C++和标准库速成
基础知识
类型
枚举类型只是一个整数值,如果试图对枚举类型进行算术操作,编译器会给出警告或错误信息。如果没有给出一个枚举成员的整型值,编译器会将上一个枚举成员的值递增1,再赋予当前的枚举成员。如果没有给第一个枚举成员赋值,编译器就给它赋值0。
强类型枚举
上面给出的枚举并不是强类型的,这意味着其并非类型安全的。它们总被解释为整型数据,因此可以比较完全不同的枚举类型中的枚举值。强类型的enum class枚举解决了这些问题,例如,下面定义前述PieceType枚举的类型安全版本:1
2
3
4
5
6enum class PieceType
King = 1,
Queen,
Rook = 10,
Pawn
};
对于enumclass,枚举值名不会自动超出封闭的作用域,这表示总要使用作用域解析操作符:1
PieceType piece = PieceType::King;
这也意味着给枚举值指定了更简短的名称,例如,用King替代PieceTypeKing。另外,枚举值不会自动转换为整数。因此,下面的代码是不合法的:1
if (PieceType: :Queen == 2) {...}
默认情况下,枚举值的基本类型是整型,但可采用以下方式加以改变:1
2
3
4
5
6enum Class PieceType : unsigned long
King = 1,
Queen,
Rook = 10,
Pawn
};
if/else
C++17允许在if中包含一个初始化器:1
if (<initializer>; <conditional_expression>) {<body>}
switch
一旦找到与switch条件匹配的case表达式,就执行其后的所有语句,直至遇到break语句为止。即使遇到另一个case表达式,执行也会继续,这称为fallthrough。下例有一组语句,会为不同的case执行:1
2
3
4
5
6
7
8
9switch (backgroundColor) {
case Color::DarkBlue:
case Color::Black:
// Code to execute for both a dark blue or black background color
break;
case Color::Red:
// Code to execute for a red background color
break;
}
如果你无意间忘掉了break语句,fllthrough 将成为bug的来源。因此,如果在switch语句中检测到fallthrough,编译器将生成警告信息,除非像上例那样case 为空。从C++17开始,你可以使用allthrough]特性,告诉编译器某个fallthrough 是有意为之,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13switch (backgroundColor) {
case Color::DarkBlue:
doSomethingForDarkBlue () ;
[[fallthrough]] ;
case Color::Black:
// Code is executed for both a dark blue or black background color
doSome thingForBlackOrDarkBlue() ;
break;
case Color::Red:
case Color::Green:
// Code to execute for a red or green background color
break;
}
逻辑符
C++对表达式求值时会采用短路逻辑。这意味着一旦最终结果可确定,就不对表达式的剩余部分求值。例如,当执行如下所示的多个布尔表达式的逻辑或操作时,如果发现其中一个表达式的值为true,立刻可判定其结果为true,就不再检测剩余部分。1
bool result = bool1 || bool2 || (i > 7) || (27 / 13 % i + 1)<2;
在此例中,如果bool1的值是true,整个表达式的值必然为true,因此不会对其他部分求值。这种方法可阻止代码执行多余操作。然而,如果后面的表达式以某种方式影响程序的状态,就会带来难以发现的bug。
短路做法对性能有好处。在使用逻辑短路时,可将代价更低的测试放在前面,以避免执行代价更高的测试。在指针上下文中,它也可避免指针无效时执行表达式的一部分的情况。本章后面将讨论指针以及包含短路的指针。
函数
函数返回类型的推断
C++14允许要求编译器自动推断出函数的返回类型。要使用这个功能,需要把auto指定为返回类型:1
2auto addNumbers (int number1, int number2)
return number1 + number2;
编译器根据return语句使用的表达式推断返回类型。函数中可有多个return语句,但它们应解析为相同的类型。这种函数甚至可包含递归调用(调用自身),但函数中的第一个return语句必须是非递归调用。
当前函数的名称
每个函数都有一个预定义的局部变量__func__, 其中包含当前函数的名称。这个变量的一个用途是用于日志记录:1
2
3
4int addNumbers(int number1, int number2) {
std::cout << "Entering function " << func << std::endl;
return numberl + number2 ;
}
std::array
上一节讨论的数组来自C,仍能在C++中使用。但C++有一种大小固定的特殊容器std:array,这种容器在<array>头文件中定义。它基本上是对C风格的数组进行了简单包装。用std:array替代C风格的数组会带来很多好处。它总是知道自身大小,不会自动转换为指针,从而避免了某些类型的bug;具有迭代器,可方便地遍历元素。
下例演示了array 容器的用法,必须在尖括号中指定两个参数。第一个参数表示数组中元素的类型,第二个参数表示数组的大小。1
2
3array<int, 3> arr = {9,8,7};
cout << "Array size = " << arr.size() << endl;
cout << "2nd element = " << arr[1] << endl ;
C风格的数组和std:array都具有固定的大小,在编译时必须知道这一点。在运行时数组不会增大或缩小。
std::vector
标准库提供了多个不同的非固定大小容器,可用于存储信息。std:vector就是此类容器的一个示例,它在<vector>中声明,用一种更灵活和安全的机制取代C中数组的概念。用户不需要担心内存的管理,因为vector将自动分配足够的内存来存放其元素。vector 是动态的,意味着可在运行时添加和删除元素。下面的示例演示了vector的基本功能。1
2
3
4
5// Create a vector of integers
vector<int> myVector = { 11, 22 };
// Add some more integers to the vector using push_ back()
myVector.push_back(33);
myVector.push_back(44);
深入研究C++
C++中的字符串
在C++中使用字符串有三种方法。一种是C风格,将字符串看成字符数组;一种是C++风格,将字符串封装到一种易于使用的string类型中;还有一种是非标准的普通类。
与I/0流一样,string类型位于std名称空间中。下面的示例说明了string 如何像字符数组那样使用:1
2
3string myString = "He1lo, world";
cout << "The value of myString is" << myString << endl;
cout << "The second letter is " << myString[1] << endl;
指针和动态内存
动态内存允许所创建的程序具有在编译时大小可变的数据,大多数复杂程序都会以某种方式使用动态内存。
堆栈和堆
C++程序中的内存分为两个部分——堆栈和堆。当前函数中声明的所有变量将占用顶部堆栈帧的内存。如果当前函数调用了另一个函数bar(),bar()就会拥有自己的堆栈帧供其运行。任何从foo()传递给bar()的参数都会从foo()堆栈帧复制到bar()堆栈帧。
堆栈帧很好,因为它为每个函数提供了独立的内存空间。如果在foo()堆栈帧中声明了一个变量,那么除非专门要求,否则调用bar()函数不会更改该变量。此外,foo()函数执行完毕时,堆栈帧就会消失,该函数中声明的所有变量都不会再占用内存。在堆栈上分配内存的变量不需要由程序员释放内存,这个过程是自动完成的。
堆是与当前函数或堆栈帧完全没有关系的内存区域。如果想在函数调用结束之后仍然保存其中声明的变量,可以将变量放到堆中。程序可在任何时候向堆中添加新位或修改堆中已有的位。必须确保释放在堆上分配的任何内存,这个过程不会自动完成。
动态分配的数组
堆也可以用于动态分配数组。使用new[]操作符可给数组分配内存:1
2int arraySize = 8;
int* myVariableSizedArray = new int[arraySize] ;
这条语句分配的内存用于存储8个整数,内存的大小与arraySize变量对应。图1-3显示了执行这条语句后堆栈和堆的情况。可以看到,指针变量仍在堆栈中,但动态创建的数组在堆中。
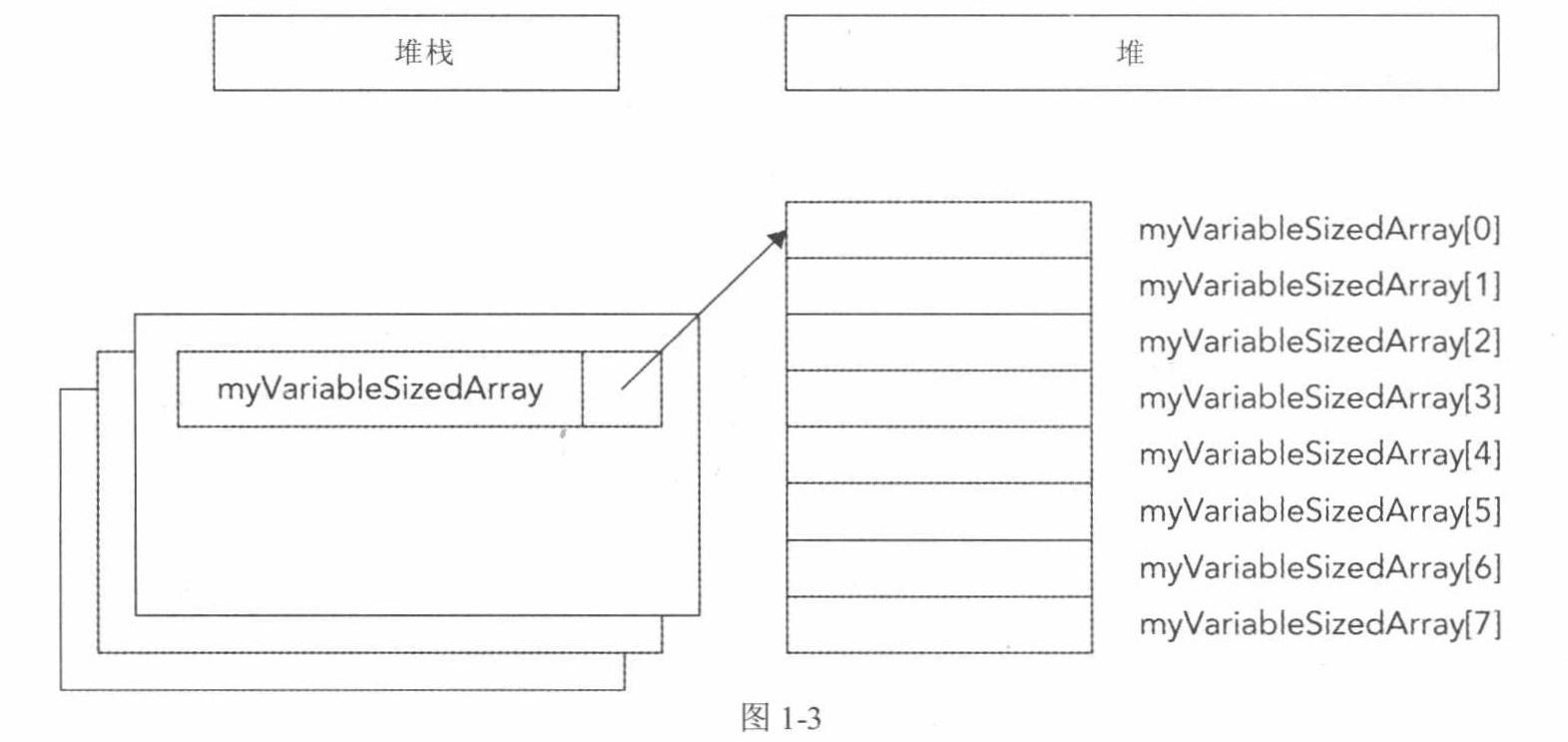
现在已经分配了内存,可将myVariableSizedArray当作基于堆栈的普通数组使用
在C++中,每次调用new时,都必须相应地调用delete;每次调用new[]时,都必须相应地调用delete[],以避免内存泄漏。如果未调用delete或delete[],或调用不匹配,会导致内存泄漏。
空指针常量
在C++11之前,常量NULL用于表示空指针。将NULL定义为常量0会导致一些问题。分析下面的例子:1
2
3
4
5
6void func(char* str) {cout << "char* version" << end1; }
void func(int i) {cout << "int version" << endl; }
int main() {
func (NULL);
return 0;
}main()函数通过参数NULL调用func(), NULL是一个空指针常量。换言之,该例要用空指针作为实参,调用func()的char*版本。但是,NULL不是指针,而等价于整数0,所以实际调用的是func()的整数版本。
可引入真正的空指针常量nullptr解决这个问题。
统一初始化
C++11之前,Struct变量和Class变量的初始化是不同的:1
2CircleStruct myCircle1 = {10, 10, 2.5};
CircleClass myCircle2(10, 10, 2.5);
对于结构版本,可使用{…}语法。然而,对于类版本,需要使用函数符号(..)调用构造函数。自C++11以后,允许使用{…}语法初始化类型,如下所示:1
2CircleStruct myCircle3 = {10, 10, 2.5};
CircleClass myCircle4 = {10,10, 2.5};
定义myCircle4时将自动调用CircleClass的构造函数。甚至等号也是可选的,因此下面的代码与前面的代码等价:1
2CircleStruct myCircle5{10, 10, 2.5};
CircleClass myCircle6{10,10, 2.5};
统一初始化并不局限于结构和类,它还可用于初始化C++中的任何内容。例如,下面的代码把所有4个变量都初始化为3:1
2
3
4int a = 3;
int b(3) ;
int c = {3}; // Uniform initial ization
int d{3};
统一初始化还可用于将变量初始化为0;使用默认构造函数构造对象,将基本整数类型(如char和int等)初始化为0,将浮点类型初始化为0.0,将指针类型初始化为nullptr。例如:1
2int e{};
// Uniform initialization, e will be 0
使用统一初始化还可以阻止窄化。C++隐式地执行窄化,例如:1
2
3
4
5void func(int i) { /*... */ }
int main() {
int x = 3.14;
func(3.14) ;
}
这两种情况下,C++在对x赋值或调用func()之前,会自动将3.14截断为3。注意有些编译器会针对窄化给出警告信息,而另一些编译器则不会。使用统一初始化,如果编译器完全支持C++11标准,x的赋值和func()的调用都会生成编译错误:1
2
3
4
5
6
7void func(int i) { /* ... */ }
int main() {
int x = {3.14};
// Error because narrowing
func({3.14});
// Error because narrowing
}
统一初始化还可用来初始化动态分配的数组:1
int* pArray = new int[4]{0, 1, 2,3};
统一初始化还可在构造函数初始化器中初始化类成员数组:1
2
3
4
5
6
7class MyClass
{
public:
MyClass() : mArray{0, 1, 2, 3} ()
private:
int mArray[4];
};
直接列表初始化与复制列表初始化
有两种初始化类型使用包含在大括号中的初始化列表:
- 复制列表初始化:
T obj = {argl, arg2, ...}; - 直接列表初始化:
T obj {argl, arg2, ...};
在C++17中,与auto类型推断相结合,直接列表初始化与复制列表初始化存在重要区别。从C++17开始,可得到以下结果:1
2
3
4
5
6
7// Copy list initialization
auto a = {11}; // initializer_list<int>
auto b = {11, 22}; // initializer_list<int>
// Direct list initialization
auto c {11}; // int
auto d {11, 22}; // Error, too many elements.
注意,对于复制列表初始化,放在大括号中的初始化器的所有元素都必须使用相同的类型。例如,以下代码无法编译:1
auto b = {11, 22.33}; // Compilation error
在早期标准版本(C++11/14)中,复制列表初始化和直接列表初始化会推导出initializer_ list<>:1
2
3
4
5
6
7// Copy list initialization
auto a = {11}; // initializer_list<int>
auto b = {11, 22}; // initializer_list<int>
// Direct list initialization
auto c {11}; // initializer_list<int>
auto d {11, 22}; // initializer_list<int>
使用string和string_view
动态字符串
C语言中并没有真正好用的string数据类型,只有固定的字节数组。“字符串库”只不过是一组非常原始的函数,甚至没有边界检查的功能。C++提供了string 类型作为数据类型。
C风格的字符串
在C语言中,字符串表示为字符的数组。字符串中的最后-一个字符是null字符(‘\0’),目前,程序员使用C字符串时最常犯的错误是忘记为’\0’字符分配空间。
C++包含一些来自C语言的字符串操作函数,它们在<string>头文件中定义。为字符串分配内存的正确方式是在实际字符所需的空间加1。所以在使用C风格的字符串时要记住这一点。正确的实现代码如下:1
2
3
4
5char* copyString (const char* str) {
char* result = new char [strlen(str) + 1] ;
strcpy(result, str);
return result;
}
C和C++中的sizeof()操作符可用于获得给定数据类型或变量的大小。例如,sizeof(char)返回1,因为字符的大小是1字节。但在C风格的字符串中,sizeof()和strlen()是不同的。绝对不要通过sizeof()获得字符串的大小。它根据C风格的字符串的存储方式来返回不同大小。如果C风格的字符串存储为char[],则sizeof()返回字符串使用的实际内存,包括’\0’字符。例如:1
2
3char text1[] = "abcdef";
size_t s1 = sizeof(text1); // is 7
size_t s2 = strlen(text1); // is 6
但是,如果C风格的字符串存储为char*,sizeof()就返回指针的大小。1
2
3const char* text2 = "abcdef";
size_t s3 = sizeof(text2); // is platform-dependent
size_t s4 = strlen(text2); // is 6
在32位模式下编译时,s3的值为4;而在64位模式下编译时,s3的值为8,因为这返回的是指针const char*的大小。
字符串字面量
与字符串字面量关联的真正内存位于内存的只读部分。通过这种方式,编译器可重用等价字符串字面量的引用,从而优化内存的使用。也就是说,即使一个程序使用了500次”hello”字符串字面量,编译器也只在内存中创建一个 hello 实例。这种技术称为字面量池(literal pooling)。
字符串字面量可赋值给变量,但因为字符串字面量位于内存的只读部分,且使用了字面量池,所以这样做会产生风险。C++标准正式指出:字符串字面量的类型为“n个const char 的数组”,然而为了向后兼容较老的不支持const的代码,大部分编译器不会强制程序将字符串字面量赋值给const char*类型的变量。这些编译器允许将字符串字面量赋值给不带有const的char*,而且整个程序可正常运行,除非试图修改字符串。一般情况下,试图修改字符串字面量的行为是没有定义的。可能会导致程序崩溃;可能使程序继续执行,看起来却有莫名其妙的副作用:可能不加通告地忽略修改行为;可能修改行为是有效的,这完全取决于编译器。
还可将字符串字面量用作字符数组(char[])的初始值。这种情况下,编译器会创建一个足以放下这个字符串的数组,然后将字符串复制到这个数组。因此,编译器不会将字面量放在只读的内存中,也不会进行字面量的
池操作。
原始字符串字面量(raw string literal)是可横跨多行代码的字符串字面量,不需要转义嵌入的双引号,像\t和\n这种转义序列不按照转义序列的方式处理,而是按照普通文本的方式处理。1
const char* str = R"(Hello "World"!)";
C++ std::string类
在C++的string 类中,operator==、operator!=和operator<等运算符都被重载了,这些运算符可以操作真正的字符串字符。单独的字符可通过运算符operator[]访问。如下面的代码所示,当string操作需要扩展string时,string 类能够自动处理内存需求,因此不会再出现内存溢出的情况了:1
2
3
4
5
6
7
8string myString = "hello";
myString += ", there";
string myOtherString = myString;
if (myString == myOtherString)
myOtherString[0] = 'H';
cout << myString << endl ;
cout << myOtherString << endl;
在这个例子中有几点需要注意。一是要注意即使字符串被分配和调整大小,也不会出现内存泄漏的情况。所有这些string对象都创建为堆栈变量。尽管string类肯定需要完成大量分配内存和调整大小的工作,但是string
类的析构函数会在string对象离开作用域时清理内存。另外需要注意的是,运算符以预期的方式工作。例如,=运算符复制字符串,这是最有可能预期的操作。
为达到兼容的目的,还可应用string类的c_str()方法获得一个表示C风格字符串的const字符指针。不过,一旦string执行任何内存重分配或string对象被销毁了,返回的这个const指针就失效了。应该在使用结果之前调用这个方法,以便它准确反映string当前的内容。永远不要从函数中返回在基于堆栈的string上调用c_str()的结果。
还有一个data()方法,在C++14及更早的版本中,始终与c_str()一样返回const char*。 从C++17开始,在非const字符上调用时,data()返回char*。
std:string字面量
源代码中的字符串字面量通常解释为const char*。 使用用户定义的标准字面量s可以把字符串字面量解释为std:string。例如:1
2
3
4auto string1 = "Hello World";
// string1 is a const char*
auto string2 = "Hello World"s;
// string2 is an std::string
用户定义的标准字面量s需要using namespace std:string_literals;或using namespace std;。
高级数值转换
std名称空间包含很多辅助函数,以便完成数值和字符串之间的转换。下面的函数可用于将数值转换为字符串。所有这些函数都负责内存分配,它们会创建一个新的string对象并返回。
string to_string(int val);string to_string(unsigned val);string to_string(long val);string to_string(unsigned long val);string to_string(long long val);string to string(unsigned long long val);string to_string(float val);string to_string(double val);string to_string(long double val);
通过下面这组也在std名称空间中定义的函数将字符串转换为数值。在这些函数原型中,str表示要转换的字符串,idx是一个指针,这个指针将接收第一个未转换的字符的索引,base表示转换过程中使用的进制。idx指针可以是空指针,如果是空指针,则被忽略。如果不能执行任何转换,这些函数会抛出invalid_argument异常,如果转换的值超出返回类型的范围,则抛出out_of_range异常。
int stoi(const string& str, size_t *idx=0, int base= 10);long stol(const string& str, size_t *idx=0, int base=10);unsigned long stoul(const string& str, size_t *idx=0, int base=10);long long stol(const string& str, size_t *idx=0, int base=10);unsigned long long stoul(const string& str, size_t *idx=0, int base= 10);float stof(const string& str, size_t *idx=0);double stod(const string& str, size_t *idx=0);long double stold(const string& str, size_t *idx=0);
std::string_view类
在C++17中,引入std:string_view类解决了开销和易用性的问题,std:string_view类是std:basic_string_view类模板的实例化,在<string_view>头文件中定义。string_view基本上就是const string&的简单替代品,但不会产生开销。它从不复制字符串,string_view支持与std:string类似的接口。一个例外是缺少c_str(),但data()是可用的。另外,string_view确实添加了remove_prefix(size_t)和remove sufix(size_t)方法;前者将起始指针前移给定的偏移量来收缩字符串,后者则将结尾指针倒退给定的偏移量来收缩字符串。
注意,无法连接一个string和一个string_view。下面的代码将无法编译:1
2
3string str = "Hello";
string_view sv = "world";
auto result = str + sv;
为进行编译,必须将最后一行替代为:1
auto result = str + sv.data() ;
内存管理
使用动态内存
这个例子展示了指针既可在堆栈中,也可在堆中。1
2
3int** handle = nullptr;
handle = new int*;
*handle = new int;
上面的代码首先声明一个指向整数指针的指针变量handle。然后,动态分配足够的内存来保存一个指向整数的指针,并将指向这个新内存的指针保存在handle中。接下来,将另一块足以保存整数的动态内存的指针保存在*handle的内存位置。一个指针保存在堆栈中(handle),另一个指针保存在堆中(*handle)。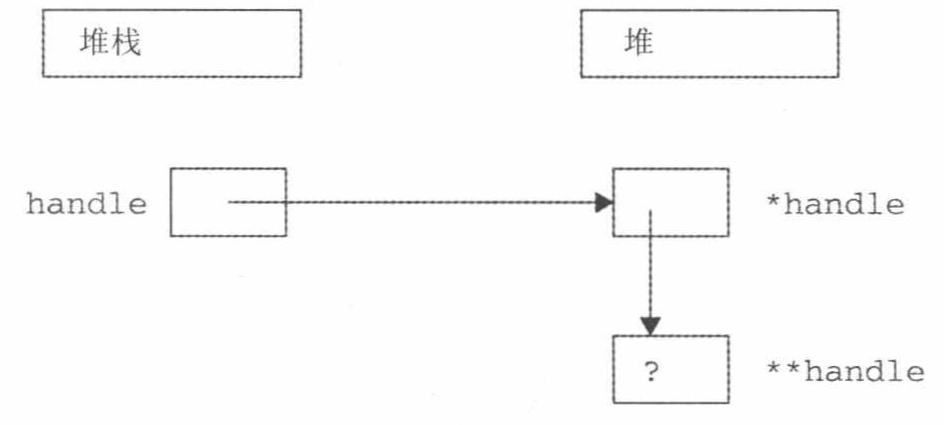
分配和释放
要为变量创建空间,可使用new关键字。要释放这个空间给程序中的其他部分使用,可使用delete关键字。
使用new和delete
要分配一块内存,可调用new,并提供需要空间的变量的类型。new 返回指向那个内存的指针,但程序员应将这个指针保存在变量中。如果忽略了new的返回值,或这个指针变量离开了作用域,那么这块内存就被孤立了,因为无法再访问这块内存。这也称为内存泄漏。
除非计算机能提供无限制的高速内存,否则就需要告诉编译器,对象关联的内存什么时候可以释放,用作他用。为释放堆中的内存,只需要使用delete关键字,并提供指向那块内存的指针,如下所示:1
2
3int* ptr = new int;
delete ptr
ptr = nullptr;
建议在释放指针的内存后,将指针重新设置为nullptr. 这样就不会在无意中使用一个指向已释放内存的指针。
在C++中不应该使用malloc()和free()函数。只使用new和delete运算符。malloc()和free()函数不会调用构造函数和析构函数。
在C++中有一个继承自C语言的函数realloc()。不要使用它!在C中,reallo()用 于改变数组的大小,采取的方法是分配新大小的新内存块,然后将所有旧数据复制到新位置,再删除旧内存块。在C++中这种做法是极其危险的,因为用户定义的对象不能很好地适应按位复制。
当内存分配失败时
默认情况下,如果new失败了,程序会终止。当new因为没有足以满足请求的内存而抛出异常失败时,程序退出。也有不抛出异常的new版本。相反,它会返回nullptr,这类似于C语言中malloc()的行为。使用这个版本的语法如下所示:1
int* ptr = new (nothrow) int;
数组
对象的数组
对象的数组和简单类型的数组没有区别。通过new[N]分配N个对象的数组时,实际上分配了N个连续的内存块,每一块足以容纳单个对象。使用new[]时,每个对象的无参构造函数=default会自动调用。这样,通过new[]分配对象数组时,会返回一个指向数组的指针,这个数组中的所有对象都被初始化了。1
2
3
4
5class Simple {
public:
Simple() { cout << "Simple constructor called!" << endl; }
~Simple() { cout << "Simple destructor called!" << endl; }
};
如果要分配包含4个Simple对象的数组,那么Simple构造函数会被调用4次。1
Simple* mySimpleArray = new Simple[4];
删除数组
如前所述,通过数组版本的new(new[])分配内存时,必须通过数组版本的delete(delete[])释放相应的内存。这个版本的delete会自动析构数组中的对象,并释放这些对象的内存。1
2
3
4Simple* mySimpleArray = new Simple[4];
// Use mySimpleArray
delete [] mySimpleArray;
mySimpleArray = nullptr;
如果不使用数组版本的delete, 程序就可能出现异常行为。在一些编译器中,可能只会调用数组中第1个元素的析构函数,因为编译器只知道要删除指向一个对象的指针,而数组中的其他所有元素都变成了孤立对象。在其他编译器中,可能出现内存崩溃的情况,因为new和new[]可能采用完全不同的内存分配方案。
数组-指针的对偶性
在堆上分配的数组通过指向该数组中第一个元素的指针来引用。基于堆栈的数组通过数组语法([])和普通的变量声明来引用。
数组就是指针
通过指针不仅能指向基于堆的数组,也可以通过指针语法来访问基于堆栈的数组的元素。数组的地址就是第1个元素(索引0)的地址。编译器知道,通过变量名引用整个数组时,实际上引用的是第1个元素的地址。从这个角度看,指针用起来就像基于堆的数组。下面的代码创建了一个堆栈上的数组,数组元素初始化为0,但通过一个指针来访问这个数组:1
2
3
4int myIntArray[10] = {};
int* myIntPtr = myIntArray;
myIntPtr[4] = 5;
向函数传递数组时,通过指针引用基于堆栈的数组的能力非常有用。下面的函数以指针的方式接收一个整数数组。请注意,调用者需要显式地传入数组的大小,因为指针没有包含任何与大小有关的信息。事实上,任何形式的C++数组,不论是不是指针,都没有内含大小信息。这是应使用现代容器(例如标准库提供的容器)的另一个原因。1
2
3
4
5void doubleInts (int* theArray, size_ _t size) {
for (size_t i=0; i < size; i++){
theArray[i] *= 2;
}
}
这个函数的调用者可以传入基于堆栈或堆的数组。在传入基于堆的数组时,指针已经存在了,且按值传入函数。在传入基于堆栈的数组时,调用者可以传入一个数组变量,编译器会自动把这个数组变量当作指向数组的指针处理,还可以显式地传入第一个元素的地址。这里展示了所有三种形式:1
2
3
4
5
6
7
8
9
10size_t arrsize = 4;
int* heapArray = new int[arrSize]{ 1, 5, 3, 4 };
doubleInts(heapArray, arrSize) ;
delete [] heapArray;
heapArray = nullptr;
int stackArray[] = { 5, 7,9, 11 };
arrSize = std::size(stackArray);
doubleInts(stackArray, arrSize) ;
doubleInts(&stackArray[0],arrSize) ;
数组参数传递的语义和指针参数传递的语义十分相似,因为当把数组传递给函数时,编译器将数组视为指针。函数如果接收数组作为参数,并修改数组中元素的值,实际上修改的是原始数组而不是副本。与指针一样,传递数组实际上模仿的是按引用传递的功能,因为真正传入函数的是原始数组的地址而不是副本。
为什么在函数定义中使用数组语法时编译器不复制数组?这样做是为了提高效率——复制数组中的元素需要时间,而且数组可能占用大量的内存。总是传递指针,编译器就不需要包括复制数组的代码。
可“按引用”给函数传递长度已知的基于堆栈的数组,但其语法并不明显。它不适用于基于堆的数组。例如,下面的doubleIntsStack0仅接收大小为4的基于堆栈的数组:1
void doubleIntsStack(int (&theArray) [4]);
低级内存操作
如果代码使用了对象,只需要确保每个类都妥善管理自己的内存。通过构造和析构,编译器可提示什么时候管理内存。将内存管理隐藏在类中可以极大地改变可用性。
指针运算
C++编译器通过声明的指针类型允许执行指针运算。如果声明一个指向int的指针,然后将这个指针递增1,那么这个指针在内存中向前移动1个int 的大小,而不是1个字节。此类操作对数组最有用,因为数组在内存中包含同构的数据序列。例如,假设在堆中声明一个整数数组:1
int* myArray = new int[8];
下面的语法给该数组中位置2的元素设置值:1
myArray[2] = 33;
使用指针运算可等价地使用下面的语法,这个语法获得myArray数组中“向前2个int”位置的内存地址,然后解除引用来设置值:1
*(myArray + 2) = 33;
作为访问单个元素的替代语法,指针运算似乎没有太大吸引力。其真正的作用在于以下事实:像myArray+2这样的表达式仍是一个指向int的指针,因而可以表示一个更小的整数数组。
自定义内存管理
在99%的情况下,C++中内置的内存分配设施是足够使用的。new和delete在后台完成了所有相关工作:分配正确大小的内存块、管理可用的内存区域列表以及释放内存时将内存块释放回可用内存列表。
自行管理内存可能减少开销。当使用new分配内存时,程序还需要预留少量的空间来记录分配了多少内存。这样,当调用delete时,可以释放正确数量的内存。对于大多数对象,这个开销比实际分配的内存小得多,所以差别不大。然而,对于很小的对象或分配了大量对象的程序来说,这个开销的影响可能会很大。
当自行管理内存时,可事先了解每个对象的大小,因此可避免每个对象的开销。
垃圾回收
内存清理的另一个方面是垃圾回收。在支持垃圾回收的环境中,程序员几乎不必显式地释放与对象关联的内存。运行时库会在某时刻自动清理没有任何引用的对象。在现代C++中,使用智能指针管理内存,在旧代码中,则在对象层次通过new和delete管理内存。
标记(mark)和清扫(sweep)是一种垃圾回收的方法。使用这种方法的垃圾回收器定期检查程序中的每个指针,并将指针引用的内存标记为仍在使用。在每一轮周期结束时,未标记的内存视为没有在使用,因而被释放。
如果愿意执行以下操作,那么可以在C++中实现标记和清扫算法:
- 在垃圾回收器中注册所有指针,这样垃圾回收器可轻松遍历所有指针。
- 让所有对象都从一个混入类中派生,这个混入类可能是GartbageCollectible,允许垃圾回收器将对象标记为正在使用中。
- 确保在垃圾回收器运行时不能修改指针,从而保护对象的并发访问。
垃圾回收存在以下缺点:
- 当垃圾回收器正在运行时,程序可能停止响应。
- 使用垃圾回收器时,析构函数具有不确定性。由于对象在被垃圾回收之前不会销毁,因此对象离开作用域时不会立即执行析构函数。这意味着,由析构函数完成的资源清理操作要在将来某个不确定的时刻进行。
智能指针
智能指针可帮助管理动态分配的内存,这是避免内存泄漏建议采用的技术。这样,智能指针可保存动态分配的资源,如内存。当堆栈变量离开作用域或被重置时,会自动释放所占用的资源。智能指针可用于管理在函数作用域内(或作为类的数据成员)动态分配的资源。也可通过函数实参来传递动态分配的资源的所有权。
C++提供的一些语言特性使智能指针具有吸引力。首先,可通过模板为任何指针类型编写类型安全的智能指针类。其次,可使用运算符重载为智能指针对象提供一个接口,使智能指针对象的使用和普通指针一样。确切地讲,可重载*和->运算符,使客户代码解除对智能指针对象的引用的方式和解除对普通指针的引用相同。
智能指针有多种类型。最简单的智能指针类型对资源有唯一的所有权, 当智能指针离开作用域或被重置时,会释放所引用的内存。标准库提供了std::unique_ptr,这是一个具有“唯一所有权” 语义的智能指针。
然而,指针的管理不仅是在指针离开作用域时释放它们。有时,多个对象或代码段包含同一个指针的多个副本。这个问题称为别名。为正确释放所有内存,使用这个资源的最后一个代码块应该释放该指针指向的资源,一种更成熟的智能指针类型实现了“引用计数”来跟踪指针的所有者。每次复制这个“引用计数”智能指针时,都会创建一个指向同一资源的新实例,将引用计数增加1。当这样的一个智能指针实例离开作用域或被重置时,引用计数会减1。当引用计数降为0时,则资源不再有所有者,因此智能指针释放资源。标准库提供了stl:shared_ptr,这是一个使用引用计数且具有“共享所有权”语义的智能指针。标准的shared_ptr是线程安全的,但这不意味着所指向的资源是线程安全的。
unique_ _ptr
作为经验法则,总将动态分配的对象保存在堆栈的unique_ptr实例中。
创建unique_ptrs
考虑下面的函数,这个函数在堆上分配了一个Simple对象,但是不释放这个对象,故意产生内存泄漏。1
2
3
4void leaky() {
Simple* mySimplePtr = new Simple(); // BUG! Memory is never released!
mySimplePtr->go() ;
}
实例unique_ptr离开作用域时(在函数的末尾,或者因为抛出了异常),就会在其析构函数中自动释放Simple对象:1
2
3
4void notLeaky() {
auto mySimpleSmartPtr = make_unique<Simple>() ;
mySimpleSmartPtr->go();
}
这段代码使用C++14中的make_unique()和auto关键字,所以只需要指定指针的类型,本例中是Simple。如果Simple构造函数需要参数,就把它们放在make_unique()调用的圆括号中。
如果编译器不支持make_unique(), 可创建自己的unique_ptr,如下所示,注意Simple必须写两次:1
unique_ptr<Simple> mySimpleSmartPtr (new Simple());
在C++17之前,必须使用make_unique(),一是因为只能将类型指定一次, 二是出于安全考虑!考虑下面对foo()函数的调用:1
foo(unique_ptr<simple> (new Simple()), unique_ptr<Bar>(new Bar (data())));
如果Simple、Bar 或data()函数的构造函数抛出异常(具体取决于编译器的优化设置),很可能是Simple 或Bar对象出现了内存泄漏。而使用make_unique(),则不会发生内存泄漏:1
foo(make_unique<Simple>(), make_unique<Bar> (data()));
使用unique_ptrs
这个标准智能指针最大的一个亮点是:用户不需要学习大量的新语法,就可以获得巨大好处。与标准指针一样,也可将其写作:1
(*mySimpleSmartPtr).go();
get()方法可用于直接访问底层指针。这可将指针传递给需要普通指针的函数1
2auto mySimpleSmartPtr = make_unique<Simple>() ;
processData(mySimpleSmartPtr.get());
可释放unique_ptr的底层指针,并使用reset()根据需要将其改成另一个指针。例如:1
2
3
4mySimpleSmartPtr.reset();
// Free resource and set to nullptr
mySimpleSmartPtr.reset (new Simple()); // Free resource and set to a new
// Simple instance
可使用release()断开unique_ptr与底层指针的连接。release()方法返回资源的底层指针,然后将智能指针设置为nullptr。实际上,智能指针失去对资源的所有权,负责在你用完资源时释放资源。例如:1
2
3
4Simple* simple = mySimpleSmartPtr.release(); // Release ownership
// Use the simple pointer...
delete simple;
simple = nullptr;
由于unique_ptr代表唯一拥有权,因此无法复制它!使用std:move()实用工具,可使用移动语义将一个unique_ptr移到另一个。这用于显式移动所有权,如下所示:1
2
3
4
5
6
7
8
9
10class Foo
{
public:
Foo (unique_ ptr<int> data) : mData (move (data)) { }
private:
unique_ptr<int> mData;
};
auto myIntSmartPtr = make_unique<int>(42);
Foo f(move (myIntSmartPtr));
unique_ptr和C风格数组
unique_ptr适用于存储动态分配的旧式C风格数组。下例创建了一个unique_ptr来保存动态分配的、包含10个整数的C风格数组:1
auto myVariableSizedArray = make_unique<int[]>(10) ;
即使可使用unique_ptr存储动态分配的C风格数组,也建议改用标准库容器,例如std:array和std:vector等。
自定义deleter
默认情况下,unique_ ptr使用标准的new和delete运算符来分配和释放内存。可将此行为改成:1
2
3
4
5
6
7
8
9
10int* malloc_int(int value) {
int* p = (int*)malloc(sizeof(int));
*p = value;
return p;
}
int main() {
unique_ptr<int, decltype(free)*> myIntSmartPtr(malloc_int(42), free);
return 0;
}
这段代码使用malloc_int()给整数分配内存。unique_ptr调用标准的free()函数来释放内存。如前所述,在C++中不应该使用malloc(),而应改用new。然而,unique_ ptr的这项特性是很有用的,因为还可管理其他类型的资源而不仅是内存。例如,当unique_ptr离开作用域时,可自动关闭文件或网络套接字以及其他任何资源。
但是,unique_ptr的自定义deleter的语法有些费解。需要将自定义deleter的类型指定为模板类型参数。在本例中,dcltype(free)用于返回free()类型。 模板类型参数应当是函数指针的类型,因此另外附加一个,如`decltype(free)`。
shared_ptr
shared_ptr的用法与unique_ptr类似。要创建shared_ptr,可使用make_shared(),它比直接创建shared_ptr更高效。例如:1
auto mySimpleSmartPtr = make_shared<Simple>();
从C++17开始,shared_ptr可用于存储动态分配的旧式C风格数组的指针。这在C++17之前是无法实现的。但是,尽管这在C++17中是可能的,仍建议使用标准库容器而非C风格数组。与unique_ptr一样,shared_ptr也支持get()和reset()方法。
与unique_ptr类似,shared_ptr默认情况下使用标准的new和delete运算符来分配和释放内存:在C++17中存储C风格数组时,使用new[]和delete[]。可更改此行为,如下所示:1
2// Implementation of malloc_ int() as before.
shared_ptr<int> myIntSmartPtr (malloc_int(42), free) ;
可以看到,不必将自定义deleter的类型指定为模板类型参数,这比unique_ptr的自定义deleter更简便。
强制转换shared_ptr
可用于强制转换shared_ptrs的函数是const_pointer_cast()、dynamic_pointer_cast()和static_pointer_cast()。C++17又添加了reinterpret_pointer_cast()。它们的行为和工作方式类似于非智能指针转换函数const_cast()、dynamic_cast()、static_cast()和reinterpret_cast()。
引用计数的必要性
作为一般概念, 引用计数(reference counting)用于跟踪正在使用的某个类的实例或特定对象的个数。引用计数的智能指针跟踪为引用一个真实指针(或某个对象)而建立的智能指针的数目。通过这种方式,智能指针可以避免双重删除。
别名
shared_ptr支持所谓的别名。这允许一个shared_ptr与另一个shared_ptr共享一个指针(拥有的指针), 但指向不同的对象(存储的指针)。例如,这可用于使用一个shared_ptr指向一个对象的成员,同时拥有该对象本身,例如:1
2
3
4
5
6
7
8class Foo {
public:
Foo(int value) : mData (value) { }
int mData;
};
auto foo = make_shared<Foo> (42) ;
auto aliasing = shared_ptr<int>(foo,&foo->mData) ;
仅当两个shared_ptrs(foo和aliasing)都销毁时,才销毁Foo对象。
“拥有的指针”用于引用计数;当对指针解引用或调用它的get()时,将返回“存储的指针”。存储的指针用于大多数操作,如比较运算符。可以使用owner_before()方法或std:owner_less类,基于拥有的指针执行比较。
在某些情况下(例如在std::set中存储shared_ptrs),这很有用。
weak_ptr
在C++中还有一个类与shared_ptr模板有关,那就是weak_ptr。weak_ptr可包含由shared_ptr管理的资源的引用。weak_ptr不拥有这个资源,所以不能阻止shared_ptr释放资源。weak_ptr 销毁时(例如离开作用域时)不会销毁它指向的资源:然而,它可用于判断资源是否已经被关联的shared_ptr释放了。weak_ptr的构造函数要求将一个shared_ptr或另一个weak_ptr作为参数。为了访问weak_ptr中保存的指针,需要将weak_ptr转换为shared_ptr。这有两种方法:
- 使用
weak_ptr实例的lock()方法, 这个方法返回一个shared_ptr。如果同时释放了与weak_ptr关联的shared_ptr, 返回的shared_ptr是nullptr。 - 创建一个新的
shared_ptr实例,将weak_ptr作为shared_ptr构造函数的参数。如果释放了与weak_ptr关联的shared_ptr,将抛出std::bad_weak_ptr异常。
下例演示了weak_ptr的用法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20void useResource (weak_ptr<Simple>& weakSimple) {
auto resource = weakSimple.lock();
if (resource)
cout << "Resource still alive." << endl;
else
cout << "Resource has been freed!" << endl;
}
int main() {
auto sharedSimple = make_shared<Simple>() ;
weak_ptr<Simple> weakSimple(sharedSimple) ;
// Try to use the `weak_ptr`.
useResource(weakSimple) ;
// Reset the shared_ptr.
// Since there is only 1 `shared_ptr`to the Simple resource, this will
// free the resource, even though there is still a `weak_ptr` alive.
sharedSimple.reset();
// Try to use the `weak_ptr` a second time.
useResource (weakSimple);
return 0;
}
上述代码的输出如下:1
2
3
4Simple constructor called!
Resource still alive.
Simple destructor called!
Resource has been freed!
从C++17开始,shared_ptr支持C风格的数组;与此类似,weak_ptr 也支持C风格的数组。
常见的内存陷阱
分配不足的字符串
大多数情况下,都是因为程序员没有分配尾部的\0终止字符。当程序员假设某个固定的最大大小时,也会发生字符串分配不足的情况。基本的内置C风格字符串函数不会针对固定的大小操作——而是有 多少写多少,如果超出字符串的末尾,就写入未分配的内存。
有三种方法用于解决可能的分配不足问题。按照优先级降序排列,这三种方法为:
- 使用C++风格的字符串,它可自动处理与连接字符串关联的内存。
- 不要将缓冲区分配为全局变量或分配在堆栈上,而是分配在堆上。当剩余空间不足时,分配一个新缓冲区,它大到至少能保存当前内容加上新内存块的内容,将原来缓冲区的内容复制到新缓冲区,将新内容追加到后面,然后删除原来的缓冲区。
- 创建另一个版本的
getMoreData(),这个版本接收一个最大计数值(包括\0字符),返回的字符数不多于这个值;然后跟踪剩余的空间数以及缓冲区中当前的位置。
访问内存越界
本章前面提到,指针只不过是一个内存地址,因此指针可能指向内存中的任何一个位置。这种情况很容易出现。例如,考虑一个C风格的字符串,它不小心丢失了’\0’终止字符。下面这个函数试图将字符串填满m字符,但实际上可能会继续在字符串后面填充m:1
2
3
4
5
6void fillWithM(char* inStr) {
int i= 0;
while (inStr[i] != '\0') {
inStr [i] = 'm';
}
}
如果把不正确的终止字符串传入这个函数,那么内存的重要部分被改写而导致程序崩溃只是时间问题。许多内存检测工具也能检测缓冲区溢出。使用像C++ string 和vector这样的高级结构有助于避免产生一些和C风格字符串和数组相关的bug。
内存泄漏
随着程序的运行,吞掉的内存越来越多。这是因为程序有内存泄漏。通过智能指针避免内存泄漏是解决这个问题的首选方法。分配了内存,但没有释放,就会发生内存泄漏。
双重删除和无效指针
通过delete 释放某个指针关联的内存时,这个内存就可以由程序的其他部分使用了。然而,无法禁止再次使用这个指针,这个指针成为悬挂指针(dangling pointer)。双重删除也是一个问题。如果第二次在同一个指针上执行delete操作,程序可能会释放重新分配给另一个对象的内存。双重删除和使用已释放的内存都是很难追查的问题,因为症状可能不会立即显现。
如果双重删除在较短的时间内发生,程序可能产生未定义的行为,因为关联的内存可能不会那么快重用。同样,如果删除的对象在删除后立即使用,这个对象很有可能仍然完好无缺。当然,无法保证这种行为会继续出现。一旦删除对象,内存分配器就没有义务保存任何对象。
熟悉类和对象
编写类
类中每个成员和方法都可用三种访问说明符之一来说明:public、protected或private。类的默认访问说明符是private:在第一个访问说明符之前声明的所有成员的访问都是私有的。类似的C++中的struct也可以拥有方法,不过struct默认的访问说明符是public。
::称为作用域解析运算符。每个普通的方法调用都会传递一个指向对象的指针,这是称为“隐藏”参数的this指针。使用这个参数可以访问数据成员或调用方法,也可将其传递给其他方法或函数。
在堆中创建对象时,通过“->”访问其成员,如同必须释放堆中的其他内存一样,也必须在对象上调用delete,释放堆中为对象分配的内存。为了避免发生内存错误,建议使用智能指针。使用智能指针不需要手动释放内存,内存会自动释放。1
2auto myCellp = make_unique<SpreadsheetCell>();
myCellp->setValue(3.7);
对象的生命周期
创建对象
声明对象或使用new显式分配空间时,就会创建对象。当创建对象时,会同时创建内嵌的对象。声明并编写一个构造函数可以初始化对象。从语法上讲,构造函数是与类同名的方法。构造函数没有返回类型,可以有也可以没有参数,没有参数的构造函数称为默认构造函数。可以是无参构造函数,也可以让所有参数都使用默认值。许多情况下,都必须提供默认构造函数,如果不提供,就会导致编译器错误。
构造函数用来创建对象并初始化其值。在基于堆栈和堆进行分配时可以使用构造函数。在堆栈中分配SpreadsheetCell对象时,可这样使用构造函数:1
2
3SpreadsheetCell myCe11(5), anotherCe1l(4);
cout << "cell 1:"<< myCell.getValue() << endl;
cout << "cell 2:"<< anotherCell.getValue() << endl;
当动态分配SpreadsheetCell对象时,可这样使用构造函数:1
2
3
4
5
6
7
8
9
10
11auto smartCellp = make_unique<SpreadsheetCell>(4);
//... do something with the cell, no need to delete the smart pointer
// Or with raw pointers, without smart pointers (not recommended)
SpreadsheetCell* myCellp = new SpreadsheetCell(5);
SpreadsheetCe11* anotherCellp = nullptr;
anotherCellp = new SpreadsheetCell (4) ;
// ... do something with the cells
delete myCellp;
myCellp = nullptr;
delete anotherCellp;
anotherCellp = nullptr;
注意可以声明一个指向SpreadsheetCell对象的指针,而不立即调用构造函数。堆栈中的对象在声明时会调用构造函数。
无论在堆栈中(在函数中)还是在类中(作为类的数据成员)声明指针,如果没有立即初始化指针,都应该像前面声明anotherCellp那样将指针初始化为nullptr。
在一个类中可提供多个构造函数。所有构造函数的名称相同(类名),但不同的构造函数具有不同数量的参数或者不同的参数类型。当具有多个构造函数时,在一个构造函数中执行另一个构造函数的想法很诱人。例如,以下面的方式让string构造函数调用double构造函数:1
2
3SpreadsheetCell::SpreadsheetCell (string_view initialValue) {
SpreadsheetCell(stringToDouble(initialValue));
}
显式调用SpreadsheetCell构造函数实际上新建了一个SpreadsheetCell类型的临时未命名对象,而并不是像预期的那样调用构造函数以初始化对象。然而,C++支持委托构造函数(delegating constructors), 允许构造函数初始化器调用同一个类的其他构造函数。
默认构造函数没有参数,也称为无参构造函数。使用默认构造函数可以在客户不指定值的情况下初始化数据成员。C++没有提供任何语法,让创建数组的代码直接调用不同的构造函数。如果想创建某个类的对象数组,最好还是定义类的默认构造函数。如果没有定义自己的构造函数,编译器会自动创建默认构造函数。如果想在标准库容器(例如stl::vector)中存储类,也需要默认构造函数。
与基于堆栈的对象的其他构造函数不同,调用默认构造函数不需要使用函数调用的语法。根据其他构造函数的语法,用户或许会试着这样调用默认构造函数:1
2
3
4SpreadsheetCell myCell(); // WRONG, but will compile.
myCell.setValue (6);
// However, this line will not compile.
cout << "cell 1:"<< myCell.getValue() << endl;
试图调用默认构造函数的行可以编译,但是后面的行无法编译。问题在于常说的most vexing parse,编译器实际上将第一行当作函数声明,函数名为myCell,没有参数,返回值为SpreadsheetCell对象。当编译第二行时,编译器认为用户将函数名用作对象!
对于堆中的对象,可以这样使用默认构造函数:1
2
3
4auto smartcellp = make_unique<SpreadsheetCell>();
// Or with a raw pointer (not recommended)
SpreadsheetCell* myCellp = new SpreadsheetCell ();
// SpreadsheetCell* myCellp = new SpreadsheetCell;
编译器生成的默认构造函数
本章的第一个SpreadsheetCell类定义如下所示:1
2
3
4
5
6
7class SpreadsheetCell {
public:
void setvalue(double invalue);
double getValue() const;
private:
double mValue;
};
这个类定义没有声明任何默认构造函数,但以下代码仍然可以正常运行:1
2SpreadsheetCell myCell;
myCell.setValue(6) ;
下面的定义与前面的定义相同,只是添加了一个显式的构造函数,用一个double值作为参数。这个定义仍然没有显式声明默认构造函数:1
2
3
4class SpreadsheetCell {
public:
SpreadsheetCell (double initialValue); // No default constructor
};
使用这个定义,下面的代码将无法编译:1
2SpreadsheetCell myCell;
myCell.setValue(6);
原因在于如果没有指定任何构造函数,编译器将自动生成无参构造函数。类所有的对象成员都可以调用编译器生成的默认构造函数,但不会初始化语言的原始类型,例如int 和double。 尽管如此,也可用它来创建类的对象。然而,如果声明了默认构造函数或其他构造函数,编译器就不会再自动生成默认构造函数。
默认构造函数与无参构造函数是一回事。术语“默认构造函数”并不仅仅是说如果没有声明任何构造函数,就会自动生成一个构造函数;而且指如果没有参数,构造函数就采用默认值。
显式的默认构造函数
在C++03或更早版本中,必须显式地编写空的默认构造函数,为了避免手动编写空的默认构造函数,C++现在支持显式的默认构造函数(explicitly defaulted constnuctor)。可按如下方法编写类的定义,而不需要在实现文件中实现默认构造函数:1
2
3
4
5
6
7class SpreadsheetCell {
public:
SpreadsheetCell() = default;
SpreadsheetCell (double initialValue) ;
SpreadsheetCell (std::string_view initialValue) ;
};
// Remainder of the class definition omitted for brevity
SpreadsheetCell定义了两个定制的构造函数。然而,由于使用了default 关键字,编译器仍然会生成一个标准的由编译器生成的默认构造函数。
C++还支持显式删除构造函数(explicitly deleted constructors)。例如,可定义一个只有静态方法的类,这个类没有任何构造函数,也不想让编译器生成默认构造函数。在此情况下可以显式删除默认构造函数:1
2
3class MyClass {
public:
MyClass() = delete;
构造函数初始化器
本章到现在为止,都是在构造函数体内初始化数据成员,例如:1
2
3SpreadsheetCell::SpreadsheetCell (double initialValue) {
setValue (initialValue);
}
C++提供了另一种在构造函数中初始化数据成员的方法,叫作构造函数初始化器或ctor-initializer。 下面的代码使用ctor-initializer语法重写了没有参数的SpreadsheetCell构造函数:1
SpreadsheetCell::SpreadsheetCell (double initialValue) : mValue (initialValue) {}
可以看出,ctor-initializer 出现在构造函数参数列表和构造函数体的左大括号之间。这个列表以冒号开始,由逗号分隔。列表中的每个元素都使用函数符号、统一的初始化语法、调用基类构造函数,或者调用委托构造函数以初始化某个数据成员。
使用ctor-initializer初始化数据成员与在构造函数体内初始化数据成员不同。当C++创建某个对象时,必须在调用构造函数前创建对象的所有数据成员。如果数据成员本身就是对象,那么在创建这些数据成员时,必须为其调用构造函数。在构造函数体内给某个对象赋值时,并没有真正创建这个对象,而只是改变对象的值。
ctor-initializer允许在创建数据成员时赋初值,这样做比在后面赋值效率高。对于类型,它少了一次调用构造函数的过程,而在函数体中赋值则会多一次调用。而对于内置数据类型则没有差别。编译器会一一操作初始化列表,以适当的顺序在构造函数之内安插初始化操作,并且在任何显示用户代码之前;list中的项目顺序是由类中的成员声明顺序决定的,不是由初始化列表的顺序决定的;
如果类的数据成员是具有默认构造函数的类的对象,则不必在ctor-initializer中显式初始化对象。例如,如果有一个std::string数据成员,其默认构造函数将字符串初始化为空字符串,那么在ctor initializer中将其初始化为””是多余的。
而如果类的数据成员是没有默认构造函数的类的对象,则必须在ctor-initializer 中显式初始化对象。例如,考虑下面的SpreadsheetCell类:1
2
3
4class SpreadsheetCell {
public:
SpreadsheetCell (double d);
};
这个类只有一个采用double 值作为参数的显式构造函数,而没有默认构造函数。可在另一个类中将这个类用作数据成员,如下所示:1
2
3
4
5
6class SomeClass {
public:
SomeClass();
private:
SpreadsheetCell mCell;
};
在ctor-initializer中初始化mCell数据成员,如下所示:1
SomeClass::SomeClass() : mCell(1.0) { }
赋值初始化,通过在函数体内进行赋值初始化;列表初始化,在冒号后使用初始化列表进行初始化。这两种方式的主要区别在于:
- 对于在函数体中初始化,是在所有的数据成员被分配内存空间后才进行的。
- 列表初始化是给数据成员分配内存空间时就进行初始化,就是说分配一个数据成员只要冒号后有此数据成员的赋值表达式(此表达式必须是括号赋值表达式),那么分配了内存空间后在进入函数体之前给数据成员赋值,就是说初始化这个数据成员此时函数体还未执行。
2) 一个派生类构造函数的执行顺序如下:
- 虚拟基类的构造函数(多个虚拟基类则按照继承的顺序执行构造函数)。
- 基类的构造函数(多个普通基类也按照继承的顺序执行构造函数)。
- 类类型的成员对象的构造函数(按照初始化顺序)
- 派生类自己的构造函数。
必须使用成员初始化的四种情况
- 当初始化一个引用成员时;
- 当初始化一个常量成员时;
- 当调用一个基类的构造函数,而它拥有一组参数时;
- 当调用一个成员类的构造函数,而它拥有一组参数时;
复制构造函数
复制构造函数(copy constructor)允许所创建的对象是另一个对象的精确副本。如果没有编写复制构造函数,C++会自动生成一个,用源对象中相应数据成员的值初始化新对象的每个数据成员。如果数据成员是对象,初始化意味着调用它们的复制构造函数。下面是SpreadsheetCell类中复制构造函数的声明:1
2
3
4
5class SpreadsheetCell {
public:
SpreadsheetCell (const SpreadsheetCell& src) ;
// Remainder of the class definition omitted for brevity
};
复制构造函数采用源对象的const引用作为参数。与其他构造函数类似,它也没有返回值。在复制构造函数内部,应该复制源对象的所有数据成员。当然,从技术角度看,可在复制构造函数内完成任何操作,但最好按照预期的行为将新对象初始化为已有对象的副本。下面是SpreadsheetCell复制构造函数的示例实现,注意ctor-initializer的用法。1
SpreadsheetCell::SpreadsheetCell (const SpreadsheetCell& src) : mValue (src.mValue)
假定有一组成员变量,名为m1、m2、…. mn,编译器生成的复制构造函数为:1
classname::classname (const classname& src) : m1(src.m1), m2(src.m2), ... mn(src.mn) { }
因此多数情况下,不需要亲自编写复制构造函数!
C++中传递函数参数的默认方式是值传递,这意味着函数或方法接收某个值或对象的副本。因此,无论什么时候给函数或方法传递一个对象,编译器都会调用新对象的复制构造函数进行初始化。
当调用setString()并传递一个string参数时,这个string参数会调用复制构造函数进行初始化。为初始化printString()中的inString对象,会调用string复制构造函数,其参数为name:1
2string name = "heading one";
printString(name) ; // Copies name
当printString()方法结束时,inString 被销毁,因为它只是name的一个副本, 所以name完好无缺。当然,可通过将参数作为const引用来传递,从而避免复制构造函数的开销。
显式调用复制构造函数
也可显式地使用复制构造函数,从而将某个对象作为另一个对象的精确副本。例如,可这样创建SpreadsheetCell对象的副本:1
2SpreadsheetCell myCelll (4) ;
SpreadsheetCell myCe112 (myCe111); // myCe112 has the same values as myCe111
按引用传递对象
向函数或方法传递对象时,为避免复制对象,可让函数或方法采用对象的引用作为参数。按引用传递对象通常比按值传递对象的效率更高,因为只需要复制对象的地址,而不需要复制对象的全部内容。此外,按引用传递可避免对象动态内存分配的问题。
按引用传递某个对象时,使用对象引用的函数或方法可修改原始对象。如果只是为了提高效率才按引用传递,可将对象声明为const以排除这种可能。这称为按const引用传递对象。
为了提高性能,最好按const引用而不是按值传递对象。但是诸如int和double等基本类型应当按值传递。按const引用传递这些类型什么也得不到。
初始化列表构造函数
初始化列表构造函数(nitializer-list constructors)将std:initializer_list<T>作为第一个参数, 并且没有任何其他参数。下面的类演示了这种用法。该类只接收initializer_list<T>,元素个数应为偶数,否则将抛出异常。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class EvenSequence {
public:
EvenSequence (initializer_ list<double> args) {
if (args.size() % 2 != 0)
throw invalid_ argument ("initializer_ list should contain even number of elements.");
mSequence. reserve(args.size());
for (const auto& value : args)
mSequence.push_back (value);
}
void dump() const {
for (const auto& value : mSequence)
cout << value << ", ";
cout << endl;
private:
vector<double> mSequence;
};
在初始化列表构造函数的内部,可使用基于区间的for循环来访问初始化列表的元素。使用size()方法可获取初始化列表中元素的数目。
EvenSequence初始化列表构造函数使用基于区间的for循环来复制给定initializer_list 中的元素。也可以使用vector 的assign()方法。
标准库完全支持初始化列表构造函数。例如,可使用初始化列表初始化stl::vector容器。1
std::vector<std::string> myVec = {"String 1", "String 2", "String 3"};
如果不使用初始化列表构造函数,可通过一些push_back()调用来初始化vector:1
2
3
4std::vector<std::string> myVec;
myVec.push_back("String 1");
myVec.push_back("String 2");
myVec.push_back("String 3");
初始化列表并不限于构造函数,还可以用于普通函数。
委托构造函数
委托构造函数(delegating constructors)允许构造函数调用同一个类的其他构造函数。然而,这个调用不能放在构造函数体内,而必须放在构造函数初始化器中,且必须是列表中唯一的成员初始化器。下面给出了一个示例:1
2
3SpreadsheetCell::SpreadsheetCell (string_view initialvalue)
: SpreadsheetCell (str ingToDouble (ini tialValue) )
{ }
当调用这个string_view构造函数(委托构造函数)时,首先将调用委托给目标构造函数,也就是double构造函数。当目标构造函数返回时,再执行委托构造函数。当使用委托构造函数时,要注意避免出现构造函数的递归。例如:1
2
3
4class MyClass {
MyClass (char c) : MyClass(1.2) { }
MyClass (double d) : MyClass('m') { }
};
第一个构造函数委托第二个构造函数,第二个构造函数又委托第一个构造函数。C++标准没有定义此类代码的行为,这取决于编译器。
总结编译器生成的构造函数
编译器为每个类自动生成没有参数的构造函数和复制构造函数。然而,编译器自动生成的构造函数取决于你自己定义的构造函数,对应的规则如表8-3所示。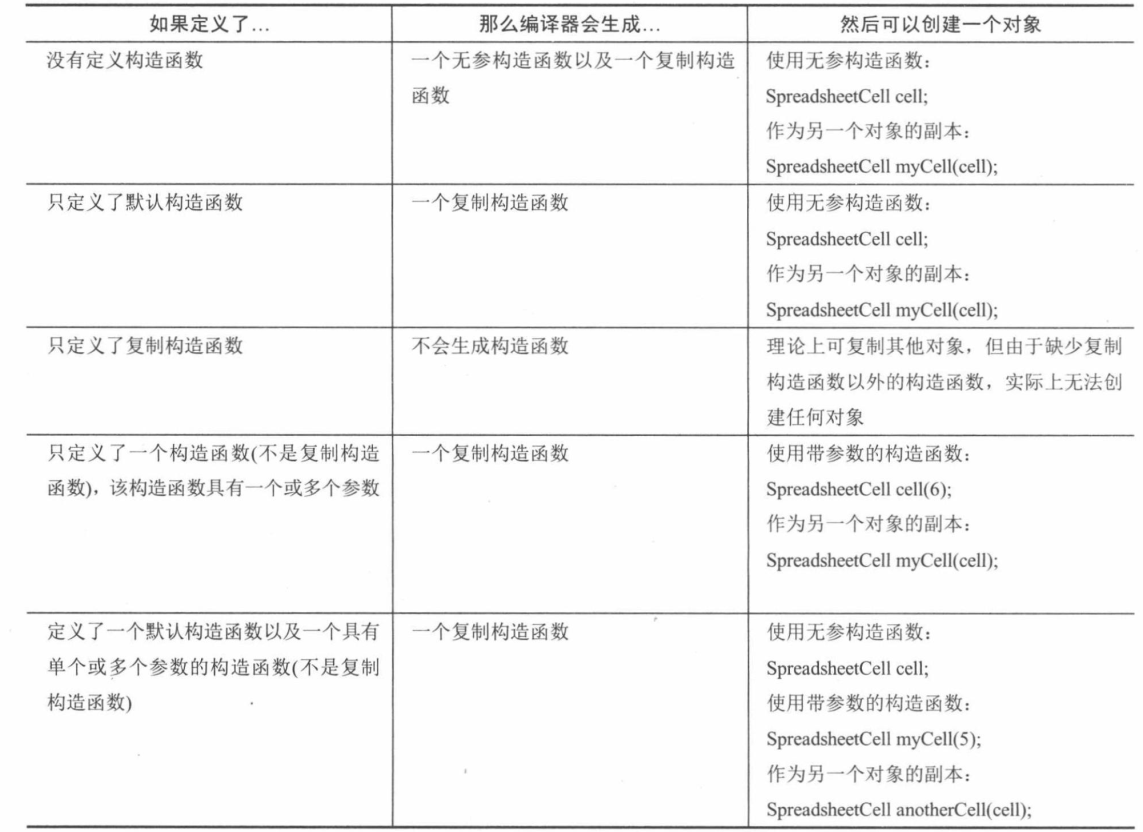
销毁对象
当销毁对象时,会发生两件事:调用对象的析构函数,释放对象占用的内存。在析构函数中可以执行对象的清理,例如释放动态分配的内存或者关闭文件句柄。如果没有声明析构函数,编译器将自动生成一个,析构函数会逐一销毁成员,然后删除对象。
当堆栈中的对象超出作用域时,意味着当前的函数、方法或其他执行代码块结束,对象会被销毁。换句话说,当代码遇到结束大括号时,这个大括号中所有创建在堆栈中的对象都会被销毁。下面的程序显示了这一行为:1
2
3
4
5
6
7
8int main() {
SpreadsheetCell myCell (5) ;
if (myCell .getValue() == 5)
SpreadsheetCell anotherCell(6) ;
} // anotherCell is destroyed as this block ends.
cout << "myCell: " << myCell.getValue() << endl;
return 0;
} // myCell is destroyed as this block ends .
堆栈中对象的销毁顺序与声明顺序(和构建顺序)相反。如果某个对象是其他对象的数据成员,这顺序也适用。数据成员的初始化顺序是它们在类中声明的顺序。因此,按对象的销毁顺序与创建顺序相反这一规则, 数据成员对象的销毁顺序与其在类中声明的顺序相反。
没有智能指针的帮助,在堆中分配的对象不会自动销毁。必须使用delete 删除对象指针,从而调用析构函数并释放内存。下面的程序显示了这一行为:1
2
3
4
5
6
7
8int main()
SpreadsheetCell* cellPtrl = new SpreadsheetCell (5) ;
SpreadsheetCell* cellPtr2 = new SpreadsheetCell (6) ;
cout << "cellPtr1: "<< cellPtr1->getvalue() << endl;
delete cellPtrl; // Destroys cellPtrl
cel1Ptrl = nullptr;
return 0;
} // cellPtr2 is NOT destroyed because delete was not called on it.
对象赋值
就像可将一个int变量的值赋给另一个int变量一样, 在C++中也可将一个对象的值赋给另一个对象。例如,下面的代码将myCell的值赋给anotherCell:1
2SpreadsheetCell myCell(5), anotherCell;
anotherCell = myCell;
在C++中,“复制”只在初始化对象时发生。如果一个已经具有值的对象被改写,更精确的术语是“赋值”。注意C++提供的复制工具是复制构造函数。因为这是一个构造函数,所以只能用在创建对象时,而不能用于对象的赋值。
因此,C++为所有的类提供了执行赋值的方法。这个方法叫作赋值运算符(assignment operator), 名称是operator=,因为实际上是为类重载了=运算符。在上例中,调用了anotherCell的赋值运算符,参数为myCell。
如果没有编写自己的赋值运算符,C++将自动生成一个,从而允许将对象赋给另一个对象。默认的C++赋值行为几乎与默认的复制行为相同:以递归方式用源对象的每个数据成员并赋值给目标对象。
声明赋值运算符
下面是SpreadsheetCell类的赋值运算符:1
2
3
4
5class SpreadsheetCell {
public:
SpreadsheetCell& operator= (const SpreadsheetCell& rhs) ;
// Remainder of the class definition omitted for brevity
}
赋值运算符与复制构造函数类似,采用了源对象的const引用。在此情况下,将源对象称为rths,代表等号的“右边”(可为其指定其他任何名称),调用赋值运算符的对象在等号的左边。与复制构造函数不同的是,赋值运算符返回SpreadsheetCell对象的引用。原因是赋值可以链接在一起。
定义赋值运算符
赋值运算符的实现与复制构造函数类似,但存在一些重要的区别。首先,复制构造函数只有在初始化时才调用,此时目标对象还没有有效的值。赋值运算符可以改写对象的当前值。其次,在C++中允许将对象的值赋给自身。例如,下面的代码可以编译并运行:1
2SpreadsheetCell cell(4);
cell = cell;
赋值运算符不应该阻止自赋值。在SpreadsheetCell类中,这并不重要,因为它的唯一数据成员是基本类型double。但当类具有动态分配的内存或其他资源时,必须将自赋值考虑在内,为阻止此类情况下的问题发生,赋值运算符通常在方法开始时检测自赋值,如果发现自赋值,则立刻返回。下面是SpreadsheetCell类的赋值运算符的定义:1
2SpreadsheetCell& SpreadsheetCell::operator= (const SpreadsheetCell& rhs) {
if (this == &rhs) {
第一行检测自赋值,但有一个神秘之处。当等号的左边和右边相同时,就是自赋值。判断两个对象是否相同的方法之一是检查它们在内存中的位置是否相同,更明确地说,是检查指向它们的指针是否相等。由于返回类型是SpreadsheeCell&,因此必须返回一个正确的值。所有赋值运算符都返回*this,自赋值情况也不例外:1
2 return *this;
}
this指针指向执行方法的对象,因此*this就是对象本身。编译器将返回一个对象的引用,从而与声明的返回值匹配。如果不是自赋值,就必须对每个成员赋值:1
2mValue = rhs.mValue;
return *this;
这个方法在这里复制了值。最后返回*this。
显式地默认或删除赋值运算符
可显式地默认或删除编译器生成的赋值运算符,如下所示:1
SpreadsheetCell& operator= (const SpreadsheetCell& rhs) = default;
或者1
SpreadsheetCell& operator= (const SpreadsheetCell& rhs) = delete;
编译器生成的复制构造函数和复制赋值运算符
在C++11中,如果类具有用户声明的复制赋值构造函数或析构函数,那么已经不赞成生成复制构造函数(可能是编译器觉得需要特殊处理,不能简单地直接复制么)。如果在此类情况下仍然需要编译器生成的复制构造函数,可以显式指定default:1
MyClass (const MyClass& src) = default;
同样,在C++11中,如果类具有用户声明的复制赋值构造函数或析构函数,也不赞成生成复制赋值运算符。如果在此类情况下仍然需要编译器生成的复制赋值运算符,可以显式指定default:1
MyClass& operator= (const MyClass& rhs) = default;
复制和赋值的区别
有时很难区分对象什么时候用复制构造函数初始化,什么时候用赋值运算符赋值。基本上,声明时会使用复制构造函数,赋值语句会使用赋值运算符。考虑下面的代码:1
2SpreadsheetCell myCe11(5);
SpreadsheetCell anotherCell (myCell);
AnotherCell由复制构造函数创建。1
SpreadsheetCell aThirdCell = myCell;
aThirdCell也是由复制构造函数创建的,因为这条语句是一个声明。这行代码不会调用operator=。不过,考虑以下代码:1
anotherCell = myCell; // Calls operator= for anotherCell
此处,anotherCell 已经构建,因此编译器会调用operator=。
按值返回对象
当函数或方法返回对象时,有时很难看出究竟执行了什么样的复制和赋值。例如,SpreadseetCel:etString0的实现如下所示:1
2
3string SpreadsheetCell::getString() const {
return doubleToString (mValue);
}
现在考虑下面的代码:1
2
3SpreadsheetCell myCe112(5);
string s1;
s1 = myCell2.getString();
当getString()返回mString时,编译器实际上调用string复制构造函数,创建一个未命名的临时字符串对象。将结果赋给s1时,会调用s1的赋值运算符,将这个临时字符串作为参数。然后,这个临时的字符串对象被销毁。因此,这行简单的代码调用了复制构造函数和赋值运算符(针对两个不同的对象)。然而,编译器可实现(有时需要实现)返回值优化(Returm Value Optimization, RVO),在返回值时优化掉成本高昂的复制构造函数。RVO
也称为复制省略(copy elision)。
了解到上面的内容后,考虑下面的代码:1
2SpreadsheetCell myCell3(5) ;
string s2 = myCell3.getString() ;
在此情况下,getString()返回时创建了一个临时的未命名字符串对象。但现在s2调用的是复制构造函数,而不是赋值运算符。通过移动语义(move semantics),编译器可使用移动构造函数而不是复制构造函数,从getString()返回该字符串,这样做效率更高。
复制构造函数和对象成员
还应注意构造函数中赋值和调用复制构造函数的不同之处。如果某个对象包含其他对象,编译器生成的复制构造函数会递归调用每个被包含对象的复制构造函数。当编写自己的复制构造函数时,可使用前面所示的ctor initializer提供相同的语义。如果在ctor initializer中省略某个数据成员,在执行构造函数体内的代码之前,编译器将对该成员执行默认的初始化(为对象调用默认构造函数)。这样,在执行构造函数体时,所有数据成员都已经初始化。
例如,可这样编写复制构造函数:1
2SpreadsheetCell::SpreadsheetCell (const SpreadsheetCell& src)
mValue = src.mValue;
然而,在复制构造函数的函数体内对数据成员赋值时,使用的是赋值运算符而不是复制构造函数,因为它们已经初始化。
精通类与对象
友元
C++运行某个类将其他类、其他类的成员函数或非成员函数声明为友元,友元可访问类的protected、private数据成员和方法。可将Bar类或或其中的一个方法、独立函数设置为Foo类的友元;1
2
3
4
5class Foo {
friend void Bar::processFoo(const Foo& foo);
friend class Bar;
friend void dumpFoo(const Foo& foo);
}
对象的动态分配
使用移动语义处理移动
对象的移动语义(movesemantics)需要实现移动构造函数(move constructor)和移动赋值运算符(move assignment operator)。如果源对象是操作结束后被销毁的临时对象,编译器就会使用这两个方法。移动构造函数和移动赋值运算符将数据成员从源对象移动到新对象,然后使源对象处于有效但不确定的状态。通常会将源代码的数据成员重置为空值。这样做实际上将内存和其他资源的所有权从一个对象移动到另一个对象。这两个方法基本上只对成员变量进行表层复制(shallow copy),然后转换已分配内存和其他资源的所有权,从而阻止悬挂指针和内存泄漏。
在实现移动语义前,你需要学习右值(rvalue)和右值引用(rvalue reference)。
右值引用
在C++中,左值(value)是可获取其地址的一个量,例如一个有名称的变量。由于经常出现在赋值语句的左边,因此将其称作左值。另外,所有不是左值的量都是右值(rvalue),例如字面量、临时对象或临时值。通常右值位于赋值运算符的右边。例如,考虑下面的语句:1
int a=4*2;
在这条语句中,a是左值,它具有名称,它的地址为&a。右侧表达式4 * 2的结果是右值。它是一个临时值,将在语句执行完毕时销毁。在本例中,将这个临时副本存储在变量a中。右值引用是一个对右值(rvalue)的引用。特别地,这是一个当右值是临时对象时才适用的概念。右值引用的目的是在涉及临时对象时提供可选用的特定函数。由于知道临时对象会被销毁,通过右值引用,某些涉及复制大量值的操作可通过简单地复制指向这些值的指针来实现。
函数可将&&作为参数说明的一部分(例如type &&name),以指定右值引用参数。通常,临时对象被当作const type&,但当函数重载使用了右值引用时,可以解析临时对象,用于该函数重载。下面的示例说明了这一点。代码首先定义了两个handleMessage()函数,一个接收左值引用,另一个接收右值引用:1
2
3
4
5
6
7
8// lvalue reference parameter
void handleMessage(std::string& message) {
cout << "handleMessage with lvalue reference: " << message << endl;
}
// rvalue reference parameter
void handleMessage (std::string&& message) {
cout << "handleMessage with rvalue reference: " << message << endl;
}
可使用具有名称的变量作为参数调用handleMessage()函数:1
2
3
4std::string a = "Hello ";
std::string b = "World";
handleMessage(a);
// Calls handleMessage (string& value)
由于a是一个命名变量,调用handleMessage()函数时,该函数接收一个左值引用。handleMessage()函数通过其引用参数所执行的任何更改来更改a的值。还可用表达式作为参数来调用handleMessage()函数:1
2handleMessage(a + b);
// Calls handleMessage (string&& value)
此时无法使用接收左值引用作为参数的handleMessage()函数,因为表达式a+b的结果是临时的,这不是一个左值。在此情况下,会调用右值引用版本。由于参数是一个临时值,handleMessage()函数调用结束后,会丢失通过引用参数所做的任何更改。
字面量也可作为handleMessage()调用的参数,此时同样会调用右值引用版本,因为字面量不能作为左值(但字面量可作为const引用形参的对应实参传递)。1
handleMessage("Hello World"); // Calls handldMessage (string&& value)
如果删除接收左值引用的handleMessage()函数,使用有名称的变量调用handleMessage(),会导致编译错误,因为右值引用参数(string&& message)永远不会与左值(b)绑定。如下所示,可使用std:move()将左值转换为右值,强迫编译器调用handleMessage()函数的右值引用版本:1
handleMessage (std::move(b)); // Calls handleMessage (string&& value)
重申一次,有名称的变量是左值。因此,在handleMessage()函数中,右值引用参数message本身是一个左值,原因是它具有名称!如果希望将这个左值引用参数,作为右值传递给另一个函数,则需要使用std:move(),将左值转换为右值。例如,假设要添加以下函数,使用右值引用参数:1
void helper (std::string&& message)
如果按如下方式调用,则无法编译:1
2
3void handleMessage (std::string&& message) {
helper (message);
}helper()函数需要右值引用,而handleMessage()函数传递message,message具有名称,因此是左值,导致编译错误。正确的方式是使用std:move():1
2
3void handleMessage (std::string&& message) {
helper (std::move(message));
}
有名称的右值引用,如右值引用参数,本身就是左值,因为它具有名称!
