded 的数组,就是每两个数字组成一个数字对儿,前一个数字表示后面的一个数字重复出现的次数。然后有一个 next 函数,让我们返回数组的第n个数字,题目中给的例子也很好的说明了题意。将每个数字对儿抽离出来,放到一个新的数组中。这样我们就只要遍历这个只有数字对儿的数组,当出现次数是0的时候,直接跳过当前数字对儿。若出现次数大于等于n,那么现将次数减去n,然后再返回该数字。否则用n减去次数,并将次数赋值为0,继续遍历下一个数字对儿。若循环退出了,直接返回 -1 即可,参见代码如下:
classRLEIterator { public: vector<pair<int, int>> m; int pointer_en, pointer_m; RLEIterator(vector<int>& encoding) { int len = encoding.size(); pointer_en = 0; pointer_m = 0; for (int i = 0; i < len; i += 2) if (encoding[i] > 0) m.push_back(make_pair(encoding[i], encoding[i+1])); } intnext(int n){ int len = m.size(); while(pointer_m < len) { if (m[pointer_m].first < n) { n -= m[pointer_m].first; pointer_m ++; } else { m[pointer_m].first -= n; break; } } if (pointer_m < len) return m[pointer_m].second; else return-1; } };
其实我们根本不用将数字对儿抽离出来,直接用输入数组的形式就可以,再用一个指针 cur,指向当前数字对儿的次数即可。那么在 next 函数中,我们首先来个 while 循环,判读假如 cur 没有越界,且当n大于当前当次数了,则n减去当前次数,cur 自增2,移动到下一个数字对儿的次数上。当 while 循环结束后,判断若此时 cur 已经越界了,则返回 -1,否则当前次数减去n,并且返回当前数字即可,参见代码如下:
Given the root node of a binary search tree (BST) and a value to be inserted into the tree, insert the value into the BST. Return the root node of the BST after the insertion. It is guaranteed that the new value does not exist in the original BST.
Note that there may exist multiple valid ways for the insertion, as long as the tree remains a BST after insertion. You can return any of them.
Design a class to find the kth largest element in a stream. Note that it is the kth largest element in the sorted order, not the kth distinct element.
Your KthLargest class will have a constructor which accepts an integer k and an integer array nums, which contains initial elements from the stream. For each call to the method KthLargest.add, return the element representing the kth largest element in the stream.
classKthLargest { public: priority_queue<int, vector<int>, greater<int>> q; int size; KthLargest(int k, vector<int>& nums) { int len = nums.size(); size = k; for(int i = 0; i < len; i ++) add(nums[i]); } intadd(int val){ q.push(val); if(q.size() > size) q.pop(); return q.top(); } };
Leetcode704. Binary Search
Given a sorted (in ascending order) integer array nums of n elements and a target value, write a function to search target in nums. If target exists, then return its index, otherwise return -1.
Example 1:
1 2 3
Input: nums = [-1,0,3,5,9,12], target = 9 Output: 4 Explanation: 9 exists in nums and its index is 4
Example 2:
1 2 3
Input: nums = [-1,0,3,5,9,12], target = 2 Output: -1 Explanation: 2 does not exist in nums so return -1
classSolution { public: intsearch(vector<int>& nums, int target){ if(nums.size() == 0) return-1; int left = 0, right = nums.size() - 1; int mid; while(left <= right) { mid = left + (right - left) / 2; if(nums[mid] < target) left = mid + 1; elseif(nums[mid] > target) right = mid - 1; else return mid; } if(nums[mid] == target) return mid; return-1; } };
Leetcode705. Design HashSet
Design a HashSet without using any built-in hash table libraries.
To be specific, your design should include these functions:
add(value): Insert a value into the HashSet. contains(value) : Return whether the value exists in the HashSet or not. remove(value): Remove a value in the HashSet. If the value does not exist in the HashSet, do nothing.
classMyHashMap { public: vector<int> v; /** Initialize your data structure here. */ MyHashMap() { v.resize(1000001, -1); } /** value will always be non-negative. */ voidput(int key, int value){ v[key] = value; } /** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */ intget(int key){ return v[key]; } /** Removes the mapping of the specified value key if this map contains a mapping for the key */ voidremove(int key){ v[key] = -1; } };
classMyHashMap { public: MyHashMap() { data.resize(1000, vector<int>()); } voidput(int key, int value){ int hashKey = key % 1000; if (data[hashKey].empty()) { data[hashKey].resize(1000, -1); } data[hashKey][key / 1000] = value; } intget(int key){ int hashKey = key % 1000; if (!data[hashKey].empty()) { return data[hashKey][key / 1000]; } return-1; } voidremove(int key){ int hashKey = key % 1000; if (!data[hashKey].empty()) { data[hashKey][key / 1000] = -1; } }
private: vector<vector<int>> data; };
Leetcode707. Design Linked List
Design your implementation of the linked list. You can choose to use the singly linked list or the doubly linked list. A node in a singly linked list should have two attributes: val and next. val is the value of the current node, and next is a pointer/reference to the next node. If you want to use the doubly linked list, you will need one more attribute prev to indicate the previous node in the linked list. Assume all nodes in the linked list are 0-indexed.
Implement these functions in your linked list class:
get(index) : Get the value of the index-th node in the linked list. If the index is invalid, return -1.
addAtHead(val) : Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
addAtTail(val) : Append a node of value val to the last element of the linked list.
addAtIndex(index, val) : Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted. If index is negative, the node will be inserted at the head of the list.
deleteAtIndex(index) : Delete the index-th node in the linked list, if the index is valid.
Example:
1 2 3 4 5 6 7
MyLinkedList linkedList = new MyLinkedList(); linkedList.addAtHead(1); linkedList.addAtTail(3); linkedList.addAtIndex(1, 2); // linked list becomes 1->2->3 linkedList.get(1); // returns 2 linkedList.deleteAtIndex(1); // now the linked list is 1->3 linkedList.get(1); // returns 3
Note:
All values will be in the range of [1, 1000].
The number of operations will be in the range of [1, 1000].
好,下面来看每个函数如何实现。首先来看根据坐标取结点函数,先判定 index 是否合法,然后从表头向后移动 index 个位置,找到要返回的结点即可。对于增加表头函数就比较简单了,新建一个头结点,next 连上 head,然后 head 重新指向这个新结点,同时 size 自增1。同样,对于增加表尾结点函数,首先遍历到表尾,然后在之后连上一个新建的结点,同时 size 自增1。下面是根据位置来加结点,肯定还是先来判定 index 是否合法,题目要求有过变动,新加一条说是当 index 为负数时,要在表头加个结点,这样的话只需要判断 index 是否大于 size 这一种非法情况。然后再处理一个 corner case,就是当 index 小于等于0的时候,直接调用前面的表头加结点函数即可。然后就是往后遍历 index-1 个结点,这里为啥要减1呢,因为要加入结点的话,必须要知道加入位置前面一个结点才行,链表加入结点的问题之前的题目中做过很多,这里就不说细节了,最后 size 还是要自增1。根据位置删除结点也是大同小异,没有太大的难度,参见代码如下:
classMyLinkedList { public: MyLinkedList() { head = NULL; size = 0; } intget(int index){ if (index < 0 || index >= size) return-1; Node *cur = head; for (int i = 0; i < index; ++i) cur = cur->next; return cur->val; } voidaddAtHead(int val){ Node *t = newNode(val, head); head = t; ++size; } voidaddAtTail(int val){ Node *cur = head; while (cur->next) cur = cur->next; cur->next = newNode(val, NULL); ++size; } voidaddAtIndex(int index, int val){ if (index > size) return; if (index <= 0) {addAtHead(val); return;} Node *cur = head; for (int i = 0; i < index - 1; ++i) cur = cur->next; Node *t = newNode(val, cur->next); cur->next = t; ++size; } voiddeleteAtIndex(int index){ if (index < 0 || index >= size) return; if (index == 0) { head = head->next; --size; return; } Node *cur = head; for (int i = 0; i < index - 1; ++i) cur = cur->next; cur->next = cur->next->next; --size; } private: structNode { int val; Node *next; Node(int x, Node* n): val(x), next(n) {} }; Node *head, *tail; int size; };
Leetcode709. 转换成小写字母
太简单了
Leetcode712. Minimum ASCII Delete Sum for Two Strings
Given two strings s1, s2, find the lowest ASCII sum of deleted characters to make two strings equal.
Example 1:
1 2 3 4 5
Input: s1 = "sea", s2 = "eat" Output: 231 Explanation: Deleting "s" from "sea" adds the ASCII value of "s" (115) to the sum. Deleting "t" from "eat" adds 116 to the sum. At the end, both strings are equal, and 115 + 116 = 231 is the minimum sum possible to achieve this.
Example 2:
1 2 3 4 5 6
Input: s1 = "delete", s2 = "leet" Output: 403 Explanation: Deleting "dee" from "delete" to turn the string into "let", adds 100[d]+101[e]+101[e] to the sum. Deleting "e" from "leet" adds 101[e] to the sum. At the end, both strings are equal to "let", and the answer is 100+101+101+101 = 403. If instead we turned both strings into "lee" or "eet", we would get answers of 433 or 417, which are higher.
这道题给了我们两个字符串,让我们删除一些字符使得两个字符串相等,我们希望删除的字符的ASCII码最小。这道题跟之前那道Delete Operation for Two Strings极其类似,那道题让求删除的最少的字符数,这道题换成了ASCII码值。其实很多大厂的面试就是这种改动,虽然很少出原题,但是这种小范围的改动却是很经常的,所以当背题侠是没有用的,必须要完全掌握了解题思想,并能举一反三才是最重要的。看到这种玩字符串又是求极值的题,想都不要想直接上DP,我们建立一个二维数组dp,其中dp[i][j]表示字符串s1的前i个字符和字符串s2的前j个字符变相等所要删除的字符的最小ASCII码累加值。那么我们可以先初始化边缘,即有一个字符串为空的话,那么另一个字符串有多少字符就要删多少字符,才能变空字符串。
classSolution { public: intminimumDeleteSum(string s1, string s2){ int m = s1.size(), n = s2.size(); vector<int> dp(n + 1, 0); for (int j = 1; j <= n; ++j) dp[j] = dp[j - 1] + s2[j - 1]; for (int i = 1; i <= m; ++i) { int t1 = dp[0]; dp[0] += s1[i - 1]; for (int j = 1; j <= n; ++j) { int t2 = dp[j]; dp[j] = (s1[i - 1] == s2[j - 1]) ? t1 : min(dp[j] + s1[i - 1], dp[j - 1] + s2[j - 1]); t1 = t2; } } return dp[n]; } };
Leetcode713. Subarray Product Less Than K
Your are given an array of positive integers nums.
Count and print the number of (contiguous) subarrays where the product of all the elements in the subarray is less than k.
Example 1:
1 2 3 4
Input: nums = [10, 5, 2, 6], k = 100 Output: 8 Explanation: The 8 subarrays that have product less than 100 are: [10], [5], [2], [6], [10, 5], [5, 2], [2, 6], [5, 2, 6]. Note that [10, 5, 2] is not included as the product of 100 is not strictly less than k.
Note:
0 < nums.length <= 50000.
0 < nums[i] < 1000.
0 <= k < 10^6.
这道题给了我们一个数组和一个数字K,让求子数组且满足乘积小于K的个数。既然是子数组,那么必须是连续的,所以肯定不能给数组排序了,这道题好在限定了输入数字都是正数,能稍稍好做一点。博主刚开始用的是暴力搜索的方法来做的,就是遍历所有的子数组算乘积和K比较,两个 for 循环就行了,但是 OJ 不答应。于是上网搜大神们的解法,思路很赞。相当于是一种滑动窗口的解法,维护一个数字乘积刚好小于k的滑动窗口,用变量 left 来记录其左边界的位置,右边界i就是当前遍历到的位置。遍历原数组,用 prod 乘上当前遍历到的数字,然后进行 while 循环,如果 prod 大于等于k,则滑动窗口的左边界需要向右移动一位,删除最左边的数字,那么少了一个数字,乘积就会改变,所以用 prod 除以最左边的数字,然后左边右移一位,即 left 自增1。当确定了窗口的大小后,就可以统计子数组的个数了,就是窗口的大小。为啥呢,比如 [5 2 6] 这个窗口,k还是 100,右边界刚滑到6这个位置,这个窗口的大小就是包含6的子数组乘积小于k的个数,即 [6], [2 6], [5 2 6],正好是3个。所以窗口每次向右增加一个数字,然后左边去掉需要去掉的数字后,窗口的大小就是新的子数组的个数,每次加到结果 res 中即可,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution { public: intnumSubarrayProductLessThanK(vector<int>& nums, int k){ if (k <= 1) return0; int res = 0, prod = 1, left = 0; for (int i = 0; i < nums.size(); ++i) { prod *= nums[i]; while (left <= i && prod >= k) prod /= nums[left++]; res += i - left + 1; } return res; } };
Leetcode714. Best Time to Buy and Sell Stock with Transaction Fee
Your are given an array of integers prices, for which the i-th element is the price of a given stock on day i; and a non-negative integer fee representing a transaction fee.
You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction. You may not buy more than 1 share of a stock at a time (ie. you must sell the stock share before you buy again.)
classSolution { public: intmaxProfit(vector<int>& prices, int fee){ // have one stock on hand vector<int> A(prices.size(), 0); // no stock on hand vector<int> B(prices.size(), 0); A[0] = A[0] - prices[0]; for (int i = 1; i < prices.size(); ++i) { A[i] = max(A[i - 1], B[i - 1] - prices[i]); B[i] = max(B[i - 1], A[i - 1] + prices[i] - fee); } return B[prices.size() - 1]; } };
Leetcode717 1-bit and 2-bit Characters
We have two special characters. The first character can be represented by one bit 0. The second character can be represented by two bits (10 or 11).
Now given a string represented by several bits. Return whether the last character must be a one-bit character or not. The given string will always end with a zero.
Example 1:
1 2 3 4 5
Input: bits = [1, 0, 0] Output: True Explanation: The only way to decode it is two-bit character and one-bit character. So the last character is one-bit character.
Example 2:
1 2 3 4 5
Input: bits = [1, 1, 1, 0] Output: False Explanation: The only way to decode it is two-bit character and two-bit character. So the last character is NOT one-bit character.
classSolution { public: intfindLength(vector<int>& A, vector<int>& B){ int m = A.size(), n = B.size(), res = 0; for (int offset = 0; offset < m; ++offset) { for (int i = offset, j = 0; i < m && j < n;) { int cnt = 0; while (i < m && j < n && A[i++] == B[j++]) ++cnt; res = max(res, cnt); } } for (int offset = 0; offset < n; ++offset) { for (int i = 0, j = offset; i < m && j < n;) { int cnt = 0; while (i < m && j < n && A[i++] == B[j++]) ++cnt; res = max(res, cnt); } } return res; } };
classSolution { public: intfindLength(vector<int>& A, vector<int>& B){ int res = 0, m = A.size(), n = B.size(); vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0)); for (int i = 1; i <= m; ++i) { for (int j = 1; j <= n; ++j) { dp[i][j] = (A[i - 1] == B[j - 1]) ? dp[i - 1][j - 1] + 1 : 0; res = max(res, dp[i][j]); } } return res; } };
Leetcode720. Longest Word in Dictionary
Given a list of strings words representing an English Dictionary, find the longest word in words that can be built one character at a time by other words in words. If there is more than one possible answer, return the longest word with the smallest lexicographical order.
If there is no answer, return the empty string. Example 1:
1 2 3 4 5
Input: words = ["w","wo","wor","worl", "world"] Output: "world" Explanation: The word "world" can be built one character at a time by "w", "wo", "wor", and "worl".
Example 2:
1 2 3 4 5
Input: words = ["a", "banana", "app", "appl", "ap", "apply", "apple"] Output: "apple" Explanation: Both "apply" and "apple" can be built from other words in the dictionary. However, "apple" is lexicographically smaller than "apply".
Note:
All the strings in the input will only contain lowercase letters.
The length of words will be in the range [1, 1000].
The length of words[i] will be in the range [1, 30].
classSolution { public: string longestWord(vector<string>& words){ sort(words.begin(), words.end()); string result = ""; vector<string> vec; vec.push_back(""); for(int i = 0; i < words.size(); i ++) { string temp = words[i]; temp.erase(temp.length()-1); if(find(vec.begin(), vec.end(), temp)!=vec.end()) { vec.push_back(words[i]); if(words[i].length() > result.length()) result = words[i]; elseif(words[i].length() == result.length()) result = result < words[i] ? result : words[i]; } } return result; } };
Leetcode721. Accounts Merge
Given a list accounts, each element accounts[i] is a list of strings, where the first element accounts[i][0] is a name, and the rest of the elements are emails representing emails of the account.
Now, we would like to merge these accounts. Two accounts definitely belong to the same person if there is some email that is common to both accounts. Note that even if two accounts have the same name, they may belong to different people as people could have the same name. A person can have any number of accounts initially, but all of their accounts definitely have the same name.
After merging the accounts, return the accounts in the following format: the first element of each account is the name, and the rest of the elements are emails in sorted order. The accounts themselves can be returned in any order.
The first and third John's are the same person as they have the common email "johnsmith@mail.com". The second John and Mary are different people as none of their email addresses are used by other accounts. We could return these lists in any order, for example the answer [['Mary', 'mary@mail.com'], ['John', 'johnnybravo@mail.com'], ['John', 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com']] would still be accepted.
Note:
The length of accounts will be in the range [1, 1000].
The length of accounts[i] will be in the range [1, 10].
The length of accounts[i][j] will be in the range [1, 30].
classSolution { public: vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) { vector<vector<string>> res; unordered_map<string, string> root; unordered_map<string, string> owner; unordered_map<string, set<string>> m; for (auto account : accounts) { for (int i = 1; i < account.size(); ++i) { root[account[i]] = account[i]; owner[account[i]] = account[0]; } } for (auto account : accounts) { string p = find(account[1], root); for (int i = 2; i < account.size(); ++i) { root[find(account[i], root)] = p; } } for (auto account : accounts) { for (int i = 1; i < account.size(); ++i) { m[find(account[i], root)].insert(account[i]); } } for (auto a : m) { vector<string> v(a.second.begin(), a.second.end()); v.insert(v.begin(), owner[a.first]); res.push_back(v); } return res; } string find(string s, unordered_map<string, string>& root){ return root[s] == s ? s : find(root[s], root); } };
Leetcode724. Find Pivot Index
Given an array of integers nums, write a method that returns the “pivot” index of this array.
We define the pivot index as the index where the sum of the numbers to the left of the index is equal to the sum of the numbers to the right of the index.
If no such index exists, we should return -1. If there are multiple pivot indexes, you should return the left-most pivot index.
Example 1:
1 2 3 4 5 6
Input: nums = [1, 7, 3, 6, 5, 6] Output: 3 Explanation: The sum of the numbers to the left of index 3 (nums[3] = 6) is equal to the sum of numbers to the right of index 3. Also, 3 is the first index where this occurs.
Example 2:
1 2 3 4 5
Input: nums = [1, 2, 3] Output: -1 Explanation: There is no index that satisfies the conditions in the problem statement.
Note:
The length of nums will be in the range [0, 10000]. Each element nums[i] will be an integer in the range [-1000, 1000].
classSolution { public: intpivotIndex(vector<int>& nums){ int sum = 0, t = 0; for (int i = 0; i < nums.size(); i++) sum += nums[i]; for(int i = 0; i < nums.size(); i ++) { sum -= nums[i]; if(sum == t) return i; t += nums[i]; } return-1; } };
Leetcode725. Split Linked List in Parts
Given the head of a singly linked list and an integer k, split the linked list into k consecutive linked list parts.
The length of each part should be as equal as possible: no two parts should have a size differing by more than one. This may lead to some parts being null.
The parts should be in the order of occurrence in the input list, and parts occurring earlier should always have a size greater than or equal to parts occurring later.
Return an array of the k parts.
Example 1:
1 2 3 4 5
Input: head = [1,2,3], k = 5 Output: [[1],[2],[3],[],[]] Explanation: The first element output[0] has output[0].val = 1, output[0].next = null. The last element output[4] is null, but its string representation as a ListNode is [].
Example 2:
1 2 3 4
Input: head = [1,2,3,4,5,6,7,8,9,10], k = 3 Output: [[1,2,3,4],[5,6,7],[8,9,10]] Explanation: The input has been split into consecutive parts with size difference at most 1, and earlier parts are a larger size than the later parts.
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ classSolution { public: vector<ListNode*> splitListToParts(ListNode* head, int k){ ListNode *cur = head, *prev; int nums = 0; while(cur != NULL) { cur = cur->next; nums ++; } vector<int> length(k, nums/k); nums = nums % k; for (int i = 0; i < nums; i ++) length[i] ++; vector<ListNode*> res; cur = head; for (int i = 0; i < length.size(); i ++) { if (length[i] <= 0) res.push_back(NULL); else { res.push_back(cur); while(cur && length[i]--) { prev = cur; cur = cur->next; } prev->next = NULL; } } return res; } };
Leetcode728 Self Dividing Numbers
A self-dividing number is a number that is divisible by every digit it contains. For example, 128 is a self-dividing number because 128 % 1 == 0, 128 % 2 == 0, and 128 % 8 == 0. Also, a self-dividing number is not allowed to contain the digit zero. Given a lower and upper number bound, output a list of every possible self dividing number, including the bounds if possible.
vector<int> selfDividingNumbers(int left, int right){ vector<int> result; bool flag; int temp; for(int i = left; i <= right; i ++) { int ii = i; flag = true; while(ii > 0) { temp = ii % 10; if(temp == 0 || i % temp != 0) { flag=false; break; } ii /= 10; } if (flag) result.push_back(i); } return result; } };
Leetcode729. My Calendar I
Implement a MyCalendar class to store your events. A new event can be added if adding the event will not cause a double booking.
Your class will have the method, book(int start, int end). Formally, this represents a booking on the half open interval [start, end), the range of real numbers x such that start <= x < end.
A double booking happens when two events have some non-empty intersection (ie., there is some time that is common to both events.)
For each call to the method MyCalendar.book, return true if the event can be added to the calendar successfully without causing a double booking. Otherwise, return false and do not add the event to the calendar.
Your class will be called like this: MyCalendar cal = new MyCalendar(); MyCalendar.book(start, end)
Example 1:
1 2 3 4 5 6 7
MyCalendar(); MyCalendar.book(10, 20); // returns true MyCalendar.book(15, 25); // returns false MyCalendar.book(20, 30); // returns true Explanation: The first event can be booked. The second can't because time 15 is already booked by another event. The third event can be booked, as the first event takes every time less than 20, but not including 20.
Note:
The number of calls to MyCalendar.book per test case will be at most 1000.
In calls to MyCalendar.book(start, end), start and end are integers in the range [0, 10^9].
classMyCalendar { public: MyCalendar() {} boolbook(int start, int end){ for (auto a : cal) { if (max(a.first, start) < min(a.second, end)) returnfalse; } cal.push_back({start, end}); returntrue; }
private: vector<pair<int, int>> cal; };
Leetcode731. My Calendar II
Implement a MyCalendarTwo class to store your events. A new event can be added if adding the event will not cause a triple booking.
Your class will have one method, book(int start, int end). Formally, this represents a booking on the half open interval [start, end), the range of real numbers x such that start <= x < end.
A triple booking happens when three events have some non-empty intersection (ie., there is some time that is common to all 3 events.)
For each call to the method MyCalendar.book, return true if the event can be added to the calendar successfully without causing a triple booking. Otherwise, return false and do not add the event to the calendar.
Your class will be called like this: MyCalendar cal = new MyCalendar(); MyCalendar.book(start, end)
classMyCalendarTwo { public: MyCalendarTwo() {} boolbook(int start, int end){ ++freq[start]; --freq[end]; int cnt = 0; for (auto f : freq) { cnt += f.second; if (cnt == 3) { --freq[start]; ++freq[end]; returnfalse; } } returntrue; }
private: map<int, int> freq; };
Leetcode733. Flood Fill
An image is represented by a 2-D array of integers, each integer representing the pixel value of the image (from 0 to 65535).
Given a coordinate (sr, sc) representing the starting pixel (row and column) of the flood fill, and a pixel value newColor, “flood fill” the image.
To perform a “flood fill”, consider the starting pixel, plus any pixels connected 4-directionally to the starting pixel of the same color as the starting pixel, plus any pixels connected 4-directionally to those pixels (also with the same color as the starting pixel), and so on. Replace the color of all of the aforementioned pixels with the newColor.
At the end, return the modified image.
Example 1:
1 2 3 4 5 6 7 8 9
Input: image = [[1,1,1],[1,1,0],[1,0,1]] sr = 1, sc = 1, newColor = 2 Output: [[2,2,2],[2,2,0],[2,0,1]] Explanation: From the center of the image (with position (sr, sc) = (1, 1)), all pixels connected by a path of the same color as the starting pixel are colored with the new color. Note the bottom corner is not colored 2, because it is not 4-directionally connected to the starting pixel.
Note:
The length of image and image[0] will be in the range [1, 50]. The given starting pixel will satisfy 0 <= sr < image.length and 0 <= sc < image[0].length. The value of each color in image[i][j] and newColor will be an integer in [0, 65535].
classSolution { public: vector<vector<int>> floodFill(vector<vector<int>>& image, int sr, int sc, int newColor) { if(image[sr][sc]==newColor) return image; int dir[4][2] = {{0,1},{0,-1},{-1,0},{1,0}}; queue<pair<int,int> > q; int m = image.size(), n = image[0].size(); q.push(make_pair(sr,sc)); int org_color = image[sr][sc]; while(!q.empty()){ pair<int,int> temp = q.front(); q.pop(); image[temp.first][temp.second] = newColor; for(int i = 0; i < 4; i ++) { int temp1 = temp.first+dir[i][0]; int temp2 = temp.second+dir[i][1]; if(0<=temp1 && temp1<m && 0<=temp2 && temp2<n && image[temp1][temp2]==org_color) { q.push(make_pair(temp1,temp2)); } } } return image; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution { voidcolor(vector<vector<int>>& image, int i, int j, int m, int n, int c, int o){ if(i>=0 && j>=0 && i<m && j<n && image[i][j] == o){ image[i][j] = c; color(image, i+1, j, m, n, c, o); color(image, i, j-1, m, n, c, o); color(image, i-1, j, m, n, c, o); color(image, i, j+1, m, n, c, o); } } public: vector<vector<int>> floodFill(vector<vector<int>>& image, int sr, int sc, int newColor) { if(newColor!=image[sr][sc]) color(image, sr, sc, image.size(), image[0].size(), newColor, image[sr][sc]); return image; } };
Leetcode735. Asteroid Collision
We are given an array asteroids of integers representing asteroids in a row.
For each asteroid, the absolute value represents its size, and the sign represents its direction (positive meaning right, negative meaning left). Each asteroid moves at the same speed.
Find out the state of the asteroids after all collisions. If two asteroids meet, the smaller one will explode. If both are the same size, both will explode. Two asteroids moving in the same direction will never meet.
Example 1:
1 2 3
Input: asteroids = [5,10,-5] Output: [5,10] Explanation: The 10 and -5 collide resulting in 10. The 5 and 10 never collide.
Example 2:
1 2 3
Input: asteroids = [8,-8] Output: [] Explanation: The 8 and -8 collide exploding each other.
Example 3:
1 2 3
Input: asteroids = [10,2,-5] Output: [10] Explanation: The 2 and -5 collide resulting in -5. The 10 and -5 collide resulting in 10.
Example 4:
1 2 3
Input: asteroids = [-2,-1,1,2] Output: [-2,-1,1,2] Explanation: The -2 and -1 are moving left, while the 1 and 2 are moving right. Asteroids moving the same direction never meet, so no asteroids will meet each other.
intcalc(string& expression, int& start){ if (expression[start] != '(') { if (islower(expression[start])) { string var = parseStr(expression, start); return map[var].back(); } else { returnparseInt(expression, start); } } int res; start ++; if (expression[start] == 'l') { start += 4; vector<string> vars; while(true) { if (!islower(expression[start])) { res = calc(expression, start); break; } string var = parseStr(expression, start); if (expression[start] = ')') { res = map[var].back(); break; } vars.push_back(var); start ++; int e = parseInt(expression, start); map[var].push_back(e); start ++; } } elseif (expression[start] == 'a') { start += 4; int t1 = calc(expression, start); start ++; int t2 = calc(expression, start); res = t1 + t2; } elseif (expression[start] == 'm') { start += 5; int t1 = calc(expression, start); start ++; int t2 = calc(expression, start); res = t1 * t2; } start ++; return res; }
intparseInt(string& expression, int& start){ int flag = 1, res = 0; int len = expression.length(); if (expression[start] == '-') { flag = -1; start ++; } while(start < len && expression[start] >= '0' && expression[start] <= '9') { res = res * 10 + (expression[start] - '0'); start++; } return res * flag; }
string parseStr(string& expression, int& start){ string res; int len = expression.length(); while(start < len && expression[start] != ' ' && expression[start] != ')') { res += expression[start]; start ++; } return res; } };
Leetcode738. Monotone Increasing Digits
An integer has monotone increasing digits if and only if each pair of adjacent digits x and y satisfy x <= y.
Given an integer n, return the largest number that is less than or equal to n with monotone increasing digits.
Example 1:
1 2
Input: n = 10 Output: 9
Example 2:
1 2
Input: n = 1234 Output: 1234
Example 3:
1 2
Input: n = 332 Output: 299
给定一个非负正整数n,求一个这样的非负整数x,x从左到右读是单调上升的(不要求严格上升),x ≤ n 并且x是满足这两个条件的最大整数。
先将n转为字符串s,然后从左向右扫描。如果一路都是递增的,那么直接返回n自己就好了。否则考虑如何求。我们找到第一个s [ i ] > s [ j ]的位置,这里下降了,需要作出调整。我们必须调整s [ i ]或者其左边的数,否则不能使得数字变得比n小。因为要使得答案尽量大,所以我们尝试改尽量低位的数字,我们就从s [ i ]开始向左找到第一个小于s [ i ]的数,如果找不到,则必须把开头改成s [ i ] − 1才能使得数字变小,接着后面全填9就行了;如果找到了,比如说s [ j ] < s [ i ],那么可以修改的最低位就是s [ j + 1 ],将其改为s [ j + 1 ] − 1然后后面全填9即可。代码如下:
classSolution { public: intmonotoneIncreasingDigits(int n){ char s[12]; int len = 0, res = n; while(n > 0) { s[len++] = '0' + n % 10; n /= 10; } int i = 0, j = len-1; while(i <= j) { char t = s[i]; s[i] = s[j]; s[j] = t; i ++; j --; } i = 0; while(i+1 < len && s[i] <= s[i+1]) i ++; if (i == len-1) return res; j = i; while (j >= 0 && s[i] == s[j]) j --; j ++; s[j++] --; for ( ; j < len; j ++) s[j] = '9'; res = 0; for (i = 0; i < len; i ++) res = res * 10 + (s[i] - '0'); return res; } };
Leetcode739. Daily Temperatures
Given an array of integers temperatures represents the daily temperatures, return an array answer such that answer[i] is the number of days you have to wait after the ith day to get a warmer temperature. If there is no future day for which this is possible, keep answer[i] == 0 instead.
classSolution { public: vector<int> dailyTemperatures(vector<int>& t){ int len = t.size(); vector<int> res(len, 0); stack<int> s; for (int i = 0; i < len; i ++) { while (!s.empty() && t[s.top()] < t[i]) { res[s.top()] = i - s.top(); s.pop(); } s.push(i); } return res; } };
Leetcode740. Delete and Earn
Given an array nums of integers, you can perform operations on the array.
In each operation, you pick any nums[i] and delete it to earn nums[i] points. After, you must delete every element equal to nums[i] - 1 or nums[i] + 1.
You start with 0 points. Return the maximum number of points you can earn by applying such operations.
Example 1:
1 2 3 4 5
Input: nums = [3, 4, 2] Output: 6 Explanation: Delete 4 to earn 4 points, consequently 3 is also deleted. Then, delete 2 to earn 2 points. 6 total points are earned.
Example 2:
1 2 3 4 5 6
Input: nums = [2, 2, 3, 3, 3, 4] Output: 9 Explanation: Delete 3 to earn 3 points, deleting both 2's and the 4. Then, delete 3 again to earn 3 points, and 3 again to earn 3 points. 9 total points are earned.
Note:
The length of nums is at most 20000.
Each element nums[i] is an integer in the range [1, 10000].
classSolution { public: intdeleteAndEarn(vector<int>& nums){ vector<int> dp(10001, 0); for (int i : nums) dp[i] += i; int use = 0, not_use = 0, prev = -2; for (int i = 0; i < 10001; i ++) { if (dp[i] > 0) { int tmp = max(use, not_use); if (i - 1 != prev) use = tmp + dp[i]; else use = not_use + dp[i]; not_use = tmp; prev = i; } } returnmax(use, not_use); } };
Leetcode743. Network Delay Time
You are given a network of n nodes, labeled from 1 to n. You are also given times, a list of travel times as directed edges times[i] = (ui, vi, wi), where ui is the source node, vi is the target node, and wi is the time it takes for a signal to travel from source to target.
We will send a signal from a given node k. Return the time it takes for all the n nodes to receive the signal. If it is impossible for all the n nodes to receive the signal, return -1.