右值引用并不局限于函数的参数。可以声明右值引用类型的变量,并对其赋值,尽管这一用法并不常见。
考虑下面的代码,在C++中这是不合法的:1
2
3int& i = 2;// Invalid: reference to a constant
int a = 2, b = 3;
int& j = a + b; // Invalid: reference to a temporary
使用右值引用后,下面的代码完全合法:1
2
3int&& i = 2;
int a = 2, b = 3;
int&& j = a + b;
前面示例中单独使用右值引用的情况很少见。
实现移动语义
移动语义是通过右值引用实现的。为了对类增加移动语义,需要实现移动构造函数和移动赋值运算符。移动构造函数和移动赋值运算符应使用noexcept限定符标记,这告诉编译器,它们不会抛出任何异常。这对于与标准库兼容非常重要,因为如果实现了移动语义,与标准库的完全兼容只会移动存储的对象,且确保不抛出异常。
下面的Spreadsheet类定义包含一个移动构造函数和一个移动赋值运算符。也引入了两个辅助方法cleanup()和moveFrom()。前者在析构函数和移动赋值运算符中调用。后者用于把成员变量从源对象移动到目标对象,接着重置源对象。1
2
3
4
5
6
7
8
9
10class Spreadsheet {
public:
Spreadsheet(Spreadsheet&& src) noexcept; // Move constructor
Spreadsheet& operator= (Spreadsheet&& rhs) noexcept; // Move assign
// Remaining code omitted for brevity
private:
void cleanup() noexcept;
void moveFrom (Spreadsheet& src) noexcept;
// Remaining code omitted for brevity
};
实现代码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34void Spreadsheet::cleanup() noexcept {
for(size_t i=0; i < mWidth; i ++)
delete[] mCells[i];
delete[] mCells;
mCells = nullptr;
mWidth = 0;
mHeight = 0;
}
void Spreadsheet::moveFrom (Spreadsheet& src) noexcept {
// Shallow copy of data
mWidth = src.mWidth; .
mHeight = src.mHeight;
mCells = src.mCells;
// Reset the source object, because ownership has been moved !
src.mWidth = 0;
src.mHeight = 0;
src.mCells = nullptr;
}
// Move constructor
Spreadsheet::Spreadsheet (Spreadsheet&& src) noexcept {
moveFrom(src);
}
// Move assignment operator
Spreadsheet& Spreadsheet::operator= (Spreadsheet&& rhs) noexcept {
// check for self-assignment
if (this = &rhs)
return *this;
// free the old memory
cleanup() ;
moveFrom(rhs);
return *this;
}
移动构造函数和移动赋值运算符都将mCells的内存所有权从源对象移动到新对象,这两个方法将源对象的mCells指针设置为空指针,以防源对象的析构函数释放这块内存,因为新的对象现在拥有了这块内存。很明显,只有你知道将销毁源对象时,移动语义才有用。例如,就像普通的构造函数或复制赋值运算符一样,可显式将移动构造函数和/或移动赋值运算符设置为默认或将其删除。
仅当类没有用户声明的复制构造函数、复制赋值运算符、移动赋值运算符或析构函数时,编译器才会为类自动生成默认的移动构造函数。仅当类没有用户声明的复制构造函数、移动构造函数、复制赋值运算符或析构函数时,才会为类生成默认的移动赋值运算符。
移动对象数据成员
moveFrom()方法对三个数据成员直接赋值,因为这些成员都是基本类型。如果对象还将其他对象作为数据成员,则应当使用std:move()移动这些对象。假设Spreadsheet类有一个名为mName的std::string数据成员。接着采用以下方式实现moveFrom()方法:1
2
3
4
5
6
7
8
9
10
11
12
13void Spreadsheet::moveFrom (Spreadsheet& src) noexcept {
// Move object data members
mName = std::move(src.mName) ;
// Move primitives :
// Shallow copy of data
mwidth = src.mWidth;
mHeight = src.mHeight;
mCells = src.mCells;
// Reset the source object, because ownership has been moved!
src.mWidth = 0;
src.mHeight = 0
src.mCells = nullptr;
}
前面的移动构造函数和移动赋值运算符的实现都使用了moveFrom()辅助方法,该辅助方法通过执行浅表复制来移动所有数据成员。
零规则
前面的讨论解释如何编写以下5个特殊的成员函数:析构函数、复制构造函数、移动构造函数、复制赋值运算符和移动赋值运算符。但在现代C++中,你需要接受零规则(rule of zero)。
“零规则”指出,在设计类时,应当使其不需要上述5个特殊成员函数。如何做到这一点?基本上,应当避免拥有任何旧式的、动态分配的内存。而改用现代结构,如标准库容器。例如,在Spreadsheet 类中,用vector<vector<SpreadsheetCell>>替代SpreadsheetCell**数据成员。该vector自动处理内存,因此不需要上述5个特殊成员函数。
与方法有关的更多内容
静态方法
与数据成员类似,方法有时会应用于全部类对象而不是单个对象,此时可以像静态数据成员那样编写静态方法。以第8章的SpreadsheetCell类为例,这个类有两个辅助方法:stringToDouble()和doubleToString()。这两个方法没有访问特定对象的信息,因此可以是静态的。下面的类定义将这些方法设置为静态的:1
2
3
4
5
6class SpreadsheetCell {
// Omitted for brevity
private:
static std::string doubleToString (double inValue) ;
static double stringToDouble(std::string_view inString);
};
这两个方法的实现与前面的实现相同,在方法定义前不需要重复static关键字。然而,注意静态方法不属于特定对象,因此没有this指针,当用某个特定对象调用静态方法时,静态方法不会访问这个对象的非静态数据成员。实际上,静态方法就像普通函数,唯一区别在于静态方法可以访问类的private和protected静态数据成员。如果同一类型的其他对象对于静态方法可见,那么静态方法也可访问其他对象的private和protected非静态数据成员。
类中的任何方法都可像调用普通函数那样调用静态方法,因此SpreadsheetCell类中所有方法的实现都没有改变。如果要在类的外面调用静态方法,需要用类名和作用域解析运算符来限定方法的名称(就像静态数据成员那样),静态方法的访问控制与普通方法一样。
将stringToDouble()和doubleTostring()设置为public,这样类外面的代码也可以使用它们。此时,可在任意位置这样调用这两个方法:1
string str = SpreadsheetCell::doubleToString(5.0);
const 方法
const(常量)对象的值不能改变。如果使用常量对象、常量对象的引用和指向常量对象的指针,编译器将不允许调用对象的任何方法,除非这些方法承诺不改变任何数据成员。为了保证方法不改变数据成员,可以用const关键字标记方法本身。下面的SpreadsheetCell类包含了用const标记的不改变任何数据成员的方法。1
2
3
4
5
6
7class SpreadsheetCell {
public:
// Omitted for brevity
double getValue() const ;
std::string getstring() const;
// Omitted for brevity
};
const规范是方法原型的一部分,必须放在方法的定义中:1
2
3
4
5
6double SpreadsheetCell::getValue() const {
return mValue;
}
std::string SpreadsheetCell::getString() const {
return doubleToString (mValue);
}
将方法标记为const,就是与客户代码立下了契约,承诺不会在方法内改变对象内部的值。如果将实际上修改了数据成员的方法声明为const,编译器将会报错。不能将静态方法声明为const,因为这是多余的。静态方法没有类的实例,因此不可能改变内部的值。
const 的工作原理是将方法内用到的数据成员都标记为const引用,因此如果试图修改数据成员,编译器会报错。非const对象可调用const方法和非const方法。然而,const 对象只能调用const方法,下面是一些示例:1
2
3
4
5
6
7
8
9SpreadsheetCell myCell (5) ;
cout. << myCell.getValue() << endl;
// OK
myCell.setString("6");
// OK
const SpreadsheetCell& myCellConstRef = myCell;
cout << myCellConstRef.getValue() << endl; // OK
myCellConstRef.setString("6");
// Compilation Error!
应该养成习惯,将不修改对象的所有方法声明为const,这样就可在程序中引用const对象。注意const对象也会被销毁,它们的析构函数也会被调用,因此不应该将析构函数标记为const。
mutable数据成员
有时编写的方法“逻辑上”是const方法,但是碰巧改变了对象的数据成员。这个改动对于用户可见的数据没有任何影响,但在技术上确实做了改动,因此编译器不允许将这个方法声明为const。解决方法是将变量设置为mutable,告诉编译器在const方法中允许改变这个值。
方法重载
注意,在类中可编写多个构造函数,所有这些构造函数的名称都相同。这些构造函数只是参数数量或类型不同。在C++中,可对任何方法或函数做同样的事情。具体来讲,可重载函数或方法,具体做法是将函数或方法的名称用于多个函数,但是参数的类型或数目不同。例如在SpreadsheetCell类中,可将setString()和setValue()全部重命名为set()。类定义如下所示:1
2
3
4
5
6
7class SpreadsheetCell {
public:
// Omitted for brevity
void set(double inValue) ;
void set(std::string_view inString) ;
// Omitted for brevity
};set()方法的实现保持不变。当编写调用set()方法的代码时,编译器根据传递的参数判断调用哪个实例,这称为重载解析。
基于const的重载
还要注意,可根据const来重载方法。也就是说,可以编写两个名称相同、参数也相同的方法,其中一个是const,另一个不是。如果是const对象,就调用const方法;如果是非const对象,就调用非const方法。
通常情况下,const版本和非const版本的实现是一样的。为避免代码重复,可使用const_cast()模式。你可像往常一样实现const版本,此后通过适当转换,传递对const版本的调用,以实现非const版本。基本上,你使用std:as_const()(在<utility>中定义)将*this转换为const Spreadsheet&,调用getCellAt()的const版本,然后使用const_cast(),从结果中删除const:1
2
3
4
5
6
7
8const SpreadsheetCell& Spreadsheet::getCellAt(size_t x,size_t y) const {
verifyCoordinate(x,y);
return mCel1s[x][y];
}
SpreadsheetCell& Spreadsheet::getCe1lAt(size_t x, size_t y) {
return const_cast<SpreadsheetCell&> (std::as_const(*this).getCellAt(x, y));
}
自C++17起,st::as_const()函数可供使用。如果你的编译器还不支持该函数,可改用以下static_cast():1
return const_cast<SpreadsheetCell&> ( static_cast<const Spreadsheet&>(*this).getCellAt(x, y));
有了这两个重载的getCellAt(),现在可在const和非const的Spreadsheet对象上调用getCellAt():1
2
3
4
5Spreadsheet sheet1 (5,6).
SpreadsheetCell& cel11 = sheet1.getCel1At(1, 1);
const Spreadsheet sheet2(5, 6);
const SpreadsheetCell& cell2 = sheet2.getCellAt(1, 1);
这里,getCellAt()的const版本做的事情不多,因此使用const_cast()模式的优势不明显。
显式删除重载
重载方法可被显式删除,可以用这种方法禁止调用具有特定参数的成员函数。例如,考虑下面的类:1
2
3
4class MyClass {
public:
void foo(int i);
};
可以用下面的方式调用foo()方法:1
2
3MyClass c;
c.foo(123);
c.foo(1.23);
在第三行,编译器将double值(1.23)转换为整型值(1),然后调用foo(int i)。 编译器可能会给出警告,但是仍然会执行这一隐式转换。显式删除foo()的double实例,可以禁止编译器执行这一转换:1
2
3
4
5class MyClass {
public:
void foo(int i);
void foo(double d) = delete;
};
通过这一改动, 以double为参数调用foo()时,编译器会给出错误提示,而不是将其转换为整数。
内联方法
编译器可以将方法体或函数体直接插入到调用方法或函数的位置。这个过程称为内联(inline)。内联比使用#define安全。inline 关键字只是提示编译器。如果编译器认为这会降低性能,就会忽略该关键字。
如果编写了内联函数或内联方法,应该将定义与原型一起放在头文件中。
高级C++编译器不要求把内联方法的定义放在头文件中。例如,Microsoft Visual C++支持连接时代码生成(LTCG),会自动将较小的函数内联,哪怕这些函数没有声明为内联的或者没有在头文件中定义,也同样如此。
C++提供了另一种声明内联方法的语法,这种语法根本不使用inline关键字,而是直接将方法定义放在类定义中。下面是使用了这种语法的SpreadsheetCell类定义:1
2
3
4
5
6
7
8
9class SpreadsheetCell {
public:
double getValue() const { mNumAccesses++; return mValue; }
std::string getString() const {
mNumAccesses++;
return doubleToString (mValue) ;
// Omitted for brevity
}
};
编译器只会内联最简单的方法和函数,如果将编译器不想内联的方法定义为内联方法,编译器会自动忽略这个指令。现代编译器在内联方法或函数之前,会考虑代码膨胀等指标,因此不会内联任何没有效益的方法。
默认参数
C++中,默认参数(default arguments)与方法重载类似。在原型中可为函数或方法的参数指定默认值。如果用户指定了这些参数,默认值会被忽略;如果用户忽略了这些参数,将会使用默认值。但是存在一个限制:能从最右边的参数开始提供连续的默认参数列表,否则编译器将无法用默认参数匹配缺失的参数。默认参数可用于函数、方法和构造函数。例如,可在Spreadsheet构造函数中设置宽度和高度的默认值:1
2
3
4
5class Spreadsheet {
public:
Spreadsheet(size_t width = 100,size_t height = 100);
// Omitted for brevity
};
现在可以用0个、1个或2个参数调用Spreadsheet构造函数,尽管只有一个非复制构造函数:1
2
3Spreadsheet s1;
Spreadsheet s2(5);
Spreadsheet s3(5, 6);
所有参数都有默认值的构造函数等同于默认构造函数。也就是说,可构建类的对象而不指定任何参数。如果试图同时声明默认构造函数,以及具有多个参数并且所有参数都有默认值的构造函数,编译器会报错。因为如果不指定任何参数,编译器不知道该调用哪个构造函数。
不同的数据成员类型
C++为数据成员提供了多种选择。除了在类中简单地声明数据成员外,还可创建静态数据成员(类的所有对象共享)、静态常量数据成员、引用数据成员、常量引用数据成员和其他成员。
静态数据成员
静态数据成员属于类但不是对象的数据成员,可将静态数据成员当作类的全局变量。下面是Spreadsheet类的定义,其中包含了新的静态数据成员sCounter:1
2
3
4
5class Spreadsheet {
// Omitted for brevity
private:
static size_t sCounter;
};
不仅要在类定义中列出static类成员,还需要在源文件中为其分配内存,通常是定义类方法的那个源文件。在此还可初始化静态成员,但注意与普通的变量和数据成员不同,默认情况下它们会初始化为0。static 指针会初始化为nullptr。
内联变量
从C++17开始,可将静态数据成员声明为inline。这样做的好处是不必在源文件中为它们分配空间。下面是一个实例:1
2
3
4
5class Spreadsheet {
// Omitted for brevity
private:
static inline size_t sCounter = 0;
};
注意其中的inline关键字。有了这个类定义,可从源文件中删除下面的代码行:1
size_t Spreadsheet::sCounter;
在类方法内访问静态数据成员
在类方法内部,可以像使用普通数据成员那样使用静态数据成员。例如,为Spreadsheet类创建一个mId成员,并在Spreadsheet构造函数中用sCounter成员初始化它。下面是包含了mId成员的Spreadsheet 类定义:1
2
3
4
5
6
7class Spreadsheet {
public:
size_t getId() const;
private:
static size_t sCounter;
size_t mId = 0;
};
下面是Spreadsheet构造函数的实现,在此赋予初始ID:1
2
3
4
5
6
7Spreadsheet::Spreadsheet (size_t width, size_t height)
: mId (sCounter++), mwidth (width), mHeight (height) {
mCells = new SpreadsheetCell* [mWidth] ;
for (size_t i = 0; i < mwidth; i++) {
mCells[i] = new SpreadsheetCell [mHeight] ;
}
}
可以看出,构造函数可访问sCounter,就像这是一个普通成员。在复制构造函数中,也要指定新的ID。由于Spreadsheet复制构造函数委托给非复制构造函数(会自动创建新的ID),因此这可以自动进行处理。在赋值运算符中不应该复制ID。一旦给某个对象指定ID,就不应该再改变。建议把mId设置为const数据成员。
在方法外访问静态数据成员
访问控制限定符适用于静态数据成员:sCounter 是私有的,因此不能在类方法之外访问。如果sCounter是公有的,就可在类方法外访问,具体方法是用::作用域解析运算符指出这个变量是Spreadsheet类的一部分:1
int c = Spreadsheet::sCounter;
静态常量数据成员
类中的数据成员可声明为const,意味着在创建并初始化后,数据成员的值不能再改变。如果某个常量只适用于类,应该使用静态常量(static const或const static)数据成员,而不是全局常量。可在类定义中定义和初始化整型和枚举类型的静态常量数据成员,而不需要将其指定为内联变量。Spreadsheet类的static const成员:1
2
3
4
5class Spreadsheet {
public:
static const size_t kMaxHeight = 100;
static const size_t kMaxWidth = 100;
};
非静态数据成员也可声明为const。例如,mId数据成员就可声明为const。因为不能给const数据成员赋值,所以需要在类内初始化器或ctor initializer中初始化它们。这意味着根据使用情形,可能无法为具有非静态常量数据成员的类提供赋值运算符。如果属于这种情况,通常将赋值运算符标记为deleted。
kMaxHeight和kMaxWidth是公有的,因此可在程序的任何位置访问它们,就像它们是全局变量一样:1
cout << "Maximum height is: " << Spreadsheet::kMaxHeight << endl;
引用数据成员
Spreadsheets和SpreadsheetCells可一起放入SpreadsheetApplication类。Spreadsheet类必须知道SpreadsheetApplication 类,SpreadsheetApplication类也必须知道Spreadsheet类。这是一个循环引用问题,无法用普通的#include解决。解决方案是在其中一个头文件中使用前置声明。下面是新的使用了前置声明的Spreadsheet类定义,用来通知编译器关于SpreadsheetApplication类的信息。1
2
3
4
5
6
7class SpreadsheetApplication; // forward declaration
class Spreadsheet {
public:
Spreadsheet(size_t width, size_t height, SpreadsheetApplication& theApp);
private:
SpreadsheetApplicatoin& mTheApp;
};
这个定义将一个SpreadsheetApplication引用作为数据成员添加进来。在此情况下建议使用引用而不是指针,因为Spreadsheet总要引用一个 SpreadsheetApplication,而指针则无法保证这一点。
常量引用数据成员
就像普通引用可引用常量对象一样,引用成员也可引用常量对象。例如,为让Spreadsheet只包含应用程序对象的常量引用,只需要在类定义中将mTheApp声明为常量引用:1
2
3
4
5
6class Spreadsheet {
public:
Spreadsheet(size_t width, size_t height, const SpreadsheetApplication& theApp);
private:
const SpreadsheetApplication& mTheApp;
};
常量引用和非常量引用之间存在一个重要差别。常量引用SpreadsheetApplication 数据成员只能用于调用SpreadsheetApplication 对象上的常量方法。如果试图通过常量引用调用非常量方法,编译器会报错。还可创建静态引用成员或静态常量引用成员,但一般不需要这么做。
嵌套类
类定义不仅可包含成员函数和数据成员,还可编写嵌套类和嵌套结构、声明typedef或者创建枚举类型。类中声明的一切内容都具有类作用域。如果声明的内容是公有的,那么可在类外使用ClassName::作用域解析语法访问。
可在类的定义中提供另一个类定义。例如,假定SpreadsheetCell类实际上是Spreadsheet类的一部分,因此不妨将SpreadsheetCell重命名为Cell。可将二者定义为:1
2
3
4
5
6
7
8
9
10class Spreadsheet {
public:
class Cell{
public:
Cell() = default;
Cell(double initialValue);
};
Spreadsheet(size_t width, size_t height, const SpreadsheetApplication& theApp);
};
现在Cell类定义位于Spreadsheet类内部,因此在Spreasheet类外引用Cell必须用Spreadsheet::作用域限定名称,即使在方法定义时也是如此。例如,Cell的double构造函数应如下所示:1
Spreadsheet::Cell::Cell (double initialValue) : mValue (initialValue) { }
甚至在Spreadsheet类中方法的返回类型(不是参数)也必须使用这一语法:1
2
3
4Spreadsheet::Cell& Spreadsheet::getCellAt(size_t x, size_t y) {
verifyCoordinate(x, y)
return mCells[x][y];
}
如果在Spreadsheet类中直接完整定义嵌套的Cell类,将使Spreadsheet类的定义略显臃肿。为缓解这一点,只需要在Spreadsheet中为Cell添加前置声明,然后独立地定义Cell类,如下所示:1
2
3
4
5
6
7
8
9
10class Spreadsheet
public:
class Cell ;
};
class Spreadsheet::Cell {
public:
Cell() = default;
Cell (double initialValue);
};
普通的访问控制也适用于嵌套类定义。如果声明了一个private或protected嵌套类,这个类只能在外围类(outer class,即包含它的类)中使用。嵌套的类有权访问外围类中的所有private或protected成员;而外围类却只能访问嵌套类中的public成员。
类内的枚举类型
如果想在类内定义许多常量,应该使用枚举类型而不是#define。例如,可在SpreadsheetCell类中支持单元格颜色,如下所示:1
2
3
4
5
6
7
8class SpreadsheetCell {
public:
enum class Color { Red = 1; Green, Blue, Yel1ow };
void setColor (Color color);
Color getColor() const;
private:
Color mColor = Color::Red;
};setColor()和getColor()方法的实现简单明了:1
2void SpreadsheetCell::setColor (Color color) { mColor = color; }
SpreadsheetCell::Color SpreadsheetCell::getColor() const { return mColor; }
运算符重载
C++允许编写自己的加号版本,为此可编写一个名为operator+的方法:1
2
3
4
5
6class SpreadsheetCell {
public:
SpreadsheetCell operator+(const SpreadsheetCell& cell) const {
return SpreadsheetCell(getValue() + cell.getValue());
}
}
当C++编译器分析一个程序,遇到运算符(例如,+、-、=或<<)时,就会试着查找名为operator+、operator-、operator=或operator<<,且具有适当参数的函数或方法。例如,当编译器看到下面这行时,就会试着查找SpreadsheetCell类中名为operator+并将另一个SpreadsheetCell对象作为参数的方法,或者查找用两个SpreadsheetCell对象作为参数、名为operator+的全局函数:1
SpreadsheetCell aThirdCell = myCell + anotherCell;
如果SpreadsheetCell类包含operator+方法,上述代码就 会转换为:1
SpreadsheetCell aThirdCell = myCell.operator+ (anotherCell);
注意,用作operator+参数的对象类型并不一定要与编写operator+的类相同。
此外还要注意,可任意指定operator+的返回值类型。运算符重载是函数重载的一种形式,函数重载对函数的返回类型并没有要求。
隐式转换
令人惊讶的是,一旦编写前面所示的operator+,不仅可将两个单元格相加,还可将单元格与string_view、double或int 值相加。1
2
3
4SpreadsheetCell myCell(4), aThirdCell;
string str = "hello";
aThirdCell = myCell + string_view(str);
aThirdCell = myCell + 5.6;
上面的代码之所以可运行,是因为编译器会试着查找合适的operator+,而不是只查找指定类型的那个operator+。为找到operator+,编译器还试图查找合适的类型转换,构造函数会对有问题的类型进行适当的转换。
隐式转换通常会带来便利。但在上例中,将SpreadsheetCell与string_view相加并没有意义。可使用explicit关键字标记构造函数,禁止将string_view隐式地转换为SpreadsheetCell:1
2
3
4
5
6class SpreadsheetCell {
public:
SpreadsheetCell() = default;
SpreadsheetCell (double initialValue);
explicit SpreadsheetCe1l (std::string_view initialvalue);
};
explicit关键字只在类定义内使用,只适用于只有一个参数的构造函数,例如单参构造函数或为参数提供默认值的多参构造函数。由于必须创建临时对象,隐式使用构造函数的效率不高。为避免与double值相加时隐式地使用构造函数,可编写第二个operator+,如下所示:1
2
3SpreadsheetCell SpreadsheetCell::operator+(double rhs) const {
return SpreadsheetCell(getValue() + rhs);
}
第三次尝试:全局operator+
隐式转换允许使用operator+方法将SpreadsheetCell对象与int和double值相加。然而,这个运算符不具有互换性,如下所示:1
2aThirdcell = myCell + 4; // Works fine.
aThirdCell = 4 + myCell; // FAILS TO COMPILE!
当SpreadsheetCell对象在运算符的左边时,隐式转换正常运行,但在右边时无法运行。加法是可互换的,因此这里存在错误。问题在于必须在SpreadsheetCell对象上调用operator+ 方法,对象必须在operator+的左边。这是C++语言定义的方式,因此使用operator+方法无法让上面的代码运行。
然而,如果用不局限于某个特定对象的全局operator+函数替换类内的operator+方法,上面的代码就可以运行,需要在头文件中声明运算符:1
2
3
4class SpreadsheetCell {
};
SpreadsheetCell operator+ (const SpreadsheetCell& lhs, const SpreadsheetCell& rhs);
那么,如果编写以下代码,会发生什么情况呢?1
aThirdCell = 4.5 + 5.5;
这段代码可编译并运行,但并没有调用前面编写的operator+。这段代码将普通的double型数值4.5和5.5相加,得到了下面所示的中间语句:1
aThirdCell = 10;
为了让赋值操作继续,运算符右边应该是SpreadsheetCell对象。编译器找到并非显式由用户定义的用double值作为参数的构造函数,然后用这个构造函数隐式地将double值转换为一个临时SpreadsheeCell对象,最后调用赋值运算符。
在C++中,不能更改运算符的优先级。例如,*和/始终在+和一之前计算。对于用户定义的运算符,唯一能做的只是在确定运算的优先级后指定实现。C++也不允许发明新的运算符号,不允许更改运算符的实参个数。
重载算术运算符
必须显式地重载简写算术运算符(Arithmetic Shorthand Operators)。这些运算符与基本算术运算符不同,它们会改变运算符左边的对象,而不是创建一个新对象。此外还有一个微妙差别,它们生成的结果是对被修改对象的引用,这一点与赋值运算符类似。简写算术运算符的左边总要有一个对象,因此应该将其作为方法而不是全局函数。下面是SpreadsheetCell类的声明:1
2
3
4
5
6
7class SpreadsheetCell {
public:
SpreadsheetCell& operator+= (const SpreadsheetCell& rhs);
SpreadsheetCell& operator-= (const SpreadsheetCe1l& rhs);
SpreadsheetCell& operator*= (const SpreadsheetCell& rhs);
SpreadsheetCell& operator/= (const SpreadsheetCell& rhs);
};
下面是operator+=的实现,其他的与此类似。1
2
3
4SpreadsheetCell& SpreadsheetCell::operator+= (const SpreadsheetCell& rhs) {
set(getValue() + rhs.getValue());
return *this;
}
简写算术运算符是对基本算术运算符和赋值运算符的结合。根据上面的定义,可编写如下代码:1
2
3SpreadsheetCell myCell(4), aThirdCell(2);
aThirdCell -= myCell;
aThirdCell += 5.4;
然而不能编写这样的代码1
5.4 += aThirdCell;
如果既有某个运算符的普通版本,又有简写版本,建议你基于简写版本实现普通版本,以避免代码重复。1
2
3
4
5SpreadsheetCell operator+ (const SpreadsheetCell& lhs, const SpreadsheetCell& rhs) {
auto result(lhs); // Local copy
result += rhs;
return result;
}
重载比较运算符
与基本的算术运算符类似,它们也应该是全局函数,这样就可在运算符的左边和右边使用隐式转换。所有比较运算符的返回值都是布尔值。当然,可改变返回类型,但并不建议这么做。下面是比较运算符的声明;1
bool operator <op> (const SpreadsheetCell& lhs,const SpreadsheetCell& rhs) ;
下面是operator==的定义,其他的与此类似:1
2
3bool operator== (const SpreadsheetCell& lhs, const SpreadsheetCell& rhs) {
return (lhs.getValue() == rhs.getValue());
}
当类中的数据成员较多时,比较每个数据成员可能比较痛苦。然而,当实现了==和<之后,可以根据这两个运算符编写其他比较运算符。例如,下面的operator>=定义使用了operator<。1
2
3bool operator>= (const SpreadsheetCell& lhs, const SpreadsheetCell& rhs) {
return !(lhs < rhs);
}
可使用这些运算符将某个SpreadsheetCell与其他SpreadsheetCell进行比较,也可与double和int值进行比较:1
2
3if (myCell > aThirdCell || myCell < 10) {
cout << myCell.getValue() << endl;
}
揭秘继承技术
使用继承构建类
扩展类
当使用C++编写类定义时,可以告诉编译器,该类继承(或扩展)了一个已有的类。通过这种方式,该类将自动包含原始类的数据成员和方法;原始类称为父类(parent class)、基类或超类(superclass)。扩展已有类可以使该类(现在称为派生类或子类)只描述与父类不同的那部分内容。
在C++中,为扩展一个类,可在定义类时指定要扩展的类。为说明继承的语法,此处使用了名为Base和Derived的类。首先考虑Base类的定义:1
2
3
4
5
6
7
8class Base {
public:
void someMethod();
protected:
int mProtectedInt;
private:
int mPrivateInt;
};
如果要构建一个从Base类继承的新类Derived,应该使用下面的语法告诉编译器:Derived类派生自Base类:1
2
3
4class Derived : public Base {
public:
void someOtherMethod();
};
Derived本身就是一个完整的类,这个类只是刚好共享了Base类的特性而已。Derived不一定是Base唯一的派生类。其他类也可是Base的派生类,这些类是Derived的同级类(sibling)。
客户对继承的看法
对于客户或代码的其他部分而言,Derived类型的对象仍然是Base对象,因为Derived类从Base类继承。这意味着Base类的所有public方法和数据成员,以及Derived类的所有public方法和数据成员都是可供使用的。
在调用某个方法时,使用派生类的代码不需要知道是继承链中的哪个类定义了这个方法。例如,下面的代码调用了Derived对象的两个方法,而其中一个方法是在Base类中定义的:1
2
3Derived myDerived;
myDerived.someMethod() ;
myDerived.someOtherMethod() ;
指向某个对象的指针或引用可以指向声明类的对象,也可以指向其任意派生类的对象。此时需要理解的概念是,指向Base对象的指针可以指向Derived对象,对于引用也是如此。客户仍然只能访问Base类的方法和数据成员,但是通过这种机制,任何操作Base对象的代码都可以操作Derived对象。
例如,下面的代码可以正常编译并运行,尽管看上去好像类型并不匹配:1
Base* base = new Derived() ; // Create Derived, store it in Base pointer .
然而,不能通过Base指针调用Derived类的方法。下面的代码无法运行:1
base->someOtherMethod();
从派生类的角度分析继承
派生类可访问基类中声明的public、 protected 方法和数据成员,就好像这些方法和数据成员是派生类自己的,因为从技术上讲,它们属于派生类。例如,Derived 类中someOtherMethod()的实现可以使用在Base类中声明的数据成员mProtectedInt。下面的代码显示了这一实现,访问基类的数据成员和方法与访问派生类中的数据成员和方法并无不同之处。1
2
3
4void Derived::someOtherMethod() {
cout << "I can access base class data member mProtectedInt." << endl;
cout << "Its value is "<< mProtectedInt << endl;
}
如果类将数据成员和方法声明为protected,派生类就可以访问它们;如果声明为private,派生类就不能访问。
private访问说明符可控制派生类与基类的交互方式。建议将所有数据成员都默认声明为private,如果希望任何代码都可以访问这些数据成员,就可以提供public的获取器和设置器。如果仅希望派生类访问它们,就可以提供受保护的获取器和设置器。把数据成员默认设置为private的原因是,这会提供最高级别的封装,这意味着可改变数据的表示方式,而public或protected接口保持不变。不直接访问数据成员,也可在public或protected设置其中方便地添加对数据的检查。方法也应默认设置为private,只有需要公开的方法才设置为public,只有派生类需要访问的方法才设置为protected。
禁用继承
C++允许将类标记为final,这意味着继承这个类会导致编译错误。将类标记为final的方法是直接在类名的后面使用final关键字。例如,下面的Base类被标记为final:1
class Base final { };
下面的Derived类试图从Base类继承,但是这会导致编译错误,因为Base类被标记为final。1
class Derived : public Base { };
重写方法
从某个类继承的主要原因是为了添加或替换功能。Derived类定义在父类的基础上添加了功能。在许多情况下,可能需要替换或重写某个方法来修改类的行为。
将所有方法都设置为virtual,以防万一
在C++中,重写(verride)方法有一点别扭,因为必须使用关键字vitual。只有在基类中声明为virtual的方法才能被派生类正确地重写。virtual关键字出现在方法声明的开头,下面显示了Base类的修改版本:1
2
3
4
5
6
7
8class Base {
public:
virtual void someMethod() ;
protected:
int mProtectedInt;
private:
int mPrivateInt;
};
virtual关键字有些微妙之处,常被当作语言的设计不当部分。经验表明,最好将所有方法都设置为virtual。即使Derived类不大可能扩展,也最好还是将这个类的方法设置为virtual。1
2
3
4class Derived : public Base {
public:
virtual void someOtherMethod() ;
};
为避免因为遗漏virtual关键字引发的问题,可将所有方法设置为virtual(包括析构函数,但不包括构造函数)。注意,由编译器生成的析构函数不是virtual!
重写方法的语法
为了重写某个方法,需要在派生类的定义中重新声明这个方法,就像在基类中声明的那样,并在派生类的实现文件中提供新的定义。例如,Base类包含了一个someMethod()方法,在Base.cpp中提供的someMethod()方法定义如下:1
2
3void Base::someMethod() {
cout << "This is Base's version of someMethod() ."<< endl;
}
注意在方法定义中不需要重复使用virtual关键字。
如果希望在Derived类中提供someMethod()的新定义,首先应该在Derived类定义中添加这个方法,如下所示:1
2
3
4
5class Derived : public Base {
public:
virtual void someMethod() override;
virtual void someOtherMethod();
};
建议在重写方法的声明末尾添加override关键字。
一旦将方法或析构函数标记为virtual,它们在所有派生类中就一直是 virtual,即使在派生类中删除了virtual关键字,也同样如此。例如,Derived类中,someMethod()仍然是virtual,可以被Derived的派生类重写,因为在Base类中将其标记为virtual。
客户对重写方法的看法
现在someMethod()的行为将根据对象所属类的不同而变化。例如,下面的代码与先前一样可以运行,调用Base版本的someMethod():1
2Base myBase;
myBase.someMethod();
如果声明一个Derived类对象,将自动调用派生类版本的someMethod():1
2Derived myDerived;
myDerived.someMethod();
Derived类对象的其他方面维持不变。从Base 类继承的其他方法仍然保持Base类提供的定义,除非在Derived类中显式地重写这些方法。
如前所述,指针或引用可指向某个类或其派生类的对象。对象本身“知道”自己所属的类,因此只要这个方法声明为vitual,就会自动调用对应的方法。例如,如果一个对Base对象的引用实际引用的是Derived对象,调用someMethod()实际上会调用派生类版本,如下所示。如果在基类中省略了virtual 关键字,重写功能将无法正确运行。1
2
3Derived myDerived;
Base& ref = myDerived;
ref.someMethod(); // Calls Derived's version
记住,即使基类的引用或指针知道这实际上是一个派生类,也无法访问没有在基类中定义的派生类方法或成员。下面的代码无法编译,因为Base引用没有someOtherMethod()方法:1
2
3
4Derived myDerived;
Base& ref = myDerived;
myDerived.someOtherMethod(); // This is fine.
ref.someOtherMethod(); // Error
非指针或非引用对象无法正确处理派生类的特征信息。可将Derived对象转换为Base对象,或将Derived对象赋值给Base对象,因为Derived对象也是Base对象。然而,此时这个对象将遗失派生类的所有信息:1
2
3Derived myDerived;
Base assignedobject = myDerived; //Assigns a Derived to a Base .
assignedObject.someMethod(); // Calls Base's version of someMethod()
为记住这个看上去有点奇怪的行为,可考虑对象在内存中的状态。将Base对象当作占据内存的盒子。Derived对象是稍微大一点的盒子,因为它拥有Base对象的一切,还添加了一点内容。对于指向Derived对象的引用或指针,这个盒子并没有变,只是可以用新的方法访问它。然而,如果将Derived对象转换为Base对象,就会为了适应较小的盒子而扔掉Derived类全部的“独有特征”。
基类的指针或引用指向派生类对象时,派生类保留其重写方法。但是通过类型转换将派生类对象转换为基类对象时,就会丢失其独有特征。重写方法和派生类数据的丢失称为截断(slicing)。
override关键字
如果修改了Base类但忘记更新所有派生类,就会发生重载失败的问题。实际上就是创建了一个新的虚方法,而不是正确的重写这个方法。可用override关键字避免这种情况,如下所示:1
2
3
4class Derived : public Base {
public:
virtual void someMethod(int i) override ;
};
Derived类的定义将导致编译错误,因为override关键字表明,重写Base类的someMethod()方法,但Base类中的someMethod()方法只接收双精度数,而不接收整数。重命名基类中的某个方法,但忘记重命名派生类中的重写方法时,就会出现上述“不小心创建了新方法,而不是正确重写方法”的问题。
要想重写基类方法,始终在方法上使用override关键字。
virtual的真相
如果方法不是virtual,也可以试着重写这个方法,但是这样做会导致微妙的错误。
隐藏而不是重写
下面的代码显示了一个基类和一个派生类,每个类都有一个方法。派生类试图重写基类的方法,但是在基类中没有将这个方法声明为virtual。1
2
3
4
5
6
7
8class Base {
public:
void go() { cout << "go() called on Base" << endl; }
};
class Derived : public Base {
public:
void go() { cout << "go() called on Derived" << endl; }
};
试着用Derived对象调用go()方法好像没有问题。1
2Derived myDerived;
myDerived.go();
正如预期的那样,这个调用的结果是“go() called on Derived”。然而,由于这个方法不是virtual,因此实际上没有被重写。相反,Derived类创建了一个新的方法,名称也是go(),这个方法与Base类的go()方法完全没有关系。为证实这一点,只需要用Base指针或引用调用这个方法:1
2
3Derived myDerived;
Base& ref = myDerived;
ref.go();
你可能希望输出是“go() called on Derived”,但实际上,输出是“go() called on Base”。这是因为ref变量是一个Base引用,并省略了virtual关键字。当调用go()方法时,只是执行了Base类的go()方法。由于不是虛方法,不需要考虑派生类是否重写了这个方法。
如何实现virtual
为理解如何避免隐藏方法,需要了解virtual关键字的真正作用。C++在编译类时,会创建一个包含类中所有方法的二进制对象。在非虚情况下,将控制交给正确方法的代码是硬编码,此时会根据编译时的类型调用方法。这称为静态绑定(static binding),也称为早绑定(early binding)。
如果方法声明为vitual, 会使用名为虚表(vtable)的特定内存区域调用正确的实现。每个具有一个或多个虚方法的类都有一张虚表,这种类的每个对象都包含指向虚表的指针,这个虚表包含指向虛方法实现的指针。通过这种方法,当使用某个对象调用方法时,指针也进入虚表,然后根据实际的对象类型执行正确版本的方法。
这称为动态绑定(dynamic binding)或晚绑定(late binding)。
为更好地理解虚表是如何实现方法的重写的,考虑下面的Base和Derived类:1
2
3
4
5
6
7
8
9
10
11class Base {
public:
virtual void func1() { }
virtual void func2 () { }
void nonVirtualFunc() { }
};
class Derived : public Base {
public:
virtual void func2() override { }
void nonVirtualFunc { }
};
对于这个示例,考虑下面的两个实例:1
2Base myBase;
Derived myDerived;
图10-4 显示了这两个实例虚表的高级视图。myBase对象包含了指向虚表的一个指针,虚表有两项,一项是func1(),另一项是func2()。这两项指向Base::func1()和Base::func2()的实现。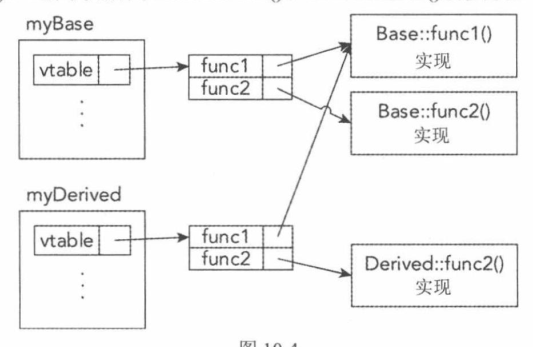
myDerived也包含指向虚表的一个指针,这个虚表也包含两项,一项是func1(),另一项是func2()。myDerived虚表的func1()项指向Base::func1(),因为Derived类没有重写func1();但是myDerived虛表的func2()项指向Derived::func2()。
使用virtual的理由
首先创建virtual的原因,与虚表的开销有关。要调用虚方法,程序需要执行一项附加操作,即对指向要执行的适当代码的指针解除应用。在多数情况下,这样做会轻微地影响性能。如果方法永远不会重写,就没必要将其声明为virtual,从而影响性能。在多数应用程序中,无法察觉到使用虛方法和不使用虛方法带来的性能差别,因此应该遵循建议,将所有方法声明为virtual,包括析构函数。
但在某些情况下,性能开销确实不小,需要避免。例如,假设Point类有一个虚方法。 如果另一个数据结构存储着数百万个甚至数十亿个Point对象,在每个Point 对象上调用虚方法将带来极大的开销。此时,最好避免在Point类中使用虚方法。
virtual对于每个对象的内存使用也有轻微影响。除了方法的实现之外,每个对象还需要一个指向虚表的指针,这个指针会占用一点空间。
虚析构函数的需求
即使认为不应将所有方法都声明为virtual的程序员,也坚持认为应该将析构函数声明为virtual。原因是,如果析构函数未声明为virtual,很容易在销毁对象时不释放内存。唯一允许不把析构函数声明为virtual的例外情况是,类被标记为final。
例如,派生类使用的内存在构造函数中动态分配,在析构函数中释放。如果不调用析构函数,这块内存将无法释放。类似地,如果派生类具有一些成员,这些成员在类的实例销毁时自动删除,如stl:unique_ptrs,那么如果从未调用析构函数,将不会删除这些成员。
如果在析构函数中什么都不做,只想把它设置为virtual, 可显式地设置“default”,例如:1
2
3
4class Base {
public:
virtual ~Base() = default;
};
除非有特别原因,或者类被标记为final,否则强烈建议将所有方法(包括析构函数,构造函数除外)声明为virtual,构造函数不需要,也无法声明为virtual,因为在创建对象时,总会明确地指定类。
禁用重写
C++允许将方法标记为final,这意味着无法在派生类中重写这个方法。考虑下面的Base类:1
2
3
4
5class Base {
public:
virtual ~Base() = default;
virtual void someMethod() final;
};
在下面的Derived类中重写someMethod()会导致编译错误,因为someMethod()在Base类中标记为final。1
2
3
4class Derived : public Base {
public:
virtual void someMethod() override; // Error
};
利用父类
编写派生类时,需要知道父类和派生类之间的交互方式。创建顺序、构造函数链和类型转换都是潜在的bug来源。
父类构造函数
创建对象时必须同时创建父类和包含于其中的对象。C++定义了如下创建顺序:
- 如果某个类具有基类,执行基类的默认构造函数。除非在ctor-initializer中调用了基类构造函数,否则此时调用这个构造函数而不是默认构造函数。
- 类的非静态数据成员按照声明的顺序创建。
- 执行该类的构造函数。
下面的代码显示了创建顺序。代码正确执行时输出结果为123。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Something {
public:
Something() { cout << "2"; }
};
class Base {
public:
Base() { cout << "1"; }
};
class Derived : public Base {
public:
Derived() { cout << "3"; }
private:
Something mDataMember;
};
int main() {
Derived myDerived;
return 0;
}
创建myDerived对象时,首先调用Base构造函数,输出字符串“1”。 随后,初始化mDataMember,调用Something构造函数,输出字符串“2”。最后调用Derived构造函数,输出“3”。
注意Base构造函数是自动调用的。C++将自动调用父类的默认构造函数(如果存在的话)。如果父类的默认构造函数不存在,或者存在默认构造函数但希望使用其他构造函数,可在构造函数初始化器(constructor initializer)中像初始化数据成员那样链接构造函数。例如,下面的代码显示了没有默认构造函数的Base版本。相关版本的Derived必须显式地告诉编译器如何调用Base构造函数,否则代码将无法编译。1
2
3
4
5
6
7
8
9
10class Base {
public:
Base(int i);
};
class Derived : public Base
public:
Derived();
};
Derived::Derived() : Base(7) { }
在前面的代码中,Derived 构造函数向Base构造函数传递了固定值(7)。如果Derived构造函数需要一个参数,也可以传递变量:1
Derived::Derived(int i) : Base(i) {}
从派生类向基类传递构造函数的参数很正常,毫无问题,但是无法传递数据成员。如果这么做,代码可以编译,但是记住在调用基类构造函数之后才会初始化数据成员。如果将数据成员作为参数传递给父类构造函数,数据成员不会初始化。
父类的析构函数
由于析构函数没有参数,因此始终可自动调用父类的析构函数。析构函数的调用顺序刚好与构造函数相反:
- 调用类的析构函数。
- 销毁类的数据成员,与创建的顺序相反。
- 如果有父类,调用父类的析构函数。
也可递归使用这些规则。链的最底层成员总是第一个被销毁。下面的代码在前面的示例中加入了析构函数。所有析构函数都声明为virtual。执行时代码将输出“123321”。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Something {
public:
virtual ~Something() { cout << "2"; }
};
class Base {
public:
virtual ~Base() { cout << "1"; }
};
class Derived : public Base
public:
Derived() { cout << "3"; }
virtual ~Derived() { cout < < "3"; }
private:
Something mDataMember;
};
即使前面的析构函数没有声明为vitual,代码也可以继续运行。然而,如果代码使用delete删除一个实际指向派生类的基类指针,析构函数调用链将被破坏。例如,下面的代码与前面示例类似,但析构函数不是virtual。当使用指向Base对象的指针访问Derived对象并删除对象时,就会出问题。1
2Base* ptr = new Derived() ;
delete ptr;
代码的输出很短,是“1231”。当删除ptr 变量时,只调用了Base析构函数,因为析构函数没有声明为virtual。结果是没有调用Derived析构函数,也没有调用其数据成员的析构函数。
从技术角度看,将Base 析构函数声明为virtual,可纠正上面的问题。派生类将自动“虚化”。然而,建议显式地将所有析构函数声明为virtual,这样就不必担心这个问题。
将所有析构函数声明为virtual!编译器生成的默认析构函数不是virtual,因此应该定义自己(或显式设置为默认)的虚析构函数,至少在父类中应该这么做。
与构造函数一样,在析构函数中调用虚方法时,虚方法的行为将有所不同。如果派生类重写了基类中的虚方法,在基类的析构函数中调用该方法,会执行该方法的基类实现,而不是派生类的重写版本。
使用父类方法
在派生类中重写方法时,将有效地替换原始方法。然而,方法的父类版本仍然存在,仍然可以使用这些方法。考虑WeatherPrediction类中的getTemperature()方法,这个方法返回当前温度的字符串表示:1
2
3
4class WeatherPrediction {
public:
virtual std::string getTemperature() const;
};
在MyWeatherPrediction类中,可按如下方式重写这个方法:1
2
3
4class MyWeatherPrediction : public WeatherPrediction
public:
virtual std::string getTemperature() const override;
};
假定派生类要先调用基类的getTemperature()方法,然后将“°F”添加到string。为此,编写如下代码:1
2
3string MyWeatherPrediction::getTemperature() const {
return getTemperature() + "\u00B0E"; // BUG
}
然而,上述代码无法运行,根据C++的名称解析规则,首先解析的是局部作用域,然后是类作用域,根据这个顺序,函数中调用的是MyWeatherPrediction::getTemperature()。其结果是无限递归,直到耗尽堆栈空间。
为让代码运行,需要使用作用域解析运算符,如下所示:1
2
3string MyWeatherPrediction::getTemperature() const {
return WeatherPrediction::getTemperature() + " \u00B0F" ;
}
在C++中,调用当前方法的父类版本是一种常见操作。如果存在派生类链,每个派生类都可能想执行基类中已经定义的操作,同时添加自己的附加功能。如果父类没有重写祖父类中的函数,C++会沿着类层次结构向上寻找实现了这个函数的类。
向上转型和向下转型
如前所述,对象可转换为父类对象,或者赋值给父类。如果类型转换或赋值是对某个普通对象执行,会产生截断:1
Base myBase = myDerived; // Slicing!
这种情况下会导致截断,因为赋值结果是Base对象,而Base对象缺少Derived类中定义的附加功能。然而,如果用派生类对基类的指针或引用赋值,则不会产生截断:1
Base& myBase = myDerived; // No slicing!
这是通过基类使用派生类的正确途径,也叫作向上转型(upcating)。这也是让方法和函数使用类的引用而不是直接使用类对象的原因。使用引用时,派生类在传递时没有截断。
当向上转型时,使用基类指针或引用以避免截断。
将基类转换为其派生类也叫作向下转型(downcasting),专业的C++程序员通常不赞成这种转换,因为无法保证对象实际上属于派生类,也因为向下转型是不好的设计。如果打算进行向下转型,应该使用dynamic_cast(),以使用对象内建的类型信息,拒绝没有意义的类型转换。这种内建信息通常驻留在虚表中,这意味着dynamic_cast只能用于具有虚表的对象,即至少有一个虚编号的对象。如果针对某个指针的dynamic_cast()失败,这个指针的值就是nullptr,而不是指向某个无意义的数据。如果针对对象引用的dynamic_cast()失败,将抛出stl::bad_cast异常。
继承与多态性
回到电子表格
下面给出了简化的SpreadsheetCell类定义。注意单元格可以是双精度值或字符串,然而这个示例中单元格的当前值总以字符串的形式返回。1
2
3
4
5
6
7
8
9
10
11class SpreadsheetCell {
public:
public:
virtual void set(double inDouble);
virtual void set(std::string_view inString);
virtual std::string getString() const;
private:
static std::string doubleTostring(double inValue);
static double stringToDouble(std::string_view inString);
double mValue;
};
设计多态性的电子表格单元格
SpreadsheeCell类急需改变层次结构。一种合理方法是让SpreadsheetCell只包含字符串,从而限制其范围,在此过程中或许将其重命名为StringSpreadsheetCell。为处理双精度值,可使用第二个类DoubleSpreadsheetCell。因为包含字符串的单元格与包含双精度值的单元格存在明显的关系。让这两个类地位同等,并有共同的父类SpreadsheetCell
- 两个派生类都支持由基类定义的同一接口(方法集)。
- 使用SpreadsheetCell对象的代码可调用接口中的任何方法,而不需要知道这个单元格是StringSpreadsheetCell还是DoubleSpreadsheetCell。
- 由于虚方法的特殊能力,会根据对象所属的类调用接口中每个方法的正确实例。
- 其他数据结构可通过引用父类类型,包含一组多类型的单元格。
SpreadsheetCell基类
初次尝试
SpreadsheeCell基类负责定义所有派生类支持的行为。在本例中,所有单元格都需要将值设置为字符串。此外,所有单元格都需要将当前值返回为字符串。基类定义中声明了这些方法,以及显式设置为默认的虚析构函数,但没有数据成员:1
2
3
4
5
6class SpreadsheetCell {
public:
virtual ~SpreadsheetCell() = default;
virtual void set (std::string_view inString) ;
virtual std::string getString() const;
};
纯虚方法和抽象基类
纯虚方法(pure virtual methods)在类定义中显式说明该方法不需要定义。如果将某个方法设置为纯虚方法,就是告诉编译器当前类中不存在这个方法的定义。具有至少一个纯虚方法的类称为抽象类,因为这个类没有实例。编译器会强制接受这个事实:如果某个类包含一个或多个纯虚方法,就无法构建这种类型的对象。
采用专门的语法指定纯虚方法:方法声明后紧接着=0。不需要编写任何代码。1
2
3
4
5
6class SpreadsheetCell {
public:
virtual ~Spreadsheetcell() = default;
virtual void set (std::string_view inString) = 0;
virtual std::string getString() const = 0;
};
一旦实现了StringSpreadsheetCell 类,下面的代码就可成功编译,原因在于实例化了抽象基类的派生类:1
std::unique_ptr<SpreadsheetCell> cell (new StringSpreadsheetCell());
抽象类提供了一种禁止其他代码直接实例化对象的方法,而它的派生类可以实例化对象。
独立的派生类
StringSpreadsheetCell类定义
编写StringSpreadsheetCell类定义的第一步是从SpreadsheetCell类继承。第二步是重写继承的纯虚方法,此次不将其设置为0。最后一步是为字符串单元格添加一个私有数据成员mValue,在其中存储实际单元格数据。这个数据成员是stl::optional,从C++17开始定义在<optional>头文件中。optional类型是一个类模板,因此必须在尖括号之间指定所需的实际类型,如optional<string>。1
2
3
4
5
6
7class StringSpreadsheetCell : public SpreadsheetCell {
public:
virtual void set(std::string_view inString) override;
virtual std: :string getString() const override;
private:
std::optional<std::string> mValue;
};
StringSpreadsheetCell的实现
StringSpreadsheetCell 的源文件包含方法的实现。set()方法十分简单,因为内部表示已经是一个字符串。如果mValue不具有值,getString()将返回一个空字符串。可使用std:optional的value_or()方法对此进行简化。使用mValue.value_or(" ")。1
2
3
4
5
6void StringSpreadsheetCell::set(string_view inString) {
mValue = inString;
}
string StringSpreadsheetCell::getString() const {
return mValue.value_or("");
}
DoubleSpreadsheetCell 类的定义和实现
与StringSpreadsheetCell相同,这个类也有一个mValue数据成员,此时这个成员的类型是optional<double>。1
2
3
4
5
6
7
8
9
10class DoubleSpreadsheetCell : public SpreadsheetCell {
public:
virtual void set (double inDouble);
virtual void set (std::string_view inString) override;
virtual std::string getString() const override;
private:
static std::string doubleToString (double inValue) ;
static double stringToDouble(std::string_view inValue);
std::optional<double> mValue;
};
1 | void DoubleSpreadsheetCell::set (double inDouble) { |
考虑将来
首先,即使不考虑改进设计,现在仍然缺少一个功能: 将某个单元格类型转换为其他类型。应添加一个转换构造函数(或类型构造函数),这个构造函数类似于复制构造函数,但参数不是对同类对象的引用,而是对同级类对象的引用。另外注意,现在必须声明一个默认构造函数,可将其显式设置为默认,因为一旦自行声明任何构造函数,编译器将停止生成:1
2
3
4
5class StringSpreadsheetCell : public SpreadsheetCell {
public:
StringSpreadsheetCell() = default;
StringSpreadsheetCell (const DoubleSpreadsheetCell& inDoubleCell) ;
};
将转换构造函数实现为如下形式:1
2
3
4StringSpreadsheetCell::StringSpreadsheetCell (
const DoubleSpreadsheetCell& inDoubleCell) {
mValue = inDoubleCell.getString();
}
通过转换构造函数,可很方便地用DoubleSpreadsheetCell创建StringSpreadsheetCell。然而不要将其与指针或引用的类型转换混淆,类型转换无法将一个指针或引用转换为同级的另一个指针或引用。
其次,如何为单元格实现运算符重载是一个很有趣的问题,一种方案是给出一种通用表示,前面的实现已将字符串作为标准化的通用类型表示。通过这种通用表示,一个operator+函数就可以处理所有情况。假定两个单元格相加的结果始终是字符串单元格,那么一个可能的实现如下所示:1
2
3
4
5StringSpreadsheetCell operator+ (const StringSpreadsheetCell& lhs, const StringSpreadsheetCell& rhs) {
StringSpreadsheetCell newCell;
newCell.set(lhs.getString() + rhs.getString()) ;
return newCell;
}
多重继承
从多个类继承
从语法角度看,定义具有多个父类的类很简单。为此,只需要在声明类名时分别列出基类:1
2class Baz : public Foo, public Bar
{ };
由于列出了多个父类,Baz 对象具有如下特性:
- Baz对象支持Foo和Bar类的public方法,并且包含这两个类的数据成员。
- Baz类的方法有权访问Foo和Bar类的protected数据成员和方法。
- Baz对象可以向上转型为Foo或Bar对象。
- 创建新的Baz对象将自动调用Foo和Bar类的默认构造函数,并按照类定义中列出的类顺序进行。
- 删除Baz对象将自动调用Foo和Bar类的析构函数,调用顺序与类在类定义中的顺序相反。
名称冲突和歧义基类
多重继承崩溃的场景并不难想象,下面的示例显示了一些必须考虑的边缘情况。
名称歧义
如果两个类都有一个eat()方法,会发生什么?eat()方法的一个版本无法重写另一个版本——在派生类中这两个方法都存在。如果客户代码试图调用派生类的eat()方法,编译器将报错,指出对eat()方法的调用有歧义。
为了消除歧义,可使用dynamic_cast()显式地将对象向上转型(本质上是向编译器隐藏多余的方法版本),也可以使用歧义消除语法。下面的代码显示了调用eat()方法的Dog版本的两种方案:1
2dynamic_cast<Dog&> (myConfusedAnimal).eat(); // Calls Dog::eat()
myConfusedAnimal.Dog::eat();
使用与访问父类方法相同的语法(::运算符),派生类的方法本身可以显式地为同名的不同方法消除歧义。例如,派生类可以定义自己的eat()方法,从而消除其他代码中的歧义错误。在方法内部,可以判断调用哪个父类版本:1
2
3
4
5
6
7
8class DogBird : public Dog,public Bird {
public:
void eat() override;
};
void DogBird::eat() {
Dog::eat();
}
另一种防止歧义错误的方式是使用using 语句显式指定,在派生类中应继承哪个版本的eat()方法,如下面的DogBird类定义所示:1
2
3
4class DogBird : public Dog, public Bird
public:
using Dog::eat; // Explicitly inherit Dog's version of eat()
};
歧义基类
另一种引起歧义的情况是从同一个类继承两次。例如,如果出于某种原因Bird类从Dog类继承,DogBird类的代码将无法编译,因为Dog变成了歧义基类。1
2
3class Dog {};
class Bird : public Dog {};
class DogBird : public Bird, public Dog {}; // Error!
数据成员也可以引起歧义。如果Dog和Bird类具有同名的数据成员,当客户代码试图访问这个成员时,就会发生歧义错误。
多个父类本身也可能有共同的父类。例如,Bird和Dog类可能都是Animal类的派生类(菱形类结构)。
使用“菱形”类层次结构的最佳方法是将最顶部的类设置为抽象类,将所有方法都设置为纯虚方法。由于类只声明方法而不提供定义,在基类中没有方法可以调用,因此在这个层次上就没有歧义。
有趣而晦涩的继承问题
修改重写方法的特征
重写某个方法的主要原因是为了修改方法的实现。然而,有时是为了修改方法的其他特征。
修改方法的返回类型
重写方法要使用与基类一致的方法声明(或方法原型)。实现可以改变,但原型保持不变。然而事实未必总是如此,在C++中,如果原始的返回类型是某个类的指针或引用,重写的方法可将返回类型改为派生类的指针或引用。这种类型称为协变返回类型(covariant return types)。如果基类和派生类处于平行层次结构(parallel hierarchy)中,使用这个特性可以带来便利。平行层次结构是指,一个类层次结构与另一个类层次结构没有相交,但是存在联系。
修改方法的参数
如果在派生类的定义中使用父类中虚方法的名称,但参数与父类中同名方法的参数不同,那么这不是重写父类的方法,而是创建一个新方法。回到本章前面的Base 和Derived类示例,可试着在Derived类中使用新的参数列表重写someMethod()方法,如下所示:1
2
3
4
5
6
7
8
9class Base {
public:
virtual void someMethod() ;
};
class Derived : public Base {
public:
virtual void someMethod(int i); // Compiles, but doesn't override
virtual void someOtherMethod();
};
这个方法的实现如下所示:1
2
3void Derived::someMethod(int i) {
cout << "This is Derived's version of someMethod with argument "<< i << "." << endl;
}
实际上,C++标准指出,当Derived 类定义了这个方法时,原始的方法被隐藏。下面的代码无法编译,因为没有参数的someMethod()方法不再存在。1
2Derived myDerived;
myDerived.someMethod(); // Error! Won't compile because original method is hidden.
如果希望重写基类中的someMethod()方法,就应该像前面建议的那样使用override关键字。如果在重写方法时发生错误,编译器会报错。
可使用一种较晦涩的技术兼顾二者。也就是说,可使用这一技术在派生类中有效地用新的原型“重写”某个方法,并继承该方法的基类版本。这一技术使用using关键字显式地在派生类中包含这个方法的基类定义:1
2
3
4
5
6
7
8
9
10class Base {
public:
virtual void someMethod();
};
class Derived : public Base {
public:
using Base::someMethod;
virtual void someMethod(int i);
virtual void someOtherMethod();
};
继承的构造 函数
允许在派生类中继承基类的构造函数。考虑下面的Base和Derived类定义:1
2
3
4
5
6
7
8
9class Base {
virtual ~Base() = default;
Base() = default;
Base(std::string_view str);
};
class Derived : public Base {
public:
Derived(int i);
};
只能用提供的Base构造函数构建Base对象,要么是默认构造函数,要么是包含string_view 参数的构造函数。另外,只能用Derived构造函数创建Derived 对象,这个构造函数需要一个整数作为参数。不能使用Base类中使用接收string_view 的构造函数来创建Derived对象。例如:1
2
3Base base ("Hello"); // OK, calls string_view Base ctor
Derived derived1 (1); // OK, calls integer Derived ctor
Derived derived2 ("Hel1o"); // Error, Derived does not inherit string_view ctor
如果喜欢使用基于string_view的Base构造函数构建Derived对象,可在Derived 类中显式地继承Base构造函数,如下所示:1
2
3
4
5class Derived : public Base {
public:
using Base::Base;
Derived(int i);
};
using语句从父类继承除默认构造函数外的其他所有构造函数,现在可通过两种方法构建Derived对象:
Derived类定义的构造函数可与从Base类继承的构造函数有相同的参数列表。与所有的重写一样,此时Derived类的构造函数的优先级高于继承的构造函数。
使用using子句从基类继承构造函数有一些限制。当从基类继承构造函数时,会继承除默认构造函数外的其他全部构造函数,不能只是继承基类构造函数的一个子集。第二个限制与多重继承有关。如果一个基类的某个构造函数与另一个基类的构造函数具有相同的参数列表,就不可能从基类继承构造函数,因为那样会导致歧义。为解决这个问题,Derived类必须显式地定义冲突的构造函数。例如,下面的Derived类试图继承Base1和Base2基类的所有构造函数,这会产生编译错误,因为使用浮点数作为参数的构造函数存在歧义。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Base1 {
public:
virtual ~Base1() = default;
Base1() = default;
Base1(float f);
};
class Base2 {
public:
virtual ~Base2() = default;
Base2() = default;
Base2 (std::string_view str);
Base2(float f);
};
class Derived : public Base1, public Base2 {
public:
using Base1::Base1;
using Base2::Base2;
Derived(char c);
};
Derived类定义中的第一条using 语句继承了Base1类的构造函数。这意味着Derived类具有如下构造函数:1
Derived(float f); // Inherited from Base1
Derived类定义中的第二条using子句试图继承Base2类的全部构造函数。然而,这会导致编译错误,因为这意味着Derived类拥有第二个Derived(float f)构造函数。为解决这个问题,可在Derived类中显式声明冲突的构造函数,如下所示:1
2
3
4
5
6
7class Derived : public Base1, public Base2 {
public:
using Base1::Basel;
using Base2::Base2;
Derived(char c);
Derived(float f);
};
现在,Derived 类显式地声明了一个采用浮点数作为参数的构造函数,从而解决了歧义问题。如果愿意,在Derived 类中显式声明的使用浮点数作为参数的构造函数仍然可以在ctor-initializer中调用Base1和Base2构造函数,如下所示:1
Derived::Derived(float f) : Base1(f), Base2(f) {}
重写方法时的特殊情况
当重写方法时,需要注意几种特殊情况。本节将列出可能遇到的一些情况。
静态基类方法
在C++中,不能重写静态方法。对于多数情况而言,知道这一点就足够了。然而,在此需要了解一些推论。首先,方法不可能既是静态的又是虚的。出于这个原因,试图重写一个静态方法并不能得到预期的结果。如果派生类中存在的静态方法与基类中的静态方法同名,实际上这是两个独立的方法。下面的代码显示了两个类,这两个类都有一个名为beStatic()的静态方法。这两个方法毫无关系。1
2
3
4
5
6
7
8class BaseStatic {
public:
static void beStatic() { cout << "BaseStatic being static." << endl;}
};
class DerivedStatic : public BaseStatic {
public:
static void beStatic() { cout << "Derivedstatic keepin' it static." << endl; }
};
由于静态方法属于类,调用两个类的同名方法时,将调用各自的方法。1
2BaseStatic::beStatic();
DerivedStatic::beStatic();
输出为:1
2BaseStatic being static.
DerivedStatic keepin' it static.
用类名访问这些方法时一切都很正常。当涉及对象时,这一行为就不是那么明显。在C++中,可以使用对象调用静态方法,但由于方法是静态的,因此没有this指针,也无法访问对象本身,使用对象调用静态方法,等价于使用classname:method()调用静态方法。回到前面的示例,可以编写如下代码,但是结果令人惊讶:1
2
3
4DerivedStatic myDerivedStatic;
BaseStatic& ref = myDerivedStatic;
myDerivedStatic.beStatic();
ref.beStatic();
对beStatic()的第一次调用显然调用了DerivedStatic版本,因为调用它的对象被显式地声明为DerivedStatic。第二次调用的对象是一个BaseStatic引用,但指向的是一个DerivedStatic对象。在此情况下,会调用BaseStatic版本的beStatic()。 原因是当调用静态方法时,C++不关心对象实际上是什么,只关心编译时的类型。在此情况下,该类型为指向BaseStatic对象的引用。
静态方法属于定义它的类,而不属于特定的对象。当类中的方法调用静态方法时,所调用的版本是通过正常的名称解析来决定的。当使用对象调用时,对象实际上并不涉及调用,只是用来判断编译时的类型。
重载基类方法
当指定名称和一组参数以重写某个方法时,编译器隐式地隐藏基类中同名方法的所有其他实例。考虑下面的Derived类,它重写了一个方法,而没有重写相关的同级重载方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14class Base {
public:
virtual ~Base() = default;
virtual void overload() { cout << "Base's overload()" << endl;
virtual void overload(int i) {
cout << "Base's overload(int i)" << endl;
}
};
class Derived : public Base {
public:
virtual void overload() override {
cout << "Derived's overload()" << endl;
}
};
如果试图用Derived对象调用以int值作为参数的overload()版本,代码将无法编译,因为没有显式地重写这个方法。然而,使用Derived对象访问该版本的方法是可行的。只需要使用指向Base对象的指针或引用:1
2
3Derived myDerived;
Base& ref = myDerived;
ref.overload(7) ;
在C++中,隐藏未实现的重载方法只是表象。显式声明为子类型实例的对象无法使用这些方法,但可将其转换为基类类型,以使用这些方法。
如果只想改变一个方法,可以使用using关键字避免重载该方法的所有版本。在下面的代码中,Derived类定义中使用了从Base类继承的一个overload()版本,并显式地重写了另一个版本:1
2
3
4
5class Derived : public Base {
public:
using Base::overload;
virtual void overload() override
};
基类方法具有默认参数
派生类与基类可具有不同的默认参数,但使用的参数取决于声明的变量类型,而不是底层的对象。下面是一个简单的派生类示例,派生类在重写的方法中提供了不同的默认参数:1
2
3
4
5
6
7
8class Base {
public:
virtual void go(int i = 2);
};
class Derived : public Base
public:
virtual void go(int i = 7) override;
};
如果调用Derived对象的go(),将执行Derived版本的go(),默认参数为7。如果调用Base对象的go(),将执行Base版本的go(),默认参数为2。然而(有些怪异),如果使用实际指向Derived对象的Base指针或Base引用调用go(),将调用Derived版本的go(),但使用Base版本的默认参数2。
产生这种行为的原因是C++根据表达式的编译时类型(而非运行时类型)绑定默认参数。在C++中,默认参数不会被“继承”。如果上面的Derived类没有像父类那样提供默认参数,就用新的非0参数版本重载go()方法。
当重写具有默认参数的方法时,也应该提供默认参数,这个参数的值应该与基类版本相同。建议使用符号常量作为默认值,这样可在派生类中使用同一个符号常量。
派生类中的复制构造函数和赋值运算符
当定义派生类时,必须注意复制构造函数和operator=。如果派生类没有任何需要使用非默认复制构造函数或operator=的特殊数据(通常是指针),无论基类是否有这类数据,都不需要它们。如果派生类省略了复制构造函数或operator=,派生类中指定的数据成员就使用默认的复制构造函数或operator=,基类中的数据成员使用基类的复制构造函数或operator=。
另外,如果在派生类中指定了复制构造函数,就需要显式地链接到父类的复制构造函数,下面的代码演示了这一内容。如果不这么做,将使用默认构造函数(不是复制构造函数!)初始化对象的父类部分。1
2
3
4
5
6
7class Derived : public Base {
public:
Derived() = default;
Derived (const Derived& src);
};
Derived::Derived(const Derived& src) : Base (src);
与此类似,如果派生类重写了operator=, 则几乎总是需要调用父类版本的operator=。唯一的例外是因为某些奇怪的原因,在赋值时只想给对象的一部分赋值。下面的代码显示了如何在派生类中调用父类的赋值运算符。1
2
3
4
5
6
7Derived& Derived: :operator= (const Derived& rhs) {
if (&rhs == this) {
return *this;
}
Base::operator=(rhs); // calls parent's operator=.
return *this;
}
如果派生类不指定自己的复制构造函数或operator=,基类的功能将继续运行。否则,就需要显式引用基类版本。
运行时类型工具
在C++中,有些特性提供了对象的运行时视角。这些特性通常归属于一个名为运行时类型信息(RunTime Type Information, RTTI)的特性集。RTTI的一个特性是typeid运算符,这个运算符可在运行时查询对象,从而判别对象的类型。大多数情况下,不应该使用typeid,因为最好用虚方法处理基于对象类型运行的代码。下面的代码使用了typeid,根据对象的类型输出消息:1
2
3
4
5
6
7
8
void speak(const Animal& animal) {
if (typeid(animal) == typeid(Dog)) {
cout << "Woof!" << endl;
} else if (typeid(animal) == typeid(Bird)) {
cout << "Chirp!" << endl;
}
}
一旦看到这样的代码,就应该立即考虑用虚方法重新实现该功能。
类至少有一个虚方法,typeid 运算符才能正常运行。如果在没有虚方法的类上使用dynamic_cast(),会导致编译错误。typeid 运算符也会从实参中去除引用和const限定符。
typeid运算符的主要价值之一在于日志记录和调试。
非public继承
将父类的关系声明为protected,意味着在派生类中,基类所有的public方法和数据成员都成为受保护的。与此类似,指定private继承意味着基类所有的public、protected方法和数据成员在派生类中都成为私有的。使用这种方法统一降低父类的访问级别有许多原因,但多数原因都是层次结构的设计缺陷。
虚基类
如果希望被共享的父类拥有自己的功能,C++提供了另一种机制来解决这个问题。如果被共享的基类是一个虚基类(virtual base class),就不存在歧义。
理解灵活而奇特的C++
引用
在C++中,引用是另一个变量的别名。对引用的所有修改都会改变被引用的变量的值。可将引用当作隐式指针,这个指针没有取变量地址和解除引用的麻烦。也可将引用当作原始变量的另一个名称。
引用变量
引用变量在创建时必须初始化,如下所示:1
2int x = 3;
int& xRef = x;
使用xRef就是使用x的当前值。对xRef赋值会改变x的值。
创建引用时必须总是初始化它。通常会在声明引用时对其进行初始化,但是对于包含类而言,需要在构造函数初始化器中初始化引用数据成员。
不能创建对未命名值(例如一个整数字面量)的引用,除非这个引用是一个const值。1
2int& unnamedRef1 = 5; // DOES NOT COMPILE
const int& unnamedRef2 = 5; // Works as expected
临时对象同样如此。不能具有临时对象的非const引用,但可具有const引用。例如:1
std::string getString() { return "Hello world!"; }
对于调用getString()的结果,可以有一个const引用;在该const引用超出作用域之前,将使std::string对象一直处于活动状态:1
2std::string& string1 = getString(); // DOES NOT COMPILE
const std::string& string2 = getString(); // Works as expected
修改引用
引用总是引用初始化的那个变量,且无法修改。如果在声明引用时用一个变量“赋值”,那么这个引用就指向这个变量。然而,如果在此后使用变量对引用赋值,被引用变量的值就变为被赋值变量的值。引用不会更新为指向这个变量。下面是示例代码:1
2
3int x = 3, y = 4;
int& xRef = x;
xRef = y; // Changes value of x to 4. Doesn't make xRef refer to y.
将一个引用赋值给另一个引用会让第一个引用指向第二个引用所指的变量吗?1
2
3
4int x = 3, z = 5;
int& xRef = x;
int& zRef = z;
zRef = xRef; // Assigns values, not references
最后一行代码没有改变zRef,只是将z的值设置为3,因为xRef指向x,x的值是3。
在初始化引用之后无法改变引用所指的变量,而只能改变该变量的值。
指向指针的引用和指向引用的指针
可创建任何类型的引用,包括指针类型。1
2
3
4int* intP;
int*& ptrRef = intP;
ptrRef = new int;
*ptrRef = 5;
语义实际上很简单:ptrRef是一个指向intP的引用,intP是一个指向int值的指针。修改ptrRef会更改intP。
注意,对引用取地址的结果与对被引用变量取地址的结果相同。例如:1
2
3int x = 3;
int* xPtr = &xRef; // Address of a reference is pointer to value
*xPtr = 100;
上述代码通过取x引用的地址,使xPtr指向x。将*xPtr赋值为100,x的值也变为100。比较表达式xPtr==xRef将无法编译,因为类型不匹配;
引用数据成员
如果不指向其他变量,引用就无法存在。因此,必须在构造函数初始化器(constructor initializer)中初始化引用数据成员,而不是在构造函数体内。下面列举一个简单示例:1
2
3
4
5class MyClass {
public:
MyClass(int& ref) : mRef(ref) { }
private:
int& mRef;
引用参数
引用经常用作函数或方法的参数。当使用引用参数时,函数将引用作为参数。如果引用被修改,最初的参数变量也会被修改。1
2
3
4
5void swap(int& first, int& second) {
int temp = first;
first = second;
second = temp;
}
就像无法用常量初始化普通引用变量一样, 不能将常量作为参数传递给“按非const引用传递”的函数:
使用“按const引用传递”或“按右值引用传递”,可将常量作为参数传递给函数。
将指针转换为引用
某个函数或方法需要以一个引用作为参数,而你拥有一个指向被传递值的指针,在此情况下,可对指针解除引用(dereferencing),将指针“转换”为引用。这一行为会给出指针所指的值,随后编译器用这个值初始化引用参数。例如:1
2
3int x = 5, y = 6;
int* xp = &x, *yp = &y;
swap(*xp, *yp);
按引用传递与按值传递
按引用传递不需要将参数的副本复制到函数,在有些情况下这会带来两方面的好处。
- 效率:复制较大的对象或结构需要较长时间。按引用传递只是把指向对象或结构的指针传递给函数。
- 正确性:并非所有对象都允许按值传递,即使允许按值传递的对象,也可能不支持正确的深度复制(deep copying)。第9章提到,为支持深度复制,动态分配内存的对象必须提供自定义复制构造函数或复制赋值运算符。
如果要利用这些好处,但不想修改原始对象,可将参数标记为const,从而实现按常量引用传递参数。
将引用作为返回值
还可让函数或方法返回一个引用。这样做的主要原因是为了提高效率。返回对象的引用而不是返回整个对象可避免不必要的复制。当然,只有涉及的对象在函数终止之后仍然存在的情况下才能使用。
如果变量的作用域局限于函数或方法(例如堆栈中自动分配的变量,在函数结束时会被销毁),绝不能返回这个变量的引用。
如果从函数返回的类型支持移动语义,按值返回就几乎与返回引用一样高效。
返回引用的另一个原因是希望将返回值直接赋为左值(lvalue)(赋值语句的左边)。一些重载的运算符通常会返回引用。
右值引用
右值(rvalue)就是非左值(Ivalue),例如常量值、临时对象或值。通常而言,右值位于赋值运算符的右侧:1
2
3
4// lvalue reference parameter
void handleMessage(std::string& message) {
cout << "handleMessage with lvalue reference: "<< message << endl;
}
对于这个handleMessage()版本,不能采用如下方式调用它:1
2
3
4handleMessage("Hello World"); // A literal is not an lvalue.
std::string a = "Hello ";
std::string b = "World";
handleMessage(a + b); // A temporary is not an 1value .
要支持此类调用,需要一个接收右值引用的版本:1
2
3
4// rvalue reference parameter
void handleMessage (std::string&& message ) {
cout << "handleMessage with rvalue reference: " << message << endl;
}
使用引用还是指针
引用比指针安全,不可能存在无效引用,也不需要显式地解除引用,因此不会遇到像指针那样的解除引用问题。
大多数情况下,应该使用引用而不是指针。对象的引用甚至可像指向对象的指针那样支持多态性。但也有一些情况要求使用指针,一个例子是更改指向的位置,因为无法改变引用所指的变量。例如,动态分配内存时,应该将结果存储在指针而不是引用中。
需要使用指针的另一种情况是可选参数,即指针参数可以定义为带默认值nullptr的可选参数,而引用参数不能这样定义。还有一种情况是要在容器中存储多态类型。
有一种方法可以判断使用指针还是引用作为参数和返回类型:考虑谁拥有内存。如果接收变量的代码负责释放相关对象的内存,那么必须使用指向对象的指针,最好是智能指针,这是传递拥有权的推荐方式。如果接收变量的代码不需要释放内存,那么应该使用引用。
考虑将一个int数组分割为两个数组的函数:一个是偶数数组;另一个是奇数数组。这个函数并不知道源数组中有多少奇数和偶数,因此只有在检测完源数组后,才能为目标数组动态分配内存,此外还需要返回这两个新数组的大小。因此总共需要返回4项:指向两个新数组的指针和两个新数组的大小。显然必须使用按引用传递,用规范的C语言方式编写的这个函数如下所示:1
void separateOddsAndEvens(const int arr[], size_t size, int** odds, size_t* numOdds, int** evens, size_t* numEvens)
如果要调用separateOddsAndEvens(),就必须传递两个指针的地址,这样函数才能修改实际的指针,还必须传递两个int值的地址,这样函数才能修改实际的int值。另外注意,主调方负责删除由separateOddsAndEvens()创建的两个数组!
如果觉得这种语法很难理解(应该是这样的),可以用引用实现真正的按引用传递,如下所示:1
void separateOddsAndEvens(const int arr[], size_t size, int*& odds, size_t& numOdds, int*& evens, size_t& numEvens)
在此情况下, adds和evens参数是指向int*的引用。separateOddsAndEvens()可以修改用作函数参数的int*(通过引用),而不需要显式地解除引用。使用这个版本的函数时,不再需要传递指针或int值的地址,引用参数会自动进行处理:1
separateOddsAndEvens(unSplit, std::size(unSplit), oddNums,numOdds, evenNums, numEvens);
关键字的疑问
const 关键字
const是constant的缩写,指保持不变的量。任何尝试改变常量的行为都会被当作错误处理。此外,当启用优化时,编译器可利用此信息生成更好的代码。关键字const有两种相关的用法。可以用这个关键字标记变量或参数,也可以用其标记方法。
const 变量和参数
可使用const来“保护”变量不被修改。这个关键字的一个重要用法是替换#define来定义常量,这是const最直接的应用。例如,可以这样声明常量PI:1
const double PI = 3.141592653589793238462;
可将任何变量标记为const,包括全局变量和类数据成员。
还可使用const指定函数或方法的参数保持不变。例如,下面的函数接收一个const参数。在函数体内,不能修改整数param。如果试图修改这个变量,编译器将生成错误。1
void func (const int param)
下面详细讨论两种特殊的const变量或参数:const指针和const引用。
const指针
当变量通过指针包含一层或多层间接取值时,const的应用将变得十分微妙。考虑下面的代码行:1
2
3int* ip;
ip = new int[10];
ip[4] = 5;
为阻止修改所指的值,可在ip的声明中这样添加关键字const:1
2
3const int* ip;
ip = new int[10];
ip[4] = 5;
下面是在语义上等价的另一种方法,将const放在int的前面还是后面并不影响其功能。1
2int const* ip;
ip[4] = 5; // DOES NOT COMPILE!