Example 1:
1 2
Input: times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2 Output: 2
classSolution { public: intnetworkDelayTime(vector<vector<int>>& times, int n, int k){ vector<vector<int>> g(n+1, vector<int>(n+1, INT_MAX)); vector<bool> flag(n+1, false); vector<int> dist(n+1, INT_MAX); int cnt = 1; flag[k] = true; for (int i = 0; i < times.size(); i ++) g[times[i][0]][times[i][1]] = times[i][2]; for (int i = 1; i <= n; i ++) dist[i] = g[k][i]; dist[k] = 0; while(cnt != n) { int tmp = -1, minn = INT_MAX; for (int i = 1; i <= n; i ++) if (!flag[i] && dist[i] < minn) { minn = dist[i]; tmp = i; } if (tmp == -1) break; flag[tmp] = true; cnt ++; for (int i = 1; i <= n; i ++) { if (!flag[i] && g[tmp][i] != INT_MAX && dist[i] > dist[tmp]+g[tmp][i]) dist[i] = dist[tmp]+g[tmp][i]; } } int res = INT_MIN; for (int i = 1; i <= n; i ++) res = max(res, dist[i]); if (res == INT_MAX) res = -1; return res; } };
Leetcode744. Find Smallest Letter Greater Than Target
Given a list of sorted characters letters containing only lowercase letters, and given a target letter target, find the smallest element in the list that is larger than the given target.
Letters also wrap around. For example, if the target is target = ‘z’ and letters = [‘a’, ‘b’], the answer is ‘a’.
classSolution { public: charnextGreatestLetter(vector<char>& letters, char target){ int cha = 99999; for(char c : letters) { if(c > target && (c-target) < cha) cha = c - target; } return target + cha > 'z' ? letters[0] : target + cha; } };
Leetcode746. Min Cost Climbing Stairs
On a staircase, the i-th step has some non-negative cost cost[i] assigned (0 indexed).
Once you pay the cost, you can either climb one or two steps. You need to find minimum cost to reach the top of the floor, and you can either start from the step with index 0, or the step with index 1.
Example 1:
1 2 3
Input: cost = [10, 15, 20] Output: 15 Explanation: Cheapest is start on cost[1], pay that cost and go to the top.
Example 2:
1 2 3
Input: cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] Output: 6 Explanation: Cheapest is start on cost[0], and only step on 1s, skipping cost[3].
Leetcode747. Largest Number At Least Twice of Others
In a given integer array nums, there is always exactly one largest element. Find whether the largest element in the array is at least twice as much as every other number in the array. If it is, return the index of the largest element, otherwise return -1.
Example 1:
1 2 3 4
Input: nums = [3, 6, 1, 0] Output: 1 Explanation: 6 is the largest integer, and for every other number in the array x, 6 is more than twice as big as x. The index of value 6 is 1, so we return 1.
Example 2:
1 2 3
Input: nums = [1, 2, 3, 4] Output: -1 Explanation: 4 isn't at least as big as twice the value of 3, so we return -1.
查找数组中最大的元素是否至少是数组中其他数字的两倍。是的话就返回最大元素的索引。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: intdominantIndex(vector<int>& nums){ int max1 = -1, max2 = -1, index = -1; for(int i = 0; i < nums.size(); i ++) { if(nums[i] > max1) { max2 = max1; max1 = nums[i]; index = i; } elseif(nums[i] > max2) { max2 = nums[i]; } } return max1 >= max2 * 2 ? index : -1; } };
Leetcode748. Shortest Completing Word
Find the minimum length word from a given dictionary words, which has all the letters from the string licensePlate. Such a word is said to complete the given string licensePlate
Here, for letters we ignore case. For example, “P” on the licensePlate still matches “p” on the word.
It is guaranteed an answer exists. If there are multiple answers, return the one that occurs first in the array.
The license plate might have the same letter occurring multiple times. For example, given a licensePlate of “PP”, the word “pair” does not complete the licensePlate, but the word “supper” does.
Example 1:
1 2 3 4 5
Input: licensePlate = "1s3 PSt", words = ["step", "steps", "stripe", "stepple"] Output: "steps" Explanation: The smallest length word that contains the letters "S", "P", "S", and "T". Note that the answer is not "step", because the letter "s" must occur in the word twice. Also note that we ignored case for the purposes of comparing whether a letter exists in the word.
Example 2:
1 2 3 4
Input: licensePlate = "1s3 456", words = ["looks", "pest", "stew", "show"] Output: "pest" Explanation: There are 3 smallest length words that contains the letters "s". We return the one that occurred first.
classSolution { public: string tolow(string s){ for (int i = 0; i < s.length(); i++) { if (s[i] >= 'A' && s[i] <= 'Z') { s[i] = s[i]-'A'+'a'; } } return s; } boolmatched(string word, int* mymap){ int tmap[26]; for (int i = 0; i < 26; i++) { tmap[i] = mymap[i]; } for (int i = 0; i < word.length(); i++) { tmap[word[i]-'a']--; } for (int i = 0; i < 26; i++) if (tmap[i] > 0 ) returnfalse; returntrue; } string shortestCompletingWord(string licensePlate, vector<string>& words){ licensePlate = tolow(licensePlate); int m[26] = {0}; for (int i = 0; i < licensePlate.length(); i ++) { if (licensePlate[i] <= 'z' && licensePlate[i] >= 'a') m[licensePlate[i]-'a']++; } string result; int minn = 1001; for (auto word : words) { if (matched(word, m) && word.length() < minn) { minn = word.length(); result = word; } } return result; } };
Leetcode752. Open the Lock
You have a lock in front of you with 4 circular wheels. Each wheel has 10 slots: ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’. The wheels can rotate freely and wrap around: for example we can turn ‘9’ to be ‘0’, or ‘0’ to be ‘9’. Each move consists of turning one wheel one slot.
The lock initially starts at ‘0000’, a string representing the state of the 4 wheels.
You are given a list of deadends dead ends, meaning if the lock displays any of these codes, the wheels of the lock will stop turning and you will be unable to open it.
Given a target representing the value of the wheels that will unlock the lock, return the minimum total number of turns required to open the lock, or -1 if it is impossible.
Example 1:
1 2 3 4 5 6
Input: deadends = ["0201","0101","0102","1212","2002"], target = "0202" Output: 6 Explanation: A sequence of valid moves would be "0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202". Note that a sequence like "0000" -> "0001" -> "0002" -> "0102" -> "0202" would be invalid, because the wheels of the lock become stuck after the display becomes the dead end "0102".
Example 2:
1 2 3 4
Input: deadends = ["8888"], target = "0009" Output: 1 Explanation: We can turn the last wheel in reverse to move from "0000" -> "0009".
Example 3:
1 2 3 4
Input: deadends = ["8887","8889","8878","8898","8788","8988","7888","9888"], target = "8888" Output: -1 Explanation: We can't reach the target without getting stuck.
classSolution { public: intopenLock(vector<string>& deadends, string target){ queue<string> q; q.push("0000"); int step = 0; set<string> visited; for (string s : deadends) visited.insert(s); while(!q.empty()) { int size = q.size(); for (int i = 0; i < size; i ++) { string tmp = q.front(); q.pop(); if (visited.count(tmp)) continue; if (tmp == target) return step; for (int j = 0; j < 4; j ++) { for (int k = -1; k < 2; k += 2) { string next = tmp; next[j] = '0' + (next[j] - '0' + k + 10) % 10; q.push(next); } } visited.insert(tmp); } step ++; } return-1; } };
Leetcode754. Reach a Number
You are standing at position 0 on an infinite number line. There is a destination at position target.
You can make some number of moves numMoves so that:
On each move, you can either go left or right.During the ith move (starting from i == 1 to i == numMoves), you take i steps in the chosen direction. Given the integer target, return the minimum number of moves required (i.e., the minimum numMoves) to reach the destination.
Example 1:
1 2 3 4 5 6
Input: target = 2 Output: 3 Explanation: On the 1st move, we step from 0 to 1 (1 step). On the 2nd move, we step from 1 to -1 (2 steps). On the 3rd move, we step from -1 to 2 (3 steps).
Example 2:
1 2 3 4 5
Input: target = 3 Output: 2 Explanation: On the 1st move, we step from 0 to 1 (1 step). On the 2nd move, we step from 1 to 3 (2 steps).
classSolution { public: intreachNumber(int target){ target = abs(target); int res = 0, sum = 0; while(sum < target || ( sum - target) % 2 == 1) { res ++; sum += res; } return res; } };
Leetcode756. Pyramid Transition Matrix
We are stacking blocks to form a pyramid. Each block has a color which is a one letter string, like ‘Z’.
For every block of color C we place not in the bottom row, we are placing it on top of a left block of color A and right block of color B. We are allowed to place the block there only if (A, B, C) is an allowed triple.
We start with a bottom row of bottom, represented as a single string. We also start with a list of allowed triples allowed. Each allowed triple is represented as a string of length 3.
Return true if we can build the pyramid all the way to the top, otherwise false.
Example 1:
1 2 3 4 5 6 7 8 9 10 11
Input: bottom = "XYZ", allowed = ["XYD", "YZE", "DEA", "FFF"] Output: true Explanation: We can stack the pyramid like this: A / \ D E / \ / \ X Y Z
This works because ('X', 'Y', 'D'), ('Y', 'Z', 'E'), and ('D', 'E', 'A') are allowed triples.
Example 2:
1 2 3 4 5
Input: bottom = "XXYX", allowed = ["XXX", "XXY", "XYX", "XYY", "YXZ"] Output: false Explanation: We can't stack the pyramid to the top. Note that there could be allowed triples (A, B, C) and (A, B, D) with C != D.
Note:
bottom will be a string with length in range [2, 8].
allowed will have length in range [0, 200].
Letters in all strings will be chosen from the set {‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’}.
classSolution { public: boolpyramidTransition(string bottom, vector<string>& allowed){ int n = bottom.size(); vector<vector<vector<bool>>> dp(n, vector<vector<bool>>(n, vector<bool>(7, false))); unordered_map<char, unordered_set<string>> m; for (string str : allowed) { m[str[2]].insert(str.substr(0, 2)); } for (int i = 0; i < n; ++i) { dp[n - 1][i][bottom[i] - 'A'] = true; } for (int i = n - 2; i >= 0; --i) { for (int j = 0; j <= i; ++j) { for (char ch = 'A'; ch <= 'G'; ++ch) { if (!m.count(ch)) continue; for (string str : m[ch]) { if (dp[i + 1][j][str[0] - 'A'] && dp[i + 1][j + 1][str[1] - 'A']) { dp[i][j][ch - 'A'] = true; } } } } } for (int i = 0; i < 7; ++i) { if (dp[0][0][i]) returntrue; } returnfalse; } };
Leetcode761. Special Binary String
Special binary strings are binary strings with the following two properties:
The number of 0’s is equal to the number of 1’s.
Every prefix of the binary string has at least as many 1’s as 0’s.
Given a special string S, a move consists of choosing two consecutive, non-empty, special substrings of S, and swapping them. (Two strings are consecutive if the last character of the first string is exactly one index before the first character of the second string.)
At the end of any number of moves, what is the lexicographically largest resulting string possible?
Example 1:
1 2 3 4 5
Input: S = "11011000" Output: "11100100" Explanation: The strings "10" [occuring at S[1]] and "1100" [at S[3]] are swapped. This is the lexicographically largest string possible after some number of swaps.
Note:
S has length at most 50.
S is guaranteed to be a special binary string as defined above.
classSolution { public: string makeLargestSpecial(string S){ int cnt = 0, i = 0; vector<string> v; string res = ""; for (int j = 0; j < S.size(); ++j) { cnt += (S[j] == '1') ? 1 : -1; if (cnt == 0) { v.push_back('1' + makeLargestSpecial(S.substr(i + 1, j - i - 1)) + '0'); i = j + 1; } } sort(v.begin(), v.end(), greater<string>()); for (int i = 0; i < v.size(); ++i) res += v[i]; return res; } };
Leetcode762. Prime Number of Set Bits in Binary Representation
Given two integers L and R, find the count of numbers in the range [L, R] (inclusive) having a prime number of set bits in their binary representation.
(Recall that the number of set bits an integer has is the number of 1s present when written in binary. For example, 21 written in binary is 10101 which has 3 set bits. Also, 1 is not a prime.)
Example 1:
1 2 3 4 5 6 7
Input: L = 6, R = 10 Output: 4 Explanation: 6 -> 110 (2 set bits, 2 is prime) 7 -> 111 (3 set bits, 3 is prime) 9 -> 1001 (2 set bits , 2 is prime) 10->1010 (2 set bits , 2 is prime)
Example 2:
1 2 3 4 5 6 7 8 9
Input: L = 10, R = 15 Output: 5 Explanation: 10 -> 1010 (2 set bits, 2 is prime) 11 -> 1011 (3 set bits, 3 is prime) 12 -> 1100 (2 set bits, 2 is prime) 13 -> 1101 (3 set bits, 3 is prime) 14 -> 1110 (3 set bits, 3 is prime) 15 -> 1111 (4 set bits, 4 is not prime)
classSolution { public: boolisprime(int x){ if(x == 0 || x == 1) returnfalse; int xx = sqrt(x); for(int i = 2; i <= xx; i ++) { if(!(x % i)) returnfalse; } returntrue; } intgetbit(int x){ int res = 0; while(x) { int temp = x & 1; res = temp == 1 ? res+1 : res; x = x >> 1; } return res; } intcountPrimeSetBits(int L, int R){ int res = 0; for(int i = L; i <= R; i ++) { int bit_num = getbit(i); printf("%d\n", bit_num); if(isprime(bit_num)) res ++; } return res; } };
Leetcode763. Partition Labels
A string S of lowercase letters is given. We want to partition this string into as many parts as possible so that each letter appears in at most one part, and return a list of integers representing the size of these parts.
Example 1:
1 2
Input: S = "ababcbacadefegdehijhklij" Output: [9,7,8]
Explanation:
The partition is “ababcbaca”, “defegde”, “hijhklij”.
This is a partition so that each letter appears in at most one part.
A partition like “ababcbacadefegde”, “hijhklij” is incorrect, because it splits S into less parts.
Note:
S will have length in range [1, 500].
S will consist of lowercase letters (‘a’ to ‘z’) only.
In a 2D grid from (0, 0) to (N-1, N-1), every cell contains a 1, except those cells in the given list mines which are 0. What is the largest axis-aligned plus sign of 1s contained in the grid? Return the order of the plus sign. If there is none, return 0.
An “ axis-aligned plus sign of1s of order k” has some center grid[x][y] = 1 along with 4 arms of length k-1going up, down, left, and right, and made of 1s. This is demonstrated in the diagrams below. Note that there could be 0s or 1s beyond the arms of the plus sign, only the relevant area of the plus sign is checked for 1s.
Order 3: 0000000 0001000 0001000 0111110 0001000 0001000 0000000
Example 1:
1 2 3 4 5 6 7 8 9
Input: N = 5, mines = [[4, 2]] Output: 2 Explanation: 11111 11111 11111 11111 11011 In the above grid, the largest plus sign can only be order 2. One of them is marked in bold.
Example 2:
1 2 3 4
Input: N = 2, mines = [] Output: 1 Explanation: There is no plus sign of order 2, but there is of order 1.
Example 3:
1 2 3 4
Input: N = 1, mines = [[0, 0]] Output: 0 Explanation: There is no plus sign, so return 0.
Note:
N will be an integer in the range [1, 500].
mines will have length at most 5000.
mines[i] will be length 2 and consist of integers in the range [0, N-1].
(Additionally, programs submitted in C, C++, or C# will be judged with a slightly smaller time limit.)
classSolution { public: intorderOfLargestPlusSign(int N, vector<vector<int>>& mines){ int res = 0, cnt = 0; vector<vector<int>> dp(N, vector<int>(N, 0)); unordered_set<int> s; for (auto mine : mines) s.insert(mine[0] * N + mine[1]); for (int j = 0; j < N; ++j) { cnt = 0; for (int i = 0; i < N; ++i) { // up cnt = s.count(i * N + j) ? 0 : cnt + 1; dp[i][j] = cnt; } cnt = 0; for (int i = N - 1; i >= 0; --i) { // down cnt = s.count(i * N + j) ? 0 : cnt + 1; dp[i][j] = min(dp[i][j], cnt); } } for (int i = 0; i < N; ++i) { cnt = 0; for (int j = 0; j < N; ++j) { // left cnt = s.count(i * N + j) ? 0 : cnt + 1; dp[i][j] = min(dp[i][j], cnt); } cnt = 0; for (int j = N - 1; j >= 0; --j) { // right cnt = s.count(i * N + j) ? 0 : cnt + 1; dp[i][j] = min(dp[i][j], cnt); res = max(res, dp[i][j]); } } return res; } };
LeetCode765. Couples Holding Hands
N couples sit in 2N seats arranged in a row and want to hold hands. We want to know the minimum number of swaps so that every couple is sitting side by side. A swap consists of choosing any two people, then they stand up and switch seats.
The people and seats are represented by an integer from 0 to 2N-1, the couples are numbered in order, the first couple being (0, 1), the second couple being (2, 3), and so on with the last couple being (2N-2, 2N-1).
The couples’ initial seating is given by row[i] being the value of the person who is initially sitting in the i-th seat.
Example 1:
1 2 3
Input: row = [0, 2, 1, 3] Output: 1 Explanation: We only need to swap the second (row[1]) and third (row[2]) person.
Example 2:
1 2 3
Input: row = [3, 2, 0, 1] Output: 0 Explanation: All couples are already seated side by side.
Note:
len(row) is even and in the range of [4, 60].
row is guaranteed to be a permutation of 0…len(row)-1.
classSolution { public: intminSwapsCouples(vector<int>& row){ int res = 0, n = row.size(); vector<int> root(n, 0); for (int i = 0; i < n; ++i) root[i] = i; for (int i = 0; i < n; i += 2) { int x = find(root, row[i] / 2); int y = find(root, row[i + 1] / 2); if (x != y) { root[x] = y; ++res; } } return res; } intfind(vector<int>& root, int i){ return (i == root[i]) ? i : find(root, root[i]); } };
Leetcode766. Toeplitz Matrix
A matrix is Toeplitz if every diagonal from top-left to bottom-right has the same element. Now given an M x N matrix, return True if and only if the matrix is Toeplitz.
Example 1:
1 2 3 4 5 6 7 8 9 10 11
Input: matrix = [ [1,2,3,4], [5,1,2,3], [9,5,1,2] ] Output: True Explanation: In the above grid, the diagonals are: "[9]", "[5, 5]", "[1, 1, 1]", "[2, 2, 2]", "[3, 3]", "[4]". In each diagonal all elements are the same, so the answer is True.
Example 2:
1 2 3 4 5 6 7 8
Input: matrix = [ [1,2], [2,2] ] Output: False Explanation: The diagonal "[1, 2]" has different elements.
classSolution { public: boolisToeplitzMatrix(vector<vector<int>>& matrix){ int m = matrix.size(), n = matrix[0].size(); for(int i = 0; i < m; i ++) { int ii = i; int constant = matrix[ii][0]; for(int j = 0; j < n && ii < m; ii ++, j ++) if(constant != matrix[ii][j]) { returnfalse; } } for(int j = 0; j < n; j ++) { int jj = j; int constant = matrix[0][jj]; for(int i = 0; i < m && jj < n; i ++, jj ++) if(constant != matrix[i][jj]) { returnfalse; } } returntrue; } };
Leetcode767. Reorganize String
Given a string S, check if the letters can be rearranged so that two characters that are adjacent to each other are not the same.
If possible, output any possible result. If not possible, return the empty string.
Example 1:
1 2
Input: S = "aab" Output: "aba"
Example 2:
1 2
Input: S = "aaab" Output: ""
Note:
S will consist of lowercase letters and have length in range [1, 500].
接下来,每次从优先队列中取队首的两个映射对儿处理,因为要拆开相同的字母,这两个映射对儿肯定是不同的字母,可以将其放在一起,之后需要将两个映射对儿中的次数自减1,如果还有多余的字母,即减1后的次数仍大于0的话,将其再放回最大堆。由于是两个两个取的,所以最后 while 循环退出后,有可能优先队列中还剩下了一个映射对儿,此时将其加入结果 res 即可。而且这个多余的映射对儿一定只有一个字母了,因为提前判断过各个字母的出现次数是否小于等于总长度的一半,按这种机制来取字母,不可能会剩下多余一个的相同的字母,参见代码如下:
classSolution { public: string reorganizeString(string S){ int n = S.size(), idx = 1; vector<int> cnt(26, 0); for (char c : S) cnt[c - 'a'] += 100; for (int i = 0; i < 26; ++i) cnt[i] += i; sort(cnt.begin(), cnt.end()); for (int num : cnt) { int t = num / 100; char ch = 'a' + (num % 100); if (t > (n + 1) / 2) return""; for (int i = 0; i < t; ++i) { if (idx >= n) idx = 0; S[idx] = ch; idx += 2; } } return S; } };
Leetcode769. Max Chunks To Make Sorted
You are given an integer array arr of length n that represents a permutation of the integers in the range [0, n - 1].
We split arr into some number of chunks (i.e., partitions), and individually sort each chunk. After concatenating them, the result should equal the sorted array.
Return the largest number of chunks we can make to sort the array.
Example 1:
1 2 3 4 5
Input: arr = [4,3,2,1,0] Output: 1 Explanation: Splitting into two or more chunks will not return the required result. For example, splitting into [4, 3], [2, 1, 0] will result in [3, 4, 0, 1, 2], which isn't sorted.
Example 2:
1 2 3 4 5
Input: arr = [1,0,2,3,4] Output: 4 Explanation: We can split into two chunks, such as [1, 0], [2, 3, 4]. However, splitting into [1, 0], [2], [3], [4] is the highest number of chunks possible.
思路:题中有一个点很重要,那就是permutation of [0, 1, …, arr.length - 1],数组中的元素是0到arr.length-1之间的 所以如果有序的话就是arr[i] == i,那么本身有序的数可以自成一段,而无序的只需要找到最大的那个错序数,作为分段的终点 也就是max 是i 之前中的最大数,如果max == i 那么就保证了前面的数字能够排列成正确的顺序,这就是一个分段,size++, 然后继续向下遍历,找到下一个满足max == i 的地方,就可以又分成一个块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: intmaxChunksToSorted(vector<int>& arr){ if(arr.size() == 0) return0; vector<int> maxx(arr.size(), 0); maxx[0] = arr[0]; for (int i = 1; i < arr.size(); i ++) { maxx[i] = std::max(maxx[i-1], arr[i]); } int count = 0; for (int i = 0; i < arr.size(); i ++) { if(i == maxx[i]) count ++; } return count; } };
Leetcode773. Sliding Puzzle
On a 2x3 board, there are 5 tiles represented by the integers 1 through 5, and an empty square represented by 0.
A move consists of choosing 0 and a 4-directionally adjacent number and swapping it.
The state of the board is solved if and only if the board is [[1,2,3],[4,5,0]].
Given a puzzle board, return the least number of moves required so that the state of the board is solved. If it is impossible for the state of the board to be solved, return -1.
Examples:
1 2 3
Input: board = [[1,2,3],[4,0,5]] Output: 1 Explanation: Swap the 0 and the 5 in one move.
1 2 3
Input: board = [[1,2,3],[5,4,0]] Output: -1 Explanation: No number of moves will make the board solved.
1 2 3 4 5 6 7 8 9 10
Input: board = [[4,1,2],[5,0,3]] Output: 5 Explanation: 5 is the smallest number of moves that solves the board. An example path: After move 0: [[4,1,2],[5,0,3]] After move 1: [[4,1,2],[0,5,3]] After move 2: [[0,1,2],[4,5,3]] After move 3: [[1,0,2],[4,5,3]] After move 4: [[1,2,0],[4,5,3]] After move 5: [[1,2,3],[4,5,0]]
classSolution { public: intslidingPuzzle(vector<vector<int>>& board){ int n = board.size(), m = board[0].size(); int res = 0; string end = "123450", start = ""; unordered_set<string> visited; queue<string> q; vector<vector<int>> dirs{{1,3}, {0,2,4}, {1,5}, {0,4}, {1,3,5}, {2,4}}; for (int i = 0; i < n; i ++) for (int j = 0; j < m; j ++) start += to_string(board[i][j]); visited.insert(start); q.push(start); while(!q.empty()) { int size = q.size(); for (int i = 0; i < size; i ++) { string t = q.front(), next; q.pop(); if (t == end) return res; int cur = t.find("0");
for (int j = 0; j < dirs[cur].size(); j ++) { next = t; next[cur] = t[dirs[cur][j]]; next[dirs[cur][j]] = t[cur]; if (visited.count(next)) continue; visited.insert(next); q.push(next); } } res ++; }
return-1; } };
Leetcode775. Global and Local Inversions
We have some permutation A of [0, 1, …, N - 1], where N is the length of A.
The number of (global) inversions is the number of i < j with 0 <= i < j < N and A[i] > A[j].
The number of local inversions is the number of i with 0 <= i < N and A[i] > A[i+1].
Return true if and only if the number of global inversions is equal to the number of local inversions.
Example 1:
1 2 3
Input: A = [1,0,2] Output: true Explanation: There is 1 global inversion, and 1 local inversion.
Example 2:
1 2 3
Input: A = [1,2,0] Output: false Explanation: There are 2 global inversions, and 1 local inversion.
Note:
A will be a permutation of [0, 1, …, A.length - 1].
classSolution { public: boolisIdealPermutation(vector<int>& A){ int n = A.size(), mn = INT_MAX; for (int i = n - 1; i >= 2; --i) { mn = min(mn, A[i]); if (A[i - 2] > mn) returnfalse; } returntrue; } };
Leetcode777. Swap Adjacent in LR String
In a string composed of ‘L’, ‘R’, and ‘X’ characters, like “RXXLRXRXL”, a move consists of either replacing one occurrence of “XL” with “LX”, or replacing one occurrence of “RX” with “XR”. Given the starting string start and the ending string end, return True if and only if there exists a sequence of moves to transform one string to the other.
Example:
1 2 3 4 5 6 7 8 9
Input: start = "RXXLRXRXL", end = "XRLXXRRLX" Output: True Explanation: We can transform start to end following these steps: RXXLRXRXL -> XRXLRXRXL -> XRLXRXRXL -> XRLXXRRXL -> XRLXXRRLX
Note:
1 <= len(start) = len(end) <= 10000.
Both start and end will only consist of characters in {‘L’, ‘R’, ‘X’}.
观察这个 test case,可以发现 start 中的R可以往后移动,没有问题,但是 start 中的L永远无法变到end中L的位置,因为L只能往前移。这道题被归类为 brainteaser,估计就是因为要观察出这个规律吧。那么搞明白这个以后,其实可以用双指针来解题,思路是,每次分别找到 start 和 end 中非X的字符,如果二者不相同的话,直接返回 false,想想问什么?这是因为不论是L还是R,其只能跟X交换位置,L和R之间是不能改变相对顺序的,所以如果分别将 start 和 end 中所有的X去掉后的字符串不相等的话,那么就永远无法让 start 和 end 相等了。这个判断完之后,就来验证L只能前移,R只能后移这个限制条件吧,当i指向 start 中的L时,那么j指向 end 中的L必须要在前面,所以如果i小于j的话,就不对了,同理,当i指向 start 中的R,那么j指向 end 中的R必须在后面,所以i大于j就是错的,最后别忘了i和j同时要自增1,不然死循环了。while 循环退出后,有可能i或j其中一个还未遍历到结尾,而此时剩余到字符中是不能再出现L或R的,否则不能成功匹配,此时用两个 while 循环分别将i或j遍历完成,需要到了L或R直接返回 false 即可,加上了这一步后就不用在开头检测 start 和 end 中L和R的个数是否相同了,参见代码如下:
classSolution { public: boolcanTransform(string start, string end){ int n = start.size(), i = 0, j = 0; while (i < n && j < n) { while (i < n && start[i] == 'X') ++i; while (j < n && end[j] == 'X') ++j; if (start[i] != end[j]) returnfalse; if ((start[i] == 'L' && i < j) || (start[i] == 'R' && i > j)) returnfalse; ++i; ++j; } while (i < n) { if (start[i] != 'X') returnfalse; ++i; } while (j < n) { if (end[j] != 'X') returnfalse; ++j; } returntrue; } };
Leetcode778. Swim in Rising Water
On an N x N grid, each square grid[i][j] represents the elevation at that point (i,j).
Now rain starts to fall. At time t, the depth of the water everywhere is t. You can swim from a square to another 4-directionally adjacent square if and only if the elevation of both squares individually are at most t. You can swim infinite distance in zero time. Of course, you must stay within the boundaries of the grid during your swim.
You start at the top left square (0, 0). What is the least time until you can reach the bottom right square (N-1, N-1)?
Example 1:
1 2 3 4 5
Input: [[0,2],[1,3]] Output: 3 Explanation: At time 0, you are in grid location (0, 0). You cannot go anywhere else because 4-directionally adjacent neighbors have a higher elevation than t = 0.
You cannot reach point (1, 1) until time 3. When the depth of water is 3, we can swim anywhere inside the grid.
classSolution { public: intswimInWater(vector<vector<int>>& grid){ int res = 0, n = grid.size(); unordered_set<int> visited{0}; vector<vector<int>> dirs{{0, -1}, {-1, 0}, {0, 1}, {1, 0}}; auto cmp = [](pair<int, int>& a, pair<int, int>& b) {return a.first > b.first;}; priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(cmp) > q(cmp); q.push({grid[0][0], 0}); while (!q.empty()) { int i = q.top().second / n, j = q.top().second % n; q.pop(); res = max(res, grid[i][j]); if (i == n - 1 && j == n - 1) return res; for (auto dir : dirs) { int x = i + dir[0], y = j + dir[1]; if (x < 0 || x >= n || y < 0 || y >= n || visited.count(x * n + y)) continue; visited.insert(x * n + y); q.push({grid[x][y], x * n + y}); } } return res; } };
classSolution { public: vector<vector<int>> dirs{{0, -1}, {-1, 0}, {0, 1}, {1, 0}}; intswimInWater(vector<vector<int>>& grid){ int n = grid.size(); vector<vector<int>> dp(n, vector<int>(n, INT_MAX)); helper(grid, 0, 0, grid[0][0], dp); return dp[n - 1][n - 1]; } voidhelper(vector<vector<int>>& grid, int x, int y, int cur, vector<vector<int>>& dp){ int n = grid.size(); if (x < 0 || x >= n || y < 0 || y >= n || max(cur, grid[x][y]) >= dp[x][y]) return; dp[x][y] = max(cur, grid[x][y]); for (auto dir : dirs) { helper(grid, x + dir[0], y + dir[1], dp[x][y], dp); } } };
Leetcode779. K-th Symbol in Grammar
On the first row, we write a 0. Now in every subsequent row, we look at the previous row and replace each occurrence of 0 with 01, and each occurrence of 1 with 10.
Given row N and index K, return the K-th indexed symbol in row N. (The values of K are 1-indexed.) (1 indexed).
class Solution { public: int kthGrammar(int N, int K) { if (N == 1) return 0; return (~K & 1) ^ kthGrammar(N - 1, (K + 1) / 2); } };
Leetcode781. Rabbits in Forest
In a forest, each rabbit has some color. Some subset of rabbits (possibly all of them) tell you how many other rabbits have the same color as them. Those answers are placed in an array.
Return the minimum number of rabbits that could be in the forest.
Examples:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Input: answers = [1, 1, 2] Output: 5 Explanation: The two rabbits that answered "1" could both be the same color, say red. The rabbit than answered "2" can't be red or the answers would be inconsistent. Say the rabbit that answered "2" was blue. Then there should be 2 other blue rabbits in the forest that didn't answer into the array. The smallest possible number of rabbits in the forest is therefore 5: 3 that answered plus 2 that didn't.
Input: answers = [10, 10, 10] Output: 11
Input: answers = [] Output: 0
Note:
answers will have length at most 1000.
Each answers[i] will be an integer in the range [0, 999].
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ classSolution { public: voiddfs(TreeNode* root, vector<int>& v){ if(root == NULL) return; dfs(root->left, v); v.push_back(root->val); dfs(root->right, v); } intminDiffInBST(TreeNode* root){ vector<int> vec; int minn = INT_MAX; dfs(root, vec); for(int i = 1; i < vec.size(); i ++) { minn = min(minn, abs(vec[i] - vec[i-1])); } return minn; } };
Leetcode784. Letter Case Permutation
Given a string S, we can transform every letter individually to be lowercase or uppercase to create another string. Return a list of all possible strings we could create.
Examples:
1 2 3 4 5 6 7 8
Input: S = "a1b2" Output: ["a1b2", "a1B2", "A1b2", "A1B2"]
Given an undirected graph, return true if and only if it is bipartite.
Recall that a graph is bipartite if we can split it’s set of nodes into two independent subsets A and B such that every edge in the graph has one node in A and another node in B.
The graph is given in the following form: graph[i] is a list of indexes j for which the edge between nodes i and j exists. Each node is an integer between 0 and graph.length - 1. There are no self edges or parallel edges: graph[i] does not contain i, and it doesn’t contain any element twice.
Example 1:
1 2 3 4 5 6 7 8 9
Input: [[1,3], [0,2], [1,3], [0,2]] Output: true Explanation: The graph looks like this: 0----1 | | | | 3----2 We can divide the vertices into two groups: {0, 2} and {1, 3}.
Example 2:
1 2 3 4 5 6 7 8 9
Input: [[1,2,3], [0,2], [0,1,3], [0,2]] Output: false Explanation: The graph looks like this: 0----1 | \ | | \ | 3----2 We cannot find a way to divide the set of nodes into two independent subsets.
Note:
graph will have length in range [1, 100].
graph[i] will contain integers in range [0, graph.length - 1].
graph[i] will not contain i or duplicate values.
The graph is undirected: if any element j is in graph[i], then i will be in graph[j].
classSolution { public: boolisBipartite(vector<vector<int>>& graph){ vector<int> colors(graph.size()); for (int i = 0; i < graph.size(); ++i) { if (colors[i] != 0) continue; colors[i] = 1; queue<int> q{{i}}; while (!q.empty()) { int t = q.front(); q.pop(); for (auto a : graph[t]) { if (colors[a] == colors[t]) returnfalse; if (colors[a] == 0) { colors[a] = -1 * colors[t]; q.push(a); } } } } returntrue; } };
Leetcode787. Cheapest Flights Within K Stops
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a price w.