如果要将ip本身标记为const(而不是ip所指的值),可以这样做:1
2
3int* const ip = nullptr;
ip = new int[10]; // DOES NOT COMPILE !
ip[4] = 5; // Error: dereferencing a null pointer
现在ip本身无法修改,编译器要求在声明ip时就执行初始化,可以使用前面代码中的nullptr,也可以使用新分配的内存,如下所示:1
2int* const ip = new int[10];
ip[4] = 5;
还可将指针和所指的值全部标记为const,如下所示:1
2int const* const ip = nullptr;
const int* const ip = nullptr;
尽管这些语法看上去有点混乱,但规则实际上非常简单:将const 关键字应用于直接位于它左边的任何内容。再次考虑这一行:1
int const* const ip = nullptr;
从左到右,第一个const直接位于int的右边,因此将const应用到ip所指的int,从而指定无法修改ip所指的值。第二个const直接位于*的右边,因此将const应用于指向int变量的指针,也就是ip变量。因此,无法修改ip(指针)本身。
还有一种易于记忆的、用于指出复杂变量声明的规则:从右向左读。考虑示例
int* const ip。从右向左读这条语句,就可以知道ip是一个指向int值的const指针。另外,int const* ip读作ip 是一个指向const int的指针。
const引用
将const应用于引用通常比应用于指针更简单,原因有两个。首先,引用默认为const,无法改变引用所指的对象。因此,不必显式地将引用标记为const。其次,无法创建指向引用的引用,所以引用通常只有一层间接取值。获取多层间接取值的唯一方法是创建指向指针的引用。
因此,C++程序员提到“const 引用”时,含义如下所示:1
2
3int z;
const int& zRef = z;
zRef = 4; // DOES NOT COMPILE
由于将const应用到int,因此无法对zRef赋值,如前所示。与指针类似,const int& zRef等价于int const& zRef。然而要注意,将zRef标记为const对z没有影响。仍然可以修改z的值,具体做法是直接改变z,而不是通过引用。
const引用经常用作参数,这非常有用。如果为了提高效率,想按引用传递某个值,但不想修改这个值,可将其标记为const引用。例如:1
2void doSomething (const BigClass& arg)
// Implementation here
将对象作为参数传递时,默认选择是const引用。只有在明确需要修改对象时,才能忽略const。
const方法
可将类方法标记为const,以禁止方法修改类的任何非可变(non-mutable)数据成员。
constexpr关键字
在某些情况下需要常量表达式。例如当定义数组时,数组的大小就必须是一个常量表达式。由于这一限制,下面的代码在C++中是无效的:1
2
3
4
5const int getArraySize() { return 32; }
int main() {
int myArray [getArraySize()]; // Invalid in C++
return 0 ;
}
可使用constexpr关键字重新定义getAraySize()函数,把它变成常量表达式。常量表达式在编译时计算。
将函数声明为constexpr会对函数的行为施加一些限制, 因为编译器必须在编译期间对constexpr函数求值,函数也不允许有任何副作用。下面是几个限制:
- 函数体不包含goto语句、try catch块、未初始化的变量、非字面量类型的变量定义,也不抛出异常,但可调用其他constexpr 函数。
- “字面量类型”(literal type)是
constexpr变量的类型,可从constexpr函数返回。 - 字面量类型可以是void(可能有const、volatile限定符)、标量类型(整型和浮点类型、枚举类型、指针类型、成员指针类型,这些类型有const/volatile 限定符)、引用类型、字面量数组类型或类类型。
- 类类型可能也有const、volatile限定符,具有普通的(即非用户提供的)析构函数,至少有一个constexpr构造函数,所有非静态数据成员和基类都是字面量类型。
- “字面量类型”(literal type)是
- 函数的返回类型应该是字面量类型。
- 如果constexpr函数是类的一个成员,那么这个函数不能是虚函数。
- 函数所有的参数都应该是字面量类型。
- 在编译单元(ranslation unit)中定义了constexpr函数后,才能调用这个函数,因为编译器需要知道完整的定义。
- 不允许使用
dynamic_cast()和reinterpret_cast()。 - 不允许使用new和delete表达式。
通过定义constexpr构造函数,可创建用户自定义类型的常量表达式变量。constexpr构造函数具有很多限制,其中的一些限制如下所示:
- 类不能具有任何虚基类。
- 构造函数的所有参数都应该是字面量类型。
- 构造函数体不应该是function-try-block。
- 构造函数体应该满足与constexpr函数体相同的要求,并显式设置为默认(=default)。
- 所有数据成员都应该用常量表达式初始化。
static关键字
静态数据成员和方法
可声明类的静态数据成员和方法。静态数据成员不是对象的一部分,这个数据成员只有一个副本,这个副本存在于类的任何对象之外。静态方法与此类似,位于类层次(而不是对象层次)。静态方法不会在某个特定对象环境中执行。
静态链接(static linkage)
默认情况下,函数和全局变量都拥有外部链接。然而,可在声明的前面使用关键字static指定内部(或静态)链接。如果f()函数具有内部(静态)链接,另一个文件无法使用这个函数。如果在源文件中定义了静态方法但是没有使用它,有些编译器会给出警告(指出这些方法不应该是静态的,因为其他文件可能会用到它们)。
将static用于内部链接的另一种方式是使 用匿名名称空间(anonymous namespaces)。可将变量或函数封装到一个没有名字的名称空间,而不是使用static,如下所示:1
2
3
4
5
6
7
namespace {
void f();
void f() {
std::cout << "f\n";
}
}
在同一源文件中,可在声明匿名名称空间之后的任何位置访问名称空间中的项,但不能在其他源文件中访问。这一语义与static关键字相同。
extern关键字
extern关键字将它后面的名称指定为外部链接。某些情况下可使用这种方法。例如,const和typedef在默认情况下是内部链接,可使用extern使其变为外部链接。然而,extern有一点复杂。当指定某个名称为extern时,编译器将这条语句当作声明而不是定义。对于变量而言,这意味着编译器不会为这个变量分配空间。必须为这个变量提供单独的、不使用extern关键字的定义行。例如,下面是AnotherFile.cpp的内容:1
2extern int x;
int x = 3;
也可在extern行初始化x,这一行既是声明又是定义:1
extern int x = 3;
这种情形下的extern并不是非常有用,因为x默认具有外部链接。当另一个源文件FirstFile.cpp使用x时,才会真正用到extern:1
2
3
4
5
extern int x;
int main() {
std::cout << x << std::endl;
}
FirstFile.cpp 使用了extern 声明,因此可使用x。编译器需要知道x的声明,才能在main()函数中使用这个变量。然而,如果声明x时未使用extern关键字,编译器会认为这是定义,因而会为x分配空间,导致链接步
骤失败(因为有两个全局作用域的x变量)。使用extern,就可在多个源文件中全局访问这个变量。
函数中的静态变量
C++中static关键字的最终目的是创建离开和进入作用域时都可保留值的局部变量。函数中的静态变量就像只能在函数内部访问的全局变量。静态变量最常见的用法是“记住”某个函数是否执行了特定的初始化操作。
非局部变量的初始化顺序
程序中所有的全局变量和类的静态数据成员都会在main()函数开始之前初始化。给定源文件中的变量以在源文件中出现的顺序初始化。例如,在下面的文件中,Demo::x一定会在y之前初始化:1
2
3
4
5
6class Demo {
public:
static int x;
};
int Demo::x = 3;
int y = 34;
然而,C++没有提供规范,用以说明在不同源文件中初始化非局部变量的顺序。如果在某个源文件中有一个全局变量x,在另一个源文件中有一个全局变量y,无法知道哪个变量先初始化。如果某个全局变量或静态变量依赖于另一个变量,这两个全局对象在不同的源文件中声明,就不能指望一个全局对象在另一个全局对象之前构建,也无法控制它们的初始化顺序。不同编译器可能有不同的初始化顺序,即使同一编译器的不同版本也可能如此。
不同源文件中非局部变量的初始化顺序是不确定的。
非局部变量的销毁顺序
非局部变量按初始化的逆序进行销毁。不同源文件中非局部变量的初始化顺序是不确定的,所以销毁顺序也是不确定的。
类型和类型转换
类型别名
类型别名为现有的类型声明提供了新名称。下面为int*类型声明指定新名称IntPtr:1
using IntPtr = int*;
类型别名最常见的用法是当实际类型的声明过于笨拙时,提供易于管理的名称。标准库广泛使用类型别名来提供类型的简短名称。例如,std:string实际上就是这样一个类型别名:1
using string = basic_string<char>;
函数指针的类型别名
在C++中,可使用函数的地址,就像使用变量那样。函数指针的类型取决于兼容函数的参数类型的返回类型。处理函数指针的一种方式是使用类型别名。类型别名允许将一个类型名指定给具有指定特征的一系列函数。 例如,下面的代码行定义了MatchFunction类型,该类型表示一个指针,这个指针指向具有两个int参数并返回布尔值的任何函数:1
using MatchFunction = bool(*) (int, int);
有了这个新类型,可编写将MatchFunction作为参数的函数。1
2
3
4
5
6
7void findMatches(int values1[], int values2[], size_t numValues, MatchFunction matcher) {
for (size_t i = 0; i < numValues; i++) {
if (matcher (values1[i],values2[i]) {
// ......
}
}
}
使用函数指针,可根据matcher参数自定义单个findMatches()函数的功能。
如果不使用这些旧式的函数指针,还可以使用
stl::function。
方法和数据成员的指针的类型别名
在C++中,取得类成员和方法的地址,获得指向它们的指针是完全合法的。但不能访问非静态成员,也不能在没有对象的情况下调用非静态方法。类数据成员和方法完全依赖于对象的存在。因此,通过指针调用方法或访问数据成员时,一定要在对象的上下文中解除对指针的引用。1
2
3Employee employee;
int (Employee::*methodPtr) () const = &Employee::getSalary;
cout << (employee.*methodPtr) () << endl;
不必担心上述语法。第二行声明了一个指针类型的变量methodPtr,该指针指向Employee类的一个非静态const方法,这个方法不接收参数并返回一个int值。同时,这行代码将这个变量初始化为指向Employee类的getSalary()方法。这种语法和声明简单函数指针的语法非常类似,只不过在*methodPtr的前面添加了Employee::。还要注意,在这种情况下需要使用&。
第3行代码调用employee对象的getSalary()方法(通过methodPtr指针)。注意在employlee.*methodPtr的周围使用了括号。
可通过类型别名简化第二行代码:1
2
3
4Employee employee;
using PtrToGet = int (Employee::*) () const;
PtrToGet methodPtr = &Employee::getSalary;
cout << (employee.*methodPtr) () << endl;
使用auto可进一步简化:1
2
3Employee employee;
auto methodPtr = &Employee::getSalary;
cout << (employee.*methodPtr)() << endl;
方法和数据成员的指针通常不会出现在程序中。然而,要记住,不能在没有对象的情况下解除对非静态方法或数据成员的指针的引用。C++允许在没有对象的情况下解除对静态方法或静态数据成员的指针的引用。
typedef
与类型别名一样,typedef为已有的类型声明提供新名称。例如,使用以下类型别名:1
using IntPtr = int*;
如果不使用类型别名,就必须使用如下typedef:1
typedef int* IntPtr;
在引入类型别名之前,必须为函数指针使用typedef,这更复杂。例如,对于以下类型别名:1
using FunctionType = int (*) (char, double);
如果用typedef定义相同的FunctionType, 形式将如下:1
typedef int (*FunctionType) (char, double);
类型别名和typedef并非完全等效。与typedef相比,类型别名与模板一起使用时功能更强大。
类型转换
C++还提供了4种类型转换:const_cast()、static_cast()、reinterpret_cast()和dynamic_cast()。使用()的C风格类型转换在C++中仍然有效。
const_cast()
const_cast()最直接,可用于给变量添加常量特性,或去掉变量的常量特性。这是上述4种类型转换中唯可舍弃常量特性的类型转换。当然从理论上讲,并不需要const类型转换。如果某个变量是const,那么应该一直是const。然而实际中,有时某个函数需要采用const变量,但必须将这个变量传递给采用非const变量作为参数的函数。因此,有时需要舍弃变量的常量特性,但只有在确保调用的函数不修改对象的情况下才能这么做,否则就只能重新构建程序。下面是一个示例:1
2
3extern void ThirdPartyLibraryMethod(char* str);
void f(const char* str)
ThirdPartyLibraryMethod(const_cast<char*>(str));
从C++17开始,<utility>中定义了一个辅助方法std:as_const(),该方法返回引用参数的const引用版本。as_const(obj)基本上等同于const_cast<const T&>(obj),其中,T的类型为obj。可以看到,与使用const_cast()相比,使用as_const()更简短。示例如下:1
2std::string str = "C++";
const std::string& constStr = std::as_const(str);
将as_const()与auto一起使用时要保持警惕。auto将去除引用和const限定符!因此,下面的result变量具有类型std::string而非const std:string&:1
auto result = std::as_const(str);
static_cast()
可使用static_cast()显式地执行C++语言直接支持的转换。例如,如果编写了一个算术表达式,其中需要将int转换为double以避免整除,可以使用static_cast()。
如果用户定义了相关的构造函数或转换例程,也可使用static_cast()执行显式转换。例如,如果类A的构造函数将类B的对象作为参数,就可使用static_cast()将B对象转换为A对象。许多情况下都需要这一行为,然而编译器会自动执行这个转换。
static_cast()的另一种用法是在继承层次结构中执行向下转换。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Base {
public:
virtual ~Base() = default;
};
class Derived : public Base {
public:
virtual ~Derived() = default;
};
int main() {
Base* b;
Derived* d = new Derived();
b = d; // Don't need a cast to go up the inheritance hierarchy
d = static_cast<Derived*>(b); // Need a cast to go down the hierarchy
Base base;
Derived derived;
Base& br = derived;
Derived& dr = static_cast<Derived&> (br) ;
return 0;
}
这种类型转换可以用于指针和引用,而不适用于对象本身。
注意static_cast()类型转换不执行运行期间的类型检测。它允许将任何Base指针转换为Derived指针,或将Base引用转换为Derived引用,哪怕在运行时Base对象实际上并不是Derived对象,也是如此。例如,下面的代码可以编译并执行,但使用指针d可能导致灾难性结果,包括内存重写超出对象的边界。1
2Base* b = new Base() ;
Derived* d = static_cast<Derived*>(b);
使用static_cast()无法将某种类型的指针转换为不相关的其他类型的指针。如果没有可用的转换构造函数,static_cast()无法将某种类型的对象直接转换为另一种类型的对象。
reinterpret_cast()
reinterpret_cast()的功能比static_cast()更强大,同时安全性更差。这种用法经常用于将指针转换为void*;这可隐式完成,不需要进行显式转换。但将void*转换为正确类型的指针需要reinterpret_cast()。void*指针指向内存的某个位置。void*指针没有相关的类型信息。下面是一些示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class X {};
class Y {};
int main() {
X x;
Y y;
X* xp = &x;
Y* yp = &y;
// Need reinterpret cast for pointer conversion from unrelated classes
// static_cast doesn't work.
xp = reinterpret_cast<X*>(yp);
// No cast required for conversion from pointer to void*
void* p = xp;
// Need reinterpret cast for pointer conversion from void*
xp = reinterpret_cast<X*>(p) ;
// Need reinterpret cast for reference conversion from unrelated classes
// static_cast doesn't work.
X& xr = x;
Y& yr = reinterpret_cast<Y&>(x);
return 0;
}
reinterpret_cast()的一种用法是与普通可复制类型的二进制I/O起使用。所谓普通可复制类型,是指构成对象的基础字节的类型可复制到数组中。如果此后要将数组的数据复制回对象,对象将保持其原始值。例如,可将这种类型的单独字节写入文件中。将文件读入内存时,可使用reinterpret_cast()来正确地解释从文件读入的字节。
dynamic_cast()
dynamic_cast()为继承层次结构内的类型转换提供运行时检测。可用它转换指针或引用。dynamic_cast()在运行时检测底层对象的类型信息。如果类型转换没有意义,dynamic_cast()将返回一个空指针(用于指针)或抛出一个stl::bad_cast异常(用于引用)。例如,下面用于引用的dynamic_cast()将拋出一个异常:1
2
3
4
5
6
7
8Base base;
Derived derived;
Base& br = base;
try {
Derived& dr = dynamic_cast<Derived&>(br);
} catch (const bad_cast&) {
cout << "Bad cast!" << endl;
}
注意可使用static_cast()或reinterpret_cast()沿着继承层次结构向下执行同样的类型转换。dynamic_cast()的不同之处在于它会执行运行时(动态)类型检测,而static_cast()和reinterpret_cast()甚至会执行不正确的类型转换。因此,为使用dynamic_cast(),类至少要有一个虚方法。如果类不具有虚表,尝试使用dynamic_cast()将导致编译错误。
类型转换总结
表11-1总结了不同情形下应该使用的类型转换。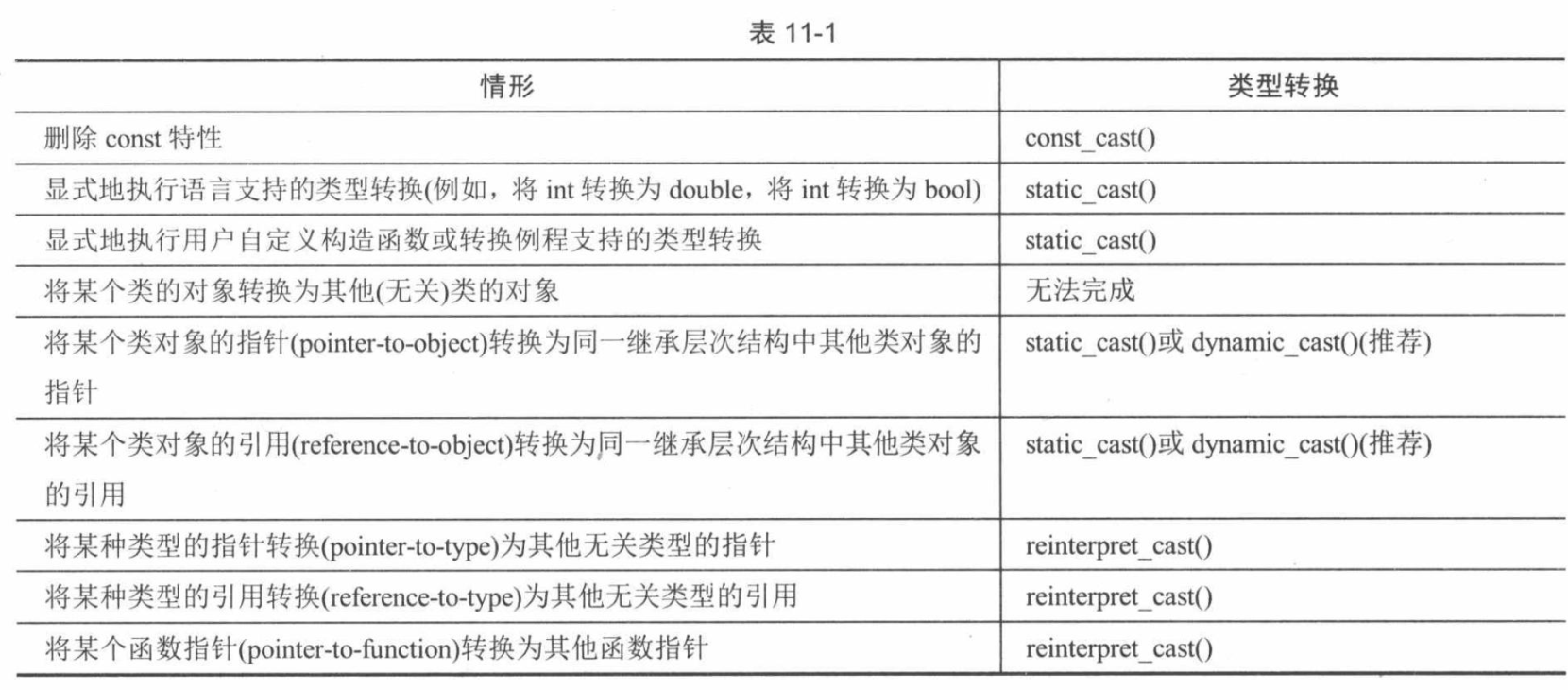
作用域解析
可使用名称空间、函数定义、花括号界定的块和类定义创建作用域。在一个for循环的初始化语句中,初始化的变量的作用域仅限于这个for循环,在这个for循环之外不可见。当试图访问某个变量、函数或类时,首先在最近的作用域内查找这个名称,然后查找相邻的作用域,以此类推,直到全局作用域。任何不在名称空间、函数、花括号界定的块和类中的名称都被认为在全局作用域内。如果在全局作用域内也找不到这个名称,编译器会给出未定义符号错误。
有时某个作用域内的名称会隐藏其他作用域内的同一名称。在另一些情况下,程序的特定行中的默认作用域解析并不包含需要的作用域。如果不想用默认的作用域解析某个名称,就可以使用作用域解析运算符::和特定的作用域限定这个名称。例如,为访问类的静态方法,第一种方法是将类名(方法的作用域)和作用域解析运算符放在方法名的前面,第二种方法是通过类的对象访问这个静态方法。下例演示了这两种方法。这个示例定义了一个具有静态方法get()的Demo类、一个具有全局作用域的get()函数以及一个位于NS名称空间的get()函数。1
2
3
4
5
6
7
8
9
10class Demo {
public:
static int get() { return 5; }
};
int get() { return 10; }
namespace NS {
int get() { return 20; }
}
全局作用域没有名称,但可使用作用域解析运算符本身(没有名称前缀)来访问。可采用以下方式调用不同的get()函数。在这个示例中,代码本身在main()函数中,main()函数总是位于全局作用域内:1
2
3
4
5
6
7
8
9
10
11int main() {
auto pd = std::make_unique<Demo>();
Demo d;
std::cout << pd->get() << std::endl; // prints 5
std::cout << d.get() << std::endl; // prints 5
std::cout << NS::get() << std::endl; // prints 20
std::cout << Demo::get() << std::endl; // prints 5
std::cout << ::get() << std::endl; // prints 10
std::cout << get() << std::endl; // prints 10
return 0;
}
注意,如果NS名称空间是一个匿名名称空间,下面的行将导致名称解析歧义错误,因为在全局作用域内定义了一个get()函数,在匿名名称空间中也定义了一个get()函数。1
std::cout << get() << std::endl;
如果在main()函数之前使用using子句,也会发生同样的错误:1
using namespace NS;
特性
特性(ttribute)是在源代码中添加可选信息(或者供应商指定的信息)的一种机制。 在C++11之前,供应商决定如何指定这些信息,例如__atribute__和__declspec等。自C++11以后,使用两个方括号语法[[attribute]]支持特性。C++标准只定义了6个标准特性。
[[noreturn]]特性
[[noreturm]]意味着函数永远不会将控制交还调用点。典型情况是函数导致某种终止(进程终止或线程终止)或者抛出异常。使用该特性,编译器可避免给出某种警告或错误,因为它现在对函数的意图了解更多。下面是
一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20[[noreturn]] void forceProgramTermination() {
std::exit(1);
}
bool isDongleAvailable () {
bool isAvailable = false;
// Check whether a licensing dongle is available...
return isAvailable;
}
bool isFeatureLicensed(int featureId) {
if (!isDongleAvailable())
// No licensing dongle found, abort program execution!
forceProgramTermination() ;
} else
bool isLicensed = false;
// Dongle available, perform license check of the given feature...
}
return isLicensed;
}
这个代码片段可正常编译,不会发出任何警告或错误。但如果删除[[noretum]]特性,编译器将生成以下警告消息:1
warning C4715: ' isFeatureLicensed': not all control paths return a value
[[deprecated]]特性
[[deprecated]]特性可用于把某个对象标记为废弃,表示仍可以使用,但不鼓励使用。这个特性接收一个可选参数,可用于解释废弃的原因,例如:1
[[deprecated ("Unsafe method, please use xyz")]] void func();
如果使用这个特性,将看到编译错误或警告。例如,GCC会给出以下警告消息:1
warning: 'void func()' is deprecated: Unsafe method, please use xyz
[[allthrough]]特性
从C++17开始,可使用[[allthrough]]特性告诉编译器:在switch语句中,fall through是有意安排的。如果没有指定该特性,用以说明这是有意为之的,编译器将给出警告消息。不需要为空的case分支指定这个特性。例如:1
2
3
4
5
6
7
8
9
10
11
12
13switch (backgroundColor) {
case Color::DarkBlue:
doSomethingForDarBlue();
[[fallthrough]];
case Color::Black:
// Code is executed for both a dar blue or black background color
doSomethingForBlackOrDarkBlue();
break;
case Color::Red:
case Color::Green:
// Code to execute for a red or green background color
break;
}
[[nodiscard]]特性
[[nodiscard]]特性可用于返回值的函数,如果函数什么也没做,还返回值,编译器将发出警告消息。下面是一个示例:1
2
3
4
5
6
7
8[[nodiscard]] int func() {
return 42;
}
int main() {
func();
return 0;
}
编译器将给出如下警告消息:1
warning C4834: discarding return value of function with 'nodiscard' attribute
例如,可将这个特性用于返回错误代码的函数。通过给此类函数添加[[nodiscard]]特性,将无法忽略错误代码。
[[maybe_unused]]特性
如果未使用某项,[[maybe_unused]]特性可用于阻止编译器发出警告消息:1
2
3int func (int param1, [[maybe_unused]] int param2) {
return 42;
}
这里给第二个参数标记了[[maybe__unused]]特性。编译器将只为param1显示警告消息:1
warning C4100: 'param1': unreferenced formal parameter
用户定义的字面量
C++有许多可在代码中使用的标准字面量(iteral),如下所示。
- ‘a’: 字符
- “character array”:以0结尾的字符数组(C风格的字符串)
- 3.14f: 浮点数
- 0xabc: 十六进制值
C++11允许定义自己的字面量。用户定义的字面量应该以下划线开头,下划线之后的第一个字符必须小写,例如_i、_s、_km和miles等。可通过编写字面量运算符(literal operators)来实现。 字面量运算符能以生(raw)模式或熟(cooked)模式运行。在生模式中,字面量运算符接收一个字符序列;在熟模式中,字面量运算符接收一种经过解释的特定类型。例如,考虑C++字面量123。生模式字面量运算符会将其作为字符1、2、3,而熟模式字面量运算符会将其作为整数123。
另一个示例:考虑C++字面量0x23。生模式字面量运算符将接收字符0、x、2、3,而熟模式字面量运算符将接收整数35。
最后一个示例: 考虑C++字面量3.14,生模式字面量运算符将接收字符3、.、1、4,而熟模式字面量运算符将接收浮点值3.14。
熟模式字面量运算符应该具有:
- 一个unsigned long long、long double、char、wchar_t、char16_t或char32_t类型的参数,用来处理数值。
- 或者两个参数,第一个参数是字符数组,第二个参数是字符数组的长度,用来处理字符串,例如
const char* str和size_t len。
下例使用熟模式字面量运算符实现了用户定义的字面量_i,_i用来定义一个复数字面量。1
2
3std::complex<long double> operator"" _i (long double d) {
return std::complex<long double>(0, d) ;
}
_i字面量可这样使用:1
2
3std::complex<long double> c1 = 9.634_i;
auto c2 = 1.23_i;
// c2 has as type std::complex<long double>
另一个示例用熟模式字面量运算符实现了用户定义的字面量s,用于定义std::string字面量:1
2
3std::string operator""_s(const char* str, size_t len) {
return std::string(str, len);
}
这一字面量可这样使用:1
2
3std::string str1 = "Hello World"_s;
auto str2 = "Hello World"_s;
// str2 has as type std::string
如果没有_s字面量,自动推导的类型将是const char*:1
2auto str3 = "Hello World";
// str has as type const char*
生模式字面量运算符需要一个const char*类型的参数,这是一个以0结尾的C风格字符串。下面的示例定义了字面量_i,此时使用的是生模式字面量运算符:1
2
3std::complex<long double> operator""_i (const char* p)
// Implementation omitted; it requires parsing the C-style
// string and converting it to a complex number
生模式字面量运算符的用法与熟模式字面量运算符的用法相同。
标准的用户定义字面量
C++定义了如下标准的用户定义字面量。注意,这些标准的用户定义字面量并非以下画线开头:
- “s”用于创建
std::string- 例如:
auto myString = "Hello World"s; - 需要
using namespace std::string_literals;
- 例如:
- “sv”用于创建
std::string_views- 例如:
auto myStringView = "Hello world"sv; - 需要
using namespace std::string_view_literals;
- 例如:
- “h” “min” “s” “ms” “us” “ns”用于创建
stl::chrono::duration时间段- 例如:
auto myDuration = 42min; - 需要
using namespace std::chrono_literals;
- 例如:
- “i”、“il”、“if”分别用于创建复数
complex<double>、complex<long double>和complex<float>- 例如:
auto myComplexNumber = 1.3i; - 需要
using namespace std::complex_literals;
- 例如:
头文件
头文件是为子系统或代码段提供抽象接口的一种机制。使用头文件需要注意的一点是:要避免循环引用或多次包含同一个头文件。可使用文件保护机制(include guards)来避免重复定义。在每个头文件的开头,用#ifndef指令检测是否还没有定义某个键值。如果这个键值已经定义,编译器
将跳到对应的#endif,这个指令通常位于文件的结尾。1
2
3
4
5
6
class Logger {
// ...
};
如今,几乎所有编译器都支持#pragma once指令(该指令可替代前面的文件保护机制)。例如:1
2
3
class Logger {
};
前置声明是另一个避免产生头文件问题的工具。如果需要使用某个类,但是无法包含它的头文件,就可告诉编译器存在这么一个类,但是无法使用#include机制提供正式的定义,可在代码中使用这个类的指针或引用。也可声明函数,使其按值返回这种前置声明类,或将这种前置声明类作为按值传递的函数参数。当然,定义函数的代码以及调用函数的任何代码都需要添加正确的头文件,在头文件中要正确定义前置声明类。
建议尽可能在头文件中使用前置声明,而不是包含其他头文件。这可减少编译和重编译时间,因为破坏了一个头文件对其他头文件的依赖。当然,实现文件需要包含前置声明类的正确头文件,否则就不能编译。
为了查询是否存在某个头文件,C++17添加了__has_include("flename")和__has_include(<filename>)预处理器常量。如果头文件存在,这些常量的结果就是1;如果头文件不存在,常量的结果就是0。1
2
3
4
5
C的实用工具
变长参数列表
C/C++可以编写参数数目可变的自定义函数。例如,假定要编写一个快速调试函数,这个函数应能接收任意数目和类型的参数并输出字符串。1
2
3
4
5
6
7
8
void debugOut(const char* str, ...) {
va_list ap
va_start(ap, str) ;
vfprintf(stderr, str, ap);
va_end(ap);
}
首先,注意debugOut()函数的原型包含一个具有类型和名称的参数str,之后...代表任意数目和类型的参数。声明一个va_list类型的变量,并调用va_start()来初始化它。va_start()的第二个参数必须是参数列表中最右边的已命名变量。所有具有变长参数列表的函数都至少应该有一个已命名参数。当vfprintf()返回时,debugOut()调用va_end()来终止对变长参数列表的访问。在调用va_start()之后必须调用va_end(),以确保函数结束后,堆栈处于稳定状态。
访问参数
如果要自行访问实参,可使用va_arg();它的第一个实参是va_list,接收要截获的实参类型。遗憾的是,如果不提供显式的方法,就无法知道参数列表的结尾是什么。例如,可以让第一个参数计算参数的数目,或者当参数是一组指针时,可以要求最后一个指针是nullptr。
下例演示了这种技术,其中调用者在第一个已命名参数中指定了所提供参数的数目。函数接收任意数目的int参数,并将其输出。1
2
3
4
5
6
7
8
9
10void printInts(size_t num, ...) {
int temp;
va_list ap
va_start(ap, num) ;
for (size_t i = 0; i < num; ++i) {
temp = va_arg(ap, int);
}
va_end(ap);
cout << endl;
}
访问C风格的变长参数列表并不十分安全,这种方法存在以下风险:
- 不知道参数的数目。
- 不知道参数的类型。
va_arg()接收一种类型,用来解释当前的值。然而,可让va_arg()将这个值解释为任意类型,无法验证正确的类型。
预处理器宏
可使用C++预处理器编写宏,这与函数有点相似。下面是一个示例:1
2
int main() {cout << SQUARE(5) << endl;}
宏是C遗留下来的特性,非常类似于内联函数,但不执行类型检测。在调用宏时,预处理器会自动用扩展式替换。预处理器并不会真正地应用函数调用语义,这一行为可能导致无法预测的结果。
宏还会影响性能,假定按如下方式调用SQUARE宏:1
cout << SQUARE (veryExpensiveFunctionCallToComputeNumber()) << endl;
预处理器把它替换为:1
cout << ( (veryExpensiveFunctionCallToComputeNumber()) * (veryExpensiveFunctionCallToComputeNumber())) << endl;
现在,这个开销很大的函数调用了两次。这是避免使用宏的另一个原因。
宏还会导致调试问题,因为编写的代码并非编译器看到的代码或者调试工具中显示的代码(因为预处理器的查找和替换功能)。为此,应该全部用内联函数替代宏。
利用模板编写泛型代码
类模板
类模板定义了一个类,其中,将一些变量的类型、方法的返回类型和或方法的参数类型指定为参数。
编写类模板
最好编写一个通用的Grid类,该类可用于存储多种类型,编写类模板可避免编写需要指定一种或多种类型的类。客户通过指定要使用的类型对模板进行实例化。这称为泛型编程,其最大的优点是类型安全。
下例展示了如何得到模板化的Grid类。这里选用不带多态性的值语义来实现这个解决方案。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23template <typename T>
class Grid {
public:
explicit Grid(size_t width = kDefaultWidth, size_t height = kDefaultHeight);
virtual ~Grid() = default;
// Explicitly default a copy constructor and assignment operator.
Grid(const Grid& src) = default;
Grid<T>& operator=(const Grid& rhs) = default;
// Explicitly default a move constructor and assignment operator.
Grid(Grid&& src) = default;
Grid<T>& operator=(Grid&& rhs) = default;
std::optional<T>& at(size_t x,size_t y) ;
const std::optional<T>& at(size_t x,size_t y) const;
size_t getHeight() const { return mHeight; }
size_t getWidth() const { return mWidth; }
static const size_t kDefaultWidth = 10;
static const size_t kDefaultHeight = 10;
private:
void verifyCoordinate(size_t x, size_t y) const;
std::vector<std::vector<std::optional<T>>> mCells;
size_t mWidth, mHeight;
};
template <typename T>:第一行表示,下面的类定义是基于模板。template和typename都是C++中的关键字。在模板中使用模板参数名称(例如T)表示调用者要指定的类型。基于历史原因,指定模板类型参数时,可用关键字class替代typename。
在Grid类中,mCells是可选值的矢量的矢量,所以编译器生成的复制构造函数和赋值运算符可以运行得很好。一旦有了用户声明的析构函数,建议不要使用编译器隐式生成复制构造函数或赋值运算符,因此Grid类模板将其显式设置为默认,并且将移动构造函数和赋值运算符显式设置为默认。下面将复制赋值运算符显式设置为默认:1
Grid<T>& operator=(const Grid& rhs) = default;
从中可以看出,rths参数的类型是const Grid&,还可将其指定为const Grid<T>&。在类定义中,编译器根据需要将Grid解释为Grid<T>。但在类定义之外,需要使用Grid<T>。在编写类模板时,以前的类名(Grid)现在实际上是模板名称。at()方法现在返回optional<T>&或const optional<T>&,而不是返回unique_ptr:1
2std::optional<T>& at(size_t x, size_t y);
const std::optional<T>& at(size_t x, size_t y) const;
Grid类的方法定义
template <typename T>访问说明符必须在Grid模板的每一个方法定义的前面。构造函数如下所示:1
2
3
4
5
6template <typename T>
Grid<T>::Grid(size_t width, size_t height) : mWidth(width), mHeight(height) {
mCells.resize(mWidth);
for (auto& column : mCells)
column.resize(mHeight);
}
模板要求将方法的实现也放在头文件中,因为编译器在创建模板的实例之前,需要知道完整的定义,包括方法的定义。
注意::之前的类名是Grid<T>。必须在所有的方法和静态数据成员定义中将Grid<T>指定为类名:1
2
3
4
5template <typename T>
void Grid<T>::verifyCoordinate(size_t x, size_t y) const {
if (x >= mWidth || y >= mHeight) {
throw std::out_of_range("");
}
如果类模板方法的实现需要特定模板类型参数(例如T)的默认值,可使用T()语法。如果T是类类型,T()调用对象的默认构造函数,或者如果T是简单类型,则生成0。这称为“初始化为0”语法。最好为类型尚不确定的变量提供合理的默认值。
使用Grid模板
创建网格对象时,不能单独使用Grid作为类型;必须指定这个网格保存的元素类型。为某种类型创建一个模板类对象的过程称为模板的实例化。1
2
3
4
5
6
7
8
9Grid<int> myIntGrid; // declares a grid that stores ints,
Grid<double> myDoubleGrid(11, 11); // declares an 11x11 Grid of doubles
myIntGrid.at(0, 0) = 10;
int x = myIntGrid.at(0, 0).value_or(0);
Grid<int> grid2 (myIntGrid); // Copy constructor
Grid<int> anotherIntGrid;
anotherIntGrid = grid2;
// Assignment operator
这里使用了value_or()。at()方法返回stl::optional引用。optional可包含值,也可不包含值。如果optional包含值,value_or()方法返回这个值;否则返回给value_or()提供的实参。
可在堆上动态分配Grid模板实例:1
2
3auto myGridOnHeap = make_unique<Grid<int>>(2, 2); // 2x2 Grid on the heap
myGridOnHeap->at(0, 0) = 10;
int x = myGridOnHeap->at(0, 0).value_or(0);
尖括号
本书的一些示例使用带双尖括号的模板,例如:1
std::vector<std::vector<T>> mCells;
自C++11以来,上述语法都是正确的。但在C++11之前,双尖括号>>只表示>>运算符。根据所涉及的类型,这个>>运算符可以是右移位运算符或流提取运算符。这与模板代码相左,因为必须在双尖括号之间放置一个空格。前面的声明可以写为:1
std::vector<std::vector<T> > mCells;
编译器处理模板的原理
编译器遇到模板方法定义时,会进行语法检查,但是并不编译模板。编译器无法编译模板定义,因为它不知道要使用什么类型。编译器遇到一个实例化的模板时,例如Grid<int> myIntGrid,就会将模板类定义中的每一个T替换为int,从而生成Grid模板的int版本代码。编译器生成代码的方式就好像语言不支持模板时程序员编写代码的方式:为每种元素类型编写一个不同的类。
选择性实例化
编译器总为泛型类的所有虚方法生成代码。但对于非虚方法,编译器只会为那些实际为某种类型调用的非虚方法生成代码。例如,给定前面定义的Grid模板类,假设在main()中编写这段代码:1
2Grid<int> myIntGrid;
myIntGrid.at(0, 0) = 10;
编译器只会为int版本的Grid类生成无参构造函数、析构函数和非常量at()方法的代码,不会为其他方法生成代码,例如复制构造函数、赋值运算符或getHeight()。
模板对类型的要求
编写与类型无关的代码时,肯定对这些类型有一些假设。如果在程序中试图用一种不支持模板使用的所有操作的类型对模板进行实例化,那么这段代码无法编译,而且错误消息几乎总是晦涩难懂。然而,就算要使用的类型不支持所有模板代码所需的操作,也仍然可以利用选择性实例化使用某些方法,而避免使用另一些方法。
将模板代码分布在多个文件中
在任何使用了模板的源代码文件中,编译器都应该能同时访问模板类定义和方法定义。
将模板定义放在头文件中
方法定义可与类定义直接放在同一个头文件中。当使用了这个模板的源文件通过include包含这个文件时,编译器就能访问需要的所有代码。该机制用于前面的Grid实现。此外,还可将模板方法定义放在另一个头文件中,然后在类定义的头文件中通过#include包含这个头文件。一定要保证方法定义的#include在类定义之后,否则代码无法编译。例如:1
2
3
4template <typename T>
class Grid { };
任何需要使用Grid模板的客户只需要包含Grid.h头文件即可。这种分离方式有助于分开类定义和方法定义。
将模板定义放在源文件中
将方法实现放在头文件中看上去很奇怪。如果不喜欢这种语法,可将方法定义放在一个源代码文件中。然而,仍然需要让使用模板的代码能访问到定义,因此可在模板类定义头文件中通过#include包含类方法实现的源文件。尽管如果之前没有看过这种方式,会感到有点奇怪,但是这在C++中是合法的。头文件如下所示:1
2
3
4
5template <typename T>
class Grid {
};
// Class definition omitted for brevity
使用这种技术时,一定不要把Grid.cpp文件添加到项目中,因为这个文件本不应在项目中,而且无法单独编译;这个文件只能通过#include包含在一个头文件中。
实际上,可任意命名包含方法实现的文件。有些程序员喜欢给包含的源代码文件添加.inl后缀,例如Grid.inl。
限制模板类的实例化
如果希望模板类仅用于某些已知的类型,就可使用下面的技术。1
2
3
4
5
6
7
8
template <typename T>
Grid<T>::Grid(size_t width, size_t height) : mWidth(width), mHeight (height) {
mCells.resize(mWidth);
for (auto& column : mCells)
column.resize(mHeight);
}
为使这个方法能运行,需要给允许客户使用的类型显式实例化模板。这个文件的末尾应如下所示:1
2
3
4// Explicit instantiations for the types you want to allow.
template class Grid<int>;
template class Grid<double>;
template class Grid<std::vector<int>>;
有了这些显式的实例化,就不允许客户代码给其他类型使用Grid类模板。
使用显式类模板实例化,无论是否调用方法,编译器都会为类模板的所有方法生成代码。
模板参数
template <typename T>这个参数列表类似于函数或方法中的参数列表。与函数或方法一样,可使用任意多个模板参数来编写类。此外,这些参数未必是类型,而且可以有默认值。
非类型的模板参数
非类型的模板参数只能是整数类型(char、int、 long 等)、枚举类型、指针、引用和std:nullptr_t。从C++17开始,可指定auto、auto&和auto*等作为非类型模板参数的类型。此时,编译器会自动推导类型。在模板列表中指定非类型参数而不是在构造函数中指定的主要好处是:在编译代码之前就知道这些参数的值了。下面是新的类定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16template <typename T, size_t WIDTH, size_t HEIGHT>
class Grid {
public:
Grid() = default;
virtual ~Grid() = default;
// Explicitly default a copy constructor and assignment operator.
Grid(const Grid& src) = default;
Grid<T, WIDTH, HEIGHT>& operator= (const Grid& rhs) = default;
std::optional<T>& at(size_t x, size_t y);
const std::optional<T>& at (size_t x, size_t y) const;
size_t getHeight() const { return HEIGHT; }
size_t getwidth() const { return WIDTH; }
private:
void verifyCoordinate(size_t X, size_t y) const;
std::optional<T> mCells [WIDTH] [HEIGHT];
};
这个类没有显式地将移动构造函数和移动赋值运算符设置为默认,原因是C风格的数组不支持移动语义。注意,模板参数列表需要3个参数:网格中保存的对象类型以及网格的宽度和高度。宽度和高度用于创建保存对象的二维数组。下面是类方法定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17template <typename T, size_t WIDTH, size_t HEIGHT>
void Grid<T, WIDTH, HEIGHT>::verifyCoordinate(size_t x, size_t y) const {
if (x >= WIDTH || y >= HEIGHT) {
throw std::out_of_range ("") ;
}
}
template <typename T, size_t WIDTH, size_t HEIGHT>
const std::optional<T>& Grid<T, WIDTH, HEIGHT>::at(size_t x, size_t y) const {
verifyCoordinate(x, y);
return mCells[x] [y];
}
template <typename T, size_t WIDTH, size_t HEIGHT>
std::optional<T>& Grid<T, WIDTH, HEIGHT>::at(size_t x, size_t y) {
return const_cast<std::optional<T>&> (std::as_const(*this).at(x, y));
}
注意之前所有指定Grid<T>的地方,现在都必须指定Grid<T, WIDTH, HEIGHT>来表示这3个模板参数。可通过以下方式实例化这个模板:1
2
3
4
5Grid<int, 10, 10> myGrid;
Grid<int, 10, 10> anotherGrid;
myGrid.at(2, 3) = 42;
anotherGrid = myGrid;
cout << anotherGrid.at(2, 3).value_or(0);
这段代码看上去很棒。遗憾的是,实际中的限制比想象中的要多。首先,不能通过非常量的整数指定高度或宽度。下面的代码无法编译:1
2size_t height = 10;
Grid<int, 10, height> testGrid; // DOES NOT COMPILE
然而,如果把height声明为const,这段代码就可以编译了:1
2const size_t height = 10;
Grid<int, 10, height> testGrid; // Compiles and works
带有正确返回类型的constexpr函数也可以编译。例如,如果有一个返回size_t的constexpr函数,就可以使用它初始化height模板参数:1
2constexpr size_t getHeight() { return 10; }
Grid<double,2,getHeight()> myDoubleGrid;
另一个限制可能更明显。既然宽度和高度都是模板参数,那么它们也是每种网格类型的一部分。这意味着Grid<int, 10, 10>和Grid<int, 10, 11>是两种不同类型。不能将一种类型的对象赋给另一种类型的对象,而且一种类型的变量不能传递给接收另一种类型的变量的函数或方法。
非类型模板参数是实例化的对象的类型规范中的一部分。
类型参数的默认值
如果继续采用将高度和宽度作为模板参数的方式,就可能需要为高度和宽度(它们是非类型模板参数)提供默认值,就像之前Grid<T>类的构造函数一样。C++允许使用类似的语法向模板参数提供默认值。在这里也可
以给T类型参数提供默认值。下面是类定义:1
2
3
4template <typename T = int, size_t WIDTH = 10, size_t HEIGHT = 10>
class Grid
// Remainder is identical to the previous version .
};
不需要在方法定义的模板规范中指定T、WIDTH和HEIGHT的默认值。例如,下面是at()方法的实现:1
2
3
4
5template <typename T, size_t WIDTH, size_t HEIGHT>
const std::optional<T>& Grid<T, WIDTH, HEIGHT>::at(size_t x, size_t y) const {
verifyCoordinate(x, y);
return mCells[x][y];
}
现在,实例化Grid时,可不指定模板参数,只指定元素类型,或者指定元素类型和宽度,或者指定元素类型、宽度和高度:1
2
3
4Grid<> myIntGrid;
Grid<int> myGrid;
Grid<int, 5> anotherGrid;
Grid<int, 5, 5> aFourthGrid;
构造函数的模板参数推导
C++17添加了一些功能,支持通过传递给类模板构造函数的实参自动推导模板参数。在C++17之前,必须显式地为类模板指定所有模板参数。函数模板始终支持基于传递给函数模板的实参自动推导模板参数。因此,make_pair()能根据传递给它的值自动推导模板类型参数。例如,编译器为以下调用推导pair<int, double>:1
auto pair2 = std::make_pair(1, 2.3);
在C++17中,不再需要这样的辅助函数模板。现在,编译器可以根据传递给构造函数的实参自动推导模板类型参数。对于pair类模板,只需要编写以下代码:1
std::pair pair3(1, 2.3);
当然,推导的前提是类模板的所有模板参数要么有默认值,要么用作构造函数中的参数。
用户定义的推导原则
也可编写自己的推导原则,即用户定义的推导原则。这允许你编写如何推导模板参数的规则。这是一个高级主题,这里不对其进行详细讨论,但会举一个例子来演示其功能。假设具有以下SpreadsheetCell类模板:1
2
3
4
5
6
7
8template<typename T>
class SpreadsheetCell {
public:
SpreadsheetCell (const T& t) : mContent(t) { }
const T& getContent() const { return mContent; }
private:
T mContent;
};
通过自动推导模板参数,可使用std::string类型创建SpreadsheetCell:1
2std::string myString = "Hello world!";
SpreadsheetCell cell (myString) ;
但是,如果给SpreadsheetCell构造函数传递const char*,那么会将类型T推导为const char*,这不是需要的结果。可创建以下用户定义的推导原则,在将const char*作为实参传递给构造函数时,将T推导为std::string:1
SpreadsheetCell (const char*) -> SpreadsheetCell<std::string>;
方法模板
C++允许模板化类中的单个方法。这些方法可以在类模板中,也可以在非模板化的类中。但是不能用方法模板编写虚方法和析构函数。
在Grid类中添加模板化的复制构造函数和赋值运算符,可生成将一种网格类型转换为另一种网格类型的方法。下面是新的Grid类定义:1
2
3
4
5
6
7
8
9
10
11template <typename T>
class Grid {
public:
template < typename E>
Grid(const Grid<E>& src);
template <typename E>
Grid<T>& operator= (const Grid<E>& rhs);
void swap (Grid& other) noexcept;
};
首先检查新的模板化的复制构造函数:1
Grid(const Grid<E>& src);
可看到另一个具有不同类型名称E(Element的简写)的模板声明。这个类在类型T上被模板化,这个新的复制构造函数又在另一个不同的类型E上被模板化。通过这种双重模板化可将一种类型的网格复制到另一种类型
的网格。下面是新的复制构造函数的定义:1
2
3
4
5
6
7template <typename T>
template <typename E>
Grid<T>::Grid(const Grid<E>& src) : Grid (src.getwidth(), src.getHeight()) {
for (size_t i = 0; i < mWidth; i++)
for (size_t j = 0; j < mHeight; j++)
mCells[i][j] = src.at(i, j);
}
可以看出,必须将声明类模板的那一行(带有T参数)放在成员模板的那一行声明(带有E参数)的前面。不能像下面这样合并两者:1
2template <typename T, typename E> // Wrong for nested template constructor!
Grid<T>::Grid(const Grid<E>& src)
除了构造函数定义之前的额外模板参数行之外,注意必须通过公共的访问方法getWidth()、getHeight()和at()访问src中的元素。这是因为复制目标对象的类型为Grid<T>,而复制来源对象的类型为Grid<E>。 这两者不是同一类型,因此必须使用公共方法。
模板化的赋值运算符接收const Grid<E>&作为参数,但返回Grid<T>&:1
2
3
4
5
6
7template <typename T>
template <typename E>
Grid<T>& Grid<T>::operator= (const Grid<E>& rhs) {
Grid<T> temp(rhs); // Do all the work in a temporary instance
swap(temp) ; // Commit the work with only non-throwing operations
return *this;
}
带有非类型参数的方法模板
有了赋值运算符和复制构造函数的方法模板后,完全可实现对不同大小的网格进行赋值和复制。下面是类定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19template <typename T, size_t WIDTH = 10, size_t HEIGHT = 10>
class Grid {
public:
Grid(const Grid& src) = default;
Grid<T, WIDTH, HEIGHT>& operator=(const Grid& rhs) = default;
template <typename E, size_t WIDTH2, size_t HEIGHT2>
Grid(const Grid<E, WIDTH2, HEIGHT2>& src) ;
template <typename E, size_t WIDTH2, size_t HEIGHT2>
Grid<T, WIDTH, HEIGHT>& operator= (const Grid<E, WIDTH2, HEIGHT2>& rhs);
void swap (Grid& other) noexcept;
std::optional<T>& at(size_t x, size_t y);
const std::optional<T>& at(size_t x, size_t y) const;
size_t getHeight() const { return HEIGHT; }
size_t getwidth() const { return WIDTH; }
private:
void verifyCoordinate(size_t x, size_t y) const; .
std::optional<T> mCells [WIDTH] [HEIGHT];
};
这个新定义包含复制构造函数和赋值运算符的方法模板,还包含辅助方法swap()。注意,将非模板化的复制构造函数和赋值运算符显式设置为默认(原因在于用户声明的析构函数)。这些方法只是将mCells从源对象复制或赋值到目标对象,语义和两个一样大小的网格的语义完全一致。
下面是模板化的复制构造函数:1
2
3
4
5
6
7
8
9
10
11
12
13template <typename T, size_t WIDTH, size_t HEIGHT>
template <typename E, size t WIDTH2, size t HEIGHT2>
Grid<T, WIDTH, HEIGHT>::Grid(const Grid<E, WIDTH2, HEIGHT2>& src) {
for (size_t i; i < WIDTH; i++) {
for (size_t j; j < HEIGHT; j ++) {
if(i < WIDTH2 && j < HEIGHT2 ) {
mCells[i][j] = src.at(i, j);
} else {
mcells[i][j].reset();
}
}
}
}
类模板的特例化
模板的另一个实现称为模板特例化(template specialization)。编写一个模板类特例化时,必须指明这是一个模板,以及正在为哪种特定的类型编写这个模板。下面是为const char*特例化:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Grid<const char*> {
public:
explicit Grid(size_t width = kDefaultwidth, size_t height = kDefaultHeight);
virtual ~Grid() = default;
// Explicitly default a copy constructor and ass ignment operator.
Grid<const char*>& operator= (const Grid& rhs) = default;
// Explicitly default a move constructor and assignment operator.
Grid<const char*>& operator= (Grid&& rhs) = default;
std::optional<std::string>& at(size_t x, size_t y);
const std::optional<std::string>& at(size_t x, size_t y) const;
size_t getHeight() const { return mHeight; }
size_t getwidth() const { return mWidth;}
static const size_t kDefaultwidth = 10;
static const size_t kDefaultHeight = 10;
private:
void verifyCoordinate(size_t x, size_t y) const;
std::vector<std::vector<std::optional<std::string>>> mCells; .
size_t mWidth, mHeight;
};
1 | template <> |
上述语法告诉编译器,这个类是Grid类的const char*特例化版本。假设没有使用这种语法,而是尝试编写下面这样的代码:1
class Grid
编译器不允许这样做,因为已经有一个名为Grid的类(原始的类模板)。只能通过特例化重用这个名称。特例化的主要好处就是可对用户隐藏。当用户创建int或SpreadsheetCell类型的Grid时,编译器从原始的Grid 模板生成代码。当用户创建const char*类型的Grid时,编译器会使用const char*的特例化版本。这些全部在后台自动完成。
下面是const char*特例化版本的方法的实现。与模板定义不同,不必在每个方法定义之前重复template<>语法:1
2
3
4
5
6Grid<const char*>::Grid(size_t width, size_t height) : mWidth(width), mHeight (height) {
mCells.resize (mWidth);
for (auto& column : mCells){
column.resize (mHeight) ;
}
}
从类模板派生
可从类模板派生。如果一个派生类从模板本身继承,那么这个派生类也必须是模板。此外,还可从类模板派生某个特定实例,这种情况下,这个派生类不需要是模板。下面针对前一种情况举一个例子:1
2
3
4
5
6template <typename T>
class GameBoard : public Grid<T> {
public:
explicit GameBoard(size_t width = Grid<T>::kDefaultwidth, size_t height = Grid<T>::kDefaultHeight);
void move(size_t xSrc, size_t ySrc, size_t xDest, size_t yDest);
};
继承的语法和普通继承一样,区别在于基类是Grid<T>,而不是Grid。: public Grid<T>语法表明,这个类继承了Grid实例化对类型参数T有意义的所有内容。
下面是构造函数和move()方法的实现。同样,要注意调用基类构造函数时对Grid<T>的使用。此外,尽管很多编译器并没有强制使用this指针或Grid<T>::引用基类模板中的数据成员和方法,但名称查找规则要求使用this指针或Grid<T>::。1
2
3
4
5
6
7
8
9
10
11template <typename T>
GameBoard<T>::GameBoard(size_t width, size_t height) : Grid<T> (width, height) { }
template <typename T>
void GameBoard<T>::move(size_t xSrc, size_t ySrc, size_t xDest, size_t yDest) {
Grid<T>::at(xDest, yDest) = std::move (Grid<T>::at(xSrc, ySrc));
Grid<T>::at(xSrc, ySrc).reset();
// or:
// this->at (xDest, yDest) = std::move (this->at(xSrc, ySrc));
// this->at (xSrC, ySrc).reset() ;
}
继承还是特例化
表12-1总结了两者的区别。
通过继承来扩展实现和使用多态。通过特例化自定义特定类型的实现。
模板别名
可使用类型别名给模板化的类赋予另一个名称。假定有如下类模板:1
2template<typename T1, typename T2>
class MyTemplateClass { };
可定义如下类型别名,给定两个模板类型参数:1
using OtherName = MyTemplateClass<int, double>;
还可仅指定一些类型, 其他类型则保持为模板类型参数,这称为别名模板(alias template),例如:1
2template<typename T1>
using OtherName = MyTemplateClass<T1, double>;
函数模板
还可为独立函数编写模板。例如,可编写一个通用函数,该函数在数组中查找一个值并返回这个值的索引:1
2
3
4
5
6
7
8
9static const size_t NOT_FOUND = static_cast<size_t>(-1);
template <typename T>
size_t Find(const T& value, const T* arr, size_t size) {
for(size_t i = 0; i < size; i ++){
if (arr[i] == value)
return i; // Found it; return the index
}
return NOT_FOUND; // Failed to find it; return NOT_FOUND
}
可通过两种方式调用这个函数;一种是通过尖括号显式地指定类型;另一种是忽略类型,让编译器根据参数自动推断类型。下面列举一些例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26int myInt = 3, intArray[] = {1, 2, 3, 4};
const size_t sizeIntArray = std::size(intArray);
size_t res;
res = Find(myInt,intArray, sizeIntArray); // calls Find<int> by deduction
res = Find<int>(myInt, intArray, sizeIntArray); // calls Find<int> explicitly
if (res != NOT_FOUND)
cout << res << endl;
else
cout << "Not found" << endl;
double myDouble = 5.6, doubleArray[] = {1.2, 3.4, 5.7, 7.5};
const size_t sizeDoubleArray = std::size(doubleArray);
// calls Find<double> by deduction
res = Find (myDouble, doubleArray, sizeDoubleArray);
// calls Find<double> explicitly
res = Find<double>(myDouble, doubleArray, sizeDoubleArray);
if (res != NOT_FOUND)
cout << res << endl;
else
cout << "Not found" << endl;
res = Find<double> (myInt, doubleArray, sizeDoubleArray);
SpreadsheetCe1l cell1(10), cellArray[] = {SpreadsheetCell(4), SpreadsheetCel1(10) };
const size_t sizeCellArray = std::size(cellArray);
res = Find(cell1, cellArray, sizeCellArray) ;
res = Find<Spreadsheetcell>(celll, cellArray, sizeCellArray) ;
前面Find()函数的实现需要把数组的大小作为一个参数。有时编译器知道数组的确切大小,例如,基于堆栈的数组。用这种数组调用Find()函数,就不需要传递数组的大小。为此,可添加如下函数模板。该实现仅把调用传递给前面的Find()函数模板。这也说明函数模板可接收非类型的参数,与类模板一样。1
2
3
4template <typename T, size_t N>
size_t Find(const T& value, const T(&arr) [N]) {
return Find(value, arr, N);
}
与类模板方法定义一样,函数模板定义(不仅是原型)必须能用于使用它们的所有源文件。因此,如果多个源文件使用函数模板,或使用本章前面讨论的显式实例化,就应把其定义放在头文件中。函数模板的模板参数可以有默认值,与类模板一样。
函数模板的特例化
就像类模板的特例化一样,函数模板也可特例化。1
2
3
4
5
6
7template<>
size_t Find<const char*> (const char* const& value, const char* const* arr, size_t size) {
for (size_t i = 0; i < size; i++)
if (strcmp(arr[i], value) == 0)
return i; // Found it; return the index
return NOT_FOUND; // Failed to find it; return NOT_FOUND
}
如果参数类型可通过参数推导出来,那么可在函数名中忽略<const char*>,将这个函数原型简化为:1
2template<>
size_t Find(const char* const& value, const char* const* arr, size_t size)
函数模板的重载
还可用非模板函数重载模板函数。例如,如果不编写用于const char*的Find()函数模板,那么需要编写一个非模板的独立Find()函数以直接操作const char*:1
2
3
4
5
6size_t Find(const char* const& value, const char* const* arr, size_t size) {
for(size_t i = 0; i < size; i ++)
if (strcmp(arr[i], value) == 0)
return i;
return NOT_FOUND;
}
这个函数的调用规则有所不同:1
2
3
4
5
6const char* word = "two";
const char* words [] = {"two", "three", "four"};
const size_t sizeWords = std::size(words);
size_t res;
res = Find(word, words, sizeWords) ; // Calls non-template function!
因此,如果想要函数在显式指定了const char*时能正常工作,以及在没有指定时能通过自动类型推导正常工作,那么应该编写一个特例化的模板版本,而不是编写一个非模板的重载版本。
同时使用函数模板重载和特例化
可同时编写一个适用于const char*的特例化Find()函数模板,以及一个适用于const char*的独立Find()函数。编译器总是优先选择非模板化的函数,而不是选择模板化的版本。然而,如果显式地指定模板的实例化,那么会强制编译器使用模板化的版本。
类模板的友元函数模板
如果需要在类模板中重载运算符,函数模板会非常有用。假定operator+是一个独立的函数模板,其定义应该直接放在Grid.h中,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17template <typename T>
Grid<T> operator+ (const Grid<T>& lhs,const Grid<T>& rhs) {
size_t minwidth = std::min (lhs.getwidth(), rhs.getwidth());
size_t minHeight = std::min(lhs.getHeight(), rhs.getHeight());
Grid<T> result (minWidth, minHeight);
for (size_t y = 0; y < minHeight; ++y) {
for (size_t x = 0; x < minWidth; ++x) {
const auto& leftElement = lhs.mCells[x][y];
const auto& rightElement = rhs.mCells[x][y];
if(leftElement.has_value() && rightElement.has_value())
result.at(x, y) = leftElement.value() + rightElement.value();
}
}
return result;
}
对模板参数推导的更多介绍
编译器根据传递给函数模板的实参来推导模板参数的类型;而对于无法推导的模板参数,则需要显式指定。例如,如下add()函数模板需要三个模板参数:返回值的类型以及两个操作数的类型。1
2template<typename RetType, typename T1, typename T2>
RetType add(const T1& t1, const T2& t2) { return t1+t2;}
调用这个函数模板时,可指定如下所有三个参数:1
auto result = add<long long, int, int>(1, 2);
但由于模板参数T1和T2是函数的参数,编译器可以推导这两个参数,因此调用add()时可仅指定返回值的类型:1
auto result = add<long long>(1, 2);
当然,仅在要推导的参数位于参数列表的最后时,这才可行。假设以如下方式定义函数模板:1
2template<typename T1, typename RetType, typename T2>
RetType add(const T1& t1, const T2& t2) { return t1 + t2; }
必须指定RetType,因为编译器无法推导该类型。但由于RetType 是第二个参数,因此必须显式指定T1:1
auto result = add<int, long 1ong>(1, 2);
也可提供返回类型模板参数的默认值,这样调用add()时可不指定任何类型:1
2
3template<typename RetType = long long, typename T1,typename T2>
RetType add(const T2& t2) { return t1 + t2; }
auto result = add(1, 2);
函数模板的返回类型
add()函数模板的返回类型取决于模板类型参数,如何才能做到这一点?例如,考虑如下模板函数:1
2template<typename T1, typename T2>
RetType add(const T1& t1, const T2& t2) { return t1 + t2; }
在这个示例中,RetType应当是表达式t1+t2的类型,但由于不知道T1和T2是什么,因此并不知道这一点。只需要编写如下add()函数模板:1
2
3auto add(const T1& t1, const T2& & t2) {
return t1 + t2;
}
但是,使用auto来推导表达式类型时去掉了引用和const限定符;decltype没有去除这些。在继续使用add()函数模板前,先分析auto和decltype(使用非模板示例)之间的区别。假设有以下函数:1
2
3
4const std::string message = "Test";
const std::string& getString() {
return message;
}
auto s1 = getString();,由于auto会去掉引用和const限定符,因此s1的类型是string,并制作一个副本。如果需要一个const引用,可将其显式地设置为引用,并标记为const,如下所示:1
const auto& s2 = getString();
另一个解决方案是使用decltype,decltype不会去掉引用和const限定符:1
decltype (getString()) s3 = getString();
这里,s3的类型是const string&,但存在代码冗余,因为需要将getString()指定两次。如果getString()是更复杂的表达式,这将很麻烦。为解决这个问题,可使用decltype(auto):1
decltype(auto) s4 = getString();
s4的类型也是const string&。
了解到这些后,可使用decltype(auto)编写add()函数,以避免去掉任何const和引用限定符:1
2
3
4template<typename T1, typename T2>
decltype (auto) add (const T1& t1, const T2& t2) {
return t1 + t2;
}
在C++14之前,不支持推导函数的返回类型和decltype(auto)。C++11 引入的decltype(expression)解决了这个问题。例如,你或许会编写如下代码:1
2template<typename T1,typename T2>
decltype(t1+t2) add(const T1& t1, const T2& t2) { return t1 + t2; }
但这是错误的。你在原型行的开头使用了t1和t2,但这些尚且不知。在语义分析器到达参数列表的末尾时,才能知道t1和t2。
通常使用替换函数语法(alternative function syntax)解决这个问题。注意在这种新语法中,返回类型是在参数列表之后指定的(拖尾返回类型),因此在解析时参数的名称(以及参数的类型,因此也包括t1+t2类型)是已知的:1
2
3
4template<typename T1, typename T2>
auto add(const T1& t1, const T2& t2) -> decltype(t1+t2) {
return t1 + t2;
}
但现在,C++支持自动返回类型推导和decltype(auto),建议你使用其中的一种机制, 而不要使用替换函数语法。
可变模板
除了类模板、类方法模板和函数模板外,C++14 还添加了编写可变模板的功能。语法如下:1
2template <typename T>
constexpr T pi = T(3.141592653589793238462643383279502884);
这是pi值的可变模板。为了在某种类型中获得pi值,可使用如下语法:1
2float piFloat = pi<float>;
long double piLongDouble = pi<long double>;
这样总会得到在所请求的类型中可表示的pi近似值。与其他类型的模板一样, 可变模板也可以特殊化。
C++ IO揭秘
C++通过流(stream)提供了更精良的输入输出方法。流是一种灵活且面向对象的IO方法。
使用流
流的含义
所有的流都可以看成数据滑槽。流的方向不同,关联的来源和目的地也不同。cout和cin都是C++在std名称空间中预定义的流实例。表13-1简要描述了所有预定义的流。
| 流 | 说明 |
|---|---|
| cin | 输入流,从“输入控制台”读取数据 |
| cout | 缓冲的输出流,向“输出控制台”写入数据 |
| cerr | 非缓冲的输出流,向“错误控制台”写入数据,“ 错误控制台”通常等同于“输出控制台” |
| clog | cerr的缓冲版本 |
缓冲的流和非缓冲的流的区别在于,前者不是立即将数据发送到目的地,而是缓冲输入的数据,然后以块方式发送;而非缓冲的流则立即将数据发送到目的地。缓冲的目的通常是提高性能,对于某些目的地(如文件)而言,一次性写入较大的块时速度更快。注意,始终可使用flush()方法刷新缓冲区,强制要求缓冲的流将其当前所有的缓冲数据发送到目的地。
有关流的另一个要点是:流不仅包含普通数据,还包含称为当前位置(current position)的特殊数据。当前位置指的是流将要进行下一次读写操作的位置。
流的来源和目的地
在C++中,流可使用3个公共的来源和目的地:控制台、文件和字符串。
- 控制台输入流允许程序在运行时从用户那里获得输入,使程序具有交互性。
- 文件流从文件系统中读取数据并向文件系统写入数据。
- 字符串流是将流隐喻应用于字符串类型的例子。使用字符串流时,可像处理其他任何流一样处理字符数据。
流式输出
输出的基本概念
输出流定义在<ostream>头文件中。大部分程序员都会在程序中包含<iostream>头文件,这个头文件又包含输入流和输出流的头文件。<iostream>头文件还声明了所有预定义的流实例:cout、cin、cerr、clog以及对应的宽版本。
使用输出流的最简单方法是使用<<运算符。通过<<可输出C++的基本类型。此外,C++的string类也兼容<<。
cout流是写入控制台的内建流,控制台也称为标准输出(standard output)。可将<<的使用串联起来,从而输出多个数据段。这是因为<<运算符返回一个流的引用,因此可以立即对同一个流再次应用<<运算符。
C++流可正确解析C风格的转义字符,例如包含\n的字符串,也可使用std::endl开始一个新行。\n和endl的区别是,\n仅开始一个新行,而endl还会刷新缓存区。使用endl时要小心,因为过多的缓存区刷新会降低性能。
输出流的方法
put()和write()
put()和write()是原始的输出方法。这两个方法接收的不是定义了输出行为的对象或变量,put()接收单个字符,write()接收一个字符数组。传给这些方法的数据按照原本的形式输出,没有做任何特殊的格式化和处理操作。例如,下面的代码段接收一个C风格的字符串,并将它输出到控制台,这个函数没有使用<<运算符:1
2const char* test = "hello there\n";
cout.write(test, strlen(test));
下面的代码段通过put()方法,将C风格字符串的给定索引输出到控制台:1
cout.put('a');
flush()
向输出流写入数据时,大部分输出流都会进行缓冲,也就是积累数据,而不是立即将得到的数据写出去。在以下任意一种条件下,流将刷新(或写出)积累的数据:
- 遇到sentinel(如endl标记)时。
- 流离开作用域被析构时。
- 要求从对应的输入流输入数据时(即要求从cin输入时,cout会刷新)。
- 流缓存满时。
- 显式地要求流刷新缓存时。
显式要求流刷新缓存的方法是调用流的flush()方法。
不是所有的输出流都会缓存。例如,cer 流就不会缓存其输出。
处理输出错误
当一个流处于正常的可用状态时,称这个流是“好的”。调用流的good()方法可以判断这个流当前是否处于正常状态。1
2if(cout.good())
cout << "All good" << end1;
通过good()方法可方便地获得流的基本验证信息,但不能提供流不可用的原因。还有一个bad()方法提供了稍多信息。如果bad()方法返回true,意味着发生了致命错误(相对于非致命错误,例如到达文件结尾)。另一个方法fail()在最近一次操作失败时返回true,但没有说明下一次操作是否也会失败。例如,对输出流调用flush()后,可调用fail()确保流仍然可用。1
2
3cout.flush();
if(cout.fall())
cerr << "Unable to flush to standard out" << endl;
流具有可转换为bool类型的转换运算符。转换运算符与调用fail()时返回的结果相同。因此,可将前面的代码段重写为:1
2
3cout.flush();
if (!cout)
cerr << "Unable to flush to standard out" << endl;
有一点需要指出,遇到文件结束标记时,
good()和fail()都会返回false。关系如下:good() == (!fail() && !eof())。
还可要求流在发生故障时抛出异常。然后编写一个catch处理程序来捕捉ios_base::failure异常,然后对这个异常调用what()方法,获得错误的描述信息,调用code()方法获得错误代码。不过,是否能获得有用信息取决于所使用的标准库实现:1
2
3
4
5
6cout.exceptions(ios::failbit | ios::badbit | ios::eofbit);
try {
cout << "Hello World." << endl;
} catch (const ios_base::failure& ex) {
cerr << "Caught exception:" << ex.what() << ", error code ="<< ex.code() << endl;
}
输出操作算子
C++流还能识别操作算子(manipulator),操作算子是能修改流行为的对象,而不是(或额外提供)流能够操作的数据。
endl就是一个操作算子。endl操作算子封装了数据和行为。它要求流输出一个行结束序列,并且刷新缓存。其他有用的操作算子大部分定义在<ios>和<iomanip>标准头文件中。列表后的例子展示了如何使用这些操作算子。
- boolalpha和noboolalpha:要求流将布尔值输出为
true和false(boolalpha)或1和0(noboolalpha)。默认行为是noboolalpha。 - hex、oct和dec:分别以十六进制、八进制和+进制输出数字。
- stprecision:设置输出小数时的小数位数。这是一个参数化的操作算子。
- setw:设置输出数值数据的字段宽度。这是一个参数化的操作算子。
- setfill:当数字宽度小于指定宽度时,设置用于填充的字符。这是一个参数化的操作算子。
- showpoint和noshowpoint:对于不带小数部分的浮点数,强制流总是显示或不显示小数点。
- put_money:一个参数化的操作算子,向流写入一个格式化的货币值。
- put_time:一个参数化的操作算子,向流写入一个格式化的时间值。
- quoted:一个参数化的操作算子,把给定的字符串封装在引号中,并转义嵌入的引号。
上述操作算子对后续输出到流中的内容有效,直到重置操作算子为止,但setw仅对下一个输出有效。
如果不关心操作算子的概念,通常也能应付过去。流通过precision()这类方法提供了大部分相同的功能。以如下代码为例:1
cout << "This should be '1.2346': "<< setprecision(5) << 1.23456789 << endl;
这行代码可转换为方法调用。该方法的优点是,它们返回前面的值以便恢复:1
2cout.precision(5);
cout << "This should be '1.2346'; "<< 1.23456789 << endl;
流式输入
输入流为结构化数据和非结构化数据的读入提供了简单方法。
输入的基本概念
读入数据对应的运算符是>>。通过>>从输入流读入数据时,代码提供的变量保存接收的值。默认情况下,>>运算符根据空白字符对输入值进行标志化。>>运算符可用于不同的变量类型,就像<<运算符一样。
处理输入错误
输入流提供了一些方法用于检测异常情形。大部分和输入流有关的错误条件都发生在无数据可读时。查询输入流状态的最常见方法是在条件语句中访问输入流。例如,只要cin保持在“良好”状态,下面的循环就继续进行:1
while (cin) ( ... )
同时可以输入数据:1
while (cin >> ch) { ... }
还可在输入流上调用good()、bad()和fail()方法,就像输出流那样。还有一个eof()方法,如果流到达尾部,就返回true。与输出流类似,遇到文件结束标记时,good()和fail()都会返回false。关系如下:good() == (!fail() && !eof())。
下面的程序展示了从流中读取数据并处理错误的常用模式。这个程序从标准输入中读取数字,到达文件末尾时显示这些数字的总和。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21int sum = 0;
if (!cin.good()) {
cerr << "Standard input is in a bad state!" << endl;
return 1;
}
int number;
while(!cin.bad()) {
cin >> number:
if (cin.good()) {
sum += number;
} else if (cin.eof()) {
break;
} else if (cin.fail()) {
// Failure!
cin.clear();
// Clear the failure state.
string badToken;
cin >> badToken; // consume the bad input.
err << "WARNTNG:Bad input encountered:" << badToken << endl;
}
}
输入方法
输入流也提供了一些方法,获得相比普通>>运算符更底层的访问功能。
get()
get()方法允许从流中读入原始输入数据。get()的最简单版本返回流中的下一个字符,其他版本一次读入多个字符。get()常用于避免>>运算符的自动标志化。
在条件环境中对一个输入流求值时,只有当这个输入流可以用于下一次读取时才会返回true。如果遇到错误或者到达文件末尾,都会使流求值为false。
unget()
对于大多数场合来说,理解输入流的正确方式是将输入流理解为单方向的滑槽。数据被丢入滑槽,然后进入变量。unget()方法打破了这个模型,允许将数据塞回滑槽。调用unget()会导致流回退一个位置,将读入的前一个字符放回流中。调用fail()方法可查看unget()是否成功。
下面的代码使用了unget(),允许名字中出现空白字符。将这段代码逐字符读入,并检查字符是否为数字。如果字符不是数字,就将字符添加到guestName;如果字符是数字,就通过unget()将这个字符放回到流中,循环停止,然后通过>>运算符输入一个整数partySize。noskipws输入操作算子告知流不要跳过空白字符,就像读取其他任何字符一样读取空白字符。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28vold getReservationData() {
string guestName;
int partySize = 0;
// Read characters until we find a digit
char ch;
cin >> noskipws;
while (cin >> ch) {
if (isdigit(ch)) {
cin.unget();
if(cin.fail ())
cout << "unget() failed" << endl;
break;
}
guestName += ch;
}
// Read partysize, if the stream is not in error state
if (cin)
cin >> partySize;
if (!cin) {
cerr << "Error getting party size." << endl;
return;
}
cout << "Thank you " << guestName << ", party of " << partysize << endl;
if (partysize> 10) {
cout << "An extra gratuity will apply." << endl;
}
}
putback()
putback()和unget()一样,允许在输入流中反向移动一个字符。区别在于putback()方法将放回流中的字符接收为参数:1
2
3
4char ch1;
cin >> chl;
cin.putback('e');
// 'e' will be the next character read oft the stream.
peek()
通过peek()方法可预览调用get()后返回的下一个值。再次以滑槽为例,可想象为查看一下滑槽,但是不把值取出来。peek()非常适合于在读取前需要预先查看一个值的场合。
getine()
getline()方法用一行数据填充字符缓存区,数据量最多至指定大小。指定的大小中包括\0字符。因此,下面的代码最多从cin 中读取kBufferSize - 1个字符,或者读到行尾为止:1
2char buffer[kBufferSize] = { 0 };
cin.getline (buffer, kBuffersize);
调用getline()时,从输入流中读取一行,读到行尾为止。不过,行尾字符不会出现在字符串中。有个版本的get()函数执行的操作和getline()一样,区别在于get()把换行序列留在输入流中。
还有一个用于C++字符串的std:getline()函数。这个函数定义在<string>头文件和std名称空间中。它接收一个流引用、一个字符串引用和一个可选的分隔符作为参数。使用这个版本的getine()函数的优点是不需要指定缓存区的大小。1
2string myString;
std::getine(cin, myString);
输入操作算子
下面列出了内建的输入操作算子,它们可发送到输入流中,以自定义数据读入的方式。
- boolalpha和noboolalpha:如果使用了boolalpha,字符串false会被解释为布尔值false;其他任何字符串都会被解释为布尔值true。如果设置了noboolalpha,0会被解释为false,其他任何值都被解释为true。
- hex、oct和dec:分别以十六进制、八进制和十进制读入数字。
- skipws和noskipws:告诉输入流在标记化时跳过空白字符,或者读入空白字符作为标记。默认为skipws。
- ws:一个简便的操作算子,表示跳过流中当前位置的一串空白字符。
- get_money:一个参数化的操作算子,从流中读入一个格式化的货币值。
- get_time:一个参数化的操作算子,从流中读入一个格式化的时间值。
- quoted:一个参数化的操作算子,读取封装在引号中的字符串,并转义嵌入的引号。
字符串流
可通过字符串流将流语义用于字符串。通过这种方式,可得到一个内存中的流(in memory stream)来表示文本数据。字符串流也非常适合于解析文本,因为流内建了标记化的功能。std::ostringstream类用于将数据写入字符串,std::istringtream类用于从字符串中读出数据。这两个类都定义在<sstream>头文件中。由于ostringstream和istringstream把同样的行为分别继承为ostream和istream,因此这两个类的使用也非常类似。
下面的程序从用户那里请求单词,然后输出到一个ostringtream中,通过制表符将单词分开。在程序的最后,整个流通过str()方法转换为字符串对象,并写入控制台。输入标记“done”,可停止标记的输入。1
2
3
4
5
6
7
8
9ostringstream outstream;
while (cin) {
string nextToken;
cout << "Next token:";
cin >> nextToken;
if (!cin || nextToken == "done")
break;
outStream << nextToken << "\t";
}
从字符串流中读入数据非常类似。下面的函数创建一个Muffin对象,并填充字符串输入流中的数据。流数据的格式固定,因此这个函数可轻松地将数据值转换为对Mufin类的设置方法的调用:1
2
3
4
5
6
7
8
9
10
11
12
13
14Muffin createMuffin(istringstream& stream) {
Muffin muftin;
string description;
int size;
bool hasChips;
stream >> description >> size >> boolalpha >> hasChips;
if (stream) {
muffin.setsize(size);
muffin.setDescription (description);
muffin.setHasChocolateChips (hasChipa);
}
return muffin;
}
文件流
文件本身非常符合流的抽象,因为读写文件时,除数据外,还涉及读写的位置。在C++中,std::ofstream和std::ifstream类提供了文件的输入输出功能。这两个类在<fstream>头文件中定义。在处理文件系统时,错误情形的检测和处理非常重要。可以通过前面描述的标准错误处理机制检测错误情形。
输出文件流和其他输出流的唯一主要区别在于:文件流的构造函数可以接收文件名以及打开文件的模式作为参数。默认模式是写文件(ios_base::out),这种模式从文件开头写文件,改写任何已有的数据。给文件流构造
函数的第二个参数指定常量ios_base::app,还可按追加模式打开输出文件流。
| 常量 | 说明 |
|---|---|
| ios_base::app | 打开文件,在每一次写操作之前,移到文件末尾 |
| ios_base::ate | 打开文件,打开之后立即移到文件末尾 |
| ios_base::binary | 以二进制模式执行输入输出操作(相对于文本模式) |
| ios_base::in | 打开文件,从开头开始读取 |
| ios_base::out | 打开文件,从开头开始写入,覆盖已有的数据 |
| ios_base::trunc | 打开文件,并删除(截断)任何已有数据 |
注意,可组合模式。例如,如果要打开文件用于输出(以二进制模式),同时截断现有数据,可采用如下方式指定打开模式:1
ios_base::out | ios_base::binary | ios_base::trunc
ifstream自动包含ios_base::in模式,ofstream自动包含ios_base::out模式,即使不显式地将in或out指定为模式,也同样如此。
下面的程序打开文件ts.txt,并输出程序的参数。istram 和ofstream析构函数会自动关闭底层文件,因此不需要显式调用close():1
2
3
4
5
6
7
8
9
10
11
12int main(int argc, char* argv[]) {
ofstream outFile("test.txt", ios_base::trunc);
if (!outFile.good()) {
cerr << "Error while opening output file!" << endl;
return -1;
}
outFile << "There were " << argc << "arguments to this program." << endl;
outFile << "They are:"<< endl;
for (int i = 0; i ≤ arge; i ++)
outFile << argv[i] << endl;
return 0;
}
文本模式与二进制模式
默认情况下,文件流在文本模式中打开。如果指定ios_base:binary标志,将在二进制模式中打开文件。在二进制模式中,要求把流处理的字节写入文件。读取时,将完全按文件中的形式返回字节。
在文本模式中,会执行一些隐式转换,写入文件或从文件中读取的每一行都以\n结束。但是,行结束符在文件中的编码方式与操作系统相关。因此,如果文件以文本模式打开,而写入的行以\n结尾,在写入文件前,底层实现会自动将\n转换为\r\n。同样,从文件读取行时,从文件读取的\r\n会自动转换回\n。
通过seek()和tell()在文件中转移
所有的输入流和输出流都有seek()和tell()方法。
seek()方法允许在输入流或输出流中移动到任意位置。seek()有好几种形式。输入流中的seek()版本实际上称为seekg(),输出流中的seek()版本称为seekp()。有的流既可以输入又可以输出,例如文件流。这种情况下,流需要记住读位置和独立的写位置。这也称为双向IO。
seekg()和seekp()有两个重载版本。其中一个重载版本接收一个参数:绝对位置。这个重载版本将定位到这个绝对位置。另一个重载版本接收一个偏移量和一个位置,这个重载版本将定位到距离给定位置一定偏移量的位置。位置的类型为std::streampos,偏移量的类型为std::streamoff,这两种类型都以字节计数。预定义的三个位置如表所示。
| 位置 | 说明 |
|---|---|
| ios_base::beg | 表示流的开头 |
| ios_base::end | 表示流的结尾 |
| ios_base::cur | 表示流的当前位置 |
例如,要定位到输出流中的一个绝对位置,可使用接收一个参数的seekp()版本,如下所示,这个例子通过ios_base::beg常量定位到流的开头:1
outStream.seekp(ios_base::beg);
在输入流中,定位方法完全一样, 只不过用的是seekp()方法:1
instream.seekg(ios_base::beg);
接收两个参数的版本可定位到流中的相对位置。第一个参数表示要移动的位置数,第二个参数表示起始点。要相对文件的起始位置移动,使用ios_base::beg常量。要相对文件的末尾位置移动,使用ios_base::end常量。要相对文件的当前位置移动,使用`ios_base::cur常量。例如,下面这行代码从流的起始位置移动到第二个字节。1
outStream.seekp(2, ios_base::beg);
下例转移到输入流中的倒数第3个字节:1
instream.seekg(-3, ios_base::end);
可通过tell()方法查询流的当前位置,这个方法返回一个表示当前位置的streampos值。利用这个结果,可在执行seek()之前记住当前标记的位置,还可查询是否在某个特定位置。和seek()一样,输入流和输出流也有不同版本的tell()。输入流使用的是tellg(),输出流使用的是tellp()。下面的代码检查输入流的当前位置,并判断是否在起始位置:1
2
3std::streampos curPos = instream.tel1g();
if (ios_base::beg == curPos)
cout << "We're at the beginning." << endl;
将流链接在一起
任何输入流和输出流之间都可以建立链接,从而实现“访问时刷新”的行为。换句话说,当从输入流请求数据时,链接的输出流会自动刷新。这种行为可用于所有流,但对于可能互相依赖的文件流来说特别有用。通过tie()方法完成流的链接。要将输出流链接至输入流,对输入流调用tie()方法,并传入输出流的地址。要解除链接,传入nullptr。
下面的程序将一个文件的输入流链接至一个完全不同的文件的输出流。也可链接至同一个文件的输出流。1
2
3
4
5
6
7
8
9
10
11
12
13
14ifstream inFile("input.txt"); // Note:input.txt must exist.
ofstream outFile ("output.txt");
// Set up a link between inFile and outFile.
inFile.tie (&soutFile);
// output some text to outFile. Normally, this would
// not flush because std::endl is not sent.
outFlle << "Hello there!";
// outFlle has NOT been. flushed.