Now given all the cities and fights, together with starting city src and the destination dst, your task is to find the cheapest price from src to dst with up to k stops. If there is no such route, output -1.
Example 1:
1 2 3 4 5 6
Input: n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] src = 0, dst = 2, k = 1 Output: 200 Explanation: The graph looks like this:
The cheapest price from city 0 to city 2 with at most 1 stop costs 200, as marked red in the picture.
Example 2:
1 2 3 4 5 6
Input: n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] src = 0, dst = 2, k = 0 Output: 500 Explanation: The graph looks like this:
The cheapest price from city 0 to city 2 with at most 0 stop costs 500, as marked blue in the picture.
Note:
The number of nodes n will be in range [1, 100], with nodes labeled from 0 to n`` - 1.
The size of flights will be in range [0, n * (n - 1) / 2].
The format of each flight will be (src, dst, price).
The price of each flight will be in the range [1, 10000].
k is in the range of [0, n - 1].
There will not be any duplicated flights or self cycles.
classSolution { public: intfindCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K){ int res = INT_MAX, cnt = 0; unordered_map<int, vector<vector<int>>> m; queue<vector<int>> q{{{src, 0}}}; for (auto flight : flights) { m[flight[0]].push_back({flight[1], flight[2]}); } while (!q.empty()) { for (int i = q.size(); i > 0; --i) { auto t = q.front(); q.pop(); if (t[0] == dst) res = min(res, t[1]); for (auto a : m[t[0]]) { if (t[1] + a[1] > res) continue; q.push({a[0], t[1] + a[1]}); } } if (cnt++ > K) break; } return (res == INT_MAX) ? -1 : res; } };
classSolution { public: intfindCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K){ vector<vector<int>> dp(K + 2, vector<int>(n, 1e9)); dp[0][src] = 0; for (int i = 1; i <= K + 1; ++i) { dp[i][src] = 0; for (auto x : flights) { dp[i][x[1]] = min(dp[i][x[1]], dp[i - 1][x[0]] + x[2]); } } return (dp[K + 1][dst] >= 1e9) ? -1 : dp[K + 1][dst]; } };
Leetcode788. Rotated Digits
X is a good number if after rotating each digit individually by 180 degrees, we get a valid number that is different from X. Each digit must be rotated - we cannot choose to leave it alone.
A number is valid if each digit remains a digit after rotation. 0, 1, and 8 rotate to themselves; 2 and 5 rotate to each other (on this case they are rotated in a different direction, in other words 2 or 5 gets mirrored); 6 and 9 rotate to each other, and the rest of the numbers do not rotate to any other number and become invalid.
Now given a positive number N, how many numbers X from 1 to N are good?
Example:
1 2 3 4 5
Input: 10 Output: 4 Explanation: There are four good numbers in the range [1, 10] : 2, 5, 6, 9. Note that 1 and 10 are not good numbers, since they remain unchanged after rotating.
classSolution { public: introtatedDigits(int N){ int count=0; for(int i = 1; i <= N; i ++) if(judge(i)) count ++; return count; } booljudge(int N){ bool flag = false; while(N){ int k = N % 10; if(k == 3 || k == 4 || k == 7){ flag = false; break; } if(k == 2 || k == 5 || k == 6 || k == 9) flag = true; N /= 10; } return flag; } };
Leetcode790. Domino and Tromino Tiling
You have two types of tiles: a 2 x 1 domino shape and a tromino shape. You may rotate these shapes.
Given an integer n, return the number of ways to tile an 2 x n board. Since the answer may be very large, return it modulo 109 + 7.
In a tiling, every square must be covered by a tile. Two tilings are different if and only if there are two 4-directionally adjacent cells on the board such that exactly one of the tilings has both squares occupied by a tile.
classSolution { public: intnumTilings(int n){ int M = 1e9 + 7; vector<long> dp(n+2, 0); dp[0] = 1; dp[1] = 1; dp[2] = 2; if (n < 3) return dp[n]; for (int i = 3; i <= n; i ++) dp[i] = (2 * dp[i-1] + dp[i-3]) % M; return dp[n]; } };
Leetcode791. Custom Sort String
S and T are strings composed of lowercase letters. In S, no letter occurs more than once.
S was sorted in some custom order previously. We want to permute the characters of T so that they match the order that S was sorted. More specifically, if x occurs before y in S, then x should occur before y in the returned string.
Return any permutation of T (as a string) that satisfies this property.
Example :
1 2 3 4 5 6 7
Input: S = "cba" T = "abcd" Output: "cbad" Explanation: "a", "b", "c" appear in S, so the order of "a", "b", "c" should be "c", "b", and "a". Since "d" does not appear in S, it can be at any position in T. "dcba", "cdba", "cbda" are also valid outputs.
Note:
S has length at most 26, and no character is repeated in S.
classSolution { public: string customSortString(string order, string s){ map<char, int> m; string res; for (int i = 0; i < s.length(); i ++) m[s[i]] ++; for (int i = 0; i < order.length(); i ++) { while(m[order[i]] --) res += order[i]; } for (auto it = m.begin(); it != m.end(); it ++) while(it->second > 0) { res += it->first; it->second --; } return res; } };
Leetcode792. Number of Matching Subsequences
Given a string s and an array of strings words, return the number of words[i] that is a subsequence of s.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
For example, “ace” is a subsequence of “abcde”.
Example 1:
1 2 3
Input: s = "abcde", words = ["a","bb","acd","ace"] Output: 3 Explanation: There are three strings in words that are a subsequence of s: "a", "acd", "ace".
Example 2:
1 2
Input: s = "dsahjpjauf", words = ["ahjpjau","ja","ahbwzgqnuk","tnmlanowax"] Output: 2
classSolution { public: intnumMatchingSubseq(string s, vector<string>& words){ int res = 0, len = s.length(); unordered_set<string> pass, out; for (int i = 0; i < words.size(); i ++) { if (pass.count(words[i])) { res ++; continue; } if (out.count(words[i])) continue; int j = 0, k = 0; for (; j < len && k < words[i].length(); j ++) if (s[j] == words[i][k]) k ++; if (k == words[i].length()) { res++; pass.insert(words[i]); } else out.insert(words[i]); } return res; } };
Leetcode794. Valid Tic-Tac-Toe State
A Tic-Tac-Toe board is given as a string array board. Return True if and only if it is possible to reach this board position during the course of a valid tic-tac-toe game.
The board is a 3 x 3 array, and consists of characters “ “, “X”, and “O”. The “ “ character represents an empty square.
Here are the rules of Tic-Tac-Toe:
Players take turns placing characters into empty squares (“ “).
The first player always places “X” characters, while the second player always places “O” characters.
“X” and “O” characters are always placed into empty squares, never filled ones.
The game ends when there are 3 of the same (non-empty) character filling any row, column, or diagonal.
The game also ends if all squares are non-empty.
No more moves can be played if the game is over.
Example 1:
1 2 3
Input: board = ["O ", " ", " "] Output: false Explanation: The first player always plays "X".
Example 2:
1 2 3
Input: board = ["XOX", " X ", " "] Output: false Explanation: Players take turns making moves.
Example 3:
1 2
Input: board = ["XXX", " ", "OOO"] Output: false
Example 4:
1 2
Input: board = ["XOX", "O O", "XOX"] Output: true
Note:
board is a length-3 array of strings, where each string board[i] has length 3.
Each board[i][j] is a character in the set {“ “, “X”, “O”}.
classSolution { public: intnumSubarrayBoundedMax(vector<int>& A, int L, int R){ int res = 0, n = A.size(); for (int i = 0; i < n; ++i) { if (A[i] > R) continue; int curMax = INT_MIN; for (int j = i; j < n; ++j) { curMax = max(curMax, A[j]); if (curMax > R) break; if (curMax >= L) ++res; } } return res; } };
classSolution { public: intnumSubarrayBoundedMax(vector<int>& A, int L, int R){ returncount(A, R) - count(A, L - 1); } intcount(vector<int>& A, int bound){ int res = 0, cur = 0; for (int x : A) { cur = (x <= bound) ? cur + 1 : 0; res += cur; } return res; } };
classSolution { public: intnumSubarrayBoundedMax(vector<int>& A, int L, int R){ int res = 0, left = -1, right = -1; for (int i = 0; i < A.size(); ++i) { if (A[i] > R) left = i; if (A[i] >= L) right = i; res += right - left; } return res; } };
Leetcode796. Rotate String
We are given two strings, A and B.
A shift on A consists of taking string A and moving the leftmost character to the rightmost position. For example, if A = ‘abcde’, then it will be ‘bcdea’ after one shift on A. Return True if and only if A can become B after some number of shifts on A.
classSolution { public: boolrotateString(string A, string B){ if(A=="" && B == "") returntrue; if(A.length() != B.length()) returnfalse; string AA = A + A; return AA.find(B) < A.length(); } };
Leetcode797. All Paths From Source to Target
Given a directed, acyclic graph of N nodes. Find all possible paths from node 0 to node N-1, and return them in any order.
The graph is given as follows: the nodes are 0, 1, …, graph.length - 1. graph[i] is a list of all nodes j for which the edge (i, j) exists.
Example:
1 2 3 4 5 6 7 8
Input: [[1,2], [3], [3], []] Output: [[0,1,3],[0,2,3]] Explanation: The graph looks like this: 0--->1 | | v v 2--->3 There are two paths: 0 -> 1 -> 3 and 0 -> 2 -> 3.
Note: The number of nodes in the graph will be in the range [2, 15]. You can print different paths in any order, but you should keep the order of nodes inside one path.
We stack glasses in a pyramid, where the first row has 1 glass, the second row has 2 glasses, and so on until the 100th row. Each glass holds one cup (250ml) of champagne.
Then, some champagne is poured in the first glass at the top. When the top most glass is full, any excess liquid poured will fall equally to the glass immediately to the left and right of it. When those glasses become full, any excess champagne will fall equally to the left and right of those glasses, and so on. (A glass at the bottom row has it’s excess champagne fall on the floor.)
For example, after one cup of champagne is poured, the top most glass is full. After two cups of champagne are poured, the two glasses on the second row are half full. After three cups of champagne are poured, those two cups become full - there are 3 full glasses total now. After four cups of champagne are poured, the third row has the middle glass half full, and the two outside glasses are a quarter full, as pictured below.
Now after pouring some non-negative integer cups of champagne, return how full the j-th glass in the i-th row is (both i and j are 0 indexed.)
Example 1:
1 2 3
Input: poured = 1, query_glass = 1, query_row = 1 Output: 0.0 Explanation: We poured 1 cup of champange to the top glass of the tower (which is indexed as (0, 0)). There will be no excess liquid so all the glasses under the top glass will remain empty.
Example 2:
1 2 3
Input: poured = 2, query_glass = 1, query_row = 1 Output: 0.5 Explanation: We poured 2 cups of champange to the top glass of the tower (which is indexed as (0, 0)). There is one cup of excess liquid. The glass indexed as (1, 0) and the glass indexed as (1, 1) will share the excess liquid equally, and each will get half cup of champange.
Note:
poured will be in the range of [0, 10 ^ 9].
query_glass and query_row will be in the range of [0, 99].
We distribute some number of candies, to a row of n = num_people people in the following way:
We then give 1 candy to the first person, 2 candies to the second person, and so on until we give n candies to the last person.
Then, we go back to the start of the row, giving n + 1 candies to the first person, n + 2 candies to the second person, and so on until we give 2 * n candies to the last person.
This process repeats (with us giving one more candy each time, and moving to the start of the row after we reach the end) until we run out of candies. The last person will receive all of our remaining candies (not necessarily one more than the previous gift).
Return an array (of length num_people and sum candies) that represents the final distribution of candies.
Example 1:
1 2 3 4 5 6 7
Input: candies = 7, num_people = 4 Output: [1,2,3,1] Explanation: On the first turn, ans[0] += 1, and the array is [1,0,0,0]. On the second turn, ans[1] += 2, and the array is [1,2,0,0]. On the third turn, ans[2] += 3, and the array is [1,2,3,0]. On the fourth turn, ans[3] += 1 (because there is only one candy left), and the final array is [1,2,3,1].
Example 2:
1 2 3 4 5 6 7
Input: candies = 10, num_people = 3 Output: [5,2,3] Explanation: On the first turn, ans[0] += 1, and the array is [1,0,0]. On the second turn, ans[1] += 2, and the array is [1,2,0]. On the third turn, ans[2] += 3, and the array is [1,2,3]. On the fourth turn, ans[0] += 4, and the final array is [5,2,3].
只考虑每次分配的糖果数,分配的糖果数为1,2,3,4,5,…, 依次加1。再考虑到分配的轮数,可以利用 i % num_people 来求得第i次应该分配到第几个人。
classSolution { public: vector<int> distributeCandies(int candies, int num_people){ vector<int> res(num_people, 0); int temp = 1, i = 0; while(candies > 0) { res[i%num_people] += min(candies, i+1); candies -= min(candies, i+1); i ++; } return res; } };
Leetcode1104. Path In Zigzag Labelled Binary Tree
In an infinite binary tree where every node has two children, the nodes are labelled in row order.
In the odd numbered rows (ie., the first, third, fifth,…), the labelling is left to right, while in the even numbered rows (second, fourth, sixth,…), the labelling is right to left.
Given the label of a node in this tree, return the labels in the path from the root of the tree to the node with that label.
You are given an array books where books[i] = [thicknessi, heighti] indicates the thickness and height of the ith book. You are also given an integer shelfWidth.
We want to place these books in order onto bookcase shelves that have a total width shelfWidth.
We choose some of the books to place on this shelf such that the sum of their thickness is less than or equal to shelfWidth, then build another level of the shelf of the bookcase so that the total height of the bookcase has increased by the maximum height of the books we just put down. We repeat this process until there are no more books to place.
Note that at each step of the above process, the order of the books we place is the same order as the given sequence of books.
For example, if we have an ordered list of 5 books, we might place the first and second book onto the first shelf, the third book on the second shelf, and the fourth and fifth book on the last shelf. Return the minimum possible height that the total bookshelf can be after placing shelves in this manner.
Example 1:
1 2 3 4 5
Input: books = [[1,1],[2,3],[2,3],[1,1],[1,1],[1,1],[1,2]], shelf_width = 4 Output: 6 Explanation: The sum of the heights of the 3 shelves is 1 + 3 + 2 = 6. Notice that book number 2 does not have to be on the first shelf.
You are given an array of flight bookings bookings, where bookings[i] = [firsti, lasti, seatsi] represents a booking for flights firsti through lasti (inclusive) with seatsi seats reserved for each flight in the range.
Return *an array answer of length n, where answer[i] is the total number of seats reserved for flight *i.
Leetcode1111. Maximum Nesting Depth of Two Valid Parentheses Strings
A string is a valid parentheses string (denoted VPS) if and only if it consists of “(“ and “)” characters only, and:
It is the empty string, or
It can be written as AB (A concatenated with B), where A and B are VPS’s, or
It can be written as (A), where A is a VPS.
We can similarly define the nesting depth depth(S) of any VPS S as follows:
depth(“”) = 0
depth(A + B) = max(depth(A), depth(B)), where A and B are VPS’s
depth(“(“ + A + “)”) = 1 + depth(A), where A is a VPS.
For example, “”, “()()”, and “()(()())” are VPS’s (with nesting depths 0, 1, and 2), and “)(“ and “(()” are not VPS’s.
Given a VPS seq, split it into two disjoint subsequences A and B, such that A and B are VPS’s (and A.length + B.length = seq.length).
Now choose any such A and B such that max(depth(A), depth(B)) is the minimum possible value.
Return an answer array (of length seq.length) that encodes such a choice of A and B: answer[i] = 0 if seq[i] is part of A, else answer[i] = 1. Note that even though multiple answers may exist, you may return any of them.
public class Foo { public void first() { print("first"); } public void second() { print("second"); } public void third() { print("third"); } }
The same instance of Foo will be passed to three different threads. Thread A will call first(), thread B will call second(), and thread C will call third(). Design a mechanism and modify the program to ensure that second() is executed after first(), and third() is executed after second().
Example 1:
1 2 3
Input: [1,2,3] Output: "firstsecondthird" Explanation: There are three threads being fired asynchronously. The input [1,2,3] means thread A calls first(), thread B calls second(), and thread C calls third(). "firstsecondthird" is the correct output.
Example 2:
1 2 3
Input: [1,3,2] Output: "firstsecondthird" Explanation: The input [1,3,2] means thread A calls first(), thread B calls third(), and thread C calls second(). "firstsecondthird" is the correct output.
voidfirst(function<void()> printFirst){ // printFirst() outputs "first". Do not change or remove this line. printFirst(); m1.unlock(); }
voidsecond(function<void()> printSecond){ m1.lock(); // printSecond() outputs "second". Do not change or remove this line. printSecond(); m1.unlock(); m2.unlock(); }
voidthird(function<void()> printThird){ m2.lock(); // printThird() outputs "third". Do not change or remove this line. printThird(); m2.unlock(); } };
Leetcode1122. Relative Sort Array
Given two arrays arr1 and arr2, the elements of arr2 are distinct, and all elements in arr2 are also in arr1.