// Read some text from inF1le. This w111 trigger flush()
// on outFile
string nextToken;
inFile >> nextToken;
// outFile HAS been flushed.
这种关系意味着:每次写入一个文件时,发送给另一个文件的缓存数据会被刷新。可通过这种机制保持两个相关文件的同步。
这种流链接的一个例子是cout和cin之间的链接。每当从cin输入数据时,都会自动刷新cout。cerr和cout之间也存在链接,这意味着到cerr的任何输出都会导致刷新cout,而clog未链接到cout。
双向I/O
双向流可同时以输入流和输出流的方式操作。双向流是iostream的子类,而iostream是istream和ostream的子类,因此这是一个多重继承示例。显然,双向流支持>>和<<运算符,还支持输入流和输出流的方法。fstram类提供了双向文件流。fstream特别适用于需要替换文件中数据的应用程序,因为可通过读取文件找到正确的位置,然后立即切换为写入文件。
双向流用不同的指针保存读位置和写位置。在读取和写入之间切换时,需要定位到正确的位置。
错误处理
错误与异常
C++提供了对异常的语言支持,但不要求使用异常。然而,在C++中无法完全忽略异常,因为一些基本工具(例如内存分配例程)会用到它们。
异常的含义
异常是这样一种机制:一段代码提醒另一段代码存在“异常”情况或错误情况,所采用的路径与正常的代码路径不同。遇到错误的代码抛出异常,处理异常的代码捕获异常。当某段代码抛出异常时,程序控制立刻停止逐步执行,并转向异常处理程序(exception handler),异常处理程序可在任何地方,可位于同一函数中的下一行,也可在堆栈中相隔好几个函数调用。
C++中异常的优点
C++错误处理标准使用函数返回的整数代码和errno宏表示错误,每个线程都有自己的errno值。errno用作线程局部整数变量(thread-local integer variable),被调用函数使用这个变量将发生的错误告诉调用函数。整数返回代码和errno的使用并不一致。有些函数可能用返回值0表示成功,用-1表示错误。这些不一致性可能会引起问题,因为程序员在遇到新函数时,会假定它的返回代码与其他类似函数相同。
异常具有许多优点。
- 将返回代码作为报告错误的机制时,调用者可能会忽略返回的代码,不进行局部处理或不将错误代码向上提交。
- 返回的整数代码通常不会包含足够的信息。使用异常时,可将任何信息从发现错误的代码传递到处理错误的代码。除错误信息外,异常还可用来传递其他信息。
- 异常处理可跳过调用堆栈的层次。也就是说,某个函数可处理沿着堆栈进行数次函数调用后发生的错误,而中间函数不需要有错误处理程序。返回代码要求堆栈中每一层调用的函数都必须在前一层之后显式地执行清理。
在现代编译器中,不抛出异常时几乎没有这个开销,实际抛出异常时这一开销也非常小。这并不是坏事,因为抛出异常应是例外情况。在C++中,并不强制异常处理。在C++中函数可抛出它想要抛出的任何异常,除非指定不会抛出任何异常(使用noexcept 关键字)。
异常机制
抛出和捕获异常
为了使用异常,要在程序中包括两部分:处理异常的try/catch结构和抛出异常的throw语句。二者都必须以某种形式出现,以进行异常处理。然而在许多情况下,throw 在一些库的深处发生,程序员无法看到这一点, 但仍然不得不用try/catch结构处理抛出的异常。try/catch 结构如下所示:1
2
3
4
5
6
7try {
// code which may result in an exception being thrown
} catch (exception-type1 exception-name) {
// code which responds to the exception of type 1
} catch (except ion-type2 exception-name) {
// code which responds to the exception of type 2
}
导致抛出异常的代码可能直接包含throw语句,也可能调用一个函数,这个函数可能直接抛出异常,也可能经过多层调用后调用为一个抛出异常的函数。如果没有抛出异常,catch 块中的代码不会执行;如果抛出了异常,throw 语句之后或者在抛出异常的函数后的代码不会执行,根据抛出的异常的类型,控制会立刻转移到对应的catch块。
如果catch块没有执行控制转移(例如返回一个值,抛出新的异常或者重新抛出异常),那么会执行catch块最后语句之后的“剩余代码”。演示异常处理的最简单示例是避免除0。这个示例抛出一个std::invalid_argument类型的异常,这种异常类型需要<stdexcept>头文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15double SafeDivide (double num, double den) {
if (den == 0)
throw invalid_argument("Divide by zero");
return num / den;
}
int main() {
try {
cout << safeDivide(5, 2) << endl;
cout << safeDivide(10, 0) << endl;
cout << SafeDivide(3, 3) << endl;
} catch (const invalid_argument& e) {
cout << "Caught exception:"<< e.what() << endl;
}
return 0;
}
输出如下所示:1
22.5
Caught exception:Divide by zero
throw是C++中的关键字,这是抛出异常的唯一方法。throw行的invalid_argument()部分意味着构建invalid_argument类型的新对象并准备将其抛出。该层次结构中的每个类都支持what()方法,该方法返回一个描述异常的const char*字符串。该字符串在异常的构造函数中提供。
异常处理是这样一种方法:“尝试”执行一块代码,并用另一块代码响应可能发生的任何错误。在下面的main()函数中,catch语句响应任何被try块抛出的exception类型异常,并输出错误消息。如果try块结束时没有抛出异常,catch 块将被忽略。可将try/catch块当作if语句。如果在try块中抛出异常,就会执行catch块,否则忽略catch 块。1
2
3
4
5
6
7
8
9
10
11
12
13
14int main() {
const string fileName = "IntegerFile.txt";
vector<int> myInts;
try {
myInts = readIntegerFile(fileName);
} catch (const exception& e) {
cerr << "Unable to open file "<< fileName << endl;
return 1;
}
for (const auto& element :myInts) {
cout << element << " ";
}
return 0;
}
尽管默认情况下,流不会抛出异常,但是针对错误情况,仍然可以调用exceptions()方法通知流抛出异常。
异常类型
可抛出任何类型的异常。可以抛出一个std:exception类型的对象,但异常未必是对象。也可以抛出一个简单的int值,如下所示:1
2
3
4
5
6
7vector<int> readIntegerFile(string_view fileName) {
ifstream inputstream (fileName.data());
if (inputstream.fail()) {
// We failed to open the file:throw an exception
throw 5;
}
}
此后必须修改catch语句:1
2
3
4
5
6try {
myInts = readIntegerFile (fileName);
} catch (int e) {
cerr << "Unable to open file "<< fileName << "(" << e << ")" << endl;
return 1;
}
另外,也可抛出一个C风格的const char*字符串。这项技术有时有用,因为字符串可包含与异常相关的信息。1
2
3
4
5
6
7vector<int> readIntegerFile(string_view fileName) {
ifstream inputStream (fileName .data());
if (inputStream.fail()) {
// We failed to open the file:throw an exception
throw "Unable to open file";
}
}
当捕获const char*异常时,可输出结果:1
2
3
4
5
6try {
myInts = readIntegerFile (fileName);
} catch (const char* e) {
cerr << e << end1;
return 1;
}
尽管前面有这样的示例,但通常应将对象作为异常抛出,原因有以下两点:
- 对象的类名可传递信息。
- 对象可存储信息,包括描述异常的字符串。
按const和引用捕获异常对象
在前面的示例中,readIntegerFile()抛出一个exception类型的对象。catch 行如下所示:1
) catch (const exception& e) (
然而,在此并没有要求按const引用捕获对象,可按值捕获对象;此外,也可按非const引用捕获对象:
抛出并捕获多个异常
可让函数抛出两种不同类型的异常。invalid_argument和runtime_error都是定义在<stdexcept>头文件中的类,这个头文件是C++标准库的一部分。1
2
3
4
5
6
7
8
9
10
11
12
13
14vector<int> readIntegerFile(string_view fileName) {
ifstream inputstream(fileName.data());
if (inputStream.fail())
throw invalid argument ("Unable to open the file.");
vector<int> integers;
int temp;
while (inputstream >> temp)
integers.push_back(temp);
if (!inputstream.eof())
throw runtime_error("Error reading the file.");
return integers;
}
invalid_argument和runtime_error类没有公有的默认构造函数,只有以字符串作为参数的构造函数。现在main()可用两个catch语句捕获invalid_argument和runtime_error异常:1
2
3
4
5
6
7
8
9try {
...
} catch (const invalid_arguments& e) {
cerr << e.what() << endl;
return 1;
} catch (const runtime_error& e) {
cerr << e.what() << endl;
return 2;
}
如果异常在try块内部抛出,编译器将使用恰当的catch处理程序与异常类型匹配。因此,如果readIntegerFile()无法打开文件并抛出invalid_argument异常,第一个catch语句将捕获这个异常。如果readntegerFile()无法正确读取文件并抛出runtime_error异常,第二个catch语句将捕获这个异常。
匹配和const
对于想要捕获的异常类型而言,增加const属性不会影响匹配的目的。也就是说,这一行可以与runtime_error类型的任何异常匹配:1
) catch (const runtime_errors e) (
匹配所有异常
可用特定语法编写与所有异常匹配的catch行,如下所示:1
2
3
4
5
6try {
myInts = readIntegeile (fileName) ;
} catch (...) {
cerr << "Error reading or opening file" << fileName << endl;
return 1;
}
三个点是与所有异常类型匹配的通配符。与所有异常匹配的catch块可以用作默认的catch处理程序。当异常抛出时,会按在代码中的显示顺序查找catch处理程序。下例用catch处理程序显式地处理invalid_argument和runtime_error异常,并用默认的catch处理程序处理其他所有异常。1
2
3
4
5
6
7
8
9try {
// Code that can throw exceptions
} catch (const invalid argument& e) {
// Handle invalid_argument exception
} catch (const runtime_errore e) {
// Handle runtime_error exception
} catch (...) {
// Handle all other exceptions
}
未捕获的异常
如果程序抛出的异常没有捕获,程序将终止。可对main()函数使用trycatch结构,以捕获所有未经处理的异常,如下所示:1
2
3
4
5try {
main(argc, argv);
} catch (...) {
// issue error message and terminate program
}
然而,这一行为通常并非我们希望的。异常的作用在于给程序一个机会,以处理和修正不希望看到的或不曾预期的情况。
当程序遇到未捕获的异常时,会调用内建的terminate()函数,这个函数调用<stdlib>中的abort()来终止程序。可调用set_terminate()函数设置自己的terminate_handler(),这个函数采用指向回调函数(既没有参数,也没有返回值)的指针作为参数。terminat()、set_terminate()和terminate_handler()都在<exception>头文件中声明。下面的代码高度概括了其运行原理:1
2
3
4
5
6
7
8try {
main(argc, argv);
) catch (...) {
if (terminate_handler != nullptr) {
terminate_handler();
} else {
terminate();
}
回调函数必须终止程序。错误是无法忽略的,然而可在退出之前输出一条有益的错误消息。下例中,main()函数没有捕获readIntegerFile()抛出的异常,而将teminate_handler()设置为自定义回调。这个回调通过调用exit()显示错误消息并终止进程。exit()函数接收返回给操作系统的一个整数,这个整数可用于确定进程的退出方式。1
2
3
4
5
6
7
8
9
10
11
12
13void myTerminate() {
cout << "Uncaught exception!" << endl;
exit(1);
}
int main() {
set_terminate (myTerminate);
const string fileName = "IntegerFile.txt";
vector<int> myInts readIntegerFile(fileName);
for (const auto& element :myInts)
cout << element << " ";
cout << endl;
return 0;
}
当设置新的terminate_handler()时,set_terminate()会返回旧的terminate_handler()。terminate_handler()被应用于整个程序,因此当需要新terminate_handler()的代码结束后,最好重新设置旧的terminate_handler()。
在专门编写的软件中,通常会设置
terminate_handler(),在进程结束前创建崩溃转储。此后将崩溃转储上传给调试器,从而允许确定未捕获的异常是什么,起因是什么。
noexcept
使用函数时,可使用noexcept关键字标记函数,指出它不抛出任何异常。
如果一个函数带有noexcept标记,却以某种方式抛出了异常,C++将调用terminate()来终止应用程序。在派生类中重写虚方法时,可将重写的虛方法标记为noexcep,即使基类中的版本不是noexcept。
抛出列表
C++的旧版本允许指定函数或方法可抛出的异常,这种规范叫作抛出列表(throw list)或异常规范(exception specification)。
自C++11之后,已不赞成使用异常规范;自C++17之后,已不再支持异常规范。但
noexcept和throw()除外。
自C++11之后,异常规范虽然仍受支持,但已经极少使用。下面的这个readIntegerFile()函数包含了异常规范:1
vector<int> readIntegerFile(string_view fileName) throw (invalid_argument, runtime_error) { }
如果函数抛出的异常不在异常规范内,C++运行时std:unexpected()默认情况下调用std:teminate()来终止应用程序。
异常与多态性
类是最有用的异常类型。实际上异常类通常具有层次结构,因此在捕获异常时可使用多态性。
标准异常体系
图14-3显了完整的层次结构。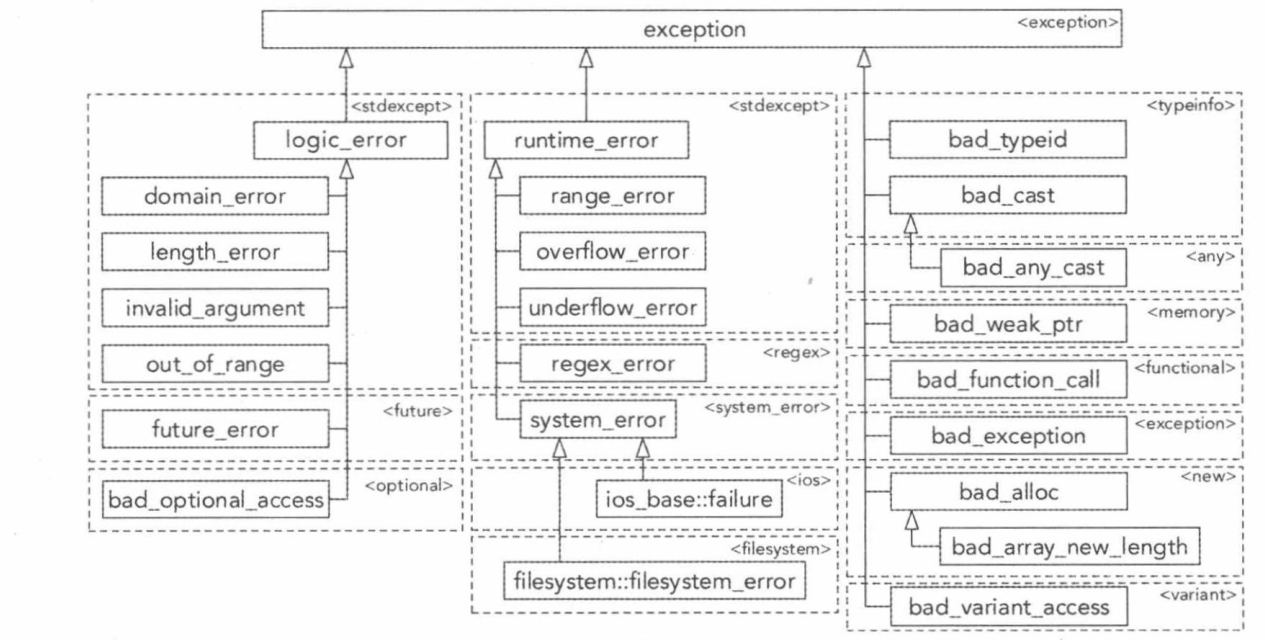
这个层次结构中的每个类都支持what()方法,这个方法返回一个描述异常的const char*字符串。可在错误信息中使用这个字符串。大多数异常类(基类exception是明显的例外)都要求在构造函数中设置what()返回的字符串。readntegerFile()的另一个版本在错误消息中包含文件名。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18vector<int> readIntegerFile(string_view fileName) {
ifstream inputstream (fileName.data());
if (inputstream.fail()) {
// We failed to open the file: throw an exception
const string error = "Unable to open file "s + fileName.data();
throw invalid_argument (error);
}
// Read the integers one-by-one and add them to a vector
vector<int> integers;
int temp;
while (inputstream >> temp) {
integers.push_back(temp);
}
if (!inputstream.eof()) {
const string error = "Unable to read file "s + fileName.data();
throw runtime_error (error);
}
return integers;
在类层次结构中捕获异常
异常层次结构的一个特性是可利用多态性捕获异常。例如,如果观察main()中调用readIntegerFile()之后的两条catch语句,就可以发现这两条语句除了处理的异常类不同之外没有区别。invalid_argument和runtime_error都是exception的派生类,因此可使用exception类的一条catch语句替换这两条catch 语句:1
2
3
4
5
6try {
myInts = readIntegerFile (fileName);
} catch (const exception& e) {
cerr << e.what() << endl ;
return 2;
}
exception引用的catch语句可与exception的任何派生类匹配。
当利用多态性捕获异常时,一定要按引用捕获。如果按值捕获异常,就可能发生截断,在此情况下将丢失对象的信息。
当使用了多条catch子句时,会按在代码中出现的顺序匹配catch子句,第一条匹配的catch子句将被执行。如果某条catch子句比后面的catch子句范围更广,那么这条catch子句首先被匹配,而后面限制更多的catch子句根本不会被执行。因此,catch子句应按限制最多到限制最少的顺序出现。例如,假定要显式捕获readIntegerFile()的invalid_argument,就应该让一般的异常与其他类型的异常匹配。正确做法如下所示:1
2
3
4
5
6
7
8try {
myInts = readIntegerFile (fileName) ;
} catch (const invalid_argument& e) ( // List the derived class first.
// Take some special action for invalid filename s
} catch (const exception& e) { // Now list exception
cerr << e.what() << endl;
return 1;
}
第一条catch子句捕获invalid_argument异常,第二条catch子句捕获任何类型的其他异常。然而,如果将catch子句的顺序弄反,第一条catch子句会捕获任何派生类类型的异常,第二条catch子句永远无法执行。
编写自己的异常类
编写自己的异常类有两个好处:
- C++标准库中的异常数目有限,可在程序中为特定错误创建更有意义的类名
- 可在异常中加入自己的信息,而标准层次结构中的异常只允许设置错误字符串
建议自己编写的异常类从标准的exception类直接或间接继承。例如,在readIntegerFile()中,invalid_argument和runtime_error不能很好地捕获文件打开和读取错误。可为文件错误定义自己的错误层次结构,从泛型类FileError开始:1
2
3
4
5
6
7
8
9
10
11
12
13
14class FileError :public exception {
public:.
FileError(string_view fileName) :mFileName (fileName) { }
virtual const char* what() const noexcept override {
return mMessage.c_str();
}
string_view getFileName() const noexcept { return mFileName; }
protected:
void setMessage (string_view message) { mMessage = message; }
private:
string mFileName;
string mMessage;
};
编写exception的派生类时,需要重写what()方法,其返回值为一个在对象销毁之前一直有效的const char*字符串。在FileError中,这个字符串来自mMessage数据成员。FileError的派生类可使用受保护的setMessage()方法设置消息。泛型类`FileError还包含文件名以及文件名的公共访问器。
在编写将其对象用作异常的类时,有一个诀窍。当某段代码抛出一个异常时,使用移动构造函数或复制构造函数,移动或复制被抛出的值或对象。因此,如果编写的类的对象将作为异常抛出,对象必须复制和或移动。这意味着如果动态分配了内存,就必须编写析构函数、复制构造函数、复制赋值运算符和或移动构造函数与移动赋值运算符。
作为异常抛出的对象至少要复制或移动一次。异常可能被复制多次,但只有按值(而不是按引用)捕获异常才会如此。
按引用(最好是const 引用)捕获异常对象可避免不必要的复制。
嵌套异常
当处理第一个异常时,可能触发第二个异常,从而要求抛出第二个异常。遗憾的是,当抛出第二个异常时,正在处理的第一个异常的所有信息都会丢失。C++用嵌套异常(nested exception)提供了解决这一问题的方案,嵌套异常允许将捕获的异常嵌套到新的异常环境。
使用std::throw_with_nested()抛出一个异常时,这个异常中嵌套着另一个异常。第二个异常的catch处理程序可使用dynamic_cast()访问代表第一个异常的nested_exception。下例演示了嵌套异常的用法。这个示例定义了一个从exception类派生的MyException类,其构造函数接收一个字符串。1
2
3
4
5
6
7
8
9class MyException :public std::exception {
public:
MyException(string_view message) : mMessage (message) {}
virtual const char* what() const noexcept override {
return mMessage.c_str();
}
private:
string mMessage;
};
当处理第一个异常且需要抛出嵌套了第一个异常的第二个异常时,需要使用std::throw_with_nested()函数。下面的doSomething()函数抛出一个runtime_error异常,这个异常立即被catch处理程序捕获。catch 处理程序编写了一条消息,然后使用std::throw_with_nested()函数抛出第二个异常,第一个异常嵌套在其中。注意嵌套异常是自动实现的。1
2
3
4
5
6
7
8void doSomething() {
try {
throw runtime_error("Throwing a runtime_error exception");
} catch (const runtime_error& e) {
cout << "caught a runtime_error" << endl;
throw_with_nested(MyException ("MyException with std::throw_with_nested()"));
}
}
当捕获到这类异常时,会编写一条消息,然后使用dynamic_cast()访问嵌套的异常。如果内部没有嵌套异常,结果为空指针。如果有嵌套异常,会调用nested_exception的rethrow_nested()方法。这样会再次抛出嵌套异常,这一异常可在另一个try/catch块中捕获。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int main() {
try {
doSomething();
} catch (const MyException& e) {
cout << "caught MyException:" << e.what() << endl;
const auto* pNested = dynamic_cast<const nested_exception*>(&e);
if (pNested) {
try {
pNested->rethrow_nested();
} catch(const runtime_error& e) {
cout << e.what() << endl;
}
}
}
return 0;
}
前面的main()函数使用dynamic_cast()检测嵌套异常。如果想要检测嵌套异常,就不得不经常执行dynamic_cast(),因此标准库提供了一个名为std::rethrow_if_nested()的小型辅助函数,其用法如下所示:1
2
3
4
5
6
7
8try {
doSomething();
} catch (const MyException& e) {
rethrow_if_nested(e);
} catch (const runtime_error& e) {
cout << "Nested exception:"<< e.what() << endl;
}
return 0;
重新抛出异常
可使用throw关键字重新抛出当前异常,如下例所示:1
2
3
4
5
6
7
8
9void g() { throw invalid_argument ("Some exception"); }
void f() {
try {
g();
} catch (const invalid_argument& e) {
cout << "caught in f:" << e.what() << endl;
throw; // rethrow
}
}
始终使用
throw;重新抛出异常。永远不要试图用throw e;重新抛出e,因为这样存在潜在的截断风险,可能丢失信息。
堆栈的释放与清理
当发现catch处理程序时,堆栈会释放所有中间堆栈帧,直接跳到定义catch处理程序的堆栈层。堆栈释放(stack unwinding)意味着调用所有具有局部作用域的名称的析构函数,并忽略在当前执行点之前的每个函数中所有的代码。然而当释放堆栈时,并不释放指针变量,也不会执行其他清理。在C++中,应该用基于堆栈的内存分配或者下面将要讨论的技术处理这种情况。
使用智能指针
如果基于堆栈的内存分配不可用,就应使用智能指针。在处理异常时,智能指针可使编写的代码自动防止内存或资源的泄漏。无论什么时候销毁智能指针对象,都会释放底层资源。下 面使用了智能指针unique_ptr:1
2
3
4
5void funcOne() {
string strl;
auto str2 = make_unique<string> ("hello");
funcTwo();
}
当从funcOne()返回或抛出异常时,将自动删除str2指针。
捕获、清理并重新抛出
避免内存和资源泄漏的另一种技术是针对每个函数,捕获可能抛出的所有异常,执行必要的清理,并重新抛出异常,供堆栈中更高层的函数处理。下面是使用这一技术修改后的funcOne()函数:1
2
3
4
5
6
7
8
9
10
11void funcOne () {
string str1;
string* str2 = new string();
try {
funcTwo () ;
} catch (...) {
delete str2;
throw; // Rethrow the exception.
}
delete str2;
}
这个函数用异常处理程序封装对funcTwo()函数的调用,处理程序执行清理(在str2上调用delete)并重新抛出异常。关键字throw本身会重新抛出最近捕获的任何异常。注意catch语句使用…语法捕获所有异常。这一方法运行良好,但有点繁杂。需要特别注意,现在有两行完全相同的代码在str2上调用delete。
常见的错误处理问题
内存分配错误
如果无法分配内存,new和new[]的默认行为是抛出bad_alloc类型的异常,这种异常类型在<new>头文件中定义。代码应该捕获并正确地处理这些异常。
不可能把对new和new[]的调用都放在try/catch块中,但至少在分配大块内存时应这么做。下例演示了如何捕获内存分配异常:1
2
3
4
5
6
7
8int* ptr = nullptr;
size_t integerCount = numeric_limits<size_t>::max();
try {
ptr = new int [integerCount];
} catch (const bad_alloc& e) {
cerr << "Unable to allocate memory:" << e.what() << endl;
return;
}
另一个考虑是记录错误时可能尝试分配内存。如果new执行失败,可能没有记录错误消息的足够内存。
不抛出异常的new
旧的C模式下,如果无法分配内存,内存分配例程将返回一个空指针。C++提供了new和new[]的nothrow版本,如果内存分配失败,将返回nullptr,而不是抛出异常。使用语
法new(nothrow)而不是new可做到这一点,如下所示:1
2
3int* ptr = new (nothrow) int [integerCount];
if (ptr == nullptr)
cerr << "Unable to allocate memory!" << endl;
定制内存分配失败的行为
C++允许指定new handler回调函数。默认情况下不存在new handler,因此new和new[]只是抛出bad_alloc异常。然而如果存在new handler,当内存分配失败时,内存分配例程会调用new handler而不是抛出异常。如果new handler返回,内存分配例程试着再次分配内存:如果失败,会再次调用new handler。这个循环变成无限循环,除非new handler用下面的3个选项之一改变这种情况。下面列出这些选项,并给出了注释:
- 提供更多的可用内存 提供空间的技巧之一是在程序启动时分配一大块内存,然后在
new handler中释放这块内存。关键在于,在程序启动时,分配一块足以完整保存文档的内存。当触发new handler时,可释放这块内存、保存文档、重启应用程序并重新加载保存的文档。 - 抛出异常 C++标准指出,如果
new handler抛出异常,那么必须是bad_alloc异常或者派生于bad_alloc的异常。- 可编写和抛出
document_recovery_alloc异常,这种异常从bad_alloc继承而来。可在应用程序的某个地方捕获这种异常,然后触发文档保存操作,并重启应用程序。 - 可编写和抛出派生于
bad_alloc的please_terminate_me异常。在顶层函数中可捕获这种异常,并通过从顶层函数返回来对其进行处理。
- 可编写和抛出
- 设置不同的
new handler从理论上讲,可使用一系列new handler,每个都试图分配内存,并在失败时设置一个不同的new handler。然而,这种情形通常过于复杂,并不实用。
如果在new handler中没有这么做,任何内存分配失败都会导致无限循环。
如果有一些内存分配会失败,但又不想调用new handler,那么在调用new之前,只需要临时将新的new handler重新设置为默认值nullptr。
调用在<new>头文件中声明的set_new_handler(),从而设置new handler。1
2
3
4
5class please_terminate_me :public bad_alloc { };
void myNewHandler () {
cerr << "Unable to allocate memory." << endl;
throw please_terminate_me();
}
new handler 不能有参数,也不能返回值。如前面列表中的第2个选项所述,new handler 抛出please_terminate_me异常。可采用以下方式设置new handler:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int main()
try {
// Set the new new_handler and save the old one.
new_handler oldHandler = set_new_handler (myNewHandler);
// Generate allocation error.
size_t numInts = numeric_limits<size_t>::max();
int* ptr = new int [numInts];
// Reset the old new_handler
set_new_handler(oldHandler);
} catch (const please_terminate_me&) {
cerr << "Terminating program." << endl;
return 1;
}
return 0;
}
注意new_handler是函数指针类型的typedef,set_new_handler()会将其作为参数。
构造函数中的错误
虽然无法在构造函数中返回值,但是可以抛出异常。通过异常可很方便地告诉客户是否成功创建了对象。在异常离开构造函数前,必须在构造函数中仔细清理所有资源,并释放分配的所有内存。本节以Matix类作为示例,这个类的构造函数可正确处理异常。1
2
3
4
5
6
7
8
9
10
11template <typename T>
class Matrix {
public:
Matrix(size_t width, size_t height);
virtual ~Matrix();
private :
void cleanup();
size_t mWidth = 0;
size_t mHeight = 0;
T** mMatrix = nullptr;
}
Matrix类的实现如下所示。注意:
- 对new的第一个调用并没有用try/catch块保护。第一个new抛出异常也没有关系,因为构造函数此时还没有分配任何需要释放的内存。如果后面的new抛出异常,构造函数必须清理所有已经分配的内存。
- 由于不知道T构造函数本身会抛出什么异常,因此用…捕获所有异常,并将捕获的异常嵌套在
bad_alloc异常中。 - 使用{}语法,通过首次调用new分配的数组执行零初始化,即每个元素都是nullptr。这简化了
cleanup()方法,因为允许它在nullptr上调用delete。
1 | template <typename T> |
如果异常离开了构造函数,将永远不会调用对象的析构函数!
构造函数的function-try-blocks
function-try-blocks用于普通函数和构造函数。本节重点介绍functin-try-blocks如何用于构造函数。下面的伪代码显示了构造函数的function-try-blocks的基本语法:1
2
3
4
5
6
7MyClass::MyClass()
try
: <ctor-initializer>
{ /* constructor body ... */
} catch (const exception& e) {
/* ... */
}
可以看出,try关键字应该刚好在ctor itializer之前。catch 语句应该在构造函数的右花括号之后,实际上是将catch语句放在构造函数体的外部。当使用构造函数的function-try-blocks时,要记住如下限制和指导方针:
- catch语句将捕获任何异常,无论是构造函数体还是ctor-intializer直接或间接抛出的异常,都是如此。
- catch语句必须重新抛出当前异常或抛出一个新异常。如果catch语句没有这么做,运行时将自动重新拋出当前异常。
- atch语句可访问传递给构造函数的参数。
- 当catch语句捕获function-tryblocks内的异常时,构造函数已构建的所有对象都会在执行catch 语句之前销毁。
- 在catch语句中,不应访问对象成员变量,因为它们在执行catch语句前就销毁了。 但是,如果对象包含非类数据成员,例如裸指针,并且它们在抛出异常之前初始化,就可以访问它们。如果有这样的裸资源,就必须在catch语句中释放它们。
- 对于functio-try-blocks中的catch语句而言,其中包含的函数不能使用return关键字返回值。构造函数与此无关,因为构造函数没有返回值。
由于有以上限制,构造函数的function-try-blocks 只在少数情况下有用:
- 将ctor-intializer抛出的异常转换为其他异常。
- 将消息记录到日志文件。
- 释放在抛出异常之前就在ctor intializer 中分配了内存的裸资源。
下例演示function-try-blocks的用法1
2
3
4
5
6
7
8class Subobject {
public:
Subobject(int i);
};
Subobject::Subobject(int i) {
throw std::runtime_error ("Exception by Subobject ctor");
}
MyClass类有一个int*类型的成员变量以及一个SubObject类型的成员变量:1
2
3
4
5
6
7class MyClass {
public:
MyClass();
private:
int* mData = nullptr;
Subobject mSubobject;
};
SubObject 类没有默认构造函数。这意味着需要在MyClass类的ctor-intializer中初始化mSubObject。MyClass类的构造函数将使用function-try-blocks 捕获ctor-intializer 中抛出的异常。1
2
3
4
5
6
7
8
9MyClass::MyClass ()
try
: mData(new int[42]{ 1, 2, 3 }), mSubobject (42) {
/* ... constructor body ... */
} catch (const std::exception6 e) {
// Cleanup memory.
delete[] mData;
mData = nullptr;
}
记住,构造函数的function-try-blocks中的catch语句必须重新抛出当前异常,或者抛出新异常。前面的catch语句没有抛出任何异常,因此C++运行时将自动重新抛出当前异常。下面的简单函数使用了前面的类:1
2
3
4
5
6
7
8int main()
try {
MyClass m;
} catch (const std::exception& e) {
cout << "main() caught: " << e.what() << endl;
}
return 0;
}
通常,仅将裸资源作为数据成员时,才有必要使用function-try-blocks. 可使用诸如std::unique_ptr的RAII类来避免使用裸资源。
析构函数中的错误
必须在析构函数内部处理析构函数引起的所有错误。不应该让析构函数抛出任何异常,原因如下:
- 析构函数会被隐式标记为noexcept,除非添加了
noexcept(false)标记,或者类具有子对象,而子对象的析构函数是noexcept(false)。如果带noexcept标记的析构函数抛出一个异常, C++运行时会调用std::teminate()来终止应用程序。 - 在堆栈释放过程中,如果存在另一个挂起的异常,析构函数可以运行。如果在堆栈释放期间从析构函数抛出一个异常,C++运行时会调用
std::terminate()来终止应用程序。<exception>头文件中声明了一个函数uncaught_exception(),该函数可返回未捕获异常的数量;所谓未捕获异常,是指已经抛出但尚未到达匹配catch的异常。如果uncaught_exceptions()的结果大于0,则说明正在执行堆栈释放。 - 客户不会显式调用析构函数:客户调用delete,delete调用析构函数。如果在析构函数中抛出一个异常,客户无法在此使用对象调用delete,也不能显式地调用析构函数。
- 析构函数是释放对象使用的内存和资源的一个机会。如果因为异常而提前退出这个函数,就会浪费这个机会,将永远无法回头释放内存或资源。
C++运算符重载
运算符重载概述
重载运算符的原因
基本指导原则是:为了让自定义类的行为和内建类型一样。自定义类的行为越接近内建类型,就越便于这些类的客户使用。
运算符重载的限制
下面列出了重载运算符时不能做的事情:
- 不能添加新的运算符。只能重定义语言中已经存在的运算符的意义。
- 有少数运算符不能重载,例如
.(对象成员访问运算符)、:(作用域解析运算符)、sizeof、?(条件运算符)以及其他几个运算符。 arity描述了运算符关联的参数或操作数的数量。只能修改函数调用、new和delete运算符的arity。其他运算符的arity不能修改。- 不能修改运算符的优先级和结合性。这些规则确定了运算符在语句中的求值顺序。
- 不能对内建类型重定义运算符。运算符必须是类中的一个方法,或者全局重载运算符函数至少有一个参数必须是一种用户定义的类型(例如一个类)。
运算符重载的选择
重载运算符时,需要编写名为operatorX的函数或方法,X是表示这个运算符的符号。例如:1
SpreadsheetCell operator+(const SpreadsheetCells lhs, const SpreadsheetCells rhs);
方法还是全局函数
当运算符是类的方法时,运算符表达式的左侧必须是这个类的对象。当编写全局函数时,运算符表达式的左侧可以是不同类型的对象。有3种不同类型的运算符:
- 必须为方法的运算符:C++语言要求一些运算符必须是类中的方法,因为这些运算符在类的外部没有意义。例如,
operator-和类绑定得非常紧密,不能出现在其他地方。大部分运算符都没有施加这种要求。 - 必须为全局函数的运算符:如果允许运算符左侧的变量是除了自定义的类之外的任何类型,那么必须将这个运算符定义为全局函数。确切地讲,这条规则适用于
operator<<和operator>>,这两个运算符的左侧是iostream对象,而不是自定义类的对象。此外,可交换的运算符(例如二元的+和-)允许运算符左侧的变量不是自定义类的对象。 - 既可为方法又可为全局函数的运算符,建议遵循如下规则:把所有运算符都定义为方法,除非根据以上描述必须定义为全局函数。这条规则的一个主要优点是,方法可以是虚方法,但全局函数不能是虚函数。因此,如果准备在继承树中编写重载的运算符,应尽可能将这些运算符定义为方法。
将重载的运算符定义为方法时,如果这个运算符不修改对象,应将整个方法标记为const。这样,就可对const对象调用这个方法。
选择参数类型
参数类型的选择有一些限制,因为如前所述,大多数运算符不能修改参数数量。真正需要选择的地方在于判断是按值还是按引用接收参数,以及是否需要把参数标记为const。
按值传递还是按引用传递的决策很简单:应按引用接收每一个非基本类型的参数。
const决策也很简单:除非要真正修改参数,否则将每个参数都设置为const。
选择返回类型
应该让运算符返回的类型和运算符对内建类型操作时返回的类型一样。如果编写比较运算符,那么应该返回bool类型。如果编写算术运算符,那么应该返回表示运算结果的对象。返回值还是引用的一般原则是:如果可以,就返回一个引用,否则返回一个值:如果运算符构造了一个新对象,那么必须按值返回这个新对象。如果不构造新对象,可返回对调用这个运算符的对象的引用,或返回对其中一个参数的引用。
可作为左值(赋值表达式左侧的部分)修改的返回值必须是非const。否则,这个值应该是const。大部分很容易想到的运算符都要求返回左值,包括所有赋值运算符(operator-、operator+-和operator-等)。
不应重载的运算符
有些运算符即使允许重载,也不应该重载。具体来说,取地址运算符operator&的重载一般没什么特别的用途,如果重载会导致混乱,因为这样做会以可能异常的方式修改基础语言的行为(获得变量的地址)。整个标准库大量使用了运算符重载,但从没有重载取地址运算符。
可重载运算符小结
在表15-1中,T表示要编写重载运算符的类名,E是一种不同的类型。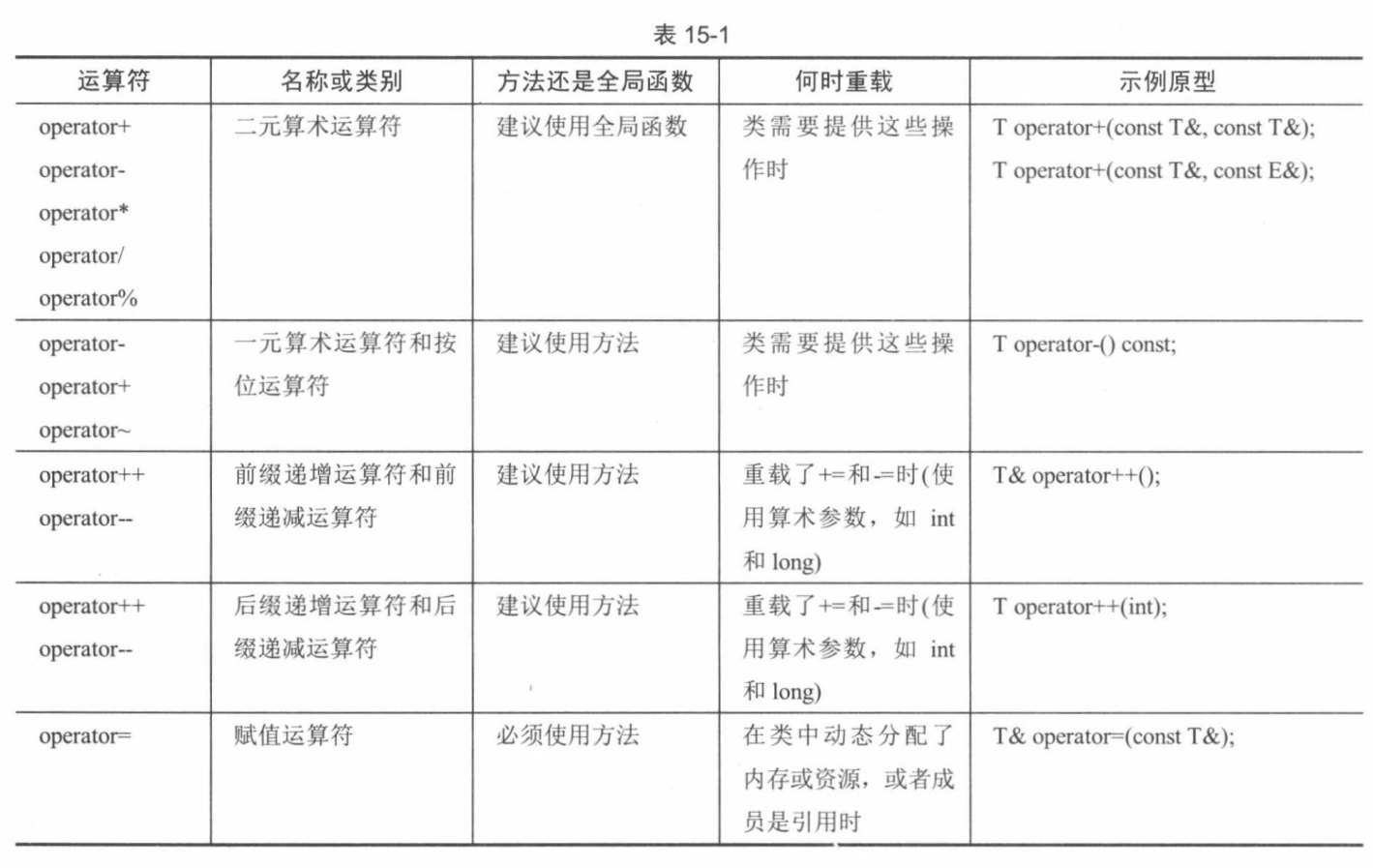
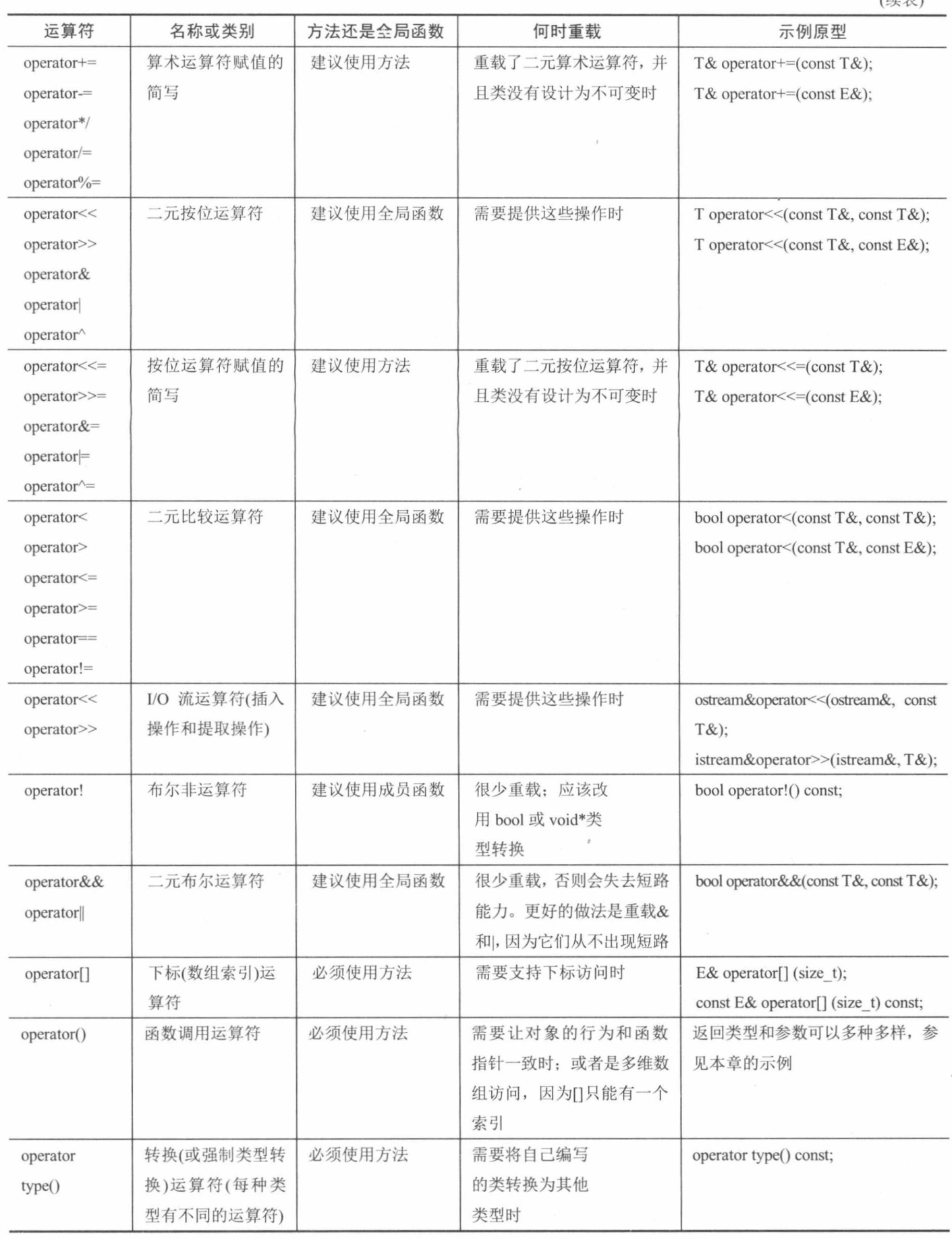
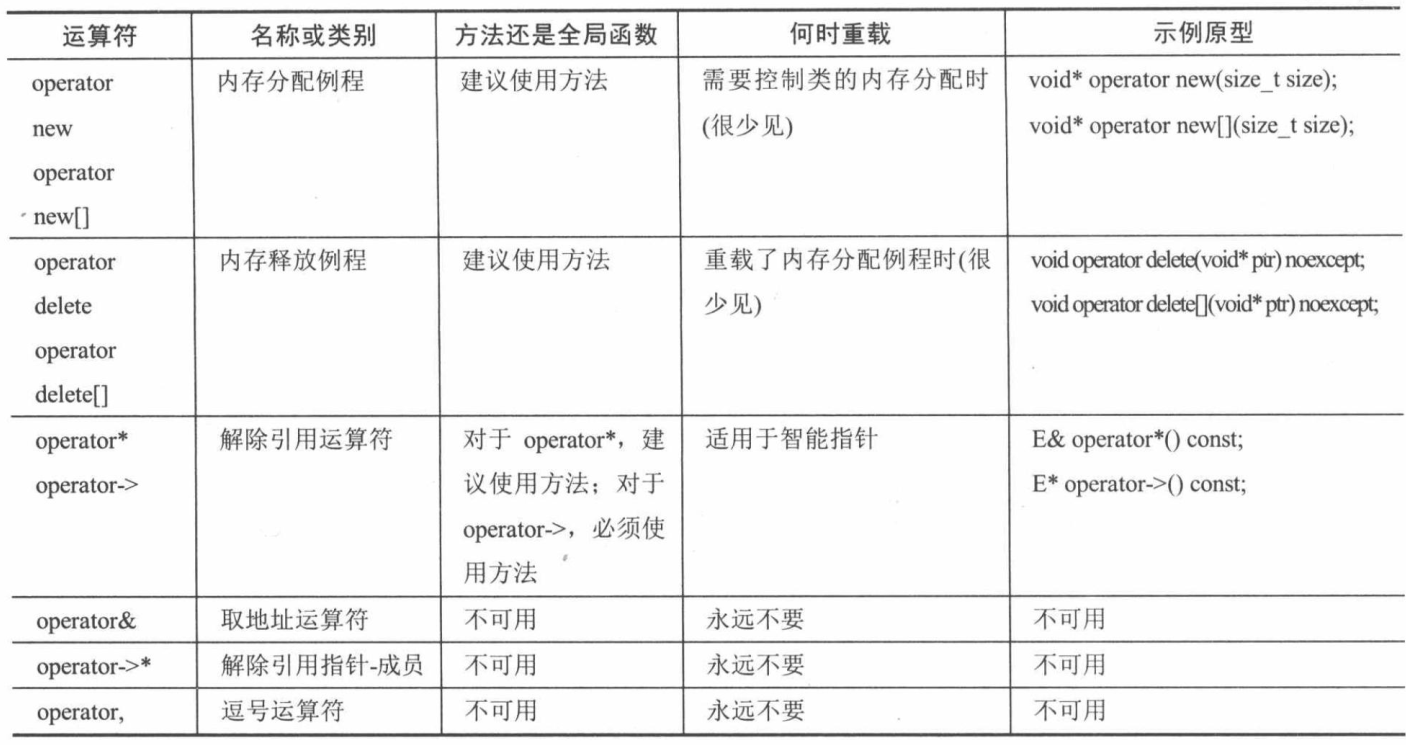
右值引用
表15-1列出的普通赋值运算符的原型如下所示:1
T& operator=(const T&);
移动赋值运算符的原型几乎一致,但使用了右值引用。这个运算符会修改参数,因此不能传递const参数。1
T& operator=(T&&);
表15-1没有包含右值引用语义的示例原型。然而,对于大部分运算符来说,编写一个使用普通左值引用的版本以及一个使用右值引用的版本都是有意义的,但是否真正有意义取决于类的实现细节。标准库中的std:string类利用右值引用实现了operator+,如下所示:1
string operator+(string&& lhs, string&& rhs);
这个运算符的实现会重用其中一个参数的内存,因为这些参数是以右值引用传递的。也就是说,这两个参数表示的都是operator+完成之后销毁的临时对象。上述operator+的实现具有以下效果:1
return std::move(lhs.append(rhs));
或1
return std::move(ths.insert(0, lhs));
事实上,std::string定义了几个具有不同左值引用和右值引用组合的重载的operator+运算符。下面列出std::string中所有接收两个字符串参数的operator+运算符1
2
3
4string operator+(const string& lhs, const string& rhs);
string operator+(string&& lhs, const string& rhs);
string operator+(const string& lhs, string&& rhs);
string operator+(string&& lhs, string&& rhs);
关系运算符
C++标准库有一个方便的<utility>头文件,它包含几个辅助函数和类,还在std::rel_ops名称空间中给关系运算符包含如下函数模板:1
2
3
4template<class T> bool operator!=(const T& a, const T& b);//Needs operator==
template<class T> bool operator>(const T& a, const T& b); //Needs operator<
template<class T> bool operator<=(const T& a, const T& b);//Needs operator<
template<class T> bool operator>=(const T& a, const T& b);//Needs operator<
这些函数模板根据==和<运算符给任意类定义了运算符!=、>、<=和>=。如果在类中实现operator--和operator<,就会通过这些模板自动获得其他关系运算符。只要添加#include <utility>和下面的using声明,就可将这些运算符用于自己的类:1
using namespace std::rel_ops;
但是,这种技术带来的一个问题在于,现在可能为用于关系操作的所有类(而非只为自己的类)创建这些运算符。还有一个问题是隐式转换不可行。
重载算术运算符
重载一元负号和一元正号运算符
C++有几个一元算术运算符。一元负号和一元正号运算符是其中的两个。这些运算符不改变调用它们的对象,所以应把它们标记为const。下例将一元operator-运算符重载为SpreadsheetCell类的成员函数。1
2
3SpreadsheetCell SpreadsheetCell::operator-() const {
return SpreadsheetCell (-getValue());
}
operator-没有修改操作数,因此这个方法必须构造一个新的带有相反值的SpreadsheetCell对象,并返回这个对象的副本。因此,这个运算符不能返回引用。可按以下方式使用这个运算符:1
2SpreadsheetCell c1(4);
SpreadsheetCell c3 = -c1;
重载递增和递减运算符
可采用4种方法给变量加1:1
2
3
4i = i + 1;
i += 1;
++ i;
i ++;
后两种称为递增运算符。第一种形式是前缀递增,这个操作将变量增加1,然后返回增加后的新值,供表达式的其他部分使用。第二种形式是后缀递增,返回旧值(增加之前的值),供表达式的其他部分使用。递减运算符的功能类似。
operator++和operator--的双重意义给重载带来了问题,C++引入了一种方法来区分前后缀:前缀版本的operator++和operator--不接收参数,而后缀版本的接收一个不使用的int类型参数。如果要为SpreadsheetCell类重载这些运算符,原型如下所示:1
2
3
4SpreadsheetCell& operator++(); // Prefix
Spreadsheetcell operator++(int); // Postfix
SpreadsheetCell& operator--(); // Prefix
SpreadsheetCell operator--(int); // Postfix
前缀形式的结果值和操作数的最终值一致,因此前缀递增和前缀递减返回被调用对象的引用。然而后缀版本的递增操作和递减操作返回的结果值和操作数的最终值不同,因此不能返回引用。下面是operator++运算符的实现:1
2
3
4
5
6
7
8
9
10SpreadsheetCell& SpreadsheetCell::operator++() {
set(getValue() + 1);
return *this;
}
SpreadsheetCell SpreadsheetCell::operator++(int) {
auto oldCell(*this); // Save current value
++(*this); // Increment using prefix + 1
return oldCell; // Return the old value
}
递增和递减还能应用于指针。当编写的类是智能指针或迭代器时,可重载operator++和operator--,以提供指针的递增和递减操作。
重载按位运算符和二元逻辑运算符
按位运算符和算术运算符类似,简写的按位赋值运算符也和简写的算术赋值运算符类似。逻辑运算符要困难一些。建议不要重载&&和||。这些运算符并不应用于单个类型,而是整合布尔表达式的结果。此外,重载这些运算符会失去短路求值,原因是在将运算符左侧和右侧的值绑定至重载的&&和运算符之前,必须对运算符的左侧和右侧进行求值。因此,一般对特定类型重载这些运算符都没有意义。
重载插入运算符和提取运算符
在编写插入和提取运算符前,需要决定如何将自定义的类向流输出,以及如何从流中提取自定义的类。在这个例子中,SpreadsheetCell将读取和写入double值。插入和提取运算符左侧的对象是istream或ostream(例如cin和cout),而不是SpreadsheetCell对象。由于不能向istream类或ostream类添加方法,因此应将插入和提取运算符写为SpreadsheetCell类的全局函数。这些函数在SpreadsheetCell类中的声明如下所示:1
2
3
4
5class SpreadsheetCell{
};
std::ostream& operator<<(std::ostream& ostr, const SpreadsheetCell& cell);
std::istream& operator>>(std::istream& istr, SpreadsheetCell& cell);
将插入运算符的第一个参数设置为ostream的引用,这个运算符就能应用于文件输出流、字符串输出流、cout、cerr和clog等。与此类似,将提取运算符的参数设置为istream的引用,这个运算符就能应用于文件输入流、字符串输入流和cin。
operator<<和operator>>的第二个参数是对要写入或读取的SpreadsheetCell对象的引用。插入运算符不会修改写入的SpreadsheetCell对象,因此这个引用可以是const引用。然而提取运算符会修改SpreadsheetCell对象,因此要求这个参数为非const引用。
这两个运算符返回的都是第一个参数传入的流的引用,所以这两个运算符的调用可以嵌套。记住,运算符的语法实际上是显式调用全局operator>>函数或operator<<函数的简写形式。 例如下面这行代码:1
cin >> myCell >> anotherCell >> aThirdCell;
实际上是如下代码行的简写形式:1
operator>>(operator>>(operator>>(cin, myCell), anotherCell), aThirdCell);
从中可以看出,第一次调用operator>>的返回值被用作下一次调用的输入值。因此必须返回流的引用,结果才能用于下一次嵌套的调用。否则嵌套调用无法编译。
重载下标运算符
一个动态分配的数组类允许设置和获取指定索引位置的元素,并会自动完成所有的内存分配操作,定义可能是这样的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16template <typename T>
class Array {
public:
Array();
virtual ~Array();
Array<T>& operator=(const Array<T>& rhs) = delete;
Array(const Array<T>& src) = delete;
const T& getElementAt(size_t x) const;
void setElementat(size_t x, const T& value):
private:
size_t getsize() const;
static const size_t kAllocSize = 4;
void resize(size_t newSize);
T* mElements = nullptr;
size_t mSize = 0;
};
这个接口支持设置和访问元素。它为随机访问提供了保证:客户可创建数组,并设置元素1、100和1000,而不必考虑内存管理问题。下面是这些方法的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17template <typename T> Array<T>::Array() {
mSize = kAllocSize;
mElements = new T[mSize] {};// Elements are zero-initialized!
}
template <typename T> Array<T>::~Array() {
delete [] mElements;
mElements = nullptr;
}
template <typename T> void Array<T>::resize(size_t newSize) {
auto newArray = std::make_unique<T[]>(newSize);
for(size_t i = 0; i < mSize; i ++) {
newArray[i] = mElements[i];
}
delete[] mElements;
mSize = newSize;
mElements = newArray.release();
}
resize()首先创建一个适当大小的新数组,将其存储在unique_ptr中。然后将所有元素从旧数组复制到新数组。如果在复制值时任何地方出错,unique_ptr会自动清理内存。最后,在成功分配新数组和复制所有元素后,即未抛出异常,我们才删除旧的mElements数组,并为其指定新数组。最后一行必须使用release()来释放unique_ptr的新数组的所有权,否则,在调用unique_ptr的析构函数时,将销毁这个数组。
通过以下方式给类添加operator[]:1
2
3
4
5template <typename T> T& Array<T>::operator[](size_t x) {
if (x >= mSize)
resize(x + kAllocSize);
return mElements[x];
}
operator[]可设置和获取元素,因为它返回的是一个对位置x处的元素的引用。可通过这个引用对这个元素赋值。当operator[]用在赋值语句的左侧时,赋值操作实际上修改了mElements数组中位置x处的值。
通过operator[]提供只读访问
理想情况下,可提供两个operator[]:一个返回引用,另一个返回const引用。为此,编写下面这样的代码:1
2
3
4
5template <typename T> const T& Array<T>::operator[](size_t x) const {
if (x >= mSize)
throw std::out_of_range("");
return mElements[x];
}
为const对象调用const operator[],因此无法增加数组大小。当给定索引越界时,当前实现抛出异常。另一种做法是返回零初始化值而非抛出零初始化元素。代码如下:1
2
3
4
5
6
7template <typename T> const T& Array<T>::operator[](size_t x) const {
if (x >= mSize) {
static T nullValue = T();
return.nullValue;
}
return mElements [x];
}
重载函数调用运算符
C++允许重载函数调用运算符,写作operator()。如果在自定义的类中编写了一个operator(),那么这个类的对象就可以当成函数指针使用。包含函数调用运算符的类对象称为函数对象,或简称为仿函数(functor)。只能将这个运算符重载为类中的非静态方法。下例是一个简单的类,它带有一个重载的operator()以及一个具有相同行为的类方法:1
2
3
4
5
6
7
8
9class FunctionObject {
public:
int operator() (int param); // Function call operator
int dosquare(int param) {return param * param; }
};
int FunctionObject::operator() (int param) {
return doSquare(param);
}
下面是使用函数调用运算符的代码示例:1
2
3
4int x = 3, xSquared, xSquaredAgain;
Functionobject square;
xSquared = square(x);
xSquaredAgain = square.doSquare (x);
相比标准的对象方法,函数对象的好处很简单:这些对象有时可以伪装成函数指针,可将这些函数对象当成回调函数传给其他函数。
相比全局函数,函数对象的好处较为复杂。有两个主要好处:
- 对象可在函数对象运算符的重复调用之间,在数据成员中保存信息。
- 可通过设置数据成员来自定义函数对象的行为。
当然,通过全局变量或静态变量都可实现上述任何好处。然而,函数对象提供了一种更简洁的方式,而使用全局变量或静态变量在多线程应用程序中可能会产生问题。
函数调用运算符还可用于提供多维数组的下标。只要编写一个行为类似于operator[],但接收多个索引的operator()即可。这项技术的唯一问题是需要使用()而不是[]进行索引,例如myArray(3,4)-6。
重载解除引用运算符
可重载3个解除引用运算符:*、->和->*,只考虑*和->的原始意义。*解除对指针的引用,允许直接访问这个指针指向的值,->是使用*解除引用之后再执行成员选择操作的简写。
在类中重载解除引用运算符,可使这个类的对象行为和指针一致。这种功能的主要用途是实现智能指针。还能用于标准库广泛使用的迭代器。
实现operator*
当解除对指针的引用时,经常希望能访问这个指针指向的内存:operator*应该返回一个引用:1
2
3
4
5
6template<typename T> T& Pointer<T>::operator*() {
return *mPtr;
}
template<typename T> T& Pointer<T>::operator*() const {
return *mPtr;
}
从这个例子可看出,operator*返回的是底层普通指针指向的对象或变量的引用。与重载下标运算符一样,同时提供方法的const版本和非const版本也很有用。
实现operator->
箭头运算符稍微复杂一些。应用箭头运算符的结果应该是对象的成员或方法。为实现这一点,应该能够实现operator*和operator,而C++有充足的理由不允许重载operator.:不可能编写单个原型来捕捉任何可能选择的成员或方法。因此,C++将operator->当成一种特例。例如下面这行代码:1
smartCell->set(5);
C++将这行代码解释为:1
(smartCell.operator->())->set(5);
从中可看出,C++给重载的operator->返回的任何结果应用了另一个operator->。因此,必须返回一个指向对象的指针,如下所示:1
2
3
4
5
6
7
8
9
10
11template <typename T> class Pointer
public:
T* operator->();
const T* operator->() const;
};
template <typename T> T* Pointer<T>::operator->() {
return mPtr;
}
template <typename T> const T* Pointer<T>::operator->() const {
return mPtr;
}
operator.和operator->的含义
在C++中,不能在没有对象的情况下访问非静态数据成员或调用非静态方法。通过指针调用方法或访问数据成员时,必须在对象的上下文中解除对指针的引用。下例演示了这点。1
2
3SpreadsheetCell myCell;
double (Spreadsheetcell::*methodPtr) () const = &SpreadsheetCell::getValue();
cout << (mycell.*methodPtr) () << endl;
注意,.*运算符解除对方法指针的引用并调用这个方法。如果有一个指向对象的指针而不是对象本身,那么还有一个等效的operator->*可通过指针调用方法。这个运算符如下所示:1
2
3SpreadsheetCell* myCell = new SpreadsheetCell();
double (Spreadsheetcell::*methodPtr)() const = &spreadsheetCell::getValue;
cout << (myCell->*methodPtr)() <<endl;
编写转换运算符
可编写一个将SpreadsheetCell转换为double类型的转换运算符。原型如下所示:1
operator double() const;
函数名为operator double。它没有返回类型,因为返回类型是通过运算符的名称确定的:double。这个函数是const,因为这个函数不会修改被调用的对象。实现如下所示:1
SpreadsheetCell::operator double() const { return getValue(); }
使用显式转换运算符解决多义性问题
注意,为SpreadsheetCell对象编写double转换运算符时会引入多义性问题。例如下面这行加粗代码:1
2SpreadsheetCell cell(1.23);
double d2 = cell + 3.3;
现在这行代码无法成功编译。编译器不知道应该通过operator double()将cell对象转换为double类型,再执行double加法,还是通过double构造函数将3.3转换为SpreadsheetCell,再执行SpreadsheetCell加法。
在C++11之前,通常解决这个难题的方法是将构造函数标记为explicit,以避免使用这个构造函数进行自动转换。自C++11以后,可将double类型转换运算符标记为explicit以解决这个问题。下面的代码演示了这种方法的应用:1
2
3SpreadsheetCell cell = 6.6;
double d1 = static_cast<double>(cell);
double d2 = static_cast<double>(cell + 3.3);
下面解释上述代码中的各行:
- 使用隐式类型转换从double转换到SpreadsheetCell。由于是在声明中,因此这是通过调用接收double参数的构造函数进行的。
- 使用
operator double()转换运算符。注意,由于这个转换运算符现在声明为explicit,因此要求进行强制类型转换。 - 通过隐式类型转换将3.3转换为SpreadsheetCell,再进行两个SpreadsheetCell对象的operator+操作,之后进行必要的显式类型转换以调用
operator double()。
重载内存分配和内存释放运算符
new和delete的工作原理
考虑下面这行代码:1
SpreadsheetCell* cell = new SpreadsheetCell();
new SpreadsheetCell()这部分称为new表达式。它完成了两件事情。首先,通过调用operator new为SpreadsheetCell对象分配了空间。然后,为这个对象调用构造函数。只有这个构造函数完成了,才返回指针。
delete的工作方式与此类似。考虑下面这行代码:1
delete cell;
这一行称为delete表达式。它首先调用cell的析构函数,然后调用operator delete来释放内存。可重载operator new和operator delete来控制内存的分配和释放,但不能重载new表达式和delete表达式。
new表达式和operator new
有6种不同形式的new表达式,每种形式都有对应的operator new。前面的章节已经展示了4种new表达式:new、new[]、new(nothrow)和new(nothrow) []。下面列出了<new>头文件中对应的4种operator new形式:1
2
3
4void* operator new(size_t size);
void* operator new[](size_t size);
void* operator new(size_t size, const std::nothrow_t&)noexcept;
void* operator new[](size_t size, const std::nothrow_t&) noexcept;
有两种特殊的new表达式,它们不进行内存分配,而在已有存储段上调用构造函数。这种操作称为placement new运算符。它们在已有的内存中构造对象,如下所示:1
2void* ptr = allocateMemorySomehow();
spreadsheetCell* cell = new (ptr) SpreadsheetCe11();
这个特性有点儿偏门,但知道这项特性的存在非常重要。如果需要实现内存池,以便在不释放内存的情况下重用内存,这项特性就非常方便。对应的operator new形式如下,但C++标准禁止重载它们:1
2void* operator new(size_t size, void* p) noexcept;
void* operator new[](size_t size, void* p) noexcept;
delete表达式和operator delete
只可调用两种不同形式的delete表达式:delete和delete[],没有nothrow和placement形式。然而,operator delete有6种形式,nothrow和placement形式只有在构造函数抛出异常时才会使用。
这种情况下,匹配调用构造函数之前分配内存时使用的operator new的operator delete会被调用。然而,如果正常地删除指针,delete会调用operator delete或operator delete[],绝不会调用nothrow或placement形式。C++标准指出,从delete抛出异常的行为是未定义的。也就是说,delete永远都不应该抛出异常。因此nothrow版本的operator delete是多余的;而placement版本的delete应该是一个空操作,因为在placement new中并没有分配内存,因此也不需要释放内存。
更有用的技术是重载特定类的operator new和operator delete。仅当分配或释放特定类的对象时,才会调用这些重载的运算符。下面这个类重载了4个非placement形式的operator new和operator delete:1
2
3
4
5
6
7
8
9
10
11class MemoryDemo {
public:
void* operator new(size_t size);
void operator delete(voId* ptr) noexcept;
void* operator new[](size_t size);
void operator delete[](void* ptr) noexcept;
void* operator new(size_t size, const std::nothrow_t&) noexcept;
void operator delete(void* ptr, const std::nothrow_t&) noexcept;
void* operator new[](size_t size, const std::nothrow_t&) noexcept;
void operator delete[](void* ptr, const std::nothrow_t&) noexcept;
};
当重载operator new时,要重载对应形式的operator delete。否则,内存会根据指定的方式分配,但是根据内建的语义释放,这两者可能不兼容。
显式地删除/默认化operator new和operator delete
下面的类删除了operator new和new[]。也就是说,这个类不能通过new或new[]动态创建:1
2
3
4
5class MyClass {
public:
void*operator new(size_t size) = delete;
void* operator new[](size_t size) = delete;
};
重载带有额外参数的operator new和operator delete
除了重载标准形式的operator new外,还可编写带额外参数的版本。这些额外参数可用于向内存分配例程传递各种标志或计数器。例如,一些运行时库在调试模式中使用这种形式。下面是MemoryDemo类中带有额外整数参数的operator new和operator delete原型:1
2void* operator new(size_t size, int extra);
void operator delete(void* ptr, int extra) noexcept;
编写带有额外参数的重载operator new时,编译器会自动允许编写对应的new表达式。new的额外参数以函数调用的语法传递。因此,可编写这样的代码:1
2MemoryDemo* memp = new (5) MemoryDemo();
delete memp;
定义带有额外参数的operator new时,还应该定义带有额外参数的对应operator delete。不能自己调用这个带有额外参数的operator delete,只有在使用了带有额外参数的operator new且对象的构造函数抛出异常时,才调用这个operator delete。
C++标准库概述
编码原则
- 使用模板:模板用于实现泛型编程。通过模板,才能编写适用于所有类型对象的代码,模板甚至可用于编写代码时未知的对象。
- 使用运算符重载:C++标准库大量使用了运算符重载。
C++标准库概述
字符串
C++在<string>头文件提供内建的string类,处理内存管理:提供一些边界检查、赋值语义以及比较操作;还支持些操作,例如串联、子字符串提取以及子字符串或字符的替换。
从技术角度看,
std::string是对std::basic_string模板进行char实例化的类型别名。
标准库还提供在<string_view>中定义的string_view类。这是各类字符串表示的只读视图,可用于简单替换const string&,而且不会带来开销。它从不复制字符串!