Sort the elements of arr1 such that the relative ordering of items in arr1 are the same as in arr2. Elements that don’t appear in arr2 should be placed at the end of arr1 in ascending order.
Leetcode1123. Lowest Common Ancestor of Deepest Leaves
Given a rooted binary tree, return the lowest common ancestor of its deepest leaves.
Recall that:
The node of a binary tree is a leaf if and only if it has no children
The depth of the root of the tree is 0, and if the depth of a node is d, the depth of each of its children is d+1.
The lowest common ancestor of a set S of nodes is the node A with the largest depth such that every node in S is in the subtree with root A.
Example 1:
1 2 3 4 5 6
Input: root = [1,2,3] Output: [1,2,3] Explanation: The deepest leaves are the nodes with values 2 and 3. The lowest common ancestor of these leaves is the node with value 1. The answer returned is a TreeNode object (not an array) with serialization "[1,2,3]".
Example 2:
1 2
Input: root = [1,2,3,4] Output: [4]
Example 3:
1 2
Input: root = [1,2,3,4,5] Output: [2,4,5]
Constraints:
The given tree will have between 1 and 1000 nodes.
Each node of the tree will have a distinct value between 1 and 1000.
classSolution { public: intlongestWPI(vector<int>& hours){ for(int i=0;i<hours.size();i++) hours[i]=hours[i]>8?1:-1; unordered_map<int, int> idx; int r = 0,inx=0; int last=0; int maxx=0; for(int i=0;i<hours.size();i++){ r += hours[i]; if(r>0){ maxx = i+1; } if (!idx.count(r)) idx[r] = i; if (idx.count(r - 1)) maxx = max(maxx, i - idx[r - 1]); } return maxx; } };
LeetCode] 1125. Smallest Sufficient Team
In a project, you have a list of required skills req_skills, and a list of people. The ith person people[i] contains a list of skills that the person has.
Consider a sufficient team: a set of people such that for every required skill in req_skills, there is at least one person in the team who has that skill. We can represent these teams by the index of each person.
For example, team = [0, 1, 3] represents the people with skills people[0], people[1], and people[3]. Return any sufficient team of the smallest possible size, represented by the index of each person. You may return the answer in any order.
It is guaranteed an answer exists.
Example 1:
1 2
Input: req_skills = ["java","nodejs","reactjs"], people = [["java"],["nodejs"],["nodejs","reactjs"]] Output: [0,2]
Example 2:
1 2
Input: req_skills = ["algorithms","math","java","reactjs","csharp","aws"], people = [["algorithms","math","java"],["algorithms","math","reactjs"],["java","csharp","aws"],["reactjs","csharp"],["csharp","math"],["aws","java"]] Output: [1,2]
Constraints:
1 <= req_skills.length <= 16
1 <= req_skills[i].length <= 16
req_skills[i] consists of lowercase English letters.
All the strings of req_skills are unique.
1 <= people.length <= 60
0 <= people[i].length <= 16
1 <= people[i][j].length <= 16
people[i][j] consists of lowercase English letters.
All the strings of people[i] are unique.
Every skill in people[i] is a skill in req_skills.
classSolution { public: vector<int> smallestSufficientTeam(vector<string>& req_skills, vector<vector<string>>& people){ int m = req_skills.size(), n = people.size(); int maxstate = 1 << m; // f[i][s] = 考虑前i个人的时候,状态为s所需的最小人数 vector<vector<int>> f(n+1, vector<int>(maxstate, 1e9)); // path[i][s] = 前i个人的时候,选人方案, vector<vector<longlong>> path(n+1, vector<longlong>(maxstate, 0)); f[0][0] = 0; for (int i = 1; i <= n; i ++) { int state = 0; for (constauto& str : people[i-1]) { int id = find(req_skills.begin(), req_skills.end(), str) - req_skills.begin(); state |= (1 << id); } for (int j = 0; j < maxstate; j ++) { if (f[i-1][j] < f[i][j]) { f[i][j] = f[i-1][j]; path[i][j] = path[i-1][j]; } int news = j | state; if (f[i-1][j] + 1 < f[i][news]) { f[i][news] = f[i-1][j] + 1; path[i][news] = path[i-1][j] | (1LL << i); } } } vector<int> ret; for (int i = 1; i <= n; i ++) if ((path[n][maxstate-1] >> i) & 1) ret.push_back(i-1); return ret; } };
Leetcode1128. Number of Equivalent Domino Pairs
Given a list of dominoes, dominoes[i] = [a, b] is equivalent to dominoes[j] = [c, d] if and only if either (a==c and b==d), or (a==d and b==c) - that is, one domino can be rotated to be equal to another domino.
Return the number of pairs (i, j) for which 0 <= i < j < dominoes.length, and dominoes[i] is equivalent to dominoes[j].
classSolution { public: intnumEquivDominoPairs(vector<vector<int>>& dominoes){ int temp; int ans = 0; map<int, int> mp;
for(int i = 0; i < dominoes.size(); i ++) { if(dominoes[i][0] > dominoes[i][1]) { temp = dominoes[i][0]; dominoes[i][0] = dominoes[i][1]; dominoes[i][1] = temp; } temp = dominoes[i][0]*10 + dominoes[i][1]; mp[temp] ++; } for(pair<int, int> i : mp) { int v = i.second; ans += (v*(v-1))/2; } return ans; } };
Leetcode1129. Shortest Path with Alternating Colors
Consider a directed graph, with nodes labelled 0, 1, …, n-1. In this graph, each edge is either red or blue, and there could be self-edges or parallel edges.
Each [i, j] in red_edges denotes a red directed edge from node i to node j. Similarly, each [i, j] in blue_edges denotes a blue directed edge from node i to node j.
Return an array answer of length n, where each answer[X] is the length of the shortest path from node 0 to node X such that the edge colors alternate along the path (or -1 if such a path doesn’t exist).
classSolution { public: vector<int> shortestAlternatingPaths(int n, vector<vector<int>>& red_edges, vector<vector<int>>& blue_edges){ vector<int> res(n); vector<vector<int>> dp(2, vector<int>(n)); vector<vector<unordered_set<int>>> graph(2, vector<unordered_set<int>>(n)); for (auto &edge : red_edges) { graph[0][edge[0]].insert(edge[1]); } for (auto &edge : blue_edges) { graph[1][edge[0]].insert(edge[1]); } for (int i = 1; i < n; ++i) { dp[0][i] = 2 * n; dp[1][i] = 2 * n; } queue<vector<int>> q; q.push({0, 0}); q.push({0, 1}); while (!q.empty()) { int cur = q.front()[0], color = q.front()[1]; q.pop(); for (int next : graph[1 - color][cur]) { if (dp[1 - color][next] == 2 * n) { dp[1 - color][next] = 1 + dp[color][cur]; q.push({next, 1 - color}); } } } for (int i = 0; i < n; ++i) { int val = min(dp[0][i], dp[1][i]); res[i] = val == 2 * n ? -1 : val; } return res; } };
Leetcode1130. Minimum Cost Tree From Leaf Values
Given an array arr of positive integers, consider all binary trees such that:
Each node has either 0 or 2 children;
The values of arr correspond to the values of each leaf in an in-order traversal of the tree. (Recall that a node is a leaf if and only if it has 0 children.)
The value of each non-leaf node is equal to the product of the largest leaf value in its left and right subtree respectively.
Among all possible binary trees considered, return the smallest possible sum of the values of each non-leaf node. It is guaranteed this sum fits into a 32-bit integer.
Example 1:
1 2 3 4 5 6 7 8 9 10
Input: arr = [6,2,4] Output: 32 Explanation: There are two possible trees. The first has non-leaf node sum 36, and the second has non-leaf node sum 32.
24 24 / \ /\ 12 4 6 8 / \ /\ 6 2 2 4
Constraints:
2 <= arr.length <= 40
1 <= arr[i] <= 15
It is guaranteed that the answer fits into a 32-bit signed integer (ie. it is less than 2^31).
classSolution { public: string alphabetBoardPath(string target){ string res; int curX = 0, curY = 0; for (char c : target) { int x = (c - 'a') / 5, y = (c - 'a') % 5; res += string(max(0, curX - x), 'U') + string(max(0, y - curY), 'R') + string(max(0, curY - y), 'L') + string(max(0, x - curX), 'D') + '!'; curX = x; curY = y; } return res; } };
Leetcode1139. Largest 1-Bordered Square
Given a 2D grid of 0s and 1s, return the number of elements in the largest square subgrid that has all 1s on its border, or 0 if such a subgrid doesn’t exist in the grid.
classSolution { public: intlargest1BorderedSquare(vector<vector<int>>& grid){ int m = grid.size(), n = grid[0].size(); vector<vector<int>> left(m, vector<int>(n)), top(m, vector<int>(n)); for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { if (grid[i][j] == 0) continue; left[i][j] = j == 0 ? 1 : left[i][j - 1] + 1; top[i][j] = i == 0 ? 1 : top[i - 1][j] + 1; } } for (int len = min(m, n); len > 0; --len) { for (int i = 0; i < m - len + 1; ++i) { for (int j = 0; j < n - len + 1; ++j) { if (top[i + len - 1][j] >= len && top[i + len - 1][j + len - 1] >= len && left[i][j + len - 1] >= len && left[i + len - 1][j + len - 1] >= len) return len * len; } } } return0; } };
上面的方法是根据边长进行遍历,若数组很大,而其中的1很少,这种遍历方法将不是很高效。我们从 grid 数组的右下角往左上角遍历,即从每个潜在的正方形的右下角开始遍历,根据右下顶点的位置取到的 top 和 left 值,分别是正方形的右边和下边的边长,取其中较小的那个为目标正方形的边长,然后现在就要确定是否存在相应的左边和上边,存在话的更新 mx,否则将目标边长减1,继续查找,直到目标边长小于 mx 了停止。继续这样的操作直至遍历完所有的右下顶点,这种遍历的方法要高效不少,参见代码如下:
classSolution { public: intlargest1BorderedSquare(vector<vector<int>>& grid){ int mx = 0, m = grid.size(), n = grid[0].size(); vector<vector<int>> left(m, vector<int>(n)), top(m, vector<int>(n)); for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { if (grid[i][j] == 0) continue; left[i][j] = j == 0 ? 1 : left[i][j - 1] + 1; top[i][j] = i == 0 ? 1 : top[i - 1][j] + 1; } } for (int i = m - 1; i >= 0; --i) { for (int j = n - 1; j >= 0; --j) { int small = min(left[i][j], top[i][j]); while (small > mx) { if (top[i][j - small + 1] >= small && left[i - small + 1][j] >= small) mx = small; --small; } } } return mx * mx; } };
Leetcode1140. Stone Game II
Alice and Bob continue their games with piles of stones. There are a number of piles arranged in a row, and each pile has a positive integer number of stones piles[i]. The objective of the game is to end with the most stones.
Alice and Bob take turns, with Alice starting first. Initially, M = 1.
On each player’s turn, that player can take all the stones in the first X remaining piles, where 1 <= X <= 2M. Then, we set M = max(M, X).
The game continues until all the stones have been taken.
Assuming Alice and Bob play optimally, return the maximum number of stones Alice can get.
Example 1:
1 2 3
Input: piles = [2,7,9,4,4] Output: 10 Explanation: If Alice takes one pile at the beginning, Bob takes two piles, then Alice takes 2 piles again. Alice can get 2 + 4 + 4 = 10 piles in total. If Alice takes two piles at the beginning, then Bob can take all three piles left. In this case, Alice get 2 + 7 = 9 piles in total. So we return 10 since it's larger.
Example 2:
1 2
Input: piles = [1,2,3,4,5,100] Output: 104
Constraints:
1 <= piles.length <= 100
1 <= piles[i] <= 104
这道题是石头游戏系列的第二道,跟之前那道 Stone Game 不同的是终于换回了 Alice 和 Bob!还有就是取石子的方法,不再是只能取首尾两端的石子堆,而是可以取 [1, 2M] 范围内的任意X堆,M是个变化的量,初始化为1,每次取完X堆后,更新为 M = max(M, X)。这种取石子的方法比之前的要复杂很多,由于X的值非常的多,而且其不同的选择还可能影响到M值,那么整体的情况就特别的多,暴力搜索基本上是行不通的。这种不同状态之间转移的问题用动态规划 Dynamic Programming 是比较合适的,首先来考虑 DP 数组的定义,题目要求的是 Alice 最多能拿到的石子个数,拿石子的方式是按顺序的,不能跳着拿,所以决定某个状态的是两个变量,一个是当前还剩多少石子堆,可以通过当前位置坐标i来表示,另一个是当前的m值,只有知道了当前的m值,那么选手才知道能拿的堆数的范围,所以 DP 就是个二维数组,其 dp[i][m] 表示的意义在上面已经解释了。接下来考虑状态转移方程,由于在某个状态时已经知道了m值,则当前选手能拿的堆数在范围 [1, 2m] 之间,为了更新这个 dp 值,所有x的情况都要遍历一遍,即在剩余堆数中拿x堆,但此时x堆必须小于等于剩余的堆数,即 i + x <= n,i为当前的位置。由于每个选手都是默认选最优解的,若能知道下一个选手该拿的最大石子个数,就能知道当前选手能拿的最大石子个数了,因为二者之和为当前剩余的石子个数。由于当前选手拿了x堆,则下个选手的位置是 i+x,且m更新为 max(m,x),所以其 dp 值为 dp[i + x][max(m, x)])。为了快速得知当前剩余的石子总数,需要建立累加和数组,注意这里是建立反向的累加和数组,其中 sums[i] 表示范围 [i, n-1] 之和。分析到这里就可以写出状态状态转移方程如下:
接下来就是一些初始化和边界定义的问题需要注意的了,dp 数组大小为 n+1 by n+1,因为选手是可能一次将n堆都拿了,比如 n=1 时,所以 dp[i][n] 是存在的,且需要用 sums[i] 来初始化。更新 dp 时需要用三个 for 循环,分别控制i,m,和 x,注意更新从后往前遍历i和m,因为我们要先更新小区间,再更新大区间。x的范围要设定为 x <= 2 * m && i + x <= n,前面也讲过原因了,最后的答案保存在 dp[0][1] 中返回即可,参见代码如下:
classSolution { public: intstoneGameII(vector<int>& piles){ int n = piles.size(); vector<int> sums = piles; vector<vector<int>> dp(n + 1, vector<int>(n + 1)); for (int i = n - 2; i >= 0; --i) { sums[i] += sums[i + 1]; } for (int i = 0; i < n; ++i) { dp[i][n] = sums[i]; } for (int i = n - 1; i >= 0; --i) { for (int m = n - 1; m >= 1; --m) { for (int x = 1; x <= 2 * m && i + x <= n; ++x) { dp[i][m] = max(dp[i][m], sums[i] - dp[i + x][max(m, x)]); } } } return dp[0][1]; } };
classSolution { public: intstoneGameII(vector<int>& piles){ int n = piles.size(); vector<int> sums = piles; vector<vector<int>> memo(n, vector<int>(n)); for (int i = n - 2; i >= 0; --i) { sums[i] += sums[i + 1]; } returnhelper(sums, 0, 1, memo); } inthelper(vector<int>& sums, int i, int m, vector<vector<int>>& memo){ if (i + 2 * m >= sums.size()) return sums[i]; if (memo[i][m] > 0) return memo[i][m]; int res = 0; for (int x = 1; x <= 2 * m; ++x) { int cur = sums[i] - sums[i + x]; res = max(res, cur + sums[i + x] - helper(sums, i + x, max(x, m), memo)); } return memo[i][m] = res; } };
Leetcode1143. Longest Common Subsequence
Given two strings text1 and text2, return the length of their longest common subsequence.
A subsequence of a string is a new string generated from the original string with some characters(can be none) deleted without changing the relative order of the remaining characters. (eg, “ace” is a subsequence of “abcde” while “aec” is not). A common subsequence of two strings is a subsequence that is common to both strings.
If there is no common subsequence, return 0.
Example 1:
1 2 3
Input: text1 = "abcde", text2 = "ace" Output: 3 Explanation: The longest common subsequence is "ace" and its length is 3.
Example 2:
1 2 3
Input: text1 = "abc", text2 = "abc" Output: 3 Explanation: The longest common subsequence is "abc" and its length is 3.
Example 3:
1 2 3
Input: text1 = "abc", text2 = "def" Output: 0 Explanation: There is no such common subsequence, so the result is 0.