正则表达式
<regex>头文件提供了正则表达式。正则表达式简化了文本处理中常用的模式匹配任务。通过模式匹配可在字符串中搜索特定的模式,还能酌情将搜索到的模式替换为新模式。
I/0流
C++引入了一种新的使用流的输入输出模型。IO功能在如下几个头文件中定义:<fstream>、<iomanip>、<ios>、<iosfwd>、<iostream>、 <istream>、<ostream>、<sstream>、<streambuf>和<strstream>。
智能指针
- 第一个问题是根本没有删除对象(没有释放存储)。这称为内存泄漏。
- 另一个问题是一段代码删除了存储,而另一段代码仍然引用了这个存储,导致指向那个存储的指针不再可用或已重新分配用作他用,这称为悬挂指针(dangling pointer)。
- 还有一个问题是一段代码释放了一块存储,而另一段代码试图释放同一块存储。这称为双重释放(doublefreeing)。
所有这些问题都会导致程序发生某种故障。C++用智能指针unique_ptr、shared_ptr和week_ptr解决了这些问题。shared_ptr和week_ptr是线程安全的,在<memory>头文件中定义。
在C++11之前,unique_ptr的功能由名为auto_ptr的类型完成,C++17废弃了auto_ptr,不应再使用这种类型。
异常
C++语言支持异常,函数和方法能通过异常将不同类型的错误向上传递至调用的函数或方法。异常支持在如下几个头文件中定义:<exception>、<stdexcept>和<system_error>。
数学工具
C++有完整且常见的数学函数可供使用,C++17增加了大量的特殊数学函数,处理勒让德多项式、B函数、椭圆积分、贝塞尔函数、柱函数和诺伊曼函数等。
标准库在<complex>头文件中提供了一个复数类,名为complex,这个类提供了对包含实部和虚部的复数的操作抽象。
标准库还在<valarray>头文件中包含一个valarray类,这个类和vector类相似,但对高性能数值应用做了特别优化。这个库提供了一些表示矢量切片概念的相关类。通过这些构件,可构建执行矩阵数学运算的类。
C++还提供了一种获取数值极限的标准方式,例如当前平台允许的整数的最大值。在C语言中,可以通过访问#define来获得这些信息,例如INT_MAX。尽管在C++中仍可使用这种方法,但建议使用定义在<limits>头文件中的numeric_limits类模板:1
2cout <<"Max int value:" <<numeric_limits<int>::max() << endl;
cout <<"Min int value:" <<numeric_limits<int>::min() << endl;
注意min()和lowest()之间的差异:
- 对于整数而言,min值等于lowest值。
- 对于浮点类型而言,min值等于可表示的最小正值,而lowest值等于可表示的最大负值,即
-max()。
时间工具
C++在<chrono>头文件中包含了Chrono库。这个库简化了与时间相关的操作,例如特定时间间隔的定时操作和定时相关的操作。
容器
标准库中的所有容器都是类模板,因此可通过这些容器保存任意类型的数据,从内建的int和double等类型到自定义的类。每个容器实例都只能保存一种类型的对象,也就是说,这些容器都是同构集合。如果需要大小可变的异构集合,可将每个元素包装在std:any实例中,并将这些实例存储在容器中。另外,可在容器中存储std:variant实例。
vector
<vector>头文件定义了vector,vector保存了元素序列,提供对这些元素的随机访问。与数组一样,vector中的元素保存在连续内存中。
vector能够在vector尾部快速地插入和删除元素(摊还常量时间,amortized constant time)。摊还常量时间指的是大部分插入操作都是在常量时间内完成的。然而,有时vector需要增长大小以容纳新元素,此时的复杂度为O(N)。这个结果的平均复杂度为0(1),或称为摊还常量时间。
vector其他部位的插入和删除操作比较慢(线性时间),因为这种操作必须将所有元素向上或向下挪动一个位置,为新元素腾出空间,或填充删除元素后留下的空间。与数组一样,vector提供对任意元素的快速访问。
对于在vector<bool>中保存布尔值有一个专门的模板。这个特制模板特别对布尔元素进行空间分配的优化,然而标准并未规定vector<bool>的实现应该如何优化空间。vector<bool>和本章后面要讨论的bitset之间的区别在于,bitset容器的大小是固定的。
list
标准库list是一种双向链表数据结构,在<list>中定义。与数组和vector一样,list保存了元素的序列。然而,与数组或vector的不同之处在于,list中的元素不一定保存在连续内存中。相反,list中的每个元素都指定了如何在list中找到前一个和后一个元素,所以得名双向链表。
list的性能特征和vector完全相反。list提供较慢的元素查找和访问(线性时间),而找到相应的位置之后,元素的插入和删除却很快(常量时间)。然而,vector通常比list更快。可使用性能分析器确认这一点。
forward_list
<forward_list>中定义的forward_list是一种单向链表,而list容器是双向链表。forward_list只支持前向迭代,需要的内存比list少。与list类似,一旦找到相关位置, forward_list允许在任何位置执行插入和删除操作(常量时间);与list一样,不能快速地随机访问元素,
deque
deque是双头队列(double-ended queue)的简称。deque在<deque>中定义,能实现快速的元素访问(常量时间)。在序列的两端还实现了快速插入和删除(摊还常量时间),但在序列中间插入和删除的速度较慢线性时间),deque中的元素在内存中的存储不连续,速度可能比vector慢,如果需要在序列两头快速插入或删除元素,还要求快速访问所有元素,那么应该使用deque而不是vector。
array
<array>头文件定义了array,这是标准C风格数组的替代品。有时可事先知道容器中元素的确切数量,因此不需要vector或list提供的灵活性,。array特别适用于大小固定的集合,而且没有vector的开销。
使用array有几点好处:
- array总能知道自己的大小;
- 不会自动转换为指针类型,从而避免了某些类型的bug。
array没有提供插入和删除操作,但大小固定。大小固定的优点是,允许array在堆栈上分配内存,而不总是像vector那样需要堆访问权限。与vector一样,对元素的访问速度极快(常量时间)。
queue
queue容器在<queue>中定义,提供标准的先入先出语义。在使用queue容器时,从一端插入元素,从另一端取出元素。插入元素(摊还常量时间)和删除元素(常量时间)的操作都很快。
priority_queue
priority_queue也在<queue>中定义,提供与queue相同的功能,但其中的每个元素都有优先级。元素按优先顺序从队列中移除。在优先级相同的情况下,删除元素的顺序没有定义。对prionity_queue的插入和删除一般比简单的队列插入和删除要慢,因为只有对元素重排序,才能支持优先级。
stack
<stack>头文件定义了stack,它提供标准的先入后出。在堆栈中,最新插入的元素第一个被移除。stack容器实现了元素的快速插入和删除(常量时间)。
set和multiset
set类模板在<set>头文件中定义。顾名思义,标准库中的set保存的是元素的集合:每个元素都是唯一的,在集合中每个元素最多只有一个实例。标准库中的set和数学中集合的概念有一点区别:在标准库中,元素按照一定的顺序保存。set提供对数时间的插入、删除和查找操作。这意味着插入和删除操作比vector快,但比list慢。查找操作比list块,但比vector慢。
如果需要保持顺序,而且要求插入,删除和查找操作的性能接近,那么应当优先使用set而不是vector或list。如果严禁出现重复元素,也应当使用set。
注意,set不允许重复元素。也就是说,set中的每个元素都必须唯一。如果要存储重复元素,必须使用<set>头文件中定义的multiset。
map和multimap
<map>头文件定义了map类模板,这是一个关联数组。可将其用作数组,其中的索引可以是任意类型,如string。map保存的是键/值对。map按顺序保存元素,排序的依据是键值而非对象值。它还提供operator[]。如果需要关联键和值,就应该使用map。
multimap也在<map>头文件中定义,它和map的关系等同于multiset和set的关系。确切地讲,multimap是允许重复键的map。
无序关联容器/哈希表
标准库支持哈希表(hash table),哈希表也称为无序关联容器(unordered associative container)。有4个无序关联容器:
- unordered map
- unordered_multimap
- unordered_set
- unordered multiset
前两个在<unordered_map>中定义,后两个在<unordered_set>中定义。更贴切的名字应该是hash_map和hash_set等。
这些无序关联容器的插入、删除和查找操作能以平均常量时间完成。最坏情况是线性时间。在无序的容器中查找元素的速度比普通map或set中的查找速度快得多。
bitset
bitset类抽象了位操作。<bitset>头文件定义了bitset容器,但没有实现某种特定的可插入或删除元素的数据结构;bitset有固定大小,不支持迭代器。可将bitset想象为可以读写的布尔值序列。
bitset不局限于int或其他基本数据类型的大小。因此,能操作40位的bitset,也能操作213位的bitset。bitset的实现会使用实现N个位所需的足够存储空间,通过bitset<N>声明bitset时指定N。
标准库容器小结
表16-1总结了标准库提供的容器。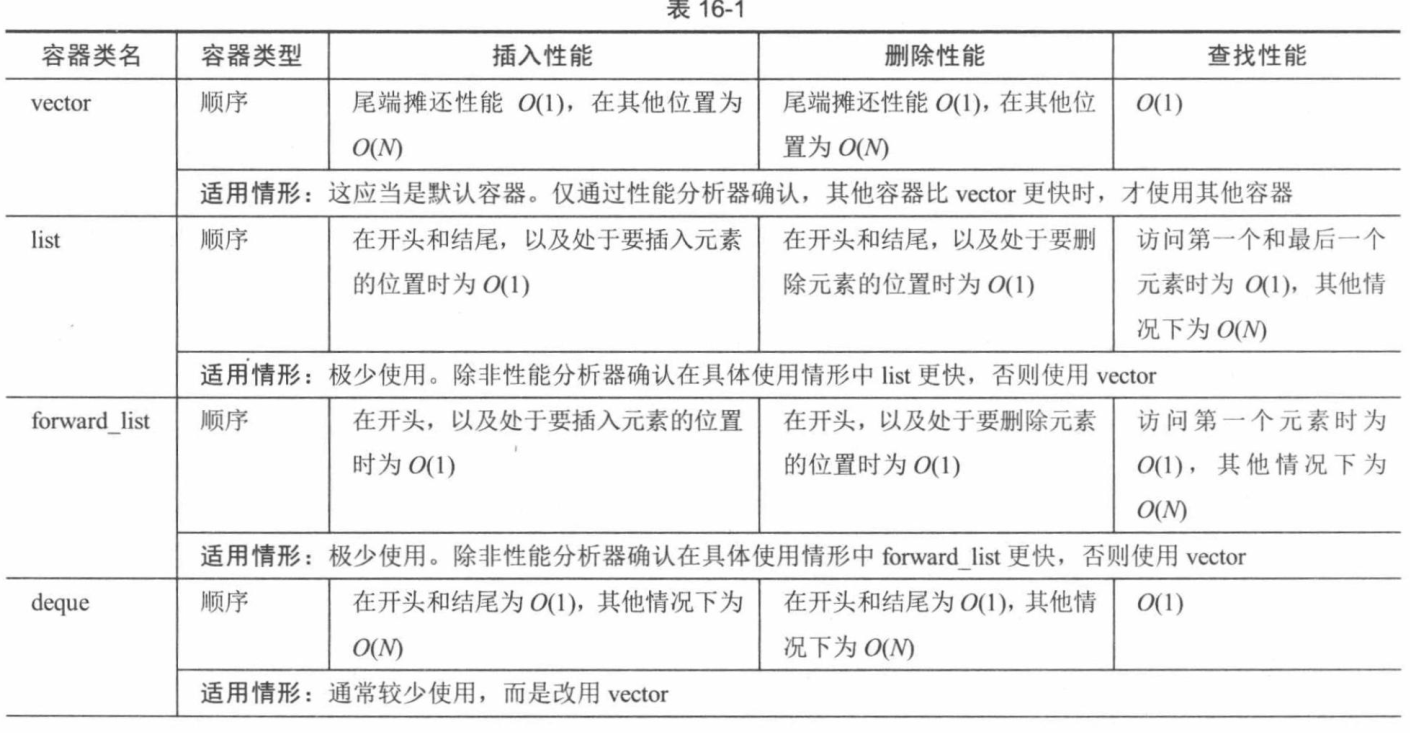
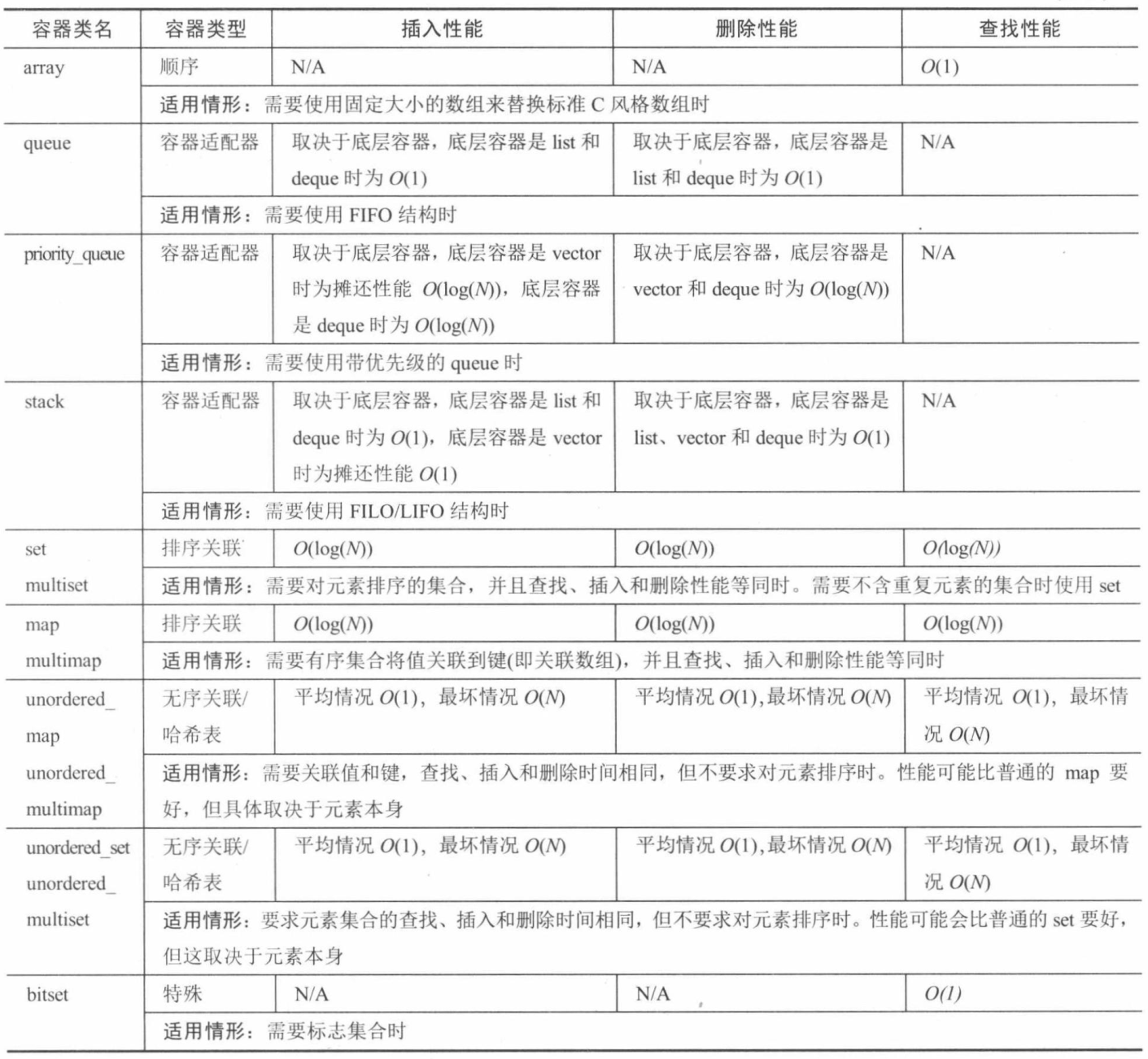
算法
除容器外,标准库还提供了很多泛型算法的实现。算法指的是执行某项任务时采取的策略,例如排序任务和搜索任务。这些算法也是用函数模板实现的,因此可用于大部分不同类型的容器。
迭代器是算法和容器之间的中介。选代器提供了顺序遍历容器中元素的标准接口,因此任何算法都可以操作任何容器。
标准库中大约有100种算法,下面将这些算法分为不同的类别。除非特别说明,否则这些算法都在<algorithm>头文件中定义。
非修改顺序算法
非修改类的算法查找元素的序列,返回一些有关元素的信息。因为是非修改类的算法,所以这些算法不会改变序列中元素的值或顺序。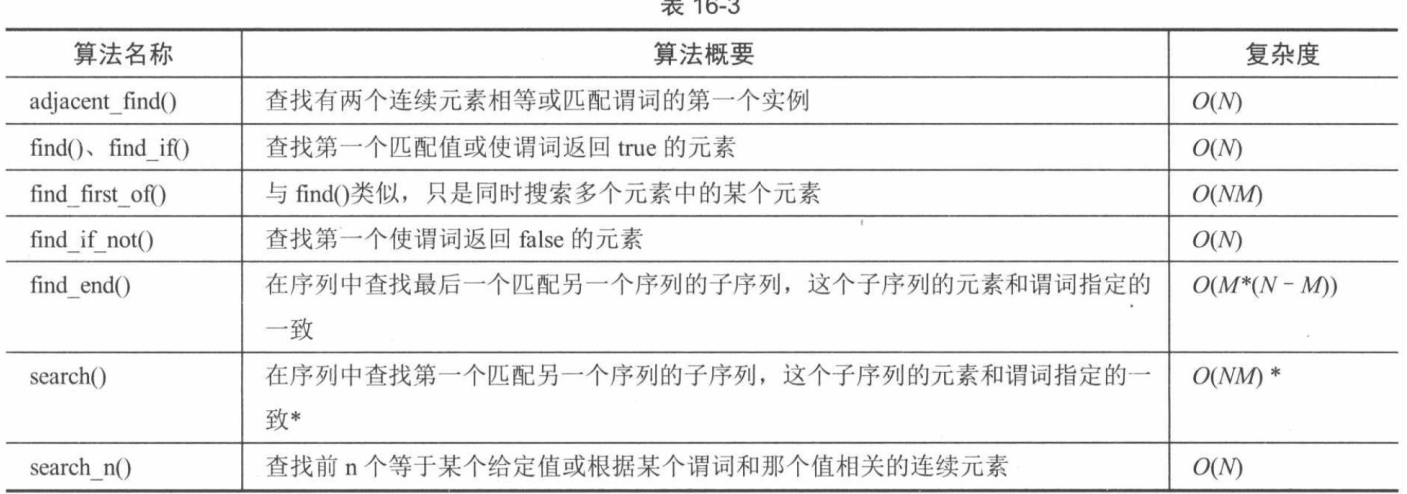
从C++17开始,search0接收一个可选的附加参数,以指定要使用的搜索算法(default_searcher、boyer_moore_searcher或boyer_moore_horspool_searcher),使用boyer_moore搜索算法,最坏情况下,模式未找到时的复杂度是O(N+M),模式找到时的复杂度为O(NM)。
标准库提供了表16-4中列出的比较算法。这些算法都不要求排序源序列。所有算法的最差复杂度都为线性复杂度
计数算法如表16-5所示。
修改序列算法
修改算法会修改序列中的一些元素或所有元素。有些修改算法在原位置修改元素,因此原始序列发生变化。另一些修改算法将结果复制到另一个不同的序列,所以原始序列没有变化。所有这些修改算法的最坏复杂度都为线性复杂度。表16-6汇总了这些修改算法。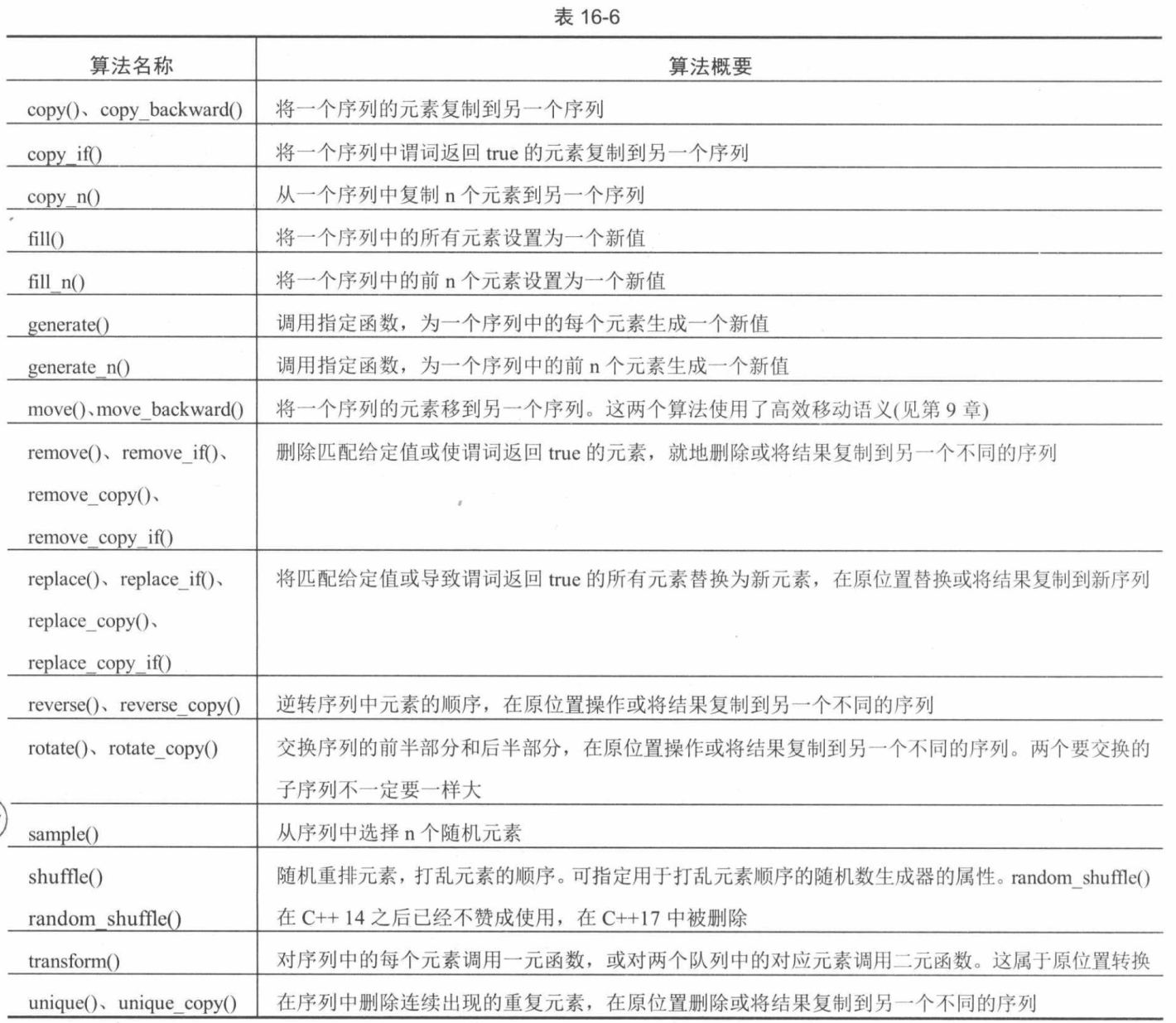
操作算法
操作算法在单独的元素序列上执行函数。C++标准库提供了两种操作算法,如表16-7所示。它们的复杂度都是线性复杂度,不要求对原始序列进行排序。
交换算法
C++标准库提供如表16-8所示的交换算法。
分区算法
如果谓词返回true的所有元素都在谓词返回false的所有元素的前面,则按某个谓词对序列进行分区。序列中不满足谓词的第一个元素称为分区点(partition point)。C++标准库提供如表16-9所示的分区算法。
排序算法
C++标准库提供了一些不同的排序算法,不同的排序算法有不同的性能保证,如表16-10所示。
二叉树搜索算法
下面的二叉树搜索算法通常用于已排序的序列。排好序的序列也满足这个要求。所有这些算法都具有对数复杂度。
集合算法
集合算法是特殊的修改算法,对序列执行集合操作,如表16-12所示。这些算法最适合操作set容器的序列,但也能操作大部分容器的排序后序列。
堆算法
堆(heap)是一种标准的数据结构,数组或序列中的元素在其中以半排序的方式排序,因此能够快速找到“顶部”元素。
最大/最小算法

数值处理算法
<numeric>头文件提供了下述数值处理算法。这些算法都不要求排序原始序列。所有算法的复杂度都为线性复杂度,如表16-15所示。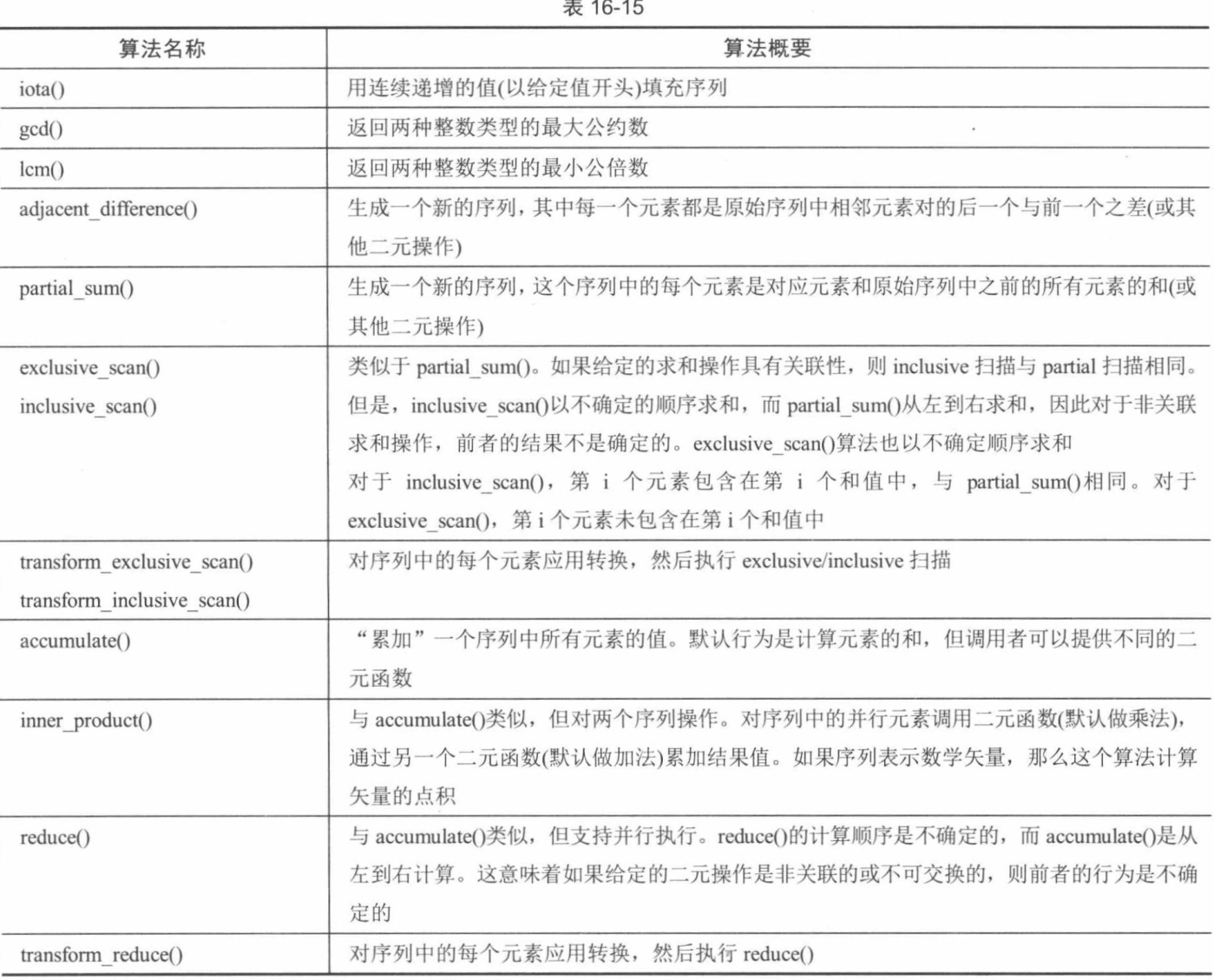
置换算法
序列的置换包含相同的元素,但顺序变了。表16-16列出了用于置换的算法。
理解容器与迭代器
容器概述
标准库提供了16个容器,分为4大类。
- 顺序容器
- vector(动态数组)
- deque
- list
- forward_list
- array
- 关联容器
- map
- multimap
- set
- multiset
- 无序关联容器或哈希表
- unordered_map
- unordered_multimap
- unordered_set
- unordered_multiset
- 容器适配器
- queue
- priority_queue
- stack
此外,C++的string和流也可在某种程度上用作标准库容器,bitset可以用于存储固定数目的位。
对元素的要求
标准库容器对元素使用值语义(value semantic)。也就是说,在输入元素时保存元素的一份副本,通过赋值运算符给元素赋值,通过析构函数销毁元素。因此,编写要用于标准库的类时,一定要保证它们是可以复制的。请求容器中的元素时,会返回所存副本的引用。
如果喜欢引用语义,可存储元素的指针而非元素本身。当容器复制指针时,结果仍然指向同一元素。另一种方式是在容器中存储std::reference_wrapper。可使用std::ref()或std::cref()创建reference_wrapper,使引用变得可以复制。reference_wrapper类模板以及ref()和cref()函数模板在<functional>头文件中定义。
在容器中,可能存储“仅移动”类型,这是非可复制类型,但当这么做时,容器上的一些操作可能无法编译。“仅移动”类型的一个例子是std::unique_ptr。
标准库容器的一个模板类型参数是所谓的分配器(allocator)。标准库容器可使用分配器为元素分配或释放内存。分配器类型参数具有默认值,因此几乎总是可以忽略它。
有关使用默认内存分配器和比较器的容器中元素的特别需求在表17-1中列出。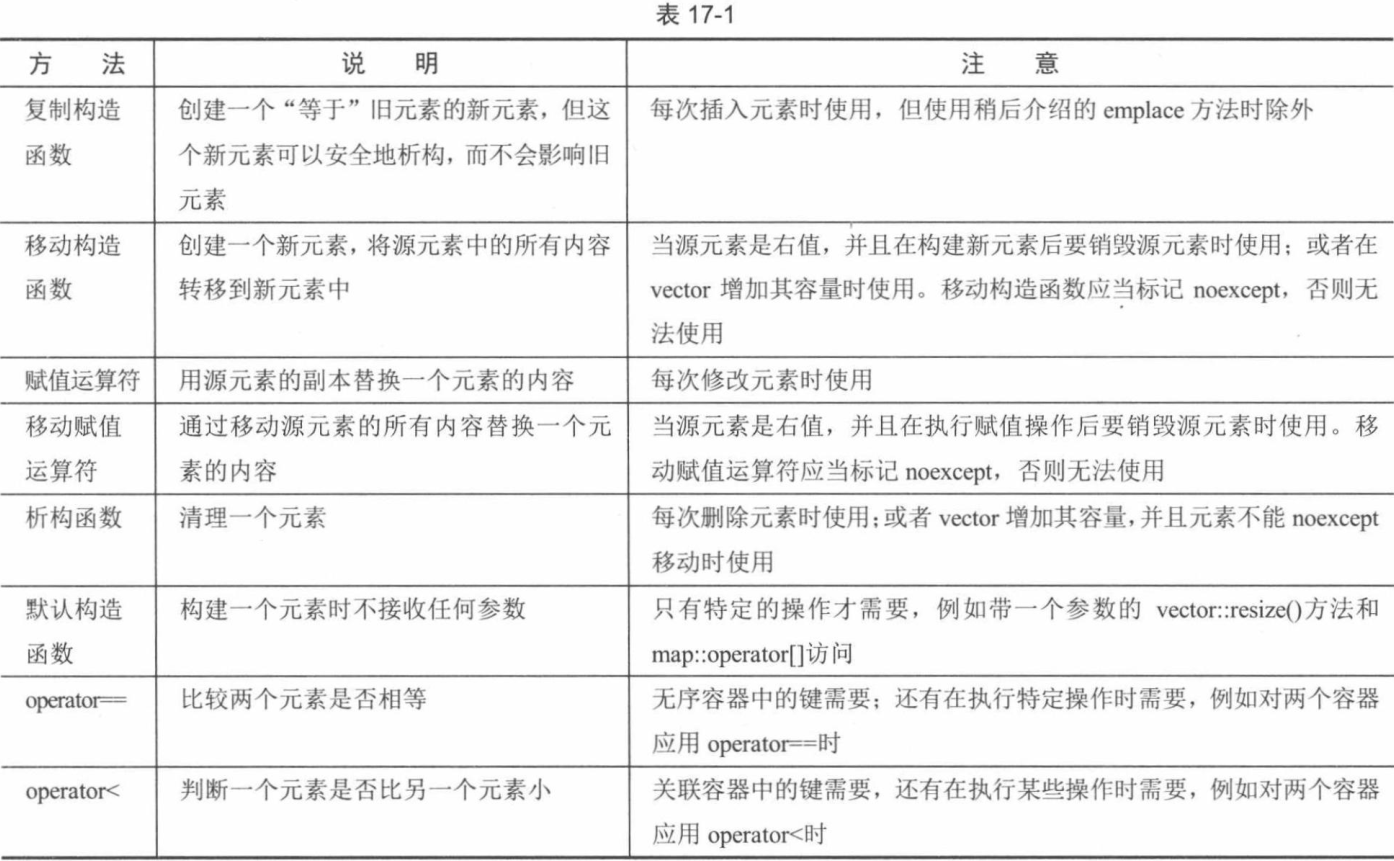
迭代器
标准库通过迭代器模式提供了访问容器元素使用的泛型抽象。每个容器都提供了容器特定的迭代器,迭代器实际上是增强版的智能指针,这种指针知道如何遍历特定容器的元素。可将迭代器想象为指向容器中特定元素的指针。与指向数组元素的指针一样,迭代器可以通过operator++移到下一个元素。C++标准定义了5大类迭代器,如表17-2所示。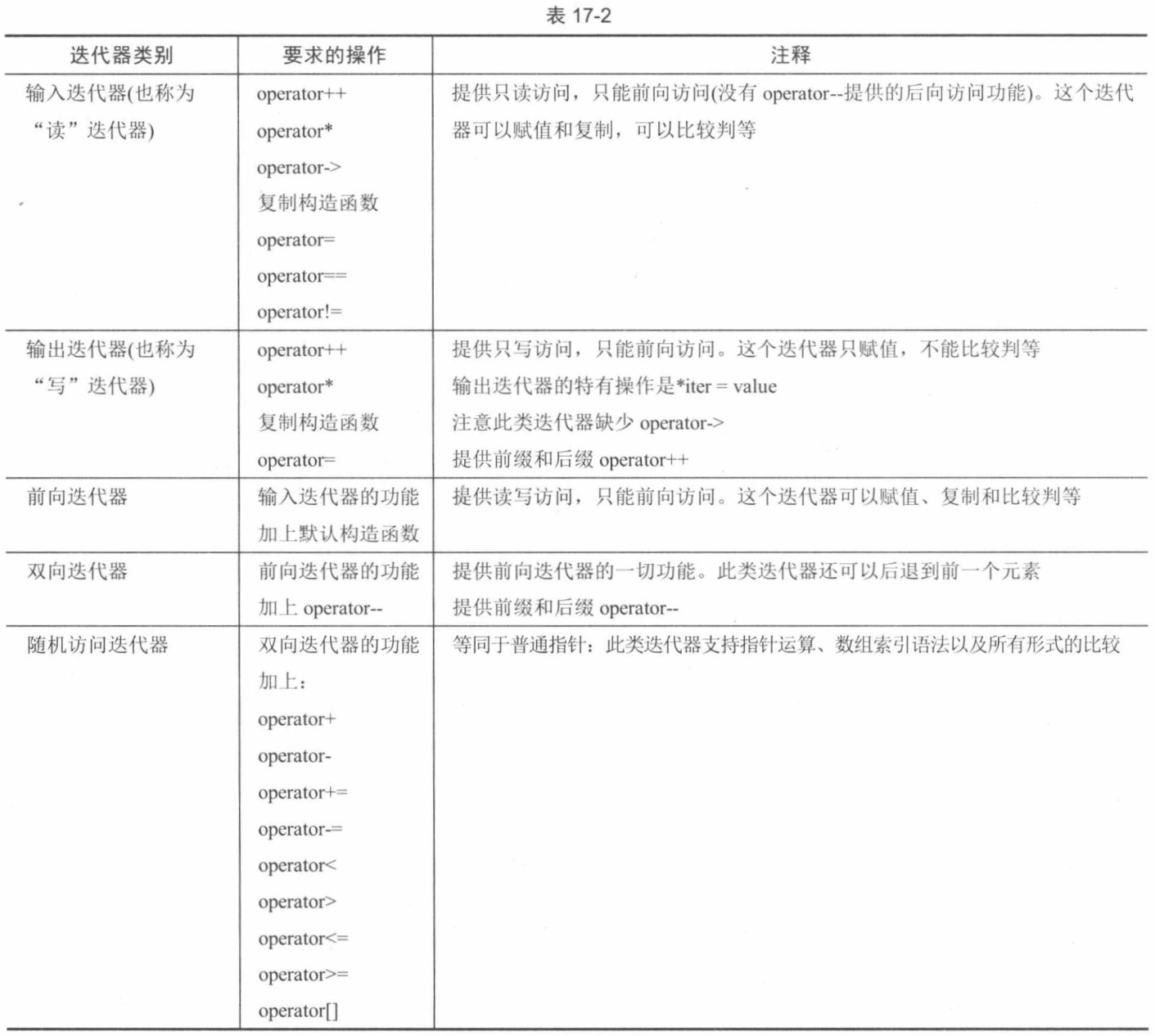
另外,满足输出迭代器要求的迭代器称为“可变迭代器”,否则称为“不变迭代器”。还可使用std::distance()计算容器的两个迭代器之间的距离。迭代器的实现类似于智能指针类,因为它们都重载了特定的运算符。
基本的迭代器操作类似于普通指针(dumb pointer)支持的操作,因此普通指针可以合法用作特定容器的迭代器。事实上,vector选代器在技术上就是通过简单的普通指针实现的。
标准库中每个支持迭代器的容器类都为其选代器类型提供了公共类型别名,名为iterator和const_iterator。允许反向迭代元素的容器还提供了名为reverse_iterator和const_reverse_iterator的公共类型别名。通过这种方式,客户使用容器迭代器时不需要关心实际类型。
const_iterator和const_reverse_iterator提供对容器元素的只读访问。
容器还提供了begin()和end()方法。begin()方法返回引用容器中第一个元素的迭代器,end()方法返回的选代器等于在引用序列中最后一个元素的选代器上执行operator++后的结果。begin()和end()一起提供了一个半开区间,包含第一个元素但不包含最后一个元素。采用这种看似复杂方式的原因是为了支持空区间(不包含任何元素的容器),此时begin()等于end()。
与此类似,还有:
- 返回const迭代器的
cbegin()和cend()方法 - 返回反向选代器的
rbegin()和rend()方法 - 返回const反向选代器的
crbegin()和crend()方法
顺序容器
vector
可以在vector中建立索引,还可以在尾部或任何位置添加新的元素。向vector插入元素或从vector删除元素通常需要线性时间,但这些操作在vector尾部执行时,实际运行时间为摊还常量时间。
vector概述
vector在<vector>头文件中被定义为一个带有两个类型参数的类模板:一个参数为要保存的元素类型,另一个参数为分配器(allocator)类型1
template <class T, class Allocator = allocator<T>> class vector;
Allocator参数指定了内存分配器对象的类型, 客户可设置内存分配器,以便使用自定义的内存分配器。这个模板参数具有默认值。
Allocator类型参数的默认值足够大部分应用程序使用。
固定长度的vector
使用vector的最简单方式是将其用作固定长度的数组。vector提供了一个可以指定元素数量的构造函数,还提供了一个重载的operator[]以便访问和修改这些元素。C++标准指出:通过operator[]访问vector边界之外的元素时,得到的结果是未定义的。
除使用operator[]运算符外,还可通过at()、front()和back()访问vector元素。at()方法等同于operator[]运算符,区别在于at()会执行边界检查,如果索引超出边界,at()会抛出out_of_range异常。front()和back()分别返回vector的第一个元素和最后一个元素的引用。
对vector应用operator[]运算符通常会返回一个对元素的引用,可将这个引用放在赋值语句的左侧。如果对const vector对象应用operator[]运算符,就会返回一个对const元素的引用,这个引用不能用作赋值的目标。
动态长度的vector
vector的真正强大之处在于动态增长的能力。push_back()方法能为新元素分配空间。基于区间的for循环不需要做任何修改。
构造函数和析构函数
默认的构造函数创建一个不包含元素的vector。1
vector<int> intVector;
可指定元素个数,还可指定这些元素的值,如下所示:1
vector<int> intVector(10, 100);
如果没有提供默认值,那么对新对象进行0初始化。0初始化通过默认构造函数构建对象。
可以使用包含初始元素的initializer_list构建vector:1
vector<int> intVector({ 1, 2, 3, 4,5,6 ));
initializer_list还可以用于第1章提到的统一初始化。统一初始化可用于大部分标准库容器。例如:1
2
3
4
5
6vector<int> intVector1 = {1, 2, 3, 4, 5, 6};
vector<int> intVector2{1, 2, 3, 4, 5, 6};
还可以在堆上分配vector:
```C++
auto elementVector = make_unique<vector<Element>>(10);
vector的复制和赋值
vector存储对象的副本,其析构函数调用每个对象的析构函数。vector类的复制构造函数和赋值运算符对vector中的所有元素执行深度复制。因此,出于效率方面的考虑,应该通过引用或const引用向函数和方法传递vector。
除普通的复制和赋值外,vector还提供了assign()方法,这个方法删除所有现有的元素,并添加任意数目的新元素。这个方法特别适合于vector的重用。下面是一个简单的例子。intVector包含10个默认值为0的元素。然后通过assign()删除所有10个元素,并以5个值为100的元素代之。1
2vector<int> intVector(10);
intVector.assign(5,100);
如下所示,assign()还可接收initializer_list。intVector现在有4个具有给定值的元素。1
intVector.assign({1, 2, 3, 4});
vector还提供了swap()方法,这个方法可交换两个vector的内容,并且具有常量时间复杂度。下面举一个简单示例:1
2
3vector<int> vectorOne(10);
vectorcint> vectorTwo(5, 100);
vectorOne.swap (vectorTwo);
vector的比较
标准库在vector中提供了6个重载的比较运算符:==、!=、<、>、<=和>=。如果两个vector的元素数量相等,而且对应元素都相等,那么这两个vector相等。两个vector的比较采用字典顺序:如果第一个vector中从0到i-1的所有元素都等于第二个vector中从0到i-1的所有元素,但第一个vector中的元素i小于第二个vector中的元素i,其中i在0到n之间,且n必须小于size(),那么第一个vector“小于”第二个vector。
通过operator==和operator!=比较两个vector时,要求每个元素都能通过operator==运算符进行比较。通过
vector迭代器
首先,看一下for循环的初始化语句:1
vector<double>::iterator iter = begin (doubleVector);
begin()返回引用容器中第一个元素的相应类型的迭代器。因此,这条初始化语句在iter变量中获取了引用doubleVector中第一个元素的迭代器。下面看一下for循环的比较语句:1
iter != end(doubleVector);
这条语句检查迭代器是否超越了vector中元素序列的尾部。当到达这一点时,循环终止。递增语句++iter递增迭代器,以引用vector中的下一个元素。
只要可能,尽量使用前递增而不要使用后递增,因为前递增至少效率不会差,一般更高效。
iter++必须返回一个新的选代器对象,而++iter只是返回对iter的引用。
上述使用迭代器的for循环可通过auto关键字简化:1
2for (auto iter = begin(doubleVector); iter != end(doubleVector); ++iter)
cout << *iter << " ";
访问对象元素中的字段
如果容器中的元素是对象,那么可对迭代器使用->运算符,调用对象的方法或访问对象的成员。1
2
3
4vector<string> stringVector(10, "hello");
for (auto it = begin(stringVector); it!= end(stringVector); ++ it)
it->append(" there");
}
使用基于区间的for循环,这段代码可以重写为:1
2
3vector<string> stringVector(10, "hello");
for (auto& str : stringVector)
str.append("there");
const_iterator
const_iterator是只读的,不能通过const_iterator修改元素。iterator始终可以转换为const_iterator,因此下面这种写法是安全的:1
vector<type>::const_iterator it = begin (myVector);
然而,const_iterator不能转换为iterator。如果myVector是const_iterator,那么下面这行代码无法编译:1
2
3
4
5
6
7vector<type>::iterator it = begin (myVector);
在使用auto关键字时,const_iterator的使用看上去有一点区别。假设有以下代码:
```C++
vector<string> stringVector(10, "hello");
for (auto iter = begin(stringVector); iter != end(stringVector); ++iter)
cout << *iter << endl;
由于使用了auto关键字,编译器会自动判定iter变量的类型,然后将其设置为普通的iterator,因为stringVector不是const_iterator。如果需要结合auto使用只读的const_iterator,那么需要使用cbegin()和cend(),而不是begin()和end(),如下所示:1
2
3vector<string> stringVector(10, "hello");
for (auto iter = cbegin(stringVector); iter != cend(stringVector); ++iter)
cout << *iter << endl;
现在编译器会将iter变量的类型设置为const_iterator,因为cbegin()返回的就是const_iterator。
基于区间的for循环也可用于强制使用const_ iterator,如下所示:1
2
3vector<string> stringVector(10, "hello");
for (const auto& element : stringVector)
cout << element << endl;
迭代器还是索引?
- 使用迭代器可在容器的任意位置插入、删除元素或元素序列。
- 使用迭代器可使用标准库算法。
- 通过迭代器顺序访问元素,通常比编制容器索引以单独检索每个元素的效率要高。
在vector中存储引用
可在诸如vector的容器中存储引用。为此,在容器中存储std:reference_wrapper。std:ref()和cref()函数模板用于创建非const和const reference_wrapper实例。需要包含<functional>头文件。示例如下:1
2
3
4
5
6
7
8
9
10
11string str1 = "Hello";
string str2 = "World";
vector<reference_wrapper<string>> vec{ ref(str1) };
vec.push_back(ref(str2));
// Modify the string referred to by the second reference in the vector.
vec[1].get() += "!";
// The end result is that str2 is actually modified.
cout << str1 << " " << str2 << endl;
添加和删除元素
根据前面的描述,通过push_back()方法可向vector追加元素。vector还提供了删除元素的对应方法:pop_back()。
pop_back()不会返回已删除的元素。如果要访问这个元素,必须首先通过back()获得这个元素。通过insert()方法可在vector中的任意位置插入元素,这个方法在迭代器指定的位置添加一个或多个元素,将所有后续元素向后移动,给新元素腾出空间。insert()有5种不同的重载形式:
- 插入单个元素
- 插入单个元素的n份副本
- 从某个迭代器范围插入元素
- 使用移动语义,将给定元素转移到vector中,插入一个元素
- 向vector中插入一列元素,这列元素是通过initializer_list指定的
push_back()和insert()还有把左值或右值作为参数的版本。两个版本都根据需要分配内存,以存储新元素。左值版本保存新元素的副本。右值版本使用移动语义,将给定元素的所有权转移到vector,而不是复制它们。
通过erase()可在vector中的任意位置删除元素,通过clear()可删除所有元素。erase()有两种形式:一种接收单个迭代器,删除单个元素;另一种接收两个迭代器,删除迭代器指定的元素范围。要删除满足指定条件的多个元素,一种解决方法是编写一个循环来遍历所有元素,然后删除每个满足条件的元素。然而,这种方法具有二次(平方)复杂度,对性能有很大影响。这种情况下,可使用删除擦除惯用法(remove-erase-idiom),这种方法的复杂度为线性复杂度。
移动语义
所有的标准库容器都包含移动构造函数和移动赋值运算符,从而实现了移动语义。这带来的一大好处是可以通过传值的方式从函数返回标准库容器,而不会降低性能。分析下面这个函数:1
2
3
4
5
6
7
8
9
10vector<int> createVectorofsize(size_t size) {
vector<int> vec(size);
int contents = 0;
for (auto& i : vec)
i = contents++;
return vec;
}
vector<int> myVector;
myVector.createVectorofsize (123);
如果没有移动语义,那么将createVectorOfSize()赋给myVector时,会调用复制赋值运算符。有了标准库容器中支持的移动语义后,就可避免这种vector复制。相反,对myVector的赋值会触发调用移动赋值运算符。
与此类似,push操作在某些情况下也会通过移动语义提升性能。vector类还定义了push_back(T&&val),这是push_back(const T& val)的移动版本。如果按照下列方式调用push_back()方法,则可以避免这种复制:1
vec.push_back(move(myElement));
现在可以明确地说,myElement应移入vector。注意在执行这个调用后,myElement处于有效但不确定的状态。不应再使用myElement,除非通过调用clear()等使其重返确定状态。也可以这样调用push_back():1
vec.push_back(string(5, 'a'));
上述vec.push_back()调用会触发移动版本的调用,因为调用string构造函数后生成的是一个临时string对象。push_back()方法将这个临时string对象移到vector中,从而避免了复制。
emplace操作
C++在大部分标准库容器中添加了对emplace操作的支持。emplace的意思是“放置到位”。emplace操作的一个示例是vector对象上的emplace_back(),这个方法在容器中分配空间,然后就地构建对象。例如:
从C++17开始,emplace_back()方法返回已插入元素的引用。在C++17之前,emplace_back()的返回类型是void。还有一个emplace()方法,可在vector的指定位置就地构建对象,并返回所插入元素的迭代器。
算法复杂度和迭代器失效
在vector中插入或删除元素,引用插入点、删除点或随后位置的所有迭代器在操作之后都失效了。vector内部的重分配可能导致引用vector中元素的所有迭代器失效,而不只是那些引用插入点或删除点之后的元素的迭代器。
vector内存分配方案
vector会自动分配内存来保存插入的元素。每次vector申请更多内存时,要分配一块更大的内存块,将所有元素复制到新的内存块。这个过程非常耗时,因此 vector的实现在执行重分配时,会分配比所需内存更多的内存,以尽量避免这个复制转移过程。
必须理解vector内部的内存工作原理有两个原因:
- 效率。vector分配方案能保证元素插入采用摊还常量时间复杂度:也就是说,大部分操作都采用常量时间,但是也会有线性时间(需要重新分配内存时)。如果关注运行效率,那么可控制vector执行内存重分配的时机。
- 迭代器失效。重分配会使引用vector内元素的所有选代器失效。因此,vector接口允许查询和控制vector的重分配。如果不显式地控制重分配,那么应该假定每次插入都会导致重分配以及所有迭代器失效。
大小和容量
vector提供了两个可获得大小信息的方法:size()和capacity(),size()方法返回vector中元素的个数,而capacity()返回的是vector在重分配之前可以保存的元素个数。因此,在重分配之前还能插入的元素个数为capacity() - size()。
C++17引入了非成员的std::size()和std::empty()全局函数。这些与用于获取迭代器的非成员函数(如std::begin()和std::end()等)类似。非成员函数size()和empty()可用于所有容器,也可用于静态分配的C风格数组(不通过指针访问)以及initializer_list。下面是一个将它们用于vector的例子:1
2
3vector<int> vec{1, 2, 3};
cout << size(vec) << endl;
cout << empty(vec) << endl;
预留容量
一种预分配空间的方式是调用reserve()。这个方法负责分配保存指定数目元素的足够空间。
另一种预分配空间的方法是在构造函数中,或者通过resize()或assign()方法指定vector要保存的元素数目。这种方法会创建指定大小的vector(容量也可能就是这么大)。
直接访问数据
vector在内存中连续存储数据,可使用data()方法获取指向这块内存的指针。C++17引入了非成员的std::data()全局函数来获取数据的指针。它可用于array. vector容器、字符串、静态分配的C风格数组(不通过指针访问)和initializer_lists。下面是一个用于vector的示例:1
2
3vector<int> vec{1, 2, 3};
int* data1 = vec.data();
int* data2 = data(vec);
vector特化
C++标准要求对布尔值的vector进行部分特化,目的是通过“打包”布尔值的方式来优化空间分配。C++没有正好保存一个位的原始类型。一些编译器使用和char大小相同的类型来表示布尔值。其他一些编译器使用int类型。vector<bool>特化应该用单个位来存储“布尔数组”,从而节省空间。可将vector<bool>表示为位字段(bit-field)而不是vector。
vector<bool>特化实际上定义了一个名为reference的类,用作底层布尔(或位)值的代理。当调用operator[]、at()或类似方法时,vector<bool>返回reference对象,这个对象是实际布尔值的代理。
由于
vector<bool>返回的引用实际上是代理,因此不能取地址以获得指向容器中实际元素的指针。
在实际应用中,通过包装布尔值而节省一点空间似乎得不偿失。更糟糕的是,访问和修改vector<bool>中的元素比访问vector<int>中的元素慢得多。应该避免使用vector<bool>,而是使用bitset。
如果确实需要动态大小的位字段,建议使用vector<std::int_fast8_t>或vector<unsigned char>。std::int_fast8_t类型在<cstdint>中定义。这是一种带符号的整数类型,编译器必须为其使用最快的整数类型(至少8位)。
deque
deque(double-ended qucue的简称)几乎和vector是等同的,但用得更少。deque定义在<deque>头文件中。主要区别如下:
- 不要求元素保存在连续内存中
- deque支持首尾两端常量时间的元素插入和删除操作(vector只支持尾端的摊还常量时间)
- deque提供了
push_front(),pop_front()和emplace_front(),而vector没有提供 - 在开头和末尾插入元素时,deque未使选代器失效
- deque没有通过
reserve()和capacity()公开内存管理方案
list
list定义在<list>头文件中,是一种标准的双链表。list支持链表中任意位置常量时间的元素插入和删除操作,但访问单独元素的速度较慢(线性时间)。事实上,list根本没有提供诸如operator[]的随机访问操作。只有通过迭代器才能访问单个元素。
访问元素
list提供的访问元素的方法仅有front()和back(),这两个方法的复杂度都是常量时间。这两个方法返回链表中第一个元素和最后一个元素的引用。对所有其他元素的访问都必须通过迭代器进行。
list支持begin()方法,这个方法返回引用链表中第一个元素的迭代器;还支持end()方法,这个方法返回引用链表中最后一个元素之后那个元素的迭代器。与vector类似,list还支持cbegin()、cend()、rbegin(),rend()、crbegin()和crend()。
list不支持元素的随机访问。
迭代器
list迭代器是双向的,不像vector迭代器那样提供随机访问。这意味着list迭代器之间不能进行加减操作和其他指针运算。
添加和删除元素
和vector一样,list也支持添加和删除元素的方法,包括push_back()、pop_back()、emplace()、emplace_back()5种形式的insert()以及两种形式的erase()和clear()。和deque一样,list还提供了push_front()、emplace_front()和pop_front()。list的奇妙之处在于,只要找到正确的操作位置,所有这些方法(clear()除外)的复杂度都是常量时间。
list大小
list不公开底层的内存模型。因此,list支持size()、empty()和resize(),但不支持reserve()和capacity()。注意,list的size()方法具有常量时间复杂度。
list特殊操作
list提供了一些特殊操作,以利用其元素插入和删除很快这一特性。
串联
由于list类的本质是链表,因此可在另一个list的任意位置串联(splice)或插入整个list,其复杂度是常量时间。
串联���作对作为参数传入的list来说是破坏性的:从一个list中删除要插入另一个list的元素。
更高效的算法版本
除splice()外,list类还提供了一些泛型标准库算法的特殊实现。
表17-3总结了list以方法形式提供特殊实现的算法。
forward_list
forward_list在<forward_list>头文件中定义,forward_list是单链表,而list是双链表。这意味着forward_list只支持前向迭代,如果需要修改任何链表,首先需要访问第一个元素之前的那个元素。由于forward_list没有提供反向遍历的迭代器,因此没有简单的方法可以访问前一个元素。所以,要修改的范围(例如提供给erase()和splice()的范围)必须是前开的。
forward_list类定义了一个before_begin()方法,它返回一个指向链表开头元素之前的假想元素的迭代器。不能解除这个迭代器的引用,因为这个迭代器指向非法数据。然而,将这个迭代器递增1可得到与begin()返回的迭代器同样的效果;因此,这个方法可以用于构建前开的范围。表17-4总结了list和forward_list之间的区别。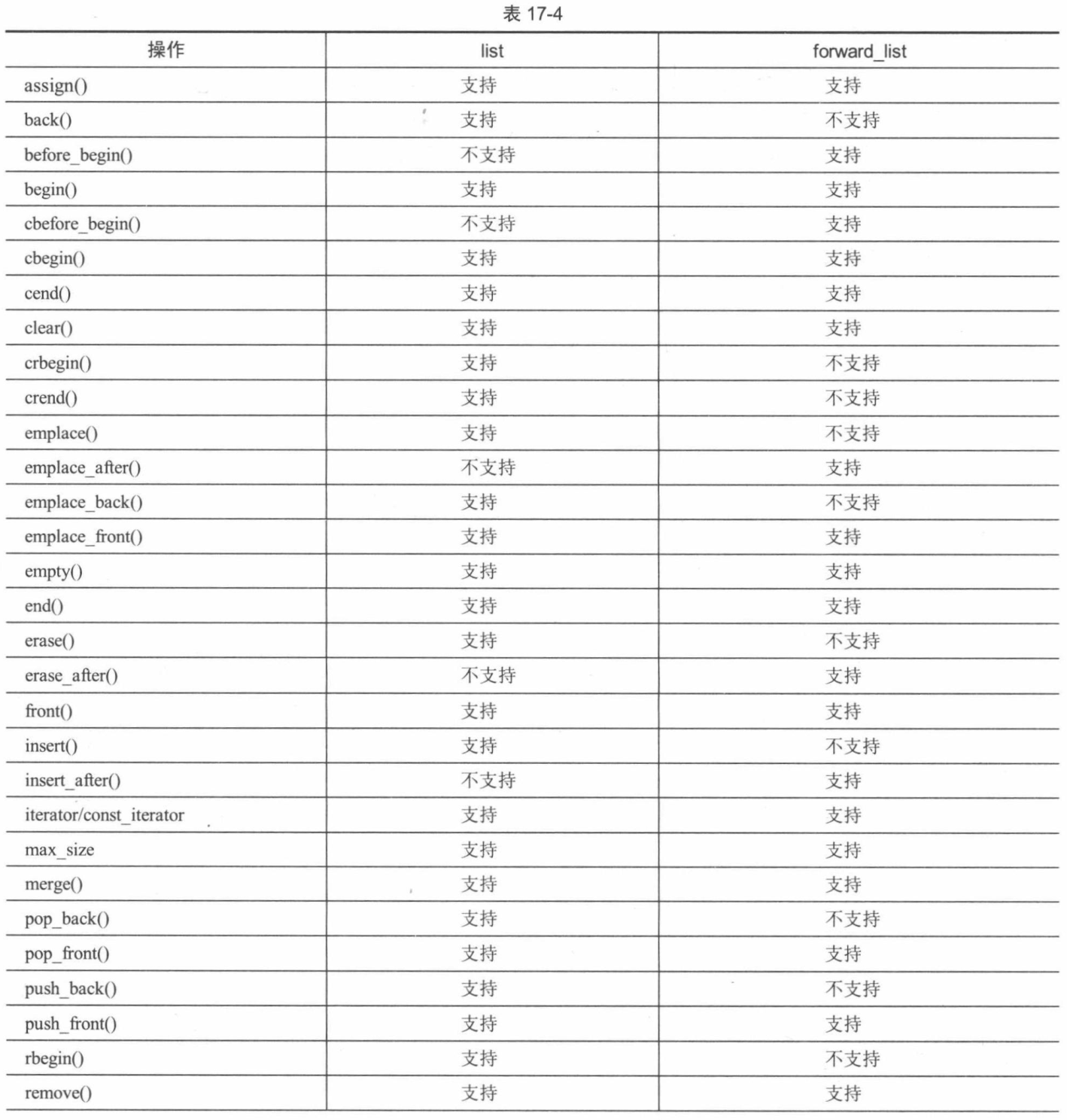
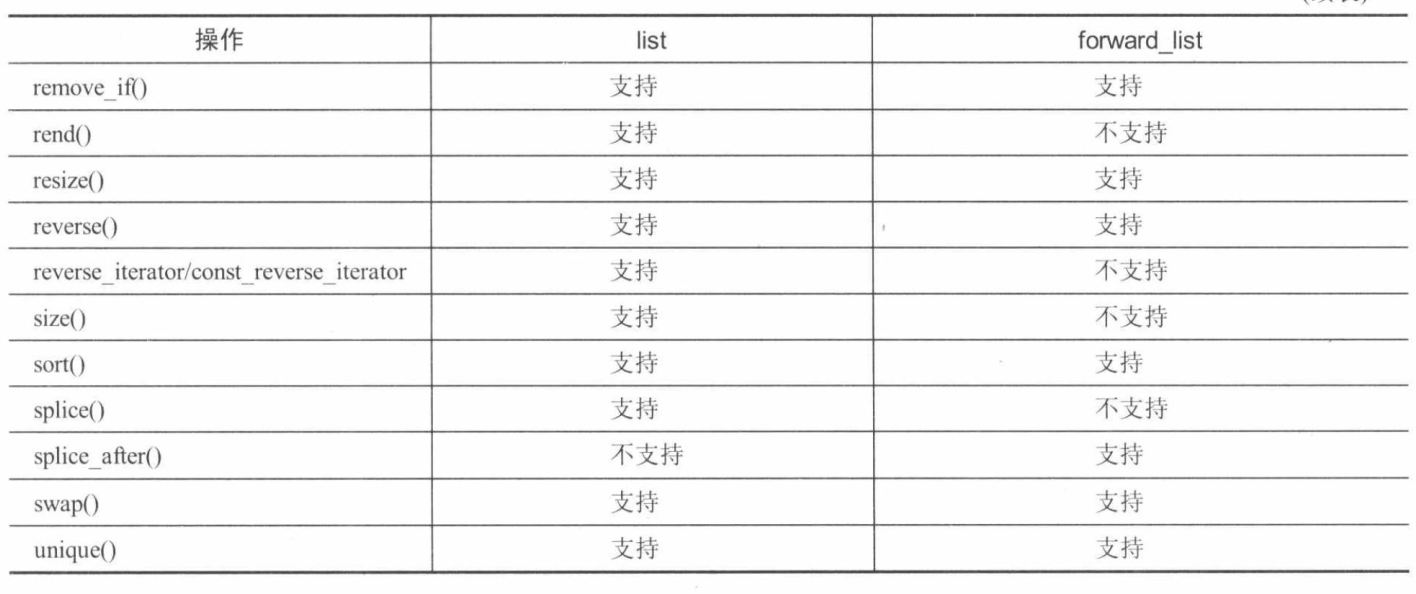
forward_list和list的构造函数及赋值运算符类似。C++标准表明forward_list应该尽可能使用最小的空间。
array
array类定义在<array>头文件中,和vector类似,区别在于array的大小是固定的,不能增加或收缩。这个类的目的是让array能分配在栈上,而不是像vector那样总是需要访问堆。和vector一样,array支持随机访问迭代器,元素都保存在连续内存中。array支持front()、back()、at()和operator[],还支持使用fill()方法通过特定元素将array填满。由于array大小固定,因此不支持push_back()、pop_back()、insert()、erase()、clear()、resize()、reserve()、capacity()。
与vector相比,array的缺点是,array的swap()方法具有线性时间复杂度,而vector的swap()方法具有常量时间复杂度。array声明需要两个模板参数:第一个参数指定元素类型,第二个参数指定array中元素的固定数量:1
2
3
4
5
6
7
8
9
10array<int, 3> arr = {9, 8, 7};
cout <<"Array size "<< arr.size() << endl;
for (const auto& i : arr)
cout << i << endl;
arr.fill(3);
for (auto iter = cbegin(arr); iter != cend(arr); ++iter)
cout << *iter << endl;
可使用std:get<n>()函数模板,从std::array检索位于索引位置n的元素。索引必须是常量表达式,不能是循环变量等。使用std:get<n>()的优势在于编译器在编译时检查给定索引是有效的,否则将导致编译错误,如下所示:1
2
3array<int, 3> myArray(11,22, 33);
cout<< std::get<1>(myArray) <<endl;
cout << std::get<10>(myArray)<< endl; // Compilation error!
容器适配器
除标准的顺序容器外,标准库还提供了3种容器适配器:queue,priority_queue和stack。每种容器适配器都是对一种顺序容器的包装。它们允许交换底层容器,无须修改其他代码。容器适配器的作用是简化接口,只提供那些stack和queue抽象所需的功能。
queue
queue容器适配器定义在头文件<queue>中,queue提供了标准的“先入先出”语义。与通常情况一样,queue也写为类模板形式,如下所示:1
template <class T, class Container = deque<T> > class queue;
T模板参数指定要保存在queue中的类型。另一个模板参数指定queue适配的底层容器。不过,由于queue要求顺序容器同时支持push_back()和pop_front()两个操作,因此只有两个内建的选项:deque和list。大部分情况下,只使用默认的选项deque即可。
queue操作
queue接口非常简单:只有8个方法,再加上构造函数和普通的比较运算符。push()和emplace()方法在queue的尾部添加一个新元素,pop()从queue的头部移除元素。通过front()和back()可以分别获得第一个元素和最后一个元素的引用,而不会删除元素。与其他容器一样,在调用const对象时,front()和back()返回的是const引用:调用非const对象时,这些方法返回的是非const引用(可读写)。
pop()不会返回弹出的元素。如果需要获得一份元素的副本,必须首先通过front()获得这个元素。queue还支持size()、empty()和swap()。
priority_queue
优先队列(priority_queue)是一种按顺序保存元素的队列。优先队列不保证严格的FIFO顺序,而是保证在队列头部的元素任何时刻都具有最高优先级。这个元素可能是队列中最老的那个元素,也可能是最新的那个元素。如果两个元素的优先级相等,那么它们在队列中的相对顺序是未确定的。priority_queue容器适配器也定义在<queue>中。其模板定义如下:1
template <class T, class Container = vector<T>, class Compare = less<T>>;
这个类没有看上去这么复杂。之前看到了前两个参数:T是priority_queue中保存的元素类型;Container是priority_queue适配的底层容器。priority_queue默认使用vector,但是也可以使用deque。这里不能使用list,因为priority_queue要求随机访问元素。第3个参数Compare复杂一些。less是一个类模板,支持两个类型为T的元素通过operator<运算符进行比较。也就是说,要根据operator<来确定队列中元素的优先级,可以自定义这里使用的比较操作。目前,只要保证为保存在priority_queue中的类型正确定义了operator<即可。
priority_queue的头元素是优先级最高的元素,默认情况下优先级是通过operator<运算符来判断的,比其他元素“小”的元素的优先级比其他元素低
priority_queue提供的操作
priority_queue提供的操作比queue还要少。push()和emplace()可以插入元素,pop()可以删除元素,top()可以返回头元素的const引用。
在非const对象上调用
top(),top()返回的也是const引用,因为修改元素可能会改变元素的顺序,所以不允许修改。priority_queue没有提供获得尾元素的机制。
pop()不返回弹出的元素。如果需要获得一份副本,必须首先通过top()获得这个元素。
与queue一样,priority_queue支持size()、empty()和swap()。然而,priority_queue没有提供任何比较运算符。
stack
stack和queue几乎相同,区别在于stack提供先入后出(FILO)的语义,这种语义也称为后入先出,以区别于FIFO。stack定义在<stack>头文件中。模板定义如下所示:1
template <class T, class Container = deque<T>>class stack;
可将vector、list或deque用作stack的底层容器。
stack操作
与queue类似,stack提供了push()、emplace()和pop()。区别在于:push()在stack项部添加一个新元素,将之前插入的所有元素都“向下推”;而pop()从stack顶部删除一个元素,这个元素就是最近插入的元素。如果在const对象上调用,top()方法返回顶部元素的const引用;如果在非const对象上调用,top()方法返回非const引用。
pop()不返回弹出的元素。如果需要获得一份副本,必须首先通过top()获得这个元素。stack支持empty()、size()、swap()和标准的比较运算符。
有序关联容器
有序关联容器将键映射到值。通常情况下,有序关联容器的插入、删除和查找时间是相等的。标准库提供的4个有序关联容器分别为map、multimap、set和multiset。每种有序关联容器都将元素保存在类似于树的有序数据结构中。还有4个无序关联容器:unordered_map、unordered_multimap、unordered_set和unordered_multiset。
pair工具类
pair类在<utility>头文件中定义。pair是一个类模板,它将两个可能属于不同类型的值组合起来。通过first和second公共数据成员访问这两个值。pair类定义了operator==和operator<,用于比较first和second元素。下面给出了一些示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17pair<string, int> myPair("hello", 5);
pair<string, int> myotherPair;
myotherPair.first = "hello";
myotherPair.second = 6;
pair<string, int> myThirdPair (myOtherPair);
if (mypair < myOtherPair)
cout <<"myPair is less than myotherPair"<<endl;
else
cout << "myPair is greater than or equal to myOtherPair" << endl;
if (myotherPair == myThirdPair)
cout << "myotherPair 1s equal to myThirdPair" << endl;
else
cout << "myOtherPair is not equal to myThirdPair" << endl;
这个库还提供了一个工具函数模板make_pair(),用于从两个值构造一个pair。例如:1
pair<int, double> aPair = make_ pair(5,10.10);
如果需要向函数传递pair,或者把它赋予已有的变量,那么make_pair()更有用。与类模板不同,函数模板可从参数中推导类型,因此可通过make_pair()构建pair,而不需要显式地指定类型。还可结合使用make_pair()与auto关键字:1
auto aSecondPair = make_pair(5, 10.10);
结构化绑定是另一个C++17特性,可用于将pair的元素分解为单独的变量。下面是一个示例:1
2
3
4
5pair<string, int> myPair("hello", 5);
auto[thestring, theint] = myPair;
cout << "theString:" << thestring << endl;
cout << "theInt: "<< theInt <<endl;
map
map定义在<map>头文件中,它保存的是键/值对,而不是只保存值。插入、查找和删除操作都是基于键的,值只不过是附属品。map根据键对元素排序存储,因此插入、删除和查找的复杂度都是对数时间。由于排好了序,因此枚举元素时,元素按类型的operator<或用户定义的比较器确定的顺序出现。通常情况下,map实现为某种形式的平衡树,例如红黑树。不过,树的结构并没有向客户公开。
构建map
map类模板接收4种类型:键类型、值类型、比较类型以及分配器类型。比较类型和之前描述的priority_queue中的比较类型类似,允许提供与默认不同的比较类。如果忽略比较参数和分配器参数,那么map的构建和vector或list的构建是一样的,区别在于,在模板实例化中需要分别指定键和值的类型。1
2
3
4
5
6
7
8
9class Data final {
public:
explicit Data(int value = 0): mValue(value) ()
int getValue() const { return mValue; }
void setValue(int value) { mValue = value; }
private:
int mValue;
};
map<int, Data> dataMaps;
map还支持统一初始化机制:1
2
3
4
5map<string, int> m = {
{ "Marc G.", 123 },
{ "Warren B.", 456},
{ "Peter V.W.", 789)
};
插入元素
map和其他关联容器插入时不需要指定位置。map的内部实现会判定要保存新元素的位置,只需要提供键和值即可。
map和其他有序关联容器提供了接收选代器位置作为参数的
insert()方法。然而,这个位置只是容器找到正确位置的一种“提示”。不强制容器在那个位置插入元素。
在插入元素时,一定要记住map需要“唯一键”:map中的每个元素都要有不同的键。如果需要支持多个带有同一键的元素,有两个选择:可使用map,把另一个容器(如vector或array)用作键的值,也可以使用后面描述的multimap。
insert()方法
可使用insert()方法向map添加元素,它有一个好处:允许判断键是否已经存在。insert()方法的一个问题是必须将键/值对指定为pair对象或initializer_list。insert()的基本形式的返回类型是迭代器和布尔值组成的pair,返回类型这么复杂的原因是,如果指定的键已经存在,那么insert()不会改写元素值。返回的pair中的bool元素指出,insert()是否真的插入了新的键/值对。迭代器引用的是map中带有指定键的元素。1
2
3
4
5
6
7
8
9
10
11
12map<int, Data> dataMap;
auto ret = dataMap.insert({1, Data(4) });
if (ret.second)
cout <<"Insert succeeded!" << endl;
else
cout << "Insert failed!" << endl;
ret = dataMap.insert(make_pair(1, Data(6))); // Using a pair object
it (ret.second)
cout << "Insert succeeded!" << endl;
else
cout << "Insert failed!" << endl;
ret变量的类型是pair,如下所示:1
pair<map<int, Data>::iterator, bool>ret;
pair的第一个元素是键类型为int、值类型为Data的map的map选代器。该pair的第二个元素为布尔值。
使用if语句的初始化器,只使用一条语句,即可将数据插入map并检查结果,如下所示:1
2
3
4if (auto result = dataMap.insert({1, Data(4) }); result.second)
cout << "Insert succeeded!"<< endl;
else
cout <<"Insert failed!" << endl;
甚至可将其与C++17结构化绑定结合使用:1
2
3
4if (auto [iter, success] = dataMap.insert({ 1, Data(4) }); success)
cout << "Insert succeeded!" << endl;
else
cout <<"Insert failed!"<<endl;
insert_or_assign()方法
insert_or_assign()与insert()的返回类型类似。但是,如果已经存在具有给定键的元素,insert_or_assign()将用新值重写旧值,而insert()在这种情况下不重写旧值。与insert()的另一个区别在于,insert_or_assign()有两个独立的参数:键和值。1
2
3
4
5ret = dataMap.insert_or_assign(1, Data(7));
if (ret.second)
cout << "Inserted." << endl;
else
cout << "Overwritten."<< endl;
operator[]
向map插入元素的另一种方法是通过重载的operator[]。这种方法的区别主要在于语法:键和值是分别指定的。此外,operator[]总是成功。如果给定键没有对应的元素值,就会创建带有对应键值的新元素。如果具有给定键的元素已经存在,operator[]会将元素值替换为新指定的值。1
2
3map<int, Data> dataMap;
dataMap[1] = Data(4);
dataMap[1] = Data(6); // Replaces the element with key 1
不过,operator[]有一点要注意:它总会构建一个新的值对象,即使并不需要使用这个值对象也同样如此。因此,需要为元素值提供一个默认的构造函数,从而可能会比insert()的效率低。
如果请求的元素不存在,operator[]会在map中创建一个新元素,所以这个运算符没有被标记为const。尽管这很明显,但有时可能会看上去违背常理。
emplace方法
map支持emplace()和emplace_hint(),从而在原位置构建元素,这与vector的emplace方法类似。C++17添加了try_emplace()方法,如果给定的键尚不存在,则在原位置插入元素;如果map中已经存在相应的键,则什么都不做。
map迭代器
map迭代器的工作方式类似于顺序容器的选代器。主要区别在于选代器引用的是键值对,而不只是值。如果要访问值,必须通过pair对象的second字段来访问。1
2for (auto iter = cbegin(dataMap); iter != cend(dataMap); ++iter)
cout << iter->second.getValue() << endl;
查找元素
map可根据指定的键查找元素,复杂度为指数时间。如果知道指定键的元素存在于map中,那么查找它的最简单方式是,只要在非const map或对map的非const引用上调用,就通过operator[]进行查找。operator[]的好处在于返回可直接使用和修改的元素引用,而不必考虑从pair对象中获得值。1
2
3
4map<int, Data> dataMap;
dataMap[1] = Data(4);
dataMap[1] = Data(6);
dataMap[1].setValue(100);
然而,如果不知道元素是否存在,就不能使用operator[]。因为如果元素不存在,这个运算符会插入一个包含相应键的新元素。作为替换方案,map提供了find()方法。如果元素在map中存在, 这个方法返回指向具有指定键的元素的选代器;如果元素在map中不存在,则返回end()选代器。1
2
3auto it = dataMap.find(1);
if(it != end(dataMap))
it->second.setValue (100);
如果只想知道在map中是否存在具有给定键的元素,那么可以使用count()成员函数。这个函数返回map中给定键的元素个数。对于map来说,这个函数返回的结果不是0就是1,因为map中不允许有具有重复键的元素
删除元素
map允许在指定的选代器位置删除一个元素或删除指定迭代器范围内的所有元素,这两种操作的复杂度分别为摊还常量时间和对数时间。从客户的角度看,用于执行上述操作的两个erase()方法等同于顺序容器中的erase()方法。
节点
所有有序和无序的关联容器都被称为基于节点的数据结构。从C++17开始,标准库以节点句柄(node handle)的形式,提供对节点的直接访问。确切类型并未指定,但每个容器都有一个名为node_type的类型别名,它指定容器节点句柄的类型。节点句柄只能移动,是节点中存储的元素的所有者。它提供对键和值的读写访问。
可基于给定的选代器位置或键,从关联容器(作为节点句柄)提取节点。从容器提取节点时,将其从容器中删除,因为返回的节点句柄是所提取元素的唯一拥有者。
C++提供了新的insert()重载,以允许在容器中插入节点句柄。使用extract()来提取节点句柄,使用insert()来插入节点句柄,可有效地将数据从一个关联容器传递给另一个关联容器,而不需要执行任何复制或移动。甚至可将节点从map移到multimap,从set移到multiset。下面的代码将键为1的节点转到第二个map:1
2
3map<int, Data> dataMap2;
auto extractedNode = dataMap.extract(1);
dataMap2.insert(std::move (extractedNode));
还有一个操作merge(),可将所有节点从一个关联容器移到另一个关联容器。无法移动的节点留在源容器中。一个示例如下:1
2
3map<int, int> src = { {1, 11}, {2, 22} };
map<int, int> dst = { {2, 22}, {3, 33}, {4, 44}, {5, 55} };
dst.merge(src);
完成合并操作后,src仍然包含一个元素{2, 22},因为目标已经包含这个元素,所以无法移动。操作后,dst包含{1, 11}、{2, 22}、{3, 33}、{4, 44}和{5, 55}。
multimap
multimap是一种允许多个元素使用同一个键的map。和map一样,multimap支持统一初始化。multimap的接口和map的接口几乎相同,区别在于:
- multimap不提供
operator[]和at()。它们的语义在多个元素可以使用同一个键的情况下没有意义。 - 在multimap上执行插入操作总是会成功。因此,添加单个元素的
multimap::insert()方法只返回iterator而不返回pair。 - map支持
insert_or_assign()和try_emplace()方法,而multimap不支持。
multimap允许插入相同的键值对。如果要避免这种冗余,必须在插入新元素之前执行显式检查。
multimap的最棘手之处是查找元素。不能使用operator[],因为并没有提供operator[]。find()也不是非常有用,因为find()返回的是指向具有给定键的任意一个元素的iterator(未必是具有这个键的第一个元素)。
然而,multimap将所有带同一个键的元素保存在一起,并提供方法以获得这个子范围的iterator,这个子范围内的元素在容器中具有相同的键。lower_bound()和upper_bound()方法分别返回匹配给定键的第一个元素和最后一个元素之后那个元素的对应 iterator。如果没有元素匹配这个键,那么lower_bound()和upper_bound()返回的iterator相等。
如果需要获得具有给定键的元素对应的iterator,使用equal_range()方法比依次调用lower_bound()和upper_bound()更高效。equal_range()返回两个iterator的pair,这两个iterator分别是lower_bound()和upper_bound()返回的iterator。
map中也有
lower_bound(),upper_bound()和equal_range()方法,但由于map中不允许多个元素带有同一个键,因此在map中,这些方法的用处不大。
set
set容器定义在<set>头文件中,和map非常类似。 区别在于set保存的不是键值对,在set中,值本身就是键。如果信息没有显式的键,且希望进行排序(不包含重复)以便快速地执行插入、查找和删除,就可以考虑使用set容器来存储此类信息。
set提供的接口几乎和map提供的接口完全相同,主要区别在于set没有提供operator[]、insert_or_assign()和try_emplace()。不能修改set中元素的键/值,因为修改容器中的set元素会破坏顺序。
multiset
multiset和set的关系等同于multimap和map的关系。multiset支持set的所有操作,但允许容器中同时保存多个互等的元素。这里没有提供multiset的例子,因为multiset与set和multimap太相似了。
无序关联容器/哈希表
标准库支持无序关联容器或哈希表。这种容器有4个:unordered_map,unordered_multimap,unordered_set和unordered_multiset。此前讨论的map、multimap、set和multiset容器对元素进行排序,而这些新的无序版本不会对元素进行排序。
哈希函数
无序关联容器也称为哈希表,这是因为它们使用了哈希函数(hash function)。哈希表的实现通常会使用某种形式的数组,数组中的每个元素都称为桶(bucket)。每个桶都有一个特定的数值索引,哈希函数将键转换为哈希值,再转换为桶索引。与这个键关联的值在桶中存储。
哈希函数的结果未必是唯一的。两个或多个键哈希到同一个桶索引,就称为冲突(collision)。当使用不同的键得到相同的哈希值,或把不同的哈希值转换为同一桶索引时,会发生冲突。可采用多种方法来处理冲突,例如二次重哈希和线性链等方法。使用线性链时,桶不直接包含与键关联的数据值,而包含一个指向链表的指针。这个链表包含特定桶中的所有数据值。图17-1展示了原理。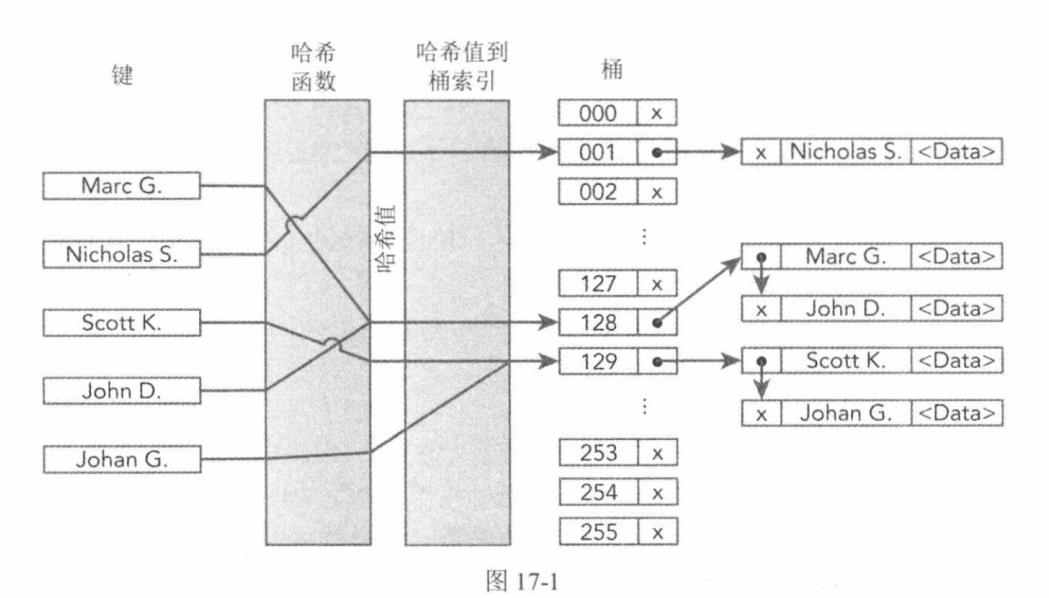
从中能看出,相比普通map的查找方式,这种查找方式要快得多,但查找速度完全取决于冲突次数。哈希函数的选择非常重要。不产生冲突的哈希函数称为“完美哈希”。完美哈希的查找时间是常量:常规的哈希查找时间平均接近于1,与元素数量无关。随着冲突数的增加,查找时间会增加,性能会降低。增加基本哈希表的大小,可以减少冲突,但需要考虑高速缓存的大小。
C++标准为指针和所有基本数据类型提供了哈希函数,还为error_code、error_condition、optional、variant、bitset、unique_ptr、shared_ptr、type_index、string、string_view、vector<bool>、thread::id提供了哈希函数。如果要使用的键类型没有可用的标准哈希函数,就必须实现自己的哈希函数。
下面的示例演示了如何编写自定义哈希函数。这个示例仅将请求传递给可用的一个标准哈希函数。1
2
3
4
5
6
7
8
9
10
11class IntWrapper {
public:
IntWrapper(int i) : mWrappedInt(i) { }
int getValue() const { return mWrappedint; }
private:
int mWrappedint;
};
bool operator--(const IntWrapper& lhs, const IntWrapper& rhs) {
return lhs.getValue() == ths.getValue();
}
为给IntWrapper编写哈希函数,应给IntWrapper编写std:hash模板的特例。std::hash模板在<functional>中定义。这个特例需要实现函数调用运算符,以计算并返回给定IntWrapper实例的哈希。对于这个示例,仅把请求传递给整数的标准哈希函数:1
2
3
4
5
6
7
8
9namespace std {
template<> struct hash<IntWrapper> {
using argument_type = IntWrapper;
using result_type = size_t;
result_type operator () (const argument_type& f) const {
return std::hash<int>()(f.getValue());
}
};
}
注意一般不允许把任何内容放在std名称空间中,但std类模板特例是这条规则的例外。hash类模板需要两个类型定义。函数调用运算符的实现只有一行代码,它为整数的标准哈希函数创建了一个实例std:hash<int>(),然后对该实例通过参数f.getValue()执行函数调用运算符。
unordered_map
unordered_map容器在<unordered_map>头文件中定义,也是一个类模板,如下所示:1
2
3
4
5
6
7template <class Key,
class T,
class Hash = hash<Key>,
Class Pred = std::equal_to<Key>,
class Alloc = std::allocator<std::pair<const Key,T>>
>
class unordered_map;
共有5个模板参数:键类型、值类型、哈希类型、判等比较类型和分配器类型。通过后面3个参数可以分别自定义哈希函数、判等比较函数和分配器函数。通常可忽略这些参数,因为它们有默认值。建议保留默认值。最重要的参数是前两个参数。与map一样,可使用统一初始化机制来初始化unordered_map, 如下所示:1
2
3
4
5
6
7
8
9
10
11unordered_map<int, string> m = {
{ 1, "Item 1"},
{ 2, "Item 2"},
{ 3, "Item 3"},
{ 4, "Item 4"}
};
cout << key << " " <<value << endl;
for (const auto&[key, value] : m)
cout << key << value << endl;
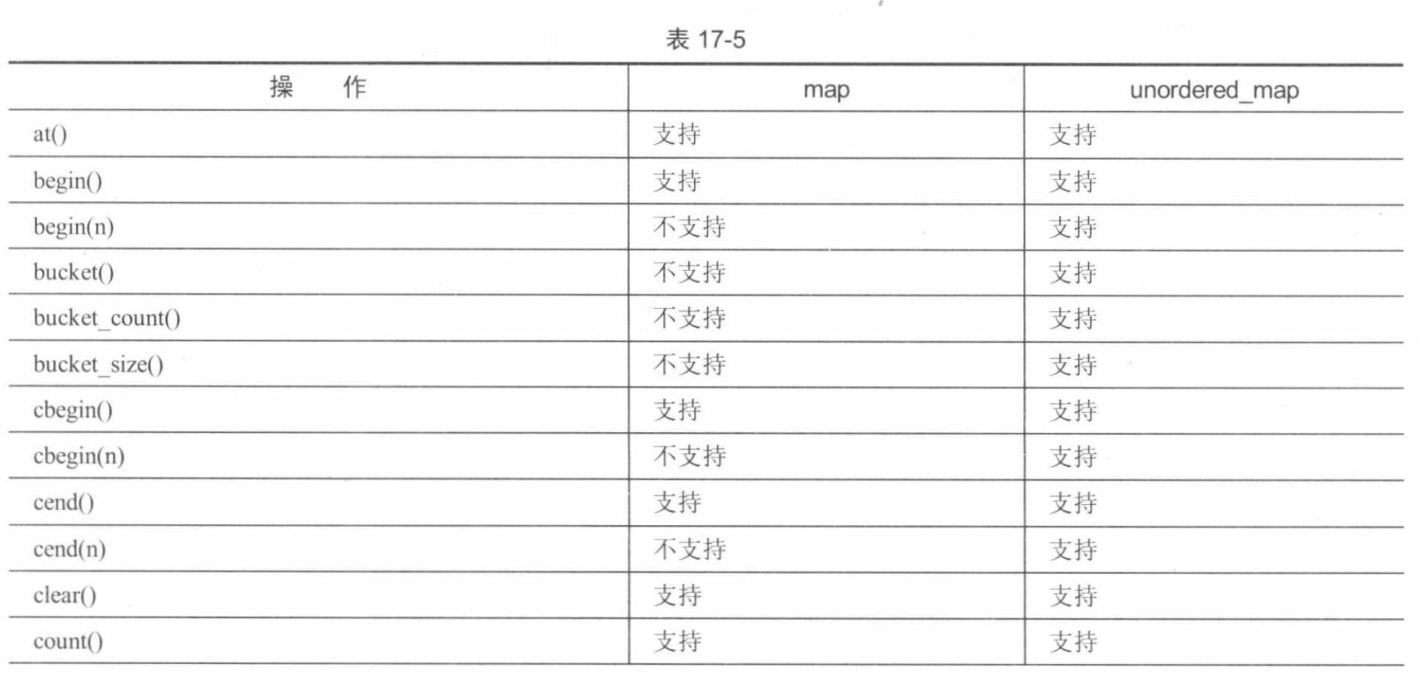
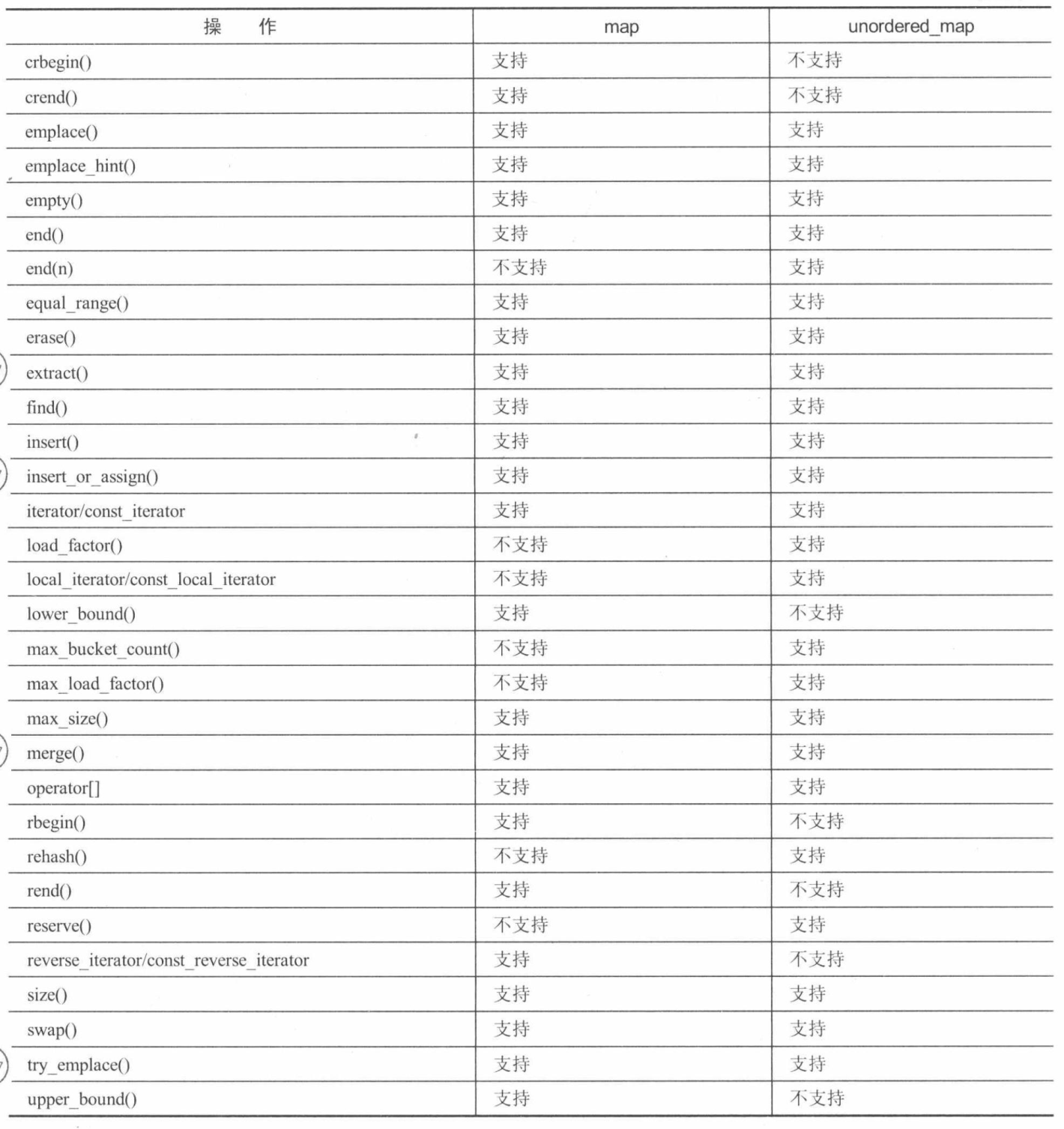
与普通的map一样,unordered_map中的所有键都应该是唯一的。
unordered_multimap
unordered_multimap是允许多个元素带有同一个键的unordered_map。 两者的接口几乎相同,区别在于:
- unordered_multimap没有提供
operator[]运算符和at(),它们的语义在多个元素可以使用同一个键的情况下没有意义。 - 在unordered_multimap上执行插入操作总是会成功。因此,添加单个元素的
unordered_multimap:insert()方法只返回迭代器而非pair。 - unordered_map支持
insert_or_assign()和try_emplace()方法,而ordered_multimap不支持这两个方法。
unordered_set/unordered_multiset
<unordered_set>头文件定义了unordered_set和unordered_multiset,这两者分别类似于set和multiset;区别在于它们不会对键进行排序,而且使用了哈希函数。unordered_set和unordered_map的区别和之前讨论的set和map之间的区别类似,因此这里不再赘述。
其他容器
标准C风格数组
string
可将string看成字符的顺序容器。因此,C++ string实际上是一种功能完备的顺序容器。string包含的begin()和end()方法返回string中的选代器,还包含insert()、push_back()、erase()、size()和empty()方法,以及基本顺序容器包含的其他所有内容。string非常接近于vector,甚至还提供了reserve()和capacity()方法。
流
传统意义上,输入流和输出流并不是容器,因为它们并不保存元素。然而,可以把它们看成元素的序列,因而具有标准库容器的一些特性。C++流没有直接提供与标准库相关的任何方法,但是标准库提供了名为istream_iterator和ostream_iterator的特殊迭代器,用于“遍历”输入流和输出流。
bitset
bitset是固定长度的位序列的抽象。一个位只能表示两个值——1和0,这两个值可以表示开关和真/假等意义。bitset还使用了设置(set)和清零(unset)两个术语。可将一个位从一个值切换(toggle)或翻转(nip)为另一个值。
bitset并不是真正的标准库容器:bitset的大小固定,没有对元素类型进行模板化,也不支持迭代。
bitset基础
bitset定义在<bitset>头文件中,根据保存的位数进行模板化。默认构造函数将bitset的所有字段初始化为0。另一个构造函数根据由0和1字符组成的字符串创建bitset。可通过set()、reset()和flip()方法改变单个位的值,通过重载的operator[]运算符可访问和设置单个字段的值。
注意对非const对象应用operator[]会返回一个代理对象,可为这个代理对象赋予一个布尔值,调用flip()或~取反。还可通过test()方法访问单独字段。此外,通过普通的插入和抽取运算符可以流式处理bitset,bitset以包含0和1字符的字符串形式进行流式处理。
下面是一个简单例子:1
2
3
4
5
6
7
8
9
10bitset<10> myBitset;
myBitset.set(3);
myBitset.set(6);
myBitset[8] = true;
myBitset[9] = myBitset[3];
if (myBitset.test (3)) {
cout << "Bit 3 is set!"<< endl;
cout << myBitset << endl;
}
按位运算符
除基本的位操作外,bitset还实现了所有的按位运算符:&、|、^、~、<<、>>、&=、|=、^=、<<=和>>=。这些运算符的行为和操作真正的位序列相同。1
2
3
4
5
6
7
8
9
10auto str1 = "0011001100";
auto str2 - "0000111100";
bitset<10> bitsOne(stri);
bitset<10> bitsTwo(str2);
auto bitsThree = bitsOne & bitsTwo;
cout << bitsThree << endl;
bitsThree <<=4;
cout << bitsThree << endl;
掌握标准库算法
算法概述
算法把迭代器作为中介操作容器,而不直接操作容器本身。这样,算法没有绑定至特定的容器实现。所有标准库算法都实现为函数模板的形式,其中模板类型参数一般都是迭代器类型。将迭代器本身指定为函数的参数。大部分算法都定义在<algorithm>头文件中,一些数值算法定义在<numeric>头文件中。它们都在std名称空间中
find()和find_if()算法
find()在某个迭代器范围内查找特定元素。可将其用于任意容器类型的元素。这个算法返回引用所找到元素的迭代器;如果没有找到元素,则返回迭代器范围的尾迭代器。注意调用find()时指定的范围不要求是容器中元素的完整范围,还可以是元素的子集。
如果
find()没有找到元素,那么返回的迭代器等于函数调用中指定的尾迭代器,而不是底层容器的尾迭代器
下面是一个std::find()示例。1
2
3
4
5
6
7
8
9while (true) {
cout <<"Enter a number to lookup (0 to stop):";
cin >> num;
if (num -- 0)
break;
auto endit = cend (myVector);
auto it = find(cbegin(myVector), endIt, num);
if (it == endit)
cout <<"Could not find "<< num << endl;
调用find()时将cbegin(myVector)和endIt作为参数,其中,endIt定义为cend(myVector),因此搜索的是vector的所有元素。如果需要搜索一个子范围,可修改这两个迭代器。
使用if语句的初始化器(C++17),可使用如下加粗语句来调用find()并查找结果:1
2if (auto it = find(cbegin(myVector), endIt, num); it == endIt) {
cout << "Found " << *it << endl;
如果容器提供的方法具有与泛型算法同样的功能,那么应该使用相应的方法,那样速度更快。比如,泛型算法find()的复杂度为线性时间,用于map迭代器时也是如此;而map中find()方法的复杂度是对数时间。
find_if()和find()类似,区别在于find_if()接收谓词函数回调作为参数,而不是简单的匹配元素。谓词返回true或false。find_if()算法对范围内的每个元素调用谓词,直到谓词返回true;如果返回了true,find_if()返回引用这个元素的迭代器。
accumulate()算法
我们经常需要计算容器中所有元素的总和或其他算术值。accumulate()函数就提供了这种功能,该函数在<numeric>中定义。通过这个函数的最基本形式可计算指定范围内元素的总和。例如,下面的函数计算vector中整数序列的算术平均值。1
2
3
4double arithmeticMean(const vector<int>& nums) {
double sum = accumulate(cbegin(nums), cend(nums), 0);
return sum / nums.size();
}
accumulate()算法接收的第三个参数是总和的初始值,在这个例子中为0(加法计算的恒等值),表示从0开始累加总和。accumulate()的第二种形式允许调用者指定要执行的操作,而不是执行默认的加法操作。这个操作的形式是二元回调。假设需要计算几何平均数。如果一个序列中有m个数字,那么几何平均数就是m个数字连乘的m次方根。在这个例子中,调用accumulate()计算乘积而不是总和。因此这个程序可以这样写:1
2
3
4
5
6
7
8int product (int num1, int num2) {
return num1 * num2;
}
double geometricMean(const vector<int>& nums) {
double mult = accumulate (cbegin(nums), cend(nums), 1, product);
return pow (mult, 1.0 / nums.size());
}
注意,将product()函数作为回调传递给accumulate(),而把累计的初始值设置为1(乘法计算的恒等值)而不是0。
在算法中使用移动语义
与标准库容器一样,标准库算法也做了优化,以便在合适时使用移动语义。这可极大地加速特定的算法,例如remove()。因此,强烈建议在需要保存到容器中的自定义元素类中实现移动语义。通过实现移动构造函数和移动赋值运算符,任何类都可添加移动语义。它们都被标记为noexcept,因为它们不应抛出异常。
std::function
std::function在<functional>头文件中定义,可用来创建指向函数、函数对象或lambda表达式的类型:从根本上说可以指向任何可调用的对象。它被称为多态函数包装器,可以当成函数指针使用,还可用作实现回调的函数的参数。std::function模板的模板参数看上去和大多数模板参数都有所不同。语法如下所示:1
std::function<R(ArgTypes...)>
R是函数返回值的类型,ArgTypes是一个以逗号分隔的函数参数类型的列表。
下例演示如何使用std::function实现一个函数指针。这段代码创建了一个函数指针f1,它指向函数func()。定义f1后,可通过函数名func或f1调用func():1
2
3
4
5
6
7
8
9void func(int num, const string& str) {
cout << "func(" << num <<", "<< str << endl;
}
int main() {
function<void(int, const string&)> f1 = func;
f1(1, "test");
return 0;
}
下面的f1定义实现了同样的功能,而且简短得多,但f1的编译器推断类型是函数指针(即void(*f1)(int, const string&))而不是std::function:1
auto f1 = func;
由于std::function类型的行为和函数指针一致,因此可传递给标准库算法,如下面这个使用了find_if()算法的例子所示:1
2
3
4
5
6
7
8
9
10
11
12bool isEven(int num1) {
return num % 2 == 0;
}
int main {
vector<int> vec{1,2,3,4,5,6,7,8,9};
function<bool (int)> fcn = isEven;
auto result = find_if(cbegin(vec), cend(vec), fcn);
if (result != cend(vec))
cout <<"First even number:"<< *result << endl;
return 0;
}
std::function真正有用的场合是将回调作为类的成员变量。在接收函数指针作为自定义函数的参数时,也可以使用std::function。下例定义了process()函数,这个函数接收一个对vector的引用和std::function。process()函数迭代给定vector中的所有元素,然后对每个元素调用指定的函数f。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void process(const vector<int>& vec, function<void(int)> f) {
for (auto& i : vec)
f(i);
}
void print (int num) {
cout << num <<" ";
}
int main() {
vector<int>vec{ 0,1,2,3,4,5,6,7,8,9 };
process(vec, print);
int sum = 0;
process (vec, [&sum](int num) {sum += num;});
return 0;
}
lambda表达式
使用lambda表达式可编写内嵌的匿名函数,而不必编写独立函数或函数对象,使代码更容易阅读和理解。
语法
下面定义一个lambda表达式,它仅把一个字符串写入控制台。
lambda表达式以方括号[]开始(这称为lambda引入符),其后是花括号{},其中包含lambda表达式体。lambda表达式被赋予自动类型变量basicLambda。第二行使用普通的函数调用语法执行lambda表达式。1
2auto basicLambda = [] {cout << "Hello from Lambda"<< endl; };
basicLambda();
lambda表达式可以接收参数。参数在圆括号中指定,用逗号分隔开,与普通函数相同。下面是使用参数的示例:1
2auto parametersLambda = [](int value){ cout <<"The value is "<<value << endl; };
parametersLambda(42);
如果lambda表达式不接收参数,就可指定空圆括号或忽略它们。
lambda表达式可返回值。返回类型在箭头后面指定,称为拖尾返回类型。下例定义的lambda表达式接收两个参数,返回它们的和:1
2auto returningLambda = [] (int a, int b) -> int { return a + b; };
int sum = returningLambda(11, 22);
可以忽略返回类型。如果忽略了返回类型,编译器就根据函数返回类型推断规则来推断lambda表达式的返回类型,如下所示:1
2auto returningLambda = [](int a, int b) { return a + b; };
int sum = returningLambda(11, 22);
lambda表达式可以在其封装的作用域内捕捉变量。例如,下面的lambda表达式捕捉变量data,将它用于lambda表达式体:1
2double data = 1.23;
auto capturingLambda = [data] { cout <<"Data "<< data << endl; };
lambda表达式的方括号部分称为lambda捕捉块(capture block)。捕捉变量的意思是可在lambda表达式体中使用这个变量。指定空白的捕捉块[]表示不从所在作用域内捕捉变量。如上例所示,在捕捉块中只写出变量名,将按值捕捉该变量。
编译器将lambda表达式转换为某种未命名的仿函数(即函数对象),捕捉的变量变成这个仿函数的数据成员。将按值捕捉的变量复制到仿函数的数据成员中。这些数据成员与捕捉的变量具有相同的const性质。在前面的capturingLambda示例中,仿函数得到非const数据成员data,因为捕捉的变量data不是const。但在下例中,仿函数得到const数据成员data, 因为捕捉的变量是const。1
2const double data = 1.23;
auto capturingLambda = [data]{ cout << "Data " << data << endl; };
仿函数总是实现函数调用运算符operator()。对于lambda表达式,这个函数调用运算符被默认标记为const,这表示即使在lambda表达式中按值捕捉了非const变量,lambda表达式也不能修改其副本。把lambda表达式指定为mutable,就可以把函数调用运算符标记为非const:1
2double data = 1.23;
auto capturinglambda = [data] () mutable { data *= 2; cout << "Data - " << data << endl; };
在这个示例中,非const变量data是按值捕捉的,因此仿函数得到了一个非const数据成员,它是data的副本。因为使用了mutable关键字,函数调用运算符被标记为非const,所以lambda表达式体可以修改data的副本。注意如果指定了mutable,就必须给参数指定圆括号,即使圆括号为空,也是如此。
在变量名前面加上&,就可按引用捕捉它。按引用捕捉变量时,必须确保执行lambda表达式时,该引用仍然是有效的。可采用两种方式来捕捉所在作用域内的所有变量。
[=]:通过值捕捉所有变量,[&]:通过引用捕捉所有变量
还可以酌情决定捕捉哪些变量以及这些变量的捕捉方法,方法是指定一个捕捉列表,其中带有可选的默认捕捉选项。前缀为&的变量通过引用捕捉。不带前缀的变量通过值捕捉。默认捕捉应该是捕捉列表中的第一个元素,可以是=或&。例如
[&x]:只通过引用捕捉x,不捕捉其他变量[x]:只通过值捕捉x,不捕捉其他变量,[=,&x,&y]:默认通过值捕捉,变量x和y是例外,这两个变量通过引用捕捉。[&,x]:默认通过引用捕捉,变量x是例外,这个变量通过值捕捉。[&x,&x]:非法,因为标识符不允许重复。[this]:捕捉周围的对象。即使没有使用this->,也可在lambda表达式体中访问这个对象。[*this]:捕捉当前对象的副本。如果在执行lambda表达式时对象不再存在,这将十分有用。
使用默认捕捉时,只有在lambda表达式体中真正使用的变量才会被捕捉,使用值(=)或引用(&)捕捉。未使用的变量不捕捉,
不建议使用默认捕捉,即使只捕捉在lambda表达式体中真正使用的变量,也同样如此。使用=默认捕捉可能在无意中引发昂贵的复制。使用&默认捕捉可能在无意间修改所在作用域内的变量,建议显式指定要捕捉的变量。
lambda表达式的完整语法如下所示:1
2
3[capture_block] (parameters) mutable constexpr
noexcept_specifier attributes ->
return_type { body }
lambda表达式包含以下部分
- 捕捉块(capture block):指定如何捕捉所在作用域内的变量,并供lambda主体部分使用。
- 参数(parameter,可选):lambda表达式使用的参数列表。只有在不需要任何参数并且没有指定mutable、constexpr、noexcep说明符、属性和返回类型的情况下才能忽略参数列表。该参数列表和普通函数的参数列表类似,
- mutable(可选):把lambda表达式标记为mutable
- constexpr(可选):将lambda表达式标记为constexpr,从而可在编译时计算。如果满足某些限制条件,即使忽略,也可能为lambda表达式隐式使用constexpr。
- noexcept说明符(可选):用于指定noexcept子句,与普通函数的noexcept子句类似。
- 特性(attribute,可选):用于指定lambda表达式的特性。
- 返回类型(可选):返回值的类型。如果忽略,编译器会根据函数返回类型推断原则判断返回类型。
泛型lambda表达式
可以给lambda表达式的参数使用自动推断类型功能,而无须显式指定它们的具体类型。要为参数使用自动推断类型功能,只需要将类型指定为auto,类型推断规则与模板参数推断规则相同。
下例定义了一个泛型lambda表达式isGreaterThan100。这个lambda表达式与find_if()算法一起使用,一次用于整数vector,另一次用于双精度vector。1
2
3
4
5
6
7
8
9
10
11auto isGreaterThan100 = [](auto i)( return i > 100; };
vector<int> ints(11, 55, 101, 200);
auto it1 = find_if(cbegin(ints), cend(ints), isGreaterThan100);
if (it1 != cend(ints))
cout << "Found a value > 100: " << *it1 <<endl;
vector<double> doubles { 11.1, 55.5, 200.2 };
auto it2 = find_if(cbegin(doubles), cend(doubles), isGreaterThan100);
if (it2 != cend(doubles))
cout << "Found a value > 100: "<< *it2 << endl;
lambda捕捉表达式
lambda捕捉表达式允许用任何类型的表达式初始化捕捉变量。这可用于在lambda表达式中引入根本不在其内部的作用域内捕捉的变量,例如,下面的代码创建一个lambda表达式,其中有两个变量:myCapture使用lambda捕捉表达式初始化为字符串Pi:,pi在内部的作用域内按值捕捉。注意,用捕捉初始化器初始化的非引用捕捉变量,如myCapture,是通过复制来构建的,这表示省略了const限定符:1
2double pi = 3.1415;
auto myLambda = [myCapture = "Pi: ", pi] { cout << myCapture << pi; };
lambda捕捉变量可用任何类型的表达式初始化,也可用std:move()初始化。这对于不能复制、只能移动的对象而言很重要,例如unique_ptr。默认情况下,按值捕捉要使用复制语义,所以不可能在lambda表达式中按值捕捉unique_ptr。使用lambda捕捉表达式,可通过移动来捕捉它,例如:1
2auto myPtr = std::make_unique<double>(3.1415);
auto mylambda = [ p = std::move(myPtr)] { cout << *p; };
将lambda表达式用作返回类型
使用前面讨论的std::function,可从函数返回lambda表达式,分析以下定义:1
2function<int(vold)> multiplyBy2Lambda(int x) {
return [x]{ return 2 * x; };
这个函数的主体部分创建一个lambda表达式,通过值捕捉所在作用域的变量x,并返回一个整数,这个整数是传给multiplyBy2Lambda()的值的两倍。multiplyBy2Lambda()函数的返回类型为function<int(void)>,即一个不接收参数并返回一个整数的函数。函数体中定义的lambda表达式正好匹配这个原型。变量x通过值捕捉,因此,
在lambda表达式从函数返回之前,x值的副本被绑定至lambda表达式中的x。可按如下方式调用该函数:1
2function<int(void)> fn = multiplyBy2Lambda(5);
cout << fn() << endl;
标准库算法示例
count_if()
下例通过count_if()算法计算给定vector中满足特定条件的元素个数。通过lambda表达式的形式给出条件,这个lambda表达式通过值捕捉所在作用域内的value变量。1
2
3vector<int> vec {1, 2, 3, 4, 5, 6, 7, 8, 9};
int value = 3;
int cnt = count_if(cbegin(vec), cend(vec), [value] (int i) { return i > value;});
可对上面的这个例子进行扩展,以演示通过引用捕捉变量的方式。下面的lambda表达式通过递增所在作用域内按引用捕捉的一个变量,来计算调用次数。1
2
3
4vector<int> vec = {1, 2, 3, 4, 5, 6, 7, 8, 9};
int value = 3;
int cntlambdaCalled = 0;
int cnt = count_if(cbegin(vec), cend(vec), [value, &cntLambdaCalled] (int i) {++cntLambdaCalled; return i > value;});
generate()
generate()算法需要一个迭代器范围,它把该迭代器范围内的值替换为从函数返回的值,并作为第三个参数。下例结合generate()算法和一个lambda表达式将2、4、8、16等值填充到vector。1
2
3vector<int> vec(10);
int value = 1;
generate(begin(vec), end(vec), [&value]{ value *= 2; return value; });
函数对象
在类中,可重载函数调用运算符,使类的对象可取代函数指针。将这些对象称为函数对象(finction object),或称为仿函数(functor)。
很多标准库算法,例如find_if()以及accumulate(),可接收函数指针、lambda表达式和仿函数作为参数,以更改函数行为。
建议尽可能使用lambda表达式,而不是小型函数对象,因为lambda表达式更便于使用、读取和理解。
算术函数对象
C++提供了5类二元算术运算符的仿函数类模板:plus,minus,multiplies,divides和modulus。此外提供了一元的取反操作。这些类对操作数的类型模板化,是对实际运算符的包装。它们接收一个或两个模板类型的参数,执行操作并返回结果。下面是一个使用plus类模板的示例:1
2
3plus<int> myPlus;
int res = myPlus(4, 5);
cout << res <<endl;
算术函数对象的好处在于可将它们以回调形式传递给算法,而使用算术运算符时却不能直接这样做。
算术函数对象只不过是对算术运算符的简单包装。如果在算法中使用函数对象作为回调,务必保证容器中的对象实现了恰当的操作。
透明运算符仿函数
C++支持透明运算符仿函数,允许忽略模板类型参数。例如,可只指定multiplies<>(而非multiplies<int>():1
2
3double geometricMeanTransparent(const vector<int>& nums)
double mult = accumulate(cbegin (nums), cend(nums), 1, multiplies<>());
return pow (mult, 1.0 / nums.size());
这些透明运算符仿函数的一个重要特性是,它们是异构的,即它们不仅比非透明运算符仿函数更简明,而且具有真正的函数性优势。例如,下面的代码使用透明运算符仿函数和双精度数1.1作为初始值,而vector包
含整数。accumulate()会把结果计算为double值,result是6.6:1
2vector<int> nums { 1,2,3 };
double result = accumulate(cbegin(nums), cend(nums), 1.1, mu1tip1ies<>());
如果这些代码使用非透明运算符仿函数,accumulate()会把结果计算为整数,result就是6。编译这些代码时,编译器会给出可能丢失数据的警告:1
2vector<int> nums { 1,2,3 };
double result - accumulate (cbegin (nums), cend(nums), 1.1, multiplies<int>());
比较函数对象
除算术函数对象类外,C++语言还提供了所有标准的比较:equal_to、not_equal_to、less、greater、less_equal和greater_equal。可将priority_queue的比较模板修改为greater。priority_queue模板定义如下所示:1
template <class T, class Container = vector<T>, class Compare = less<T>>;
遗憾的是,Compare类型参数是最后一个参数,这意味着要指定比较操作,还必须指定容器类型。如果希望priority_queue通过greater按升序对元素排序,需要把上例中的priority_queue定义改为:1
priority_queue<int, vector<int>, greater<>>myQueue;
注意,使用透明运算符greater<>定义了myQueue。与使用非透明运算符相比,使用透明比较回调的性能稍好一些。
逻辑函数对象
C++为3个逻辑操作提供了函数对象类,它们分别是:logical_not(operator!)、logical_and(operator&&)和logical_or(operator||)。逻辑操作只操作true和false值。
例如,可使用逻辑仿函数来实现allTrue()函数,这个函数检查容器中的所有布尔标志是否都为true:1
2
3bool allTrue (const vector<bool>& flags) {
return accumulate(begin(flags), end(flags), true, logical_and<>());
}
类似地,可使用logical_or仿函数实现anyTrue()函数,如果容器中至少有一个布尔标志为true,那么这个函数返回true:1
2
3bool anyTrue (const vector<bool>& flags) {
return accumulate(begin(flags),end(flags), false, logical_or<>());
}
按位函数对象
C++为所有按位操作添加了函数对象,它们分别是:bit_and(operator&)、bit_or(operator|)、bit_xor(operator^)和bit_not(operator!)。
函数对象适配器
函数适配器对函数组合(functional composition)提供了一些支持,也就是能将函数组合在一起,以精确提供所需的行为。
绑定器
绑定器(binder)可用于将函数的参数绑定至特定的值。为此要使用<functional>头文件中定义的std::bind(),它允许采用灵活的方式绑定可调用的参数。既可将函数的参数绑定至固定值,甚至还能重新安排函数参数的顺序。下面通过一个例子进行解释,假定有一个func()函数,它接收两个参数:1
void func(int num, string_view str)
下面的代码演示如何通过bind()将func()函数的第二个参数绑定至固定值myString。结果保存在f1()中。使用auto关键字是因为C++标准未指定bind()的返回类型,因而是特定于实现的。没有绑定至指定值的参数应该标记为_1、_2和_3等。这些都定义在std::placeholders名称空间中。
在f1()的定义中,_1指定了调用func()时,f1()的第一个参数应该出现的位置。之后,就可以用一个整型参数调用f1()。1
2
3string mystring = "abc";
auto f1 = bind(func, placeholders::_1, myString);
f1(16);
bind()还可用于重新排列参数的顺序,如下列代码所示。_2指定了调用func()时,20的第二个参数应该出
现的位置。换句话说,12(绑定的意义是:f2()的第一个参数将成为函数func()的第二个参数,f2()的第二个参数将成为函数func()的第一个参数1
2auto f2 = bind(func, placeholders::_2, placeholders::_1);
f2("Test",32);
<functional>头文件定义了std::ref()和cref()辅助模板函数。它们可分别用于绑定引用或const引用。如果使用bind()调用函数,引用变量的值就不递增,因为建立了变量的一个副本。使用std::ref()正确传递对应的引用后会递增。
结合重载函数使用时,绑定参数会出现一个小问题。如果要对这些重载的函数使用bind(),那么必须显式地指定绑定这两个重载中的哪一个。如果需要绑定接收浮点数参数的重载函数的参数,需要使用以下语法:1
auto f4 = bind((void(*)(float))overloaded, placeholders::_1);
取反器
not_fn
取反器(negator)类似于绑定器(binder),但对调用结果取反。例如,如果想要找到测试分数序列中第一个小于100的元素,那么可以对perfectScore()的结果应用notl()取反器适配器,如下所示:1
2
3
4auto enditer = end(myVector);
auto it = find_if(begin(myVector), endIter, not_fn(perfectScore));
if (it == enditer)
cout << "All perfect scores" << endl;
not_fn()仿函数对作为参数传入的每个调用结果取反。注意在这个示例中,也可以使用find_if_not()算法。
前面使用not_fn()取反器的find_if()调用可以用lambda表达式更简洁地表达:1
auto it = find_if(begin(myVector), endIter, [](int i){return i < 100; });
not1和not2
C++17引入了std::not_fn()适配器。在C++17之前,可使用std:not1()和not2()适配器。not1中的“1”是指:它的操作数必须是一个一元函数(只接收一个参数)。如果操作数是二元函数(接收两个参数),则必须改用not2()。下面是一个示例:1
2
3auto enditer = end(myVector);
function<bool(int)> f = perfectscore;
auto it = find_if(begin(myVector), endIter, not1(f));
如果想将not1()用于自己的仿函数类,则必须确保仿函数类的定义包含两个typedef:argument_type和result_type。如果想要使用not2(),则仿函数类的定义必须提供3个typedef:first_argument_type、second_argument_type和result_type。为此,最简便的方式是从unary_function或binary_function派生自己的函数对象类,具体取决于使用的是一个参数还是两个参数。在<functional>中定义的两个类在所提供函数的参数和返回类型上模板化。例如:1
2
3
4
5
6class Perfectscore : public std::unary_function<int, bool> {
public:
result_type operator() (const argument_type& score) const {
return score >= 100;
}
};
可采用如下方式使用这个仿函数:1
auto it = find_if(begin(myVector), endIter, not1(PerfectScore()));
调用成员函数
假设有一个对象容器,有时需要传递一个指向类方法的指针作为算法的回调。调用方法指针的代码和调用普通函数指针的代码是不一样的,因为前者必须在对象的上下文中调用。C++提供了mem_fn()转换函数,在传递给算法之前可以对函数指针调用这个函数。必须将string中的empty()方法指针指定为&string::empty。&string::部分不是可选的。1
2
3
4
5void findEmptyString(const vector<string>& strings) {
auto enditer = end(strings);
auto it = find_if(begin(strings), endIter, mem_fn(&string::empty));
if (it == enditer)
cout <<"No empty strings!"<< endl;
mem_fn()生成一个用作find_if()回调的函数对象。每次调用它时,都会对参数调用empty()方法。
即使容器内保存的不是对象本身,而是对象指针,mem_fn()的使用方法也完全一样,例如:1
2
3void findEmptystring(const vector<string*>& strings) {
auto enditer = end(strings);
auto it = find_if(begin(strings), enditer, mem_fn(&string::empty));
std::invoke()
C++17引入了std::invoke(),std::invoke()在<functional>中定义,可用于通过一组参数调用任何可调用对象。下例使用了三次invoke():一次调用普通函数,另一次调用lambda表达式,还有一次调用string实例的成员函数1
2
3
4
5
6
7
8
9void printMessage(string_view message) { cout << message << endl; }
int main() {
invoke(printMessage, "Hello invoke.");
invoke([](const auto& msg) { cout << msg << endl; }, "Hello invoke.");
string msg = "Hello invoke.";
cout << invoke(&string::size, msg) << endl;
}
invoke()本身的作用并不大,因为可以直接调用函数或lambda表达式。但在模板代码中,如果需要调用任意可调用对象,invoke()的作用会发挥出来。
算法详解
迭代器
迭代器有5类:输入、输出、正向、双向和随机访问迭代器。确切地讲,每个随机访问迭代器也是双向的,每个双向迭代器也是正向的,每个正向迭代器也是输入迭代器。满足输出迭代器要求的迭代器称为可变迭代器(mutable iterator),否则称为不可变迭代器(constant iterator)。
算法指定要使用的迭代器类型的标准方法是,在迭代器模板类型参数中使用以下名称:InputIterator、OutputIterator、ForwardIterator、BidirectionalIterator、RandomAccessIterator。这些只是名称,没有提供绑定类型的检查。因此,可在调用需要RandomAccessIterator的算法时,传入双向迭代器。模板不会进行类型检查,因此允许这样的实例化。然而,函数中使用随机访问迭代器功能的代码,在使用双向迭代器时将无法成功编译。
非修改序列算法
非修改序列算法包括在某个范围内搜索元素的函数、比较两个范围的函数以及许多工具算法。
搜索算法
标准库提供了基本find()算法的一些其他变种,这些算法对元素序列执行操作。所有算法都使用默认的比较运算符operator==和operator<,还提供了重载版本,以允许指定比较回调。下面是一些搜索算法的示例:1
2
3
4
5
6
7vector<int> myVector = {5, 6, 9. 8, 8, 3};
auto beginiter = cbegin (myVector);
auto enditer = cend(myVector);
auto it = find_if_not(beginiter, enditer, [](int i){ return i<8;});
if (it != enditer)
cout <<"First element not < 8 is "<< *it << endl;
专用的搜索算法
C++17给search()算法增加了额外的可选参数,允许指定要使用的搜索算法。有三个选项:default_searcher、boyer_moore_searcher或boyer_moore_horspool_searcher,它们都在<functional>中定义。后两个选项实现了知名的Boyer-Moore和Boyer-Moore-Horspool搜索算法。它们十分高效,可用于在一大块文本中查找子字符串。Boyer-Moore搜索算法的复杂度如下,N是在其中搜索的序列的大小,M是要查找的模式的大小。如果未找到模式,最坏情况下的复杂度为O(N+M),如果找到模式,最坏情况下的复杂度为O(NM)。Boyer-Moore和 Boyer-Moore-Horspool算法的区别在于,在初始化以及算法的每个循环迭代中,后者的固定开销较少;但是,后者在最坏情况下的复杂度明显高于前者算法。
比较算法
可通过3种不同的方法比较整个范围内的元素:equal()、mismatch()和lexicographical_compare()`。这些算法的好处是可比较不同容器内的范围。例如,可比较vector和list的内容。一般情况下,这些算法最适用于顺序容器。这些算法的工作方法是比较两个集合中对应位置的值。下面列出每个算法的工作方式。
equal():如果所有对应元素都相等,则返回true。最初,equal()接收三个迭代器,分别是第一个范围的首尾迭代器,以及第二个范围的首迭代器。该版本要求两个范围的元素数目相同。mismatch():返回多个迭代器,每个范围对应一个迭代器,表示范围内不匹配的对应元素。与equal()一样,存在三迭代器版本和四迭代器版本。lexicographical_compare():如果第一个范围内的第一个不相等元素小于第二个范围内的对应元素,或如果第一个范围内的元素个数少于第二个范围,且第一个范围内的所有元素都等于第二个范围内对应的初始子序列,那么返回true。
如果要比较两个同类型容器的元素,可使用运算符operator==和operator<,而不是equal()和lexicographical_compare()。
计数算法
非修改计数算法有all_of()、any_of()、none_of()、count()和count_if()。下面是一个算法的示例。1
2
3
4//all_of()
vector<int> vec2 = {1, 1, 1, 1};
if(all_of(cbegin(vec2), cend(vec2), [](int i){ return i== 1;)))
cout << “All elements are == 1"<<endl;
修改序列算法
标准库提供了多种修改序列算法,这些算法执行的任务包括:从一个范围向另一个范围复制元素、删除元素以及反转某个范围内元素的顺序。
修改算法不能将元素插入目标范围中,仅可重写/修改目标范围中已经存在的元素。
map和multimap的范围不能用作修改算法的目标范围。这些算法改写全部元素,而在map中,元素是键值对。map和multimap将键标记为const,因此不能为其赋值。set和multiset也是如此。 替换方案是使用插入迭代器。
转换
transform()算法对范围内的每个元素应用回调,期望回调生成一个新元素,并保存在指定的目标范围中。如果希望transform()将范围内的每个元素替换为调用回调产生的结果,那么源范围和目标范围可以是同一范围。其参数是源序列的首尾迭代器、目标序列的首迭代器以及回调。例如,可按如下方式将vector中的每个元素增加100:1
transform(begin(myVector), end(myVector), begin(myVector), [](int i){ return it 100;}};
transform()的另一种形式对范围内的元素对调用二元函数,需要将第一个范围的首尾迭代器、第二个范围的首迭代器以及目标范围的首迭代器作为参数。 下例创建两个vector,然后通过transform()计算元素对的和,并将结果保存回第一个vector:1
transform(begin(vec1), end(vec1), begin(vec2), begin(vec1), [](int a, int b){return a + b;});
transform()和其他修改算法通常返回一个引用目标范围内最后一个值后面那个位置(past-the-end)的迭代器。
复制
copy()算法可将一个范围内的元素复制到另一个范围,从这个范围内的第一个元素开始直到最后一个元素。源范围和目标范围必须不同,但在一定限制条件下可以重叠。限制条件如下:对于copy(b,e,d),如果d在b之前,则可以重叠;但如果d处于[b,e]范围,则行为不确定。与所有修改算法类似,copy()不会向目标范围插入元素,只改写已有的元素。
下面举一个使用copy()的简单例子,这个例子对vector应用resize()方法,以确保目标容器中有足够空间。这个例子将vec1中的所有元素复制到vec2:1
2
3
4vector<int> vecl, vec2;
vec2.resize(size(vec1));
copy(cbegin(vec1), cend(vec1), begin(vec2));
还有一个copy_backward()算法,这个算法将源范围内的元素反向复制到目标范围。换句话说,这个算法从源范围的最后一个元素开始,将这个元素放在目标范围的最后一个位置,然后在每一次复制之后反向移动。分析copy_backward(),源范围和目标范围必须是不同的,但在一定限制条件下可以重叠。限制条件如下:对于copy_backward(b,e,d),如果d在e之后,则能正确重叠;但如果d处于(b,e]范围,则行为不确定。前面的例子可按如下代码修改为使用copy_backward()而不是copy()。注意第三个参数应该指定end(vec2)而不是begin(vec2):1
copy_backward (cbegin (vec1),cend(vec1), end(vec2));
得到的输出完全一致。
在使用copy_if()算法时,需要提供由两个迭代器指定的输入范围、由一个迭代器指定的输出范围以及一个谓词(函数或lambda表达式)。该算法将满足给定谓词的所有元素复制到目标范围。记住,复制不会创建或扩大容器,只是替换现有元素。因此,目标范围应当足够大,从而保存要复制的所有元素。当然,复制元素后,最好删除超出最后一个元素复制位置的空间。为便于达到这个目的,copy_if()返回了目标范围内最后一个复制的元素后面那个位置的迭代器,以便确定需要从目标容器中删除的元素个数。1
2
3
4
5vector<int> vec1, vec2;
vec2.resize(size(vec1));
auto enditerator = copy_if(cbegin(vec1), cend(vec1), begin(vec2), [](int i){ return i % 2 == 0;});
vec2.erase(enditerator, end(vec2));
copy_n()从源范围复制n个元素到目标范围。copy_n()的第一个参数是起始迭代器,第二个参数是指定要复制的元素个数,第三个参数是目标迭代器。copy_n()算法不执行任何边界检查,因此一定要确保起始迭代器递增n个要复制的元素后,不会超过集合的end(),否则程序会产生未定义的行为。1
2
3
4
5
6vector<int> vec1, vec2;
size_t cnt = 0;
cnt = min(cnt, size(vec1));
vec2.resize(cnt);
copy_n(cbegin(vec1), cnt, begin(vec2));
移动
有两个和移动相关的算法:move()和move_backward()。如果要在自定义类型元素的容器中使用这两个算法,那么需要在元素类中提供移动赋值运算符。main()函数创建了一个带有3个MyClass对象的vector,然后将这些元素从vecSrc移到vecDst。注意这段代码包含两种不同的move()用法。一种是,move()函数接收一个参数,将Ivalue转换为rvalue;而另一种是,接收3个参数的move()是标准库的move()算法,这个算法在容器之间移动元素。1
2
3
4
5
6
7Class MyClass {}
int main() {
vector<MyClass> vecSrc{MyClass("a"), MyClass("b"), MyClass("c")};
vector<MyClass> vecDst(vecSrc.size());
move(begin(vecSrc), end(vecSrc),begin(vecDst));
}
替换
replace()和replace_if()算法将一个范围内匹配某个值或满足某个谓词的元素替换为新的值。比如replace_if()算法的第一个和第二个参数指定了容器中元素的范围。第三个参数是一个返回true或false的函数或lambda表达式,如果它返回true,那么容器中的对应值被替换为第四个参数指定的值;如果它返回false,则保留原始值。例如,假定要将容器中的所有奇数值替换为0:1
2vector<int> vec;
replace_if(begin(vec),end(vec), [](int i) { return i%2 != 0;}, 0);
replace()和replace_if()也有名为replace_copy()和replace_copy_if()的变体,这些变体将结果复制到不同的目标范围。它们类似于copy(),因为目标范围必须足够大,以容纳新元素。
删除
如果对vector容器应用erase(),这个解决方案的效率非常低下,因为要保持vector在内存中的连续性,会涉及很多内存操作,因而得到:二次(平方)复杂度;所谓二次复杂度,是指运行时间是输入大小的平方的函数。这个问题的正确解决方案是“删除擦除法”,
算法只能访问迭代器抽象,不能访问容器。因此删除算法不能真正地从底层容器中删除元素,而是将匹配给定值或谓词的元素替换为下一个不匹配给定值或渭词的元素。为此使用移动赋值。结果是将范围分为两个集合:一个用于保存要保留的元素,另一个用于保存要删除的元素。返回的迭代器指向要删除的元素范围内的第一个元素。如果真的需要从容器中删除这些元素,必须先使用remove()算法,然后调用容器的erase()方法,将从返回的迭代器开始到范围尾部的所有元素删除。这就是删除擦除法。1
2
3auto it = remove_if(begin(strings), end(strings), [](const string& str) { return str.empty(); });
strings.erase(it, end(strings));
使用“删除擦除法”时,切勿忘记erase()的第二个参数!如果忘掉第二个参数,erase()将仅从容器中删除一个元素,即作为第一个参数传递的迭代器指向的元素。
remove()和remove_if()的remove_copy()和remove_copy_if()变体不会改变源范围,而将所有未删除的元素复制到另一个目标范围。这些算法和copy()类似,要求目标范围必须足够大,以便保存新元素。
唯一化
unique()算法是特殊的remove(),remove()能将所有重复的连续元素删除。list容器提供了自己的具有同样语义的unique()方法。
抽样
sample()算法从给定的源范围返回n个随机选择的元素,并存储在目标范围。它需要5个参数:
- 要从中抽样的范围的首尾迭代器
- 目标范围的首迭代器,将随机选择的元素存储在目标范围
- 要选择的元素数量
- 随机数生成引擎
反转
reverse()算法反转某个范围内元素的顺序。将范围内的第一个元素和最后一个元素交换,将第二个元素和倒数第二个元素交换,依此类推。reverse()最基本的形式是就地运行,要求两个参数:范围的首尾迭代器。还有一个名为reverse_copy()的版本,这个版本将结果复制到新的目标范围,它需要3个参数:源范围的首尾迭代器以及目标范围的起始迭代器。
目标范围必须足够大,以便保存新元素。
shuffle()以随机顺序重新安排某个范围内的元素,其复杂度为线性时间。它可用于实现洗牌等任务。shuffle()的参数是要乱序的范围的首尾迭代器,以及一个统一的随机数生成器对象,它指定如何生成随机数。
操作算法
此类算法只有两个:for_each()和for_each_n(),后者是在C++17中引入的。它们对范围内的每个元素执行回调,或对范围内的前n个元素执行回调。
for_each()
下例说明如何使用for_each()算法和lambda表达式,计算范围内元素的和与积。注意,lambda表达式只显式捕捉需要的变量,它按引用捕捉变量,否则lambda表达式内对sum和product的修改无法在lambda表达式外可见:1
2
3
4
5vector<int> myVector;
int sum = O;
int product = 1;
for_each(cbegin(myVector), cend(myVector), [&sum, &product](int i){ sum += i; product *= i;});
for_each_n()
for_each_n()算法需要范围的起始迭代器、要迭代的元素数量以及函数回调。它返回的迭代器等于begin+n。它通常不执行任何边界检查。下例只迭代map的前两个元素:1
for_each_n(cbegin(myMap),2, [] (const auto& p) {cout << p.first << p.second << endl; });
交换算法
C++标准库提供了以下交换算法
swap()
std::swap()用于有效地交换两个值,并使用移动语义(如果可用的话)。它的使用十分简单:1
2
3
4
5int a = 11;
int b = 22;
cout << "Before swap(): a = "<< a << ", b = "<< b << endl;
swap(a, b);
cout << "After swap(): a =" << a << ", b = "<< b << endl;
exchange()
std::exchange()在<utility>中定义,用新值替换旧值,并返回旧值,如下所示:1
2
3
4
5int a = 11;
int b = 22;
cout << "Before exchange(): a = "<< a << ", b = "<< b << endl;
int returnedValue = exchange(a, b);
cout << "After exchange(): a = " << a << ", b = "<< b << endl;
exchange()用于实现移动赋值运算符。移动赋值运算符需要将数据从源对象移到目标对象。通常,源对象中的数据会变为null。
分区算法
partition_copy()算法将来自某个来源的元素复制到两个不同的目标。为每个元素选择特定目标的依据是谓词的结果:true或false。partition_copy()的返回值是一对迭代器:一个迭代器引用第一个目标范围内最后复制的那个元素的后一个位置,另一个迭代器引用第二个目标范围内最后复制的那个元素的后一个位置。将这些返回的迭代器与erase()结合使用,可删除两个目标范围内多余的元素。1
2
3
4
5
6vector<int> vec1, vecodd, veceven;
vecodd.resize(size(vec1));
vecEven.resize(size(vec1));
auto pairIters = partition_copy(cbegin(vec1), cend(vec1), begin (veceven), begin (vecodd), [](int i){return i%2 == 0;});
vecEven.erase(pairIters.first, end(veceven));
vecodd.erase (pairIters.second, end(vecodd));
partition()算法对序列排序,使谓词返回true的所有元素放在前面,使谓词返回false的所有元素放在后面,在每个分区中不保留元素最初的顺序。下例演示了如何把vector分为偶数在前、奇数在后的分区:1
2vector<int> vec;
partition(begin(vec), end(vec), [] (int i) {return i%2==0;});
排序算法
“排序算法”重新排列容器中元素的顺序,使集合中的元素保持连续顺序。因此,排序算法只能应用于顺序集合。通用的排序算法最适用于vector、deque、array和C风格数组。sort()函数一般情况下在O(NlogN)时间内对某个范围内的元素排序。将sort()应用于一个范围之后,根据运算符operator<,这个范围内的元素以非递减顺序排列(最低到最高)。如果不希望使用这个顺序,可以指定一个不同的比较回调,例如greater。sort()函数的一个名为stable_sort()的变体能保持范围内相等元素的相对顺序。然而,由于这个算法需要维护范围内相等元素的相对顺序,因此这个算法比sort()算法低效。
二叉树搜索算法
有几个搜索算法只用于有序序列或至少已分区的元素序列。这些算法有binary_search()、lower_bound()、upper_bound()和equal_range()。lower_bound()、upper_bound()和equal_range()算法类似于map和set容器中的对应方法。
lower_bound()算法在有序范围内查找不小于(即大于或等于)给定值的第一个元素,经常用于发现在有序的vector中应将新值插入哪个位置,使vector依然有序。下面是一个示例:1
2auto iter = lower_bound(begin (vec), end(vec), num);
vec.insert(iter, num);
binary_search()算法以对数时间而不是线性时间搜索元素,需要指定范围的首尾迭代器、要搜索的值以及可选的比较回调。如果在指定范围内找到这个值,这个算法返回true,否则返回false。 下面的例子演示了这个算法:1
2if (binary_search(cbegin (vec), cend(vec),num))
cout<<"That number is in the vector."<<endl;
集合算法
集合算法可用于任意有序范围。includes()算法实现了标准的子集判断功能,检查某个有序范围内的所有元素是否包含在另一个有序范围内,顺序任意。
set_union()、set_intersection()、set_difference()、set_symmetric_difference()算法实现了这些操作的标准语义。在集合论中,并集得到的结果是两个集合中的所有元素。交集得到的结果是所有同时存在于两个集合中的元素。差集得到的结果是所有存在于第一个集合中,但是不存在于第二个集合中的元素。对称差集得到的结果是两个集合的“异或”:所有存在于其中一个集合中,但不同时存在于两个集合中的元素。
务必确保结果范围足够大,以保存操作的结果。对于set_union()和set_symmetric_difference(),结果大小的上限是两个输入范围的总和。对于set_intersection(),结果大小的上限是两个输入范围的最小大小。对于set_difference()结果大小的上限是第一个输入范围的大小。
不能使用关联容器(包括set)中的迭代器范围来保存结果,因为这些容器不允许修改键。下面是这些算法的使用示例:1
2
3
4if (includes(cbegin(vec1), cend(vec1), cbegin (vec2), cend(vec2)))
cout << "The second set is a subset of the first." << endl;
auto newEnd = set_union(cbegin (vec1), cend(vecl), cbegin (vec2), cend (vec2), begin(result));
merge()算法可将两个排好序的范围归并在一起,并保持排好的顺序。结果是一个包含两个源范围内所有元素的有序范围。这个算法的复杂度为线性时间。这个算法需要以下参数:
- 第一个源范围的首尾迭代器
- 第二个源范围的首尾迭代器
- 目标范围的起始迭代器
- (可选)比较回调
如果没有merge(),还可通过串联两个范围,然后对串联的结果应用sort(),以达到同样的目的,但这样做的效率更低,复杂度为O(NlogN)而不是merge()的线性复杂度。
最大/最小算法
min()和max()算法通过运算符operator<或用户提供的二元谓词比较两个或多个任意类型的元素,分别返回一个引用较小或较大元素的const引用。minmax()算法返回一个包含两个或多个元素中最小值和最大值的pair。这些算法不接收迭代器参数。还有使用迭代器范围的min_element()、max_element()和minmax_element()。下面的程序给出了一些示例:
并行算法
对于60多种标准库算法,C++17支持并行执行它们以提高性能,示例包括for_each()、all_of()、copy()、count_if()、find()、replace()、search()、sort()和transform(}等。支持并行执行的算法包含选项,接收所谓的执行策略作为第一个参数。
执行策略允许指定是否允许算法以并行方式或矢量方式执行。有三类标准执行策略,以及这些类型的三个全局实例,它们全部定义在std::execution名称空间的<execution>头文件中。如表所示。
| 执行策略类型 | 全局实例 | 描述 |
|---|---|---|
sequenced_policy|seq|不允许算法并行执行|
parallel_policy|par|允许算法并行执行|
parallel_unscquenced_policy|par_unscq|允许算法并行执行和矢量化执行,还允许在线程之间迁移执行|
注意,使算法使用parallel_unsequenced_policy执行策略,以允许对回调进行交错函数调用,即不按顺序执行,这意味着会对函数回调施加诸多限制。例如,不能分配释放内存、获取互斥以及使用非锁std::atomics等。对于其他标准策略,函数调用按顺序执行,但顺序无法确定。此类策略不会对函数调用操作施加限制。
下例使用并行策略,对vector的内容进行排序:1
sort(std::execution::par, begin (myVector), end(myVector));
数值处理算法
inner_product()
<numeric>中定义的inner_product()算法计算两个序列的内积,例如,下面程序中的内积计算为(1*9)+(2*8)+(3*7)+(4*6):1
2
3vector<int> v1{1, 2, 3, 4};
vector<int> v2{9, 8, 7, 6};
cout << inner_product(cbegin(v1),cend(v1), cbegin(v2), 0) << endl;
iota()
<numeric>头文件中定义的iota()算法会生成指定范围内的序列值,从给定的值开始,并应用operator++来生成每个后续值。下面的例子展示了如何将这个新算法用于整数的vector,不过要注意这个算法可用于任意实现了operator++的元素类型:1
2
3
4vector<int> vec(10);
iota(begin (vec), end(vec), 5);
for (auto& i : vec)
cout << i << endl;
gcd()和lcm()
gcd()算法返回两个整数的最大公约数,而lcm()算法返回两个整数的最小公倍数。它们都定义在<numeric>中。下面是一个示例:
reduce()
需要使用新引入的std:reduce()算法,通过并行执行选项,计算广义和。例如,以下两行同样是求和,但是reduce()以并行和矢量化方式运行,因此速度更快,对于大型输入范围尤其如此:1
2double result1 = std::accumulate(cbegin(vec), cend(vec),0.0);
double result2 = std::reduce(std::execution::par_unseq, cbegin(vec), cend(vec));
transform_reduce()
std::inner_product()是另一个不支持并行执行的算法。 相反,需要使用广义的transform_reduce()算法,它具有并行执行选项,可用于计算内积等。
字符串的本地化与正则表达式
本地化
本地化字符串字面量
为能正确地本地化字符串,可采用下面的方式来实现:1
cout << Format (IDS_TRANSFERRED, n) << endl;
IDS_TRANSFERRED是字符串资源表中一个条目的名称。对于英文版,IDS_TRANSFERRED可定义为"Read $1 bytes";对于荷兰语版,这条资源可以定义为"$1 bytes gelezen"。Format()函数加载字符串资源,并将$1替换为n的值。
宽字符
用字节表示字符的问题在于,并不是所有的语言(或字符集)都可以用8位(即1个字节)来表示。C++有一种内建类型wchar_t,可以保存宽字符(wide character)。带有非ASCII字符的语言,例如日语和阿拉伯语,在C++中可以用wchar_t表示。然而,C++标准并没有定义wchar_t的大小。一些编译器使用16位,而另一些编译器使用32位。
在使用wchar_t时,需要在字符串和字符字面量的前面加上字母L,以表示应该使用宽字符编码。例如,要将wchar_t字符初始化为字母m,应该编写以下代码:1
wchar_t myWideCharacter = L"m";
大部分常用类型和类都有宽字符版本。宽字符版本的string类为wstring。“前缀字母w”模式也可以应用于流。wofstrcam处理宽字符文件输出流,wifstream处理宽字符文件输入流。cout、cin、cerr和clog也有宽字节版本:wcout、wcin、wcerr和wclog。这些版本的使用和非宽字节版本的使用没有区别:
非西方字符集
宽字符是很大的进步,因为宽字符增加了定义一个字符可用的空间。在宽字符集中,和ASCII一样,字符用编号表示,现在称为码点。唯一的区别在于编号不能放在8个位中。下面的列表总结了支持的所有字符类型。
- char:存储8个位。可用于保存ASCII字符,还可用作保存UTF-8编码的Unicode字符的基本构建块。使用UTF-8时,一个Unicode字符编码为1到4个char。
- char16_t:存储16个位。可用作保存UTF-16编码的Unicode字符的基本构建块。其中,一个Unicode字符编码为一个或两个charl6_t。
- char32_t:存储至少32个位。可用于保存UTF-32编码的Unicode字符,每个字符编码为一个char32_t。
- wchar_t:保存一个宽字符,宽字符的大小和编码取决于编译器。
使用char16_t和char32_t而不是wchar_t的好处在于:char16_t的大小至少16位,char32_t的大小至少32位,它们的大小和编译器无关,而wchar_t不能保证最小的大小。
C++标准还定义了以下两个宏。
__STDC_UTF_32__:如果编译器定义了这个宏,那么类型char32_t使用UTF-32编码。如果没有定义这个宏,那么类型char32_t使用与编译器相关的编码。__STDC_UTF_16__:如果编译器定义了这个宏,那么类型char16_I使用UTF-16编码。如果没有定义这个宏,那么类型char16_t使用与编译器相关的编码。
使用字符串前缀可将字符串字面量转换为特定类型。下面列出所有支持的字符串前缀。
- u8:采用UTF-8编码的char字符串字面量
- u:表示char16t字符串字面量,如果编译器定义了`_STDC_UTF_16`宏,则表示UTF-16编码。
- U:表示char32t字符串字面量,如果编译器定义了`_STDC_UTF_32`宏,则表示UTF-32编码。
- L:采用编译器相关编码的wchar_t字符串字面量。
所有这些字符串字面量都可与第2章介绍的原始字符串字面量前缀R结合使用。例如:1
2
3
4const char* s1 = u8R"(Raw UTF-8 encoded string literal)";
const wchar_t* s2 = LR"(Raw wide string literal)";
const char16_t* s3 = uR"(Raw char16_t string literal)";
const char32_t* s4 = UR"(Raw char32_t string literal)";
如果通过u8 UTF-8字符串字面量使用了Unicode编码,或者编译器定义了__STDC_UTF_16__或__STDC_UTF_32__宏,那么在非原始字符串字面量中可通过\uABCD符号插入指定的Unicode码点。例如,\u03C0表示pi字符。
除std::string类外,目前还支持wstring、u16string和u32string。它们的定义如下:1
2
3
4using string = basic_string<char>;
using wstring = basic_string<wchar_t>;
using u16string = basic_string<char16_t>;
using u32string = basic_string<char32_t>;
多字节字符由一个或多个依赖编译器编码的字节组成,类似于Unicode通过UTF-8用1到4个字节表示,或者通过UTF-16用一个或两个16位值表示。
转换
C++标准提供codecvt类模板,以帮助在不同编码之间转换。<locale>头文件定义了如表19-1所示的4个编码转换类。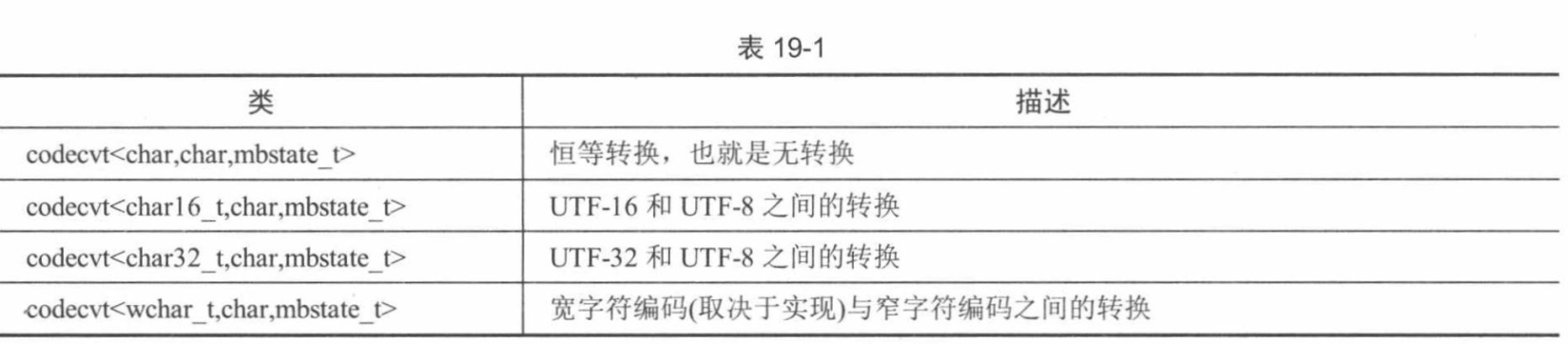
在C++17之前,<codecvt>中定义了以下三种代码转换:codecvt_utf8、codecvt_utf16和codecvt_utf8_utf16。可通过两种简便的转换接口使用它们:wstring_convert和wbuffer_convert。
正则表达式
正则表达式在<regex>头文件中定义,是标准库中的一个强大工具。C++包含对以下几种语法的支持。
- ECMAScript:基于ECMAScript标准的语法。 ECMAScript是符合ECMA-262标准的脚本语言。
- JavaScript:ActionScript和Jscript等语言的核心都使用ECMAScript语言标准。
- basic:基本的POSIX语法
- extended:扩展的POSIX语法
- awk:POSIX awk实用工具使用的语法。
- grep:POSIX grep实用工具使用的语法。
- egrep:POSIX grep实用工具使用的语法,包含E参数,
ECMAScript语法
正则表达式模式是一个字符序列,这种模式表达了要匹配的内容。正则表达式中的任何字符都表示匹配自己,但以下特殊字符除外:^ $ \ . * ? () [] {} |下面将逐一讲解这些特殊字符。如果需要匹配这些特殊字符,那么需要通过\字符将其转义
锚点
特殊字符^和字符匹配行终止符所在的位置。^和$默认还分别匹配字符串的开头和结尾位置,但可以禁用这种行为。
例如,^test$只匹配字符串test,不匹配包含test和其他任何字符的字符串,例如Itest、test2和testabc等。
通配符
通配符(wildcard)可用于匹配除换行符外的任意字符。例如,正则表达式a.c可以匹配abc和aSc,但不匹配ab5c和ac。
替代
|字符表示“或”的关系。例如,a|b表示匹配a或b。
分组
圆括号()用于标记子表达式,子表达式也称为捕捉组(capture group)。捕捉组有以下用途:
- 捕捉组可用于识别源字符串中单独的子序列,在结果中会返回每一个标记的子表达式(捕捉组)。以如下正则表达式为例:
(.)(ab|cd)(.)。 其中有3个标记的子表达式。对字符串1cd4运行regex_search(),执行这个正则表达式会得到含有4个条目的匹配结果。第一个条目是完整匹配1cd4,接下来的3个条目是3个标记的子表达式。这3个条目为:1、cd和4。 - 捕捉组可在匹配的过程中用于后向引用(back reference)的目的。
- 捕捉组可在替换操作的过程中用于识别组件。
重复
使用以下4个重复字符可重复匹配正则:表达式中的部分模式:
*匹配零次或多次之前的部分。例如:a*b可匹配b、ab、aab和aaaab等字符串。+匹配一次或多次之前的部分。例如:a+b可匹配ab、aab和aaaab等字符串,但不能匹配b。?匹配零次或一次之前的部分。例如:a?b匹配b和ab,不能匹配其他任何字符串。{...}表示区间重复。a{n}重复匹配a正好n次;a{n,}重复将a匹配n次或更多次;a{n,m}重复将a匹配n到m次,包含n次和m次。例如,^a{3,4}$可以匹配aaa和aaaa,但不能匹配a、aa和aaaaa等字符串。
以上列表中列出的重复匹配字符称为贪婪匹配,因为这些字符可以找出最长匹配,但仍匹配正则表达式的其余部分。为进行非贪婪匹配,可在重复字符的后面加上一个?,例如*?、+?、??和{...}?。非贪婪匹配将其模式重复尽可能少的次数,但仍匹配正则表达式的其余部分。
优先级
与数学公式一样,正则表达式中元素的优先级也很重要。正则表达式的优先级如下。
- 元素:例如a,是正则表达式最基本的构建块.
- 量词:例如
+、*、?和{...},紧密绑定至左侧的元素,例如b+。 - 串联:例如
ab+c,在量词之后绑定, - 替代符:例如,最后绑定。
例如正则表达式ab+c|d,它匹配abc、abbc和abbbc等字符串,还能匹配d。圆括号可以改变优先级顺序。例如,ab+(c|d)可以匹配abc、abbc、abbbc、 …abd、abbd和abbbd等字符串。不过,如果使用了圆括号,也意味着将圆括号内的内容标记为子表达式或捕捉组。
字符集合匹配
(a|b|c|...|z)这种表达式既冗长,又会引入捕捉组,为了避免这种正则表达式,可以使用一种特殊的语法,指定一组字符或字符的范围。此外,还可以使用“否定”形式的匹配。在方括号之间指定字符集合,[c1c2...cn]可以匹配字符c1、c2、…、cn中的任意字符。例如,[abc]可以匹配a、b和c中的任意字符。如果第一 一个字符是^表示“除了这些字符之外的任意字符”:
ab[cde]匹配abc、abd和abeab[^cde]匹配abf和abp等字符串,但不匹配abc、abd和abe
如果想要指定所有字母,可编写下面这样的字符集合:
- 使用方括号内的范围描述,这允许使用
[a-zA-Z]这样的表达方式,这种表达方式能识别a到z和A到Z范围内的所有字母。如果需要匹配连字符,则需要转义这个字符,例如[a-zA-Z\-]+匹配任意单词,包括带连字符的单词。
词边界
词边界(word boundary的意思可能是:
- 如果源字符串的第一个字符在单词字符(即字母、数字或下划线)之后,则表示源字符串的开头位置。匹配源字符串的开头位置默认为启用,但也可以禁用。
- 如果源字符串的最后一个字符是单词字符之一,则表示源字符串的结束位置。匹配源字符串的结束位置默认为启用,但也可以禁用。
- 单词的第一个字符,这个字符是单词字符之一,而且之前的字符不是单词字符。
- 单词的结尾字符,这是单词字符之后的非单词字符,之前的字符是单词字符。
通过\b可匹配单词边界,通过\B匹配除单词边界外的任何内容。
后向引用
通过后向引用可引用正则:表达式本身的捕捉组:\n表示第n个捕捉组,且n>0。例如,正则表达式(d+)-.*-\1匹配以下格式的字符串:
- 在一个捕捉组中
(d+)捕捉的一个或多个数字 - 接下来是一个连字符
- - 接下来是0个或多个字符
.* - 接下来是另一个连字符
- - 接下来是第一个捕捉组捕捉到的相同数字
\1
这个正则表达式能匹配123-abc-123和1234-a-1234等字符串,但不能匹配123-abc-1234和123-abc-321等字符串。
regex库
正则表达式库的所有内容都在<regex>头文件和std名称空间中。正则表达式库中定义的基本模板类型包括如下几种
- basic_regex:表示某个特定正则表达式的对象。
- match_results:匹配正则表达式的子字符串,包括所有的捕捉组。它是sub_match的集合。
- sub_match:包含输入序列中一个迭代器对的对象,这些迭代器表示匹配的特定捕捉组。迭代器对中的一个迭代器指向匹配的捕捉组中的第一个字符,另一个迭代器指向匹配的捕捉组中最后一个字符后面的那个字符。它的
str()方法把匹配的捕捉组返回为字符串
regex库提供了3个关键算法:regex_match()、regex_search()和regex_replace()。所有这些算法都有不同的版本,不同的版本允许将源字符串指定为STL字符串、字符数组或表示开始和结束的迭代器对。迭代器可以具有以下类型:
const char*const wchar_t*string::const_iteratorwstring::const_iterator
regex库还定义了以下两类正则表达式迭代器,这两类正则表达式迭代器非常适合于查找源字符串中的所有模式
regex_iterator:遍历一个模式在源字符串中出现的所有位置。regex_token_iterator:遍历一个模式在源字符串中出现的所有捕捉组。
为方便regex库的使用,C++标准定义了很多属于以上模板的类型别名,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21using regex = basic_regex<char>;
using wregex = basic_regex<wchar_t>;
using csub_match = sub_match<const char*>;
using wcsub_match = sub_match<const wchar_t*>;
using ssub_match = sub_match<string::const_iterator>;
using wssub_match = sub_match<wstring::const_iterator>;
using cmatch = match_results<const char*>;
using wcmatch = match_results<const wchar_t*>;
using smatch = match_results<string::const_iterator>;
using wsmatch = match_results<wstring::const_iterator>;
using cregex_iterator = regex_iterator<const char*>;
using wcregex_iterator = regex_iterator<const wchar_t*>;
using sregex_iterator = regex_iterator<string::const_iterator>;
using wsregex_iterator = regex_iterator<wstring::const_iterator>;
using cregex_token_iterator = regex_token_iterator<const char*>;
using wcregex_token_iterator = regex_token_iterator<const wchar_t*>;
using sregex_token_iterator = regex_token_iterator<string::const_iterator>;
using wsregex_token_iterator = regex_token_iterator<wstring::const_iterator>;
regex_match()
regex_match()算法可用于比较给定的源字符串和正则表达式模式。如果正则表达式模式匹配整个源字符串,则返回true,否则返回false。这个算法很容易使用。regex_match()算法有6个版本,这些版本接收不同类型的参数。它们都使用如下形式:1
2template<...>
bool regex_match (InputSequence[, MatchResults], RegEx[, Flags]);
InputSequence可以表示为:
- 源字符串的首尾迭代器
- std::string
- C风格的字符串
可选的MatchResults参数是对match_results的引用,它接收匹配。如果regex_match()返回false,就只能调用match_results::empty()或match_results::size(),其余内容都未定义。如果regex_match(),返回true表示找到匹配,可以通过match_results对象查看匹配的具体内容。
RegEx参数是需要匹配的正则表达式。可选的Flags参数指定匹配算法的选项。大多数情况下,可使用默认选项。
regex_search()
如果整个源字符串匹配正则表达式,那么前面介绍的regex_match()算法返回true,否则返回false。这个算法不能用于查找源字符串中匹配的子字符串,但通过regex_search()算法可以在源字符串中搜索匹配特定模式的子字符串。regex_search()算法有6个不同版本。 它们都具有如下形式:1
2template<...>
bool regex_search(InputSequence[, MatchResults], RegEx[,Flags]);
在输入字符串中找到匹配时,所有变体返回true,否则返回false;参数类似于regex_match()的参数。有两个版本的regex_search()算法接收要处理的字符串的首尾迭代器。你可能想在循环中使用regex_search()的这个版本,通过操作每个regex_search()调用的首尾迭代器,找到源字符串中某个模式的所有实例。千万不要这样做!如果正则表达式中使用了锚点(^或$)和单词边界等,这样的程序会出问题。由于空匹配,这样会产生无限循环。
regex_iterator
根据前面的解释,绝对不要在循环中通过regex_search()获得模式在源字符串中的所有实例。应改用regex_iterator或regex_token_iterator。这两个迭代器和标准库容器的迭代器类似。
regex_iterator示例
这个例子中的正则表达式为[\\w]+,以搜索一个或多个单词字母。这个例子使用std::string作为来源,所以使用sregex_iterator作为迭代器。 这里使用了标准的迭代器循环,但是在这个例子中,尾迭代器的处理和普通标准库容器的尾迭代器稍有不同。一般情况下,需要为某个特定的容器指定尾迭代器,但对于regex_iterator,只有一个end迭代器。只需要通过默认的构造函数声明regex_iterator类型,就可获得这个尾迭代器。
for循环创建了一个首迭代器iter,它接收源字符串的首尾迭代器以及正则表达式作为参数。每次找到匹配时调用循环体,在这个例子中是每个单词。sregex_iterator遍历所有的匹配。通过解引用sregex_iterator,可得到一个smatch对象。访问这个smatch对象的第一个元素[0]可得到匹配的子字符串:1
2
3
4
5regex reg("[\\w]+");
const sregex_iterator end;
for (sregex_iterator iter(cbegin(str), cend(str), reg);
iter != end; ++iter)
cout << (*iter)[0] << endl;
从这个例子中可以看出,即使是简单的正则表达式,也能执行强大的字符串操作。
注意,regex_iterator和regex_token_iterator在内部都包含一个指向给定正则表达式的指针。它们都显式删除接收右值正则表达式的构造函数,因此无法使用临时regex对象构建它们。例如,下面的代码无法编译:1
for (sregex_iterator iter (cbegin(stc), cend(str), regex("[\\w]+")); iter != end; ++iter)
regex_token_iterator
regex_token_iterator可用于在所有匹配的模式中自动遍历所有的或选中的捕捉组。regex_token_iterator有4个构造函数,格式如下:1
2
3
4
5regex_token_iterator (BidirectionalIterator a,
Bidirectionaliterator b,
const regex_type& re
[, SubMatches
[, Flags1]]);
所有构造函数都需要把首尾迭代器作为输入序列,还需要一个正则表达式。可选的SubMatches参数用于指定应迭代哪个捕捉组。可以用4种方式指定SubMatches:
- 一个整数,表示要迭代的捕捉组的索引。
- 一个vector,其中的整数表示要迭代的捕捉组的索引。
- 带有捕捉组索引的initializer_list.