Constraints:
1 <= text1.length <= 1000
1 <= text2.length <= 1000
The input strings consist of lowercase English characters only.
classSolution { public: intlongestCommonSubsequence(string word1, string word2){ int m = word1.length(), n = word2.length(); vector<vector<int>> dp(m+1, vector(n+1, 0)); for (int i = 1; i <= m; i ++) for (int j = 1; j <= n; j ++) if (word1[i-1] == word2[j-1]) dp[i][j] = dp[i-1][j-1] + 1; else dp[i][j] = max(dp[i-1][j], dp[i][j-1]); return dp[m][n]; } };
Leetcode1144. Decrease Elements To Make Array Zigzag
Given an array nums of integers, a move consists of choosing any element and decreasing it by 1.
An array A is a zigzag array if either:
Every even-indexed element is greater than adjacent elements, ie. A[0] > A[1] < A[2] > A[3] < A[4] > … OR, every odd-indexed element is greater than adjacent elements, ie. A[0] < A[1] > A[2] < A[3] > A[4] < … Return the minimum number of moves to transform the given array nums into a zigzag array.
Example 1:
1 2 3
Input: nums = [1,2,3] Output: 2 Explanation: We can decrease 2 to 0 or 3 to 1.
classSolution { public: intmovesToMakeZigzag(vector<int>& nums){ int n = nums.size(), res[2] = {0, 0}; for (int i = 0; i < n; ++i) { int left = i > 0 ? nums[i - 1] : 1001; int right = i < n - 1 ? nums[i + 1] : 1001; res[i % 2] += max(0, nums[i] - min(left, right) + 1); } returnmin(res[0], res[1]); } };
Leetcode1146. Snapshot Array
Implement a SnapshotArray that supports the following interface:
SnapshotArray(int length) initializes an array-like data structure with the given length. Initially, each element equals 0.
void set(index, val) sets the element at the given index to be equal to val.
int snap() takes a snapshot of the array and returns the snap_id: the total number of times we called snap() minus 1.
int get(index, snap_id) returns the value at the given index, at the time we took the snapshot with the given snap_id
Example 1:
1 2 3 4 5 6 7 8 9
Input: ["SnapshotArray","set","snap","set","get"] [[3],[0,5],[],[0,6],[0,0]] Output: [null,null,0,null,5] Explanation: SnapshotArray snapshotArr = new SnapshotArray(3); // set the length to be 3 snapshotArr.set(0,5); // Set array[0] = 5 snapshotArr.snap(); // Take a snapshot, return snap_id = 0 snapshotArr.set(0,6); snapshotArr.get(0,0); // Get the value of array[0] with snap_id = 0, return 5
Constraints:
1 <= length <= 50000
At most 50000 calls will be made to set, snap, and get.
0 <= index < length
0 <= snap_id < (the total number of times we call snap())
You are given a string text. You should split it to k substrings (subtext1, subtext2, …, subtextk) such that:
subtexti is a non-empty string.
The concatenation of all the substrings is equal to text (i.e., subtext1 + subtext2 + … + subtextk == text).
subtexti == subtextk - i + 1 for all valid values of i (i.e., 1 <= i <= k).
Return the largest possible value of k.
Example 1:
1 2 3
Input: text = "ghiabcdefhelloadamhelloabcdefghi" Output: 7 Explanation: We can split the string on "(ghi)(abcdef)(hello)(adam)(hello)(abcdef)(ghi)".
Example 2:
1 2 3
Input: text = "merchant" Output: 1 Explanation: We can split the string on "(merchant)".
Example 3:
1 2 3
Input: text = "antaprezatepzapreanta" Output: 11 Explanation: We can split the string on "(a)(nt)(a)(pre)(za)(tpe)(za)(pre)(a)(nt)(a)".
Example 4:
1 2 3
Input: text = "aaa" Output: 3 Explanation: We can split the string on "(a)(a)(a)".
Constraints:
1 <= text.length <= 1000
text consists only of lowercase English characters.
这道题是关于段式回文的,想必大家对回文串都不陌生,就是前后字符对应相同的字符串,比如 noon 和 bob。这里的段式回文相等的不一定是单一的字符,而是可以是字串,参见题目中的例子,现在给了一个字符串,问可以得到的段式回文串的最大长度是多少。由于段式回文的特点,你可以把整个字符串都当作一个子串,则可以得到一个长度为1的段式回文,所以答案至少是1,不会为0。而最好情况就是按字符分别相等,那就变成了一般的回文串,则长度就是原字符串的长度。比较的方法还是按照经典的验证回文串的方式,用双指针来做,一前一后。不同的是遇到不相等的字符不是立马退出,而是累加两个子串 left 和 right,每累加一个字符,都比较一下 left 和 right 是否相等,这样可以保证尽可能多的分出来相等的子串,一旦分出了相等的子串,则 left 和 right 重置为空串,再次从小到大比较,参见代码如下:
解法一:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: intlongestDecomposition(string text){ int res = 0, n = text.size(); string left, right; for (int i = 0; i < n; ++i) { left += text[i], right = text[n - i - 1] + right; if (left == right) { ++res; left = right = ""; } } return res; } };
classSolution { public: boolis_equal(string text, int x, int y, int len){ for (int i = 0; i < len; i ++) if (text[x+i] != text[y+i]) returnfalse; returntrue; } intlongestDecomposition(string text){ int n = text.length(); for (int i = 1; i <= n/2; i ++) { if (is_equal(text, 0, n-i, i)) return2 + longestDecomposition(text.substr(i, n-i*2)); } return n > 0 ? 1 : 0; } };
Leetcode1154. Day of the Year
Given a string date representing a Gregorian calendar date formatted as YYYY-MM-DD, return the day number of the year.
Example 1:
1 2 3
Input: date = "2019-01-09" Output: 9 Explanation: Given date is the 9th day of the year in 2019.
Example 2:
1 2
Input: date = "2019-02-10" Output: 41
Example 3:
1 2
Input: date = "2003-03-01" Output: 60
Example 4:
1 2
Input: date = "2004-03-01" Output: 61
判断一个日期是一年中的第几天。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: intdayOfYear(string date){ int days[] = {0,31,28,31,30,31,30,31,31,30,31,30,31}; int year = stoi(date.substr(0, 4)); int month = stoi(date.substr(5,7)); int day = stoi(date.substr(8, 10)); int ans = 0; for(int i = 0; i < month; i ++) ans += days[i]; ans += day; if((year%100==0 && year%400 == 0) || (year%100 != 0 && year%4 == 0)) if(month > 2) ans += 1; return ans; } };
Leetcode1156. Swap For Longest Repeated Character Substring
You are given a string text. You can swap two of the characters in the text.
Return the length of the longest substring with repeated characters.
Example 1:
1 2 3
Input: text = "ababa" Output: 3 Explanation: We can swap the first 'b' with the last 'a', or the last 'b' with the first 'a'. Then, the longest repeated character substring is "aaa" with length 3.
Example 2:
1 2 3
Input: text = "aaabaaa" Output: 6 Explanation: Swap 'b' with the last 'a' (or the first 'a'), and we get longest repeated character substring "aaaaaa" with length 6.
Example 3:
1 2 3
Input: text = "aaaaa" Output: 5 Explanation: No need to swap, longest repeated character substring is "aaaaa" with length is 5.
classSolution { public: intmaxRepOpt1(string text){ vector<vector<pair<int, int> > > mapp(26, vector<pair<int, int>>());; int i = 0, n = text.length(); while(i < n) { int j = i+1; while(j < n && text[i] == text[j]) j ++; mapp[text[i]-'a'].push_back(make_pair(i, j-1)); i = j; } int res = 0; for (i = 0; i < 26; i ++) { if (mapp[i].size() == 0) continue; int len = mapp[i].size(); bool has_equal = len > 1; for (int j = 0; j < len; j ++) { res = max(res, mapp[i][j].second - mapp[i][j].first + 1 + has_equal); } if (len >= 2) { has_equal = len > 2; for (int j = 0; j < len-1; j ++) if (mapp[i][j+1].first - mapp[i][j].second == 2) res = max(res, mapp[i][j].second-mapp[i][j].first+1 + mapp[i][j+1].second-mapp[i][j+1].first+1 + has_equal); } } return res; } };
Leetcode1155. Number of Dice Rolls With Target Sum
You have d dice and each die has f faces numbered 1, 2, …, f.
Return the number of possible ways (out of fd total ways) modulo 109 + 7 to roll the dice so the sum of the face-up numbers equals target.
Example 1:
1 2 3 4
Input: d = 1, f = 6, target = 3 Output: 1 Explanation: You throw one die with 6 faces. There is only one way to get a sum of 3.
Example 2:
1 2 3 4 5
Input: d = 2, f = 6, target = 7 Output: 6 Explanation: You throw two dice, each with 6 faces. There are 6 ways to get a sum of 7: 1+6, 2+5, 3+4, 4+3, 5+2, 6+1.
Example 3:
1 2 3 4
Input: d = 2, f = 5, target = 10 Output: 1 Explanation: You throw two dice, each with 5 faces. There is only one way to get a sum of 10: 5+5.
Example 4:
1 2 3 4
Input: d = 1, f = 2, target = 3 Output: 0 Explanation: You throw one die with 2 faces. There is no way to get a sum of 3.
Example 5:
1 2 3 4
Input: d = 30, f = 30, target = 500 Output: 222616187 Explanation: The answer must be returned modulo 10^9 + 7.
Constraints:
1 <= d, f <= 30
1 <= target <= 1000
这道题题说是给了d个骰子,每个骰子有f个面,现在给了一个目标值 target,问同时投出这d个骰子,共有多少种组成目标值的不同组合,结果对超大数字 1e9+7 取余。首先来考虑 dp 数组该如何定义,根据硬币找零系列的启发,目标值本身肯定是占一个维度的,因为这个是要求的东西,另外就是当前骰子的个数也是要考虑的因素,所以这里使用一个二维的 dp 数组,其中dp[i][j]表示使用i个骰子组成目标值为j的所有组合个数,大小为d+1 by target+1,并初始化dp[0][0]为1。接下来就是找状态转移方程了,当前某个状态dp[i][k]跟什么相关呢,其表示为使用i个骰子组成目标值k,那么拿最后一个骰子的情况分析,其可能会投出[1,f]中的任意一个数字j,那么之前的目标值就是k-j,且用了i-1个骰子,其dp值就是dp[i-1][k-j],当前投出的点数可以跟之前所有的情况组成一种新的组合,所以当前的dp[i][k]就要加上dp[i-1][k-j],那么状态转移方程就呼之欲出了:
classSolution { public: intnumRollsToTarget(int d, int f, int target){ int M = 1e9 + 7; vector<int> dp(target + 1); dp[0] = 1; for (int i = 1; i <= d; ++i) { vector<int> t(target + 1); for (int j = 1; j <= f; ++j) { for (int k = j; k <= target; ++k) { t[k] = (t[k] + dp[k - j]) % M; } } swap(dp, t); } return dp[target]; } };
Leetcode1160. Find Words That Can Be Formed by Characters
You are given an array of strings words and a string chars.
A string is good if it can be formed by characters from chars (each character can only be used once).
Return the sum of lengths of all good strings in words.
Example 1:
1 2 3 4
Input: words = ["cat","bt","hat","tree"], chars = "atach" Output: 6 Explanation: The strings that can be formed are "cat" and "hat" so the answer is 3 + 3 = 6.
Example 2:
1 2 3 4
Input: words = ["hello","world","leetcode"], chars = "welldonehoneyr" Output: 10 Explanation: The strings that can be formed are "hello" and "world" so the answer is 5 + 5 = 10.
Note:
1 <= words.length <= 1000
1 <= words[i].length, chars.length <= 100
All strings contain lowercase English letters only.
Given the root of a binary tree, the level of its root is 1, the level of its children is 2, and so on.
Return the smallest level X such that the sum of all the values of nodes at level X is maximal.
Example 1:
1 2 3 4 5 6 7
Input: [1,7,0,7,-8,null,null] Output: 2 Explanation: Level 1 sum = 1. Level 2 sum = 7 + 0 = 7. Level 3 sum = 7 + -8 = -1. So we return the level with the maximum sum which is level 2.
classSolution { public: intmaxLevelSum(TreeNode* root){ queue<TreeNode*> q; q.push(root); int maxx = -99999; int layer = 0, max_layer = 0; while(!q.empty()){ int len = q.size(); int sum = 0; layer++; for(int i = 0; i < len; i ++){ TreeNode* temp = q.front(); q.pop(); if(temp->left != NULL) q.push(temp->left); if(temp->right != NULL) q.push(temp->right); sum += temp->val; } if(sum > maxx){ maxx = sum; max_layer = layer; } } return max_layer; } };
Leetcode1162. As Far from Land as Possible
Given an n x n grid containing only values 0 and 1, where 0 represents water and 1 represents land, find a water cell such that its distance to the nearest land cell is maximized, and return the distance. If no land or water exists in the grid, return -1.
The distance used in this problem is the Manhattan distance: the distance between two cells (x0, y0) and (x1, y1) is |x0 - x1| + |y0 - y1|.
Example 1:
1 2 3
Input: grid = [[1,0,1],[0,0,0],[1,0,1]] Output: 2 Explanation: The cell (1, 1) is as far as possible from all the land with distance 2.
Example 2:
1 2 3
Input: grid = [[1,0,0],[0,0,0],[0,0,0]] Output: 4 Explanation: The cell (2, 2) is as far as possible from all the land with distance 4.
Constraints:
n == grid.length
n == grid[i].length
1 <= n <= 100
grid[i][j] is 0 or 1
这道题给了一个只有0和1的二维数组,说是0表示水,1表示陆地,现在让找出一个0的位置,使得其离最近的1的距离最大,这里的距离用曼哈顿距离表示。这里最暴力的方法就是遍历每个0的位置,对于每个遍历到的0,再遍历每个1的位置,计算它们的距离,找到最小的距离保存为该0位置的距离,然后在所有0位置的距离中找出最大的。这种方法不是很高效,目测无法通过 OJ,博主都没有尝试。其实这道题的比较好的解法是建立距离场,即每个大于1的数字表示该位置到任意一个1位置的最短距离,在之前那道 Shortest Distance from All Buildings 就用过这种方法。建立距离场用 BFS 比较方便,因为其是一层一层往外扩散的遍历,这里需要注意的是要一次把所有1的位置都加入 queue 中一起遍历,而不是对每个1都进行 BFS,否则还是过不了 OJ。这里先把位置1都加入 queue,然后这里先做个剪枝,若位置1的个数为0,或者为 n^2,表示没有陆地,或者没有水,直接返回 -1。否则进行 while 循环,步数 step 加1,然后用 for 循环确保进行层序遍历,一定要将 q.size() 放到初始化中,因为其值可能改变。然后就是标准的 BFS 写法了,取队首元素,遍历其相邻四个结点,若没有越界且值为0,则将当前位置值更新为 step,然后将这个位置加入 queue 中继续遍历。循环退出后返回 step-1 即可,参见代码如下:
classSolution { public: intmaxDistance(vector<vector<int>>& grid){ int res = 0, n = grid.size(); for (int i = 0; i < n; ++i) { for (int j = 0; j < n; ++j) { if (grid[i][j] == 1) continue; grid[i][j] = 201; if (i > 0) grid[i][j] = min(grid[i][j], grid[i - 1][j] + 1); if (j > 0) grid[i][j] = min(grid[i][j], grid[i][j - 1] + 1); } } for (int i = n - 1; i >= 0; --i) { for (int j = n - 1; j >= 0; --j) { if (grid[i][j] == 1) continue; if (i < n - 1) grid[i][j] = min(grid[i][j], grid[i + 1][j] + 1); if (j < n - 1) grid[i][j] = min(grid[i][j], grid[i][j + 1] + 1); res = max(res, grid[i][j]); } } return res == 201 ? -1 : res - 1; } };
Leetcode1165. Single-Row Keyboard
There is a special keyboard with all keys in a single row.
Given a string keyboard of length 26 indicating the layout of the keyboard (indexed from 0 to 25), initially your finger is at index 0. To type a character, you have to move your finger to the index of the desired character. The time taken to move your finger from index i to index j is |i - j|.
You want to type a string word. Write a function to calculate how much time it takes to type it with one finger.
Example 1:
1 2 3 4
Input: keyboard = "abcdefghijklmnopqrstuvwxyz", word = "cba" Output: 4 Explanation: The index moves from 0 to 2 to write 'c' then to 1 to write 'b' then to 0 again to write 'a'. Total time = 2 + 1 + 1 = 4.
Example 2:
1 2
Input: keyboard = "pqrstuvwxyzabcdefghijklmno", word = "leetcode" Output: 73
Constraints:
keyboard.length == 26
keyboard contains each English lowercase letter exactly once in some order.
1 <= word.length <= 10^4
word[i] is an English lowercase letter.
简单打表即可。
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution { public: intcalculateTime(string keyboard, string word){ vector<int> pos(26,-1); int k=0; for(int i=0;i<keyboard.length();i++) pos[keyboard[i]-'a'] = k++; int res=pos[word[0]-'a']; for(int i=1;i<word.length();i++) res += abs(pos[word[i]-'a']-pos[word[i-1]-'a']); return res; } };
Leetcode1170. Compare Strings by Frequency of the Smallest Character
Let’s define a function f(s) over a non-empty string s, which calculates the frequency of the smallest character in s. For example, if s = “dcce” then f(s) = 2 because the smallest character is “c” and its frequency is 2.