- 带有捕捉组索引的C风格数组
忽略SubMatches或把它指定为0时,获得的迭代器将遍历索引为0的所有捕捉组,这些捕捉组是匹配整个正则表达式的子字符串。可选的Flags参数指定匹配算法的选项。大多数情况下,可以使用默认选项。
regex_token_iterator示例
可用regex_token_iterator重写前面的regex_iterator示例,如下所示。注意,与regex_iterator示例一样,在循环体中使用*iter而非(*iter)[0],因为使用submatch的默认值0时,记号迭代器会自动遍历索引为0的所有捕捉组。这段代码的输出和regex_iterator示例完全一致:1
2
3regex reg("[\\w]+");
for (sregex_token_iterator iter(cbegin(str), cend(str), reg); iter != end; ++iter)
cout<< "\"" << *iter << "\"" << endl;
regex_replace()
regex_replace()算法要求输入一个正则表达式,以及一个用于替换匹配子字符串的格式化字符串。这个格式化字符串可通过表中的转义序列,引用匹配子字符串中的部分内容。
| 转义序列 | 替换为 |
|---|---|
| $n | 匹配第n个捕捉组的字符串,例如$1表示第一个捕捉组,$2表示第二个捕捉组,依此类推;n必须大于0 |
| $& | 匹配整个正则表达式的字符串 |
| $` | 在输入序列中,在匹配正则表达式的子字符串左侧的部分 |
| $’ | 在输入序列中,在匹配正则表达式的子字符串右侧的部分 |
| $$ | 单个美元符号 |
regex_replace()算法有6个不同版本。这些版本之间的区别在于参数的类型。其中的4个版本使用如下格式:1
string regex_replace (InputSequence, RegEx, FormatString[, Flags]);
这4个版本都在执行替换操作,后返回得到的字符串。InputSequence和 FormatString可以是std::string或C风格的字符串。RegEx参数是需要匹配的正则表达式。可选的Flags参数指定替换算法的选项。
regex_replace()算法的另外两个版本采用如下形式:1
2
3
4OutputIterator regex_replace (OutputIterator,
Bidirectionaliterator first,
BidirectionalIterator last,
RegEx, FormatString[, Flags]);
这两个版本把得到的字符串写入给定的输出迭代器,并返回这个输出迭代器。输入序列给定为首尾迭代器。其他参数与regex_replace()的另外4个版本相同。
其他库工具
ratio库
可通过ratio库精确地表示任何可在编译时使用的有限有理数。ratio对象在std::chrono:duration类中使用。与有理数相关的所有内容都在<ratio>头文件中定义,并且都在std名称空间中。有理数的分子和分母通过类型为std:intmax_t的编译时常量表示,这是一种有符号的整数类型,其最大宽度由编译器指定。ratio对象的定义方式和普通对象的定义方式不同,而且不能调用ratio对象的方法。需要使用类型别名。例如,下面这行代码定义了一个表示1/60的有理数编译时常量:1
using r1 = ratio<1,60>;
r1有理数的分子和分母是编译时常量,可通过以下方式访问:1
2intmax_t num = r1::num;
intmax_t den = r1::den;
记住ratio是一个编译时常量,也就是说,分子和分母需要在编译时确定。下面的代码会产生编译错误:1
2
3intmax_t n = 1;
intmax_t d = 60;
using r1 = ratio<n, d>;
将n和d定义为常量就不会有编译错误了。
有理数总是化简的。对于有理数ratio<n,d>,计算最大公约数gcd、分子num和分母den的定义如下:1
2num = sign(n)*sign(d)*abs(n)/gcd
den = abs(d)/gcd
ratio库支持有理数的加法、减法、乘法和除法运算。由于所有这些操作都是在编译时进行的,因此不能使用标准的算术运算符,而应使用特定的模板和类型别名组合。可用的算术ratio模板包括ratio_add、ratio_subtract、ratio_multiply、ratio_divide。这些模板将结果计算为新的ratio类型。这种类型可通过名为type的内嵌类型别名访问。
例如,下面的代码首先定义了两个ratio对象,一个表示1/60,另一个表示1/30。ratio_add模板将两个有理数相加,得到的result有理数应该是化简之后的1/20。1
2
3using r1 = ratio<1, 60>;
using r2 = ratio<1, 30>;
using result = ratio_add<r1, r2>::type;
C++标准还定义了一些ratio比较模板:ratio_equal、ratio_not_equal、ratio_less、ratio_less_equal、ratio_greater、ratio_greater_equal。与算术ratio模板一样,ratio比较模板也是在编译时求值的。这些比较模板创建了一种新类型std::bool_constant来表示结果。bool_constant也是std::integral_constant,即struct模板,里面保存了一种类型和一个编译时常量值。
例如,integral constant<int, 15>保存了一个值为15的整型值。bool_constant还是布尔类型的integral_constant。例如,bool_constant<true>是integral_constant<bool,true>,存储值为true的布尔值。ratio比较模板的结果要么是bool_constant<bool,true>,要么是bool_constant<bool, false>。与bool_constant或integral_constant关联的值可通过value数据成员访问。
下面的代码演示了ratio_less的使用。1
2
3
4using r1 = ratio<1,60>;
using r2 = ratio<1,30>;
using res = ratio_less<r2, r1>;
cout << res::value << endl;
chrono库
chrono库是一组操作时间的库。这个库包含以下组件:
- 持续时间
- 时钟
- 时点
所有组件都在std::chrono名称空间中定义,而且需要包含<chrono>头文件。 下面讲解每个组件。
持续时间
持续时间(duration)表示的是两个时间点之间的间隔时间,通过模板化的duration类来表示。duration类保存了滴答数和滴答周期(tick period)。滴答周期指的是两个滴答之间的秒数,是一个编译时ratio常量,也就是说可以是1秒的分数。duration模板接收两个模板参数,定义如下所示:1
template <class Rep, class Period = ratio<1>> class duration {...}
第一个模板参数Rep表示保存滴答数的变量类型,应该是一种算术类型,例如long和double等。第二个模板参数Period是表示滴答周期的有理数常量。如果不指定滴答周期,那么会使用默认值ratio<1>,也就是说默认滴答周期为1秒。
duration类提供了3个构造函数:一个是默认构造函数;另一个构造函数接收一个表示滴答数的值作为参数;第三个构造函数接收另一个duration作为参数。后者可用于将一个duration转换为另一个duration,例如将分钟转换为秒。
duration支持算术运算,还支持比较运算符。duration类包含多个方法,如表所示。
| 方法 | 说明 |
|---|---|
| Rep count() const | 以滴答数返回duration值,返回类型是duration模板中指定的类型参数 |
| static duration zero() | 返回持续时间值等于0的duration |
| static duration min() | 返回duration模板指定的类型参数表示的最小值/最大值持续时间的duration值 |
| static duration max() | 返回duration模板指定的类型参数表示的最小值/最大值持续时间的duration值 |
C++17添加了用于持续时间的floor()、ceil()、round()和abs()操作,行为与用于数值数据时类似。
下面看一下如何在实际代码中使用duration。 每一个滴答周期为1秒的duration定义如下所示:1
duration<long> d1;
由于ratio<1>是默认的滴答周期,因此这行代码等同于:1
duration<long, ratio<1>> d1;
下面的代码指定了滴答周期为1分钟的duration(滴答周期为60秒):1
duration<long, ratio<60>> d2;
下面的代码定义了每个滴答周期为1/60秒的duration:1
duration<double, ratio<1, 60>> d3;
下面的例子展示了duration的几个方面。它展示了如何定义duration,如何对duration执行算术操作,以及如何将一个duration转换为另一个滴答周期不同的duration:1
2
3
4
5
6
7
8
9duration<long, ratio<60>> d1(123);
cout << d1.count() << endl;
duration<double> d2;
d2 = d2.max();
cout << d2.count () << endl;
duration<long, ratio<60>> d3(10); // = 10 minutes
duration<long, ratio<1>> d4(14); // = 14 seconds
特别注意下面两行:1
2duration<double, ratio<60>>d5 = d3+d4;
duration<long, ratio<1>>d6 = d3+d4;
这两行都计算了d3+d4,但第一行将结果保存在表示分钟的浮点值中,第二行将结果保存在表示秒的整数中。分钟到秒的转换(或秒到分钟的转换)自动进行。
chrono库还提供了以下标准的duration类型,它们位于std::chrono名称空间中:1
2
3
4
5
6using nanoseconds = duration<X 64 bits, nano>;
using microseconds = duration<X 55 bits, micro>;
using milliseconds = duration<X 45 bits, milli>;
using seconds = duration<X 35 bits>;
using minutes = duration<X 29 bits, ratio<60>>;
using hours = duration<X 23 bits, ratio<3600>>;
X的具体类型取决于编译器,但C++标准要求X的类型为至少指定大小的整数类型。使用这些预定义的类型,不是编写:1
duration<long, ratio<60>> d9(10); // minutes
而是编写:1
minutes d9(10);
时钟
clock类由time_point和duration组成。C++标准定义了3个clock。第一个称为system_clock,表示来自系统实时时钟的真实时间。第二个称为steady_clock,是一个能保证其time_point绝不递减的时钟。system_clock无法做出这种保证,因为系统时钟可以随时调整。第三个称为high_resolution_clock,这个时钟的滴答周期达到了最小值。high_resolution_clock可能就是stead_clock或system_clock的别名,具体取决于编译器。
每个clock都有一个静态的now()方法,用于把当前时间用作time_point。system_clock定义了两个静态辅助函数,用于time_point和C风格的时间表示方法time_t之间的相互转换。第一个辅助函数为to_time_t(),它将给定time_point转换为time_t;第二个辅助函数为from_time_t(),它返回用给定time_t初始化的time_point。time_t类型在<ctime.h>头文件中定义。下例展示了一个完整程序,它从系统获得当前时间,然后将这个时间以可供用户读取的格式输出到控制台。localtime()函数将time_t转换为用tm表示的本地时间,定义在<ctime>头文件中。1
2
3
4system_clock::time_point tpoint = system_clock::now();
time_t tt = system_clock::to_time_t(tpoint);
tm* t m localtime(&tt);
如果想要将时间转换为字符串,可使用std::stringstream,定义在<ctime>中。使用strftime()函数时,要求提供一个足够大的缓冲区,以容纳用户可读格式的给定时间。1
2
3
4
5system_clock::time_point tpoint = system_clock::now();
time_t tt = system_clock::to_time_t(tpoint);
char buffer[80] = {0};
strftime(buffer, sizeof(buffer), "%H:%M:%S", t);
通过chrono库还可计算一段代码执行所消耗的时间。下例展示了这个过程。变量start和end的实际类型为system_clock::time_point,diff的实际类型为duration:1
2
3
4
5
6
7
8auto start = high_resolution_clock::now();
double d = 0;
for (int i = 0; i < 1000000; ++i)
d += sqrt(sin(i) * cos(i));
auto end = high_resolution_clock::now();
auto diff = end - start;
时点
time_point类表示的是时间中的某个时点,存储为相对于纪元(epoch)的duration。time_point总是和特定的clock关联,纪元就是所关联clock的原点。例如,经典UNIX/Linux的时间纪元是1970年1月1日。
time_point类包含time_since_epoch()函数,它返回的duration表示所关联clock的纪元和保存的时间点之间的时间,C++支持合理的time_point和duration算术运算。C++支持使用比较运算符来比较两个时间点,提供了两个静态方法:min()返回最小的时间点,而max()返回最大的时间点。
time_point类有3个构造函数
time_point():构造一个time_point,通过duration::zero()进行初始化。得到的time_point表示所关联clock的纪元time_point(const duration& d):构造一个time_point,通过给定的duration进行初始化。得到的time_point表示纪元+dtemplate <class Duration2> time_point(const time_point<clock, Duration2>&t):构造一个time_point,通过t.time_since_epoch()进行初始化
每个time_point都关联一个clock。创建time_point时,指定clock作为模板参数:1
time_point<steady_clock> tp1;
每个clock都知道各自的time_point类型,因此可编写以下代码:1
steady_clock::time_point tpl;
下面的示例演示了time_point类:1
2
3
4
5time_point<steady_clock> tp1;
tp1 += minutes(10);
auto d1 = tp1.time_since_epoch();
duration<double> d2(dl);
生成随机数
在C++11之前,生成随机数的唯一方法是使用C风格的srand()和rand()函数。srand()函数需要在应用程序中调用一次,这个函数初始化随机数生成器,也称为设置种子(sccding)。通常应该使用当前系统时间作为种子。初始化随机数生成器后,通过rand()生成随机数。下例展示了如何使用srand()和rand()。time(nullptr)调用返回系统时间,这个函数在<ctime>头文件中定义:1
2srand(static_cast<unsigned int> (time(nullptr)));
cout << rand() << endl;
可通过以下函数生成特定范围内的随机数:1
2
3int getRandom(int min, int max) {
return (rand() % static_cast<int>(max + 1 - min)) + min;
}
C++11的库能根据不同的算法和分布生成随机数。这个库定义在<random>头文件中。这个库有3个主要组件:随机数引擎(engine)、随机数引擎适配器(engine adapter)和分布(distribution)。 随机数引擎负责生成实际的随机数,并将生成后续随机数需要的状态保存起来。分布判断生成随机数的范围以及随机数在这个范围内的数学分布情况。随机数引擎适配器修改相关联的随机数引擎生成的结果。
随机数引擎
以下随机数引擎可供使用:
- random_device
- linear_congruential_engine
- mersenne_twister_engine
- subtract_with_carry_engine
random_device引擎不是基于软件的随机数生成器;这是一种特殊引擎,要求计算机连接能真正生成不确定随机数的硬件。随机数生成器的质量由随机数的熵(entropy)决定。如果random_device类使用的是基于软件的伪随机数生成器,那么这个类的entropy()方法返回的值为0.0。random_device的速度通常比伪随机数引擎更慢。因此,如果需要生成大量的随机数,建议使用伪随机数引擎,使用random_device为随机数引擎生成种子,除了random_device随机数引擎之外,还有3个伪随机数引擎:
- 线性同余引擎(linear congruential engine)保存状态所需的内存量最少。状态是一个包含上一次生成的随机数的整数,如果尚未生成随机数,则保存的是初始种子。
- 在这3个伪随机数引擎中,梅森旋转算法生成的随机数质量最高。梅森旋转算法的周期取决于算法参数,但比线性同余引擎的周期要长得多。梅森旋转算法保存状态所需的内存量也取决于算法参数,但是比线性同余引擎的整数状态高得多。例如,预定义的梅森旋转算法mt9937的周期为2^19937-1,状态包含625个整数,约为2.5KB。它是最快的随机数引擎之一
- 带进位减法(subtract withcarry)引擎要求保存大约100字节的状态。不过,这个随机数引擎生成的随机数质量不如梅森旋转算法。
optional
std::optional在<optional>中定义,用于保存特定类型的值,或什么都不保存。如果希望值是可选的,可将其用作函数的参数。如果函数可以返回一些值,或什么都不返回,通常也可将其用作函数的返回类型。这样,就不必从函数返回特殊值,如nullptr、-1和EOF等。在下面的示例中,函数返回optional:1
2
3
4
5optional<int> getData(bool givelt) {
if (giveIt)
return 42;
return nullopt;
}
可采用如下方式调用该函数:1
2auto data1 = getData(true);
auto data2 = getData(false);
要确定optional是否具有值,可使用has_value()方法,或在证语句中使用optional:1
2
3
4cout << "datal.has_value = "<< datal.has_value() <<endl;
if(data2) {
cout << "data2 has a value." << endl;
}
如果optional具有值,可使用value()接收它,或使用以下反引用运算符:1
2cout << "data1.value = " << data1.value() << endl;
cout << "data1.value = " << *data1 << endl;
如果在空的optional上调用value(),将抛出bad_optional_access异常。可使用value_or()返回optional值,或在optional为空时返回另一个值:1
cout << "data2.value" << data2.value_or(0) << endl;
注意,不能在optional中存储引用,因此optional<T&>不可行。相反,应当使用<optionakT*>、optional<reference_wrapper<T>>或optional<reference_wrapper<const T>>。
variant
std::variant在<variant>中定义,可用于保存给定类型集合的一个值。定义variant时,必须指定它可能包含的类型。例如,以下代码定义variant一次可以包含整数、字符串或浮点值:1
variant<int, string, float> v;
这里,这个默认构造的variant包含第一个类型(此处是int)的默认构造值。要默认构造variant,务必确保variant的第一个类型是默认可构造的。例如,下面的代码无法编译,因为Foo不是默认可构造的。1
2
3
4
5class Foo { public: Foo() = delete; Foo(int) { } };
class Bar { public: Bar() = delete; Bar(int) { } };
int main () {
variant<Foo, Bar> v;
}
事实上,Foo和Bar都不是默认可构造的。如果仍需要默认构造variant,可使用std:monostate(一个空的替代)作为variant的第一个类型:1
variant<monostate, Foo, Bar> v;
可使用赋值运算符,在variant中存储内容:1
2
3
4variant<int, string, float> v;
v = 12;
v = 2.5f;
v = "An std::string"s;
variant在任何给定时间只能包含一个值。因此,对于这三行代码,首先将整数12存储在variant中,然后将variant改为包含浮点值,最后将variant改为包含字符串。
可使用index()方法来查询当前存储在variant中的值类型的索引。std:holds_alternative()函数模板可用于确定variant当前是否包含特定类型的值:1
2cout <<"Type index: "<< v.index() << endl;
cout <<"Contains an int:" << holds_alternative<int>(V) << endl;
使用std::get<index>()或std::get<T>()从variant检索值。如果使用类型的索引,或使用与variant的当前值不匹配的类型,这些函数抛出bad_variant_access异常:1
2
3
4
5
6cout << std::get<string>(v) << endl;
try {
cout << std::get<0>(v)<<endl;
} catch (const bad_variant_access& ex) {
cout <<"Exception: " << ex.what()<<endl;
}
为避免异常,可使用std::get_if<index>()或std::get_if<T>()辅助函数。这些函数接收指向variant的指针,返回指向请求值的指针;如果遇到错误,则返回nullptr。1
2string* theString = std::get_if<string>(&v);
int* theint = std::get_if<int>(&v);
可使用std::visit()辅助函数,将visitor模式应用于variant。假设以下类定义了多个重载的函数调用运算符,variant中的每个可能类型对应一个:1
2
3
4
5
6class MyVisitor {
public:
void operator ()(int i) { cout << "int " << i<< endl; }
void operator ()(const string& s) { cout<< "string" << s << endl; }
void operator ()(float t) { cout <<"float" << f << endl; }
};
可将其与std::visit()一起使用,如下所示:1
visit(MyVisitor(), v);
这样就会根据variant中当前存储的值,调用适当的重载的函数调用运算符。
any
std::any在<any>中定义,是一个可包含任意类型值的类。一旦构建,可确认any实例中是否包含值,以及所包含值的类型。要访问包含的值,需要使用any_cast(),如果失败,会抛出bad_any_cast类型的异常。下面是一个示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16any empty;
any anint(3);
any aString("An std::string."s);
cout << "empty.has_value = " << empty.has_value() << endl;
cout << "anint.has_value = " << anint.has_value() << endl << endl;
cout <<"anint wrapped type = " << anint.type().name() << endl;
cout <<"aString wrapped type = " << aString.type().name() << endl <<endl;
int theInt = any_cast<int>(anInt);
cout << theInt << endl;
try {
int test = any_cast<int>(aString);
cout << test << endl;
} catch (const bad_any_cast& ex) {
cout << "Exception: " << ex.what() << endl;
}
输出如下所示。注意,aString的包装类型与编译器相关。1
2
3
4
5
6empty.has_value = 0
anint.has_value = 1
anInt wrapped type = int
astring wrapped type = class std: :basic_string<char, struct std::char_traits<char>,class std::allocator<char> >
3
Exception: Bad any_cast
可将新值赋给any实例,甚至是不同类型的新值:1
2
3any something(3);
// Now it contains an integer.
something = "An std::string"s; //Now the same instance contains a string.
any的实例可存储在标准库容器中。这样就可在单个容器中存放异构数据。这么做的唯一缺点在于,只能通过显式执行any_cast来检索特定值,如下所示:1
2
3
4vector<any> v;
v.push_back(any(42));
v.push_back(any("An std::string"s));
cout << any_cast<string>(v[1]) << endl;
与optional和variant一样,无法存储any实例的引用。可存储指针,也可存储reference_wrapper<const T>或reference_wrapper<T>的实例。
元组
在<utility>中定义的std::pair类可保存两个值,每个值都有特定的类型。每个值的类型都应该在编译时确定。下面是一个简单的例子:1
2pair<int, string> p1(16, "Hello World");
pair<bool, float> p2(true, 0.123f);
还有std::tuple类,这个类定义在<tuple>头文件中。tuple(元组)是pair的泛化,允许存储任意数量的值,每个值都有自己特定的类型。和pair一样,tuple的大小和值类型都是编译时确定的,都是固定的。tuple可通过tuple构造函数创建,需要指定模板类型和实际值。例如,下面的代码创建了一个tuple,其第一个元素是一个整数,第二个元素是一个字符串,最后一个元素是一个布尔值:1
2using MyTuple = tuple<int, string, bool>;
MyTuple t1(16, "Test", true);std::get<i>()从tuple中获得第i个元素,i是从0开始的索引;因此<0>表示tuple的第一个元素,<1>表示tuple的第二个元素,依此类推。返回值的类型是tuple中那个索引位置的正确类型:1
cout << "t1 = (" << get<0>(t1) << "," << get<1>(t1) << "," << get<2>(t1) << ")" << endl;
可通过<typeinfo>头文件中的typeid()检查get<i>()是否返回了正确的类型。下面这段代码的输出表明,get<I>(t1)返回的值确实是std::string:1
2cout << "Type of get<1>(t1) = " << typeid(get<1>(t1)).name() << endl;
// Outputs: Type of get<1>(t1) = class std::basic_string<char, struct std::char_traits<char>, class std::allocator<char>>
也可根据类型使用std::get<T>()从tuple中提取元素,其中T是要提取的元素(而不是索引)的类型。如果tuple有几个所需类型的元素,编译器会生成错误。例如,可从tl中提取字符串元素:1
cout << "String = "<< get<string>(t1) << endl;
遗憾的是,迭代tuple的值并不简单。无法编写简单循环或调用get<i>(mytuple)等,因为i的值在编译时必须是已知的。
可通过std:tuple_size模板来查询tuple的大小。 注意,tuple_size要求指定tuple的类型,而不是实际的tuple实例,例如t1:1
2cout << "Tuple Size " << tuple_size<MyTuple>::value << endl;
// Outputs: Tuple Size 3
如果不知道准确的tuple类型,始终可以使用decltype(),如下所示:1
cout << "Tuple Size - " << tuple_size<decltype(t1)>::value << endl;
在C++17中,提供了构造函数的模板参数推导规则。在构造tuple时,可忽略模板类型形参,让编译器根据传递给构造函数的实参类型,自动进行推导。例如,下面定义同样的t1元组,它包含一个整数、一个字符串和一个布尔值。1
std::tuple t1(16, "Test"s, true);
缘于类型的自动推导,不能通过&来指定引用。如果需要通过构造函数的模板参数推导方式,生成一个包含引用或常量引用的tuple,那么需要分别使用ref()和cref()。ref()和cref()辅助函数在<functional>头文件中定义。例如,下面的构造会生成一个类型为tuple<int, double&, const double&, string&>的tuple:1
2
3double d = 3.14;
string str1 = "Test";
std::tuple t2(16, ref(d), cref(d), ref(str1));
为测试元组t2中的double引用,下面的代码首先将double变量的值写入控制台。然后调用get<1>(t2),这个函数实际上返回的是对d的引用,因为第二个tuple(索引1)元素使用了ref(d)。第二行修改引用的变量的值,最后一行展示了d的值的确通过保存在tuple中的引用修改了。注意,第三行未能编译,因为cref(d)用于第三个tuple元素,也就是说,它是d的常量引用。1
2
3
4
5
6cout << "d = "<< d << endl;
get<1>(t2) *= 21
// get<2>(t2) *= 2;
// ERROR because of cref()
cout <<"d = " << d << endl;
如果不使用构造函数的模板参数推导方法,可以使用std::make_tuple()工具函数创建一个tuple。利用这个辅助函数模板,只需要指定实际值,即可创建一个tuple。在编译时自动推导类型,例如:1
auto t2 = std::make_tuple(16, ref(d), cref(d), ref(str1));
分解元组
可采用两种方法,将一个元组分解为单独的元素:结构化绑定(C++17)以及std::tie()。
结构化绑定
C++17引入了结构化绑定,允许方便地将一个元组分解为多个变量。例如,下面的代码定义了一个tuple,这个tuple包括一个整数、一个字符串和一个布尔值;此后,使用结构化绑定,将这个tuple分解为三个独立的变量:1
2
3tuple t1(16, "Test"s, true);
auto[i, str, b] = t1;
cout<< "Decomposed: i = " << i << ", str = " << str << ", b = " << b << endl;
使用结构化绑定,无法在分解时忽略特定元素。如果tuple包含三个元素,则结构化绑定需要三个变量。如果想忽略元素,则必须使用tie()。
tie()
如果在分解元组时不使用结构化绑定,可使用std:tie()工具函数,它生成一个引用tuple。下例首先创建一个tuple,这个tuple包含一个整数、一个字符串和一个布尔值;然后创建三个变量,即整型变量、字符串变量和布尔变量,将这些变量的值写入控制台。tie(i, str, b)调用会创建一个tuple,其中包含对i的引用、对str的引用以及对b的引用。使用赋值运算符,将t1赋给tie()的结果。由于tie()的结果是一个引用tuple,赋值实际上更改了三个独立变量中的值。1
2
3
4
5
6
7tuple<int, string, bool>t1(16, "Test", true);
int i = 0;
string str;
bool b = false;
cout << "Betore: i = " << i << ", str = " << str << ", b = "<< b <<endl;
tie(I, str, b) = t1;
cout << "After: i = " << i << ", str = " << str << ", b = "<< b <<endl;
串联
通过std::tuple_cat()可将两个tuple串联为一个tuple。在下面的例子中,t3的类型为tuple<int, string, bool, double, string>:1
2
3tuple<int, string, bool> t1(16, "Test", true);
tuple<double, string> t2(3.14, "string 2");
auto t3 = tuple_cat(t1, t2);
比较
tuple还支持以下比较运算符:==、!=、<、>、<=和>=。为了能使用这些运算符,tuple中存储的元素类型也应该支持这些操作。例如:1
2
3
4
5
6tuple<int, string> t1(123, "def");
tuple<int, string> t2(123, "abc");
if(t1<t2)
cout << "tl < t2"<< endl;
else
cout << "t1 >= t2" << endl;
make_from_tuple()
使用std:make_from_tuple()可构建一个T类型的对象,将给定tuple的元素作为参数传递给T的构造函数。例如,假设具有以下类:1
2
3
4
5
6
7Class Foo {
public:
Foo(string str, int i):mStr(str), mInt(i) {}
private:
string mStr;
int mint;
};
可按如下方式使用make_from_tuple():1
2auto myTuple = make_tuple("Hello world.", 42);
auto foo = make_from_tuple<Foo>(myTuple);
提供给make_from_tuple()的实参未必是一个tuple,但必须支持std:get<>()和std::tuple_size。std::array和std::pair也满足这些要求。
apply()
std::apply()调用给定的函数、lambda表达式和函数对象等,将给定tuple的元素作为实参传递。下面是一个例子:1
2int add(int a, int b) { return a + b; }
cout << apply(add, std::make_tuple(39, 3)) << endl;
与make_from_tuple()一样,在日常工作中,该函数并不实用;不过,如果要编写使用模板的泛型代码,或进行模板元编程,那么这个函数可提供便利。
文件系统支持库
C++17引入了文件系统支持库,它们全部定义在<filesystem>头文件中,位于std::filesystem名称空间。它允许你编写可移植的用于文件系统的代码。使用它,可以区分是目录还是文件,迭代目录的内容,操纵路径,检索文件信息(如大小、扩展名和创建时间等)。下面介绍这个库最重要的两个方面:path(路径)和directory_entry(目录项)。
path
这个库的基本组件是path。path可以是绝对路径,也可以是相对路径,可包含文件名,也可不包含文件名。例如,以下代码定义了一些路径,注意使用了原始字符串字面量来避免对反斜线进行转义。1
2
3
4
5path p1(LR"(D:\Foo\Bar)");
path p2(L"D:/Foo/Bar");
path p3(L"D:/Foo/Bar/MyFile.txt");
path P4(LR"(..\SomeFolder)");
path p5(L"/usr/lib/X11");
将path转换为字符串(如使用c_str()方法)或插入流时,会将其转换为运行代码的系统中的本地格式。例如:1
2
3
4path p1(LR"(D:\Foo\Bar)");
path p2(L"D:/Foo/Bar");
cout << p1 << endl;
cout << p2 << endl;
可使用append()方法或operator/=,将组件追加到路径。路径会自动添加分隔符。例如:1
2
3
4path p(L"D:\\Foo");
p.append("Bar");
P /= "Bar";
cout << p << endl;
输出是D:\Foo\Bar\Bar。
可使用concat()方法或operator+=,将字符串与现有路径相连。此时路径不会添加分隔符。append()和operator/=自动添加路径分隔符,而concat()和operator+=不会自动添加。
path接口支持remove_filename、replace_filename()、replace_extension()、root_name()、parent_path()、extension()、has_extension()、is_absolute()、is_relative()等操作。
directory_entry
path只表示文件系统的目录或文件。path可能指不存在的目录或文件。如果想要查询文件系统中的实际目录或文件,需要从path构建一个directory_entry。 如果给定目录或文件不存在,该结构会失败。directory_entry接口支持is_directory()、is_regular_file()、is_socket()、is_symlink()、file_size()、last_write_time()等操作。
辅助函数
有一组完整的辅助函数可供使用。例如,可使用copy()复制文件或目录,使用create_directory()在文件系统中创建新目录,使用exists()查询给定目录或文件是否存在,使用file_size()获取文件大小,使用last_write_time()获取文件最近一次的修改时间,使用remove()删除文件,使用temp_directory_path()获取适于保存临时文件的目录,使用space()查询文件系统中的可用空间,等等。
目录迭代
如果想要递归地迭代给定目录中的所有文件和子目录,可使用如下recursive_directory_iterator:1
2
3
4
5
6
7
8
9
10
11
12
13
14void processPath (const path& p) {
if (!exists(p))
return;
auto begin = recursive_directory_iterator(p);
auto end = recursive_directory_iterator();
for (auto iter = begin; iter != end; ++ iter) {
const string spacer(iter.depth()*2, ' ');
auto& entry = *iter;
if (is_regular_file(entry))
cout << spacer << "File: " << entry << endl;
else if (is_directory(entry))
cout << spacer << "Dir: "<< entry << endl;
自定义和扩展标准库
分配器
每个标准库容器都接收Allocator类型作为模板参数,大部分情况下默认值就足够了。例如,vector模板的定义如下所示1
template <class T, class Allocator = allocator<T>>class vector;
容器构造函数还允许指定Allocator类型的对象。通过这些额外参数可自定义容器分配内存的方式。容器执行的每一次内存分配都是通过调用Allocator对象的allocate()方法进行的,每一次内存释放都是通过调用Allocator对象的deallocate()方法进行的。
有几种原因需要使用自定义的分配器。例如:
- 如果底层分配器的性能无法接受,但可构建替换的分配器
- 如果内存碎片问题(大量不同的分配和释放操作导致内存中出现很多不可用的小空洞)严重
- 如果必须给操作系统特定的功能分配空间,
C++17引入了多态内存分配器的概念。对于指定为模板类型参数的容器的分配器,问题在于两个十分相似但具有不同分配器类型的容器区别很大。例如,具有不同分配器模板类型参数的两个vectorstd::pmr名称空间的<memory_resource>中定义的多态内存分配器有助于解决这个问题。std::pmr::polymorphic_allocator是适当的分配器类,因为它满足各种要求,如具有allocate()和deallocate()方法。polymorphic allocator的分配行为取决于构建期间的memory_resource,而非取决于模板类型参数。因此,在分配和释放内存时,虽然具有相同的类型,但不同polymorphic_allocator的行为迥异。
流适配器
标准库提供了4个流适配器(stream iterator)。它们是类似于迭代器的类模板,允许将输入流和输出流视为输入迭代器和输出迭代器。通过这些迭代器可对输入流和输出流进行适配,将它们在不同的标准库算法中分别当成来源和目标。下面列出可用的流迭代器:
ostream_iterator是一个输出流迭代器istream_iterator是一个输入流迭代器
输出流迭代器
ostream_iterator是一个输出流迭代器,是一个类模板,接收元素类型作为类型参数。这个类的构造函数接收的参数包括一个输出流以及要在写入每个元素之后写入流的分隔符字符串。ostream_iterator通过operator<<运算符写入元素。可以用ostream_iterator一行代码打印出容器中的元素。1
2
3vector<int> myVector(10);
iota(begin (myVector), end (myVector), 1); // Fill vector with 1,2,3...10
copy (cbegin (myVector), cend (myVector), ostream_iterator<int>(cout, " "));
输入流迭代器
还可使用输入流迭代器istream_iterator通过迭代器抽象从输入流中读取值。这是类模板,将元素类型作为类型参数,通过operator>>运算符读取元素。istream_iterator可用作算法和容器方法的来源。
迭代器适配器
标准库提供了3个迭代器适配器(iterator adapter), 它们是基于其他迭代器构建的特殊迭代器。这3个迭代器适配器都在<iterator>头文件中定义。
反向迭代器
标准库提供了std::reverse_iterator类模板,以反向遍历双向迭代器或随机访问迭代器。标准库中所有可反向迭代的容器都提供了类型别名reverse_iterator以及rbegin()和rend()方法。这些reverse_iterator类型别名的类型是std::reverse_iterator<T>,T等于容器的iterator类型别名。rbegin()方法返回指向容器中最后一个元素的reverse_iterator,rend()方法也返回一个reverse_iterator,这个迭代器指向容器中第一个元素之前的元素。对reverse_iterator应用operator++运算符,会对底层容器迭代器调用operator--运算符,反之亦然。例如,可通过以下方式从头到尾遍历一个集合:1
for (auto iter = begin(collection); iter != end (collection); ++iter)
要从尾到头遍历这个集合的元素,可调用rbegin()和rend()来使用reverse_iterator。注意,这里仍使用++iter:1
for(auto iter = rbegin(collection); iter != rend(collection); ++iter)
std::reverse_iterator主要用在标准库中没有等价算法能够反向运行的情况。
插入迭代器
为了让copy()这类算法的用途更广泛,标准库提供了3个插入迭代器以真正将元素插入容器:insert_iterator、back_insert_iterator和front_insert_iterator。插入迭代器根据容器类型模板化,在构造函数中接收实际的容器引用。通过提供必要的迭代器接口,这些适配器可用作copy()这类算法的目标迭代器。这些适配器不会替换容器中的元素,而通过调用容器真正插入新元素。
基本的insert_iterator调用容器的insert(position, element)方法,back_insert_iterator调用push_back(element)方法,front insert_iterator调用push_front(element)方法,例如,结合back_insert_iterator和copy_if()算法能为vectorTwo填充来自vectorOne的不等于100的所有元素:1
2
3
4vector<int> vectorone, vectorTwo;
back_insert_iterator<vector<int>> inserter(vectorTwo);
copy_if(cbegin (vectorOne), cend (vectorone), inserter, [](int i){return i != 100;});
copy (cbegin (vectorTwo), cend (vectorTwo), ostream_iterator<int>(cout, ""));
从这段代码可看出,在使用插入迭代器时,不需要事先调整目标容器的大小。
也可通过std::back_inserter()工具函数创建一个back_insert_iterator。例如,在前一个例子中,可删除定义inserter变量的那一行代码,然后将copy_if()调用改写为以下代码。结果和之前的实现完全相同:1
copy_if(cbegin (vectorOne), cend (vectorOne), back_inserter (vectorTwo), [](int i){return i!=100;});
front_insert_iterator和insert_iterator的工作方式类似,区别在于insert_iterator在构造函数中还接收初始的迭代器位置作为参数,并将这个位置传入第一次insert(position, element)调用。后续的迭代器位置提示通过每一次insert()调用的返回值生成。
使用insert_iterator的一个巨大好处是可将关联容器用作修改类算法的目标。关联容器实际上支持将接收迭代器位置作为参数的insert(),并将这个位置用作“提示”,但这个位置可忽略。在关联容器上使用insert_iterator时,可传入容器的begin()或end()迭代器用作提示。insert_iterator在每次调用insert()后修改传输给insert()的迭代器提示,使其成为刚插入元素之后的那个位置。
移动迭代器
迭代适配器std:move_iterator的解除引用运算符会自动将值转换为rvalue引用,也就是说,这个值可移动到新的目的地,而不会有复制开销。在使用移动语义前,需要保证对象支持移动语义。
扩展标准库
编写标准库算法
find_all()
假设需要在指定范围内找到满足某个谓词的所有元素。find()和find_if()是最符合条件的备选算法,但这些算法返回的都是仅引用一个元素的迭代器。可使用copy_if()找出所有满足谓词的元素, 但会用所找到元素的副本填充输出。如果想要避免复制,可使用copy_in()和back_insert_iterator()在vector<reference_wrapper<T>>中),但这不能给出所找到元素的位置。可自行编写能提供这个功能的版本,称为find_all()。
与copy_if()一样, 该算法给输出序列返回一个迭代器,指向输出序列中存储的最后一个元素后面的那个元素。下面是算法原型:1
2template <typename InputIterator, typename OutputIterator, typename Predicate>
OutputIterator find_all(InputIterator first, InputIterator last, OutputIterator dest, Predicate pred);
另一种可选方案是忽略输出迭代器,给输入序列返回一个迭代器,遍历输入序列中所有匹配的元素,但是这种方案要求编写自定义的迭代器类。
下一项任务是编写算法的实现。find_all()算法遍历输入序列中的所有元素,给每个元素调用谓词,把匹配元素的迭代器存储在输出序列中。下面是算法的实现:1
2
3
4
5
6
7
8
9
10
11template <typename InputIterator, typename OutputIterator, typename Predicate>
OutputIterator find_all(InputIterator first, Inputiterator last,OutputIterator dest, Predicate pred) {
while (first != last) {
if(pred(*first)) {
*dest = first;
++dest;
}
++first;
}
return dest;
}
iterator_traits
一些算法的实现需要迭代器的额外信息。例如,为保存临时值,算法可能需要知道迭代器引用的元素的类型,还可能需要知道迭代器是双向访问的还是随机访问的。C++提供了一个名为iterator_traits的类模板,以找到这些信息。通过要使用的迭代器类型实例化iterator_traits类模板,然后可访问以下5个类型别名:value_type、difference_type、iterator_category、pointer、reference。例如,下面的模板函数声明了一个临时变量,其类型是iteratorType类型的迭代器引用的类型。注意,在iterator_traits这行前面要使用typename关键字。访问基于一个或多个模板参数的类型时,必须显式地指定typename。在这个例子中,模板参数IteratorType用于访问value_type类型:1
2
3
4
5template <typename IteratorType>
void iteratortraitsTest(IteratorType it) {
typename std::iterator_traits<IteratorType>::value_type temp;
temp = *it;
cout << temp << endl;
可通过以下代码测试这个函数:1
2vector<int> v{ 5 };
iteratorTraitsTest(cbegin(v));
在这段代码中,iteratorTraitsTest()函数中temp变量的类型为int。输出是5。
高级模板
深入了解模板参数
实际上有3种模板参数:类型参数、非类型参数和template template参数。
深入了解模板类型参数
模板的类型参数是模板的精髓。可声明任意数目的类型参数。标准库定义了几个模板化的容器类,包括vector和deque。下面是带有额外模板参数的类定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23template <typename T, typename Container>
class Grid {
public:
explicit Grid(size_t width = kDefaultwidth, size_t height = kDefaultHeight);
virtual ~Grid() = default;
Grid(const Grid& src) = default;
Grid<T, Container>& operator=(const Grid& rhs) = default;
Grid(Grids& src) = default;
Grid<T, Container>& operator= (Gride&& rhs) = default;
typename Container::value_type& at(size_t x, size_t y);
const typename Container::value_types at(size_t x, size_t y) const;
size_t getHeight()const { return mHeight; }
size_t getwidth()const { return mwidth; }
static const size_t kDefaultwidth = 10;
static const size_t kDefaultHeight = 10;
private:
void verifyCoordinate(size_t x, size_t y) const;
std::vector<Container> mCells;
size_t midth = 0, mHeight = 0;
};
现在这个模板有两个参数:T和Container。因此,所有引用了Grid<T>的地方现在都必须指定Grid<T, Container>以表示两个模板参数。其他仅有的变化是,mCells现在是Container的vector,而不是vector的vector。下面是构造函数的定义:1
2
3
4
5
6template <typename T, typename Container>
Grid<T, Container>::Grid(size_t width, size_t height) : mwidth(width), mheight(height) {
mCells.resize(mWidth);
for (auto& column : mCells)
column.resize(mHeight);
}
这个构造函数假设Container类型具有resize()方法。如果尝试通过指定没有resize()方法的类型来实例化这个模板,编译器将生成错误。at()方法的返回类型是存储在给定类型容器中的元素类型。可以使用typename Container:value_type访问该类型。下面是其余方法的实现:1
2
3
4
5template <typename T, typename Container>
void Grid<T, Container>::verifyCoordinate(size_t x, size_t y) const {
if(x >= mWidth || y >= mHeight)
throw std::out_of_range("");
}
现在,可按以下方式实例化和使用Grid对象:1
2Grid<int, vector<optional<int>>> myIntVectorGrid;
Grid<int, deque<optional<int>>> myIntDequeGrid;
给参数名称使用Container并不意味着类型必须是容器。可尝试用int实例化Grid类:1
Grid<int, int> test; // WILL NOT COMPILE
此行代码无法成功编译,在尝试处理类模板定义的这一行之前,一切都正常1
typename Container::value_types at(size_t x, size_t y);
在这一行,编译器意识到column是int类型,没有嵌入的value_type类型别名。
与函数参数一样,可给模板参数指定默认值。例如,可能想表示Grid的默认容器是vector。这个模板类定义如下所示:1
template <typename T, typename Container = std::vector<std::optional<T>>>
可以使用第一个模板参数中的类型T作为第二个模板参数的默认值中optional模板的参数。C++语法要求不能在方法定义的模板标题行中重复默认值。现在有了这个默认参数后,实例化网格时,客户可指定或不指定底层容器:1
2
3Grid<int, deque<optional<int>>> myDequeGrid;
Grid<int, vector<optional<int>>> myVectorGrid;
Grid<int> myVectorGrid2 (myVectorGrid);
template template参数介绍
如果能编写以下代码就好了:1
Grid<int, vector> myIntGrid;
Grid类应该能够判断出需要一个元素类型为int的optional vector。不过编译器不会允许传递这样的参数给普通的类型参数,因为vector本身并不是类型,而是模板。如果想要接收模板作为模板参数,那么必须使用一种特殊参数,称为template template参数。指定template template参数时,template template参数的完整规范包括该模板的参数。例如,vector和deque等容器有一个模板参数列表,如下所示。1
2
3template <typename E, typename Allocator = std::allocator<E>>
class vector {
};
要把这样的容器传递为template template参数, 只能复制并粘贴类模板的声明(在本例中是template <typename E, typename Allocator = allocator<E>> class vector),用参数名(Container)替代类名(vector),并把它用作另一个模板声明的template template参数,而不是简单的类型名。有了前面的模板规范,下面是接收一个容器模板作为第二个模板参数的Grid类的类模板定义:1
2
3
4
5
6
7
8
9
10
11template <typename T,
template <typename E, typename Allocator = std::allocator<E>> class Container = std::vector>
class Grid {
public:
std::optional<T>& at(size_t x, size_t y);
const std::optional<T>& at(size_t x, size_t y) const;
private:
void verifyCoordinate(size_t x, size_t y) const;
std::vector<Container<std::optional<T>>>mCells;
size_t mWidth = 0, mHeight = 0;
};
第一个模板参数与以前一样:元素类型T。第二个模板参数现在本身就是容器的模板,如vector或dcque。如前所述, 这种“模板类型”必须接收两个参数:元素类型E和分配器类型。
注意嵌套模板参数列表后面重复的单词class。这个参数在Grid模板中的名称是Container。默认值现为vector而不是vector<T>,因为Container是模板而不是实际类型。
template template参数更通用的语法规则是:1
template <..., template <TemplateTypeParams> class ParameterName, ...>
从C++17开始,也可以用typename关键字替代class,如下所示:1
template <..., template <TemplateTypeParams> typename ParameterName, ...>
在代码中不要使用Container本身,而必须把Container<std::optiona<T>>指定为容器类型。例如,现在mCells的声明如下:1
std::vector<Container<std::optional<T>>> mCells;
不需要更改方法定义,但必须更改模板行,例如:1
2
3
4
5
6template <typename T,
template <typename E, typename Allocator = std::allocator<E>> class Container>
void Grid<T, Container>::verifyCoordinate(size_t x, size_t y) const {
if (x >= mWidth || y >= mHeight)
throw std::out_of_range("");
}
可以这样使用Grid模板:1
2
3
4Grid<int, vector>myGrid;
myGrid.at(1, 2) = 3;
cout << myGrid.at(1,2).value_or(0) << endl;
Grid<int, vector> myGrid2(myGrid);
上述C++语法有点令人费解,因为它试图获得最大的灵活性。尽量不要在这里陷入语法困境,记住主要概念:可向其他模板传入模板作为参数
深入了解非类型模板参数
有时可能想让用户指定一个默认元素,用来初始化网格中的每个单元格。下面是实现这个目标的一种完全合理的方法,它使用T()作为第二个模板参数的默认值:1
2template <typename T, const T DEFAULT = T()>
class Grid { };
这个定义是合法的。可使用第一个参数中的类型T作为第二个参数的类型,非类型参数可为const,就像函数参数一样。可使用T的初始值来初始化网格中的每个单元格:1
2
3
4
5
6
7
8
9
10template <typename T, const T DEFAULT>
Grid<T, DEFAULT>::Grid(size_t width, size_t height) : mWidth(width), mHeight(height) {
mCells.resize(mWidth);
for (auto& column : mcells) {
column.resize(mHeight);
for (auto& element : column) {
element = DEFAULT;
}
}
}
其他的方法定义保持不变,只是必须向模板行添加第二个模板参数,所有Grid<T>实例要变为Grid<T,DEFAULT>。完成这些修改后,可实例化一个int网格,并为所有元素设置初始值:1
2Grid<int> myIntGrid;
Grid<int, 10> myIntGrid2;
非类型参数不能是对象,甚至不能是double和float值。非类型参数被限定为整型、 枚举、指针和引用。
允许用户指定网格初始元素值的一种更详尽方式是使用T引用作为非类型模板参数。下面是新的类定义:1
2template <typename T, const T& DEFAULT>
class Grid {};
现在可为任何类型实例化这个模板类。C++17标准指定,作为第二个模板参数传入的引用必须是转换的常量表达式(模板参数类型),不允许引用子对象、临时对象、字符串字面量、typeid表达式的结果或预定义的__func__变量。下例声明了带有初始值的int网格和SpreadsheetCell网格。1
2
3
4
5
6
7int main () {
int defaultint = 11;
Grid<int, defaultint> myIntGrid;
SpreadsheetCell defaultCe11(1.2);
Grid<Spreadsheetcell, defaultcell> mySpreadsheet;
return 0;
}
但这些是C++17的规则,大多数编译器尚未实施这些规则。在C++17之前,传给引用非类型模板参数的实参不能是临时的,不能是无链接(外部或内部)的命名左值。因此,对于上面的示例,下面使用C++17之前的规则。使用内部链接定义初始值:1
2
3
4
5
6
7
8
9namespace {
int defaultInt = 11;
spreadsheetcell defaultCell(1.2);
}
int main () {
Grid<int, defaultint> myIntGrid;
Grid<Spreadsheetcell, defaultcell> mySpreadsheet;
return 0;
}
模板类部分特例化
可编写部分特例化的类,这个类允许特例化部分模板参数,而不处理其他参数。例如,基本版本的Grid模板带有宽度和高度的非类型参数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15template <typename T, size_t WIDTH, size_t HEIGHT>
class Grid {
public:
Grid() = default;
virtual ~Grid() = default;
Grid(const Grid& src) = default;
Grid& operator=(const Grid& rhs) = default;
std::optional<T>& at(size_t x, size_t y);
const std::optional<T>& at(size_t x, size_t y) const;
size_t getHeight() const { return HEIGHT; }
size_t getWidth() const { return WIDTH; }
private:
void verifyCoordinate(size_t x, size_t y) const;
std::optional<T> mCells[WIDTH][HEIGHT];
};
可采用这种方式为char*C风格字符串特例化这个模板类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15template <size_t WIDTH, size_t HEIGHT>
class Grid<const char*, WIDTH, WEIGHT> {
public:
Grid() = default;
virtual ~Grid() = default;
Grid(const Grid& src) = default;
Gride operator-(const Grid& rhs) = default;
std::optional<std::string>& at(size_t x, size_t y);
const std::optional<std::string>& at(size_t x, size_t y) const;
size_t getHeight()const { return HEIGHT; }
size_t getWidth() const { return WIDTH; }
private:
void verifyCoordinate(size_t x, size_t y) const;
std::optional<std::string> mCells [WIDTH][HEIGHT];
};
在这个例子中,没有特例化所有模板参数。因此,模板代码行如下所示:1
2template <size_t WIDTH, size_t HEIGHT>
class Grid<const char*, WIDTH, HEIGHT>
注意,这个模板只有两个参数:WIDTH和HEIGHT。然而,这个Grid类带有3个参数:T、WIDTH和HEIGHT。因此,模板参数列表包含两个参数,而显式的Grid<const char*, WIDTH, HEIGHT>包含3个参数。实例化模板时仍然必须指定3个参数。不能只通过高度和宽度实例化模板:1
2
3Grid<int, 2, 2> myIntGrid;
Grid<const char*, 2, 2> myStringGrid;
Grid<2, 3> test;
上述语法的确很乱。更糟糕的是,在部分特例化中,与完整特例化不同,在每个方法定义的前面要包含模板代码行,如下所示:1
2
3
4
5
6template <size_t WIDTH, size_t HEIGHT>
const std::optional<std::string>&
Grid<const char*, WIDTH, HEIGHT>::at(size_t x, size_t y) const {
verifyCoordinate(x, y);
return mCells[x][y];
}
需要这一带有两个参数的模板行,以表示这个方法针对这两个参数做了参数化处理。注意,需要表示完整类名时,都要使用Grid<const char*, WIDTH, HEIGHT>。
前面的例子并没有表现出部分特例化的真正威力。可为可能的类型子集编写特例化的实现,而不需要为每种类型特例化。下面是类的定义,假设只用一个参数特例化最早版本的Grid。在这个实现中,Grid成为所提供指针的拥有者,所以它在需要时自动释放内存:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22template <typename T>
class Grid<T*> {
public:
explicit Grid(size_t width = kDefaultWidth, size_t height = kDefaultHeight);
virtual ~Grid() = default;
Grid(const Grid& src);
Grid<T*>& operator=(const Grids rhs);
Grid(Grid&& src) = default;
Grid<T*>& operator=(Grid&& rhs) = default;
void swap(Gride other) noexcept;
std::unique_ptr<T>& at(size_t x, size_t y);
const std::unique_ptr<T>& at(size_t x, size_t y) const;
size_t getHeight() const { return mHeight; }
size_t getwidth()const { return mWidth; }
static const size_t kDefaultwidth = 10;
static const size_t kDefaultHeight = 10;
private:
void verlfyCoordinate(size_t x, size_t y) const;
std::vector<std::vector<std::unique_ptr<T>>>mCells;
size_t mwidth = 0, mileight = 0;
像往常一样,下面这两行代码是关键所在:1
2template <typename T>
class Grid<T*>
上述语法表明这个类是Grid模板对所有指针类型的特例化。只有T是指针类型的情况下才提供实现。请注意,如果像下面这样实例化网格:Grid<int*> myIntGrid,那么T实际上是int而非int*。这不够直观,但遗憾的是,这种语法就是这样使用的。下面是一个示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14Grid<int> myIntGrid; // Uses the non-specialized grid
Grid<int*> psGrid(2, 2); // Uses the partial specialization for pointer types
psGrid.at(0, 0) = make_unique<int>(1);
psGrid.at(0, 1) = make_unique<int>(2);
psGrid.at(1, 0) = make_unique<int>(3);
Grid<int*> psGrid2(psGrid);
Grid<int*> psGrid3;
psGrid3 = psGrid2;
auto& element = psGrid2.at(1, 0);
if (element) {
cout << *element << endl;
*element = 6;
}
通过重载模拟函数部分特例化
C++标准不允许函数的模板部分特例化。相反,可用另一个模板重载函数。区别十分微妙。假设要编写一个特例化的Find()函数模板,这个特例化对指针解除引用,对指向的对象直接调用operator--。根据类模板部分特例化的语法,可能会编写下面的代码:1
2
3
4
5
6
7template <typename T>
size_t Find<T*>(T* const& value, T* const* arr, size_t size) {
for (size_t i = 0; i < size; i ++)
if (*arr[i] == *value)
return i;
return NOT_FOUND;
}
然而,这种声明函数模板部分特例化的语法是C++标准所不允许的。实现所需行为的正确方法是为Find()编写一个新模板,区别看似微不足道且不切合实际,但不这样就无法编译:1
2
3
4
5
6
7template <typename T>
size_t Find(T* const& value, T* const* arr, size_t size) {
for (size_t i = 0; i < size; i ++)
if (*arr[i] == *value)
return i;
return NOT_FOUND;
}
这个Find()版本的第一个参数是T* const&,这是为了与原来的Find()函数模板(它把const T&作为第一个参数)保持一致,但这里将T*(而不是T* const&)用作Find()部分特例化的第一个参数,这也是可行的。
模板递归
N维网格:初次尝试
前面的Grid模板示例到现在为止只支持两个维度,这限制了它的实用性。一种方法是只编写一个一维网格。然后,利用另一个网格作为元素类型实例化Grid,可创建任意维度的网格。这种Grid元素类型本身可以用网格作为元素类型进行实例化,依此类推。下面是OneDGrid类模板的实现。这只是前面例子中Grid模板的一维版本,添加了resize()方法,并用operator[]替换了at()。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25template <typename T>
class OneDGrid {
public:
explicit OneDGrid(size_t size = kDefaultsize);
virtual ~OneDGrid() = default;
T& operator[](size_t x);
const T& operator[](size_t x) const;
void resize(size_t newSize);
size_t getsize() const { return mElements.size();}
static const size_t kDefaultsize = 10;
private:
std::vector<T> mElements;
};
template <typename T>
OneDGrid<T>::OneDGrid(size_t size) {
resize(size);
}
template <typename T>
void OneDGtid<T>::resize(size t newSize) {
mElements.resize(newSize);
}
template <typename T>
T& OneDGrid<T>::operator [] (size_t x) {
return mElements[x];
}
有了OneDGrid的这个实现,就可通过如下方式创建多维网格:1
2
3
4
5
6OneDGrid<int> singleDGrid;
OneDGrid<OneDGrid<int>> twoDGrid;
OneDGrid<OneDGrid<OneDGrid<int>>> threeDGrid;
singleDGrid[3] = 5;
twoDGrid[3][3] = 5;
threeDGrid[3][3][3] = 5;
真正的N维网格
可以编写一个类模板来自动进行递归。然后,可创建如下N维网格:1
2
3NDGrid<int, 1> singleDGrid;
NDGrid<int, 2> twoDGrid;
NDGrid<int, 3> threeDGrid;
NDGrid类模板需要元素类型和表示维度的整数作为参数。这里的关键问题在于,NDGrid的元素类型不是模板参数列表中指定的元素类型,而是上一层递归的维度中指定的另一个NDGrid。换句话说,三维网格是二维网格的矢量,二维网格是一维网格的各个矢量。
使用递归时,需要处理基本情形(base case)。 可编写维度为1的部分特例化的NDGrid,其中元素类型不是另一个NDGrid,而是模板参数指定的元素类型。下面是NDGrid模板定义的一般形式,突出显示了与前面OneDGrid的不同之处:1
2
3
4
5
6
7
8
9
10
11
12
13template <typename T, size_t N>
class NDGrid {
public:
explicit NDGrid(size_t size = kDefaultSize);
virtual ~NDGrid() = default;
NDGrid<T, N-1>& operator[](size_t x);
const NDGrid<T, N-1>& operator [] (size_t x) const;
void resize(size_t newSize);
size_t getsize() const { return mElements.size();}
static const size_t kDefaultsize =10;
private:
std::vector<NDGrid<T, N-1>> mElements;
};
注意,mElements是NDGrid<T, N-1>的矢量:这是递归步骤。此外,operator[]返回一个指向元素类型的引用,依然是NDGrid<T, N-1>而非T。基本情形的模板定义是维度为1的部分特例化:1
2
3
4
5
6
7
8
9
10
11
12
13template <typename T>
class NDGrid<T, 1> {
public:
explicit NDGrid(size_t size = kDefaultSize);
virtual ~NDGrid() = default;
T& operator[](size_t x);
const T& operator[](size_t x) const;
void resize(size_t newSize);
size_t getSize() const { return mElements.size();}
static const size_t kDefaultsize = 10;
private:
std::vector<T> mElements;
};
模板递归实现最棘手的部分不是模板递归本身,而是网格中每个维度的正确大小。这个实现创建了N维网格,每个维度都是一样大的。为每个维度指定不同的大小要困难得多。
下面是NDGrid主模板的实现,这里突出显示了与OneDGrid之间的差异:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15template <typename T, size_t N>
NDGrid<T, N>::NDGrid(size_t size) {
resize(size);
}
template <typename T, size_t N>
void NDGrid<T, N>::resize(size_t newSize) {
mElements.resize(newSize);
for (auto& element : mElements)
element.resize(newSize);
}
template <typename T, size_t N>
NDGrid<T, N-1>& NDGrid<T, N>::operator[](size_t x) {
return mElements[x];
}
下面是部分特例化的实现(基本情形)。请注意,必须重写很多代码,因为不能在特例化中继承任何实现。1
2
3
4
5
6
7
8
9
10
11
12
13template <typename T>
NDGrid<T, 1>::NDGrid(size_t size) {
resize(size);
}
template <typename T>
void NDGrid<T, 1>::resize(size_t newSize) {
mElements.resize (newSize);
}
template <typename T>
T& NDGrid<T, 1>::operator[](size_t x) {
return mElements[x];
}
现在,可编写下面这样的代码:1
2
3
4NDGrid<int, 3> my3DGrid;
my3DGrid[2][1][2] = 5;
my3DGrid[1][1][1] = 5;
cout << my3DGrid[2][1](2]<< endl;
可变参数模板
普通模板只可采取固定数量的模板参数。可变参数模板(variadic template)可接收可变数目的模板参数。例如,下面的代码定义了一个模板,它可以接收任何数目的模板参数,使用称为Types的参数包(parameter pack):1
2template<typename... Types>
Class MyVarladicTemplate { };
可用任何数量的类型实例化MyVariadicTemplate,例如:1
2MyVariadicTemplate<int> instancel;
MyVariadicTemplate<string, double, list<int>>instance2;
甚至可用零个模板参数实例化:1
MyVariadicTemplate<> instance3;
为避免用零个模板参数实例化可变参数模板,可以像下面这样编写模板:1
2template<typename T1, typename... Types>
class MyVariadicTemplate { };
类型安全的变长参数列表
可变参数模板允许创建类型安全的变长参数列表。下面的例子定义了一个可变参数模板processValues(),它允许以类型安全的方式接收不同类型的可变数目的参数。函数processValues()会处理变长参数列表中的每个值,对每个参数执行handleValue()函数。 这意味着必须对每种要处理的类型编写handleValue()函数,例如下例中的int、double和string:1
2
3
4
5
6
7
8
9
10void handleValue(int value) { cout <<"Integer: " << value << endl; }
void handleValue(double value) { cout << "Double: " << value << endl; }
void handleValue(string_view value) { cout << value << endl; }
void processValues() { /* Nothing to do in this base case.*/ }
template<typename T1, typename... Tn>
void processValues(T1 arg1, Tn... args) {
handleValue(arg1);
processValues(args...);
}
在前面的例子中,三点运算符“…”用了两次。这个运算符出现在3个地方,有两个不同的含义。首先,用在模板参数列表中typename的后面以及函数参数列表中类型Tn的后面。在这两种情况下,它都表示参数包。参数包可接收可变数目的参数。
“…”运算符的第二种用法是在函数体中参数名args的后面。这种情况下,它表示参数包扩展。这个运算符会解包/展开参数包,得到各个参数。它基本上提取出运算符左边的内容,为包中的每个模板参数重复该内容,并用逗号隔开。从前面的例子中取出以下行:1
processValues (args...);
这一行将args参数包解包(或扩展)为不同的参数,通过逗号分隔参数,然后用这些展开的参数调用processValues()函数。模板总是需要至少一个模板参数: T1。通过args...递归调用processValues()的结果是: 每次调用都会少一个模板参数。
由于processValues()函数的实现是递归的,因此需要采用一种方法来停止递归。为此,实现一个processValues()函数,要求它接收零个参数。可通过下面的代码来测试processValues()可变参数模板:1
processValues(1, 2, 3.56, "test", 1.1f);
这个例子生成的递归调用是:1
2
3
4
5
6
7
8
9
10
11processValues(1, 2, 3.56, "test", 1.1f);
handleValue(1);
processValues(2, 3.56, "test", 1.1f);
handleValue(2);
processValues(3.56, "test", 1.1f);
handleValue(3.56);
processValues("test", 1.1f);
handleValue("test");
processValues(1.1f);
handleValue(1.1f);
processValues();
重要的是要记住,这种变长参数列表是完全类型安全的。processValues()函数会根据实际类型自动调用正确的handleValue()重载版本。C++中也会像通常那样自动执行类型转换。然而,如果调用processValues()时带有某种类型的参数,而这种类型没有对应的handleValue()函数,编译器会产生错误。
为了在使用非const引用的同时也能使用字面量值,可使用转发引用(forwarding references)。以下实现使用了转发引用T&&,还使用std::forward()完美转发所有参数。“完美转发”意味着,如果把rvalue传递给processValues(),就将它作为ralue引用转发:如果把lvalue或lvalue引用传递给processValues(),就将它作为lvalue引用转发。1
2
3
4
5
6void processValues() {/* Nothing to do in this base case.*/}
template<typename T1, typename... Tn>
void processValues(T1&& arg1, Tn&&... args) {
handleValue(std::forward<T1> (arg1));
processValues(std::forward<Tn>(args)...);
}
有一行代码需要做进一步解释:1
processValues(std::forward<Tn> (args)...);
“…”运算符用于解开参数包,它在参数包中的每个参数上使用std::forward(),用逗号把它们隔开。例如,假设args是一个参数包,有三个参数(al、a2和a3),分别对应三种类型(A1、A2和A3)。扩展后的调用如下:1
processValues(std::forward<A1>(a1), std::forward<A2>(a2), std::forward<A3>(a3));
在使用了参数包的函数体中,可通过以下方法获得参数包中参数的个数:1
int numOfArgs = sizeof...(args);
折叠表达式
C++17增加了对折叠表达式(folding expression)的支持。这样一来,将可更容易地在可变参数模板中处理参数包。下面分析一些示例。以递归方式定义前面的processValues()函数模板,如下所示:1
2
3
4
5
6void processValues(){/* Nothing to do in this base case.*/}
template<typename T1, typename... Tn>
void ProcessValues(T1 arg1, Tn...args) {
handleValue(arg1);
processValues(args...);
}
由于以递归方式定义,因此需要基本情形来停止递归。使用折叠表达式,利用一元右折叠,通过单个函数模板来实现。此时,不需要基本情形:1
2
3
4template<typename... Tn>
void processvalues (const Tn&... args) {
(handleValue(args), ...);
}
基本上,函数体中的三个点触发折叠。扩展这一行,针对参数包中的每个参数调用handleValue(),对handleValue()的每个调用用逗号分隔。例如,假设args是包含三个参数(a1、a2和a3)的参数包。一元右折叠扩展后的形式如下:1
(handleValue(a1), (handleValue(a2), handleValue(a3)));
下面是另一个示例。printValues()函数模板将所有实参写入控制台,实参之间用换行符分开。1
2
3
4template<typename... Values>
void printValues (const Values&... values) {
((cout << values << endl), ...);
}
假设values是包含三个参数(v1、v2和v3)的参数包。一元右折叠扩展后的形式如下:1
((cout << v1 << endl), ((cout << v2 << endl), (cout << v3 << endl)));
调用printValues()时可使用任意数量的实参,如下所示:1
printValues(1, "test", 2.34);
模板元编程
模板元编程的目标是在编译时而不是运行时执行一些计算。模板元编程基本上是基于C++的一种小型编程语言。下面首先讨论一个简单示例,这个例子在编译时计算一个数的阶乘,并在运行时能将计算结果用作简单的常数。
编译时阶乘
下面的代码演示了在编译时如何计算一个数的阶乘。代码使用了本章前面介绍的模板递归,我们需要一个递归模板和用于停止递归的基本模板。根据数学定义,0的阶乘是1,所以用作基本情形:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16template<unsigned char f>
class Factorial {
public:
static const unsigned long long val = (f * Factorial<f - 1>::val);
};
template<>
class Factorial<0> {
public:
static const unsigned long long val = 1;
};
int main () {
cout << Factorial<6>::val << enal;
return 0;
}
这将计算6的阶乘,数学表达为6!,值为1x2x3x4x5x6或720。
上面这个具体示例在编译时计算一个数的阶乘,但未必需要使用模板元编程。由于引入了constexpr,可不使用模板,写成如下形式。不过,模板实现仍然是实现递归模板的优秀示例。1
2
3
4
5
6constexpr unsigned long long factorial (unsigned char f) {
if(f == 0)
return 1;
else
return f * factorial(f-1);
}
如果调用如下版本,则在编译时计算值:1
constexpr auto f1 = factorial(6);
不过,在这条语句中,切勿忘掉constexpr。 如果编写如下代码,将在运行时完成计算!1
auto f1 = factorial(6);
在模板元编程版本中,不能犯此类错误。始终使计算在编译时完成。
循环展开
模板元编程的第二个例子是在编译时展开循环,而不是在运行时执行循环。注意循环展开(loop unrolling)应仅在需要时使用,因为编译器通常足够智能,会自动展开可以展开的循环。
这个例子再次使用了模板递归,因为需要在编译时在循环中完成一些事情。在每次递归中,Loop模板都会通过i-1实例化自身。当到达0时,停止递归。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16template<int i>
class Loop {
public:
template <typename FuncType>
static inline void Do(FuncType func) {
Loop<i - 1>::Do(func);
func(i);
}
};
template<>
class Loop<0> {
public:
template <typename FuncType>
static inline void Do(FuncType /* func*/){}
};
可以像下面这样使用Loop模板:1
2
3
4void DoWork(int i) { cout << "DoWork("<< i<<")" << endl;}
int main() {
Loop<3>::Do(DoWork);
}
这段代码将导致编译器展开循环,并连续3次调用DoWork()函数。这个程序的输出如下所示:1
2
3DoWork(1)
DoWork(2)
DoWork(3)
使用lambda表达式,可使用接收多个参数的DoWork20版本:1
2
3
4
5
6
7void DoWork2(string str, int i) {
cout << "DoWork2("<< str << ", " << i << ")" << endl;
}
int main() {
Loop<2>::Do([](int i) { DoWork2("TestStr", i); });
return 0;
}
上述代码首先实现了一个函数,这个函数接收一个字符串和一个int值。main()函数使用lambda表达式,在每个迭代上将一个固定的字符串TestStr作为第一个参数调用DoWork20。编译并运行上述代码,输出应该如下所示:1
2DoWork2(TestStr, 1)
DoWork2(TestStr, 2)
打印元组
这个例子通过模板元编程来打印std::tuple中的各个元素。与模板元编程中的大部分情况一样,这个例子也使用了模板递归。tuple_print类模板接收两个模板参数:tuple类型和初始化为元组大小的整数。然后在构造函数中递归地实例化自身,每一次调用都将大小减小。当大小变成0时,tuple_print的一个部分特例化停止递归。main()函数演示了如何使用这个tuple_print类模板。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20template<typename TupleType, int n>
class tuple_print {
public:
tuple_print (const TupleType& t) {
tuple_print<TupleType, n - 1> tp(t);
cout << get<n - 1>(t) << endl;
}
};
template<typename TupleType>
class tuple_print<TupleType, 0> {
public:
tuple_print(const TupleType&) {}
};
int main() {
using MyTuple = tuple<int, string, bool>;
MyTuple t1(16, "Test", true);
tuple_print<MyTuple, tuple_size<MyTuple>::value> tp(t1);
}
constexpr if
C++17引入了constexpr if。这些是在编译时(而非运行时)执行的if语句。如果constexpr if语句的分支从未到达,就不会进行编译。这可用于简化大量的模板元编程技术,也可用于本章后面讨论的SFINAE。
例如,可按如下方式使用constexpr if,简化前面的打印元组元素的代码。注意,不再需要模板递归基本情形,原因在于可通过constexpr if语句停止递归。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15template<typename TupleType, int n>
class tuple_print_helper {
public:
tuple_print_helper (const TupleTypes t) {
if constexpr(n>1) {
tuple_print_helper<TupleType, n - 1>tp(t);
}
cout << get<n - 1>(t) << endl;
}
};
template<typename T>
void tuple_print(const T& t) {
tuple_print_helper<T, tuple_size<T>::value>tph(t);
}
现在,甚至可丢弃类模板本身,替换为简单的函数模板tuple_print_helper:1
2
3
4
5
6
7
8
9
10
11
12template<typename TupleType, int n>
void tuple_print_helper (const TupleType& t) {
if constexpr(n>1) {
tuple_print_helper<TupleType, n - 1>(t);
}
cout << get<n - 1>(t) << endl;
}
template<typename T>
void tuple_print (const T& t) {
tuple_print_helper<T, tuple_size<T>::value>(t);
}
可对其进一步简化。将两个方法合为一个,如下所示:1
2
3
4
5
6template<typename TupleType, int n = tuple_size<TupleType>::value>
void tuple_print(const TupleType& t) {
if constexpr(n > 1)
tuple_print<TupleType, n - 1>(t);
cout << get<n - 1>(t) << endl;
}
仍然像前面那样进行调用:1
2auto t1 = make_tuple(167, "Testing", false, 2.3);
tuple_print(t1);
使用编译时整数序列和折叠
C++使用std::integer_sequence(在<utility>中定义)支持编译时整数序列。模板元编程的一个常见用例是生成编译时索引序列,即size_t类型的整数序列。此处,可使用辅助用的std::index_sequence。可使用std::index_sequence_for生成与给定的参数包等长的索引序列。
下面使用可变参数模板、编译时索引序列和C++17折叠表达式,实现元组打印程序:1
2
3
4
5
6
7
8template<typename Tuple, size_t... Indices>
void tuple_print_helper(const Tuple& t, index_sequence<Indices...>) {
((cout << get<Indices>(t) << endl), ...);
}
template<typename... Args>
void tuple_print (const tuple<Args...>& t) {
tuple_print_helper(t, index_sequence_for<Args...>());
}
可按与前面相同的方式调用:1
2auto t1 = make_tuple(167, "Testing", false, 2.3);
tuple_print(t1);
调用时,tuple_print_helper()函数模板中的一元右折叠表达式扩展为如下形式:1
2
3
4(((cout << get<0>(t) << endl),
((cout << get<1>(t) << endl),
((cout << get<2>(t) << endl),
(cout << get<3>(t) << endl)))));
类型trait
通过类型trait可在编译时根据类型做出决策。例如,可编写一个模板,这个模板要求从某种特定类型派生的类型,或者要求可转换为某种特定类型的类型,或者要求整数类型,等等。C++标准为此定义了一些辅助类。所有与类型trait相关的功能都定义在<type_traits>头文件中。类型trait分为几个不同类别。下面列出了每个类别的可用类型trait的一些例子。
使用类型类别
在给出使用类型trait的模板示例前,首先要了解一下诸如is_integral的类的工作方式。C++标准对integral_constant类的定义如下所示:1
2
3
4
5
6
7
8template <class T, T v>
struct integral_constant {
static constexpr T value = v;
using value_type = T;
using type = integral_constant<T,v>;
constexpr operator value_type() const noexcept { return value; }
constexpr value_type operator() () const noexcept { return value; }
};
这也定义了bool_constant、true_type和false_type类型别名:1
2
3
4template <bool B>
using bool_constant = integral_constant<bool,B>;
using true_type = bool_constant<true>;
using false_type = bool_constant<false>;
这定义了两种类型:true_type和false_type。当调用true_type::value时,得到的值是true;调用false_type::value时,得到的值是false。还可调用true_type::type。这将返回true_type类型。这同样适用于false_type。诸如is_integral和is_class的类继承了true_type或false_type。例如,is_integral为类型bool特例化,如下所示:1
template<> struct is_integral<bool> : public true_type { };
这样就可编写is_integral<bool>::value,并返回true。注意,不需要自己编写这些特例化,这些是标准库的部分。下面的代码演示了使用类型类别的最简单例子:1
2
3
4
5
6
7
8if (is_integral<int>::value)
cout <<"int is integral" << endl;
else
cout << "int is not integral" << endl;
if (is_class<string>::value)
cout << "string is a class" << endl;
else
cout << "string is not a class" << endl;
这个例子通过is_integral来检查int是否为整数类型,并通过is_class来检查string是否为类。输出如下:1
2int is integral
string is a class
对于每一个具有value成员的trait,C++17添加了一个变量模板,它与trait同名,后跟_v。不是编写some_trait<T>::value,而是编写some_trait_v<T>,例如is_integral_v<T>和is_const_v<T>等。 下面用变量模板重写了前面的例子:1
2
3
4
5
6
7
8if (is_integral_v<int>)
cout <<"int is integral" << endl;
else
cout <<"int is not integral" << endl;
if(is_class_v<string>)
cout <<"string is a class"<< endl;
else
cout <<"string is not a class" <<endl;
只有结合模板根据类型的某些属性生成代码时,类型trait才更有用。下面的模板示例演示了这一点。代码定义了函数模板process_helper()两个重载版本,这个函数模板接收一种类型作为模板参数。第一个参数是一个值,第二个参数是true_type或false_type的实例。process()函数模板接收一个参数,并调用process_helper()函数:1
2
3
4
5
6
7
8
9
10
11
12template<typename T>
void process_helper(const T& t, true_type) {
cout << t <<" is an integral type." << endl;
}
template<typename T>
void process_helper (const T& t, talse_type) {
cout << t <<"is a non-integral type."<<endl;
}
template<typename T>
void process (const T& t) {
process_helper(t, typename is_integral<T>::type());
}
process_helper()函数调用的第二个参数定义如下:1
typename is_integral<T>::type()
该参数使用is_integral判断T是否为整数类型。使用::type访问结果integral_constant类型,可以是true_type或false_type。process_helper()函数需要true_type或false_type的一个实例作为第二个参数,这也是为什么::type后面有两个空括号的原因。注意,process_helper()函数的两个重载版本使用了类型为true_type或false_type的无名参数。因为在函数体的内部没有使用这些参数,所以这些参数是无名的。这些参数仅用于函数重载解析。
这些代码的测试如下:1
2
3process(123);
process(2.2);
process("Test"s);
这个例子的输出如下:1
2
3123 is an integral type,
2.2 is a non-integral type.
Test is a non-integral type
前面的例子只使用单个函数模板来编写,但没有说明如何使用类型trait,以基于类型选择不同的重载。1
2
3
4
5
6
7
8template<typename T>
void process (const T& t) {
if constexpr (is_integral_v<T>){
cout <it <<" is an integral type."<<endl;
} else {
cout <<t <<"is a non-integral type."<<endl;
}
}
使用类型关系
有三种类型关系:is_same,is_base_of和is_convertible。下面将给出一个例子来展示如何使用is_same。其余类型关系的工作原理类似。下面的same()函数模板通过is_same类型trait特性判断两个给定参数是否类型相同,然后输出相应的信息。1
2
3
4
5
6
7
8
9
10
11
12template<typename T1, typename T2>
void same (const T1& t1, const T2& t2) {
bool areTypesTheSame = is_same_v<T1,T2>;
cout << "'" << t1 << "' and '" << t2 << "' are '";
cout << (areTypesTheSame ? "the same types." : "different types.") << endl;
}
int main() {
same(1, 32);
same(1, 3.01);
same(3.01, "Test"s);
}
输出如下所示:1
2
3'1' and '32' are the same types.
'1’ and '3.01' are different types
'3.01' and 'Test' are different types
使用enable_if
使用enable_if需要了解“替换失败不是错误”SFINAE特性,这是C++中一个复杂晦涩的特性。下面仅讲解SFINAE的基础知识。
如果有一组重载函数,就可以使用enable_if根据某些类型特性有选择地禁用某些重载。enable_if通常用于重载函数组的返回类型。enable_if接收两个模板类型参数。第一个参数是布尔值,第二个参数是默认为void的类型。如果布尔值是true,enable_if类就有一种可使用::type访问的嵌套类型,这种嵌套类型由第二个模板类型参数给定。如果布尔值是false,就没有嵌套类型。
C++标准为具有type成员的trait(如enable_if)定义别名模板,这些与trait同名,但附加了_t。例如,不编写如下代码:1
typename enable_if<...,bool>::type
而编写如下更简短的版本:1
enable_if_t<..., bool>
通过enable_if,可将前面使用same()函数模板的例子重写为一个重载的check_type()函数模板。在这个版本中,check_type()函数根据给定值的类型是否相同, 返回true或false。如果不希望check_type()返回任何内容,可删除return语句,可删除enable_if的第二个模板类型参数,或用void替换。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21template<typename T1, typename T2>
enable_if_t<is_same_v<T1, T2>, bool>
check_type (const T1& t1, const T2& t2) {
cout << "'" << t1 << "' and '" << t2 << "' ";
cout << "are the same types."<< endl;
return true;
}
template<typename T1, typename T2>
enable_if_t<!is_same_v<T1,T2>, bool>
check_type (const T1& t1, const T2& t2) {
cout << "'" << t1 << "' and '" << t2 <<"' ";
cout << "are different types." << endl;
return false;
}
int main () {
check_type(1, 32);
check_type(1, 3.01);
check_type(3.01, "Test"s);
}
输出与前面的相同。
上述代码定义了两个版本的check_type(),它们的返回类型都是enable_if的嵌套类型bool。首先,通过is_same_v检查两种类型是否相同,然后通过enable_if_t获得结果。当enable_if_t的第一个参数为true时,enable_if_t的类型就是bool;当第一个参数为false时, 将不会有返回类型。这就是SFINAE发挥作用的地方。
当编译器开始编译main()函数的第一行时,它试图找到接收两个整型值的check_type()函数。编译器会在源代码中找到第一个重载的check_type()函数模板,并将T1和T2都设置为整数,以推断可使用这个模板的实例。然后,编译器会尝试确定返回类型。由于这两个参数是整数,因此是相同的类型,is_same_v<T1,T2>将返回true,这导致enable_if_t<true, bool>返回类型bool。这样实例化时一切都很好,编译器可使用该版本的check_type()。
然而,当编译器尝试编译main()函数的第二行时,编译器会再次尝试找到合适的check_type()函数。编译器从第一个check_type()开始, 判断出可将T1设置为int类型,将T2设置为double类型。然后,编译器会尝试确定返回类型。这一次,T1和T2是不同的类型,这意味着is_same_v<T1,T2>将返回false。因此enable_if_t<false,bool>不表示类型,check_type()函数不会有返回类型。编译器会注意到这个错误,但由于SFINAE,还不会产生真正的编译错误。编译器将正常回溯,并试图找到另一个check_type()函数。这种情况下,第二个check_type()可以正常工作,因为!is_same_v<T1,T2>为true,此时enable_if_t<true,bool>返回类型bool。
如果希望在一组构造函数上使用enable_if,就不能将它用于返回类型,因为构造函数没有返回类型。此时可在带默认值的额外构造函数参数上使用enable_if。
使用constexpr if简化enable_if结构
从前面的示例可以看到,使用enable_if将十分复杂。某些情况下,C++17引入的constexpr if特性有助于极大地简化enable_if。例如,假设有以下两个类:1
2
3
4
5
6class IsDoable {
public:
void doit() const { cout << "IsDoable::doit()"<<endl;}
};
class Derived : public IsDoable { };
可创建一个函数模板call_doit()。如果方法可用,它调用doit()方法;否则在控制台上打印错误消息。为此,可使用enable_if,检查给定类型是否从IsDoable派生:1
2
3
4
5
6
7
8
9
10template<typename T>
enable_if_t<is_base_of_v<IsDoable, T>,void>
call_doit (const T& T) {
t.doit();
}
template<typename T:
enable_if_t<!is_base_of_v<IsDoable, T>, void>
call_doit (const T&) {
cout << "Cannot call doit()!" << endl;
}
下面的代码对该实现进行测试:1
2
3Derived d;
call_doit(d);
call_doit(123);
输出如下:1
2IsDoable::doit()
Cannot call doit()!
使用C++17的constexpr if可极大地简化enable_if实现:1
2
3
4
5
6
7template<typename T>
void call_doit(const T& [[maybe_unused]] t) {
if constexpr(is_base_of_v<IsDoable, T>){
t.doit();
else
cout << "Cannot call doit()!"<< endl;
}
无法使用普通if语句做到这一点!使用普通if语句,两个分支都需要编译,而如果指定并非从IsDoable派生的类型T,这将失败。此时,t.doit()一行无法编译。但是,使用constexpr if语句,如果提供了并非从IsDoable派生的类型,t.doit()一行甚至不会编译!