Now, given string arrays queries and words, return an integer array answer, where each answer[i] is the number of words such that f(queries[i]) < f(W), where W is a word in words.
Example 1:
1 2 3
Input: queries = ["cbd"], words = ["zaaaz"] Output: [1] Explanation: On the first query we have f("cbd") = 1, f("zaaaz") = 3 so f("cbd") < f("zaaaz").
Example 2:
1 2 3
Input: queries = ["bbb","cc"], words = ["a","aa","aaa","aaaa"] Output: [1,2] Explanation: On the first query only f("bbb") < f("aaaa"). On the second query both f("aaa") and f("aaaa") are both > f("cc").
Return the number of permutations of 1 to n so that prime numbers are at prime indices (1-indexed.)
(Recall that an integer is prime if and only if it is greater than 1, and cannot be written as a product of two positive integers both smaller than it.)
Since the answer may be large, return the answer modulo 10^9 + 7.
Example 1:
1 2 3
Input: n = 5 Output: 12 Explanation: For example [1,2,5,4,3] is a valid permutation, but [5,2,3,4,1] is not because the prime number 5 is at index 1.
classSolution { public: boolisprime(int n){ int nn = sqrt(n); for(int i = 2; i <= nn; i ++) { if(n % i == 0) returnfalse; } returntrue; } intnumPrimeArrangements(int n){ int count1 = 0, count2; for(int i = 2; i <= n; i ++) { if(isprime(i)) count1 ++; } count2 = n - count1; long res = 1; for(int i = 1; i <= count1; i ++) res = (res*i)%(1000000007); for(int i = 1; i <= count2; i ++) res = (res*i)%(1000000007); return res; } };
Leetcode1177. Can Make Palindrome from Substring
Given a string s, we make queries on substrings of s.
For each query queries[i] = [left, right, k], we may rearrange the substring s[left], …, s[right], and then choose up to k of them to replace with any lowercase English letter.
If the substring is possible to be a palindrome string after the operations above, the result of the query is true. Otherwise, the result is false.
Return an array answer[], where answer[i] is the result of the i-th query queries[i].
Note that: Each letter is counted individually for replacement so if for example s[left..right] = “aaa”, and k = 2, we can only replace two of the letters. (Also, note that the initial string s is never modified by any query.)
Example :
1 2 3 4 5 6 7 8
Input: s = "abcda", queries = [[3,3,0],[1,2,0],[0,3,1],[0,3,2],[0,4,1]] Output: [true,false,false,true,true] Explanation: queries[0] : substring = "d", is palidrome. queries[1] : substring = "bc", is not palidrome. queries[2] : substring = "abcd", is not palidrome after replacing only 1 character. queries[3] : substring = "abcd", could be changed to "abba" which is palidrome. Also this can be changed to "baab" first rearrange it "bacd" then replace "cd" with "ab". queries[4] : substring = "abcda", could be changed to "abcba" which is palidrome.
Constraints:
1 <= s.length, queries.length <= 10^5
0 <= queries[i][0] <= queries[i][1] < s.length
0 <= queries[i][2] <= s.length
s only contains lowercase English letters.
这道题给了一个只有小写字母的字符串s,让对s对子串进行查询。查询块包含三个信息,left,right 和k,其中 left 和 right 定义了子串的范围,k表示可以进行替换字母的个数。这里希望通过替换可以将子串变为回文串。题目中还说了可以事先给子串进行排序,这个条件一加,整个性质就不一样了,若不能排序,那么要替换的字母可能就很多了,因为对应的位置上的字母要相同才行。而能排序之后,只要把相同的字母尽可能的排列到对应的位置上,就可以减少要替换的字母,比如 hunu,若不能重排列,则至少要替换两个字母才行,而能重排顺序的话,可以先变成 uhnu,再替换中间的任意一个字母就可以了。
这里是对每个子串都建立字母出现次数的映射,所以这里用一个二维数组,大小为 n+1 by 26,因为限定了只有小写字母。然后遍历字符串s进行更新,每次先将 cnt[i+1] 赋值为 cnt[i],然后在对应的字母位置映射值自增1。累加好了之后,对于任意区间 [i, j] 的次数映射数组就可以通过 cnt[j+1] - cnt[i] 来表示,但数组之间不好直接做减法,可以再进一步访问每个字母来分别进行处理,快速得到每个字母的出现次数后除以2,将结果累加到 sum 中,就是出现奇数次字母的个数了,再除以2和k比较即可,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution { public: vector<bool> canMakePaliQueries(string s, vector<vector<int>>& queries){ vector<bool> res; vector<vector<int>> cnt(s.size() + 1, vector<int>(26)); for (int i = 0; i < s.size(); ++i) { cnt[i + 1] = cnt[i]; ++cnt[i + 1][s[i] - 'a']; } for (auto &query : queries) { int sum = 0; for (int i = 0; i < 26; ++i) { sum += (cnt[query[1] + 1][i] - cnt[query[0]][i]) % 2; } res.push_back(sum / 2 <= query[2]); } return res; } };
Leetcode1179. Reformat Department Table
Table: Department
1 2 3 4 5 6 7
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | revenue | int | | month | varchar | +---------------+---------+
(id, month) is the primary key of this table. The table has information about the revenue of each department per month. The month has values in [“Jan”,”Feb”,”Mar”,”Apr”,”May”,”Jun”,”Jul”,”Aug”,”Sep”,”Oct”,”Nov”,”Dec”].
Write an SQL query to reformat the table such that there is a department id column and a revenue column for each month.
The query result format is in the following example:
1 2 3 4 5 6 7 8 9 10
Department table: +------+---------+-------+ | id | revenue | month | +------+---------+-------+ | 1 | 8000 | Jan | | 2 | 9000 | Jan | | 3 | 10000 | Feb | | 1 | 7000 | Feb | | 1 | 6000 | Mar | +------+---------+-------+
Note that the result table has 13 columns (1 for the department id + 12 for the months).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# Write your MySQL query statement below select id, sum(casewhenmonth="Jan" then revenue elsenullend) as Jan_Revenue, sum(casewhenmonth= "Feb" then revenue elsenullend) as Feb_Revenue, sum(casewhenmonth= "Mar" then revenue elsenullend) as Mar_Revenue, sum(casewhenmonth= "Apr" then revenue elsenullend) as Apr_Revenue, sum(casewhenmonth= "May" then revenue elsenullend) as May_Revenue, sum(casewhenmonth= "Jun" then revenue elsenullend) as Jun_Revenue, sum(casewhenmonth= "Jul" then revenue elsenullend) as Jul_Revenue, sum(casewhenmonth= "Aug" then revenue elsenullend) as Aug_Revenue, sum(casewhenmonth= "Sep" then revenue elsenullend) as Sep_Revenue, sum(casewhenmonth= "Oct" then revenue elsenullend) as Oct_Revenue, sum(casewhenmonth= "Nov" then revenue elsenullend) as Nov_Revenue, sum(casewhenmonth= "Dec" then revenue elsenullend) as Dec_Revenue from Department groupby id orderby id
Leetcode1184. Distance Between Bus Stops
A bus has n stops numbered from 0 to n - 1 that form a circle. We know the distance between all pairs of neighboring stops where distance[i] is the distance between the stops number i and (i + 1) % n.
The bus goes along both directions i.e. clockwise and counterclockwise.
Return the shortest distance between the given start and destination stops.
Example 1:
1 2 3
Input: distance = [1,2,3,4], start = 0, destination = 1 Output: 1 Explanation: Distance between 0 and 1 is 1 or 9, minimum is 1.
Example 2:
1 2 3
Input: distance = [1,2,3,4], start = 0, destination = 2 Output: 3 Explanation: Distance between 0 and 2 is 3 or 7, minimum is 3.
Example 3:
1 2 3
Input: distance = [1,2,3,4], start = 0, destination = 3 Output: 4 Explanation: Distance between 0 and 3 is 6 or 4, minimum is 4.
Leetcode1186. Maximum Subarray Sum with One Deletion 删除一次得到子数组最大和
Given an array of integers, return the maximum sum for a non-empty subarray (contiguous elements) with at most one element deletion. In other words, you want to choose a subarray and optionally delete one element from it so that there is still at least one element left and the sum of the remaining elements is maximum possible.
Note that the subarray needs to be non-empty after deleting one element.
Example 1:
Input: arr = [1,-2,0,3] Output: 4 Explanation: Because we can choose [1, -2, 0, 3] and drop -2, thus the subarray [1, 0, 3] becomes the maximum value. Example 2:
Input: arr = [1,-2,-2,3] Output: 3 Explanation: We just choose [3] and it’s the maximum sum. Example 3:
Input: arr = [-1,-1,-1,-1] Output: -1 Explanation: The final subarray needs to be non-empty. You can’t choose [-1] and delete -1 from it, then get an empty subarray to make the sum equals to 0. Constraints:
classSolution { public: intmaxNumberOfBalloons(string text){ unordered_map<char, int> mp; for(char c : text) mp[c] ++; int aa[5] = {mp['b'], mp['a'], mp['l']/2, mp['o']/2, mp['n']}; int minn = 99999; for(int i = 0; i < 5; i ++) minn = min(minn, aa[i]); return minn; } };
Leetcode1190. Reverse Substrings Between Each Pair of Parentheses
You are given a string s that consists of lower case English letters and brackets.
Reverse the strings in each pair of matching parentheses, starting from the innermost one.
Your result should not contain any brackets.
Example 1:
1 2
Input: s = "(abcd)" Output: "dcba"
Example 2:
1 2 3
Input: s = "(u(love)i)" Output: "iloveu" Explanation: The substring "love" is reversed first, then the whole string is reversed.
Example 3:
1 2 3
Input: s = "(ed(et(oc))el)" Output: "leetcode" Explanation: First, we reverse the substring "oc", then "etco", and finally, the whole string.
Example 4:
1 2
Input: s = "a(bcdefghijkl(mno)p)q" Output: "apmnolkjihgfedcbq"
Constraints:
0 <= s.length <= 2000
s only contains lower case English characters and parentheses.
It’s guaranteed that all parentheses are balanced.
这道题给了一个只含有小写字母和括号的字符串s,现在让从最内层括号开始,每次都反转括号内的所有字符,然后可以去掉该内层括号,依次向外层类推,直到去掉所有的括号为止。可能有的童鞋拿到题后第一反应可能是递归到最内层,翻转,然后再一层一层的出来。这样的做的话就有点麻烦了,而且保不齐还有可能超时。比较好的做法就是直接遍历这个字符串,当遇到字母时,将其加入结果 res,当遇到左括号时,将当前 res 的长度加入一个数组 pos,当遇到右括号时,取出 pos 数组中的最后一个数字,并翻转 res 中该位置到结尾的所有字母,因为这个区间刚好就是当前最内层的字母,这样就能按顺序依次翻转所有括号中的内容,最终返回结果 res 即可,参见代码如下:
classSolution { public: string reverseParentheses(string s){ string res = ""; stack<int> st; int len = s.length(); for (int i = 0; i < len; i ++) if (s[i] == '(') st.push(i); elseif (s[i] == ')') { int last = st.top(); st.pop(); reverse(s.begin()+last+1, s.begin()+i); } for (int i = 0; i < len; i ++) if (s[i] != '(' && s[i] != ')') res += s[i]; return res; } };
根据k的大小,若等于1,则对原数组用 Kadane 算法,若大于1,则只拼接一个数组,那么这里就可以用 min(k, 2) 来合并这两种情况,不过在取数的时候,要用 arr[i % n] 来避免越界,这样就可以得到最大子数组之和了,不过这也还是针对 k 小于等于2的情况,对于 k 大于2的情况,还是要把减去2剩余的次数乘以整个数组之和的值加上,再一起比较,这样最终的结果就是三者之中的最大值了,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution { public: intkConcatenationMaxSum(vector<int>& arr, int k){ int res = INT_MIN, curSum = 0, n = arr.size(), M = 1e9 + 7; long total = accumulate(arr.begin(), arr.end(), 0); for (int i = 0; i < n * min(k, 2); ++i) { curSum = max(curSum + arr[i % n], arr[i % n]); res = max(res, curSum); } returnmax<long>({0, res, total * max(0, k - 2) + res}) % M; } };
Leetcode1192. Critical Connections in a Network
There are n servers numbered from 0 to n - 1 connected by undirected server-to-server connections forming a network where connections[i] = [ai, bi] represents a connection between servers ai and bi. Any server can reach other servers directly or indirectly through the network.
A critical connection is a connection that, if removed, will make some servers unable to reach some other server.
Return all critical connections in the network in any order.
Example 1:
1 2 3
Input: n = 4, connections = [[0,1],[1,2],[2,0],[1,3]] Output: [[1,3]] Explanation: [[3,1]] is also accepted.
Example 2:
1 2
Input: n = 2, connections = [[0,1]] Output: [[0,1]]
Constraints:
2 <= n <= 10^5
n - 1 <= connections.length <= 10^5
0 <= ai, bi <= n - 1
ai != bi
There are no repeated connections.
这道题说是有n个服务器互相连接,定义了一种关键连接,就是当去掉后,会有一部分服务无法访问另一些服务。说白了,就是让求无向图中的桥,对于求无向图中的割点或者桥的问题,需要使用塔里安算法 Tarjan’s Algorithm。该算法是图论中非常常用的算法之一,能解决强连通分量,双连通分量,割点和桥,求最近公共祖先(LCA)等问题,可以参见知乎上的这个贴子。Tarjan 算法是一种深度优先遍历 Depth-first Search 的算法,而且还带有一点联合查找 Union Find 的影子在里面。和一般的 DFS 遍历不同的是,这里用了一个类似时间戳的概念,就是用一个 time 数组来记录遍历到当前结点的时间,初始化为1,每遍历到一个新的结点,时间值就增加1。这里还用了另一个数组 low,来记录在能够访问到的所有节点中,时间戳最小的值,这样,在一个环上的结点最终 low 值都会被更新成一个最小值,就好像 Union Find 中同一个群组中都有相同的 root 值一样。这是非常重要且聪明的处理方式,因为若当前结点是割点的话,即其实桥一头的端点,当过桥之后,由于不存在其他的路径相连通(假设整个图只有一个桥),那么无法再回溯回来的,所以不管桥另一头的端点 next 的 low 值如何更新,其一定还是会大于 cur 的 low 值的,则桥就找到了。可能干讲不好理解,建议看下上面提到的知乎帖子,里面有图和视频可以很好的帮助理解。
这里首先根据给定的边来建立图的结构,这里使用 HashMap 来建立结点和其所有相连的结点集合之间的映射。对于每条边,由于是无向图,则两个方向都要建立映射,然后就调用递归,要传的参数还真不少,图结构,当前结点,前一个结点,cnt 值,time 和 low 数组,还有结果 res。在递归函数中,首先给当前结点 cur 的 time 和 low 值都赋值为 cnt,然后 cnt 自增1。接下来遍历和当前结点所有相邻的结点,若 next 的时间戳为0,表示这个结点没有被遍历过,则对该结点调用递归,然后用 next 结点的 low 值来更新当前结点的 low 值。若 next 结点已经之前访问过了,但不是前一个结点,则用 next 的 time 值来更新当前结点的 low 值。若回溯回来之后,next 的 low 值仍然大于 cur 的 time 值,说明这两个结点之间没有其他的通路,则一定是个桥,加入到结果 res 中即可,参见代码如下:
classSolution { public: vector<vector<int>> criticalConnections(int n, vector<vector<int>>& connections) { int cnt = 1; vector<vector<int>> res; vector<int> time(n), low(n); unordered_map<int, vector<int>> g; for (auto conn : connections) { g[conn[0]].push_back(conn[1]); g[conn[1]].push_back(conn[0]); } helper(g, 0, -1, cnt, time, low, res); return res; } voidhelper(unordered_map<int, vector<int>>& g, int cur, int pre, int& cnt, vector<int>& time, vector<int>& low, vector<vector<int>>& res){ time[cur] = low[cur] = cnt++; for (int next : g[cur]) { if (time[next] == 0) { helper(g, next, cur, cnt, time, low, res); low[cur] = min(low[cur], low[next]); } elseif (next != pre) { low[cur] = min(low[cur], time[next]); } if (low[next] > time[cur]) { res.push_back({cur, next}); } } } };
Leetcode1200. Minimum Absolute Difference
Given an array of distinct integers arr, find all pairs of elements with the minimum absolute difference of any two elements.
Return a list of pairs in ascending order(with respect to pairs), each pair [a, b] follows
a, b are from arr
a < b
b - a equals to the minimum absolute difference of any two elements in arr
Example 1:
1 2 3
Input: arr = [4,2,1,3] Output: [[1,2],[2,3],[3,4]] Explanation: The minimum absolute difference is 1. List all pairs with difference equal to 1 in ascending order.