不使用is_base_of类型trait,也可使用C++17新引入的is_invocabletrait,这个trait可用于确定在调用给定函数时是否可以使用一组给定的参数。下面是使用is_invocable trait的call_doit()实现:1
2
3
4
5
6
7template<typename T>
void call_doit (const T& [[maybe_unused]] t) {
if constexpr (is_invocable_v<decltype (6IsDoable::doit),T>){
t.doit();
else
cout << "Cannot call doit()!" << endl;
}
逻辑运算符trait
在三种逻辑运算符trait:串联(conjunction)、分离(disjunction)与否定(negation)。以_v结尾的可变模板也可供使用。这些trait接收可变数量的模板类型参数,可用于在类型trait上执行逻辑操作,如下所示:1
2
3
4cout << conjunction_v<is_integral<int>, is_integral<short>> << " ";
cout << conjunction_v<is_integral<int>, is_integra1<double>> << " ";
cout << disjunction_v<is_integral<int>, is_integral<double>, is_integral<short>> << " ";
cout << negation_v<is_integral<int>> << " ";
C++多线程编程
多线程编程概述
C++98/03不支持多线程编程,所以必须借助第三方库或目标操作系统中的多线程API。自C++11开始,C++有了一个标准的多线程库,使编写跨平台的多线程应用程序变得更容易了。目前的C++标准仅针对CPU,不适用于GPU,这种情形将来可能会改变。
争用条件
当多个线程要访问任何种类的共享资源时,可能发生争用条件。共享内存上下文的争用条件称为“数据争用”。当多个线程访问共享的内存,且至少有一个线程写入共享的内存时,就会发生数据争用。
撕裂
撕裂(tearing)是数据争用的特例或结果。有两种撕裂类型:撕裂读和撕裂写。如果线程已将数据的一部分写入内存,但还有部分数据没有写入,此时读取数据的其他任何线程将看到不一致的数据,发生撕裂读。如果两个线程同时写入数据,其中一个线程可能写入数据的一部分,而另一个线程可能写入数据的另一部分,最终结果将不一致,发生撕裂写。
死锁
死锁指的是两个线程因为等待访问另一个阻塞线程锁定的资源而造成无限阻塞,这也可扩展到超过两个线程的情形。例如,假设有两个线程想要访问某共享资源,它们必须拥有权限才能访问该资源。如果其中一个线程当前拥有访问该资源的权限,但由于其他一些原因而被无限期阻塞,那么此时,试图获取同一资源权限的另一个线程也将无限期阻塞。
现在设想两个线程中的代码按如下顺序执行。
- 线程1:获取A
- 线程2:获取B
- 线程1:获取B(等待/阻塞,因为B被线程2持有)
- 线程2:获取A(等待/阻塞,因为A被线程1持有)
现在两个线程都在无限期地等待,这就是死锁情形。可以看到一个表示死锁情形的环。这两个线程将无限期地等待。
最好总是以相同的顺序获得权限,以避免这种死锁。也可在程序中包含打破这类死锁的机制。一种可行的方法是试图等待一定的时间,看看能否获得某个资源的权限。如果不能在某个时间间隔内获得这个权限,那么线程停止等待,并释放当前持有的其他锁。线程可能睡眠一小段时间,然后重新尝试获取需要的所有资源。这种方法也可能给其他线程获得必要的锁并继续执行的机会。这种方法是否可用在很大程度上取决于特定的死锁情形。
不要使用前一段中描述的那种变通方法,而是应该尝试避免任何可能的死锁情形。如果需要获得由多个互斥对象保护的多个资源的权限,而非单独获取每个资源的权限,推荐使用标准的std::lock()或std::try_lock()函数。这两个函数会通过一次调用获得或尝试获得多个资源的权限。
伪共享
大多数缓存都使用所谓的“缓存行(cache line)”。对于现代CPU而言,缓存行通常是64个字节。如果需要将一些内容写入缓存行,则需要锁定整行。如果代码结构设计不当,对于多线程代码而言,这会带来严重的性能问题。可使用显式的内存对齐(memory alignment)方式优化数据结构,确保由多个线程处理的数据不共享任何缓存行。为了以便携方式做到这一点,C++17引入了hardware_destructive_interference_size常量,该常量在<new>中定义,为避免共享缓存行,返回两个并发访问的对象之间的建议偏移量。可将这个值与alignas关键字结合使用,以合理地对齐数据。
线程
借助在<thread>头文件中定义的C++线程库,启动新的线程将变得非常容易。可通过多种方式指定新线程中需要执行的内容。可让新线程执行全局函数、函数对象的operator()、lambda表达式甚至某个类实例的成员函数。
通过函数指针创建线程
标准C++的std::thread类使用的函数可以有任意数量的参数。假设counter()函数接收两个整数:第一个表示ID,第二个表示这个函数要循环的迭代次数。函数体是一个循环,这个循环执行给定次数的迭代。1
2
3
4
5void counter(int id, int numIterations) {
for(int i = 0; i < numIterations; ++i) {
cout << "Counter" << id << " has value " << i << endl;
}
}
可通过std::thread启动执行此函数的多个线程。 可创建线程t1,使用参数1和6执行counter():1
thread t1 (counter, 1, 6);
thread类的构造函数是一个可变参数模板,也就是说,可接收任意数目的参数。第一个参数是新线程要执行的函数的名称。当线程开始执行时,将随后可变数目的参数传递给这个函数。
如果一个线程对象表示系统当前或过去的某个活动线程,则认为它是可结合的(joinable)。即使这个线程执行完毕,该线程对象也依然处于可结合状态。默认构造的线程对象是不可结合的。在销毁一个可结合的线程对象前,必须调用其join()或detach()方法。对join()的调用是阻塞调用,会一直等到线程完成工作为止。调用detach()时,会将线程对象与底层OS线程分离。此时,OS线程将继续独立运行。调用这两个方法时,都会导致线程变得不可结合。如果一个仍可结合的线程对象被销毁,析构函数会调用std::terminate(),这会突然间终止所有线程以及应用程序本身。
下面的代码启动两个线程来执行counter()函数。启动线程后,main()调用这两个线程的join()方法。1
2
3
4thread t1(counter, 1, 6);
thread t2(counter, 2, 4);
t1.join();
t2.join();
这个示例的可能输出如下所示:1
2
3
4
5
6
7
8
9
10Counter 2 has value 0
Counter 1 has value 0
Counter 1 has value 1
Counter 1 has value 2
Counter 1 has value 3
Counter 1 has value 4
Counter 1 has value 5
Counter 2 has value 1
Counter 2 has value 2
Counter 2 has value 3
输出取决于系统中处理核心的数量以及操作系统的线程调度。
默认情况下,从不同线程访问cout是线程安全的,没有任何数据争用,除非在第一个输出或输入操作之前调用了cout.sync_with_stdio(false)。然而,即使没有数据争用,来自不同线程的输出仍然可以交错。
线程函数的参数总是被复制到线程的某个内部存储中。通过
<functional>头文件中的std::ref()或cref()按引用传递参数。
通过函数对象创建线程
不使用函数指针,也可以使用函数对象在线程中执行。之前使用函数指针技术,给线程传递信息的唯一方式是给函数传递参数。而使用函数对象,可向函数对象类添加成员变量,并可以采用任何方式初始化和使用这些变量。下例首先定义Counter类。这个类有两个成员变量:一个表示ID,另一个表示循环迭代次数。这两个成员变量都通过类的构造函数进行初始化。为让Counter类成为函数对象,需要实现operator()。operator()的实现和counter()函数一样:1
2
3
4
5
6
7
8
9
10
11Class Counter {
public:
Counter(int id, int numIterations) : mId(id), mNumIterations(numIterations) { }
void operator () () const {
for (int i = 0; i < mNumIterations; ++i)
cout << "Counter" << mId << " has value " << i << endl;
}
private:
int mId;
int mNumIterations;
};
下面的代码片段演示了通过函数对象初始化线程的三种方法。
- 第一种方法使用了统一初始化语法。通过构造函数参数创建Counter类的一个实例,然后把这个实例放在花括号中,传递给thread类的构造函数。
- 第二种方法定义了Counter类的一个命名实例,并将它传递给thread类的构造函数。
- 第三种方法类似于第一种方法:创建Counter类的一个实例并传递给thread类的构造函数,但是使用了圆括号而不是花括号。
1 | thread t1 { Counter{ 1,20 } }; |
通过lambda创建线程
lambda表达式能很好地用于标准C++线程库。下例启动一个线程来执行给定的lambda表达式:1
2
3
4
5
6
7
8
9int main () {
int id = 1;
int numIterations = 5;
thread t1([id, numIterations] {
for (int i = 0; i < numIterations; ++i) {
cout << "Counter" << id << " has value " << i << endl;
}
});
t1.join();
通过成员函数创建线程
还可在线程中指定要执行的类的成员函数。下例定义了带有process()方法的基类Request。main()函数创建Request类的一个实例,并启动一个新的线程,这个线程执行Request实例req的process()成员函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Request {
public:
Request (int id) : mId(id) { }
void process () {
cout <<"Processing request "<< mId << endl;
}
private:
int mId;
}
int main() {
Request req(100);
thread t { sRequest::process, &req };
t.join();
}
通过这种技术,可在不同线程中执行某个对象中的方法。如果有其他线程访问同一个对象,那么需要确认这种访问是线程安全的,以避免争用条件。
线程本地存储
C++标准支持线程本地存储的概念。通过关键字thread_local,可将任何变量标记为线程本地数据,即每个线程都有这个变量的独立副本,而且这个变量能在线程的整个生命周期中持续存在。对于每个线程,该变量正好初始化一次。例如,在下面的代码中,定义了两个全局变量;每个线程都共享唯一的k副本,而且每个线程都有自己的n副本:1
2int k;
thread_local int n;
注意,如果thread_local变量在函数作用域内声明,那么这个变量的行为和声明为静态变量是一致的,只不过每个线程都有自己独立的副本,而且不论这个函数在线程中调用多少次,每个线程仅初始化这个变量一次。
取消线程
C++标准没有包含在一个线程中取消另一个已运行线程的任何机制。实现这一目标的最好方法是提供两个线程都支持的某种通信机制。最简单的机制是提供一一个共享变量,目标线程定期检查这个变量,判断是否应该终止。其他线程可设置这个共享变量,间接指示线程关闭。这里必须注意,因为是由多个线程访问这个共享变量,其中至少有一个线程向共享变量写入内容。
从线程获得结果
一种方法是向线程传入指向结果变量的指针或引用,线程将结果保存在其中。另一种方法是将结果存储在函数对象的类成员变量中,线程执行结束后可获得结果值。只有使用std:ref(),将函数对象按引用传递给thread构造函数时,这才能生效。
然而,还有一种更简单的方法可从线程获得结果:future。通过future也能更方便地处理线程中发生的错误。
复制和重新抛出异常
如果一个线程抛出的异常不能在另一个线程中捕获,C++运行库将调用std:terminate(),从而终止整个应用程序。从一个线程抛出的异常不能在另一个线程中捕获。
不使用标准线程库,就很难在线程间正常地处理异常,甚至根本办不到。标准线程库通过以下和异常相关的函数解决了这个问题。这些函数不仅可用于std::exception,还可以用于所有类型的异常:int、string、自定义异常等。
exception_ptr current_exception() noexcept;
这个函数在catch块中调用,返回一个exception_ptr对象,这个对象引用目前正在处理的异常或其副本。如果没有处理异常,则返回空的exception_ptr对象。 只要存在引用异常对象的exception_ptr类型的对象,引用的异常对象就是可用的。exception_ptr对象的类型是NullablePointer,这意味着这个变量很容易通过简单的if语句来检查。
[[noreturn]] void rethrow_exception(exception_ptr p);
这个函数重新抛出由exception_ptr参数引用的异常。 未必在最开始生成引用的异常的那个线程中重新抛出这个异常,因此这个特性特别适合于跨不同线程的异常处理。[[noretun]]特性表示这个函数绝不会正常地返回。
templateexception_ptr make_exception_ptr(E e)noexcept;
这个函数创建一个引用给定异常对象副本的exception_ptr对象。这实际上是以下代码的简写形式:1
2
3
4
5try {
throw e;
} catch(...) {
return current_exception();
}
下面看一下如何通过这些函数实现不同线程间的异常处理。下面的代码定义了一个函数,这个函数完成一些事情并抛出异常。这个函数最终将运行在一个独立的线程中:1
2
3
4
5
6void doSomeWork() {
for (int i = 0; i < 5; ++ i)
cout << i << endl;
cout << "Thread throwing a runtime_error exception..."<<endl;
throw runtime_error("Exception from thread");
}
下面的threadFunc()函数将上述函数包装在一个try/catch块中,捕获doSomeWork()可能抛出的所有异常。为threadFunc()传入一个参数,其类型为exception_ptr&。一旦捕获到异常,就通过current_exception()函数获得正在处理的异常的引用,然后将引用赋给exception_ptr参数。之后,线程正常退出:1
2
3
4
5
6
7
8void threadFunc (exception_ptr& err) {
try {
dosomeWork();
} catch (...) {
cout << "thread caught exception, returning exception..." << endl;
err = current_exception();
}
}
以下doWorkInThread()函数在主线程中调用,其职责是创建一个新的线程,并开始在这个线程中执行threadFunc()函数。对类型为exception_ptr的对象的引用被作为参数传入threadFunc()。一旦创建了线程,doWorkInThread()函数就使用join()方法等待线程执行完毕,之后检查error对象。由于exception_ptr的类型为NullablePointer,因此很容易通过if语句进行检查。如果是一个非空值,则在当前线程中重新抛出异常,在这个例子中,当前线程即主线程。在主线程中重新抛出异常,异常就从一个线程转移到另一个线程。1
2
3
4
5
6
7
8
9
10
11void doWorkInThread() {
exception_ptr error;
thread t{ threadFunc, ref(error) };
t.join();
if (error) {
cout << "Main thread received exception, rethrowing it..." << endl;
rethrow_exception (error);
} else {
cout << "Main thread did not receive any exception." << endl;
}
main()函数相当简单。它调用doWorkInThread(),将这一个调用包装在一个try/catch块中,捕获由doWorkInThread()创建的任何线程抛出的异常:1
2
3
4
5
6int main() {
try {
doWorkInThread();
} catch (const exception& e) {
cout << "Main function caught: " << e.what() << endl;
}
为让这个例子紧凑且更容易理解,main()函数通常使用join()阻塞主线程,并等待线程完成。当然,在实际的应用程序中,你不想阻塞主线程。例如,在GUI应用程序中,阻塞主线程意味着UI失去响应。此时,可使用消息传递范型在线程之间通信。例如,可让前面的threadFunc()函数给UI线程发送一条消息,消息的参数为current_exception()结果的一份副本。
原子操作库
原子类型允许原子访问,这意味着不需要额外的同步机制就可执行并发的读写操作。没有原子操作,递增变量就不是线程安全的,因为编译器首先将值从内存加载到寄存器中,递增后再把结果保存回内存。另一个线程可能在这个递增操作的执行过程中接触到内存,导致数据争用。
为使这个线程安全且不显式地使用任何同步机制,可使用std::atomic类型。下面是使用原子整数的相同代码:1
2atomic<int> counter(0);
++counter;
为使用这些原子类型,需要包含<atomic>头文件。 C++标准为所有基本类型定义了命名的整型原子类型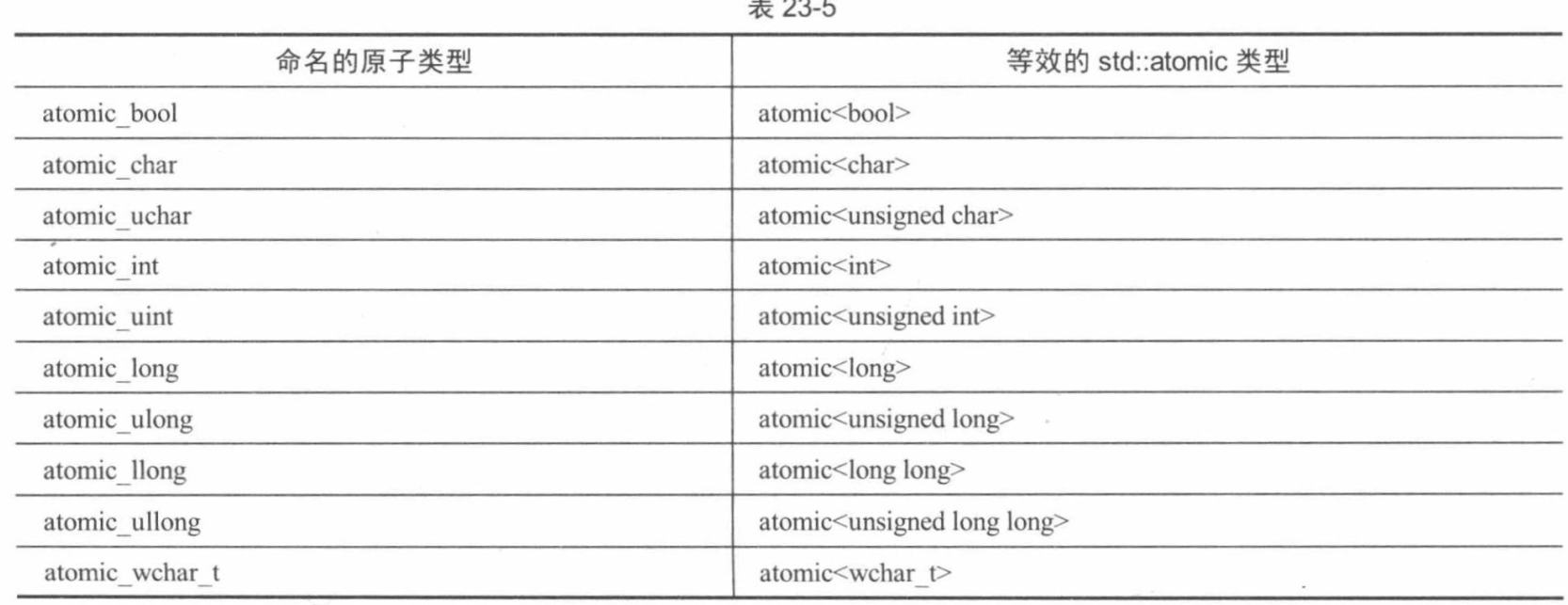
可使用原子类型,而不显式使用任何同步机制。但在底层,某些类型的原子操作可能使用同步机制。如果目标硬件缺少以原子方式执行操作的指令,则可能发生这种情况。可在原子类型上使用is_lock free()方法来查询它是否支持无锁操作;所谓无锁操作,是指在运行时,底层没有显式的同步机制。
可将std::atomic类模板与所有类型一起使用,并非仅限于整数类型。例如,可创建atomic<double>或atomic<MyType>,但这要求MyType具有is_trivially_copy特点。底层可能需要显式的同步机制,具体取决于指定类型的大小。在下例中,Foo和Bar具有is_trivially_copy特点,即std::is_trivially_copyable_v都等于true。但atomic<Foo>并非无锁操作,而atomic<Bar>是无锁操作。1
2
3
4
5
6
7
8
9
10
11class Foo { private: int mArray[123]; };
class Bar { private: int mInt; };
int main() {
atomic<Foo> f;
cout << is_trivially_copyable_v<Foo> <<" "<<f.is_lock_free() <<endl;
// output: 1 0
atomic<Bar> b;
cout << is_trivially_copyable_v<Bar> <<" "<<b.is_lock_free() << endl;
// output: 1 1
}
原子操作
下面是一个原子操作示例:1
bool atomic<T>::compare_exchange_strong(T& expected, T desired);
这个操作以原子方式实现了以下逻辑,伪代码如下:1
2
3
4
5
6
7if (*this == expected) {
*this = desired;
return true;
} else {
expected = *this;
return false;
}
这个逻辑初看起来令人感到陌生,但这是编写无锁并发数据结构的关键组件。无锁并发数据结构允许不使用任何同步机制来操作数据。
另一个例子是用于整型原子类型的atomic<T>::fetch_add()。这个操作获取该原子类型的当前值,将给定的递增值添加到这个原子值,然后返回未递增的原始值。例如:1
2
3
4
5atomic<int> value(10);
cout <<"Value = "<< value << endl;
int fetched = value.fetch_add(4);
cout << "Fetched = " << fetched << endl;
cout <<"Value = "<< value << endl;
如果没有其他线程操作fetched和value变量的内容,那么输出如下:1
2
3Value = 10
Fetched = 10
Value = 14
整型原子类型支持以下原子操作:fetch_add()、fetch_sub(),fetch_and(),fetch_or(),fetch_xor(),++,--,&=,^=,|=。原子指针类型支持fetch_add(),fetch_sub(),++,--,+=,-=。
大部分原子操作可接收一个额外参数,用于指定想要的内存顺序。例如:1
T atomic<T>::fetch_add(T value, memory_order = memory_order_seq_cst);
可改变默认的memory_order。C++标准提供了memory_order_relaxed、memory_order_consume、memory_order acquire、memory_order_release、memory_order_acq_rel、memory_order_seq_cst,这些都定义在std名称空间中。然而,很少有必要使用默认之外的顺序。尽管其他内存顺序可能会比默认顺序性能好。
互斥
标准库支持互斥的形式包括互斥体(mutex)类和锁类。这些类都可以用来实现线程之间的同步。
互斥体类
互斥体(mutex,代表mutual exclusion)的基本使用机制如下:
- 希望与其他线程共享内存读写的一个线程试图锁定互斥体对象。如果另一个线程正在持有这个锁,希望获得访问的线程将被阻塞,直到锁被释放,或直到超时。
- 一旦线程获得锁,这个线程就可随意使用共享的内存,因为这要假定希望使用共享数据的所有线程都正确获得了互斥体对象上的锁
- 线程读写完共享的内存后,线程将锁释放,使其他线程有机会获得访问共享内存的锁。如果两个或多个线程正在等待锁,没有机制能保证哪个线程优先获得锁,并且继续访问数据。
C++标准提供了非定时的互斥体类和定时的互斥体类。
非定时的互斥体类
标准库有三个非定时的互斥体类:std::mutex、recursive_mutex和shared_mutex。前两个类在<mutex>中定义,最后一个类在<shared_mutex>中定义。每个类都支持下列方法。
lock():调用线程将尝试获取锁,并阻塞直到获得锁。这个方法会无限期阻塞。如果希望设置线程阻塞的最长时间,应该使用定时的互斥体类try_lock():调用线程将尝试获取锁。如果当前锁被其他线程持有,这个调用会立即返回。如果成功获取锁,try_lock()返回true,否则返回falseunlock():释放由调用线程持有的锁,使另一个线程能获取这个锁
std::mutex是一个标准的具有独占所有权语义的互斥体类。只能有一个线程拥有互斥体。如果另一个线程想获得互斥体的所有权,那么这个线程既可通过lock()阻塞,也可通过try_lock()尝试失败。已经拥有std::mutex所有权的线程不能在这个互斥体上再次调用lock()和try_lock(),否则可能导致死锁!
std::recursive_mutex的行为几乎和std::mutex一致,区别在于已经获得递归互斥体所有权的线程允许在同一个互斥体上再次调用lock()和try_lock()。调用线程调用unlock()方法的次数应该等于获得这个递归互斥体上锁的次数。
shared_mutex支持“共享锁拥有权”的概念,这也称为readerswriters锁。线程可获取锁的独占所有权或共享所有权。独占拥有权也称为写锁,仅当没有其他线程拥有独占或共享所有权时才能获得。共享所有权也称读锁,如果其他线程都没有独占所有权,则可获得,但允许其他线程获取共享所有权。shared_mutex类支持lock()、try_lock()和unlock()。这些方法获取和释放独占锁。另外,它们具有以下与共享所有权相关的方法:lock_shared()、try_lock_shared()和unlock_shared()。这些方法与其他方法集合的工作方式相似,但尝试获取或释放共享所有权。
不允许已经在shared_mutex上拥有锁的线程在互斥体上获取第二个锁,否则会产生死锁!
定时的互斥体类
标准库提供了3个定时的互斥体类:std:timed_mutex、recursive_timed_mutex和shared_timed_mutex。前两个类在<mutex>中定义,最后一个类在<shared_mutex>中定义。它们都支持lock()、try_lock()和unlock()方法,shared_timed_mutex还支持lock_shared(),try_lock_shared()和unlock_shared()。所有这些方法的行为与前面描述的类似。此外,它们还支持以下方法。
try_lock_for(rel_time):调用线程尝试在给定的相对时间内获得这个锁。如果不能获得这个锁,这个调用失败并返回false。如果在超时之前获得了这个锁,这个调用成功并返回true。try_lock_until(abs_time):调用线程将尝试获得这个锁,直到系统时间等于或超过指定的绝对时间。如果能在超时之前获得这个锁,调用返回true。如果系统时间超过给定的绝对时间,将不再尝试获得锁,并返回false。
shared_timed_mutex还支持try_lock_shared_for()和try_lock_shared_until()。
已经拥有timed_mutex或shared_timed_mutex所有权的线程不允许再次获得这个互斥体上的锁,否则可能导致死锁!
recursive_timed_mutex的行为和recursive_mutex类似,允许一个线程多次获取锁。
锁
锁类是RAII类,可用于更方便地正确获得和释放互斥体上的锁;锁类的析构函数会自动释放所关联的互斥体。C++标准定义了4种类型的锁:std::lock_guard、unique_lock、shared_lock和scoped_lock。最后一类是在C++17中引入的
lock_guard
lock_guard在<mutex>中定义,有两个构造函数
explicit lock_guard(mutex_type& m);- 接收一个互斥体引用的构造函数。这个构造函数尝试获得互斥体上的锁,并阻塞直到获得锁。
lock_guard(mutex_type& m, adopt_lock_t);- 接收一个互斥体引用和一个
std::adopt_lock_t实例的构造函数。C++提供了一个预定义的adopt_lock_t实例,名为std:adopt_lock。该锁假定调用线程已经获得引用的互斥体上的锁,管理该锁,在销毁锁时自动释放互斥体。
- 接收一个互斥体引用和一个
unique_lock
std:unique_lock定义在<mutex>中,是一类更复杂的锁,允许将获得锁的时间延迟到计算需要时,远在声明时之后。使用owns_lock()方法可以确定是否获得了锁。unique_lock也有bool转换运算符,可用于检查是否获得了锁。
unique_lock有如下几个构造函数。
explicit unique_lock(mutex_type& m);- 接收一个互斥体引用的构造函数。这个构造函数尝试获得互斥体上的锁,并且阻塞直到获得锁。
unique_lock(mutex_type& m, defer_lock_t) noexcept;- 接收一个互斥体引用和一个
std::defer_lock_t实例的构造函数。C++提供了一个预定义的defer_lock_t实例,名为std::defer_lock。unique_lock存储互斥体的引用,但不立即尝试获得锁,锁可以稍后获得。
- 接收一个互斥体引用和一个
unique_lock(mutex_type& m, try_to_lock_t);- 接收一个互斥体引用和一个
std::try_to_lock_t实例的构造函数。C++提供了一个预定义的try_to_lock_t实例,名为std::try_to_lock。这个锁尝试获得引用的互斥体上的锁,但即便未能获得也不阻塞;此时,会在稍后获取锁
- 接收一个互斥体引用和一个
unique_lock(mutex_type& m, adopt_lock_t);- 接收一个互斥体引用和一个
std::adopt_lock_t实例的构造函数。这个锁假定调用线程已经获得引用的互斥体上的锁。锁管理互斥体,并在销毁锁时自动释放互斥体。
- 接收一个互斥体引用和一个
unique_lock(mutex_type& m, const chrono:time_point<Clock, Duration>& abs_time);- 接收一个互斥体引用和一个绝对时间的构造函数。这个构造函数试图获取一个锁,直到系统时间超过给定的绝对时间。
unique_lock(mutex_type& m, const chrono:duration<Rep, Period>& rel_time);- 接收一个互斥体引用和一个相对时间的构造函数。这个构造函数试图获得一个互斥体上的锁,直到到达给定的相对超时时间。
unique_lock类也有以下方法:lock()、try_lock()、try_lock_for()、try_lock_until()、unlock()。
shared_lock
shared_lock类在<shared_mutex>中定义,它的构造函数和方法与unique_lock相同。区别是,shared_lock类在底层的共享互斥体上调用与共享拥有权相关的方法。因此,shared_lock的方法称为lock()、try_lock()等,但在底层的共享互斥体上,它们称为lock_shared()、try_lock_shared()等。所以,shared_lock与unique_lock有相同的接口,可用作unique_lock的替代品,但获得的是共享锁,而不是独占锁。
一次性获得多个锁
C++有两个泛型锁函数,可用于同时获得多个互斥体对象上的锁,而不会出现死锁。这两个泛型锁函数都在std名称空间中定义,都是可变参数模板函数。第第一个函数lock()不按指定顺序锁定所有给定的互斥体对象,没有出现死锁的风险。如果其中一个互斥锁调用抛出异常,则在已经获得的所有锁上调用unlock()。原型如下:1
template <class L1, class L2, class L3> void lock(L1&, L2&, L3&...);
try_lock()函数具有类似的原型,但它通过顺序调用每个给定互斥体对象的try_lock(),试图获得所有互斥体对象上的锁。如果所有try_lock()调用都成功,那么这个函数返回-1。如果任何try_lock()调用失败,那么对所有已经获得的锁调用unlock(),返回值是在其上调用try_lock()失败的互斥体的参数位置索引。
scoped_lock
std::scoped_lock在<mutex>中定义,与lock_guard类似,只是接收数量可变的互斥体。这样,就可极方便地获取多个锁。例如,可以使用scoped_lock,编写包含process()函数的那个示例,如下所示:1
2
3
4
5mutex mut1;
mutex mut2;
void process() {
scoped_lock locks(mutl, mut2);
}
std::call_once
结合使用std:call_once()和std::once_flag可确保某个函数或方法正好只调用一次,不论有多少个线程试图调用call_once()(在同一once_flag上)都同样如此。 只有一个call_once()调用能真正调用给定的函数或方法。如果给定的函数不抛出任何异常,则这个调用称为有效的call_once()调用。如果给定的函数抛出异常,异常将传回调用者,选择另一个调用者来执行此函数。某个特定的once_flag实例的有效调用在对同一个once_flag实例的其他所有call_once()调用之前完成。 在同一个once_flag实例上调用call_once()的其他线程都会阻塞,直到调用结束。
下例演示了call_once()的使用。这个例子运行使用某个共享资源的processingFunction(),启动了3个线程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17once_flag gOnceFlag;
void initializeSharedResources {
cout <<"Shared resources initialized."<< endl;
}
void processingEunction () {
call_once (gOnceFlag, initializeSharedResources);
cout << "Processing" << endl;
}
int main () {
vector<thread> threads (3);
for (auto& t : threads)
t = thread{ processingFunction };
for (autos t : threads)
t.join();
}
这段代码的输出如下所示:1
2
3
4Shared resources initialized
Processing
Processing
Processing
互斥体对象的用法示例
以线程安全方式写入流
下面的例子同步Counter类中所有对cont的访问。为实现这种同步,向这个类中添加一个静态的mutex对象。这个对象应该是静态的,因为类的所有实例都应该使用同一个mutex实例。在写入cout之前,使用lock_guard获得这个mutex对象上的锁。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Counter {
public:
Counter(int id, int numIterations) : mId(id), mNumIterations(numIterations) { }
void operator () () const {
for (int i = 0; i < mNumIterations; ++i) {
lock_guard 1ock(sMutex);
cout << "Counter" << mid <<" has value "<< i << endl;
}
}
private:
int mid;
int mNumIterations;
static mutex sMutex;
};
mutex Counter::sMutex;
这段代码在for循环的每次迭代中创建了一个lock_guard实例。建议尽可能限制拥有锁的时间,否则阻塞其他线程的时间就会过长。例如,如果lock_guard实例在for循环之前创建一次,就基本上丢失了这段代码中的所有多线程特性,因为一个线程在其for循环的整个执行期间都拥有锁,所有其他线程都等待这个锁被释放。
使用定时锁
下面的示例演示如何使用定时的互斥体。结合unique_lock使用了timed_mutex。将200毫秒的相对时间传给unique_lock构造函数,试图在200毫秒内获得一个锁。如果不能在这个时间间隔内获得这个锁,构造函数返回。之后,可检查这个锁是否已经获得,对这个lock变量应用if语句就可执行这种检查,因为unique_lock类定义了bool转换运算符。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Counter {
public:
Counter(int id, int numIterations) : mId(id), mNumIterations(numIterations) { }
void operator () () const
for (int i = 0; i < mNumIterations; ++ i) {
unique_lock lock (sTimedMutex, 200ms);
if(lock)
cout << "Counter" << mId << " has value " << i << endl;
else
// Lock not acquired in 200ms, skip output
}
private:
int mId;
int mNumIterations;
static timed_mutex sTimedMutex;
}
timed_mutex Counter::sTimedMutex;
条件变量
条件变量允许一个线程阻塞,直到另一个线程设置某个条件或系统时间到达某个指定的时间。条件变量允许显式的线程间通信。需要包含<condition_variable>头文件来使用条件变量。有两类条件变量。
std::condition_variable:只能等待unique_lock<mutex>上的条件变量:根据C++标准的描述,这个条件变量可在特定平台上达到最高效率,std::condition_variable_any:可等待任何对象的条件变量,包括自定义的锁类型。
condition_variable类支持以下方法。
notify_one();- 唤醒等待这个条件变量的线程之一。
notify_all();- 唤醒等待这个条件变量的所有线程。
wait(unique_lock<mutex>& lk);- 调用
wait()的线程应该已经获得lk上的锁。调用wait()的效果是以原子方式调用lk.unlock()并阻塞线程,等待通知。当线程被另一个线程中的notify_one()或notify_all()调用解除阻塞时,这个函数会再次调用lk.lock(),可能会被这个锁阻塞,然后返回。
- 调用
wait_for(unique_lock<mutex>& lk, const chrono::duration<Rep, Period>& rel_time);- 类似于此前的
wait()方法,区别在于这个线程会被notify_one()或notify_all()调用解除阻塞,也可能在给定超时时间到达后解除阻塞。
- 类似于此前的
wait_until(unique_lock<mutex>& lk, const chrono::time_point<Clock, Duration>& abs_time);- 类似于此前的
wait()方法,区别在于这个线程会被notify_one()或notify_all()调用解除阻塞,也可能在系统时间超过给定的绝对时间时解除阻塞
也有一些其他版本的wait()、wait_for()和wait_until()接收一个额外的谓词参数。例如,接收一个额外谓词的wait()等同于:1
2while (!predicate())
wait(lk);
condition_variable_any类支持的方法和condition_variable类相同,区别在于condition_variable_any可接收任何类型的锁类,而不只是unique_lock<mutex>。锁类应提供lock()和unlock()方法。
假唤醒
等待条件变量的线程可在另一个线程调用notify_one()或notify_all()时醒过来,或在系统时间超过给定时间时醒过来,也可能不合时宜地醒过来。这意味着,即使没有其他线程调用任何通知方法,线程也会醒过来。因此,当线程等待一个条件变量并醒过来时,就需要检查它是否因为获得通知而醒过来。一种检查方法是使用接收谓词参数的wait()版本。
使用条件变量
例如,条件变量可用于处理队列项的后台线程。可定义队列,在队列中插入要处理的项。后台线程等待队列中出现项。把一项插入到队列中时,线程就醒过来,处理项,然后继续休眠,等待下一项。假设有以下队列:1
queue<string> mQueue;
需要确保在任何时候只有一个线程修改这个队列。可通过互斥体实现这一点:1
mutex mutex;
为了能在添加一项时通知后台线程,需要一个条件变量:1
condition_variable mCondVar;
需要向队列中添加项的线程首先要获得这个互斥体上的锁,然后向队列中添加项,最后通知后台线程。无论当前是否拥有锁,都可以调用notify_one()或notify_all(),它们都会正常工作:1
2
3
4
5// Lock mutex and add entry to the queue.
unique_lock lock (mMutex);
mQueue.push (entry);
// Notify condition variable to wake up thread.
mCondVar.notify_all();
后台线程在一个无限循环中等待通知。注意这里使用接收谓词参数的wait()方法正确处理线程不合时宜地醒过来的情形。谓词检查队列中是否有队列项。对wait()的调用返回时,就可以肯定队列中有队列项了。1
2
3
4unique_lock lock(mMutex);
while (true) {
// Wait for a notification.
mCondVar.wait (lock, [this]{ return !mQueue.empty();});
C++标准还定义了辅助函数std::notify_all_at_thread_exit(cond, lk),其中cond是一个条件变量,lk是一个unique_lock<mutex>实例。调用这个函数的线程应该已经获得了锁lk。当线程退出时,会自动执行以下代码:1
2lk.unlock();
cond.notify_all();
注意将锁lk保持锁定,直到该线程退出为止。所以,一定要确保这不会在代码中造成任何死锁,例如由于错误的锁顺序而产生的死锁。
future
可使用future更方便地获得线程的结果,并将异常转移到另一个线程中,然后另一个线程可以任意处置这个异常。当然,应该总是尝试在线程本身中处理异常,不要让异常离开线程。
future在promise中存储结果。可通过future来获取promise中存储的结果。也就是说,promise是结果的输入端;future是输出端。一旦在同一线程或另一线程中运行的函数计算出希望返回的值,就把这个值放在promise中。然后可以通过future来获取这个值。可将future/promise对想象为线程间传递结果的通信信道。
C++提供标准的future,名为std::future。可从std::future检索结果。T是计算结果的类型。1
2future<T> myFuture;
T result = myFuture.get();
调用get()以取出结果,并保存在变量result中。如果另一个线程尚未计算完结果,对get()的调用将阻塞,直到该结果值可用。只能在future上调用一次get()。按照标准,第二次调用的行为是不确定的。可首先通过向future询问结果是否可用的方式来避免阻塞:1
2
3
4if (myFuture.wait_for(0))
T result = myFuture.get();
else
// Value is not yet available
std::promise和std::future
C++提供了std::promise类,作为实现promise概念的一 种方式。可在promise上调用set_value()来存储结果,也可调用set_exception()在promise中存储异常。注意,只能在特定的promise上调用set_value()或set_exception()一次。如果多次调用它,将抛出std::future_error异常。
如果线程A启动另一个线程B以执行计算,则线程A可创建一个std::promise将其传给已启动的线程。注意,无法复制promise,但可将其移到线程中。线程B使用promise存储结果。将promise移入线程B之前,线程A在创建的promise上调用get_future(),这样,线程B完成后就能访问结果。下面是一个简单示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void DoWork (promise<int> thePromise) {
thePromise.set_value(42);
}
int main () {
promise<int> myPromise;
// Get the future of the promise.
auto theFuture = myPromise.get_future();
// Create a thread and move the promise into it.
thread theThread{ DoWork, std::move(myPromise) };
// Get the result,
int result = theFuture.get();
cout << "Result: " << result << endl;
// Make sure to join the thread,
theThread.join();
}
std::packaged_task
有了std::packaged_task,将可以更方便地使用promise,下面的代码创建一个packaged_task来执行CalculateSum(),通过调用get_future(),从packaged_task检索future。启动一个线程,并将packaged_task移入其中。无法复制packaged_task!启动线程后,在检索到的future上调用get()来获得结果。在结果可用前,将一直阻塞。
CalculateSum()不需要在任何类型的promise中显式存储任何数据。packaged_task自动创建promise,自动在promise中存储被调用函数(这里是CalculateSum())的结果,并自动在promise中存储函数抛出的任何异常。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int CalculateSum(int a, int b) { return a+b; }
int main () {
// Create a packaged task to run CalculateSum.
packaged_task<int(int, int)> task (CalculateSum);
// Get the future for the result of the packaged task.
auto theFuture = task.get_future():
// Create a thread, move the packaged task into it, and
// execute the packaged task with the given arguments.
thread theThread{ std::move(task), 39, 3};
// Do some more work...
int result = theFuture.get();
cout << result << endl;
// Make sure to join the thread.
theThread.join();
}
std::async
如果想让C++运行时更多地控制是否创建-一个线程以进行某种计算,可使用std::async()。它接收一个将要执行的函数,并返回可用于检索结果的future。async()可通过两种方法运行函数:
- 创建一个新的线程,异步运行提供的函数。
- 在返回的future上调用
get()方法时,在主调线程上同步地运行函数。
如果没有通过额外参数来调用async(),C++运行时会根据一些因素(例如系统中处理器的数目)从两种方法中自动选择一种方法。也可指定策略参数,从而调整C++运行时的行为。
launch::async:强制C++运行时在一个不同的线程上异步地执行函数。launch::deferred:强制C++运行时在调用get()时,在主调线程上同步地执行函数。launch::async|launch::deferred:允许C++运行时进行选择(一默认行为)。
下例演示了async()的用法:1
2
3
4
5
6
7
8
9
10
11
12
13int calculate () {
return 123;
}
int main () {
auto myFuture = async (calculate);
//auto myFuture = async (launch::async, calculate);
//auto myFuture = async(launch: :deferred, calculate);
// Do some more work..
// Get the result.
int result = myFuture.get();
cout << result << endl;
}
从这个例子可看出,std::async()是以异步方式(在不同线程中)或同步方式(在同一线程中)执行一些计算并在随后获取结果的最简单方法之一。
异常处理
使用future的一大优点是它们会自动在线程之间传递异常。在future上调用get()时,要么返回计算结果,要么重新抛出与future关联的promise中存储的任何异常。使用packaged_task或async()时,从已启动的函数抛出的任何异常将自动存储在promise中。如果将std::promise用作promise, 可调用set_exception()以在其中存储异常。下面是一个使用async()的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int calculate() {
throw runtime_error("Exception thrown from calculate().");
}
int main() {
// Use the launch::async policy to force asynchronous execution.
auto myFuture = async (launch::async, calculate);
// Get the result.
try {
int result = myFuture.get();
cout << result << endl;
} catch (const exception& ex) {
cout << "Caught exception: " << ex.what() << endl;
}
}
std::shared_future
std::future<T>只要求T可移动构建。在future<T>上调用get()时,结果将移出future,并返回给你。这意味着只能在future<T>上调用get()一次。
如果要多次调用get(),甚至从多个线程多次调用,则需要使用std::shared_future<T>,此时,T需要可复制构建。可使用std::future::share(),或给shared_future构造函数传递future,以创建shared_future。注意,future不可复制,因此需要将其移入shared_future构造函数。
shared_future可用于同时唤醒多个线程。例如,下面的代码片段定义了两个lambda表达式,它们在不同的线程上异步地执行。每个lambda表达式首先将值设置为各自的promise,以指示已经启动。接着在signalFuture
调用get(),这一直阻塞,直到可通过future获得参数为止:此后将继续执行。每个lambda表达式按引用捕获各自的promise,按值捕获signalFuture,因此这两个lambda表达式都有signalFuture的副本。主线程使用async()在不同线程上执行这两个lambda表达式,一直等到线程启动,然后设置signalPromise中的参数以唤醒这两个线程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29promise<void> thread1started, thread2Started;
promise<int> signalPromise;
auto signalFutrue = signalPromise.get_future().share();
//shared_future<int> signalFuture (signalPromise.get_future());
auto function1 = [&thread1started, signalFuture] {
threadistarted.set_value();
// Wait until parameter is set
int parameter = signalFuture.get();
};
auto function2 = [&thread2Started, signalFuture] {
thread2started.set_value();
// Wait until parameter is set.
int parameter = signalFuture.get();
};
// Run both lambda expressions asynchronously.
// Remember to capture the future returned by async()!
auto result1 = async (launch::async, function1);
auto result2 = async (launch::async, function2);
// Wait until both threads have started.
thread1started.get_future().wait();
thread2started.get_future().wait();
// Both threads are now waiting for the parameter.
// Set the parameter to wake up both of them.
signalPromise.set_value(42);
线程池
如果不在程序的整个生命周期中动态地创建和删除线程,还可以创建可根据需要使用的线程池。这种技术通常用于需要在线程中处理某类事件的程序。
由于线程池中的所有线程都是预先存在的,因此操作系统调度这些线程并运行的效率大大高于操作系统创建线程并响应输入的效率。此外,线程池的使用允许管理创建的线程数,因此根据平台的不同,可以少至1个线程,也可以多达数千个线程有几个库实现了线程池。
线程设计和最佳实践
本节简要介绍几个有关多线程编程的最佳实践
- 使用并行标准库算法:标准库中包含大量算法。从C++17开始,有60多个算法支持并行执行。尽量使用这些并行算法,而非编写自己的多线程代码。
- 终止应用程序前,确保所有thread对象都不是可结合的:确保对所有thread对象都调用了
join()或detach()。仍可结合的thread析构函数将调用std::terminate(),从而突然间终止所有线程和应用程序。最好的同步就是没有同步:如果采用合理的方式设计不同的线程,让所有的线程在使用共享数据时只从共享数据读取,而不写入共享数据,或者只写入其他线程不会读取的部分,那么多线程编程就会变得简单很多。 - 尝试使用单线程的所有权模式:这意味着同一时间拥有1个数据块的线程数不多于1。拥有数据意味着不允许其他任何线程读写这些数据。当线程处理完数据时,数据可传递到另一个线程,那个线程目前拥有这些数据的唯一且完整的责任/拥有权。这种情况下,没必要进行同步。
- 在可能时使用原子类型和操作:通过原子类型和原子操作更容易编写没有争用条件和死锁的代码,因为它们能自动处理同步。如果在多线程设计中不可能使用原子类型和操作,而且需要共享数据,那么需要使用同步机制(如互斥)来确保同步的正确性。
- 使用锁保护可变的共享数据:如果需要多个线程可写入的可变共享数据,而且不能使用原子类型和操作,那么必须使用锁机制,以确保不同线程之间的读写是同步的。
- 尽快释放锁:当需要通过锁保护共享数据时,务必尽快释放锁。当一个线程持有一个锁时,会使得其他线程阻塞等待这个锁,这可能会降低性能
- 不要手动获取多个锁:应当改用
std::lock()或std::try_lock()。如果多个线程需要获取多个锁,那么所有线程都要以同样的顺序获得这些锁,以防止死锁。可通过泛型函数std::lock()或std::try_lock()获取多个锁。 - 使用RAII锁对象:使用
lock_guard、unique_lock、shared_lock或scoped_lockRAII类,在正确的时间自动释放锁 - 使用支持多线程的分析器:通过支持多线程的分析器找到多线程应用程序中的性能瓶颈,分析多个线程是否确实利用了系统中所有可用的处理能力。
- 使用线程池,而不是动态创建和销毁大量线程:动态地创建和销毁大量的线程会导致性能下降。这种情况下,最好使用线程池来重用现有的线程。
- 使用高级多线程库:尽可能使用高级多线程库,例如Intel Threading Building Blocks(TBB). Microsoft Parallel Pattems Library(PPL)等,而不是自己实现。
充分利用软件工程方法
编写高效的C++程序
语言层次的效率
使用某些语言级别的优化(如按引用传递)是良好的编码风格。
高效地操纵对象
C++在幕后做了很多工作,特别是和对象相关的工作。总是应该注意编写的代码对性能的影响。
通过引用传递
应该尽可能不要通过值向函数或方法传递对象。如果函数形参的类型是基类,而将派生类的对象作为实参按值传递,则会将派生对象切片,以符合基类类型。这导致信息丢失,而按引用传递能避免这种开销。这条规则很难记住的一个原因是:从表面上看,按值传递不会有任何问题。
如果函数必须修改对象,可通过引用传递对象。如果函数不应该修改对象,可通过const引用传递。
应避免通过指针传递,因为相对按引用传递,按指针传递相对过时,相当于倒退到C语言了,很少适合于C++。
按引用返回
正如应该通过引用将对象传递给函数一样,也应该从函数返回引用,以避免对象发生不必要的复制。但有时不可能通过引用返回对象,例如编写重载的operator+和其他类似运算符时。永远都不要返回指向局部对象的引用或指针,局部对象会在函数退出时被销毁。
自C++11以后,C++语言支持移动语义,允许高效地按值返回对象,而不是使用引用语义。
通过引用捕捉异常
应该通过引用捕捉异常,以避免分片和额外的复制。抛出异常的性能开销很大,因此任何提升效率的小事情都是有帮助的。
使用移动语义
应该为类实现移动构造函数和移动赋值运算符,以允许C++编译器为类对象使用移动语义。根据“零规则”,设计类时,使编译器生成复制和移动构造函数以及复制和移动赋值运算符便足够了。如果编译器不能隐式定义这些类,那么在允许的情况下,可显式将它们设置为default。如果这行不通,应当自行实现。
对象使用了移动语义时,从函数中通过值返回不会产生很大的复制开销,因而效率更高。
避免创建临时对象
有些情况下,编译器会创建临时的无名对象。为一个类编写全局operator+之后,可对这个类的对象和其他类型的对象进行加法运算,只要其他类型的对象可转换为这个类的对象即可。
返回值优化
通过值返回对象的函数可能导致创建一个临时对象。
预分配内存
使用C++标准库容器的一个重要好处是:它们自动处理内存管理。给容器添加元素时,容器会自动扩展。但有时,这会带来性能问题。例如,std::vector容器在内存中连续存储元素。如果需要扩展,则需要分配新的内存块,然后将所有元素移动(或复制)到新的内存中。
如果预先知道要在vector中添加的元素数量,或大致能够评估出来,就可以在开始添加元素前预分配足够的内存。vector具有容量(capacity)和大小(size),容量指不需要重新分配的情况下可添加的元素数量,大小指容器中的实际元素数量。可以预分配内存,使用reserve()更改容量,使用resize()重新设置vector的大小。
使用内联方法和函数
内联(inline)方法或函数的代码可以直接插到被调用的地方,从而避免函数调用的开销。
一方面,应将所有符合这种优化条件的函数和方法标记为inline。但不要过度使用该功能,因为它实际上背离了基本设计原则;基本设计原则是将接口与实现分离,这样一来,不需要更改接口即可完善实现。仅考虑为常用的基本类使用该功能。另外记住,程序员的内联请求只是给编译器提供的建议,编译器有权拒绝这些建议。
另一方面,编译器会在优化过程中内联一些适当的函数和方法,即使这些函数没有用inline关键字标记,甚至即使这些函数在源文件(而非头文件)中实现也是如此。
设计层次的效率
尽可能多地缓存
下面是通常执行缓慢的任务清单。
- 磁盘访问:在程序中应避免多次打开和读取同一个文件。如果内存可用,并且需要频繁访问这个文件,那么应将文件内容保存在内存中,
- 网络通信:如果需要经由网络通信,那么程序会受网络负载的影响而行为不定。将网络访问当成文件访问处理,尽可能多地缓存静态信息。
- 数学计算:如果需要在多个地方使用非常复杂的计算结果,那么执行这种计算一次并共享结果。但是,
- 如果计算不是非常复杂,那么计算可能比从缓存中提取更快。如果需要确定这种情形,可使用分析器。
- 对象分配:如果程序需要大量创建和使用短期对象,可以考虑使用本章后面讨论的对象池。
- 线程创建:这个任务也很慢。可将线程“缓存”在线程池中,类似于在对象池中缓存对象。
常见的缓存问题是:保存的数据往往是底层信息的副本。在缓存的生命周期中,原始数据可能发生变化。
缓存失效的技术之一是要求管理底层数据的实体通知“程序数据发生了变化”。可通过程序在管理器中注册回调的方式实现这一点。另外,程序还可轮询某些会触发自动重新填充缓存的事件。
使用对象池
存在不同类型的对象池。一种对象池是一次分配一大块内存,此时,对象池就地创建多个较小对象。可将这些对象分发给客户,在客户完成时重用它们,这样就不必另外调用内存管理器为各个对象分配内存或解除内存分配
本节描述另一类对象池。如果程序需要大量同类型的短期对象,这些对象的构造函数开销很大,分析器确认这些对象的内存分配和释放是性能瓶颈,就可为这些对象创建对象池或缓存。每当代码中需要一个对象时,可从对象池中请求一个。当用完对象时,将这个对象返回对象池中。对象池只创建一次对象,因此对象的构造函数只调用一次,而不是每次需要使用时都调用。
因此,对象池适用于构造函数需要为很多对象进行一些设置操作的情况,也适用于通过构造函数之外的方法调用为对象设置一些实例特有的参数。
对象池的实现
对象池实现中最困难的部分是跟踪哪些对象是空闲的,哪些对象正在使用。这个实现采取的方法是将空闲对象保存在一个队列中。每次客户端请求对象时,对象池从队列前端取出一个对象给客户端。
代码使用std::queue类。实现并非是线程安全的。要达到线程安全的目的,一种方式是使用无锁并发队列。但标准库并不提供任何并发数据结构,因此必须使用第三方库。
1 | template <typename T> |
使用这个对象池时,必须确保对象池自身的寿命超出对象池给出的所有对象的寿命。对象池的用户通过模板参数,指定用于创建对象的类的名称。
acquireObject()从空闲列表返回顶部对象,如果没有空闲对象,则首先分配新对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14template <typename T>
typename ObjectPool<T>::Object ObjectPool<T>::acquireObject() {
if (mFreeList.empty())
mFreeList.emplace (std::make_unique<T>());
std::unique_ptr<T> obj(std::move(mFreeList.front()));
mFreeList.pop();
Object smartobject(obj.release(), [this](T* t){
mFreelist.emplace(t);
});
return smartobject;
}
使用对象池
假设一个应用程序使用了大量短期对象,这些短期对象具有昂贵的构造函数。假设有如下ExpensiveObject类定义:1
2
3
4
5
6
7
8class ExpensiveObject {
public:
Expensiveobject() { /*Expensive construction */ }
virtual ~ExpensiveObject() = default;
private:
// Data members (not shown)
};
不是在程序的生命周期中创建和删除大量此类对象,而是可以使用前面开发的对象池。程序结构如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24ObjectPool<ExpensiveObject>::Object getExpensiveObject(ObjectPool<ExpensiveObject>& pool) {
// Obtain an ExpensiveObject object from the pool.
auto object = pool.acquireObject();
// Populate the object. (not shown)
return object;
}
void processExpensiveObject(ObjectPool <Expensiveobject>::Object& object) {
// Process the object. (not shown)
}
int main() {
ObjectPool<ExpensiveObject> requestPool;
{
vector<ObjectPool<ExpensiveObject>::Object> objects;
for(size_t i = 0; i < 10; ++ i)
objects.push_back (getExpensiveobject (requestPool));
}
for (size_t i = 0; i < 100; ++ i) {
auto reg = getExpensiveObject (requestPool);
processExpensiveObject (req);
}
return 0;
}
main()函数的第一部分包含一个内部代码块,它创建了10个ExpensiveObject对象,并将它们存储在Object容器中。由于创建的所有Object对象都存储在vector中并持续存在,对象池将不得不创建10个ExpensiveObject实例。在这个内部代码块的闭括号处,vector超出作用域,其中的所有Object对象会自动释放,回到对象池中。
在第二个for循环中,getExpensiveObject()返回的Object对象(=shared_ptrs)在for循环每个迭代的结束处超出作用域,因此自动释放,回到对象池中。如果给ExpensiveObject类的构造函数添加一条输出语句,你将看到,在整个程序运行期间,只对构造函数调用10次,即使main()函数中第二个for循环的循环次数达到数百次也同样如此。
熟练掌握调试技术
调试的基本定律
断言
<cassert>头文件定义了assert宏。它接收一个布尔表达式,如果表达式求值为false,则打印出一条错误消息并终止程序。如果表达式求值为true,则什么也不做。
断言可迫使程序在bug来源的确切点公开bug。如果没有在这一点设置断言,那么程序可能会带着错误的值继续执行,因而bug可能在后面才显现出来。因此,断言允许尽早检测到bug。
标准assert宏的行为取决于NDEBUG预处理符号:如果没有定义该符号,则发生断言,否则忽略断言。编译器通常在编译发布版本时定义这个符号。如果要在发布版本中保留断言,就必须改变编译器的设置,或者编写自己的不受NDEBUG值影响的断言。
可在代码中任何需要“假设”变量处于某些状态的地方使用断言。例如,如果调用的库函数应该返回一个指针,并且声称绝对不会返回nullptr,那么在函数调用之后抛出断言,以确保指针不是nullptr。
注意,假设应该尽可能少。例如,如果正在编写一个库函数,不要断言参数的合法性。相反,要对参数进行检查,如果参数非法,返回错误代码或抛出异常作为规则,断言应只用于真正有问题的情形,因此在开发过程中遇到的断言绝不应忽略。如果在开发过程中遇到一个断言,应修复而不是禁用它。
静态断言
static_assert允许在编译时对断言求值。static_assert调用按收两个参数:编译时求值的表达式和字符串。当表达式计算为false时,编译器将给出包含指定字符串的错误提示。下例核实是否在使用64位编译器进行编译:1
static_assert(sizeof(void*) == 8, "Requires 64-bit compilation.");
如果编译时使用32位编译器,指针是4个字符,编译器将给出错误提示,如下所示:1
test.cpp(3): error C2338: Requires 64-bit compilation.
从C++17开始,字符串参数变为可选的,如下所示:1
static_assert (sizeof(void*)==8);
此时,如果表达式的计算结果是false,将得到与编译器相关的错误消息。
另一个展示static_assert强大功能的例子是和类型trait结合使用。例如,如果编写一个函数模板或类模板,那么可结合使用static_assert和类型trait,当模板类型不符合一定条件时,生成编译器错误。下例要求process()的模板类型将Base1作为基类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Base1 {};
class Base1child : public Base1 {};
class Base2 {};
class Base2Child : public Base2 {};
template<typename T>
void process (const T& t) {
static_assert(is_base_of_v<Base1, T>, "Basel should be a base for T.");
}
int main() {
process(Base1());
process (Base1Child());
// process(Base2());
// Exror
// process(Base2Child());
// Error
}
调试技术
调试可重复的bug
可一致高效地重现bug时,应开始在代码中找到导致bug的根源。此时的目标是找到触发这个问题的准确代码行。可采用两种不同的策略
- 记录调试消息:在程序中添加足够的调试消息并观察bug重现时的输出
- 使用调试器:通过调试器可单步跟踪程序的执行,定点观察内存状态和变量的值。
调试不可重现的bug
- 尝试将不可重现的bug转换为可重现的bug。
- 分析错误日志。如果程序根据前面的描述带有生成错误日志的功能,那么这一点很容易实现。
- 获取和分析跟踪。如果程序带有跟踪输出(例如之前描述的环形缓冲区),那么这一点很容易实现。
- 如果有的话,检查崩溃/内存文件。在UNIX和Linux上,这些内存转储文件称为核心文件(core file)。每个平台都提供了分析这些内存转储文件的工具。例如,这些工具可用来生成应用程序的堆栈跟踪信息,或查看应用程序崩溃之前内存中的内容。
- 检查代码。遗憾的是,这往往是检查不可重现bug的根源的唯一策略。
- 使用内存观察工具。
调试内存问题
内存错误的分类
下面介绍内存错误的分类。
表总结了5种涉及释放内存的主要错误。

可以看出,有些内存释放错误不会立即导致程序终止。这些bug更微妙,会导致程序在运行一段时间之后出错。
内存访问错误另一类的内存错误涉及实际的内存读写,如表所示。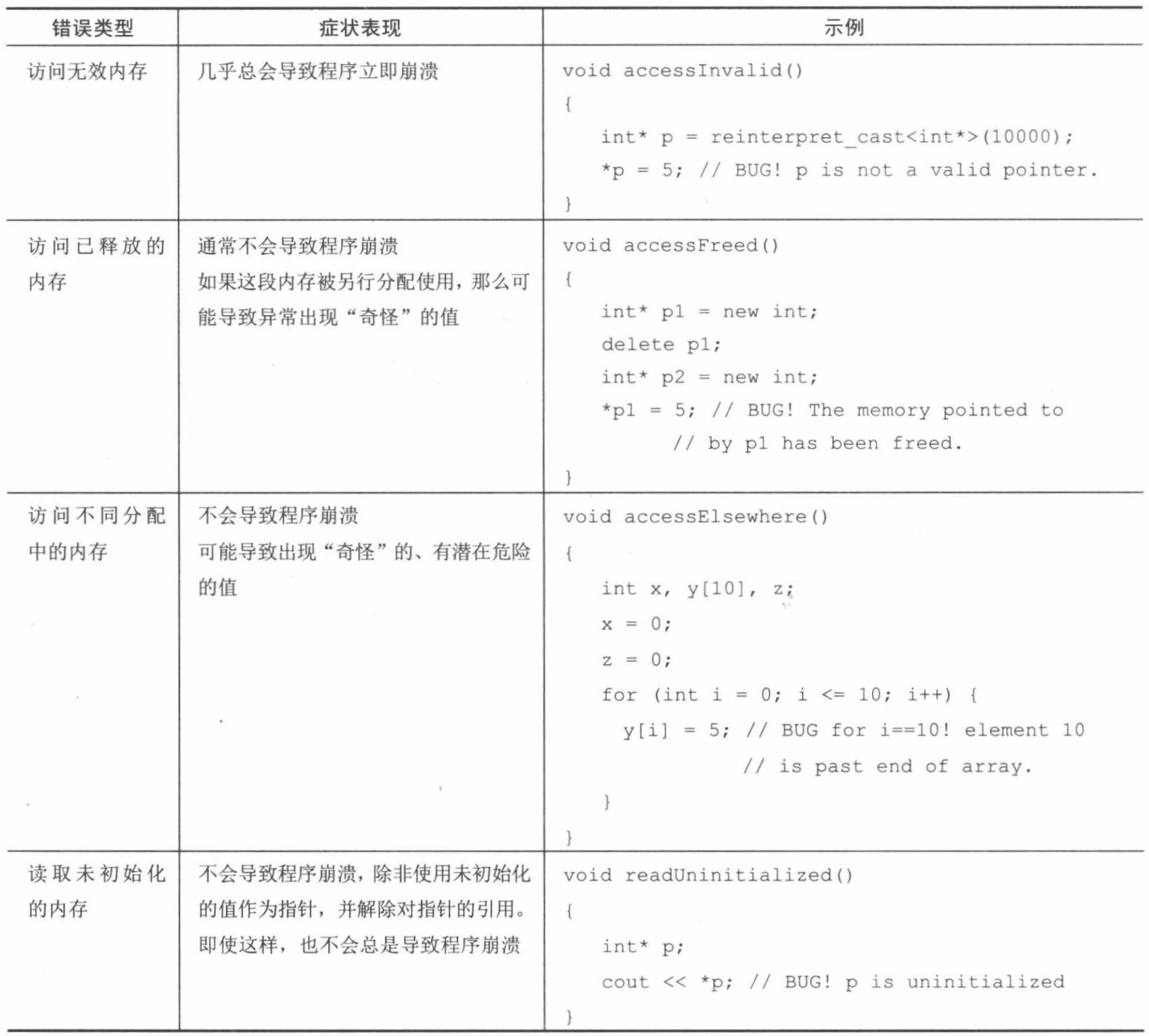
调试内存错误的技巧
- 验证带有动态分配内存的类具有以下这种析构函数:能准确地释放对象中分配的内存,不多也不少。
- 确保类能够通过复制构造函数和赋值运算符:正确处理复制和赋值。确保移动构造函数和移动赋值运算符把源对象中的指针,正确设置为nullptr,这样其析构函数才不会释放该内存。
检查可疑的类型转换。如果将对象的指针从一种类型转换为另一种类型,确保转换是合法的。在可能的情况下,使用dynamic_cast。
确保每个new调用都匹配一个delete调用。同样,每个对malloc、alloc和calloc的调用都要匹配一个对free的调用。每个
new[]调用也要匹配一个delete[]调用。为避免多次释放内存或使用已释放的内存,建议释放内存后将指针设置为nullptr。- 检查缓冲区溢出。每次迭代访问数组或读写C风格的字符串时,验证没有越过数组或字符串的结尾访问内存。
- 检查无效指针的解除引用。
- 在堆栈上声明指针时,确保总是在声明中初始化指针。例如,使用
T* p = nullptr或T* p = new T,但是绝不要使用T* p。 - 同样,确保总在类的初始化器或构造函数中初始化指针数据成员,既可以在构造函数中分配内存,也可将指针设置为nullptr。
651 673
使用设计技术和框架
容易忘记的语法
编写类
不要忘了开头部分。下面是一个简单的类定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Simple {
public:
Simple();
virtual ~Simple() = default;
Simple(const Simple& src) = delete;
Simple& operator=(const Simple& rhs) = delete;
Simple (Simple&& src) = default;
Simple& operator=(Simple&& rhs) = default;
virtual void publicMethod();
int mPublicinteger;
protected:
virtual void protectedMethod();
int mProtectedinteger = 41;
private:
virtual void privateMethod();
int mPrivateInteger = 42;
static const int kconstant = 2;
static int sStaticInt;
};
通常,至少要将析构函数设置为virtual,因为其他人可能想从这个类派生新类。也允许保留析构函数为非virtual,但这只限于将类标记为final,以防止其他类从其派生的情况。如果只想将析构函数设置为virtual,但不需要析构函数中的任何代码,则可显式地设置为default,如Simple类示例所示。
这个示例也说明,可显式地将特殊成员函数设置为delete或default。将复制构造函数和复制赋值运算符设置为delete,以防止赋值和按值传递,而将移动构造函数和移动赋值运算符显式设置为default。
派生类
要从现有的类派生,可声明一个新类,这个类是另一个类的扩展类。下面是DerivedSimple类的定义,DerivedSimple从Simple派生而来:1
2
3
4
5
6
7
8
class Derivedsimple : public Simple {
public:
DerivedSimple();
virtual void publicMethod() override; // Overridden method
virtual void anotherMethod();
};
使用“复制和交换”惯用语法
只需要创建对象的一个副本,修改这个副本(可以是复杂算法,可能抛出异常)。最后,当不再抛出异常时,将这个副本与原始对象进行交换。赋值运算符是一个可使用“复制和交换”惯用语法的操作示例。赋值运算符首先制作原始对象的一个本地副本,此后仅使用不抛出异常的swap()实现,将这个副本与当前对象进行交换。
始终存在更好的方法
RAII
RAII(Resource Acquisition Is Initialization,资源获得即初始化)是一个简单却十分强大的概念。它用于在RAII实例离开作用域时自动释放已获取的资源。这是在确定的时间点发生的。基本上,新RAII实例的构造函数获取特定资源的所有权,并使用资源初始化实例,因此得名RAII。在销毁RAII实例时,析构函数自动释放所获取的资源。下面的RAII类File安全地包装C风格的文件句柄(std::FILE),并在RAII实例离开作用域时自动关闭文件。RAII类也提供get()、release()和reset()方法,这些方法的行为类似于标准库类(如std::unique_ptr)中的同名方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
class File final {
public:
File(std::FILE* file);
~File();
File(const File& src) = delete;
File& operator=(const File& rhs) = delete;
File(File&& src) noexcept = default;
File& operator=(File&& rhs) noexcept = default;
std::FILE* get() const noexcept;
std::FILE* release() noexcept;
void reset(std::FILE* file = nullptr) noexcept;
private:
std::FILE* mFile;
};
File::File(std::FILE* file): mFile(file) { }
File::~File() {
reset();
}
std::FILE* File::get() const noexcept {
return mFile;
}
std::FILE* File::release() noexcept {
std::FILE* file = mFile;
mFile = nullptr;
return file;
}
void File::reset (std::FILE* file) noexcept {
if (mFile)
fclose(mFile);
mFile = file;
}
用法如下:1
File myFile(fopen("input.txt", "z"));
myFile实例一旦离开作用域,就会调用它的析构函数,并自动关闭文件。
双分派
双分派(double dispatch)技术用于给多态性概念添加附加维度。C++没有提供相应的语言机制,以根据多个对象的运行时类型选择行为。虚方法本身不足以建立这种场景的模型,它们仅根据接收对象的运行时类型来确定方法或行为。
有些面向对象语言允许基于两个或多个对象的运行时类型,在运行时选择方法,它们将该功能称为多方法(multi-methods)。而在C++中,并没有支持多方法的核心语言功能,但可以使用双分派技术,从而创建针对多个对象的虚函数。
注意双分派实际上是多分派的特例。所谓多分派,是指根据两个或多个对象的运行时类型来选择行为。在实践中,双分派可根据两个对象的运行时类型选择行为,这通常就能满足需要。
首先重点分析单个派生类,可能是Bear类。该类需要一个具有以下声明的方法:1
virtual bool eats (const Animal& prey) const override;
双分派的关键在于基于参数上的方法调用来确定结果。假设Animal类有一个eatenBy()方法,该方法将Animal引用作为参数。如果当前Animal会被传入的动物捕食,该方法返回true。有了这个方法,eats()方法的定义变得十分简单:1
2
3bool Bear::eats(const Animal& prey) const {
return prey.eatenBy(*this);
}
初看起来,这个解决方案给单多态方法添加了另一个方法调用层。毕竟,每个派生类都必须为每个Animal派生类实现eatenBy()版本。但有一个重要区别:多态发生了两次!当调用eats()方法时,多态性确定,是调用Bear::eats()、Fish::eats()还是其他。当调用eatenBy()方法时,多态性再次确定要调用哪个类的方法版本,调用prey对象的运行时类型的eatenBy()。注意,*this的运行时类型始终与编译时类型相同,这样,编译器可为实参(这里是Bear)调用eatenBy()的正确重载版本。
下面是使用双分派的Animal层次结构的类定义。注意forward declarations是必需的,因为基类使用派生类的引用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Fish;
class Bear;
class Dinosaur;
class Animal {
public:
virtual bool eats (const Animal& prey)const = 0;
virtual bool eatenBy (const Bear&) const = 0;
virtual bool eatenBy (const Fish&) const = 0;
virtual bool eatenBy (const Dinosaur&) const = 0;
};
class Bear : public Animal {
public:
virtual bool eats(const Animal& prey) const override;
virtual bool eatenBy(const Bear&) const override;
virtual bool eatenBy(const Fish&) const override;
virtual bool eatenBy(const Dinosaur&) const override;
};
实现代码如下所示。注意,Animal的派生类以相同的方式实现eats()方法,但不能向上延伸到基类;如果尝试这么做,编译器不知道要调用eatenBy()方法的哪个重载版本,因为*this是Animal而非特定的派生类。根据对象的编译时类型(而非运行时类型)来确定方法重载方案。1
2
3
4
5
6
7
8
9
10
11
12
13
14bool Bear::eats(const Animal& prey) const { return prey.eatenBy(*this); }
bool Bear::eatenBy(const Bear&) const { return false; }
bool Bear::eatenBy(const Fish&) const { return false; }
bool Bear::eatenBy(const Dinosaur&) const { return true; }
bool Fish::eats(const Animal& prey) const { return prey.eatenBy(*this): }
bool Fish::eatenBy(const Bear&) const { return true; }
bool Fish::eatenBy(const Fish&) const { return true; }
bool Fish::eatenBy(const Dinosaur&) const { return true; }
bool Dinosaur::eats(const Animal& prey) const { return prey.eatenBy(*this); }
bool Dinosaur::eatenBy(const Bear&) const { return false; }
bool Dinosaur::eatenBy (const Fish&) const { return false; }
bool Dinosaur::eatenBy(const Dinosaur&) const { return true; }
开发跨平台和跨语言应用程序
跨平台开发
整数大小
C++标准并未定义整数类型的准确大小。C++标准仅指出:有5种标准的有符号整数类型:signed char、short int、int、long int、long long int。在这个列表中,后一种类型占用的存储空间大于或等于前一种类型。
二进制兼容性
为支持不具备二进制兼容性的平台,一种解决方案是在每个目标平台上使用编译器分别构建每个版本。另一种解决方案是交叉编译(cross-compiling)。 如果为开发使用平台X,但想使程序运行在平台Y和Z上,可在平台X上使用交叉编译器,为平台Y和Z生成二进制代码。
地址大小
当提到架构是32位时,通常是说地址大小是32位或4字节。通常而言,具有更大地址大小的系统可处理更多内存,在复杂系统上的运行速度更快,由于指针是内存地址,自然与地址大小密切相关。许多程序员都认为,指针的大小始终是4字节,但这是错误的。需要意识到,大多数大小都不是C+标准预先确定的。C++标准只是说,short integer占用的空间小于或等于integer,integer占用的空间小于或等于long integer。
指针的大小未必与整数大小相同。例如,在64位平台上,指针是64位,但整数可能是32位。将64位指针强制转换为32位整数时,将丢失32个关键位!C++标准在<cstdin>中定义了std::intptr_t整数类型,它的大小至少足以存储一个指针。根据C++标准,这种类型的定义是可选的,但几乎所有编译器都支持它。
字节顺序
现在将数字分为“内存大小”部分。剩余的唯一问题是如何将它们存储在内存中。需要两个字节,但字节序是不确定的,事实上取决于相关系统的架构,一种表示数字的方式是将高位字节首先放入内存,接着将低位字节放入内存。这种策略被称为大端序,因为数字的较大部分首先放入。另一种是按相反顺序放置字节,首先将低序字节放入内存。这种策略被称为小端序,因为数字的较小部分首先放置。
跨语言开发
链接C代码
在C++程序中开始使用已经编译的C代码之前,首先需要了解“名称改编”这个概念。为实现函数重载,会对复杂的C++名称平台进行“扁平化”。例如,如果有一个C++程序,则编写以下代码是合法的:1
2
3void MyFunc(double);
void MyFunc(int);
void MyFunc(int, int);
这意味着链接器将看到MyFunc,但是不知道该调用哪种版本的MyFunc函数。因此,所有C++编译器执行名称改编操作,以生成合理的名称,如下所示:1
2
3MyFunc_double
MyFunc_int
MyFunc_int_int
为避免与定义的其他名称发生冲突,生成的名称通常使用一些字符。对于链接器而言,这些字符是合法的;对于C++源代码而言,这些字符是非法的。例如,Microsoft VC++生成如下名称:1
2
3?MyFunc8@YAXN@Z
?MyFunc8@YAXH@Z
?MyFunc@@YAXHH@Z
C语言不支持函数重载(编译器将报错,指出是重复定义)。因此,C编译器生成的名称十分简单,例如_MyFunc。因此,如果用C++编译器编译一个简单的程序,即便仅有一个MyFunc名称实例,也仍会生成一个请求,要求链接到改编后的名称。但是当链接C库时,找不到所需的已改编名称,因此链接器将报错。因此,有必要告知C++编译器不要改编相应的名称。为此,需要在头文件中使用extern"language"限定,以告知客户端代码创建与指定语言兼容的名称;如果库源是C++,还需要在定义站点使用这个限定,以告知库代码生成与指定语言兼容的名称。
extern"language"的语法如下:1
2extern "language" declaration1();
extern "language" declaration2();
也可能如下:1
2
3
4extern "language" {
declaration1();
declaration2();
}
C++标准指出,可使用任何语言规范;因此,从原理上讲,编译器可支持以下代码:1
2
3
4extern "C" MyFunc(int i);
extern "Fortran" MatrixInvert (Matrix* M);
extern "Pascal" SomeLegacySubroutine(int n);
extern "Ada" AimMissileDefense (double angle);
但实际上,许多编译器只支持C。每个编译器供应商都会告知你所支持的语言指示符。
例如,在以下代码中,将doCFunction()的函数原型指定为外部C函数:1
2
3
4
5
6
7
8extern "C" {
void docFunction(int i);
}
int main() {
doCFunction(8); // Calls the C function.
return 0;
}
在链接阶段,在附加的已编译二进制文件中提供doCFunction()的实际定义。 extern关键字告知编译器:链接的代码是用C编译的。使用extern的更常见模式是在头文件级别。可以编写另一个头文件,将原始文件打包到extern块中,以指定定义函数的整个头文件是用C编写的。
另一个常见模型是编写单个头文件,然后根据条件针对C或C++对其进行编译。如果为C++编译,C++编译器将预定义__cplusplus符号。该符号不是为C编译定义的。因此,可以经常看到以下形式的头文件:1
2
3
4
5
6
7
8
extern"C" {
declaration1();
declaration2();
}
附录C
标准库头文件C++标准库的接口包含87个头文件,其中有26个表示C标准库。要记住源代码中应该包含哪些头文件往往很难,所以这个附录简要描述每个头文件的内容,按照以下8类组织:
- C标准库
- 容器算法、迭代器和分配器
- 通用工具
- 数学工具
- 异常
- I/O流
- 线程支持库
C标准库
C++标准库包含完整的C标准库。头文件通常是一样的,除了以下两点:
- 头文件为
<cname>而不是<name.h> <cname>头文件中声明的所有名称都在std名称空间中
为了后向兼容,如有必要,仍可包含<name.h>。然而,这样会把名字放在全局名称空间而不是std名称空间中。另外,<name.h>已不赞成使用。建议避免这种用法。
表C-1总结了最常用功能。注意建议避免使用C功能,而尽量使用等价的C++功能。
| 头文件名 | 内容 |
|---|---|
<cassert> |
assert()宏 |
<ccomplex> |
只包括<complex>。从C++17开始,已不赞成使用 |
<cctype> |
字符谓词和操作函数,例如isspace()和tolower() |
<cerrno> |
定义errno表达式,它是一个宏,获得某些C函数的最后一个错误编号 |
<cfenv> |
支持浮点数环境,例如浮点异常、浮点数取整等 |
<cfloat> |
和浮点数算术相关的C风格定义,例如FLT_MAX |
<cinttypes> |
定义与printf()、scanf()和类似函数结合使用的一些宏,还定义一些操作intmax_t的函数 |
<ciso646> |
在C语言中,<iso646.h>文件定义宏and和or等。在C++中,这些都是关键字,所以这个头文件为空 |
<climits> |
C风格的限制定义,例如INT_MAX。建议改用C++中对应的<limits> |
<clocale> |
用于本地化的宏和函数,例如LC_ALL和setlocale()。见C++中对应的<locale> |
<cmath> |
数学工具,包括三角函数、sqrt()和fabs()等 |
<csetjmp> |
setjmp()和longjmp()`,绝不要在C++中使用 |
<csignal> |
signal()和raise(),避免在C++中使用 |
<cstdalign> |
和对齐相关的宏__alignas_is_defined,从C++17开始已不赞成使用 |
<cstdarg> |
处理变长参数列表的宏和类型 |
<cstdbool> |
与布尔类型相关的宏__bool_true_false_are_defined,从C++17开始已不赞成使用 |
<cstddef> |
重要的常量,例如NULL,以及重要的类型,例如size_t |
<cstdint> |
定义一些标准的整数类型,例如int8_t和int64_t等,还包含表示这些类型的最大值和最小值的宏 |
<cstdio> |
文件操作,包括fopen()和fclose()。格式化I/O:printf()、scanf()等系列函数。字符I/O:getc()、putc()等系列函数。文件定位:fseck()和ftell()。建议改用C++流 |
<cstdlib> |
随机数操作:rand()和srand(),从C++14开始已不建议使用,而改用C++<random>。这个头文件包含abort()和exit()函数,应该避免使用这两个函数。C风格的内存分配函数:calloc()、malloc()、realloc()和free()。C风格的排序和搜索函数;qsort()和bscarch(),字符串到数值的转换函数;atof()和atoi()等。一组与多字节/宽字符串处理相关的函数 |
<cstring> |
底层内存管理函数,包括memcpy()和memset()。C风格的字符串函数,例如strcpy()和strcmp() |
<ctgmath> |
只包含<ccomplex>和<cmath>,从C++17开始已不赞成使用 |
<ctime> |
时间相关的函数,包括time()和localtime() |
<cuchar> |
定义一些与Unicode相关的宏和函数例如mbrtoc16() |
<cwchar> |
宽字符版本的字符串、内存和I/O函数 |
<cwctype> |
<cctype>中函数的宽字符版本:iswspace()和towlower()等 |
容器
可在以下12个头文件中找到标准库容器的定义,如表C-2所示。
| 头文件名 | 内容 |
|---|---|
<array> |
array类模板 |
<bitset> |
bitset类模板 |
<deque> |
deque类模板 |
<forward_list> |
forward list类模板 |
<list> |
list类模板 |
<map> |
map和multimap类模板 |
<queue> |
queue和priority_queue类模板 |
<set> |
set和multisct类模板 |
<stack> |
stack类模板 |
<unordered_map> |
unordered_map和unordered_multimap类模板 |
<unordered_set> |
unordered_set和unordered multiset类模板 |
<vector> |
vector类模板和vector<bool>特例化 |
每个头文件都包含使用特定容器需要的所有定义,包括迭代器。
算法、迭代器和分配器
表中的不同头文件定义可用的标准库算法、迭代器和分配器。
| 头文件名 | 内容 |
|---|---|
<algorithm> |
标准库中大部分算法的原型 |
<execution> |
定义与标准库算法起使用的执行策略类型 |
<functional> |
定义内建函数对象、取反器、绑定器和适配器 |
<iterator> |
定义iterator_trait、迭代器标签、iterator、reverse_iterator、插入迭代器(例如back_insert_iterator)和流迭代器 |
<memory> |
定义默认分配器、一些处理容器内未初始化内存的工具函数 |
<memory_resource> |
定义多态分配器和内存资源 |
<numeric> |
一些数值算法的原型,比如accumulate()、inner_product()、partial_sum()和adjacent_difference()等 |
<scoped_allocator> |
可用于内嵌容器的分配器,例如字符串的vector、map的vector |
通用工具
标准库在一些不同的头文件中包含一些通用的工具函数
| 头文件名 | 内容 |
|---|---|
<any> |
定义any类 |
<charconv> |
定义chars_format枚举类、from_chars()函数、to_chars()函数和相关结构 |
<chrono> |
定义chrono库 |
<codecvt> |
为不同字符编码提供代码转换的facet。从C++17开始,已经不赞成使用这个头文件 |
<filesystem> |
定义用于处理文件系统的可用类和函数 |
<initializer_list> |
定义initializer_list类 |
<limits> |
定义numeric_limits类模板,以及大部分内建类型的特例化 |
<locale> |
定义locale类、use_facet()和has_facet()模板函数以及facet系列函数 |
<new> |
定义bad_alloc异常和set_new_handler()函数,以及operator new和operator delete的所有6种原型 |
<optional> |
定义optional类 |
<random> |
定义随机数生成器库 |
<ratio> |
定义Ratio库,以操作编译时有理数 |
<regex> |
定义正则表达式库 |
<string> |
定义basic_string类模板以及string和wstring的类型别名实例 |
<string_view> |
定义basic_string_view类模板和类型别名aliases string_view和wstring_view |
<system_error> |
定义错误分类和错误代码 |
<tuple> |
定义tuple类模板,作为pair类模板的泛化 |
<type_traits> |
定义模板元编程中使用的类型trait |
<typeindex> |
定义type_info的简单包装,可在关联容器和无序关联容器中用作索引类型 |
<typeinfo> |
定义bad_cast和bad_typeid异常。 定义type_info类,typcid运算符返回这个类的对象 |
<utility> |
定义pair类模板和make_pair()。这个头文件还定义了工具函数swap()、exchange()和move()等 |
<variant> |
定义variant类 |
数学工具
C++提供了一些数值处理功能。
| 头文件名 | 内容 |
|---|---|
<complex> |
定义处理复数的complex类模板 |
<valarray> |
定义valarray类,以及处理数学矢量和矩阵的相关类和类模板 |
异常
| 头文件名 | 内容 |
|---|---|
<exception> |
定义exception和bad_exception类,以及set_unexpected()、set_terminate()和uncaught_exception()函数 |
<stdexcept> |
没有定义在<exception>中的非领域相关的异常 |
I/O流
通常情况下应用程序只需要包含<fstream>、<iomanip>、<iostream>、<istream>、<ostrcam>和<sstream>。
| 头文件名 | 内容 |
|---|---|
<fstream> |
定义了basic_filebuf、basic_ifstream、basic_ofstream和basic_fstream类,声明了filebuf、wfilebuf、ifstream、wifstream、ofstream、wofstream、fstream、wfstream类型别名 |
<iomanip> |
声明了其他地方没有声明的I/O运算符 |
<ios> |
定义了ios_base和basic_ios类,声明了大部分流运算符。几乎不需要直接包含这个头文件 |
<iosfwd> |
其他I/O流头文件中出现的模板和类型别名的前向声明。几乎不需要直接包含这个头文件 |
<iostream> |
声明了cin、cout. cerr和clog以及对应的宽字符版本。注意这不仅是<istream>和<ostrcam>的组合 |
<istream> |
定义了basic_istream、basic_iostream类,声明了istream、wistream、iostream、wiostream类型别名 |
<ostream> |
定义了basic_ostream类。声明了ostream和wostream类型别名 |
<sstream> |
定义了basic_stringbuf、basic_istringstream、basic_ostringstream、basic_stringstream类,声明了stringbuf、wstringbuf、istringstream、wistringstream、ostringstream、wostringstream、stringstream、wstringstream类型别名 |
<strcambuf> |
声明了basic_streambuf类以及streambuf和wstreambuf类型别名。 几乎不需要直接包含这个头文件 |
<strstream> |
已不赞成使用 |
线程库
C++包含一个线程库,允许编写与平台无关的多线程应用程序。
| 头文件名 | 内容 |
|---|---|
<atomic> |
定义了原子类型、atomic<T>以及原子操作 |
<condition_variable> |
定义了condition_variable和condition_variable_any类 |
<future> |
定义了future、promise、packaged_task和async() |
<mutex> |
定义了不同的非共享互斥体、锁类以及call_once() |
<shared_mutex> |
定义了shared_mutex、shared_timed_mutex、shared_lock类 |
<thread> |
定义了thread类 |